
Abstract
The present study investigates third language (L3) learners’ processing of Chinese subject and object relative clauses in a supportive context. Using a self-paced reading task, we tested native Italian L3 learners of Mandarin Chinese and native Chinese speakers. The results showed that the L3 learners read significantly more slowly than the native speakers in all the target regions. Also, in the head noun region, they read object relative clauses significantly more slowly compared to subject relative clauses, indicating a preference for the latter. By contrast, for the native speakers, no significant differences were observed between subject and object relative clauses in any of the target regions. The L3 learners’ performance offers support for the Structural Distance Hypothesis over the Dependency Locality Theory, and the contrast between the two populations indicates that context is at play in the processing of relative clauses.
Keywords
I Introduction
Relative clauses (RCs) have been extensively studied in psycholinguistics literature. Specifically, the comparison between subject RCs and object RCs with animate noun phrases (NPs), as exemplified in (1), has often been investigated in order to establish the relationship between the sentence processing mechanism and computational resources (Gibson, 1998).
(1) a. The reporteri [that _i attacked the senator] ignored the president. (Subject RCs) b. The reporteri [that the senator attacked _i] ignored the president. (Object RCs)
In the first language (L1) processing, object RCs with animate NPs have been reported to be harder to process than subject RCs across many languages with head-initial RCs (e.g. for English, see Gibson et al., 2005; Traxler et al., 2002; for Italian, see Carminati et al., 2006; Guasti et al., 2018). By contrast, controversial results have been observed in typologically different languages with head-final RCs, such as Mandarin Chinese (hereinafter Chinese), with some studies confirming a subject RC preference (e.g. Jäger et al., 2015; Li et al., 2010; Lin and Bever, 2006; Vasishth et al., 2013), and other studies reporting an object RC preference (e.g. Chen et al., 2008; Gibson and Wu, 2013; Hsiao and Gibson, 2003; Xu et al., 2020). Mixed results have been produced by second language (L2) learners of Chinese, but in this case participants recruited in the same study were from different L1 backgrounds, including head-initial languages (e.g. English, French and Spanish) and head-final languages (e.g. Japanese and Korean) (e.g. Cui, 2013; Li et al., 2016; Packard, 2008). This variation may be responsible for the mixed results through transfer. It is well established that the investigation of third and additional language (L3/Ln) acquisition offers great insights about the language learning process that neither L1 nor L2 acquisition can offer, such as unconfounding certain factors left confounded in L1/L2 acquisition (Flynn et al., 2004). Moreover, to the best of our knowledge, studies on L3 adults’ acquisition of RCs are relatively rare, and have not made any claim about the subject/object RC asymmetry (Hermas, 2014, 2015; Hui, 2010). Therefore, in the current study, we aim to investigate the processing of subject and object RCs by testing L3 learners with the same L1 (i.e. Italian, a language with head-initial RCs) and L2 (i.e. English, which is also a language with head-initial RCs). In addition, in our experiment, the target stimuli were always preceded by a supportive context in order to exclude the potential confound of temporary ambiguity due to a null context; in fact, without a context, the initial fragment of Chinese object RCs is generally misanalysed as the main clause, i.e. subject–verb–object (SVO) word order similar to the word order of a canonical declarative clause (Gibson and Wu, 2013).
This article is organized as follows. We first discuss some theoretical approaches to RC processing and previous studies about the processing of Chinese RCs. Then we report our experiment and offer a critical discussion of the results.
1 Theoretical approaches to relative clause processing and L1 processing of Chinese relative clauses
The subject/object asymmetry in the processing of RCs has been discussed by two main approaches: experience-based theories and memory-based theories, each of which has several variants. According to the experience-based theories, processing difficulties are related to comprehenders’ experience (familiarity) with structures. Under this framework, head-initial subject RCs with animate NPs are easier to process than object RCs of the same type because the former is more common in the input than the latter. Several subclasses of accounts have been proposed, such as the word-order frequency theory (Bever, 1970; MacDonald and Christiansen, 2002), surprisal/expectation (Hale, 2001; Levy, 2008), and entropy reduction accounts (Hale, 2003, 2006). In contrast to these theories, the memory-based theories hold that the human parsing system consumes working memory resources in the process of keeping track of syntactic heads over a distance between the head and its dependent. Under this view, head-initial subject RCs with animate NPs are easier to process than object RCs because they require less working memory resources. Several models have been proposed, such as the Dependency Locality Theory (DLT; Gibson, 1998, 2000), the Structural Distance Hypothesis (SDH; Hawkins, 2004; O’Grady, 1997; O’Grady et al., 2003), and the activation-based model (Lewis and Vasishth, 2005; Vasishth and Lewis, 2006). The experience-based theories and the memory-based theories are not mutually exclusive, and both are supported by prior work across many languages (for a detailed discussion see Gibson and Wu, 2013).
