
Abstract
It remains unclear whether second language prosody–syntax integration resembles native language mechanisms. This study examines how first language (L1) Chinese second language (L2) English learners integrate prosody and syntax compared with native English speakers, and explores L1 Chinese and L2 English processing within L2 learners. Using the Rapid Prosody Transcription method, 89 participants, including native English speakers and Chinese L2 learners, judged prosodic boundaries under manipulated acoustic and syntactic conditions. Results showed that Chinese L2 learners exhibited stronger syntactic constraints in English sentence judgments compared with native speakers. Furthermore, they relied more on syntactic information when processing L2 English than L1 Chinese. These results were examined in relation to the Shallow Structure Hypothesis (SSH), as heuristic processing appears to dominate in L2, leading learners to prioritize syntactic over acoustic cues for rapid and global interpretation. This study proposes that ‘shallow’ in the SSH indicates that L2 processing prioritizes higher-level information.
Keywords
1. Introduction
Despite the growing focus on the interaction and mapping among linguistic modules (such as syntax, morphology, semantics, and prosody) in second language acquisition over the past two decades, the integration of prosody and syntax in second language (L2) learners remains relatively underexplored (e.g. Nickels and Steinhauer, 2018; White, 2011). Research has suggested that prosody–syntax integration in second language (L2) learners might be influenced by several factors, including language transfer (Xue and Yue, 2024), second language processing mechanisms (Ip and Cutler, 2018), and language proficiency (Nickels and Steinhauer, 2018). Previous studies have only identified potential factors; the underlying mechanisms remain to be explored in relation to current L2 theories. Moreover, research is needed to investigate whether L2 processing aligns with the patterns observed in first language (L1) processing. The present study aims to compare how L1 English speakers and L2 English learners process prosody–syntax integration, and to examine how processing mechanisms in L2 English learners’ L1 Chinese differ from those in L2 English.
1.1. Interaction between prosody and syntax among L1 listeners
The interactions between the phonetic and syntactic levels have been extensively explored in the processing of L1. Linguistic prosody, composed of multiple acoustic cues, hierarchically organizes information into different sentence types and conveys both explicit and implicit meanings (Dankovičová et al., 2004; Peters, 2005). One of the key functions of prosody is speech segmentation. Relatively large boundaries, referring to prosodic boundaries beyond the word level, disambiguate sentences and convey information through three main prosodic cues: pause, final lengthening, and pitch change. The use of these cues for speech segmentation has been shown to be universal across different languages (Chinese: Ji et al., 2024; Yang et al., 2014; English: Carlson et al., 2001; Clifton et al., 2002; Morrill et al., 2014; Streeter, 1978). Pause refers to the silent interval that typically occurs between syntactic units (Peters, 2005; Scott, 1982). Final lengthening refers to the increased duration of the word preceding the prosodic boundary. A prosodic boundary is signaled by pitch changes, such as a pitch reset (suspension of downstep with a return to a higher pitch after the boundary) or a pitch rise (the rise of intonation before the boundary). For example, Chinese speakers use pitch reset to indicate a prosodic boundary (Yang et al., 2014), whereas German and English speakers tend to use pitch rise as a prosodic boundary cue (Petrone et al., 2017). These prosodic cues determine how words are grouped, often coinciding with syntactic boundaries (Ji et al., 2024). For instance, the phrase ‘mango salad and juice’ can convey different meanings based on these boundaries: [[mango salad] and juice] suggests two items, and [[mango] [salad] and [juice]] implies three.
Listeners not only rely on prosodic information to disambiguate syntactic structures, but also use syntactic and semantic information to anticipate prosodic structure. Bishop (2012) found that listeners’ judgments of prosodic prominence varied significantly across different question contexts and information structures, even when presented with the same acoustic information. Van der Burght et al. (2021) investigated how pitch accents influenced both syntactic and semantic expectations in sentence processing. The results showed that syntactic expectations were strong enough to interfere with sentence comprehension when violated, indicating a primary reliance on syntax for guiding auditory sentence comprehension.
The annotation methods further revealed how syntax affects prosodic information. Rapid Prosody Transcription (RPT) is one of the latest methods used to capture listeners’ judgments on prosodic features in auditory stimuli (Cole et al., 2017). To assess prosodic boundaries, listeners made binary judgments (e.g. 1 for boundary, 0 for no-boundary) before each word in the auditory materials, meaning any word could potentially be marked. With a group of annotators, these scores indicate the likelihood that a new annotator from the same population would perceive a prosodic boundary before each word. Cole et al. (2010) used the RPT method to investigate the relationship between syntactic and prosodic phrase structures in spontaneous speech using data from the Buckeye corpus and real-time prosodic transcription by untrained listeners. The results demonstrated that syntactic context was the most reliable predictor, suggesting that listeners’ judgments were heavily influenced by their syntactic expectations. Building on Cole et al.’s (2010) method, subsequent studies (Kim et al., 2016; Pintér et al., 2014; You, 2012) have continued to explore this interaction between syntax and prosody. For instance, Buxó-Lugo and Watson (2016) investigated the effect of syntactic expectations on boundary perception using the RPT method. The sentences used in the experiment were unambiguous, such as ‘Put the big bowl on the tray’. The strength of acoustic cues was systematically controlled at 9 steps and placed at both syntactical licensed locations (e.g. after bowl) and syntactically unlicensed locations (e.g. after big). The results showed that listeners identified more boundaries at the syntactically licensed location even with the same acoustic strength, indicating that both acoustic cues and syntactic expectations played a role in processing relatively large prosodic boundaries.
The mutual influence between higher-level syntactic anticipation and bottom-up acoustic cue processing is supported by parallel-process models (e.g. Brodbeck et al., 2023; Kim and Osterhout, 2005; Tabor and Tanenhaus, 1999). Although these models differ in specifics, they generally propose that multiple systems process speech input in parallel. Listeners receive phonemes and words as local units of representation, and this mechanism processes local information. In addition to this local processing, there are two other processing streams: top-down and bottom-up. In the bottom-up manner, auditory information represented by phonemes combines to form words, which then convey syntactic information. In the top-down manner, prior words provide context that sets expectations for possible word and phoneme candidates, and the following sentence context further refines these expectations. These three systems operate in parallel and influence each other during speech comprehension. The interaction between top-down and bottom-up processes has been widely investigated among L1 speakers (e.g. Donhauser and Baillet, 2019). Although such interactions have also been examined in L2 learners (e.g. Wiener and Liu, 2021), how these models align with other second language theories remains unclear.
1.2. Interactions of prosody and syntax in L2 learners
Compared with studies on L1 speakers, research on the integration of prosody and syntax among L2 learners is relatively underdeveloped. Several studies have shown that L2 learners are less precise than native speakers when using acoustic cues for sentence comprehension. For example, Vanlancker-Sidtis (2003) tested how L1 speakers and L2 learners at different proficiency levels use auditory information to distinguish between prosodic patterns signaling idiomatic and literal meanings in ambiguous sentences. The results showed that L1 speakers significantly outperformed L2 speakers across different proficiency levels. Ip and Cutler (2020) found that L1-Chinese L2-English speakers used prosodic cues to anticipate the position of accented words in their L1, and a similar effect was observed among L1 English speakers in their own language. However, the Chinese learners were unable to use this entrainment strategy in their L2 English.
