
Abstract
Applied early adolescent researchers often sample students (Level 1) from within classrooms (Level 2) that are nested within schools (Level 3), resulting in data that requires multilevel modeling analysis to avoid Type 1 errors. Although several articles have been published to assist researchers with analyzing sample data nested at two levels, few articles are available to researchers seeking assistance with three-level data analyses. The purpose of this article is to extend the presentational logic and pedagogical flow employed in previous two-level pedagogical publications to illustrate the relevant issues researchers face, the decisions to be made, and the proper procedures needed, when analyzing cross-sectional three-level data. These procedures are demonstrated with a generated three-level data example based on the Early Childhood Longitudinal Study (ECLS-K) public use dataset. The generated data used in this article, as well as the SPSS, SAS, and Mplus model specification syntax files needed to reproduce all analyses in this article, and additional illustrative examples, are available as supplemental online materials at http://jea.sagepub.com/content/early/recent.
Researchers interested in investigating cross-sectional research questions involving early adolescent populations often need to employ clustered sampling designs to obtain an adequate sample size for a given study. For example, a cross-sectional research design might require that early adolescent students (Level 1) be sampled from within several classrooms (Level 2) to obtain adequate statistical power. The need to use multilevel statistical modeling techniques (e.g., hierarchical linear modeling; HLM) to analyze two-level nested data structures that result from such cluster sampling techniques has been well documented (e.g., Raudenbush & Bryk, 2002; Snijders & Bosker, 1999). Researchers interested in the proper procedures needed to analyze cross-sectional data nested at two levels via multilevel modeling can choose from the numerous published pedagogical sources (e.g., Clements, Bolt, Hoyt, & Kratochwill, 2007; Graves & Frohwerk, 2009; Peugh, 2010; Peugh & Enders, 2005; Raudenbush & Bryk, 2002; Singer, 1998; Singer & Willett, 2003; Snijders & Bosker, 1999).
However, adolescent researchers frequently deal with cross-sectional data that is nested at three levels: Students (Level 1) may have been sampled from several classrooms (Level 2) across a number of schools (Level 3). Relative to the pedagogical literature available to guide two-level data analysis efforts, the pedagogical literature available to researchers seeking additional methodological details on cross-sectional three-level analyses is scarce. The goal of this article is to illustrate the steps needed to conduct, present, and interpret the results of cross-sectional three-level analyses using the presentational format, procedural logic, pedagogical flow, and linear model notational schemes (Raudenbush & Bryk, 2002; pp. 228-245) used in the previous two-level modeling pedagogical publications (e.g., Peugh, 2010; Peugh & Enders, 2005; Singer, 1998).
Data Description and Procedural Overview
This article uses simulated three-level cross-sectional sample data modeled after the fifth grade cohort of the ECLS-K (Pollack, Atkins-Burnett, Najarian, & Rock, 2005; Tourangeau, Le, & Nord, 2005; Tourangeau, Nord, Le, Pollack, & Atkins-Burnett, 2006) consisting of (i = 17,565; Level 1) students (coded as STUDENT_ID) nested within (j = 3,158; Level 2) classrooms (coded as CLASSROOM_ID) nested within (k = 992; Level 3) schools (coded as SCHOOL_ID). The three-level cross-sectional example analysis multilevel model used here will examine the effects of student socioeconomic status (SES; Level 1), classroom size (C_SIZE; Level 2), and school tuition cost (TUITION; Level 3) on reading achievement scores (READ_DV) scaled using item response theory (IRT; for a review, see Montague, Penfield, Enders, & Huang, 2010). A model-building procedure will be used to determine the nature and significance of the relationships between student SES, classroom size, and school tuition cost as they affect reading achievement scores.
In general, a model-building approach would first involve including a Level 1 predictor variable such as SES to a multilevel model analysis to determine whether, on average, student SES significantly predicts reading achievement (i.e., a fixed effect). Subsequent model-building steps would involve testing whether the estimated fixed effect of SES on reading achievement shows significant variation across classrooms (i.e., a Level 2 random effect) and across schools (i.e., a Level 3 random effect). A Level 2 predictor of reading achievement, such as classroom enrollment size, could then be entered into the multilevel model to determine whether, on average, classroom size is significantly related to reading achievement; additional model-building steps would determine whether the predictive effect of classroom size on reading achievement varies significantly across schools in a similar fashion.
This model-building approach balances accuracy and parsimony and is prudent for multilevel analyses for three reasons. First, from a pragmatic perspective, researchers are accustomed to specifying the data analytic model dictated by the research question and performing a single analysis (e.g., ANOVA or regression). However, multilevel modeling efforts often do not proceed in such a straightforward fashion. For example, it is well known (e.g., Raudenbush & Bryk, 2002; Singer & Willett, 2003) that model estimation problems (i.e., parameter estimate nonconvergence) tend to increase as the number of random effects increases. As such, it is important to retain only those random effects whose inclusions are critical to properly answering the research question. Second, from a methodological perspective, proper specification of the model under consideration is critical to obtaining accurate parameter estimates. This is especially true for multilevel analyses because the reading achievement score variation that is present across students (Level 1), classrooms (Level 2), and schools (Level 3) is not independent but correlated (shown further below). As such, if a multilevel model is misspecified at Level 1, that misspecification can propagate to higher analysis levels and result in biased parameter estimates at Level 2 and Level 3. Finally, from a functional perspective, proper specification of the multilevel analysis model at all levels (and assuming no estimation errors) enables researchers to clearly interpret fixed effect regression coefficients and random effect variance estimates, as will also be shown below.
The model-building approach described above will be illustrated using SPSS with the ECLS-K simulated dataset to specify and model the effects of student SES, classroom size, and school tuition on reading achievement. The equivalent SAS and Mplus analysis syntax for each of the models shown below is also included in the supplemental online materials (available at http://jea.sagepub.com/content/early/recent). As shown elsewhere (Peugh, 2010; Peugh & Enders, 2005; Singer, 1998), SPSS and SAS use a “combined” multilevel model regression equation (similar to a multiple regression equation) that contains fixed effects for predictor variables, and random effects to address nested data nonindependence, to correctly specify a multilevel analysis model. The combined model is so named because it results from combining the level-specific linear model equations into a large multilevel prediction equation. Only the combined multilevel model equations are given for the multilevel analysis examples presented here. However, the specific Level 1, Level 2, and Level 3 equations 1 for each analysis model illustrated below are shown in the appendix, and detailed descriptions of how the Level 1, Level 2, and Level 3 equations can be merged to form the combined model equations for all the example analyses are included in the supplemental online materials (see “Obtaining the Combined Model” folder at http://jea.sagepub.com/supplemental).
