
Abstract
Various explanations have been put forth for the asymmetrical acquisition of tense and aspect morphology across categories of lexical aspect. This experiment tested the adequacy of a subset of such accounts by examining English native speakers’ (n = 40) use of progressive and past tense morphology within activity and accomplishment verb frames during their early acquisition of a miniature artificial language. Participants completed a lesson in which types and tokens of lexical aspect and past and present morphology were balanced. Although significant effects at p < .05 were found for lexical aspect and morphological marking, the interaction between these factors, expected by the aspect hypothesis, was non-significant. The experiment suggests that the effects of lexical aspect may be absent during the earliest phases of second language acquisition or may be due to factors methodologically excluded in this study such as distributional biases in second language input.
Keywords
I Introduction
During the last three decades, the acquisition of tense and aspect has been investigated intensively by researchers interested in first-language (L1) and second-language (L2) acquisition. Much of this research has focused on the intriguing finding that acquisition of aspect- and tense-related morphology in languages is asymmetrical, with a tendency to appear initially with specific classes of lexical aspect before spreading to other classes.
Extensive research has established convincing descriptive accounts of this tense–aspect acquisition asymmetry as it occurs within various contexts to include L1 acquisition, child L2 acquisition, and adult L2 acquisition and within both naturalistic and classroom contexts in both foreign language and immersion environments (for an excellent discussion of the literature, see Bardovi-Harlig, 2000). Approximately a dozen hypotheses have been put forth to explain why this association occurs. The proliferation of explanations has created a need for research designs that test specific hypotheses to the exclusion of others.
To test specific explanatory accounts, this study used an innovative design involving a miniature artificial language. A highly-controlled learning context in the treatment phase of the experiment was used to determine if the tense–aspect asymmetry can be explained solely through a limited subset of the hypotheses proposed thus far in the literature.
II Background
1 Lexical and grammatical aspect
According to Comrie (1976), ‘aspect’ refers to the internal structure of a situation, as opposed to ‘tense’, which is a deictic category that locates situations in time. The terms ‘inherent’ or ‘lexical aspect’ were originally used to refer to the ways in which a verb ‘presupposes and involves the notion of time’ (Vendler, 1967: 97). Researchers into second language acquisition (SLA) have generally adopted Vendler’s four-fold classification of verbs or verb phrases based on the features of dynamicity, telicity, and punctuality. Lexical aspect categorizations typically take into account how the verb and its arguments are understood within a given sentence and discourse context.
2 Literature review
This review will cover previous descriptive research and hypotheses as a prelude to examining the relevance of various explanatory accounts. Based on the reviewed literature, the tense–aspect acquisition asymmetry will be shown to be a pervasive phenomenon found in typologically distinct languages, which is applicable to language acquisition across learning contexts and key tense and aspect contrasts. It will be furthermore argued that the pervasive nature of the phenomenon limits the pool of explanatory factors to those that have broad applicability across multiple acquisitional contexts and linguistic domains.
Interest in the tense–aspect acquisition asymmetry within L1 research has often taken the form of longitudinal case studies based on conversational data (e.g. Antinucci and Miller, 1976). Studies found that children’s verbal morphology was initially used to mark aspect rather than tense. Weist et al. (1984) explained such acquisitional patterns through the defective tense hypothesis, which claimed that children’s acquisitional sequences reflect cognitive deficits related to their inability to understand temporal location. In an alternative account, Robison (1990) put forth the primacy of aspect hypothesis, which claimed that ‘verbal morphology correlates with lexical aspect during some stage’ of learner development (p. 330). Along similar lines, Andersen and Shirai (1994) formulated the aspect hypothesis, which claimed that ‘first and second language learners will initially be influenced by the inherent semantic aspect of verbs or predicates in the acquisition of tense and aspect markers associated with or affixed to these verbs’ (p. 133). While similar to the primacy of aspect hypothesis, the latter formulation is stronger as it predicts that the influence will appear at a particular stage of development. Such an influence in the earliest stages of acquisition is still subject to some debate. For example, Salaberry (1999), in a study of English-L1 learners of Spanish, found that at the beginning stages of acquisition, learners were insensitive to lexical aspect.
The aspect hypothesis makes two key predictions. First, progressive aspectual morphology should first appear with activities (e.g. walk) before it appears with accomplishments (e.g. drown) and achievements (e.g. recognize). Perfective past marking, on the other hand, should appear with achievements and accomplishments before spreading to activities and then finally to statives (e.g. know). The acquisitional sequence predicted by the aspect hypothesis has been demonstrated in dozens of studies across a wide range of languages and learning contexts to include untutored learners in an immersion environment (Robison, 1990), tutored learners in a foreign language environment (Bardovi-Harlig and Bergström, 1996), and tutored learners in an immersion environment (Bardovi-Harlig and Reynolds, 1995; Shirai and Kurono, 1998).
Data collection has ranged from more open-ended methods such as free conversation, natural interaction, and oral interviews (Robison, 1990) to more constrained elicitation tasks such as oral (Salaberry, 2000) and written (Bardovi-Harlig and Bergström, 1996; Salaberry, 2000) film retell, to highly constrained methods such as cloze-type tests (Bardovi-Harlig, 1992a; Bardovi-Harlig and Reynolds, 1995), a sentence-picture matching task (Vogel, 2017), and a bilingual equivalent-sentence judgment task (Nishi, 2008).
The less constrained methods are more likely to elicit automatized language that reflects learners’ competence as it appears under real-time communicative pressures. Yet such data can be difficult to interpret. One potential problem is that realistic oral tasks are likely to elicit numerous forms that have been acquired and are accessed as chunks, and these chunks, reflecting potentially distinct acquisitional routes and mechanisms, may skew the distribution of target forms in experimental measures.