Several factors may influence the integration of prosody and syntax among L2 learners. Language proficiency plays a crucial role in shaping their integration strategies. Dekydtspotter et al. (2008) investigated how L1-English L2-French learners use prosodic and syntactic information to process ambiguous relative clause attachment sentences. The results revealed that college-level L2 learners at different proficiency levels used different processing strategies. Fourth-semester learners demonstrated an improved ability to revise their initial parse strategy based on prosodic cues compared with second-semester college-level learners. Language background, as another significant factor, might interact with proficiency to affect how L2 learners perceive prosody and syntax. Nickels and Steinhauer (2018) used event-related potentials (ERP) methods to investigate the online processing of garden-path sentences among L1 listeners and L2 learners. The results showed that although the Chinese participants had greater L2 immersion at a Canadian university compared with the German learners tested in Germany, they exhibited different perception patterns from both L1 speakers and the German L2 learners. This might be due to the prosodic structures of German and English being more similar to each other than to those of Chinese and English. Therefore, further studies focusing on Chinese learners of English are necessary to explore how prosodic and syntactic integration is influenced by differences in prosodic structures between their L1 and target L2 languages.
Language transfer is another key factor influencing L2 processing, as it reflects the influence of learners’ L1 on their L2 processing. Atterer and Ladd (2004) demonstrated that L1 German speakers transferred the feature of prenuclear rising accents at the segmental level to their L2 English. In a recent study, Xue and Yue (2024) found that Chinese-English L2 learners relied solely on maximum F0 for focus marking in English speech production, whereas L1 English speakers used a combination of pitch cues. This difference could be attributed to L1 language transfer, given that Chinese has a narrower range of prosodic cues for indicating focus compared with English.
It should be noted that language transfer is not an all-or-nothing phenomenon (O’Brien et al., 2014), as some studies have reported only limited language transfer effects. For instance, O’Brien et al. (2014) examined how German-English and English-German L2 learners used prosodic cues to disambiguate prepositional phrase attachment in both German and English. The findings indicated that both groups used the same pitch cues when speaking English and German, suggesting that L2 learners did not fully transfer prosodic cues from their L1. Furthermore, Ip and Cutler (2018) reported that L2 listeners did not automatically transfer L1 strategies to L2 but instead developed new strategies for processing syntactic ambiguities in L2.
Given that most previous studies used ambiguous sentences as materials, Zhang and Ding (2020) further proposed that awareness of ambiguity significantly influences how L2 learners use prosodic cues to resolve syntactic ambiguities. They found that without awareness of ambiguity, L2 learners’ judgments were less accurate and they used a ‘good-enough’ heuristic strategy, leading to incorrect interpretations. However, explicit awareness of ambiguity significantly enhanced L2 learners’ ability to integrate prosodic and syntactic information.
Although previous studies have revealed that the relationship between syntax and prosody among L2 learners differs from that of L1 speakers, the underlying mechanisms remain unclear. The present study aims to further investigate this relationship within the framework of L2 theories.
1.3. The shallow structure hypothesis
A related theory concerning syntactic constraints is the Shallow Structure Hypothesis (SSH), which proposes that L2 learners are less sensitive to syntactic constraints than L1 speakers and tend to rely more on non-structural information, such as lexical, pragmatic, and real-world knowledge (Clahsen and Felser, 2006b; Papadopoulou, 2005; Papadopoulou and Clahsen, 2006). The SSH is grounded in a multiple-pathway model of language processing (Clahsen and Felser, 2018), which posits that morphologically complex words can be processed through more than one route: a heuristic pathway that relies on global interpretation, and an algorithmic pathway that constructs detailed grammatical representations. The relationship between these two types of processing and the parallel mechanisms of top-down and bottom-up models is one of correlation rather than direct mapping. Heuristic processing relies more on semantic content through top-down processing, whereas algorithmic processing relies primarily on bottom-up mechanisms, organizing unfolding input according to successive linguistic rules (Karimi and Ferreira, 2016).
The SSH raises two important aspects for further discussion. First, although Clahsen and Felser (2018) noted that the SSH has mainly focused on between-group comparisons between L1 and L2 speakers, research examining the influence of learners’ L1 on L2 acquisition remains limited (Gerth et al., 2017; Marinis et al., 2005). To achieve a deeper understanding of the SSH, it is necessary to combine L1–L2 between-group comparisons with cross-linguistic investigations among L2 learners.
Second, it is important to consider how acoustic cues interact with syntactic processing in L2 listening. Both the original proposal of the SSH (Clahsen and Felser, 2006a) and the subsequent note by the authors (Clahsen and Felser, 2018) emphasized that L2 learners rely more on non-structural information. The non-structural information also includes acoustic information such as prosody (Clahsen and Felser, 2006b). However, later studies examining the SSH have focused on the interaction between semantic and syntactic cues (Felser et al., 2003; Song et al., 2020; Witzel et al., 2012). Few studies have examined the SSH in the auditory modality. Fernandez et al. (2017) investigated the cognitive cost of speech perception in German L2 speakers of English, examining how participants used prosodic cues to process both complex and simpler syntactic constructions. The results showed that L2 learners and native speakers had similar grammaticality ratings across different sentence types. The increase in cognitive cost for complex sentences compared to simpler ones, as indicated by pupil dilation, did not differ significantly between groups.
Two unsolved problems remain in their study. First, the study examined sentences with different syntactic structures in the auditory modality but did not, as acknowledged by the authors, compare different acoustic conditions. As a result, the findings might only reflect listeners’ performance under one acoustic condition, which could differ when acoustic cues such as intonation change. Secondly, the results were interpreted as inconsistent with the original proposal of the SSH, as L2 learners did not exhibit shallower processing of syntactic constraints. However, whether the underlying mechanism of the SSH could explain the results warrants further discussion. The SSH pattern may differ in speech perception tasks compared with reading tasks. In previous studies on sentence reading and lexical selection tasks, top-down information mainly involves heuristic processing and originates from semantic memory to syntactic structure. It should be noted that in speech perception tasks, syntactic licensing is generally considered a higher-level process relative to acoustic cues. Using syntactic information to predict acoustic patterns constitutes a top-down process, which is associated with heuristic processing (Brodbeck et al., 2023). Thus, in the relationship between syntactic and acoustic cues, the SSH’s claim that heuristic processing dominates in L2 appears to contradict its original proposal that L2 learners prioritize non-structural over syntactic information.
2. The present study
Based on previous literature, we proposed two research questions.
L2 processing in this study is examined from two perspectives: (1) cross-group comparison to investigate whether prosody–syntax integration differs between L1 English speakers and Chinese L2 English learners, and (2) cross-language comparison to examine how L2 learners integrate prosody and syntax in their L1 (Chinese) versus their L2 (English).
This study differs from previous research in terms of the materials used. First, we specifically investigated prosodic boundary judgment using acoustic continua. Previous studies on syntax and prosody integration have tended to investigate prosody as a whole (e.g. Clahsen and Felser, 2018). They examined prosodic features such as intonation or focus across entire sentences, rather than focusing on specific acoustic components or continua of acoustic features. The use of acoustic continua contributes to revealing the dynamic and gradual transitions between bottom-up and top-down mechanisms. Bottom-up mechanisms involved the perception of prosodic cues under different syntactically licensed conditions, and top-down mechanisms used syntactic information to predict prosodic boundary cues. Second, most studies on L2 prosody–syntax integration have focused on how listeners perceive ambiguous sentences. However, the processing of such sentences may be influenced by factors such as limited cognitive resources, L2 parsing strategies (Ip and Cutler, 2018), and awareness of ambiguity (Zhang and Ding, 2020) due to their structural complexity. Therefore, this study used sentences with clear and simple syntactic structures, allowing for a more precise and controlled investigation of the mechanisms underlying prosody–syntax integration.
