
Abstract
Acoustic and perceptual studies investgate B2-level Polish learners’ acquisition of second language (L2) English word-boundaries involving word-initial vowels. In production, participants were less likely to produce glottalization of phrase-medial initial vowels in L2 English than in first language (L1) Polish. Perception studies employing word monitoring and word counting tasks found that glottalization of word-initial vowels had a negligible impact on the processing of L2 word boundaries. Taken together, these experiments suggest that B2-level learners are relatively successful in acquiring word-boundary linking processes that are for the most part absent from L1 Polish, and challenge the notion of an L2 ‘Word Integrity’ constraint. The cross-language interactions observed in these experiments are compatible with the claim that the realization of word-initial vowels is governed by a representational parameter, which may be derived in the Onset Prominence framework.
I Introduction
In the domains of both speech production and speech perception, there is a fairly substantial body of literature devoted to word boundaries. Lengthening and/or articulatory strengthening of word-edge segments is commonly described, as well as shortening and/or weakening of segments not directly adjacent to word boundaries (Beckman and Edwards, 1990; Fougeron and Keating, 1997; Lehiste, 1972). For example, durational differences have been observed in sequences that might be referred to as ‘boundary minimal pairs’ in English, with similar segmental makeup differing only in the location of the boundary, such as help a snail vs. help us nail (Christie, 1997), free Danny vs. freed Annie (Boucher, 1988), and tune acquire vs. tuna choir (Turk and Shattuck-Hufnagel, 2000).
By contrast, in the field of second language (L2) speech research, only a small amount of work has investigated the production and perception of word boundaries (for a review, see Section II). Consequently, it is difficult to find common themes with respect to word-boundary phenomena in the speech of second language learners. However, in this relatively sparse literature we do encounter one hypothesis that makes strong predictions about word boundaries in L2 speech. Cebrian (2000: 19) posits the existence of ‘an interlanguage prosodic constraint that restricts the application of rules to the level of the phonological word’, which may be formulated as a propsal for L2 ‘Word Integrity’ (WI; see also discussion in Zsiga, 2011). According to the WI hypothesis, L2 learners should not be expected to transfer L1 sandhi processes by which word-edge segments are subject to the effects of segments in the neigboring word, and they should be expected to have difficulty in the acquisition of processes that obscure word boundaries.
Probably the most widely studied L2 boundary phenomena are the French processes of liaison and enchaînement, by which consonants are inserted at the beginning of vowel-initial words. Research in this area includes classroom studies investigating learners’ production of liaison with a focus on the lexical and stylistic variation observed in the target language (e.g. Howard, 2004, 2006, 2008; Sturm, 2013), as well as experimental studies (e.g. Shoemaker, 2010; Spinelli et al., 2003) of the acoustic and perceptual properties associated with pairs that differ only by boundary location (un air ~ un nerf). Likewise, a number of perception studies have been performed on such boundary minimal pairs in L2 English (e.g. a nice man ~ an ice man; Altenberg, 2005; Ito and Strange, 2009; Shoemaker, 2014).
In addition to testing learners’ ability to segment the speech stream in an L2, these studies have provided data on the relative perceptual salience of different types of boundary phenomena, including aspiration of initial stops (keeps talking vs. keep stalking) and glottalization of initial vowels. In each case, vowel glottalization has been found to be a more robust boundary cue than aspiration for non-native listeners. An implicit or even partially explicit assumption of this work is that glottalization of word-initial vowels is a kind of ‘universal phonetic default’ (Ratcliffe, 1996; cited in Altenberg, 2005: 345) that is also common in English. As a ‘universal default’, the phonological status of glottalization is implicitly assumed to be largely equivalent in the L1 and the L2. However, with regard to vowel glottalization, there is reason to suggest that its phonological status may differ across languages. Word-initial vowels in English are frequently susceptible to linking processes (e.g. Cruttenden, 2001) that are reminiscent of liaison and enchaînement, including resyllabification (find out ~ fine doubt), linking or intrusive /r/, as well as glide-like transitions (two eyes ~ too wise). 1 This contrasts with languages such as German (Wiese, 1996), Czech (Palková, 1997) or Polish (Schwartz, 2013a), in which vowel glottalization is common phrase-medially and even word-medially, and blocks the type of linking processes found in French and English.
This article will present acoustic data from Polish learners of English producing C#V sequences in both L1 and L2, as well as perceptual data from L2. The purpose of the experiments was to shed light on the predictions of the Word Integrity proposal as applied to Polish learners of English. Linking processes involving vowel-initial words are common in English, so learners constrained by a putative L2 WI constraint should be expected to have difficulty in this area. This challenge should be even greater for L1 Polish speakers for whom glottalization of vowels is a common phenomenon. Thus, the WI proposal predicts that our participants should produce more glottalization in L2 than in L1, and that their processing of linked initial vowels should be hindered.
The rest of this article will proceed as follows. Section II will review the literature on word boundary effects in L2 speech. Section III provides a comparative review of vowel glottalization in English and Polish. This is followed by the production study in Section IV and the two perception studies in Section V. Section VI offers general discussion of the phonological considerations underlying the effects investigated in this article, and a brief sketch of a representational proposal from which the cross-language differences observed in this article may be derived.
II Previous work on word boundaries in L2 speech acquisition
The literature on boundary effects in L2 speech is quite limited, because segmental contrasts, which are the focus of the most influential models of second language phonology, tend to dominate acquisition studies. The previous research that is relevant for our purposes may be placed into three categories: (1) production studies that have investigated the degree to which learners transfer boundary effects from L1 to L2, (2) the acquisition of boundary processes in an L2, and (3) perception studies that have investigated learner sensitivity to phonetic detail in the discrimination of so-called boundary minimal pairs.
One current in L2 research investigates whether learners transfer boundary effects from L1 into L2. These studies bear on Cebrian’s (2000) Word Integrity proposal discussed earlier, which was borne out of a discrepancy in the transfer of L1Catalan phonological processes into L2 English. Catalan is characterized by two processes that neutralize laryngeal contrasts: final obstruent devoicing and voicing assimilation at word boundaries. Final devoicing is described as a domain-internal process. Voicing assimilation is a sandhi process that spans prosodic constituents. In the speech of Catalan learners of English, Cebrian found that devoicing is widespread, but the assimilation process is not. It thus appears as though the sandhi process is not a candidate for L1 interference, leading Cebrian to claim that L1 sandhi processes are not transferred into the L2; interlanguage Word Integrity is maintained.
In another study, Zsiga (2003) examined articulatory overlap at word boundaries in English and Russian as both an L1 and an L2. Earlier studies had suggested that L1 Russian is characterized by less overlap than L2 English. In Zsiga’s study, English speakers tended not to transfer their L1 patterns of articulatory coordination (e.g. palatization of /sj/ in miss you, but not Boris Yeltsin). Zsiga’s results may be said to provide some support for the proposal of Word Integrity, since the English speakers, whose L1 shows greater articulatory overlap at word boundaries, did not transfer their native pattern. In later work, Zsiga (2011) studied a sandhi obstruent nasalization process in L1 Korean and in Korean-accented English. As a group, Korean learners of English transferred the L1 nasalization process into the L2 at a relatively high rate, a result that may be taken as evidence against Word Integrity. At the same time, however, three of the 12 speakers in her study maintained separation between words. Zsiga therefore includes the possibility of Word Integrity in her model of L1–L2 articulatory coordination.
In a study with more direct bearing on the present study of vowel glottalization, Lleo and Vogel (2004) investigated the acquisition of L2 German by Spanish L1 speakers. They focused on two phonological processes with implications for the Word Integrity proposal. L1 Spanish is characterized by a sandhi spirantization process by which word-initial voiced stops are realized as fricatives or approximants between vowels. German is characterized by harter Einsatz or ‘hard attack’, realized as glottalization on foot-initial vowels (e.g. Wiese, 1996: 59). The Word Integrity proposal would predict that Spanish learners of German should be successful in both the suppression of L1 spirantization as well as the acquisition of glottalization, since both would result in strong word-initial segments. Lleo and Vogel’s analysis revealed conflicting results. The learners in their study managed for the most part to suppress the spirantization process (around 80%), yet their acquisition of harter Einsatz was less successful (under 50%). Under the assumption that harter Einsatz serves to preserve Word Integrity in L2 German, its unsuccessful acquisition by L1 Spanish learners constitutes evidence against the WI proposal.
While the research discussed above has investigated the transfer or lack of transfer of L1 sandhi processes into the L2, much less work has been devoted to the acquisition of L2 sandhi. One exception to this generalization is L2 French. A number of studies (e.g. de Monas, 2013; Howard, 2004, 2006, 2008; Sturm, 2013) have examined L1 English speakers’ production of liaison. This research has investigated the variable status of liaison (obligatory, forbidden, optional) in the target language. A common finding is that Anglophone learners are successful in producing obligatory liaisons, but often overgeneralize the pattern to contexts where liaison is not produced in L1 French. These studies have for the most part have been impressionistic in nature, and have not explored the phonetic realization of learners’ productions in detail. By contrast, Shoemaker (2010) examined the perceptual effects of duration as a cue to disambiguating word boundary minimal pairs in French. She found that advanced L1 English learners showed near-native performance in a forced-choice identification task.
With regard to L2 English, Whitworth (2003) examined prevocalic boundaries in the speech of German–English bilinguals. Those for whom German was L1 for the most part did not suppress German-style glottalization. Schwartz et al. (2014) investigated the phonetic interaction between linking and final voicing in C#V sequences in Polish-accented English. They found a robust link between the suppression of glottalization and native-like production of final voiced obstruents. Final obstruent devoicing is an established feature of a Polish accent in English (Gonet and Pietroń, 2004; Scheuer, 2003). Since linking alters the ‘final’ status of word-final obstruents, its acquisition by Polish learners may be a pre-emptive step in avoiding final voicing errors. In another study, Šimáčková et al. (2014) looked at the production of linking vs. glottalization of vowel-initial words in Czech-accented English. They found that linking was more common in faster utterances. This finding is compatible with other findings of glottalization in L1 German (Pompino-Marschall and Żygis, 2011) and Polish (Schwartz, 2014).