However, previous work on Chinese RCs have produced mixed results, with some studies lending support to the memory-based theories (e.g. Gibson and Wu, 2013; Hsiao and Gibson, 2003) and other studies lending support to the experience-based theories (e.g. Jäger et al. 2015; Wu et al., 2018). Those conflicting results have been associated with multiple factors, such as word order, discourse context, early cues (e.g. the presence of classifiers and passive marker bèi), animacy, and individuals’ working memory skills (see, amongst many others, Bulut et al., 2018; Gibson and Wu, 2013; Hsiao and Gibson, 2003; Mansbridge et al., 2017; Vasishth et al., 2013; Wu et al., 2012, 2018). In the present study, we explore two factors in particular: word order and context.
Chinese RCs are head-final in contrast to English/Italian head-initial RCs. As exemplified in (2), taken from Hsiao and Gibson (2003), the RC precedes the relativizer de and the head noun (hereinafter HN). Subject RCs (2a) have the verb–object–subject (VOS) word order, with the HN located in the final position, while object RCs (2b) have the SVO word order, which is canonical in Chinese. This feature potentially makes the object RC temporarily ambiguous during processing, as the subject–verb (SV) order can be misanalysed as part of main clauses (Lin and Bever, 2011).
(2) a. [ _i yāoqǐng fùháo de] guānyuáni (Subject RCs) invite ycoon REL official ‘the official that invited the tycoon’
b. [fùháo yāoqǐng _i de] guānyuáni (Object RCs) tycoon invite REL official ‘the official that the tycoon invited’
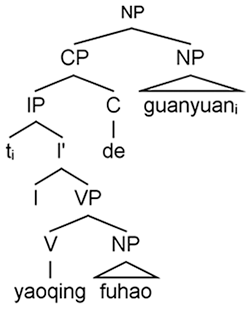
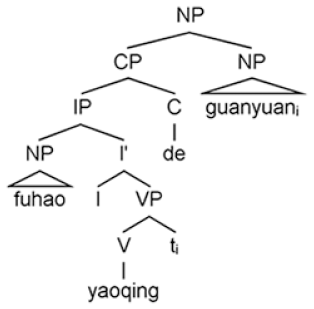
Cross-linguistically, head-final RCs are extremely rare in verb–object (VO) languages, with relevant exceptions such as Chinese, Wu and Cantonese (Dryer, 2013; Hu et al., 2018). The typological uniqueness of Chinese RCs gives us an opportunity to tease apart the predictions of different theories. In the present article, we focus on two influential versions of the memory-based theories, namely, the DLT and the SDH, because both theories deal with filler–gap dependencies, but provide different predictions with respect to the processing of head-initial and head-final RCs. The DLT focuses on the linear distance between the filler and the gap (e.g. counting new referents intervening between them), while the SDH focuses on the hierarchical (structural) distance (e.g. counting the number of intervening structural nodes inside the filler–gap dependency). 1 The two theories predict a subject RC preference in the processing of head-initial RCs (e.g. English and Italian RCs), because of more referents and more structural nodes between the filler–gap dependencies in object RCs than in subject RCs. However, the predictions of the two theories diverge when it comes to Chinese RC processing: The DLT predicts that readers should have more difficulty when processing Chinese subject RCs, as the linear distance between the gap and the filler is greater in subject RCs (because of a new intervening referent) (2a) than in object RCs (2b). In contrast, the SDH predicts that readers should have more difficulty when processing Chinese object RCs, as the hierarchical (structural) distance between the gap and the filler is greater in object RCs (because of intervening structural nodes) (2b) than in subject RCs (2a).
Another important factor related to RC processing is the presence of appropriate discourse contexts preceding the RCs. Lin (2014, 2015) observed that the comprehension of Chinese RCs is sensitive to the thematic order consistency between RCs and the preceding discourse context. For instance, Lin (2014) manipulated the orders of thematic roles in the preceding discourse context and found that a passive sentence with the PATIENT-action-AGENT order in the preceding context did not facilitate the comprehension of a subject RC with the action-PATIENT-AGENT order nor that of an object RC with the AGENT-action-PATIENT order. However, a canonical SVO sentence in the preceding context facilitated the comprehension of an object RC, since it has full thematic order overlap with the SVO sentence. The role of the preceding context has also been discussed in a cross-linguistic perspective (e.g. Mak et al., 2008; Roland et al., 2012) and the results show that the difficulty in processing object RCs with full NPs was reduced when the embedded NP referred to a discourse topic.
To summarize, in head-initial RCs, such as those in English and Italian, a clear contrast with a subject preference is uniformly reported and both the DLT and the SDH can explain this. Conversely, this contrast is not as clear-cut in the L1 processing of Chinese RCs, which, in spite of being an SVO language, has head-final RCs. Here, interestingly, the two theories mentioned above diverge in predicting either an object or a subject preference for Chinese RCs, with multiple factors such as word order and context, possibly playing a role.
