
Abstract
In the online processing of long-distance wh-dependencies, native speakers have been found to make use of intermediate syntactic gaps, which has the effect of facilitating dependency resolution. This strategy has also been observed in second language (L2) speakers living in an L2 immersion context, but not in classroom L2 learners. This research note investigates whether there is evidence of use of the intermediate gap among L2 speakers that have received considerable naturalistic exposure to the L2 from a young age, but do not live in a standard immersion context. Two groups of participants, one L1 English and one L1 Afrikaans–L2 English, completed a self-paced reading task involving English sentences containing long-distance wh-dependencies. The data were analysed using Bayesian regression. The results indicate that the intermediate gap facilitated dependency resolution in the L1 English group but not in the L2 group. Increased L2 exposure seemed to increase sensitivity to the intermediate gap among the L2 speakers, but was not associated with faster dependency resolution. The findings suggest that although non-immersive L2 experience affects L2 processing of abstract grammatical cues, it may be less effective than fully immersive experience in engendering nativelike processing of long-distance wh-dependencies.
I Introduction
In the debate regarding whether first (L1) and second language (L2) syntactic processing can converge, the processing of long-distance wh-dependencies – as e.g. in (1) – has received considerable attention.
(1) a. The manager
b. The manager
To comprehend a sentence like (1), the reader or listener must reintegrate the moved element (or ‘filler’) into its original position (or ‘gap’) in the sentence so that it can be assigned a grammatical and semantic/thematic role. To do so, the filler must be held in working memory until the gap position is reached, at which point reintegration can occur. Generative syntactic approaches (see, for example, Chomsky, 1977, 1986; Ross, 1967) propose that in this process, the clause boundary – marked by that in (1b) – is a site at which the filler can be reactivated (also termed an ‘intermediate gap’). This reactivation in turn accelerates filler reintegration at the upcoming gap in comparison to equivalent sentences in which no clause boundary is present (1a).
Such a facilitative effect has repeatedly been observed in L1 English speakers (Fernandez et al., 2018; Gibson and Warren, 2004; Marinis et al., 2005; Pliatsikas and Marinis, 2013). However, amongst L2 speakers, findings have been less consistent. Classroom L2 learners seem to process sentences of the form in (1a) and (1b) identically, which has led to the suggestion that they do not make use of the clause boundary when processing dependencies of this type (Marinis et al., 2005; Pliatsikas and Marinis, 2013; Pliatsikas et al., 2017; although, for different findings in the auditory modality, see Fernandez et al., 2018). This seems to hold even when the classroom learners have relatively high levels of proficiency, as was the case in Marinis et al. (2005) and Pliatsikas et al. (2017). Consequently, it has been suggested that high L2 proficiency alone is not sufficient to engender use of the intermediate gap (Pliatsikas and Marinis, 2013: 180).
One factor that has been found to influence the L2 processing of long-distance wh-dependencies is naturalistic L2 exposure, where a facilitative effect of the clause boundary has been identified among L2 speakers who have spent time in L2 immersion contexts (Pliatsikas and Marinis, 2013; Pliatsikas et al., 2017). This result has been attributed to increased proceduralization of grammatical knowledge brought about by extensive L2 exposure, in line with an account in which L2 grammatical processing becomes more automatic as L2 proficiency and exposure increase (see, for example, Ullman, 2001). Naturalistic exposure has indeed been suggested to be a ‘crucial factor for efficient native-like performance in the non-native language’ (Pliatsikas and Chondrogianni, 2015: 2). However, it has also been said to be most effective in immersion contexts in which the learner’s L2 ‘is exclusively or mostly used’ (Pliatsikas and Chondrogianni, 2015: 2).
The question addressed in this research note relates to the extent of naturalistic exposure required to bring about nativelike L2 processing of long-distance wh-dependencies. The focus is on the societally multilingual South African context. Although the South African Constitution recognizes 11 official languages – in alphabetical order, Afrikaans, English, isiNdebele, isiXhosa, isiZulu, Sepedi, Sesotho, Setswana, siSwati, Tshivenda, and Xitsonga – English, the L1 of only 9.6% of the population (Census, 2011), enjoys a privileged and even hegemonic status in the country. It is described as ‘the language of power and access – economically, politically, socially’ (Probyn, 2001: 250), and consequently it is widespread as an additional language (see also Posel and Zeller, 2016). English is also the dominant language in the education system: from Grade 4 (approximately age 10 years) onwards, 1 English and Afrikaans are the only two media of instruction provided for at the vast majority of schools (Department of Basic Education, 2010), and they are the only two languages in which the national secondary school exit examinations for non-language subjects can be written.
In the Western Cape province of South Africa, where the study was conducted, the three main languages are Afrikaans, isiXhosa and English, which are the ‘first language[s] spoken at home’ by 49.7%, 24.3% and 20.2% of the province’s population, respectively (Census, 2011). The L2 participants in the study were highly proficient early Afrikaans–English bilinguals who were attending a bilingual English–Afrikaans university at the time the study was conducted. They had received exposure to both Afrikaans and English at school. The more extensive use possibilities for their L1, compared to those for minority languages in more monolingual settings (e.g. Greek in the UK, as in Pliatsikas and Marinis, 2013), distinguishes their situation from the immersion contexts described by Pliatsikas and Chondrogianni (2015). This population therefore serves as a useful case study to investigate whether non-immersive naturalistic L2 exposure is sufficient to engender nativelike long-distance wh-dependency processing. Aside from this environmental factor, the analyses also take into account the potential effects of individual differences in L2 exposure, L2 proficiency and working memory on use of the intermediate gap.