Parameter Estimation and Model Comparison
SPSS and SAS have two options available to researchers for parameter estimation 2 : full information maximum likelihood (ML) and restricted maximum likelihood (REML). As described elsewhere (e.g., Searle, Casella, & McCulloch, 1992), the two parameter estimation techniques differ only in how fixed effect estimates and their degrees of freedom are treated in estimation. At very large sample sizes (such as the N = 17,565 for the ECLS-K simulated dataset), REML and ML multilevel model parameter estimates are very similar. However, at sample sizes considered typical of applied research, REML gives more accurate estimates of random effects and fixed effect standard errors (Snijders & Bosker, 1999), while ML random effects estimates are negatively biased (Browne & Draper, 2000; Bryk & Raudenbush, 1992; Longford, 1993; Maas & Hox, 2004). REML is used in all multilevel analysis examples shown here because although both estimation methods tend to produce identical fixed effect estimates at large sample sizes, REML gives more accurate random effect estimates at sample sizes more commonly found in research settings.
Further, an important related parameter estimation issue warrants mention. In multiple regression analyses, predictor variables can be tested for significance because, with no cluster sampling and only a single random effect (eij), the reference distribution for testing predictors for significance is a t-distribution with known degrees of freedom. In contrast, the appropriate reference distribution for testing predictor variables (fixed effects) in multilevel models is unknown due to cluster sampling and the possibility of unequal sample sizes within Level 2 and Level 3 units, but is typically approximated by a t-distribution with various corrective factors applied to degrees of freedom computations to improve the accuracy of fixed effects significance tests (e.g., see Bauer, Sterba, & Hallfors, 2008). Several degrees of freedom computational corrections are available. Research has shown that the Kenward-Rogers correction (Kenward & Roger, 1997) better maintained the nominal Type 1 error rate for fixed effects significance tests than the Satterthwaite (e.g., Fai & Cornelius, 1996) correction under small sample size, and unbalanced design conditions, especially as multilevel models became more complex and did so without a loss of statistical power (see Schaalje, McBride, & Fellingham, 2002; Spilke, Piepho, & Hu, 2005b). Currently, SPSS (version 20) only offers the Satterthwaite correction for fixed effects tests of significance, but the Kenward-Rogers correction is available in SAS (e.g., Spilke, Piepho, & Hu, 2005a). 2
Implicit in a model-building approach to multilevel analyses is the assumption that the parameter estimates added at each stage of the building process significantly improves the fit of the multilevel model to the data. Researchers are often interested in testing whether the parameter estimates added to the multilevel model, whether fixed effects, random effects, or both, result in an improved model fit. Although intuitively appealing to do so, using the single parameter significance tests results of multilevel model analyses can lead researchers to incorrect conclusions regarding model comparisons. Single parameter significance tests, such as the Wald test, for variance estimates (or random effects) assume that the variances are normally distributed in the population when, in reality, they are highly skewed (e.g., Hox, 2010; Pawitan, 2000). As such, Wald tests are contraindicated for model comparison purposes if models differ only in random effect parameter estimates. A likelihood ratio nested model test is needed to compare multilevel models that differ only in one or more random effects (Raudenbush & Bryk, 2002). The steps involved in conducting a likelihood ratio nested model test are reviewed briefly here.
A likelihood ratio nested model test is conducted in three steps. The first step involves estimating two models: a “full” model and a “restricted” model that is nested within the “full” model. Two models are nested if, for example, removing one or more parameters from the “full” model produces the “nested” model. In the second step, the chi-square model fit statistic for the “full” model is subtracted from the chi-square model fit statistic for the “reduced” model (i.e.,
Further, if two multilevel models under comparison differ only in two or more predictor variable fixed effect estimates, the likelihood ratio nested model test described above could also be used to conduct a model comparison. However, a more efficient model testing approach is available. Just as an omnibus F-test of an R2 statistic tests all the predictor variables included in a multiple regression model as a “set,” a multi-parameter Wald test (e.g., see Hox, 2010, pp. 51-53) tests a “set” of fixed effect estimates added to a multilevel model for a significant improvement in model fit. A multi-parameter Wald test is a more efficient model comparison approach because, rather than estimating a “full” and a “restricted” model, the added predictor variable fixed effects estimates can be tested in the same analysis step by adding the “/TEST” subcommand to the SPSS “MIXED” command (or, with the “/CONTRAST” subcommand for PROC MIXED in SAS), as will be shown below. 3
Coding Multilevel Identification Variables in SPSS and SAS
Before presenting the analysis examples, an additional important but rarely mentioned issue regarding the proper nested coding of the identifying (or classifying) variables at all three levels also warrants mention. Researchers often encounter multilevel datasets in which the identifying variables are not explicitly nested. For example, using the ECLS-K simulated dataset as an example, the Level 2 identifying variable (CLASSROOM_ID) might be coded with as many as J = 3,158 different and nonconsecutive values (and by extension, the Level 1 identifying variable [STUDENT_ID] might be coded with as many as I = 17,565 different nonconsecutive values) if the identifying variables were not nested. Nested coding of the identifying variables, for example, involves coding the Level 2 identifying variable (CLASSROOM_ID) with consecutive integer values from 1, 2, . . . to the jth classroom in school k, then restarting the coding of CLASSROOM_ID with consecutive integer values from 1, 2, . . . to the jth classroom within the next k + 1 school, and would continue for all J classrooms within all K schools. The Level 1 identifying variable, STUDENT_ID, could be coded in similar fashion: Students could be coded with consecutive integer values from 1, 2, . . . to the ith student within classroom j, the coding of STUDENT_ID would then restart with consecutive integer values from 1, 2, . . . to the ith student within the next j + 1 classroom, and continue for all I students within all J classrooms within all K schools. This more efficient nested coding scheme, along with the correct Level 2 syntax specification (i.e., RANDOM = | SUBJECT [SCHOOL_ID*CLASSROOM_ID], described below), enables statistical analysis software packages such as SPSS (SAS uses a similar syntax specification) to analyze data nested at three (or more) levels while minimizing the amount of computer memory and computational time needed (e.g., see Kiernan, Tao, & Gibbs, 2012; SAS Institute, 2009). Syntax programs written in SPSS and SAS that recode the identifying variables in the simulated example dataset to a nested format are included in the supplemental online materials 4 (see “1_Nested Identification Variables” folder at http://jea.sagepub.com/supplemental).
Response Variable Variance and the Intra-Class Correlations
Prior to the estimation of multilevel models that test the effects of predictor variables, estimating an unconditional means three-level model that allows the computation of intra-class correlations (ICC) is considered by many to be a useful initial analysis step (e.g., Peugh, 2010; Peugh & Enders, 2005; Raudenbush & Bryk, 2002; Singer, 1998). The ICC can be defined as the proportion of response variable (i.e., reading achievement) variance present at the student (Level 1), classroom (Level 2), and school (Level 3) levels and also as an estimate of the correlation between the reading achievement scores of two students sampled from the same classroom (Level 2) or the same school (Level 3), as shown below.
The combined linear model for an unconditional three-level analysis is shown in Equation 1 below. Interested readers can find the separate-model (i.e., HLM) equations for all example analyses in the appendix. Interested readers can also find a description in the supplemental online materials (“Obtaining the Combined Model”) of how all the separate-model equations shown in the appendix are integrated to produce all the combined models, such as shown in Equation 1.
