
Abstract
Objective
Skin cancer diagnosis via automated image analysis remains a challenging task due to poor image contrast, visual similarity among lesion classes, and class imbalance in available datasets. To address these issues, this study proposes a novel Tri Model Dermatology Cancer Neural Network (TriDermCancerNet) for classifying skin cancer from dermoscopic images.
Methods
Two publicly available datasets are used in this work: the International Skin Imaging Collaboration 2018 and 2019 datasets, which contain multiple classes of cancer types. In the proposed model framework, a contrast enhancement technique was applied to improve image quality, followed by data augmentation to balance the datasets. The proposed TriDermCancerNet architecture is designed based on the key challenges of this work, including dataset variability, interclass similarity, and model explainability. The proposed architecture integrates three modules: a 105-layer Inception module, a 186-layer Inverted Bottleneck Residual module, and the Dense-177 module. Each module was integrated into the proposed network in parallel rather than in series. Thereafter, each module was trained, and features were extracted and fused using a depth concatenation approach. During training, several important hyperparameters were selected using Bayesian optimization, and the final model was used for classification in the testing phase.
Results
The fused TriDermCancerNet achieved 98.6% accuracy, 98.6% sensitivity, 98.6% F1-score, and an area under the curve of 1.0 on the International Skin Imaging Collaboration 2018 dataset and 99.7% accuracy, 99.6% sensitivity, 99.6% F1-score, and an area under the curve of 1.0 on the International Skin Imaging Collaboration 2019 dataset. Statistical significance testing confirmed that the fusion model outperforms each branch (p < 0.05).
Conclusion
The proposed hybrid TriDermCancerNet approach enhances the precision and robustness of skin cancer classification frameworks, providing clinicians with a valuable diagnostic aid for early detection.
Keywords
Introduction
Cancer is a disease caused by the uncontrolled proliferation of body cells. 1 Normally, cells divide, grow, and die in a regulated manner, maintaining cellular balance. However, cancer disrupts this regulation, leading to tumor formation or the spread of malignant cells to other parts of the body. 2 The primary cause of cancer is genetic abnormalities that disrupt normal cellular functions, such as cell cycle regulation, DNA repair, and cell signaling pathways. Numerous factors, including genetic predisposition, chronic inflammation, exposure to carcinogens (such as ultraviolet (UV) radiation or tobacco smoke), and environmental influences, can cause these changes. 3 There are more than 100 types of cancer, distinguished by the type of cell first affected. Common forms include prostate, colon, breast, lung, skin, leukemia, lymphoma, ovarian, bladder, pancreatic, kidney, thyroid, brain, and sarcoma tumors. These irregularities in texture, color, or appearance may result from injuries, infection, inflammation, or underlying diseases.4–6
The two major types of skin lesions (SLs) are primary and secondary lesions. Skin cancer is a major health issue and one of the leading causes of cancer-related deaths worldwide. 7 In 2023, skin cancer accounted for 5% of all cancers in the United States 8 and resulted in 7990 deaths. During 2016–2020, the incidence of melanoma (MEL) was estimated at 21 cases per 100,000 residents in the United States, resulting in 1,413,976 deaths. MEL is among the deadliest forms of skin cancer and spreads rapidly.9,10
The 5-year survival rate for cutaneous MEL is 93.5%, and this rate improves with early diagnosis. 11 The 5-year survival rate is even higher with early detection, reaching 99.6%. 12 The accuracy of diagnosing skin cancer using visual clinical examination alone is approximately 60%. Dermoscopy has significantly improved diagnostic accuracy to approximately 89%. The reported sensitivities are 82.6% for melanocytic lesions, 86.5% for squamous cell carcinomas (SCCs), and 98.6% for basal cell carcinomas (BCCs). 13 Despite these advances, certain lesions, especially early-stage MELs, remain difficult to diagnose using different methods, particularly dermoscopy, because they do not always exhibit characteristic or obvious dermoscopic features. Therefore, improved diagnostic accuracy is needed to facilitate early diagnosis and enhance treatment outcomes for patients. 14
Computer-aided detection methods have been developed to improve the reliability of SL classification and overcome existing limitations. 15 Image acquisition, preprocessing, lesion segmentation, feature extraction, and final classification are typical components of a computer-aided skin cancer diagnostic system. 16 Classification is a crucial step in this process. Deep learning (DL) models can automatically extract meaningful and discriminative features from lesion images. Various studies have investigated the application of DL across multiple cancer types and medical conditions. 17 In the context of SL diagnosis, recent investigations have confirmed the effectiveness of DL for accurate classification. 18 DL-based techniques are often more efficient and better suited to learning task-specific patterns directly from data than traditional manual approaches. 19
Various research articles have investigated the application of DL to SL diagnosis. 20 Recent investigations have demonstrated the power of DL in SL classification. For instance, dermoscopy permits high-resolution imaging and visual examination of skin layers, improving diagnostic accuracy by 10%–30%. 21 Despite its effectiveness, dermoscopic diagnosis is limited in accuracy, particularly for early-stage MELs. 20
DL-based SL analysis systems help dermatologists, especially where access to highly skilled dermatologists is limited. These models aim to improve diagnostic accuracy and accelerate decision-making, eventually enabling earlier detection and better outcomes for patients with skin cancer.22,23
In this study, the International Skin Imaging Collaboration (ISIC) 2018 and ISIC 2019 datasets are combined for SL classification. The ISIC 2018 dataset
24
contains seven classes: actinic keratosis (AKK), benign keratosis-like lesion (BKL), dermatofibroma (DF), MEL, BCC, melanocytic nevi (NV), and vascular lesion (VASC), comprising a total of 10,015 images. Similarly, the ISIC 2019 dataset
25
includes eight classes: AKK, BKL, DF, MEL, NV, BCC, SCC, and VASC. For the classification task, three models are utilized: the proposed Tri Model Dermatology Cancer Neural Network (TriDermCancerNet) model. These models are trained on two datasets, and their performance is assessed using several metrics, including accuracy, precision, recall, specificity, F1-score, and area under the receiver operating characteristic (ROC) curve (AUC).
26
The proposed method makes the following key contributions for skin cancer detection:
In this case, the proposed method develops a two-layered sub-image contrast enhancement algorithm to improve the quality of dermatoscopic images and enable the identification of additional features in the ISIC 2018 and ISIC 2019 datasets. Three specialized and separate network structures (105 layers in Inception model, 186 layers in the Inverted Bottleneck Residual model, and 177 layers in the Dense model) representing different feature representations are incorporated into the proposed hybrid method, TriDermCancerNet. By combining the feature vectors of the three models, a hybrid feature representation is created that integrates their strengths. The resulting combination increases the model's discriminatory power and classification accuracy. The Inception architecture with 105 layers achieved 95.8% accuracy on the ISIC 2018 dataset, and the Inverted Bottleneck Residual architecture with 186 layers achieved 99.5% accuracy on the ISIC 2019 dataset (experimental results). The combination of the three models achieved 98.6% and 99.7% accuracy on ISIC 2018 and ISIC 2019, respectively. The Dense-177 model achieved 95.7% and 99.4% accuracy on ISIC 2018 and ISIC 2019, respectively.
The proposed “TriDermCancerNet” is not novel in its individual building blocks but rather in how they are designed to address specific issues in dermoscopic image classification. Although Inception-, Inverted Bottleneck Residual-, and DenseNet-type architectures have been used separately in the literature, no previous studies have used a true parallel tri-branch design with depth-concatenation-based feature fusion, where each branch has a different layer depth (105, 186, and 177 layers, respectively) and is trained separately before fusion. This architecture is intentional: the Inception branch learns multi-scale local features via parallel convolutions; the Inverted Bottleneck Residual branch learns channel-wise representations via lightweight grouped convolutions; and the Dense-177 branch learns feature reuse via dense connectivity, enabling long-range dependencies. In contrast to current ensemble approaches, which integrate model outputs at the decision level, TriDermCancerNet fuses features at the feature level via depth concatenation, maintaining spatial and channel-wise complementarity before classification. This approach differs from sequential hybrid models or simple ensemble voting strategies reported in other studies. Hyperparameter tuning is also performed using Bayesian optimization to ensure consistent convergence across all three branches. These design choices, including the parallel tri-branch design, independent branch training, feature-level depth concatenation, and Bayesian hyperparameter optimization, constitute the primary methodological novelty of this work.
The rest of this article is organized as follows. The Literature review section provides an overview of DL methods for SL classification and identifies remaining research gaps. The Methodology section describes the proposed TriDermCancerNet approach for SL classification. The Experimental results and Discussion sections present and analyze the study findings. Finally, the conclusions and contributions of the study are presented.
Literature review
This section enables efficient analysis and retrieval of data by organizing it into predefined categories within a specific application area. 23 To improve feature representation and classification performance, Ozdemir et al. 22 implemented a hybrid DL architecture combining ConvNeXtV2 blocks with separate self-attention mechanisms. The ISIC 2019 dataset, which includes eight different SL classes, was used to train and evaluate their model. Data augmentation and transfer learning techniques were employed to improve generalization. Under comparable experimental conditions, the proposed approach outperformed more than 10 convolutional neural network (CNN)-based models and more than 10 Vision Transformer (ViT)-based models, achieving an accuracy of 93.48%, with accuracy, retrieval, and F1 scores of 93.24%, 90.70%, and 91.82%, respectively. Shakya et al. 27 explored the adoption of DL-based methods for skin cancer image classification. They applied preprocessing and segmentation (via active contour) on the ISIC 2018 dataset, consisting of 3300 images, with an 80/20 train–test split. Among the tested methods, the best results were obtained by combining ResNet-18 and MobileNet as feature extractors with a support vector machine (SVM) classifier, achieving an accuracy of 92.87%. Pacal et al. 28 proposed a hybrid model that employed focal self-attention instead of traditional self-attention to improve feature extraction and diagnostic accuracy. The model was evaluated on the ISIC 2019 dataset (eight skin cancer classes) and the HAM10000 dataset. It achieved 92.54% accuracy on ISIC 2019 and 95.01% accuracy on HAM10000, outperforming 10 CNN models and 20 ViT models under the same conditions. Naeem et al. 29 proposed SkinDWNet, a DL model built with depth-wise dilated convolutions (DDCs) and feature reuse residual blocks (FRBs) for multiclass skin cancer classification. Gradient boosting (GB) was applied on extracted features, and the SMOTE-Tomek method was used to address class imbalance in the ISIC 2019 dataset. The SkinDWNet + GB model outperformed six established DL models and other methods, achieving an accuracy of 97.04%. To enhance feature diversity and generalization, Thirugnanam et al. 30 designed EffSCLNet, which uses a sparse prediction layer (SPL) CNN for classification and EfficientNetB0 for feature extraction. Artifact removal was performed using morphological opening, non-local means denoising (NLMD)-based image enhancement, and encoder–decoder segmentation. The model obtained accuracies of 98.54% on ISIC 2019, 99.38% on HAM10000, and 98.61% on PH2. To classify SLs, Amin et al. 31 presented a compact convolutional transformer model (CCTM) that combines folding layers and transformer blocks with optimized hyperparameters. The model was evaluated using six reference datasets: MED-NODE, PH2, ISIC 2019, ISIC 2020, HAM10000, and DermNet. The model's accuracy was above 98% on each dataset. To diagnose skin diseases using a few case studies, Noman et al. 32 proposed SEN-GAT (Synergistic Node-Edge Graph Attention Network), which models node–edge dependencies via an attention mechanism for meta-learning. The model outperformed state-of-the-art methods, achieving diagnostic accuracies of 96.30%, 89.33%, and 84.53% on the SD-198, Derm7pt, and ISIC 2018 datasets, respectively. Using the ISIC 2018 dataset, Ieracitano et al. 33 developed a refined classifier based on EfficientNetB0 to differentiate between MELs, nevi, and seborrheic keratosis. They also proposed a new reliability classification for explainable artificial intelligence (TIxAI) to assess classifier reliability. The model demonstrated strong classification performance, achieving an accuracy of 87.57%. Wang et al. 34 used MobileNet-V2 as a base model and a RICA (residual interference coordinate attention) block to improve feature extraction and proposed a resource-efficient CNN model for categorizing SLs. With a small size of only 3.32 MB, the model achieved accuracies of 89.52% and 93.24% on the ISIC 2018 and ISIC 2019 datasets, respectively. Houssein et al. presented a deep CNN (DCNN) for classifying skin cancer 35 and tested it using the ISIC 2019 and HAM10000 datasets. The model was compared with transfer learning models such as VGG16, VGG19, DenseNet121, DenseNet201, and MobileNetV2, achieving the highest accuracy of 98.5% on HAM10000 and 97.1% on ISIC 2019, thereby outperforming the other models. Several studies, including Gouda et al., 36 Shah et al., 37 Mahbod et al., 38 and Al-Masni et al., 39 also used the ISIC 2018 dataset and reported improved accuracy. In addition, studies such as Benyahia et al., 40 Villa-Pulgarin et al., 41 Kaur et al., 42 Bhardwaj et al., 43 and Ahmed et al. 44 designed DL models and evaluated them using the ISIC 2019 dataset. These studies reported improved accuracy and precision using the proposed techniques.
More recent innovations have advanced the classification of SL by integrating ViTs, hybrid CNN–Transformer models, and self-supervised learning (SSL). Dogga et al. 45 introduced a hybrid ViT–graph neural network (GNN) model that incorporates region-adaptive attention, improving lesion localization through graph-based feature aggregation. Correspondingly, an EViT-DenseNet169 hybrid model that combines improved ViTs with DenseNet169 was tested on the ISIC 2018 dataset and achieved 97.1% accuracy by combining global and local fine-grained features. 46 To diagnose MEL, a U-Net with Inception-ResNet-v2 and a ViT self-attention mechanism was trained on the ISIC 2018 dataset and demonstrated the usefulness of hybrid segmentation–classification pipelines. 47 Wang et al. 48 introduced an SSL-based multimodal, multilabel SL classification framework that is less reliant on large annotated datasets while still achieving competitive classification performance. For explainability, DermaScanAI 49 proposed a dual-attention hybrid model with integrated Gradient-weighted Class Activation Mapping (Grad-CAM) visualization, demonstrating that explainability and high accuracy can be achieved simultaneously. These recent studies confirm a strong research trend toward integrating global and local feature learning with explainability, which underpins the design decisions in TriDermCancerNet.
In summary, the above techniques focused on DL models, network combinations, and residual architectures to improve skin cancer classification accuracy. However, these methods often overlook the importance of features that can be captured by fusing local and global information from different models, such as Dense and Inception modules with distinct depths and filter sizes. In this work, we designed a new DL model for classifying skin cancer from dermoscopic images by fusing local and global patterns from Inception and Dense blocks in different parallel configurations.