II Method
1 Participants
Participants were one group of 36 L1 English speakers (mean age: 20 years, SD: 1.2 years, range: 18–23) and one group of 38 L1 Afrikaans–L2 English speakers (mean age: 20 years, SD: 1 year, range: 18–22). All participants had lived in South Africa from birth with no significant amount of time spent outside of the country, and all L2 participants were early L2 acquirers (mean age of acquisition 5.16 years, SD 2.2 years). The L2 participants had been exposed to both Afrikaans and English at school, with on average a longer duration of Afrikaans exposure in this domain (Afrikaans: mean = 13.67 years, SD = 4.4 years; English: mean = 11.12 years, SD = 6.2 years). They reported having high proficiency in their L1 (speaking: mean = 9.1/10, SD = 0.9; comprehension: mean = 9.6/10, SD = 0.5; reading: mean = 9.3/10, SD = 0.8).
The Language Experience and Proficiency Questionnaire (LEAP-Q; Marian et al., 2007) was administered to assess participants’ language backgrounds, and participants’ English proficiency was evaluated by means of a C-test based on Keijzer (2007). The participants’ background data and C-test scores are summarized in Table 1.
Background data on L1 English and L1 Afrikaans speakers (standard deviation).
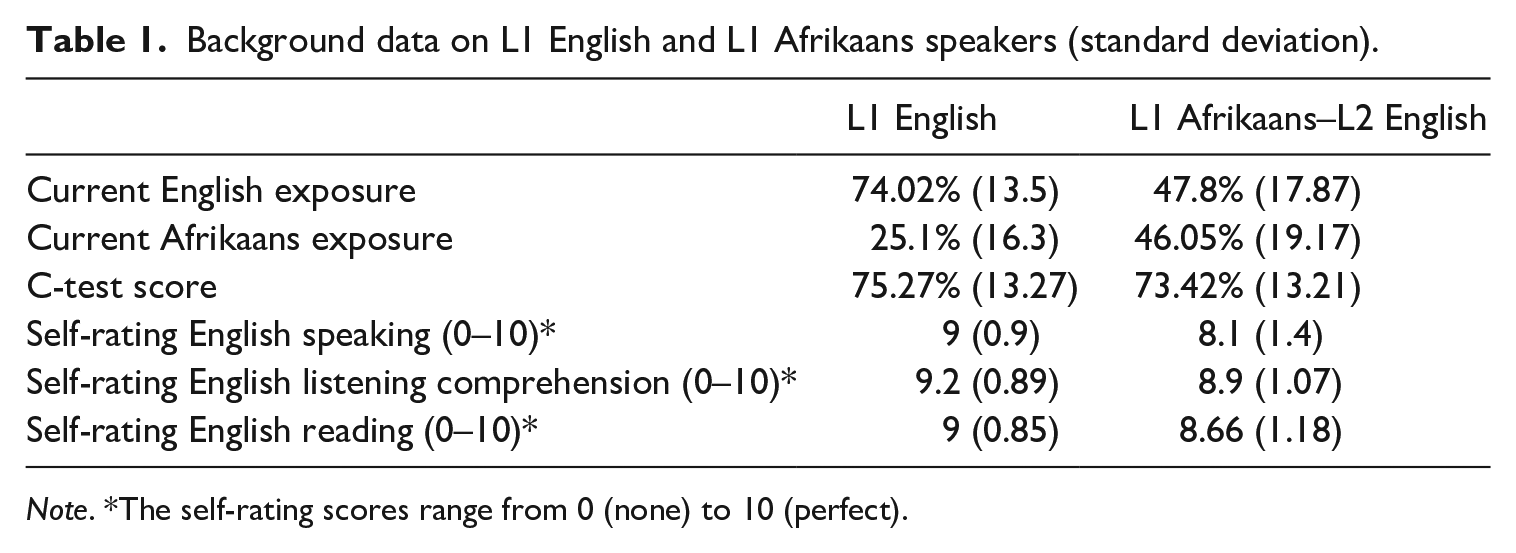
Note. *The self-rating scores range from 0 (none) to 10 (perfect).
2 Materials
To enable comparisons with previous results to be drawn, the experiment used the stimuli and experimental design employed in Marinis et al. (2005) and Pliatsikas and Marinis (2013). In the main experiment, participants read a total of 66 sentences. Six were practice items, 20 were experimental items, and the remaining 40 were fillers.
Each experimental sentence came in four versions. These were distributed in a 2 × 2 design, in which the conditions Extraction (Present or Absent) were crossed with Phrase Type (NP or VP). The four experimental conditions are illustrated below. The complete list of experimental items can be found in Marinis et al. (2005).
(2) a. [CP The nurse [CP whoi the doctor argued [CP ei that the rude patient had angered ei ]] is refusing to work late.]
(Extraction VP)
b. [CP The nurse [CP whoi the doctor’s argument about the rude patient had angered ei] is refusing to work late.]
(Extraction NP)
c. [CP The nurse thought [CP the doctor argued [CP that the rude patient had angered the staff at the hospital.]]]
(Non-Extraction VP)
d. [CP The nurse thought [CP the doctor’s argument about the rude patient had angered the staff at the hospital.]]
(Non-Extraction NP)
In the two Extraction conditions, the initial NP (the nurse) is followed by a relative clause headed by who, which is the object of the embedded verb (had angered). The Extraction VP condition provides an intermediate gap for the filler at the embedded clause boundary. The verbs in the embedded clause were all transitive and biased towards taking a sentential object in order to prevent the filler who being construed as a direct object. The embedded verbs were also bridge verbs that permit wh-extraction from their complement clause. The Extraction NP sentences were identical in length to the Extraction VP sentences, but provided no intermediate landing site. The Non-Extraction sentences also had the same number of words as their Extraction counterparts. No syntactic movement was involved in these sentences.
All sentences were divided into six segments as follows:
(3) The nurse whoi / the doctor argued / ei that / the rude patient / had angered ei /
1 2 3 4 5
is refusing to work late
6
The segments of interest are segments 3 and 5. Segment 3, which marks the beginning of the embedded clause, is the position of the intermediate gap in the Extraction VP sentences. Segment 5 contains the subcategorizing verb, at which point reintegration of the filler must occur.
