
Abstract
This article reports on the first results of a large-scale research programme that aims to define and circumscribe the construct of phraseological complexity and to theoretically and empirically demonstrate its relevance for second language theory. Within this broad agenda, the study has two main objectives. First, it investigates to what extent measures of phraseological complexity can be used to describe second language (L2) performance at different proficiency levels. Second, it compares measures of phraseological complexity with traditional measures of syntactic and lexical complexity. Variety and sophistication are postulated to be the first two dimensions of phraseological complexity, which is approached via relational co-occurrences, i.e. co-occurring words that appear in a specific structural or syntactic relation (e.g. adjective + noun, adverbial modifier + verb, verb + direct object). Phraseological diversity is operationalized as root type–token ratio computed for each syntactic relation. Two methods are tested to approach phraseological sophistication. First, sophisticated word combinations are defined as academic collocations that appear in the Academic Collocation List (Ackermann and Chen, 2013). Second, it is approximated with the average pointwise mutual information score as this measures has been shown to bring out word combinations made up of closely associated medium to low-frequency (i.e. advanced or sophisticated) words.
The study reveals that unlike traditional measures of syntactic and lexical complexity, measures of phraseological sophistication can be used to describe L2 performance at the B2, C1 and C2 levels of the Common European Framework of References for Languages (CEFR), thus suggesting that essential aspects of language development from upper-intermediate to very advanced proficiency level may be situated in the phraseological dimension.
I Introduction
Word combinations – be they framed in terms of phraseological units, formulaic sequences, collocations, constructions or collostructions – have been shown to play crucial roles in language acquisition, processing, fluency, idiomaticity and change (e.g. Bybee and Beckner, 2012; Ellis, 1996; Ellis and Cadierno, 2009; Goldberg, 2006; Römer, 2009; Schmitt, 2004; Sinclair, 1991; Stefanowitsch and Gries, 2003; Wray, 2002). So far, however, second language (L2) complexity research has proved largely impervious to these theoretical and empirical developments. L2 complexity is admittedly no longer narrowed down to syntactic complexity as it used to be (Ortega, 2003). Researchers have also recognized that interlanguage complexity can, and should, be studied in other domains of the language system, such as phonology, lexis or morphology (e.g. Bulté and Housen, 2012; De Clercq and Housen, 2019; Housen et al., 2019; Pallotti and Brezina, 2019; van der Slik et al., 2019; Wolfe-Quintero et al., 1998). However, no systematic attempt has been made to date to theorize and operationalize linguistic complexity at the level of word combinations. This is particularly unfortunate since complexity is regarded as one of the ‘major research variables in applied linguistic research’ (Housen and Kuiken, 2009): measures of linguistic complexity are widely used to describe L2 performance, assess L2 proficiency, and trace L2 development (Housen et al., 2012; Norris and Ortega, 2009; Wolfe-Quintero et al., 1998).
The need for measures of complexity that account for how words naturally combine to form conventional patterns of meaning and use, i.e. ‘complex linguistic gestalts’ (see Hanks, 2013: 283–89), is particularly evident from examples (1a) to (1j). Measures of lexical complexity, for example, are all single-word based measures. The 10 instances of meet will be considered repetitions of a single form, which will contribute to lowering the lexical range or diversity of this set of sentences. In terms of lexical sophistication, all instances of meet would be regarded as occurrences of the same high-frequency verb, despite its much varied patterns of use (e.g. restricted collocations such as meet + needs/expectation/target, figurative idioms such as meet your Waterloo, and speech formulae such as Nice to meet you!). At the syntactic level, no measure will do justice to the variety of syntactic constructions in which the verb meet is used (e.g. verb + object, verb + particle, non-finite complement in a causative structure, head of a to-infinitive structure).
(1) a. I’ll b. I c. This app has different versions to d. To e. If you f. ‘Here I believe my brother has g. There is more than h. Many students are finding it difficult to make ends i. Nice to j. It’s a pleasure to
As illustrated in (1), traditional measures of complexity fail to capture much of the complexity of language use. Most particularly, they need to be complemented with measures that tell us something about the way words combine in a meaningful way. To this end, this article introduces a number of phraseological measures to the study of interlanguage complexity.
The article reports on the first results of a large-scale research programme that aims to define and circumscribe the linguistic construct of phraseological complexity and to theoretically and empirically demonstrate its relevance for second language theory in general and L2 complexity research in particular. In the first section, I briefly explore how previous approaches to the definition and operationalization of L2 complexity have been or can be applied to a phraseological perspective. The next sections elaborate on the dataset and analytical procedures used in the study, which focuses on phraseological complexity in the form of diversity and sophistication. A presentation of the results of the corpus analysis is then followed by an in-depth discussion of how the proposed measures represent L2 development.
II Linguistic complexity and phraseology
Despite its widespread use, there is no generally accepted definition of the construct of complexity in L2 research (and in language sciences in general). Bulté and Housen (2012) and Pallotti (2015), two recent attempts at clarifying the theoretical basis of complexity and discussing how it can be operationalized and measured, both adopt Rescher’s (1998: 1) definition of complexity, i.e. ‘a matter of the number and variety of an item’s constituent elements and of the elaboratedness of their interrelational structure’ and share the view that it can be evaluated across various language domains (including syntax, lexis and morphology). In agreement with this definition, most L2 research studies have opted for quantitative operationalizations of linguistic complexity (i.e. the more/longer…, the more complex) (Bulté and Housen, 2012: 29; Housen et al., 2019). At the same time, the authors conclude that, despite its multifaceted nature, only a small portion of what constitutes linguistic complexity has been explored in L2 research to date, typically using measures that tap into lexical diversity and syntactic complexity. In the case of lexical diversity, existing measures (e.g. type–token ratios or TTRs, D, Advanced Guiraud, MTLD; see e.g. Malvern et al., 2004; McCarthy and Jarvis, 2010) generally represent their underlying construct through the number of different individual words in a text, whereas measures of syntactic complexity often represent either structure length (e.g. mean length of utterance or MLU) or the amount of subordination per multiclausal unit (e.g. clauses/T-Unit) without attention to specific lexical patterns (e.g. Wolfe-Quintero et al., 1998).
The absence of measures representing word combinations is unfortunate as a word may be complex ‘because of the constraints on its co-occurrence with other words’ (Pallotti, 2015: 125). Examples of ‘maximally complex words’ include prepositions and light verbs (e.g. the verb ‘make’ in make a decision or make a step), which vary unpredictably in their semantic and syntagmatic complexity (see Hanks, 2013: 287–88). As further put by Hanks (2013: 288): any attempt to reduce expressions [such as take account of something, take place, take someone’s place or take the plunge] to compositional structures in which each element makes a distinctive semantic contribution to the whole phrase is doomed: the meaning potential gets lost in the course of such a reductionist analysis, because the meaning potential resides in the combination, not in the individual words.
As the examples (1a–1j) above indicated, both traditional lexical diversity measures and length-based syntactic complexity measures can therefore not accurately represent how this additional layer of meaning is manifested in L2 production data.
Pallotti (2015: 9) comments that ‘while these aspects are worth noting from a theoretical point of view, they seem to be impervious to practical operationalization in production data.’ One of the objectives of this study, then, is to address this methodological difficulty and to take a first step at examining phraseological complexity in learner writing. To do so, we adopt Gries’s (2008) definition of a phraseologism or phraseological unit: the co-occurrence of a form or a lemma of a lexical item and one or more additional linguistic elements of various kinds which functions as one semantic unit in a clause or sentence and whose frequency of co-occurrence is larger than expected on the basis of chance. (Gries, 2008: 6)
Phraseological units thus include a wide variety of word combinations such as statistical collocations, collocational frameworks, colligations, collostructions and lexical bundles (Granger and Paquot, 2008).
To investigate phraseological complexity in learner production, it is essential to determine the inherent properties of the construct and to develop valid measures of those properties (Jarvis, 2013: 22). A number of authors have distinguished, especially in relation to lexical complexity, between two dimensions of complexity, one representing the breadth of knowledge (e.g. how many words or structures are known) and the other the depth of knowledge (e.g. how elaborate or difficult the words or structures are) (e.g. Bulté and Housen, 2012; Housen et al., 2019). In turn, these two dimensions have been measured by looking at the diversity of words in L2 productions and at the sophistication of lexical items (e.g. Bulté and Housen, 2012; Housen et al., 2019; Ortega, 2003, 2012; Wolfe-Quintero et al., 1998). Diversity is commonly operationalized as the number of unique words (or types) in a text, in the form of simple ratios (e.g. TTR) or more computationally advanced calculations (e.g. D), while sophistication is typically operationalized as the frequency of lexical items in the corpus under investigation against the frequency of use in external reference corpora (e.g. Laufer and Nation, 1995). These two dimensions of complexity cover both more absolute forms of complexity (diversity) as well as relative forms of linguistic complexity (sophistication) (Bulté and Housen, 2012; Dahl, 2004).
