
Abstract
This article examines the effect of phonological context (singleton vs. clustered consonants) on full phoneme segmentation in Hebrew first language (L1) and in English second language (L2) among typically reading adults (TR) and adults with reading disability (RD) (n = 30 per group), using quantitative analysis and a fine-grained analysis of errors. In line with earlier findings, overall mean scores revealed significant differences between the two groups. However, no qualitative differences were found. In both groups and languages, full phoneme segmentation overall scores for CVC stimuli were higher than CCVC stimuli. This finding does not align with previous findings, obtained from a phoneme isolation task, showing that isolation from a cohesive CV unit is the most difficult. A fine-grained analysis of errors was conducted to glean insight into this finding. The analysis revealed a preference for creating and preserving CV units in phoneme segmentation in both L1 and L2. This is argued to support the cohesion of the CV unit. The article argues that the effect of language-specific sub-syllabic representations on phonemic analysis may not be always observed in overall scores, yet it is reflected in specific patterns of phonological segmentation errors.
I Introduction
Researchers converge on the idea that phonological awareness, the ability to access and manipulate the sounds of spoken words, is foundational to the development of reading in an alphabetic orthography, both among children and adults (Adams, 1990; Bruck, 1992; Goswami and Bryant, 1990; National Reading Panel, 2000), and regardless of orthographic depth (Ziegler and Goswami, 2005; Ziegler et al., 2010). It has also been suggested that this ability has a reciprocal relationship to reading and benefits from the acquisition of reading skills (Gombert, 1992; Morais et al., 1979; Read et al., 1986). Phonological awareness appears to also be a critical factor in second-language (L2) reading (Genesee and Geva, 2006; Genesee et al., 2006), and a reliable predictor of L2 reading difficulty (e.g. Geva and Yaghoub-Zadeh, 2006; Geva et al., 2000).
Despite its universal relevance to reading acquisition in alphabetic orthographies, the developmental trajectory of phonological awareness and the factors that affect this construct might differ in different languages depending on the linguistic and orthographic structure of the specific language, as well as on the availability of different linguistic units to readers in different languages (Ziegler and Goswami, 2005). For example, Caravolas and Bruck (1993) found that Czech-speaking children were better able to isolate and delete single consonants embedded in consonant clusters than English-speaking children because of the predominance of clusters in this language. Similar findings were reported by Zaretsky (2002), who examined Russian-speaking and English-speaking pre-readers. These results were explained in light of the phonological distributional and structural differences between the two languages. In other words, the complexity and frequency of sub-syllabic units in a given language have an impact on the ability to access and manipulate phonological units (Saiegh-Haddad et al., 2010). The present study continues to explore this notion in a different linguistic context by examining the effect of phoneme context (singleton as opposed to clustered initial consonants) on full phoneme segmentation in Hebrew (first language, or L1) and English (L2) among typically reading adults and adults with reading disability.
1 Factors influencing phonological awareness
In what follows, different factors that have been found to influence phonological awareness will be discussed.
a Linguistic distance between L1 and L2 phonemes
Language-specific phonological factors appear to be implicated in the development of phonological awareness and in its relation to reading in L1 as well as L2 (e.g. Branum-Martin et al., 2012; Russak and Saiegh-Haddad, 2011). For instance, Russak and Saiegh-Haddad (2011) found that both reading disabled and typical readers of English L2 found novel phonemes that are not within Hebrew L1 more difficult to operate on than familiar L1 phonemes (Saiegh-Haddad, 2003; Russak and Saiegh-Haddad, 2011). Similarly, Geva and colleagues found that phonological awareness in L2 was affected by L1–L2 phonological distance (Wade-Woolley and Geva, 2000; Wang and Geva, 2003).
b Task requirements
In addition to linguistic distance, specific task requirements appear to affect phonological awareness performance in L1 and L2 (e.g. López, 2012; Martin, 2015; McBride-Chang, 1995; Stahl and Murray, 1994). For instance, phonological awareness tasks that require speech manipulation, such as phoneme isolation, are more difficult than tasks requiring a forced choice, such as phoneme matching (McBride, 2016). Similarly, tasks that target smaller grain size units, such as phonemes, are more difficult than those targeting larger units like syllables (McBride, 2016). Thus, full phoneme segmentation which targets the smallest phonological units within the word, and which requires explicit access to all of the phoneme constituents within the word, appears to be among the most difficult phoneme awareness tasks (Adams, 1990; Saiegh-Haddad, 2007b; Stahl and Murray, 1994).
c Orthographic structure
Another factor that affects phonological processing in L1 and L2 is orthographic structure (Koda, 2008; Morais et al., 1979). Ehri and Wilce (1980) examined the effect of orthographic word spellings on phonological processing by asking a group of English-speaking fourth graders to say how many phonemes were in pairs of words with shared phonological but not orthographic rime patterns (such as the words rich and pitch). They found that when children were familiar with the spellings of the words, they tended to mention additional phonemes whose spellings symbolized these phonemes (for example, mentioning the phoneme /t/ in the word pitch) in their phoneme counting. Extra phonemes were rarely detected in the control words (for example rich), nor were they detected by children who were not familiar with word spellings. Similar findings were reported by Treiman and Cassar (1997) among both children and adults using a phoneme-counting task of vowel monophthongs (as in hi) vs. vowel diphthongs (as in haʊ). Orthographic effects on phoneme counting were also reported in cross-linguistic settings. Mathieu (2016) examined a group of native English-speaking college participants learning novel phonological contrasts in Arabic. He found that familiarity with the target script mediated the processing of phonological contrasts. He concluded that the more familiar the orthographic representations in the target language (L2) are to the native language, the more contributory the orthographic input will be to the learning of novel phonological representations.
d Underlying structure of syllable
An additional linguistic factor that appears to impact the development of phonological awareness in different languages is the underlying sub-syllabic structure of the syllable in a given language and, consequently, the position that a target phoneme occupies within the syllable. Until recently, the underlying structure of the syllable was thought to be universal, and to take the form of an onset–rime structure (C-VC): formulated as the ‘rime-cohesion hypothesis’. According to this hypothesis, syllables are composed of phonemes structured hierarchically into these constituents: the onset; the initial consonant(s); and the rime, the nucleus vowel with the coda of any following consonant(s) (Fudge, 1969; Goldsmith, 1990). In line with the predictions of this hypothesis, psycholinguistic evidence in English, in particular, has shown that children and adults show a tendency to break syllables at the boundary between onsets and rimes. English speakers of varying ages were also found to have greater difficulty segmenting–coda phonemes than onset phonemes, and cluster phonemes than singleton phonemes (Bruck and Treiman, 1990; Goswami, 1986, 1991; Treiman, 1983, 1985; Treiman and Danis, 1988; Treiman and Kessler, 1995; Treiman and Weatherson, 1992; Treiman and Zukowski, 1991).
Recently, however, results emerging from similar research in languages other than English suggest an alternative internal hierarchical structure to the syllable. In turn, it has been suggested that the cohesion of the rime may be an English-specific rather than a universal property, and that this structure might reflect the phonological and orthographic properties of English. In support of this, Geudens and colleagues tested children’s explicit and implicit segmentation of two-phoneme syllables in English and in Dutch and did not find support for the view that children treated onsets and rimes as cohesive constituents (Geudens and Sandra, 2003; Geudens et al., 2004, 2005). In the same way, Saiegh-Haddad (2003, 2004, 2007a) examined Arabic native-speaking children in kindergarten through third grade and found that they had more difficulty isolating the initial prevocalic consonantal phoneme than the final coda phoneme in both real and pseudo-word stimuli. In addition, it was found that isolating the initial consonant from a cluster in a CCVC stimulus was easier than isolating the same initial consonant from a CVC stimulus; yet final phoneme isolation from CVCC or CVC stimuli were not significantly different. These findings supported a strong cohesiveness of the CV unit in Arabic: a body within a body–coda CV-C structure or probably, as argued elsewhere, a core-CV syllable (Chen, 2011). Similar findings were reported for a group of typically reading and reading disabled adults using an initial phoneme isolation task in both Hebrew L1 and in English L2; both groups of adults showed greater difficulty isolating initial singleton consonants than initial consonants from clustered consonant units in both languages (Russak and Saiegh-Haddad, 2011). This finding replicated earlier findings from Hebrew-speaking children (Saiegh-Haddad, 2007b; Saiegh-Haddad et al., 2010; Share and Blum, 2005) and adults (Ben-Dror et al., 1995) and was argued to support the cohesion of the CV unit in Hebrew too.