The experimental items were distributed across four lists in a Latin Square design and combined with the fillers in pseudorandom order. Each list was divided into three blocks of 20 sentences each. Participants took a short break between each block. All participants saw the same six practice items at the beginning of the experiment.
Comprehension questions were asked after all of the experimental sentences and 45% of the filler sentences. As in Marinis et al. (2005), the comprehension questions following the experimental items all asked which person mentioned in the sentence had committed a particular action; for example, the question following (2a) was Who is refusing to work late?, with The nurse and The doctor offered as answers.
3 Procedure
The self-paced reading task was designed and administered in PsychoPy (Peirce, 2007). The accuracy of participants’ question responses as well as their reaction times (RTs) for each segment were captured. 2 The experiment employed the non-cumulative moving window procedure. The sentences were presented segment-by-segment in black letters (font: Consolas) on a light grey background, and the end of each sentence was marked by a full stop. The text was displayed in the centre of a 15-inch (380 mm) laptop screen (resolution: 1366 × 768) and always ran over two lines, where only the final segment of each sentence appeared on the second line. 3 Participants used the space bar on the keyboard to prompt the display of the next sentence segment.
Participants had two self-timed breaks during the task, where they could press any key whenever they were ready to continue with the experiment. The task took approximately 20 minutes to complete. Subsequently, the participants filled in the LEAP-Q and completed the C-test.
III Analysis
The data were analysed using Bayesian regression. The shift from conventionally employed frequentist methods to Bayesian methods has been a key tenet in calls for reform of data analysis practices in the social and behavioral sciences (Dienes and Mclatchie, 2018; Etz and Vandekerckhove, 2018; Kruschke and Liddell, 2018; for treatments of the subject focused on second language acquisition and related fields, see Norris, 2015; Norouzian et al., 2018, 2019). Two of the central benefits of Bayesian approaches are that (1) they allow for relevant prior empirical findings to be incorporated into the analysis process, and (2) they enable the relative strength of evidence in favor of/against the existence of a particular effect to be assessed. As is well known, the latter is not possible in frequentist null hypothesis significance testing, where a null result only indicates a failure to reject the null hypothesis (i.e. that there is no effect of the variable in question in the actual population). In contrast, Bayesian hypothesis testing involves the calculation of a Bayes factor, which is a numerical indicator of the extent to which the observed data provide evidence for the alternative rather than the null hypothesis. Bayes factors make it possible not only to reject but also to accept the null hypothesis; for example, a Bayes factor of 0.01 indicates that the null hypothesis is 100 times more likely to be true given the observed data.
Current beliefs about the nature of a particular effect are termed ‘priors’ in Bayesian parlance, and they take the form of a probability distribution specifying the likely values of the effect. Informative priors are those for which the researcher sets a specific range based, for example, on extant research or expert opinion; where vague (also termed ‘non-informative’) priors have probability distributions that are not restricted. In the present analysis, we used informative priors for those effects that were of interest to the research question, and for which previous studies had returned converging results. These informative priors were specified in milliseconds, based on the averages of the raw reading times reported in Marinis et al. (2005) and Pliatsikas and Marinis (2013), with a standard deviation that captured the observed spread around the means. For all effects that were not of direct relevance to the article’s research question, or for which the two studies listed above returned conflicting results, vague priors were used. Further, to check the results’ robustness, the models were also run with vague priors for all effects. The outcomes were unchanged.
To fit each model, we utilized four chains with 5,000 samples per chain, a warm-up of 2,500 samples, and no thinning, resulting in 10,000 samples for each parameter estimate. Results are presented in the text with an indication of the parameter estimate (b), reflecting the estimated value of the effect; the 95% credible interval, the interval within which the parameter lies with 95% certainty; and the evidence ratio (or Bayes factor), P(b), which provides an indication of the evidence regarding the existence of the effect. Evidence ratios were interpreted in line with the guidelines in Jeffreys (1998), where ratios of 3 or greater indicate substantial evidence for an effect, and ratios of 1/3 or smaller indicate substantial evidence for the non-existence of this effect.
IV Reading time predictions
As noted, the critical segments in this experiment are segments 3 and 5. At segment 3, both participant groups are expected to slow down in the Extraction conditions, as this reflects the cost of holding the filler in working memory. In theory, an Extraction × Phrase Type interaction should also be observed here, such that the slowdown is greater in the Extraction VP vs. the Extraction NP condition due to the additional cost of positing the intermediate syntactic structure; however, Gibson and Warren (2004: 62–63) point out that lexical differences in the segment 3 material across the two conditions may mask this effect. At segment 4, the filler cost also entails that participants should be slower in the Extraction conditions compared to the Non-Extraction conditions (see Dekydtspotter et al., 2006).
At segment 5, where the subcategorizing verb is located, the filler must be reintegrated into the original gap position. This is also expected to reflect in a time cost, and so participants should be slower here in the Extraction than in the Non-Extraction conditions. If participants have made use of the intermediate gap, an Extraction × Phrase Type interaction should be observed at this segment, indicating lower RTs in the Extraction VP compared to the Extraction NP condition.
