
Abstract
Recent studies in the acquisition of a second language (L2) phonology have revealed that orthography can influence the way in which L2 learners come to establish target-like lexical representations (Escudero et al., 2008, 2014; Escudero and Wanrooij, 2010; Showalter, 2012; Showalter and Hayes-Harb, 2013). Most of these studies, however, involve language pairs relying on Roman-based scripts. In comparison, the influence of a foreign or unfamiliar written representation on L2 phonological acquisition remains understudied. The present study therefore considers the effects of three L2 scripts on the early acquisition of an Arabic consonantal contrast word-initially (e.g. /ħal/–/χal/). Monolingual native speakers of English with no prior knowledge of Arabic participated in a word-learning experiment where they were instructed to learn six pairs of minimally contrastive words, each associated with a unique visual referent. Participants were assigned to one of four learning conditions: no orthography, Arabic script, Cyrillic script, and Roman/Cyrillic blended script. After an initial learning phase, participants were then tested on their phonological knowledge of these L2 minimal pairs. The results show that the degree of script unfamiliarity does not in itself seem to significantly affect the successful acquisition of this particular phonological contrast. However, the presence of certain foreign scripts in the course of phonological acquisition can yield significantly different learning outcomes in comparison to having no orthographic representation available. Specifically, the Arabic script exerted an inhibitory effect on L2 phonological acquisition, while the Cyrillic and Roman/Cyrillic blended scripts exercised differential inhibitory effects based on whether grapheme–phoneme correspondences activated first language (L1) phonological units. Besides revealing, for the first time, that foreign written input can significantly hinder learners’ ability to reliably encode an L2 phonological contrast, this study also provides further evidence for the irrepressible hold of native orthographic rules on L2 phonological acquisition.
Keywords
I Introduction
It is well known that at the outset of second language (L2) acquisition, learners struggle to hear differences between unfamiliar sounds; for models of non-native/L2 1 speech perception and acquisition, see, for example Speech Learning Model (Flege, 1988, 1992, 1995), Perceptual Assimilation Model (Best, 1993, 1994, 1995; Best and Tyler, 2007), Native Magnet Model (Kuhl, 1992, 1994, 2000a; Kuhl and Iverson, 1995; Kuhl et al., 2008), Second Language Linguistic Perception Model (Escudero, 2005). Japanese learners of English, for instance, are notorious for misperceiving the difference between /l/ and /ɹ/ in words such as < light > and < right > due to Japanese’s lack of such a distinction among native sounds (Aoyama et al., 2004; Bradlow et al., 1997, 1999; Goto, 1971; Iverson et al., 2003; Logan et al., 1991; MacKain et al., 1981; Takagi, 2002). Thus, upon hearing an English /l/–/ɹ/ contrast, Japanese speakers readily neutralize it to fit a close perceptual target or category of their native language. The task of the L2 learner then is to form separate mental categories to rectify this initial homophony and build a distinct phonological inventory/system capable of supporting adequate representations of non-native words. Put differently, the task of the learner is to create a second language lexicon that reliably encodes non-native phonemes.
Research in the domain of L2 speech perception and acquisition has long acknowledged the fact that native linguistic knowledge considerably shapes how L2 listeners/learners perceive and subsequently learn sound distinctions that are not present in their own language (Cutler et al., 2006; Darcy et al., 2012; Hayes, 2003; Hayes-Harb, 2007; Hayes-Harb and Masuda, 2008; Ota et al., 2009, 2010). More recently, a burgeoning body of research has also recognized the fact that second language learners, whether in a classroom or immersion setting, are commonly exposed to both spoken and written forms of the target language (Bassetti, 2006, 2008; Escudero et al., 2008, 2014; Escudero and Wanrooij, 2010; Showalter, 2012; Showalter and Hayes-Harb, 2013; Simon et al., 2010; Weber and Cutler, 2004). On their journey to acquiring an L2, learners therefore encounter language input that is not only auditory in nature, but is oftentimes also orthographic 2 ; and such learning experience has been shown to significantly influence the outcome of L2 phonological development (see Section II).
The impact of written representations on the early formation of an L2 phonological lexicon is however still not well understood, especially as it relates to an unfamiliar writing system (where ‘unfamiliar’ refers to what is not known or recognized). The present study aims to provide some answers relating to the L2 experience of ab initio or first-exposure learners, where unfamiliar script and L2 phonology may interact in the course of their lexical acquisition. The main question that was asked concerned L2 learners’ ability to recruit unfamiliar phonographic information (see Showalter and Hayes-Harb, 2013) presented to them in the course of lexical acquisition so as to inform their phonological representations of non-native words. More specifically, this study seeks to uncover the degree of script foreignness, as well as the level of graphical representation, at which non-native phonological category formation is being affected.
II Background
Besides purely perceptual and phonological considerations, another contributing factor of L2 learners’ ability to perceive and lexically discriminate pairs of non-native sounds relates to orthography. Bassetti (2008) notes that ‘[f]or literate L2 learners, the orthographic input provides a visual and permanent analysis of the acoustic input, which may complement a defective perception’ (p. 192). This section presents an overview of the research conducted in L2 phonological acquisition that directly addresses the influence of an orthographic representation on non-native sound representation. Based on available studies, this orthographic influence can be categorized as either positive, negative, or nonexistent.
1 Positive influence of orthography on L2 phonological acquisition
In a word-learning study, Escudero et al. (2008) investigated whether orthographic knowledge of a non-native phonemic contrast – i.e. /ɛ/–/æ/ for first language (L1) Dutch learners of L2 English – is recruited when establishing contrastive L2 phonological representations. In other words, they asked the following question: does the presence of a spelled form while learning new L2 English words affect Dutch learners’ ability to recognize (and encode) a phonemic contrast not present in their native language? The results of an eye-tracking experiment showed that auditorily confusable L2 words (e.g. /tɛn|zə/ vs. /tæn|dək/) lead to asymmetric word recognition when learned both with their auditory and spelled forms (e.g. < tenzer > and < tandek >). That is to say, participants looked at pictures of words exhibiting the two non-native vowels when hearing /æ/ tokens, but looked preferentially at pictures of words containing /ɛ/ when presented with /ɛ/ tokens. Additionally, auditory presentation of the stimuli as the sole source of information yielded a symmetric recognition pattern (i.e. both pictures were looked at regardless of the heard token, a pattern not present for participants who had seen the stimuli’s written forms), suggesting that orthographic knowledge of the stimuli can be responsible for the observed asymmetric pattern in lexical activation (see Weber and Cutler, 2004). Based on their findings, the authors contend that abstract knowledge in the form of grapheme–phoneme mappings are exploited in the creation of a phonological representation for newly-acquired L2 words.