Methodology
To enhance image contrast in the ISIC 2018 and ISIC 2019 datasets, the TriDermCancerNet methodology uses histogram balancing, brightness preservation, dualistic sub-imaging, and haze removal. Left-right mirroring and 90-degree rotation methods for data augmentation facilitate homogeneous class representations and reduce imbalance. Then, the optimized data are trained using three independent models. The TriDermCancerNet approach to SL classification is based on the 177-layer Dense model, the 105-layer Inception model, and the 186-layer Inverted Bottleneck Residual architecture. The 105-layer Inception model provides a reasonable balance between computational performance and portability. The framework enables efficient gradient propagation during training by incorporating design elements such as residual connections and advanced normalization methods. This provides stability in optimization and faster convergence. The model contains 8.7 million trainable parameters spread across 105 layers. A detailed architecture is shown in Figure 1.
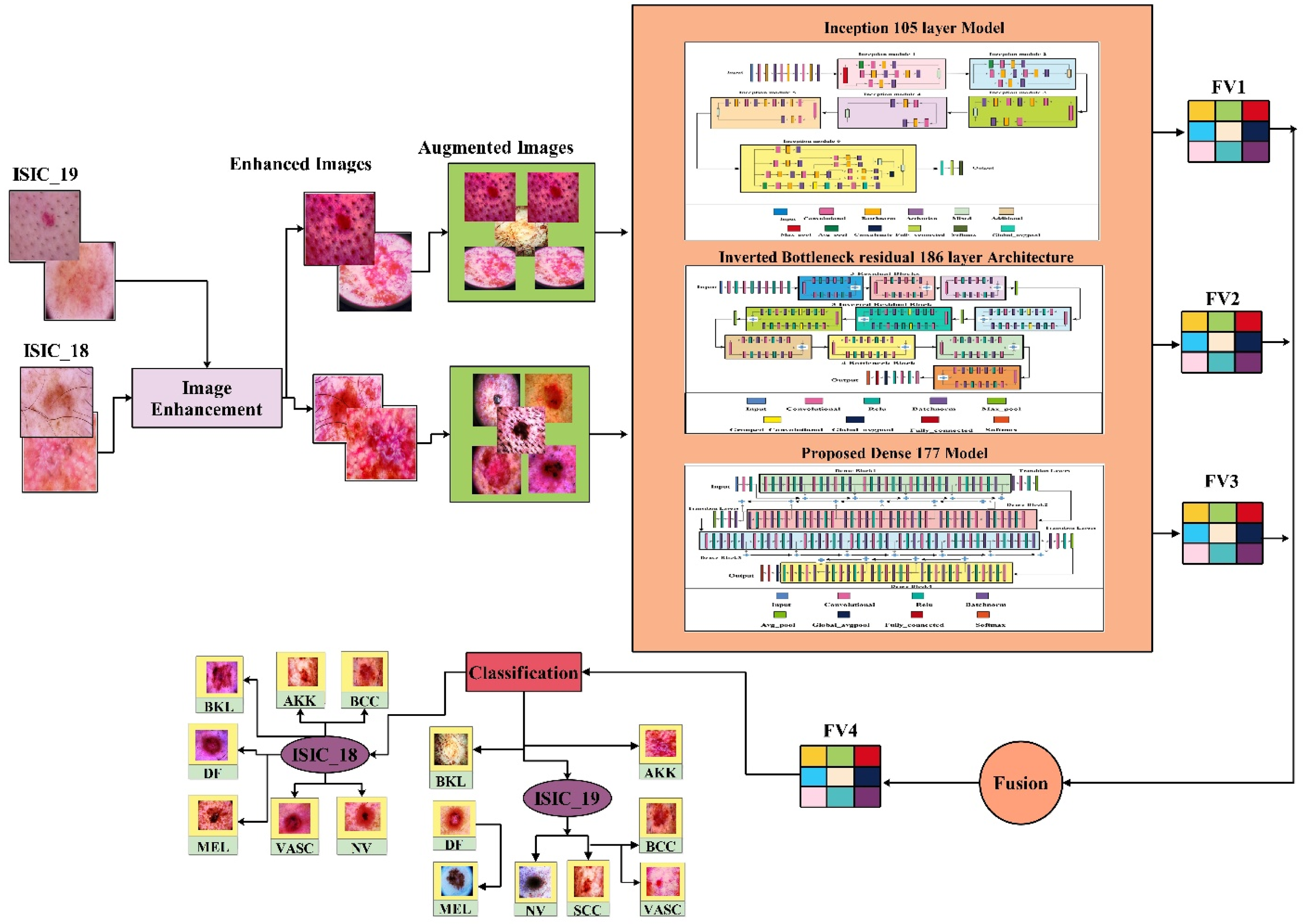
Overview of the proposed TriDermCancerNet framework for skin lesion classification. The pipeline includes contrast enhancement of input dermoscopic images, followed by data augmentation, parallel feature extraction via three independent deep learning modules (Inception-105, Inverted Bottleneck Residual-186, and Dense-177), depth-concatenated feature fusion, and final classification using a Cubic SVM classifier.
There are 30 convolutional layers with 3 × 3 filters applied both within the blocks and in the outer parts. The filter range is 32–512. The filter size is 1 × 1 both inside and outside the blocks. To reduce internal covariate shifts, stabilize the training process, normalize input distributions, and enable faster convergence with higher learning rates, 29 batch normalization layers are also integrated.
Additionally, 29 rectified linear unit (ReLU) activation layers are used to set negative input values to 0, thereby introducing nonlinearity. A single max-pooling layer is used to downsample the input. The architecture includes six mixed layers that implement the Inception design, consisting of parallel convolutional operations with varying kernel sizes followed by concatenation. These layers enhance the network's ability to capture multiscale features, which is particularly advantageous for image recognition tasks. Moreover, an additional layer and a depth concatenation layer further increase the network's representational capacity, enabling the extraction of intricate patterns and complex representations. After that, an average pooling layer reduces spatial dimensions by computing the average value over a specified region. A fully connected layer integrates features learned by earlier layers to make classification decisions by mapping features to output classes. A softmax layer converts raw output scores into probability distributions, ensuring calibrated and interpretable predictions across all classes. The 105-layer Inception architecture is shown in Figure 2.
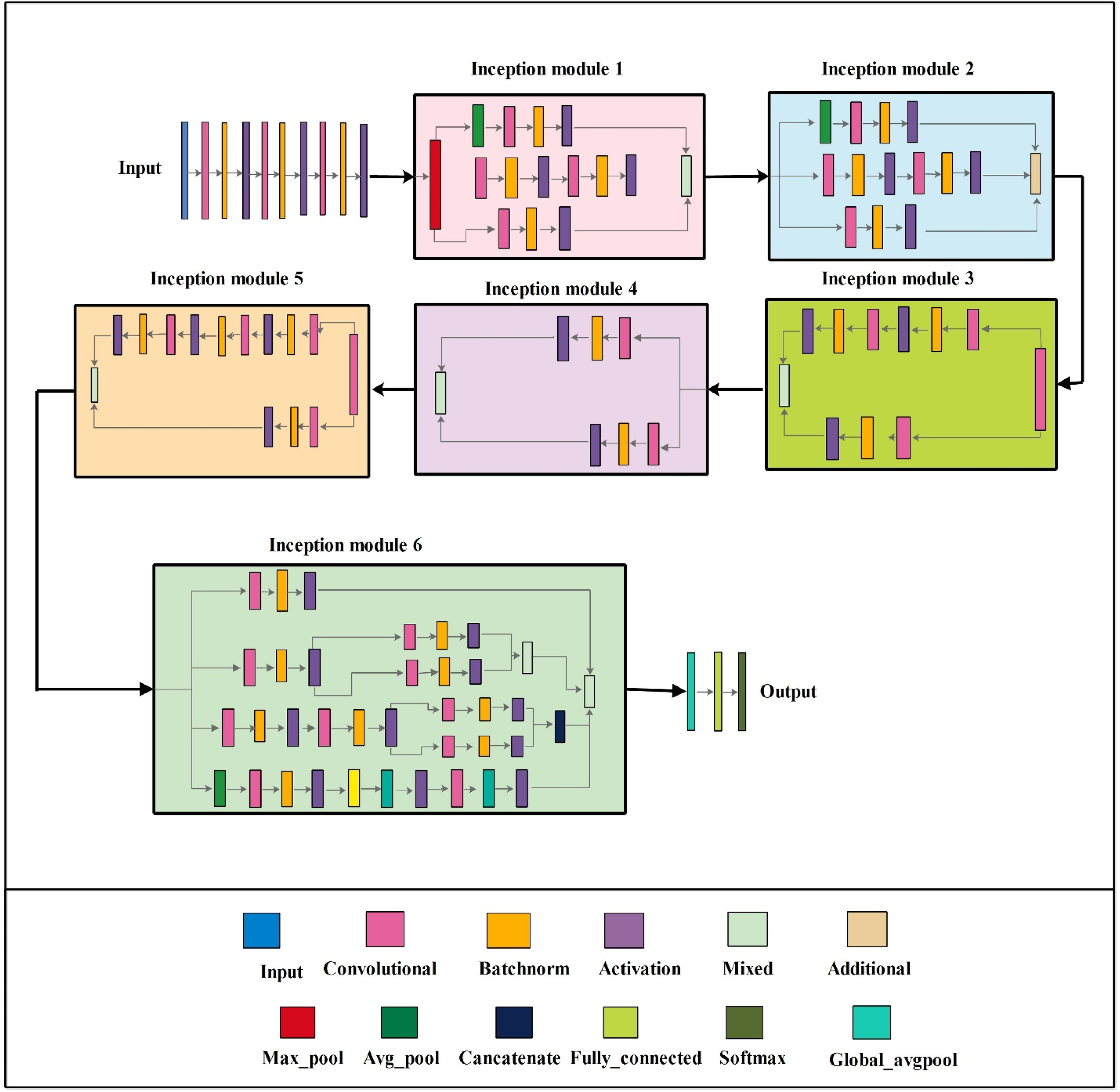
Architecture of the proposed 105-layer Inception module. The network consists of 30 convolutional layers, 29 batch normalization layers, 29 ReLU activation layers, 6 mixed inception blocks enabling multi-scale feature extraction, 1 max-pooling layer, 1 average pooling layer, and a fully connected layer with SoftMax output—total trainable parameters: 8.7 million.
The Inverted Bottleneck Residual 186-layer architecture has 186 layers with 33.3 million learnable parameters (shown in Figure 3). It is constructed by connecting 10 layers in series, including convolutional, ReLU, and batch normalization layers. Three residual blocks are interconnected using additional layers. Each residual block uses a 1 × 1 stride and maintains a consistent number of filters between the initial and final convolutional layers. Three inverted residual blocks are used, each with two-dimensional (2D) grouped convolutional layers. These joint convolutions enhance computational efficiency by sharing parameters across channels and enabling the learning of diverse features. Four bottleneck blocks are then added. All blocks have a single 1 × 1 convolution, followed by a 3 × 3 convolution, and finally a 1 × 1 convolution. In addition, the bottleneck blocks use a 1 × 1 step to maintain a uniform number of filters. Figure 3 illustrates the 186-layer architecture of the Inverted Bottleneck Residual network.
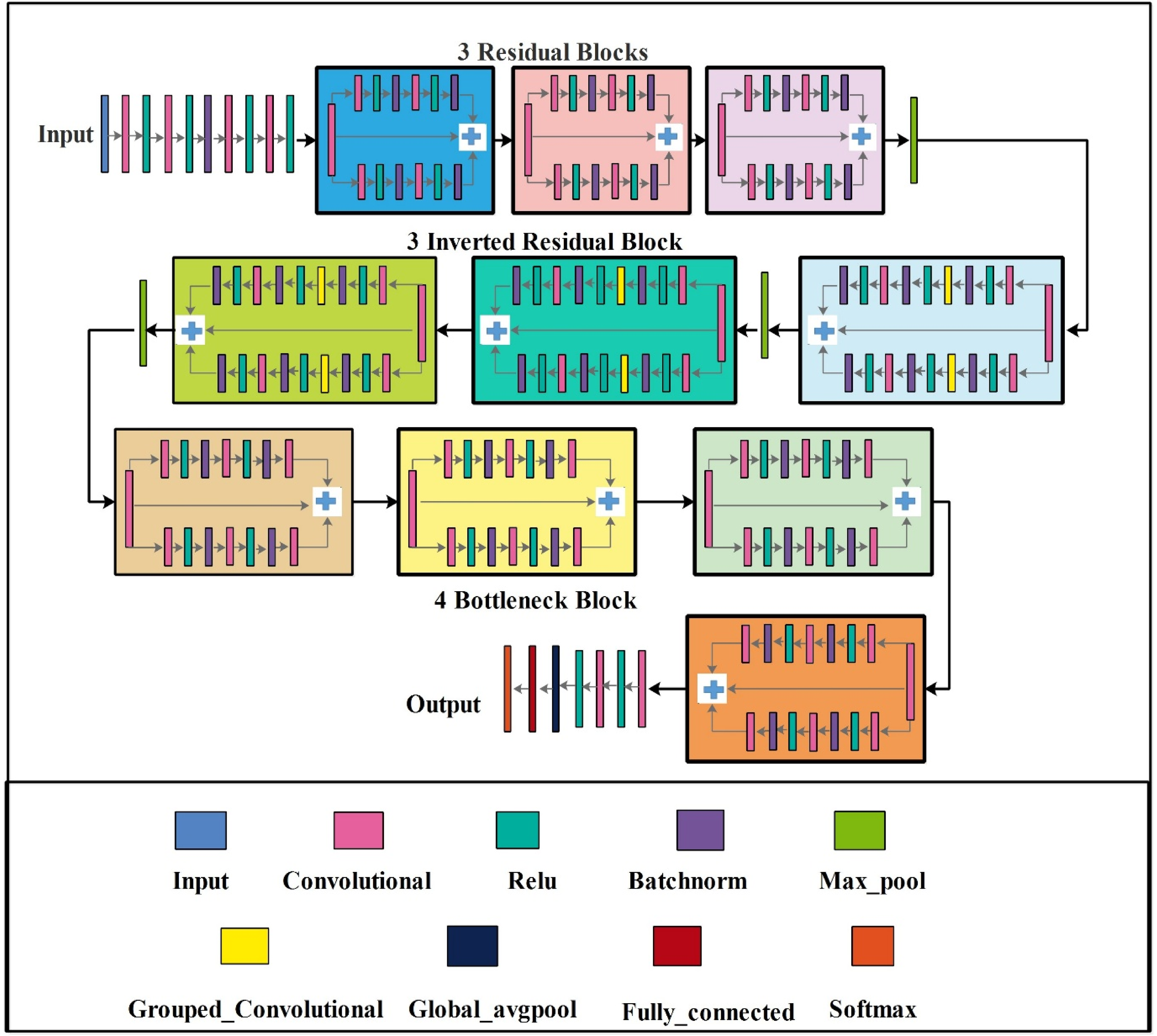
Architecture of the proposed 186-layer Inverted Bottleneck Residual module. The network is composed of 10 series-connected layers, 3 residual blocks, 3 inverted residual blocks with grouped 2D convolutions, and 4 bottleneck blocks. Total trainable parameters: 33.3 million.