V Results
1 Accuracy
For all comprehension questions, the mean accuracy score was 84.1%. For the questions following the experimental items, the mean accuracy score was 76.13%, with the L1 English group scoring 78.2% and the L1 Afrikaans group 74.12%. The data from two L1 English and three L1 Afrikaans participants who performed close to chance (below 60% correct) were removed from further analysis. This raised the overall accuracy score to 77.5% (range 60–100%). The L1 English participants’ mean score was 79.7%, and that of the L1 Afrikaans participants was 75.3%. These scores are comparable to those obtained in Marinis et al. (2005) and Pliatsikas and Marinis (2013). 4
2 Reading times
In accordance with standard practice in sentence processing studies, only data from trials where the comprehension question was answered correctly were analysed. Following Pliatsikas and Marinis (2013), we excluded the data of five participants (two L1 English, three L1 Afrikaans) whose mean RTs were more than two SDs above the group mean across all conditions. We then screened RTs for extreme values and outliers. Also in accordance with Pliatsikas and Marinis (2013), extreme values were defined as below 100 ms and above 4,000 ms, and outliers were defined as values greater than two standard deviations above or below the mean for each condition per subject and per item. Extreme values and outliers were replaced with the participant’s mean RT for that condition and segment, unless this mean value itself was extreme, in which case the extreme value or outlier in question was eliminated. Following this procedure, 0.27% of the L1 Afrikaans data and 0.19% of the L1 English data were eliminated. Mean values replaced 3.59% of the L1 Afrikaans data and 4% of the L1 English data.
The mean reading times (standard deviations) per group per condition are shown in Table 2. Reading times were log-transformed to meet the normality requirement for linear regression. Bayesian regression models were fit using the brms package (version 2.9.0; Bürkner, 2017, 2018) in R (version 3.6; R Core Team, 2018). In all models, L1 Group (L1 Afrikaans or L1 English, coded as −1 and 1), Extraction (Absent or Present; coded as −1 and 1) and Phrase Type (NP or VP; coded as −1 and 1) were fixed effects. We employed the maximal random effects structure that would converge (Barr et al., 2013), which for all models included random intercepts for Participants and Items and by-participants and by-items random slopes for Extraction, Phrase Type and their interaction.
Mean reading times in milliseconds (standard deviations) per group per condition.

The overall pattern of the RT data is illustrated in Figure 1 below. Subsequently, RT data for segments 3–5 are presented in Figures 2–4. Instead of group and condition means, which are plotted in Figure 1, Figures 2–4 show the individual data points. This not only gives an overview of the distribution of the data (as recommended by e.g. Larson-Hall and Plonsky, 2015), but also more accurately reflects the input to the mixed effects analyses. The results of the Bayesian regression models for each segment are presented in Table 3.
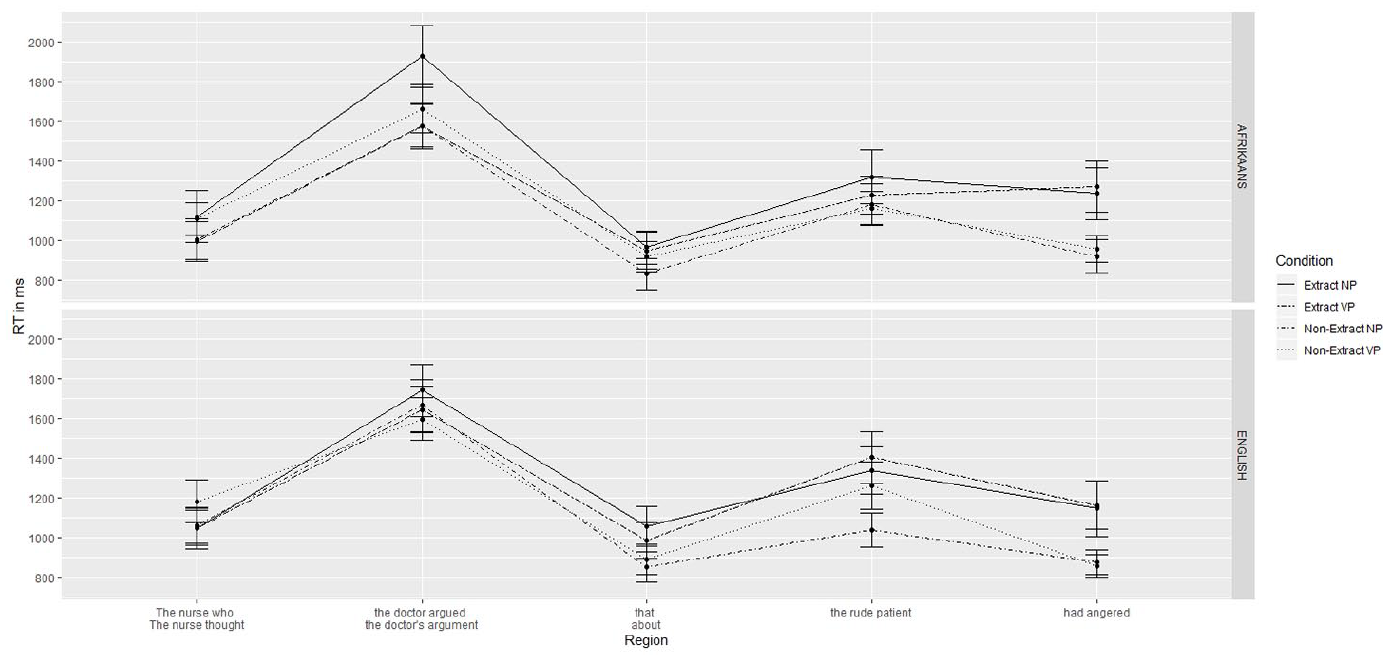
Reading times in ms for regions of interest.