More recently, Showalter and Hayes-Harb (2013) also explored the potential influence of an unfamiliar script on L2 phonological acquisition in the form of diacritic marks appended to an otherwise familiar script (e.g. < fiān >, < fián >). In addition, by investigating the acquisition of contrastive tonal contours in Mandarin, this study also expands the domain of L2 structures examined thus far. The first experiment had L1 English participants learn eight non-words forming four minimal quadruplets based on tone (i.e. high-level, high-rising, falling-rising, and high-falling). Resorting to a similar experimental design as Showalter (2012; described below), participants were assigned to one of two word-learning conditions differentiated by whether the Roman script available to them in the course of novel-word learning featured tone marks or not (e.g. < fiān > vs. < fian > for a high-level tone). The results show that participants exposed to a tone-marked script performed significantly better at memorizing the phonological shape of the newly-acquired items, consequently learning with more accuracy to form contrastive, target-like tonolexical representations. These results demonstrate that the provision of visual cues, here in the form of unfamiliar diacritics, can help participants learn foreign phonological dimensions. In order to tease apart the exact nature of the contribution of unfamiliar diacritics to L2 phonological acquisition, the second experiment examined whether participants learned to associate tone marks with tonal contours (e.g. < ā, á, ă, à > for high-level, high-rising, falling-rising, and high-falling tones, respectively), or if they were merely guided to focus on tonal contours via overt visual information. The outcome is that English learners may, to some extent, be able to establish correspondences between lexical tone and tone diacritics, although accuracy in performance was not very high.
In sum, both studies suggest that the presence of a written form can benefit learners in their acquisition of a confusable contrast in a second language. Other studies on the other hand have reported results where orthography interferes with L2 phonological acquisition.
2 Negative influence of orthography on L2 phonological acquisition
A number of studies have revealed that the presence of misleading orthography can actually hinder the acquisition of non-native phonological contrasts, therefore standing in opposition with the abovementioned studies. Bassetti (2006), for instance, presents a duo of experiments intended to examine the influence of orthographic representations on the developing phonological lexicon of L2 learners. As indicated in the introduction to this article, this study rests on the premise that L2 learners are more often than not confronted with two types of L2 input, orthographic and oral, which can supposedly shape one another in the course of acquisition. The author therefore took on the task to investigate the impact of pinyin – the writing system employed to alphabetically represent Mandarin Chinese – on the creation of target representations by native English beginning learners of Chinese as a foreign language. Resorting to both a phoneme counting task and a phoneme segmentation task, Bassetti’s hypothesis was that if L2 pronunciation omits the main (central) vowel in Chinese triphthongal rimes (e.g. /uei/, /iou/, and /uən/), transcribed in the pinyin orthography with no such vowel (e.g. < ui >, < iu >, and < un >, respectively), then L2 mental representations of such rimes are also bereft of this main vowel. Both experimental tasks support the author’s hypothesis and yielded results suggesting that written representations informed the establishment of L2 phonological representations, given that the absence of a pinyin main vowel in the orthographic representation directly correlated (via L1 grapheme–phoneme correspondences) to its absence in the L2 phonological representation. This suggests that decipherable written input can negatively affect the formation of a second language phonological system, resulting in non-target-like representations.
Similarly, Escudero and Wanrooij (2010) further extended the investigation of L1 orthographic effects on speech perception. Their study focused on determining whether orthographic effects can be obtained sublexically through the auditory perception of non-native Dutch vowels in a non-lexical context (with and without the presence of orthography). For Experiment 1, the hypotheses of a two alternative, forced-choice vowel categorization auditory task were that Spanish-speaking participants would have more difficulty in perceiving the Dutch contrasts /a–ɑ/, /i–ɪ/ and /y–ʏ/ (because of their phonetic proximity, and their mapping onto the single Spanish categories /a, i, u/, respectively), than perceiving the Dutch contrasts /i–y/ and /ɪ–ʏ/ (because potentially mapping onto the distinct Spanish categories /i/ and /u/, respectively). The predictions of a multiple-alternative forced-choice auditory and orthographic task were that Spanish participants would have more difficulty in perceiving the Dutch vowels /i/, /ɪ/, /ʏ/, and /y/ (corresponding to the spellings <ie or i>, <i>, <u>, and <u or uu>, respectively) than perceiving the vowels /a/ and /ɑ/ (corresponding to the spellings <a or aa> and <a>, respectively) when presented with their orthographic representations as response options. Such difficulty would arise from Spanish’s transparent orthographic conventions, yielding faster grapheme–phoneme conversion, consequently interfering with the auditory input of the first set of vowels, whereas the second set is more consistent with Spanish grapheme–phoneme mapping. In Experiment 2, with Peruvian Spanish listeners unencumbered by experience with spoken or written Dutch, the confound of Experiment 1 (i.e. having different experimental tasks: two-alternative vs. multiple-alternative forced-choice) is eliminated by relying on comparable XAB auditory and orthographic tasks. The expectations of Experiment 2 were the same as those of Experiment 1. In both experiments, the predictions were borne out, indicating that the difficulty of auditorily processing L2 vocalic input is affected by the presence or absence of an orthographic representation in the decision-making process. The results also signal the participation of sublexical representational units (i.e. individual graphemes), but are inconclusive in determining whether the orthographic effect observed can be attributed to a prelexical level of processing.
As a follow-up to this previous study, Escudero et al. (2014) further examined the role of orthographic exposure in L2 word learning when the written representation available is either congruent or incongruent with the listeners’/learners’ native phonographic system. While the authors replicated Escudero et al.’s (2013) experimental method (i.e. word-learning task), their participant populations (i.e. L1 Spanish naive listeners of Dutch, and L1 Spanish learners of L2 Dutch), and some of their stimuli items (i.e. perceptually easy/difficult vocalic contrasts), they also introduced orthographic conditions differing in terms of their L1/L2 graphophonological correspondences. Given that L1 orthography is activated during non-native speech perception (Escudero et al. 2008; Escudero and Wanrooij, 2010), the authors predicted that both groups of participants would encounter greater processing and learning difficulty when the Dutch orthographic input is at odds with their native Spanish grapheme–phoneme correspondences (e.g. incongruent: L1 Spanish < a > ≡ /a/, L2 Dutch < a > – < aa > ≡ /ɑ/ – /a/) than when it nearly matches with their Spanish orthographic rules (e.g. congruent: L1 Spanish < i > – < u > ≡ /i/ – /u/, L2 Dutch < i > – < u > ≡ /ɪ/ – /ʏ/). Conversely, when both Spanish and Dutch phonographic systems align, facilitation should be observed. The results support the hypothesis that incongruent orthography for both naive and Dutch-learning listeners hindered their acquisition of new words featuring vocalic contrasts, while congruent orthography facilitated such acquisition. It was also found that L2 Dutch learners, compared to L2 Dutch naive listeners, were more accurate on congruent items than on incongruent ones, suggesting that even with some L2 experience, L1 grapheme–phoneme correspondences are very much active in the mind of the L2 learner.