With regard to perception of boundaries in L2 English, a number of studies have dealt with allophonic cues to boundaries in pairs of words with similar segmental sequences (a nice man ~ an ice man). Altenberg (2005) found that vowel glottalization had a greater effect than aspiration on correct identification rates for L1 Spanish listeners. That is, Spanish listeners were more accurate in discriminating between a nice man from an ice man (with glottalization in the latter), then they were in pairs such as keeps talking ~ keep stalking (with aspiration on the /t/ in talking). This finding has been reproduced for L1 Japanese listeners (Ito and Strange, 2009), and L1 French listeners (Shoemaker, 2014). Other perceptual studies on word boundaries in L2 English have employed word monitoring tasks (Bissiri et al., 2011; Volín et al., 2012), which tested the effects of vowel glottalization on reaction times in response to a target word. In these works, glottalization was found to quicken response times for Czech, Spanish, and Slovak learners of English.
In sum, research on boundary effects in L2 speech is still quite limited, and a number of questions remain. The word monitoring experiments, as well as the ‘minimal pair’ studies of Altenberg, Ito and Strange, and Shoemaker, say nothing about production of boundaries by L2 learners. The latter works also deal with L1s (Spanish, Japanese, French) in which word integrity appears to be relatively weak and glottalization is relatively uncommon, yet the vowel-initial stimuli used in those studies were glottalized. Finally, data on the relative robustness of different boundary cues (aspiration vs. glottalization) provide little insight into the question of word integrity; such studies are more concerned with the identification of boundary location rather than the relative strength of the boundaries. Of the production studies on linking and glottalization, only Whitworth, which featured speakers from bilingual families rather than L2 learners, provided data from the same speakers in both L1 and L2. Zsiga’s works are quite important in this regard, since she includes L1 and L2 data from the same speakers. However, her studies do not address C#V linking or the perception of boundary effects. In what follows, we shall try to fill some of these gaps, presenting production data from Polish learners of English on linking vs. glottalization in both L1 and L2, as well as perception data investigating the effects of glottalization vs. linking on the processing of word boundaries.
III Linking vs. glottalization of vowel-initial words in English and Polish
In the experiments described in this article, the realization of word-initial vowels will be operationalized as a binary distinction between linked vs. glottalized productions. While this may be something of a simplification, cross-language oppositions between languages like German with robust glottalization, and French with almost no glottalization and robust linking processes, suggest that the behavior of initial vowels is governed by some sort of categorical feature setting that may differ across languages. In Section VI we will discuss the phonological implications of this issue in more detail.
Textbooks dealing with English phonetics and phonology (e.g. Cruttenden, 2001; Giegerich, 1992; Roach, 1983) suggest that English is a language of the linking type. For example, Giegerich (1992: 280) describes a sentence These are old eggs, syllabified as [ðiː.za.roʊl.degz], in which, according to a process he calls liaison, the word-final consonants become onsets to the following word-initial vowels. Related effects, such as the well-known phenomena of linking /r/ and intrusive /r/, have been observed in vowel hiatus contexts. These linking processes are typically assumed to be motivated by a universal preference for syllables with consonantal onsets.
Experimental phonetic studies of vowel glottalization in English (e.g. Dilley et al., 1996; Garellek, 2012; Redi and Shattuck-Hufnagel, 2001) have for the most part examined the effects of higher-level prosodic structure, as well as other factors, on the likelihood of vowel glottalization. Phrase-initial position and stress have been consistently identified as robust predictors of glottalization. Other factors include the preceding segment (in particular hiatus environments), vowel quality, word type (content vs. function words), and sex. For a review, see e.g. Garellek (2012).
Since phonetic studies have described glottalization and its realization in English extensively, it is tempting to dismiss the earlier pedagogical tradition and suggest that English is a ‘glottalizing’ rather than a ‘linking’ language. However, when data from these studies are sorted for stress and prosodic position, it becomes clear that glottalization is far from being the default realization for word-initial vowels in English. For example, although Garellek (2012: 8) notes that 53% of the word-initial vowels in his corpus showed some form of glottalization, when his results are sorted for prosodic factors (Garellek, 2002: Figure 3, p. 12), we see robust effects of prominence and prosodic position such that the glottalization rate for unstressed vowels ranges from less than 5% (after Break Index 0) to only about 25% (after Break Index 5, post-pausal). Even at Break Index 3, the intermediate phrase boundary, the glottalization rate given by Garellek is lower than 10%. By the same token, Davidson and Erker (2014) found a relatively high glottalization rate of 44%, but 75% of the initial vowels in their reading text were stressed. Unstressed vowels were glottalized at a rate of around 20% in their study. 2
There are far fewer experimental studies of vowel glottalization in Polish. Malisz et al. (2013) examined a corpus including both spontaneous utterances and prepared speeches, observing an overall glottalization rate of about 45% (58.1% vs. 40% sorted for stress, and 55.1% vs. 34.6% sorted for phrasal position). These rates are much higher than what has been found for English for phrase-medial position and for unstressed initial vowels. Schwartz (2013a) employed a sentence reading task of phrase-medial hiatus tokens and found a higher rate of 76% (94% stressed, 68% unstressed). The differences between the Malisz et al. and Schwartz studies may be attributable to the experimental tasks. In the latter study, participants produced shorter utterances in a reading task, while the former included spontaneous speech in larger utterances. In sum, although direct cross-language comparisons are not available, the general picture that emerges is as follows. In phrase-medial and unstressed positions, Polish is more likely to glottalize word-initial vowels than English. In more prominent positions, the likelihood of glottalization in English increases significantly, obscuring the cross-language differences.
The realization of word-initial vowels in Polish may be related to a more general aspect of Polish prosody. It is widely accepted (see e.g. Dogil, 1999; Kraska-Szlenk, 2003; Malisz & Wagner, 2012) that word-initial syllables in Polish are in fact marked with secondary stress (when they are not penultimate and bear primary stress). Phonetic evidence for this prominence has been found by Dogil (1999) and Newlin-Łukowicz (2012). When initial syllables lack an onset consonant, glottalization may be seen as a fortition that preserves the vowel and prevents elision or weakening. Thus, the function of glottalization appears to differ in the two languages. In English, it is a phrase-level boundary marker, while in Polish it is a word-level phenomenon that maintains the prosodic integrity of a prominent syllable. In the parlance of Optimality Theory (OT; Prince and Smolensky, 2004), glottalization in English is therefore an insertion of an element that is absent from the phonological representation (
The tendency for glottalization in Polish, along with the phonetic prominence of initial syllables more generally, appear to reflect a further reaching aspect of Polish with respect to word boundaries. On the basis of a comparison between German and Spanish, Lleo and Vogel (2004) propose a typology of ‘demarcating’ vs. ‘grouping’ languages. In the former type, of which German is an example, word boundaries are strong, as evidenced by vowel glottalization. By contrast, Spanish is an example of a ‘grouping’ language in which words are linked by means of sandhi processes rendering word boundaries essentially indistinguishable. For example, due to a C#V resyllabification process, the items porosos ‘porous’ and por osos ‘for bears’, are identical, pronounced as /po.ɾo.sos/ (Lleo and Vogel, 2004: 87). Thus, the word internal syllabification pattern is observed also at word boundaries.
According to Lleo and Vogel’s typology, English must be considered a grouping language. Sandhi processes that obscure word boundaries are quite common. These include C#V linking (find out ~ fine doubt), /t/ lenition (I bough[ɾ] everyone a drink), linking /r/ (car /kaː/ ~ car always [kaː ɹɔːlweiz] breaks down), and intrusive /r/ (saw [sɔː] ~ saw everything [sɔːɹ]). By contrast, Polish appears to be a demarcating language. Beyond the question of vowel glottalization, sandhi processes of the type described for grouping languages are unattested. If Polish were a grouping language, the word initial /t/ in a phrase such as do teatru ‘to the theatre’ would be pronounced as [do θeatru] or [do ɾeatru] at neutral speech rates. I have never heard such pronunciations in Polish, nor have I seen them described in any published work.
An important aspect of the grouping-demarcating distinction is that it appears to allow for categorical cross-language classification. Thus, although the phonetic realization of various boundary effects may be subject to variability on the basis of speech rate, style, or any number of other factors – glottalization rates never reach 100% in actual speech – the behavior of word boundaries across languages is clearly governed by forces that phonological in nature. Assuming that the glottalization vs. linking opposition has implications for Cebrian’s Word Integrity proposal and Lleo & Vogel’s demarcating vs. grouping typology, Polish learners of English should constitute a rich testing ground for an examination of word boundaries in L2 speech. Polish appears to be a demarcating language in which Word Integrity is strong, a feature that learners must suppress in their acquisition of L2 English.
IV Production of C#V sequences by Polish learners of English
This section will describe a production study of C#V sequences in the speech of Polish students of English, both in their L1 and L2. The study aims to test the following alternative hypotheses:
Hypothesis 1: Under the influence of an L2 WI constraint, learners should be expected to produce more glottalization of vowels in L2 English than in L1 Polish.
Hypothesis 2: In the absence of an L2 WI constraint, learners should be expected to produce less glottalization in L2 than in L1, having made progress in acquiring English-style linking processes.
1 Participants
14 Polish students of English, in their first year of studies at the Faculty of English, Adam Mickiewicz University (UAM) in Poznan, participated in the production study. Ten of the participants were female and four were male. Their level of English was B2 according to the Common European Framework for Languages. They were all between the ages of 19 and 26 years, and they all had studied English in primary and secondary schools. None of the participants reported spending more than one month in an English-speaking country.
Seven native speakers of English also participated in the experiment as controls. All of the speakers were males between the ages of 35 and 50 employed as practical English teachers in the Faculty of English at UAM. Unfortunately, at the university in Poznan it was not feasible to gather a homogeneous group of L1 English speakers. Of the seven, two were from the South of England, two from the North of England, and one each from the USA (born in Ohio), Canada (Alberta), and Australia (Perth). All of the native speakers had been living in Poland for more than 10 years.
2 Materials
The L2 English data set was comprised of 16 phrases (4–7 words) containing C#V sequences (see Appendix 1). L2 English data were collected in two conditions: a reading task and a repetition task (see below). A total of 448 (2 repetitions * 16 items * 14 speakers) L2 vowel-initial tokens were recorded. The control group only produced one repetition, yielding a total of 116 native English tokens (7 speakers * 16 items). The L1 Polish materials were comprised of a set of 30 two-word phrases (see Appendix 1) in which the second word was vowel-initial (C#V).
In the preparation of the data sets, an attempt was made to elicit the effects of L2 Word Integrity by creating materials that would favor glottalization in L2 English but not in L1 Polish. Consequently, in the English data set, all of the vowel-initial words were content words that were stressed on the initial syllable, factors that are conducive to glottalization (e.g. Garellek, 2012). Unlike the English set, the Polish initial vowels were counterbalanced for stressed and unstressed positions. In addition, the slightly shorter phrases in Polish guaranteed that the target items were produced in phrase-medial position, diminishing the likelihood of glottalization. Finally, three of the Polish items were prepositions or pronouns, function words that are unstressed and less likely to be produced with glottalization.
