
Abstract
Korean learners of English are known to repair consonant clusters, which are not allowed in their native language, with an epenthetic vowel [ɨ]. The purpose of the present study is to examine whether the perception–production link of such an illusory vowel in a second language (L2) is only within and not across processing levels, as proposed in a previous study regarding L2 segments. We assessed the perception and production of English onset clusters by Korean learners and native English speakers at the prelexical (AX discrimination and pseudoword read-aloud tasks) and lexical (lexical decision and picture-naming tasks) levels, using the same participants and stimuli across the tasks. Results showed that accuracy in not producing an epenthetic vowel between the two consonants of onset cluster was not significantly associated with accurate perception of the cluster either within or across processing levels. The results suggest that production and perception accuracy in L2 phonotactics are independent to a certain extent.
I Introduction
In many second language (L2) models, such as SLM (Flege, 1995) and PAM-L2 (Best and Tyler, 2007), it is assumed that perception and production are closely related in phonetic/phonological acquisition and that accurate L2 perception tends to precede accurate L2 production. However, empirical evidence has yielded mixed results (for a review, see Gorba and Cebrian, 2021). In some research, perception was shown to precede production in L2 (Baker and Trofimovich, 2006; Bohn and Flege, 1990; Flege et al., 2003; Nagle, 2018). For example, if first language (L1) and L2 phones are similar, learners may not detect the phonetic differences between them, potentially leading to incorrect production. Other research has shown that L2 learners may produce L2 phones accurately even if they are unable to perceive them in a target-like manner (Bohn and Flege, 1997; Caramazza et al., 1973; Flege and Eefting, 1986; Sheldon and Strange, 1982). Sheldon and Strange (1982) found that native Japanese learners can produce /l/ and /r/ in English, while still showing perception errors between the two phonemes. Due to these inconsistent results, Flege and Bohn (2021) presented a revised version of the SLM (SLM-r), positing that L2 segmental perception and production co-evolve without precedence and that although there is a strong bidirectional influence between the two modalities, their correspondence is never perfect even in monolinguals. In fact, Flege and Bohn (2021) cited significant empirical evidence to support these hypotheses. Specifically, it was shown that even the positive perception–production correlations did not show causality (Peperkamp and Bouchon, 2011), and that even native speakers exhibited differences in the use of the primary acoustic cues such as voice onset time (VOT) and F0 for voicing of stops between production and perception (Shultz et al., 2012).
While there has been abundant work on the relationship between perception and production of individual L2 segments, few have investigated their relationship of phonotactic constraints, language-specific licit versus illicit sound sequences. Each language has its own phonotactic restrictions, which determine the specific sound sequences that can appear in syllable onset or coda positions. To our knowledge, de Leeuw et al. (2021) may be the only study that directly examined the perception and production of phonotactic constraints in L2. Specifically, they investigated whether Spanish learners of English perceived and produced onset /sC/ clusters in English with a prothetic vowel /e/, owing to the phonotactics of their native language prohibiting consonant clusters in syllable onset; however, they found no significant correlation between production and perception accuracy.
The purpose of the present study was to further elucidate the relationship between perception and production of L2 phonotactics by systematically examining methodological issues that may influence the L2 perception–production link. Specifically, we investigated whether the perception–production link can be found within, but not across, processing levels. Accordingly, we examined Korean learners’ perception and production of word-initial consonant clusters in English at both prelexical and lexical processing levels.
1 Perception and production of L2 phonotactics
Language-specific phonotactics may play a role in processing spoken words in L2. When L1 and L2 phonotactics differ, L2 learners may adjust phonotactically illicit sequences in L2 in various ways. Previous research on L2 phonotactic constraints addressed the perception of illusory vowels by L2 learners whose L1 does not allow specific consonant clusters (Dupoux et al., 1999, 2011; Durvasula and Kahng, 2015; Kilpatrick et al., 2020). For example, Dupoux et al. (1999) tested native French and Japanese listeners using offline phoneme detection and speeded ABX discrimination tasks. Unlike French listeners, Japanese listeners perceived illusory vowels (/u/) inside consonant clusters in VCCV stimuli (e.g. ebuzo from ebzo), and had trouble discriminating between VCCV and VC/u/CV stimuli. These results were based on Japanese phonotactic constraints that do not allow consonant clusters in word-medial position. In Brazilian Portuguese, for very similar contexts, the epenthetic vowel is /i/, not /u/, showing that epenthetic vowels are specific to each language (e.g. ebina from ebna; Dupoux et al., 2011; Parlato-Oliveira et al., 2010). Parlato-Oliveira et al. (2010) compared the perception of illusory epenthetic vowels in early and late Japanese–Brazilian bilinguals and monolingual Japanese listeners. Interestingly, similar to native Japanese listeners, late Japanese–Brazilian bilinguals perceived the epenthetic vowel /u/, while early bilinguals were more likely to perceive the epenthetic vowel /i/, similar to Brazilian monolinguals.
Another interesting case of phonological repair can be found among Spanish speakers who produce a prothetic /e/ in word-initial /sC/ sequences (e.g. esport for sport), which is motivated by the phonotactic ban on /sC/ clusters in word-initial position in Spanish (Cuetos et al., 2011; Freeman et al., 2016). Theodore and Schmidt (2003) found that native Spanish speakers reported hearing an utterance-initial /e/ in all the stimuli in the [stib]–[estib] continuum, regardless of the manipulated duration of the initial vowel (from 0 ms to 100 ms), while English-speaking listeners did not hear /e/ if it was shorter than 20–30 ms. Carlson et al. (2016) examined whether knowledge of English weakens perceptual repair in fluent Spanish–English bilinguals. In two tasks based on conscious metalinguistic judgments and low-level perceptual processes, bilinguals, even those dominant in Spanish, showed weaker perceptual repair effects relative to Spanish monolinguals, while the repair effects were even weaker in English-dominant bilinguals. These results suggest that conflicting phonotactic systems can jointly influence bilinguals’ perceptual repair of acoustic signals; however, this is modulated by degree of integration and mutual influence of knowledge between the two languages.
De Leeuw et al. (2021) examined the relationship between perception and production of illusory prothetic vowels in Spanish–English bilinguals. To assess perception, Spanish–English bilinguals and English monolinguals participated in a same–different discrimination task, in which they judged whether two tokens, such as [spi] and [espi], were identical. Speech production of vowel prothesis was assessed through a phonemic verbal fluency task, in which participants were asked to produce as many words as possible, starting with a given letter or letters (e.g. speak for a word starting with <sp>). To examine relationship between the perception and production of onset /sC/ clusters by Spanish–English bilinguals, the mean perception accuracy score was included as a possible predictor for accuracy of pronunciation, and accuracy score of perception was not shown to be a significant predictor nor correlated with correct production. Unlike English monolinguals, Spanish–English bilinguals did not produce the prothetic vowel accurately in the phonemic fluency task; however, this was not associated with accurate perception of prothetic vowels. Interestingly, production was likely to be modified by increased exposure to L2 and grammatical proficiency, whereas perception was not. Moreover, analysis of the individual participants’ results did not indicate that accurate perception is a prerequisite for accurate production. Whereas some participants were more accurate in the production than in the perception task, others were more accurate in the perception than in the production task. However, the dissociation between perception and production in de Leeuw et al. (2021) may be related to the differences of lexical status of the stimuli used in each task: a prelexical task in perception (same–different discrimination task) and a lexical task in production (phonemic verbal fluency task).
Recently, processing levels have also been shown to play a role in the perception–production link. Melnik-Leroy et al. (2022) found that, among English–French bilinguals, perception of the French vowel contrast /u/–/y/ in a prelexical perceptual task (ABX discrimination) was associated with its production in a prelexical production task (pseudoword reading), but not in a lexical production task (picture naming). Melnik-Leroy et al. (2022) explained the lack of association between these two modalities across levels with the fact that tasks tapping into different processing levels might not be directly comparable as they involve different skills that require different amounts of cognitive load and get access to different types of representation. Similarly, Gorba and Cebrian (2021) pointed out the fact that the perception and production measures used in their study were not fully comparable, which could lead to a weak relationship between these two modalities. Accordingly, the dissociation between perception and production in de Leeuw et al. (2021) may be attributable to the use of a prelexical task to assess perception (same–different discrimination task) and a lexical task to assess production (phonemic verbal fluency task).
2 Korean and English phonotactics
The present study targets differences in Korean and English phonotactic constraints on syllable-onset consonants. In syllable onset and coda positions, Korean allows maximally a single consonant; thus, the Korean syllable template is (C)(G)V(C) (C = consonant, G = glide, V = vowel). This template mandates that the onset is either blank (e.g. [i] ‘tooth’, [an] ‘inside’) or with a single consonant except /ŋ/ (e.g. [pi] ‘rain,’ [pok] ‘fortune’) (Shin et al., 2013; Sohn, 1999). The underlying consonant clusters in the coda of the previous syllable thus undergo deletion (e.g. [tak.cuk] < /talk.cuk/ ‘chicken soup’), or resyllabification when followed by a vowel-initial syllable (e.g. [tal.gi] < /talk.i/ ‘chicken is …’). However, in English, three consonants are maximally allowable, with specific restrictions on consonant types (Hammond, 1999). When a single consonant occurs in the onset position, all consonants except /ŋ/ can occur, although /ʒ/ occurs only sporadically, particularly in foreign/borrowed words (e.g. genre). All two-consonant onsets are composed of either /s/ followed by a voiceless stop, a fricative or nasal (e.g. spin, snail), or a stop or fricative followed by /w, j, l, ɹ/ (e.g. blue, free). The three-consonant onsets should begin with /s/, the following consonant should be a voiceless stop, and the final consonant should be an approximant, /w, j, ɹ, l/ (e.g. spring, skew).