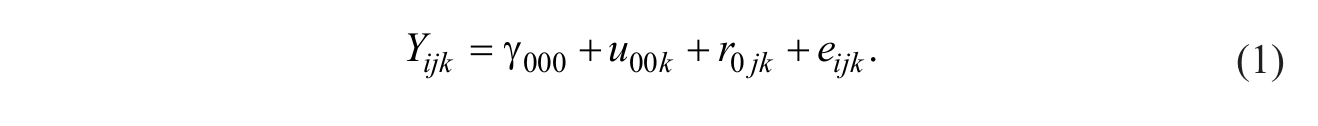
In an unconditional means model, the reading achievement score for student i in classroom j within school k (Yijk) is modeled as a function of the grand mean reading achievement score for the sample (
MIXED READ_DV
/PRINT SOLUTION TESTCOV
/METHOD = REML
/FIXED = INTERCEPT
/RANDOM = INTERCEPT | SUBJECT (CLASSROOM_ID*SCHOOL_ID) COVTYPE (ID)
/RANDOM = INTERCEPT | SUBJECT (SCHOOL_ID) COVTYPE (ID).
Prior to linking the combined model shown in Equation 1 to the SPSS syntax above, a brief description of the SPSS MIXED model syntax is needed. For all analyses shown in this article: (a) the reading achievement response variable (READ_DV) is listed immediately after the MIXED command, (b) the /PRINT subcommand controls the output of multilevel analysis results; SOLUTION prints the significance tests for fixed effects (predictor variables), and TESTCOV prints significance tests for random effects (variances), and (c) for reasons described previously, restricted maximum likelihood (/METHOD=REML) estimation was used for all examples shown.
The fixed and random effects shown in the combined model (Equation 1) are specified in SPSS syntax using the FIXED and RANDOM statements. It is important to note that, of the four effects shown in Equation 1 to be estimated, two of the effects are estimated by default. First, the Level 1 random effect (
Results for the unconditional means model analysis are shown in the second column of Table 1. The grand mean reading achievement score (i.e., the intercept) was (
Model Summaries: Unconditional and Level 1 Examples.
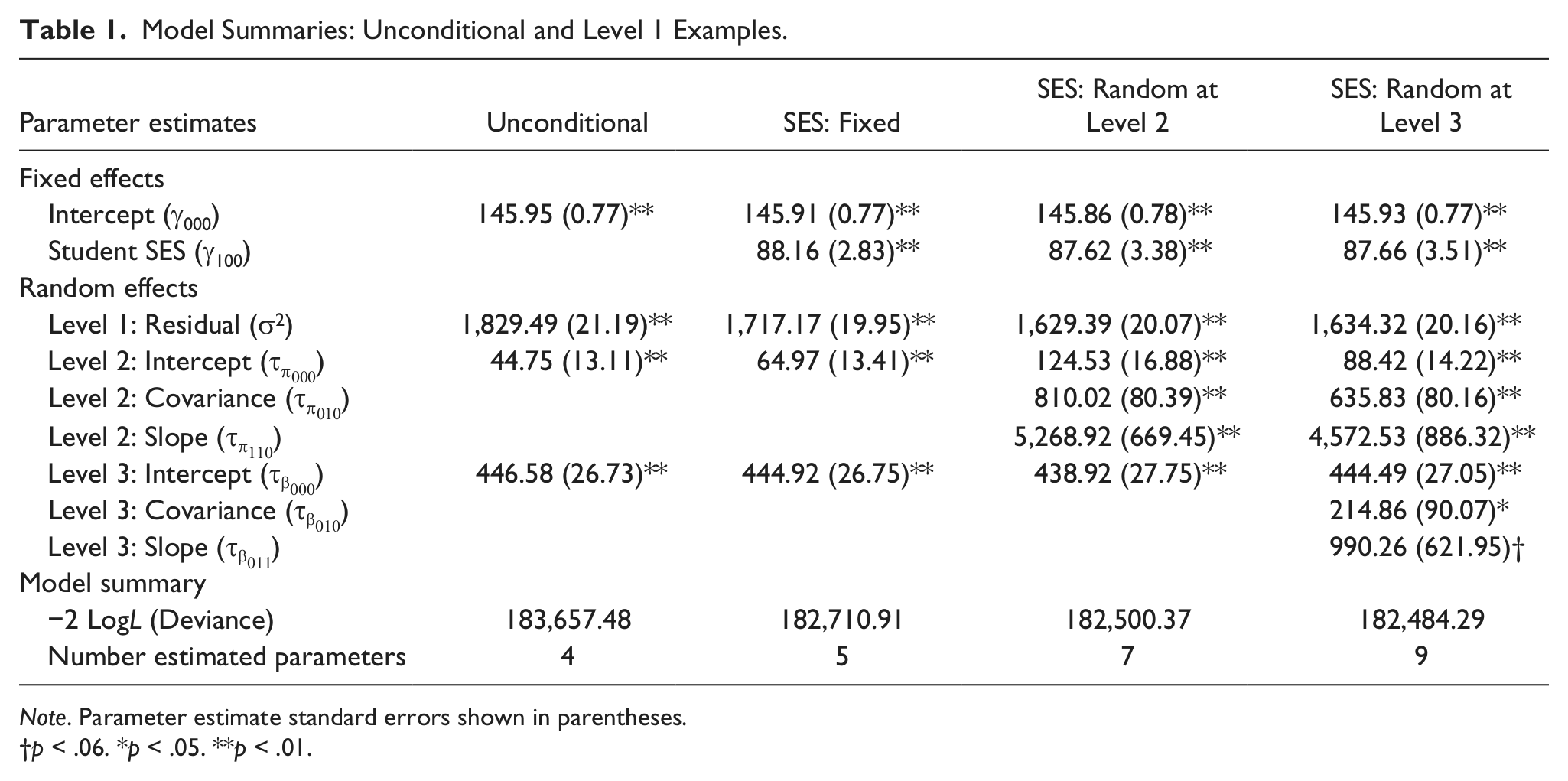
Note. Parameter estimate standard errors shown in parentheses.
p < .06. *p < .05. **p < .01.