Tasks that elicit production in the form of a structured narrative (e.g. film retell tasks) have certain advantages as they are sensitive to discourse-related linguistic strategies such as backgrounding or foregrounding of information and events. An inherent limitation is that such tasks provide only a partial picture of cognitive tense–aspect representations. Progressive and past marking, after all, are often used in isolated utterances within a conversation, and linguistic competence entails understanding and producing morphology within both simple and complex discourse.
Highly constrained tasks offer some clear advantages as it becomes possible to manipulate the activity so as to elicit target forms that occur infrequently in more open-ended tasks. They thereby enable the researcher to rule out avoidance as the reason for the underproduction of a specific target form. On the other hand, more constrained tasks, particularly those that involve writing, are likely to measure learners’ ability to apply metalinguistic rules instead of their underlying competence.
Even after the limitations of the methodologies employed to test the aspect hypothesis have been taken into account, it is clear that the hypothesis has received robust cumulative support in studies conducted over the last four decades. Nevertheless, the main thrust of these studies has been descriptive, noting the correlation between lexical and grammatical tense–aspect morphology.
Seeking an explanation: Researchers who emphasize the role of frequency in acquisition have put forth a number of explanations for the aspect hypothesis. It has been noted that while there is variation in the distribution of inherent aspectual classes across languages, within the general distribution of verbs, achievements and activities are more frequent (Andersen and Shirai, 1996; Nishi, 2008). Andersen’s (1993) distributional bias hypothesis (DBH) suggests that learners are influenced by the skewed distribution of lexical aspect categories with specific verbal morphology within the input. This distribution purportedly leads learners to err in the direction of the bias. Andersen concedes that distributional biases do not necessarily lead to errors (p. 59), a caveat that suggests that the DBH needs to be augmented by further criteria, such as similarity in meaning or contingency in order to make strong theoretical predictions (see Ellis, 2013; Li and Shirai, 2000; Wulff et al., 2009).
As applied specifically to the aspect hypothesis, the DBH also has difficulty accounting for some empirical findings. Shirai and Kurono (1998) found that Chinese (Experiment 1) and other learners (Experiment 2) of Japanese followed the predictions of the aspect hypothesis, in spite of the fact that the frequency of -te i- (the progressive marking in Japanese) was found to be higher in NS discourse for achievement verbs than for activity verbs.
L1 transfer is also likely to play a role. Nishi (2008), in a study that examined the same language combination (i.e. Chinese L1 learners of Japanese), found lower accuracy rates for items that were not equivalent in the L1 and L2, a finding that may help explain the Shirai and Kurono results (see also Gabriele, 2009; Gabriele et al., 2003; Montrul and Slabakova, 2002, 2003; Ryu et al., 2015). While L1 transfer is likely to affect patterns of results in previous research, it cannot account fully for the consistent tense–aspect asymmetry found across diverse studies involving a wide range of L1 and L2 combinations.
Acquisitional patterns predicted by the DBH may also be influenced by a one-to-one principle by which learners initially seek to associate a single form with a single meaning (for a related discussion, see Bybee, 1985: 3, 4). Andersen (1984) argued, based on features of pidginization and interlanguage construction, that a tendency to match a single form to a single meaning characterized second language acquisition, particularly during its earliest stages.
Andersen and Shirai (1996) have also attempted to account for the aspect hypothesis through prototype theory. This theory (Rosch, 1975) was originally put forth to explain how certain members (e.g. robins) of natural categories (e.g. birds) are regarded as more central than other members (e.g. penguins). Later researchers applied the notion of prototypes to lexical semantics (e.g. Coleman and Kay, 1981) and grammar (Langacker, 1987). According to Taylor (1989), the prototypical meaning of the past tense as morphosyntactic category is deictic past, whereas less prototypical members are unreality and counterfactuality and its meaning as a pragmatic softener. The notion of prototypes has been applied to progressive aspect as well. According to Sag (1973), the morphological marking of progressive aspect has several meanings including process, futurate (e.g. We’re leaving tomorrow), and habitual meanings. Andersen and Shirai (1996) claim that action in progress is the prototype of progressive aspect. Because prototypes result from the semantic association between the prototypical meaning of tense–aspect morphology and the semantic content of the verb frame (i.e. lexical aspect), the effects of prototypes should appear gradually as the learner encounters repeated instances of a tense–aspect morpheme.
Other researchers (e.g. Bardovi-Harlig, 1992b, 1995) have attempted to account for the tense–aspect asymmetry through discourse principles. As Bardovi-Harlig (2000) points out, the finding that backgrounding and foregrounding affect the asymmetry is fairly robust. Past marking typically appears in the foreground and gradually increases, overtaking the use of base forms in learners who use past tense with about 40% accuracy (Bardovi-Harlig, 1995). It should be noted that the discourse hypothesis may not apply to all learners. In an earlier study, Bardovi-Harlig (1992b) found that some learners appeared to be insensitive to discourse, even after proficiency was taken into account. A further limitation to the discourse hypothesis is that it has not been expanded beyond narration to a full range of discourse contexts and thus would not apply to the tense–aspect asymmetry if sentences were not embedded in extended narrative.
3 Hypotheses
This study examined whether the tense–aspect acquisition asymmetry would appear during initial L2 aquisition when past and progressive morphology were presented with a balanced distribution across the targeted lexical aspect categories. The asymmetry, if it were to appear within the current experiment, would be consistent with explanatory accounts such as (1) prototype theory and (2) the one-to-one principle. If learners are acquiring forms based on prototypes, they should initially associate past tense marking with bounded situations (accomplishments), which have a semantic affinity with deictic past. Likewise, they should associate progressive marking with activity frames, which have a semantic affinity with processes. The one-to-one principle would explain participants’ preference for an initial one-to-one match between grammatical forms and lexical aspect.
The list of hypotheses and their relationship to the current study are presented in Table 1. The study tested the following hypotheses:
Hypothesis 1: Aspectual morphology will tend to be acquired before tense morphology. Participants will therefore demonstrate greater accuracy in both production and reception on items requiring progressive marking, an aspectual distinction, as opposed to items requiring past tense marking.