For initial consonant clusters in English, native Korean learners of English have shown phonotactic repairs through a vowel epenthesis (Darcy and Thomas, 2019; Kabak and Idsardi, 2007). For example, illicit consonant clusters in Korean are known to be perceptually repaired by inserting [ɨ]-like vowel to break them up in most contexts (Kabak and Idsardi, 2007). 1 The Korean [ɨ] is the least marked vowel in Korean, which frequently appears in the adaptation of English loanwords with onset consonant clusters and coda non-palatal consonants (e.g. [sɨphocɨ] for sports) (Sohn, 1999). Further, Korean learners had more difficulties than English listeners in discriminating between pairs such as /phakma/–/phakɨma/, because Korean does not allow a sequence such as /km/. In a same–different discrimination task, learners’ scores were significantly lower than those of native English listeners. Darcy and Thomas (2019) investigated the potential consequences of such perceptual repairs in Korean learners’ mental lexicon, and observed that Korean learners accepted nonwords containing epenthetic vowels (e.g. b[ɨ]lue < blue) as real English words more often than native English listeners did in a lexical decision task. These results led to the conclusion that perceptual epenthesis can be lexically encoded in the mental lexicon of at least some Korean learners.
3 The present study
Given the dearth of research on the relationship between perception and production of L2 phonotactic constraints, we examined the relationship between these two modalities with Korean–English sequential bilinguals and English monolinguals. We focused on the perception and production of English obstruent–sonorant clusters in syllable onset position (e.g. block), addressing a methodological issue as a factor in the perception–production link. Whether a link is present between perception and production has been shown to depend on multiple factors, such as target sound contrasts, L2 proficiency, and L2 learners’ motivation (e.g. Bohn and Flege, 1997; Levy and Law, 2010; Sheldon, 1985). In the present study we investigated whether the perception and production of L2 phonotactics are linked within, but not necessarily across, processing levels, as suggested by Melnik-Leroy et al. (2022). To this end, we systematically controlled prelexical and lexical levels, and examined the perception and production of L2 epenthetic repairs within and across those levels. 2 To assess speech perception, a pseudoword AX discrimination task (prelexical) and a lexical decision task (lexical) were performed, while for production, a pseudoword read-aloud task (prelexical) and a picture-naming task (lexical) were conducted. By comparing the results of these tasks, we aimed to add to the current understanding of the perception–production link in relation to L2 phonotactic constraints.
II Materials and methods
1 Participants
A total of 39 participants were included in the study: 30 Korean learners of English (21 females) and 9 native English speakers as controls (2 females). The Korean learners of English were all late learners who began learning English after the age of 6 years and had grown up in Korean monolingual households, without any experience living in a foreign country for more than 6 months. Most of the Korean speakers had studied English as a compulsory subject since Grade 3 in elementary school, and thus had learned English as an L2 in the instructional context for 10 years. While a few speakers had taken private lessons from native English speakers, they had little experience using English in daily communication, and thus demonstrated a much lower proficiency in English than in their native language. All participants reported normal or corrected-to-normal vision and hearing and no articulation disorders. To evaluate their English proficiency, the Korean learners completed a multiple-choice L2-English vocabulary size test (The Vocabulary Size Test (VST); Nation and Beglar, 2007) after participating in the experimental tasks. The Korean learners of English had an average L2 vocabulary of 7,140 words (range: 4,000–10,500, SD = 1,555.5). Based on Nation’s (2006) criteria, the participants were considered intermediate- to advanced-level English learners. The native English speakers were either exchange students (n = 3) who had arrived in Korea less than 6 months ago or English teachers at the time of study. They demonstrated a wide range of experience in Korean; three of the English speakers could not speak Korean at all, while one individual was barely able to communicate in Korean. Table 1 summarizes the participants’ demographic and language background information.
Participant background information (mean (sd; range)).

2 General procedure
The present study comprised four tasks. Perception and production were each examined using two tasks: evaluating pre-lexical (pseudoword AX discrimination and pseudoword read-aloud tasks) and lexical (lexical decision and picture-naming tasks) processing. Participants first completed the two pre-lexical tasks, and then proceeded to the two lexical tasks, with a 12-minute break between to allow participants to focus on the tasks without fatigue. 3 In the perception and production tasks at the same processing level the same stimuli (pseudowords or words) were used, and the task order was counterbalanced. Accordingly, half of the participants performed the perception tasks first and the other half, the production tasks. After the four experimental tasks, participants completed a word familiarity test and background questionnaire. The participants were tested individually in a soundproof booth, which included a computer with E-Prime 2.0 software installed. A Marantz (PMD 670) recorder and microphone (Shure KSM 44) were also used for speech production tasks (pseudoword read-aloud task and picture-naming task), and Sennheiser HD600 headphones were used for speech perception tasks (pseudoword AX discrimination task and lexical decision task).
3 Pre-lexical perception and production tasks
a Stimuli
The experimental stimuli for the AX discrimination and pseudoword read-aloud tasks consisted of 20 English pseudowords containing onset clusters, with the structure C1C2V(C3), where V = [u] or [i], C3 = /s/ or /t/. 4 The onset clusters (C1C2) contained a stop (/p, t, k, b, d, g/) and a liquid (/l, ɹ/), resulting in 10 cluster types, excluding the clusters /tl-, dl-/, which are not observed in English phonotactics. Each pseudoword was presented in the Roman alphabet in the read-aloud task. These pseudowords were modified to create two types of nonwords for each cluster type. The first nonword type contained the epenthetic [ɨ] (e.g. [bɨlut] from [blut]), and the second type contained the epenthetic [ɪ] (e.g. [bɪlut] from [blut]) between the onset clusters. The epenthetic vowel [ɨ] is similar to the Korean epenthetic vowel for onset clusters, while the vowel [ɪ] was inserted to serve as a control (for more details, see Darcy and Thomas, 2019). This resulted in 60 trials: 10 clusters × 2 vowels × 3 conditions, without the epenthetic vowel (CC), with [ɨ] (C[ɨ]C), and with [ɪ] (C[ɪ]C). The stimuli were recorded by two native English speakers (one female), in a Midwestern American dialect. The male and female speakers were 37 and 29 years of age, respectively, and both lived in Seoul, Korea, at the time the stimuli were recorded. They had lived in Korea for approximately 5 and 10 years, respectively. The stimuli were recorded in a soundproof booth at a sampling rate of 44,100 Hz with 16-bit resolution. They read the target words in a frame sentence (‘The word is ___’) twice, and the second recordings were used as the experimental stimuli, unless mispronounced. The temporal and spectral properties of the epenthetic vowels in the recorded stimuli were measured manually by the first author using Praat (Boersma and Weenink, 2021). Table 2 summarizes the duration of each type of epenthetic vowel and the formant values (F1, F2). The beginning and end of the target vowels were marked by the onset and cessation of a periodic waveform with a regular formant structure, particularly F2. To avoid any influence from loudness, the stimuli were scaled using a Praat script for scaling intensity (Winn, 2020), such that their average intensity was 65 dB. A complete list of the stimuli is provided in Appendix 1.
Characteristics of epenthetic vowels [ɨ] and [ɪ] in the recorded stimuli for AX discrimination task (standard deviation in parentheses).
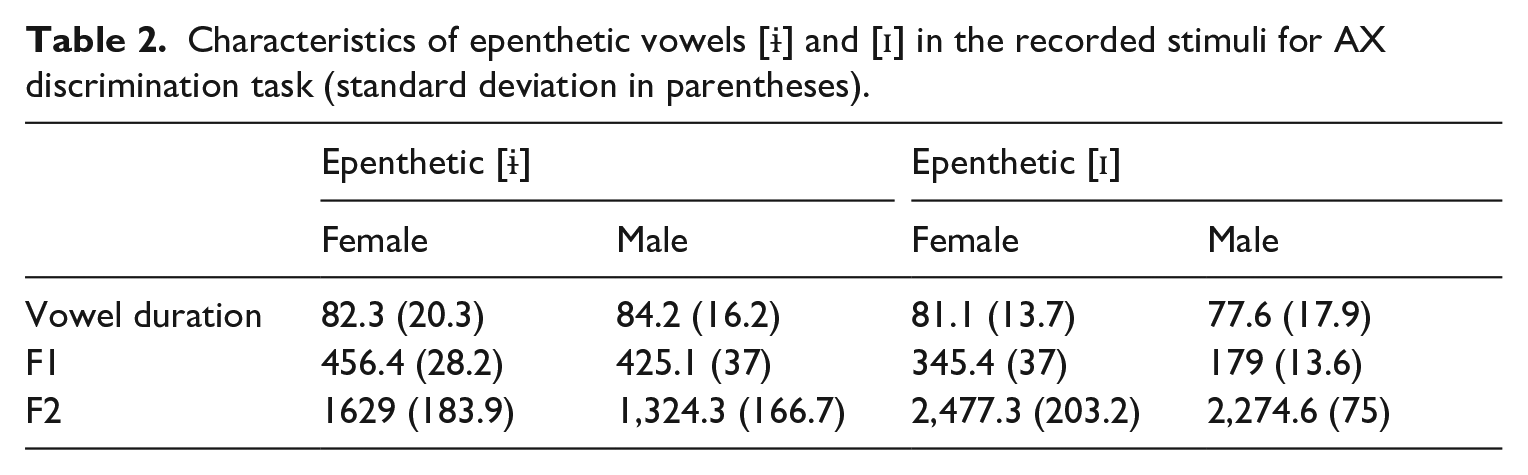
As Table 2 shows, the two epenthetic vowels, [ɨ] and [ɪ], were clearly distinguished in terms of F2 (vowel frontness); the average duration of either [ɨ] or [ɪ] was similar to that of epenthetic vowels used in previous studies (Darcy and Thomas, 2019; Shin and Iverson, 2014). For example, in Darcy and Thomas (2019), the mean duration of [ɨ] in the target words was 103.8 ms (range: 93.7–113.8, SD = 26.9), while that of [ɪ] was 89.2 ms (range: 80.1–98.4, SD = 24.5). Shin and Iverson (2014) also observed a mean duration of 85 ms (SD = 26.9), with high variability across speakers.
b Procedure
The AX discrimination task was administered to evaluate perception. Participants were presented with two items – the first one produced by the female speaker and the second by the male speaker – and were asked to determine whether the two items were identical or different as quickly and accurately as possible, using designated keys on the keyboard (‘1’ for ‘identical’, and ‘3’ for ‘different’). The participants were instructed to direct their attention toward linguistic information, ignoring any additional indexical dimension of the spoken stimulus. Each trial began with a blank screen for 1,000 ms, followed by a fixation point ‘+’ for 500 ms. Then, two items recorded by the male and female speakers were presented over headphones with 150-ms ISI (Melnik-Leroy et al., 2022). If a participant did not respond within 2,500 ms, the next trial began. In total, there were 120 trials (10 clusters × 2 vowels × 3 conditions (without an epenthetic vowel, with [ɨ], and with [ɪ]) × 2 orders (AX or XA)) divided into 3 blocks. To avoid any priming effect, the 3 items according to the stimulus condition (e.g. troot, t[ɨ]root, and t[ɪ]root) were presented in different blocks. Before the task started, 12 practice trials, which were not included in the experimental stimuli, were administered. Each of the 3 blocks contained an approximately equal number of tokens for the 3 conditions. The target words were presented in a randomized order within each block. The participants were allowed to take as much rest as they wanted between blocks, and the task lasted approximately 10 minutes.
