
Abstract
This study investigates how feature specification in a learner’s native language (L1) – specifically, whether a feature is contrastively specified or overspecified – influences discrimination in naive perception. We focus on the perception of four high vowels ([i], [y], [ʉ], [u]) by Mandarin and Italian speakers. We propose that Italian specifies /u/ as [labial], while Mandarin overspecifies this vowel as both [labial] and [dorsal]. The vowel /y/ is native in Mandarin but non-native in Italian, while the vowel /ʉ/ is not native in either language. We test two possible feature redeployment mechanisms, fusion and fission, using an ABX task to examine four contrasts, /i/–/y/, /u/–/y/, /ʉ/–/u/, and /ʉ/–/y/. Feature fusion predicts that the non-native /y/ can be built by Italian naive learners by combining [coronal] and [labial] from /i/ and /u/, such that Italian participants should show similar discrimination accuracy for both /i/–/y/ and /u/–/y/ contrasts as Mandarin participants. In contrast, feature fission predicts that [labial] can detach from /u/ in Mandarin to form /ʉ/ without causing a merger. However, this process should not be possible in Italian, where fission would cause /ʉ/ to merge with /u/, since /u/ is exclusively represented with [labial]. Thus, Mandarin participants should show better discrimination accuracy for the /ʉ/–/u/ and /ʉ/–/y/ contrasts than Italian participants. Results from the discrimination task align with these predictions, supporting the proposed feature specifications and demonstrating the effects of L1 feature specification and feature redeployment (fusion/fission) on naive second language (L2) vowel perception. Importantly, while phonetic cues form the perceptual basis for sound discrimination, our findings indicate that language-specific feature representations guide how these cues are phonologically interpreted.
Keywords
1. Introduction
Features are the fundamental building blocks of phonological representation, serving to distinguish one sound from another within a language (Chomsky and Halle, 1968; Jakobson et al., 1952). For instance, Russian uses the feature [voice] to differentiate voiceless and voiced stop contrasts, which are acoustically cued by Voice Onset Time (VOT; positive for voiceless stops, negative for voiced ones) (Lisker and Abramson, 1964). Beyond expressing contrasts, features also capture phonological processes, like voicing assimilation in Russian. For a feature to be involved in such processes, it must be specified within the phonological grammar of the language (Dresher, 2009). Thus, features are grounded in both phonetics and phonological patterns.
In second language (L2) phonology, features are also the basic building blocks of sound systems. Archibald (2005) argues that L2 phonology repurposes native language (L1) phonological knowledge, meaning that the way learners perceive sounds in their first language shapes how they learn new sounds in a second language. However, we still do not fully understand how this works. For example, does missing a certain feature in the L1 make it more difficult to learn certain L2 sounds? And how can features be reused to build novel L2 sounds? These unanswered questions leave a gap in our understanding of L2 acquisition from a feature-based perspective.
This study aims to address this gap by investigating how language-specific feature specifications influence L2 naive perception. Specifically, we examine how Mandarin and Italian speakers discriminate high vowels, focusing on languages with overlapping vowel inventories but different feature specifications. By studying Mandarin and Italian listeners’ discrimination patterns, we test two possible feature operations, feature fusion and feature fission, to evaluate how the L1 grammar guides and constrains L2 perception at the onset of learning.
1.1. Feature theory
Segments are not holistic; they are composed of subphonemic features. Phonologists employ different features depending on their analytical perspective: features can be primarily rooted in articulation, in acoustics, or they can take more abstract forms (see, for example, Mielke, 2008). This study adopts the Unified Features Theory, which proposes a set of monovalent features applicable to both consonants and vowels (Clements, 1991; Clements and Hume, 1995). For example, in SPE (Chomsky and Halle, 1968), labiality was represented as [+anterior, -coronal] for consonants and as [+round] for vowels. In contrast, the Unified Features Theory uses a single feature, [labial], to represent all sounds involving the lips: bilabials, labiodentals, and round vowels and glides. This broader approach captures consonant-vowel interactions more effectively than the non-overlapping features of SPE.
Features define the articulatory and acoustic properties of segments and determine membership in natural classes. However, the presence of a phonetic gesture does not automatically entail specification of a corresponding feature. Underspecification theory (Archangeli, 1988; Steriade, 1995) proposes that not all features are underlyingly specified. Rather, the specified features need to be active in phonological processes (Dresher, 2009). This captures why languages with identical contrasts can exhibit divergent phonological behaviors. For example, Yoruba and Gengbe share the same vowel inventory, yet their front vowels /i/ and /e/ show complementary phonological patterning: Pulleyblank (1988) argues that /i/ must be underspecified in Yoruba to explain its transparency to phonological processes compared with other vowels. Conversely, Abaglo and Archangeli (1989) show that in Gengbe, it is /e/ that must be underspecified to explain its asymmetric behavior across morpheme boundaries. Consequently, feature specification must integrate phonetic attributes, contrasts, and language-specific phonological behavior. Features thus allow meaningful comparisons between diverse sound systems, informing theories of linguistic universals and typology (Anderson, 2021).
1.2. Perceptual basis of features
Speech perception provides a crucial window onto phonological representations, as listeners’ perceptual behavior can reflect the feature specifications encoded in their mental grammar. Converging evidence from perceptual and neurobiological studies establishes a strong foundation for understanding features as perceptually real entities that correspond to independent acoustic dimensions in speech processing.
Miller and Nicely’s (1955) seminal study examines how listeners identify English consonants under challenging conditions. They find systematic confusion patterns that correspond to the articulatory properties of speech sounds: voicing and nasality remain relatively preserved, while place of articulation suffers significant degradation under low-pass filtering and noise conditions. These findings indicate that listeners rely on separate information streams to distinguish different categories of speech sounds. (For functional magnetic resonance imaging (fMRI) evidence that distributed patterns of neural activation are associated with the category structure observed in Miller and Nicely’s study, see Arsenault and Buchsbaum, 2015.)
Features are warranted when the acoustic profiles of the sounds in a natural class differ, but their phonological behaviors are similar. For example, using neurophysiological methods, Monahan (2018) and Monahan et al. (2022) demonstrate that while the acoustic realization of features like [spread glottis] differs between stops and fricatives (relying on temporal vs. spectral cues, respectively), speakers encode them with the same phonological feature. This shows that speakers abstract away from modality-specific acoustic information to represent generalized phonological categories.
Turning to the contrastive properties of features, cross-linguistic research shows that listeners’ sensitivity to acoustic cues depends on the phonological contrasts present in their L1. Through exposure, they learn which acoustic dimensions signal meaningful distinctions and store this information in long-term memory. For instance, Johnson and Babel (2010) compare perception of the feature [anterior] in sibilants across English and Dutch, as Dutch lacks a phonemic /s-ʃ/ contrast while English has one. Using two vowel discrimination tasks, one normal-speed and one speeded task, they find that in the normal-speed task, where phonological (as well as phonetic) processing is assumed to be involved, Dutch listeners rate [s] and [ʃ] as more similar than English listeners do. However, in the speeded task, where phonological processing is assumed to be minimal, there are no group differences in similarity judgments (although reaction times in the speeded task correlate with the ratings from the normal-speed task). These results suggest that while auditory perception drives similarity patterns, language-specific experience, i.e. phonological processing, modulates them.
While the above observations can be explained by features and, partially, by their underlying acoustic-phonetic correlates, feature theory goes beyond surface phonetic similarity, in positing that only features are stored in long-term memory and, further, that phonological representations are not necessarily fully specified in the grammar. To exemplify, Schluter et al. (2016) provide event-related brain potential evidence from the Mismatch Negativity (MMN) paradigm that supports abstract, non-redundant feature-based models like the Featurally Underspecified Lexicon (FUL; Lahiri and Reetz, 2002). Their findings are twofold: First, they show an asymmetric MMN response between /s/ and /f/, which aligns with the FUL model’s prediction that /f/ is fully specified for [labial], while /s/ is underspecified for [coronal]. Second, they find no such asymmetry between /s/ and /h/. This suggests that oral and laryngeal dimensions are represented distinctly and that /h/ lacks an oral place specification.
Beyond place features, studies using MMN have examined laryngeal features (Hestvik and Durvasula, 2016), supporting the underspecification of [voice] on English /d/ but not [spread glottis] on /t/ (Iverson and Salmons, 1995), a pattern replicated across vowels (Cornell et al., 2011; Scharinger et al., 2016), consonants (Hestvik et al., 2020), and lexical tones (Politzer-Ahles et al., 2016).
