
Abstract
Traditionally, it has been claimed that the non-canonical word order of passives makes them inherently more difficult to comprehend than their canonical active counterparts both in the first (L1) and second language (L2). However, growing evidence suggests that non-canonical word orders are not inherently more difficult to process than canonical counterparts when presented with discourse contexts that license their information structure constraints. In an eye-tracking experiment, we investigated the effect of information structure on the online processing of active and passive constructions and whether this effect differed in monolinguals and L1-Spanish–L2-English speakers. In line with previous corpus studies, our results indicated that there was an interaction between word order and information structure according to which passive sentences were much more costly to process with new–given information structure patterns. Crucially, we failed to find evidence that the effect of information structure on word order constraints in comprehension differed between monolingual and L2 speakers.
I Introduction
A ubiquitous feature of human languages is that word order can be variable, licensing different alternatives to encode a message. For instance, an English speaker can use an active or passive construction when talking about an event involving two entities and an action. Actives (e.g. ‘The boy broke the vase’) use Subject–Verb–Object (SVO) word order to encode information about a subject performing an action; passives (e.g. ‘The vase was broken by the boy’) follow Object–Verb–Subject (OVS) word order to encode information about a patient who receives the effect of an action. In languages like English, the active is considered the canonical word order because it is the most frequent choice, whereas the passive is the non-canonical, less frequent, alternative (Blanco-Gomez, 2002; Roland et al., 2007; Runnqvist et al., 2013).
Active and passive constructions have long been an object of study among linguists and psycholinguists alike. Beginning with Chomsky’s Syntactic structures (Chomsky, 1957), it has been assumed that passives are syntactically more complex than actives, and that this complexity asymmetrically affects sentence comprehension (Chomsky, 1965: 22). The notion that passive constructions are inherently more difficult to process than actives has also been a core claim in psycholinguistic studies; in fact, past research has shown that passives are more difficult to comprehend both in first language (L1) processing (Abbot-Smith et al., 2017; Caramazza and Zurif, 1976; Dąbrowska and Street, 2006; Ferreira, 2003; Fox and Grodzinsky, 1998; Gough, 1965, 1966; Mack et al., 2013; McMahon, 1963; Johnson-Laird, 1968; Olson and Filby, 1972; Slobin, 1966; Stromswold, 2006; Townsend et al., 2001) and in second language (L2) processing (Crossley et al., 2018; Hinkel, 2002; Marinis, 2007; Marinis and Saddy, 2013; Master, 1991; Mathieson, 2017; Yokoyama et al., 2006).
While many psycholinguistic studies have reported a relationship between word order (active vs. passive) and processing difficulty, there is increasing evidence that the cost of processing constructions with non-canonical word order can be reduced when presented with preceding contexts that license their discourse constraints. Studies have shown that while canonical word orders tend to be more flexible, non-canonical word orders only have a small set of discourse contexts in which they are felicitous. Thus, considering the discourse constraints of different word orders is crucial to understand processing asymmetries and how they can be mitigated (Bader and Meng, 1999; Brown et al., 2008, 2012; Bornkessel-Schlesewsky et al., 2003; Clifton and Frazier, 2004; Erdocia et al., 2009; Kaiser and Trueswell, 2004; Kristensen et al., 2013, 2014; Slioussar, 2011; Weskott and Fanselow, 2011).
In the case of the English passive, research using corpora of natural language has shown that its main discourse requirement is a preference for presenting given information (previously mentioned in the discourse) before new information (previously unmentioned; Birner and Ward, 1996, 1998, 2009; Givón, 1993; Ward and Birner, 2001, 2011). In other words, passive constructions are dependent on a given–new information structure pattern in discourse for their felicitous interpretation (Halliday, 1967). In contrast, actives are more flexible and can be interpreted with more or less equal ease with given–new and new–given information structure patterns. To illustrate, consider the following examples extracted from the Brown Corpus (Kučera and Francis, 1960). In comparison to sentence (1), a sentence like (2) violates the information structure constraints on passive constructions, as new information is presented first (examples from Birner and Ward, 1998: 200): (1) The mayor’s present term of office expires Jan. 1. He-GIVEN will be succeeded by Ivan Allen Jr-NEW. (2) Ivan Allen Jr. will take office Jan. 1. The mayor-NEW will be succeeded by him-GIVEN.
These discourse constraints on passives have been robustly studied by means of corpora of natural language. In a seminal study, Birner and Ward (1996) analysed the first 200 by-phrase passives appearing in the Brown Corpus (Kučera and Francis, 1960). Results showed that given information was presented first in the majority of the by-phrase passives (see Table 1). By contrast, there were no instances of new–given information structure patterns.
Distribution of information structure in passive constructions (percentages).
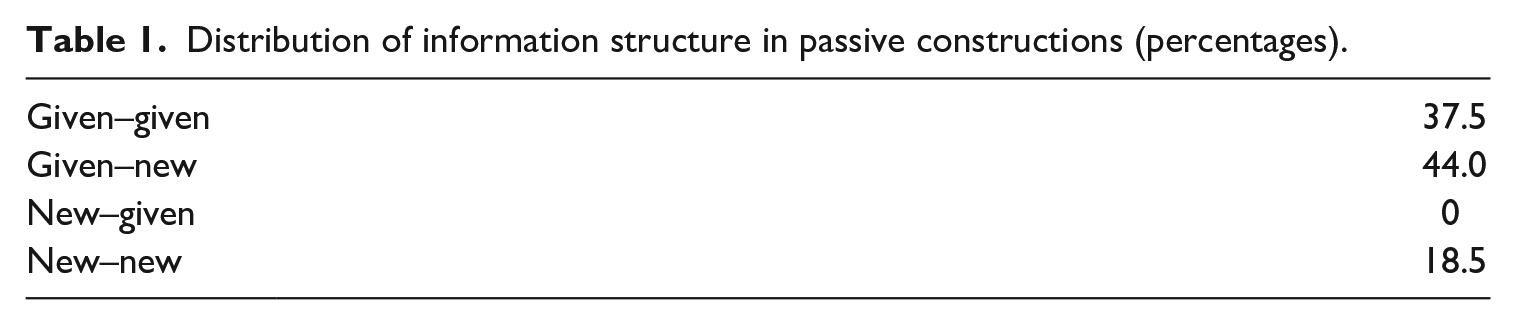
Thus, it is possible that much of the difficulty that has been observed in past studies when L1 and L2 speakers comprehend passive constructions might not be because passives are inherently more complex than actives, but rather because their discourse requirements have not been met. While previous studies have presented passive constructions in isolation (Abbot-Smith et al., 2017; Bencini and Valian, 2008; Carrithers, 1989; Crossley et al., 2018; Ferreira, 2003; Gough, 1966; Kim and McDonough, 2008; Mack et al., 2013; Marinis and Saddy, 2013; Mehler, 1963; Messenger et al., 2012; Olson and Filby, 1972; Savin and Perchonock, 1965; Slobin, 1966; Yokoyama et al., 2006), here we investigate the comprehension of contextualized passive and active constructions using eye-tracking. We designed experimental materials that respect the information structure licensing conditions observed during the production of naturalistic speech, which are critical for understanding how actives and passives are comprehended.
The study described here aims at answering two research questions: (1) Does information structure have an effect on the comprehension of passive and active constructions? and (2) Does this effect differ in monolinguals and L2 speakers? To this end, we compared the performance of highly proficient L2 speakers of English (L1 Spanish) and monolingual speakers of English as they read contextualized active and passive sentences while their eye movements were monitored. Crucially, although Spanish and English follow the same licensing discourse constraints for active and passive constructions, there is evidence that even when there are similarities between the L1 and the L2, L2 speakers often experience difficulty processing information structure constraints on word order during online L2 comprehension (Bel et al., 2016; Belletti and Leonini, 2004; Belletti et al., 2007; Lozano, 2006, 2009; Prentza and Tsimpli, 2013; Roberts et al., 2008; Sorace and Filiaci, 2006; Valenzuela, 2006; Wilson and Chalton, 2009).
In the following section, we discuss the extant literature on the processing asymmetries between active and passive constructions. Next, we provide an overview of the literature investigating the effects of information structure on the processing of word order variation in monolingual and L2 speakers. We then present our methods and results, ending with a discussion of the findings.