Hypothesis 2: There will be a significant difference between participants’ performance on the activity and accomplishment verbs marked with progressive aspectual marking, and this performance will coincide with an implicational order of activities > accomplishments as predicted by the aspect hypothesis.
Hypothesis 3: There will be a significant difference between participants’ performance on the activity and accomplishment verbs marked with past tense, and this performance will coincide with an implicational order of accomplishments > activities as predicted by the aspect hypothesis.
Explanatory accounts of the tense–aspect asymmetry and their relationship to current study.
III Method
The study involved a single session of instruction of an artificial language called Nesperanto (see Appendix 1) to English native speakers followed by productive and receptive measures of acquisition of aspect and tense morphology based on lexical classes. Through the employment of a single intensive instructional phase, the study focuses on patterns of L2 acquisition that occur very early in the acquisition of morphosyntax when grammatical forms are still not automatized (for a discussion of automatization in SLA, see Segalowitz, 2003).
1 Participants
Experimental data came from 40 adult English speakers who were not heritage speakers of another language. Those who had studied Japanese (upon which Nesperanto morphosyntax is based) were excluded from the study. Participants were recruited using flyers posted at a college campus. They were paid $20 for their participation in the full experiment and $10 if they only completed the initial vocabulary-learning phase. To ensure active engagement, the participant with the top score on outcome measures was paid an extra $20. In a short survey, participants were asked their native language, second languages, age, and educational background. Based on survey responses, the mean age of the participants was 22 (range 18–27) and all were undergraduate college students.
2 Nesperanto
As pointed out by Hulstijn (1997), classroom-based SLA studies are often plagued by a medley of interfering variables that interact in complex ways with targeted variables, and artificial languages provide a potential methodological option aimed at avoiding such confounds. For this reason, artificial languages have been used by a number of researchers to test SLA hypotheses in theory-driven research (e.g. DeKeyser, 1995; Kiss and Nikolov, 2005). A key practical constraint when designing an artificial language is limitations in participants’ willingness to spend extensive amounts of time learning a language that is of no practical benefit. To simplify the learning task, researchers have used semi-artificial languages and miniature artificial languages. The former are typically based on the participants’ L1. As a result, features of the language that are not being manipulated for experimental purposes can be left intact. While more readily acquired, such languages have some inherent drawbacks as participants may process the language ‘through the lens of’ the natural language (typically, participants’ L1) upon which the semi-artificial language is based (Kachinske et al., 2015: 405).
To help ensure that the L2 learning task in the current study was realistic, the study used a miniature language called Nesperanto. This language, designed especially for this study, was modeled on Japanese. Sugaya and Shirai (2007) have demonstrated that the tense–aspect asymmetry is observed in English-L1 learners of Japanese, so it is reasonable to expect a similar acquisitional pattern among English-L1 learners of a language modeled on Japanese.
The Nesperanto lexicon consists of 12 verbs associated with activity frames, 12 verbs associated with accomplishment frames, 3 stative verbs, 1 adverb, and 8 nouns. The verbs and nouns were chosen so as to be semantically distinct from other Nesperanto words. For example, the language contains a word (zo) that means cup, so the language does not contain a word meaning mug. The entire lexicon consists of 36 items. Previous research (e.g. Rogers et al., 2015: Experiments 1 and 2) suggests that experimental participants find it difficult to learn morphology when long words are used in an artificial language. To alleviate the learning burden, all nominal and verbal base forms in Nesperanto consist of a single syllable.
Nesperanto has a rigid SOV word order and suffixes marking nominative and accusative cases as well as verbal suffixes marking progressive aspect and past tense. As in both Japanese and English, past tense and progressive marking are required when referring to past and on-going actions respectively. In other words, Nesperanto has been designed so that negative L2 transfer (i.e. transfer of the semantics of English to Nesperanto) should not be a confounding factor. In Nesperanto, present tense receives zero-marking. All morphological marking and syntactic rules are completely regular. Recent research (e.g. Simoens et al., 2018) suggests that the perceptual salience of morphology influences ease of acquisition. To ensure that this did not constitute a confound, the two grammatical suffixes in the current study (i.e. -bi and -da) were both matched in terms of being a single syllabus that consisted of a voiced consonant followed by an open vowel.
The grammatical morphemes as well as all lexical items were created by selecting random combinations of consonants and vowels. These form–meaning combinations were then examined and those that resembled English words with a similar meaning were changed.
a Phonology
Multi-syllabic Nesperanto words are lightly accented on the root word and never on an affix. There are 14 consonants (b, d, f, g, j, k, l, m, n, p, s, t, v, z), which are pronounced as they typically are in English and five vowels (a, e, i, o, u) pronounced as they are in Spanish. Syllables consist solely of open consonant + vowel combinations.
b Lexical aspect
To determine the categories of lexical aspect, this article used the tests presented in Shirai and Andersen (1995: 749). Because of the study’s design, the choice of tests was not a straightforward matter. Previous studies have used tests developed for natural languages. The test was therefore applied to translation equivalents in English. The tests were deemed appropriate for the current study as the semantics of the target phrases in the artificial language used in this article were modeled directly upon English in all relevant respects.
3 Materials and procedure
The experiment consisted of (1) a preparatory vocabulary learning phase, (2) an online learning phase, (3) a speaking test, and (4) a listening test. The treatment materials and the materials used for the speaking and listening tests were designed to ensure that participants would encounter the same number of target forms in each of the four conditions (Accomplishment + Progressive, Accomplishment + Past, Activity + Progressive, Activity + Past) during each part of the experiment and to ensure that exposure time to target forms in the four conditions would be identical. In other words, the participants heard exactly the same number of tokens and types of verbs marked for progressive and past during each treatment phase and during the two testing phases.