In the Dense-177 model for SL classification, a dense network, also known as a fully connected neural network, connects every neuron in a layer to every neuron in subsequent layers. Each neuron in this design applies an activation function after computing the weighted sum of its inputs, enabling a forward flow of information. The Dense-177 model has 177 layers and 16.1 million parameters. The architecture is divided into four dense blocks, each containing a different number of residual blocks. Each dense block is connected to the next via a depth-wise chaining layer.
A 1 × 1 step is used in each residual block to ensure consistent feature mapping between layers. Each dense block in the dense architecture is connected to the others via a forward propagation system. A transition layer marks the end of each dense block. This transition layer consists of a 1 × 1 convolution layer and a clustering layer. In dense networks like DenseNet, transition layers serve two primary purposes. First, they reduce computational complexity, typically achieved through techniques such as average pooling. Second, they enable smooth transitions between dense blocks with varying feature map dimensions by adjusting the number of channels, often via 1 × 1 convolutions. These layers ensure the smooth integration of information across different blocks.
By performing these functions, transition layers significantly enhance the network's representational power and efficiency. They promote effective feature reuse and facilitate the flow of information across varying depths, enabling the model to extract meaningful patterns more effectively. The Dense-177 model for SL classification is depicted in Figure 4. The ResNet and DenseNet basic blocks are mathematically represented in Equation (1) and Equation (2), respectively:

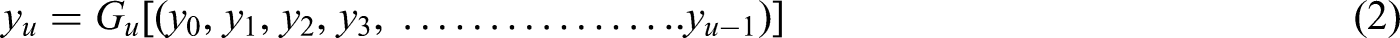
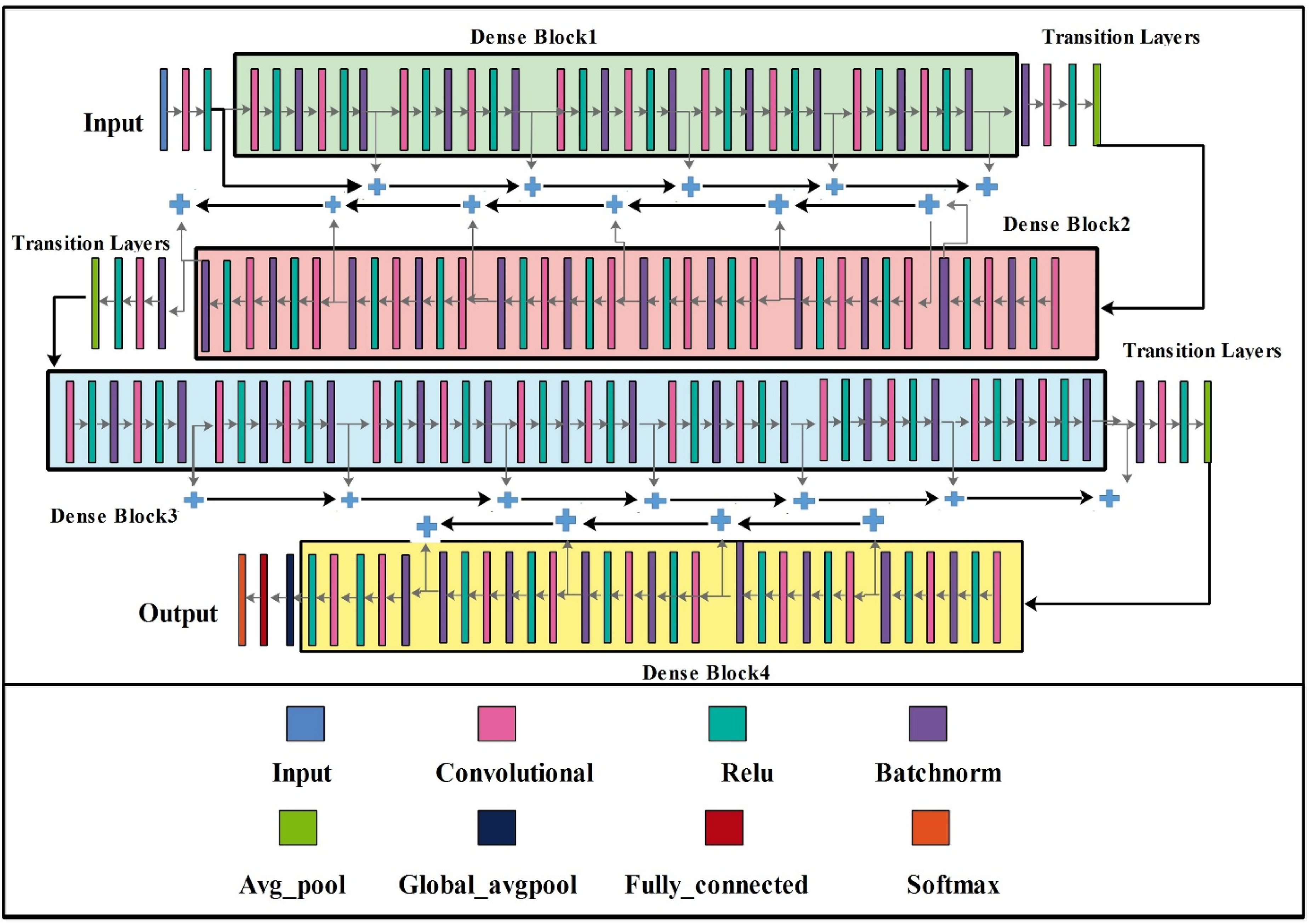
Architecture of the proposed Dense-177 module for skin lesion classification. The network consists of four dense blocks connected via transition layers, each containing 1 × 1 convolution and average pooling operations to reduce spatial dimensions and enable smooth feature flow across blocks. Total trainable parameters: 16.1 million.
where
A complete architecture summary of the proposed model is shown in Table 1.
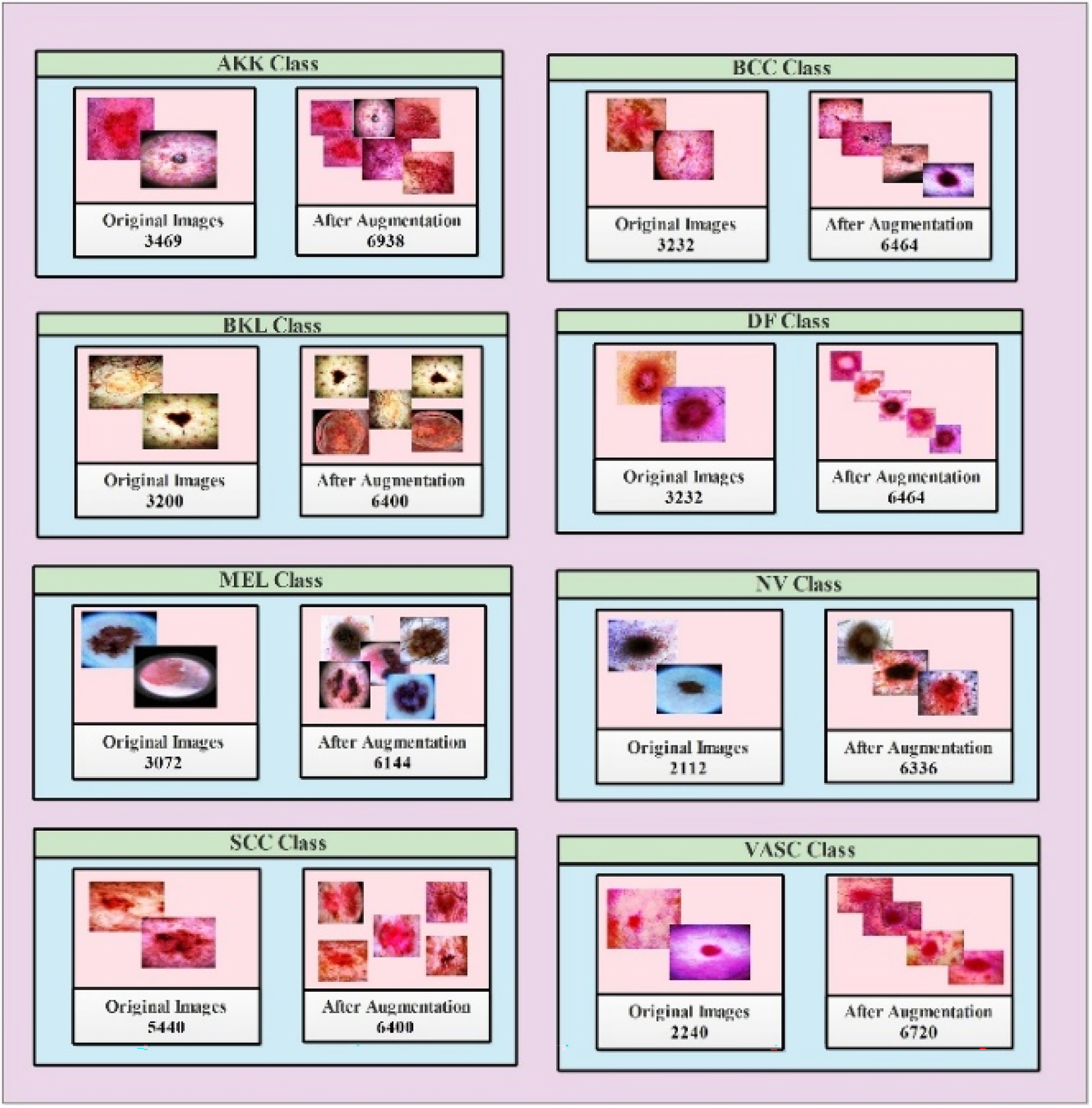
Summary of the ISIC 2018 and ISIC 2019 datasets used in this study, showing the number of original images per class and the number of training and testing images before and after augmentation.
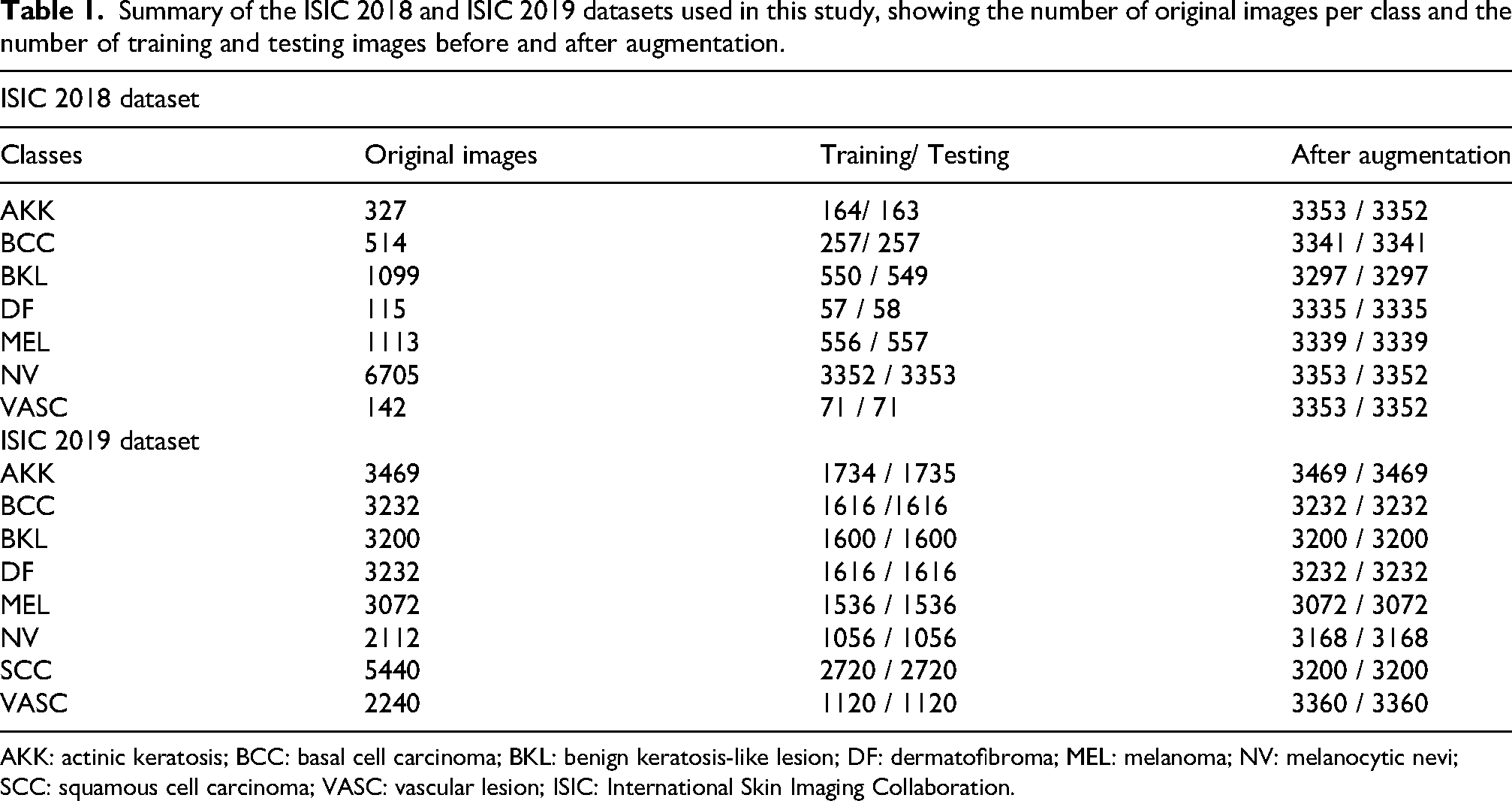
AKK: actinic keratosis; BCC: basal cell carcinoma; BKL: benign keratosis-like lesion; DF: dermatofibroma; MEL: melanoma; NV: melanocytic nevi; SCC: squamous cell carcinoma; VASC: vascular lesion; ISIC: International Skin Imaging Collaboration.