Diversity and sophistication will also be postulated as two key dimensions of phraseological complexity. While existing studies on the use of phraseological units by L2 learners have not explicitly considered this two-way distinction, it can nonetheless be applied in a relatively straightforward fashion to the measurement of phraseological complexity: a learner text with a wide range of (target-like) phraseological units and a high proportion of sophisticated units will be said to be more complex than one where the same few basic word combinations are often repeated. Thus, phraseological complexity is defined as the range of phraseological units that surface in language production and the degree of sophistication of such phraseological units (see Ortega, 2003: 492). 1
The measurement of phraseological diversity could be performed through a (derived) type–token ratio representing the number of unique phraseological units to the total number of phraseological units, by analogy with the measurement of lexical diversity. In the case of sophistication, the operationalization first requires that sophisticated word combinations be defined and singled out from other word combinations. By analogy with lexical sophistication, phraseological sophistication is here defined as the selection of word combinations that are ‘appropriate to the topic and style of writing, rather than just general, everyday vocabulary’, which ‘includes the use of technical terms […] as well as the kind of uncommon [word combinations] that allow writers to express their meanings in a precise and sophisticated manner’ (Read, 2000: 200). Unlike for single words, there is currently no general list of word combinations and their frequencies in English. It is therefore not possible to adopt a frequency-based approach to phraseological sophistication and count word combinations as sophisticated if they do not belong to, say, the 2,000 most frequent word combinations as is commonly done in lexical sophistication research. An alternative would be to use academic collocation lists to identify sophisticated word combinations, in line with previous research on lexical sophistication relying on academic word lists of individual lexical items (e.g. Laufer, 1994; Laufer and Nation, 1995).
A second way of operationalizing the sophistication of phraseological units is through pointwise mutual information (MI) scores. MI is a measure borrowed from information theory that compares the probability of observing word a and word b together with the probabilities of observing a and b independently (Church and Hanks, 1990). As explained by Ellis et al. (2008: 391), phraseological units that score very high on this measure have quite distinctive meanings (e.g. technical phrases such as the citric acid cycle, idioms such as come into play, or constructions with clear discourse functions such as the causative that leads to). Native speakers have been shown to be ‘attuned to these constructions as packaged wholes’ (Ellis et al., 2008: 391): their processing is affected by the MI of [phraseological units] when they are reading them for recognition of correct form, reading them to access its pronunciation, and reading aloud the final word after having processed the rest of the expression.
MI has recently been used in a number of studies as a measure of collocational strength in L2 writing. Durrant and Schmitt (2009) assigned to each noun/adjective + noun sequence extracted from a corpus of L2 texts its MI score as computed on the basis of a large native reference corpus. They showed that, compared to native writers, L2 writers of English tend to underuse less common, strongly associated items as identified by high MI scores (e.g. densely populated, bated breath, preconceived notions). In a recent study that investigated the full range of contiguous word pairs instead of being restricted to modifier + noun sequences, Granger and Bestgen (2014) demonstrated that the same difference could be observed between intermediate and advanced EFL learners: intermediate learners tend to underuse the more strongly associated bigrams as identified with high MI scores. Although Ellis et al. (2008), Durrant and Schmitt (2009) and Granger and Bestgen (2014) did not use the term, it may be argued that, by promoting the relatively less frequent and more semantically complex word pairs in learner productions, MI ultimately taps into the ‘sophistication’ of word combinations. To illustrate further, while bad weather and cold weather are the two most frequent adjective + noun combinations with the noun weather in the Corpus of Contemporary English (COCA; Davies, 2008), phraseological units such as severe weather, extreme weather, stormy weather, windy weather and wintry weather get higher MI scores, which point to their higher semantic specialization (despite the fact that all these sequences are made up of high-frequency words).
In this study, phraseological diversity and sophistication will be measured for word combinations containing adjectival modifiers, adverbial modifiers and direct objects. Diversity will be operationalized as a root type–token ratio and sophistication as the ratio of academic collocations to the total number of collocations, as well as through pointwise mutual information (PMI) scores associated to word combinations. The study is guided by the following two research questions:
Research question 1: To what extent can measures of phraseological complexity be used to describe L2 performance at different proficiency levels?
Research question 2: How do measures of phraseological complexity compare with traditional measures of complexity as an index of L2 proficiency?
III Data
The learner texts used come from the Varieties of English for Specific Purposes database (VESPA; https://uclouvain.be/en/research-institutes/ilc/cecl/vespa.html; accessed February 2017) and consist of 98 research papers written outside the classroom by French EFL learners as part of the requirements for linguistics courses at the University of Louvain, Belgium, between 2009 and 2013. The students are 58 females and 20 males enrolled in a Bachelor or Master programme in Modern Languages that involves the study of two languages (i.e. English + Dutch, Spanish, German, French or Italian). They have been studying English at university for an average of 3.5 years (minimum = 1, maximum = 6), and the large majority of them (i.e. 75) are 19–26-years-old (average = 22.7; minimum = 19; maximum = 47).
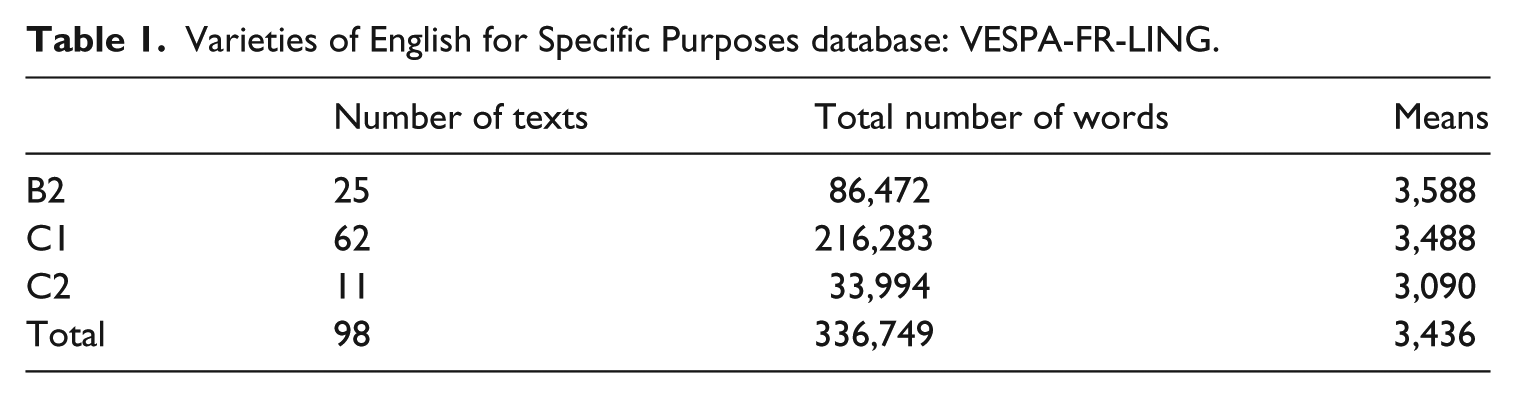
Each of the learner texts was evaluated by two professional raters (three in case of disagreement) according to the Common European Framework of References for Languages (CEFR; Council of Europe, 2001) descriptors for linguistic competence, which describes foreign language proficiency (i.e. grammatical accuracy, vocabulary control, vocabulary range, orthographic control, and coherence and cohesion) at six levels: A1 and A2, B1 and B2, C1 and C2. As a result, each text was assigned a global proficiency score ranging from B2 (upper intermediate) to C2 (near-native) (for more details about the assessment procedure, see Paquot, 2018). Table 1 shows the distribution of learner texts per CEFR levels and the total number of words in each learner sub-corpus.
Varieties of English for Specific Purposes database: VESPA-FR-LING.
IV Method
1 Phraseological complexity
The phraseological dimension is approached in this study via word combinations used in three grammatical relations, i.e. adjectival modifiers (amod: adjective + noun), adverbial modifiers (advmod: adverb + adjective, adverb or verb) and verb + direct object (dobj). I first made use of the Stanford CoreNLP suite of tools (http://nlp.stanford.edu/software/corenlp.shtml; accessed February 2017) to lemmatize, part-of-speech (POS) tag and parse each VESPA learner text. The next steps consisted in extracting from each VESPA text all the pairs of words found in the amod, advmod and dobj Stanford typed dependency relations in the form of lemmas and simplified part-of-speech tags. As illustrated in (2), a Stanford typed dependency is a binary grammatical relation between a governor and a dependent (see De Marneffe and Manning, 2013).
(2) a. amod adjective modifier She has black hair. amod(hair+NN,black+JJ) b. advmod adverbial modifier She has very black hair. advmod(black+JJ,very+RB) Repeat less quickly. advmod(quicly+RB,less+RB) She eats slowly. advmod(eat+VBZ,slowly+RB) c. dobj direct object He won the lottery. dobj(win+VV,lottery+NN)
For each dependency, the total frequency of each individual word in each pair was recorded as well as their combined frequency. Measures of phraseological diversity and sophistication were computed on the basis of such frequency tables.