It may be expected that the combination of the factors of stress, target items, and hypothesized L2 Word Integrity should contribute to higher rates of glottalization in L2 English than in L1 Polish (Hypothesis 1). 3 It is for this reason that the differences in design between Ll and L2 were necessary, particularly with regard to stress. If the data set were balanced with regard to stress in L1 and L2, it would be impossible to tease apart the effects of stress to provide an effective test of the L2 Word Integrity hypothesis. That is, the true focus of this study is the acquisition of linking in L2 English. To isolate the acquisition of linking, it was necessary to skew the L2 materials in favor of glottalization, a strategy that would provide more solid confirmation of Hypothesis 2 that the participants had made progress in learning to produce linked word boundaries.
The other challenge underlying the design of the study was the need to control for sentence-level prosody. With regard to this issue, the experimental materials were carefully constructed to ensure that vowel-initial items were not phrase-initial. As mentioned earlier, phrase-initial position has been identified as the most consistent predictor of glottalization in previous studies. Control of sentence-level prosody was bolstered by the short duration of the utterances, and the fact that half of the L2 items were imitations of an L1 model. However, most importantly, all speakers produced the same utterances in the present experiment, unlike most (but not all; see Davidson and Erker, 2014) studies of glottalization in which speakers produced distinct utterances.
3 Procedure
Recordings were made in a soundproof booth at the Faculty of English at Adam Mickiewicz University in Poznan. The booth was equipped with a professional quality microphone connected to a USB audio interface, which allowed recordings directly onto the experimenter’s laptop computer (44 kHz sampling rate, 16 bit quantization). The stimuli were presented to the participants on PowerPoint slides via a monitor that was located inside the recording booth. The experimenter operated the PowerPoint program from outside the booth. The participants were instructed to try to read the phrase quickly, and they were informed that the next slide would be presented immediately after the complete reading of the current slide. This procedure was adopted to avoid a tendency on the part of the participants, while in a recording studio, to produce speech that is slower and more careful than normal.
In the case of the L2 English stimuli, half of the slides were accompanied by an audio recording of one of the native controls’ linked productions of the target item, and the participants were instructed to repeat after the recording. The slides containing an audio recording contained a speaker icon that informed the participants that the task was to repeat after the voice rather than simply read the slide. The L2 English data set was also counterbalanced for repetition. That is, the first repetition of a given item was elicited in the reading task for half of the items, while for the other half the first repetition was an imitation of the native model. The L1 and L2 sets were recorded in separate sessions (one week apart) in an attempt to prevent language mixing effects (e.g. Grosjean, 1998). The students received course credit for their participation.
4 Analysis
Acoustic analysis was performed in Praat (Boersma and Weenink, 2013) by the author of the study, a native speaker of American English with native-like proficiency in Polish. The total duration of the stimulus phrases was measured in order to calculate speech rate in syllables/second. The vowel-initial tokens were coded as either glottalized or linked on the basis of visual analysis of the spectrogram and waveform displays, and confirmed by auditory impression. Illustrations of the annotation procedure are given in Figures 1 and 2. Figure 1 shows the sequence played excellent (songs), in which glottalization of the word-initial vowel in excellent is robustly visible in the selected portion of the waveform/spectrogram display. Note in this token that there is no full glottal stop: irregular periodicity begins immediately after the release of the /d/. Note also that the closure of the /d/ in played is almost fully voiced, so the voicing of the consonant has not inhibited glottalization (see Footnote 3). Figure 2 shows the sequence showed everyone, in which the initial vowel of everyone is selected. In this token, coded as linked, no irregularities in the periodicity of the vocal wave are visible.
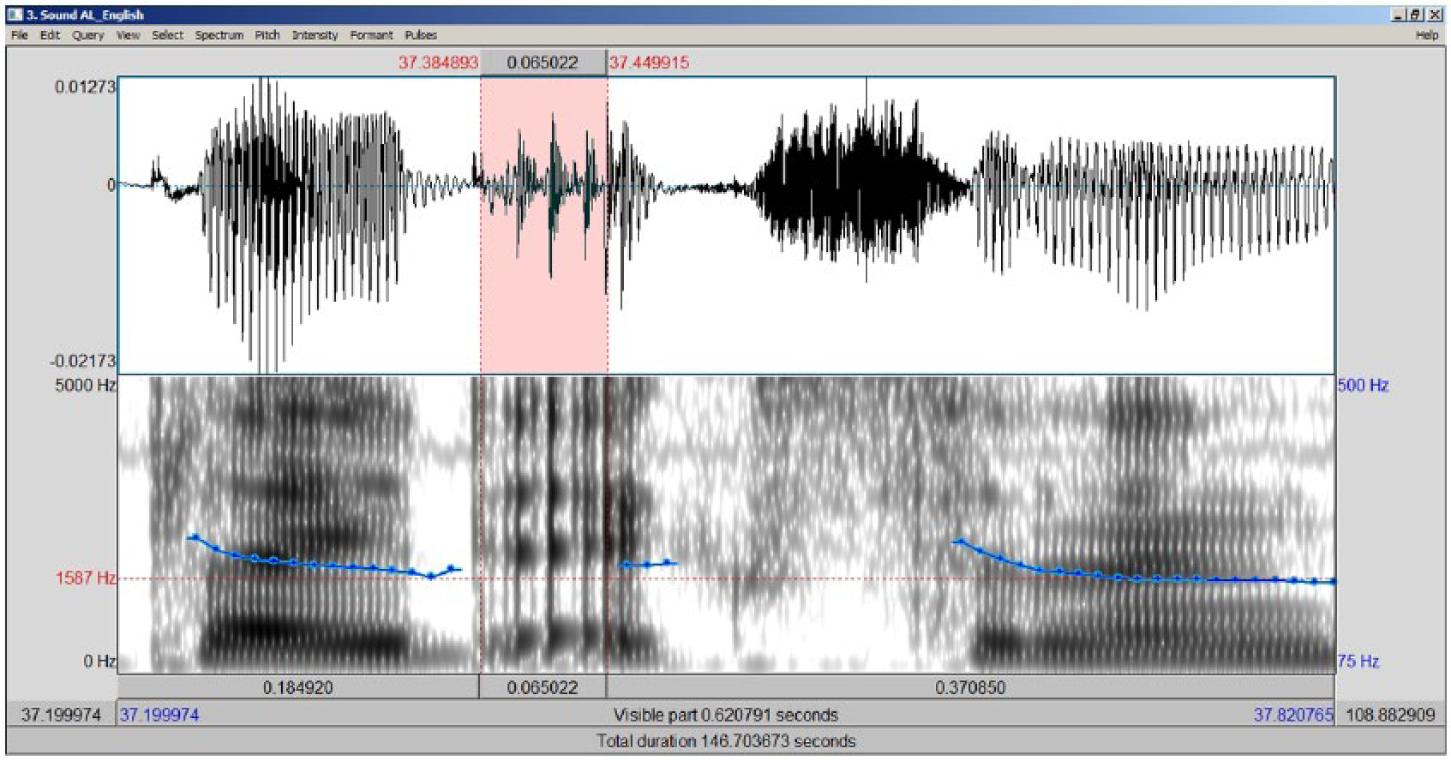
Glottalized /e/ in played excellent.
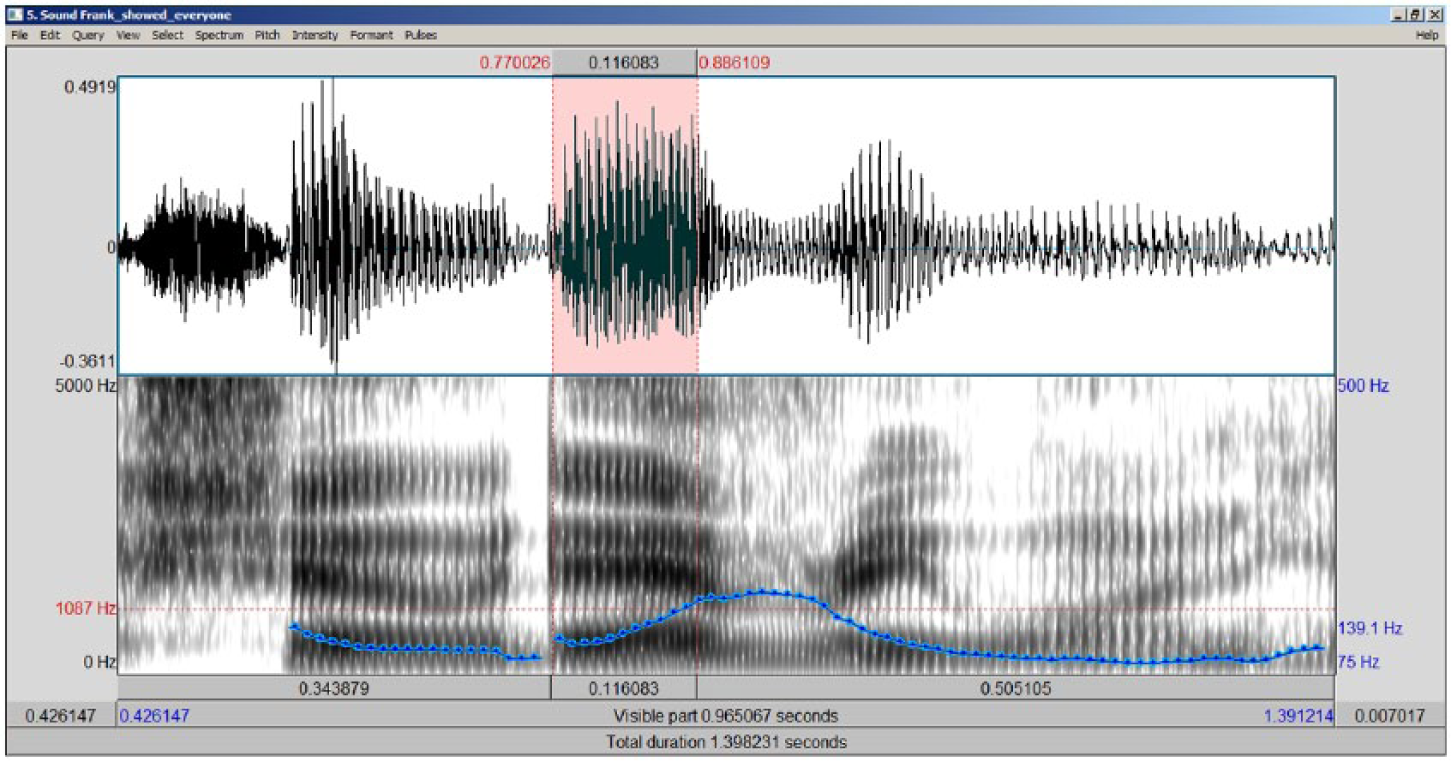
Linking in showed everyone.