1 The processing of active and passive constructions
An ample body of studies with monolingual speakers has provided evidence that passives are more difficult to comprehend than actives, and passives have a higher tendency to be misinterpreted by monolingual children and adults alike (Abbot-smith et al., 2017; Caramazza and Zurif, 1976; Dąbrowska and Street, 2006; Fox and Grodzinsky, 1998; Gough, 1965, 1966; Mack et al., 2013; McMahon, 1963; Johnson-Laird, 1968; Olson and Filby, 1972; Slobin, 1966; Stromswold, 2006; Townsend et al., 2001). For instance, Ferreira (2003) compared the processing of actives and passives in adults using biased reversible (‘The dog bit the man’), non-reversible (‘The mouse ate the cheese’) and reversible-symmetrical (‘The woman visited the man’) constructions. Participants listened to active and passive sentences and were asked to identify the agent and patient. Results indicated that participants were overall more accurate and faster in actives across all conditions. Other studies have also shown that it takes longer for monolinguals to judge the validity of passives (Forster and Olbrei, 1973; McMahon, 1963), that passives are harder to memorize (Mehler, 1963; Savin and Perchonock, 1965) and that they can only be primed by other passive constructions (Bencini and Valian, 2008; Bernolet et al., 2009; Bock, 1986; Hartsuiker et al., 2004; Gãmez and Shimpi, 2016).
The difficulty with passives relative to actives extends to child language acquisition and language impairment. There is evidence that passives are acquired later by children (Baldie, 1976; Brooks and Tomasello, 1999; Diessel, 2004; Guasti, 1994; Marchman et al., 1991; Maratsos et al., 1985; Messenger et al., 2012), and that they are selectively impaired in aphasia and brain damage (Caramazza and Zurif, 1976; Grodzinsky et al., 1991; Zurif et al., 1993). Similar results have been reported showing that the passive is more difficult to learn and comprehend both for adult and child L2 speakers. In addition, there is evidence that L2 speakers can show persistent errors in the use of the passive voice even at advanced levels of proficiency (Balcom, 1997; Hinkel, 2002; Izumi and Lakshmanan, 1998; Ju, 2000; Li and Yang, 2014; Marinis, 2007; Marinis and Saddy, 2013; Master, 1991; Pae et al., 2014; Tankó, 2010; Yip, 1995; Zobl, 1989). For example, Crossley et al. (2018) compared the processing of actives and passives in native and non-native speakers of English. Participants completed an aural forced-choice picture identification task while their reaction times and hand motions were captured by a mouse-tracking system. This allowed researchers to examine how fast participants chose the correct picture, as well as the computer-mouse positions as they traversed the screen to click on a picture. Results showed that both groups of participants were faster at responding to active constructions, traveled less distance with the mouse and made fewer mouse directional changes.
However, it is possible that much of the difficulty that has been observed when L1 and L2 speakers comprehend passive constructions in the studies discussed so far may, in part, be caused by the fact that passive constructions were presented in isolation, without contexts that licensed their discourse requirements. In the next sections we provide an overview of the literature investigating the effects of information structure on the processing of word order variation in monolingual and L2 speakers and take direction from these studies to design the experiment reported here.
2 Psycholinguistic evidence on the processing of information structure and word order
Psycholinguistic studies examining the effects of information structure on the online comprehension of word order have mostly reported diverging results for monolinguals and L2 speakers. Although, to our knowledge, there is no study investigating the effects of information structure on the online processing of English active and passive constructions, many other constructions have been investigated.
Within studies with monolingual populations, SVO and OVS orders are among the most extensively examined. Studies have shown that monolinguals’ comprehension of the non-canonical OVS word order is modulated by information structure constraints. In a seminal study, Kaiser and Trueswell (2004) used eye-tracking to investigate the effects of information structure on the processing of canonical SVO and non-canonical OVS word order. Because non-canonical word orders require given–new information structure patterns, they predicted that the comprehension of OVS constructions would be facilitated when this discourse requirement was respected. Indeed, results showed that when presented with the more frequent given–new patterns, there was no evidence of differential processing difficulty between SVO and OVS constructions (see also: Brown et al., 2008, 2012; Clifton and Frazier, 2004; Fedorenko and Levy, 2007; Weskott and Fanselow, 2011).
Other variables that might influence how discourse constraints modulate the processing of non-canonical word order have also been investigated. Evidence in support of the relevance of information structure comes from studies showing that discourse information is quickly accessed and integrated during online and offline comprehension. Slioussar (2011) examined the processing of sentences with SVO and OVS word order in Russian using self-paced reading. Her findings showed that the effects of information structure appeared immediately once participants encountered the first noun that either respected or violated the information structure pattern of each construction, and that this effect was faster for canonical word orders. Similarly, Stolterfoht (2005) recorded event related potentials while participants read contextualized SVO and OVS constructions in German. Results indicated that non-canonical word order was not only read faster with a given–new information pattern, it was also rated as being more acceptable (Bader and Meng, 1999; Kaan, 2001). In addition, he observed that this facilitation effect was different for pronouns and definite noun-phrases. Finally, some studies have reported analogous findings in using brain neuroimaging. For example, Kristensen et al. (2013) examined comprehension on SVO and OVS Danish constructions using functional magnetic resonance imaging. According to the results, the processing of non-canonical constructions was facilitated when they were presented with given–new information structure patterns, as indexed by faster reading times (RTs) and lower activation levels in the left inferior frontal gyrus.
Within the L2 literature, however, studies examining L2 speakers’ sensitivity to information structure have often presented contradicting results. On the one hand, an ample body of studies have shown that L2 speakers seem not to be sensitive to the constraints that information structure places on word order, especially in real time. It has been argued that this is caused by pervasive difficulties integrating discursive and syntactic information simultaneously, even at high proficiency levels (Sorace, 2011; Sorace and Filiaci, 2006). Again, a wide variety constructions have been investigated (split intransitivity and SV inversion: Hertel, 2003, Lozano, 2006, Domínguez and Arche, 2014; scrambling: Hopp, 2005, 2006, 2009; wh-questions: Jackson, 2007; Jackson and Bobb, 2009; Jackson and Van Hell, 2011, amongst others). Among these, subject pronoun expression and clitic left dislocations are some of the most widely discussed. Studies examining subject expression have shown that even very advanced L2ers tend to use and interpret pronominal and null subjects in a non-native-like manner (Belletti and Leonini, 2004; Belletti et al., 2007; Leonini and Belletti, 2004; Ballester, 2013; Prentza and Tsimpli, 2013; Tsimpli and Sorace, 2006; Roberts et al., 2008; Wilson, 2009). Most Romance languages are pro-drop, which means that the subject of a sentence can be omitted under certain conditions. It has been suggested that the production of overt and null subjects is governed at the syntax–discourse interface: morphosyntactically, the rich verbal morphology of Spanish licenses and identifies null subjects (Lozano, 2009); discursively, the distribution of null or overt pronouns depends on discourse–pragmatic factors such as whether the subject is a topic, introduces a switch reference, or establishes focus/contrast (Montrul and Rodríguez Louro, 2006: 404; see also, Lafond et al., 2001; Liceras, 1988; Rizzi, 1982; Sorace, 2003; White, 1989). For instance, while null pronouns are used to indicate topic continuity, overt pronouns are pragmatically infelicitous (marked with #) in such contexts, as seen in example (3) in Spanish.
(3) Martai lloró mientras Øi/#ellaj leía la carta. ‘Martai cried while Øi/#shej read the letter.’
Lozano (2018) used an offline contextualized acceptability judgment to examine the use of overt/null pronominal subjects in topic-continuity contexts in L1 Greek–L2 Spanish speakers at different proficiency levels, while Bel et al. (2016) used an online self-paced reading task to test L2 Spanish speakers with different proficiency levels and L1 backgrounds on the same construction. The results of both studies indicated that even very advanced speakers showed deficits, tolerating pragmatically redundant overt pronouns in topic-continuity contexts where native speakers would prefer a null pronoun.
Likewise, research on clitic left dislocations (CLLD) has shown that even highly proficient L2 Speakers often fail to acquire the information structural constraints on this construction in a native-like way. Spanish, for instance, allows fronting of constituents that represent given information into the left periphery (4b). In English, while the given constituent is still dislocated to the left-periphery, a clitic is not allowed; this structure is known as topicalization (4a).