1.3. Language-specific flexibility in feature specification: The case of Mandarin and Italian
Feature theory suggests that languages are flexible in how they assign phonological features, with active features participating in language-specific processes while passive features may remain unspecified (Dresher, 2009). This flexibility can be found in vowel harmony: some languages show backness harmony (requiring [dorsal]), like Finnish (Ringen and Heinämäki, 1999), while others have rounding harmony (requiring [labial]), such as Yawelmani Yokuts (Archangeli, 1985); languages like Turkish exhibit both types of harmony for high vowel targets (Clements and Sezer, 1982).
Differences in phonological behavior like these can be reflected in the phonetic realization of segments across languages. For example, while high back vowels tend to be rounded, languages differ in their implementation of this vowel: Japanese /ɯ/ is unrounded (Labrune, 2012), English /u/ is fronted and rounded (/u/-fronting, similar to [ʉ]; Harrington et al., 2008), and Spanish /u/ is fully back and round (Bradlow, 1995).
Such variation suggests that languages may adopt distinct representational strategies to express contrasts. Specifically, a vowel like /u/ may be underlyingly specified in at least three ways: [dorsal], [labial], or [dorsal] + [labial]. The last case exemplifies ‘overspecification’, which we define as a representational configuration in which a segment is specified for more than one feature when one alone would suffice to distinguish it contrastively. Crucially, overspecification is not motivated by contrast alone, but is instead behavior-driven: it is required when a segment participates in multiple natural classes or triggers multiple phonological processes that employ different features.
Italian and Mandarin provide an ideal test case showing this language-specific flexibility in feature specification, and for examining how L1 features may constrain L2 phonology. While both languages share the high vowels /i/ and /u/, Mandarin additionally has /y/ (a high front rounded vowel). The feature representations we propose for high vowels are in Table 1. The representations we motivate for /u/ are novel to this study; specifically, the representations include (or exclude) overspecification where behaviorally warranted. Below, we detail the empirical motivation for the feature specifications in the table, providing evidence from assimilation patterns, syllable structure, phonotactic constraints, and loanword adaptation.
Feature specifications for Italian and Mandarin high vowels.

Note. Shaded areas show phonological gaps.
We begin with the feature [coronal]. Both Italian and Mandarin exhibit palatalization, where velar consonants shift to palato-alveolar or alveolo-palatal before /i/ (Italian) or /i, y/ (Mandarin), as in (1).
1
(1) a. Italian: /k/→[tʃ]/_[i] [ˈko.mi.ko]–[ˈko.mi.tʃi] ‘comedian’–‘comedians’ b. Mandarin: /k/→[tɕ]/_[i, y] *[ki55] [tɕi55] ‘chicken’ *[ky55] [tɕy55] ‘snipe’
Italian shows palatalization through morphophonemic alternations. Mandarin has no alternations since it is largely an isolating language, but the distributional pattern, i.e. palatal [tɕ] before high front vowels versus velar [k] elsewhere, suggests that the two sounds are allophones of the same phoneme. Both cases support specifying [coronal] on high front vowels in the two languages. 2
Mandarin’s consonant-glide (CG) patterns further support the specification of [coronal]. CG sequences arise when high vowels surface as glides (/i/→[j], /y/→[ɥ], /u/→[w]). Following Clements and Keyser (1983), we treat glides as featurally identical to their high vowel counterparts. Following Duanmu (2007), we analyze glides in CG strings as secondary articulators (2), consistent with the observation that C and G are simultaneously produced (e.g. Chao, 1934).
(2) [j] [ɥ] [w] labial C [mj] *[mɥ] *[mw] coronal C [nj] [nɥ] [nw] velar C *[kj] *[kɥ] [kw]
The examples in (2) show that [ɥ] and [w] pattern together following labials and coronals (*[mɥ] and *[mw] are ill-formed; [nɥ] and [nw] are well-formed), and that [j] and [ɥ] pattern together following velars and coronals (*[kj] and *[kɥ] are ill-formed; [nj] and [nɥ] are well-formed). That is, [ɥ] behaves like both [w] and [j] in Mandarin. Since *[mɥ] and *[mw] are prohibited due to a constraint against adjacent labial articulations, i.e. *[labial][labial], [labial] must be specified for [ɥ] and [w]. This constraint falls under the Obligatory Contour Principle (OCP), which states that ‘adjacent identical elements are prohibited’ (McCarthy, 1986: 208). In contrast, since *[kj] and *[kɥ] are prohibited due to place assimilation, where [j] and [ɥ] trigger palatalization of the velar stop /k/ to [tɕ], [coronal] must be specified for [j] and [ɥ]. That is, Mandarin [ɥ] must be both [coronal] and [labial].
The above analysis supports a [coronal] specification on /i/ and /y/ and a [labial] specification on /u/ and /y/, making all three vowels distinct. While the processes discussed so far do not reveal whether /u/ requires a [dorsal] specification in addition to [labial], the possibility of overspecification arises when a segment participates in multiple natural classes. Another process, backness agreement within rhymes triggered by /u/, suggests that [dorsal] is indeed necessary for Mandarin /u/; thus, this vowel must be overspecified as both [labial] and [dorsal]. The data in (3a-b) show that in Mandarin, /a/ and /ə/ harmonize in backness with immediately following sounds. /a/ is fronted to [a̟] before /i, n/ and backed to [ɑ] before /u, ŋ/. /ə/ is fronted to [ə̟] before /n/ and backed to [ə̠] before /ŋ/; it is fronted to [e] before /i/ yielding [ei], and backed and rounded to [o] before /u/ yielding [ou]. Since /ŋ/ is not [labial] and the change from /a/ to back [ɑ] does not involve rounding, the feature that /u/ and /ŋ/ must share to trigger backing is [dorsal]. Given both types of evidence for /u/, it follows that this vowel in Mandarin must be overspecified as [labial] + [dorsal].
(3) a. /a/→[a̟]/_[i, n] [coronal] /a/→[ɑ]/_[u, ŋ] [dorsal] b. /ə/→[ə̟]/_[n] [coronal] /ə/→[ə̠]/_[ŋ] [dorsal] /ə/→[e]/_[i] [coronal] /ə/→[o]/_[u] [labial] + [dorsal]
In Italian, the palatalization of velars triggered by /i/ indicates that /i/ is specified as [coronal] (1a). For /u/, however, three feature specifications are possible: [labial], [dorsal], or [labial] + [dorsal]. The symmetry in Italian’s secondarily articulated consonants suggests that [w] and [j] share the same number of features: the language contains both labio-velar stops ([kw]/[kw]) and palato-velar stops ([kj]/[kj]). Since /i/ is [coronal], this symmetry implies /u/ should be either [labial] or [dorsal], not overspecified as both. Moreover, given that /k/ is [dorsal], the existence of [kw]/[kw] indicates that [k] and [w] differ in features, meaning [w] must be [labial]. If [w] were [dorsal], [kw]/[kw] would violate the OCP (*[dorsal][dorsal]), analogous to how Mandarin *[pw] violates *[labial][labial]. We have provided two transcriptions for these consonants due to disagreements in their analysis: Krämer (2009) treats /kw/ and /kj/ as underlying two-segment sequences (either simple onsets plus glide-initial diphthongs or complex onsets), while Calabrese (1993, 2005) argues that they derive from velar fronting and labialization of /k/ conditioned by following vowels. Regardless, both analyses confirm that /j/ and /w/ adhere to parallel distributional constraints, implying that their corresponding vowels (/i/ and /u/) likely have symmetrical feature specifications: one feature each, with /i/ as [coronal] and /u/ as [labial].
Italian diphthongs further support this symmetrical specification. The phonotactic distribution of rising and falling diphthongs is nearly symmetrical. (4a) shows that rising (head-final) diphthongs are perfectly symmetrical, with high vowels /i/ and /u/ combining freely with all other vowels. For falling (head-initial) diphthongs (4b), only /iu/, /ou/, and /ɔu/ are prohibited. If /ou/ and /ɔu/ violate the OCP (*[labial][labial]), the only asymmetry lies in /iu/, 3 reinforcing that /i/ and /u/ have similar representational complexity. Since /i/ is [coronal], /u/ must be either [labial] or [dorsal]; evidence from OCP constraints on consonant-glide sequences and phonotactics points to [labial].