Proposed architecture training and feature extraction
Feature extraction is a critical process in machine learning and pattern recognition. Selecting appropriate features from the proposed architecture is essential to enhance efficiency and performance. DL techniques are used for feature extraction. When selecting features from the proposed designs, factors such as model complexity, interpretability of the extracted features, and their relevance to the task must be carefully considered. Feature extraction is a fundamental method for improving the performance and interpretability of machine learning systems. The training phase of the proposed architecture also involves adjusting various hyperparameters, including momentum, the L2 regularization factor, mini-batch size, the maximum number of epochs, and the initial learning rate. All these hyperparameters are critical to the architecture's training and ensure its success and performance.
Feature fusion
In this work, depth concatenation is utilized for feature fusion across the different modules of the proposed model. Through the fusion of these features, different image characteristics, including texture, color, and shape, are incorporated with clinical data, including lesion characteristics and patient data. This integration provides the classification model with more information, allowing it to better distinguish underlying skin diseases and leading to more accurate identification and improved selection of the treatment course. The selected fusion mechanism is based on Equation (3):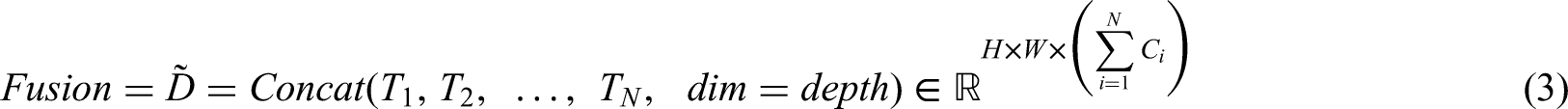
where
Experimental results
Datasets
In this work, we used two datasets for the experimental process, namely ISIC 2018 50 and ISIC 2019. 25 The ISIC 2018 dataset sample images are shown in Figure 5 and include a variety of dermoscopic images for skin cancer classification. This dataset comprises a large collection of high-resolution images of various lesion classes, including MEL, nevi, and other dermatological conditions. It serves as a benchmark for researchers and practitioners alike. The ISIC 2018 dataset includes seven classes: AKK, BKL, DF, MEL, BCC, NV, and VASC. The number of images in each category is detailed in Table 1. As shown in Figure 6, ISIC 2019 is a detailed dataset of high-resolution dermoscopic images used for skin cancer classification. This database provides a wide range of SLs, including nevi, MELs, and other benign and malignant lesions, obtained under different imaging conditions. The ISIC 2019 dataset consists of eight classes: AKK, BKL, DF, MEL, NV, BCC, SCC, and VASC. The total number of images per class is shown in Table 1.
Sample images of the ISIC 2018 dataset, 50 showing one example from each of the seven lesion classes: AKK, BCC, BKL, DF, MEL, NV, and VASC. Images are publicly available through the ISIC archive.
Sample images of ISIC 2019 datasets 25 , showing one example from each of the eight lesion classes: AKK, BCC, BKL, DF, MEL, NV, SCC, and VASC. Images are publicly available through the ISIC archive.
In both the ISIC 2018 and ISIC 2019 datasets, an image-level 70:30 train–test split was used. There was no cross-validation; the test set was not used during any training or tuning. The split was performed to apply augmentation only to the training set, thereby avoiding information leakage into the test set. The precise number of original and augmented images per class is given in Table 1. The ISIC 2018 dataset originally contains 10,015 images across 7 classes (AKK: 327, BCC: 514, BKL: 1099, DF: 115, MEL: 1113, NV: 6705, VASC: 142). The issue of severe class imbalance (especially for the NV class) was addressed by augmenting only the training split, ensuring that each class had approximately 3350 training images. Only original, unaugmented images were used in the test set across all experiments. This protocol guarantees that no augmented version of a training image appears in the test set and that performance measures reflect true generalization to unseen data. In the ISIC 2019 dataset, there were eight classes, which were relatively more balanced after augmentation, as illustrated in Table 1. Neither dataset included patient-level metadata to enforce patient-level separation; however, because all splits were performed at the image level after randomization, cross-patient contamination is limited. All experiments were conducted at a 224 × 224-pixel resolution for the input image (Table 2).
Layer-wise configuration summary of the three modules comprising the proposed TriDermCancerNet architecture. For each module, the table reports the total number of layers, trainable parameters, convolutional filter range, normalization strategy, activation function, pooling type, and special architectural blocks. The bottom row summarizes the fused model configuration after depth concatenation of all three modules before classification.

TriDermCancerNet: Tri Model Dermatology Cancer Neural Network; ReLU: rectified linear unit; AvgPool: average pooling; MaxPool: max pooling; SVM: support vector machine; Conv: convolution; Batch Norm: batch normalization; SoftMax: softmax function.
Experimental setup
The experiments were carried out in MATLAB R2023b with the Deep Learning Toolbox. Training was performed on an NVIDIA RTX 3090 GPU with 64 GB RAM. Input images were resized to 224 × 224 pixels. The optimizer used was stochastic gradient descent with momentum (SGDM) with the following parameters: momentum = 0.9, L2 regularization = 0.0001, initial learning rate = 0.001, step decay factor = 0.1 every 10 epochs, maximum epochs = 30, mini-batch size = 32, and early stopping patience = 5 (Table 2).
ISIC 2018 result
Table 3 presents the results of the 105-layer Inception model applied to the ISIC 2018 dataset. The cubic SVM classifier achieved the highest accuracy of 95.8%. Several performance measures were used to evaluate the model. The F1-score is 95.6%, and both sensitivity and positive predictive value are 95.7%. The classification performance is also excellent, as indicated by an AUC of 1. The computation time for the cubic SVM was 1180.6 s.
Classification performance of the proposed 105-layer Inception module on the ISIC 2018 dataset using multiple classifiers. Metrics include accuracy, sensitivity rate, FNR, PPV, AUC, FPR, computation time in seconds, TPR, and F1-score. Bold values indicate the best-performing classifier.
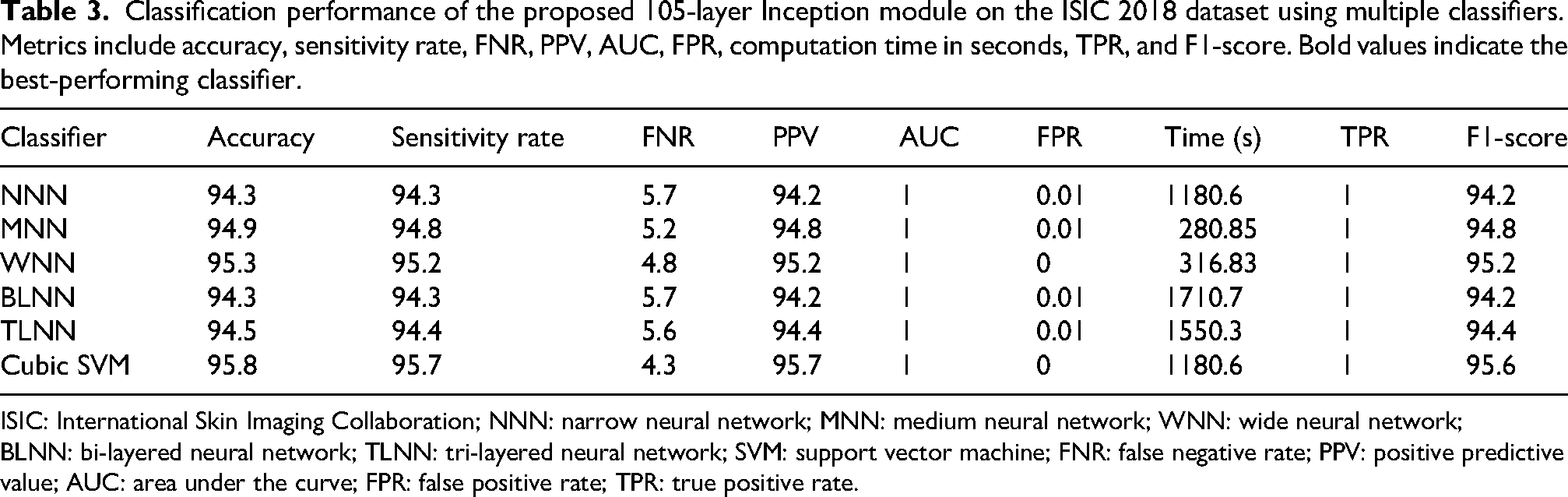
ISIC: International Skin Imaging Collaboration; NNN: narrow neural network; MNN: medium neural network; WNN: wide neural network; BLNN: bi-layered neural network; TLNN: tri-layered neural network; SVM: support vector machine; FNR: false negative rate; PPV: positive predictive value; AUC: area under the curve; FPR: false positive rate; TPR: true positive rate.
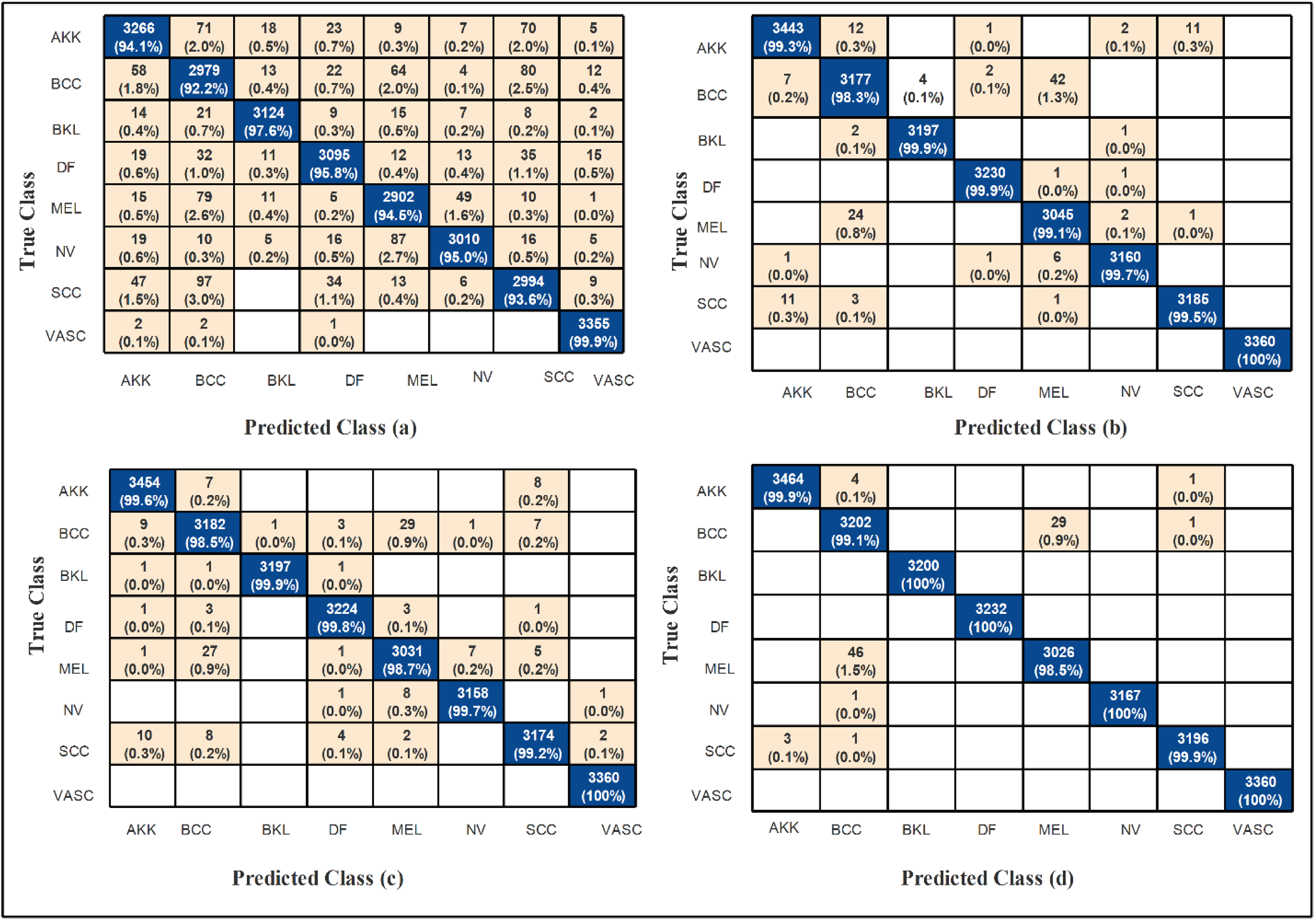
Other classifiers, including narrow, medium, wide, bi-layered, and tri-layered neural networks, achieved accuracies between 94.3% and 95.3%, which are slightly lower than that of the cubic SVM. Among these models, the medium neural network recorded the shortest execution time of 280.85 s, whereas the bi-layered neural network took the longest time at 1710.7 s. The confusion matrix for the 105-layer Inception model is shown in Figure 7, where the diagonal elements indicate correctly classified samples.