2 L2 and L3 processing of Chinese relative clauses
Regarding the processing of Chinese RCs by L2 learners, controversial results have been reported (e.g. Cui, 2013; Li et al., 2016; Packard, 2008; Sung et al., 2016; Xu, 2014a, 2014b; Yao, 2019), while extremely few studies examining the L3 acquisition of Chinese RCs have found a subject RC preference (Chan et al., 2017). Also, there are several studies exploring L2/L3 acquisition of Chinese RCs that did not explore subject/object asymmetry (Hsieh, 2015; Hu and Liu, 2007; Hui, 2010). In this section, we conduct a brief review.
Several studies have reported an object RC preference. Packard (2008) examined subject and object RCs with a self-paced reading task. Participants were undergraduate students in the third- and fourth-year of Chinese classes, who learned Chinese as their L2 and had different L1 backgrounds, including 13 speakers of English, 4 of Japanese, 1 of Korean, 1 of German and 1 of Indonesian; no native Chinese controls were tested. The results showed that the L2 learners read subject RCs more slowly than object RCs, but note that the RCs in the study involved both animate NPs (e.g. zuòjiā ‘writer’) and inanimate NPs (e.g. píjiŭ ‘beer’) in a way that was not controlled, and this might have been a confounding factor. Sung et al. (2016) tested subject and object RCs, employing an eye-movement technique. They tested native speakers (hereinafter NSs) of Chinese and Japanese L2 learners, who had learned Chinese for a mean of 2.1 years. The results showed that both the L1 and the L2 participants spent less time on the HN regions in object RCs than in subject RCs, and the L2 participants spent less time on the embedded verb regions in object RCs than in subject RCs, and their regression rate for embedded verbs was generally lower in object RCs than in subject RCs. The findings indicate that the two groups experienced more processing difficulty in subject RCs than object RCs. Thus, the authors concluded that object RCs were preferred in both L1 and L2 processing.
Nevertheless, a subject RC preference has been reported by other studies. Cui (2013), using a self-paced reading task modified from Packard (2008), tested Chinese NSs and L2 learners, who had studied Chinese for an average of 3 years. The L2 learners were further divided into two groups based on their native languages: the group of head-initial languages (e.g. English, French and Spanish) and the group of head-final languages (e.g. Japanese and Korean). The data showed that for the Chinese NSs, object RCs were read more quickly than subject RCs only in subject-modifying RCs; for the L2 learners whose L1 was head-final, no preference was found; for the L2 learners whose L1 was head-initial, a subject RC preference was found in subject-modifying RCs as well as in object-modifying RCs. The study showed that the processing pattern of L2 learners differed from that of NSs, and the L1 background played a role in the processing of RCs. The author attributed the difference to the L1 transfer. However, we have to point out that Cui tested RCs with a complex HN, whose HN included a demonstrative, a classifier, an adjective, and a noun, such as nà-gè shànliáng de nánhái ‘that-Cl kind boy’. Indeed, the position of the demonstrative and classifier was a significant factor affecting L2 learners’ processing (Xu, 2014b). In Chinese, RCs modified by a demonstrative and a classifier (DCl) can have a DCl-first sequence (3a–b) or a DCl-second sequence (3c–d). A distinction between these two patterns can be made in terms of modification scope: RC modifies the noun in the former case, while RC modifies the DCl and noun in the latter case. In addition, the demonstrative in the two patterns functions differently: it is a deictic expression in (3a–b), referring to a designated definite entity (‘this one’), while, in (3c–d), it is an ‘anaphoric’ expression (see Huang et al., 2009 for more discussion).
(3) a. Subject RCs with a DCl-first sequence [Zhè gè [_ i xǐhuān Xiǎo Lín de] réni] hěn shuài. this Cl like Xiao Lin REL person very handsome ‘The person that likes Xiao Lin is very handsome.’ b. Object RCs with a DCl-first sequence [Zhè gè [[Xiǎo Lín xǐhuān __i de] réni]] hěn shuài. this Cl Xiao Lin like REL person very handsome ‘The person that Xiao Lin likes is very handsome.’ c. Subject RCs with a DCl-second sequence [[__i Xǐhuān Xiǎo Lín de] [zhè gè rén]i] hěn shuài. like Xiao Lin REL this Cl person very handsome ‘The person that likes Xiao Lin is very handsome.’ d. Object RCs with a DCl-second sequence [[Xiǎo Lín xǐhuān __i de] [zhè gè rén]i ] hěn shuài. Xiao Lin like REL this Cl person very handsome ‘The person that Xiao Lin likes is very handsome.’
Xu (2014b) tested L2 learners with an English L1 background by completing a self-paced word-order judgment task, and found that RCs with a DCl-first sequence were read more quickly than those with a DCl-second sequence. In addition, the subject/object RC asymmetry was obvious only in the DCl-first sequence, but not in the DCl-second sequence.
