
Abstract
How do movement and sound combine to produce an audiovisual aesthetics of dance? We assessed how audiovisual congruency influences continuous aesthetic and psychophysiological responses to contemporary dance. Two groups of spectators watched a recorded dance performance that included the performer’s steps, breathing, and vocalizations but no music. Dance and sound were paired either as recorded or with the original soundtrack in reverse so that the performers’ sounds were no longer coupled to their movements. A third group watched the dance video in silence. Audiovisual incongruency was rated as more enjoyable than congruent or silent conditions. In line with mainstream conceptions of dance as movement-to-music, arbitrary relationships between sound and movement were preferred to causal relationships in which performers produce their own soundtrack. Performed synchrony Granger caused changes in electrodermal activity only in the incongruent condition consistent with “aesthetic capture.” Sound structures the perception of dance movement, increasing its aesthetic appeal.
Introduction
Dance is often performed to music (Jordan, 2011), and the relationship between sound and movement has been a constant topic of interest for composers and choreographers alike (Cunningham, 1982; De Keersmaeker & Cvejić, 2014; Hagendoorn, 2004). If music and dance are combined, their relationship can be congruent, illustrating or amplifying structural and expressive similarities (Krumhansl & Schenck, 1997), or incongruent with no direct and sometimes even conflicting relationship between auditory and visual information. Cook (2000) refers to music–image relationships where each medium represents a different narrative structure that arises in a sense of collision or contradiction as in contest. In movies, music is considered empathetic if it resembles the rhythm, tone or phrasing of a scene, or unempathetic if it appears indifferent to what is displayed on screen (Chion, 1994). In this context, music is considered to be the composite mix of musical score alongside, ambient sound, dialogue, sound effects, and silence, (Lipscomb & Tulchinsky, 2004). Compared with a long history of research in music perception from both humanities and empirical perspectives, the relationship between movement and sound from a dance perspective has only recently come into focus (Jordan, 2011). At the same time, embodied interactions with music play an increasingly important role in studies of music perception (Leman, Lesaffre, & Maes, 2017), including the cultural practice of embodiment itself (Hinberg, 2017; Van Dyck, Burger, & Orlandatou, 2017). In this study, we examine the role of movement and sound congruency during aesthetic perception of contemporary dance and relate our findings to a prominent model of audiovisual integration in the arts, the congruence-association model (CAM).
The CAM focuses on two analytic processes in audiovisual engagement; temporal structure on the one hand, and the corresponding associated meaning on the other hand (Cohen, 2013a, 2013b; Marshall & Cohen, 1988). Temporal structure refers to how visual and auditory patterns change across time and space. Cohen (2016) argues that structural congruencies between the auditory and visual streams of movies direct attention to particular elements of the visual stream, and that these congruencies emphasize specific aspects of the narrative. Previous studies found that more congruent soundtracks enhance absorption in the movie (Cohen, MacMillan, & Drew, 2006) and engagement with the narrative (Cohen & Siau, 2008). Audiovisual congruency also influences the meaning of a movie on an aggressive-friendly dimension (Bolivar, Cohen, & Fentress, 1994). These studies show that structural and expressive congruency between audio and visual streams heightens spectators experience of movies, such influence however will also depend on meaningfulness of audio and visual streams, that is, speech sounds versus music (Cohen, 2013a, 2013b).
Audiovisual congruency of movement and sound is central to dance and choreography. For example, Krumhansl and Schenck (1997) demonstrated that people experience expressive similarities between music and dance, if dance movements are choreographed to a specific musical score. All three experimental conditions—music and dance, dance only, and music only recordings of a choreography by George Balanchine to a Mozart Divertimento—were rated very similarly across a range of emotion dimensions. Another study demonstrated that audiences can detect a “match” between dance choreography and music that are intended go together, when asked to select from three pieces of music, even when the music and dance pieces are presented seperately (Mitchell & Gallaher, 2001). Moreover, meter perception in dance choreography can be disrupted by a competing musical meter, and this effect is even stronger when a well-known choreography is used, such as the popular dance to Gangnam Style (Lee, Barrett, Kim, Lim, & Lee, 2015). Together, these studies show that audiovisual congruency indeed contributes to dance perception.
Congruent choreomusic parallels such as intertwining rhythms of movement and music are a common feature of contemporary dance and choreography (Jordan, 2011). Yet, postdramatic forms of dance and choreography (Lehmann, 2006) also apply incongruent movement/sound relationships that appear unconnected and do not exhibit any obvious or intended choreomusical parallels, that is, in the collaborations between choreographer Merce Cunningham and composer John Cage (Cunningham & Lesschaeve, 1985). Incongruence of musical and movement features arguably encourages to divide attention between visual and auditory streams of information (Fogelsanger & Afanador, 2006). Yet from an audience perspective, perceiving deliberate incongruencies or unconnectedness may be difficult to achieve. Intended or unintended, the mere presence of a soundtrack will likely influence how dance movements are perceived and interpreted. Accordingly, visual and auditory congruency may still occur incidentally, in line with gestalt principles of perception (Arnheim, 1974). In effect, this can lead to a sense of aesthetic capture or driving, where one element affects how the other element is perceived (Mitchell & Gallaher, 2001).