(4) a. Rising diphthongs in Italian (Krämer, 2009):
b. Falling diphthongs in Italian:
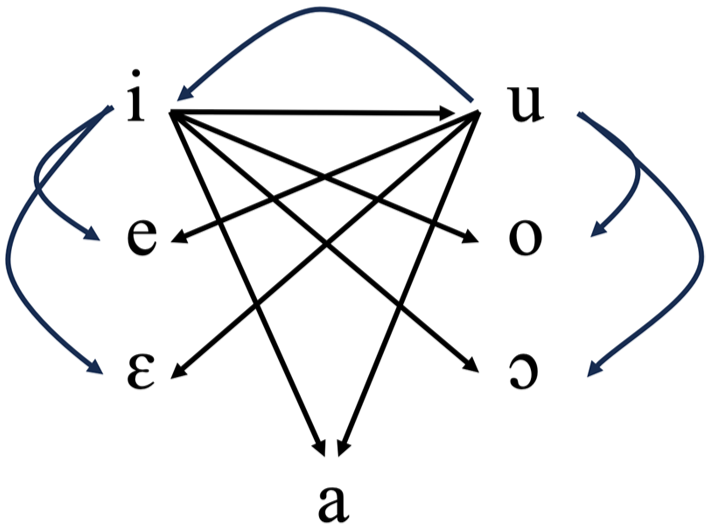
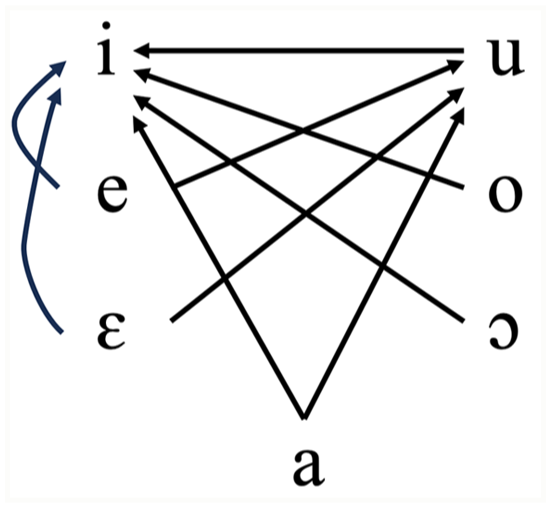
Loanword adaptation provides additional evidence for [labial] on Italian /u/. Loanwords are often adjusted to fit the borrowing language’s phonological constraints, illuminating the phonological structure of that language. Italian’s adaptation of German /y/, which is [coronal] + [labial], reveals /u/’s specification. If Italian /i/ is [coronal] and /u/ is [labial], the borrowed /y/ should sometimes retain labiality (/y/→/u/) and sometimes frontness (/y/→/i/). If /u/ were [dorsal], /y/ (lacking [dorsal]) would always adapt to /i/. Instead, Italian speakers vary, producing German /y/ as [i], [u], or [iu] (sequential articulation), with [iu] being preferred (Calabrese, 1988). This variation confirms that /u/ cannot be [dorsal]; with only one feature, it must be [labial].
2. The present study
Thus far, we have motivated the idea that speech perception serves as a window onto feature specification, and that high vowels are specified differently in Italian and Mandarin. Building on this, we aim to investigate how language-specific feature specifications influence L2 naive perception.
In this article, we first consider two possible cases where L1 feature specifications can potentially constrain L2 perception. Archibald (2005) assumes that second language phonology involves a redeployment of L1 phonological knowledge. For example, Archibald shows that English learners can easily acquire the Czech palatal stops /c/ and /ɟ/ because [coronal] and [posterior] are both phonologically specified in English. That is, two native features combine to represent novel segments in the L2, which we refer to as feature ‘fusion’.
We then extend the scope of Archibald’s proposal and explore another possible feature operation, ‘fission’, where specified features can be dissociated from their host segments to build novel segments. One example can be Mandarin /u/, which is overspecified as [labial] + [dorsal]. This overspecification should allow either [labial] or [dorsal] to detach and independently represent a novel segment, e.g. [ʉ]. Two conditions must be met for feature fission to occur: (1) multiple features must be specified on a single segment, allowing one feature to detach without causing a contrast merger; and (2) the feature to be redeployed must be phonologically active in the learner’s L1 grammar. Here, feature fission, as we conceptualize it, is not a mechanism that alters the underlying phonological grammar of the L1. Both feature fusion and fission are proposed as mechanisms for building phonological representations during the naive perception of novel L2 sounds.
To explore whether both feature operations (fusion and fission) are available to naive learners, we employ an ABX task to test four high vowel contrasts: /i/–/y/, /u/–/y/, /ʉ/–/u/, and /ʉ/–/y/. These contrasts involve four vowels, /i/, /y/, /ʉ/, and /u/, where /y/ is novel to Italian listeners and /ʉ/ is novel to both Mandarin and Italian listeners. The critical difference lies in the feature specifications of the two native vowels across the two languages: both Mandarin and Italian have native /i/ and /u/, with /i/ specified as [coronal]; however, /u/ is specified as [labial] only in Italian, and as both [labial] and [dorsal] in Mandarin.
This design aims to address two research questions:
Research question 1: Do Italian listeners discriminate /y/ from other vowels as effectively as Mandarin listeners?
The feature fusion hypothesis predicts that [y] can be built for Italian learners by combining [coronal] and [labial], as shown in Figure 1B. 4 If feature fusion is available in naive perception, we predict that Italian listeners will discriminate both the /i/–/y/ and /u/–/y/ contrasts no worse than Mandarin listeners. If fusion is unavailable, Italian listeners will discriminate the two contrasts worse than Mandarin listeners.
Research question 2: Do Italian listeners discriminate /ʉ/ from other vowels as effectively as Mandarin listeners?
The feature fission hypothesis predicts that [ʉ], which has no target on the front/back dimension, can be built only for Mandarin learners by detaching [labial] from /u/ to represent this novel sound, as shown in Figure 1A. In contrast, despite being phonologically specified, [labial] in Italian cannot be redeployed without causing a contrast merger. Therefore, if feature fission is a possible mechanism for feature redeployment, we predict that Mandarin listeners will discriminate both the /ʉ/–/u/ and /ʉ/–/y/ contrasts better than Italian listeners. If fission is unavailable, no group differences will emerge.
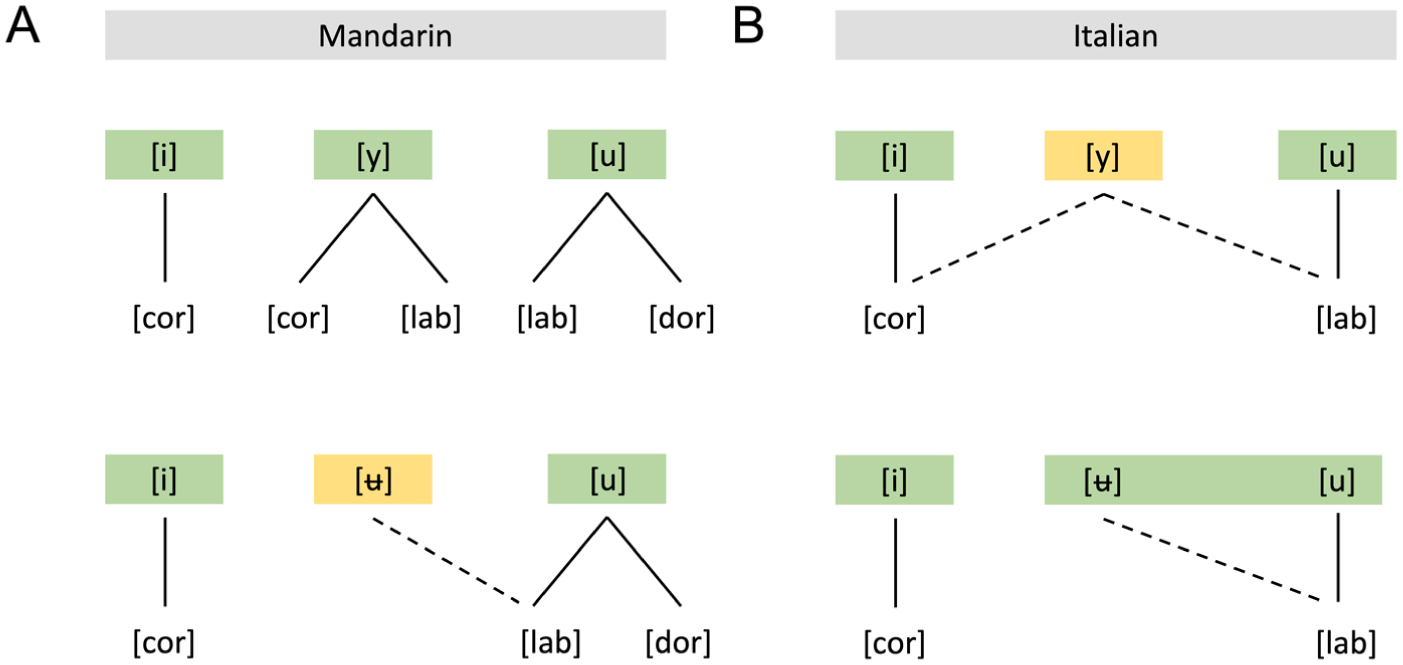
Schematic illustration of feature fusion and fission for (A) Mandarin. (B) Italian.