To assess production, a pseudoword read-aloud task was administered. For each trial, participants sat in front of a computer, which presented a blank screen for 1,000 ms, followed by a fixation point ‘+’ for 500 ms. Then, a pseudoword appeared at the center of the computer screen (32-point Times New Roman font) for 2,000 ms (e.g. <bloot> for [blut]), followed by ‘*****’ which flickered for 150 ms, and then a frame sentence ‘I say ____ only’ (32-point Arial font). The participants were asked to read aloud the sentence with the pseudoword (e.g. ‘I say bloot only’) twice, and to press the space bar to proceed to the next trial. The participants’ responses were recorded. In total, 20 trials (10 clusters × 2 vowels) were presented in 1 block after a short practice session with 4 filler tokens, which were not used for experimental stimuli. The task lasted approximately 5 minutes. 5
4 Lexical perception and production tasks
a Stimuli
The experimental stimuli consisted of 30 common English words containing onset clusters (TW, target words), with 3 items for each consonant cluster (/pl-, bl-, kl-, gl-, pɹ-, bɹ-, tɹ-, dɹ-, kɹ-, gɹ-/). The randomized list of test words was presented to 9 Korean learners of English, who did not participate in the tasks, and their familiarity of the words was evaluated, using a 7-point Likert scale (1 = unknown, 7 = well known). The mean ranking for word familiarity was 5.9 (range: 4.5–6, SD = 0.4). Except for the words priest and grave, all items had rankings above 5. Similar to the pseudoword tasks, nonwords were created by modifying the test words. Specifically, 30 nonwords were created by inserting the epenthetic vowel [ɨ] between the onset clusters (e.g. b[ɨ]louse) (TW-[ɨ], target words with [ɨ]), and another 30 nonwords were created with the vowel [ɪ] between the clusters (e.g. b[ɪ]louse) (TW-[ɪ], target words with [ɪ]). The tokens with [ɨ] were expected to be considered real words for less proficient learners, but nonwords for more proficient learners. The distractor items were 45 words (e.g. deer, egg) (FW, filler words) and 45 nonwords (FNW, filler nonwords) (e.g. beff, costle) that did not begin with a consonant cluster. Each word item was matched to a simple drawing, mostly selected from Broder et al. (2010), Szekely et al. (2004), and Snodgrass and Vanderwart (1980), except for the word pray, which was obtained from online icon platform (Zoucas, 2021). A complete list of the test words is provided in Appendix 2. Table 3 summarizes the characteristics of the epenthetic vowels [ɨ] and [ɪ] in the recorded stimuli.
Characteristics of epenthetic vowels [ɨ] and [ɪ] in the recorded stimuli for lexical decision task (standard deviation in parentheses).

As in the prelexical perception task, the two epenthetic vowels, [ɨ] and [ɪ] were clearly distinguished in terms of F2; the average duration of both [ɨ] and [ɪ] was slightly shorter than in the prelexical perception task and previous studies (Darcy and Thomas, 2019; Shin and Iverson, 2014).
b Procedure
To evaluate perception, a lexical decision task was administered. Each trial began with a blank computer screen for 1,000 ms, followed by a fixation point ‘+’ for 500 ms. Then, each word or nonword, recorded by a male speaker, was presented through the headphones. The participants were asked to indicate as quickly and accurately as possible whether what they had heard was a real English word, using the designated keys. If a participant did not answer within 2,500 ms, the next trial began. In total, there were 180 trials (30 words + 30 nonwords with [ɨ] + 30 nonwords with [ɪ] + 45 filler words + 45 filler nonwords), which were presented in 3 blocks. To avoid any priming effect, the 3 items according to the stimulus condition (e.g. blouse, b[ɨ]louse, and b[ɪ]louse) were presented in different blocks. The task was preceded by 12 practice trials, which were not used as experimental stimuli. Within each block, the test words were presented in a randomized order. The participants were allowed to rest as much as they wanted between blocks, and the task lasted approximately 12 minutes.
In a picture-naming task to assess production, participants were presented with 75 black-and-white line drawings corresponding to 30 target words (TW) and 45 filler words (FW). Before the task, participants were presented with the list of 75 pictures. If the name of a picture was unclear, the name was provided once. Each trial started with a blank computer screen for 1,000 ms, followed by a fixation mark ‘+’ at the center of the screen for 500 ms. This was followed by the target picture, and participants were instructed to name the picture as quickly and accurately as possible, and then press the space bar to proceed to the next trial. The task was preceded by 4 practice trials, which were not used as experimental stimuli. The 75 items were presented across 3 blocks. Within each block, the test words were presented in a randomized order. The task lasted approximately 18 minutes, and participants were allowed to take as much rest as they wanted between the blocks.
After performing the four tasks, participants completed a word familiarity test for 75 English (test and filler) words. For each word, participants were instructed to rate the familiarity of the word, using a 7-point Likert scale (1 = unknown, 7 = well known), additionally writing its meaning on a provided blank sheet of paper.
III Results
1 Prelexical processing
a Perception
We analysed the accuracy scores and reaction times (RTs) for correct responses in the AX discrimination task. In total, 4,680 trials were analysed (Korean: 3,600, native English: 1,080). No responses (0.36%) and trials for which the RTs were above or below 2 SD (5%) were eliminated from the analysis. The data from two native speakers of English were not included in the analysis, because they were considered to have hearing deficits, due to the accuracy scores below chance level in the discrimination of identical pseudowords (CC-CC condition). The background information for the remaining seven native English speakers was additionally presented in Table 1. As a result, 66.9% of the trials performed by Korean learners and 75.6% of those by native English listeners were analysed. Table 4 summarizes the mean accuracy scores and RTs.
Percentage of correct responses (%) and reaction times (RTs in ms) per stimulus condition for Korean and native English listeners in the AX discrimination task (standard deviations in parentheses).
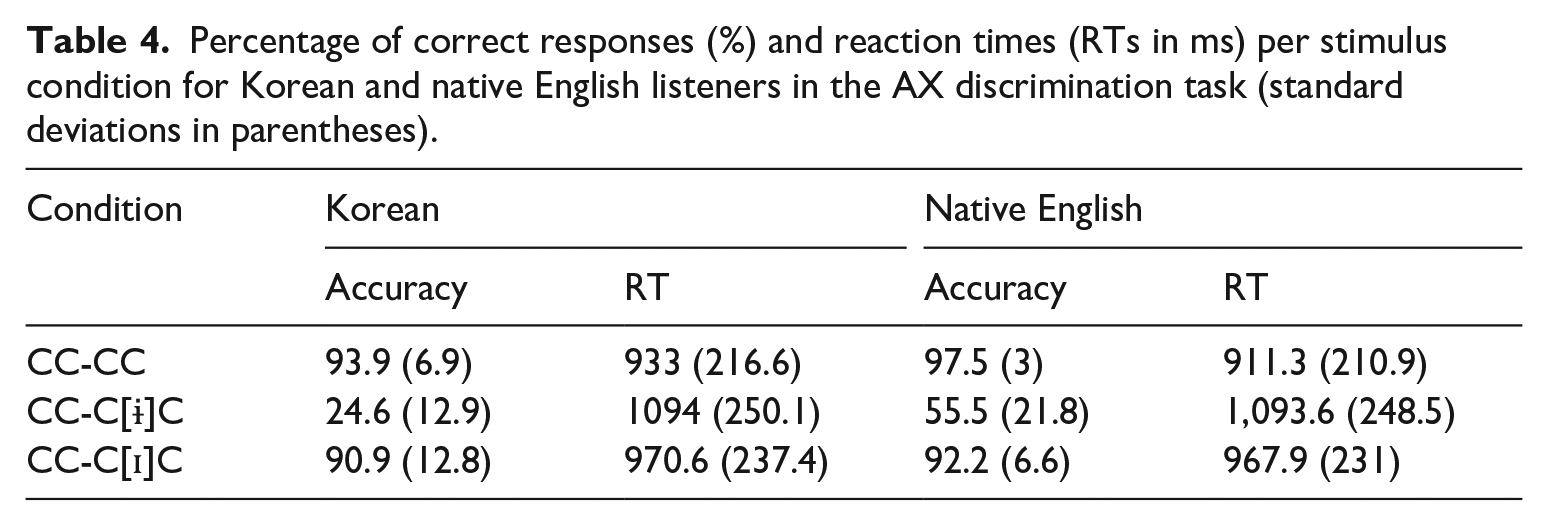
The accuracy results in Table 4 show that Korean learners of English performed least accurately in the test condition (CC-C[ɨ]C), compared with the identical (CC-CC) and control (CC-C[ɪ]C) conditions, and less accurately than the native English listeners. The RT results showed a similar pattern to the accuracy results. Both Korean and native English listeners had the shortest RTs in the CC-CC condition and the longest RTs in the CC-C[ɨ]C condition. However, unlike in the case of the accuracy tasks, the two listener groups showed similar RTs in the CC-C[ɨ]C and CC-C[ɪ]C conditions.
