
Abstract
Faces convey very rich information that is critical for intact social interaction. To extract this information efficiently, faces should be easily detected from a complex visual scene. Here, we asked which features are critical for face detection. To answer this question, we presented non-face objects that generate a strong percept of a face (i.e., Pareidolia). One group of participants rated the faceness of this set of inanimate images. A second group rated the presence of a set of 12 local and global facial features. Regression analysis revealed that only the eyes or mouth significantly contributed to faceness scores. We further showed that removing eyes or mouth, but not teeth or ears, significantly reduced faceness scores. These findings show that face detection depends on specific facial features, the eyes and the mouth. This minimal information leads to over-generalization that generates false face percepts but assures that real faces are not missed.
Faces convey rich and valuable information including expression, eye gaze, gender, race, and identity that is critical for intact social functioning. To enable fast and efficient extraction of this rich information, face processing engages a specialized processing mechanism (Kanwisher, 2000). An important initial step in face processing is the detection of a face in the visual environment (Hershler & Hochstein, 2005; Tsao & Livingstone, 2008). This process requires the extraction of features that differentiate a face from non-face stimuli. Developmental studies have shown that newborns look longer at face-like stimuli already during the first 24 hours after birth (Cassia, Turati, & Simion, 2004). They further show that early on, the visual system is not tuned to faces but to a general T-shape like pattern (a.k.a. top-heavy configuration) that is correlated with the overall structure of the internal facial features. These findings suggest the existence of an innate template that gives priority to face-like stimuli and biases the processing of information from the environment towards faces for further processing of more detailed information about expression, gaze or identity (Morton & Johnson, 1991).
The priority that is given to face-like stimuli by the visual system is also manifested by the generation of a face percept by a subset of inanimate stimuli, a phenomenon known as pareidolia (see Figure 1). These face-like inanimate stimuli were shown to elicit longer looking time relative to similar inanimate stimuli that do not generate a face percept in both humans and non-human primates (Taubert, Wardle, Flessert, Leopold, & Ungerleider, 2017). Furthermore, neuroimaging studies have shown that these stimuli generate a face-like neural response. For example, in a MEG study, real faces generated a larger response than face-like inanimate stimuli at 130 ms, but a similar response at 165 ms after stimulus onset (Hadjikhani, Kveraga, Naik, & Ahlfors, 2009). In a functional magnetic resonance imaging experiment, the pattern of response of the fusiform face area, but not the lateral occipital complex or parahippocampal place area, was correlated with the faceness of the face-like inanimate stimuli (Wardle, Seymour, & Taubert, 2017) indicating that the face-selective area is tuned to non-face stimuli that generate a percept of a face (Meng, Cherian, Singal, & Sinha, 2012).

Inanimate images that received the five highest scores (a), five intermediate scores (b), and five lowest scores (c) for the question do you see a face in the image (i.e., faceness score).Note: Please refer to the online version of the article to view the figures in colour.
Taken together, these findings imply that face-detection mechanisms are broadly tuned and overgeneralize to a certain class of inanimate stimuli. Because these inanimate stimuli are highly variable, they can be used to answer the basic question of what are the critical features that are used by face-detection mechanisms to classify a stimulus as a face. This question cannot be answered with real face stimuli, as humans are very sensitive to all facial features of real faces and can easily detect them as faces even when the information that is provided is partial, distorted and impoverish (Sinha, Balas, Ostrovsky, & Russell, 2006). The inanimate stimuli perceived as faces, on the other hand, contain non-facial information that makes them look like a face. We therefore exploit this type of stimuli to answer the basic question of what information is needed to make a stimulus perceived as a face?
In this study, we presented participants with inanimate stimuli and asked them to rate the degree to which they look like a face (i.e., faceness rating). A different group of subjects rated these same stimuli on a list of 12 facial features including local features such as eyes, mouth and teeth, as well as global features such as facial expression, symmetry or face proportion. By correlating the feature rating with the faceness rating, we discovered which features are needed to perceive a stimulus as face and which are not critical. One previous study that also examined the correlation between ratings of faceness and a set of a few features (eyes, mouth, eyebrows, expression and typicality) revealed that eyes, mouth and expression predicted faceness rating (Ichikawa, Kanazawa, & Yamaguchi, 2011). However, the predictors and predicted measures were not independent, as the same participants rated all the measures. To avoid this possible influence of faceness and feature ratings, different groups of participants provided these measures of the faceness and feature rating scores (Experiment 1). In addition, in this study, we conducted a follow-up experiment (Experiment 2), in which we removed critical or non-critical features based on the correlational results and examined the effect on faceness rating. We expect that removing critical features (i.e., features that were correlated with faceness scores) would reduce faceness rating, whereas removing non-critical feature (i.e., features that are not correlated with faceness scores) will not influence faceness rating.