This theory has primarily been examined concerning the relationship between semantics and syntax, and the discussion of how this model fits into speech perception is still lacking. As Clahsen and Felser (2018) claimed, the SSH requires further examination to evaluate how different types of constraints are weighed. The SSH proposals that the heuristic pathway is more dominant in L2 (Clahsen and Felser, 2018) and that L2 learners rely more on non-structural information in parsing (Clahsen and Felser, 2006b) may not be simultaneously feasible in L2 listening. If L2 processing relies more on syntax than acoustics compared to L1 processing, then it is more likely to be top-down and mainly driven by heuristic processing. If L2 processing relies more on acoustics than syntax, then it is more likely to be bottom-up and mainly driven by algorithmic mechanisms. How the SSH fits into speech perception requires further discussion.
3. Method
3.1. Participants
A total of 89 participants were recruited online, including 30 L1 English speakers from the United States (M = 24.60 years, SD = 3.73), 29 Chinese L2 learners with lower English proficiency (M = 22.40 years, SD = 3.84), and 30 Chinese L2 learners with higher English proficiency (M = 22.27 years, SD = 2.77). None of the L2 learners had lived or studied in English-speaking countries. The mean age of acquisition (AOA) was 6.60 years (SD = 1.10) for higher proficiency learners, and 7.07 years (SD = 1.14) for lower proficiency L2 learners. The higher proficiency group had achieved an IELTS score of 7 or above within the past two years, and the lower proficiency group had achieved an IELTS score between 5 and 6 within the past two years. All participants were compensated for their participation. All procedures were conducted with written consent from participants and with the approval of the Ethical Review Board (PolyU Institutional Review Board; Protocol number: HSEARS20240416002; Title: Syntax and Prosody Perception among L1 and L2 Listeners).
3.2. Materials
An American English L1 speaker recorded the English materials, and a L1 Chinese speaker recorded the Mandarin materials. Following Buxó-Lugo and Watson (2016), the English materials included four sentences, each produced at two syntactic boundary positions: one at an unlicensed boundary (e.g. between key nouns and modifiers) and the other at a licensed boundary (see Table 1). For example, item (2a) in Table 1 was produced with a relatively large boundary at a syntactically licensed location, and item (2b) was produced with a boundary at an unlicensed location.
English materials.

Notes. Boundary locations are indicated by ‘|’s. Words that were acoustically manipulated are in bold.
The Chinese materials followed the same phrase structure with four tone combinations to enhance generalizability, reflecting the variability of tone combinations in Chinese (see Table 2). These controlled positions were selected based on prior research. Previous studies have indicated that relatively large prosodic boundaries were more likely to occur at major syntactic boundaries, such as the boundary between an object phrase and a prepositional phrase, rather than at non-major syntactic boundaries (e.g. between a noun and a modifier: Watson and Gibson, 2004; Wang et al., 2004).
Chinese materials.
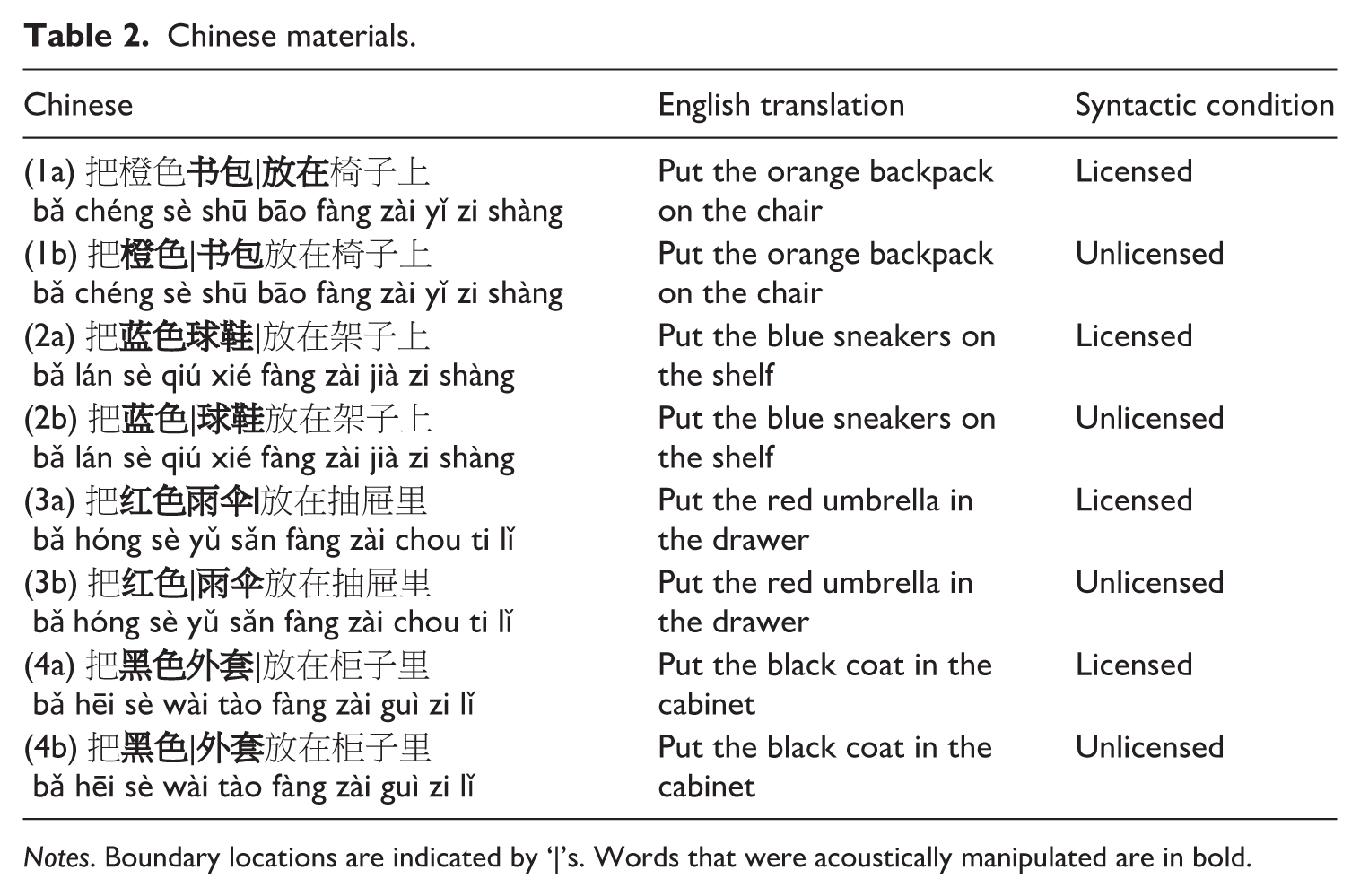
Notes. Boundary locations are indicated by ‘|’s. Words that were acoustically manipulated are in bold.
Following Buxó-Lugo and Watson (2016), boundary continua were separately created at syntactically licensed locations – e.g. Table 1, item (1a) – and unlicensed locations; e.g. Table 1, item (1b). The endpoints of each boundary continuum, representing the absence of a boundary and the presence of a prosodic boundary, were based on L1 speaker productions. For example, the continuum at the syntactically licensed locations between bowl and on was constructed using productions from two sentences at the same sentence positions. Item (2b) in Table 1 indicates no prosodic boundary between on and bowl, whereas item (2a) in Table 1 indicates a prosodic boundary between on and bowl.
In each continuum, the three main prosodic cues (pause, final lengthening, and pitch change) were simultaneously manipulated across nine steps for both the licensed and unlicensed conditions in each language. The endpoints of each continuum were Step 1 and Step 9, with Step 9 representing a prosodic boundary and Step 1 representing no boundary. Specifically, Step 1 included the pause, final lengthening, and pitch change corresponding to the absence of a boundary. Step 5 represented the midpoint of the continuum, with the pause, final lengthening, and pitch change adjusted to intermediate values between the endpoints. Step 9 included all three cues at the boundary position, representing the presence of a prosodic boundary.