Glottalization is frequently characterized by variability in its realization (Redi and Shattuck-Hufnagel, 2001), including full glottal stops, and various types of irregularities in the periodicity of the vocal wave. Local drops in pitch and/or amplitude have also been found to induce a percept of a glottal stop (Hillenbrand and Houde, 1996). However, only in hiatus contexts is it feasible to reliably identify such items. Thus, no attempt was made to include variability in the realization of glottalization in the analysis: items were coded simply as glottalized or linked. If the final consonant was followed by a silence of more than 50 ms (see Dilley et al. 1996), the item was dismissed as a pause and not included in the analysis. Seventeen items were eliminated as either a pause or an error.
To investigate the effects of various factors on the probability of glottalization, a series of generalized linear mixed models (GLMMs) was fitted in the SPSS statistical program (IBM corporation, 2013). The models employed a logit link function to the binary response variable of glottalization. Predictor variables included Target Language (English), Imitation, Stress, Repetition Number, Final Consonant, Native Language, and Speech Rate. In each case, Speaker and Item were included in the model as random factors. The model to be presented had the best fit according to the Aikake Information Criterion.
5 Results
Figure 3 summarizes the glottalization rates as a function of the Target Language variable, i.e. whether or not the participants were speaking in English or Polish. The rows separate the learners (top row) from the native controls. The bars are color-coded for stress, while the columns sort the data according to the reading and imitation tasks. We can see in the figure that the glottalization rates of the items produced in English are consistently lower. In the case of stressed items in the reading task, the glottalization rate in Polish was 89% (63% for unstressed) and 57% in English. The imitation task induced a glottalization rate of 46% in the Polish paticipants, while the natives produced glottalization in 44% of the items.
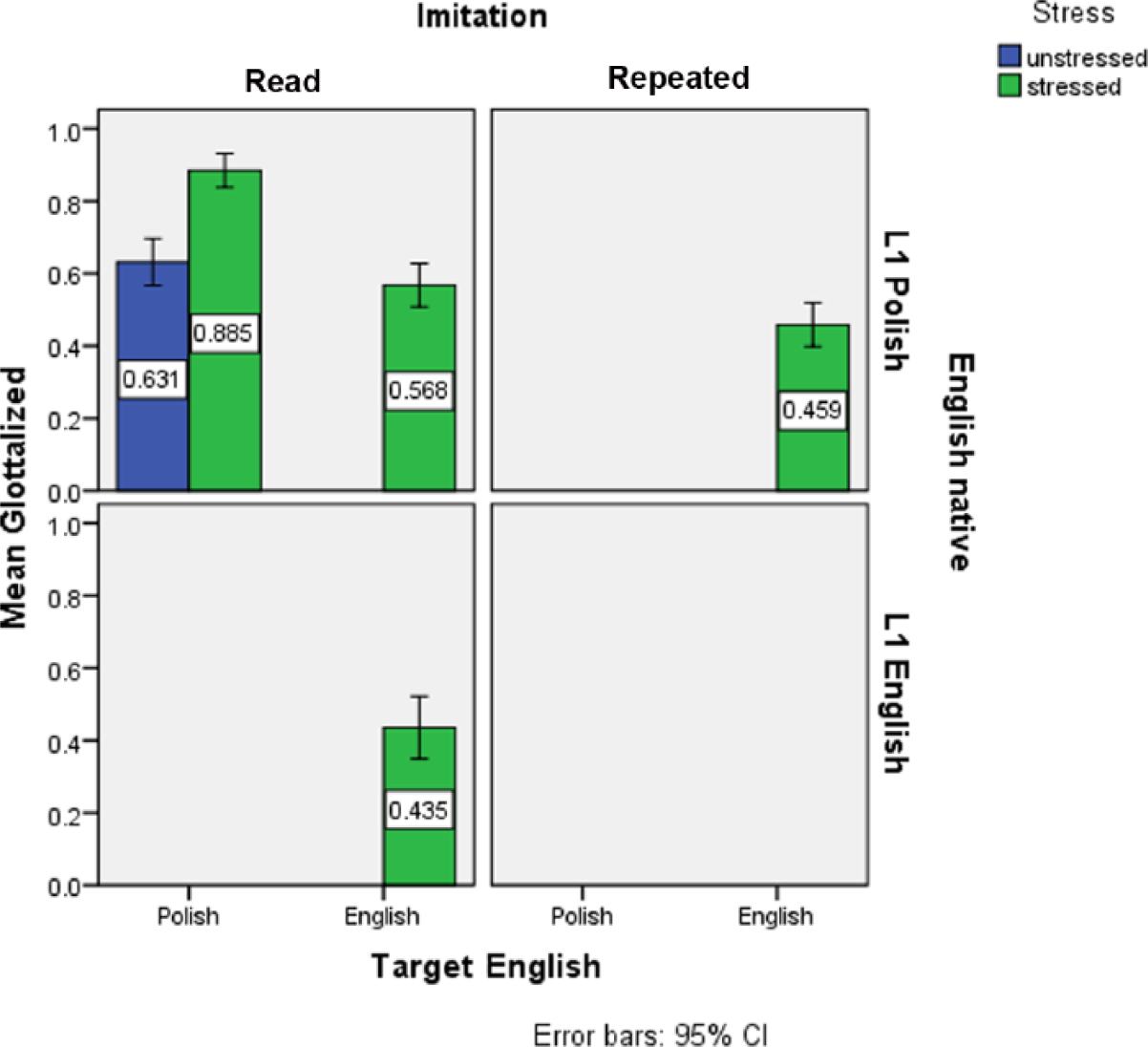
Proportion of glottalized tokens by Target Language (sorted for stress, task and native language).
In the best fitting statistical model, Target Language (Polish), Stress, and Task (Imitation) were significant predictors of glottalization. None of the other predictors, including Final Consonant, Speech Rate, and Native language, was significant. Thus, the best fitting model in the analysis included only those three predictors, the effects of which are shown in Table 1.
Significant predictors of glottalization according to the mixed effects model.

In an attempt to address potential problems stemming from the differences in experimental materials in L1 and L2, a series of five additional models was run. In each case, only a subset of the data was included to allow for more reliable comparison across speakers and items. Possible confounds were added as random factors, or simply not included in the data set. A summary of these models is given in Table 2. For each model, the relevant data set is provided, as well as a list of random factors and the results associated with the predictor variable of interest.
Summary of additional statistical models of the probability of glottalization.
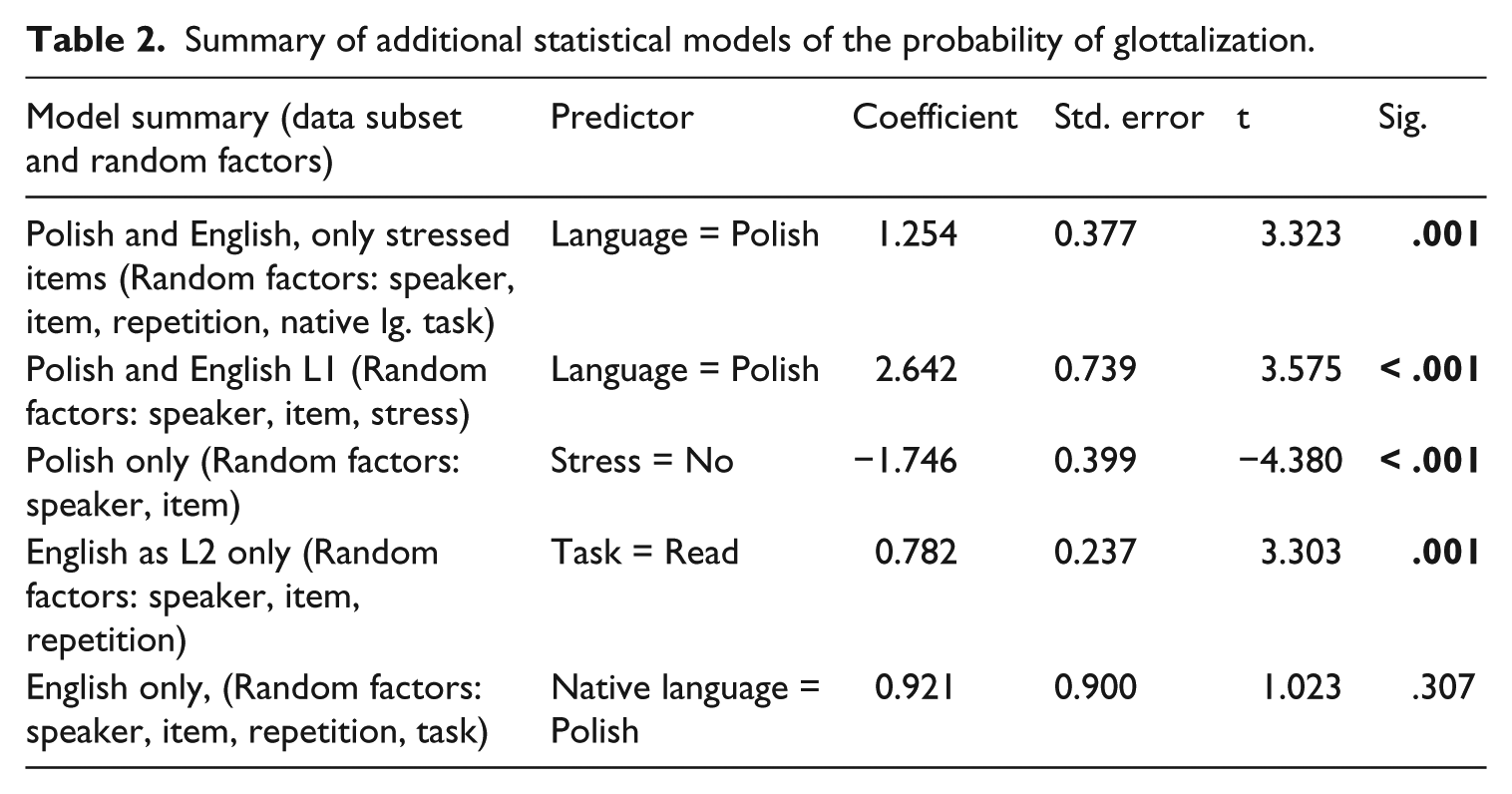
The first model looked only at stressed items in the two languages, with Target Language as significant predictor, p = .001. The second looked only at L1 production, again with Target Language as a significant predictor, p < .001. The third model was run on Polish items only, with stress as a significant predictor, p < .001. The fourth model was run on L2 data only, with Task as a significant predictor, p = .001. The final model was run on English items only, with Native Language as a predictor that was not significant, p = .307. In sum, the individual models confirm the results of the overall model in Table 1, with an additional comparison of L1 Polish with L1 English (the second model).