Cohesion of the CV unit, rather than the rime VC, was also reported in Russian monolingual children, and in Russian–Hebrew bilingual children (Saiegh-Haddad et al., 2010). For instance, it was reported that preschool bilingual Russian–Hebrew speakers had greater difficulty deleting initial as compared to final phonemes, and clustered as opposed to singleton consonants, in both initial and final positions within words. These results were interpreted in light of the fact that the structure of the Russian syllable, like that of the Hebrew syllable, follows a body–coda dichotomy. This hierarchical structure implies a stronger cohesiveness of the CV body. The cohesion of the CV unit was also reported among Chinese L1 learners of English as a foreign language (Chen, 2011). This study showed that the segmentation preferences of Chinese speakers in English reflected a particular cohesion of the CV units with children preserving CV units more than VC units or CCV units. Children found it easier to isolate an initial consonant from a consonantal cluster than isolating the onset cluster as a whole. This preference was interpreted by Chen (2011) as reflecting loyalty to a core-CV plus appendices.
The present study investigated whether the phonological segmentation performance, as well as specific segmentation errors, in Hebrew L1 and in English L2 would reflect cohesion of the CV unit, and would support the CV-C underlying phonological representation that earlier research on monolingual and bilingual Hebrew-speaking children and adults proposes. In order to do this, full phonemic segmentation performance for CVC vs. CCVC words was compared. Moreover, we tested if cohesion of the CV unit would surface among typically reading adults as well as among adults with reading disability, in Hebrew L1 and in English L2. In order to address these questions, overall scores for CVC vs. CCVC words in the two groups and in the two languages were calculated and compared. Earlier research showed that overall initial phoneme isolation for CVC words was easier than initial phoneme isolation for CCVC words, and this finding was used to support the cohesion of the CV unit in Hebrew. It was predicted that overall scores on the phoneme segmentation task used in this study would reveal a similar pattern. Moreover, we tested this issue in the two languages of our participants (Hebrew L1 and English L2) and by conducting an analysis of segmentation errors for phonemes in initial singleton position (from CVC words) vs. initial clustered contexts (from CCVC words). It was predicted that if the CV unit is cohesive in Hebrew L1, but not in English L2, as earlier research on Hebrew and English L1 learners respectively shows, then significant differences in the facility with which adults become aware of initial singleton vs. initial clustered phonemes would emerge, with singleton phonemes being more difficult to manipulate in Hebrew L1 but easier in English L2. However, if the CV unit is cohesive in both languages, probably due to transfer from Hebrew L1, similar patterns in the two languages would be observed. In order to reduce the effect of L1 transfer in L2 phonological segmentation, so that the effect of language-specific factors may be detected, adult English L2 college students were targeted. In order to probe if differences in reading ability and phonological skills interact with the effect of phonological representation on phoneme segmentation, both typically reading adults and adults with reading disability were tested.
2 The syllable in Hebrew vs. English
Our study probed whether phoneme segmentation in Hebrew L1 and in English L2 would be sensitive to the position the phoneme occupies within the syllable in the two languages, and whether patterns of phonemic segmentation would support a CV-C underlying phonological representation in the two languages. This comparison between English and Hebrew is theoretically interesting and informative because the two languages differ in phonological and orthographic structure, and this was found to have direct implications for the underlying representation of the syllable in the two languages. In the following section, we provide a brief overview of some of the relevant phonological and orthographic differences between English and Hebrew.
The syllable structure of Modern Hebrew is considered to be relatively simple. The most frequently occurring syllables in both the spoken and the written form of the language are CV (47%) and CVC (40%) (Ben-David and Bat-El, 2016). Syllables with complex onsets CCV(C) are rare (4%), and syllables with complex codas (C)VCC are even rarer (Ben-David and Bat-El, 2016). Thus, the CV unit appears to be the unmarked syllable in Hebrew (Ben-David and Bat-El, 2016; Cohen-Gross, 2015). As the CV unit is the most commonly occurring phonological unit in Hebrew, it has been suggested that this unit may serve as a particularly salient unit in the development of phonological awareness in this language, and hence to reveal particularly strong cohesion in the phonological analysis of CVC words (Saiegh-Haddad, 2007b; Share and Blum, 2005).
The phonological cohesion of the CV unit in spoken Hebrew is further strengthened by the orthographic cohesion of this unit in written Hebrew. Hebrew has two orthographies: a pointed orthography, in which diacritics are used to map mainly the vowels of the language and are appended beneath and above letters, and an unpointed orthography in which diacritics are not marked and only consonantal letters are used. The unpointed orthography is the default orthography, which is most commonly used in books, newspapers and other written communications (Shimron and Sivan, 1994), whereas the pointed orthography is used in children’s books, beginning reading texts, poetry, and sacred scriptures. Because vowel diacritics are generally not graphically marked in the Hebrew abjad (Daniels, 2000) single letters in specific position within the Hebrew unpointed word can map onto CV phonological units (Shimron, 1993). For example, the initial letter in the word בַּת /bat/ ‘girl’ corresponds to the CV body phonological unit /ba/, whereas the second letter corresponds to the coda phoneme /t/. Similarly, the same letter in the word בֵּן /ben/ ‘son’ corresponds to the CV spoken unit /bε/, which differs from the CV that the same letter in the word בַּת /bat/ ‘girl’ corresponds to, in the identity of the vowel /a/ vs. /ε/. Moreover, the same letter in the initial position of the unpointed words סל /sal/ ‘basket’ and סט /set/ ‘sin’ correspond to two different CV phonological units: /sa/ and /sε/, respectively.
In contrast with the Hebrew abjad, in which only the consonantal materials of words are represented, English is an alphabetic orthography in which graphemes equally represent consonants and vowels (Daniels, 1992). Moreover, the English syllable structure is more complex than that of Hebrew, and it allows a variety of complex consonantal clusters both in onset and in coda positions (Seymour et al., 2003). Finally, the syllabic structure of English appears to reflect a different sub-syllabic hierarchy in which, unlike Hebrew, the VC rime is a particularly cohesive unit. For instance, an analysis of a large number of English CVC words has demonstrated close statistical dependencies between the vowel and the following coda consonant and argued that phonological neighborhood in English is dominated by rime-neighborhood (e.g. De Cara and Goswami, 2002; Fudge, 1969, 1987; Luce and Pisoni, 1998; Treiman and Kessler, 1995; Treiman et al., 1995). The VC rime in English is not only phonologically cohesive but is also orthographically consistent. It has been shown that consonants in the coda position substantially increase the phonological consistency of the preceding vowel, whereas onset consonants provide little or no help in recovering the sound of the vowel letter (Kessler and Treiman, 2001).
The question that looms large is whether the CV body will predominate among Hebrew L1 adults, and whether Hebrew-based CV body or the English-based VC rime will predominate among adults in their English L2 phonological segmentation. Two competing hypothesis arise here. One is that Hebrew CV body will transfer in the phonological analysis of adult learners of English L2 leading to similar segmentation patterns in Hebrew and English. Alternatively, adult English L2 learners adapt their representation of the syllable in English L2, given years of experience with the phonology and the orthography of English, and will diverge in their segmentation patterns from Hebrew L1 patterns. A further pending question pertains to differences between typically reading adults and adults with reading disability in this regard. The question we addressed was whether patterns of segmentation in the two languages would interact with reading ability. Gaining insight into the phoneme segmentation patterns of adult readers with and without reading disability in Hebrew L1 and English L2 would shed light on the important question of similarities and differences between these two populations. It also has the potential to impact phonological awareness assessment task design and intervention for this population. The current study employed a within-participant design to study the two alternative hypotheses by asking adults to perform phonological segmentation in Hebrew L1 and in English L2, and by targeting initial consonants in singleton contexts (from CVC stimuli) vs. clustered contexts (in CCVC stimuli). Differences in the general facility with which phonemes from CVC vs. CCVC are segmented was expected to reflect the underlying sub-syllabic representation in the two languages; A body-based CV structure was expected to make the segmentation of a consonant from the CV unit particularly difficult to perform, and even more difficult than segmentation from a consonantal cluster, whereas a rime-based VC structure was expected to make the segmentation of the consonant from a VC unit the most difficult to perform. Also, if the CV body structure predominates then the most predominant error type would reflect incomplete segmentation of the CV sub-syllabic unit. In the case of CVC words, which begin with singleton phonemes, this would be reflected as errors in which the CV unit is preservedd ‘bɪt’ as ‘bɪ - t’), whereas in the case of CCVC words, which begin with a clustered consonant, this would lead to creating a CV unit (by adding a vowel) in an attempt to segment the first consonant from the consonantal cluster, or the final consonant, and preserving the CV unit in the attempt to segment the second consonant from within the CV unit (for example segmenting the word ‘stap’ as ‘sa - ta - ap’). These patterns of errors would support the cohesiveness of the CV unit. In contrast, it was predicted that if the VC rime unit predominates then segmentation errors would preserve the rime unit (for example segmenting the word ‘bɪt’ as ‘b - ɪt’), and the word stap as ‘st - ap’ or ‘s - t - ap’). We tested for differences in error patterns in Hebrew L1 and in English L2 in order to test these hypotheses.