These manipulations formed a continuous prosodic gradient for sentences in each language. First, we used Praat to manipulate the pause duration across 9 steps. Then, for each pause step, we employed MATLAB with the TANDEM-STRAIGHT toolbox (Kawahara et al., 2009), which allows simultaneous adjustment of pitch changes and final lengthening to match the corresponding pause step. The three acoustic features were manipulated as follows.
Pause: Pauses were adjusted across nine steps, ranging from no prosodic boundary to a prosodic boundary, based on visual inspection in Praat. These steps were based on the measurements of a naturally produced boundary – e.g. production of the sentence (1a) in Table 1 – and non-boundary phrases – e.g. production of the sentence (1b) in Table 1 – forming the two endpoints of a boundary continuum. Equally spaced intermediate steps were created to ensure a smooth transition between these endpoints, simulating the gradual perception of boundary strength (see Figures S1 and S2 in supplemental material).
Final Lengthening: Vowel durations in both Chinese and English sentences were manipulated across 9 steps, ranging from no boundary to boundary, using the TANDEM-STRAIGHT toolbox (Kawahara et al., 2009). This manipulation was equally spaced intermediate steps to reflect a gradual increase in boundary-likeness (see Figures S3 and S4 in supplemental material).
Pitch Change: F0 contours were measured for words in different positions. In English, only the pre-boundary words were manipulated from boundary to no boundary (see Figure S5 in supplemental material), as pitch change is signaled by a rise in the pre-boundary word in English: the ‘bowl’ in Table 1 (2a). In Chinese, both pre-boundary and post-boundary words were manipulated, as pitch changes are indicated by a pitch reset (see Figure S6 in supplemental material), which is a suspension of downstep and a return to a higher pitch following the boundary (Wang et al., 2004). The F0 changes for both Chinese and English were manipulated in 9 steps from no boundary to boundary using the TANDEM-STRAIGHT MATLAB toolbox.
A total of 144 trials (2 languages × 4 sentences × 2 syntactic license conditions × 9 prosodic boundary steps) were created. The average intensity of sentences was normalized to 70 dB. Example spectrograms of the stimuli are shown in Figures S7 to S10 in supplemental material.
3.3. Procedure
All recordings were uploaded to Gorilla. The procedure followed Buxó-Lugo and Watson (2016) by using the RPT method. The instructions explained that speakers often group utterances into chunks, and that these chunks are often divided by what we call boundaries. They were informed that words before boundaries have a ‘different’ sound compared with those that do not. The instructions were chosen to ensure listeners would not consciously search for specific cues, such as pauses, to identify boundaries (see Appendix A).
For each question, participants saw a media player icon with the instructions: ‘There is a boundary after: . . .’ The sentence was displayed below the instructions. Participants were asked to check the boxes under the words they believed were followed by a boundary. They could replay the recordings and mark as many words as they wanted. We analyzed the perceived boundary responses at the controlled boundary position after the controlled words for each recording.
L1 English speakers were required to complete the section for the judgment of English sentences, while Chinese L2 participants had an additional section for the judgment of Chinese sentences. The order of the sections was randomized for L2 participants, and the recordings were randomized within each section.
3.4. Analysis
We obtained binary boundary judgments for each word in the presented sentences. Previous studies have suggested that the results of the RPT method experiments can be analyzed at specific positions (e.g. Buxó-Lugo and Watson, 2016; Turnbull et al., 2017). Therefore, we analyzed responses in the syntactically licensed condition – e.g. boundary judgment for the syntactically licensed position after bowl in sentence Table 1(2a) – and unlicensed condition – e.g. boundary judgment for the syntactically unlicensed position after big in sentence Table 1 (2b) – under different prosodic boundary steps. The first analysis included the responses for 89 listeners across three groups of listeners (L1 English speakers and L2 learners with higher English proficiency and L2 learners with lower English proficiency) to 72 recordings of English sentences, totaling 6,408 data points. The second analysis included responses from 59 listeners (L2 learners with higher and lower English proficiency) on 144 recordings of English and Chinese sentences, totaling 8,496 data points.
We constructed mixed-effects logistic regression models using the ‘lme4’ package (Bates et al., 2015) in R Version 4.4.1 (R Core Team, 2024). The model construction followed previous studies on speech perception that involved multiple factors, as overall models were built first, followed by separate models based on specific groups or conditions (e.g. Durvasula and Kahng, 2016; Kwon, 2017; Zhang and Peng, 2021). In this study, two overall models incorporating all possible factors were initially constructed; the first analysis compared how different groups (L1 English speakers and L2 English learners) process English, and the second analysis compared languages (L1 Chinese and L2 English) within the group of L2 English listeners. Subsequently, separate models were then built for different groups and conditions to investigate the interactions observed in the overall models.
The first overall model for cross-group comparison was a mixed-effects logistic regression incorporating all relevant factors. The dependent variable was the listener’s response in the English section (0 = no boundary judgment and 1 = boundary judgment). The model included main effects for syntactic condition (syntactically licensed and unlicensed locations), group (Chinese listeners with higher English proficiency, Chinese listeners with lower English proficiency, and L1 English listeners), and prosodic boundary step (9 boundary steps), and their possible interactions. The random effects structure selected was the most complex one justified by the study design (Barr et al., 2013), including the intercepts of subject and item. The items consisted of the four sentence types under two conditions, totaling 8 items.
The second overall model for cross-language comparison was a mixed-effects logistic regression incorporating all relevant factors, built for two groups of English L2 learners. The dependent variable was the listeners’ response (0 = no boundary judgment and 1 = boundary judgment) in both the English and Chinese sections. The model included main effects for syntactic condition (syntactically licensed and unlicensed locations), group (Chinese listeners with higher English proficiency, Chinese listeners with lower English proficiency), language (Chinese L1 and English L2) and prosodic boundary step (9 boundary steps), and their possible interactions. The random effects included the intercepts of subject and item.
4. Results
4.1. Cross-group comparison of English L1 listeners and Chinese L2 listeners
The first analysis examines whether prosody–syntax integration differs between L1 English speakers and Chinese L2 English learners. Figure 1 shows the boundary response percentage for L1 English speakers and L2 English learners across different boundary steps under syntactically licensed and unlicensed locations. The results for the first overall model are shown in Table 3. There was a significant three-way interaction of Syntactic Condition × Group × Step. These results suggested that L1 English listeners had different prosodic and syntactic integration patterns compared with Chinese L2 English listeners, highlighting the need for further analysis to explore these integration patterns in detail.

Mean percentage of boundary responses for English across three groups.
Results of the overall model for cross-group comparison in English sentence processing.