These studies therefore reveal the irrepressible activation of native phonographic conventions, potentially interfering with learners’ ability to mentally form target-like representations in a second language. Finally, a couple of studies have reported finding neither facilitative nor inhibitory effects of orthography on L2 phonological acquisition.
3 No influence of orthography on L2 phonological acquisition
The absence of an orthographic effect on learners’ early formation of a phonological lexicon in a second language is hardly described in the literature, perhaps because of the difficulty of interpreting such results and their presumed lack of relevance for the questions at hand. Even so, two studies focusing on the contribution of orthography to L2 phonological acquisition are worthy of consideration.
The first, conducted by Simon et al. (2010), follows Escudero et al. (2008) in their investigation of whether or not exposure to a written representation during L2 word learning facilitates the establishment of separate phonemic categories for confusable L2 vowels; in that case, the French vowels /y/–/u/. In the same vein as Escudero et al. (2008), the researchers hypothesized that knowledge of contrastive L2 spelled forms (e.g. < vu > [vy] vs. < vous > [vu]) leads to the formation of contrastive L2 lexical representations (or, more specifically, leads to the formation of novel L2 phonemic contrasts). In opposition to Escudero et al. (2008), however, this hypothesis was not supported by their first experiment: task performance was not significantly different between participants who learned novel L2 words with and without exposure to orthography. In Experiment 2, the consonantal context following the French vowel was found to be important for categorization to the closest American English vowel: the bilabial or velar nature of the coda guided participants’ distinct categorization pattern of /y/ and /u/. In Experiment 3, the constant alveolar coda enabled single-category assimilation (i.e. non-native /y/ and /u/ were categorized similarly), and variability in the stimuli was eliminated (with a single speaker recording). The discordant lack of an orthographic effect is explained by the fact that native English speakers’ opaque orthographic system may put them at a disadvantage when establishing one-to-one correspondences between graphemes and (L2) phonemes. In other words, because English readers are used to interacting with a complex system of multiple phoneme–grapheme mappings, they may approach the L2 written input with the same assumption of complexity. The reliance on an orthographic distinction reflecting the L2 vocalic contrast may therefore not be utilized when phonologically encoding such contrast. The authors suggest that further research with an L1 transparent orthographic system might yield different results.
The second study, conducted by Showalter (2012), investigated whether native speakers of English would be influenced by the presence of an unfamiliar script in the course of L2 word learning. More specifically, the goal was to examine their ability to learn non-words in Arabic, contrasting /k/–/q/ word-initially (e.g. [kita] vs. [qita]), and if that learning can be modulated by their exposure to the Arabic script. In two word-learning experiments, two groups of participants were instructed to memorize 12 non-words (6 minimal pairs) by associating their phonological form with a visual referent. One group saw a written representation in Arabic script under each pictured object, while the other saw a string of four identical Arabic characters (e.g. < طططط >). After satisfactorily completing a test of lexical memorization, a final test served to measure participants’ memory of the phonological form of the lexical items learned, and to compare their performance across experimental conditions (i.e. L2 word learning with or without the presence of the Arabic script). In Experiment 1, the test required participants to assess the association of auditory stimuli with only their visual referents, while in Experiment 2, the association to be evaluated was between auditory stimuli and their orthographic forms only. The outcome of both experiments revealed no significant difference between the two groups of participants, which suggests that phonological acquisition remained unaffected by the availability of a foreign script, and that participants did not establish reliable L2 grapheme–phoneme correspondences. These results are in stark contrast with those of Showalter and Hayes-Harb (2013), which reported a facilitatory effect of a semi-unfamiliar script.
These studies therefore offer a perspective on the L2 phonology–orthography acquisition interface that defies a binary characterization (i.e. positive or negative influence), which in turn invites further inquiry into this subtle interrelationship.
4 Summary of orthographic influences
Table 1 summarizes the various outcomes thus far attested with regards to orthographic effects on the development of a non-native phonological lexicon. This table also highlights the fact that most of these studies have relied on languages sharing or utilizing a similar script, namely a Roman/Latin-based script. With the exception of Showalter (2012) and Showalter and Hayes-Harb (2013), the investigation of the influence of a foreign or unfamiliar written representation on the early acquisition of a non-native phonological contrast remains, in comparison, understudied. The present study therefore investigates the potential effect of three unfamiliar scripts on L2 phonological acquisition.
Summary of orthographic influences in L2 phonological acquisition studies.

III Experiment
This experiment focuses on the acquisition of minimally contrastive words in Arabic. The phonemes in question are the word-initial voiceless pharyngeal /ħ/ and uvular /χ/ fricatives. This contrast remained constant throughout the experiment, while three unfamiliar scripts (i.e. Arabic, Cyrillic, Hybrid) were presented to different groups of L2 learners. Such set-up enables us to examine with greater detail the effects of different graphical elements on participants’ ability to satisfactorily establish novel phonological representations. Comparisons across script conditions are also juxtaposed to a learning condition in which no orthography per se was available to learners. This condition essentially served as baseline, as is customary from previous word-learning studies of this kind (Hayes-Harb et al., 2010; Showalter, 2012; Showalter and Hayes-Harb, 2013). The rationale for using these three unfamiliar scripts is detailed below.
1 Arabic script
The reliance on the Arabic script served to extend Showalter’s (2012) Arabic study, which showed no effect of written input on native English speakers’ acquisition of a /k/–/q/ contrast. One possible reason for her finding is that this stop contrast contains one native phoneme (/k/) and one non-native phoneme (/q/). Such auditory contrast might not have been distinct enough to exclude the possibility that the uvular stop merged with the velar stop during the learning process (Best, 1995; Escudero, 2005). Hence, only one phonological category may have been established instead of the intended two. In that case, L1 category assimilation may be such that the presence of an unfamiliar script is of no relevance to the discriminability of the L2 contrast. The present study investigates the acquisition of another place of articulation type of Arabic contrast where both phonemes are absent from English’s phonemic inventory. Thereby, the examination of the acquisition of a /ħ/–/χ/ contrast has the advantage of minimizing the assimilation with a single L1 phonemic category 3 (even if it may be more difficult to learn according to the Markedness Differential Hypothesis; Eckman 1977, 2008).