Experiment 1
Methods
Participants
Seventy-two subjects participated in this study (40 women and 32 men), age range 21–44 years (mean: 30.61, SD: 6.06), 61 right-handed and 11 left-handed. This sample size was determined based on a previous similar study, which included 46 participants but collected all measures from the same sample (Ichikawa et al., 2011). To assure that feature rating was independent from faceness rating, here we collected these measures from separate groups of participants. Thirty-five participants completed the faceness rating experiment, and 37 participants completed the facial feature rating experiment. Seven participants were excluded from the facial feature rating experiment because they did not complete the second part of the experiment. One additional subject used the same rating score for all 12 features and was excluded. All participants signed a consent form. The experiment was approved by the Ethics Committee of Tel Aviv University.
Stimuli
One hundred sixteen colored images were used in this study, including photos of landscapes, houses, vehicles or furniture. The images were found on different Internet websites (wtface.com, themarysue.com, reddit.com) and also by using the key words ‘things that look like faces’ in google search engine. Of the 116 images, 86 images were perceived as faces by the experimenters. In addition, 30 non-face images that matched the ‘face images’ in depicting similar objects/landscapes were selected.
Procedure
Two rating experiments were performed on separate groups of participants. A faceness rating experiment in which subjects were asked to rate the faceness of the images. A facial feature rating experiment, in which participants were asked to rate the extent to which they see each of 12 facial features as detailed as follows:
Faceness rating: A group of 35 participants completed the faceness rating experiment. Each of the 116 images was presented on a computer screen for 2 seconds in a random order. After the disappearance of the image, a scale appeared and subjects were asked to rate the extent to which they detected a face in the photo, on a scale of 1 (there was no face in the photo) to 7 (there was definitely a face in the photo). The experiment lasted about 10 minutes.
Facial feature rating: 37 participants completed the facial feature rating experiment. Each of the 116 images was presented on the screen in a random order. The subjects were asked to rate on a scale the extent to which they can detect each of the following 12 facial features: eyes, mouth, nose, forehead, teeth, ears, eyebrows, hair, frame, proportion, symmetry and emotional expression. The scale ranged from 1 (the feature does not exist in the photo) to 7 (the feature definitely exists in the photo). The instructions stated that each feature can be either present or absent in any of the images, and that features that are clearly seen in the image should be scored 7, while a less evident feature should get a lower rating. The instructions also included clarifications with respect to the features frame, proportion and symmetry. Frame – If you see any facial features, do they appear inside any sort of frame? Proportion – If you see any facial features, are their size and distance from one another is similar to an ordinary face? Symmetry – Is the object that is perceived as a face in the image symmetric?
Each image remained on the screen till participants completed rating all the features. Because the feature rating experiment was long, it was divided into two parts, each part included half of the photos. The subjects were allowed to take a break between the two parts as long as they needed. Each part took about half an hour to complete.
Data Analysis
The rating scores were converted to Z-scores within each subject for the faceness score and for each feature separately. The Z-scores were averaged for each of the 116 images across subjects, so each image had one averaged Z-score faceness rating and one averaged Z-score for each of the 12 features. Two subjects used the same rating score for one feature for all 116 images, one for ‘frame’ and one for ‘ears’. Those features were excluded.
Results
Figure 1 shows example images that received the highest, the intermediate or the lowest faceness scores. To determine which features are important for face detection, we computed the correlations across the 116 images of each of the facial features rating with the faceness rating (Figure 2).
To determine the unique contribution of each of the features to faceness rating, we performed multiple regression in which rating of all 12 features was used to predict rating of the faceness score. The regression model explained 92% of the variance in faceness scores. Of the 12 features, eyes and mouth contributed mostly and significantly to faceness rating (p < .004 corrected for 12 multiple comparisons). Eyebrows, the hair and the emotion also had a marginally significant contribution to faceness rating (see Table 1). These findings are consistent with Ichikawa et al. (2011) who revealed that the eyes were the best predictor for faceness scores and mouth and expression contributed as well. In this study, however, ratings of faceness and features were collected from the same group of participants and, therefore, the predictors were not measured independently.