3 Reading disability
In addition to differences in underlying phonological representations as an explanation for differences in phonological processing in Hebrew L1 and English L2, the present study also considered the possible contribution of reading disability as a factor that could explain phonological processing differences. Earlier research across a range of age groups has demonstrated that individuals experiencing difficulties learning to read often have basic problems originating in very specific aspects of speech and phonological processing skills (Apthorp, 1995; Bruck, 1990; Lyon et al., 2003; Simon, 2000). This idea has been put forth as the ‘phonological core deficit hypothesis’ (Stanovich, 1988, 1998) and it claims that dyslexia is characterized by a constellation of deficits at a core phonological level, including difficulties with phonological awareness, verbal short-term memory and naming. It has been further suggested that most of these phonological deficits share a common underlying deficiency at the level of phonological representation (Snowling, 2000). Thus, individuals with reading disability tend to perform more poorly than typical readers on tasks involving any form of phonological processing or coding, such as phonological awareness tasks, reading, and spelling. In turn, it has been suggested that the same cognitive and linguistic characteristics that account for a reading disability in one language will manifest as parallel difficulties in additional languages (Sparks and Ganschow, 1993; Sparks et al., 1989), although the degree of difficulty may be tempered by specific orthographic characteristics of different languages, as well as by different task characteristics (Shankweiler et al., 1992; Ziegler and Goswami, 2005). In line with the phonological core deficit hypothesis, we hypothesized that the participants with reading disability would score significantly lower than the typical readers on phonological tasks in both languages.
Yet, despite clear quantitative differences between typical readers and individuals with reading disability on phonological processing tasks, there are indications that, qualitatively, these two groups of readers may not be so different on certain tasks (Bruck, 1988; Share, 1996). Bruck and Treiman (1990) examined phonological awareness and spelling in a group of typical and dyslexic elementary school children and found that although the dyslexic group scored lower than the typically functioning children, there were no differences in error type between the two groups, with both groups showing more difficulty with recognition and deletion of a consonant from a clustered onset than from a singleton onset, and with both groups making more spelling errors on words containing consonantal clusters. The question still remains, however, whether there will be qualitative differences between the two groups of adults with regards to the types of errors and the possible effects of a cohesive CV unit in Hebrew L1 on phonological processing in both L1 Hebrew and L2 English.
II Method
1 Participants
The sample of the study reported in this article is the same sample tested in Russak and Saiegh-Haddad (2011). The sample consisted of a total of 60 Hebrew-speaking university participants, 30 typical readers (TR) and 30 participants with reading disability (RD), sampled from 9 academic institutions in Israel. There were an equal number of males (n = 30) and females (n = 30). Participation in the study was on a voluntary basis. Typical readers reported no history of difficulties with reading in L1 or in L2 (English). The group of participants with reading disability was selected based on referrals from the Support Center for Students with Learning Disabilities at the academic institutions. In order to be eligible for support services at academic institutions in Israel, students must submit relevant documentation of a learning disability, which includes a psycho-educational evaluation in which scores on nationally recognized standardized tests are reported. Diagnostic criteria included normative performance on measures of verbal and non-verbal cognitive and linguistic skills, with specific difficulties in tasks such as reading/decoding, writing, mathematical calculations, and/or processing of visual and/or auditory information. In the present study, special attention was paid to scores in real and pseudo word reading in Hebrew, and documentation indicating a history of difficulties with reading acquisition in Hebrew L1, as well as reports of difficulties with English L2 acquisition. As the study of English as a foreign language formally begins in the 4th grade in Israel, all participants had learned English since the ages of 8 or 9, and had completed an English matriculation examination at the end of the 12th grade. Based on responses to a language background questionnaire, used as another screening tool for all participants, it was ascertained that none of the participants were bilingual, or had had ever stayed in an English-speaking country for more than three months. As all of the participants with reading disability were recruited through the support centers of the academic institutions, it is possible that some of them had received some form of support services with the study of academic English during their studies.
2 Tasks
A full segmentation task was developed for the study, with two parallel versions: one in Hebrew (L1) and another in English (L2). Each task was comprised of two sub-tests representing real and pseudo word stimuli. Stimuli in both languages were primarily high frequency words as based on corpus lists for each language, as well as the Revised Curriculum for English (State of Israel, 2013). All items were monosyllabic, and phonologically comprised of either simple CVC or complex CCVC stimuli. Pseudo words were created by changing one phoneme from the real word items used. The English task was composed of 16 simple real and pseudo words (e.g. ‘feed’ and ‘feep’, respectively), and the Hebrew task was composed of 8 parallel words: real and pseudo (e.g. /pil/ ‘elephant’ and /pif/). Before the segmentation task was administered, participants were asked to repeat the word in order to ensure that the stimulus was perceived accurately and that the full phonological form had been encoded by participants before phonological segmentation started. Then, participants were required to segment each stimulus into all of its constituent phonemes, i.e. say each phoneme within the stimulus word or pseudo word out loud, one at a time. Successful segmentation of all of the phonemes within the word was given a score of one and incomplete segmentation was given a zero score. (Cronbach’s Alpha: Hebrew real words .87, Hebrew pseudo words .88, English real words .87, English pseudo words .90).
3 Procedure
All tasks were administered by the first author: an English–Hebrew bilingual, and order of administration was counterbalanced across languages and tasks. Participant responses, including erroneous responses, were recorded and written on the test protocol during testing for further qualitative analysis. Test administration for each task began after a series of five practice trials.
4 Data analysis
The data for the study consisted of the overall phonological awareness scores obtained on the full phoneme segmentation tasks for CVC and CCVC stimuli in both real and pseudo word conditions. The data for the study also consisted of a fine-grained analysis of the errors on the full phoneme segmentation of CVC and CCVC stimuli in order to examine the phonological segmentation patterns and to glean insight into the underlying phonological representations used in phonological analysis: a body–coda or an onset–rime structure. The errors were each classified as belonging to one of five categories:
preserving the CV body unit, as in segmenting the word ‘mad’ into /mæ - d/ or the word ‘sweet’ into /swi - t/;
creating a CV body unit by adding a vowel, as in segmenting ‘mad’ into /mæ - æ - d/ or ‘sweet’ into /s-wi-i-t/ or /sə-wə-i-t/;
preserving the VC (rime), as in segmenting the word ‘mad’ into /m - æd/ or segmenting sweet as /s-w-it/;
dropping the vowel from the word resulting in no body or rime units as in segmenting ‘mad’ as /m - d/ and sweet as /s-w-t/;
Errors that did not fit within any of the four categories above were coded as a separate error category and this included repeating the target word without performing any segmentation, adding a consonant at the end of the word, etc.
Errors were very infrequent and made up only 3% of the total number of errors. In this respect, it is noteworthy that in categorizing the segmentation errors that participants performed we were particularly interested in finding out whether the errors could be accounted for by a preference for a body–coda or an onset–rime sub-syllabic structure. Therefore, we focused on the errors that specifically reflected these two units and overlooked phonetic errors that were reflective of inter-language phonology or inaccurate phonological representations of words (Russak and Saiegh-Haddad, 2011), such as segmenting the word ‘with’ as /wi - z/ because interdental phonemes do not exist in Hebrew. In this case, mispronunciation was overlooked and the error was analysed as reflecting the error category in which a body was preserved. The errors were analysed and coded separately by two independent scorers. Instances of discrepancy in coding were each discussed separately by the two judges and scoring was moderated accordingly. Inconsistencies were rare and were always resolved satisfactorily.