(4) Context: Where did you buy theses shoes? a. Topicalization: b. CLLD:
Another crucial difference is that CLLD in Spanish occurs only when the dislocated constituent represents given information (e.g. la manzana, la-clitic comí, ‘the apple, Ø-clitic I ate’), and not when it is new (e.g. una manzana, comí, ‘an apple, I ate’). On the contrary, given that there is no clitic in English topicalized structures, information structure does not play a role in this construction. Thus, in order to successfully process CLLD constructions, L1-English–L2-Spanish speakers need to learn the nuanced information structural constraints at play in this construction. For instance, Valenzuela (2005, 2006) examined L1-English–L2-Spanish speakers’ sensitivity to the information structure requirements on CLLD. Participants completed three tasks: an oral acceptability judgment task, an oral sentence selection task and a sentence completion task. Significant differences were found between L2 speakers and a matched monolingual Spanish baseline. For example, results from the sentence completion task showed that while native speakers only produced clitics for dislocated constituents 17% of the time, L2 speakers did so 47% of the time, suggesting that L2 speakers were not sensitive to the information structural constraints on CLLD (for analogous results see Donaldson, 2011; García-Alcaraz, 2015; García-Alcaraz and Bel, 2011; Judy, 2015; Lozano, 2009).
Despite the robust results of these studies, recent research has provided evidence that convergence at the syntax–discourse interface is indeed possible for L2 speakers. Rothman (2009) studied L1 English–L2 Spanish intermediate and advanced speakers’ use of subject expression in topic continuity contexts. According to the results of an online task testing production (Overt Pronoun Production task) and an offline task testing comprehension (pragmatic felicitousness judgment task), the group of advanced L2 speakers converged with the native speakers in their use of null subjects, displaying systematic knowledge of both the syntactic and discursive constraints of subject expression in Spanish (for similar results see: Blackwell and Quesada, 2012; Krass, 2008; Lozano, 2009, 2016; Margaza and Gavarró, 2020; Montrul and Rodríguez Louro, 2006).
Similar studied can be found within the clitic left dislocation literature. Leal et al. (2017) L1 English–L2 speakers of Spanish at different proficiency levels. Participants completed a self-paced reading task designed to determine whether they could predict that a clitic would occur in the later in the sentence after being exposed to a left-dislocated phrase (e.g. A aquellas estudiantes la linda secretaria felizmente les-clitic contó que probablemente las-clitic admitirán en el programa. ‘To those students the lovely secretary happily Ø-clitic told that they would probably Ø-clitic admit in the program.’). Results indicated that L2 speakers read the verb significantly faster when it was preceded by a clitic, thus demonstrating that they were expecting a clitic in that position. Importantly, this effect was modulated by their proficiency levels, such that more advanced L2 speakers were more native-like. Along the same lines, Slabakova et al. (2012) showed similar results using offline tasks (clitic knowledge test and felicity judgment task). According to their findings, the near-native and advanced L2 speakers in their sample were sensitive to the syntax–discourse constraints on subject expression, while the intermediate L2 speakers did not display any discourse knowledge (for similar results see: Donaldson, 2011; Ivanov, 2012; Leal, 2016; Leal et al., 2018; Slabakova and Ivanov, 2011).
In all, the studies discussed in this section provide strong evidence that information structure is critical for the processing of word order variation. For this reason, we explore the possibility that the comprehension asymmetry traditionally found between actives and passives might, at least in part, be caused by the fact that these constructions have always been presented in isolation, thus violating their discourse requirements. In addition, given that the literature shows contradicting results regarding L2 speakers sensitivity to information structure, we also examine whether presenting actives and passives with contexts that license their discourse requirements may have similar effects in the online processing of L2 speakers and monolinguals.
3 Research questions and predictions
In the present study, we use eye-tracking to investigate the role of information structure in the comprehension of contextualized active and passive constructions by monolingual and L2 speakers of English. We use experimental materials that respect the information structure requirements of these word orders, which we propose to be critical for understanding how they are comprehended. Thus, we put forward the following research questions and their associated predictions:
• Research question 1: Does information structure have an effect on the comprehension of contextualized passive and active constructions? ○ Prediction 1a: There should be a main effect of information structure on word order such that sentences with given–new patterns will be read overall faster. ○ Prediction 1b: There should be an interaction between information structure and word order such that: ▖ Within new–given information structures, passives should be more costly to process (i.e. higher RTs). ▖ Within given–new information structures, the difference in RTs between passives and actives should be reduced.
• Research question 2: Does the effect of information structure differ in monolinguals and L2 speakers? ○ Prediction 2a: Based on findings from the L2 literature, only monolinguals should be sensitive to the effects of information structure in the comprehension of active and passive constructions. L2 speakers should show a difference in RTs between actives and passives regardless of their information structure pattern. ○ Prediction 2b: Alternatively, both monolinguals and L2 speakers might be sensitive to the effects of information structure in the comprehension of active and passive constructions.
II Method
1 Participants
Thirty L1-Spanish–L2-English speakers (16 females; mean age 26.93, SD = 5.96) living in the USA. (mean age of acquisition 6.43 years of age, SD = 3.99) and 30 ‘functionally-monolingual’ 1 English speakers (20 females; mean age 24.43, SD = 4.02) were recruited. All participants reported having normal vision, or vision corrected to normal with glasses, and no history of neurological disorders.
Participants first completed a battery of behavioral tasks that assessed proficiency, as well as a working memory task, as there is evidence that individual differences in these factors affect L2 outcomes (Leeser, 2007; Dörnyei and Skehan, 2003). The tasks are described below and are used primarily to provide information about the participants’ past and present use of English and Spanish (in the case of the L2 speakers), as none of the proficiency measures were returned as significant in the analyses conducted. In addition, participants completed a language background questionnaire (LHQ) to collect basic information about them and to characterize their life-long linguistic experience with English, and also with Spanish. This information was used to determine L2 status, as explained below.
a Language background questionnaire
Participants answered a language background questionnaire containing questions about their acquisition and use of their L1 and L2 respectively. For the L2 speaker sample, given that there was considerable variation in participants’ mean age of L2 acquisition (M = 6.43; SD = 3.99, range = 10), their status as L2 speakers was established following the criteria in Lynch (2017):
Context of acquisition: all L2 speakers reported grew up in Spanish-speaking countries, having monolingual parents and receiving their primary education (5–12 years of age) fully in Spanish. This suggests a predominantly monolingual upbringing.
Age of acquisition: while some L2 speakers listed acquiring the L2 early (e.g. 3 years of age), none of them reported any functional proficiency in the L2 (i.e. English) before age 14 (M = 14.87, SD = 4.00; range = 13). This suggests that while they may have had some exposure to the L2, this language was not used consistently during their childhood.
Degree of proficiency: all L2 speakers rated themselves as being less proficient in English than in Spanish (t(17) = 8.21, p < .001).
Identification: all L2 speakers reported being Spanish dominant, which is considered an indicator of identification with their L1.