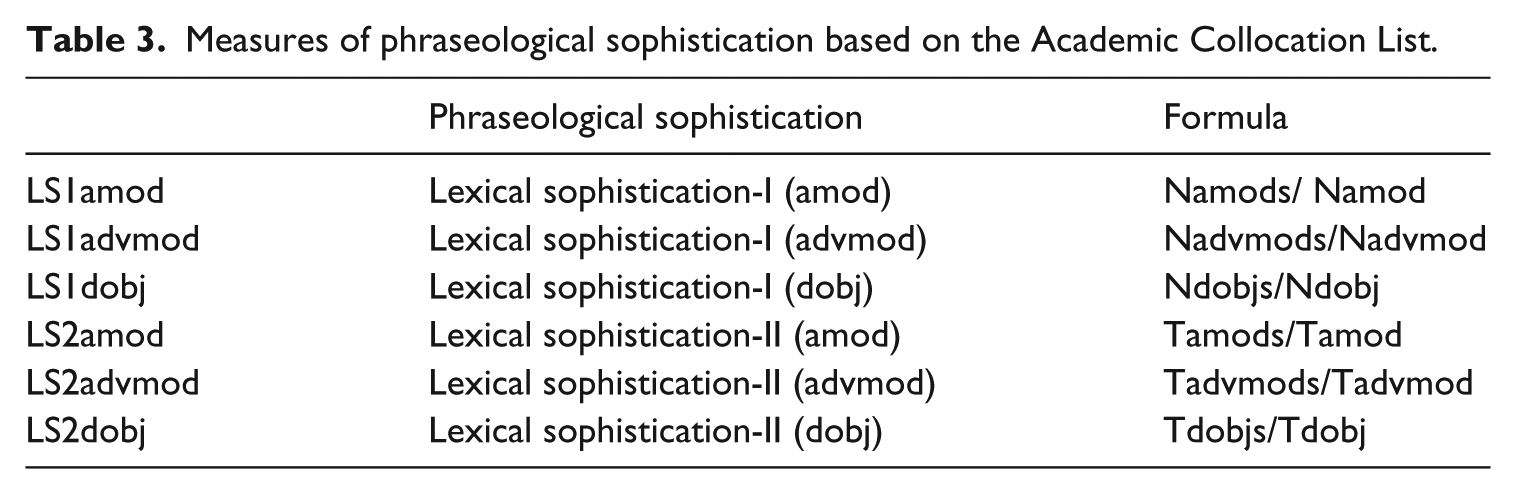
Phraseological diversity, the first dimension of phraseological complexity, was operationalized as a root type–token ratio (TTR) computed for each dependency relation (Table 2). As for phraseological sophistication, two methods were implemented and tested. First, in the same way as sophisticated single words have sometimes been equated with university-level vocabulary (e.g. Laufer, 1994; Laufer and Nation, 1995), sophisticated word combinations were defined as academic collocations and operationalized as word combinations that appear in the Academic Collocation List (ACL; Ackermann and Chen, 2013). The ACL was compiled from the written curricular component of the Pearson International Corpus of Academic English (PICAE; over 25 million words) and includes the 2,469 most frequent and (according to its authors) pedagogically relevant cross-disciplinary lexical collocations in written academic English (Ackermann and Chen, 2013). It is available from http://pearsonpte.com/research/academic-collocation-list (accessed February 2017). Table 3 lists the six measures of phraseological sophistication based on the Academic Collocation List. As for lexical sophistication (see below), measures of phraseological sophistication-I (LS1amod, LS1advmod, LS1dobj) are token-based ratios of the number of sophisticated amod, advmod, and dobj tokens to the total number of amod, advmod, and dobj tokens respectively. LS2amod, LS2advmod and LS2dobj are type-based ratios of the number of sophisticated amod, advmod, and dobj types to the total number of amod, advmod, and dobj types respectively.
Measures of phraseological diversity.

Notes. RTTR = root type–token ratio; TTR = type–token ratio.
Measures of phraseological sophistication based on the Academic Collocation List.
In a second analysis, phraseological sophistication in a learner text was approximated with the average pointwise mutual information (MI) score for amod, advmod and dobj dependencies. While previous studies have calculated MI scores on the basis of general corpora, 2 these corpora may not be representative for our data. As VESPA texts are all research papers in linguistics, the L2 Research Corpus (L2RC) seemed a more comparable reference corpus for this study. The L2RC consists of 7,765 texts published in 16 leading journals in L2 research from 1980 to 2014 and amounts to approximately 66 million words. 3
As the VESPA corpus, the L2RC was first part-of-speech tagged, lemmatized and parsed with the Stanford CoreNLP suite of tools. The resulting list of dependency-based pairs of words with frequency information was then used as input to the Ngram Statistics Package (NSP, http://www.d.umn.edu/~tpederse/nsp.html; accessed February 2017), and an MI score was calculated for each word pair that appears with a frequency of at least five occurrences in L2RC. Each word pair in the VESPA learner texts was then looked up in the list of dependencies extracted from the L2RC to determine its MI value in a reference corpus of expert academic writing. If a word pair was not found or appeared less than five times in L2RC, it was removed from further analysis. 4 The last step involved computing three mean MI scores for each learner text on the basis of all the different word pairs found in the amod, advmod and dobj dependencies (i.e. types). Mean MI scores were calculated with R (R Core Team, 2014). Table 4 summarizes the different steps of the corpus preprocessing workflow and Table 5 lists the three measures of phraseological sophistication based on the L2RC.
Corpus preprocessing workflow.

Notes. L2RC = L2 Research Corpus; VESPA = Varieties of English for Specific Purposes database
Measures of phraseological sophistication based on the L2 Research Corpus (L2RC).

2 Traditional measures of syntactic and lexical complexity
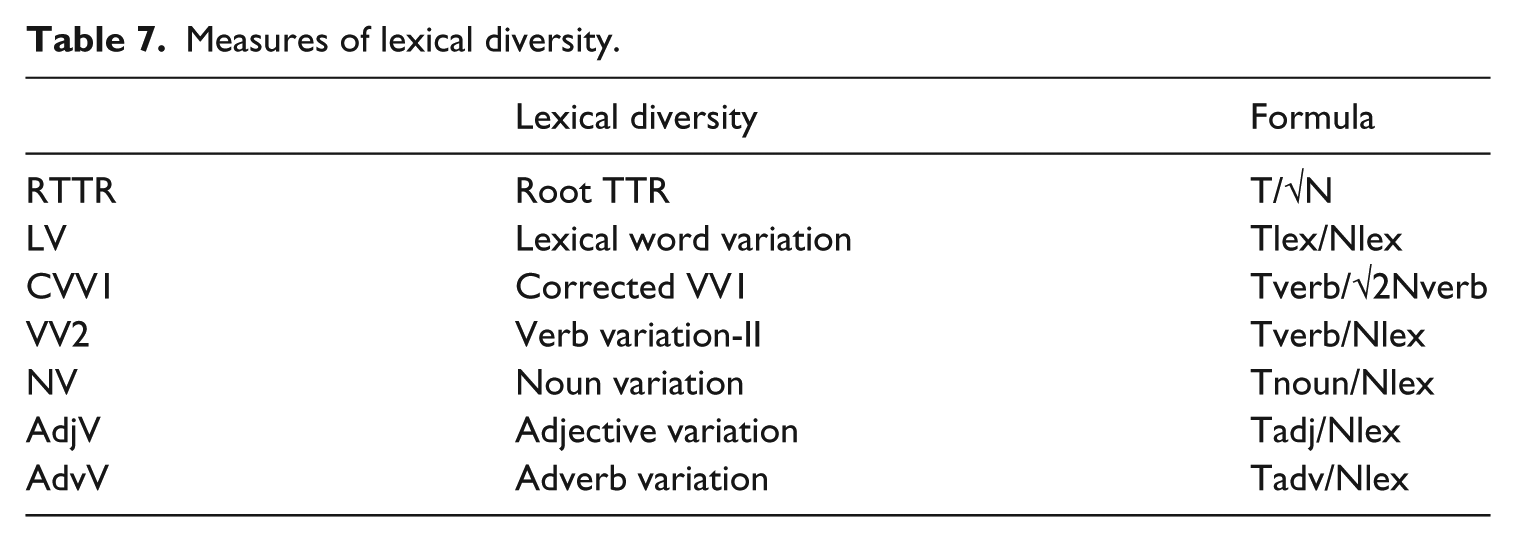
Measures of syntactic complexity were automatically computed with the L2 Syntactic Complexity Analyzer (Lu, 2010). I selected a set of seven measures that tap into various dimensions of syntactic complexity: complexity by subordination, phrasal elaboration and specific part-of-speech-based structures (Table 6). 5 Measures of lexical complexity were automatically computed with the Lexical Complexity Analyzer (Lu, 2012). Tables 7 and 8 provide a list of the seven measures of lexical diversity and the five measures of lexical sophistication. All measures of lexical diversity are transformations of the type–token ratio (TTR) used to assess the variation of total vocabulary (i.e. RTTR) or specific word categories. Lexical-word variation (LV) is the ratio of the number of lexical word types (Tlex) to the total number of lexical words (Nlex) in the text. Corrected VV1 is the ratio of the total number of verb types (Tverb) to the total number of verbs (Nverb) squared to reduce the sample size effect. The following four ratios have verb types (Tverb), noun types (Tnoun), adjective types (Tadj) and adverb types (Tadv) as numerator respectively and the same denominator, i.e. the number of lexical words.
Measures of syntactic complexity.

Measures of lexical diversity.
Measures of lexical sophistication.