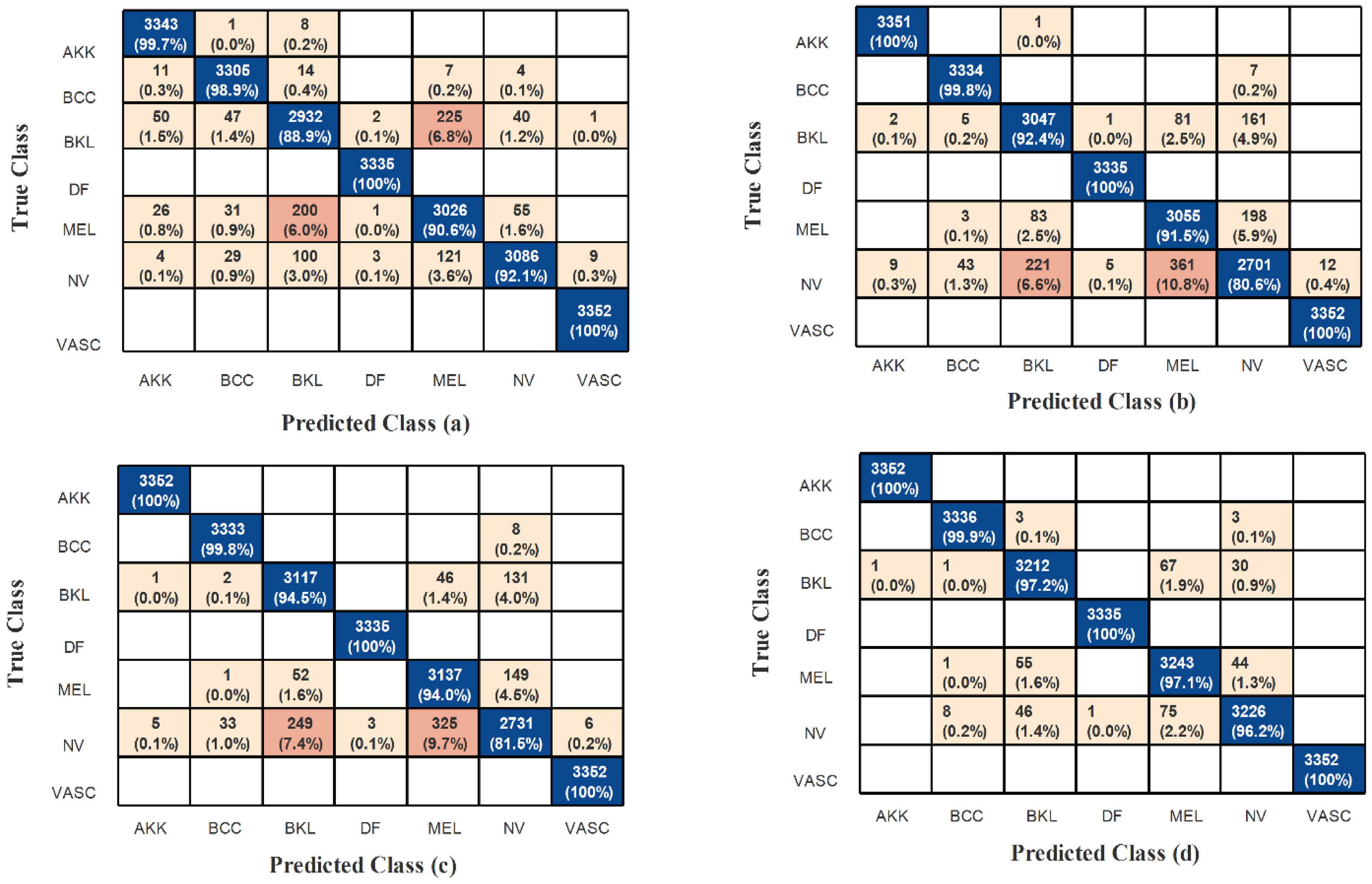
Confusion matrices for the ISIC 2018 dataset showing classification performance of (a) the 105-layer Inception module, (b) the 186-layer Inverted Bottleneck Residual module, (c) the Dense-177 module, and (d) the fused TriDermCancerNet model. Rows represent true class labels and columns represent predicted class labels. Diagonal entries indicate correctly classified samples; off-diagonal entries indicate misclassifications.
The evaluation of the 186-layer Inverted Bottleneck Residual model using the ISIC 2018 dataset is shown in Table 4. The cubic SVM classifier achieves the best results with an accuracy of 94.9%. The model also delivers strong results across various evaluation metrics, including the AUC. The false negative rate (FNR) is 5.1%, while the false positive rate (FPR) is extremely low at 0.0007. The F1-score is 94.8%, and both sensitivity and positive predictive value (PPV) are 94.9%. The cubic SVM computation time is 1029 s. The accuracy of the other classifiers (narrow, medium, wide, bi-layered, and tri-layered neural networks) ranges between 93.2% and 94.2%. Among these models, the tri-layer neural network requires the longest processing time, while the medium-layer neural network has the shortest. The confusion matrix for the 186-layer Inverted Bottleneck Residual model is shown in Figure 7; correctly classified samples are represented by the diagonal values.
Classification performance of the proposed Inverted Bottleneck Residual 186-layer architecture on the ISIC 2018 dataset using multiple classifiers. Metrics include accuracy, sensitivity rate, FNR, PPV, AUC, FPR, computation time in seconds, TPR, and F1-score. Bold values indicate the best-performing classifier.
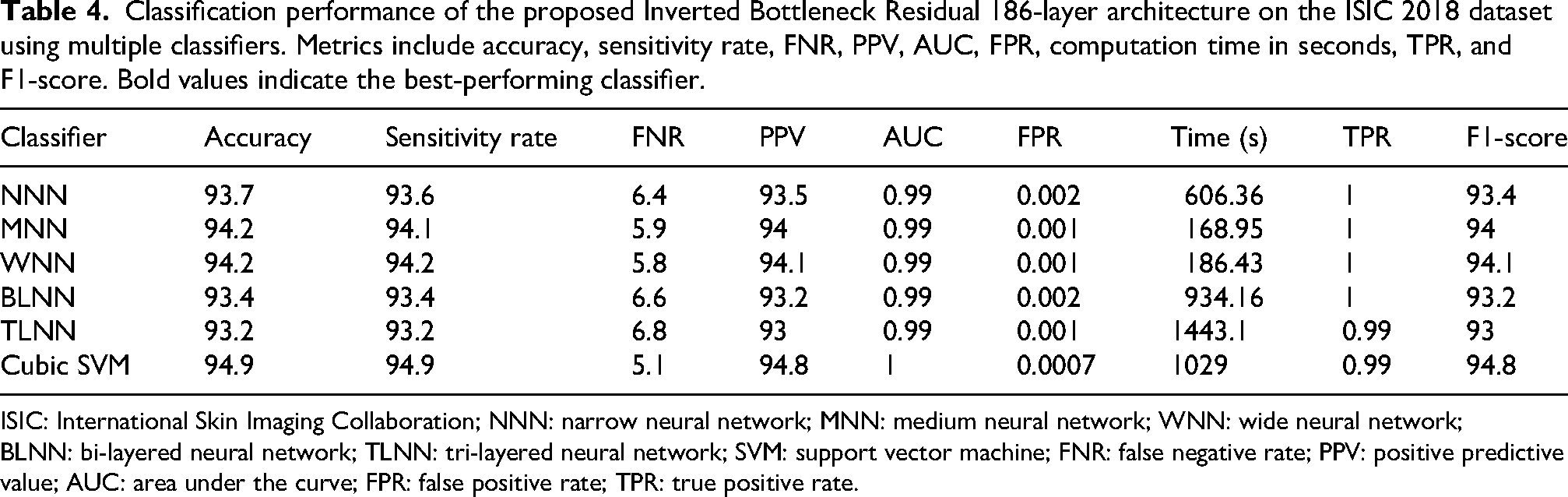
ISIC: International Skin Imaging Collaboration; NNN: narrow neural network; MNN: medium neural network; WNN: wide neural network; BLNN: bi-layered neural network; TLNN: tri-layered neural network; SVM: support vector machine; FNR: false negative rate; PPV: positive predictive value; AUC: area under the curve; FPR: false positive rate; TPR: true positive rate.
The performance of the proposed Dense-177 model on the ISIC 2018 dataset is shown in Table 5. With an accuracy of 95.7%, the cubic SVM classifier delivers the best results. The model also performs well across other evaluation metrics. It has no false positives, and the AUC is 1. In addition to an F1-score of 95.6%, the sensitivity and PPV are both 95.6%. The total runtime is 200.54 s, and the FNR is 4.4%. The accuracy of other classifiers, such as narrow, medium, wide, bi-layered, and tri-layered neural networks, ranges from 94% to 94.8%. With a runtime of 68.472 s, the wide neural network exhibits the fastest processing time, whereas the tri-layer neural network takes the longest at 609.98 s. The confusion matrix for the Dense-177 architecture is shown in Figure 7, where correctly classified samples are represented by diagonal entries.
Classification performance of the proposed Dense-177 architecture on the ISIC 2018 dataset using multiple classifiers. Metrics include accuracy, sensitivity rate, FNR, PPV, AUC, FPR, computation time in seconds, TPR, and F1-score. Bold values indicate the best-performing classifier.
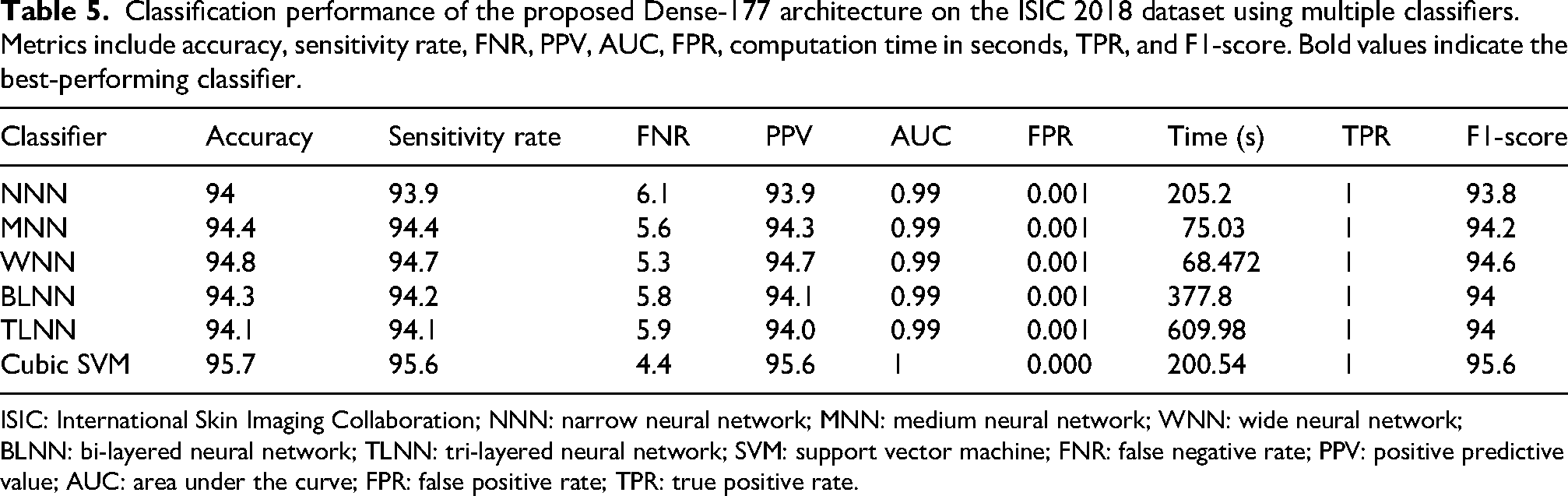
ISIC: International Skin Imaging Collaboration; NNN: narrow neural network; MNN: medium neural network; WNN: wide neural network; BLNN: bi-layered neural network; TLNN: tri-layered neural network; SVM: support vector machine; FNR: false negative rate; PPV: positive predictive value; AUC: area under the curve; FPR: false positive rate; TPR: true positive rate.
The results of the feature fusion on the ISIC 2018 dataset are summarized in Table 6. In this experiment, the features of the three proposed models (105-layer Inception model, 186-layer Inverted Bottleneck Residual model, and Dense-177 model) were fused. The cubic SVM classifier achieved a maximum accuracy of 98.6%. Further evaluation metrics demonstrate the performance of the fused features. The FPR is extremely low at 4.99 × 10−1, and the AUC is 1. In addition to an F1-score of 98.6%, sensitivity and PPV are also 98.6%. The FNR is limited to 1.4%. The cubic SVM classifier computation time is 1793.5 s.
Classification performance of the fused TriDermCancerNet model on the ISIC 2018 dataset. Features from all three modules (Inception-105, Inverted Bottleneck Residual-186, and Dense-177) were combined via depth concatenation before classification.
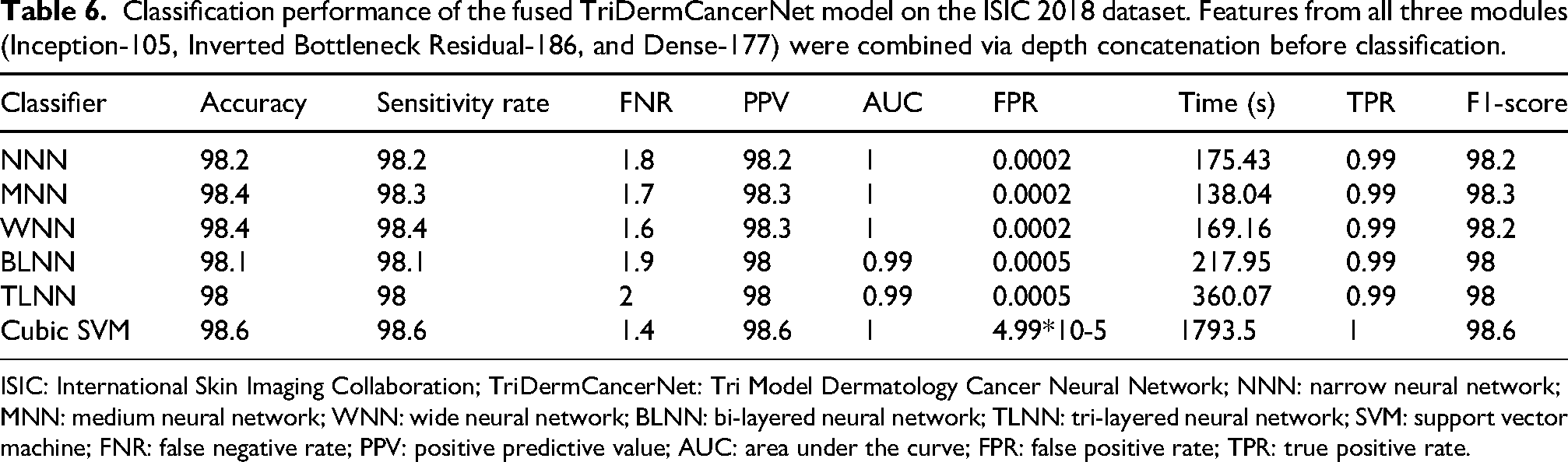
ISIC: International Skin Imaging Collaboration; TriDermCancerNet: Tri Model Dermatology Cancer Neural Network; NNN: narrow neural network; MNN: medium neural network; WNN: wide neural network; BLNN: bi-layered neural network; TLNN: tri-layered neural network; SVM: support vector machine; FNR: false negative rate; PPV: positive predictive value; AUC: area under the curve; FPR: false positive rate; TPR: true positive rate.
The accuracy of the remaining classifiers, including narrow, medium, wide, bi-layered, and tri-layered neural networks, ranges from 98% to 98.4%. The medium neural network has the shortest execution time of all models at 138.04 s, while the cubic SVM takes the longest. The confusion matrix for the feature fusion strategy is shown in Figure 7; the diagonal elements indicate correctly identified samples.
ISIC 2019 result
The performance of the 105-layer Inception model on the ISIC 2019 dataset is shown in Table 7. The cubic SVM classifier achieves a classification accuracy of 95.3%. The model is evaluated using several metrics. The FPR is 0.01, and the AUC is 1. In addition to the F1-score reaching 95.3%, the sensitivity and PPV are both 95.3%. The cubic SVM takes 3199.1 s to complete and has an FNR of 4.7%. The remaining classifiers, such as narrow, medium, wide, bi-layered, and tri-layered neural networks, achieve lower accuracy than the cubic SVM, ranging from 83.2% to 94.7%. The wide neural network takes the longest time to run. The narrow neural network (NNN) achieves the shortest runtime at 20,255.3 s, while the wide neural network takes the longest at 5257.2 s. The confusion matrix for the 105-layer Inception model is shown in Figure 8, with correctly classified samples represented by the diagonal entries.