Results of a Multiple Regression of the 12 Facial Features and Faceness Rating (Sorted by t Value).
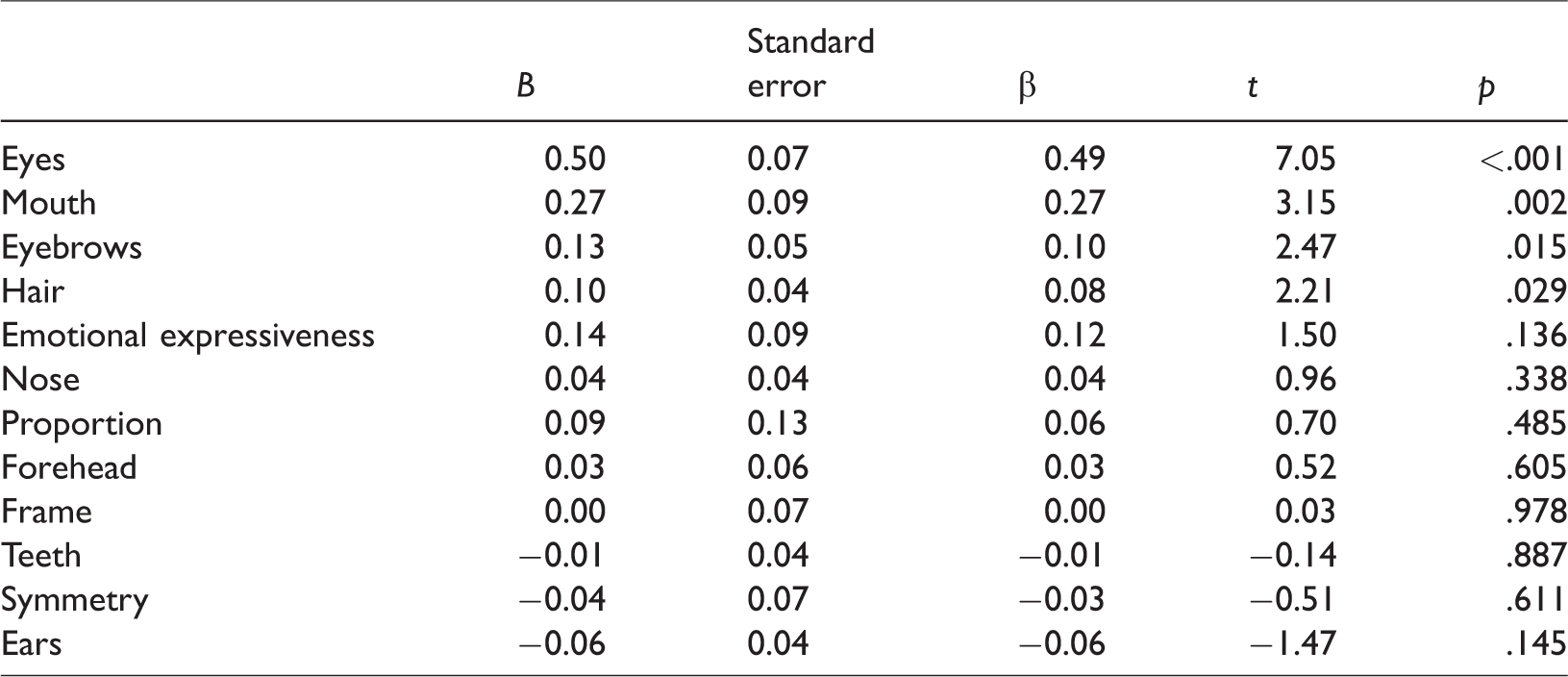
Another measure that may be correlated with faceness scores is the number of features that are present in any of the images. An image with a higher number of features is likely to be correlated more with faceness scores than an image with a lower number of features. We therefore examined whether this variable accounts for the correlations that we found for the eyes and the mouth. For each image, we calculated the number of features that received a Z-score higher than 0, indicating the presence of this feature in the image (see Supplementary Tables S1 and S2). The correlation of the number of features with faceness score was 0.86, p < .0001. We then included this variable in the regression analysis with the 12 features. This model accounts for the same proportion of variance (92%) of faceness scores as the model that did not include the number of features. Eyes (β = .48, t = 6.7, p < .001) and mouth (β = .25, t = 2.9, p = .005) were still significant predictors of the faceness rating score (see full regression model in Supplementary Table S3), indicating that their contribution to face detection was not mediated by the number of features present in the image.