The accuracy results were analysed using mixed-effects logistic regression model utilizing the glmer function from the package lmerTest (Kuznetsova et al., 2017) in R (version 3.2.2, R Core Team, 2017). The dependent variable was responses (binary-coded as ‘correct’ or ‘incorrect’), and the fixed factors were stimulus condition (CC-CC, CC-C[ɨ]C, CC-C[ɪ]C) and listener group (Korean, native English). Subject and word were included as random intercepts. To build the model, several models were first constructed in a stepwise manner from the maximal model containing all factors, such as stimulus condition and listener group, and nested models were compared using the likelihood ratio test of significance. The optimal model contained only significant predictors or predictors that participated in a significant interaction (Barr et al., 2013). The model with the best fit was as follows: responses ~ listener group * stimulus condition + (1|subject) + (1|word). In addition, a post-hoc analysis using the emmeans package (Lenth et al., 2021) was conducted to more closely examine the interaction of the two fixed factors. The model parameters and comparisons are shown in Table 5.
Statistical results for perception accuracy in AX discrimination task.
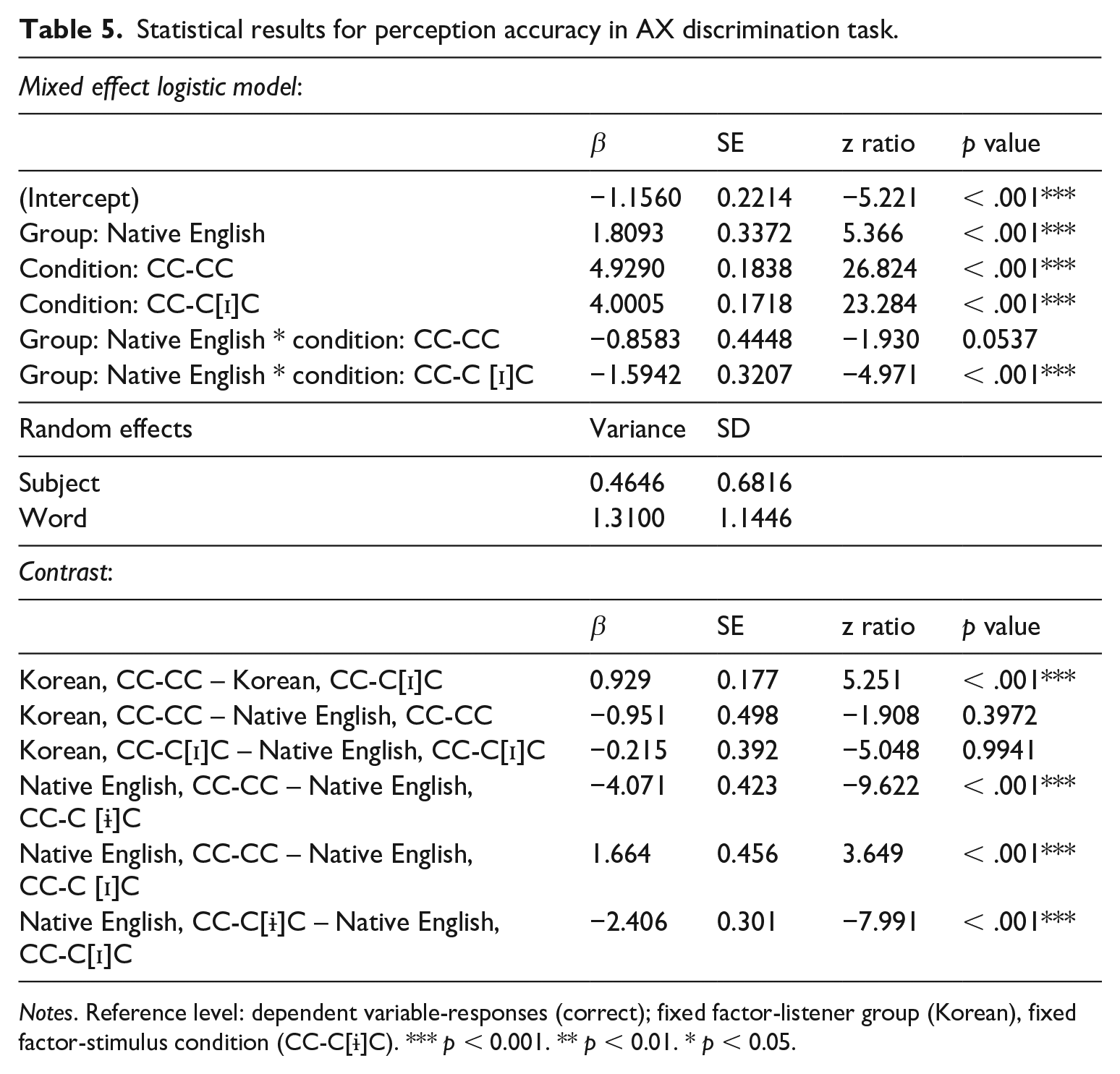
Notes. Reference level: dependent variable-responses (correct); fixed factor-listener group (Korean), fixed factor-stimulus condition (CC-C[ɨ]C). *** p < 0.001. ** p < 0.01. * p < 0.05.
Table 5 shows that (1) Korean listeners’ mean accuracy scores were significantly lower than those of native English listeners in the CC-C[ɨ]C condition, and (2) for Korean listeners, mean accuracy scores for the CC-C[ɨ]C condition were significantly lower than those for the CC-CC condition and CC-C[ɪ]C condition. Two interaction terms were also significant between listener group and stimulus condition. Specifically, the difference between Korean and native English listeners in slope was significant from CC-C[ɨ]C to CC-C[ɪ]C, and marginally significant from CC-C[ɨ]C to CC-CC.
To examine the interaction, all possible pairwise comparisons were conducted. Table 5 presents only the relevant results. Both Korean and native English listeners exhibited significantly lower accuracy scores in the CC-C[ɨ]C condition than in the CC-CC and CC-C[ɪ]C conditions. The two listener groups showed a significant difference in accuracy scores only in the CC-C[ɨ]C condition, in which Korean listeners performed less accurately than native English listeners.
For the RT analysis, a mixed-effect linear regression model was built using the lmer function from the package lmerTest (Kuznetsova et al., 2017) in R (version 3.2.2, R Core Team, 2017). The RTs were log-transformed to fit normality as a dependent variable, and listener group (Korean, native English) and stimulus condition (CC-CC, CC-C[ɨ]C, CC-C[ɪ]C) were fixed factors. Subject and word were included as random factors. In the process of finding an optimal model, the fixed factor of listener group was excluded, leaving the model as follows: RT ~ condition + (1|subject) + (1|word). As the model was unable to show differences between listener groups, two separate models were built for Korean and native English listeners to investigate how stimulus condition influenced RTs. These two separate models included RT as a dependent variable and stimulus condition as a fixed factor. In addition, by-subject and by-word intercepts were considered random effects. Korean listeners were shown to have significantly longer RTs in the CC-C[ɨ]C condition than in either the CC-CC (β = −188.99, SE = 18.18, df = 135.14, t = −10.394, p < 0.001) or CC-C[ɪ]C condition (β = −138.28, SE = 18.18, df = 134.15, t = −7.605, p < 0.001). Similarly, native English listeners had longer RTs in the CC-C[ɨ]C condition than in either the CC-CC (β = −211.37, SE = 23.058, df = 644.212, t = −9.167, p < 0.001) or CC-C[ɪ]C condition (β = −139.804, SE = 23.296, df = 643.686, t = −6.001, p < 0.001). This indicated that both listener groups had difficulty processing the stimuli in the critical CC-C[ɨ]C condition.
b Production
To determine whether an epenthetic vowel was present between the two consonants of the target cluster in English, acoustic analyses were conducted on recordings obtained from all speakers who participated in the production tasks. Using Praat (Boersma and Weenink, 2021), waveforms and spectrograms of each target word were examined. For each target word, the epenthesized vowels, if any, were measured manually based on the same measurement criteria used for the perception task stimuli. The Korean and native English speakers produced 600 and 140 tokens, respectively. Recording failures and erroneous productions of targets were not included in the analysis (0.7% of the recordings for Korean listeners, and none for native listeners). To distinguish between intended phonological vowel epenthesis and purely phonetic epenthesis, various previous studies considered vowels more than 45 ms to be epenthesized (Masuda and Arai, 2010; Verdonschot and Masuda, 2020), but without any empirical evidence. Accordingly, we included all tokens with clear vowel formants between the consonants of the onset cluster in the analysis, regardless of their duration. The threshold for the phonological epenthesis will be discussed in more detail later.
Table 6 presents mean percentages of words produced with an epenthetic vowel by Korean and native English speakers in the pseudoword read-aloud task along with the acoustic characteristics of the epenthetic vowel in each speaker group. Korean speakers inserted an epenthetic vowel between target consonant clusters more often than native English speakers did. The mean percentage of words produced with an epenthetic vowel was 25.11 (range: 0–100, SD = 25.6) for Korean speakers, and 7.9 (range: 0 – 20, SD = 7.6) for native English speakers. Percentages of vowel epenthesis were analysed using a mixed-effects logistic model, in which the dependent variable was the presence of vowel epenthesis (binary-coded with ‘yes’ or ‘no’) and the fixed factor was speaker group (Korean, native English). By-subject and by-word were considered random intercepts. The model revealed a marginally significant difference between Korean and native English speakers. Specifically, Korean speakers inserted an epenthetic vowel more frequently than native English speakers did (β = −1.9432, SE = 0.9944, z = −1.954 p = .0507). The acoustic characteristics of the epenthetic vowels were further examined in temporal (duration) and spectral (F1 and F2) aspects. Even though there were only small number of epenthetic tokens for the native English speakers (7.9%; n = 9), the data were analysed using the mixed-effects linear regression model that included the measurements as a dependent variable, the speaker group as a fixed factor, and by-subject and by-word as random intercepts. First, Korean speakers produced epenthetic vowels for a longer average duration than the native English speakers, which was, however, not significant (β = −6.856, SE = 8.883, df = 58.531, t = −0.772, p = 0.443). Notably, the Korean speakers demonstrated a wide range of vowel duration, some of which comparable to those obtained for lexical vowels, whereas the vowel duration of the native English speakers showed a more narrow range, mostly comparable to the nonlexical vowels (Davidson, 2006). In addition, the differences of the first formant (F1), but not the second formant (F2), between the two groups of speakers, were marginally significant (β = 50.963, SE = 25.637, df = 40.127, t = 1.988, p = .05 for F1; β = −101.15, SE = 111.89, df = 30.63, t = −0.904, p = .373 for F2); the Korean speakers showed a lower F1 than the native English speakers. These results suggest that both Korean and native English speakers produced the epenthetic vowels in central region of the vowel space (clearly distinguished from [ɪ] as shown in Table 2), but the Korean speakers produced the epenthetic vowels close to the Korean [ɨ] (high central vowel).