At the beginning of the experiment, participants were briefed and then given a vocabulary sheet with all the Nesperanto words. They then listened to a short audio file that provided the pronunciations. After this, they were asked to memorize the list using the Pauker 1.7 vocabulary flashcard program. When participants felt they knew all the words, they were given a vocabulary test. Participants had to achieve criterion on the vocabulary test (95% accuracy). Those who failed to do so were allowed to study the vocabulary for an extra 10 minutes and retake the test. Failure to achieve criterion on the second try resulted in participants being dropped from the study.
The subsequent treatment, which focused on progressive and past tense suffixes, was presented via computer using a PowerPoint slideshow presentation with automated timed slide transitions. Participants watched the slide show as they listened with headphones. The treatment consisted of two phases. The first phase exposed participants to two slides, each with an accompanying audio. These two slides were followed by a quiz segment in which the two slides were shown again without the accompanying audio and in a random order. Participants were instructed to wait until a microphone icon appeared along with a beep and then repeat the sentence that corresponded to each slide. Nesperanto verbs with progressive and past marking appeared an equal number of times during this phase in a pseudo-random order (to ensure that they appeared equally during the beginning, middle, and end of this phase of the treatment). The second treatment phase was similar, except that three slides were shown in succession instead of two. Again, verbs with progressive and past marking appeared an equal number of times during each segment of the treatment in pseudo-random order.
In the progressive slides, participants watched a video clip of a person performing an action. Half a second after the movie clip began to play, an audio clip began with the target Nesperanto sentence. Because the sentence included a progressive verb frame, the video continued to play during the entire time in which the sentence was uttered and for a short time after the audio ended (5 seconds in total).
Slides depicting past tense also began with a person performing an action but with no audio playing. This initial clip, like that used for the progressive frames, appeared at the upper right-hand corner of the screen. The participant then saw the person stop performing the action. An arrow pointing downward and to the left then appeared and half a second later, a sepia-colored still photo of a person performing the target action appeared in the lower left corner of the screen (see Figure 1). At this point, an audio file played the Nesperanto sentence targeting the past-tense verb. The sepia figure (representing past action) was placed on the left since English speakers appear to more naturally associate past tense events with the left side of a horizontal axis (Eikmeier and Ulrich, 2014; Tversky et al., 1991). These slides were also shown for 5 seconds in total.

Slide used in the training materials.
The materials for the treatment thus included a PowerPoint treatment with a total play time of 30 minutes in which 24 Nesperanto verbs (12 activity and 12 accomplishment verbs) each appeared 8 times (4 times with past marking and 4 times with progressive marking). Sentences using stative verbs with null marking (i.e. present tense) also appeared interspersed throughout the training materials along with occasional slides showing Nesperanto sentences in which the activity and accomplishment verb frames appeared with null marking (indicating habitual actions).
Following the instructional phase, participants were asked to complete a speaking test and a listening test. As pointed out by one of the reviewers of this article, the use of multiple measures in an experiment makes it likely that participants’ performance on the later measure will be influenced by their processing of language when completing the earlier measure. In the current experiment, participants were likely to have solidified their knowledge of the Nesperanto grammar and vocabulary as they completed the speaking task. However, this period of practice should not create a confound in the experimental design as the number of items for past tense and progressive aspect were balanced on the speaking test and the items showing past tense and progressive marking appeared in a pseudo-random order equally on the first and second half of the test.
To create tasks that entailed realistic time pressures associated with language use, the current experiment employed both productive and receptive measures that were fast-paced. The speaking test consisted of 53 items (40 target items and 13 distractor items), which were arranged in pseudo-random order so that the items in the four experimental conditions (i.e. activity and accomplishment verbs appearing with both progressive and past tense marking) appeared equally on the first and second half of the test. For the test, participants responded to items on a PowerPoint. These items were designed like the quiz items in the treatment phase. For each item, a microphone icon appeared with a beep at the point at which the audio would normally begin. In other words, the microphone appeared while the action was still being performed on slides showing a progressive frame, whereas it appeared after the sepia picture appeared on the lower left of the screen on slides showing a past tense frame. Participants had to produce the Nesperanto sentence corresponding to the PowerPoint slide when they heard the beep. Responses were recorded and later transcribed. Prior to the treatment, participants were instructed that they would hear sentences describing ongoing action taking place in the video, actions that took place at a previous point of time as shown in a faded picture, or sentences that describe an object or what someone does on a regular basis (i.e. sentences with null marking for present, which involve stative verb frames or descriptions of habitual actions).
Cronbach’s alpha, a measure of internal consistency among items, was .789 for the entire speaking test (including distractors) and .783 for the test when only the 40 target items were included. The reliability was thus in the lower range of acceptability for an experimental instrument. Distractors were used for both the initial and final item on the test. The distractors were present-tense Nesperanto sentences that were not marked for the progressive which were added to make the artificial language more realistic.
The listening test likewise consisted of 53 similar items, which were also arranged in pseudo-random order so that (1) the items in the four experimental conditions appeared equally on the first and second half of the test, and (2) distractors appeared for the initial and final items. The listening test consisted of a recorded audio file. For each item, the item number followed by the Nesperanto sentence lasted for approximately 4 seconds. This was followed by 12 seconds of silence prior to the subsequent item. All items were recorded by a male voice. Participants were provided with numbered answer sheets with directions. They then listened to Nesperanto sentences, which they translated into English. They were instructed to translate as much as they understood, even if this resulted in a partial translation. Participants then completed a short background survey.