To provide further support for the results that eyes and mouth are critical for the detection of a stimulus as a face, we created a new set of images in which we removed the critical features – either the eyes or the mouth. In addition, we created another set of images in which we removed non-critical features – either the Ears or the Teeth. Figure 3 shows example of these type of figures. These images were replaced with their original version and were presented in a faceness rating study, which included all the stimuli that were included in the previous experiment to have a similar context in both experiments. We compared the faceness scores for the stimuli with and without the removed features.
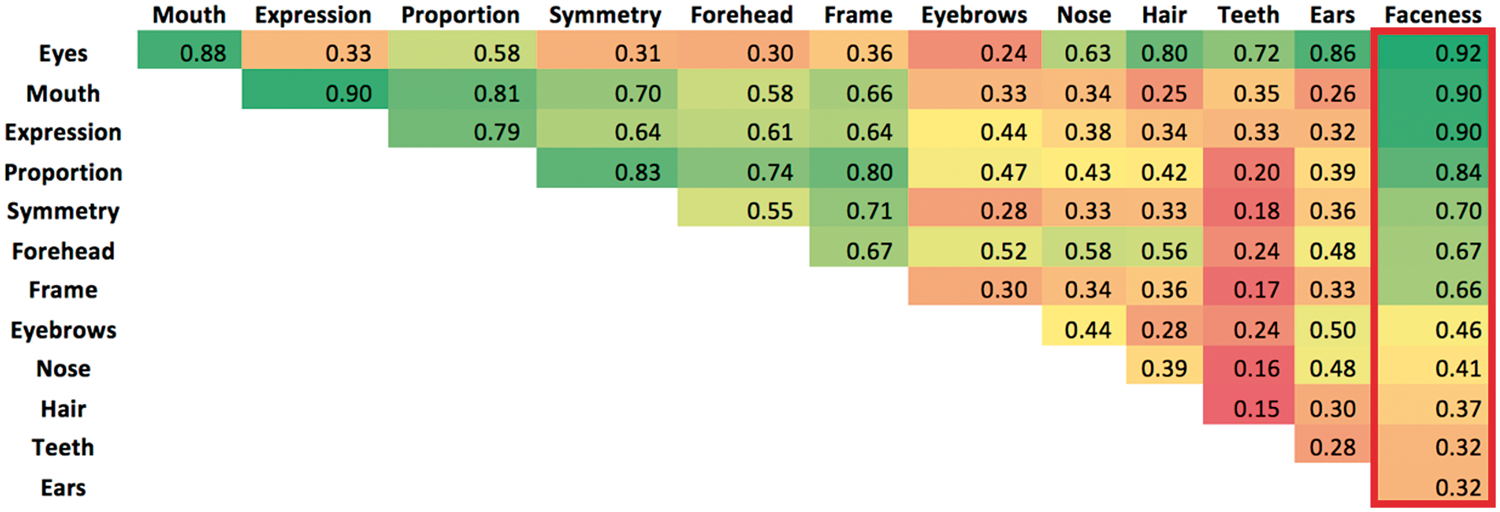
The correlation matrix between the 12 features and the faceness score sorted based on the correlations between each feature and the faceness score (right column). The color coding indicates the strength of the correlation. Green correlations are the highest and red correlations are the lowest.Note: Please refer to the online version of the article to view the figures in colour.
Experiment 2
Methods
The experiment was similar to the previous faceness rating experiment but included a subset of images in which one of the features was removed. Participants were asked to rate the faceness of 116 images.
Participants
Ninety-nine participants volunteered to participate in the experiment for course credit. They were randomly assigned to one of the five experiments: 20 participants were presented with the ears removed stimuli (three males, mean age = 21); 19 participants were presented with the eye-removed stimuli (three males, mean age = 23); 20 participants were presented with the mouth-removed stimuli (two males, mean age = 23.5); 20 participants were presented with the teeth-removed stimuli (two males, mean age = 21.5); and 20 subjects were presented with the original stimuli (six males, mean age = 22.5), replicating Experiment 1. All participants signed a consent form. The experiment was approved by the Ethics Committee of Tel Aviv University.
