
Abstract
Much has been written about the evaluation of faculty research productivity in promotion and tenure decisions, including many articles that seek to determine the rank of various marketing journals. Yet how faculty evaluators combine journal quality, quantity, and author contribution to form judgments of a scholar’s performance is unclear. A mathematical model of faculty judgment is presented that estimates a scholar’s research productivity that is surprisingly consistent with actual faculty evaluations. The model does not replace human judgment in evaluating a scholar’s research performance, but the model enhances clarity and objectivity in the evaluation process. The method is demonstrated with marketing faculty at one university.
Faculty research productivity is one of the most important variables in evaluating faculty performance (Beltramini, Schlacter, & Kelly, 1985; Burnett, Amason, & Cunningham, 1989; Coe & Weinstock, 1983; Noble, Bentley, Campbell, & Singh, 2010; Seggie & Griffith, 2009). Yet evaluating research productivity can be challenging and controversial—challenging because of the complexity of the task and controversial because faculty members often disagree on the quantity and quality of research required for tenure and promotion.
To simplify the evaluation of publication quality, many schools use a surrogate indicator of quality—lists of “journals that count” (Polonsky, Jones, & Kearsley, 1999; Steward & Lewis, 2010). Some schools used tiered lists (e.g., A journals, B journals, C journals), and much has been written about which journals belong to which tiers (see Steward & Lewis, 2010, for a recent review and example). However, even within these tiers, the quality of the journals varies. Many faculty members also consider the order of authorship or article contribution in evaluating faculty research performance (cf. Bak, Vitell, & Rose, 2000; Noble et al., 2010; Seggie & Griffith, 2009). And then there is the issue of how the quality and quantity of publications should be jointly considered in performance evaluations (Urban, Wayland, & McDermott, 1992).
It is often difficult for evaluators to simultaneously consider all these and other factors in evaluating a scholar’s research. Thus, conclusions can be somewhat unreliable, which is troubling given the substantial impact these evaluations can have on a faculty member’s career. This raises the need for tools that simplify and clarify the evaluation process, and in this regard, mathematical models hold great promise (Armstrong, 2001). Models developed from past performance evaluations have been found to outperform judges on present evaluations. Bootstrapping—the process of substituting a simple linear model of judgments in place of the judgments themselves (Huber, 1975)—has been shown to be surprisingly effective in a wide variety of contexts (see Dawes & Corrigan, 1974, for a review).
In this article, we present a method for generating a mathematical equation that computes faculty research scores. A research score is a quantitative measure of a scholar’s research productivity. The simple mathematical model developed here combines journal quality and quantity, whereas the complete model also integrates author contribution into an equation with parameters that can be unique to a particular school. The model achieves four objectives: (a) it identifies how faculty judges evaluate the relative quality of different journals; (b) it simulates how faculty combine indicators of quality, quantity, and contribution; (c) it clarifies research expectations for junior faculty; and (d) it improves the objectivity of the evaluation process. As such, the new tool should be useful to any school that evaluates research performance and considers publication outlets at various levels of journal quality. We demonstrate how standards for promotion can be established in terms of the research scores.
Importantly, the model is not intended to be the sole or most significant determinant of a scholar’s research productivity. Qualitative factors requiring human judgment are an essential element of the performance review. Given that these factors and subjective human judgment cannot and should not be removed from the research evaluation process, the model is intended to serve as a supplement to human judgment, and it can make the research evaluation process more transparent and objective for all. It is recognized that research productivity is only one aspect of faculty performance evaluation, as teaching and service performance should also be considered.
The article proceeds with a review of the literature on evaluating faculty research productivity and studies drawn from the judgmental bootstrapping, policy capturing, and goal setting literatures that provide support for an effort to mathematically model performance judgments. The model is presented and a method for estimating the key model parameters is demonstrated in the context of one marketing department at a western university. The validity of the model is also empirically demonstrated.
Literature Review
Evaluating Research Productivity
One of the simplest models for evaluating faculty research productivity is to count the number of publications an author has produced. Standards can be set for the number of published articles a scholar must produce, and the scholar’s production level is compared with the standard. In Seggie and Griffith’s (2009) analysis of this approach, only the top four journals in marketing are considered (Journal of Marketing, Journal of Marketing Research, Journal of Consumer Research, and Marketing Science). Seggie and Griffith found that the average level of productivity at the top 10 marketing departments was .57 articles a year, but in the group of schools ranked in the top 41 to 70, the productivity was less than half of that average, at .26 articles per year.
Although Seggie and Griffith (2009) make an important contribution to our understanding of research productivity, their research is of limited use to most business schools. A total of 620 schools now hold AACSB accreditation (AACSB, 2011a). As the productivity drops from .57 to .26 among the top 70 schools, one wonders how much further reasonable expectations are reduced for the other 550 schools (89% of accredited business schools). The limits of focusing on the top journals is further evidenced in additional analyses by Seggie and Griffith, where they note that 2,672 faculty published in these top journals from 1982 to 2006. However, there are approximately 25,000 academically qualified faculty members among AACSB schools (Shinn, 2008). Thus, although Seggie and Griffith’s “A-count” metric offers a good understanding of those who publish in the top journals, many marketing faculty need a more realistic metric to assess research productivity.