It has to be noted however that a recent study (Mahmoud, 2013) investigating the perceptual discriminability of various consonantal contrasts in Modern Standard Arabic (MSA) by native speakers of American English revealed that the abovementioned stop and fricative contrasts were discriminatorily equivalent. In an AXB task where the target contrasts were embedded in /ʔaːˈCaː/ nonwords, the ability of 22 beginning learners of MSA to discriminate /k/–/q/ (64.8%) and /ħ/–/χ/ (54.5%) was not found to be statistically different. Thus, these results indicate that both contrasts are comparably difficult to distinguish for L1 English speakers. Nonetheless, according to the Perceptual Assimilation Model (Best, 1995), both contrasts were predicted to be discriminably ‘very good’, which was clearly not the case. To make sense of these results, Mahmoud (2013) contends that the ‘confusability between /k/–/q/ may have arisen primarily due to the new consonant being well assimilated to an already familiarly known segment’ (p. 286). In the case of /ħ/–/χ/, the author attributes its poor discriminability rate to a possible influence of orthography given the high degree of resemblance of both phonemes in the Arabic writing system (see Appendix 1). It is not clear however whether participants in his study had access to a written representation of the stimuli during the AXB task. 4 The present experiment aims to address that point.
Another study related to the interaction between Arabic script and Arabic phonology also deserves mention here. Hansen (2010) conducted a study on visual word recognition in Arabic with L1 English, Danish, and German participants at three levels of Arabic proficiency (beginner, intermediate, and advanced), in addition to having a control group of native Arabic speakers. This study aimed to examine the influence of both script and phonological unfamiliarity on reading proficiency. In her first experiment, all participants read 117 Arabic pseudowords split into three lists containing 39 pseudowords featuring no Arabic-specific phonemes, 39 pseudowords including Arabic-specific phonemes, and 39 pseudowords written in the Roman alphabet (all complying with the rules governing which sequences of letters and sounds are allowed in the participants’ native language). The three lists of stimuli were presented in all possible permutations, and decoding errors were recorded as reflecting misreadings of Arabic letters, including omissions, additions, repetitions, and confusions of letters. The results show that, at all levels of Arabic proficiency, decoding speed and accuracy was significantly affected by the graphical representation of the Arabic script compared to decoding performance when the stimuli were in Roman script. Phonological unfamiliarity on the other hand did not constitute such an obstacle, leading Hansen to assert that ‘when learners experience their reading in Arabic to be very slow, the unfamiliar graphics of the Arabic alphabet may indeed be one of the reasons. Other linguistic aspects might have an influence as well, but the unfamiliar phonology does not seem to be one of them’ (2010: 577). Although Hansen’s study did not directly address questions of phonological acquisition, her results nevertheless imply that the Arabic script brings about processing slowdown at all levels of L2 reading proficiency, with or without novel phonemes.
If the Arabic script, by its nature, presents more difficulty in reading than a Roman script, regardless of the phonological content of L2 words, the visual presence of such script in the course of non-native word learning could potentially also interfere with the acquisition of the novel or unfamiliar L2 contrast. In other words, this script-specific difficulty in L2 reading may well expand to the domain of L2 acquisition. Consequently, exposure to the Arabic script may yield two conceivable outcomes regarding participants’ acquisition of the contrastive phonemes:
exposure to the Arabic written forms has a negative effect (compared to all other word-learning conditions); or
exposure to such labels has no effect on L2 phonological acquisition (as was the case in Showalter, 2012).
2 Cyrillic script
To further explore the potential influence of a foreign script on the acquisition of the same L2 contrast, a Cyrillic script was chosen; this script, compared to Arabic, is graphically closer to Roman script. Indeed, Arabic script appears as cursive, making it more difficult to parse (Hansen, 2010), whereas Cyrillic and Roman scripts feature adjoining yet seemingly independent characters. In that respect, a Cyrillic script, although foreign, may appear less so to native English speakers. This notable difference in graphical form may be of importance for participants’ simultaneous processing of auditory and visual stimuli, and may temper a potential effect of foreign, written representations on L2 phonological acquisition. In other words, the attenuated degree of foreignness of the Cyrillic script (compared to the Arabic script) may be such that it may not significantly distract participants in their effort to develop a non-native phonological lexicon.
It has to be noted also that the Cyrillic script used in this experiment is that of Kazakh, which features many superficially Roman-like characters. Consequently, while the script is entirely Cyrillic, the graphical representation of some characters may appear more familiar to L1 English participants, modulo differences in phoneme–grapheme correspondences. Crucially also, the characters encoding the L2 contrast, which exists in Kazakh, are superficially Roman-like (i.e. < h > and < x >). This may more or less disturb learners’ acquisition of the /ħ/–/χ/ contrast: more, because the Roman-looking characters might incorrectly trigger native grapheme–phoneme correspondences (GPCs; Escudero et al., 2014) or, less, because the learner’s perceived degree of familiarity with some of the Roman-looking characters may attenuate the otherwise overall foreignness of the Cyrillic script.
Taking all of these things into consideration then, in terms of learners’ acquisition of the /ħ/–/χ/ contrast, it was predicted that participants exposed to the Cyrillic script would perform significantly better than those exposed to the Arabic script (assuming that the difference in graphical representation plays a greater role than the confounding GPCs 5 ), while at the same time, perform significantly worse than those not exposed to any relevant written representation.
3 Hybrid script
The Hybrid script was designed to address a particular confound that could arise with the use of the Cyrillic script just described. Indeed, given the resemblance of some of the Cyrillic characters with Roman letters, if any foreign script effect is found, the question regarding the source of the effect would still remain: is it due to the foreignness of the Cyrillic script or to the potential activation of native phonological units via superficial L1 GPCs? To address this issue, another learning condition was therefore devised in which the characters representing the non-native phonological contrast were Cyrillic while the rest of the written forms contained Roman letters (e.g. < ҵal > for /ħal/ and < жal > for /χal/). This experimental change in stimuli thus eliminates the possibility that L1 GPCs may be wrongly activated in the course of L2 phonological learning, while it maintains the unfamiliarity factor of the script that is at the core of this research. Such graphical configuration also serves to evaluate whether individual foreign characters (as opposed to a complete foreign string) are capable of inducing an effect on L2 phonological acquisition
Regarding participants’ learning outcomes when exposed to this Hybrid script, the predictions are that they would (1) perform significantly better than their peers exposed to the Arabic and Cyrillic scripts, given that the Hybrid script as a whole features fewer foreign-looking characters, and can therefore be considered as less foreign, 6 but (2) perform equally or worse than those exposed to no relevant written forms. In that latter case, if learners in the Hybrid script condition have a significantly lower performance than those in the orthography-free condition, it would entail that a foreign script can exert an inhibiting influence on L2 phonological acquisition even at the level of individual characters.