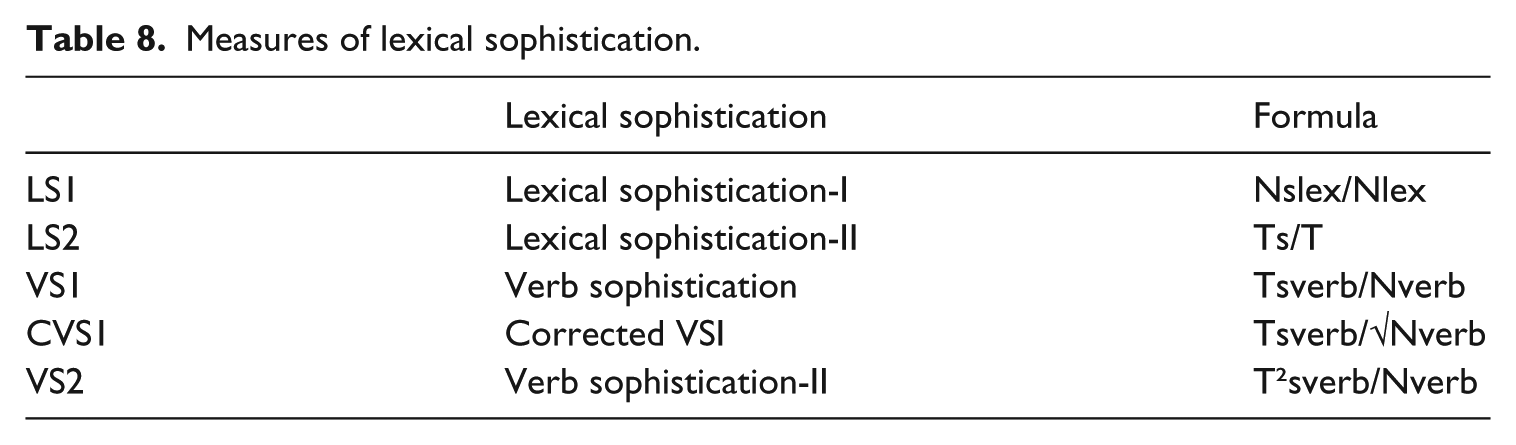
Measures of lexical sophistication are also all ratio-based. LS1 is the ratio of the number of sophisticated lexical word tokens (Nslex) to the total number of lexical word tokens (Nlex), while LS2 is the ratio of the number of sophisticated word types to the total number of word types in a learner text. VS1 is computed as the ratio of the number of sophisticated verb types (Tsverb) to the total number of verb tokens (Nverb) in a text. CVS1 and VS2 are two adaptations of VS1 (for more details, see Lu, 2012). Words, lexical words and verbs are counted as sophisticated if they are not on the list of the 2,000 most frequent words generated from the British National Corpus (Lu, 2012: 192).
3 Comparison of B2, C1 and C2 learner texts
Distributions in the CEFR-based learner sub-corpora were systematically checked for normality with the Shapiro–Wilk test (see Appendix 1). Normally distributed frequency counts were compared with ANOVAs followed by Tukey contrasts. Otherwise, Kruskal–Wallis rank sum tests were used instead. The significance of the statistical tests was set at 0.05 and Bonferroni corrections were used to correct alpha for multiple comparisons. Alpha was set at 0.05/7 = 0.007 to compare the seven measures of lexical diversity, 0.05/5 = 0.01 to compare the five measures of lexical sophistication, 0.05/3 = 0.017 to compare the three measures of phraseological diversity as well as the mean MI scores in amod, advmod and dobj dependencies, and 0.05/6 = 0.008 to compare the six measures of phraseological sophistication based on the Academic Collocation List across B2, C1 and C2 learner texts. All statistical analyses were performed with R (R Core Team, 2014).
V Results
1 Measures of phraseological complexity
Table 9 shows the mean RTTRs per CEFR levels for the amod, advmod and dobj dependencies. No clear pattern emerges for amod_RTTR and advmod_RTTR. Only the mean RTTR for dobj dependencies displays a slight decrease from B2 to C1 and C2, showing that phraseological diversity tends to decrease with proficiency level. The difference between groups, however, is not statistically significant.
Measures of phraseological diversity.
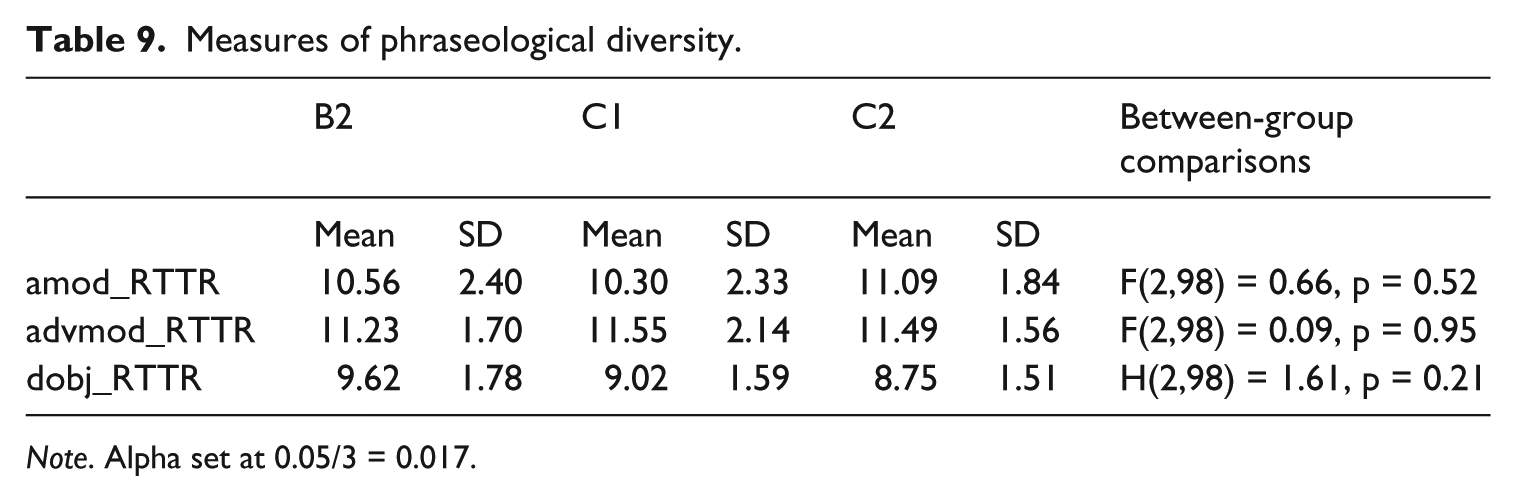
Note. Alpha set at 0.05/3 = 0.017.
Measures of phraseological sophistication are of two types. The first set of measures is based on the Academic Collocation List (ACL). Table 10 provides mean percentages of amod, advmod and dobj dependencies that belong to the ACL at the B2, C1 and C2 levels. LS1-measures are computed on the basis of types; LS2-measures are token-based. Measures for amod dependencies increase from B2/C1 to C2. The same pattern is observed for LS1dobj, and a systematic increase from B2 to C1 and C2 is observed for the token-based version of the measure, i.e. LS2dobj. Measures of advmod dependencies both increase systematically from one proficiency level to the next. No differences, however, are statistically significant.
Measures of phraseological sophistication based on the Academic Collocation List.
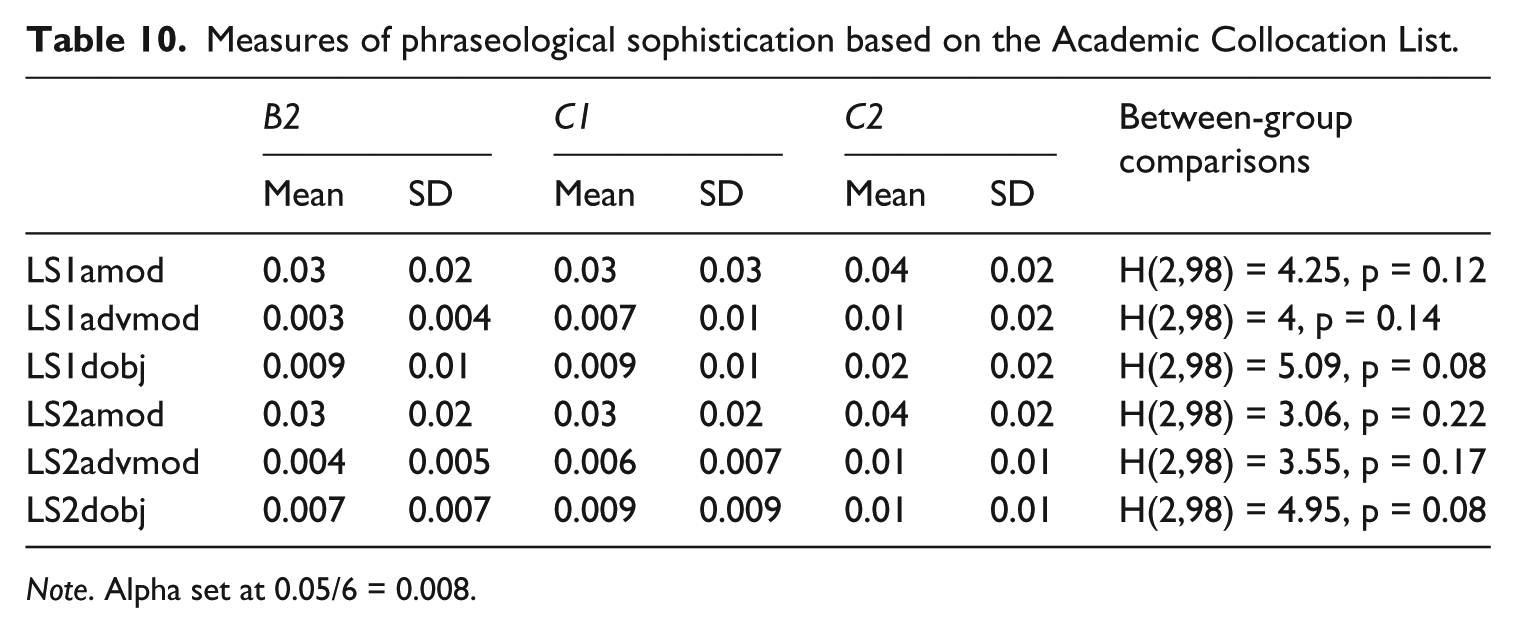
Note. Alpha set at 0.05/6 = 0.008.