Summary statistics and ANOVA was used to analyse the quantitative data consisting of overall scores on the full phoneme segmentations task in the two languages: L1 Hebrew and L2 English, and by the two groups: typical readers (TR) and readers with reading disability (RD). A fine-grained analysis of errors was conducted using a cross-classified multi-level analysis in which two levels of variation sources were crossed, namely items (words segmented) and participants. For an illustration of this multilevel structure of the data, see Figure 1.
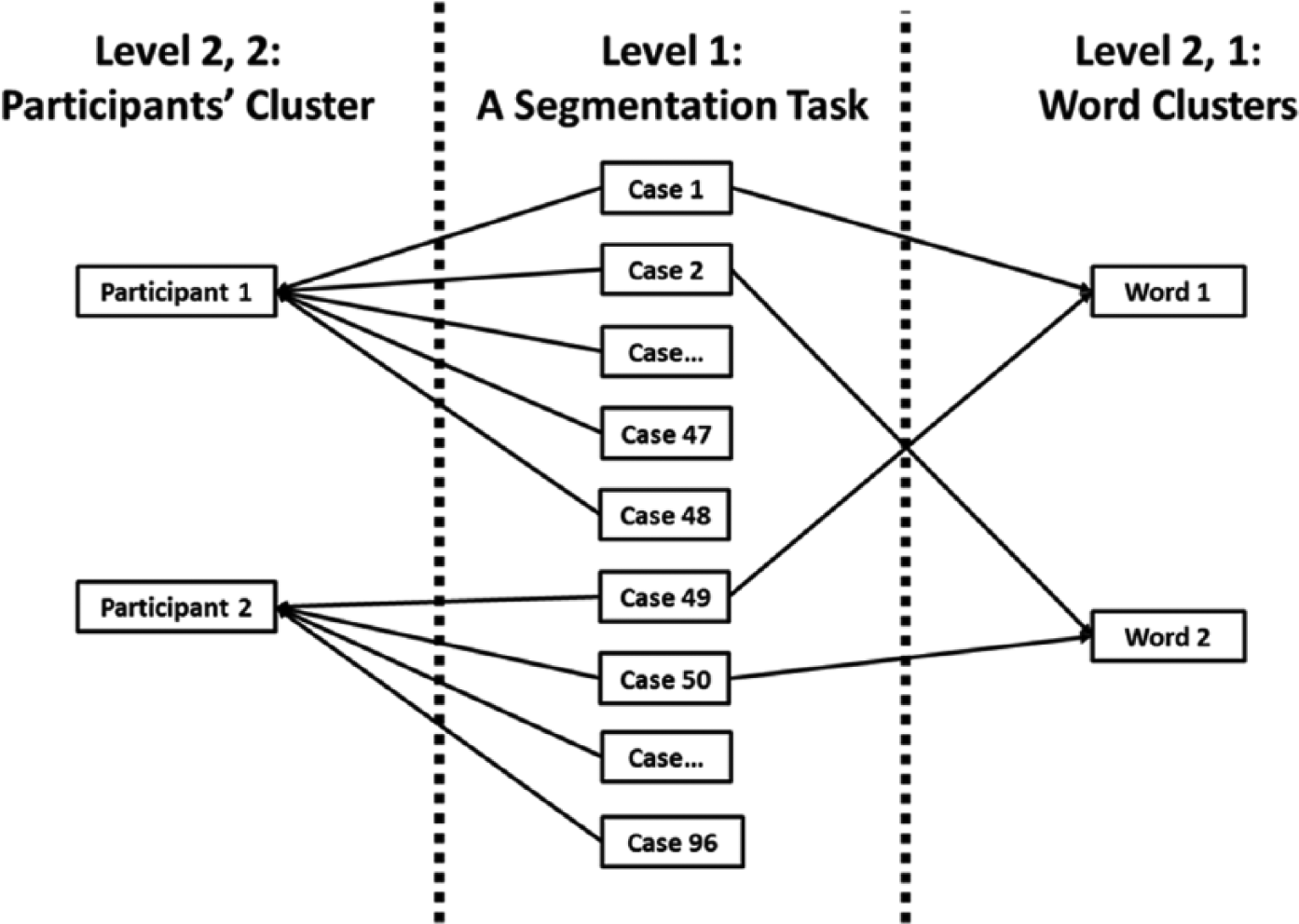
Illustration of multilevel cross-classified model.
As may be seen in Figure 1, cases (word segmentation attempts) are nested in words (level 2,1) and participants (level 2,2), such that each word is attempted by each participant (Baayen 2008; Baayen, Davidson, and Bates, 2008). Thus, in the present study, 48 words (16 real and 16 pseudo words in English, and 8 real and 8 pseudo words in Hebrew) were segmented by 60 participants (cases or word attempts), hence the first participant attempted 48 items (words), and these 48 items (cases 1–48) are nested within this specific participant’s data (participant 1). This procedure was repeated for each participant such that the same number of attempts was repeated for the second participant (participant 2). This is a level-two participant, shown on the right side of the figure. The level-two word data is shown on the left side of this figure. Case 1 and case 49, as well as the other 58 first cases are all nested in the first word, and case 2 and case 50 as well as the other 58 second cases in each participant’s list of attempts are nested within the second word and so on. Altogether, this set of data is clustered within 60 participants and 48 words leading to a total of 2,880 segmentation cases for the entire sample of 60 participants. This constitutes the total error analysis data corpus we analysed in this study. The statistical package HLM v.7 was used to analyse the data (Raudenbush et al. 2013). This cross-classified multilevel analysis was chosen because it integrates the assumption that participants differ from each other over all segmentation tasks they perform, and similarly, words differ from each other across the participants who performed segmentation tasks across all words.
III Results
Table 1 provides descriptive statistics of accuracy scores (correct vs. incorrect responses) on the full segmentation task by group (Typical Readers TR, Reading Disabled RD), language (L1 Hebrew, L2 English), lexical status (real words, pseudo words) and context (singleton, clustered context).
Descriptive statistics for correct vs. incorrect full segmentation attempts by group, language, and lexical status for words in both the singleton and clustered context.