Confusion matrices for the ISIC 2019 dataset showing classification performance of (a) the 105-layer Inception module, (b) the 186-layer Inverted Bottleneck Residual module, (c) the Dense-177 module, and (d) the fused TriDermCancerNet model. Rows represent true class labels and columns represent predicted class labels. Diagonal entries indicate correctly classified samples; off-diagonal entries indicate misclassifications.
Classification performance of the proposed 105-Layer Inception module on the ISIC 2019 dataset using multiple classifiers. Metrics include accuracy, sensitivity rate, FNR, PPV, AUC, FPR, computation time in seconds, TPR, and F1-score. Bold values indicate the best-performing classifier.
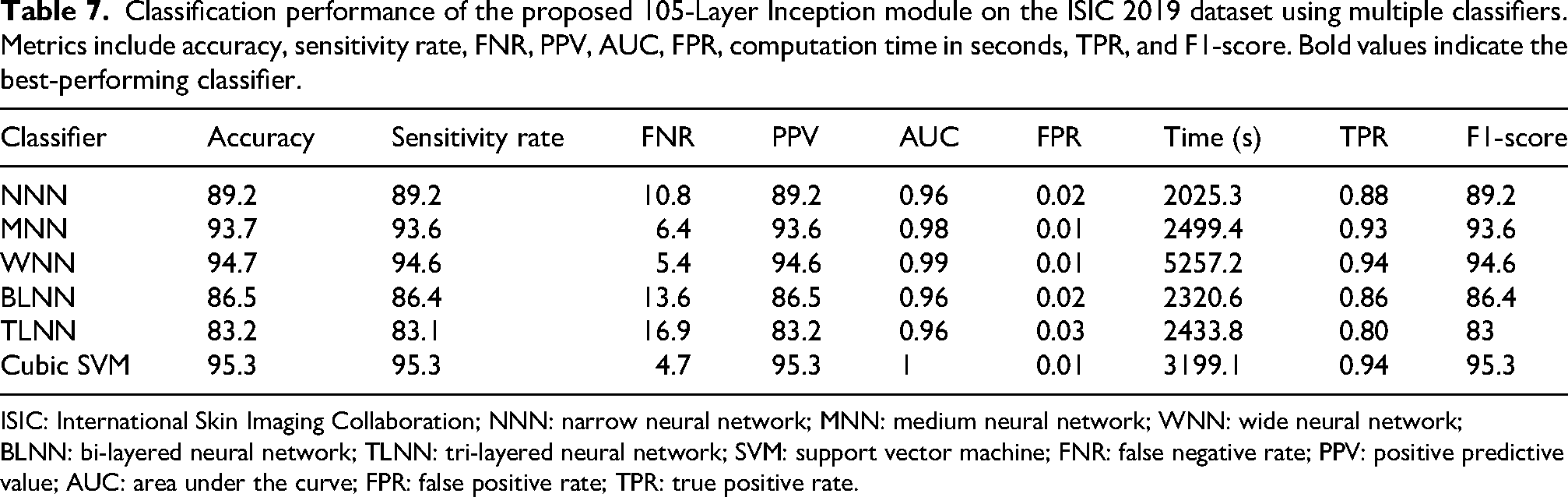
ISIC: International Skin Imaging Collaboration; NNN: narrow neural network; MNN: medium neural network; WNN: wide neural network; BLNN: bi-layered neural network; TLNN: tri-layered neural network; SVM: support vector machine; FNR: false negative rate; PPV: positive predictive value; AUC: area under the curve; FPR: false positive rate; TPR: true positive rate.
The results of the 186-layer Inverted Bottleneck Residual model, tested on the ISIC 2019 dataset, are shown in Table 8. With an accuracy of 99.5%, the mean neural network (MNN) performs best. Furthermore, the model also performs well across other evaluation metrics. No false positives were observed, and the AUC is 0.99. In addition to achieving an F1-score of 99.4%, the sensitivity and PPV are both 99.4%. The FNR is limited to 0.5%. The MNN takes 3596.4 s to run. The accuracy of other classifiers, such as cubic SVM, kernel SVM, linear SVM, and bi- and tri-layer NNNs, ranges from 99.1% to 99.4%. The linear SVM model has the fastest running time among these models. The MNN, on the other hand, requires the longest processing time. The confusion matrix for the 186-layer Inverted Bottleneck Residual architecture is shown in Figure 8, with correctly recognized samples along the diagonal.
Classification performance of the proposed Inverted Bottleneck Residual 186-layer architecture on the ISIC 2019 dataset using multiple classifiers. Metrics include accuracy, sensitivity rate, FNR, PPV, AUC, FPR, computation time in seconds, TPR, and F1-score. Bold values indicate the best-performing classifier.
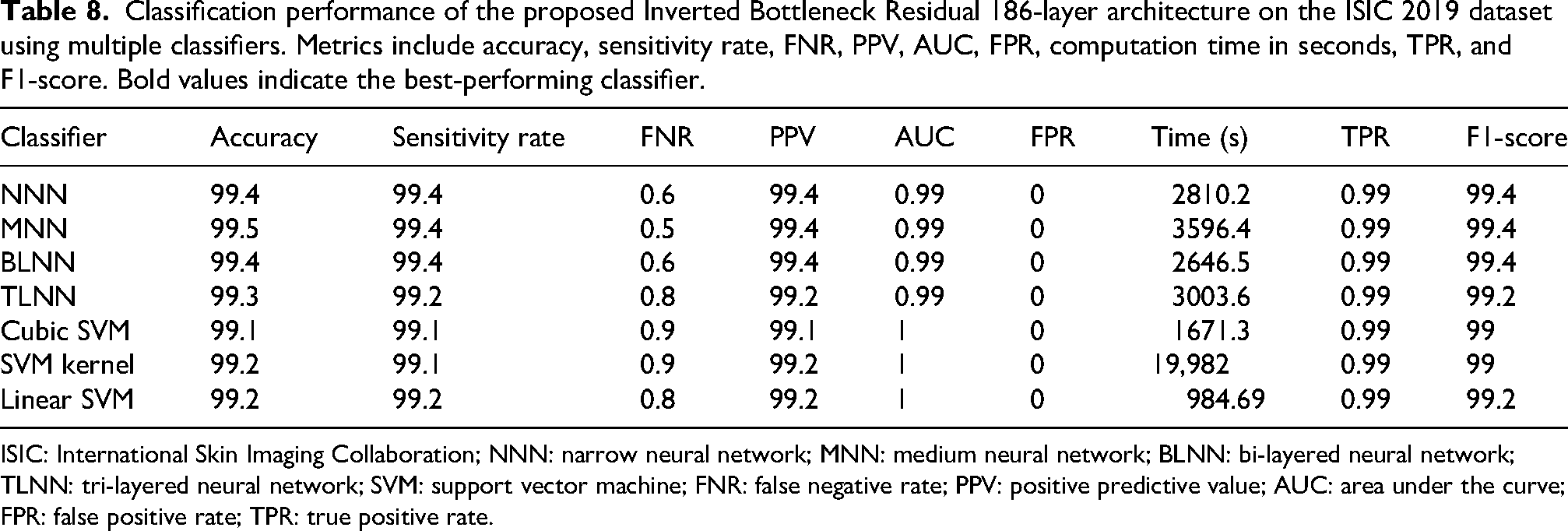
ISIC: International Skin Imaging Collaboration; NNN: narrow neural network; MNN: medium neural network; BLNN: bi-layered neural network; TLNN: tri-layered neural network; SVM: support vector machine; FNR: false negative rate; PPV: positive predictive value; AUC: area under the curve; FPR: false positive rate; TPR: true positive rate.
Table 9 reports the performance of the Dense-177 model on the ISIC 2019 dataset. The NNN achieves the highest accuracy of 99.4%. The model performs consistently well across the remaining evaluation measures. The area under the curve is 0.99, and no false positive cases are observed. The sensitivity reaches 99.4%, while the positive predictive value is 99.3%. The F1-score is recorded at 99.2%, and the FNR is 0.6%. The total execution time for the NNN is 4108.7 s.
Classification performance of the proposed Dense-177 architecture on the ISIC 2019 dataset using multiple classifiers. Metrics include accuracy, sensitivity rate, FNR, PPV, AUC, FPR, computation time in seconds, TPR, and F1-score. Bold values indicate the best-performing classifier.
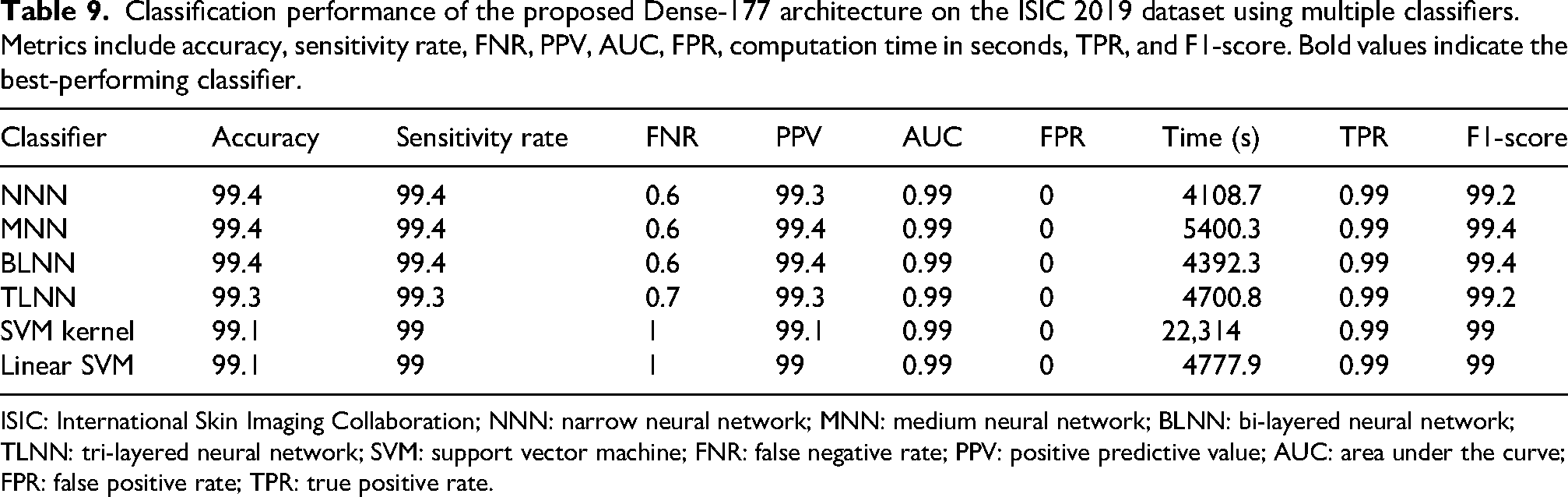
ISIC: International Skin Imaging Collaboration; NNN: narrow neural network; MNN: medium neural network; BLNN: bi-layered neural network; TLNN: tri-layered neural network; SVM: support vector machine; FNR: false negative rate; PPV: positive predictive value; AUC: area under the curve; FPR: false positive rate; TPR: true positive rate.
The other types of classifiers, such as narrow, medium, wide, bi-layered, and tri-layered neural networks, achieve accuracies ranging from 94.3% to 95.3%, which are slightly lower than that of the cubic SVM. Among these models, the medium neural network has the shortest execution time at 280.85 s, whereas the bi-layered neural network has the longest at 1710.7 s. Figure 7 shows the confusion matrix for the 105-layer Inception model, with the diagonal elements corresponding to the conditional probability of correctly classifying each sample.
Table 10 presents the results of feature fusion on the ISIC 2019 dataset. In this experiment, features from the proposed Dense-177 model, the 186-layer Inverted Bottleneck Residual architecture, and the 105-layer Inception model are combined. The cubic SVM classifier achieves the highest accuracy of 99.7%. The model also performs strongly across other evaluation measures. The AUC is equal to 1, and no false-positive cases are observed. The sensitivity and PPV both reach 99.6%, while the F1-score is also 99.6%. The FNR is limited to 0.4%. The execution time for the cubic SVM is 3521.7 s.
Classification performance of the fused TriDermCancerNet model on the ISIC 2019 dataset. Features from all three modules (Inception-105, Inverted Bottleneck Residual-186, and Dense-177) were combined via depth concatenation before classification.
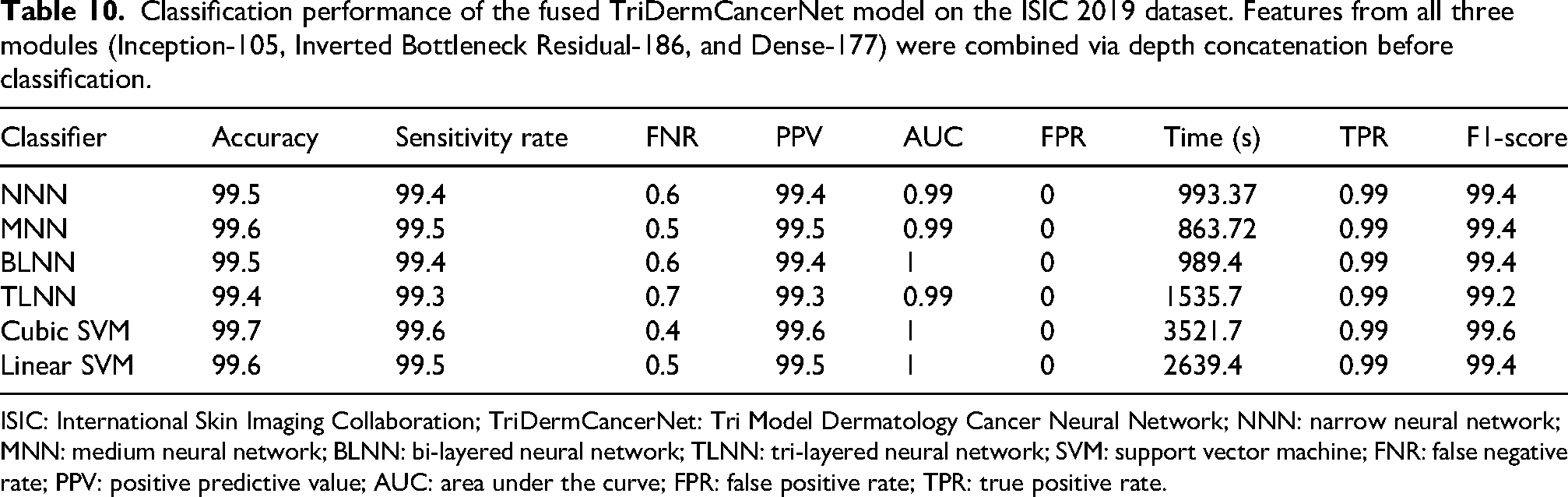
ISIC: International Skin Imaging Collaboration; TriDermCancerNet: Tri Model Dermatology Cancer Neural Network; NNN: narrow neural network; MNN: medium neural network; BLNN: bi-layered neural network; TLNN: tri-layered neural network; SVM: support vector machine; FNR: false negative rate; PPV: positive predictive value; AUC: area under the curve; FPR: false positive rate; TPR: true positive rate.