The second set of measures of phraseological complexity report on the strength of association between words. Table 11 provides mean MI values for amod, advmod and dobj dependencies across CEFR proficiency levels. For each dependency relation, mean MI scores increase systematically from B2 to C1 and C2. This suggests that the more proficient learners are, the more dependencies with higher MI scores they use or, to put it differently, the less they rely exclusively on dependencies with low MI scores that are usually considered non-collocational. It is indeed common practice in the literature to adopt MI = 3 as a minimum value for collocational status (e.g. Durrant and Schmitt, 2009; Granger and Bestgen, 2014; Hunston, 2002). To illustrate, examples (3)–(5) are amod, advmod and dobj dependencies found in the VESPA learner texts that were either assigned a MI score of 3 or above, or a low MI score of 1.
(3) amod dependencies with MI > 3: overwhelming majority, hasty conclusion, integral part, slight predominance, keen interest, exhaustive list, wide range, illustrative example, chronological order, wide variety, spontaneous speech, next section, possible explanation, large majority, significant difference, clear preference amod dependencies with MI = 1: main function, only conclusion, final part, common history, different field, same number, enough material, theoretical definition, common word, long word, real power, specific form, common method, certain way, different function, general definition, simple form (4) advmod dependencies with MI > 3: grammatically incorrect, statistically significant, quite rightly, perfectly understandable, evenly + distribute, constantly + evolve advmod dependencies with MI = 1: quite interesting, also possible, more puzzling (5) dobj dependencies with MI > 3: arouse + curiosity, fill + gap, serve + purpose, pay + attention, play + role, divert + attention, corroborate + finding, avoid + misunderstand dobj dependencies with MI = 1: have + function, consider + characteristic, have + characteristic, classify + adjective, mention + agent
Mean mutual information (MI) scores per proficiency level.
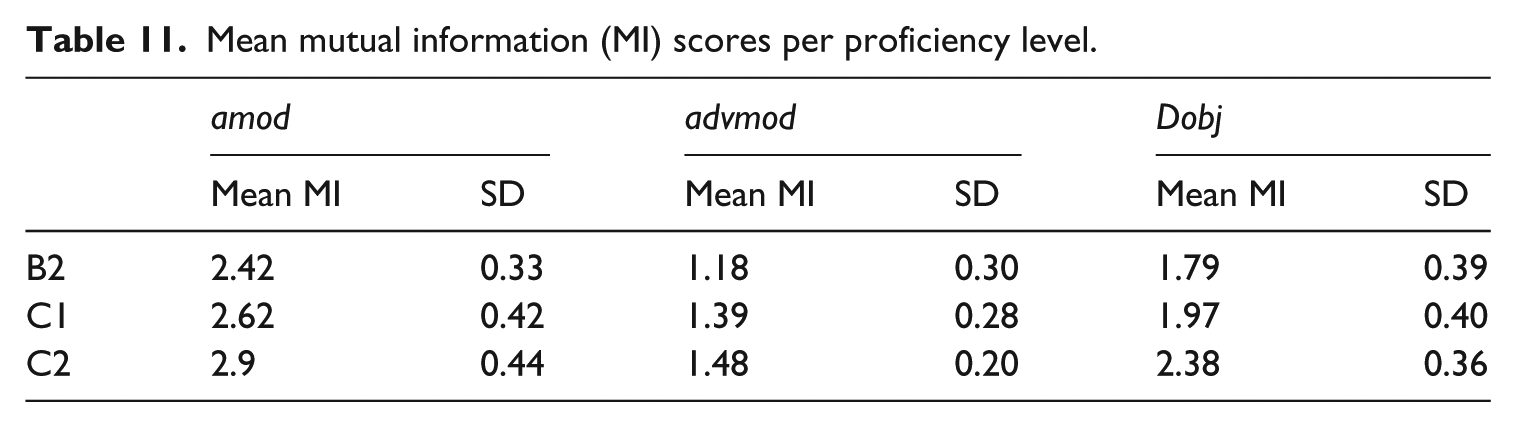
Dependencies with MI > 3 include strongly associated combinations of medium to low frequency words that tend to be rich in semantic content and are also more characteristic of the genre of academic writing (e.g. overwhelming + majority, statistically + significant, perfectly + understandable, serve + purpose, corroborate + finding). They also include some extremely frequent combinations of relatively common words that are conventionalized or preferred ways of saying things (e.g. wide variety, quite rightly). By contrast, dependencies with MI = 1 feature two main types of less sophisticated combinations:
Word combinations with basic or nuclear vocabulary (e.g. have, main, only, more, different). Nuclear words are of high frequency in most uses of the language: they give no indication of the field of discourse from which a text is taken, i.e. its domain of experience or social settings, and are also neutral with respect to tenor and mode of discourse (Stubbs, 1986: 104–06).
Pairs of medium frequency words that are sometimes found together but are not strongly associated (e.g. mention + agent).
There is a statistically significant difference between groups for mean MI scores based on amod dependencies (F(2,98) = 5.642, p = 0.00484, eta squared (ŋ²) = 0.1062). Tukey contrasts however reveal non-significant differences between adjacent proficiency levels (i.e. B2 vs. C1, C1 vs. C2). The increase in mean MI scores is only significant from B2 to C2 (Table 12).
amod dependencies: Tukey contrasts between proficiency levels.
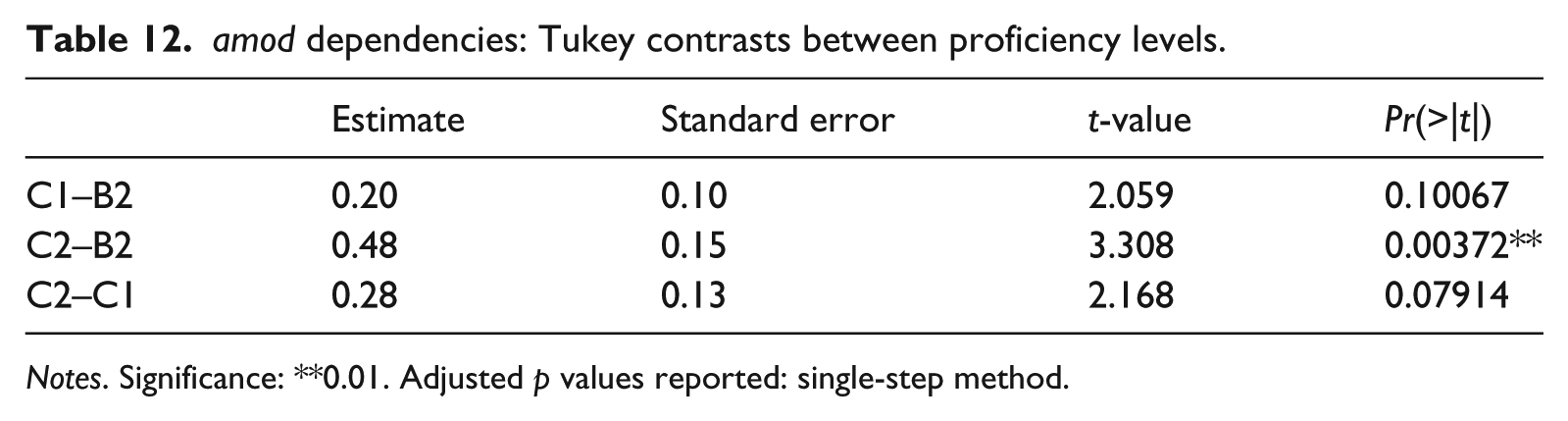
Notes. Significance: **0.01. Adjusted p values reported: single-step method.
Mean MI scores also indicate a significant difference in the way EFL learners use adverb modifiers across proficiency levels (F(2,98) = 6.382, p = 0.00251, eta squared (ŋ²) = 0.1184). The difference in mean MI scores is significant between upper intermediate learners (i.e. B2) and advanced learners (C1 and C2) but it is non-significant between C1 and C2 (Table 13).
advmod dependencies: Tukey contrasts between proficiency levels.
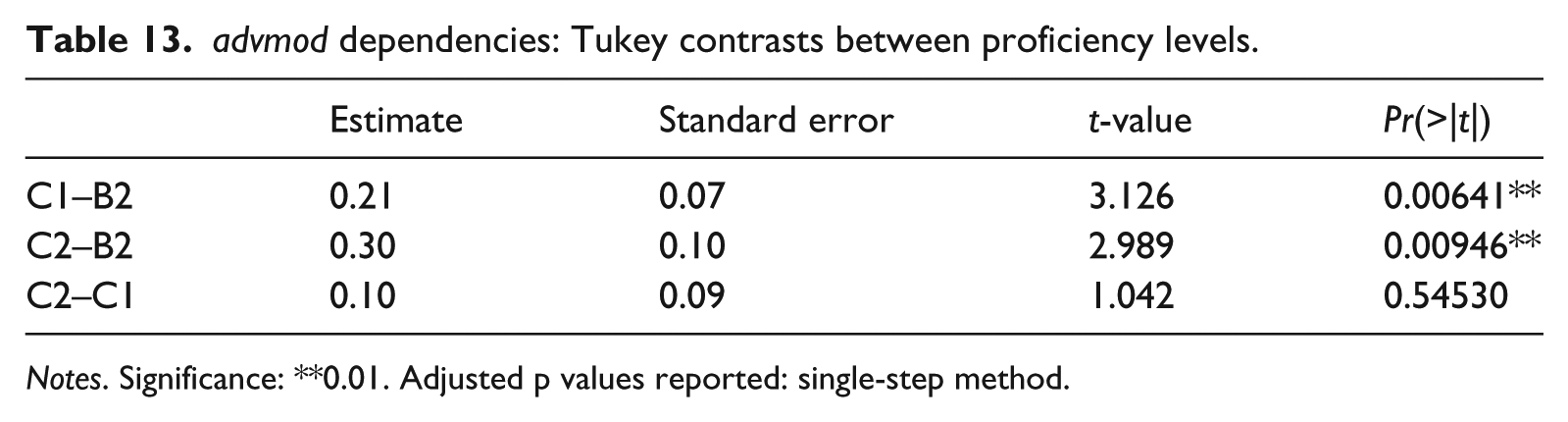
Notes. Significance: **0.01. Adjusted p values reported: single-step method.