One of the first studies to examine the role of audiovisual congruency in aesthetic perception of live dance combined a qualitative approach with functional magnetic resonance imaging (Reason, Jola, Kay, Reynolds, Kauppi, Grobras, et al., 2016). Reason and colleagues (2016) compared qualitative aesthetic reactions with a live dance performance, performed 3 times, in the presence of three different soundtracks; Bach’s concerto for Oboe and Violin in C, the sound of breathing and footfalls without music, and electronic music. While Reason and colleagues (2016) expected each soundtrack to lead to a different interpretation by the audience, they did not find any differences between the two music conditions. However, they found that the novice audience members did not like the condition with the breathing soundtrack due to a heightened sense of physical presence that was perceived as unpleasant by some spectators. The authors interpreted this result as evidence for a stronger embodied response if the dancers breathing sounds were audible (Jola, Pollick, & Calvo-Merino, 2014; Reason et al., 2016). In line with the concept of kinaesthetic empathy, which suggests that increased bodily awareness operates as a mediator for aesthetic experience, due to a shift from primarily visual engagement to a proprioceptive body-to-body experience. However, completely different soundtracks were used for each condition, so it is possible that spectators preferred specific soundtracks rather than specific relationships between movement and soundtrack. To examine the role of audiovisual congruency in dance perception, it is essential to use identical soundtracks and only manipulate the temporal relationship between movement and sound.
In this experiment, we examine how congruency between sound and movement impacts on the aesthetic appreciation of contemporary dance videos. Importantly, we manipulate audiovisual congruency using a single soundtrack, thus matching both sound conditions for lower level sound features. In the congruent condition, movement and sound were presented as recorded; in the incongruent condition, the soundtrack was played in reverse. Congruency of movement and sound might either enhance or reduce audience engagement with the dance video. Congruency may be preferred, as it emphasizes expressive structural features across visual and auditory domains (Krumhansl & Schenck, 1997). Alternatively, incongruency may lead to a sense of aesthetic capture, ambiguity, and surprise that is potentially enjoyable (Fogelsanger & Afanador, 2006; Mitchell & Gallaher, 2001). Accordingly, the aesthetics of movement–sound congruency allow to empirically test the applicability of the CAM model to contemporary dance.
Method
Participants
Thirty-four participants (9 male, 25 female) ranging in age from 18 to 51 years (M = 27.41; SD = 7.3), volunteered to take part. Musicality ranged from 48 to 100 (M = 74.71; SD = 17.85) on the Goldsmiths Musical Sophistication Index (GMSI) v1.0 Musicality Scale. Musicality involves a wide range of musical behaviors and musical engagement such as understanding and evaluation (Müllensiefen, Gingras, Musil, & Stewart, 2014). The GMSI is a standardized instrument that provides a measure of musicality in the general population, which ranges from 18 to 126 with an average score of 81.58 (SD = 20.62) across the general population (Müllensiefen et al., 2014). Dance experience was assessed using a custom-made questionnaire, which asked people how many years dance experience they had, and how often they watched recorded dance. Fifty-three percent of participants reported previous formal dance training, but none were professional dancers, see Table 1 for a demographic breakdown by experimental group. Participants volunteered in response to a Goldsmiths participation page on Facebook, and all participants signed a written consent form before taking part in the experiment. Participants were signed up to experimental groups based on their availability; allocation of experimental group to condition was randomized using numbered sealed envelopes containing randomization cards for the congruent, incongruent, or silent conditions. The groups included 10, 14, and 10 participants in the congruent, silent, and incongruent groups, respectively. All participants were included in the physiological and qualitative analyses; however, the tablet data of eight participants were lost due to technical problems, leaving only 8, 10, and 8 in the congruent, silent, and incongruent groups for the enjoyment analyses.
Demographics.

Note. SD = standard deviation; M = mean; GMSI = Goldsmiths Musical Sophistication Index.
aNo distinction was made in terms of the type of dance watched, be it contemporary or otherwise.