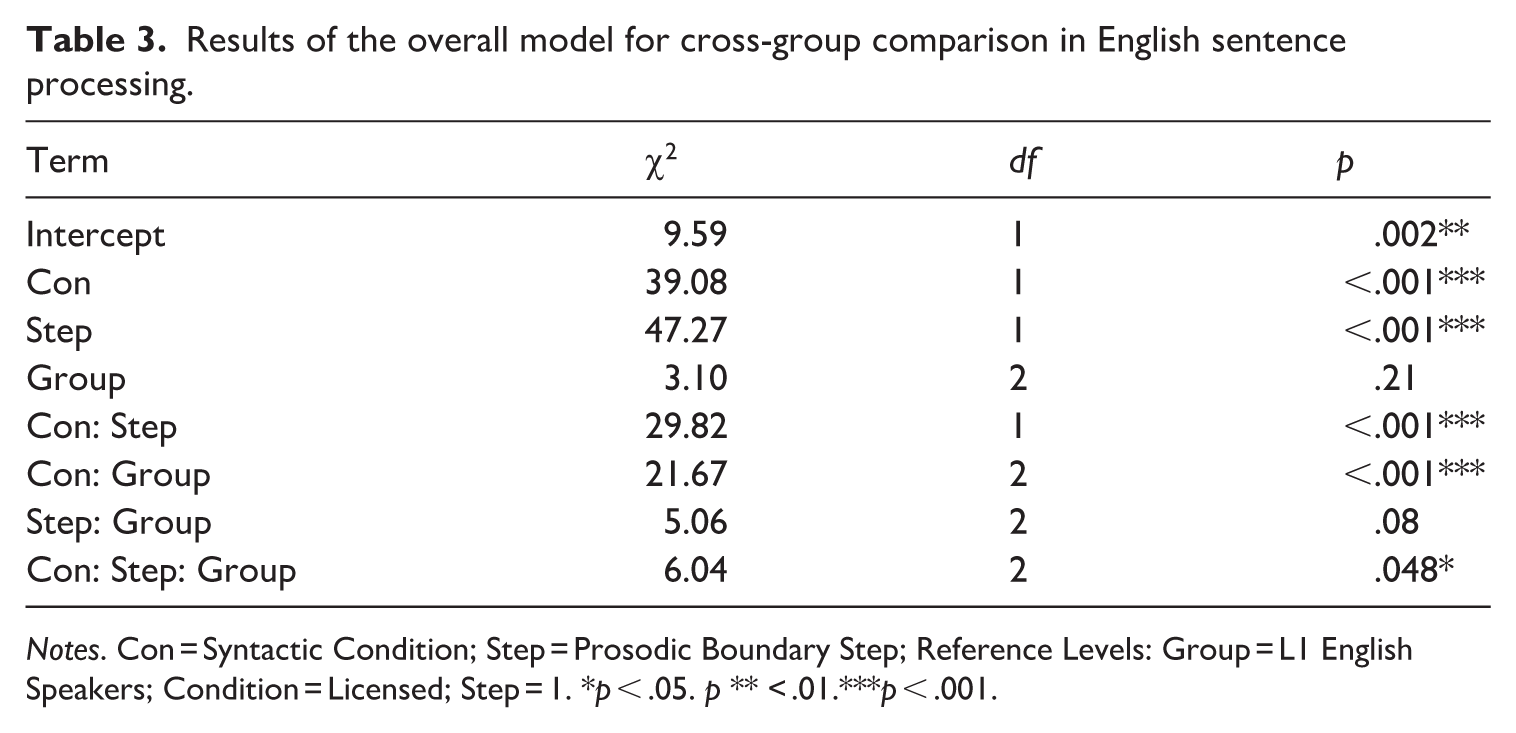
Notes. Con = Syntactic Condition; Step = Prosodic Boundary Step; Reference Levels: Group = L1 English Speakers; Condition = Licensed; Step = 1. *p < .05. p ** < .01.***p < .001.
To compare how syntactic information influenced listeners’ prosodic boundary perception, three mixed-effects logistic regression models were fitted for each of the three groups. The dependent variable was the listener’s response. In each group model, the fixed effects included syntactic condition (syntactically licensed and unlicensed conditions) and prosodic boundary step (9 boundary steps). The random effects included the intercepts for both subject and item. The results are presented in Table 4. In each of the three models, there were significant main effects of syntactic condition and prosodic boundary step and a significant interaction of prosodic boundary step × syntactic condition. Bonferroni post hoc tests indicated that the effect of prosodic boundary step was significant in both unlicensed and licensed conditions (all ps < .001). This indicated that acoustic cues significantly influenced the boundary judgments under different syntactic conditions. In addition, all three groups of listeners made more prosodic boundary judgments under the syntactically licensed locations compared with the syntactically unlicensed locations when controlling for prosodic boundary step (all ps < .05). These results suggested that with the same acoustic cue strength, the judgments of all three groups of listeners were significantly influenced by syntactic information. Overall, these findings implied that both syntactic expectations and acoustic cues influenced prosodic boundary processing.
Model output for each group in English sentence processing.
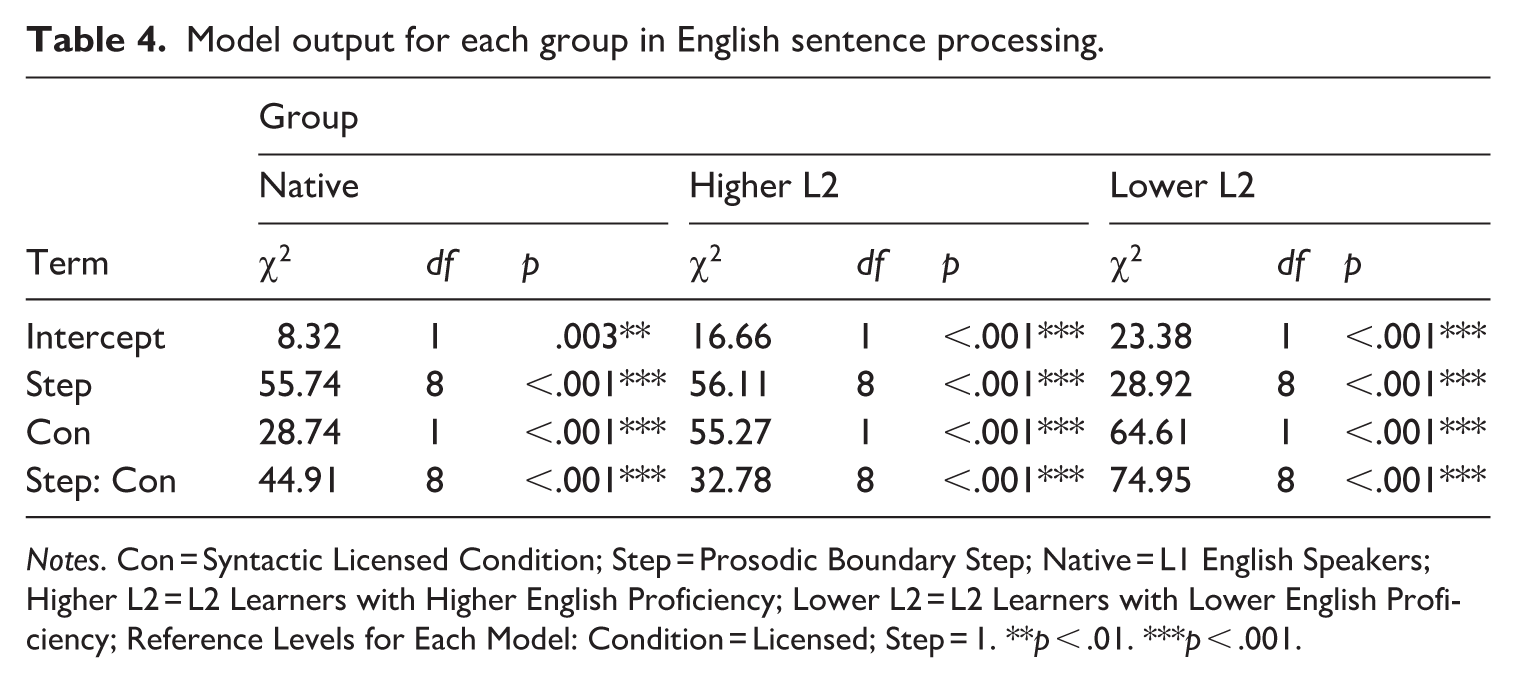
Notes. Con = Syntactic Licensed Condition; Step = Prosodic Boundary Step; Native = L1 English Speakers; Higher L2 = L2 Learners with Higher English Proficiency; Lower L2 = L2 Learners with Lower English Proficiency; Reference Levels for Each Model: Condition = Licensed; Step = 1. **p < .01. ***p < .001.