Li et al. (2016) examined Chinese RCs with a discourse context, using a self-paced reading task. They tested L2 learners with different L1 backgrounds, including 18 speakers of Russian, 8 of Japanese, 6 of Korean, 5 of Thai, 2 of Vietnamese, 1 of Italian, and 1 of Mongolian. The data showed faster and more accurate processing of subject RCs in both subject- and object-modifying conditions. This subject RC preference may have been driven by the L1. Following Cui (2013), we can divide the participants into two groups: the group of head-initial L1s (i.e. Russian, Thai, Vietnamese and Italian) and the group of head-final L1s (i.e. Korean, Japanese and Mongolian). It is possible that the two groups had different preferences that cancelled each other out, such as a subject RC preference in the head-initial group, but an object RC preference or no preference in the head-final group. All in all, since the L1 background was not considered in the analysis, we cannot be sure of the role played by the context.
A few L3 studies have investigated RC acquisition (Chan et al., 2017; Flynn et al., 2004; Hermas, 2014, 2015; Hui, 2010), but most of them did not examine subject/object asymmetry. Flynn et al. (2004) tested L1 Kazakh-L2 Russian-L3 English adults’ production of English RCs, and found that the L1 did not play a privileged role in the acquisition of L3 English by learners at the pre-intermediate stage. On the other hand, Hermas (2015) tested L1 Arabic-L2 French-L3 English adults’ grammaticality judgment of English RCs, and reported simultaneous L1 non-facilitative and L2 facilitative transfer effects at the pre-intermediate L3 acquisition stage. The different results might have been due to the different tasks employed or different properties of the languages tested. Note that in Flynn et al., L1 Kazakh is an object–verb (OV) language with head-final RCs, while L2 Russian and L3 English are both VO languages with head-initial RCs; in Hermas, all three languages are VO languages with head-initial RCs (Dryer, 2013). A facilitative transfer from L1 to L3 was reported in trilingual children’s comprehension of RCs. Chan et al. (2017) tested L1 Cantonese-L2 English-L3 Chinese 5- to 6-year-old trilingual children, and observed that L1 Cantonese alone predicted their performance in L3 Chinese. For all three languages, the trilingual children comprehended subject RCs better than object RCs. Note that L1 Cantonese and L3 Chinese are VO languages with head-final RCs, while L2 English is a VO language with head-initial RCs.
To sum up, similar to the L1 literature, the literature on L2/L3 processing of Chinese RCs presents inconsistent and mixed results, largely due to the fact that some variables were not properly controlled for in the experimental design, such as head-NP animacy, or the presence and positions of demonstratives and classifiers. The roles of the L1 and the context have been discussed in the literature, but sometimes the two factors were confounded, leaving open the debate pertaining to subject/object asymmetry in the L2/L3 processing of Chinese RCs. In the present study, we controlled for L1, and used a relatively understudied language triplet (i.e. L1 Italian-L2 English-L3 Chinese) and supportive contexts in order to address the questions of whether speakers of Italian process Chinese RCs in a similar way to NSs, and whether context plays a similar role in the RC processing of both populations.
II The present study
1 Research questions and predictions
The present study investigates the processing of Chinese RCs preceded by a supportive context by testing Italian L3 learners and NSs of Chinese. The main goals of the study are to establish whether L3 learners display a subject/object asymmetry in the processing of Chinese RCs and to examine the role of context in the comprehension of Chinese RCs by comparing the performance of L3 learners and NSs.
Our first prediction is that since our L3 learners had the same L1 and L2 (i.e. Italian and English, which have canonical SVO word order and head-initial RCs), we would expect a subject RC preference as predicted by the SDH, according to which the hierarchical (structural) distance between the gap and the filler in object RCs is greater than that in subject RCs.
Our second prediction is that, if context is relevant for the processing of RCs, differences between NSs and L3 learners will be observed. In particular, we expect that no asymmetry will emerge from the NSs’ performance, as they may integrate the contribution from context rapidly, whereas an asymmetry will show for L3 learners, who have an intermediate proficiency level and may not be able to integrate the information as rapidly.
2 Participants
Twenty native Italian L3 learners of Chinese and 20 NSs of Chinese participated in the study. All the participants had normal or corrected to normal vision and were naive to the purpose of the study.
The L3 learners (age 21;1-25;1, M = 22;7, SD = 1.30, 12 females) were recruited at University of Milano-Bicocca, Italy. They were all born and raised in Italy. They had studied Chinese as an L3 for about 2 years and 9 months (SD = 0.65), and came from classes of the same proficiency level. According to the learning materials associated with the standard of the Common European Framework of Reference for Languages (CEFR), their level of proficiency in the L3 Chinese corresponded to the B1-B2 level. They had also studied English as an L2 for about 14 years and 2 months (SD = 1.18), and all of them had taken an English exam, corresponding to the B1 level of the CEFR, during their second year of university. Three participants from the original group of 23 learners were removed, as they had visited China and stayed there for more than 3 months.