Further evidence that the A-count metric is inadequate for many schools comes from Yeh, Thomas, Weaver, and Price (2011), in their analysis of the American Marketing Association [AMA] docSIG’s annual Who Went Where? survey of 103 recently placed marketing PhD graduates. The 4-point scale that was used to assess publication expectations included the following labels: (a) “Only A journals count”; (b) “B journals count, but only very little”; (c) “B journals count, but there is some expectations for A journals”; and (d) “B journals count and A journals are not expected.” The mean score on this scale was 2.82, indicating that B journals are relevant at many schools. At private and public balanced research/teaching schools, the means were even higher, at 3.29 and 4.00 (respectively). On a separate question, the overall average count of A journals expected was 2.02, but the overall average for the total number of publications was 5.79, offering evidence that B journals are more common at most schools than A journals.
Recognizing that the A-count metric alone is not used at most schools, a plethora of studies have been published on the relative quality of a much broader set of marketing journals. Steward and Lewis (2010) offer an excellent synthesis of these studies. Importantly, they note that many of the studies’ results are highly correlated. Thus, a fairly reliable metric of journal quality can be constructed by combining several studies.
For journals that are not on any published list, several aspects have been suggested for determining its quality including the use of blind review, the acceptance rate (however, see Van Fleet, McWilliams, & Siegel, 2000, for arguments on why not to use acceptance rate), the number of years the journal has been published, and other factors (Urban et al., 1992). Soutar and Murphy (2009) suggest a more systematic approach that is widely applicable. They demonstrate how the impact of journals not captured in the ISI citations from Thomson Scientific’s database can be estimated using Google scholar citation counts. By comparing new or unfamiliar journals with those with established ranks, the rank of most journals should be estimable.
Journal quality is the most popular but not the only metric of publication quality. Coe and Weinstock (1983) note that colleague and the department chair’s evaluations of the article itself are measures of publication quality. The article’s citation counts in other published research are also of interest to some faculty, but this metric is limited in that citations may not peak for several years after the article’s publication, and they may grow at different rates (Bergh, Perry, & Hanke, 2006).
In addition to peer-reviewed journal articles, many schools consider other scholarly activities in evaluating research productivity. Shepherd, Carley, and Stuart (2009) surveyed marketing department chairs and found that many considered national or regional conference proceedings, non-peer-reviewed publications, textbooks or textbook supplements, or trade publications as evidence of productivity. The percentage of schools that considered these alternative forms of evidence was much higher among non-doctoral-granting institutions than among doctoral-granting institutions.
In addition to journal quality, some schools weigh the contribution that the scholar made to each article. The order of authorship or number of coauthors is sometimes used as a surrogate measure of contribution (Noble et al., 2010; Seggie & Griffith, 2009). Noble et al. (2010) found only partial support for a relationship between number of lead-authored articles and author reputation, but their sample was small and somewhat limited to exceptionally productive scholars. Thus, the findings may not be generalizable. In their survey of factors that departments consider in performance evaluation, Shepherd et al. (2009) found that 18% of schools consider order of authorship in performance evaluation. At the authors’ university, candidates for promotion must report their percentage contribution to each of their joint-authored publications so that the promotion committee can consider this information in forming their recommendations to the dean.
In summary, evaluating journal quality is challenging, but many resources are available to help faculty who wish to use this metric. Judging the relative quality of other publication outlets, such as texts or trade publications, is more difficult. Combining the quality estimates of a number of publications, along with the contribution the scholar made to each one, is a quite complex mental task.
Judgmental Bootstrapping
When individuals are presented with a complex set of stimuli to form holistic evaluative judgments, these judgments are likely to be unreliable and subject to a host of biases. In evaluating a scholar’s publication record, a judge will likely consider every article that the scholar has published, the quality of the publication outlet, the order of authorship on each article, the topics of the articles, any trends or streams of research among the articles, and so on. The amount and complexity of this information taxes a judge’s working memory, and thus the judge’s summary judgment will be at least somewhat unreliable (Stewart, 2001).
Judges are also subject to biases. For example, a member of the promotion and tenure committee might have formed an impression, based on personal interactions, that a candidate is a strong researcher. With this estimate as an anchor, the evaluator may pay less attention to or even discount information that is inconsistent with this initial impression. In failing to appropriately adjust the initial estimate, the judge succumbs to the classic anchoring and adjusting bias (Tversky & Kahneman, 1974). Other biases may come into play, including racial or gender biases. Thus, a system that can minimize these harmful effects has significant value to the department and the institution.