Materials
Dance Performance Video
A full-length video recording of Matthias Sperling’s choreography “Group Study,” (https://www.youtube.com/playlist?list=PLDAYdl_CLkZj2qWBDkxx Vug4c5HQmCiB1) with a running time of 33 minutes 54 seconds, was used as the basis for the three audiovisual conditions. A full-length presentation was used to enhance the ecological validity of the study in line with previous recommendations (Jola & Christensen, 2015). The perspective and point of view were identical in all three videos; there was no visual difference in the dance videos presented to the groups, and only the soundtrack was altered to allow for a controlled comparison. This performative work for 10 performers was initially developed in the context of research on aesthetic perception of movement synchrony in dance (Vicary, Sperling, von Zimmermann, Richardson, & Orgs, 2017). The choreography was based on a contemporary dance style that consisted of a series of rule-based improvised group movement tasks. Rather than specifying a fixed movement sequence, the choreographic score specifies dynamic relationships between performers and is based on a pedestrian movement vocabulary consisting of walking, running, and falling movements, often associated with postmodern performing dance (Dempster, 2008). Familiarity with a movement vocabulary is an important predictor of aesthetic judgment (Kirsch, Drommelschmidt, & Cross, 2013; Orgs, Hagura, & Haggard, 2013). Using a pedestrian movement vocabulary therefore allows to control for movement vocabulary across spectators (Orgs, Dombrowski, Heil, & Jansen-Osmann, 2008). In addition to the rhythmical sounds associated with these movements, the score specified vocalizations by the dancers with a similar, rule-based structure. The dance performance did not include any music. In the congruent condition, performer movement and sounds were presented as recorded. These sounds included breathing, humming, counting, and running noises, which were rhythmic for some parts of the dance. The reversed soundtrack played the end of the soundtrack first, and all the corresponding sounds were played backward in reverse order, to disrupt the temporal congruency of the music and dance presentation. Congruent and incongruent conditions were thus matched for lower level acoustic features but only differed with respect to the correct alignment of performers sounds to performer movement. The silent condition was devoid of any sound, with the original soundtrack muted.
Continuous Measures of Dance Movement, Audience Engagement, and Arousal
To account for the dynamic experience of the performing arts (Orgs, Caspersen, & Haggard, 2016; Vicary et al., 2017), we used continuous rather than discrete measures to capture audience enjoyment of the entire performance rather than short excerpts, which would potentially eliminate important dramaturgical cues. We used tablet computers and wrist sensors to collect these continuous measures and applied agreement analysis and Granger Causality (GC) time series analysis (Dean & Bailes, 2010; Dean & Dunsmuir, 2015; Granger, 1969; Schubert, Vincs, & Stevens, 2013; Stevens et al., 2009).
Aesthetic perception of the dance video was tracked with respect to three continuous variables, synchrony of the dancers, overall movement acceleration of the dancers, and the spectral power of the soundtrack. Performed synchrony was calculated by applying crossrecurrence quantification analysis to the nonwindowed acceleration vectors to obtain a continuous measure of synchrony among performers across time using identical methodology to the procedure outlined by Vicary and colleagues (2017). Movement of the performers was based on the acceleration series extracted from the wrist sensors of each of the 10 performers. The magnitude of acceleration was then calculated from the three-axis acceleration data, by taking the square root of the sum of squared x, y, and z values, leaving a single time series vector for each performer, with greater values indicating increased acceleration. The spectral power of the soundtrack at each time point was analyzed using the miraudio toolbox for MATLAB (Lartillot, Toiviainen, & Eerola, 2008). All measures were computed in nonoverlapping time windows with a length of 2 seconds.
Asus tablets with a pixel display of 800 × 1,280, running the android version of “OpenSesame” experiment software based on Python script (Mathôt, Schreij, & Theeuwes, 2012), were used to collect continuous enjoyment ratings. This was done using a custom finger-tracking application which was programmed to continuously collect the location of the participants index finger on the touch screen. The touch screen displayed a single axis ranging from enjoyed very little to enjoyed very much, with white text on a black background (see Figure 1(c)), as a measure of the spectator’s enjoyment of the recorded dance video over time. The numerical range for the enjoyment data was reflected in the number of pixels on the screen and ranged from +400 for liked very much to −400 for liked very little; however, these numerical values were never visible or made known to the spectators. Enjoyment data were collected at a rate of 25 samples per second.

Experimental apparatus. (a) Empatica E4 wristband worn by each member of the audience to measure electrodermal activity and heart rate while watching the dance performance. (b) A still image from the contemporary dance performance “group study.” (c) Axis used to collect continuous enjoyment measures ranging from “enjoyed very little” to “enjoyed very much.”
Ten Empatica E4 wristbands (Empatica, 2015; Garbarino, Lai, Bender, Picard, & Tognetti, 2014; see Figure 1(a)) were used to collect the physiological variables of heart rate (HR) and electrodermal activity (EDA) from the audience. HR data were collected at 1 Hz, and EDA was collected at 4 Hz. Together HR and EDA can be used as direct measures of physiological arousal and are regularly interpreted as indirect measures of spectator engagement (Potter & Bolls, 2012). Acceleration was also collected by the sensors at a rate of 32 Hz but was only used to align the start and end times of the data sets, from the sensors and was not used in further analyses.
Qualitative Analysis of Spectator Engagement
Using the same tablet computers, we also collected qualitative data at the end of the experiment. The open question asked participants to: Please use the space below to leave any comments that you have about the performance (e.g., what you liked/disliked the most, something strange you noticed, etc.) or your experience during the session (e.g., if you couldn’t hear the performance or you were distracted); and a blank box was provided to allow participants to write whatever they wished. The spectator’s comments were analyzed using summative content analysis (Hsieh & Shannon, 2005).
