
Abstract
Objectives
Lipedema is a chronic disorder characterized by pain and disproportionate fat distribution, and its diagnosis is frequently overlooked. The aim of this study was to evaluate and compare the responses generated by contemporary artificial intelligence models—ChatGPT-5o, Gemini-3, and Perplexity AI—to structured clinical questions developed in accordance with the 2024 S2k Lipedema Guideline. The models were analyzed in terms of clinical accuracy, readability, and reference reliability to assess their performance in delivering guideline-based medical information.
Methods
This cross-sectional and comparative study was conducted by submitting 30 structured clinical questions, prepared on the basis of the relevant guideline, to three large language models. Responses collected on 10 February 2026, were evaluated using a seven-point Likert scale (reliability) and a five-point scale (accuracy). Text readability was assessed using six established indices, including the Flesch Reading Ease Score (FRES), Flesch–Kincaid Grade Level (FKGL), and Gunning Fog Index (GFOG). Reference reliability was examined by analyzing hallucination tendencies as defined in the literature.
Results
A statistically significant difference in reliability was observed among the models (p = .041); Perplexity (4.95 ± 1.20) achieved significantly higher scores than ChatGPT-5o (4.38 ± 1.05) (p = .038). In readability analyses, Perplexity (12.80 ± 2.10) required a significantly higher educational level according to FKGL scores compared to both ChatGPT-5o (p = .041) and Gemini-3 (p = .036). Regarding reference reliability, ChatGPT-5o outperformed Perplexity in source verifiability (p = .031), bibliographic precision (p = .044), and total RHS scores (p = .027), emerging as the most robust model in this domain. No statistically significant differences were found among the models in terms of clinical accuracy and usefulness (p > .05). Inter-rater agreement was excellent (Kappa: 0.92–0.97).
Conclusion
In this study, ChatGPT-5o distinguished itself in reference quality, whereas Perplexity demonstrated superior reliability. However, the complex linguistic structures accompanying efforts to maintain high medical accuracy may constitute a significant barrier for individuals with limited e-health literacy. Although these systems show strong potential as medical information resources, they cannot yet replace expert physician oversight in terms of patient safety. A balanced approach between technical reliability and patient-centered simplification remains necessary.
Keywords
Introduction
Lipedema is a chronic disorder that predominantly affects women and is characterized by pain and bilateral, symmetrical fat distribution of the extremities. Despite its distinct clinical features, it is frequently misdiagnosed. Within the pathophysiology of lipedema, pain is regarded not only as a core symptom but also as a diagnostic prerequisite. Current evidence suggests that pain may arise from localized inflammation, with persistent inflammatory activity potentially triggering fibrotic tissue changes. Clinical studies have reported tenderness to palpation in all patients (100%), while spontaneous pain has been observed with a high prevalence of 82%.1,2
This clinical presentation—marked by pain, pressure sensitivity, and easy bruising—may overlap with obesity, lymphedema, and chronic venous disorders, leading to diagnostic delays and substantial variability in therapeutic approaches. In the management of lipedema, accurate diagnostic evaluation and the timely implementation of appropriate conservative or surgical treatment options are critical for preserving patient quality of life. In this context, evidence-based clinical guidelines serve as essential reference frameworks to standardize diagnostic and therapeutic processes and to reduce variability in clinical practice.3–6
One of the most recent and comprehensive guidance documents addressing lipedema is the German S2k Lipedema Guideline (2024), which provides a multidisciplinary consensus on the definition, epidemiology, differential diagnosis, staging, and treatment strategies of the disease. In clinical decision-making processes, structured and evidence-based guidelines of this nature play a pivotal role in ensuring patient safety and optimizing treatment effectiveness. 7
In recent years, rapid advancements in artificial intelligence (AI) technologies have introduced new opportunities for the evaluation and management of chronic diseases. In particular, large language models (LLMs) have attracted attention as potential clinical decision-support tools due to their capacity to synthesize extensive medical literature and generate structured, natural-language responses to clinical queries. LLM-based systems such as ChatGPT, Gemini, and Perplexity are capable of rapidly summarizing diagnostic criteria, outlining differential diagnoses, and comparing therapeutic options.8,9
However, in conditions such as lipedema—where clinical overlap is common and multidisciplinary management is required—the guideline adherence and recommendation consistency of LLM-generated outputs are of critical importance. The provision of inaccurate or incomplete clinical information may result in errors in differential diagnosis, while ambiguous recommendation levels or guideline-inconsistent treatment statements may pose risks to patient safety. Furthermore, the generation of unverifiable or fabricated references (reference hallucination) represents a significant limitation affecting the credibility of these systems.10,11
Given the increasing use of large language models by clinicians, a systematic evaluation of their performance in delivering guideline-based information on lipedema is warranted. Accordingly, this study aims to analyze the responses generated by ChatGPT, Gemini, and Perplexity to structured, open-ended clinical questions derived from the 2024 S2k Lipedema Guideline—encompassing definitions, diagnosis, differential diagnosis, staging, and treatment recommendations—using a multidimensional evaluation framework assessing clinical accuracy, guideline adherence, reliability, readability, and potential reference hallucination.