Judgmental bootstrapping is a method that replaces expert judges with mathematical models that estimate their judgments. In the literature, the simpler term bootstrapping is generally used, but this approach should not be confused with the statistical technique for understanding sampling error (Armstrong, 2001). One classic example of bootstrapping from Dawes (1971) involves a graduate admissions committee. The committee was given each applicant’s undergraduate transcript, GRE score, and letters of recommendation. The committee then rated each candidate, and the ratings were later compared with how well the admitted students actually performed in the program. The correlation was found to be .19 (n = 111). In parallel, a regression model was estimated using similar information. Rated program performance was used as the dependent variable, and GRE score, GPA, and an index of the quality of the undergraduate institution were the independent variables. The average cross-validated correlation based on the regression results was .38, a substantial improvement over the admissions committee, even though both methods used very similar information.
Armstrong (2001) argues that bootstrapping may make personnel decisions more ethical because the model rules are revealed, and the model cannot be accused of hiding a bias for or against certain candidates. Thus, establishing a mathematical model of research productivity with clear standards for promotion will help junior faculty to more clearly understand their progress toward promotion and to become more aware of what adjustments are necessary.
In the human resources literature, judgmental bootstrapping studies are often referred to as policy-capturing studies (Aiman-Smith, Scullen, & Barr, 2002; Hobson & Gibson, 1983; Karren & Barringer, 2002). Like other bootstrapping studies, policy-capturing studies often use regression-based techniques to model a judge’s decision-making process. The focal decisions are often related to the evaluation of job applications, performance evaluation, or promotion decisions (Karren & Barringer, 2002), and therefore the findings from this stream are particularly relevant.
One difference between the bootstrapping and policy-capturing literatures is that the use of experimental designs is more common in the latter. Karren and Barringer (2002) synthesize the findings from many policy-capturing experiments and find that full factorial experiments still appear to be the norm, although respondent fatigue, boredom, and stress may create problems with large designs. They note that researchers are beginning to consider designs than include only a subset of the full factorial set, such as fractional factorial designs or incomplete block designs (see also Graham & Cable, 2001). There are calls in the policy-capturing literature for the use of conjoint analysis (Aiman-Smith et al., 2002; Karren & Barringer, 2002), where the use of abbreviated designs has a long history (e.g., Green, 1974). However, to date, we are not aware of any policy-capturing studies that explicitly use conjoint analysis.
A conjoint-like design would be particularly useful for the problem at hand. Small departments may make tenure decisions once every few years, and therefore modeling actual decisions may seem impossible because of the small sample size. However, with conjoint analysis, a faculty member could be presented with many different hypothetical candidates and be asked to evaluate each one. Through this process, the judge’s model can easily be estimated. Conjoint analysis also offers the advantage of orthogonal designs, eliminating the covariance among the attributes and thus providing more accurate parameter estimates.
Goal Setting
Typically, untenured assistant professors want to know how much they must publish to be promoted. Too often, the response from the tenured faculty is vague, such as “We’ll know it when we see it” or “Just do your best.” These responses are unacceptable for at least three reasons. First, the goal setting literature recommends setting clear and measurable goals to maximize performance (Locke & Latham, 2002). Second, these vague standards lead to frustrated tenure-track faculty. Finally, vague standards can lead to very contentious promotion decisions, and in our increasingly litigious society, the inconsistent application of vague standards exposes the department to the risk of a lawsuit. Hence, bootstrapping decision makers would provide clear guidance regarding tenure and promotion requirements and would be beneficial to all parties. However, one size does not fit all in terms of types of decision-making processes. Different departments should decide which factors work best in evaluating research performance.
This article does not present a model that works at every business school. Instead, schools value research differently, consistent with past research (e.g., Shepherd et al., 2009). For example, if the institution is focused on issues such as ethics, innovation, and advertising, it should seek to align journal listings with its research focus, types of educational programs, and resource capabilities. Research focus can vary based on whether the institution emphasizes pure academic research only or whether teaching is a higher priority than research. In the former case, as is typical in doctorate-granting programs with substantial resource capabilities, the focus would be on quality publication in top-ranking journals, such as the JM. In the latter case, the focus may be on publication in journals such as the Journal of Marketing Education (Polonsky, 2004; Polonsky et al., 1999). Different schools should develop their own estimation models. We demonstrate how such a model can be estimated, using data from faculty at one school, so that readers can apply the method in customized fashion at their own schools.
In summary up to this point, the literature suggests that linear models of human judgment are often more valid than human judgment, and such might well be the case in evaluating research because of the complexity of the process and the availability of data. Furthermore, the development of such an explicit model would clarify department goals, leading to increased performance and reduced frustration.
Methodology and Results
To create a research scoring model, a series of five steps are necessary. Each of these steps is described below, and each step is demonstrated using data from one marketing department. For clarity in exposition, relevant results are presented immediately following each section of the methodology.
Step 1: Identify How Faculty Trade Off Quality and Quantity
We begin with a simple research evaluation model that considers only the quality and quantity of publications. In the simple model, the Research Score (RS) for any scholar’s research profile can be conceptualized as follows:

where n is the number of research items (e.g., articles) accepted or published and q i is a quality score for each article.