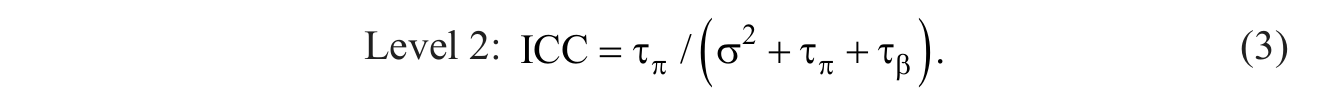
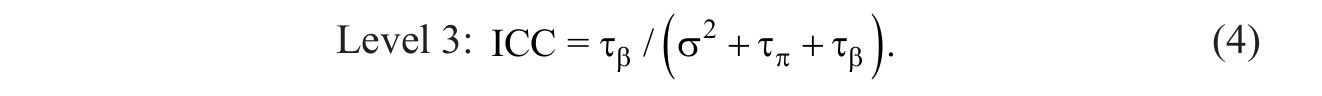
Substituting the random effect estimates from the second column of Table 1 into Equations 2 to 4 above showed that (1,829.49/[1,829.49 + 44.75 + 446.58] = 0.79) 79% of the reading achievement score variance occurred between students, (44.75/[1,829.49 + 44.75 + 446.58] = 0.02) 2% of the variance occurred across classrooms, and (446.58446.58/ / [1,829.49 + 44.75 + 446.58] = 0.19) 19% occurred across schools. The ICC can also be interpreted as the expected correlation between the reading achievement scores of two students sampled from the classroom (rPearson = .02) or the same school (rPearson = .19) (see “2_Nested Identification Variables” folder at http://jea.sagepub.com/supplemental).
Level 1 Predictor: Socioeconomic Status
Prior to including one or more Level 1 predictor variables as a first step in the model-building process, researchers need to address the question of how the predictor variables should be centered. Predictor variables in many research disciplines are often measured on an interval scale, meaning that a value of zero has no substantive interpretation (e.g., IQ). In multilevel modeling, this makes interpreting the intercept (i.e.,
Two types of predictor variable centering are available in multilevel modeling: group-mean centering and grand-mean centering. The Level 1 predictor variable student SES will be used in illustrative examples of the two centering options. Group mean centering (also referred to as “centering within cluster”; Enders & Tofighi, 2007) involves subtracting the mean SES value for classroom j in school k
As shown previously, the response variable reading achievement showed notable variation and nonzero ICC values at all the three levels. Level 1 predictor variables such as student SES can also show variation and nonzero ICC values at all three levels (i.e., SESijk). Statistically, the difference between group-mean and grand-mean centering options is the effect that each has on the ICC values for a Level 1 or a Level 2 predictor variable (e.g., see Enders & Tofighi, 2007). Grand-mean centering has no effect on predictor variable ICC values; a grand-mean centered predictor will still show the same nonzero variation and nonzero ICC values at all levels as it would if it were left un-centered. In contrast, group-mean centering a Level 1 predictor variable such as SES does affect the ICC values. For example, if student SES scores were centered on the mean of their respective classrooms (i.e.,
From a practical perspective, researchers can be aided in the process of choosing between group-mean and grand-mean centering by considering whether, according to theory, a researcher suspects that the predictor variable will have a relative or absolute effect on the response variable (e.g., see Klein, Dansereau, & Hall, 1994). If the theory under consideration says that a predictor variable would have a relative effect on the response variable—sometimes referred to as a “frog-pond” (Firebaugh, 1980), a “within-groups” (Glick & Roberts, 1984), or a “parts” (Dansereau, Alutto, & Yammarino, 1984) effect—group-mean centering of the predictor variable would be appropriate. One scenario that would indicate the need for group-mean centering would involve two students from families with the same income levels that would be expected to have different reading achievement scores contingent on the classroom they attend (same “frogs” placed in different “ponds”). A second scenario that would indicate the need for group-mean centering would involve a student from a lower SES family that would be expected to have a reading achievement disadvantage if they attend a classroom (within a school) with a higher average income (a smaller income “frog” in a larger income “pond”). Group-mean centering of student SES would be needed in both scenarios because the effect of SES on reading achievement is considered dependent on the kind of classroom (within school) attended. In contrast, if a theory suggested that the impact of SES on reading achievement is independent of the type of classroom (within school) attended, grand-mean centering of student SES is appropriate because a student’s absolute level of SES and its impact on reading achievement, not their SES relative to their classroom peers, are of theoretical interest (for exceptions, see Enders & Tofighi, 2007; Hofmann & Gavin, 1998; Kreft, de Leeuw, & Aiken, 1995). In all analysis examples, student SES was group-mean centered (i.e., student SES scores were centered based on j classroom [Level 2] means
The combined linear model that includes group-mean centered SES as a predictor variable is shown below
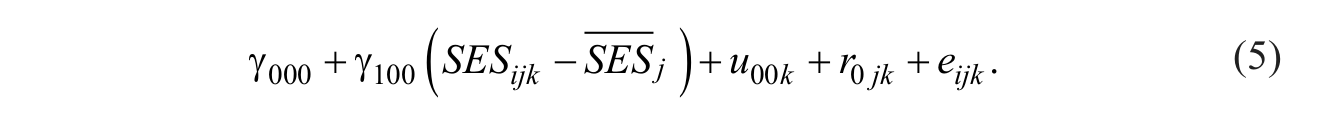
As shown in Equation 5, two fixed effects (the intercept
MIXED READ_DV
/PRINT SOLUTION TESTCOV
/METHOD = REML
/FIXED = INTERCEPT GROUP_SES
/RANDOM = INTERCEPT | SUBJECT (CLASSROOM_ID*SCHOOL_ID) COVTYPE (ID)
/RANDOM = INTERCEPT | SUBJECT (SCHOOL_ID) COVTYPE (ID).
The estimate for the fixed effect of group-mean centered student SES on reading achievement is specified by adding the variable “GROUP_SES” to the “/FIXED =” subcommand line.
Results for the fixed effects Level 1 model are shown in the third column of Table 1. The expected reading achievement score for a student of average SES was (
SES Varying Randomly at Level 2
After adding a Level 1 predictor variable such as SES to a multilevel model, a second question for researchers to address is whether the effect of SES on the reading achievement varies significantly across classrooms (Level 2 units). For example, if the effects of student SES on reading achievement were estimated separately for each of the (j = 3,158) classrooms, 3,158 separate
Specifically, a combined multilevel model that allows the effect of student SES to vary randomly across Level 2 classrooms is defined as
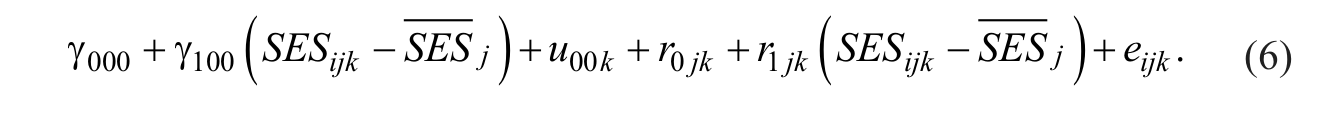
The two fixed effects (
The SPSS syntax needed to estimate the effect of SES varying randomly at Level 2 as shown in Equation 6 is,
MIXED READ_DV
/PRINT SOLUTION TESTCOV
/METHOD = REML
/FIXED = INTERCEPT GROUP_SES
/RANDOM = INTERCEPT GROUP_SES | SUBJECT (CLASSROOM_ID*SCHOOL_ID) COVTYPE (UN)
/RANDOM = INTERCEPT | SUBJECT (SCHOOL_ID) COVTYPE (ID).