Percentage of words with epenthetic vowel (%) and acoustic characteristics (duration (ms), F1 and F2 (Hz)) of epenthetic vowel produced by Korean and native English speakers in the pseudoword read-aloud task.

2 Lexical processing
a Perception
Regarding the results of the lexical decision task, accuracy scores and RTs for the correct responses (69.6%) were analysed. Of the 7,020 trials (Korean: 5,400, native English: 1,620), no responses (1%), and RTs above or below 2 SD (5.1%) were not included for analysis. Additionally, trials of the target words with a score below 3 in the familiarity test were excluded (0.3%). As a result, 77.6% of the trials performed by Korean learners and 90.9% of those by native English listeners were analysed. Two trials with corresponding target nonwords (TW-[ɨ] and TW-[ɪ]) created by modifying the omitted target words were also excluded. Table 7 summarizes the mean accuracy scores and RTs.
Percentage of accuracy (%) and RTs (ms) per word type in lexical decision task for Korean and native English listeners (standard deviations in parentheses).
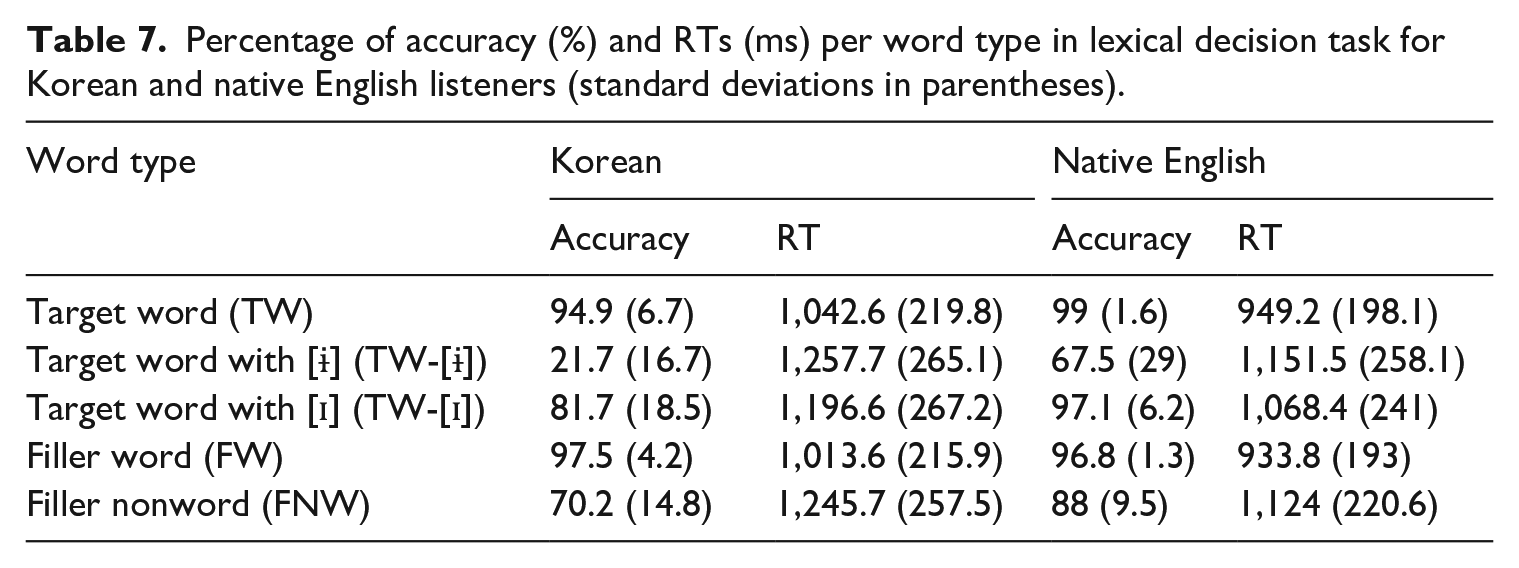
Regarding the target words and nonwords which were the study’s main focus, Korean listeners performed less accurately than native English listeners for all three target types, TW, TW-[ɨ], and TW-[ɪ]. Both Korean and native English listeners showed poor performance for target nonwords (TW-[ɨ] and TW-[ɪ]) compared with real words (TW), with the lowest accuracy scores in the TW-[ɨ] condition. The RT results are likely to be in accordance with those for accuracy. Korean listeners responded more slowly than native English listeners for all target word types. Across participant groups, TW-[ɨ] resulted in slower RTs than any other word type.
A mixed-effects logistic regression analysis was used to examine the accuracy results. The dependent variable was responses, and listener group and word type were fixed factors. Random effects included by-subject and by-word intercepts. The optimal model was the maximal model containing all fixed factors, such as listener group and word type, and the interaction between the two fixed factors as follows: responses ~ listener group * word type + (1|subject) + (1|word). Building the glmer model, we added bound optimization by quadratic approximation (BOBYQA, Powell, 2009) for model convergence, increasing the number of iterations to 10,000. Table 8 summarizes the model parameters and comparisons.
Statistical results for perception accuracy in lexical decision task.

Notes. Reference level: dependent variable-responses (correct); fixed factor-listener group (Korean), fixed factor-stimulus condition (TW-[ɨ]). *** p < 0.001. ** p < 0.01. * p < 0.05.
As shown in Table 8, there was a significant difference between the two listener groups in TW-[ɨ], with Korean listeners performing less accurately than native English listeners. For Korean listeners, TW-[ɨ] resulted in significantly more incorrect responses than TW or TW-[ɪ]. The interaction terms indicated that Korean and native English listeners exhibited similar response patterns. There were no significant differences in the slopes from either TW-[ɨ] to TW or TW-[ɨ] to TW-[ɪ] for both listener groups.
Although the interaction of the two fixed factors was not significant in the model, post-hoc analysis using emmeans (Lenth et al, 2021) was conducted to examine the effects of listener group for each word type and of word type among native English listeners. All possible pairwise comparisons of two fixed factors (listener group and word type) were conducted. Table 8 shows only the relevant results. For all three target types (TW, TW-[ɨ], and TW-[ɪ]), accuracy scores were significantly different between the two listener groups, indicating that native English listeners performed the task with more accuracy than Korean listeners. Both Korean and native English listeners had lower accuracy scores for TW-[ɨ] compared with TW and TW-[ɪ]; however, native English listeners did not show a significant difference in scores between TW and TW-[ɪ].
For the RT analysis, a mixed-effect linear regression model was built with RTs log-transformed to fit normality as a dependent variable, and listener group and word type as fixed factors. By-subject and by-word were included as random factors. The full model was built as the optimal model as follows: RT ~ group * word type + (1|subject) + (1|word). The statistical results for the RTs showed a similar pattern to the accuracy results. There was a significant difference between listener groups in TW-[ɨ] (β = −0.1122, SE = 0.044929, df = 49.29, t = −2.275, p < 0.05). For Korean listeners, the RTs were significantly longer for TW-[ɨ] than TW-[ɪ] or TW (TW-[ɪ]: β = −0.06347, SE = 0.02099, df = 363.4, t = −10.499, p < 0.01; TW: β = −0.2181, SE = 0.02077, df = 350.8, t = −3.025, p < 0.001). The interaction terms demonstrated that the slope differences among word types across both listener groups were not significant between TW-[ɨ] and TW (β = −0.01944, SE = 0.02429, df = 4,833, t = 0.801, p = .423) or TW-[ɨ] and TW-[ɪ] (β = −0.02296, SE = 0.0002454, df = 4,830, t = −0.936, p = .349). This indicated that there was no listener group effect for the three target types (TW, TW-[ɨ], and TW-[ɪ]). As in the regression model used to analyse the accuracy results, post-hoc analysis was conducted using emmeans to investigate RT differences for native English listeners. As with Korean listeners, the RTs were slower for TW-[ɨ] than for TW or TW-[ɪ] (TW: β = 0.1986, SE = 0.0239, df = 655.4, t = 8.321, p < .01; TW-[ɪ]: β = 0.0864 SE = 0.0239, df = 661.6, t = 3.612, p < .05).
b Production
Regarding the results of the picture-naming task, only the recordings of the target words (n = 30) were analysed to evaluate the lexical-level production of L2 illusory vowels. The results from the pictures that received responses other than the designated words or no response were excluded in the analysis (2.9%), leading to 869 and 209 trials from the Korean and native English speakers, respectively. Table 9 presents the percentages of words produced with an epenthetic vowel by Korean and native English speakers and the summary of their acoustic characteristics.
Percentage of words with epenthetic vowel (%) and acoustic characteristics (duration (ms), F1 and F2 (Hz)) of epenthetic vowel produced by Korean and native English speakers in the picture naming task.