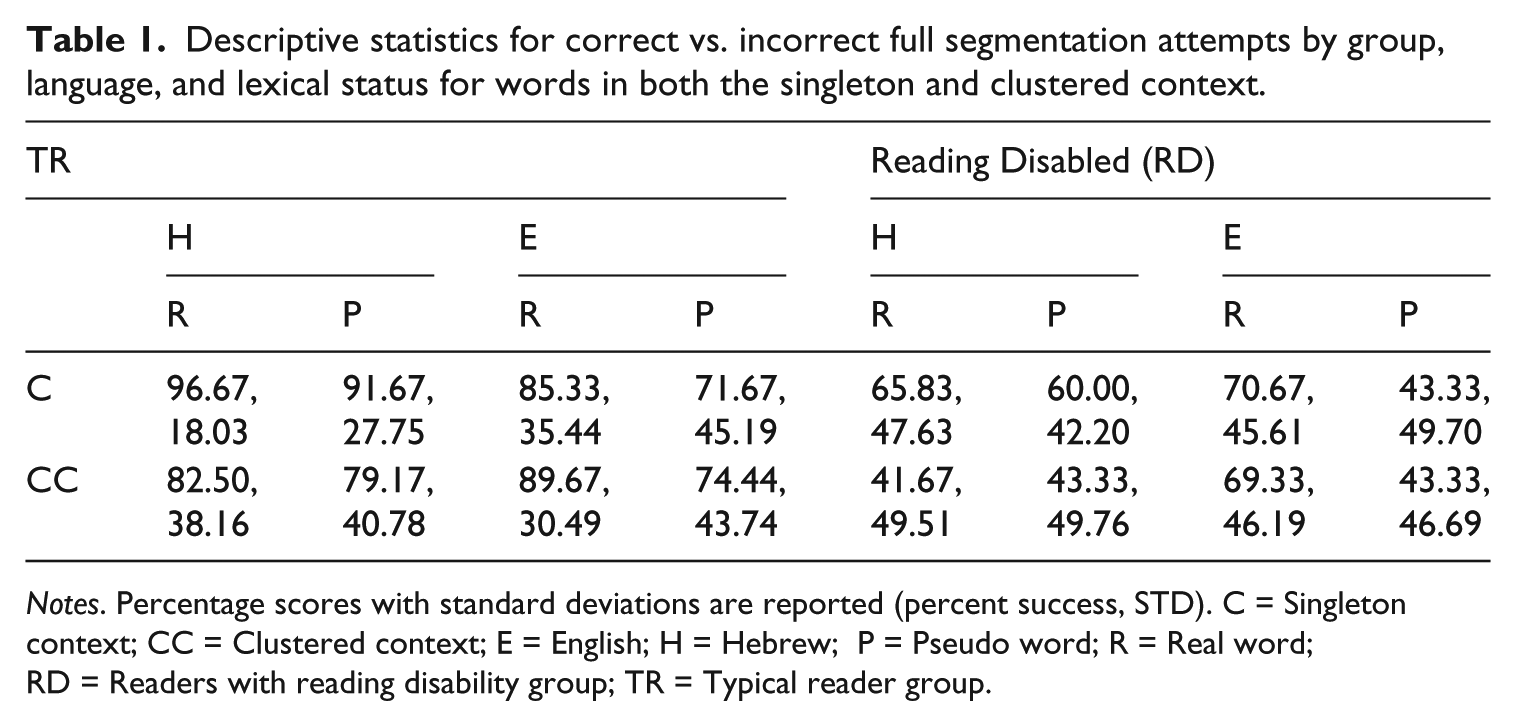
Notes. Percentage scores with standard deviations are reported (percent success, STD). C = Singleton context; CC = Clustered context; E = English; H = Hebrew; P = Pseudo word; R = Real word; RD = Readers with reading disability group; TR = Typical reader group.
In order to examine the effects of language, group, lexical status and phonological context on full segmentation we used an interclass correlation analysis (see previous section). Table 2 provides the estimates of the effects of group, language, lexical status, and phonological context on full segmentation. The first column, model 1, shows the variance component for the unconditional model, that is, a model without independent variables. Two level-two indices for the intra-class correlation (ICC) are presented which indicate the within cluster correlation: the participant level variance over the total variance is 0.45, vs. the word variance 0.11. Note that when the dependent variable is nominal, the ICC is calculated as a proxy for each level separately (Heck et al., 2010). The second column adds the effects.
Results of multilevel cross-classified binary logistic regression, success vs. error.
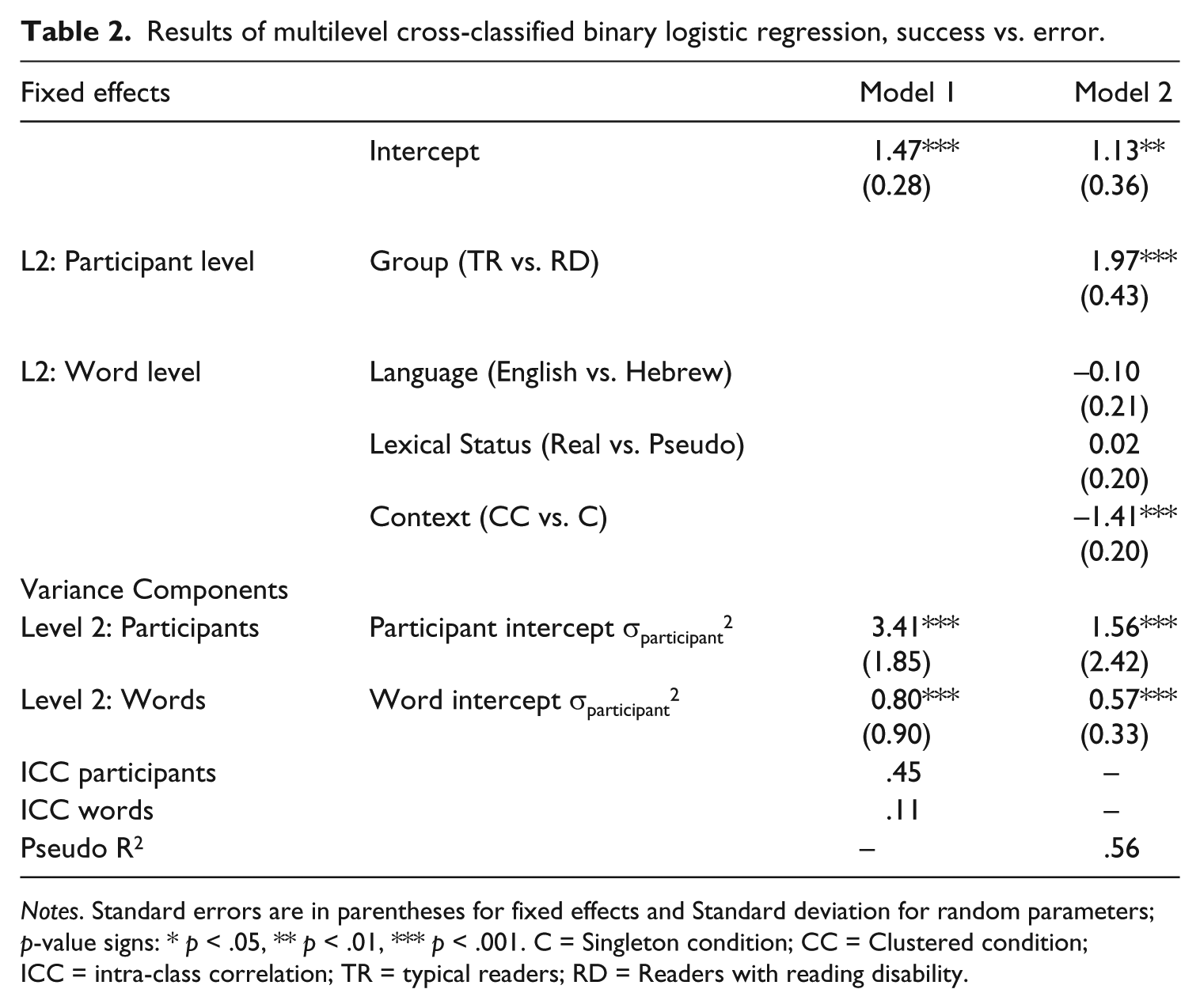
Notes. Standard errors are in parentheses for fixed effects and Standard deviation for random parameters; p-value signs: * p < .05, ** p < .01, *** p < .001. C = Singleton condition; CC = Clustered condition; ICC = intra-class correlation; TR = typical readers; RD = Readers with reading disability.
As Table 2 shows, group (TR vs. RD) had a positive effect on the probability of success (correct response) (1.97, p < .001). In other words, typical readers had a higher probability of success at full segmentation than participants with reading disability. At the word level, the context of initial consonant clusters had a lower probability of success (–1.41, p < .001), meaning that full phonemic segmentation of words and pseudo words beginning with a consonantal cluster (CC) had a lower probability of success rate than full segmentation of words beginning with a singleton consonant (C). It can also be seen from Table 2 that the variables of language and lexical status did not contribute significant variance to full segmentation performance (–0.10; 0.02 respectively).