The addition of “GROUP_SES” to the “/RANDOM | SUBJECT (CLASSROOM_ID*SCHOOL_ID)” subcommand line results in the estimation of the SES slope variance and the intercept-slope covariance by default. “COVTYPE(UN)” specifies an unstructured Level 2 covariance matrix, meaning that SES intercept variance, SES slope variance across classrooms, and the intercept-slope covariance are all estimated as Level 2 random effects.
Results for the model that allows the effect of student SES on reading achievement to vary randomly across classrooms at Level 2 model are shown in the fourth column of Table 1. The expected reading achievement score for a student of average SES (

As shown in the third and fourth columns of Table 1, a model that allows the effect of student SES on reading achievement to vary randomly across j classrooms at Level 2 differs from a model that estimates student SES as a fixed effect by only two random effect parameter estimates (i.e.,
A likelihood ratio nested model test is conducted by first subtracting the relevant model fit statistic for the random effects model (i.e., −2LogLFull = 182,500.37) from the model fit statistic for the fixed effects model (i.e., −2LogLReduced = 182,710.91; Δ-2LogL = 182,710.91 − 182,500.37 = 210.54). In step two, the difference in model fit statistics (Δ-2LogL = 210.54) is referred to a chi-square distribution at degrees of freedom equal to the difference in the number of parameters estimated between the two models under comparison (2,
SES Varying Randomly at Level 2 and Level 3
The effect of student SES on reading achievement was shown to vary randomly across (j = 3,158) classrooms. The student SES effect on reading achievement could also vary significantly across (k = 992) schools. A multilevel model that allows the effect of SES on reading achievement to vary across j classrooms and k schools is specified by
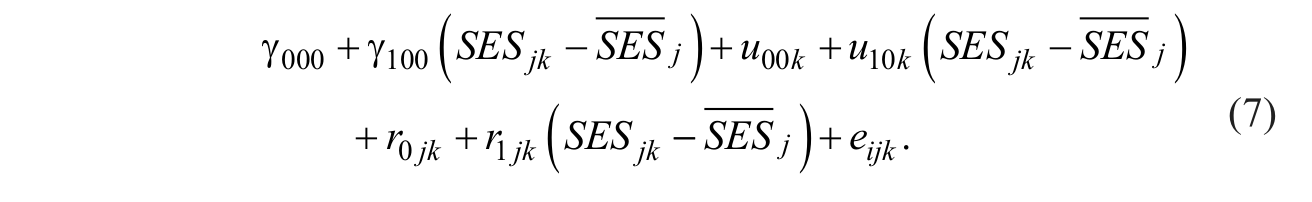
Two fixed effects are again estimated, the three random effects at Level 2 estimated in the previous model are again estimated, but three additional random effects are now estimated at Level 3 (intercept variance:
MIXED READ_DV
/PRINT SOLUTION TESTCOV
/METHOD = REML
/FIXED = INTERCEPT GROUP_SES
/RANDOM = INTERCEPT GROUP_SES | SUBJECT (CLASSROOM_ID*SCHOOL_ID) COVTYPE (UN)
/RANDOM = INTERCEPT GROUP_SES | SUBJECT (SCHOOL_ID) COVTYPE (UN).
Similar to the previous analysis, the addition of “GROUP_SES” to the “/RANDOM | SUBJECT (SCHOOL_ID)” subcommand line results in the estimation of SES slope variance and the intercept-slope covariance (by default) at Level 3, and the “COVTYPE(UN)” statements specify an unstructured covariance matrix at Level 2 and Level 3.
Results for the model allowing the effect of SES on reading achievement to vary randomly at Level 2 and Level 3 are shown in the last column of Table 1. The expected reading achievement score for a student of average SES (
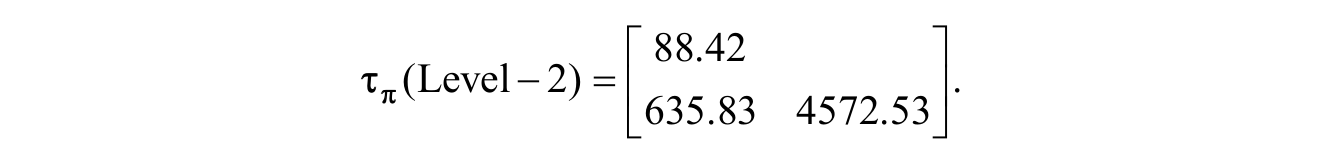
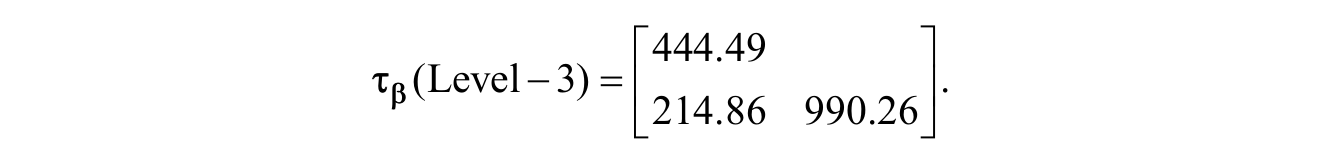
Level 2 Predictor: Classroom Size
Prior to adding a Level 2 covariate to the multilevel model, it is important to again consider the question of covariate centering. The important question remains whether an absolute or relative effect of the Level 2 covariate classroom size (C_SIZEjk) on reading achievement is of theoretical interest. Specifically, if a researcher’s theory specified a relative effect of classroom size on reading achievement, such that two classrooms of equal size could have very different classroom mean reading achievement scores based on the different schools to which each classroom belonged, group-mean centering is needed. However, if the absolute effect of classroom size on reading achievement, not the size of a classroom relative to other classrooms in a school is of theoretical interest, grand-mean centering of classroom size is needed. For these examples, classroom size was group-mean centered around each k school’s mean classroom size
The combined multilevel model that adds the group-mean centered Level 2 predictor variable classroom size
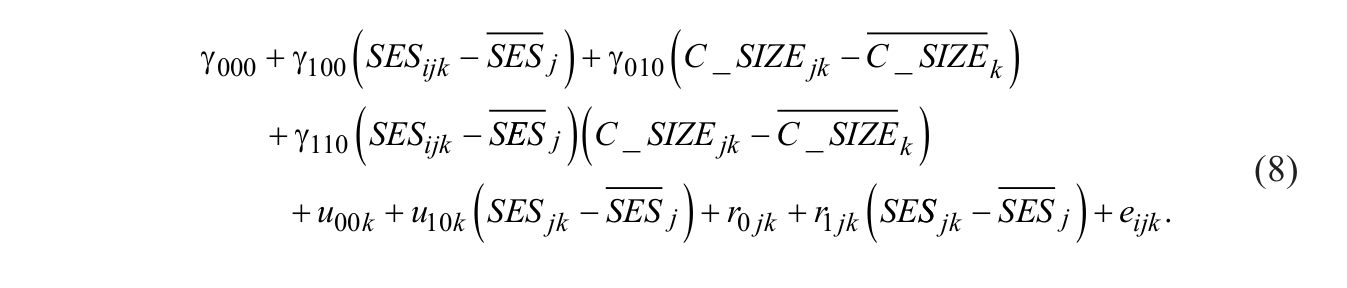
Compared with the previous model (Equation 7), two additional fixed effects are estimated. The term
The SPSS syntax needed to estimate the additional effect of classroom size (shown as GROUP_CLASS_SIZE in all the SPSS syntax examples) on reading achievement as shown in Equation 8 above is,
MIXED READ_DV
/PRINT SOLUTION TESTCOV
/METHOD = REML
/FIXED = INTERCEPT GROUP_SES GROUP_CLASS_SIZE GROUP_CLASS_SIZE*GROUP_SES
/RANDOM = INTERCEPT GROUP_SES | SUBJECT (CLASSROOM_ID*SCHOOL_ID) COVTYPE (UN)
/RANDOM = INTERCEPT GROUP_SES | SUBJECT (SCHOOL_ID) COVTYPE (UN).