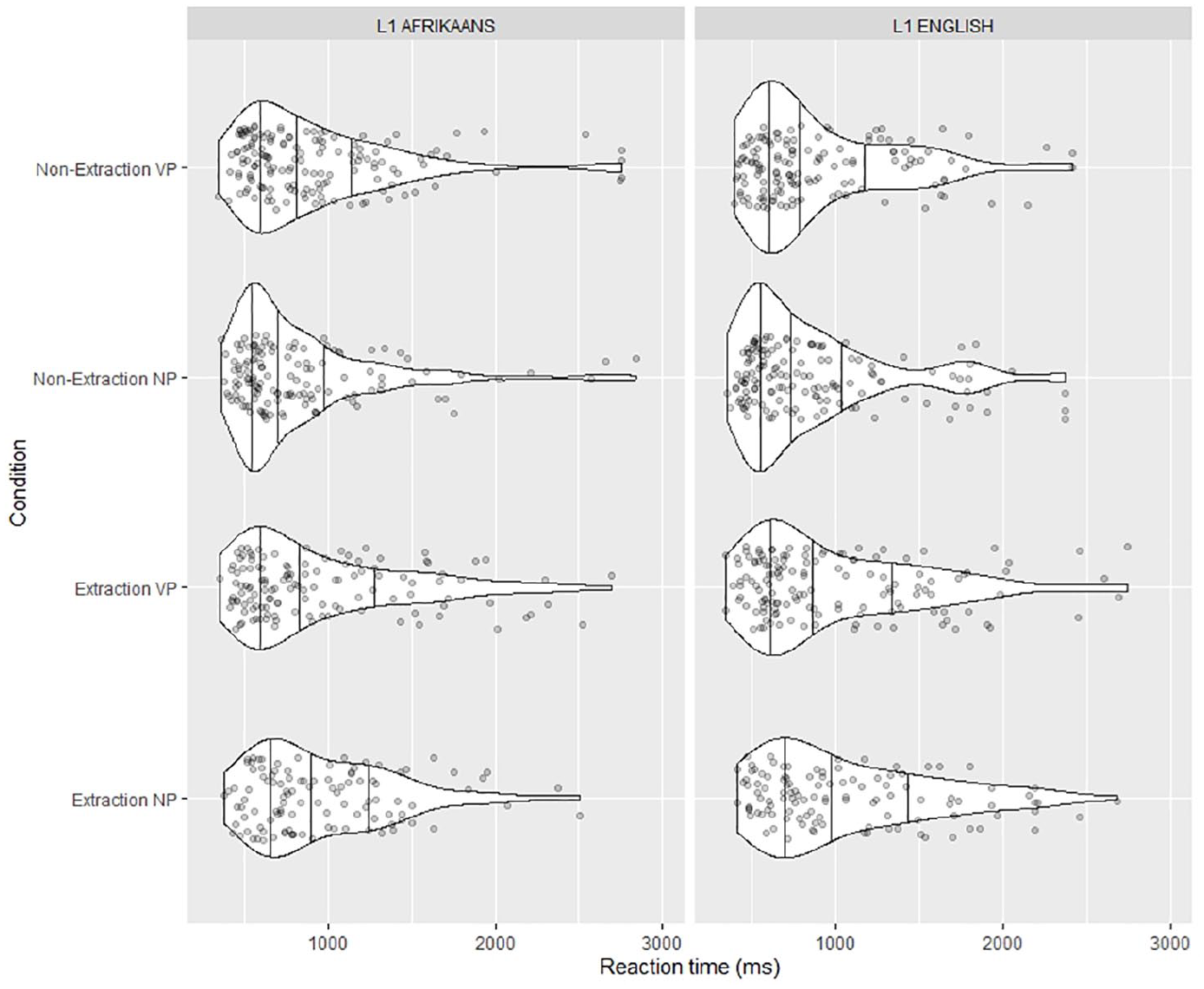
Distribution of reading times in ms per group at segment 3.

Distribution of reading times in ms per group at segment 4.
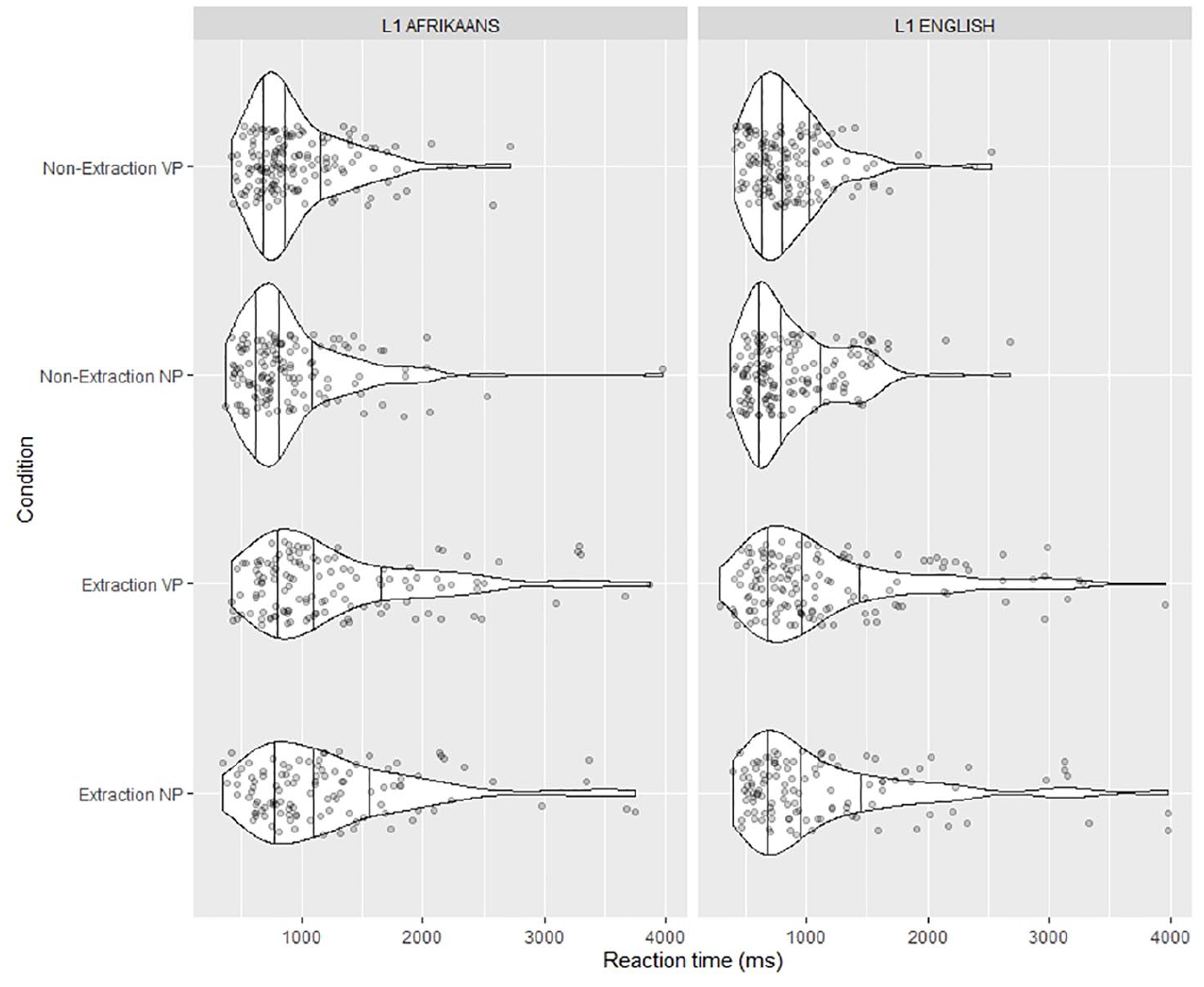
Distribution of reading times in ms per group at segment 5.