Experimental Procedure
All three dance videos were shown in a large dimly lit lecture theatre with tiered seating in order to approximate the context of a live performance in a theatre setting (Jola & Christensen, 2015). All members of each experimental group watched the recorded dance performance together, and each group only watched one dance performance. The three conditions consisted of the dance choreography described earlier with the congruent soundtrack in which the sounds and movements were not altered, the incongruent soundtrack, or no soundtrack. As participants arrived, they were shown to a seat and asked to complete the written consent form, the GMSI (Müllensiefen et al., 2014) and the dance experience questionnaire. Participants were seated adjacent to each other in rows of three or four participants. Once seated, participants were equipped with a wrist sensor on their left wrist and instructed to keep that arm as still as possible to minimize movement artifacts (Picard, Fedor, & Ayzenberg, 2015). Next participants were each given an Asus tablet running the finger-tracking application (open sesame) to record continuous aesthetic ratings. Participants were instructed to move their finger toward the top of the screen if they were enjoying the performance and to move their finger toward the bottom of the screen if they were not enjoying their performance. Participants were given an opportunity to practice using the continuous rating scale in a demo version of the experiment, directly before the performance started. Following a short practice session using the app, participants were asked to focus on the performance and avoid looking at the tablet. Then, participants were asked to read a piece of information about the performance and choreographic style, written by the choreographer before watching the video stimuli to increase their understanding of the piece. The information about the dance film outlined that performers decided what movements to make themselves according to a set of instructions given by the choreographer, producing a unique combination of movements each time. Participants then watched the entire performance video without further interruption. As soon as the performance ended, all participants answered a written open-ended question assessing their summative aesthetic judgment. The open question asked participants to “Please use the space below to leave any comments that you have about the performance (e.g., what you liked/disliked the most, something strange you noticed, etc.) or your experience during the session (e.g., if you couldn’t hear the performance or you were distracted)”; and a blank box was provided to allow participants to write whatever they wished. Participants were debriefed at the end of the experimental session.
Time Series Analyses
Temporal alignment
From each participant, we recorded three time series, continuous enjoyment ratings, HR, and EDA. To align time series data across participants, all sensors were shaken at the beginning of the experiment. The resulting acceleration signal was then used as the reference signal. MATLAB was then used to count the number of UNIX time points between the reference signal and the timestamp that indicated the start of the performance, and each participant’s data were shifted accordingly. The same process was applied to HR, EDA, and enjoyment data. The number of points was adjusted to take into account the sampling rate of each variable, as HR data were collected at one sample per second and EDA was collected at four samples per second, EDA was shifted by 4 times more points than HR.
Downsampling
Granger causality analysis requires stationary time series with identical sampling rates. All time series were therefore resampled at 2 Hz, assuming that aesthetic judgments and physiological responses respond within seconds. The two second time frame is consistent with information sampling periods in the context of aesthetic appreciation of music (Lindsen, Moonga, Shimojo, & Bhattacharya, 2011). The collected time points were sorted into 1,018 bins for each variable and the average of the data points in each bin was used for each time point (see Appendix for corresponding MATLAB script). Finally, the first 5 minutes of the performance were removed to allow for the audience to settle, and the last 5 minutes were removed as this is when the performers started leaving the stage, preventing a computation of synchrony across all performers (Vicary et al., 2017). This corresponded to the first and last 150 data points. In the end, 718 data points for each variable, for each participant were included, corresponding to 24 minutes of dance performance at a rate of one sample every 2 seconds, for the three dependent variables of enjoyment, EDA, and HR.
Granger causality analyses
A variable X Granger causes Y if past values of X help to predict Y, above and beyond the information contained in Y alone (Seth, 2007; Granger, 1969). Unlike standard correlations or regression analysis, Granger causality is more robust as it controls for the risk of autocorrelation and allows to assess the temporal order of observed effects, that is, whether changes in Y precede or follow changes in X. Granger causality was calculated using a bivariate Granger causality R software package, which mathematically accounts for potential autocorrelation (Wessa, 2013). An ARX (AutoRegression with one variable treated as the eXogeneous predictor) model was used with features of the video treated as the exogenous predictors, indicating that the features of the videos could influence physiological arousal or aesthetic judgment in a one-way interaction. A one-way ARX model was considered appropriate in this context because only one interaction was possible; the features of the video can impact audience responses, but audience responses cannot impact video features (Vicary et al., 2017). To meet the necessary assumption of stationarity and linearity, each data set was plotted to check for stationarity of the mean. Where an upward or downward trend was observed, data sets were transformed using Box–Cox transformations based on Box–Cox normality plots for each data set (Wessa, 2016). Following this, the stationarity of the mean level was checked using the autocorrelation function and 1.96 standard deviations from the correlation coefficient as the threshold for stationarity (Dean & Dunsmuir, 2015). Where data were observed to be stationary, no differencing was performed. Where a linear trend was observed, first-order differencing was implemented, and where a quadratic trend was observed, second-order differencing was implemented according to the differencing equation by Box and Jenkins (1976). In line with Vicary et al. (2017), we computed unidirectional Granger causality at temporal lags between 2 and 10 seconds. For each condition, bivariate Granger causality analyses were conducted to see whether performed synchrony, visual change predicted HR, EDA, or enjoyment. In addition, for the congruent and incongruent sound conditions, Granger causality analysis was used to see whether the spectral centroid of the soundtrack predicted HR, EDA, or enjoyment.