3. Methods
3.1. Participants
Participants were recruited through social media advertisements and online platforms, with initial screening based on age and language background. The participant pool included 30 Mandarin Chinese speakers from northern dialect regions (Mean age = 22.95 years, SD = 2.63; Female = 17) and 30 Italian speakers from northern Italy (Mean age = 24.65 years, SD = 3.66; Female = 15). Participants self-identified as monolingual speakers of either Mandarin Chinese or standard Italian. None had studied or lived in a foreign country for more than three months. The Mandarin speakers had learned English as a foreign language in formal educational settings (they had no exposure to Italian). These participants’ English level was evaluated with the China’s College Entrance Examination and the College English Test 4, which suggested that their English proficiency was between A1 and B1 levels on the CEFR. The Italian participants had taken English, French, Spanish, or German classes in high school but reported no continued practice after graduation (they had no exposure to Mandarin); their proficiency for these languages was reported as B1 or below on the CEFR. All participants were healthy adults with no reported speech or hearing impairments. Each participant provided written informed consent before the experiment and received compensation for their participation.
3.2. Stimuli
We used a set of synthesized vowel stimuli based on four high vowels in the F2-F3 acoustic space: [i], [y], [ʉ], and [u], as shown in Figure 2. For each vowel, we created a prototype and eight non-prototypical variants distributed in equidistant positions around the prototype, as shown in Figure 2B.
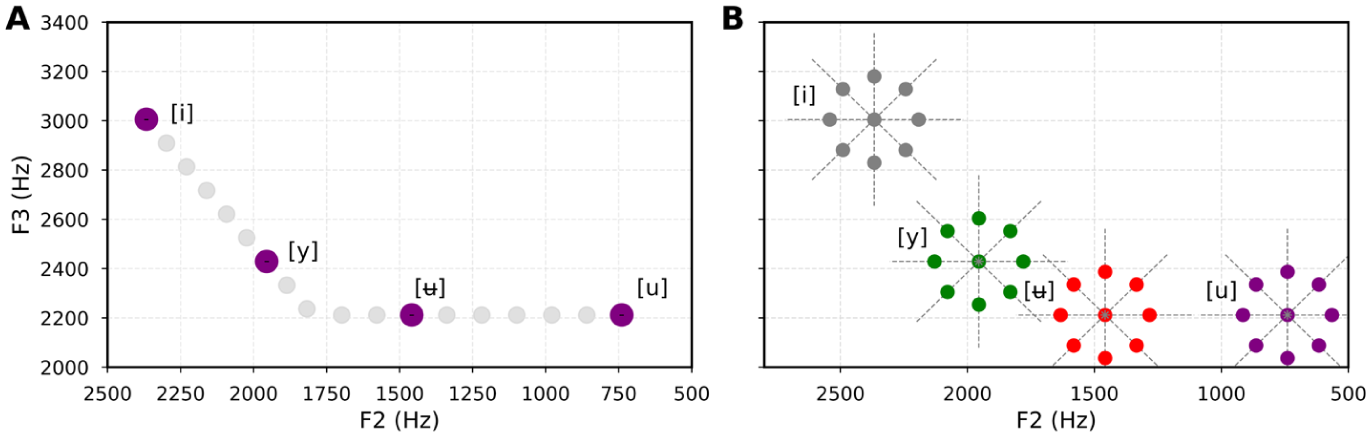
(A) High vowel continuum and the four selected target vowel prototypes. (B) Manipulated high vowels in F2–F3 acoustic space.
We first decided on the four prototypical vowels along the continuum in Figure 2A (Rochet, 1995). In this continuum, F1 was held constant at 300 Hz, F3 was kept at 2,212 Hz for stimuli with F2 values under 1,800 Hz, and was calculated by the equation, F3 = 1.4 × (F2-220), for stimuli with F2 values above 1,800 Hz (Nearey, 1989; Rochet, 1995). The [i] prototype (F2: 2,367 Hz; F3: 3,005 Hz) and [u] prototype (F2: 740 Hz; F3: 2,212 Hz) were chosen around the estimated mean values of Mandarin and Italian prototypical /i/ and /u/ (Bertinetto and Loporcaro, 2005; Lee and Zee, 2003). The [y] prototype (F2: 1,955 Hz; F3: 2,429 Hz) was determined by the first author, a native speaker of Mandarin, then validated by another 20 Mandarin speakers by asking which sound best represents the vowel /y/ in Mandarin. The consistency of judgments across speakers was 85%. The [ʉ] prototype (F2: 1,458 Hz; F3: 2,212 Hz) was decided based on the recording of the [ʉ] example on the speech sound archive webpage (Ladefoged and Johnson, 2010).
For each prototype, we created eight variants by manipulating F2 and F3 values systematically along eight directions (at 0°, 45°, 90°, 135°, 180°, 225°, 270°, and 315°). These variants were positioned at the same distance (175 Hz) from their respective prototypes. This distance ensures that the variants remained within the acoustic category of their prototype while being distinct enough to test discrimination sensitivity.
All stimuli were synthesized in Praat (Boersma and Weenink, 2020) with identical duration (500 ms), F0 (level at 120 Hz), and amplitude envelope (including 50 ms onset and offset ramps). F1 was held constant across all stimuli to isolate the effects of F2 and F3 manipulations. All other acoustic parameters remained identical across the stimulus set to control for potential confounding variables.
3.3. Procedure
Following Brown (2000) and Martinez et al. (2023), sound discrimination was evaluated using an ABX task, which was conducted via an online experiment service implemented in jsPsych (De Leeuw, 2015). Participants sat in a quiet room facing a computer and received written instructions in their native language displayed on the screen. Before the experimental task, an anti-phase headphone test (Woods et al., 2017) was conducted to ensure correct headphone positioning. All participants were required to pass this test to continue. The test consisted of six trials in which participants had to identify the perceptually softest sound among three consecutive 200 Hz sinusoidal tones. Two of the tones were presented diotically: the standard tone and the target tone, which was presented at −6 dB relative to the standard. The third tone had the same amplitude as the standard but was presented dichotically, with the left and right signals in opposite polarity (anti-phase, 180°; for details, see Milne et al., 2021).
Participants then completed the ABX task across four experimental blocks, each focusing on a specific vowel pair: [i]–[y], [u]–[y], [u]–[ʉ], and [y]–[ʉ]. Each block consisted of 36 main trials and one attention check trial, for a total of 148 main trials across the entire experiment. In each trial, participants heard three consecutive vowel stimuli (A, B, and X) and were tasked with indicating whether the third stimulus (X) matched the first (A) or the second (B) by pressing the ‘F’ key (if X matched A) or the ‘J’ key (if X matched B) on the keyboard. Participants had 3,000 ms to respond, with the response time measured from the onset of the second stimulus. The 4 attention check trials (1 per block) used variants (X) identical to either A or B to verify participants’ attention throughout the experiment. For example, A was variant 1 of [i], B was variant 2 of [y], and X matched A with variant 1 of [i] (e.g. A = [i]1; B = [y]2; X = [i]1). In contrast, the main trials used X variants that differed from the target vowel (e.g. A = [i]1; B = [y]2; X = [i]3).