4 Participants
Participants were recruited in undergraduate courses at the University of Arizona, and received either a monetary compensation or course credit for their participation. They were first asked to complete a short questionnaire reporting their first language(s), as well as any foreign language(s) exposed to in a formal learning context and/or while living abroad for an extended period of time, regardless of their level of proficiency. Also reported was any knowledge of a speech, hearing, and/or reading impairment. Participants were then randomly assigned to one of four word-learning conditions: a
In order to maintain a certain degree of control over participants’ language profiles, data selection for the analysis only included participants who:
self-identified as monolingual native speakers of English; that is to say, individuals whose first language is English and who strictly spoke it at home without any other languages;
had no knowledge and/or study of the target language and target scripts (i.e. Arabic and Cyrillic); and
had no speech, hearing, and/or reading impairment.
Based on these criteria, data from 21 participants in each of the four word-learning conditions were analysed (
5 Materials
The auditory stimuli consisted of 6 minimal pairs of CVC Arabic words and non-words, contrasting the voiceless pharyngeal /ħ/ and uvular /χ/ fricatives in onset position. Where possible, each member of a minimal pair was a word of Arabic (9 items). In three cases however, the necessary pairing required the use of non-words (i.e. / χas/, / χin/, and / χub/). Since none of the participants included in the data analysis had any experience with Arabic, this difference in lexical status was of no consequence. To them, all of the stimuli items are effectively real words of Arabic.
A young adult, female native speaker of Lebanese Arabic was recruited to record the stimuli. She was asked to read four blocks of stimulus items, all items appearing in isolation and written in Arabic script. 7 Each block contained the 12 target words, randomly interleaved amongst 12 filler non-words not containing the phonemes /ħ/ or /χ/. These filler items only served to prevent articulatory confusion in the sequential production of the target words. They were used for recording purposes only and not as stimulus items in the reported experiment. In each block, the order of presentation for the target and filler items was randomized. Out of four productions of each target word, the clearest instance (based on the author’s auditory judgment as a trained phonetician) was chosen as the target stimulus for this experiment.
Visual stimuli consisted of single line-drawing pictures of recognizable objects, randomly selected from the Bank of Standardized Stimuli (Brodeur et al., 2010). In the
6 Procedure
Following the procedure used by Showalter (2012), and Showalter and Hayes-Harb (2013), the experiment had three consecutive stages, detailed below. Throughout the experiment, participants were seated in a sound-proofed booth in front of a computer monitor and wore headphones. A keyboard was positioned in front of them, with the ‘shift’ keys labeled ‘YES’ and ‘NO’ to register their answers. Before the experiment started, the author gave verbal instructions to each participant, which were reiterated on the computer screen. The entire experimental session lasted about 30 minutes.
a Word-learning phase
The word-learning phase introduced participants to the 12 lexical items, presented as real words of Arabic (for those in the

Sample screens of visual stimuli for the word /ħal/, by word learning condition.
When a picture appeared, participants concurrently heard a corresponding auditory form, so that they would associate the latter with the former (i.e. a picture–word pair). Each pictured object and text underneath disappeared after 4 seconds of presentation and was immediately followed by the next picture–word pair. In both conditions, each of the 12 stimuli (6 minimal pairs) was presented once, altogether forming a block. One block was presented four times in random order each time and for each participant, for a total of 48 item presentations. At this stage of the experiment, no response was required of participants who simply listened to and learned the words presented to them. No information about the nature or reading directionality of the scripts was given to those assigned to a script condition.
b Criterion test phase
At the end of the word-learning phase, participants took a computer-mediated test to ensure that they memorized the auditory label for a pictured object. Instructions on the screen asked participants to indicate whether a pictured object, presented without the written form, matched (or not) the accompanying auditory stimuli by pressing YES/NO labeled keys on the keyboard. Each of the 12 picture–word pairs was presented twice: once in a matched condition, where the word and picture were associated at training (e.g. a picture of a fan coupled with the correct auditory label [ħal]), and once in a mismatched condition, where the word and picture were not associated at training (e.g. a picture of a fan coupled with the incorrect auditory label [χif]), for a total of 24 item presentations. To successfully accomplish this task, participants only needed to know the overall phonological shape of the items, given that they were not yet tested on minimal pairs. All of the mismatched pairings only involved auditory stimuli and visual referents that participants had seen during the previous phase of the experiment.
Based on studies by Hayes-Harb et al. (2010), Showalter (2012) and Showalter and Hayes-Harb (2013), the accuracy threshold needed to pass the criterion test was set at 90% (or 21/24 items correctly recognized). For each trial, participants received feedback regarding the correctness of their answers: a correct response yielded a ‘correct’ message, while an erroneous one yielded a ‘wrong’ message. Failure to pass the criterion test looped participants back to the word-learning phase until criterion was reached. No limit was set on the number of word-learning cycles participants needed to reach criterion. Successful performance led to the next and last phase of the experiment.
c Phonological test phase
The phonological test phase tested participants on their knowledge of the items learned, and more specifically on their knowledge of minimal pairs based on the L2 phonological contrast. Here, participants were similarly presented with a picture–word pair on which they had to make a yes/no matching decision. Again, no written form was provided so as to reveal whether or not learners’ phonological knowledge of the words was informed by the written input they had received in the initial phase of the experiment. In the absence of an orthographic support in this phase of the experiment, participants had to rely on their phonological (and potentially orthographic) memory of the items learned, and therefore signal whether or not they successfully encoded the non-native contrast.
The nature of the (mis)match here was based on the non-native phonological contrast under study, /ħ/–/χ/, such that all lexical items were now paired with their corresponding visual referent as well as with the visual referent of their minimally contrastive counterpart. Hence, each of the 12 picture–word pairs was again presented twice: once in a matched condition, and once in a mismatched condition, for a total of 24 item presentations. Again, all of the mismatched pairings only involved auditory stimuli and visual referents that participants had seen during the word-learning phase. For all participants, the phonological test phase marked the end of the study.