Results
We report analyses of overall aesthetic judgments and spectator agreement, followed by Granger causality analyses and qualitative analyses of the open-ended questionnaire.
Enjoyment
On average, people disliked the congruent and silent conditions which had mean enjoyment scores of −79.27 (SD = 46.75) and −75.45 (SD = 46.93), respectively. However, aesthetic judgments were on average neutral in the incongruent condition, which had a mean enjoyment score of −4.6 (SD = 1.18), with participants spending more time liking the video with a reversed soundtrack. Level of enjoyment was demonstrated using one sample t-tests, which indicated that group enjoyment scores were significantly different from 0 for the congruent sound, t(717) = −45.44; p < .001, 95% confidence interval (CI) [−79.27, −82.69]; incongruent, t(717) = −3.91; p < .001, 95% CI [−4.91, −6.91], and silent conditions, t(717) = −43.08; p < .001, 95% CI [−75.45, −78.89]. To assess overall differences between performances, the mean enjoyment ratings of all three performances were compared collapsed across time. A one-way analysis of variance showed a main effect of sound condition on enjoyment, F(2, 2151) = 707.8, p < 0.001, η2 = .397. Post hoc Games–Howell tests revealed that enjoyment ratings were significantly higher for the incongruent condition compared with the congruent condition (p < .001, 95% CI [−79, −69]), and the silent condition (p < .001, 95% CI [65.42, 76.09]). No difference found between the congruent and silent conditions (p = .202).
Agreement Analysis
An agreement analysis was performed on the enjoyment data as outlined by Schubert et al., (2013). This involved computing the mean (M1) and SDs (SD1) of group enjoyment ratings for each time point. Then, the mean and standard deviation of SD1 were calculated which resulted in SD2. Higher SD2 values indicate less agreement in the group. The cut-off value was adjusted to 0.5*SD2 above M1, and values below this level were considered points of good agreement. This analysis demonstrated that 67%–72% of all data points occurred within 0.5 standard deviations above the mean of all enjoyment values (congruent: 71.71%; incongruent: 67.41%; and silent: 68.52%, see Figure 2). Overall, these results show that there was good agreement between audience members in each sound condition and that the incongruent sound condition was rated as least unpleasant compared with congruent and silent conditions.
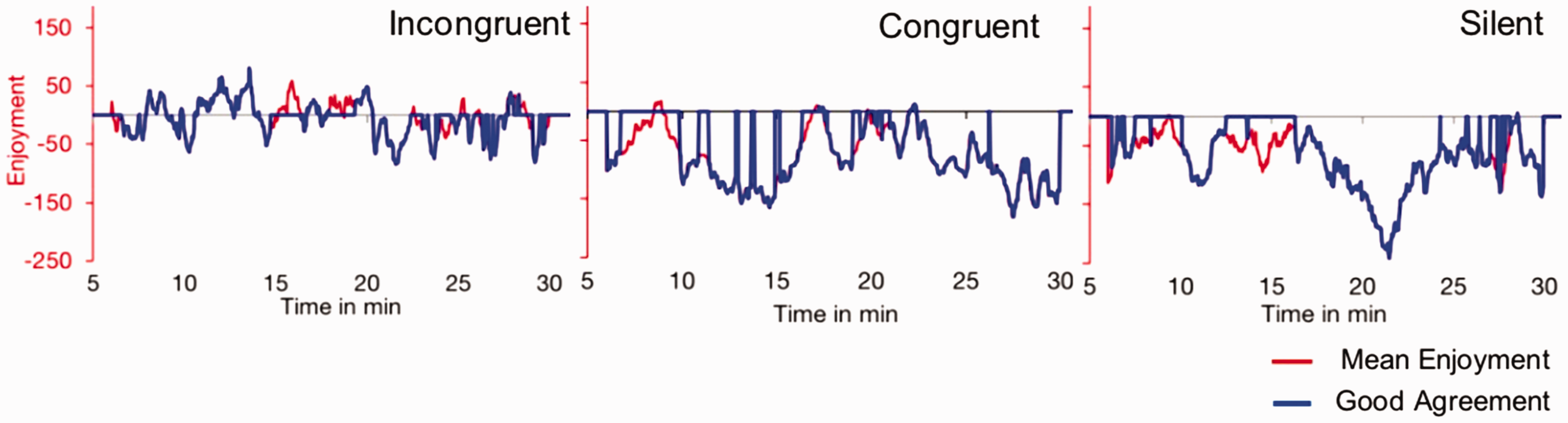
Results of agreement analysis. Mean enjoyment is shown in red. Good agreement is shown in blue; good agreement defined in text. The blue line represents 67.4% of time points in the incongruent condition, 71.1% of time points in the congruent condition, and 68.52% of time points in the silent condition. It also indicates the specific time periods in each condition that the audience had good agreement. The overall mean enjoyment for the incongruent condition was −4.6 (SD = 1.18), the congruent condition was −79.27 (SD = 46.75), and the silent condition was –75.45 (SD = 46.93).