/TEST = ALL 0 0 1 1.
The fixed (GROUP_CLASS_SIZE;
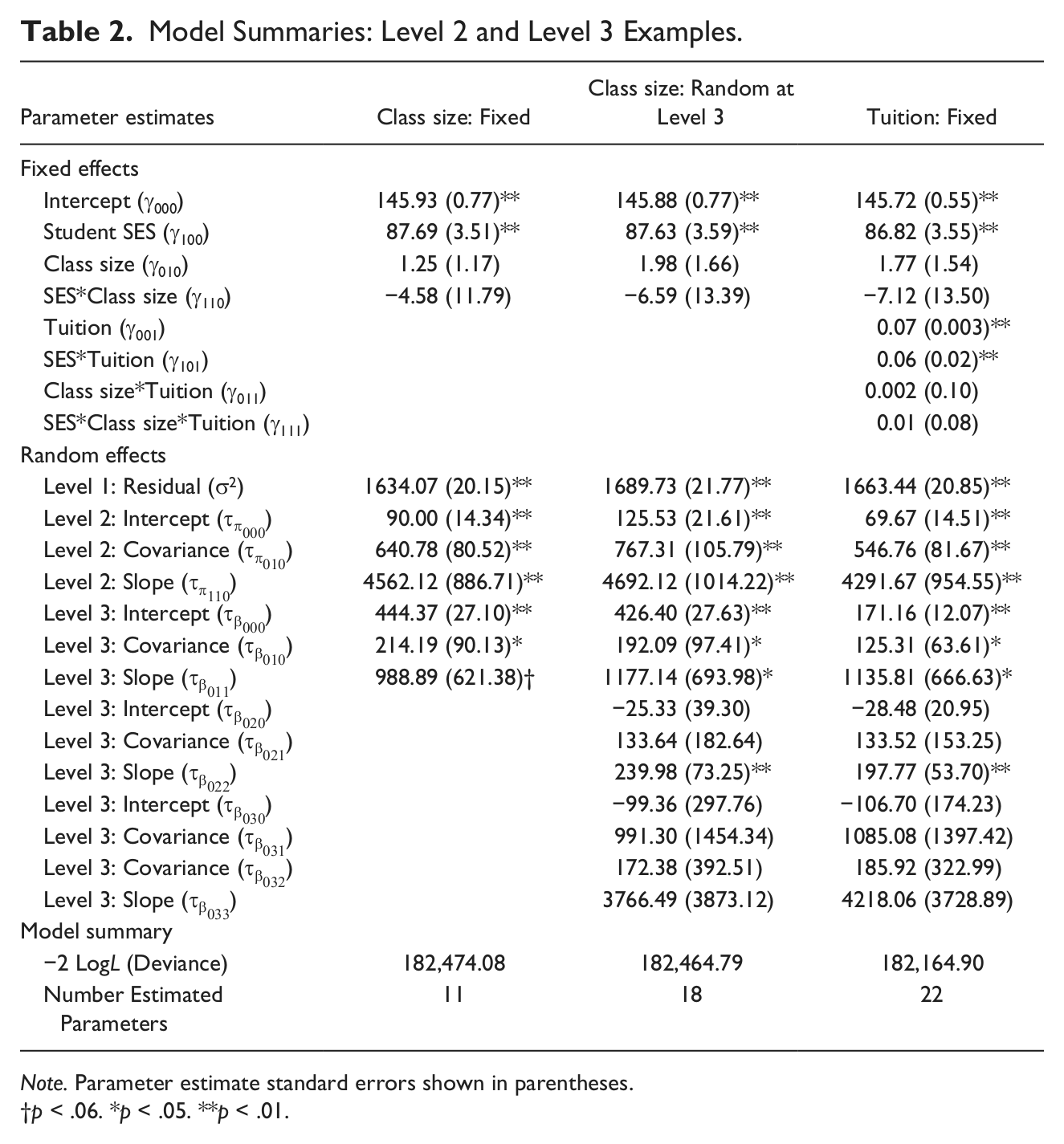
Model Summaries: Level 2 and Level 3 Examples.
Note. Parameter estimate standard errors shown in parentheses.
p < .06. *p < .05. **p < .01.