4 Analysis
The speaking test was scored using both within-category and across-category methods. Bardovi-Harlig (2000), in her reanalysis of previous studies, has demonstrated that the two types of analysis are not equivalent. The use of the across-category analysis for the speaking task data ensured that participants’ undersuppliance and oversuppliance of certain morphological forms was captured. This additional within-participants analysis answered the question, ‘Where do participants use the grammatical morphemes that they have learned?’ In other words, it examined the contexts in which base, progressive, and past forms occurred in participant production. This analysis determined the marking that participants used for the four target conditions (activity and accomplishment frames dealing with past or ongoing action), present tense situations (i.e. those describing what someone does every day), and stative situations. Participants’ verbal affixes were classified as: (1) -bi (past-tense marker), (2) -da (progressive), (3) null marking for present, (4) anomalous marking, or (5) failure to produce both verb and marking. This across-category analysis did not involve dichotomous measures, and as a result, the findings were used solely for post hoc analysis of an exploratory nature.
For the within-category analysis, items were scored dichotomously. If the participant’s response contained the target verb with the appropriate morphological marking, the item was marked as correct, and if not, it was marked incorrect.
For the listening test, the analysis was based on participants’ ability to render the verb along with its appropriate aspect and tense into English. Participants’ performance on the other parts of the sentence was not considered. Cronbach’s alpha was .816 for the entire test (including distractors) and .802 for the test when only the 40 target items were included.
IV Results
Six participants were unable to reach criterion on the vocabulary test, and one participant’s computer malfunctioned during the speaking test. These participants were all replaced so that 40 participants completed all phases of the study.
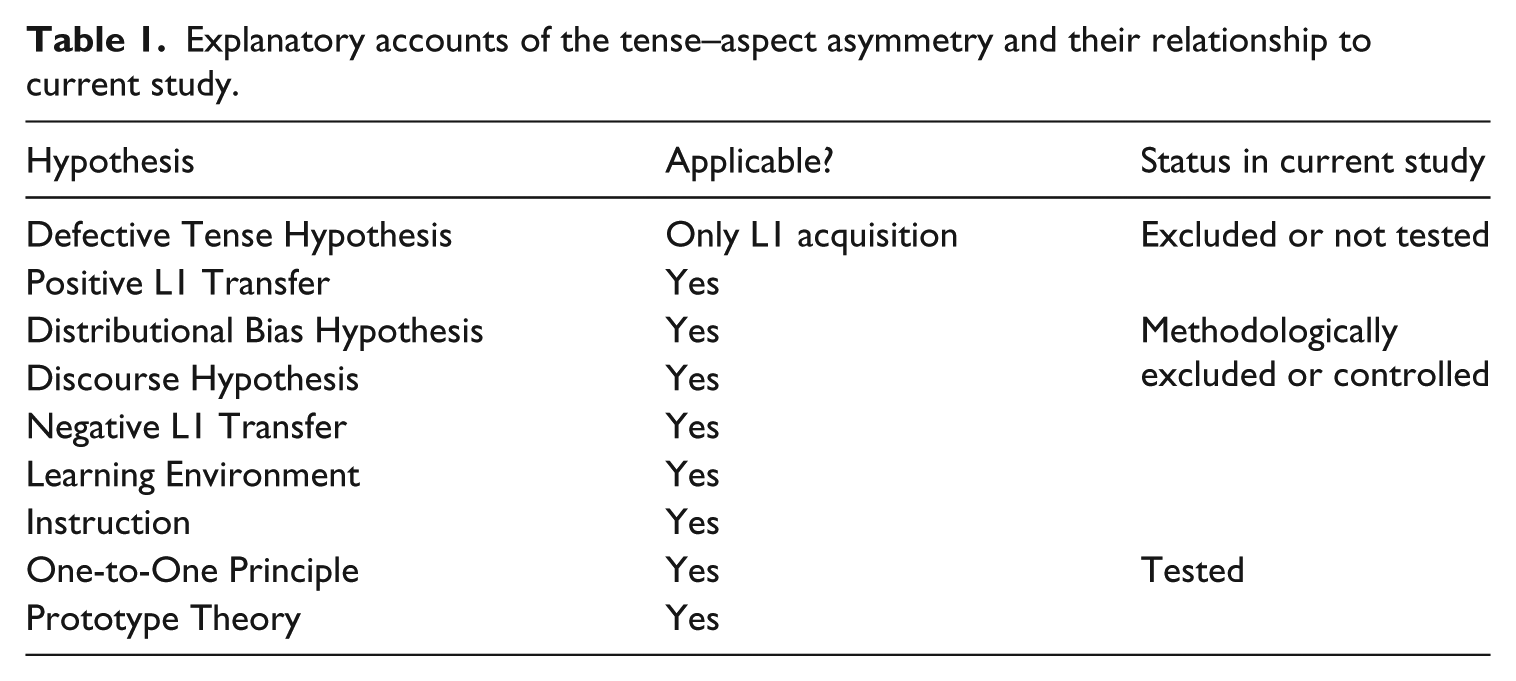
The descriptive statistics for the speaking test are shown in Table 2. As can be seen, the means for past tense items are higher, as are the means for accomplishment verbs. The SDs are high, an indication that the participants vary in their ability to learn the artificial language within the short period of intense instruction and exposure provided during the treatment. The tense–aspect asymmetry would predict that activity verbs with progressive marking would yield higher scores, but this is not the case.
Speaking test descriptive statistics: Accuracy on the four categories of items: Speaking test target items (10 items per category, n = 40).
Note. * Scores represent the number of correct responses on the 10 target items for each category. The mean score of 4.9 thus equates to 49% accuracy on the 10 activity frames occurring in the past.
The descriptive statistics for the listening test are shown in Table 3. As can be seen, the scores resemble those from the speaking test, with higher scores for both past tense and accomplishment verbs. The higher scores on the speaking test were somewhat unexpected as learners tend to have greater difficulties with production than reception, yet it should be noted that the speaking test occurred immediately after the treatment, and learners would therefore presumably have greater ability to employ recently acquired linguistic knowledge. The activity item scores on both tests, instead of reflecting the hypothesized tense–aspect asymmetry, are in an inverted relationship.