Granger Causality Analysis
As our hypothesis only focused on the impact of video features on immediate audience enjoyment responses, we examined lags of +10 seconds. In addition, the presence of spurious relationships in the data was controlled for by calculating Granger causality between performed synchrony and spectator time series of the same performance and comparing these to Granger causality relationships derived from a mismatched performance. The mismatched performance data were derived from a previous study (Vicary et al., 2017; synchrony of performance 1 or P1) which included three additional performances to the recorded performance displayed in this study, and accordingly corresponding time series data sets. As in our previous study, Granger causality results are only interpreted if they are performance-specific. Granger causality analysis indicated that performer synchrony Granger caused EDA in the incongruent sound condition (F = 4.37, p = .0369; see Figure 3) but not in the silent or congruent conditions. This relationship was both unidirectional and performance specific (all p > .05). No other significant Granger causal relationships were found between any the video features, movement of the performer, or spectral power of the soundtrack and enjoyment, EDA, or HR. Thus, the only significant effect found in the Granger causality analysis was that performed synchrony Granger caused EDA in the incongruent movement and sound condition.
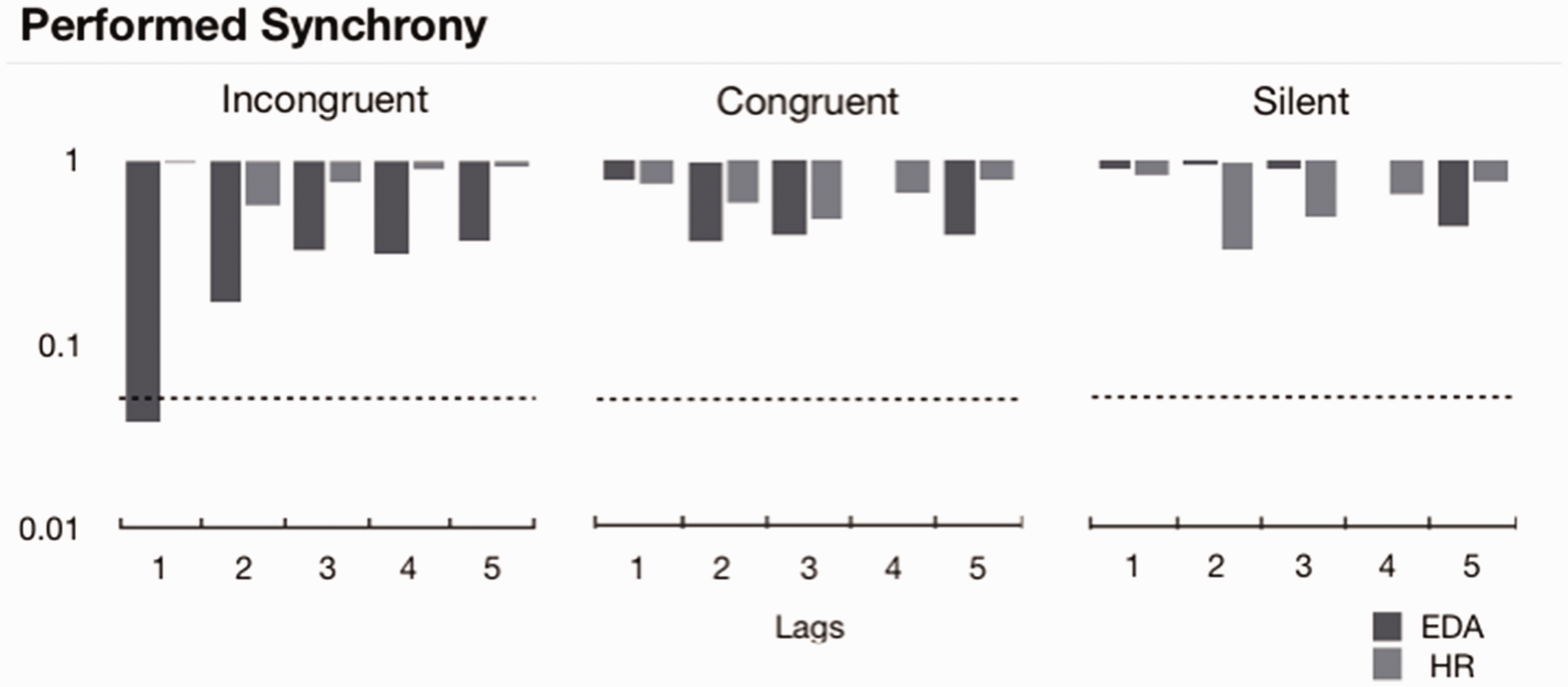
Granger causality results for performed synchrony in each soundtrack condition. Demonstrating significant p < .05 for the relationship between performed synchrony and EDA in the incongruent condition at Lag 1. Also showing the nonsignificant p > .05 for HR in each condition and the relationship between synchrony and EDA in the congruent and silent conditions. The dashed line indicates the significance level of p = .05. HR = heart rate; EDA = electrodermal activity.