Participants within the monolingual group, were considered to be ‘functionally monolingual’ given that 14 of them reported having been exposed to another language at some point in their lives (mean age of exposure 6.79 years, SD = 7.79), although they hardly ever used it (90% of participants reported never or almost never using their L2). In addition, they rated themselves as being considerably less proficient in their L2 than in English (t(31) = 17.39, p < .001).
b Language proficiency test
A modified version of The Michigan English Language Institute College Entrance Test (MELICET) was also administered. This is a placement test created to assess non-native speakers’ knowledge of English. It consists of 50 multiple choice elements that test L2 speakers; knowledge in several domains (grammar, vocabulary, and reading) by means of a sentence completion task and a cloze-reading paragraph. The mean score was 45.57 out of 50 (SD = 4.00, range = 21) for monolinguals and 40.12 (SD = 4.85, range = 19) for L2 speakers. The difference between groups was not statistically significant (t(58) = 6.78, p = 1.00).
c Verbal fluency
Participants were given four out of eight possible categories (e.g.: body parts, colors, furniture, fruits, animals, vegetables, clothing and musical instruments) and were asked to name as many exemplars as possible in each category in 30 seconds. L2 speakers named four categories in Spanish and four in English. The order of the languages and categories was counterbalanced by language so that if one participant named furniture in one language, the next participant would name that same category in Spanish. During coding, one point was given per word named. Between-group comparisons revealed that L2 speakers named significantly less items in English (M = 46.36) than monolinguals (M = 56.70, t(58) = −4.83, p < 0.001). Within group comparisons revealed that L2 speakers named significantly less words in their L2 (M = 46.36) than in their L1 (M = 52.36, t(58) = −2.76, p < 0.01).
d Picture naming
Participants were presented with pictures and were asked to name them out loud. Their reaction times were recorded and their responses were coded for accuracy. The order of the language was counterbalanced by participant, such that one participant would name in English before Spanish, while the next named in Spanish before English. All pictures were frequency-matched across languages and consisted of simple black and white drawings. In total, participants named 66 pictures in each language. Statistical analyses revealed that when naming in English, monolingual participants were significantly faster (M = 782.63 ms) than L2 speakers (M = 1035.18 ms, t(56) = 8.74, p < 0.001), but numerically less accurate (monolinguals, M = 94%., L2 speakers, M = 96%, t(53) = 1.20, p = 0.23).
e Operation span
Participants were administered a cognitive task to measure their working memory span. They were presented with simple math problems alongside a potential solution and were instructed to press yes/no in a response box to indicate whether the solution was correct or incorrect. After each problem, a word in English appeared on the screen; participants were told to memorize these words for later recall. Responses were coded in order to obtain recall and accuracy scores. Monolinguals recalled significantly more words (M = 47.56) than L2 speakers (M = 39.37, t(45) = −3.86, p < 0.001), but both groups were highly accurate (monolinguals, M = 87%, L2 speakers, M = 79%, t(44) = 2.61, p = 0.01).
2 Materials and design
The experimental stimuli consisted of 80 stimulus-sets, each of which contained four different versions of the same target sentence resulting in a total of 320 experimental sentences. Each stimulus consisted of a prior context and a target sentence (see Table 2). In understanding the design of the stimuli, it is important to note that that there are differences in the use of thematic roles in actives and passives; while actives place agents in subject position, passives place themes, as shown in examples (5) and (6).
Experimental stimuli.

(5) Active: The girl-AGENT threw a ball-THEME (6) Passive: The ball-THEME was thrown by the girl-AGENT
In addition to this, because the prior context introduced a noun that was also mentioned in the target sentence (e.g. the policeman or the criminal), the target sentences had different information structure patterns. Thus, within the four experimental conditions created: active sentences could contain a given agent subject and a new theme object (Condition 1) or a new agent subject and a given theme object (Condition 2). Passive sentences could contain a new theme subject and a given agent object (Condition 3) or a given theme subject and a new agent object (Condition 4). All target sentences had a ‘construction critical region’ consisting of the subject, verb and object of the sentence (e.g. active: the criminal saw a policeman; passive: a policeman was seen by a criminal). The construction critical region of each sentence varied by information structure (given–new or new–given), depending on the previous context, and voice (active or passive).
It is important to note that we followed the assumption that there is a relationship between givenness and definiteness (Clifton and Frazier, 2004). Given entities introduced in the previous context are preceded by a definite article, such as the policeman in (Condition 1) and the criminal in (Condition 4). New entities, however, are preceded by an indefinite article, such as a policeman in (Condition 2) and a criminal in (Condition 3). In addition to the experimental sentences, 80 filler sentences with their corresponding preceding contexts were created. The fillers contained entities not mentioned in the probes (e.g.: proper names and other nouns) with similar syntactic structures.
Comprehension statements were also included for all experimental and filler items, consisting of simple statements based on the entities or actions mentioned. Participants were asked to indicate whether the statements were true or false. These were included to keep participants actively engaged in the task, and to check the accuracy of their reading comprehension. Four 166-item lists were created, each of which contained 80 experimental items (20 for each condition), 80 fillers and six practice sentences. Each list only contained one version of each of the 80 experimental stimuli sets, and all items in each list were presented in a randomized fashion.
The experimental sentences were controlled for orthographic length and lexical frequency; both measures were extracted from the 100 million-word British National Corpus (Davies, 2004). We report lexical frequency per million and orthographic length in number of characters. Ninety-eight nouns were used in the experimental sentences; of these, 49 were subject/patient (mean lexical frequency, 80.90; mean length, 6.82), and 49 were object/agent (mean lexical frequency, 60.20; mean length 6.94); there were no statistically significant differences between both groups of nouns neither in lexical frequency (t(70) = 0.55, p = 0.58) nor in orthographic length (t(94) = 0.30, p = 0.76). Regarding verbs, only transitive verbs were used (mean lexical frequency, 365.5; mean length, 5.30). These were in the past tense in actives, or in participle form in passives; they were never repeated.
Before data collection, we normed our materials for naturalness by means of two online surveys implemented through Amazon’s Mechanical Turk (www.MTurk.com). For the first norming study, we collected data from 23 monolingual native speakers of American English (17 male, mean age 34.71, SD = 9.57); for the second one, we collected data from 17 monolingual native speakers of American English (11 females, mean age 36.75, SD = 10.46). Participants were presented with contexts followed by two experimental sentences (as shown in Table 2) and were asked to rate how natural each sentence was as a continuation of the prior context. All sentences were scored on a 7-point Likert scale (with 1 being the most natural and 7 the most unnatural). Scores were analysed using weighted means according to which higher weights were given to the points of the scale labeled as ‘natural’, ‘moderately natural’ and ‘slightly natural’. By means of this analysis, we excluded all the sentences that were considered unnatural, which resulted in the removal of 49 stimuli in the first norming study. We replaced these sentences with new ones and submitted the entire list of materials to a second, and final, norming study using the same procedure and scoring process followed for the first norming study. This time, only 7 sentences were excluded. All mean acceptability ratings by condition obtained in the final norming can be found in Table 1 in Appendix 2 in the supplemental material.
3 Procedure
Participants read sentences while their eye movements were recorded with a desktop-mounted Eyelink 1000 Plus eye-tracker (SR Research) sampling from the right eye at 1,000 Hz. To improve stability during recording, participants rested their heads in a chin rest. All button presses were collected using a VPixx RESPONSEPixx dual handheld button box. After participants were seated and the camera was adjusted, a nine-point calibration and validation was carried out to ensure proper tracking. After the calibration process, participants were presented with the instructions for the practice phase of the experiment. Once this phase was completed and potential questions were answered by the researcher, instructions for the experimental phase of the study were displayed and the experiment proceeded.
During the experimental phase, each trial started with a fixation point placed at the same location as the start of the text during which a drift check was performed. This was done to increase gaze accuracy by avoiding overshoot on the first word as participants’ eyes moved to the start of the sentence. After this, the context was displayed on the screen. Pressing any button on the button box displayed the target sentence which appeared on the screen in a single line. Finally, another button press displayed the comprehension statement to which participants answered True by pressing a button with their left hand, or False with their right hand. All text elements were displayed in the center of the screen and left-aligned so that the start of each corresponded to the same location on screen (i.e. the location of the fixation point).
The experiment took place in a single two-hour session. Participants completed the Language Background Questionnaire, MELICET, Picture Naming and English Verbal Fluency tasks first, followed by the reading experiment in the eye-tracker. Finally, they completed the Operation Span and, if they were L2 speakers, a Spanish Verbal Fluency task. Participants received payment for their participation.
4 Data cleaning
The region analysed was the construction critical region, which consist of the grammatical subject, verb and grammatical object of each sentence. The examples in (7) are repeated from Table 2.
(7) Active Given–New: Soon after, Active New–Given: Soon after, Passive New–Given: Soon after, Passive Given–New: Soon after,
The sentence-initial preamble and sentence-final adjunct were not included in the critical region analyses to concentrate on those elements of the sentence that contained the linguistic manipulation of interest in this experiment. The measure total duration, calculated as the sum of all fixations made in the construction critical region for a given trial, was extracted by aggregating all fixations across the interest areas corresponding to the grammatical subject, verb, and grammatical object. We chose this measure for two reasons: First, this was the most methodologically sound way to ensure that the measure was reflecting the fact that participants had already read everything that they needed in order to know that the sentence was an active or a passive. Second, total duration reflects later stages of processing and integration; this is critical for the present study given that there is evidence that discourse effects may surface later in processing, especially in the L2 (Ardal et al., 1990; Kutas et al., 2006). In addition to total duration, the number of characters in the critical region was extracted and used as a covariate to account for differences in length between the active and passive constructions.