Listening test descriptive statistics: Accuracy on the four categories of items: Listening test target items (10 items per category, n = 40).

Note. * Scores represent the number of correct responses on the 10 target items for each category. The mean score of 4.9 thus equates to 49% accuracy on the 10 activity frames occurring in the past.
The initial analysis of speaking test scores was performed with a 2 × 2 factor ANOVA using the General Linear Model in SPSS. The first within-participant factor, lexical aspect, had two levels (i.e. activity and accomplishment frames). The second within-participant factor, morphological marking, also had two levels (i.e. progressive and past-tense frames). The effect of lexical aspect was significant: F(1,39) = 8.101, p = .007, ηp2 = .172. The effect of morphological marking was also significant: F(1,39) = 10.964, p = .002, ηp2 = .219. The significant differences for the two within-participant factors were due to participants’ better performance on accomplishment vs. activity verbs (49.0% vs. 44.4% accuracy) and the markedly superior performance on frames requiring past vs. progressive marking (51.6% vs. 41.7% accuracy).
For the purpose of testing the experiment’s hypotheses, the more relevant contrast was between past and progressive marking for each category of lexical aspect. If learner acquisition exhibited the tense–aspect asymmetry, there should have been an interaction between lexical aspect and morphological marking. However, the interaction between the two within-participants factors was non-significant: F(1,39) = 0.187, p = .668, ηp2 = .005.
The analysis of listening test scores was also performed with a 2 × 2 factor ANOVA using the General Linear Model in SPSS. The first within-participant factor, lexical aspect, had two levels (i.e. activity and accomplishment frames). The second within-participant factor, morphological marking, also had two levels (i.e. progressive and past tense). The effect of lexical aspect was significant: F(1,39) = 5.943, p = .019, ηp2 = .132. The effect of morphological marking was also significant: F(1,39) = 10.973, p = .002, ηp2 = .220. As with the speaking results, the significant differences for the two within-participant factors were due to participants’ better performance on accomplishment vs. activity verbs (40.7% vs. 37.1% accuracy) and the markedly superior performance on frames requiring past vs. progressive marking (46.7% vs. 31.1% accuracy). The interaction between lexical aspect and morphological marking was non-significant at p < .05: F(1,39) = 2.968, p = .093, ηp2 = .071.
An additional across-category analysis was performed on the speaking test results to determine the contexts in which participants tended to use Nesperanto morphemes. The results are shown in Table 4. The left column shows the morphology used: (1) -bi (past tense), (2) -da (progressive aspect), (3) null marking (present tense), (4) anomalous marking (a monosyllabic suffixed morpheme that is a non-target form), and (5) omission (failure to produce both the verb and accompanying morphology). The contexts represent the type of frame suggested by the movie clip in the item on the speaking test. Marking on the distractors targeting habitual action were excluded, resulting in 45 items per participant being included in the analysis.
Across-category speaking test data: Occurrence of morphological marking by context.
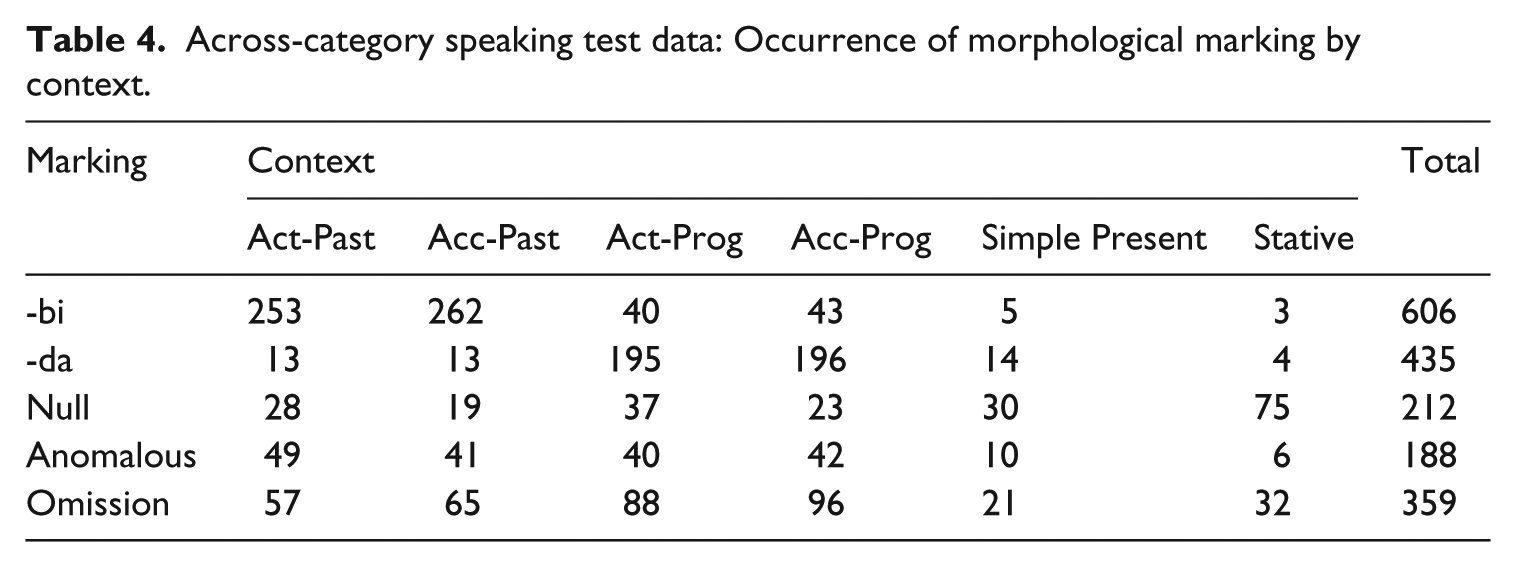
As can be seen, -bi and -da tend to appear in an equal distribution across past and progressive contexts respectively, unaffected by the lexical aspect of the verbs. The greater overextension of -bi to progressive contexts can be partly explained by the greater use of -bi overall. Overall, the items listed in the table included 800 contexts requiring the past tense marker -bi and 800 requiring the progressive marker -da; yet, -bi was used in 64.4% of total contexts requiring past test whereas -da was used in 48.9% of total contexts requiring the progressive form.