Open-Ended Questionnaire
After watching the dance performance, participants were given an optional written questionnaire that asked to: please make a comment, and a majority of participants decided to do so. Although comments tended to be brief, a summative content analysis was performed (see Figure 4) in line with recommendations from Hsieh and Shannon (2005). Several categories were repeated across comments including;

Qualitative themes. Themes identified in participant’s responses to open-ended question, for each experimental condition of congruent, silent, and incongruent.
Repetitive, P2: “Boring. I already have a low attention span. I would never be entertained by something that wasn’t more stimulating.”
Searching for meaning, P3: “I really enjoyed trying to figure out who was the leader/who was following who/what the ‘rules’ were.”
Physical movement, P9: “Liked it the most when there was a lot of movement & when the movement contained a pattern I could decipher. flying guy was funny. really disliked the arm clapping making it seems their arms were broken.”
Sound, P13: “Not hearing even the movements of the dancers was sort of distorting the ‘experience’ of watching this performance: hearing bodies moving, even if there is no music is part of dance and rhythm and I really missed this part.”
P25: “The sounds were kind of unsettling, but occasionally made the performance more interesting, especially when it was congruent with the dancer’s movements.” Note that this participant was in the incongruent group, where the soundtrack and visual stimuli were intended to be incongruent throughout the entire performance.
Patterns, P8: “Spent time looking for patterns or beat couldn’t find either.”
Enjoyable, P19: “I liked when the performers were synchronizing, but when they weren’t I felt confused.”
Unpleasant, P21: “The noise was unpleasant and distracting. The performance at the end was more interesting. The middle bit, when the noise bits were increased was unbearable!”
Discussion
The aim of this study was to explore how changes in the temporal congruency between movement and sound impact aesthetic judgments of recorded contemporary dance, in relation to the CAM (Cohen, 2013a, 2013b; Cohen & Siau, 2008). A secondary aim was to examine whether any change in aesthetic judgment was reflected in spectator arousal. Audience enjoyment was least negative for the incongruent condition, the only experimental conditions that also elicited an EDA response to the synchrony of the performer’s movements. Importantly, sound itself was not predictive of spectator arousal, implying that its influence on arousal was indirect, emphasizing or drawing attention to specific aspects of the dance. In contrast, the congruent and silent conditions that were judged more negatively did not induce any changes in spectator arousal. Thus, group enjoyment increased when the sounds were no longer coupled in time to the actions that produced these sounds. In line with these quantitative findings, qualitative participant reports suggest that participants in the incongruent condition found the presentation less boring than participants in the congruent and silent conditions. It is also worth noting that overall high levels of agreement were found for each audience group, with slightly higher agreement observed in the congruent condition than in the incongruent condition. This indicates that decoupling sound from movement was not only perceived as more enjoyable but might suggest that audience responses became more varied as the unequivocal causal link between sound and movement was replaced by the individual spectator’s idiosyncratic associations between auditory and visual input. Variability of aesthetic judgment increased with greater ambiguity.
Spectators did not enjoy the congruent condition, in line with Reason et al. (2016) who found that participants did not enjoy the sounds of the performer’s movements in the absence of music and even reported a sense of relief when this section of the performance ended. Our findings show that discomfort does not necessarily result from the sounds per se but rather from the sounds being a direct consequence of the performers’ movements. In our study, when the same sounds were temporally decoupled from their movement origin, enjoyment ratings improved. Perhaps, removing the causal, embodied relationship between the performer’s actions and their auditory consequences disrupted the role of kinaesthetic empathy on aesthetic judgments. This would suggest that in this particular study, the auditory channel was prioritized over the kinaesthetic channel as mentioned in recent versions of the CAM. This might suggest hierarchical layers between each channel of audiovisual engagement rather than parallel processing (Cohen, 2016). By removing the causal link between the performer’s actions, the corresponding sounds for each movement were turned into an independent soundtrack that invited spectators to actively search for correspondences between movement and sound. Similar to dancing to music, the performers’ movements do not produce the movements, which seem to align with the incongruent condition. Our findings suggest that nonexpert spectators of dance typically expect musical accompaniment or at least an arbitrary relationship between movement and sound that allows them to search for interesting correspondences and conflicts between auditory and visual content and structure, structuring their attention within the visual continuous stream of dance movement (Cook, 2000). It would be interesting to test whether our findings translate to Tap or Irish dance, where the rhythmical sound of the dancer’s steps is an intrinsic feature of the dance style. Further research in these different contexts may help to resolve these questions.