Materials and methods
Study design
This study was designed as a cross-sectional and comparative methodological analysis to examine the extent to which large language models accurately, reliably, and in a guideline-consistent manner present recommendations for the diagnosis and treatment of lipedema. The investigation was based exclusively on the evaluation of written textual outputs. No patients, volunteers, or clinical datasets were involved, and no interventions were performed on humans or animals. Therefore, ethics committee approval was not required. Similar methodological approaches have been employed in previously published studies. 12 The research process was conducted in accordance with the ethical principles outlined in the Declaration of Helsinki.
Selection and rationale of the clinical reference
The open-ended clinical questions used in this study were developed on the basis of an evidence-based and consensus-driven clinical reference document addressing the diagnosis and treatment of lipedema. For this purpose, the multidisciplinary guideline titled S2k Guideline: Lipedema (2024) was selected as the primary reference source. 7
This guideline was chosen because it provides explicit and structured recommendations regarding the definition, diagnostic criteria, staging, differential diagnosis, and treatment options of lipedema; encompasses both conservative and surgical approaches; and represents an internationally recognized consensus document. Furthermore, its systematic and recommendation-based structure offers a suitable framework for objectively evaluating the guideline interpretation performance of large language models. 7
Development of guideline-based open-ended questions
The S2k Lipedema guideline was reviewed in detail, and sections containing structured recommendation statements and consensus declarations were included in the study scope.
Following the methodological approach described by Liu et al., 13 a question pool was generated to represent the principal clinical decision domains addressed in the guideline, and 30 open-ended clinical questions were selected for final analysis.
The questions were structured to cover the following domains: definition and pathophysiology, diagnostic criteria, differential diagnosis, staging and classification, conservative treatment, and surgical treatment. The question development process was conducted by two physicians with clinical experience in lipedema management. Each question was reformulated to preserve the original clinical intent and core meaning of the guideline while ensuring clarity and direct answerability by large language models. Discrepancies were resolved through mutual discussion until consensus was achieved.
To enable standardized evaluation of both clinical content and reference accuracy, the following uniform prompt was appended to each question:
“Please first answer the question directly without specifying levels of evidence. Then, provide a reference list consisting of exactly 10 scientific sources supporting your statements. For each source, include the title, authors, journal name, publication year, DOI, and a direct link.”
Structured questions based on the S2k Lipedema guideline.

Large language models evaluated and response collection
Three large language models accessible through publicly available free web interfaces were evaluated: ChatGPT-5o (OpenAI, San Francisco, CA, USA) Gemini-3 (Google LLC, Mountain View, CA, USA) Perplexity AI (Perplexity AI Inc., USA)
Premium versions, paid subscription plans, or API-based access methods were not used. This decision was made to reflect real-world user conditions and to evaluate platforms accessible across different socioeconomic groups. 14
All open-ended questions were submitted during a single session period on the same day (10 February 2026), under comparable technical conditions. To ensure comparability, the identical question set and standardized prompt were used for each model. No modifications were made to the generated responses; outputs were recorded verbatim for analysis.
To minimize user-related bias, separate and independent sessions were created for each model. Prior to each session, browser history and cookies were cleared, user accounts were logged out, and all interactions were conducted in incognito mode. To prevent carryover effects, each question was presented in a separate conversation window, ensuring independent interactions.
Evaluation of model responses
The responses generated by each large language model were independently and blindly evaluated by two experienced physicians.
Reliability and practical usefulness were assessed using a previously defined seven-point Likert scale, 15 where higher scores indicate greater reliability and usefulness.