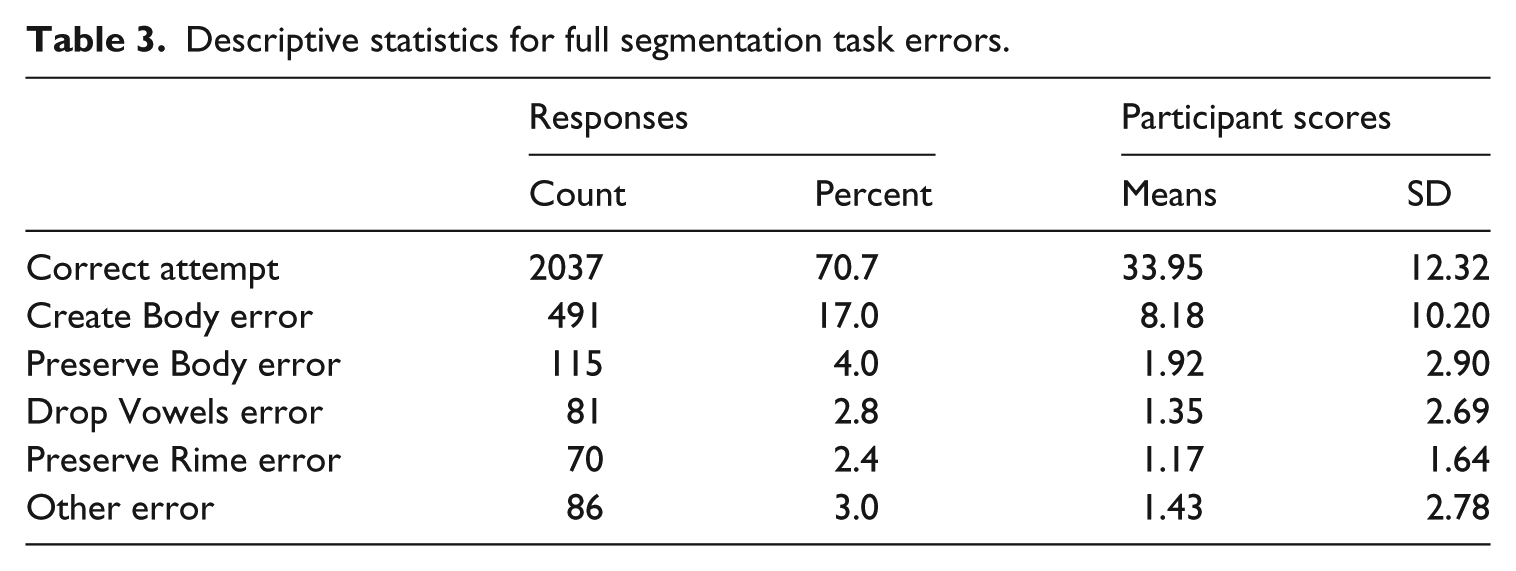
The next set of analyses examined error types and their relative distribution within the entire sample of segmentation attempts by all participants. Table 3 shows descriptive statistics for errors by error type categories. Due to the fact that language (Hebrew vs. English) and lexical status (real vs. pseudo words) were not found to contribute significant variance to full segmentation (see Table 2), these factors were collated in this analysis. As may be seen from Table 3, approximately 70% of the segmentation attempts were performed correctly by the participants. With respect to errors, it can be seen that the most frequent error type was ‘creating a body (n = 491, 17%). The category of creating a body errors was followed by preserving a body, which was observed in only 4% of the erroneous attempts. The other errors, including preserving the rime, dropping the vowel, as well as other errors occurred very infrequently (2.4%–3.0%).
Descriptive statistics for full segmentation task errors.
The following multinomial logistic analysis (see Table 4) provides a fine-grained account of the errors in relation to successful segmentation. The modeling procedure estimates the probability of making each of the error types vs. a correct answer (successful full segmentation of a word) which functions as the reference alternative (Field, 2009). A model that differentiated all error types vs. the correct responses could not be converged, thus the solution was to annex similar error types. This resulted in three categories of errors (creating a body, preserving a body and a third category comprised of dropping the vowel, preserving the rime and other error types) vs. the correct responses as shown in Table 4. Each column in Table 4 presents the estimated parameters for the probability of an erroneous response, whereas success, the reference category, is the complementary probability. The ICC (intra-class correlation) of each part of the model, e.g. creating a body vs. a correct response, preserving a body vs. a correct response, and dropping a vowel, preserving the rime, and other errors vs. a correct response, can be seen in the table. Note that this table is arranged such that the unconditional model results are on the upper block and the conditional model results are shown in the lower block. ICCs provide the justification for the cross-classified model (ICC > .05, Twisk, 2006), although the ICC for word level received for creating a body vs. correct response is smaller than the others (0.09). In the lower block an effect for group can be seen, as typically reading participants (TR) show lower probability of making an error with full segmentation across all error types, which means they have a higher probability of success in comparison to participants with reading disabilities (RD). Whereas, the performance of the RD group was significantly poorer across all error types, there was no specific error type that was significantly more frequent in the RD group than in the TR group. In other words, the distribution of errors by type was similar across groups. At the word level, context was shown to increases the probability of success. Errors on full segmentation of words containing initial singletons were significantly higher than errors for words containing initial clustered consonants across all error categories, thus confirming the results obtained from the quantitative analysis. Odd ratio values appear in the table in order to show the ratio between the probability of success and the probability of error.
Results of multilevel cross-classified multinomial logistic regression, error categories vs. success.
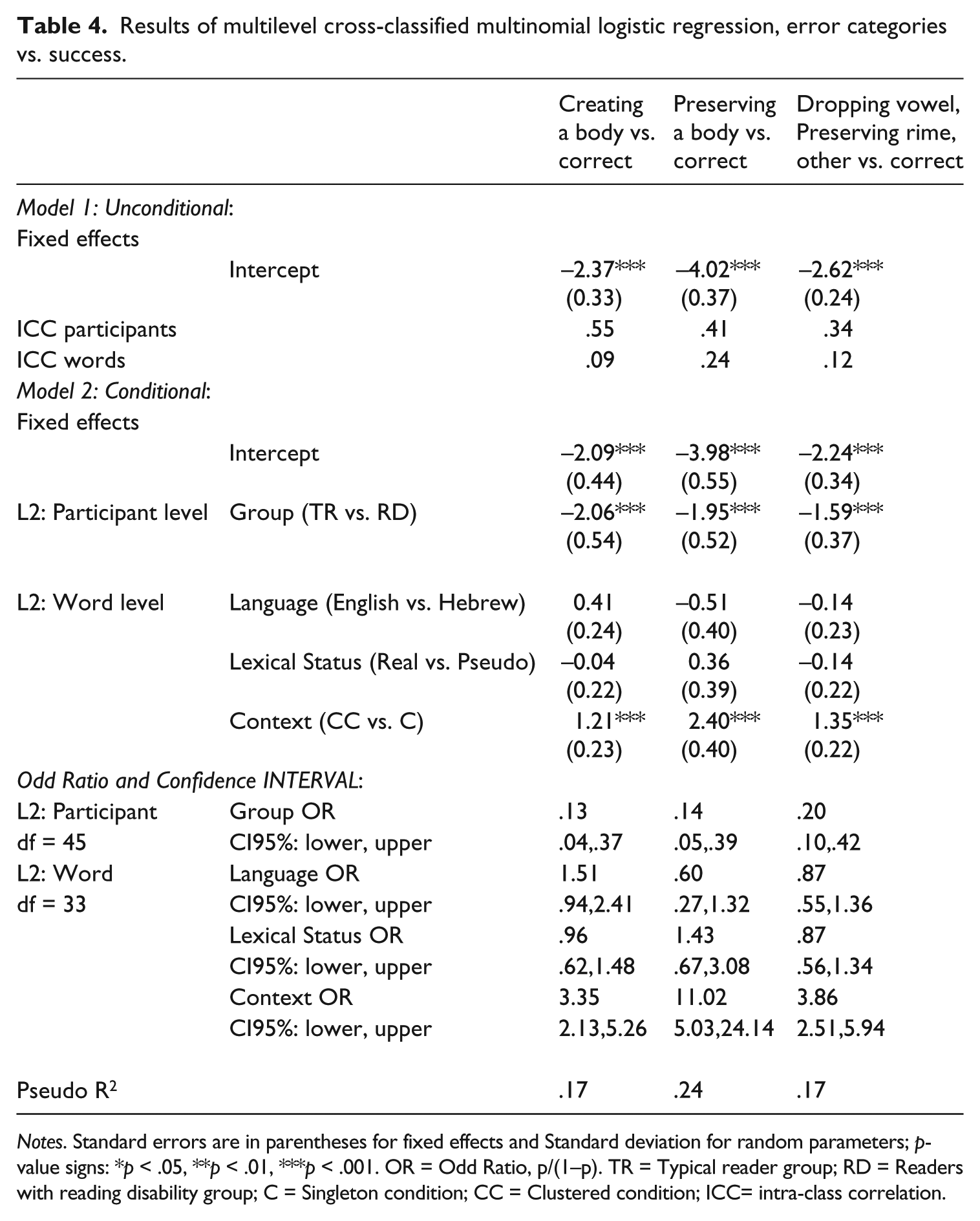
Notes. Standard errors are in parentheses for fixed effects and Standard deviation for random parameters; p-value signs: *p < .05, **p < .01, ***p < .001. OR = Odd Ratio, p/(1–p). TR = Typical reader group; RD = Readers with reading disability group; C = Singleton condition; CC = Clustered condition; ICC= intra-class correlation.