To clean the data, all trials where the total duration was 0 were excluded, usually the result of recording errors during data collection (monolinguals = 4.8%; L2 speakers = 0.1%), as well as any trials where the comprehension statement was answered incorrectly (monolinguals = 2.3%; L2 speakers = 4.6%). Next, any trials where the first fixation occurred later than the two words of the sentence-initial preamble (e.g.
After this initial data trimming, there were 1,644 eligible trials remaining for the monolinguals and 1,701 for the L2 speakers. At this point, the data were examined in order to verify whether or not they approximated a normal distribution. Quantile–Quantile (QQ) Plots were created using the qqPlot function in the car library (v. 3.0-8; Fox and Weisberg, 2019) in R (v. 4.0.0; R Core Team, 2020), showing that the data was highly skewed. To address this, the data were log normalized; further data cleaning and all analyses were conducted on these log-normalized total durations. QQ plots and density plots for both monolinguals and L2 speakers are provided in Appendix 1 in the supplemental material.
Lastly, using this trimmed and log-normalized data, outliers were identified and excluded using the median absolute deviation (MAD) method (Leys et al., 2013) using the normalize function in the Rling package (v. 1.0; Levshina, 2015). This method is much more robust than using the mean and standard deviation because the median is less impacted by outliers or sample size. Based on these values, a cutoff point of 2.5 deviations below or above the median was established to remove outliers (monolinguals = 2.2%; L2 speakers = 2.7%). In total, 28.6% of all trials were excluded for monolinguals, while 27.5% of all trials were excluded for L2 speakers.
5 Modeling
Linear mixed-effects models were fitted using the buildmer function in the buildmer package (v. 1.6; Voeten, 2020) in the statistical software R (v. 4.0.0, R Core Team, 2020). This function uses lmer from the lme4 package (v. 1.1-23; Bates, Maechler, Bolker and Walker, 2015) but allows for a systematic and replicable way of simplifying random effects structures and testing fixed effects. The function starts by attempting to fit the most maximal model possible. If the model fails to converge, the function then simplifies the random effects structure via backwards stepwise elimination; in other words, it attempts to find the maximal random effects structure that still allows the model to converge. Once the maximally converging model has been identified, the function calculates p-values for all fixed effects based on Satterthwaite denominator degrees of freedom using the lmerTest package (v. 3.1-2; Kuznetsova et al., 2017). The resulting models were the maximally converging models that the data were able to support (Bates, Kliegl, Vasishth and Baayen, 2015).
Before creating the maximal model, factors were re-coded as centered contrasts: rather than the standard ‘dummy’ coding of 0 and 1, the two levels of each factor were centered around 0 such that the mean is 0. As opposed to sum contrasts (e.g. –0.5 and 0.5), this method allows us to account for the fact that the number of observations in each level of the factor is not the same (due to excluded trials from data cleaning) such that the intercept represents the Grand Mean over all conditions (Engqvist, 2005; Gelman and Hill, 2007; Schielzeth, 2010; Schad et al., 2020). That the mean of each factor is now 0 allows us to estimate the effects of voice and information structure (and their interaction) across both groups simultaneously.
The maximal model for between-groups comparison submitted to buildmer included the two-level fixed effects of group (
III Results
The maximally converging model consisted of the main effects of voice, group, and information structure, as well as all two- and three-way interactions, plus the number of characters in the critical region as a covariate. Ultimately, only a random intercept of participant was supported with no random slopes, as well as the random intercept for item with a random slope for group. The summary of the fixed effects is provided in Table 3.
Summary of fixed effects.

Notes. * equal or smaller than p < .05, the * indicates a result is significant.
The model revealed main effects of group, voice, information structure, number of characters, and a significant two-way interaction between information structure and voice. The remaining three interactions with group were not significant; as a result, there was no statistical justification to separate the two groups and analyse them separately. Nonetheless, to examine possible differences between the two groups, we ran the same model two more times: once with Monolinguals as the reference level of Group, and once with L2 Speakers as the reference level of group. Thus, Group was given treatment coding while the remaining two factors retained centered coding. This differs from the first model, where the centered contrasts estimated the interactions across both groups combined, and instead allows us to estimate the interactions for each group separately without separating the two groups. Table 4 provides the t- and p-values for the fixed effects of each model, with the relevant rows highlighted.
Comparison of fixed effects.
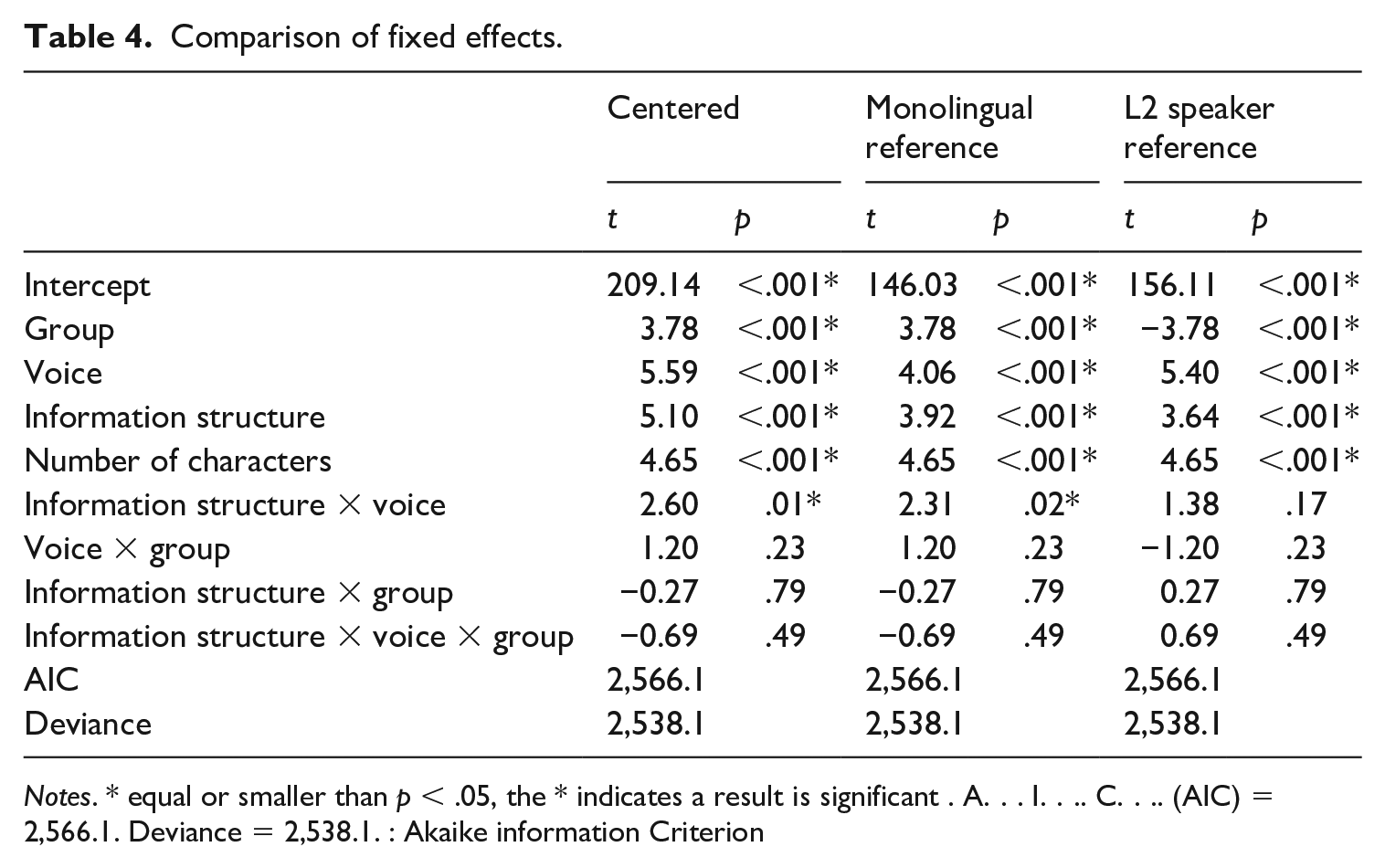
Notes. * equal or smaller than p < .05, the * indicates a result is significant . A. . . I…. C…. (AIC) = 2,566.1. Deviance = 2,538.1. : Akaike information Criterion
In the first model, which estimates both groups together, the two-way interaction is significant; when Monolinguals are the reference level of Group, the two-way interaction is also significant; but when L2 Speakers are the reference level of group, the two-way interaction is not significant. This, however, is not sufficient evidence to say that the two groups are different. Instead, we must look at the three-way interaction between Information Structure, Voice, and Group: in all three models, this interaction is non-significant. In other words, while there may be numerical differences between the two groups with respect to the two-way interaction, the non-significant three-way interaction tell us that these differences are not statistically reliable. As such, we argue that we have failed to find evidence that the effect of information structure on word order constraints in comprehension differed between the two groups.