Equation (1) is based on the assumption that additional journal publications have linear, independent effects on the overall evaluation of the profile and that journals do not interact with each other in the evaluation of a research profile. These are common implicit assumptions in studies of research productivity (e.g., Abernethy & Padgett, 2011; Seggie & Griffith, 2009).
Trade-off analysis, a simple form of conjoint analysis, can be used to estimate several key parameters in the model. In the language of conjoint, the quality of each journal is an attribute and the number of publications in each journal is the number of levels of the attribute. Trade-off analysis is used here because attributes can be considered in pairs, and setting up trade-off matrices does not require specialized software (see Johnson, 1974).
Sample
The participants in this study include the faculty from the marketing department at a medium-sized private school in the western United States. The school considers itself to be a balanced school in terms of teaching and research. Two untenured assistant professors, one tenured associate professor, and four tenured full professors comprised the department’s tenure-track faculty at the time the study was conducted. All but one full professor completed the instrument. The average correlation among the respondents was .90, indicating that the data from all respondents could be combined into a single homogeneous set.
Instrument
The instrument contained a series of five trade-off tables. Specific questions were then added to the questionnaire to gain more insight into the evaluation model (see Appendix A, Section 3, Questions 6, 7, 8, and 9 in Likert-type format). For some promotion committees, a scholar’s publication record can be analyzed as a portfolio, and not just as the sum of its parts. For example, a committee may want to see that an assistant has published at least one sole-authored piece, but beyond that, the committee might not highly value additional sole-authored pieces. The additional questions can be used to check for the presence of noncompensatory models.
The instrument reflects an incomplete block design. Thus, respondents do not consider all possible pairs of journals. However, pairs of attributes must be connected so that it is possible to estimate the relationships among all the attributes. For example, if an A journal is compared with a B, and a B is compared with a C, then it will be possible to estimate the relationship between an A and a C journal. Such a design is advantageous because A and C journals may differ so much in quality that a direct comparison would be challenging.
Even with an incomplete block design, it is not generally feasible to include all possible publication outlets in a single design. Instead, a representative sample of outlets is compared. In Step 2 (discussed below), the scores of this sample are compared with published journal rankings, and the scores of omitted outlets are estimated with linear interpolation.
Even with an incomplete block design, this instrument might be confusing or fatiguing for traditional survey respondents. However, all respondents to this survey had PhDs in marketing and were very interested in obtaining valid results, and therefore problems with confusion and fatigue did not emerge.
Following the bootstrapping tradition (Dawes & Corrigan, 1974), the trade-off between quality and quantity was modeled with a linear regression model. The model assumes that a certain number of lower quality outlets would be seen as nearly equivalent to a single high tier journal. Although these assumptions may appear to be overly simplistic, the overall validity of the model is critically evaluated below in Step 5: Validate the Model.
Separate regression models were estimated for each of Trade-off Tables 2, 3, 4, and 5 (Section 2 of the questionnaire in Appendix A), using the number of each type of publication as the two independent variables and the ranking as the dependent variable. The effective sample sizes for Trade-off Tables 2, 3, and 5 was 60, but for Trade-off Table 4, the sample was limited to 40 because of nonresponses. (Two of the six respondents were not familiar with the Journal of Consumer Marketing.)
The data were analyzed using ordinary least squares (OLS) regression analysis. Because of the use of an ordinal dependent variable (ranks), the assumptions of OLS are violated, but conjoint researchers have found that rankings and ratings are generally highly correlated, and OLS regression can actually provide more accurate estimates than competing techniques that are designed for use with ordinal dependent variables (Wittink & Cattin, 1981). The use of ranks is more troublesome with fractional factorial designs (Darmon & Rouzies, 1999), but the present research employs essentially full factorial designs, considering two attributes at a time. Furthermore, Dawes (1979) found that in bootstrapping studies, importance weights developed by nonoptimal methods often outperformed clinical judgments. All this may explain Armstrong’s (2001) conclusion that bootstrapping is not highly sensitive to the type of regression analysis used.
The coefficients from the five regression models, created using data from five Trade-Off Tables, are shown together in Table 1. All regressions fit the data quite well, with R2s ranging from .88 (Table 1, JBR [Journal of Business Review] vs. JM) to .94 (Table 5, JBR vs. AMA Proceedings), and all were significant at p < .01. (More technical details are described in Appendix B.) With these results, ratio-level journal quality measure can be created in “JM units.” These units were selected because the JM emerges consistently as the top marketing journal across nearly all marketing journal quality studies (cf. Hult, Reimann, & Schilke, 2009). Note that in the regression model for Trade-off Table 2, JM is associated with a coefficient of 3.5, whereas the Journal of Business Research (JBR) is associated with a coefficient of 1.5. Thus, a scholar with one JM would be evaluated at this school as being at the same level as a scholar with 2.33 JBRs (1 × 3.5 = 2.33 × 1.5). Dividing each coefficient by 3.5, a JBR can be seen as worth .42 of a JM (1.5/3.5), or .42 JM units. The results for Trade-off Tables 3 and 4 can be rescaled similarly. For Trade-off Table 5, the JBR coefficient is rescaled to .42 using the results from Trade-off Table 2, and therefore the AMA Proceedings coefficient is rescaled to .11 JM units (1.2/4.4 × .42 = 0.11). In other words, according to the faculty at this school, nine AMA Proceedings would be equivalent to about one JM (9 × .11 ≈ 1.0).