The results demonstrated that Korean speakers inserted a vowel between onset clusters more often than native English speakers did, showing a wider range of values. The mean percentage of words produced with an epenthetic vowel was 18.85 (range: 0–58.6, SD = 15.35) for Korean speakers, and 2.38 (range: 0–10, SD = 4.18) for native English speakers. For the analysis, a mixed-effects logistic model was built. The dependent variable was the presence of vowel epenthesis (binary-coded as ‘yes’ or ‘no’), and the fixed factor was the speaker group (Korean and native English). Random effects included by-subject and by-word intercepts. The model showed a significant difference between Korean and native English speakers (β = −3.7478, SE = 0.9884, z = −3.792, p < 0.001). Even though there were minimal epenthetic vowel tokens for the native English speakers (even fewer than those in the read-aloud task) (2.38%; n = 5), the acoustic characteristics of the epenthetic vowels between the Korean and native English speakers demonstrated a similar pattern to those in the read-aloud task in both temporal and spectral values. The results of the statistical analysis showed that the mean duration of epenthetic vowels produced by Korean speakers was slightly longer than that of native English speakers, but without significance (β = −4.109, SE = 9.129, df = 36.583, t = −0.45, p = .655). The Korean speakers also demonstrated a wider range of vowel duration than the native English speakers; the group difference was more evident than that in the read-aloud task. In addition, the mean F1, but not F2 of the epenthetic vowels, was significantly different between these two groups of speakers (β = 94.62, SE = 31, df = 39.07, t = 3.052, p < .01 for F1; β = −25.68, SE = 99.31, df = 50.41, t = −0.259, p = .797 for F2); the Korean speakers demonstrated a lower F1 than the native English speakers. In the central region of the vowel space, the Korean speakers produced epenthetic vowels, close to the Korean [ɨ], whereas those of the native English speakers spread out from high to mid regions. In addition, comparing the durations of epenthetic vowels produced by Korean learners between the two production tasks further demonstrated that the mean duration of vowels was shorter in the picture-naming task than in the pseudoword read-aloud task. This result was partly related to participants’ relatively high familiarity with the real words used in the picture-naming task. This is addressed in more detail in Section IV.
3 Perception–production relationship
In accordance with the technique reported by de Leeuw et al. (2021), the mean perception accuracy in the critical CC-C[ɨ]C and TW-[ɨ] condition was analysed for the prelexical and lexical perception task, respectively. Accuracy was included as a fixed factor in the analysis of both prelexical and lexical production results, to examine whether perceptual accuracy influenced production accuracy. A mixed-effects logistic regression model was built, with accuracy scores for the two perception tasks (accuracy scores of the CC-C[ɨ]C condition in the AX discrimination task and accuracy scores of the TW-[ɨ] condition in the lexical decision task) as fixed factors, and the presence of epenthetic vowels as a dependent variable (binary-coded as ‘yes’ or ‘no’). To determine whether accuracy scores for perception influenced those for production, models were manually stepped down, using likelihood ratio tests, from the full model containing all factors. However, the accuracy scores for both AX discrimination and lexical decision tasks were removed in the process of finding an optimal model, leaving the model without any fixed factors.
The data were further examined using Pearson correlation analysis to confirm whether the results of the perception and production tasks correlated among Korean participants. AX discrimination and lexical decision accuracy scores were examined with the percentage of vowel epenthesis in either the pseudoword read-aloud task or picture-naming task. Figure 1 depicts the relationship between perception accuracy and proportion of epenthetic vowel production in the pseudoword read-aloud task.
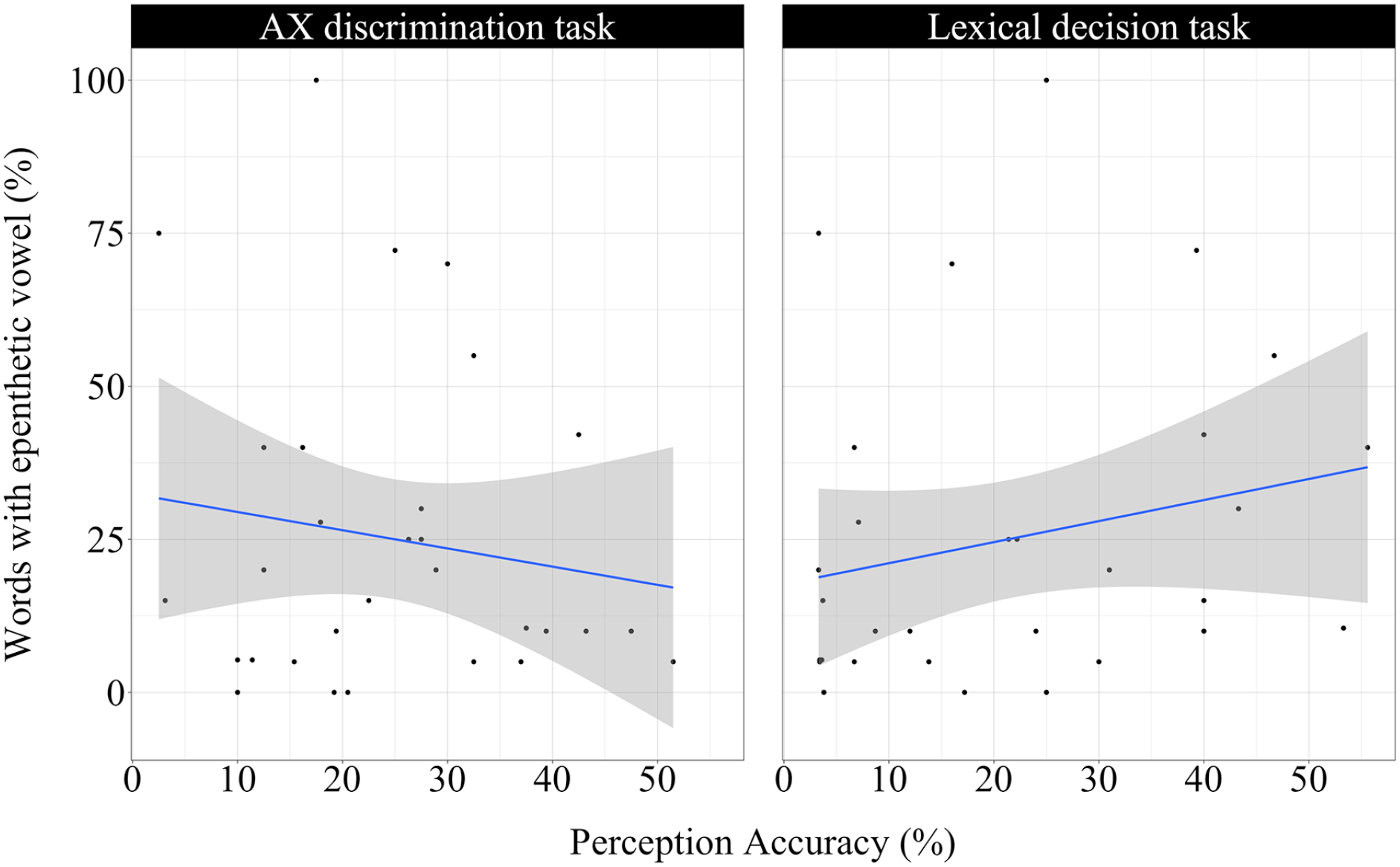
Production of epenthetic vowels over AX discrimination accuracy (left) or lexical decision accuracy (right) in pseudoword read aloud task.
The scatter plot in Figure 1 shows the points representing individual participants’ scores spread across a rather broad range. The accuracy scores for both perception tasks were distributed between 0 and 60%, whereas less than 30% of the words were produced with an epenthetic vowel. The bottom left-hand quarter of the scatterplot is relatively crowded, indicating that many Korean learners of English showed perception accuracy below chance level, but still displayed accurate production. These results suggest that accurate perception is not necessary for accurate production. The non-significant relationship between perception and production accuracy is supported by the statistical results. We computed the correlation coefficient of the percentage of words with epenthetic vowel in pseudoword read-aloud task as a function of the accuracy scores of AX discrimination task (correlation coefficient = −0.1407, t = −0.7518, df = 28, p = .4584) and those of lexical decision task (correlation coefficient = 0.2233, t = 1.2121, df = 28, p = .2356), confirming the dissociation between them.

Production of epenthetic vowels over AX discrimination accuracy (left) or lexical decision accuracy (right) in picture naming task.
Figure 2 displays the correlation plots between the accuracy scores of the two perception tasks and the percentage of words with an epenthetic vowel in the picture-naming task. As shown in Figure 2, there was no significant linear relationship between accuracy in the two perception tasks and the percentage of words with an epenthetic vowel in the picture-naming task. While the words with an epenthetic vowel in the picture-naming task were mostly concentrated below 30%, the accuracy scores ranged from 0 to 60% for each perception task. The correlation coefficients of the proportion of words produced with an epenthetic vowel in the picture-naming task, each with accuracy in the AX discrimination and lexical decision tasks, showed a non-significant relationship between perception and production accuracy in the picture-naming task. The correlation coefficient of the percentage of words with epenthetic vowel as a function of the accuracy scores of AX discrimination task was 0.0521 (t = 0.2763, df = 28, p = .7844) and that of lexical decision task was 0.2493 (t = 1.362, df = 28, p = .1841). Thus, the lack of a clear relationship between perception and production may not be attributable to processing levels.
IV Discussion
To examine whether the link between perception and production of illusory vowels in L2 is within, but not across, processing levels, as proposed in a previous study regarding L2 segments (Melnik-Leroy et al., 2022), we assessed Korean learners’ perception and production of English onset clusters at prelexical and lexical levels. Using the same participants and items, to assess perception, we employed an AX discrimination task (prelexical) and a lexical decision task (lexical), while for production we used a pseudoword read-aloud task (prelexical) and a picture-naming task (lexical). For all tasks, we compared the performance of the late Korean learners (with intermediate- or advanced-level proficiency) to that of a control group of native English speakers.