Results for the individual participants are summarized in Figure 4, which presents glottalization rates per individual participant in L1 Polish (the top row) and L2 English (the bottom row). The L1 glottalization rates are higher than L2 for all but two speakers: P8 (96.6% vs. 97.4%) and P5 (28% vs. 34%). The range of individual glottalization rates in L1 was 28% to 100%, while the lowest individual rate in L2 was 3% and the highest was 97%. As suggested by the figure, there was a significant correlation of glottalization rates in the L1 and L2 of individual speakers, rs (12) = .607, p = .021). The glottalization rates of the control groups were also subject to variability, ranging from 12% to 59%.
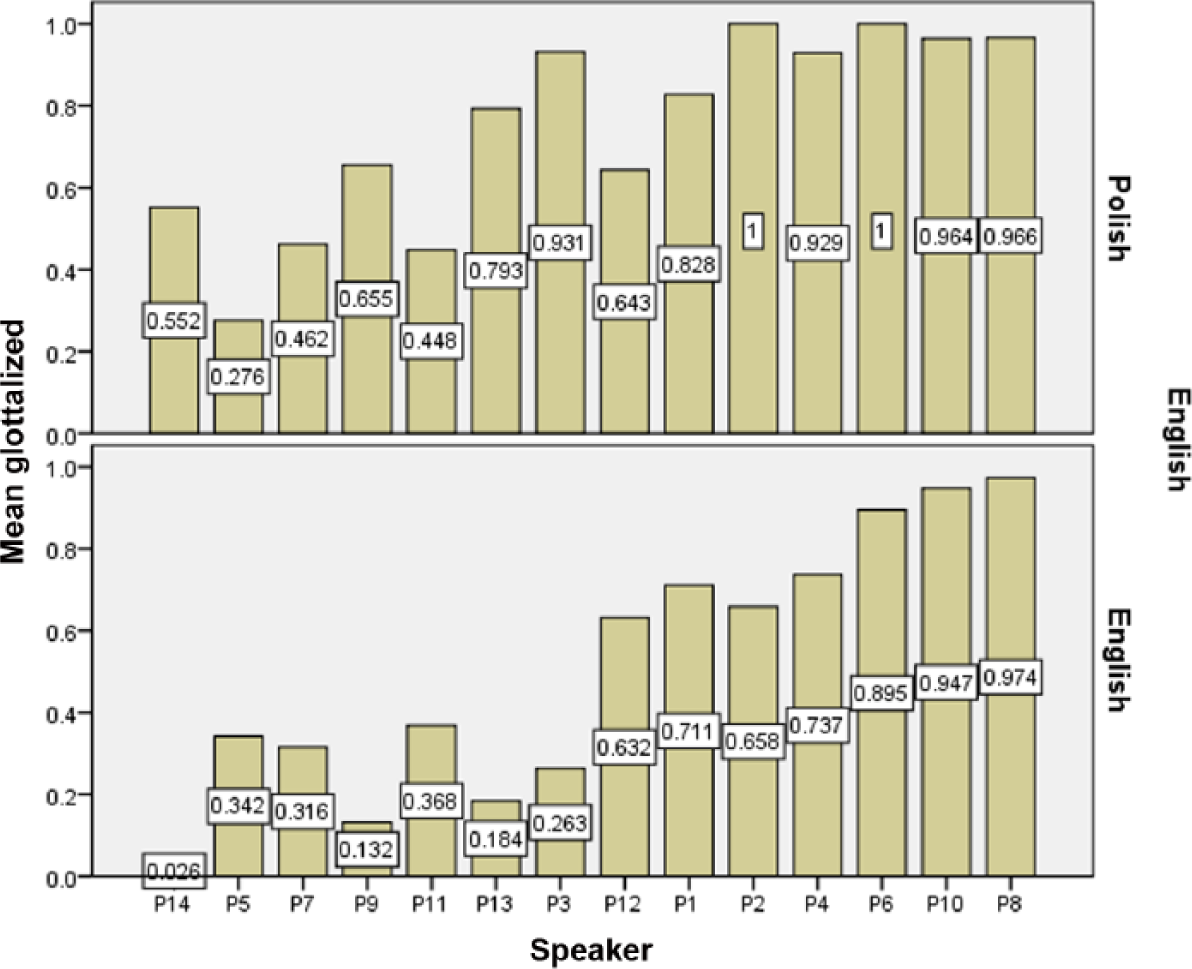
Proportion of glottalized realizations by individual Polish speakers in L1 (top) and L2.
6 Discussion
The results of the production study show that B2-level Polish learners of English produce less glottalization and more linking in L2 English than in L1 Polish, supporting Hypothesis 2 and suggesting that Hypothesis 1 should be rejected. The overall glottalization rate of the participants was 73% in L1, 57% in the read L2 tokens, and 46% in the imitated L2 tokens. It must be noted that the higher glottalization rate in L1 was observed despite the fact that all the L2 tokens bore lexical stress, compared to only half of the L1 items. Thus, these results show strong evidence against Word Integrity in the speech of the L2 learners, at least in the case of B2-level learners. The Word Integrity proposal, combined with the design of the data sets in the two languages, would have us expect more glottalization in L2 English, while the opposite effect was observed.
Despite the general trend that the Polish participants of this study have to some degree learned to suppress glottalization and have acquired English-style linking, there were still differences between L1 English speakers and Polish learners. When the natives’ reading results are compared with learners’ imitations of linked tokens, the glottalization rates were comparable. Since speech imitation tasks have been found to elicit convergence of non-contrastive phonetic detail (e.g. Shockley et al., 2004), the relatively high glottalization rate of 46% in the learners’ imitations, compared to 0% in the native stimulus tokens being imitated, suggests that glottalization in the speech of Polish learners is a phenomenon that is phonological in nature. In other words, glottalization in Polish English is observable even in an imitation task where it would be expected to be neutralized. It is therefore likely that is attributable to L1 phonological interference.
The variability in the data from the individual participants obscures the glottalization results to some extent, and should be studied more thoroughly with a larger number of participants. However, the general trend in the data, by which glottalization is more prevalent in the participants’ L1 Polish, appears to be quite robust. Additional comments on variability and how it might be studied are provided near the end of Section VI.
V Polish learners’ perception of linked vs. glottalized word boundaries
This section will present the results of two perception experiments designed to address the following research question: Does linking of vowel-initial words in L2 English hinder processing for L1 Polish learners relative to glottalization?
1 Word monitoring
The first perception data that we shall present are from a word monitoring task, modeled on the studies described in Bissiri et al. (2011) and Volín et al. (2012).
a Participants
Twenty B2 level Polish learners of English took part in the experiment. They were all students at the UAM Faculty of English. They performed the tasks at the beginning of their second year of studies. None of the participants reported spending more than 1 month in an English speaking country. None reported any hearing disabilities. The students received course credit for their participation. Additionally, a group of 10 native speakers of English took the test as controls.
b Stimuli
The stimuli were created from audio recordings of sentences produced by native speakers of English. Tokens were taken from 4 of the 7 speakers recorded in control group in the production study. In the word monitoring test 17 pairs of recordings (see Appendix 1), one with a linked vowel-initial word and one with a glottalized vowel-initial word were chosen, along with 18 additional recordings used as distractors. The durations of the paired stimuli were normalized using duration points from the manipulation option in Praat (Boersma and Weenink, 2013), then resynthesized using the PSOLA method. The point of the target word onset was entered into E-prime in order to calculate response time to the target word (rather than to the start of the audio file). The stimuli were divided into two blocks of trials to counterbalance linked and glottalized items. 4
c Procedure
The experiment was run on E-Prime (Psychology Software Tools, 2013) in the Language and Communication Laboratory at the UAM Faculty of English. Participants were seated at a computer and listened to the audio stimuli on high quality headphones. The volume was set to a comfortable level. In each trial in the word monitoring task, a target word was presented on the computer screen. This was preceded by a warning telling to the participants to get ready to respond. Then the recording started playing. Participants were instructed to press the space bar the instant they recognized the target word. The audio file stopped playing when the space bar was pressed. To obtain response time measures, the time of target word onset was recorded, enabling the calculation of response time to initial vowel of interest.
As in other studies (e.g. Bissiri et al., 2011), reaction times below 150 ms and above 1,000 ms were not included in the analysis, being attributable to false alarms and hesitations, respectively. Of the 1,020 (17 items * 2 conditions * 30 participants) responses to target items, 74 responses were discarded for this reason.
d Results
The mean response times for the linked vs. glottalized items are shown in Figure 5. A linear mixed model with Reaction Time as the dependent variable, fixed factors of Glottalization and Native Language, and random factors of Participant and Item revealed no significant effects, p > .05.