We next examined whether language, group, lexical status, and context were associated with different error types. In order to do so, we compared the most frequent error types of creating a body and preserving a body to all other errors as reference using a multi-level cross-classified multinomial logistic regression; see Table 5. In the first column, the language effect is positive (b = 0.75, p < .05), which means that full segmentation of words in English increases the probability of creating a body in comparison to other error types (dropping the vowel, preserving the rime, other). We also found that the clustered consonant context increases the probability of preserving the body. Differences between error types and phonological contexts (singleton vs. clustered consonant) were not found to be affected by group or lexical status.
Results of multilevel cross-classified multinomial logistic regression, error categories vs. other errors.
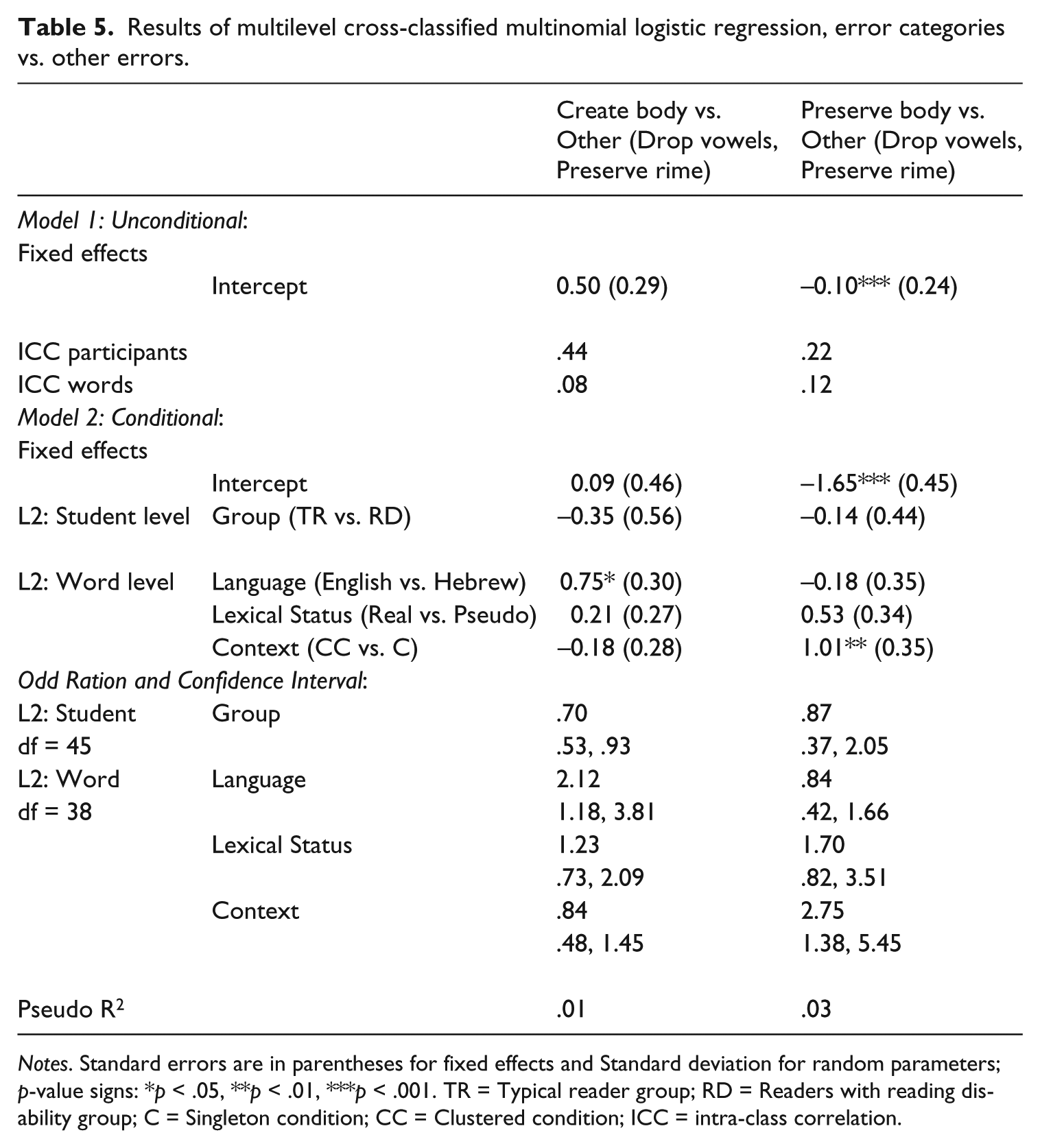
Notes. Standard errors are in parentheses for fixed effects and Standard deviation for random parameters; p-value signs: *p < .05, **p < .01, ***p < .001. TR = Typical reader group; RD = Readers with reading disability group; C = Singleton condition; CC = Clustered condition; ICC = intra-class correlation.
To sum up, the results of the study showed that typical readers (TR) outperformed readers with reading disability (RD) on full segmentation of words in both languages. These results were corroborated by the analysis of error frequency across all variables tested. The results further revealed an effect of phonological context with higher phonological awareness scores on words containing a singleton consonant (consonant immediately followed by a vowel as in a CV unit) as opposed to a clustered consonant (followed by another consonants as in a CC context) in both Hebrew and English, regardless of the lexical status of the target word (real as opposed to pseudo word). In line with earlier findings supporting CV cohesion, the fine grained analysis of specific error types showed that the most frequently occurring error was creating a body, followed remotely by preserving a body error in both languages and even more so in English.
IV Discussion
The objective of the study was to examine the underlying sub-syllabic phonological representations, and, in turn, the grain-size phonological unit that is most accessible in phonological awareness in Hebrew L1 and English L2 among typical readers and readers with reading disability as reflected in full phonological segmentation patterns in the two languages. To address this issue, we compared full phoneme segmentation scores for two types of stimuli: CVC and CCVC in both languages. In addition, the specific nature of the phonological segmentation errors was examined in order to probe if these errors could be explained by preference for a body–coda as opposed to an onset–rime underlying sub-syllabic structure, and in order to check if there were differences in error patterns between typically reading and reading disabled adults.
The main question addressed in this study pertains to the effect of the phonological context in which the phoneme is embedded: a singleton context (the first consonant of a CVC word), and a clustered context (the first consonant of a CCVC word), on full phoneme segmentation. This question has direct implications for the nature of the underlying phonological representation of the syllable in the two languages targeted: Hebrew L1 and English L2. We proposed two possible hypotheses: Based on the CV-based phonological and orthographic structure of Hebrew, it was hypothesized that the segmentation of initial consonants in a singleton context would be harder than the segmentation of initial consonants from within a clustered context. This is because the former requires breaking a particularly cohesive CV unit. Research has supported this prediction in phoneme isolation tasks showing that in languages with a body–coda structure, like Russian and Arabic, isolating the initial consonant was harder than isolating the final consonant (Russak, 2007; Saiegh-Haddad, 2007a, 2007b; Saiegh-Haddad et al., 2010; Share and Blum, 2005). Moreover, isolating an initial consonant from a CV unit was even more difficult than isolating the same consonant from an initial cluster (Saiegh-Haddad, 2007a; Russak and Saiegh-Haddad, 2011). A similar pattern was predicted to emerge on a full phoneme segmentation task. Yet, it was predicted that the type of segmentation errors would be affected by the underlying sub-syllabic representation with different patterns of errors in the two types of words. The results of the study only partly supported our predictions. The results showed that CCVC words were associated with significantly lower phonemic segmentation scores than CVC words. This is probably because they are phonemically longer. Besides phonemic length, CCVC words also embody a consonantal cluster, which is not a very frequent structure in Hebrew (Ben-David and Bat-El, 2016). Thus, the fact that CCVC words are longer than CVC words, and the fact that Hebrew speakers do not have many initially clustered words in their language might have contributed to the observed difficulty in phonemically segmenting CCVC words as against CVC words (Caravolas and Bruck, 1993; Zaretsky, 2002).