Each response was additionally evaluated using a five-point accuracy scale ranging from 1 (completely incorrect content) to 5 (completely accurate and guideline-consistent content). 16
In cases of scoring discrepancies between evaluators, a final decision was reached through consensus. Inter-rater agreement was analyzed using Cohen’s kappa coefficient.
Readability and reference reliability analysis
Readability formulas.

W: number of words; S: number of sentences; B: number of syllables; C: number of polysyllabic words (≥3 syllables); l: average number of letters per word; ASL: average sentence length (number of words); E: average number of letters per 100 words.
Calculations were independently performed using two online readability tools (readabilityformulas.com and onlineutility.org). For each response, values obtained from both platforms were recorded separately, and final model-level scores were derived by averaging the results from the two sources. Findings were presented as median (minimum–maximum) for each model. 8
The accuracy and reliability of references generated by the LLMs were evaluated using a framework previously defined in the literature. Based on the approach proposed by Aljamaan et al., 10 the following criteria were assessed: consistency of publication year, journal validity, title accuracy, author information, topical relevance, link functionality, and accessibility. Higher scores indicated a greater tendency toward reference hallucination.
Statistical analysis
Statistical analyses were performed using SPSS for Windows version 24.0 (SPSS Inc., Chicago, IL, USA). Numerical data were presented as mean ± standard deviation and median (minimum–maximum). Inter-model comparisons were conducted using paired-samples t-tests or Wilcoxon signed-rank tests, depending on data distribution. Inter-rater agreement was analyzed using Cohen’s kappa coefficient. A p-value <.05 was considered statistically significant.
Results
Following evaluation of the responses generated by ChatGPT-5o, Gemini-3, and Perplexity to the 30 open-ended clinical questions derived from the S2k Lipedema Guideline, statistically significant inter-model differences were identified across selected outcome measures.
Comparison of clinical performance metrics.
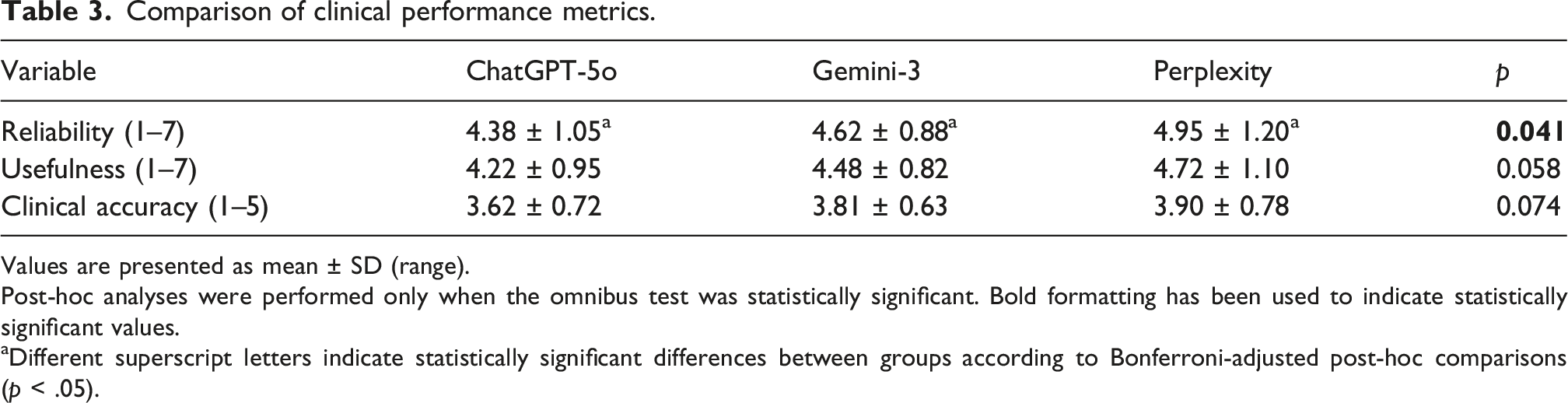
Values are presented as mean ± SD (range).
Post-hoc analyses were performed only when the omnibus test was statistically significant. Bold formatting has been used to indicate statistically significant values.
aDifferent superscript letters indicate statistically significant differences between groups according to Bonferroni-adjusted post-hoc comparisons (p < .05).
Comparison of readability metrics.