The NSs of Chinese (age 19;0-25;0, M = 20;7, SD = 2.23, 10 females) were recruited at Zhejiang International Studies University and Xiamen University, China. They were all born and raised in China and pursued majors in fields unrelated to the language sciences.
3 Materials and design
Sixteen pairs of sentences were constructed, each featuring a subject and an object RC, as in (4). The RC involved the same words in each of the conditions, with the verb (V) preceding the noun (N) in the subject RCs and the N preceding the V in the object RCs. Also, the HN modified by the RC (i.e. the subject in subject RCs and the object in object RCs) was identical in both conditions. The target regions consisted of an N and a V, a relativizer de, an HN, and the next two words after the HN (HN+1 and HN+2), as indicated in (4). All NPs in the target stimuli were human. They were typed in simplified Chinese characters, which were known by the L3 learners.
(4) a. Zànměi dǎoyǎn de yǎnyuán qùguò yìdàlì. (Subject RCs) V N de HN HN+1 HN+2 praise director REL actor go-ASP Italy ‘The actor that praised the director has been to Italy.’ b. Dǎoyǎn zànměi de yǎnyuán qùguò yìdàlì. (Object RCs) N V de HN HN+1 HN+2 director praise REL actor go-ASP Italy ‘The actor that the director praised has been to Italy.’
Each target RC was preceded by a four-sentence context, as exemplified in (5). The former two context-sentences described the event; the latter two context-sentences, i.e. a statement and a question, were prefaced by Xiaoming, i.e. Xiǎomíng shuō ‘Xiaoming said’ which indicates that Xiaoming was the speaker of these utterances. The question asked by Xiaoming was always a wh-question. Chinese wh-questions are formed by leaving interrogative constituents in situ. As shown in (5), the wh-phrase nǎ yī gè ‘which one’ is kept in the base position, which can be answered by supplying the information in the same position. The contexts set up a scenario in which both a subject and an object RC can be appropriate. Following the prompt question, one pair of the target sentences exemplified in (4) was provided by the interlocutor, Xiaomei, as a response, i.e. Xiǎoměi shuō ‘Xiaomei said’. Finally, a comprehension sentence related to the context or the target RCs was presented with the aim of encouraging the participants to focus equally on all parts of each sentence. Half of the comprehension sentences were correct, and the other half were incorrect.
(5) a. Supportive context: Zài yī chǎng bānjiǎng diǎnlǐ shàng, yǒu yī gè yǎnyuán zànměi le dǎoyǎn. Hòulái, zhè gè dǎoyǎn zànměi le lìngwài yī gè yǎnyuán. ‘At an awards ceremony, an actor praised the director. Later, the director praised another actor.’ Xiǎomíng shuō: Wǒ tīngshuō qízhōng yī gè yǎnyuán qùguò yìdàlì, lìngwài yī gè méi qùguò. Nǎ yī gè yǎnyuán qùguò yìdàlì? ‘Xiao Ming said: I heard that one of the actors has been to Italy and the other has not. Which actor has been to Italy?’ b. Target sentence: Xiǎoměi shuō: {Zànměi dǎoyǎn/ Dǎoyǎn zànměi} de yǎnyuán qùguò yìdàlì. Xiaomei said: The actor that {praised the director/ the director praised} has been to Italy. c. Comprehension sentence: Zhè jiàn shìqíng shì fāshēng zài xīnpiàn xuānchuánhuì shàng. ‘This incident took place during a promotional event for the new movie.’
The materials were modelled after Gibson and Wu (2013), which were originally translated from Gibson et al. (2007). Note that the materials in Gibson and Wu (2013) also included RCs with inanimate nouns. For instance, in subject RC zhuī zhòngxíngjīchē de chē ‘the car that chased the motorcycle’, the HN chē ‘car’ and the embedded noun zhòngxíngjīchē ‘motorcycle’ are inanimate. Since the asymmetry is modulated by the animacy of the head and the embedded noun (for Chinese, see Wu et al., 2012; for other languages, see Mak et al., 2002, 2006), we eliminated the items in Gibson and Wu (2013), which involved inanimate nouns.
The experiment included 2 lists, each consisting of 8 items with subject RCs and 8 items with object RCs; and additionally, 32 filler items with various syntactic structures were included. In total, each list included 48 items. Each participant saw one list, hence they only read one subject RC or one object RC in each pair of target sentences. The stimuli were pseudo-randomized, so that one target sentence never immediately followed another.
The task was a self-paced reading task using E-Prime 2.0 software, recording accuracy and response latency (Schneider et al., 2012). Context and comprehension sentences were presented sentence-by-sentence, and target sentences were presented word-by-word. At the beginning of each target sentence, the participant saw a series of dashes marking the position and the upcoming segments. As the mouse button was pressed, a new segment was unmasked while previous and following segments were kept masked. The amount of time spent on each word or each sentence was recorded.