The presentation order was counterbalanced and randomized across participants. Within each block, we controlled for: (1) equal numbers of ABX and BAX trials; (2) balanced cases of X matching A and X matching B; and (3) equal frequency of all 9 variants (including prototypes) for each vowel. Each variant appeared twice as X per block and was paired with different AB variants to avoid bias.
Participants first completed 6 practice trials with feedback to ensure that they understood the task. They then completed 148 main trials across the four blocks. The practice trials followed the same structure as the main trials but provided immediate feedback on response accuracy. The inter-stimulus interval (ISI) was set at 1,500 ms to encourage phonological processing of the stimuli (Werker and Logan, 1985). The between-trial interval was also 1,500 ms to signal the transition from one trial to the next.
3.4. Data analysis
To investigate the effects of group and block on response accuracy, a generalized linear mixed-effects model (GLMM) was fitted using the glmer function from the lme4 package in R (Bates et al., 2015; R Development Core Team, 2022). The model assumed a binomial distribution for the binary outcome variable (accuracy; correct = 1 vs. incorrect = 0) and used the bobyqa optimizer to ensure convergence. The model included fixed effects for Group (Italian vs. Mandarin), Block (/i/–/y/, /u/–/y/, /ʉ/–/u/, and /ʉ/–/y/), and their interaction, with random intercepts for participants and items, as well as random slopes for blocks by participant to account for individual variability. The Group variable was contrast-coded (Italian = −0.5 vs. Mandarin = 0.5), and the Block variable was treatment-coded as a factor with four levels.
Post-hoc analyses were conducted using the emmeans package (Lenth, 2022) to estimate marginal means and perform pairwise comparisons. Estimated marginal means for the probability of correct responses were computed for each block-by-group combination, with confidence intervals derived using the asymptotic approximation. Pairwise comparisons of group effects within each block were performed on the log-odds scale, with Tukey adjustments applied to control for multiple comparisons. Confidence intervals for log-odds differences were calculated using a 95% confidence level (estimate ± 1.96 × standard error).
4. Results
Figure 3 A shows the between-group differences in response accuracy across four blocks for Italian and Mandarin speakers. In the /i/–/y/ block, both groups exhibit similar accuracy, and in the /u/–/y/ block, both groups achieve high accuracy, though Italian speakers seem to show a marginal advantage over Mandarin speakers. In contrast, the /ʉ/–/u/ block reveals a notable decline in accuracy for both groups compared to the first two blocks, with Mandarin speakers performing better than Italian speakers. The /ʉ/–/y/ block also shows lower accuracy for both groups, with Mandarin speakers again demonstrating slightly higher accuracy. Overall, accuracy tends to decrease from the /i/–/y/ and /u/–/y/ blocks to the /ʉ/–/u/ and /ʉ/–/y/ blocks for both language groups. Mandarin speakers generally outperform Italian speakers in the latter two blocks, while performance is more comparable in the first two, with a slight edge for Italian speakers in the /u/–/y/ block. Figure 3B presents the accuracy for individual participants across blocks and languages, with diamond markers indicating mean values. Each box plot displays the median (solid black line), interquartile range (IQR, shown as the box), and whiskers extending to the data’s range. Consistent with Figure 3A, Italian and Mandarin speakers seem to show comparable accuracy for the /i/–/y/ and /u/–/y/ blocks. However, a pronounced between-group difference is evident in the /ʉ/–/u/ and /ʉ/–/y/ blocks, where Mandarin speakers appear to outperform Italian speakers.
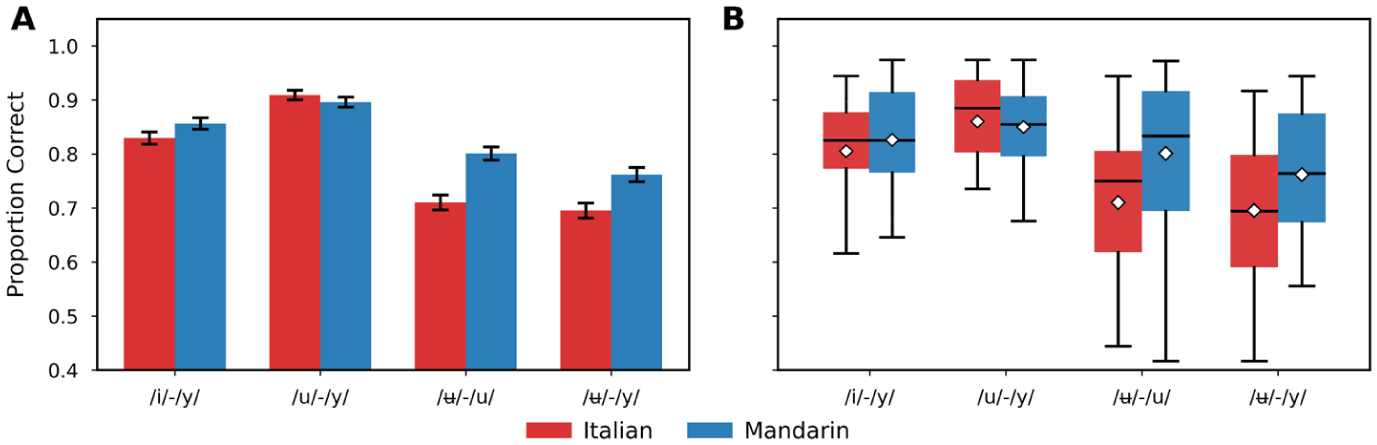
(A) Accuracy for each block across languages with error bars. (B) Accuracy for each individual participant across blocks and languages in boxplots.
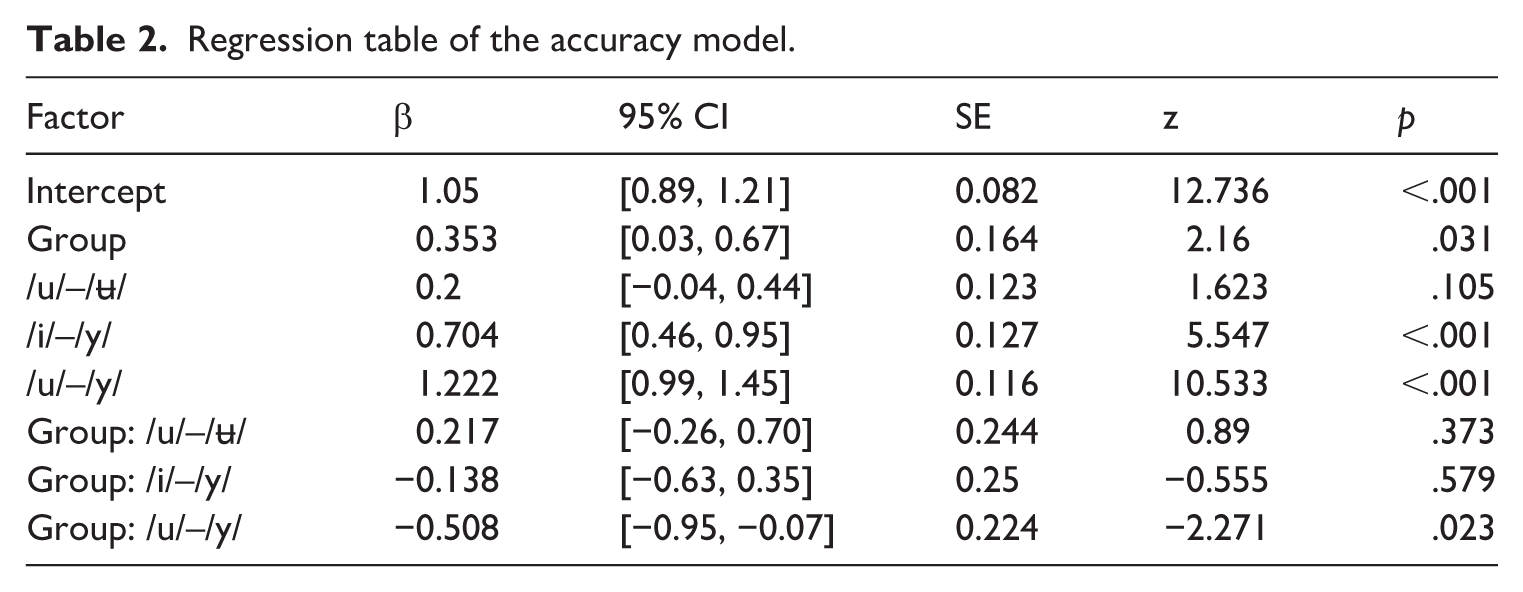
A mixed-effects logistic regression model was fitted to examine the effects of language group and blocks (vowel contrasts) on discrimination accuracy (Table 2). The baseline level for Block was /ʉ/–/y/, and Italian speakers were coded as the reference group. The model revealed a significant main effect of Group, where Mandarin speakers demonstrated higher overall discrimination accuracy than Italian speakers on the /ʉ/–/y/ contrast. Significant main effects of Block emerged for two comparisons relative to the baseline /ʉ/–/y/ contrast: Performance on /i/–/y/ was significantly higher, as was performance on /u/–/y/, which suggests that these contrasts were more discriminable than /ʉ/–/y/. The /u/–/ʉ/ contrast, however, did not differ significantly from the baseline. Crucially, a significant Group × Block interaction emerged for /u/–/y/, indicating that the Mandarin advantage was reduced for this particular contrast compared with the baseline contrast /ʉ/–/y/. No significant interactions were found for the /u/–/ʉ/ or /i/–/y/ contrasts.