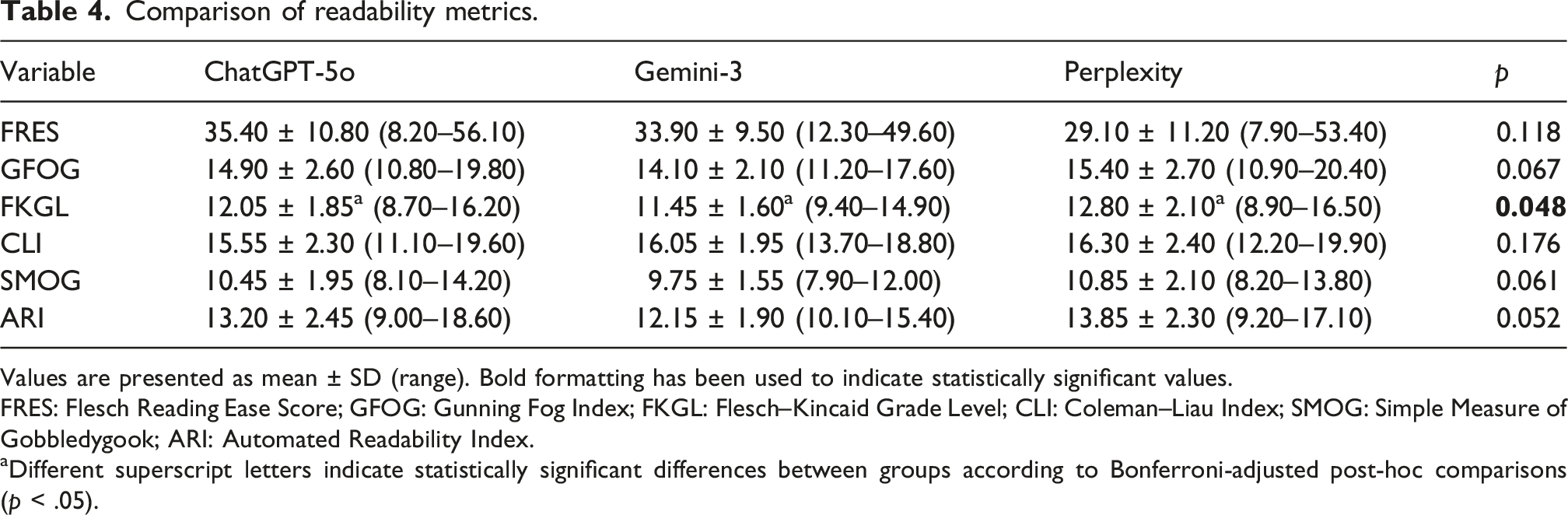
Values are presented as mean ± SD (range). Bold formatting has been used to indicate statistically significant values.
FRES: Flesch Reading Ease Score; GFOG: Gunning Fog Index; FKGL: Flesch–Kincaid Grade Level; CLI: Coleman–Liau Index; SMOG: Simple Measure of Gobbledygook; ARI: Automated Readability Index.
aDifferent superscript letters indicate statistically significant differences between groups according to Bonferroni-adjusted post-hoc comparisons (p < .05).
Comparison of reference hallucination score components.
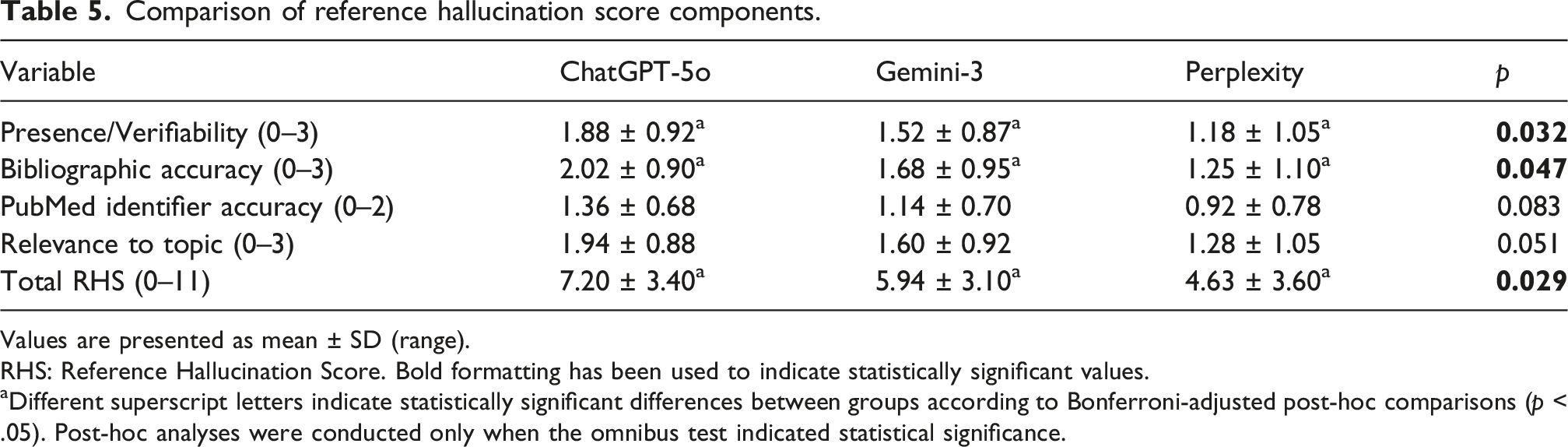
Values are presented as mean ± SD (range).