4 Procedure
Before the experiment, a list of words was given to the learners’ teacher to ensure that the unknown words were taught during the semester. Both the teacher and the students were naive to the purpose of the experiment.
During the experimental phase, we asked participants to read a series of sentences. They were instructed to read the sentences by pressing the mouse button to view each successive segment, and to answer the questions as quickly and as accurately as possible. Before the experiment started, three practice trials were presented in order to familiarize the participants with the task. As previously mentioned, in each trial, participants read the materials at their own pace, and then judged a comprehension sentence by clicking the left mouse bar for ‘‘correct’’ and the right mouse bar for ‘‘incorrect.’’ No feedback was provided.
Participants took approximately 50 minutes to complete the experiment. Each experiment was divided into three sessions, in which participants were able to take a short break if they needed.
5 Statistical analysis
The different statistical analyses (e.g. an F-test on raw reading times and a linear mixed-effects model on log-transformed data) give different results. 2 As pointed out by Barr et al. (2013), the linear mixed-effects model is a more conservative statistical analysis. Following Vasishth et al. (2013), we performed statistical analyses of response accuracy and reading time with a linear mixed-effects model, using the lme4 and lmerTest packages in the R environment (Baayen et al., 2008; R Core Team, 2018).
The critical manipulation involved the RC modifier position, and we concentrated our analyses on the processing of the RC itself. We removed the data from one L3 learner from the analysis because of a script error. Thus, in total, 19 L3 learners and 20 native Chinese speakers were included in the analysis. Regarding the reading time, all the target items read by the participants were analysed regardless of whether the comprehension sentences were responded to correctly or not, following Gibson and Wu (2013). The first two words of each RC (V/N and N/V), the relativizer de, the HN and the next two words after the HN (HN+1 and HN+2), illustrated in (4), are the target regions that we analysed. Reading times shorter than 50 ms were excluded for the analysis, because these were likely response key errors (a total of 1 case). Then, for each target region, means were calculated per condition for each subject. Following Roland et al. (2012), any reading time beyond ±2.5 standard deviations from the mean was replaced with the appropriate boundary value (a total of 0.05% of the data). Finally, reading time was logarithmically transformed. In the analyses, Group (L3 vs. NSs) and Sentence Type (subject RCs vs. object RCs) were introduced as potentially significant fixed factors, and subjects and items as random factors. We used the NSs as the reference category for the Group factor, and the object RCs for the Sentence Type factor. Effects were evaluated one by one on the basis of likelihood ratio tests; both first-level effects and the interactions between the fixed factors were tested.
We also analysed the accuracy and reaction times of the comprehension sentences that immediately followed the target RCs.
III Results
1 Reading times in RCs
Figure 1 presents the mean word-by-word reading times in the target regions for each group. As revealed in the figure, the L3 learners read significantly more slowly than the NSs in all the regions. In addition, the L3 learners read subject RCs much more quickly than object RCs in the HN region, while the NSs read the two types of RCs similarly in this region or in any other regions.

Mean of reading times per word in the target regions for the L3 learners and the native speakers.
These observations are confirmed by the statistical analysis. Initially, we analysed the first two words of the RC, i.e. V and N in the subject RCs, and N and V in the object RCs. Only the main effect of Group was significant (ß = 0.53, t = 10.56, p < .001).
We then analysed the relativizer and the HN regions. In the relativizer region, the main effect of Group was significant (ß = 0.31, t = 7.79, p < .001). In the HN region, there was a main effect of Group (ß = 0.47, t = 9.82, p < .001), and, more importantly, an interaction of Group and Sentence Type (ß = −0.08, t = –2.76, p < .01). There was no main effect of Sentence Type (ß = 0.02, t = 0.82, p = .42). The results indicate that the L3 learners displayed a different picture with respect to the HN region, than did the NSs.
Lastly, we analysed the two words after the HN (i.e. HN+1 and HN+2). In the HN+1 region, there was a main effect of Group (ß = 0.35, t = 7.19, p < .001), and similarly, in the HN+2 region, only a main effect of Group was significant (ß = 0.22, t = 4.20, p < .001).
To better understand the performance of the L3 learners and the NSs, we analysed their data separately, as reported in the following sections.
A Reading times by the L3 learners
We first analysed the two words in the RC, as we did earlier. Subject RCs were read more slowly than object RCs, but no significant difference between them was observed (ß = 0.01, t = 0.34, p = .73).
Then, we analysed the relativizer and the HN region. In the relativizer region, object RCs were read more slowly than subject RCs, but this difference did not reach significance (ß = −0.01, t = −0.73, p = .47). In the HN region, object RCs were read significantly more slowly than subject RCs (ß = −0.06, t = –2.94, p < .01).
Finally, we analysed the two words after the HN. In the HN+1 region, subject RCs were read more quickly than object RCs, but this difference did not reach significance (ß = −0.04, t = –1.83, p = .07). In the HN+2 region, although subject RCs were read more slowly than object RCs, this difference did not reach significance (ß = −0.01, t = −0.28, p = .78).