Regression table of the accuracy model.
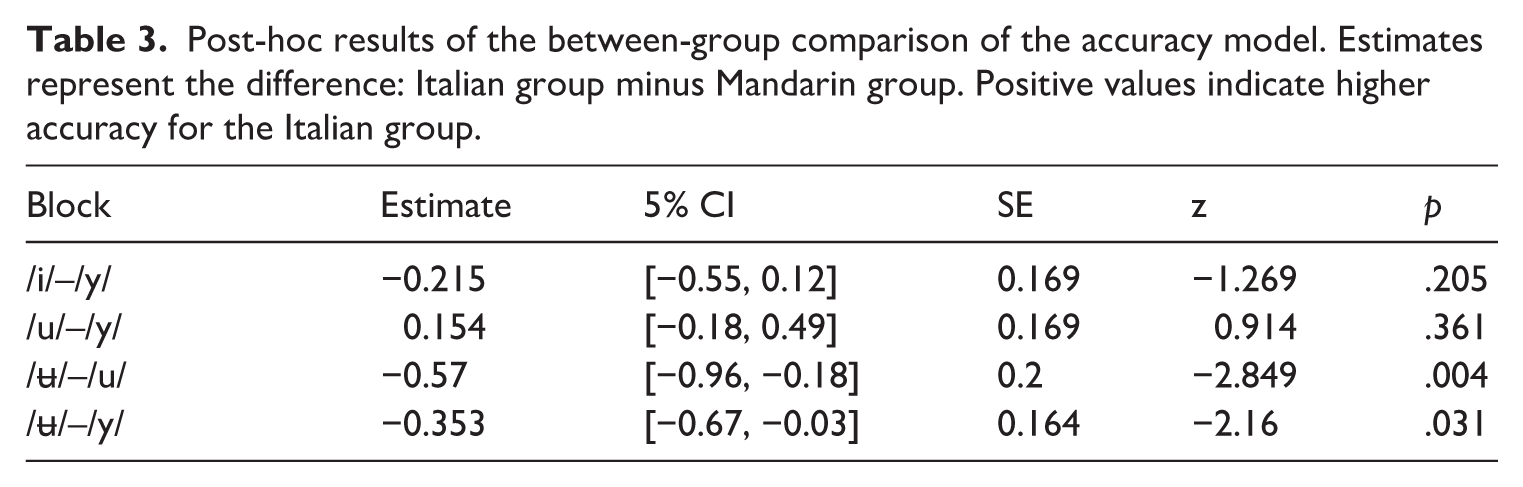
To further explore between-group differences in response accuracy across the four blocks, post-hoc pairwise comparisons were conducted for the accuracy model. The results are summarized in Table 3. For the /i/–/y/ block, the comparison between Mandarin and Italian speakers showed no significant difference, indicating similar accuracy levels for both groups. Similarly, in the /u/–/y/ block, the between-group difference was not significant, suggesting comparable performance between Mandarin and Italian speakers. In contrast, significant between-group differences were observed in the /ʉ/–/u/ block, with Mandarin speakers demonstrating higher accuracy than Italian speakers. Likewise, in the /ʉ/–/y/ block, Mandarin speakers significantly outperformed Italian speakers. In short, post-hoc tests revealed no significant differences in accuracy between Mandarin and Italian speakers for the /i/–/y/ and /u/–/y/ blocks. However, Mandarin speakers exhibited significantly higher accuracy in the more challenging /ʉ/–/u/ and /ʉ/–/y/ blocks, suggesting a group-specific advantage in discriminating these vowel contrasts.
Post-hoc results of the between-group comparison of the accuracy model. Estimates represent the difference: Italian group minus Mandarin group. Positive values indicate higher accuracy for the Italian group.
To further examine the pattern of performance across vowel contrasts within each language group, pairwise comparisons, as visualized in Figure 4, were conducted using estimated marginal means on the logit scale (Table 4). For Italian speakers, discrimination accuracy on the baseline /ʉ/–/y/ contrast did not differ significantly from /u/–/ʉ/. However, /ʉ/–/y/ was significantly less accurate than both /i/–/y/ and /u/–/y/, suggesting that these latter contrasts were more discriminable. Compared to /u/–/ʉ/, Italian speakers showed significantly higher accuracy for /i/–/y/ and /u/–/y/. Finally, /i/–/y/ performance was significantly lower than /u/–/y/. The data suggests a discrimination hierarchy: /u/–/y/ > /i/–/y/ > /ʉ/–/y/ ≈ /u/–/ʉ/.
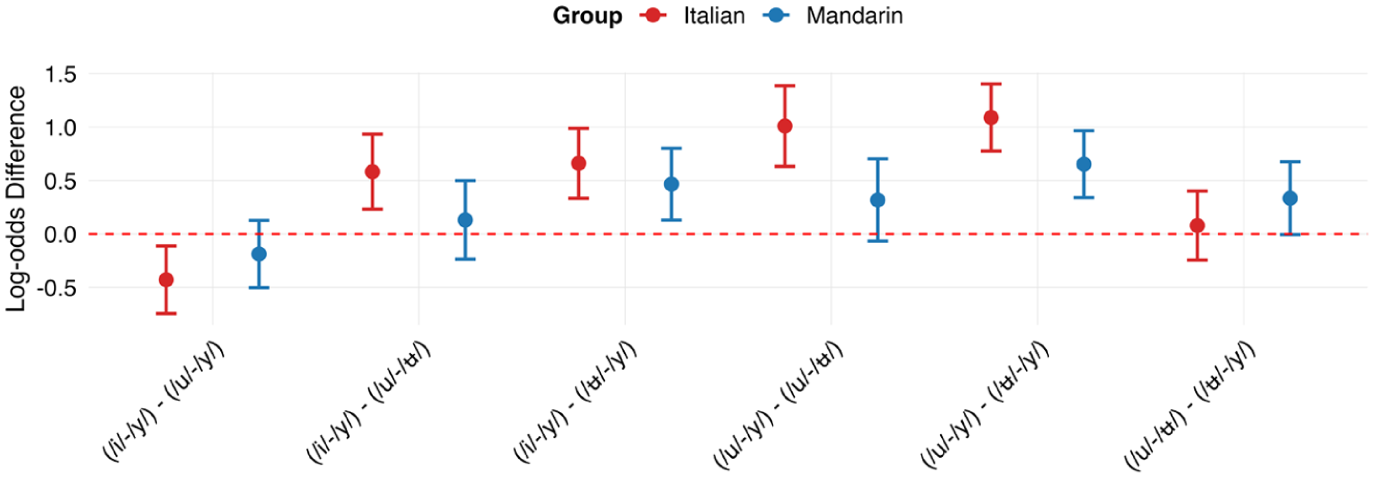
Within-group pairwise comparisons of block differences.
Post-hoc results of the between-block pairwise comparisons across languages.