Quality Versus Quantity Trade-Off Regression Results
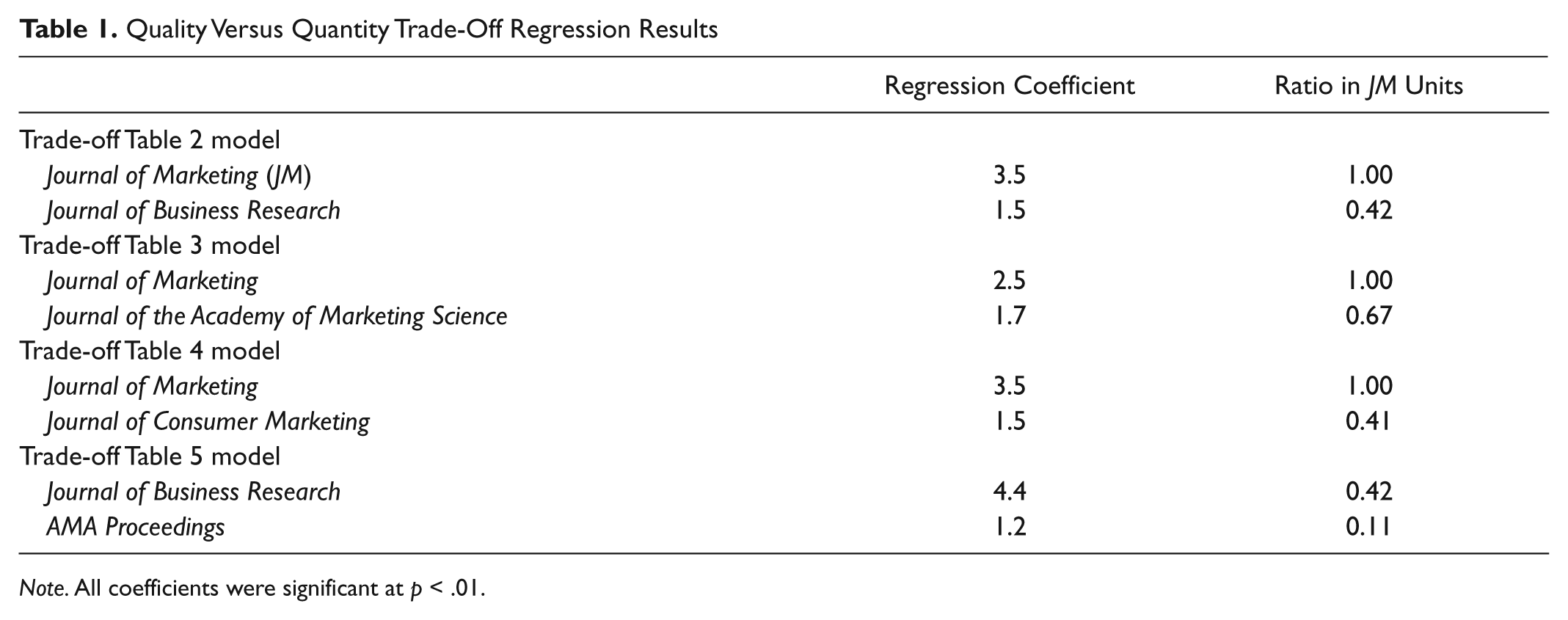
Note. All coefficients were significant at p < .01.
It is possible that some schools do not want to apply a simple compensatory model, and instead want to have constraints, such as requiring candidates to have at least one “A” journal hit (cf. Yeh et al., 2011). In the method presented here, this possibility is tested using Question 9 on the survey in Appendix A. Only one in six respondents indicated any agreement with the statement that scholars must have at least one “A” journal, indicating it was not necessary to add this constraint to the model.
Step 2: Identify the Quality Parameters of Outlets Not Considered in Step 1
Although the previous analysis generated metrics for just five outlets, metrics can now be estimated for many other outlets by integrating secondary data about journal quality. The results from several published studies were combined to form a reliable measure of journal quality (cf. Steward & Lewis, 2010). The quality ratings published in Hult et al. (2009) were used, including their popularity/familiarity index from 2007, their importance/prestige index from 2007, the SSI Impact Scores averaged from 2002 through 2006, the ratings from Baumgartner and Pieters (2003), and two ratings from Theoharakis and Hisrt (2002). These scores were first z-standardized and then combined to form an average. The average intercorrelation among these scales was .78, leading to a Cronbach α for the combined measure of .95. These scores are shown graphically in Figure 1. Although this figure only shows the quality score for the top 50 or so publications in marketing, a quality score for any publication outlet not shown in the table could be developed using any of the methods described previously (e.g., a comparison of Google scholar citation frequency; cf. Soutar & Murphy, 2009).