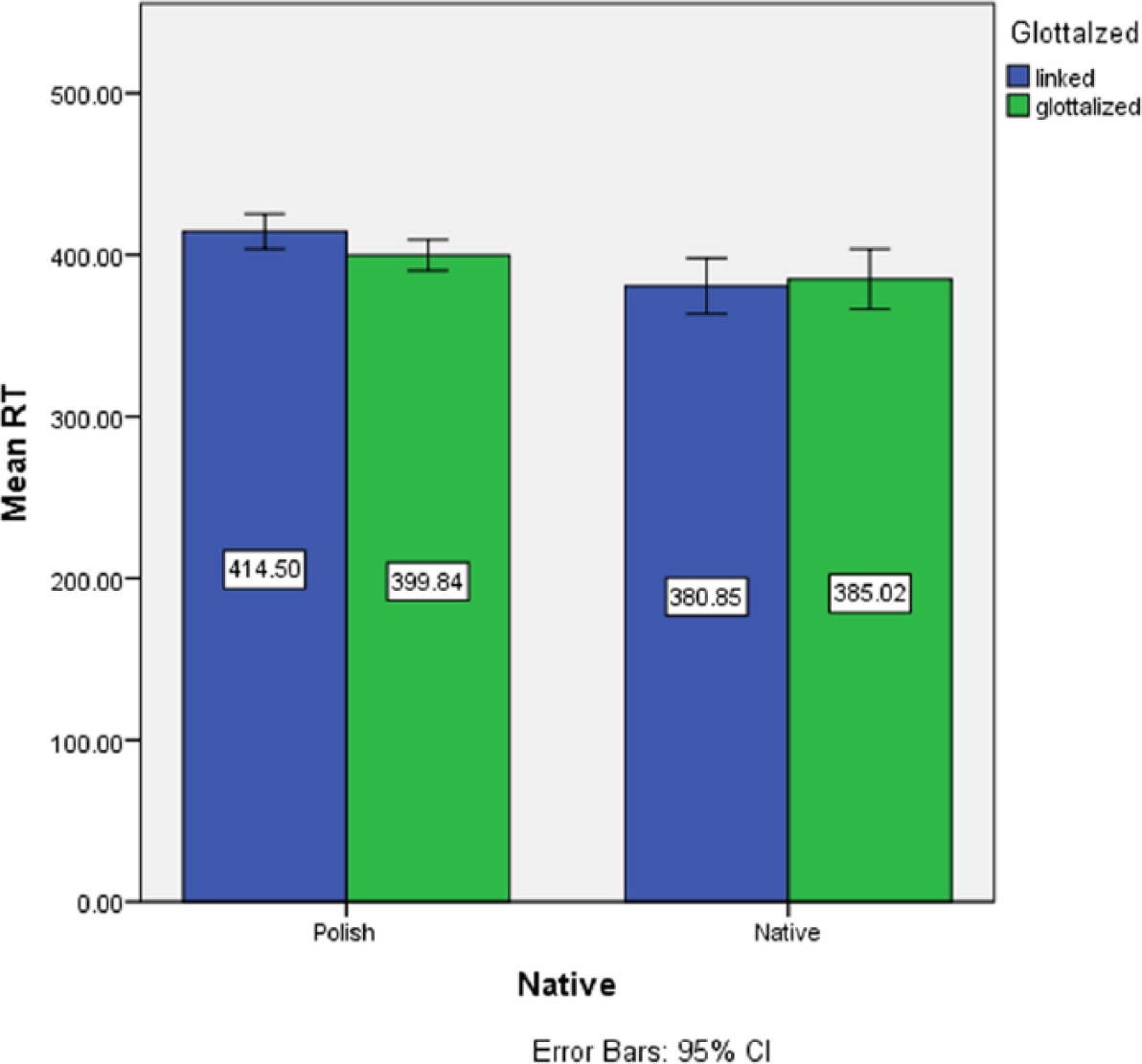
Mean response times (RTs) for linked vs. glottalized items in word monitoring task.
2 Word counting task
One possible weakness of the word monitoring paradigm is that the target word may prime higher-level biases that are not phonological. Thus, to provide further insight into the effects of glottalization vs. linking, an additional perception task was carried out. Rather than priming listeners with a target word for monitoring, this experiment required participants to respond whether they heard one word or two. Thus, this ‘word counting’ task may be claimed to investigate the perception of boundaries more directly than the word monitoring task.
a Participants
The participants of the word counting task were the same as in the word monitoring task.
b Stimuli
In the word counting test 12 pairs of recordings were chosen, which were later edited so that the recording only contained the two word sequence (see Appendix 1). These sequences were divided into pairs in which one was linked and one was glottalized. In addition, an additional set of 25 recordings of single words were included as stimuli for the word counting test. With 30 participants this produced 720 responses of interest (12 items * 2 conditions * 30 participants = 480), and 750 responses to distractors.
c Procedure
The experiment was implemented in E-Prime at the Language and Communication Laboratory at the UAM Faculty of English. Participants were instructed to listen to an audio stimulus and determine as quickly as possible whether they heard one word or two. Responses were set to the keys ‘A’ for 1 word and ‘L’ for 2 words, to which post-it notes with the numerals 1 and 2 were attached in order to guide the participants. During each stimulus, the text How many words? was displayed on the computer screen. After the response, the words Thank you for your response were displayed for 1,000 ms before the experiment moved on to the following item.
The time of the onset to the second word was noted in order to calculate response times from the word boundary in the case of two-word sequences. Response times for the one-word sequences were not analysed. The percentage of correct responses was also noted. The procedure started with 5 practice items, and participants were prompted to move from the first block to the second. Several practice runs of the word counting test revealed response times that were noticeably longer than for the word monitoring task. As a result, the upper limit of response times not classified as hesitations was increased to 1,500 ms. Fifty responses were classified as false alarms or hesitations and excluded from the analysis.
d Results
Figure 6 shows the proportion of correct responses, i.e. two-word sequences that were correctly identified as containing two words as opposed to one. As might be expected, accuracy rates were nearly at ceiling level, exceeding 95% with the exception of non-native listeners for linked items (93%).
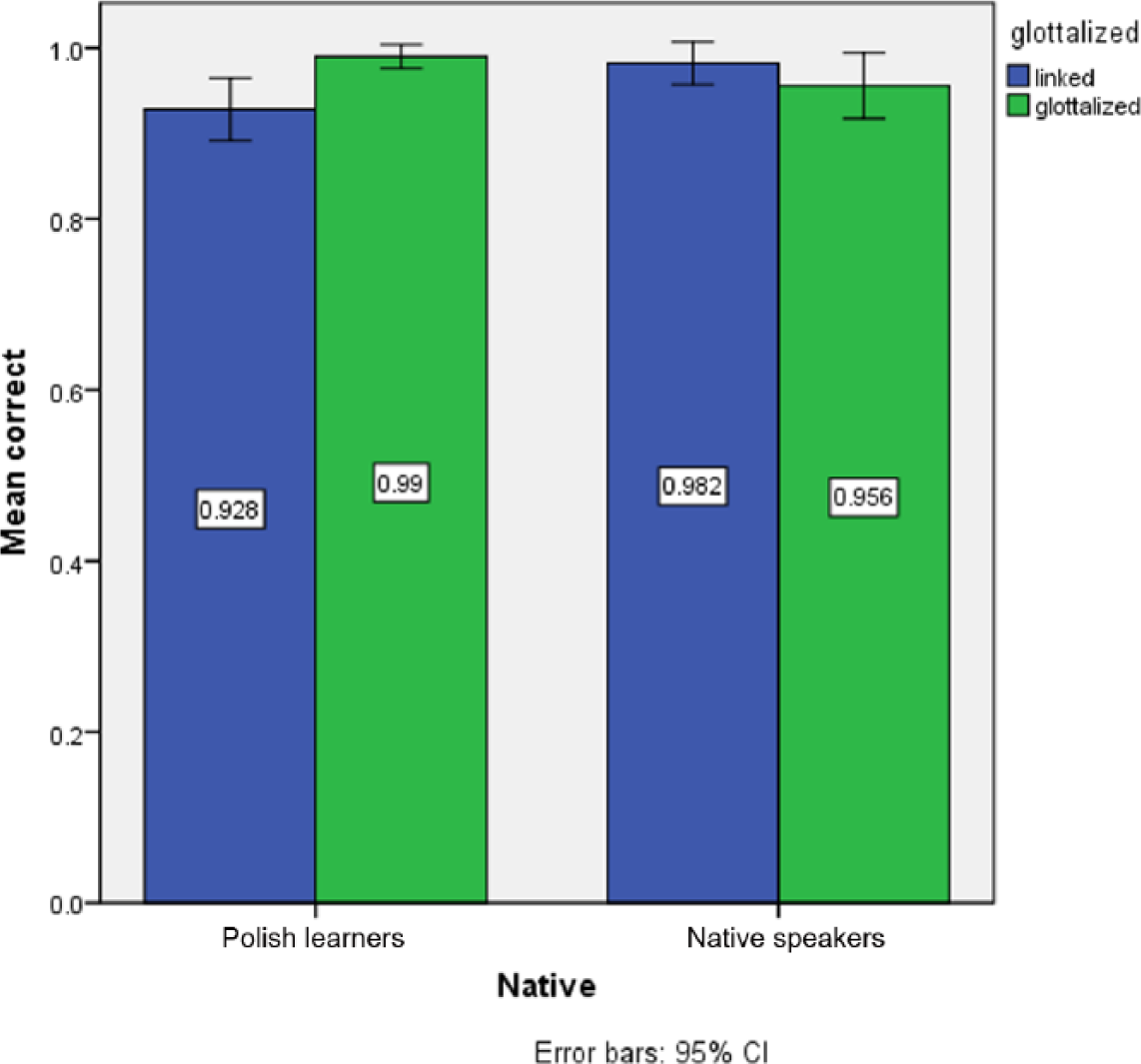
Mean proportion of correct responses in word counting task.
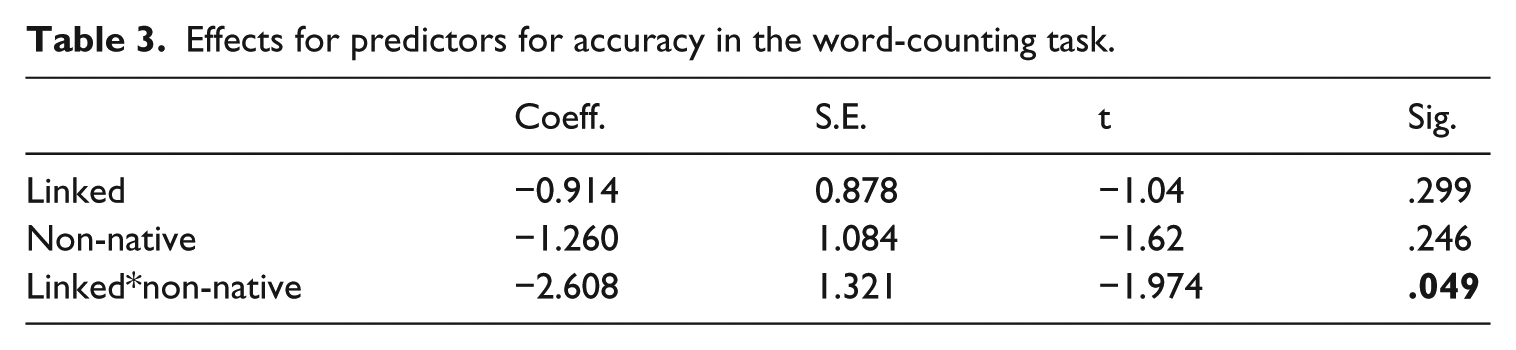
A generalized linear mixed model was fitted to the accuracy data, employing a logit link function to the binary response variable of correct responses. Predictor variables included Glottalization and Native Language as fixed effects, and Participant and Item as random effects. The model revealed a significant interaction by which the Polish learners were less accurate on the linked than on the glottalized tokens, as suggested in Figure 6. The effects of the predictors are given in Table 3.