Figure 1 visualizes the mean total durations for each group across all four conditions. To facilitate interpretation, raw total durations are visualized instead of log-normalized total durations, and the condition each bar represents is indicated below them. 3
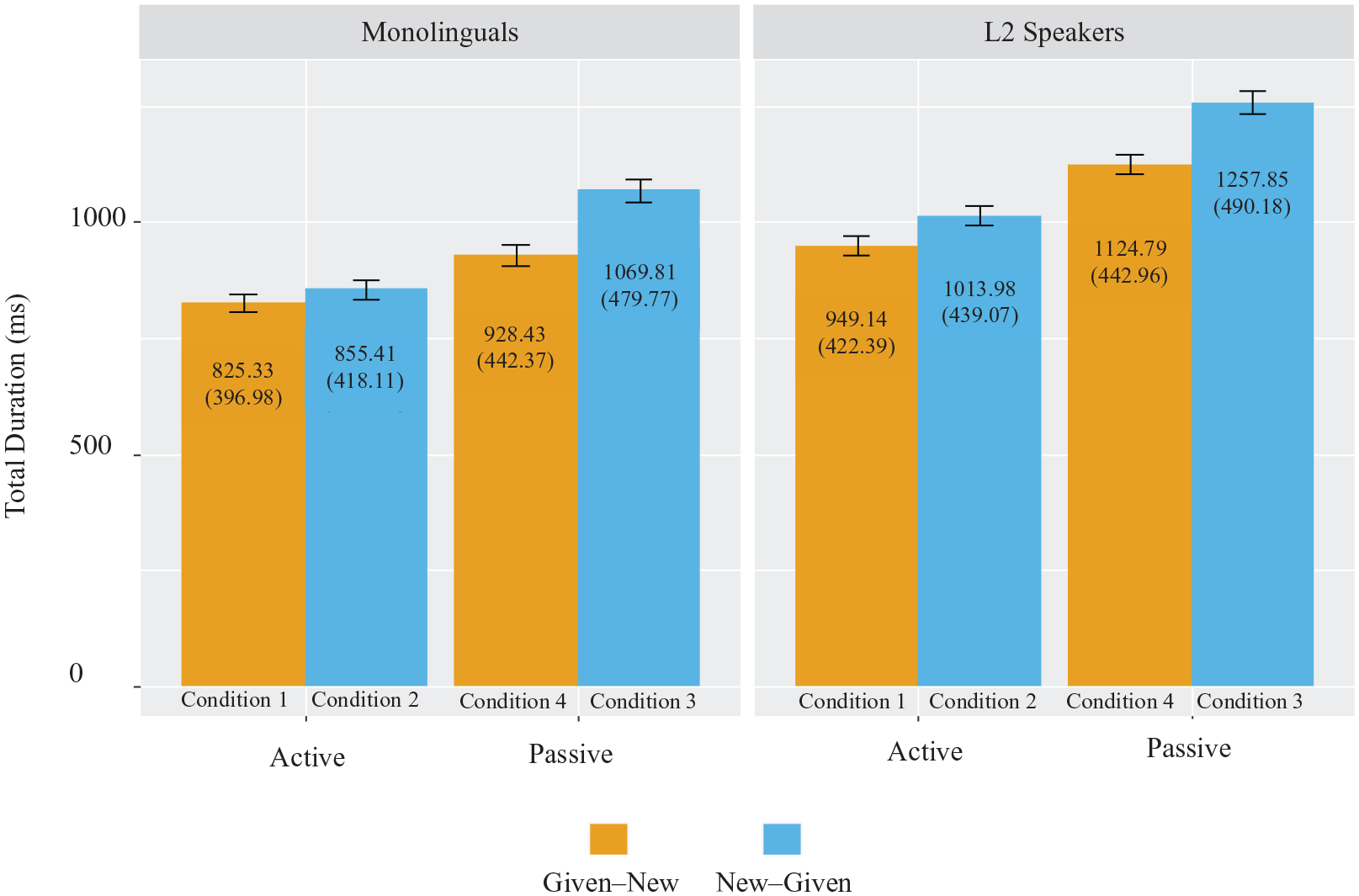
Mean total durations (in milliseconds); means and standard deviations shown inside bars.
Overall, total durations were significantly shorter for monolinguals (M = 917.6, SD = 444.22) than L2 speakers (M = 1085.22, SD = 463.15); for active constructions (M = 911.32, SD = 425.71) than passive constructions (M = 1094.9, SD = 477.83); and for the given–new context (M = 957.93, SD = 439.62) than the new–given context (M = 1049.39, SD = 479.11). In addition, total durations significantly increased as the number of characters in the construction critical region increased. To further examine the two-way interaction between information structure and voice, the given–new and new–given conditions were analysed separately to compare actives and passives directly. Maximal models for each information structure pattern were created using the same method outlined in Section II.5, only without the effect of information structure in both the fixed and random effects. The effect of voice was significant for both the given–new context (β = 0.08, SE = 0.02, df = 357.19, t = 3.23, p < .01) and the new–given context (β = 0.13, SE = 0.03, df = 147.02, t = 4.38, p < .001). Cohen’s d was calculated to compare the effect size of voice within each information structure using the cohen.d function in the effsize package (v. 0.8.0; Torchiano, 2020). The effect of voice was stronger in the new–given context (Cohen’s d = −0.54; medium) than in the given–new context (Cohen’s d = −0.35; small), suggesting that the difference between actives and passives was greater in the new–given than in the given–new context. Taken together, the results presented above suggest that both monolinguals and L2 speakers show differential effects of information structure on actives and passives, with the difference between actives and passives significantly reduced in given–new contexts but exacerbated in new–given contexts.
IV Discussion
Traditionally, it has been claimed that the non-canonical word order of passives makes them inherently more difficult to comprehend than their canonical active counterparts. However, studies on the online comprehension of word order variation have shown that the processing of non-canonical constructions such as the passive can be facilitated by presenting them with preceding contexts that license their information structure constraints. In the study described here, we used eye-tracking to investigate the comprehension of contextualized passive and active constructions. Our goal was to examine the effect of information structure on the comprehension of passive and active word orders, and whether this effect differed in monolinguals and L2 speakers. First, we predicted that if there was an effect of information structure on the processing of active and passive constructions, we would observe an interaction between information structure (given–new vs. new–given) and voice (actives vs. passives), indicating that passive sentences are especially costly to process (i.e. higher RTs) when presented with new–given information structure patterns. Second, we predicted that both monolinguals and L2 speakers would be sensitive to the differential effects of information structure in the comprehension of active and passive constructions.
Our results support these predictions. The significant main effects of voice and information structure indicate that active sentences were read faster than passives, and that sentences with given–new patterns were read faster than those with new–given patterns. Initially, one might think that participants were sensitive not to information structure per se but solely to the bias towards more frequent constructions (i.e. actives and given–new patterns). However, the fact that there was a significant interaction between voice and information structure reveals a much more complex picture: according to follow-up analyses, the interaction was driven by higher RTs on passive sentences with new–given information structure patterns. The fact that the magnitude of the information structure effect differs depending on word order lends robust support to the notion that much of the difficulty in processing passives that has been observed in past studies might be due, at least in part, to the fact that their discourse requirements were not met. In addition, we failed to find evidence that the two groups behaved differently, given the lack of any interactions with group and, specifically, the lack of a significant three-way interaction between information structure, voice, and group.