Standardized ratings of publication outlets averaged across six studies
It should be noted that while the average ranks shown in Figure 1 are interval measures, schools can value journal quality differently. For example, some schools may consider the top four journals to be of a similar high value and all other journals to be of zero value, whereas other schools may consider the top tier journals to be of similar high value but the lower tier journals to still be of some substantial value. Thus, although the measures in Figure 1 are interval measures, it is more practical to regard these as somewhat ordinal measures. Each school will need to “stretch,” or rescale these quality ratings to obtain a scaling that best reflects the research values of the school. This rescaling can be accomplished via the quality/quantity trade-off analysis conducted in the previous section.
Rescaling journal quality scores
The results from Table 1 provide rescaled scores for five outlets, or five points along the quality curve. The standardized scores shown in Figure 1 were rescaled in between these points using linear interpolation to reflect scores that are consistent with the judges’ attitudes at this school. For ease of use, the scores were all multiplied by 10. The rescaled scores are shown in Table 2. These rescaled scores can be inserted in Equation 1 above to generate a meaningful simple RS for any scholar.
Rescaled Quality Scores for Various Outlets

Step 3: Identify How Faculty Weigh Differing Author Contributions
The simple model describe in Equation (1) can now be extended to integrate author contribution. The contribution interacts with the quality of each publication, but otherwise the model is additive. Thus, the complete RS for any scholar’s research profile can be conceptualized as follows:

where c i is the contribution to an article (e.g., .30 for a 30% contribution).
Data from Trade-off Table 1 (in the instrument discussed above) was used to model author contribution. After comparing the results with two competing models (Appendix B), it was determined that the linear model fit the data nearly as well as a nonlinear model and was therefore retained for further analysis. With these findings, the complete scoring model from Equation (2) was revised as follows:

In this model, an author’s complete RS is reduced for coauthored articles. It is recognized that some schools may wish to reward research collaboration, perhaps especially schools that place more emphasis on teaching, and therefore these schools might prefer to omit contribution and use only the simple RS shown in Equation (1). The tasks of setting research standards and validating the model (described below) would be much the same even if the contribution parameter were omitted from the model.
An examination of the Likert-type responses sheds additional light on faculty attitudes at the research site regarding contribution. All respondents agreed (two somewhat and four strongly) that a scholar should have at least one first-authored journal article (Question 6, Appendix A), but the respondents were more mixed concerning whether there must be one sole-authored article in the portfolio (two strongly disagree, two neutral, two somewhat agree). The respondents were even more mixed in their opinions about the number of sole or first-authored articles (one response in each of five agreement categories, with an additional response in the neutral category). Thus, it appears that although the simple model identified above will serve as a good approximation, most judges at this school would like to see at least one first-authored article, in addition to an acceptable RS score.
Generating meaningful research scores for faculty is only the first part of the challenge of evaluating research performance. In the next stage, meaningful standards, or cut-scores, must be generated in order to use this metric for promotion purposes.
Step 4: Identify Promotion Standards
A second instrument was used to establish the target RS, or cut-score, for promotion (see Appendix C). These data were also used as the holdout sample to validate the model (see Step 5, below). This instrument contained a description of 11 hypothetical assistant professor research profiles. Respondents were asked to rate each profile and to indicate whether or not each research profile was worthy of promotion to associate. The profiles were selected based on a knowledge of the school’s history and the expectation that most of the marketing faculty at this school would find at least one profile to be unacceptable and at least one to be acceptable. Four tenured faculty members completed this second instrument more than 2 weeks after completing the earlier questionnaire.
The simple RS of each hypothetical scholar in Appendix C can be estimated by inserting the rescaled outlet scores from Table 2 into Equation (1), and the complete RS can be estimated by inserting the proper values into Equation (3). For example, the simple and complete RS for Profile A in Appendix C would be computed as shown in Table 3. The complete RS was of greater interest at the research site. The resulting complete research scores for the 11 profiles ranged from 6.1 to 17.2.