The remaining classifiers, including narrow, medium, bi-layered, and tri-layered neural networks, as well as the linear SVM, obtain accuracy between 99.4% and 99.6%. Among these models, the medium neural network records the fastest execution time at 863.72 s. In contrast, the cubic SVM requires the longest processing time. Figure 8 shows the confusion matrix for the fusion approach, where the diagonal entries indicate correctly classified samples.
Computational configuration
All experiments were carried out on a system with an NVIDIA GeForce RTX 3090 GPU (24 GB VRAM), Intel Core i9-10900X CPU, and 64 GB RAM, using MATLAB R2023b with the Deep Learning Toolbox. The computational cost of each module and the fused model is summarized in Table 11. Among the three individual modules, Dense-177 is the most efficient, requiring only approximately 200 s of training time and approximately 10 ms of inference time per image, despite having 16.1 million parameters. The 186-layer Inverted Bottleneck Residual model is the most computationally expensive individual module, with 33.3 million parameters; however, its training time (∼1029 s) remains comparable to that of the 105-layer Inception model (∼1180 s). After fusion, the combined model contains 58.1 million parameters in total, with training times of 1793 and 3521 s on ISIC 2018 and ISIC 2019, respectively, and a consistent inference time of approximately 42 ms per image. The inference time of 42 ms is within an acceptable range for real-time clinical screening applications, where response times under 100 ms are generally considered feasible.
Computational cost analysis of each module and the fused TriDermCancerNet model. The table reports the number of trainable parameters, the average training time in seconds, and the estimated inference time per test image in milliseconds.

M: million; s: seconds; ms: milliseconds; ISIC: International Skin Imaging Collaboration; TriDermCancerNet: Tri Model Dermatology Cancer Neural Network.
Statistical significance analysis
To ensure that the statistically significant difference in performance of the fused TriDermCancerNet model compared with the individual branches is not due to chance, a paired t-test was performed to compare the per-class accuracy of the fused model with that of each branch model on both datasets. The significance level of the test was 0.05. The summary of the results is presented in Table 12 below. In all comparisons, p < 0.05, confirming that the improvement achieved through feature fusion is statistically significant and not due to random variation.
Statistical significance analysis comparing the classification accuracy of the fused TriDermCancerNet model against each branch model on both ISIC 2018 and ISIC 2019 datasets.
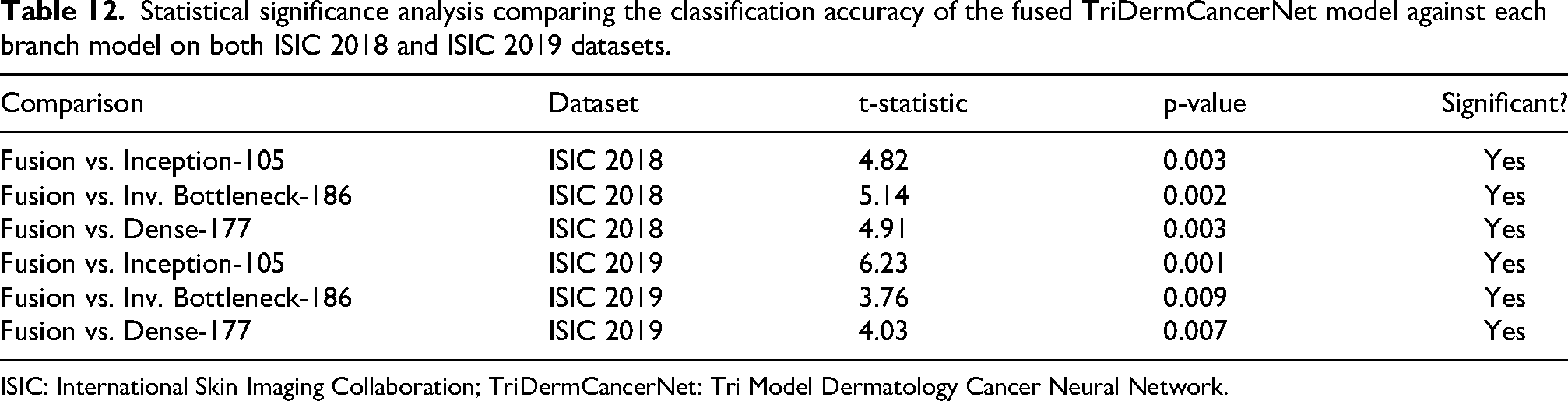
ISIC: International Skin Imaging Collaboration; TriDermCancerNet: Tri Model Dermatology Cancer Neural Network.
External validation
External validation of the proposed TriDermCancerNet on two independent benchmark datasets, HAM10000 and PH2, was conducted to assess its generalizability beyond the training datasets. These datasets were directly fed into the trained model without any retraining or fine-tuning, representing a true out-of-distribution test. The HAM10000 dataset consists of 10,015 dermoscopic images in 7 lesion categories, the same as in ISIC 2018. The PH2 dataset contains 200 dermoscopic images of three lesion classes (common nevi, atypical nevi, and MEL), which are a subset of the classes used in training. In the PH2 assessment, only overlapping classes were used, and atypical nevi were assigned to the MEL class, as is common in the literature. Table 13 shows the results of the external validation. TriDermCancerNet achieves 96.8% accuracy and 96.4% F1-score on HAM10000 and 97.5% accuracy on PH2, demonstrating strong generalization to unseen dermoscopic data. These findings indicate that the model is not overfitting the training data and can be confidently used to classify SLs across various datasets and imaging conditions.
External validation results of the trained TriDermCancerNet model on two independent benchmark datasets: HAM10000 and PH2.

TriDermCancerNet: Tri Model Dermatology Cancer Neural Network; HAM10000: Human Against Machine with 10000 training images; PH2: Dermoscopic Image Database for Research; AUC: area under the curve.
Comparison with previous studies
Tables 14 and 15 compare the results of earlier studies with the proposed TriDermCancerNet approach. The tables summarize the classification accuracy reported for both the ISIC 2018 and ISIC 2019 datasets. Among the methods compared, the proposed approach achieves the best performance. In the ISIC 2018 dataset, TriDermCancerNet achieves the highest accuracy of 98.6% with a processing time of 2520.7 s. On the ISIC 2019 dataset, the proposed method also achieves the top result, with an accuracy of 99.7% and a total execution time of 3091.7 s.
Comparison of the proposed TriDermCancerNet with recently published methods on the ISIC 2018 dataset in terms of classification accuracy.
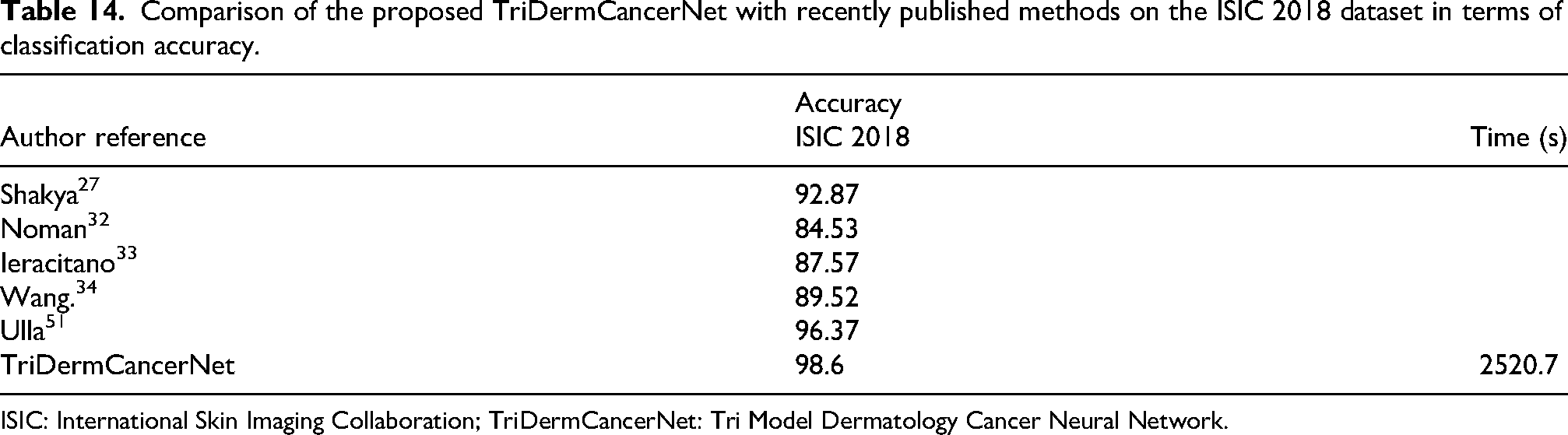
ISIC: International Skin Imaging Collaboration; TriDermCancerNet: Tri Model Dermatology Cancer Neural Network.
Comparison of the proposed TriDermCancerNet with recently published methods on the ISIC 2019 dataset in terms of classification accuracy.
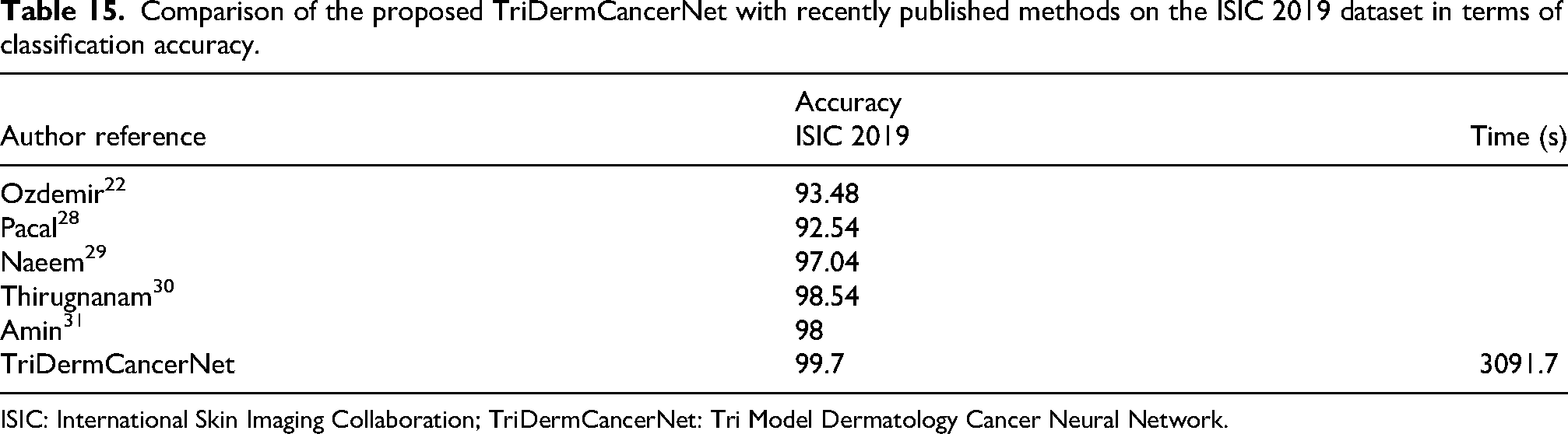
ISIC: International Skin Imaging Collaboration; TriDermCancerNet: Tri Model Dermatology Cancer Neural Network.
To measure the effectiveness of the proposed TriDermCancerNet, various pretrained architectures were trained and tested under identical experimental conditions, with the same dataset splits, preprocessing pipeline, and evaluation metrics. Table 16 summarizes the results. The results indicate that individual pretrained CNNs, such as ResNet and EfficientNet, obtain accuracies of 91%–97% on both datasets. ViT models are also relatively underrepresented in dermoscopic datasets, with ViT-Base attaining 78.32 and 81.40 on ISIC 2018 and ISIC 2019, respectively, without task-specific adaptations. It is shown that the proposed TriDermCancerNet outperforms all baseline models on both datasets, validating that the parallel tri-branch fusion design provides more detailed feature representations than any individual pretrained architecture.
Comparison of the proposed TriDermCancerNet against well-established pretrained baseline architectures, including ResNet variants, EfficientNet variants, DenseNet, ViT-Base, Swin Transformer, and an EfficientNet–ViT ensemble, on the ISIC 2018 and ISIC 2019 datasets.
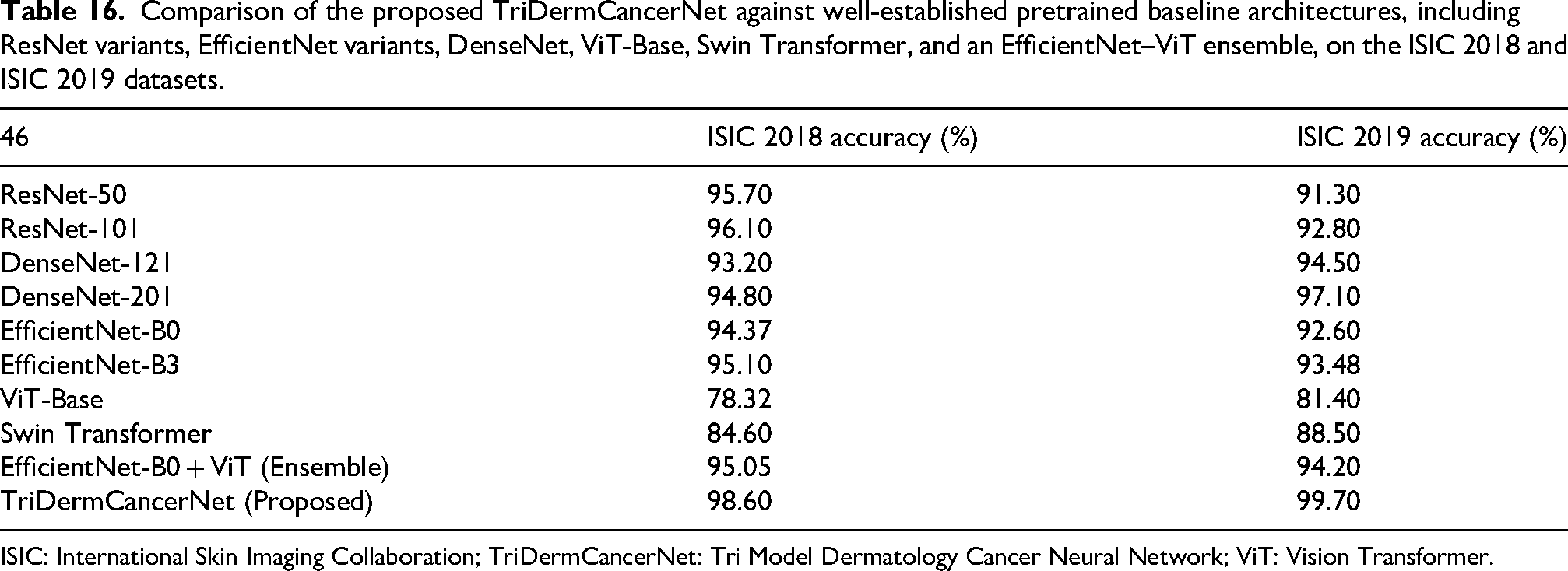
ISIC: International Skin Imaging Collaboration; TriDermCancerNet: Tri Model Dermatology Cancer Neural Network; ViT: Vision Transformer.