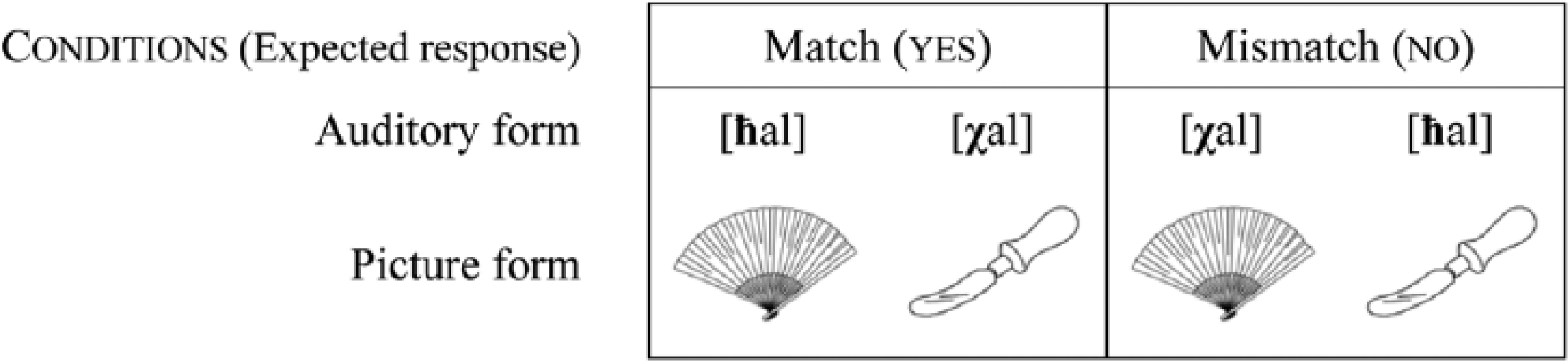
Example stimuli of matched and mismatched picture–word phonological pairs.
IV Results
First, regarding the analysis of word-learning phases, the mean numbers of word-learning phases required to reach 90% criterion was 2.8 cycles (SD = 1.1, range 1–6) for the
With regards to the results of the phonological test phase, percent accuracy was calculated for each participant for each word-learning condition and for matched and mismatched picture–word pairs, as well as their overall accuracy. Group means and standard deviations are presented in Table 2.
Mean percent accuracy for the matched, mismatched, and overall picture–word pairs by word-learning condition (standard deviation in parentheses).
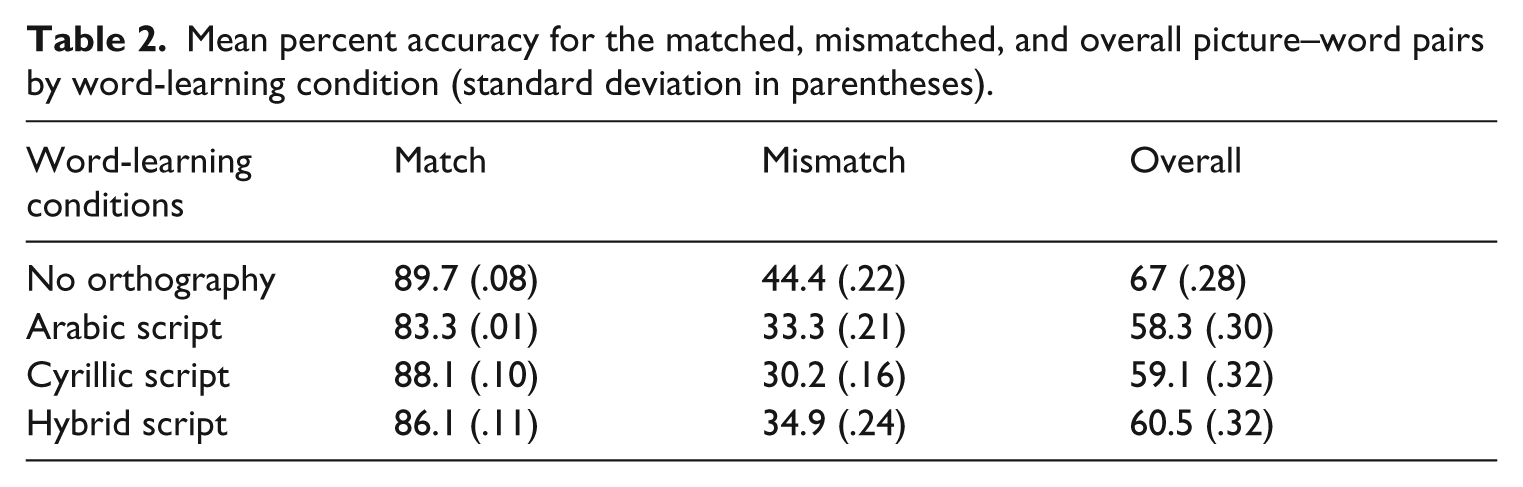
The table indicates that performance on the matched picture–word pairs was high in all word-learning conditions (89.6% − 83.3%), while performance on the mismatched picture–word pairs was low for all word-learning conditions (44.4% − 30.1%). Numerically, overall performance was better in the
Because of the experimental constant throughout the experiment (i.e. the /ħ/–/χ/ contrast), a mixed-design ANOVA by participant with Condition as a between-participant variable (four levels:

Mean accuracy of response as a function of Condition and Picture-Word Pair for all experimental conditions (bars represent confidence intervals).
Although the lack of a significant main effect of Condition does not warrant pairwise comparisons, the statistical analyses are nevertheless worth pursuing in order to uncover potential differences among the various script treatments. Such analyses comparing performances across script conditions yielded no significant differences, indicating no inhibitory or facilitatory prevalence of one unfamiliar script over another in the acquisition of the L2 contrast (
Indeed, significant simple effects of Condition were found between the
Because the experimental task required participants to perform a choice between only two available responses, YES (the picture and word match) and NO (the picture and word do not match), biases towards either response options could have been introduced. In order to tease apart actual sensitivity to the signal (i.e. the information-bearing stimuli capturing the phonological contrast) from the noise (i.e. random response patterns distracting away from the target stimuli), a signal detection analysis using the sensitivity index d-prime and decision criterion C was conducted for all groups of learners. This analysis essentially serves to reveal the degree of detectability of the non-native phonological contrast, which was higher for participants in the
Finally, in order to determine whether a significant relationship exists between the number of learning cycles and accuracy on the phonological test, a Pearson’s correlation analysis for all groups of learners was performed comparing individual participants’ number of learning cycles with their percentage accuracy in the test phase. These analyses revealed no significant correlation between the number of learning cycles participants went through to reach criterion and their subsequent performance on the phonological test phase (
V Discussion
The present study reports results from a word-learning experiment investigating the role of script unfamiliarity in the ability of English-speaking participants to memorize Arabic words exhibiting the phonological contrast /ħ/–/χ/ word-initially. These participants had no prior knowledge of the target language and performed like early learners of a second language.