Application of Research Scoring Model to a Hypothetical Profile
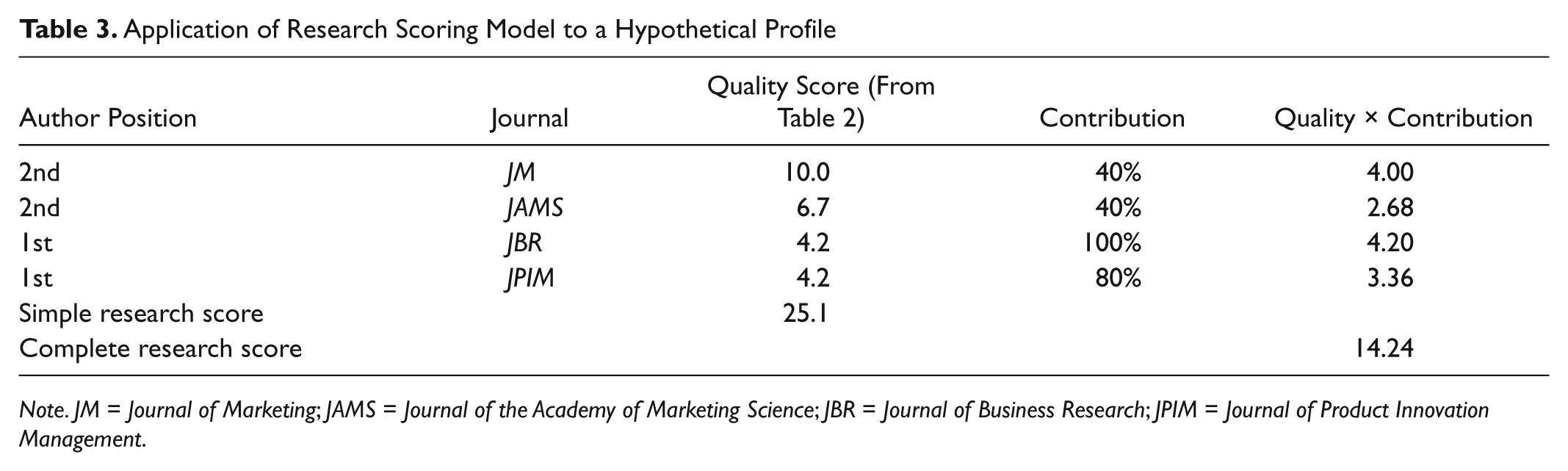
Note. JM = Journal of Marketing; JAMS = Journal of the Academy of Marketing Science; JBR = Journal of Business Research; JPIM = Journal of Product Innovation Management.
To establish the promotion standard, or cut-score for the complete RS metric, each judge’s responses were examined to find the acceptable profile with the lowest RS and the unacceptable profile with the highest score. The average of these two scores formed an estimate of that judge’s cut-score. The average cut-score across all judges was found to be 11.8. Thus, based on the input from this set of faculty, assistant professors could be told that they need to achieve a complete RS of at least 11.8 to be acceptable on the research dimension for promotion. For example, the scholar whose research is reflected in Table 3 as having a complete RS of 14.24 would know that he or she has achieved an acceptable RS. Schools wishing to set standards using the simple RS could follow the same procedure but instead focus on the acceptable and unacceptable simple RS. As will be discussed below, additional considerations can be factored in to make the final determination of research acceptability. As mentioned previously, other criteria related to teaching and service may then be applied to determine if the scholar should be promoted.
Step 5: Validate the Model
The validity of the model was tested using a method similar to the use of a holdout sample in conjoint analysis (Johnson, 1974). Although the model was developed using trade-off matrices, the model was validated using ratings of full profiles. Note that the RS for each profile was calculated based on the parameter estimates from previous tasks, not from the ratings of the full profiles. The correlation between the complete RS, determined by the model, and the average profile rating of the faculty respondents was found to be .90, demonstrating strong validity. Interestingly, the average intercorrelation among the faculty ratings was .80, and the average correlation between each faculty rating and the RS was .84. Thus, in this sample, the model predicted faculty ratings more accurately than other faculty did, on average.
Discussion
This article has presented arguments for why bootstrapping or policy capturing should be considered as a supplemental tool when evaluating research productivity, and a method has been demonstrated that generates a research scoring model. Although the sample used here was small, it comprised four of the five faculty members who would be involved in marketing tenure decisions and thus is viewed as nearly a census. Because of the within-subject nature of conjoint design used here, the method can generate a research-scoring model even with a single respondent. Thus, the method should be useful to large and small schools alike.
Some readers may be daunted by the prospect of scoring so many journals. A simpler model can be developed by assigning journals to categories, such as A, B, or C journals. The AACSB has suggested that schools develop a target list of journals (Standard 2, Intellectual Contributions, AACSB, 2011b), and many schools divide this list into categories (Van Fleet et al., 2000). The scoring model developed here can easily be applied at schools with a target list by establishing separate point values for each category. These values can be established by conjoint analysis or by faculty vote. For example, A journals may be worth 10 points, Bs worth 4, and Cs worth 1. If desired, contribution weights can then be applied as shown in Table 3. Although not quite as precise as the model presented here, this simpler model might be acceptably accurate and much easier to explain and apply.
As this model is new at the research site, its use in practice is considered experimental. Still, the model has been well received by the department’s assistant professors as it gives clear expectations and yet offers flexibility in how those expectations can be met. The department also considers teaching and service in promotion and tenure decisions, but does not yet have a rigorous model for evaluating these dimensions. The possibility of creating a teaching score, analogous to the RS described here, presents an interesting opportunity for future research. Such a model might include the teaching dimensions identified as important by Shepherd et al. (2009), including student evaluations, a teaching portfolio, classroom observation, peer review of syllabi, class size, graduate versus undergraduate classes, and delivery approach (online vs. traditional). Such a model may be more complex than the analysis presented here and may require the use of advanced software and more complicated fractional factorial or incomplete block designs.