Further, as shown in the second column of Table 2, adding the Level 2 predictor variable classroom size as a fixed effect results in a model that differs by two fixed effect parameter estimates only (GROUP_CLASS_SIZE; γ010 and GROUP_CLASS_SIZE* GROUP_SES; γ110) compared with the previous multilevel model that allowed the effect of student SES to vary randomly at Level 2 and Level 3 (see last column of Table 1). As stated previously, a likelihood ratio nested model test could be used to compare the “full” model that adds classroom size as a fixed effect to a “reduced” model that allows the effect of SES to vary across Level 2 and Level 3 units. However, a more efficient multi-parameter Wald test could also be used to compare the two models. As stated previously, multi-parameter Wald tests allow for linear combinations of two or more parameter estimates to be tested for significance as a single “set.” In SPSS, the “/TEST” subcommand is used to request a multi-parameter Wald test. The keyword “ALL” makes all fixed effect and random effect parameter estimates available for additional testing. After the “ALL” keyword, fixed effect contrast coefficients are listed first in the order they appear on the “/FIXED =” subcommand line (if random effects were also to be tested, the “|” symbol would be used to separate fixed effect from random effect contrast coefficients). The first two values of “0” indicate that the intercept
Classroom Size Varying Randomly at Level 3
The results from previous analyses showed that the effect of student SES on reading achievement varied significantly across classrooms and schools. The effect of classroom size on reading achievement could vary significantly across schools in similar fashion. Specifically, although not statistically significant, the main effect of classroom size on reading achievement
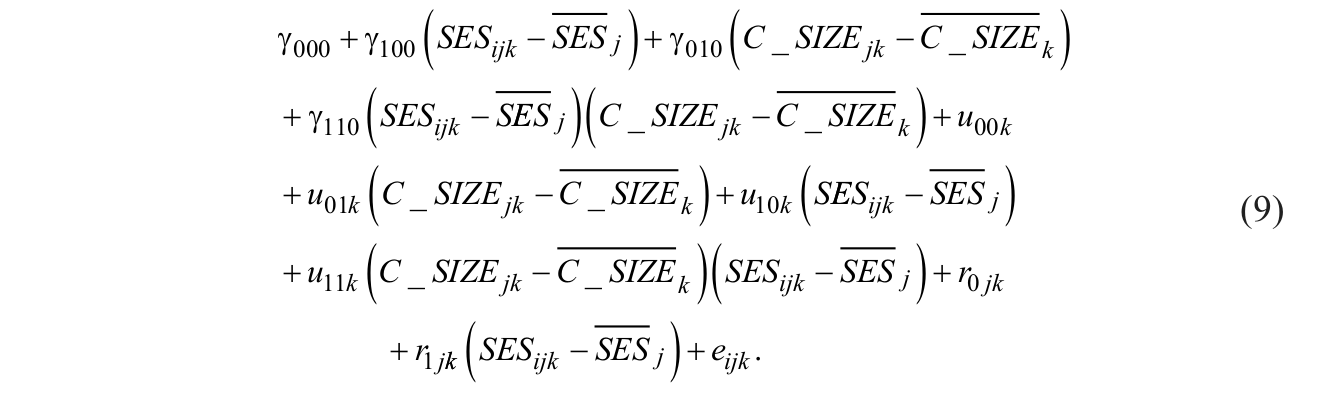
Compared with the previous combined model, two additional random effect estimates (
The SPSS syntax that allows Level 2 covariate effects to vary randomly at Level 3, as shown in Equation 9 above, is specified as,
MIXED READ_DV
/PRINT SOLUTION TESTCOV
/METHOD = REML
/FIXED = INTERCEPT GROUP_SES GROUP_CLASS_SIZE GROUP_CLASS_SIZE*GROUP_SES
/RANDOM = INTERCEPT GROUP_SES | SUBJECT (CLASSROOM_ID*SCHOOL_ID) COVTYPE (UN)
/RANDOM = INTERCEPT GROUP_SES GROUP_CLASS_SIZE GROUP_CLASS_SIZE*GROUP_SES
|SUBJECT (SCHOOL_ID) COVTYPE (UN).
Allowing the main (GROUP_CLASS_SIZE;
Interpretation of the Level 3 random effect estimates begins by clarifying the relationship between the Level 3 covariance matrix (
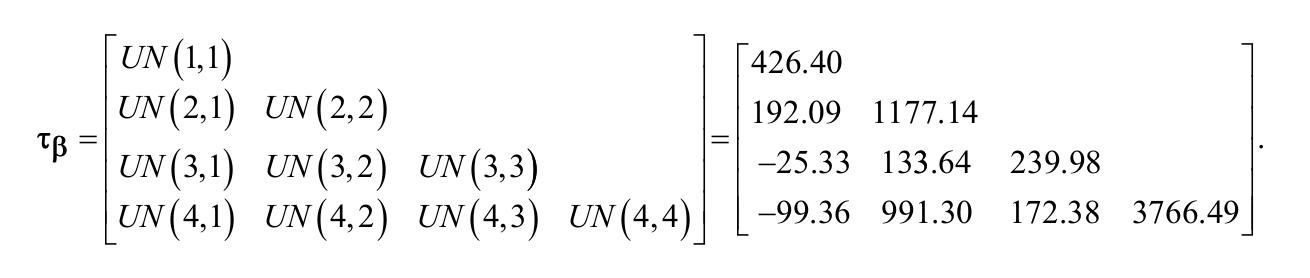
As shown in the third column of Table 2 and in the Level 3 random effects covariance matrix (
Level 3 Predictor: School Tuition
Just as in the previous models, the issue of covariate centering should be again addressed before adding an additional predictor variable to the multilevel model. However, grand-mean centering (TUITIONk −
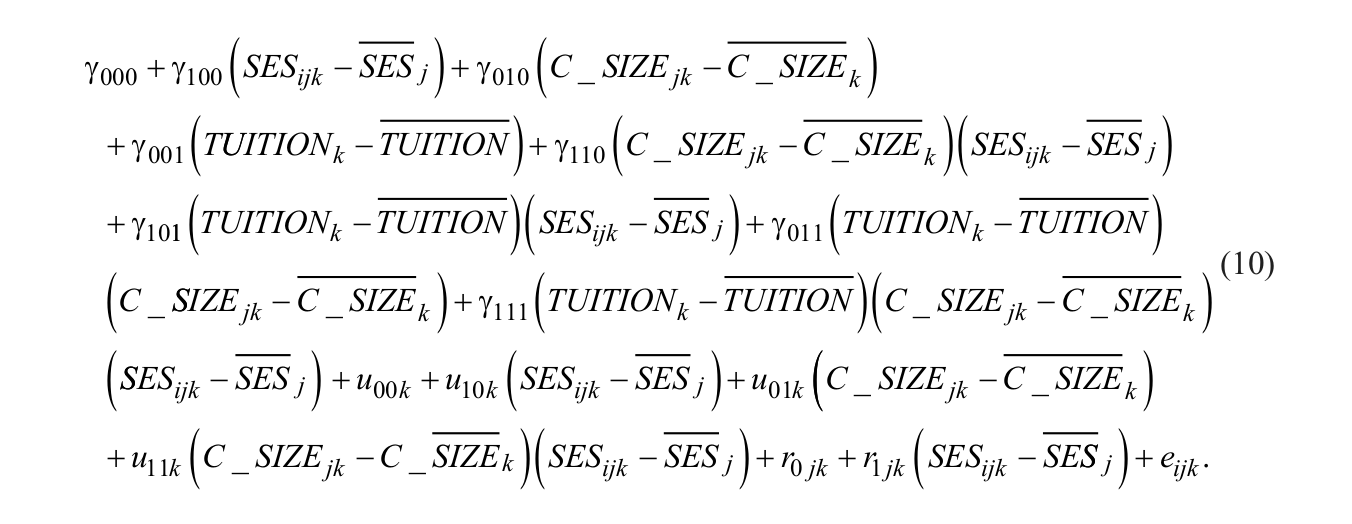
The main effects of SES
The SPSS syntax that adds the grand-mean centered Level 3 predictor variable school tuition cost (shown as GRAND_TUITION in the SPSS and SAS syntax) to the multilevel model, as shown in Equation 10 above, is specified as,
MIXED READ_DV
/PRINT SOLUTION TESTCOV
/METHOD = REML
/FIXED = INTERCEPT GROUP_SES GROUP_CLASS_SIZE GRAND_TUITION
GROUP_SES*GROUP_CLASS_SIZE GROUP_SES*GRAND_TUITION GROUP_CLASS_SIZE*GRAND_TUITION GROUP_SES *GROUP_CLASS_SIZE*GRAND_TUITION
/RANDOM = INTERCEPT GROUP_SES | SUBJECT (CLASSROOM_ID*SCHOOL_ID) COVTYPE (UN)
/RANDOM = INTERCEPT GROUP_SES GROUP_CLASS_SIZE GROUP_CLASS_SIZE*GROUP_SES |SUBJECT (SCHOOL_ID) COVTYPE (UN).