RHS: Reference Hallucination Score. Bold formatting has been used to indicate statistically significant values.
aDifferent superscript letters indicate statistically significant differences between groups according to Bonferroni-adjusted post-hoc comparisons (p < .05). Post-hoc analyses were conducted only when the omnibus test indicated statistical significance.
Regarding Bibliographic Accuracy, ChatGPT-5o (2.02 ± 0.90) outperformed Perplexity (1.25 ± 1.10), with the difference reaching statistical significance (p = .044). However, comparisons between ChatGPT-5o and Gemini-3 (p = .082), as well as between Gemini-3 and Perplexity (p = .109), did not demonstrate statistical significance.
For the total RHS score, the difference between ChatGPT-5o (7.20 ± 3.40) and Perplexity (4.63 ± 3.60) was statistically significant (p = .027). In contrast, differences between ChatGPT-5o and Gemini-3 (5.94 ± 3.10; p = .082) and between Gemini-3 and Perplexity (p = .119) were not statistically significant. No significant inter-model differences were identified for PubMed Identifier (PMID) Accuracy (p = .083) or Relevance to Topic (p = .051).
Inter-rater agreement analysis demonstrated excellent consistency across all evaluated domains. Cohen’s kappa coefficients were calculated as 0.92 for clinical accuracy, 0.95 for completeness, 0.97 for absence of incorrect or missing information, and 0.96 for consistency, indicating near-perfect agreement among evaluators (all p < .001).
Discussion
This study provides a comparative evaluation of contemporary large language models in delivering guideline-based information regarding lipedema, a chronic and frequently misunderstood disorder characterized by pain, tenderness, disproportionate adipose tissue accumulation, and diagnostic complexity. The findings revealed notable inter-model differences in reliability, reference quality, and readability characteristics. Perplexity AI achieved significantly higher reliability scores, whereas ChatGPT-5o demonstrated superior performance in source verifiability, bibliographic precision, and overall reference reliability. Although most readability indices were comparable among the models, all systems generally required relatively high educational levels for comprehension.
An important contextual issue underlying these findings is the limited strength of the existing evidence base in lipedema research itself. Although lipedema has increasingly attracted scientific attention in recent years, the current literature still contains relatively few high-quality original investigations, while opinion papers, narrative reviews, expert consensus documents, and patient-generated online content remain disproportionately abundant. The German S2k Lipedema Guideline, which served as the reference framework for this study, also emphasizes the limited and heterogeneous nature of the available evidence. 6 Consequently, large language models trained on extensive internet-based datasets may reflect this imbalance within the underlying information environment, in which scientifically robust evidence is relatively scarce compared with a large volume of lay and opinion-based content. Within this context, differences in response characteristics across models may be interpreted as a potential reflection of the balance between scientific caution and linguistic accessibility, rather than a directly measurable causal relationship. Accordingly, more readable outputs may involve simplification of complex or uncertain medical concepts, whereas more academically structured responses may adopt a more cautious and formal language style.
The findings of the present study are generally consistent with previous investigations evaluating online health information and AI-generated medical content in lipedema and related vascular or lymphatic disorders. Earlier studies examining websites, social media platforms, and YouTube videos concerning lipedema and lymphedema have consistently reported deficiencies in readability, transparency, reliability, and scientific quality.17–22 Similarly, investigations evaluating earlier generations of AI systems in vascular medicine demonstrated variability in guideline adherence and information quality.23,24 Our findings extend this literature by suggesting that newer-generation models may provide more clinically aligned and academically structured responses; however, important limitations related to accessibility and patient comprehension persist.