Results of Bayesian regression models for the segment 3–5 reading times.
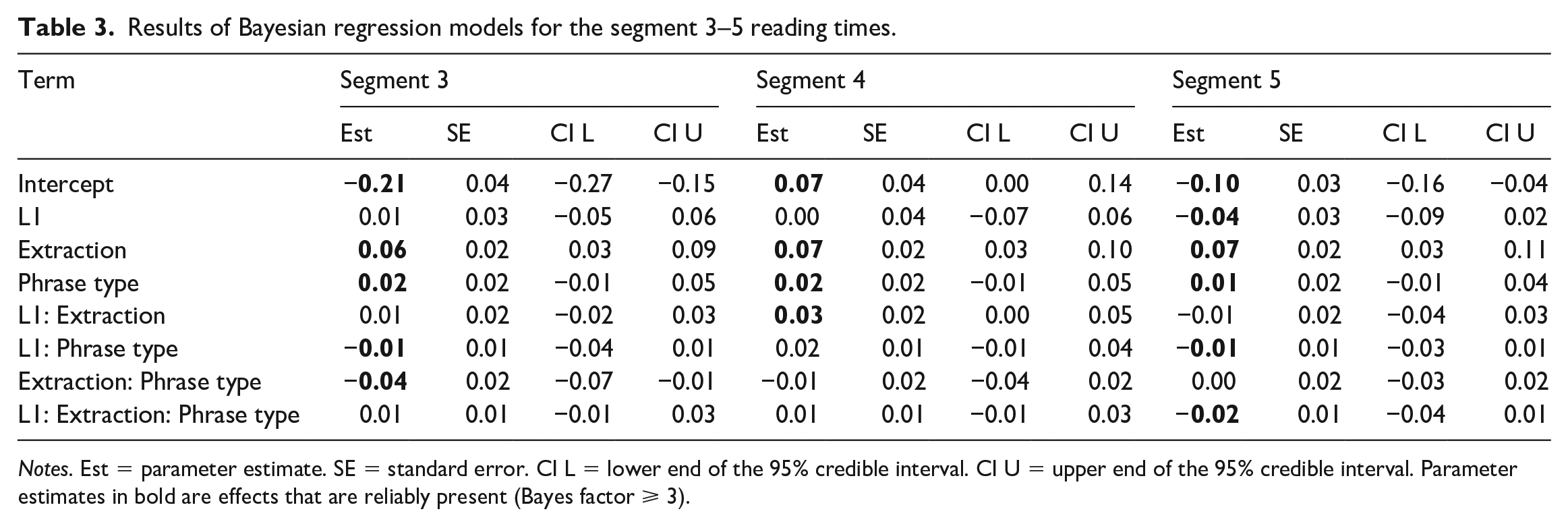
Notes. Est = parameter estimate. SE = standard error. CI L = lower end of the 95% credible interval. CI U = upper end of the 95% credible interval. Parameter estimates in bold are effects that are reliably present (Bayes factor ⩾ 3).
Segment 3: The model revealed four robust effects at segment 3. First, RTs were higher in the Extraction than the Non-Extraction conditions, indicating the cost of holding the moved element in working memory (b = 0.06, 95% credible interval [0.03, 0.09], P(b > 0) = 587.24). Second, RTs were higher in the VP than the NP condition (b = 0.02, 95% credible interval [–0.01, 0.05], P(b > 0) = 6.94) Thirdly, there was an Extraction × Phrase Type interaction (b = −0.04, 95% credible interval [–0.07, –0.01], P(b < 0) = 187.68), where participants were faster in the Extraction VP than in the Extraction NP condition. The latter effect was also found in Pliatsikas and Marinis’ (2013) L2 groups. Further, a reliable interaction between L1 and Phrase Type was also observed, such that the L1 speakers were faster in the VP condition relative to the NP condition compared to the L2 speakers (b = −0.01, 95% credible interval [–0.04, 0.01], P(b < 0) = 5.76). This effect is not related to the processing of intermediate gaps.
Segment 4: At this segment, there was again a robust effect of Extraction (b = 0.07, 95% credible interval [0.03, 0.1], P(b > 0) = 1249), where RTs were higher in the Extraction than the Non-Extraction conditions. Reaction times were again longer in the VP compared to the NP condition (b = 0.02, 95% credible interval [–0.01, 0.05], P(b > 0) = 4.54). There was also a reliable interaction between L1 and Extraction (b = 0.03, 95% credible interval [0, 0.05], P(b > 0) = 31.68), where the L1 speakers were slower in the Extraction conditions than the L2 speakers. No other effects were robust at this segment.