In the following sections, we first elaborate on why information structure patterns modulate the comprehension of actives and passives. Then, we discuss why, unlike previous research, we observed no differences between monolinguals and L2 speakers in the processing of information structure.
1 The shaping of asymmetries in the information structure constraints on word order
A question that arises from the results of the present study is how to explain the asymmetrical effect of information structure on the comprehension of active and passive constructions. We propose that this effect may have to do with differences in the use of thematic roles across these word orders (see explanation in Section IV.2.b). Prior literature has shown that there is a marked preference in the ordering of thematic roles such that agents tend to occur first (Zubin, 1979). This ‘agent-first’ preference likewise extends to comprehension (Ferreira, 2003; Tannenbaum and Williams, 1968), where previous studies have argued a privileged role of processing for agents (Segalowitz, 1982; Cohn and Paczynski, 2013; Cohn et al., 2017). Indeed, ‘the agent advantage has cognitive foundations that [. . .] point to agents having a central role in how we view events’ (Cohn and Paczynski, 2013: 75), a centrality that may make agents more accessible and thus more likely to be placed in utterance initial position. Similarly, given information, having recently been mentioned, can be considered more highly activated and thus more accessible to the speaker which increases its probability to be produced earlier (Bock, 1986). This accessibility effect makes given–new information structure patterns more frequent than new–given patterns across languages and constructions (Clark and Haviland, 1977; Halliday, 1967).
That both agentivity and givenness may increase the accessibility of subjects is crucial for understanding the asymmetrical information structure constraints on actives and passives, as well as what this entails for the processing of these constructions. The stronger preference for given-first in passives may be the result of the fact that themes are less salient and, in order to appear in subject position, require a ‘boost’ in accessibility. Conversely, subjects in actives are already more salient by virtue of being agents, thus mitigating the need for them to also be given. Thus, a bias emerges such that given–new information structure patterns are more likely to occur when the subject of the sentence is less accessible – in passives, rather than actives. This readily explains why the processing of passives takes a greater hit when presented in a new–given pattern compared to the more flexible active construction.
However, it is also important to point out that, unlike in other studies (e.g. Kaiser and Trueswell, 2004), differences were still observed between the canonical active and non-canonical passive word orders even when information structure was accounted for; that is, actives with given–new patterns were still read faster than passives with given–new patterns. This suggests that there might be other factors at play as well (e.g. frequency, semantics, etc.), which is indeed an interesting avenue for future research.
2 L2 speakers processing of information structure during online comprehension
The results presented in this study do not support previous research showing that, even at very high proficiency levels, L2 speakers have difficulties processing information structure constraints on word order during online comprehension (Belletti and Leonini, 2004; Belletti et al., 2007; Hertel, 2003; Montrul and Rodríguez Louro, 2006; Lozano, 2006, 2009; Prentza and Tsimpli, 2013; Roberts et al., 2008; Sorace and Filiaci, 2006; Valenzuela, 2006; Wilson, 2009). These previous studies are couched within the ‘Interface Hypothesis’ (IH; Sorace, 2011; Sorace and Serratrice, 2009; Tsimpli and Sorace, 2006), according to which interfaces of language modules are loci of contact between different aspects of language which can be internal (e.g. syntax, lexicon, morphology) or external (e.g. discourse, semantics). The interface between syntax and information structure has, by far, been the most examined to this day. The IH predicts that this interface is particularly problematic for L2 speakers because it requires that they process and integrate discursive and syntactic information simultaneously. This heavily burdens L2 speakers’ cognitive resources, which are already taxed by the suppression of the L1 grammar (see Sorace’s [2011] Processing Resource Allocation Account).
Unlike prior research, our results did not provide evidence that the two groups were different in their sensitivity to the effect of information structure on active and passive word orders. Why might this be the case? While the population sampled and the methodology employed might indeed have played a role, we propose two potential sources for the conflicting findings: (1) the construction under study and (2) the design of the materials used. Each factors is discussed in turn below.
a Construction’s characteristics
Conflicting results could be explained by the fact that sensitivity to information structure is construction-specific. In particular, we argue that the frequency of a construction within a language crucially modulates L2 speakers’ sensitivity to its information structure constraints. There is, in fact, some evidence in support of this: the study by Slabakova (2015) was the first to study L2 speakers’ sensitivity to the interaction between information structure constraints and the frequency distributions of canonical and non-canonical word orders. She examined L1-Spanish–L2-English, and L1-English–L2-Spanish speakers’ sensitivity to information structure in two OVS constructions: clitic left dislocation in Spanish and topicalization in English. Crucially, the fact that the clitic left dislocation is much more frequent in Spanish than topicalization is in English was reflected in the results: while English–Spanish L2 speakers were sensitive to the discourse requirements of clitic left dislocations in Spanish, Spanish–English L2 speakers showed no such sensitivity to topicalization in English (for similar results, see Ivanov, 2012;).
In this same vein, Hopp, Bail and Jackson (2018) investigated L1-German–L2-English, and L1-English–L2-German speakers’ sensitivity to information structure in sentences presented in broad or narrow-focus contexts. Participants judged the naturalness of fronted locative (LP) and temporal (TP) adverbial phrases and fronted objects in both English and German in comparison to a monolingual baseline. Importantly, English and German differ in the frequency with which they employ these constructions, such that fronted objects are more common in German than in English. Their findings indicated that L2 speakers were sensitive to the frequency with which non-canonical constructions are used in the L2, such that their ratings for the less frequent fronted objects were the only ones that differed from native speakers (for similar results, see Hopp, Bail and Jackson, 2020).
In the case at hand, active and passive constructions are very frequent in the input and follow the same distribution in Spanish and English, with actives being the canonical word order. However, the passive is used twice as frequently in English than in Spanish (60% in English vs. 34% in Spanish; see Blanco-Gómez, 2002; Roland et al., 2007; Runnqvist et al., 2013). Corpus analyses show that the passive is frequent in L2 speakers’ production, which is to be expected given that it is taught explicitly in the L2 classroom even at beginner levels (Hinkel, 2002). For instance, O’Donnell (2013) examined passive constructions in the Written Corpus of Learner English (WriCLE; Rollinson and Mendikoetxea, 2010). This corpus contains 521 essays of around 1,000 words each, written by L1 Spanish–L2 English speakers at various proficiency levels. His analyses revealed a gradual increase in the use of the passive with proficiency, such that while passive clauses accounted for only about 3% of clauses in beginner L2 speakers, this increased to about 9% by the time they reach advanced proficiency. This suggests that L2 speakers are exposed to passive constructions early on in their acquisition of English. One important question, however, is whether there is any evidence that L2 speakers are also able to learn the information structure requirements of passive constructions from the earliest moments in the acquisition process. To investigate this, we analysed a subset of sentences from the WriCLE corpus with the goal of examining the frequency with which L2 speakers used passive constructions with given–new information structure patterns. A potential limitation that needs to be addressed is that corpus-based materials are oftentimes problematic for studying information structure in that it can be difficult to determine in a definitive way what is informationally new or old. In trying to bypass this problem, we carefully examined the previous context of each utterance in order to code the grammatical subject and object all sentence in terms of its information status (given vs. new), analysing a total of 670 tokens. It is important to note that acquiring the information structure constraints on the English actives and passive is made easier for L1 Spanish speakers by the fact that English and Spanish have matching information structure patterns for these constructions. This, of course, raises the possibility that our findings are the result of cross-linguistic transfer. However, there is evidence that L2 speakers at lower proficiency levels are not sensitive to L2 information structure constraints, even when they match those of their L1(Marefat, 2005; Park, 2014; Reichle and Birdsong, 2014). The distribution of results showed that, overall, L2 speakers produced the passive with licensed given–given (N = 416/655, 63.51%) and given–new patterns (N = 179/655, 27.32%) much more than with unlicensed new–given (N = 42/655, 6.41%) and new–new (N = 18/655, 2.74%) patterns (see Figure 2). Together with the results from the eye-tracking experiment in the present study, these data suggest that L2 speakers are sensitive to information structure not only in their utterances, but also when they process active/passive sentences during online reading.