To further investigate the group differences in syntactic and prosodic integration strategies, two mixed-effects logistic regression models were fitted separately for the syntactically licensed and unlicensed conditions. The dependent variable was listeners’ response under each condition. In each model, the fixed effects included group (Chinese listeners with higher English proficiency, Chinese listeners with lower English proficiency, and L1 English listeners), prosodic boundary step (9 boundary steps), and their possible interactions. The random effects included the intercepts for both subject and item. The results are shown in Table 5. Under the syntactically licensed condition, there was a significant main effect of prosodic boundary step, indicating that prosodic cues had a significant effect on listeners. However, there was no significant main effect of group and no significant interaction of prosodic boundary step × group, indicating that the three groups had similar integration strategies for syntactic and acoustic cues. Under the syntactically unlicensed condition, there were significant main effects of prosodic boundary step and group. There was no significant interaction of prosodic boundary step × group. To explore the significant main effect of group, Bonferroni post-hoc tests were conducted. The results revealed no significant difference between L2 listeners with higher proficiency and those with lower proficiency (β = 0.20, SE = 0.30, z = 0. 67, p = 1.00), indicating that listeners’ proficiency levels did not influence their processing strategy. However, L2 listeners with lower proficiency (β = −1.01, SE = 0.33, z = −3. 12, p = .006) and higher proficiency (β = −0.81, SE = 0.32, z = −2. 51, p = .036) differed from L1 English listeners. This suggested that L1 listeners made more prosodic boundary judgments under the syntactic unlicensed condition, and they were less influenced by syntactic information compared with the two groups of L2 learners.
Model output for the two syntactic conditions.
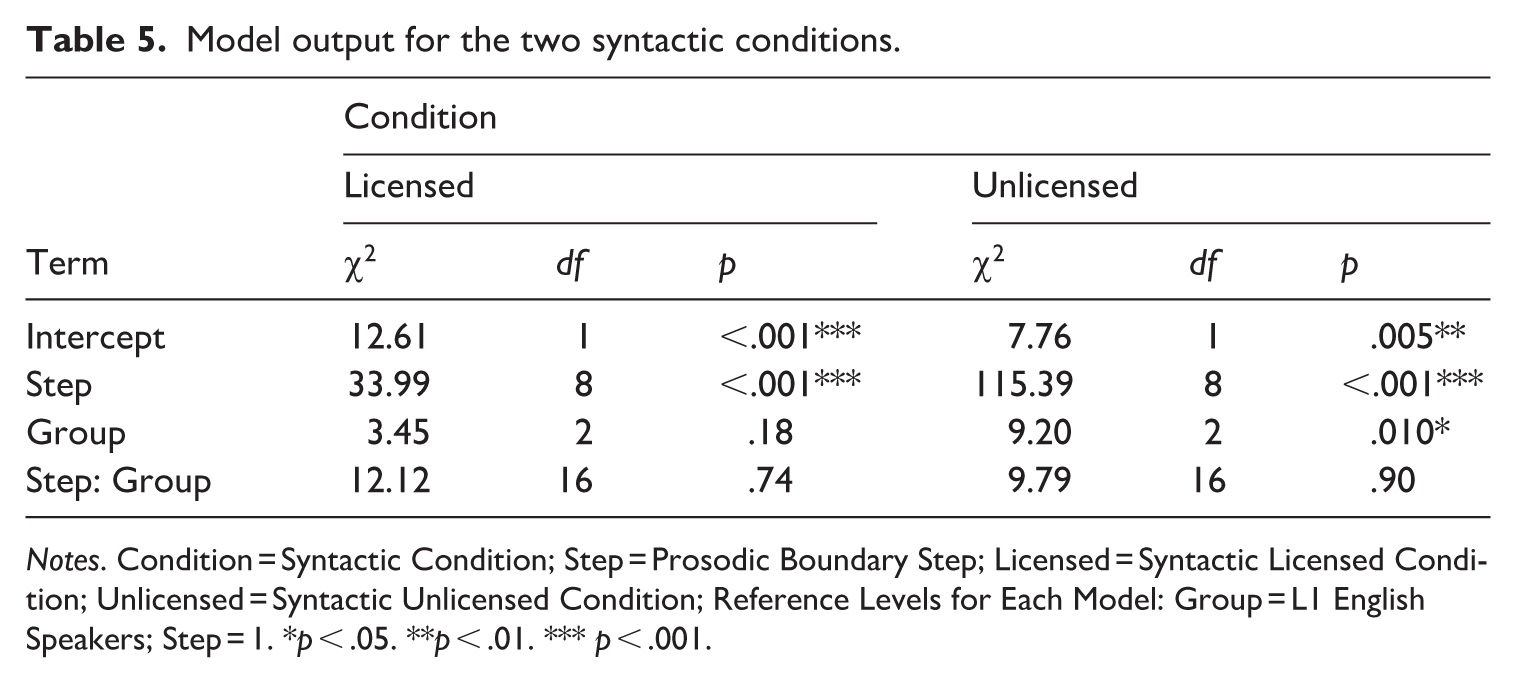
Notes. Condition = Syntactic Condition; Step = Prosodic Boundary Step; Licensed = Syntactic Licensed Condition; Unlicensed = Syntactic Unlicensed Condition; Reference Levels for Each Model: Group = L1 English Speakers; Step = 1. *p < .05. **p < .01. *** p < .001.
4.2. Cross-language comparison of Chinese L1 and English L2
The second analysis examines how L2 English learners integrate prosodic and syntactic cues in their L1 Chinese and L2 English. Figure 2 presents the boundary response percentages for L2 learners with higher and lower English proficiency for processing L1 Chinese and L2 English across different boundary steps.

Mean percentage of boundary responses in first language (L1) Chinese and second language (L2) English.
The results for the second overall model are shown in Table 6. A significant four-way interaction of syntactic condition × prosodic boundary step × group × language was found, indicating that L2 listeners might have different integration patterns in L1 and L2. Further models were needed to investigate this four-way interaction.
Overall model output for Chinese and English processing in L2 learners.

Notes. Con = Syntactic Licensed Condition; Step = Prosodic Boundary Step; Lang = Language; Reference Levels: Group = Higher-level L2 Learners; Condition = Licensed; Step = 1; Language = Chinese. *p < .05. **p < .01. ***p < .001.
To further investigate this four-way interaction, two models were built for each L2 group to examine how L1 Chinese listeners integrate prosodic and syntactic information in their L1 and L2. The dependent variable was the response from each group of listeners. Each model included main effects for syntactic condition (licensed and unlicensed locations), prosodic boundary step (9 boundary steps), language (L1 Chinese and L2 English), and all possible interactions. The random effects included the intercepts of subject and item. The results are shown in Table 7.
Model output for Chinese and English processing in each Chinese learner group.