The estimation of the main effect of school tuition (GRAND_TUITION), the two-way interaction effects of student SES by school tuition (GROUP_SES*GRAND_TUITION) and classroom size by school tuition (GROUP_CLASS_SIZE*GRAND_TUITION), and the three-way interaction effect of student SES by classroom size by school tuition (GROUP_SES *GROUP_CLASS_SIZE*GRAND_TUITION) on reading achievement are all specified by adding those four effects to the “/FIXED =” subcommand line.
Results for the Level 3 model are shown in the final column of Table 2. Neither the two way class size by school tuition interaction
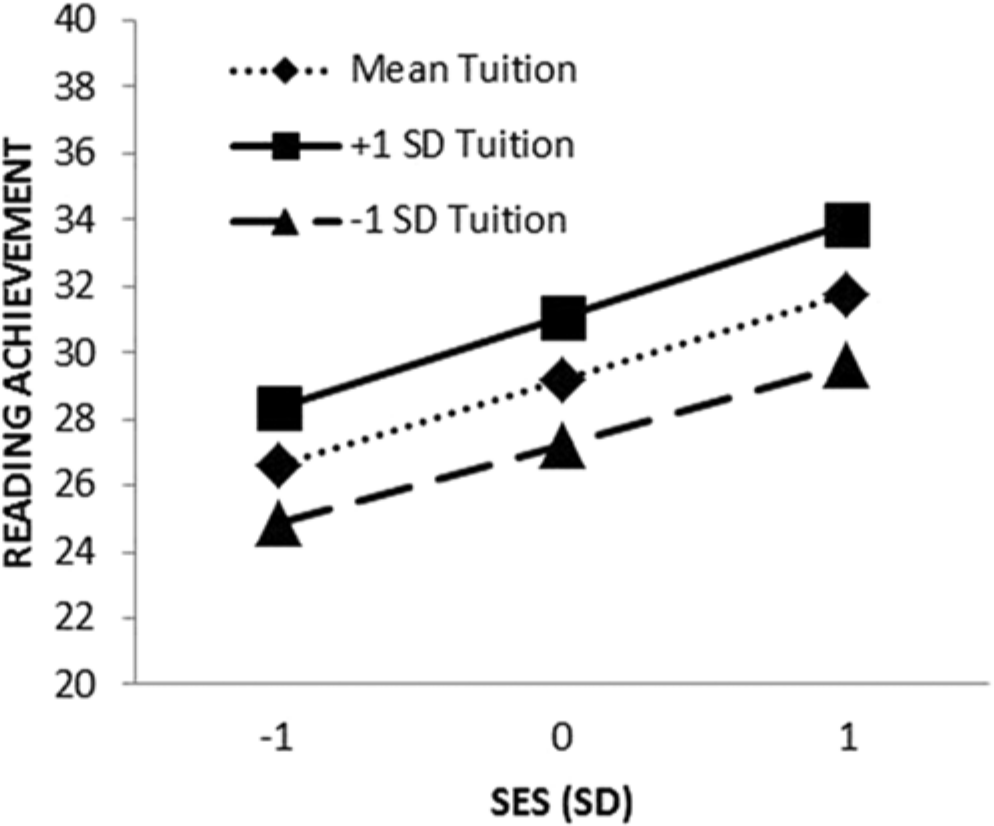
Effect of student SES and school tuition on reading achievement.
A Suggested Ten-Question Multilevel Model Checklist
Researchers face many decisions prior to, during, and following multilevel model analyses in the process of answering research questions that require multilevel analysis techniques. As such, researchers can then be faced with the daunting task of summarizing all the decisions made, techniques used, and results obtained in a manner that can be clearly understood by a target audience. Offered below, in the form of a checklist, are 10 questions that can guide researchers in their multilevel modeling summarization and presentation efforts:
Has the research question been clearly articulated, and a description of the higher level nesting units (e.g., classrooms at Level 2 and schools at Level 3) and all predictor variable(s), control covariate(s), and response variable(s) described?
Has a clear connection been established between the research question and the model-building steps needed to answer the question accurately?
Has the choice of parameter estimation method (ML, REML, MLR) and associated issues (e.g., the chosen denominator degrees of freedom correction method used in SAS) been discussed?
Have the choices and rationales for centering of all continuous and categorical predictor variables been presented?
Have the linear model equations (i.e., the combined model equation [for SPSS and SAS analyses], or the Level 1, Level 2, and Level 3 equations [for Mplus or HLM analyses]) been presented and discussed?
Have all the multilevel parameter estimates (fixed and random effects) been interpreted in the context of the research question?
Have results been summarized in table form (see Tables 1 and 2) in a way that can be linked back to the model equations that allow readers to understand the model tested and the results obtained?
Have the appropriate model comparison tests (likelihood ratio nested model tests or multi-parameter Wald tests) been presented and their implications for a model-building process discussed?
Have any statistically significant interaction effects been presented graphically as well as discussed in text?
Have global (pseudo-R2) and local (PRV) effect sizes been presented for the model(s) of theoretical interest?
Summary and Conclusion
The primary goal of this article was to expand on the previous procedural logic and presentational flow of published articles that have demonstrated the steps needed to analyze two-level nested data to consider the nested three-level cross sectional data analysis case. A secondary goal of this article was to illustrate a model-building process that helps to (a) reduce the possibility of parameter estimation errors and un-interpretable parameter estimates, (b) ensure correct multilevel model specification, and (c) reduce the possibility of parameter estimate bias being propagated throughout the multilevel model. In addition, researchers face numerous important decisions prior to (e.g., choice of parameter estimator and denominator degrees of freedom correction), during (e.g., predictor variable centering and random effect estimation), and following (displaying results tabular and graphical form and computing global and local effect sizes) multilevel modeling analyses. These decisions have been integrated into a suggested checklist to help guide researchers’ efforts in conceptualizing, analyzing, summarizing, and presenting their research findings. Finally, although SPSS syntax was used for all example analyses, (SAS and Mplus syntax for all analysis examples are available in the supplemental online materials), the necessary methodological considerations and needed statistical analysis steps have been presented in sufficient detail to allow researchers to use the multilevel modeling statistical analysis software package of their choice.
Footnotes
Appendix
Acknowledgements
The author wishes to extend his appreciation and gratitude to Tashia Abry, Craig K. Enders, Ting Sa, Yelena Wu, and several anonymous reviewers for their insightful comments and helpful suggestions that greatly improved the quality of this manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Notes
Author Biography
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.