Effects for predictors for accuracy in the word-counting task.
With regard to response time, the results are summarized in Figure 7. A generalized linear mixed model was run with Response Time as dependent variable, Glottalization, Native Language, and Accuracy as fixed factors, and Listener and Item as random factors. There was an overall effect of linking, p = .04, and as suggested in Figure 8, an interaction of Linking*Native Language by which linking affected the native speakers, p = .031, but not the Polish learners, p = .332. These effects are summarized in Table 4. Note that although it appears as though the native speakers were faster, this effect was not significant, p = .117.
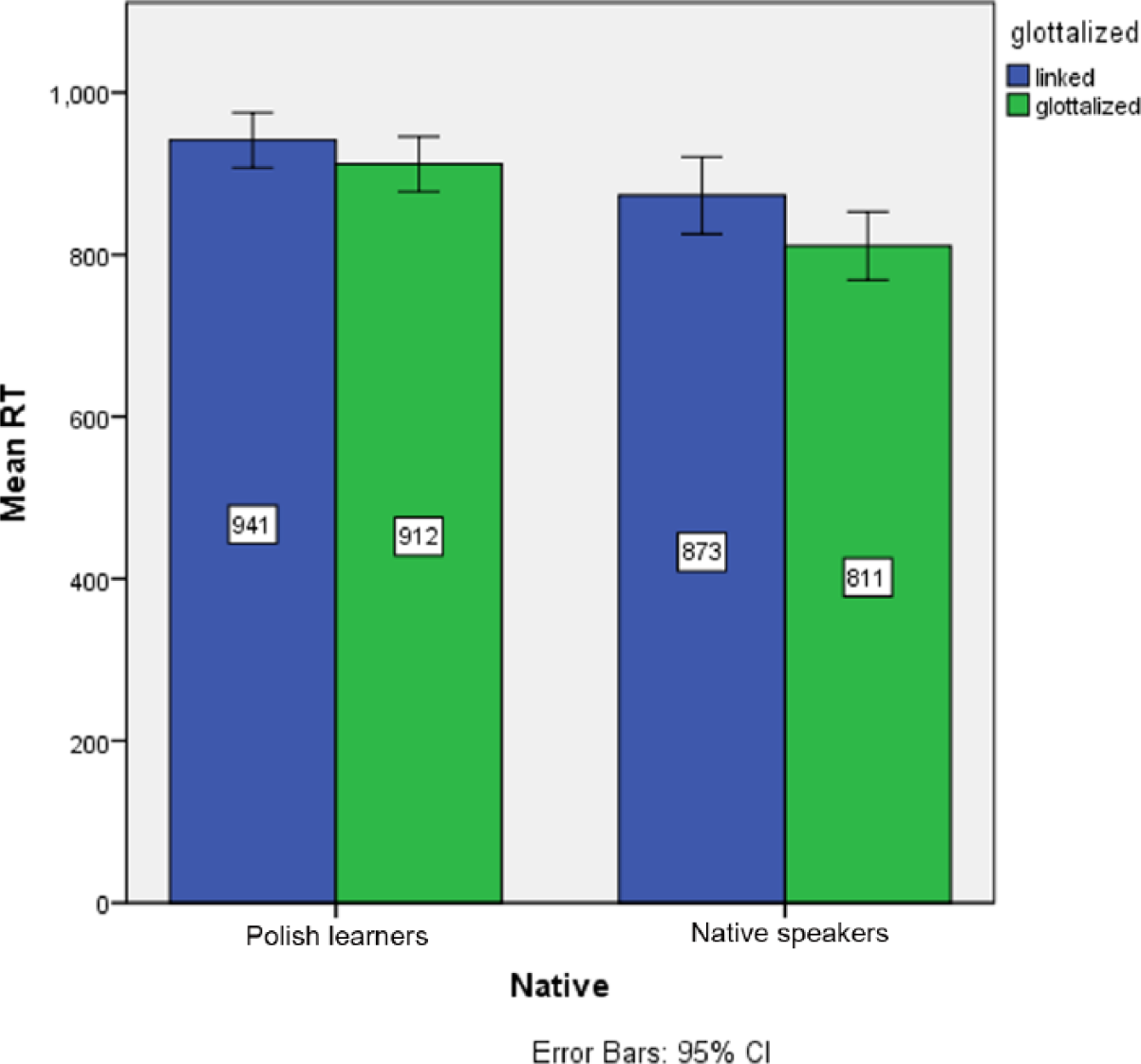
Mean response times (RTs) to linked vs. glottalized items in word counting task.
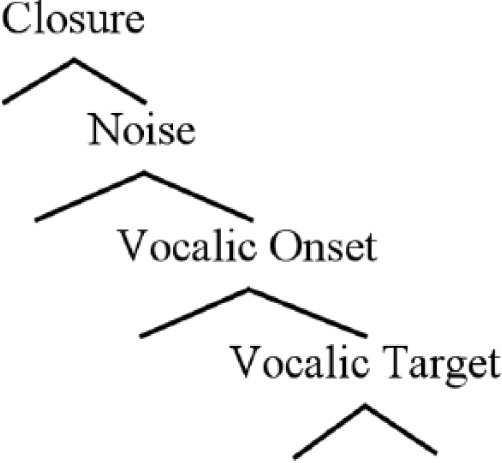
Onset Prominence representational hierarchy
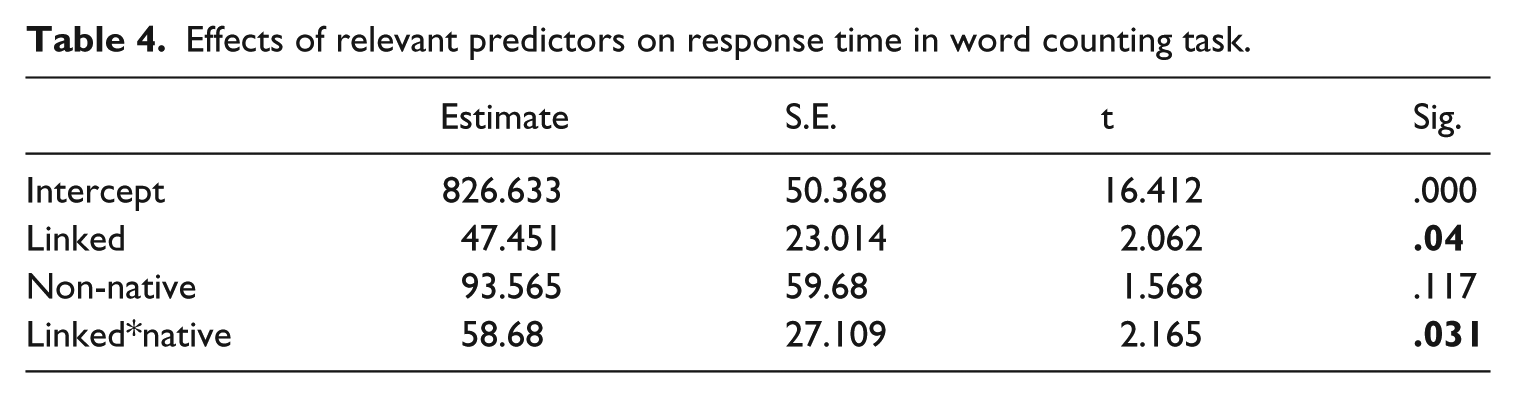
Effects of relevant predictors on response time in word counting task.
e Discussion
Taken together, the results of the perception studies suggest a negligible impact of glottalization on the processing of English vowel-initial words by B2-level L1 Polish learners. No effects of glottalization on response time were found in either the word monitoring or word counting tasks for the L2 learner group, although together with the control group there was an overall effect of linking in the word counting task. The only notable effect of linking vs. glottalization for the L1 Polish group was found for accuracy in the word counting task: linked items were more likely to induce errors by L1 Polish group. However, learner accuracy was still over 90%.
The negative results of the perception studies may be interpreted in a number of ways. One possibility is that the participants’ level of English was sufficiently advanced that they were able to process vowel-initial words in L2 regardless of whether they were produced with glottalization. In other words, it might be claimed that these students had ‘acquired’ linking in perception, similar to what was observed in the production study. 5 If such an interpretation is correct, it would suggest that any putative constraint of L2 Word Integrity has been overcome by these learners.
At the same time, it is interesting to note that in the word counting task, the native controls showed significantly longer response times (RTs) to the linked items than to the glottalized ones (Figure 7). The RT difference between the experimental and control groups in the word counting task may at first glance seem surprising. One might expect that the native listeners should be accustomed to linking and that it should not hinder their perception of the word boundary. However, this was apparently not the case, suggesting that glottalization is a more reliable boundary cue for English listeners than for Polish listeners.
In this connection, it is possible that glottalization provides a greater aid to the processing of word boundaries when it is a realization that is unexpected by listeners. Since L1 Polish listeners are accustomed to hearing phrase-medial glottalized initial vowels, the glottalized realizations may be rendered perceptually transparent. That is, glottalization is the expected realization, so it does not contribute to faster processing by Poles. The results of related studies on L1 Polish (Schwartz, 2014) are compatible with this interpretation. In those experiments, glottalization exerted only a small effect on response times. Differences in the relative salience of glottalization as a boundary cue for English and Polish listeners, as suggested by the word counting results, may be attributable to differences in the phonological status of glottalization in the two languages. In what follows, we shall consider these phonological issues in more detail.
VI General discussion: Cross-language differences in the phonology of word boundaries
The production and perception studies described in this article allow us to characterize the acquisition of vowel-initial words by B2-level Polish learners of English. The glottalization rate of the learners decreases in L2 production, suggesting that the participants have to some degree acquired the type of C#V sandhi linking that has been described in English, but is absent in Polish. The perception data are also compatible with this general conclusion: linked items were on the whole processed with the same speed as glottalized items. These findings present a challenge to Cebrian’s proposal of a ‘Word Integrity’ constraint for L2, which postulates that learners should have trouble acquiring L2 phonological processes that obscure word boundaries.
The relative strength of word boundaries across languages appears to be a systematic phenomenon that is encoded in phonological systems. In this connection, it is reasonable to consider the data from these experiments in terms of Lleo and Vogel’s (2004) demarcating vs. grouping typology. Polish should be described as a demarcating language, while English is a grouping language (see Section III). In what follows, we will briefly discuss the phonological origins of this division, and show that a plausible explanation may be found in the representation of initial vowels in terms of a built-in consonantal element that is present in Polish but not in English. For a more complete account, see Schwartz (2015).