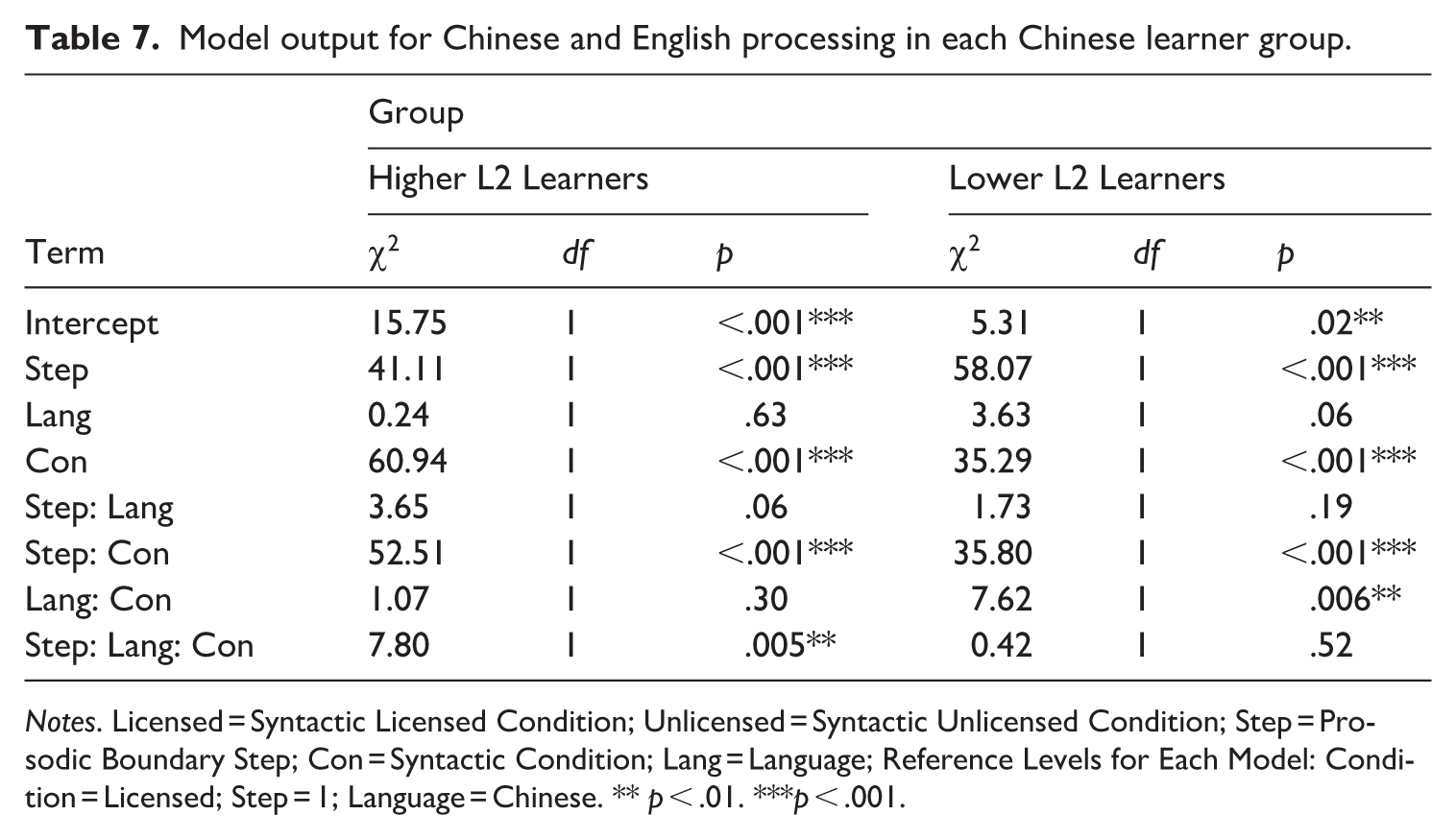
Notes. Licensed = Syntactic Licensed Condition; Unlicensed = Syntactic Unlicensed Condition; Step = Prosodic Boundary Step; Con = Syntactic Condition; Lang = Language; Reference Levels for Each Model: Condition = Licensed; Step = 1; Language = Chinese. ** p < .01. ***p < .001.
For L2 listeners with higher English proficiency, there was a significant three-way interaction of prosodic boundary step × syntactic condition × language (see Table 7). To further investigate this three-way interaction, two separate models were built for the licensed condition and unlicensed condition for the responses of L2 listeners with higher English proficiency. The results of these two models are presented in Table 8. Under the licensed condition, there was a significant main effect of prosodic boundary step, indicating that L2 listeners with higher English proficiency identified more prosodic boundaries when stronger acoustic cues were present. However, there was no significant effect of language, nor a significant interaction of language × prosodic boundary step, suggesting that L2 listeners with higher English proficiency used similar processing strategies in both L1 and L2 built for the syntactically licensed conditions. Under the syntactically unlicensed condition, there were significant main effects of prosodic boundary step and language. There was a significant interaction effect of prosodic boundary step × language. Bonferroni post-hoc tests on the interaction effect revealed that listeners made more prosodic judgments in Chinese L1 than English L2 (β = 0.98, SE = 0.22, z = 4. 48, p < .001) in the syntactic unlicensed condition.
Model output for different conditions for higher proficiency L2 learners.

Notes. Step = Prosodic Boundary Step; Licensed = Syntactic Licensed Condition; Unlicensed = Syntactic Unlicensed Condition; Reference Levels for Each Model: Step = 1; Language = Chinese. *p < .05. **p < .01. ***p < .001.
For L2 listeners with lower English proficiency, significant main effects of step and syntactic condition were found. Two-way interactions were found between prosodic boundary step × syntactic condition and language × syntactic condition (see Table 7). To investigate the interaction between step and syntactic condition, Bonferroni post-hoc tests revealed a significant difference between the syntactically licensed and unlicensed conditions when the prosodic boundary step was controlled (β = 0.93, SE = 0.24, z = 3.96, p < .001). This indicated a significant effect of syntactic cues when presented with the same prosodic cue strength. To investigate the interaction between language and syntactic condition, Bonferroni post-hoc tests were conducted. The results showed no significant difference between Chinese L1 and English L2 under the syntactically licensed condition (β = −0.34, SE = 0.34, z = 1.02, p = .31). However, under the syntactically unlicensed condition, listeners made more prosodic boundary judgments in L1 Chinese than L2 English (β = 0.91, SE = 0.33, z = 2.75, p = .006). These results indicated that Chinese L2 listeners with lower English proficiency had similar processing strategies between L1 Chinese and L2 English under syntactic licensed condition, but had different processing strategies between L1 Chinese and L2 English in the unlicensed condition.
5. Discussion
This study examined the prosodic boundary and syntactic license integration in L2 processing. We investigated how L1-Chinese L2 -English learners integrated syntactic and prosodic boundary cues by comparing the processing of English in L1 speakers and L2 learners, and the processing of L1 Chinese and L2 English among L2 English learners. The results demonstrated that syntactic expectations influenced prosodic boundary judgments. L2 English learners were more influenced by syntactic information than L1 English speakers. These results were discussed in relation to the SSH by suggesting that ‘shallow’ processing reflects the prioritization of higher-level information, as learners rely more on syntactic cues when acoustic information is less informative.
To address research question 1 (how syntactic and prosodic boundary cues are integrated in L2 processing), both cross-group and cross-language comparisons were conducted. The cross-group analysis examined prosody–syntax integration between L1 English speakers and L2 English learners. Both groups showed a similar dynamic pattern in integrating syntactic and prosodic boundary cues. When acoustic information was weak or absent, listeners primarily relied on syntactic expectations. However, when prosodic cues were strong (i.e. involving a long pause, increased final lengthening, and sharp pitch changes, corresponding to steps 5–9 in our experiment), both L1 and L2 listeners identified boundaries even in syntactically unlicensed conditions, indicating that prosodic information alone can trigger boundary perception. These results replicate previous findings (Buxó-Lugo and Watson, 2016; Cole et al., 2010), demonstrating that L1 listeners’ prosodic judgments are influenced by syntactic cues. Importantly, this effect was also observed in L2 listeners, consistent with studies showing that L2 listeners can form prosodic expectations based on syntactic information in a manner similar to L1 listeners (e.g. Fernandez et al., 2017; Ganga et al., 2024).