There is also a statistically significant difference between groups for mean MI scores based on dobj dependencies (F(2,98) = 8.636, p = 0.000358, eta squared (ŋ²) = 0.1538). Despite a medium effect size, Tukey contrasts reveal a non-significant difference between the B2 and C1 levels. However, mean MI scores at the C2 level are significantly different from scores at the B2 and C1 levels (Table 14).
dobj dependencies: Tukey contrasts between proficiency levels.
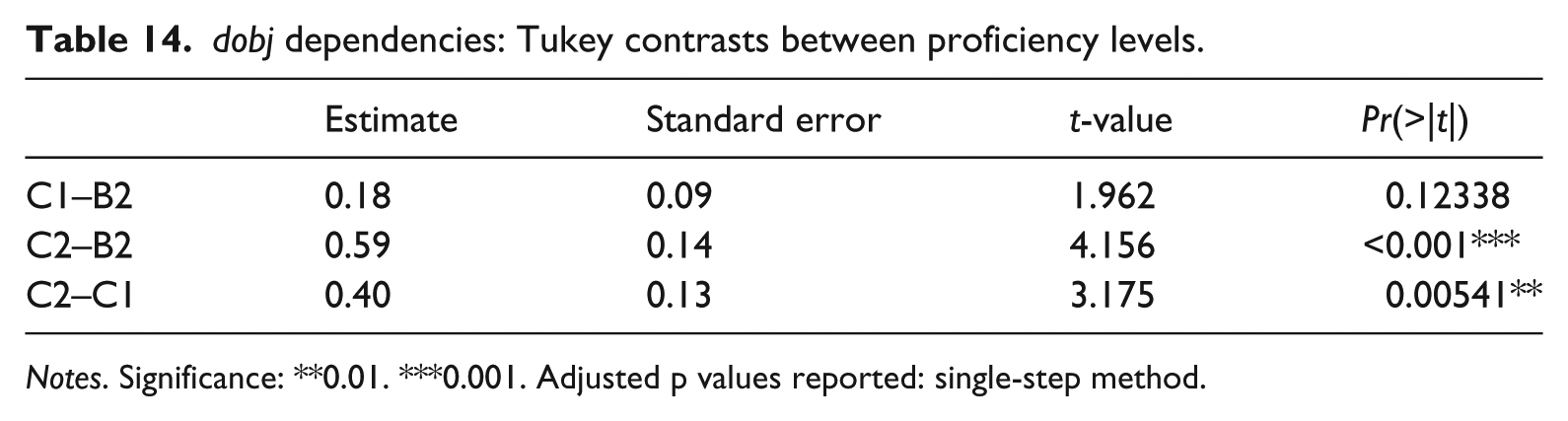
Notes. Significance: **0.01. ***0.001. Adjusted p values reported: single-step method.
2 Syntactic and lexical complexity
Tables 15, 16 and 17 show the mean scores per CEFR level for the five measures of syntactic complexity, seven measures of lexical diversity and five measures of lexical sophistication analysed in this study. Mean scores for measures of syntactic and lexical complexity do not show a systematic increase (or decrease) across proficiency levels except for the two syntactic complexity measures of mean length of clause (MLC) and complex nominals per clause (CN/C) and the two lexical diversity measures of RTTR and CVV1 (highlighted in bold in Tables 15 and 16). Three additional measures of lexical diversity, i.e. LV, VV2 and AdjV, show an increase from B2/C1 to C2. The same pattern is also observed for one measure of lexical sophistication, i.e. VS1. However, none of the differences was found to be statistically significant.
Syntactic complexity measures.

Measures of lexical diversity.
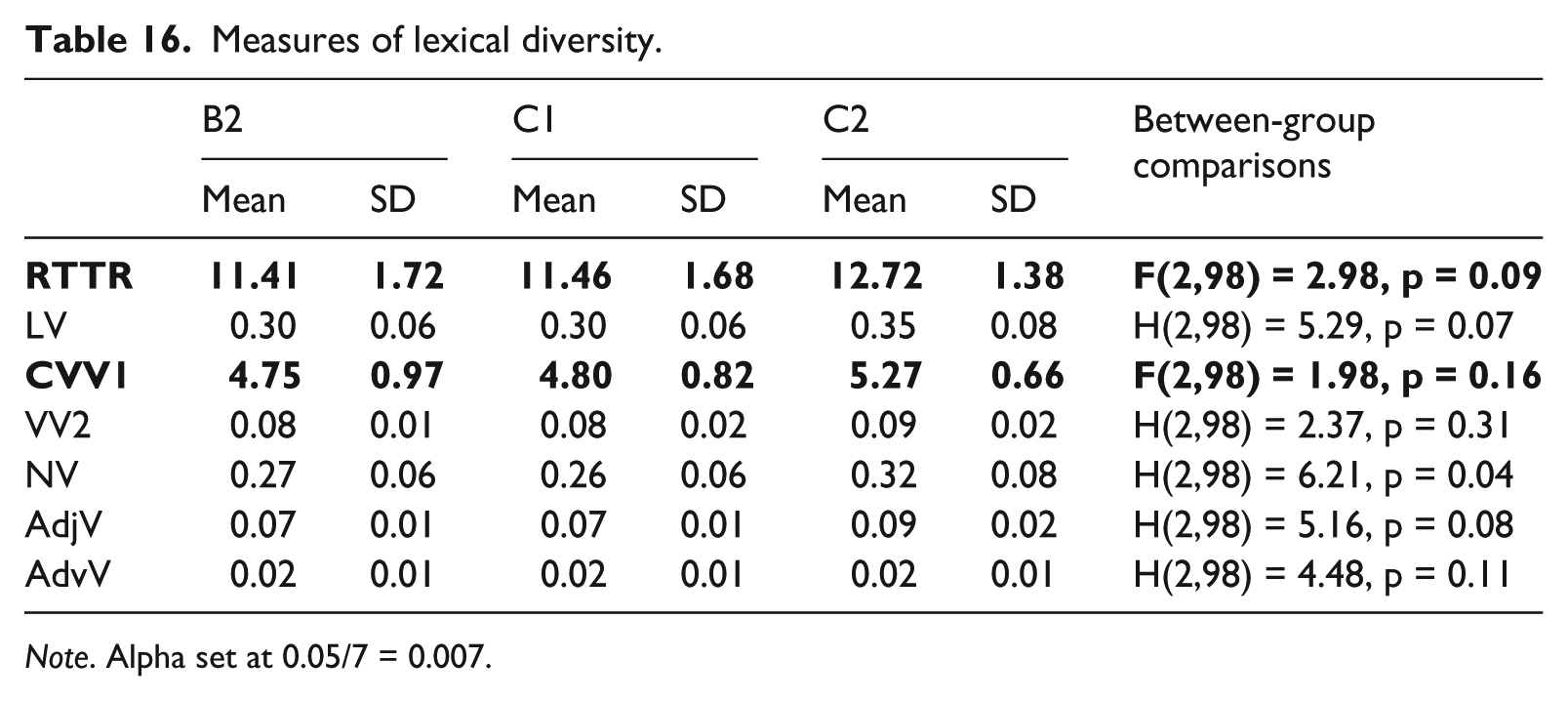
Note. Alpha set at 0.05/7 = 0.007.
Measures of lexical sophistication.

Note. Alpha set at 0.05/5 = 0.01.
VI Discussion
Two key properties of phraseological complexity, i.e. diversity and sophistication, were investigated in this study. Phraseological diversity was operationalized as root type–token ratios (RTTRs) based on amod, advmod and dobj dependencies. The three measures proved not useful to describe L2 performance at different proficiency levels: like for measures of lexical diversity, no difference between groups was found to be statistically significant but, unlike for measures of lexical diversity such as RTTR and CVV1, no systematic increase in mean scores was observed from one proficiency level to the next one. However, this does not mean that the construct of phraseological diversity cannot be used to characterize learner language development. This exploratory study only used one type of diversity measure and other indices should be tested in future research. More particularly, recent development in lexical diversity research has provided the field with more sophisticated measures that are not transformations of type–token ratios (e.g. D, MTLD) and these could be adapted to take into account the properties of word combinations and compute their diversity in a learner text (e.g. Jarvis and Daller, 2013).