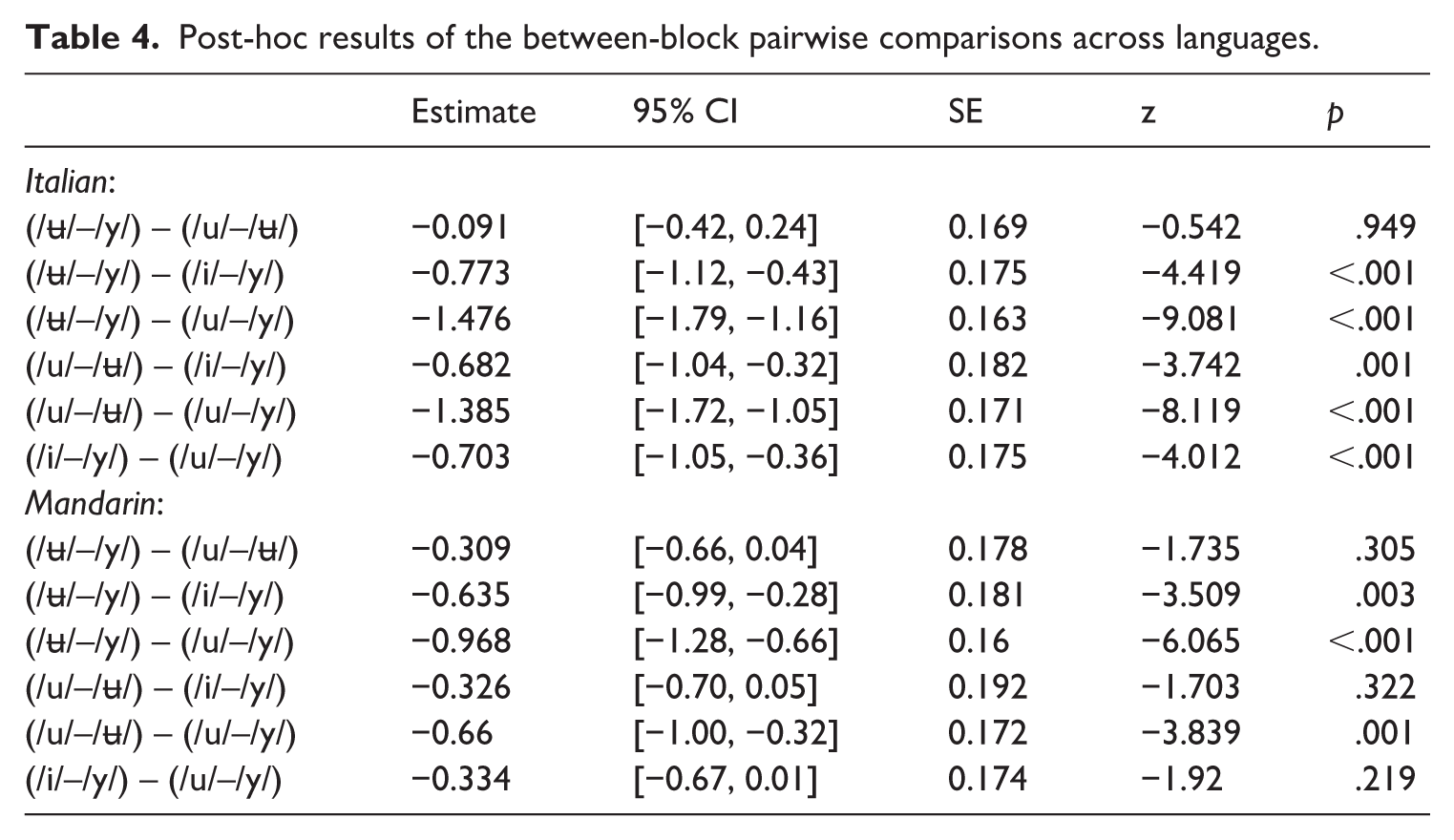
Mandarin speakers demonstrated a somewhat different pattern. While /ʉ/–/y/ and /u/–/ʉ/ performance did not differ significantly, /ʉ/–/y/ was significantly less accurate than /i/–/y/ and /u/–/y/. Critically, /u/–/ʉ/ and /i/–/y/ contrasts did not differ significantly for Mandarin speakers, though /u/–/ʉ/ performance remained significantly lower than /u/–/y/. Notably, unlike Italian speakers, Mandarin speakers showed no significant difference between /i/–/y/ and /u/–/y/, suggesting relatively comparable accuracy on these two contrasts. These pairwise comparisons reveal that while both groups found /u/–/y/ most discriminable, and /ʉ/–/y/ and /u/–/ʉ/ most challenging, the magnitude of differences varied by language.
5. General discussion
This study investigated how language-specific feature specifications in Mandarin and Italian influence naive L2 perception of high vowel contrasts, focusing on the operations of feature fusion and feature fission. By examining the performance of Mandarin and Italian speakers in an ABX discrimination task across four vowel contrasts (/i/–/y/, /u/–/y/, /ʉ/–/u/, /ʉ/–/y/), we addressed two research questions. Below, we discuss our findings in relation to the interaction between auditory and linguistic discrimination, the predictions of phonetic models, the unique contributions of feature-based approaches, and the implications for L1 and L2 phonological theory, as well as limitations and directions for future research.
Research question 1 asks whether Italian listeners discriminate /y/ from other vowels as effectively as Mandarin listeners. The feature fusion hypothesis posited that Italian listeners could discriminate the novel vowel /y/ by combining [coronal] from /i/ and [labial] from /u/. Our results support this hypothesis: Italian and Mandarin speakers appeared to show comparable accuracy in the /i/–/y/ and /u/–/y/ blocks, with no significant between-group differences (Table 3: /i/–/y/, p = .205; /u/–/y/, p = .361). However, we should acknowledge that this interpretation relies on null results, so it should be treated with caution. We can only conclude that there is insufficient evidence for a difference in discrimination behavior between the two groups. Despite this, these findings indicate that feature fusion is available to naive L2 learners, allowing Italian speakers to construct novel phonological representations by redeploying existing L1 features, aligning with Archibald’s (2005) proposal that L2 phonology repurposes L1 knowledge.
Research question 2 addresses whether Italian listeners discriminate /ʉ/ from other vowels as effectively as Mandarin listeners. The feature fission hypothesis predicted that Mandarin speakers could discriminate /ʉ/ by detaching [labial] from their overspecified /u/ ([labial] + [dorsal]), while Italian speakers, with /u/ specified only as [labial], would struggle due to a potential contrast merger. Our results confirm this prediction: Mandarin speakers significantly outperformed Italian speakers in the /ʉ/–/u/ (p = .004) and /ʉ/–/y/ (p = .031) blocks (Table 3). These findings suggest that feature fission is a viable mechanism for Mandarin speakers, allowing them to redeploy [labial] independently to represent /ʉ/, a novel vowel for both groups. In contrast, Italian speakers’ lower accuracy indicates that their [labial] could not be dissociated, leading to poorer discrimination of /ʉ/.
Our findings further indicate the interaction between auditory and linguistic discrimination in L2 sound perception. Specifically, Mandarin speakers showed comparable accuracy in distinguishing /i/–/y/ and /u/–/y/ contrasts, while Italian speakers performed better in the /u/–/y/ block than in the /i/–/y/ block (see Figure 4). For Mandarin speakers, all three sounds, /i/, /u/, and /y/, are processed as distinct phonological categories, leading to consistent discrimination accuracy across blocks. In contrast, for Italian speakers, /y/ is a novel sound. Their discrimination of /y/ likely involves both redeploying phonological features, i.e. [coronal] and [labial], and relying on acoustic cues, e.g. differences in F2 and F3 formants. In this experiment, the acoustic distinction between /u/ and /y/ was greater than that between /i/ and /y/, allowing Italian speakers to exploit these cues more effectively, potentially resulting in higher accuracy for the /u/–/y/ block. However, their accuracy remained lower in the /ʉ/–/u/ and /ʉ/–/y/ blocks, where /ʉ/ cannot be built using feature redeployment. These results align with prior research, such as Johnson and Babel (2010), who observed that Dutch listeners, whose language lacks a phonemic /s/–/ʃ/ contrast, perceive [s] and [ʃ] as more similar than English listeners do, but in a speeded discrimination task, both groups showed similar judgments, suggesting that the general pattern of similarity was based on auditory perception with additional superimposed language-specific effects. Our findings also indicate that auditory cues form the basis for sound discrimination, while linguistic representations, such as feature specifications, shape how these cues are interpreted. This supports the view that perception is guided by phonological grammar (Lahiri and Reetz, 2002).