Although the general pattern was similar, there were notable differences in syntactically unlicensed conditions. In the licensed conditions, both English L1 speakers and L2 English learners exhibited similar boundary judgments, as syntactic information alone provided sufficient cues. All groups of listeners showed over 70% boundary judgments even in the absence of prosodic boundary cues. In unlicensed conditions, where syntactic and acoustic information conflicted, L2 English learners relied more on syntax and made fewer boundary judgments based on acoustic cues. This may be due to L2 listeners relying more on syntactic information compared to acoustic cues, reflecting a top-down processing manner. These differences could also be influenced by factors such as L1 transfer or L2 processing strategies that differ from those used in L1. To better understand the prosody–syntax integration mechanism in L2 processing, we conducted a comparison between L1 Chinese and L2 English processing among L2 English learners.
We investigated how L1 Chinese speakers integrate prosody and syntax in their L1 Chinese and L2 English. The results indicated that L2 English learners employed similar strategies in both L1 and L2 under syntactically licensed conditions, suggesting that syntactic expectations influenced listeners’ judgments in both languages. However, in the syntactically unlicensed condition, L2 English learners relied more on syntactic information in their L2 English than in their L1 Chinese. This demonstrated a different processing strategy in L2 when prosody and syntax conflicted. These findings implied that the increased syntactic constraints in L2 processing compared with L1 were due to the L2 processing strategy rather than L1 transfer, consistent with research showing differences between L1 and L2 processing strategies (O’Brien et al., 2014). In addition, previous studies on Chinese syntax have indicated that Chinese is an analytic language with a more flexible syntactic structure, which tends to be less constrained by syntactic information compared with English (e.g. Li and Thompson 1989). Therefore, it was unlikely that the greater reliance on syntactic cues among L2 learners was transferred from their L1 Chinese.
Another important finding of our study was that no significant differences were observed among listeners of different proficiency levels. The first analysis compared the groups in their perception of English phrases, showing that both groups of Chinese listeners made prosodic boundary judgments when acoustic cues were salient, regardless of syntactic condition. While L2 listeners were more influenced by syntactic information under unlicensed conditions compared with L1 English listeners, both higher and lower proficiency L2 learners demonstrated similar constraints in both the licensed and unlicensed conditions. The second analysis compared English and Chinese phrase perception among L2 English listeners of different proficiency levels, revealing that both groups were more constrained by syntax in L2 than in L1 in the unlicensed conditions. The results suggested that the reliance on syntactic cues in L2 remained stable and did not change with increased English proficiency.
We examined how the results relate to the SSH to answer research question 2. Our results compared L1 speakers with L2 learners, and L2 learners’ L1 with their L2, indicating that L2 processing was more constrained by syntactic information than L1 processing was. This finding seems to contrast with the initial proposal of the SSH (Clahsen and Felser, 2006a), which claims that L2 learners’ sentence comprehension is shallower and less detailed than that of L1 speakers. However, our results support the SSH’s underlying mechanism, suggesting that heuristic processing dominates L2 processing (Clahsen and Felser, 2018). Our findings indicate that this dominance is maintained among L2 learners with different levels of English proficiency. The greater reliance on syntactic cues in L2 processing is likely due to the limited role of acoustic features in achieving precise sentence comprehension. In contrast, grammatical information provides an overall structural representation of the sentence, allowing for a rapid and global interpretation of meaning. This reflects a ‘fast and frugal’ heuristic processing strategy that reduces cognitive effort in L2 processing, even for learners who have attained a higher proficiency level (Karimi and Ferreira, 2016).
Building on this finding, we reconsider the SSH to clarify what ‘shallow’ processing represents. We argue that ‘shallow’ processing reflects the prioritization of higher-level information. According to parallel processing models, semantic information for overall understanding represents a higher level than syntactic information, and syntactic information represents a higher level than acoustic cues. In L2 comprehension, the shallower processing observed in L2 learners depended on the type of available information, with learners relying more on semantic and pragmatic cues than on syntactic cues, while giving precedence to syntactic cues when acoustic cues were less informative.
We need to note that this proposal might be influenced by sentence type, task type, and L2 learner proficiency. Clahsen and Felser (2018) acknowledged that their original hypothesis was too broad and required refinements for different grammatical structures. In this study, we used sentences with clear structures. It is possible that for ambiguous sentences, where interpretation depends on acoustic cues, L2 listeners must rely more on these cues to achieve an accurate understanding of the meaning. Task type might also influence the results. In the RPT, listeners judged auditory stimuli containing both acoustic and syntactic information, and then made prosodic judgments with the words in the sentence presented on screen. If the task required overall sentence interpretation rather than prosodic judgments, the results might be different. Further studies are needed to investigate whether L2 learners prioritize acoustic cues for integrating acoustic and syntactic information. It is also necessary to examine whether the effects we observed apply to different sentence types and task conditions, or only to sentences with clear structures using the RPT method. English proficiency might also influence the processing patterns. In this study, we focused on L2 English learners with an IELTS score above 5 who had not studied or lived in English-speaking countries. Future research is needed to examine whether English learners with lower proficiency, or those who have studied or lived in English-speaking countries, exhibit the same processing mechanisms.
This study has methodological implications. The advantage of RPT lies in its ability to efficiently and straightforwardly collect data on prosody perception. This method has proven feasible in both online and offline experiments across different participant groups, capturing listeners’ holistic perception of prosodic form and function. While several studies have applied this method to examine how L2 learners annotate prosody (Pintér et al., 2014; You, 2012), its feasibility in investigating the integration of syntax and prosody among L2 learners remains underexplored. Buxó-Lugo and Watson (2016) used this method to reveal how L1 listeners process prosodic cues alongside syntactic information. In this study, we demonstrated the feasibility of this method in exploring L2 syntax–prosody integration. Another methodological advantage of our study is the use of prosodic continua to reveal how listeners’ boundary judgments change with increasing acoustic cue salience under different syntactic licensing conditions.
6. Conclusions
We investigated how syntactic cues and prosodic boundary cues integrate in L2 processing and their relation to the SSH. The findings showed that both L1 and L2 listeners made more boundary judgments in a syntactically licensed condition when acoustic information was controlled. However, L2 learners were more influenced by syntactic information than L1 speakers under syntactically unlicensed conditions. In addition, L2 learners demonstrated a stronger reliance on syntactic information in their L2 compared with their L1, indicating a limited influence of language transfer and highlighting a distinct L2 processing strategy when prosodic cues conflict with syntax. Both higher and lower proficiency L2 groups exhibited similar patterns in English processing, suggesting that proficiency might not significantly affect their reliance on syntactic cues in L2. These results seem to contrast with the original proposal of the SSH, but in fact align with its underlying mechanism, in that L2 processing relies more on a heuristic route than L1 processing does, leading learners to rely more on syntactic information than acoustic cues, enabling rapid and global interpretation. We reconsider the SSH by suggesting that ‘shallow’ processing prioritizes higher-level information, with syntactic cues taking precedence over acoustic cues in sentences with clear structure.
Supplemental Material
sj-docx-1-slr-10.1177_02676583261445731 – Supplemental material for Integrating syntactic and prosodic boundary cues in second language processing: Evidence from L1-Chinese L2-English learners and L1 English speakers
Supplemental material, sj-docx-1-slr-10.1177_02676583261445731 for Integrating syntactic and prosodic boundary cues in second language processing: Evidence from L1-Chinese L2-English learners and L1 English speakers by Jinxin Ji, Wencui Liu, Jiaxin Li, Xiaohu Yang and Gang Peng in Second Language Research
Footnotes
Appendix A
Ethical considerations
All procedures were conducted with written consent from participants and with the approval of the Ethical Review Board (The Hong Kong Polytechnic University Institutional Review Board; Protocol number: HSEARS20240416002; Title: Syntax and Prosody Perception among L1 and L2 Listeners).
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.