This study was conducted on the premise that the acquisition of a /ħ/–/χ/ contrast, with less potential for a single category assimilation in English (see Huthaily, 2008), might be influenced by the presence of a foreign written representation in the course of novel word learning. Several hypotheses were entertained regarding the potential effect(s) of three unfamiliar scripts, recapitulated below.
Exposure to the Arabic script could yield:
significantly worse performance compared to all other word-learning conditions; equal performance compared to all other word-learning conditions.
Exposure to the Cyrillic script could yield:
significantly better performance compared to the Arabic script; significantly worse performance compared to the no orthography condition
Exposure to the Hybrid muld yield:
significantly better performance compared to the Arabic and Cyrillic scripts; equal or worse performance compared to the no orthography condition.
As reported above, no significant differences across script conditions have been found, suggesting that the degree of script foreignness has little incidence on learners’ acquisition of that non-native phonological contrast. In other words, the type of unfamiliar written input itself does not seem to significantly impact the outcome of L2 phonological learning. It is important to note that these cross-scriptal comparisons reflect a rather marginal case of second language learning, given that mixed-script languages are typologically rare (Cook and Bassetti, 2005; Comrie, 2013). What is therefore more pertinent is the comparison between each of the script conditions with an orthography-free condition, where significant differences have been attested. These comparisons are indeed more in line with the acquisition of a foreign language with or without the support of its written form (see Section II). The following discussion thereby proceeds with each script condition, starting with the Arabic script.
1 No orthography vs. Arabic script
Participants exposed to the Arabic script in the course of non-native word learning performed significantly less well on establishing distinct phonological representations than those who saw a string of Xs underneath each pictured object. These results support the hypothesis that a foreign script can exert a negative influence on L2 phonological acquisition. This inhibitory effect of a written input has thus far not been attested in any other L2 acquisition studies of this kind involving a foreign script.
Two questions about these findings are whether the Arabic script or the L2 phonological contrast, or both, was an inhibitory factor in phonological acquisition. First, recall from the discussion of Showalter’s results (2012) that no significant difference was found between two groups of L2 Arabic learners differing on the basis of their spelling exposure (i.e. Arabic script vs. a string of non-discrete Arabic letters). On the other hand, the present experiment used a similar experimental design and did find a significant difference in phonological accuracy between the two groups of learners. It therefore follows that the availability of the Arabic script in these two experiments cannot be the sole explanation for the differential outcomes observed since both experiments made use of the same foreign script. Furthermore, note that for literate English participants approaching the Arabic script from the words’ left edge, all the relevant minimal pairs appear nearly identical, thus engendering a similar contrast-neutralizing influence of script in both Showalter’s study (2012) and the present one. Hence, the nature of the L2 contrast to be acquired seems to be important here. Second, recall from Mahmoud (2013) that perceptual discriminability between the contrasts /k/–/q/ and /ħ/–/χ/ was not found to be significant, although discrimination was lower for the latter contrast. Based on these results then, the inhibitory effect obtained with the Arabic script cannot be ascribed to a significant difference in perceptual discriminability between Showalter’s (2012) stop contrast and the fricative contrast chosen here. Essentially, both contrasts appear to be difficult to distinguish for English listeners, whether naive (Showalter, 2012) or more experienced (Mahmoud, 2013).
If the foreign script, on one hand, and the unfamiliar contrast, on the other hand, cannot independently account for the present results, the only other possible explanation for the present inhibitory effect stems from the association of these two variables. Hence, the complete foreignness of the phonological contrast compounded by the complete foreignness of the script have joined forces in exerting too much confusion on the part of participants, so as to obliterate their successful creation of distinct phonological representations. In addition, although participants were not given any information about the Arabic script (such as its directionality of reading), it may be possible that some of them came to the experiment with that knowledge already. Accordingly, they would have then paid attention to the correct edge of the written words, but would have been equally hampered by the script because of the high similarity of the characters representing /ħ/ and /χ/, where only a dot serves to distinguish them (e.g. <
In sum, the unfamiliarity of the Arabic script coupled with an arguably more unfamiliar contrast led to significantly lower accuracy in establishing contrastive phonological representations, than learning this contrast without the support of any meaningful written representation. In parallel with Hansen’s (2010) research, these results therefore suggest that the Arabic script may have made it too difficult for learners to acquire the L2 contrast. Comparison to Showalter’s (2012) work also suggests that the contrast may have been too foreign.
2 No orthography vs. Cyrillic script
The reliance on a Cyrillic script served to explore the effect of another foreign script on the acquisition of minimal pairs exhibiting a /ħ/–/χ/ contrast. It was hypothesized that, given an allegedly challenging contrast to learn, the availability of an unfamiliar written representation in the course of that learning process would complicate the task of participants. It was nevertheless also hypothesized that given the Roman-like nature of the Cyrillic script used, such graphical representation would not be foreign enough to be able to exert an inhibiting influence, and may actually yield greater performance in comparison to another foreign script. The results demonstrate that participants in the
The results of this No orthography–Cyrillic script comparison are therefore analogous to those of the previous comparison. However, while the latter suggests that the foreign script effect occurs at a word-based level of representation given the complete foreignness of the Arabic script, the former suggests that this effect may also manifest itself at a letter-based level of representation since not all Cyrillic characters composing a non-native word were foreign looking (especially the ones standing in for the L2 contrast). This may have actually introduced a potential confound of L1 GPC activation inadvertently driving the effect (Escudero et al., 2014). The use of a hybrid script served to address this issue.
3 No orthography vs. Hybrid script
The implementation of a hybrid script aimed to probe the possible letter-based effect of a foreign script on the acquisition of the Arabic contrast. Consequently, the Hybrid script was used to investigate the input of character unfamiliarity by relying on word-initial non-Roman-like Cyrillic letters while keeping the rest of the orthographic material in Roman script. Even though performance in the
VI Conclusions
The current results present a scenario that has thus far not been attested with respect to the influence of unfamiliar written input on L2 phonological acquisition: exposure to a foreign script in the early stages of L2 vocabulary learning can significantly hinder the formation of target-like phonological representations. Specifically, the unfamiliar graphics of the Arabic script are particularly distracting to second language learners accustomed to Roman-based writing systems (see Hansen, 2010). It remains to be seen whether other completely foreign-looking scripts (e.g. Hangul, Hiragana, Kanji) can exert a similar influence on the acquisition of novel phonological properties (e.g. contrasts, phonotactics, tones).