Regarding perception, Korean learners performed less accurately than native English listeners did in both the prelexical and lexical tasks, although the two listener groups did not show significant differences in RTs. Notably, Korean listeners were less successful at discriminating between CC and C[ɨ]C tokens (troot–t[ɨ]root), and judged the tokens with an epenthetic vowel between a consonant cluster (b[ɨ]lue) as real words more often than native English listeners did. Similarly, regarding production, results for both the pseudoword read-aloud and picture-naming tasks showed that Korean learners produced target clusters with an epenthetic vowel, [ɨ], more frequently than native speakers did. Further, Korean learners produced epenthetic vowels of slightly, but not significantly longer, duration than native English speakers did. Both Korean and native English speakers produced the epenthetic vowels in the central region of the vowel space, but the Korean speakers produced the epenthetic vowels close to the Korean [ɨ], while the native English speakers’ epenthetic vowels were more distributed around the mid central region of the vowel space. Therefore, in all aspects of the productions such as proportion of epenthesis, duration, and formant values, the epenthetic vowels produced by Korean learners were close to the L1 vowel [ɨ], unlike the native English speakers. The results of both the perception and production tasks indicated the strong effect of L1 phonotactic constraints on the processing of L2 phonotactics. Owing to L1 phonotactic constraints prohibiting consonant clusters, Korean learners of English are likely to perceive illusory vowels between the consonants of the cluster and produce epenthetic vowels in the cluster. Given that the Korean learners of English in the present study showed either an intermediate or advanced level of English proficiency, this reflects the persistent effects of L1 phonotactics. We will discuss the issue of L2 proficiency later in this section.
More importantly, accuracy in not producing an epenthetic vowel between the two consonants of the onset cluster was not associated with accurate perception of the consonant clusters at the same processing level (i.e. between the prelexical production and perception, or between the lexical production and perception) or across processing levels (i.e. between the prelexical production and prelexical/lexical perception or between lexical production and prelexical/lexical perception). By examining the scatterplots for correlation between perception and production accuracy, it can be seen that the accuracy scores for both the AX discrimination and lexical decision tasks were widely distributed, while the proportion of words produced with an epenthetic vowel was below 30%. This suggests that Korean learners who did not successfully discriminate between consonant clusters in the tokens with and without an epenthetic vowel were still able to accurately produce the clusters.
The present results are in accordance with those of a previous study on the perception–production link of L2 phonotactics (de Leeuw et al., 2021) and some previous studies on L2 segments (e.g. Baker and Trofimovich, 2006; Peperkamp and Bouchon, 2011; Sheldon and Strange, 1982). In de Leeuw et al. (2021), Spanish-speaking learners’ perception and production of onset /sC/ clusters in English were assessed, and accurate production of the clusters (without a prothetic vowel) was not found to be related to accurate perceptual discrimination of this contrast. In the same–different discrimination task, Spanish-speaking learners of English were less successful at discriminating between tokens with and without a prothetic vowel (spi–espi) than were native English listeners, although both groups of listeners were more accurate in the control pair spi–spu (with a phonologically different vowel) and the identical pair spi–spi than the spi–espi pair. Focusing on the crucial condition with and without a prothetic vowel (spi–espi), discrimination accuracy was included as a possible predictor to examine whether this factor was influential in determining pronunciation accuracy; however, no significant effects were found. Further, de Leeuw et al. (2021) put forth various possible explanations for the lack of correlation between perception and production, including the difference of processing levels between the two modalities. The discrimination task employed to assess perception simply required low-level auditory judgments on whether auditory input was the same or different, which might be easier than determining whether the auditory input was a real word. Moreover, without applying their grammatical knowledge, the same–different discrimination task might have been easier than the phonemic verbal fluency task assessing production. The verbal fluency task required that participants access their mental lexicon and select words meeting the constraints, and then spell out the words. Accordingly, the researchers suggested a low-level production task, such as a reading task, should be conducted.
The effect of processing level was more explicitly proposed in a previous study on the relationship between perception and production of L2 segments (Melnik-Leroy et al., 2022). The researchers employed an AX discrimination task for perception, and pseudoword reading (prelexical) and picture naming (lexical) tasks for production, and found that the perception–production relationship could be restricted to the same processing level, namely, between the AX discrimination and pseudoword reading tasks, but not between the AX discrimination and picture-naming tasks. These results led to the hypothesis that the prelexical and lexical processing levels are independent to a certain extent, and that the perception–production relationship can be restricted to a specific level. Specifically, while pseudoword reading and AX discrimination tasks might have similar difficulty levels, as both involve only low-level phonetic category analysis, a picture-naming task might be more difficult, as it would additionally require mapping the incoming speech signal onto phonological representations of words stored in the participants’ mental lexicon.
However, the present findings did not support the hypothesis of Melnik-Leroy et al. (2022), as no direct perception–production link was observed within or across processing levels, at least in the acquisition of L2 phonotactics. Neither discrimination accuracy at the prelexical level nor lexical decision accuracy at the lexical level was a possible predictor for the accurate production of pseudowords or real words with an epenthetic vowel in onset clusters. The results of Pearson correlation analysis also demonstrated no significant correlation between these two modalities within and across processing levels. The scatter plot shows that the perception accuracy scores were spread across a wide range, while the proportion of vowel epenthesis was concentrated in the region below 30%. Alternatively, not only processing levels but also cognitive loads may be directly related to the perception–production link. Generally, prelexical processing requires less cognitive demand than lexical processing, because the latter requires accessing the mental lexicon and selecting the optimal item, inhibiting all other possible candidates. However, in the production tasks, participants showed similar percentages of vowel epenthesis between pseudoword reading (25%) and picture-naming (19%), although the numerical values showed that participants produced the target clusters with more epenthetic vowels in pseudoword reading than picture-naming. The mean word familiarity ranking of the test words used in the picture-naming was 6.8 (SD = 0.3), ranging 5.6 to 7 (for more details, see Appendix 2), suggesting that participants were familiar with most of the test words. However, pseudowords might have sounded new to participants, potentially creating some confusion with existing English words. Nonetheless, the present results demonstrated that, even when the perception and production tasks required similar cognitive functions, there was no strong perception–production link, given the non-significant relationship in all possible combinations of the prelexical and lexical task results. Thus, this also refutes the proposal regarding cognitive loads.
Relatedly, Gorba and Cebrian (2021) argued that the lack of a clear link between these two modalities may be related to methodological factors. They conducted a forced-choice identification task and a reading task involving English and Spanish voiceless stops with English-speaking learners of Spanish, and found only a weak relationship between these modalities. These results were explained with the different nature of perceptual and production measures. Specifically, the measure used for production represented relatively variable measures, such as different amount of voice onset time (VOT), while the measure for perception was categorical and less variable (e.g. /p/ or /b/). However, the present results are not in line with their explanation, as the presence or absence of epenthetic stops (categorical) and the duration of epenthetic stops (variable) were considered in analysing production results, and no clear relationship between the two modalities was observed.
Accordingly, it is necessary to consider the reason for the discrepancy between Melnik-Leroy et al. (2022), and de Leeuw et al. (2021) and the present study. The reason may be differences in the target phonology: the former study addressed the perception–production link in the acquisition of L2 segments and found a correlation within a processing level, while the latter two studies examined the link in L2 phonotactic acquisition and found a non-significant relationship between perception and production either within or across processing levels. Thus, unlike segments, higher-level phonotactics may show a less close, or even independent, relationship between perception and production. Target sounds have been proposed as one factor contributing to inconsistent results regarding the perception–production link of L2 segments. For example, Bohn and Flege (1990) found a stronger perception–production link for vowels compared with consonants. Thus, the relationship between perception and production could differ according to the target phonological structure. However, given the limited data, further studies are required to clarify the role of target phonology in the perception–production link.
In addition, it should be noted that the participants of this study as well as de Leeuw et al. (2021) comprised mostly proficient learners, all of whom showed no close relationship between perception and production in L2 phonotactics. Melnik-Leroy et al. (2022) also used proficient learners and found a nonsignificant relationship between these two modalities in L2 segments. A question that arose from these results is whether the perception–production link also applied to less proficient or even beginner-level learners. The study of Gorba and Cebrian (2021) might give us a hint to answer this question. They recruited three groups of English learners of Spanish who differed in their amount and type of L2 experience (inexperienced learners who majored in Spanish but had no experience in immersion setting, and two experienced learners with more or less experience in living in Spanish-speaking countries) to assess the potential effect of L2 experience on the perception and production of English and Spanish voiceless stops. They found that all groups, regardless of L2 experience, lacked a clear link between the two modalities. Even though it is necessary to test beginner-level learners, it appears that L2 experience or L2 proficiency may not modulate the relationship between perception and production in L2 phonotactics or L2 segments, against the general claim that learners with more L2 experience may present a greater alignment between the two modalities than inexperienced learners (Bohn and Flege, 1990).
The presence of an epenthetic vowel in some of the native English speakers’ production of the onset clusters may be unsurprising, given that we analysed tokens with not only intended (lexical) epenthetic vowels but also short vocalic sounds that may be produced by mis-coordination of the two consonants in the cluster, or due to a clear form in speech when read aloud. The stimuli in the perception tasks had slightly shorter epenthetic vowels than those in previous studies, and the production results also included all tokens with a vocalic sound, regardless of vowel duration. Accordingly, even native speakers did not show ceiling effects in the discrimination or lexical decision tasks, and produced epenthetic vowels in some tokens. Thus, it may be that both phonetic and phonological epenthetic vowels were included in the present analyses. This result may also be associated with the fact that the native speakers were living in an L2 setting at the time of experiment. It is possible that their perception and production have become more lenient toward Korean than native English speakers who never left their home countries. There is ample evidence that experience with an L2 can affect many features of the L1 at both segmental and suprasegmental levels (for a review, see Schmid and Köpke, 2019). Chang (2012), for example, found that even with brief experience in L2 (the first weeks of elementary Korean studies), English learners of Korean produced the VOT of their L1 voiceless stops as drifted toward the longer VOT norms of a similar L2 stop (i.e. Korean aspirated stop). Indeed, in the present study, closer examination of the data of individual speakers revealed considerable variability. In the pseudoword read-aloud task, two out of seven native English speakers did not show vowel epenthesis, while the remaining speakers showed vowel epenthesis ranging 5 (1 out of 20 stimuli) to 20% (4 out of 20). In the picture-naming task, only two speakers showed vowel epenthesis, with percentages of 6.7% (2 out of 30) and 10.3% (3 out of 30), respectively, while the remaining speakers did not produce epenthetic vowels. These results might be partly attributed to their Korean experience, which could have altered their L1. Nevertheless, it is worth noting that there were significant differences in the vowel epenthesis between the Korean learners and the native English speakers.