This study provides tentative evidence that in the context of contemporary dance, perfect congruency between sound and movement may not be desirable, in line with predictions by Fogelsanger and Afanador (2006). However, in line with original models of the CAM, it does seem that this change in aesthetic judgment was not simply a direct response to the soundtrack but occurred as a result of a different viewing pattern. This corresponds with the finding that musical meter influence or disrupt the perceived dance meter (Lee et al., 2015). The less negative aesthetic judgments in the incongruent condition coincided with an EDA response that was not predicted by the soundtrack, but by the visual movements of the performers, despite the fact that the visual movements were identical in all three performances. Therefore, this study lends support to the role of aesthetic capture in contemporary dance, where the music drives visual attention to different physical gestures (Fogelsanger & Afanador, 2006; Mitchell & Gallaher, 2001). In addition, this finding suggests that potentially conflicting media that do not share the same underlying narrative can be perceived as complementary in a contemporary dance performance rather than being perceived as conflicting, contradicting or in contest (Cook, 2000; Fogelsanger & Afanador, 2006). Conceivably, perfect audiovisual congruence conveys a relationship between sound and movement that is too simple, highlighting the importance of ambiguity and remoteness from the habitual in contemporary dance appreciation (Kreitler & Kreitler, 1972) compared with other audiovisual contexts. In this particular study, reversing audiovisual input may have resulted in analogous, accidental audiovisual gestalts, paradoxically heightening the experience of congruency. It seems that in practice, multimodal incongruence is difficult to achieve because each instance of coincident movement and sound can be perceived as a perceptual unity, in line with gestalt principles of perception (Sloboda, 1985). In fact, one participant explicitly reported a sense of congruency in the incongruent condition, and a similar outcome has been reported in the previous studies (Bolivar et al., 1994; Iwamiya, 1994; Lipscomb & Kendall, 1994). Perceived matching between music and dances not intended to go together (Mitchell & Gallaher, 2001) suggests that discovering patterns is an important feature of aesthetic appreciation (Muth & Carbon, 2013). Dance and music may benefit from being relative abstract, allowing people to project their own interpretation or meaning onto the performance.
The main strength of this study is that it examines the empirical evidence for extension of the CAM to contemporary dance settings, which until now was not empirically investigated (Cohen, 2016). This study also successfully employed advanced methodological approaches to the study of aesthetic responses to dance, using continuous enjoyment ratings as well as self-report accounts which gives a more complete picture of enjoyment ratings (Schubert et al., 2013), compared with previous studies that tend to solely rely on post hoc accounts (Kirsch et al., 2013; Reason et al., 2016;). In addition, this study maximized ecological validity by using a full-length dance designed by a choreographer and scientific rigor by using a recorded version which guaranteed that all participants were exposed to identical dance movements (Jola & Christensen, 2015).
However, despite these strengths, the small sample size limits the generalizability of our findings. While the sample in our study was comparable in size to those used in the published literature (Cross, Kirsch, Ticini, & Schütz-Bosbach, 2011; Reason et al., 2016), a replication of our study with a larger sample size is necessary to confirm that structural incongruence between sound and movements is preferred to structural congruency. Another point to note in our results is that aesthetic appreciation was more often negative than positive. This may result from the lack of an immersive live performance context which has been shown to reduce aesthetic responsiveness to watching dance (Jola & Grosbras, 2013), or indeed, it may have arisen from the experimental nature of the performance which does not reflect mainstream styles of dance. Perhaps future studies should include a wider range of spectator experiences, for example, the Sense of Presence Inventory Questionnaire (Lessiter, Freeman, Keogh, & Davidoff, 2001), to deduce the audience level of immersion and how this impacts on aesthetic engagement. Finally, we deliberately focused our analyses on the performance in its entirety rather than specific sections of the performance. Future studies should explicitly manipulate the relationship between audiovisual congruency, specific movement vocabulary, and dramaturgy of the dance performance.
To conclude, this study provides tentative evidence that crossmodal incongruence can be perceived as aesthetically pleasant, increasing ambiguity, and thereby idiosyncratic associations. Our findings are consistent with the idea of aesthetic capture in the audiovisual context of contemporary dance, where the music drives visual attention to different physical gestures (Fogelsanger & Afanador, 2006; Mitchell & Gallaher, 2001). However, replication and extension of our findings to larger samples and using a variety of dance and music styles would be necessary before firmer conclusions can be drawn.
Supplemental Material
Supplemental material for Audiovisual Aesthetics of Sound and Movement in Contemporary Dance
Supplemental Material for Audiovisual Aesthetics of Sound and Movement in Contemporary Dance by Claire Howlin, Staci Vicary and Guido Orgs in Empirical Studies of the Arts
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Economic and Social Research Council.
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.