Finally, this study also provides further evidence for the influential role of native orthographic rules in the early acquisition of a non-native phonological contrast. Indeed, a decipherable written input may well encourage assimilation to L1 phonemic categories. In other words, the processing of the visual input prompts the auditory system to strengthen activation of native phonological units, in turn impeding the complete appreciation of novel sound distinctions. Early L2 speech perception and subsequently acquisition is thereby very much multimodal, subject to instantaneous and automatic processing akin to the well-known McGurk Effect (McGurk and MacDonald, 1976). The task of forming a nascent interlanguage phonology becomes therefore complicated by this early integration of audiovisual information that pushes learners to converge on already established categories in the L1. Future research will have to determine the extent of this audiovisual integration as well as the specific factors leading to differential effects of orthography (whether familiar or unfamiliar) on first-exposure learners’ acquisition of a second language phonological system.
Footnotes
Appendix
Auditory, visual, and written stimuli for each L2 word-learning conditions.
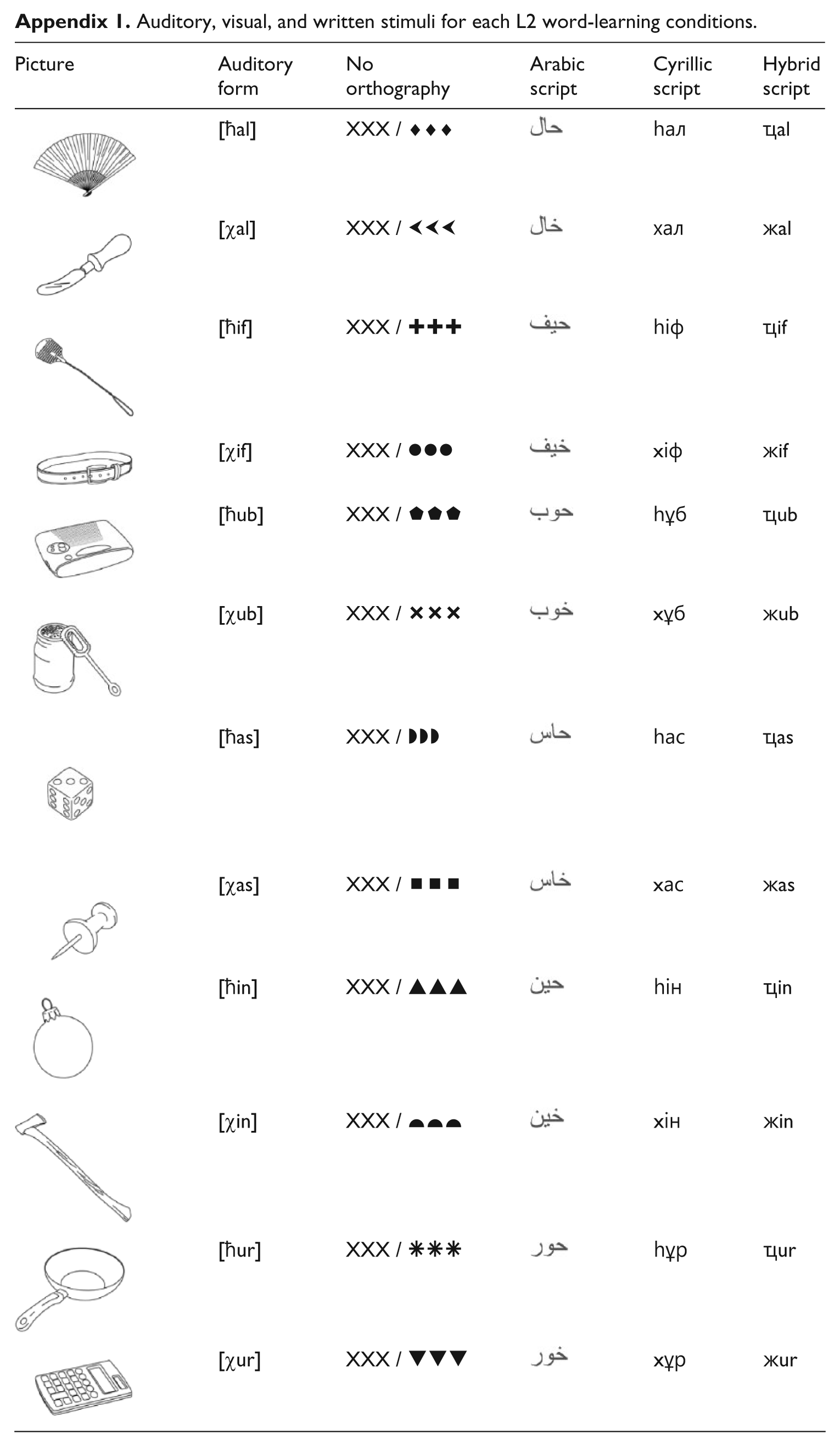
| Picture | Auditory form | No orthography | Arabic script | Cyrillic script | Hybrid script |
|---|---|---|---|---|---|
| [ħal] | һал | ҵal | |||
| [χal] | хал | жal | |||
| [ħif] | һіф | ҵif | |||
| [χif] | xіф | жif | |||
| [ħub] | һұб | ҵub | |||
| [χub] | xұб | жub | |||
| [ħas] | һас | ҵas | |||
| [χas] | xас | жas | |||
| [ħin] | һін | ҵin | |||
| [χin] | xін | жin | |||
| [ħur] | һұр | ҵur | |||
| [χur] | xұр | жur |
Acknowledgements
I am grateful to Michael Hammond, Diane Ohala, Rachel Hayes-Harb, Janet Nicol, and Jessamyn Schertz for their guidance and insightful comments on earlier drafts of this work. I am also grateful to Sean Harley and Vincent Ruhl for their assistance in the data collection phase of this study conducted at the University of Arizona. A portion of this study was presented at the 32nd Annual Second Language Research Forum in Provo, Utah, USA.
Declaration of conflicting interest
The author declares that there is no conflict of interest.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The University of Arizona has provided university-internal doctoral grant to support this research.