To sum up, the significant difference between subject and object RCs was observed in the HN region, but not in other regions of the RCs. This result suggests that the L3 learners have a subject RC preference in the processing of Chinese RCs.
B Reading times by the native speakers
Again, we first analysed the two words in the RC. Subject RCs were read more slowly than object RCs, but no significant difference between them was found (ß = 0.01, t = 0.47, p = .64).
We then analysed the relativizer and the HN regions. In the relativizer region, subject RCs were read more slowly than object RCs, but this difference did not reach significance (ß = 0.03, t = 1.64, p = .10). In the HN region, subject RCs were read more slowly than object RCs, but this difference did not reach significance (ß = 0.02, t = 0.98, p = .33).
We finally analysed the two words after the HN. In the HN+1 region, although subject RCs were read more quickly than object RCs, this difference did not reach significance (ß = −0.01, t = −0.09, p = .93). In the HN+2 region, although subject RCs were read more slowly than object RCs, this difference did not reach significance (ß = −0.01, t = −0.15, p = .88).
To sum up, no significant differences were observed between subject and object RCs in any of the target regions for the NSs. This result is in line with Gibson and Wu (2013), using the statistical analysis reported in Vasishth et al. (2013). Importantly, this result is different from what we observed for the L3 learners, who exhibited a significant difference between subject and object RCs in the HN region.
2 Comprehension sentence performance
The means of correct responses and reaction time of comprehension sentences are given in Figures 2 and 3, respectively. Regarding mean accuracy, the L3 learners comprehended the sentences similarly in the subject RC and the object RC conditions (M = 0.65, SD = 0.19; M = 0.66, SD = 0.16, respectively), and the NSs did as well (M = 0.73, SD = 0.13; M = 0.76, SD = 0.11, respectively). We only found a main effect of Group (ß = −0.61, z = –2.11, p < .05). Regarding the mean reaction time, the L3 learners comprehended the sentences descriptively faster in the subject RC condition than in the object RC condition (M = 8288.01 ms, SD = 3034.67; M = 9349.49 ms, SD = 4433.32, respectively), and the NSs comprehended them similarly (M = 3741.50 ms, SD = 1074.53; M = 3635.84 ms, SD = 1115.84, respectively). However, again, we only observed a main effect of Group (ß = 0.39, t = 8.73, p < .001). These results reflect the fact that, the L3 learners were unsurprisingly much less proficient than the NSs.

Mean accuracy of comprehension sentences for the L3 learners and the native speakers.

Mean reaction time of comprehension sentences for the L3 learners and the native speakers.
IV Discussion
The present study investigated L3 learners’ processing of subject and object RCs preceded by a supportive context by testing native Italian learners of L3 Chinese and native Chinese speakers. As expected, the results showed that the L3 learners read significantly more slowly than the NSs in all the regions. The L3 learners read object RCs significantly more slowly than subject RCs in the HN region, whereas no difference was found in this region or in any other regions for the NSs. Also, the L3 learners’ responses to comprehension sentences were less accurate and slower than those of the NSs.
The reading time difference in the HN region between subject and object RCs indicates that the L3 learners have more difficulties in processing object RCs than subject RCs. It seems that this result offers support for the SDH over the DLT. As introduced earlier, the two theories diverge in predicting the direction of the processing asymmetry in Chinese RCs. The SDH predicts a subject RC preference due to the greater structural distance between the gap and the filler in object RCs, while the DLT predicts an object RC preference due to the shorter linear distance between the gap and the filler in object RCs. The current study found robust effects of complexity in object RCs compared to subject RCs, resulting in the former being read significantly more slowly than the latter in the HN region, and being descriptively slower in the HN+1 region. To succeed in processing object RCs, a structural analysis is required, and L3 learners, due to their lower proficiency, may have difficulties in establishing the filler–gap dependencies in that analysis. Therefore, our results seem to provide evidence supporting the SDH.