The findings of the present study are generally consistent with previous investigations evaluating online health information and AI-generated medical content in lipedema and related vascular or lymphatic disorders. Earlier studies examining websites, social media platforms, and YouTube videos concerning lipedema and lymphedema have consistently reported deficiencies in readability, transparency, reliability, and scientific quality.17–22 Similarly, investigations evaluating earlier generations of AI systems in vascular medicine demonstrated variability in guideline adherence and information quality.23,24 More recent studies in vascular and lymphatic diseases have also shown that, despite improvements in overall informational quality, AI-generated medical content may still present important limitations regarding guideline concordance, readability, consistency, and patient comprehension.25–29 Our findings extend this literature by suggesting that newer-generation models may provide more clinically aligned and academically structured responses; however, important limitations related to accessibility and patient comprehension persist.
These findings are particularly relevant in the context of e-health literacy. Patients increasingly rely on internet-based resources and conversational AI systems to better understand chronic conditions before or after professional consultations.29,30 In diseases such as lipedema, where delayed diagnosis and misinformation are common, AI systems may offer important advantages by rapidly synthesizing large volumes of medical information into interactive responses.31,32 Nevertheless, if generated content exceeds the average patient’s reading capacity, the practical benefit of technically accurate information may remain limited. The inverse relationship observed between medical reliability and readability therefore represents not only a linguistic issue, but also a potential equity concern affecting access to understandable healthcare information.
Several limitations should be considered when interpreting the findings of this study. First, the analysis was restricted to 30 structured questions derived from the S2k Lipedema Guideline and did not include patient-generated questions obtained from social media or online communities. Second, the evaluation was conducted exclusively in English and may not reflect language-specific variations in AI performance. Third, only three contemporary AI models were assessed, and the rapidly evolving nature of these systems limits the long-term generalizability of the findings. Finally, because AI platforms undergo frequent algorithmic updates, performance characteristics may vary over time.
Despite these limitations, this study has several important strengths. To our knowledge, this is the first investigation specifically evaluating large language models in the context of lipedema management. In addition to readability, the analysis incorporated multidimensional assessment domains including clinical accuracy, reliability, bibliographic precision, reference verifiability, and hallucination-related tendencies. The simultaneous evaluation of multiple contemporary AI systems using standardized guideline-based questions provides clinically relevant insights regarding the current capabilities and limitations of conversational AI technologies in chronic disease education.
Conclusion
Contemporary large language models demonstrated substantial potential for delivering guideline-based information regarding lipedema. However, an important trade-off persists between scientific rigor and patient-level readability. While academically stronger responses tended to provide more reliable and verifiable information, they also required higher educational levels for comprehension. Given the limited evidence base in lipedema research and the widespread presence of non-scientific online content, AI-generated medical information should still be interpreted cautiously and under professional supervision. Future developments in conversational artificial intelligence should aim not only to improve technical accuracy and reference reliability, but also to optimize accessibility for individuals with varying levels of e-health literacy.
Footnotes
Ethical considerations
The investigation was based exclusively on the evaluation of written textual outputs. No patients, volunteers, or clinical datasets were involved, and no interventions were performed on humans or animals. Therefore, ethics committee approval was not required. The research process was conducted in accordance with the ethical principles outlined in the Declaration of Helsinki.
Consent to participate
Written informed consent was obtained from all individual participants included in the study.
Author contributions
All authors contributed to the conception and design of the study. Material preparation, data collection, and analysis were performed by all authors. All authors read and approved the final manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Data Availability Statement
The datasets generated and/or analyzed during the current study are available from the corresponding author upon reasonable request.
Declaration of generative AI use in writing
During the preparation of this manuscript, the authors used OpenAI’s ChatGPT (version 5-turbo) to assist in refining the English language, including improvements in clarity, coherence, and academic tone during the revision process. All content, data interpretation, and scientific conclusions were generated, critically reviewed, verified, and approved by the authors, who take full responsibility for the integrity and originality of the published work.
Guarantor
Dr Ilhan Celil Ozbek is the guarantor of this work and takes full responsibility for the integrity of the data and the accuracy of the data analysis.