Null marking shows greater use in progressive contexts relative to past contexts, which is probably due to greater semantic similarity between progressive and simple present meaning (a similarity suggested by the conflation of these categories in many languages). Likewise, -da appears more than -bi in simple present contexts, further evidence of confusion between progressive and simple present contexts. An interesting pattern is the greater use of null marking with activity verbs in both past and progressive contexts relative to accomplishment verbs. The disproportionate use of null marking in this context could also help explain the unexpectedly low scores on the activity progressive items in the within-category results for the speaking test.
The across-category data were further subjected to a Target-Like Use (TLU) Analysis. The TLU formula, taken from Lightbown et al. (1980), involves placing as numerator the score for morphemes used correctly in obligatory contexts and then placing as denominator the total number of obligatory contexts plus the number of tokens of suppliance within non-obligatory contexts. The TLU formula is conventionally used for elicited data. Even so, it is useful in this study as it provides a more accurate picture of correct use by accounting for the effects of both undersuppliance and oversuppliance of target forms.
On the speaking test, the TLU score for all 40 participants was 57.8% (SD = 40.8%) for the past-tense morpheme -bi and 46.3% (SD = 40.9%) for the progressive marker -da. 1 A two-tailed paired sample t-test showed that there was a significant effect for morphological marking at p < .05: t(39) = 3.598, p < .001. Examined individually, 26 participants exhibited higher TLU on past tense morphology, 14 had higher TLU on progressive morphology, and 14 had equal TLU scores on both. To determine whether participants who exhibited different levels of acquisition of the Nesperanto target forms would display different TLU scores for the target morphemes, the group was divided between those whose average TLU for both of the target morphemes was less than 50% (n = 19) and those whose target TLU was over 50% (n = 21). The ‘low proficiency’ group had a mean TLU of 21.7% for the past-tense and 5.9% for the progressive, whereas the ‘high proficiency’ group had a 92.0% TLU for the past-tense and 83.1% for the progressive. The 10 participants whose TLU scores averaged between 20% to 80% were then examined to determine whether those in an intermediate state of acquisition would display the same tendency. These participants showed a markedly greater tendency to acquire accuracy with past tense first, scoring an average TLU of 70.1% on the past tense in contrast with a TLU of 35.2% on the progressive. Moreover, all 10 of these participants had higher scores for past tense items.
V Discussion
The results showed a lack of support for all three of the study’s hypotheses. Perhaps the most startling result is the lack of support for hypothesis 1. Participants demonstrated greater accuracy on past tense relative to the progressive on both the speaking and listening tests. This is true even when the speaking scores are viewed in terms of an across-category tally that is subjected to a TLU analysis. Results clearly showed an unexpected advantage for past tense on both tests in spite of some loss of sensitivity in the measures due to floor and ceiling effects. The speaking test TLU scores for the 10 participants who had between 20%–80% TLU totals are especially relevant. This group, which unanimously performed better on past tense items, was accurate on approximately two-thirds of all past-tense items but only on one-third of progressive items. In other words, the effect for morphological marking is reversed precisely where one would expect to find it in its most pronounced form, namely, among participants who are at neither floor nor ceiling on the experimental measures.
This preference for past tense contrasts sharply with findings of previous studies. In the early ‘natural order’ studies, acquisition of the English progressive has been found to precede acquisition of the irregular past, which, in turn, has been found to precede the acquisition of the regular past. This finding has held true for both L1 learners (Brown, 1973), early L2 learners (Dulay and Burt, 1974), and adult L2 learners (Bailey et al., 1974; Larsen-Freeman, 1975). Bardovi-Harlig and Reynolds (1995), in their study of 182 learners’ performance on cloze-type test that asked learners to conjugate verbs, found that learners undergeneralized the use of past tense, a finding in direct contrast with that of the current study. As one reviewer pointed out, the current findings, coming from a study that examined initial learning under highly artificial conditions, must be interpreted carefully regarding this point. The criterion used for acquisition in L1 studies on the natural order of acquisition was high (90% in Brown, 1973). It is therefore possible that the participants of the current study, if trained extensively in Nesperanto, may eventually display a U-shaped developmental curve, with accuracy on progressive marking passing that of past tense marking.
On the other hand, the discrepancy in findings regarding this point may be related to language-specific differences between English progressive and past tense morphology that make these forms difficult. DeKeyser (2005) has posited three general features of morphosyntax that are inherently problematic for L2 learners: complexity of form, complexity of meaning, and complexity (and transparency) of the form–meaning relationship. English past tense has both irregular forms and allomorphs that can affect both pronunciation and spelling and thereby complicate form–meaning mapping. The progressive, on the other hand, is phonologically salient and can be applied in the same form across large classes of verbs. The use of similar monosyllabic morphemes for both past and progressive in Nesperanto may have eliminated this advantage for the progressive.
Some research on the acquisition of Asian languages suggests that greater facility in acquisition of the progressive compared to past tense or perfective aspect may be a language-specific phenomenon. For example, Wen’s (1997) study of 19 English-L1 Chinese-L2 speakers’ performance in a series of oral tasks found that the Chinese perfective marker -le and past experience marker -guo were acquired before the progressive -zhe. Kim and Lee (2006) likewise found that learners of Korean supplied the Korean progressive marker only 28.8% of the time on a cloze task compared to 87.8% for past tense, although it should be noted that Korean progressive forms, unlike those in English and Japanese, are not obligatory when referring to ongoing actions, hence acquisition of the Korean progressive may also be hampered by low form-function covariance (see Cintrón-Valentín and Ellis, 2016; Ellis, 2018).