With respect to the phonetic versus phonological epenthetic vowels, some previous studies only counted vowels longer than approximately 40 ms as epenthetic vowels, and shorter vowels were considered purely phonetic variants. There are only a few studies that addressed the issue of the threshold between phonological and phonetic epenthesis. Verdonschot and Masuda (2020), for example, examined Japanese speakers’ production of English consonant clusters, judging the vowels longer than 45 ms to be phonologically epenthesized. This criterion is based on a previous study (Masuda and Arai, 2010) in which trained phoneticians acoustically analysed the epenthetic vowels produced by Japanese learners of English and then categorized them into three categories: ‘full epenthesis’, ‘partial epenthesis’, and ‘no epenthesis’, such that vowels longer than 45 ms were regarded as phonologically epenthesized, while those ranging 25 to 30 ms were considered as not epenthesized. This suggests that the threshold suggested in Verdonschot and Masuda (2020) seems to be arbitrary, without any empirical evidence. Even the authors pointed out that ‘45 ms seems to be a rather conservative threshold as short /u/ in Japanese can be shorter’ (p. 4). The non-epenthesized vowel /u/ in Japanese has a duration of approximately 20 to 50 ms (Shaw and Kawahara, 2019). More importantly, the durations of epenthesized vowels may differ depending on the specific L1 type, L2 learners’ proficiency, phonological contexts, etc. Indeed, the Korean /ɨ/ demonstrates a wider range of duration than the Japanese /u/. The most recent and large-scale study on the Korean monophthongs (produced by 40 Korean native speakers) showed that the durations of non-epenthesized [ɨ] ranged from 13 to 249 ms (mean = 50 ms), with high variability across speakers (Oh, 2021). The epenthesized [ɨ] produced by the participants of the present study also ranged 15 to 159 ms in the psuedoword read-aloud task, and 13 to 121 ms in the picture naming task (as shown in Table 6 and Table 9, respectively). Therefore, it does not seem appropriate to apply the threshold suggested for Japanese learners of English, as in Verdonschot and Masuda (2020), for the analysis of the production of Korean learners of English and also native English speakers in this study. 6
Based on the present findings, the premise of many L2 speech acquisition models, such PAM-L2, may need revisiting. The results of the present study showed that L2 learners may accurately produce L2 words, observing L2 phonotactics even if they are unable to perceive them in a nativelike manner. The statistical results clearly showed that perceptual accuracy was not directly related to production accuracy. Hence, instead of simply proposing that incorrect production would have a perceptual basis, a more detailed approach is required that considers all possible aspects of L2 phonological processing. Recently, in the revised version of the SLM (SLM-r), Flege and Bohn (2021) posited that segmental perception and production co-evolve without precedence, and that although there is a strong bidirectional influence between the two modalities, their correspondence is never perfect. The same explanation may be applied to the findings of the present study regarding L2 phonotactics.
While the results of the present study improve our understanding of the perception–production link by systematically examining the methodological issue on whether the perception–production link can be found within, but not across, processing levels, there are several potential limitations that would be important to address in future work. One potential limitation lies in the language background of native English speakers, who lived in Korea at the time of study. Their L2 experience might render the native English speakers alter their L1, and they did not show ceiling effects in the perception tasks and produced epenthetic vowels in some tokens. Thus, to fully understand the Korean learners’ performance, it is necessary to replicate the present study with ‘monolingual’ native English speakers living in the English-speaking countries. We leave it for future study.
Another limitation of the study is related to the inclusion of phonetic as well as phonological epenthetic vowels. Various previous studies considered vowels more than 45 ms to be epenthesized (Masuda and Arai, 2010; Verdonschot and Masuda, 2020), but (1) there was no empirical evidence for this threshold, and (2) it does not seem to be appropriate to use the same threshold for the Korean learners of English and/or the native English speakers. Thus, a perception study is necessary to evaluate the exact threshold of the phonological versus phonetic epenthesis of vowels for Korean learners of English as well as the native English speakers. We also leave it for future study.
In conclusion, using well-controlled experimental conditions, we tested Korean learners’ perception and production of English obstruent–sonorant clusters in the syllable onset position, and found that no clear relationship between the two modes was observed, and processing level (prelexical versus lexical) does not moderate the perception–production link. The presence or absence of a perception–production link likely hinges on several factors, only some of which are methodological. Future research should compare multiple methodological factors to examine the relationship between perception and production.
Footnotes
Appendix
Stimuli for lexical decision and picture naming tasks.
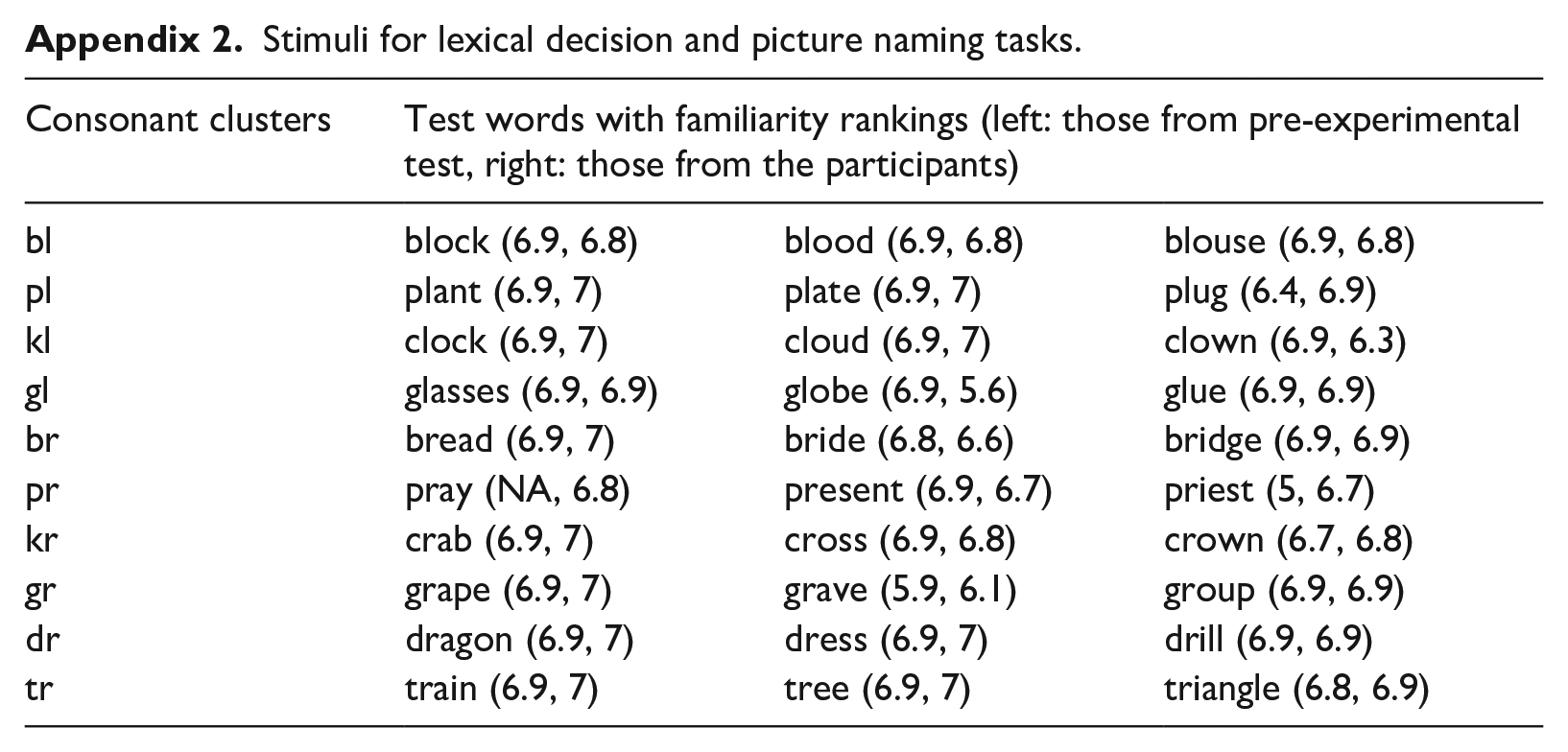
| Consonant clusters | Test words with familiarity rankings (left: those from pre-experimental test, right: those from the participants) | ||
|---|---|---|---|
| bl | block (6.9, 6.8) | blood (6.9, 6.8) | blouse (6.9, 6.8) |
| pl | plant (6.9, 7) | plate (6.9, 7) | plug (6.4, 6.9) |
| kl | clock (6.9, 7) | cloud (6.9, 7) | clown (6.9, 6.3) |
| gl | glasses (6.9, 6.9) | globe (6.9, 5.6) | glue (6.9, 6.9) |
| br | bread (6.9, 7) | bride (6.8, 6.6) | bridge (6.9, 6.9) |
| pr | pray (NA, 6.8) | present (6.9, 6.7) | priest (5, 6.7) |
| kr | crab (6.9, 7) | cross (6.9, 6.8) | crown (6.7, 6.8) |
| gr | grape (6.9, 7) | grave (5.9, 6.1) | group (6.9, 6.9) |
| dr | dragon (6.9, 7) | dress (6.9, 7) | drill (6.9, 6.9) |
| tr | train (6.9, 7) | tree (6.9, 7) | triangle (6.8, 6.9) |
Acknowledgements
We would like to thank three anonymous reviewers and Charles Chang for their insightful comments on various aspects of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.