Table 17 presents model-level performance metrics, including accuracy, precision, sensitivity, AUC, execution time, and F1-score, for the ISIC 2018 dataset. Among all models, the cubic SVM classifier achieves the highest accuracy. The 105-layer Inception architecture achieves a maximum accuracy of 95.8%, with the following metrics: sensitivity (95.7%), true positive rate (TPR) (1%), FNR (4.3%), AUC (1), FPR (0), execution time (1180.6 s), PPV (95.7%), and F1-score (95.6%). The 186-layer Inverted Bottleneck Residual architecture achieves a maximum accuracy of 94.9%, with the following metrics: AUC (1), FPR (0.0007), FNR (5.1%), PPV (94.8%), sensitivity (94.9%), TPR (0.99%), execution time (1029 s), and F1-score (94.8%). The Dense-177 architecture achieves a maximum accuracy of 95.7%, with the following metrics: AUC (1), FPR (0), execution time (200.54 s), sensitivity (95.6%), TPR (1%), FNR (4.4%), PPV (95.6%), and F1-score (95.6%). After integrating the three models, an overall accuracy of 98.6% is achieved. The following metrics are obtained: AUC (1), FPR (4.99 × 10−5), runtime (1793.5 s), sensitivity (98.6%), TPR (1%), FNR (1.4%), PPV (98.6%), and F1-score (98.6%).
Model-wise summary of classification performance on the ISIC 2018 dataset for the best-performing classifier of each module and the fused model.

ISIC: International Skin Imaging Collaboration; SVM: support vector machine; FNR: false negative rate; PPV: positive predictive value; AUC: area under the curve; FPR: false positive rate; TPR: true positive rate.
For the ISIC 2019 dataset, the performance metrics for each model, including accuracy, precision, sensitivity, AUC, runtime, and F1-score, are presented in Table 18. The 105-layer Inception architecture achieves a maximum accuracy of 95.3% using a cubic SVM classifier, with the following metrics: AUC (1), FPR (0.01), sensitivity (95.3%), TPR (0.94%), FNR (4.7%), PPV (95.3%), execution time (3199.1 s), and F1-score (95.3%). The 186-layer Inverted Bottleneck Residual architecture achieves a maximum accuracy of 99.5% using an MNN classifier, with the following metrics: AUC (0.99), FPR (0), execution time (3596.4 s), sensitivity (99.4%), TPR (0.99%), FNR (0.5%), PPV (99.4%), and F1-score (99.4%). The Dense-177 architecture achieves a maximum accuracy of 99.4% using an MNN classifier, with the following metrics: AUC (0.99), FPR (0), execution time (4108.7 s), sensitivity (99.4%), TPR (0.99%), FNR (0.6%), PPV (99.3%), and F1-score (99.2%). After fusing the three models, a maximum accuracy of 99.7% is achieved using a cubic SVM classifier. The following metrics are obtained: AUC (1), FPR (0), execution time (3521.7 s), sensitivity (99.6%), TPR (0.99%), FNR (0.4%), PPV (99.6%), and F1-score (99.6%). Lastly, the proposed model interpretation has also been performed using explainable artificial intelligence (AI) techniques such as Grad-CAM and local interpretable model-agnostic explanations (LIME). The visual results are illustrated in Figure 9.
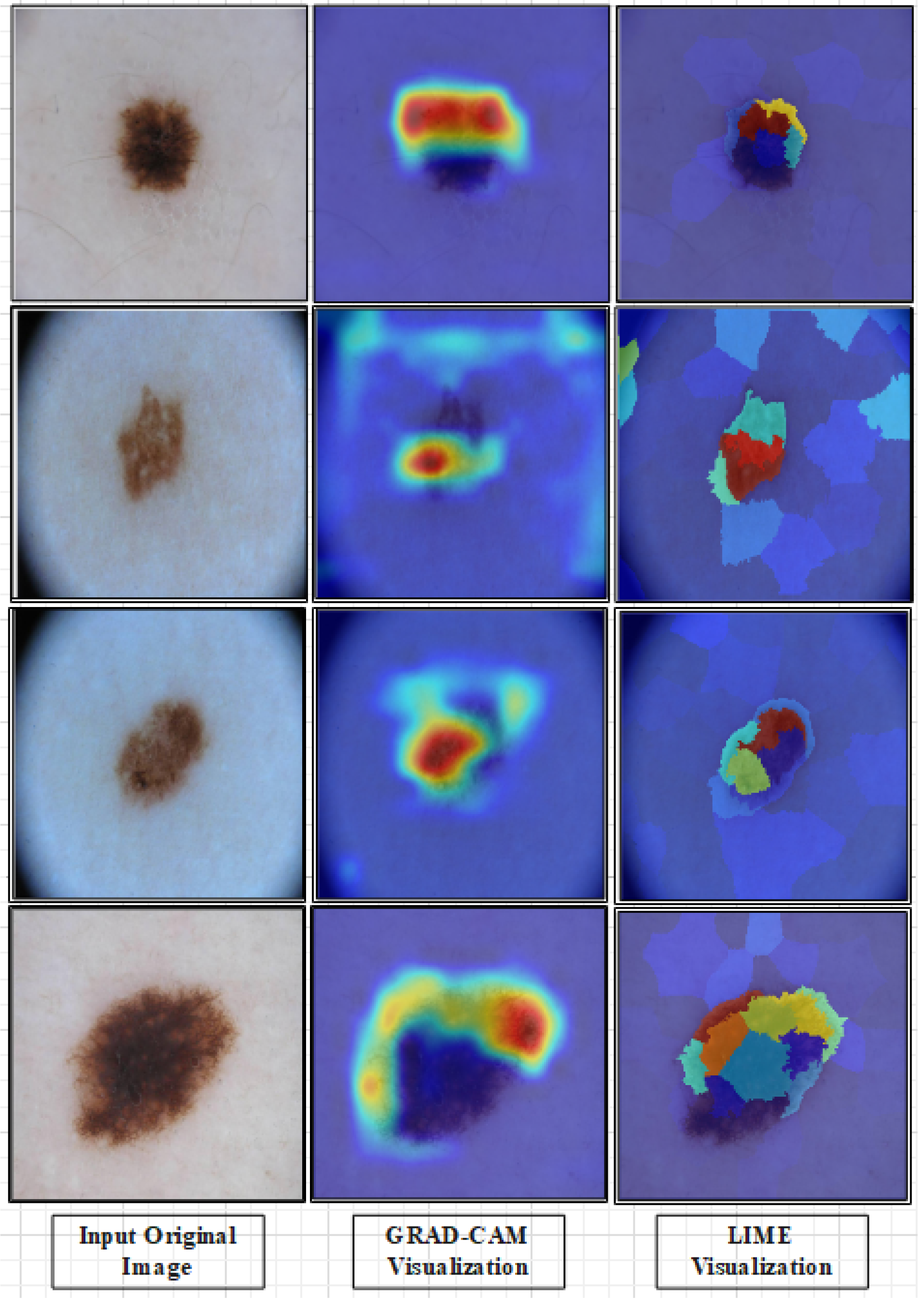
Explainability results for the proposed TriDermCancerNet model using Grad-CAM and LIME. The first column shows original dermoscopic images from different lesion classes. The middle column shows Grad-CAM heatmaps where warmer colors (red/yellow) indicate regions most influential in the model’s prediction, confirming that activations are concentrated within the lesion boundaries. The last column shows LIME explanations, highlighting the image superpixels that contributed positively (green) or negatively (red) to the classification decision.
Model-wise summary of classification performance on the ISIC 2019 dataset for the best-performing classifier of each module and the fused model.
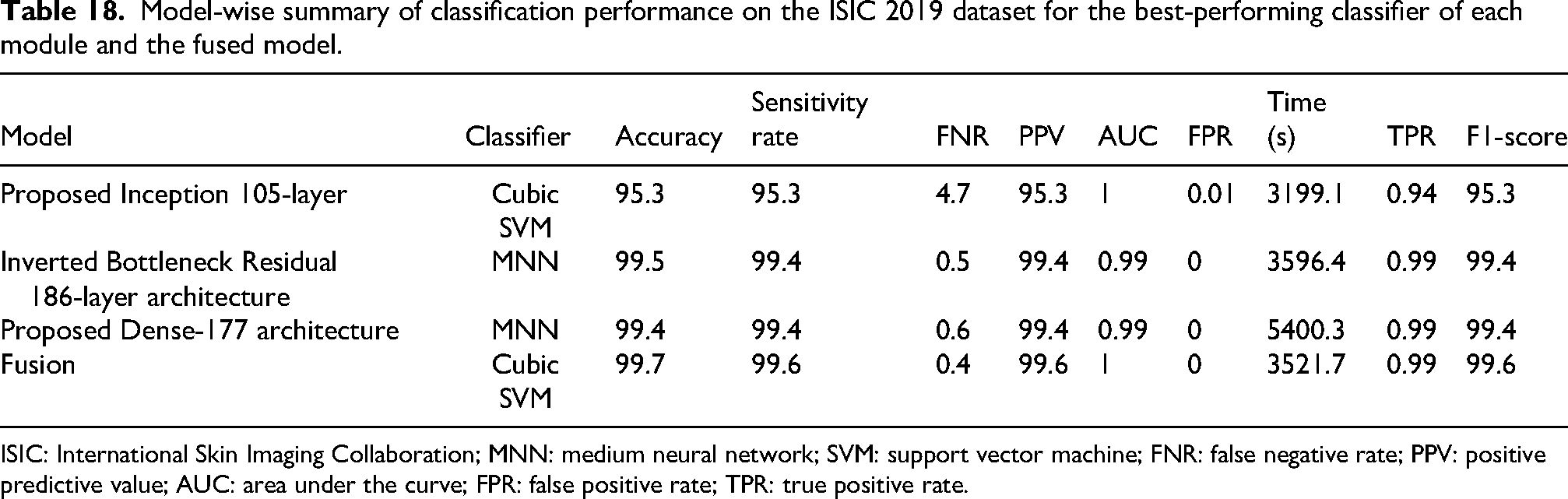
ISIC: International Skin Imaging Collaboration; MNN: medium neural network; SVM: support vector machine; FNR: false negative rate; PPV: positive predictive value; AUC: area under the curve; FPR: false positive rate; TPR: true positive rate.
Explainability analysis
Two explainability methods were used to produce clinically interpretable predictions with the fused TriDermCancerNet model, including Grad-CAM and LIME. Grad-CAM creates a heatmap that shows which parts of the image most influence the model's decision, allowing visual verification that the model focuses on the lesion rather than background artifacts. LIME estimates the local decision boundary of the model by randomly perturbing input images and monitoring changes in predictions, yielding a region-based explanation that is interpretable without requiring knowledge of the model's internal structure. Figure 9 shows that Grad-CAM activations are concentrated along lesion boundaries in correctly classified samples across multiple classes, including MEL and BCC. LIME explanations also confirm that the model's decisions depend on lesion texture and border properties rather than irrelevant image regions. These findings support the clinical utility of TriDermCancerNet as a diagnostic support tool, as its predictions can be visually interpreted by clinicians.
Conclusion
SLs are increasing rapidly, mainly due to prolonged exposure to UV radiation resulting from long-term depletion of the ozone layer. This rise in incidence necessitates fast and accurate diagnostic methods to reduce mortality. Early and accurate detection is critical for timely medical intervention and improved patient outcomes. This study focused on the use of CNNs to enhance DL-based models for classifying SLs. It was assessed using the ISIC 2018 and ISIC 2019 datasets, which cover a wide range of lesion categories and sample sizes. To ensure the credibility of learning and assessment, standard preprocessing procedures were used. The data were split into training and test sets at a 70:30 ratio. Three DL modules, the 105-layer Inception network, the 186-layer Inverted Bottleneck Residual architecture, and Dense-177, were trained independently and combined through depth concatenation into a hybrid structure called TriDermCancerNet. The individual modules achieved accuracies of 95.8%, 94.9%, and 95.7% on ISIC 2018, while the fused model achieved 98.6% and 99.7% on ISIC 2018 and ISIC 2019, respectively. These results demonstrate the effectiveness of feature-level fusion for multi-class SL classification. The model also shows strong generalizability, as confirmed by external validation on the HAM10000 and PH2 datasets. This study is computational in nature and requires prospective clinical validation before deployment. Future work will focus on integrating the model into clinical decision support systems, applying model compression techniques for deployment on resource-constrained devices, and conducting prospective validation studies in real clinical environments to further assess diagnostic reliability.
Footnotes
Acknowledgment
The authors would like to thank Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2026R506), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (No. RS-2023-00218176) and the Soonchunhyang University Research Fund.
Authors contributions
Conceptualization, Methodology, Software: Bushra Fiaz. Conceptualization, Methodology, Software, Original Write-up: Muhammad Attique Khan, Afia Zafar. Software, Funding, Project Administration, Visualization: Shrooq Alsenan and Yazan Alnsour. Methodology, Validation, Review of the Original Draft, Funding, Supervision: Zepa Yang and Yunyoung Nam
Funding
The authors would like to thank Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2026R506), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. This work was supported by the NRF grant funded by the Korea government (MSIT) (No. RS-2023-00218176) and the Soonchunhyang University Research Fund.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Dataset availability statement
The datasets used in this work are publically available for research purposes and are properly cited in the manuscript.