Based on the tense–aspect acquisition asymmetry found in previous research, hypothesis 2 had predicted that participants would achieve greater accuracy using progressive morphology on activity frames. However, the results of both the speaking and listening tests did not indicate such an effect. Hypothesis 3 had likewise stated that participants would perform better on measures in which past tense marking was matched with accomplishment frames. This hypothesis also failed to achieve support from either the speaking or listening test results. Although both lexical aspect and morphological marking had a significant effect on both speaking and listening scores, the tense–aspect asymmetry should create an interaction between the two factors. This interaction was not found. Even so, the greater accuracy on the listening test for accomplishment frames with past marking did show a slight trend in the direction predicted by the tense–aspect asymmetry.
A straightforward interpretation of the results would be that the failure to find tense–aspect asymmetry effects for both activity and accomplishment frames is related to acquisitional stage. Bardovi-Harlig (2000) has suggested that the aspect hypothesis may not apply to the earliest stages of learning. Salaberry’s (1999) study of tutored Spanish learners asked to provide a ‘Modern Times’ excerpt narration found that those in the initial stages of acquisition seemed to use the Spanish preterit simply as a marker of tense rather than as a marker of perfective aspect (see Bonilla, 2013). Although insensitive to lexical aspect, these early learners did use preterit forms extensively, using the preterit for nearly a third of their production at the beginning of the semester and nearly half of their production two months later.
The current study did not test all hypothesized explanatory factors listed in Table 1; however, few of these factors are plausible as a general explanation of the tense–aspect asymmetry as found broadly in previous research. For example, L1 transfer can be ruled out as the sole explanatory mechanism based on the large number of language combinations previously tested. Studies that have found an effect for L1 (e.g. Sugaya and Shirai, 2007) have concluded that its role was minor and that it did not explain all the asymmetry effects in the results.
Discourse features are known to play a role in the tense–aspect asymmetry. The current study’s design prevented participants from using background-foreground contrasts during both the treatment and testing phases. This may have inhibited typical discourse-related acquisitional sequences and, in the current study, may have had particularly strong inhibitory effects on the acquisition of the progressive. Yet as Bardovi-Harlig has pointed out, sensitivity to discourse context can only account for part of the asymmetry.
One possible explanation of the current results and those in other studies suggesting a lack of consistent tense–aspect asymmetry effects for the initial stages of learning is that the asymmetry is solely associated with implicit frequency-based learning mechanisms that are not sufficiently engaged in early acquisition due to learners’ inability to process adequate input at this stage (or, in the case of the Nesperanto experiment, the lack of both processing ability and adequate input).
The final causal factor that was controlled for in the current study was distributional bias. It is reasonable to assume that progressive and past tense forms in languages tend to appear in an imbalanced distribution in natural discourse and that the resulting skewed distributions in L2 input influence the tense–aspect asymmetry (Andersen and Shirai, 1996). Evidence for these skewed distributions has appeared in recent corpus research. For example, Collins et al. (2009), in an analysis of a 110,000 word corpus of speech directed to English L2 learners, found that 72% of past forms occurred with telics. In another study, Wulff et al. (2009) analysed the profiles of highly frequent English verbs in two large corpora. Their analysis of contingency for the past and progressive categories showed that the correlation between association strength and frequency was much higher for the progressive than for past tense. They suggest that this distribution ‘may be a partial explanation’ for the acquisition of the progressive prior to the past in L1 and L2 acquisition (p. 365). The failure to find such an advantage for the progressive in the current study could thus be explained by the balanced distributions of the target Nesperanto tense and aspect classes in the input. However, this would still not explain participants’ superior performance on past tense.
A particularly intriguing possibility is that learners are adopting a default strategy of associating past tense forms chiefly with transitive verb frames and progressive forms with chiefly intransitive verb frames due to skewed distributions in English. The current experiment used exclusively transitive frames in all but the distractor items, which were excluded from the analysis. The use of transitivity as a structural cue to telicity has recently been found in L1 research. Wagner (2006) tested children (age 2–5 years) in an event-counting task using telic and atelic predicates in both transitive and intransitive structures. She found that 2-year-old children exhibited a bias toward linking transitive structures to telic meanings. While acknowledging that the results can be interpreted via a multiplicity of factors (including general cognitive development), Wagner entertains the possibility that children may be simply responding to a statistical bias in the input. If so, there is a possibility that adult learners rely on the same syntactic bootstrapping as a useful, albeit imperfect, heuristic for learning the telicity of verbs.
To determine whether learners initially conflate transitivity and tense–aspect morphology, future research could compare performance on activity, accomplishment, and achievement verbs that occur solely within transitive frames. Future research may also make use of the artificial language learning paradigm used in this study as it allows for much greater control over linguistic variables and input. Admittedly, the methodology has some drawbacks. Participants must make a considerable time commitment without the learning benefits ordinarily associated with language learning tasks. Even with a miniature lexicon and rules, Nesperanto represented a challenge for the participants, who almost unanimously reported difficulty in acquiring the miniature language in such a short time.
The null results in the current study suggest that the tense–aspect asymmetry does not apply to early learners. This finding supports Tong and Shirai’s (2016) argument that at the initial stages, learners, especially those in a foreign language setting, may be less sensitive to lexical aspect due to the paucity of input. It could also be that the explanatory factors remain outside those tested. Most excluded factors are unable to account for the empirical results put forth in the extensive studies carried out on the tense–aspect asymmetry thus far. Multiple factors are likely to influence the asymmetry, but in the end, most are unable to account for the fairly consistent positive empirical results using diverse language combinations, diverse tasks, and different learning environments. One of the few plausible factors with wide application is distributional frequency within the input. Future research should therefore give this greater attention.
Footnotes
Appendix 1
The Nesperanto lexicon and example sentences
Declaration of Conflicting Interest
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.