Segment 5: At segment 5, there is substantial evidence that the L1 speakers were faster than the L2 speakers (b = −0.04, 95% credible interval [–0.09, 0.02], P(b < 0) = 6.93). There is also a robust effect of Extraction, where RTs were higher in the Extraction than the Non-Extraction conditions (b = 0.07, 95% credible interval [0.03, 0.11], P(b > 0) = 665.67), and of Phrase Type, where RTs were higher in the VP vs. the NP condition (b = 0.01, 95% credible interval [–0.01, 0.04], P(b > 0) = 3.67). Then, there is substantial evidence that the L1 speakers were faster in the VP condition relative to the NP condition compared to the L2 speakers (b = −0.01, 95% credible interval [–0.03, 0.01], P(b < 0) = 3.48).
At segment 5, shorter RTs in the Extraction VP compared to the Extraction NP condition would indicate that participants had made use of the intermediate gap in processing the experimental items. The model provides only anecdotal evidence of such an effect (b = 0, 95% credible interval [–0.03, 0.02], P(b < 0) = 1.27). There is however substantial evidence that the L1 speakers’ RTs across the two Extraction conditions differed to a larger extent than those of the L2 speakers (L1 × Extraction × Phrase Type: b = −0.02, 95% credible interval [–0.04, 0.01], P(b < 0) = 7.82). As such, we conducted separate analyses for the groups at this segment.
For the L1 English group, RTs in the Extraction conditions were higher than in the Non-Extraction conditions (b = 0.07, 95% credible interval [0.02, 0.13], P(b > 0) = 105.38). Further, there is substantial evidence of an Extraction × Phrase Type interaction, reflecting that RTs were lower in the Extraction VP than the Extraction NP condition (b = −0.02, 95% credible interval [–0.05, 0.02], P(b < 0) = 3.58).
The L1 Afrikaans groups’ RTs were also higher in the Extraction than the Non-Extraction conditions (b = 0.08, 95% credible interval [0.02, 0.14], P(b > 0) = 46.62). Reaction times in this group were slower in the VP than the NP condition (b = 0.02, 95% credible interval [–0.01, 0.06], P(b > 0) = 6.13). Finally, the model results provide borderline substantial evidence of the absence of a facilitatory Extraction × VP interaction (b = 0.01, 95% credible interval [–0.02, 0.05], P(b < 0) = 0.34).
3 Effects of L2 exposure, L2 proficiency and working memory
As a follow-up to the main analysis, we examined whether individual differences in the L2 participants’ L2 exposure, L2 proficiency (as measured by C-test scores) and working memory (measured among a subset of the L2 participants by means of a reading span task) affected their processing patterns. To this end, we conducted three separate analyses at each of the three segments of interest. The model configurations were the same as in the main analyses, with the addition of the continuous predictor (either L2 Exposure, L2 Proficiency or Working Memory), centered around the mean. Below, only the effects that differed from those of the main analyses are reported; the full model outputs can be found in Appendix 1.
a L2 exposure
At segment 4, there was robust evidence that participants with greater L2 exposure were slower overall (L2 Exposure: b = 0.04, 95% credible interval [–0.04, 0.12], P(b > 0) = 5.05), but faster in the Extraction vs. the Non-Extraction conditions compared to participants with lower L2 exposure (Extraction × L2 Exposure: b = −0.04, 95% credible interval [–0.1, 0.01], P(b < 0) = 10). An Extraction × Phrase Type interaction reflects that participants were faster in the Extraction VP than the Extraction NP condition (b = −0.02, 95% credible interval [–0.05, 0.01], P(b < 0) = 6.7), while an Extraction × Phrase Type × L2 Exposure interaction indicates that participants with greater L2 exposure were slower in the Extraction VP compared to the Extraction NP conditions (b = 0.02, 95% credible interval [–0.01, 0.06], P(b > 0) = 8.23). At segment 5, an Extraction × Phrase Type interaction reflects that participants were slower in the Extraction VP than the Extraction NP condition (b = 0.02, 95% credible interval [–0.01, 0.05], P(b > 0) = 4.03), while an Extraction × Phrase Type × L2 Exposure interaction indicates that this slowdown was more pronounced in participants with greater L2 exposure (b = 0.03, 95% credible interval [0, 0.06], P(b > 0) = 15).
b L2 proficiency
Robust effects of L2 proficiency were only found at segment 3. Here, a main effect of L2 Proficiency indicated that participants with higher L2 proficiency were faster overall (b = −0.04, 95% credible interval [–0.11, 0.04], P(b < 0) = 3.69). There was also a reliable interaction between Extraction, Phrase Type and L2 Proficiency (b = −0.02, 95% credible interval [–0.05, 0.01], P(b < 0) = 6.17). This effect reflected that participants with higher proficiency were faster in the Extraction VP condition vs. the Extraction NP condition. At segment 5, there is again substantial evidence that participants were slower in the Extraction VP than the Extraction NP condition (Extraction × Phrase Type: b = 0.01, 95% credible interval [–0.02, 0.05], P(b > 0) = 3.3).
c Working memory
Possible effects of working memory were investigated among a subset of the L2 participants (n = 19). These participants completed a computerized reading span task (Stone and Towse, 2015; von Bastian et al., 2013) in which they were presented with a set of sentences. They had to judge each sentence as either ‘makes sense’ or ‘does not make sense’. Each sentence was followed by a number, and at the end of each set of sentences, participants had to provide the numbers they had seen in that set in order of appearance. The sets ranged in size from two to five sentences. Scores were calculated as the proportion of numbers correctly recalled. The participants’ mean score was 0.51 (SD = 0.15, range = 0.26–0.83).