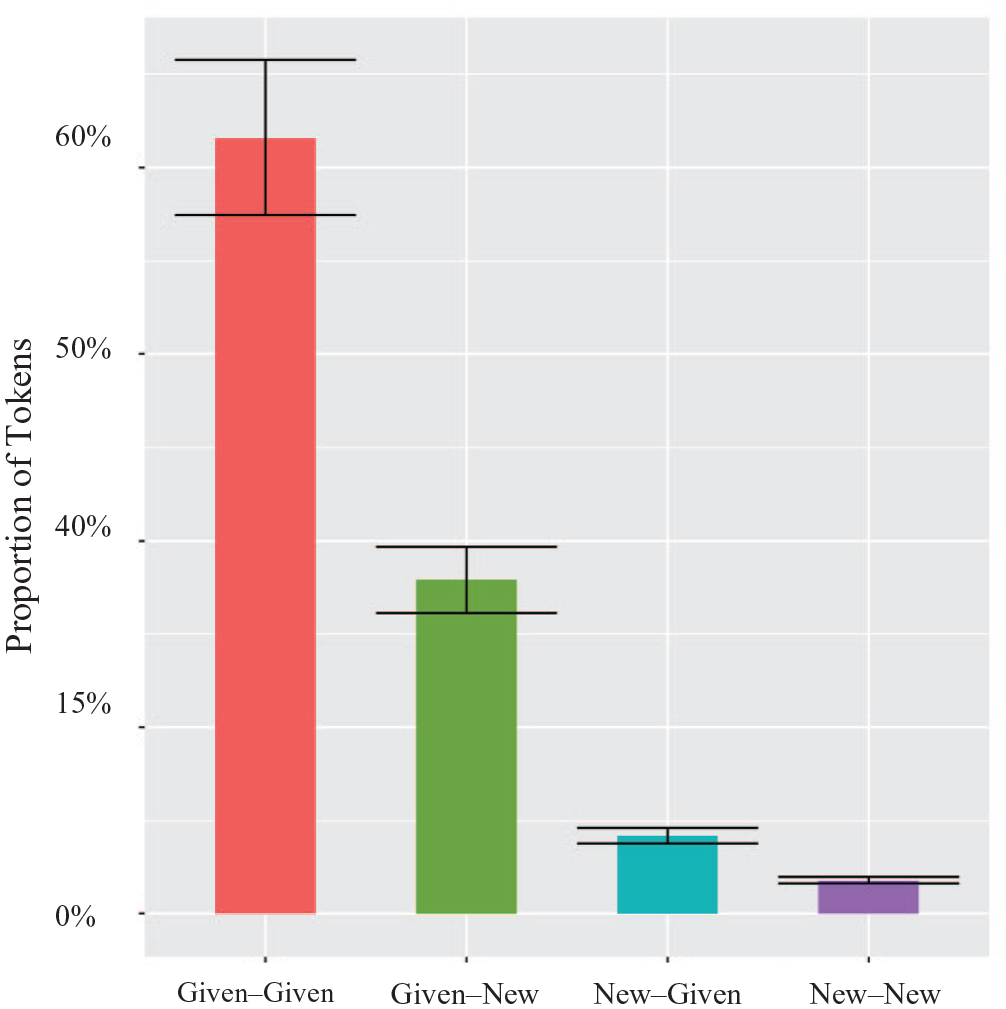
Distribution of information structure patterns in the production of passives by second language (L2) speakers.
b Design of materials
The literature discussed above provides robust evidence that frequency distributions play a crucial role in the development of sensitivity to information structure in the L2. This underscores the relevance of utilizing corpus-based materials that reflect naturalistic usage of information structure constraints on word order. The incorporation of naturalistic corpus data into the design of tightly controlled psycholinguistic stimuli is crucial for the development of experiments that are more ecologically valid and can contribute to theories of L2 acquisition and processing that have greater explanatory adequacy (Lozano and Mendikoetxea, 2013; Mendikoetxea and Lozano, 2018; Gilquin and Gries, 2009; Meunier and Littre, 2013; Tracy-Ventura and Myles, 2015). Nevertheless, many past psycholinguistic studies of language comprehension have employed experimental materials that have been either intuited or generated from introspection. A clear example comes from the literature on variable subject expression in Spanish.
As explained in Section I, Spanish is a pro-drop language, which means that under certain conditions the grammatical subject of a sentence can be omitted. It has been suggested that the production of overt and null subjects in Spanish is governed at the syntax–pragmatics interface (Lozano, 2009). Although there are conflicting results, the majority of studies with L2 speakers have shown that even advanced and near-native L2 learners often accept redundant, pragmatically infelicitous overt pronouns where native speakers would prefer a null pronoun. However, corpus studies have shown that morphosyntactic and pragmatic factors are not the only variables at play in constraining null and overt subjects in Spanish. Travis and Torres Cacoullos (2012) claim that ‘such factors [morphosyntactic and pragmatic] are often left without operational definitions and are applied without attention to differences between persons, syntactic roles and genres’ (p. 712). Using the Corpus of Conversational Colombian Spanish (approximately 40,500 words; Travis, 2005) they analysed all instances of first person singular verbs with pre-verbal overt and null subjects (i.e. yo ‘I’) in order to uncover their linguistic conditioning. The results of their multivariate analysis demonstrated that speakers’ choice of an overt 1st person singular pronoun in Spanish is modulated by a myriad of factors such as: the semantic class of the verb, structural priming, referential distance, tense-aspect-mood and polarity.
Crucially, Travis and Torres Cacoullos’ results raise the possibility that previous studies which have shown that L2 speakers’ knowledge of overt and null subjects in Spanish is not native-like have presented stimuli that did not match learners’ experience with variable subject expression and, therefore, it is likely that sensitivity to its constraints was not observed. The same rationale, applied to studies on L2 learners’ sensitivity to information structure, helps better understand the conflicting results found in the extant literature. It is possible that previous findings showing that even highly proficient L2 speakers are not sensitive to information structure may be due to the fact that the stimuli used did not reflect naturalistic usage of L2 information structure constraints on word order.
V Conclusions
In conclusion, the findings of the present study suggest that the comprehension asymmetry traditionally observed between actives and passives can be better understood by presenting these constructions in a contextualized fashion and considering the effects that information structure constraints have on their processing. In addition, our results go in line with those of previous research, providing evidence that L2 speakers can be sensitive to information structure constraints during comprehension to the same extent as monolinguals in certain constructions, such as actives and passives. Crucially, we also argue that L2 speakers’ sensitivity to information structure is construction-specific, such that learners may take longer to acquire the information structure requirements of constructions that are less frequent in their input, but show more sensitivity to frequent structures. Considering the frequency distribution of syntactic structures and their information structure constraints is crucial for a better and more unified theory of L1 and L2 processing. This calls for the design of corpus-based materials that reflect naturalistic usage of information structure constraints on word order. Although different sources of data may have their place in psycholinguistic research, studies of language comprehension that present comprehenders with contexts are not part of their prior linguistic experience effectively create linguistic environments that comprehenders have learned to not expect, giving rise to concomitant processing costs or null effects.
Supplemental Material
sj-pdf-1-slr-10.1177_0267658321992461 – Supplemental material for The effects of information structure in the processing of word order variation in the second language
Supplemental material, sj-pdf-1-slr-10.1177_0267658321992461 for The effects of information structure in the processing of word order variation in the second language by Priscila López-Beltrán, Michael A Johns, Paola E Dussias, Cristóbal Lozano and Alfonso Palma in Second Language Research
Supplemental Material
sj-pdf-2-slr-10.1177_0267658321992461 – Supplemental material for The effects of information structure in the processing of word order variation in the second language
Supplemental material, sj-pdf-2-slr-10.1177_0267658321992461 for The effects of information structure in the processing of word order variation in the second language by Priscila López-Beltrán, Michael A Johns, Paola E Dussias, Cristóbal Lozano and Alfonso Palma in Second Language Research
Footnotes
Acknowledgements
We are grateful to Isabel Deibel and Carrie N Jackson for helpful comments on an earlier version of this article, as well as all the reviewers that made this manuscript into what it is.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The writing of this article was supported in part by a Foreign Fulbright Fellowship to Priscila López-Beltrán, NSF Grant No. DGE-1255832 to Michael A Johns, and NSF Grant No. OISE-1545900 to Paola E Dussias.
Supplemental material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.