Given the mixed results in the literature and the results concerning the type of L1 in studies, it is possible that our results can be accounted for by the influence exerted by the L1. As discussed earlier, with no supportive context, the type of L1 has proven to play a critical role. L2 learners of Chinese whose L1 features head-final RCs displayed no preference, while L2 learners whose L1 features head-initial RCs displayed a subject preference (Cui, 2013). With respect to experiments featuring RCs preceded by supportive contexts, a subject RC preference was reported by Li et al. (2016), but it might have been due or enhanced by the L1, which was not controlled for. Since in our study we used supportive contexts and controlled for L1, we may conjecture that the subject RC preference is due to L1 transfer. Previous studies on Italian RC processing have reported a subject RC preference by NSs (e.g. Carminati et al., 2006; Guasti et al., 2018) and in our study, this preference may have been transferred to Chinese. Alternatively, it is also possible that the subject RC preference in our study is due to two sources of transfer (i.e. L1 and L2), particularly for those participants with advanced proficiency in L2 English, for which a subject preference in the L1 processing of RCs has also been reported (e.g. Ford, 1983; Gibson et al. 2005). Given that the two languages pattern similarly with respect to RCs (i.e. both Italian and English are VO languages with head-initial RCs), the presence of the L2 might not represent a critical confound in terms of transfer, and the subject RC preference might be even more pronounced. However, we did not control for L2 proficiency exactly and systematically: if we had, we might have found a difference between participants with higher and lower L2 proficiency. Those with a higher proficiency have two available sources of transfer, whose ‘joint effort’ could show in an even more marked subject RC preference. On the other hand, those with a lower proficiency might only have L1 as a viable source of transfer. Previous studies have offered evidence that a property not acquired in the L2 cannot be transferred to, and hence cannot exert any influence on the L3 (Hermas, 2015; see discussion in Slabakova, 2017). In order to clarify and corroborate these conjectures, the next step which can be taken is to replicate our study dividing the L3 learners based on their L2 proficiency, and/or test a group of L3 learners whose L1 and L2 feature different head-directionality.
A point of interest in our study is the clear difference between NSs and the L3 group, in that the former did not show any preference for either subject or object RCs, whereas the learners showed a clear subject RC preference. This raises the question of why there is no asymmetry in NSs. The most likely explanation for this, in our view, is that the preceding discourse in our experiment involved a canonical SVO sentence, whose thematic order fully overlaps with that of the object RCs. As introduced earlier, Lin (2014) manipulated the thematic role orders in the preceding discourse, using passive sentences with the PATIENT-action-AGENT order and canonical sentences with the AGENT-action-PATIENT order, respectively. He found that the subject RC preference disappeared when the preceding discourse contexts presented the same thematic order as that shown in object RCs. By contrast, the L3 learners are not as sensitive to this overlap and thus cannot integrate context as rapidly. Their heavy reliance on the RC structure itself leads to a subject RC preference. Note that our L3 learners are intermediate proficiency learners, who had studied Chinese as an L3 for about 2 years and 9 months (SD = 0.65). In addition, our experimental material was modelled after an L1 processing study (i.e. Gibson and Wu, 2013), which contained vocabulary items that were low-frequency lexical items for the learners. Even though those words had been explicitly taught to the learners before the experiment, we did not control to what extent they were familiar with the lexical items, and to what extent unfamiliar vocabulary may have caused reaction time delays. Therefore, their reading speed of target sentences and reaction times with respect to the comprehension sentences were significantly slower than those of the NSs. Indeed, previous studies have provided some evidence that differences between NSs and L2/L3/Ln learners in online reading data could largely be explained by differences in reading speed (Kaan et al., 2015; Roberts and Felser, 2011). If our conjecture is correct, we expect that more proficient learners of Chinese will also be influenced in their processing of RCs by the order overlap with the preceding context. Our results suggest that it may be fruitful to test advanced L3 learners whose proficiency level is more comparable to that of NSs, and take differences in reading speed into account when interpreting differences across populations.
V Conclusions
We presented the first study comparing native Italian learners of L3 Chinese with native Chinese speakers in the processing of Chinese subject and object RCs in a supportive context. We found clear evidence that the L3 learners processed subject RCs more quickly than object RCs in the HN region, whereas the NSs did not show any significant difference between the two types of RCs in any of the target regions. In sum, this study showed that learners and NSs exhibit a different pattern, namely, a subject RC preference for the former and no preference for the latter. The asymmetry observed in the L3 group offers support for the SDH over the DLT, and suggests that linguistic experience, i.e. proficiency, plays an important role during comprehension. In addition, the contrast between the two populations indicates that the context is at play in the processing of RCs. Further research is needed to determine a) whether the same subject RC preference holds for advanced L3 learners and for learners whose L1 and L2 feature different head-directionality, and b) whether there is any significant difference in subject RC preference between L3 learners with differing L2 proficiency levels.
Footnotes
Acknowledgements
We sincerely thank all the participants in the study; H-H Iris Wu who generously released experimental materials to us; XU Yi who shared articles with us; Francesco Giannelli and NIE Bin who helped us out with the data collection; GU Xiaoming, HU Shuangling, YU Chongzhuo, YU Weichan, and ZHANG Yuanyuan for recruiting participants. We are grateful to Carlo Cecchetto, YU Yue and anonymous Second Language Research reviewers for their constructive suggestions, and to Roumyana Slabakova for her warm message during the Covid-19 pandemic. Authors’ contribution is as follows: Shenai Hu conceived the research question, developed and programmed the experimental task, recruited and tested participants, performed the statistical analyses, and drafted the article; Carlo Toneatto programmed the experiment task; Silvia Pozzi taught the vocabulary and recruited participants; Maria Teresa Guasti conceived the experimental question, developed the experimental task and commented on the article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the National Social Science Fund of China under grant agreement no. 18BYY080.