In a traditional OT analysis (1), the effects we observe in Polish and English with regard to C#V sequences might be claimed to reflect different relative rankings of the constraint
(1)

There is a major problem with this analysis. At C#V sequences in English, the final consonant is often resyllabified (or is ambisyllabic), satisfying the
In Polish,
(2)
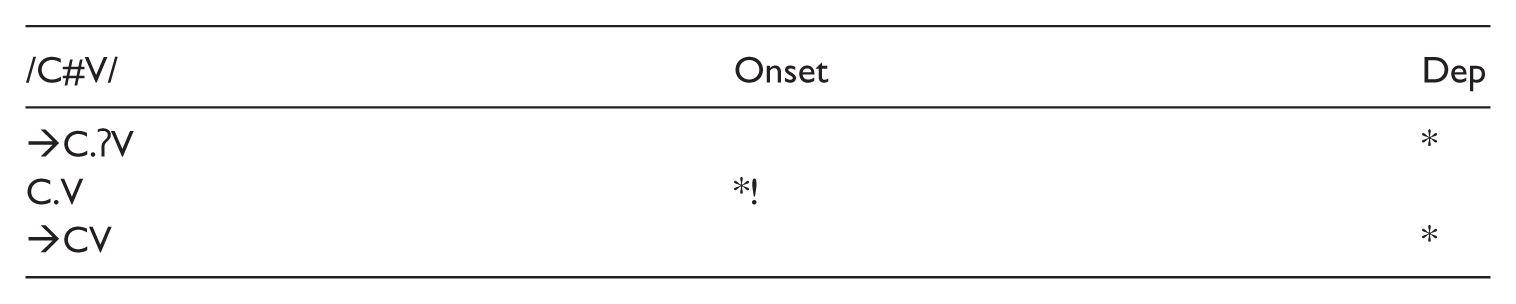
This analysis is also problematic, since it has no way of specifying that in Polish glottalization is preferable to linking as a strategy to satisfy
This alternative solution considers the representation of the initial vowel itself. Vowel-initial syllables have often been observed to exhibit ambiguous behavior across languages (Downing, 1998; Marlett and Stemberger, 1983; McCarthy and Prince, 1993; Schwartz, 2013b). In some instances, they show evidence of prosodic deficiency in that they are not counted for prosodic processes such as stress assignment, tone assignment, or reduplication. In other cases, vowel-initial syllables behave in an identical fashion to syllables with a consonantal onset. This ambiguity has been attributed to the presence of what might be referred to as an ‘empty onset’ position (e.g. Marlett and Stemberger, 1983). That is, when vowel-initial syllables are well-formed prosodically, this ‘empty onset’ is present and the
The tendency for linking in languages like English and French is compatible with the claim that onsetless syllables in these languages are prosodically ill-formed and cannot stand alone. Under this view, the lack of the Polish-style ‘empty onset’ motivates linking. The data described in this article suggest that B2-level Polish learners of English have made progress in acquiring a new representation of initial vowels. They have learned to suppress the L1 consonantal element to produce and process linked vowel-initial words. They appear not to be constrained by a requirement of Word Integrity in L2. If Word Integrity is indeed a constraint on L2 acquisition, it is something that learners are able to overcome.
The representation of ‘empty onsets’
While empty positions in phonology may at first glance appear to be abstractions without any reflection in the physical reality of speech, the ‘empty onset’ can in fact be derived from phonetic principles. This may be envisioned in the Onset Prominence representational framework (OP; Schwartz, 2013b, 2015), in which the phonetic properties associated with the initial portion of vowels give rise to configurations by which onsetless vowels may or may not contain what might be thought of as a ‘consonantal’ element. In what follows, we shall offer a brief sketch of how this is derived. For a more through presentation of the framework, see Schwartz (2013b, 2015).
OP representations are derived from a hierarchy of phonetic events associated with a stop-vowel sequence. This hierarchy is shown in Figure 8. The hierarchy in its entirety represents a CV ‘syllable’, a well-formed prosodic constituent from which individual segmental representations are extracted. These segmental structures replace traditional features associated with manner of articulation. Some examples are given in Figure 9. Each tree contains a single labial place specification, for which the segmental symbols may be seen as shorthand. Laryngeal specifications are not shown. The highest-level node of the hierarchy is Closure, present in stops and nasals. The Noise node is derived from stop/affricate release, as well as noise associated with fricatives. The Vocalic Onset node (VO) derives from the initial portion of segments with robust formant structure, including vowels approximants and glides, as well as formant transitions that act as cues for the perception of obstruents. The Vocalic Target (VT) node is at the bottom of the hierarchy.
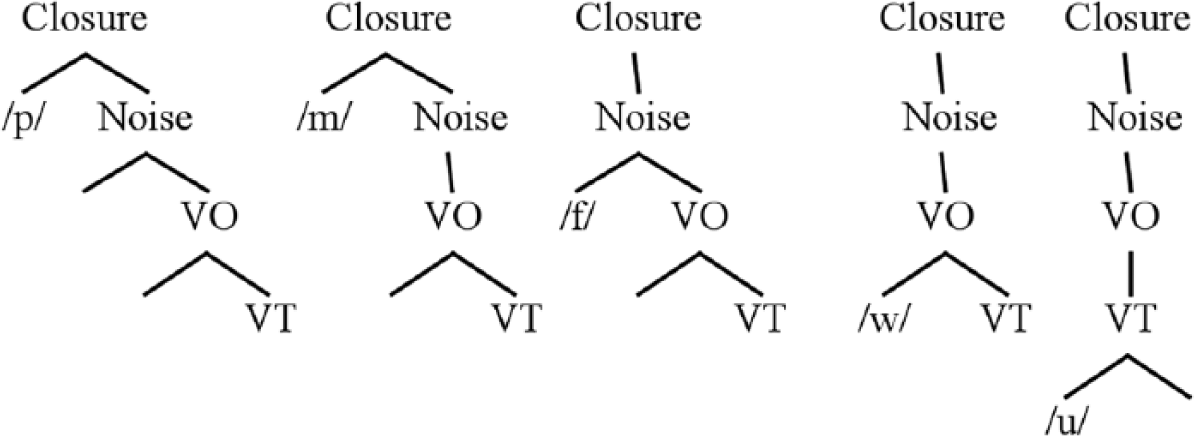
Manner of articulation in the Onset Prominence representational framework.
Since OP prosodic constituents and individual segmental representations are built from the same materials, there is no need for constraints such as
(3) Minimal Constituent requirement for OP structures (after Schwartz, 2013b):
Violations of the MC condition motivate mechanisms that combine individual segmental structures into well-formed ‘syllables’. None of the single segmental structures shown above satisfies the MC condition. Thus, the vowel /u/ as shown in the rightmost tree in Figure 9 is not a well formed prosodic unit. In traditional terms, this would be seen as an
The key representational aspect driving the formation of ‘empty onsets’ in OP representations is the Vocalic Onset (VO) layer of structure, encoding the initial portion of vocoids with robust formant structure. The initial portion (30–40 ms) of a periodic signal containing formant structure presents listeners with a number of possibilities as to the phonological parse of that acoustic event. Strictly speaking, this phonetic entity is vocalic, but it is acoustically similar to sonorant consonants. At the same time, this section of the acoustic signal is often crucial for the identification of preceding obstruents. Thus, individual phonological systems must resolve this ambiguity to determine the ‘segmental’ affiliation of the VO node. This single layer of structure may be claimed by multiple segment types as shown in Figure 9. On its own, VO represents the class of approximants and glides. It may also be active in the representation of obstruents and nasals, representing formant transitions that are crucial for consonant perception (e.g. Wright, 2004). At the same time, the VO node is derived from a portion of the signal that is vocalic, so we might expect to find it built into the representation of vowels as well as consonants.
The presence or absence of VO in vowel representations creates a parametric setting to govern the behavior of initial vowels that underlies the data investigated in this article. Representations are given in Figure 10. The structure on the left is a VO-specified vowel. Note that it satisfies the MC constraint: it is a well-formed prosodic constituent. The structure on the right, lacking VO, is not.
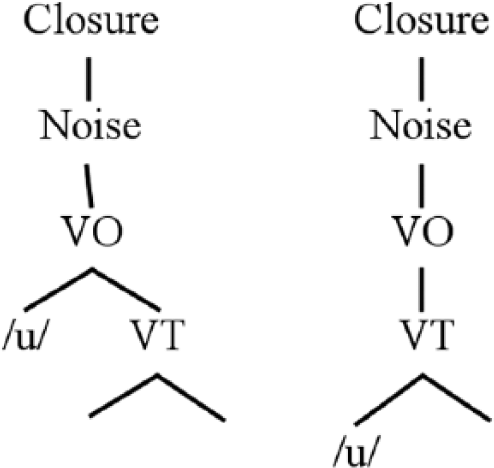
Parametric settings for initial vowels in the Onset Prominence representational framework.
In Polish, the VO parameter is set to the structure on the left. As a result, initial vowels constitute well-formed ‘syllables’ with no phonological motivation to undergo linking processes. In languages such as English and French, initial vowels lack VO and are not well-formed, so linking is more common. 6 Since the VO parameter is derived from phonetic ambiguity in perceptual affiliation of the initial portion of vowels, it has independent motivation. From this perspective, the ‘empty onset’ is therefore compatible with phonetic considerations, and is not an ad hoc stipulation.
Before concluding, one additional issue warrants discussion as a possible area for further research. As seen in the individual production results in Figure 4, beyond the cross-linguistic differences there is a notable amount of individual variation with regard to whether glottalization is produced. While variation is not a focus of this study, it may be noted that the representational proposal advocated here makes concrete predictions about the types of realizations that will be preserved despite individual variation. For example, if we consider the Polish phrase bardzo ambitny ‘very ambitious’, the realization of the initial /a/ in ambitny may be produced in a number of ways. One might observe a full glottal stop, non-modal phonation, pitch or amplitude drops, or no visible boundary marking at all. In rapid speech, the V#V sequence may be subject to vowel elision. However, if elision occurs, it will always be the final /o/ that is elided, and not the initial /a/. We might hear bardz
In sum, the insight of the representational approach advocated here is that it offers a principled explanation of cross-language differences governing the phenomena described in this article. Polish–English differences in the behavior of vowel-initial words cannot be explained by a constraint such as
Footnotes
Appendix 1
Declaration of conflicting interest
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research reported in this paper was supported by a grant from the Polish National Science Centre (Narodowe Centrum Nauki), project number UMO-2012/5/B/HS2/04036, “Sandhi in second language speech”.