In parallel with the simple mathematical RS model, this department’s promotion standards include several other objective and subjective criteria that can be used to evaluate research performance. The department documentation specifically mentions that the promotion and tenure committee will read all of a scholar’s publications and decide whether the quality is consistent with the publication outlet (cf. Coe et al., 1983). Quality scores may be adjusted up or down based on this subjective assessment of quality. The department also expects the research to be reasonably programmatic (not just a random set of articles), show some evidence of growth in skills, and reflect continuous productivity. Furthermore, to discourage a portfolio comprising entirely of low-level outlet articles, the department limits the total contribution from conference proceedings to no more than 4 points. Others schools may choose to put similar limits on C or even B journal contributions. We expect that in actual promotion decisions, a vote of the tenured faculty will be used. As the new model is exploratory, faculty will likely use their own judgments to make the decision they feel is most appropriate.
Another way to limit the number of publication in the same, low-level outlets would be to implement a nonlinear model. Thus, for example, although an AMA Proceedings might be worth 1/9 of a JM, five AMA Proceedings might still be worth less than half a JM. A full exploration of the advantages and disadvantages of nonlinear models in this context is left to future research.
One aspect of standards that is not explicitly included in the model is that standards can change over time. Schools may choose to increase or decrease their emphasis on research and may therefore need to adjust the research cut-score. Ideally, assistant professors would be given ample advance notice of any changes. Ideally, an assistant professor would know the standards on his or her date of hire, and the standards would not change until after the tenure decision is made. It is recognized that in an ever-changing academic environment, this ideal may be difficult to meet.
Not surprisingly, there was not perfect agreement among the faculty studied. When faculty do not agree on what the appropriate standards should be, setting clear and meaningful standards will be difficult no matter what system is used. Although the model suggested here offers no specific system for resolving these disagreements, attempting to apply the model helps identify areas of disagreement, which could then be resolved through thoughtful discussion.
The cut-score used at the point of the promotion-with-tenure decision can also be used to offer meaningful interim feedback. If the cut-score is to be achieved at the end of Year 5, each year of the scholar’s career should show approximately one fifth of the RS contribution to the score. The frequency of a scholar’s publications is seldom uniform (e.g., two articles every year) and instead will tend to show variation (e.g., no hits one year, three the next). Still, the RS trend line can provide useful feedback to assistants and be a worthwhile method for determining whether or not the assistant is roughly “on track.” At the research site, assistants are encouraged to develop a plan for how they will achieve the necessary cut-score by the end of the pre–tenure period. With this plan in hand, assistants can see for themselves if they are ahead or behind schedule.
For annual merit reviews, an RS metric can be estimated for any tenure-track faculty. Following the AACSB standards for being academically qualified (Standard 10), a 5-year rolling score can be created, where each new publication contributes to the score for 5 years and then drops out of the calculation. Interestingly, this research has drawn attention to the fact that at this research site, expectations for untenured faculty productivity, in terms of RS, appear to be substantially higher than expectations for tenured faculty. The standard used at the school for maintaining academic qualification amounts to an RS of only about 4.0 (assuming 50% average article contribution or authorship), whereas the standard for promotion requires an RS of close to 12 in about a 5-year period. To some degree, this discrepancy is appropriate because assistant professors are often given easier course preparations, course releases, or summer funding in order to accelerate their research programs. Perhaps another round of trade-off matrices could be used to estimate how these resources are expected to impact research productivity. Thereafter, different standards could be set based on the resources provided to the scholar. Again, the RS model serves to highlight existing discrepancies and thus can encourage important conversations about research goals, resource deployment, and how expectations shift as faculty progress through their lifecycle at the school (as noted in Beltramini et al., 1985).
Conference presentations are not included in the RS model shown here because they were not considered sufficiently important at the research site. Some schools may want to include presentations, whereas at the other end of the research continuum, other schools may not want to include any outlets except the top three or four journals. In either case, an RS model could be estimated among the faculty that would be meaningful for that school.
This model has not yet been used to evaluate research performance for promotion to full professor. Some schools may wish to consider a broader set of criteria at this point, including the development of a national reputation in a research area. This criterion clearly goes beyond the RS model shown here. How the model can be modified to fit this application is an interesting area for future research.
One final area for future consideration is how this model might be extended across the entire college of business. Using a sample of faculty who publish in multiple disciplines (e.g., marketing and management), it would be possible to develop a model that could score any business school faculty member on the same underlying metric. Such a model could form a basis for equitable promotion and merit decisions across the entire college. Unfortunately, the challenge of reaching agreement on a model across disciplines would be even more daunting than reaching agreement within a discipline.
In conclusion, this article has demonstrated how a mathematical model of expert judgment can be developed as an aid for evaluating research performance. By bootstrapping the experts and with some additional subjective input, research expectations are clarified for all faculty, and fairness is improved in the performance evaluation process.
Footnotes
Appendix A
Appendix B
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.