In order to better understand the role of the underlying sub-syllabic representation on phonemic segmentation the study conducted a fine-grained analysis of the phonological awareness errors on the full segmentation task, and probed if these errors may be explained by a preference for a cohesive CV (body–coda) sub-syllabic structure. Indeed, the analysis of errors showed that creating a CV body was the most frequently occurring error among all participants. This error type was followed by preserving the CV body unit. These two error types are clearly indicative of a preference for a cohesive body CV unit in the full phoneme segmentation task, as opposed to a preference for the rime VC unit, and therefore support and extend data reported in earlier research from Hebrew-speaking children (Russak and Saiegh-Haddad, 2011; Share and Blum, 2005) and adults (Ben-Dror et al., 1995).
The results of the current study also showed that among our adult sample, CV errors were the most frequent in both Hebrew (L1) and in English (L2). This finding implies that the CV unit appears to be the most cohesive not only in the L1 of Hebrew-speaking adults, but also in their L2 English processing. This is an important finding because it is at odds with data obtained from English L1 speakers. While the literature supports the view that the syllable has an onset–rime structure, this evidence is based primarily on data obtained from native English speakers (Treiman, 1985, 1995; Treiman and Danis, 1988; Treiman and Weatherson, 1992; Treiman and Zukowski, 1991; Treiman et al., 1995). Our results obtained from English L2 learners indicate that the onset–rime structure might not apply to English L2, especially when the L1 uses a different underlying sub-syllabic structure, such as Hebrew, and by extension probably also Arabic and Russian.
The fine-grained analysis further indicated that whereas error types were not significantly influenced by reader ability group or lexical status (real vs. pseudo word), there was a higher incidence of creating CV units (i.e. by adding an extra vowel) in English than in Hebrew. This finding may be attributed to the phonological and orthographic differences between Hebrew abjad and alphabetic English. Whereas Hebrew shows a cohesion of the CV unit in its phonology (Ben-David and Bat-El, 2016) and orthography (Shimron, 1993), English shows a phonological and orthographic cohesion of the VC rime. Statistical analysis of word tokens indicates that English CVC words are orthographically highly regular with regards to grapheme–phoneme correspondence rules (De Cara and Goswami, 2002; Kessler and Treiman, 1997), and this is partly because the number of phonemes in a given CVC word, in English, tends to equal the number of graphemes (for example, the word top is comprised of three phonemes /t - a - p/ (in US English) and three letter graphemes. In the context of the present study, it is possible that when our Hebrew L1 participants were required to segment an English L2 word, they first invoked their Hebrew based CV dominated representation of the stimulus word (for example, the word /bɪt/ might be segmented first as /bɪ - t/). Yet, this representation was soon rejected because it did not align with their orthographically invoked representation of the word (which in the case of the English word would involve three letters). Thus, it could be that adding an additional phoneme, as in the case of segmenting bit as /bɪ - ɪ - t/, illustrates an attempt on the part of the Hebrew L1 speaker to represent the orthographic reality of the English CVC written word while remaining loyal to the Hebrew predisposition for CV bodies. The literature supports the role of orthographic representation in phonological analysis among both adults and children, where words with more letters are assigned more phonemes in phoneme counting tasks (Ehri, 1987; Morais et al., 1979; Treiman and Cassar, 1997). It is interesting to note that the participants’ verbal reports, which were solicited retroactively in special sessions following data collection, support a segmentation tendency to equate phonological units with graphemes and orthographic representations. For example one participant said: ‘Basically I try to figure out which letters are in the words and then match them to sounds.’
In Hebrew, an orthographic effect in the form of adding a vowel in order to equate phonemes with letter graphemes would not be expected to occur as often because letter graphemes can correspond to CV phonological units. Therefore, less attempts were expected in which participants would create bodies than preserve them, and the results support this prediction. Yet, the orthographic representation of Hebrew words led to another error type, namely dropping vowels (as segmenting the word /zman/ ‘time’ as /z - m – n/). The higher number of errors of this type in Hebrew than in English lends further support to the idea that orthographic features of the language impact phonological awareness performance (Landerl et al., 1996; Ziegler and Goswami, 2005). One participant explained: ‘Hebrew is harder because in English all the letters are separate; it’s not like that with the diacritics.’
With respect to the question of the effect of reading ability on phonological segmentation patterning, in line with findings reported in our previous study (Russak and Saiegh-Haddad, 2011), significant differences in overall phonemic segmentation ability were observed between typical and disabled readers. This finding was not surprising as low performance on phonological awareness tasks is a hallmark of reading disability, even among adult participants (Bruck, 1992; Wilson and Lesaux, 2001), and probably even more so when the phonological awareness task involves a second language (Crombie, 1997; Simon, 2000). However, the noteworthy finding was that, even though differences in overall performance were observed, no differences between the two groups in error types were found. Both groups showed segmentation errors that favored the creation and the preservation of the CV body sub-syllabic unit. This error type, reflects a general preference in Hebrew for a cohesive CV body, and is compatible with data reported in other studies of segmentation patterns for Hebrew speakers (Russak and Saiegh-Haddad, 2011; Saiegh-Haddad, 2007b; Share and Blum, 2005). Moreover, this finding supports the conjecture that whereas the phonological processing skills of adults with reading disability are quantitatively different from those of typically reading individuals, they may not be qualitatively different in both L1 and L2 (Russak and Saiegh-Haddad, 2011; Bruck and Treiman, 1990).
Future research should further test this hypotheses by addressing similarities and differences between typical and disabled readers on other phonological awareness tasks, as well as among individuals with different degrees of reading disability, and at different developmental points in order to tease apart the contribution of task complexity and reading disability to phonological processing in the two groups. Future research should also test the possible effect of different levels of language proficiency in the two groups on phonological processing.
To sum up, the present findings support the claim that the sub-syllabic phonological representation of the Hebrew CVC syllable consists of a cohesive CV body unit and that this structure impacts phonological analysis and is reflected in the phoneme segmentation errors of Hebrew L1 speakers. Moreover, the results support a cross-linguistic transfer of this structure to phonological analysis in English L2, even though the latter employs a different sub-syllabic structure consisting of an onset and a rime. Finally, the results imply that the nature of the impact of the L1 sub-syllabic structure on L1 and on L2 phonological analysis is similar in typically reading adults and those with reading disability.
These finding have important theoretical implications. Phonological awareness appears not to be an all-or-none ability. Rather, it is heavily impacted by underlying sub-syllabic linguistic representations, and can be therefore different in different languages. Moreover, the effect of language-specific linguistic and phonological representations on phonological awareness may not always be observed in overall phonological awareness scores, and can sometimes only be detected when an in-depth analysis of the phonological segmentation errors is conducted. A fine-grained examination of the specific phonological segmentation errors, as the one followed in the current study, reveals that both phonological and orthographic features of the language are clearly implicated in phonological segmentation, hence highlighting language specific aspects of phonological awareness. All this lends support to the notion that phonological awareness is a concept-based ability, and not a merely mechanical skill (Byrne and Fielding-Barnsley, 1990; McBride-Chang, 1995; Russak and Saiegh-Haddad, 2011; Stahl and Murray, 1994; Swan and Goswami, 1997).
There results also have important practical implications. With regard to assessment of phonological awareness skill, it is essential to construct tasks that take into account the language-specific properties of the language under question, and not to blindly adopt or literally translate existing phonological awareness measures from one language into the other. Specifically, it is important to include tasks that require different operations of phonological analysis (isolation, deletion, full segmentation) and to target different phonological units within a syllable (body, rime, coda as well as individual phonemes). Further, when individuals struggle with phoneme manipulation, it is essential to examine the nature of the manipulation errors, including the specific linguistic context in which the phoneme is embedded, and evaluate that against the linguistic background of the individuals. This information may help explain specific error trends and predict certain difficulties.
Footnotes
Acknowledgements
This research is part of a doctoral dissertation conducted by the first author under the supervision of the second author at Bar Ilan University, Israel.
Declaration of conflicting interest
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was partially funded to the first author by the Mofet Institute, Israel and Beit Berl College, Israel.