Measures of phraseological sophistication based on the Academic Collocation List proved more useful than measures of lexical sophistication to describe, compare and distinguish between VESPA texts at the B2, C1 and C2 levels. Increases in mean scores were either found between adjacent levels or between B2 and C2. However, differences were not statistically significant. The ACL was primarily compiled to help EFL learners increase their collocational competence and support English for Academic Purposes (EAP) teachers in their lesson planning. As such, it consists in a manually filtered list of 2,468 frequent collocations that were evaluated as the most pedagogically relevant word combinations by a panel of experts. Ackermann and Chen (2013) report an overall coverage of the ACL in the source corpus of 1.4%. This is not much compared to the coverage of word frequency lists that are commonly used to assess lexical sophistication in learner texts. The Academic Word List (Coxhead, 2000), for example, has been shown to cover c. 10% of academic texts. While the ACL already shows research value, it is desirable that, in the future, a larger list be designed as a research tool for investigating phraseological sophistication and academic language development. 6
Results also indicate that the proposed MI-based measures of phraseological sophistication proved useful to describe the development of L2 performance across proficiency levels. A systematic increase in mean MI scores from one proficiency level to the next is found for the three dependencies under study, i.e. amod, advmod and dobj. All in all, there is a significant effect of proficiency on mean MI scores and this independent variable explains 11%, 14% and 15% of the variance in mean MI scores for amod, advmod and dobj dependencies respectively. These results are encouraging: Ellis and Larsen-Freeman (2006: 559) commented that single factors rarely account for more than 16% of the variance (r = 0.4) in a given language phenomenon.
Mean MI scores, however, paint a different picture of the development of phraseological complexity from one proficiency level to the next depending on the grammatical structure investigated. Adjective + noun dependencies show a significant difference in mean MI scores between the B2 and C2 levels but differences are not large enough to distinguish between adjacent levels such as B2–C1 and C1–C2. As adjective + noun sequences are the most easily extracted type of grammatical relations, their use in learner writing has already been analysed with the help of association scores (e.g. Durrant and Schmitt, 2009). Results seem to indicate however that this category is the least powerful to distinguish between different proficiency levels and that it may prove extremely useful to focus on other grammatical relations.
Adverbial modifiers (i.e. adverb + adverb, adverb + adjective, adverb + verb) single out upper intermediate (i.e. B2) learner writing from the more advanced (i.e. C1 and C2) learner productions. The advmod dependencies listed in (6) are examples of word combinations with high MI score > 6. Such phraseological units are rich in content, precise and ‘appropriate to the topic and style of [academic] writing’ (Read, 2000: 200).
(6) Examples of advmod dependencies with MI score > 6: mutually exclusive, fiercely debated, scarcely tenable, evenly distributed, firmly rooted, stylistically heavy, regret profoundly, intimately intertwined, disproportionately large, strangely enough, totally unprecedented, seriously endangered, officially approved, roughly equivalent, rely heavily, point + rightly, represent + graphically, behave + differently, comment + briefly, evolve + constantly, closely intertwined, overlap + partially, test + empirically
Examples of advmod dependencies comprised between 0 and 1 in (7) are mostly correct collocations in English, but they are less specialized: they are often made up of relatively basic or ‘nuclear’ vocabulary, i.e. high-frequency words that give no indication of the domain of experience or social settings from which a text is taken (see Stubbs, 1986). In that sense, they can be described as less sophisticated.
(7) Examples of advmod dependencies with 0 > MI score > 1: clearly negative, clearly described, important enough, measure + typically, represent + directly, very theoretical, much important, less striking, realize + even, remain + especially, rather neutral, find + usually, especially negative, even pertinent, belong + usually, quite + relevant, probably easy, express + commonly, particularly frequent, very surprising, plan + obviously, undoubtedly important, allow + generally, still common, slightly often, use + differently, highly likely, influence + clearly, very varied, previously said, provide + interestingly, often considered, already said, very frequently, describe + simply, focus + only, define + easily, very critical, confirm + clearly, refer + simply, very formal, entirely true, obviously possible
It should be noted that some of these word combinations would probably receive a higher MI score if another reference corpus were used. In the COCA, for example, word combinations such as first attempt, already identified, very critical and entirely true have MI scores > 3. By selecting the L2RC as reference corpus to compute MI scores, it is possible to cater for the context-dependent nature of sophistication and prioritize formal, precise and academic-like vocabulary when evaluating the phraseological sophistication of EFL learners’ term papers as found in the VESPA corpus (see below for a more detailed discussion of the importance of context in interlanguage complexity research).
Verb + direct object structures are the best discriminators of the most advanced level: mean MI scores on dobj dependencies set C2 texts apart from B2 and C1 texts. To illustrate, Table 18 lists the twenty top-ranked dobj dependencies by decreasing MI score in UCL0007-LING-01, i.e. the learner text with the minimum average MI score, and UCL0020-LING-02, i.e. the learner text with the maximum MI score. The former text was ranked at B2 by two human raters; the latter was ranked at C2. Word combinations in UCL0020-LING-02 stand out as being perfect native-like restricted collocations typical of academic writing that ‘allow writers to express their meanings in a precise and sophisticated manner’ (Read, 2000: 200) (e.g. pursue a career, place emphasis). Top-ranked dependencies in UCL0007-LING-01 are fine but, as their MI scores quickly become lower, they also quickly become less ‘idiomatic’, precise (e.g. distinguish + kind), and genre-appropriate (e.g. pick term, say many words). It should also be noted that only 6 dobj dependencies in UCL0007-LING-01 (4.51%; against 55 or 42.64% in UCL0020-LING-02) are above the MI threshold of 3 often used in the literature to separate out statistical collocations from free combinations (Evert, 2004).
Twenty top-ranked dobj dependencies in B2 vs. C2 learner text.

Note. MI = mutual information.
Another important difference between the two learner texts is the percentage of word combinations that are assigned negative MI scores: 27.82% of all the dobj dependencies in UCL0007-LING-01 have MI scores below 0, thus suggesting that the two words that make up each combination appear together less frequently than their respective frequencies would predict by chance. Examples include define + source, have + change, or include + increase. In 6, for example, the use of the verb define is neither collocationally right nor semantically correct (in the sense that what follows is a list of terms, not definitions) and verbs such as identify, provide or locate should have been used instead.
Algeo (1991, pp. 3–14)
These findings are in line with results from previous studies that have shown that verb + object collocations are particularly difficult to master even at the more advanced proficiency levels (e.g. Laufer and Waldman, 2011; for a survey, see Paquot and Granger, 2012). These results also find resonance in Ellis and Larsen-Freeman’s (2006: 559) statement that ‘each variable is but a small part of a complex picture’ and point to the need of developing a more elaborate metric that would allow the various dimensions of phraseological sophistication (here based on different syntactic relations) ‘to be quantified, weighted, and eventually synthesized into overall values that can be extracted from each language sample’ (Ortega, 2012).
Although mean MI scores may be considered crude measures of phraseological sophistication, ‘lumping everything together’ as put by one reviewer, they provide a useful summary of the learner’s ability to select word combinations that are precise, semantically correct, collocationally constrained and/or genre appropriate; in short sophisticated. A mean MI score will increase if a learner uses a large proportion of sophisticated word combinations with high MI scores as UCL0020-LING-02 did; it will decrease if a learner uses few high-scoring combinations or relies on word combinations with negative MI scores as done by UCL0007-LING-01. Importantly, an average MI score does not measure a learner’s (lack of) creativity: word combinations that are not found in the reference corpus are discarded from further analysis (as MI scores come from the reference corpus).
This study made use of mean MI scores based on amod, advmod and dobj dependencies, but other types of word combinations could be investigated, including lexical bundles or constructions. Working with lexical bundles (i.e. repeated sequences of contiguous words such as take the example, I think, by contrast, as argued in) would have the advantage of facilitating the extraction procedure and lowering the unavoidable error rate brought by the part-of-speech tagging (POS-tagging) and parsing of learner language. Second, pointwise mutual information (PMI) scores are averaged per learner text in this study, but they could also be categorized in collocational bands so that frequencies and proportions of word combinations with low, medium and high MI scores per text could also be computed (see Durrant and Schmitt, 2009; Granger and Bestgen, 2014). Third, other statistical measures could also be evaluated, most particularly perhaps that of delta P, i.e. a directional measure derived from the domain of associative learning which is based on the principle that ‘associations are not necessarily reciprocal in strength’ (Ellis and Ferreira-Junior, 2009: 198). This being said, the measures used here already indicate that phraseological sophistication is a fundamental dimension of L2 writing quality. In Paquot and Naets (2015), we showed that measures of phraseological sophistication can also be used to trace language development in a longitudinal learner corpus.
It may even be argued that language development at upper-intermediate to very advanced proficiency level is for the most part situated in the phraseological complexity dimension, and not in syntactic or lexical complexity. Unlike the MI-based measures of phraseological sophistication, no measure of lexical complexity distinguishes with statistical significance between proficiency levels in the VESPA corpus. Similarly, B2, C1 and C2 learners cannot be contrasted on the basis of traditional measures of syntactic complexity. This is surprising as the measures used have been identified in previous research as measures that point at differences in complexity across proficiency levels (Lu, 2012; Wolfe-Quintero et al., 1998). However, to the best of the author’s knowledge, they have typically been used on argumentative essays or narratives produced by beginner to intermediate EFL learners; they have not often been employed on the type of learner texts represented in the VESPA corpus, i.e. research papers written by upper intermediate to very advanced learners. On the other hand, results seem to support the view that traditional measures of complexity may not be adequate or sensitive enough to tap into the more advanced stages of foreign language development (e.g. Biber et al., 2011; Ortega, 2012).