At segment 3, the effect of working memory was robust, such that participants with higher working memory scores had lower RTs (b = −0.06, 95% credible interval [–0.17, 0.04], P(b < 0) = 5.64). There was also an Extraction × Working Memory interaction (b = −0.02, 95% credible interval [–0.04, 0.01], P(b < 0) = 5.23), where participants with higher working memory scores again had lower RTs in the Extraction vs. the Non-Extraction conditions. At segments 4 and 5, the reverse effect was found, such that participants with higher working memory scores had higher RTs in the Extraction vs. the Non-Extraction conditions (segment 4: b = 0.01, 95% credible interval [–0.02, 0.04], P(b > 0) = 3.35; segment 5: b = 0.04, 95% credible interval [0.01, 0.07], P(b > 0) = 35.63). At segment 5, there was an Extraction × Phrase Type × Working Memory interaction (b = 0.02, 95% credible interval [–0.01, 0.05], P(b > 0) = 6.05), where participants with higher working memory scores were slower in the Extraction VP condition relative to the Extraction NP condition. Lastly, at this segment, the evidence is inconclusive regarding the existence of an Extraction × Phrase Type interaction in either direction (Extraction × Phrase Type: b = 0.01, 95% credible interval [–0.04, 0.06], P(b > 0) = 1.7).
VI Discussion and conclusions
This study’s aim was to investigate whether previously observed L1–L2 differences in the processing of long-distance wh-dependencies are found with L2 speakers who have received extensive naturalistic L2 exposure in a non-immersion environment.
The results showed that the L1 group performed reintegration of the moved element more quickly when an intermediate gap was present, in line with the findings of previous studies with L1 speakers (Gibson and Warren, 2004; Marinis et al., 2005; Pliatsikas and Marinis, 2013). However, this facilitatory effect was not present in the L2 group, whose processing patterns more closely resembled those of the classroom English learners in Marinis et al. (2005) and Pliatsikas and Marinis (2013).
Although the background variable analyses did not reveal L1-like filler reintegration behavior among our L2 participants, they did show some effects of individual differences on the processing patterns. In this regard, the effect of L2 proficiency was limited, in accordance with previous findings (e.g. Pliatsikas and Marinis, 2013). 5 However, the L2 exposure and working memory effects were more extensive. The Working Memory × Extraction interaction at segments 4 and 5 indicated that participants with higher working memory scores were slower in the Extraction conditions. These effects may reflect that participants with greater working memory capacity actively attempted to maintain the filler in working memory and perform reintegration at the subcategorizing verb, rather than waiting until the end of the sentence was encountered to derive a global interpretation of its meaning (see e.g. Roberts et al., 2007 for discussion of similar findings in an antecedent priming task). Working memory, however, cannot clearly be related to use of the intermediate gap, since at segment 5 increased working memory is associated with elevated RTs in the Extraction VP vs. the Extraction NP condition.
Similarly, greater L2 exposure was associated with higher RTs in the Extraction VP relative to the Extraction NP condition at the fourth and fifth segments Speculatively, especially given the presence of the reverse pattern for the L2 group as a whole at segment 3, it might be that the increased RTs at segment 4 for individuals with greater L2 exposure reflect delayed processing of the intermediate gap. If lower L2 exposure is associated with reduced L2 processing automaticity (see e.g. Ullman, 2001), increases in exposure may increase sensitivity to the presence of the intermediate gap as a site for filler reactivation and facilitate its use as such.
If processing of the intermediate gap occurred only at segment 4 for those participants with greater L2 exposure, the elevated RTs in the Extraction VP relative to the Extraction NP condition for these participants at segment 5 might reflect a spillover effect. Thus, while the exposure effects may seem to run counter to accounts in which increased exposure leads to greater processing automaticity, it may rather be the case that while this factor contributed to increased sensitivity to the intermediate gap, it was not sufficient to enable faster filler reintegration in the Extraction VP condition. Again speculatively, sensitivity to abstract syntactic information may be separable from the lexical access and retrieval processes involved in identifying the subcategorizing element and resolving the dependency. In light of previous findings, the absence of a nativelike processing pattern at segment 5 might plausibly be related to the L2 participants’ continued exposure to their native language. Processing ease in the L2, particularly in terms of lexical access, has been found to correlate inversely with L1 exposure (Whitford and Titone, 2012, 2015; see also Gollan et al., 2008), and even those of our L2 participants with relatively high L2 exposure still received considerable exposure to their L1.
Reduced sensitivity to abstract syntactic cues – such as the clause boundary as a marker of a site for filler reactivation – has been suggested to be a general characteristic of L2 processing, which is said to rely to a greater extent on ‘semantic, pragmatic, probabilistic and surface-level information’ (Clahsen and Felser, 2018: 2). The present findings provide some indication that this sensitivity might be increased given greater L2 exposure. They also, however, qualify the suggestion that reduced sensitivity to syntactic cues is characteristic of ‘only . . . L2 learners with limited or no naturalistic exposure’ (Pliatsikas and Marinis, 2013: 180). We find instead that even given the relatively extensive naturalistic exposure received by the least exposed of our L2 participants, sensitivity to the intermediate gap is not a given.
The present findings call for a more careful consideration of the nature of naturalistic L2 exposure across different linguistic settings. A comparison across L2 groups with varying levels of L2 exposure would be one way to gain further insight into the workings of the naturalistic exposure effect on L2 processing.
Footnotes
Appendix 1
Acknowledgements
The author would like to acknowledge the work of Theodore Marinis, Leah Roberts, Claudia Felser and Harald Clahsen in developing the stimuli used in this study and thank them for making the stimuli publically available. The author would also like to thank the anonymous Second Language Research reviewers for their feedback on an earlier version of this manuscript.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/ or publication of this article: The research for this article was funded by the National Research Foundation and the Deutscher Akademischer Austauschdienst.