We consider now whether the perception patterns observed could also be captured by other learning models, specifically, phonetic models such as the Speech Learning Model (SLM; Flege, 1995), Perceptual Assimilation Model (PAM; Best, 1995), Native Language Magnet Model (NLMM; Kuhl, 1991), and Perceptual Interference Hypothesis (PIH; Iverson et al., 2003). These models emphasize the role of acoustic/gestural similarity and attention to phonetic cues in L2 perception (see also Chang, 2018; Holt et al., 2018; Grenon et al., 2019).
SLM predicts that novel L2 sounds are learned based on their phonetic distance from L1 categories, while PAM suggests that L2 sounds are assimilated to the closest L1 categories based on articulatory similarity. In our study, SLM would predict that /y/ and /ʉ/ are discriminated based on their acoustic proximity to /i/ and /u/, respectively. PAM would predict that [ʉ] and [y] are discriminated according to whether the members of the contrast assimilate to the same vowel category or different vowels, and with what ‘goodness of fit’. For instance, the frontness and rounding of /y/ might be assimilated to either /i/ (front) or /u/ (rounded) by Italian speakers, and the centralized position of /ʉ/ might pose challenges for both groups due to its lack of direct L1 equivalents. As expected, both groups showed lower accuracy for /ʉ/–/u/ and /ʉ/–/y/ compared to /i/–/y/ and /u/–/y/, suggesting that the acoustic/gestural properties of /ʉ/ (e.g. centralized F2) are less distinct from L1 categories.
Like feature-based models, cue-based models (e.g. Chang, 2018; Iverson et al., 2003) can account for the overall pattern that Mandarin speakers outperform Italian speakers on the /ʉ/–/u/ and /ʉ/–/y/ contrasts. This is because Mandarin speakers, who must differentiate /y/ from other high vowels in their L1, have developed heightened sensitivity to the acoustic dimensions (such as F2 and F3) that are critical for distinguishing these sounds. However, what remains underspecified in cue-based models is which specific cues listeners are attending to. Given that both /u/ and /y/ involve coordinated changes in F2 and F3 relative to /ʉ/, these models do not, on their own, predict the nuanced finding that Italian speakers perform comparably to Mandarin speakers on /y/. This specific pattern, where Italians succeed on /y/ but struggle with /ʉ/, is more directly captured by the feature-based model, which provides a principled explanation, grounded in the L1’s featural architecture, for why redeployment potential differs across groups and which contrasts will be affected.
Conversely, models based on acoustic similarity might predict a disadvantage for Mandarin speakers in discriminating /ʉ/ from /y/, since /ʉ/ is acoustically closer to /y/ than to other vowels and could thus be assimilated to /y/. An earlier study (Chen et al., 2023) confirmed this possibility: in an ABX task where listeners judged whether an ambiguous sound was more like [y] or [u], Mandarin listeners tended to categorize [ʉ] as [y], whereas Italian listeners categorized it as [u]. Yet, our results show that Mandarin speakers effectively distinguished /y/, /ʉ/, and /u/, and significantly outperformed Italian speakers on contrasts involving /ʉ/.
This discrepancy draws attention to the limitations of SLM, PAM, and related phonetic models. It appears that cue-based and similarity-based models do not directly predict the full patterns found in our data. Feature-based models, by contrast, seem to provide a more principled explanation. They explain the between-group differences, not through general acoustic sensitivity, but through the availability of language-specific phonological representations. This demonstrates that phonological representations, beyond acoustic cues, shape L2 perception in a patterned way.
Focusing on features offers unique insights into L2 phonology that phonetic models sometimes cannot provide. Features are subphonemic units that capture both phonetic and phonological attributes of segments, which enables systematic comparisons across languages (Anderson, 2021). Unlike phonetic models, which prioritize surface acoustic or articulatory similarity, feature-based approaches reveal how underlying phonological grammars constrain perception. For example, our study demonstrates that Mandarin’s overspecification of /u/ as [labial] + [dorsal] allows feature fission, a mechanism unavailable in Italian due to its [labial]-only specification for /u/. This accounts for why Mandarin speakers excel at discriminating /ʉ/, highlighting the role of feature redeployment in L2 learning.
Our findings contribute to phonological theory by elucidating the roles of overspecification and feature redeployment. Overspecification, as observed in Mandarin /u/, captures segments that participate in multiple natural classes, and thus enables operations like feature fission. This contrasts with underspecification, where features are underspecified to capture phonological transparency (e.g. Yoruba /i/; Pulleyblank, 1988). While underspecification reduces representational complexity, overspecification increases flexibility, opening up different types of redeployment, such as fission and fusion, for learners to build novel L2 sounds. Our results suggest that overspecification is not merely redundant but functionally advantageous in L2 perception, challenging views that enforce underspecification as a universal mechanism (e.g. Archangeli and Pulleyblank, 1989; Kiparsky, 1985).
However, we note that our results challenge Martinez et al. (2023), whose findings suggest that feature fission does not facilitate naive perception in L2 learning. Their study showed that English listeners unfamiliar with nasal vowel phonemes struggled to redeploy the [nasal] feature from their L1 vowel system to distinguish Brazilian Portuguese [ĩ] from [i]. Their performance mirrored that of non-Caribbean Spanish listeners, whose vowel system lacks the [nasal] feature entirely. We argue that this discrepancy can be attributed to the conditions required for feature fission: (1) the feature must be contrastive for the particular class of segments, and (2) the host segment must be overspecified. In English, nasal vowels are non-contrastive: their [nasal] feature is allophonic, derived via sharing that feature with the following consonant that licenses it. As a result, [nasal] cannot detach from the vowel, as the vowel itself cannot license (is not contrastively specified for) this feature (for further details, see Goad, 2025). In contrast, Mandarin /u/ licenses both [labial] and [dorsal] features in the overspecified vowel /u/, allowing [labial] to detach without neutralizing the distinction between /u/ and the L2 vowel [ʉ]. Therefore, feature fission can serve as an effective mechanism for redeploying features in naive L2 perception, provided that certain phonological conditions, i.e. feature licensing and segment overspecification, are met.
Our study has several limitations. While our findings from Mandarin and Italian speakers support the role of feature specification in L2 vowel perception, further research is needed to disentangle these effects through targeted cross-linguistic comparisons. By selecting languages with distinct phonological and phonetic properties, future studies can better isolate the specific influence of phonological factors on vowel discrimination. For instance, comparing European French and Italian, which both have [labial] /u/ but differ in the presence of /y/, could help pinpoint phonetic effects in the perception of [ʉ]. Similarly, a comparison between European French and Mandarin, which share similar high vowel inventories (/i, y, u/) but differ in their feature specification of /u/, could clarify the role of phonological effects in perceiving [u]. Additionally, examining languages with a two-way high vowel contrast (/i, u/) but varying feature specifications for /u/ could further distinguish the effects of feature specification from contrast in shaping perception of [ʉ] and [u]. For example, comparing Hindi (having /i, u/), where /u/ is overspecified as [labial] + [dorsal] like Mandarin (Mokha and Goad, 2024), with Italian, where /u/ is specified only as [labial], could test whether overspecification enhances the perceptual distinctiveness of [u] and [ʉ], independent of contrast. Alternatively, comparing Japanese (having /i, ɯ/), where /ɯ/ is specified as [dorsal], with Italian could reveal how different feature specifications influence the perception of [u].
6. Conclusions
In conclusion, feature-based models enable predictions about which L2 sounds are acquirable based on a learner’s L1 grammar. This is seen in Italian speakers’ successful discrimination of /y/ through feature fusion and Mandarin speakers’ effective discrimination of /ʉ/ via feature fission. This predictive capability highlights the value of feature-based approaches in modeling L2 acquisition. However, as noted earlier, phonetic models may provide an alternative explanation for some of the observed perceptual outcomes. Given that the phonological status of features like [labial] and [dorsal] is partly tied to their phonetic realization, integrating featural and phonetic models holds promise for a more comprehensive understanding of L2 perception. We leave further exploration of this to future research.
Footnotes
Acknowledgements
We thank Morgan Sonderegger for assistance in statistics of this article. We also thank the CRBLM for the support during the research. The CRBLM is funded by the Government of Quebec via the Fonds de Recherche Nature et Technologies and Société et Culture.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is funded by Social Sciences and Humanities Research Council of Canada (number 435-2022-0770); Fonds de recherche du Québec – Société et culture (number 2021-SE3-28335); and NSERC (number RGPIN-2021-04117).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.