More generally, recent studies have also insisted that interlanguage complexity research should account for context (e.g. Rimmer, 2009). This is particularly crucial for measures of phraseological sophistication which should be able to evaluate appropriate selection of word combinations in terms of topic and style (see Read, 2000). Accordingly, the proposed measures of phraseological sophistication are genre-sensitive extrinsic measures: the Academic Collocation List was compiled on the basis of a corpus of academic writing and MI scores are also derived from a large reference corpus of research articles in linguistics. Provided the appropriate list of phraseological units or reference corpus is used, measures of phraseological sophistication thus have the potential to tap into the specificities of different genres, tasks and modalities, thus better answering teachers’ and students’ needs. In this study, EAP resources were used and the derived measures of phraseological complexity also tell us something about EFL learners’ mastery of the phraseology of academic writing. If a general reference corpus such as the British National Corpus or the Corpus of Contemporary American English had been used instead, results would have informed us about learners’ general knowledge of the English language. The choice of reference corpus to compute measures of phraseological sophistication thus fundamentally depends on the type of learner texts under study and the general objective of the study. Ultimately, this may also mean that to gain a better idea of EFL learners’ phraseological complexity, measures computed on the basis of several reference corpora should be used.
VII Conclusions
Today, interlanguage complexity research clearly stands at a crossroads. Ortega (2012) has recently described complexity as ‘a construct in search of theoretical renewal’. Measures of complexity have been repeatedly criticized for their lack of theoretical foundation and construct validity (e.g. Biber et al., 2011; Norris and Ortega, 2009; Pallotti, 2015). Leading researchers in the field have also called for an expanded view of complexity as a multifaceted and multidimensional construct that cannot be fully explored via just one of its dimensions (as is commonly done) but requires to be operationalized with a battery of measures (including new and more specific measures) tapping different properties of the construct in multivariate research designs (e.g. Bulté and Housen, 2012; Ortega, 2012). Within this framework, this study has shown that a successful renewal of the domain will also require a better appreciation of the phraseological dimension of language use, arguing that there is a theoretical need to develop the construct of phraseological complexity. Methodologically, it has also demonstrated that corpus linguistics and natural language processing provide the tools and techniques to operationalize the dimensions of such a construct.
The research presented here is preliminary and leaves the ground open for a wide range of follow-up studies. As already discussed above, other measures of phraseological complexity should be developed and empirically validated. Other types of learner production should also be analysed to determine how phraseological complexity interacts with foreign language proficiency and development across modes, tasks and genres. It will also be essential to establish whether sophistication and diversity are the only properties of phraseological complexity and whether the construct is theoretically valid across languages (see also De Clercq, 2015). The range of envisaged measures of phraseological complexity is not language-specific per se (even extrinsic measures such as the proposed mean MI scores could be computed on the basis of large reference corpora in French, Spanish, Dutch, etc.), and it should be verified whether the measures could be used to gauge proficiency and trace language development in other foreign languages (see Pallotti and Brezina, 2019, De Clercq and Housen, 2019). This is a particularly promising avenue for research as it will make it possible to appraise the role of complexification vis-à-vis crosslinguistic influence in foreign language development (see Ehret and Szmrecsanyi, 2019; van der Slik et al., 2019).
Although much remains to be done, research findings already have significant implications for foreign language teaching and more particularly language assessment and testing. Phraseological complexity appears to be an essential dimension of L2 writing quality (and probably even more so at the more advanced proficiency levels) and should therefore feature more prominently in language proficiency descriptors and second language assessment rubrics than it currently does (see Paquot, 2018). For example, there is not a single mention of phraseology, collocations, or formulaic sequences in the Structured Overview of all CEFR scales published by the Council of Europe (2001). 7 Ultimately, measures of phraseological complexity should also be used to augment the set of linguistic indices used to automatically score L2 productions. While word combinations of different types (compounds, collocations, idioms) are now being incorporated in educational technology, the focus largely remains on the use of n-gram models in error detection and correction (e.g. Burstein et al., 2013; Futagi et al., 2008).
Footnotes
Appendix
Shapiro–Wilk tests.
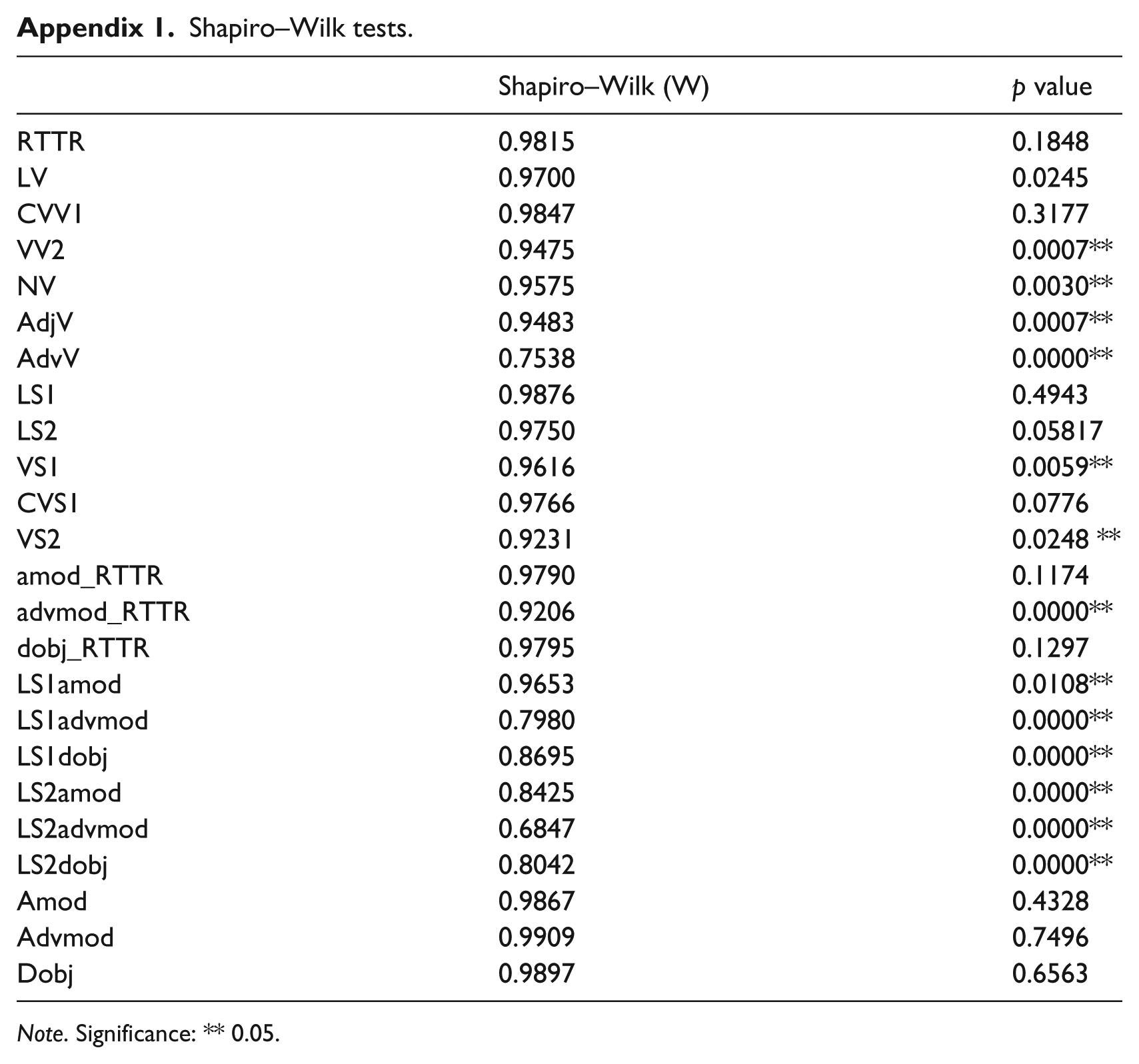
| Shapiro–Wilk (W) | p value | |
|---|---|---|
| RTTR | 0.9815 | 0.1848 |
| LV | 0.9700 | 0.0245 |
| CVV1 | 0.9847 | 0.3177 |
| VV2 | 0.9475 | 0.0007** |
| NV | 0.9575 | 0.0030** |
| AdjV | 0.9483 | 0.0007** |
| AdvV | 0.7538 | 0.0000** |
| LS1 | 0.9876 | 0.4943 |
| LS2 | 0.9750 | 0.05817 |
| VS1 | 0.9616 | 0.0059** |
| CVS1 | 0.9766 | 0.0776 |
| VS2 | 0.9231 | 0.0248 ** |
| amod_RTTR | 0.9790 | 0.1174 |
| advmod_RTTR | 0.9206 | 0.0000** |
| dobj_RTTR | 0.9795 | 0.1297 |
| LS1amod | 0.9653 | 0.0108** |
| LS1advmod | 0.7980 | 0.0000** |
| LS1dobj | 0.8695 | 0.0000** |
| LS2amod | 0.8425 | 0.0000** |
| LS2advmod | 0.6847 | 0.0000** |
| LS2dobj | 0.8042 | 0.0000** |
| Amod | 0.9867 | 0.4328 |
| Advmod | 0.9909 | 0.7496 |
| Dobj | 0.9897 | 0.6563 |
Note. Significance: ** 0.05.
Acknowledgements
I thank Hubert Naets for his invaluable help with the corpus preprocessing steps. I also thank Sylviane Granger and Alex Housen for their constructive comments and suggestions at various stages of this research.
Declaration of Conflicting Interest
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Fonds de la Recherche Scientifique (FNRS).