Stimuli
From the image set used in Experiment 1, we removed eyes from 11 images (Figure 3(a)), the mouth from nine images (Figure 3(b)), the ears from seven images (Figure 3(c)) and the teeth from nine images (Figure 3(d)). We selected images that enabled the removal of a feature in a way that does not distort or modify the original image in any way but the removal of that specific feature (see Figure 3 for examples of stimuli with and without the feature).
Data Analysis
Similar to Experiment 1, the ratings were standardized within each participant and were averaged across participants to obtain a faceness score for each image.
Results
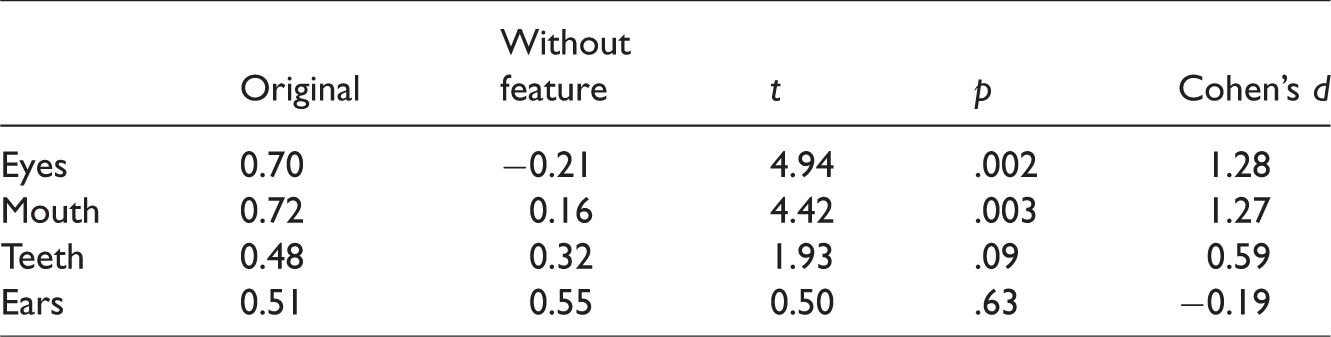
Paired t tests were performed to compare the faceness scores for images with and without the removed feature. Table 2 shows the original faceness scores and the scores of the same images without the removed feature. Removing the Eyes and Mouth significantly reduced the faceness scores (see Table 2). Removing teeth and mouth did not change faceness scores significantly. These findings therefore show the importance of both the eyes and mouth for detecting a face. When one of them is removed, faceness ratings are reduced significantly.
Averaged Faceness Scores (Standardized), Effect Size, and Paired t Tests for Images With and Without One Feature.
General Discussion
The goal of this experiment was to discover which features are critical for face detection. To answer this question, we used inanimate images that generated a strong percept of a face and examined the correlations across stimuli between the presence of 12 facial features and faceness scores based on human ratings. Results showed that the presence of the eyes or the mouth in the image is highly correlated with its faceness score. To further examine whether eyes and mouth are indeed critical for face detection, in a second experiment, we removed either the eyes or the mouth, or two features that were not correlated with faceness, the ears or the teeth, and measured faceness scores for the edited images. Results showed that removing the eyes or the mouth significantly reduced faceness scores, whereas faceness scores of images following the removal of the teeth or the ears were not significantly different from faceness scores of the original images. These findings confirm and extend the correlational findings, further showing that perceiving a face in an image depends on the presence of the eyes or the mouth in the image.
One limitation of Experiment 2 is that different images were selected for the removal of different features. This was necessary because most images did not have all the features that were selected for removal or in some cases removal of a feature distorted the image in a global way. Nevertheless, each picture was compared to itself, thus reducing the impact of this limitation. Furthermore, the faceness score of images after the removal of the non-critical features was much higher than the score for images after the removal of the critical features. Thus, removal of critical features resulted in a lower faceness score than removal of non-critical features, indicating that the smaller effect of removal of non-critical features was not due to floor effect.
Correlation analysis among the facial features (Figure 2) revealed high correlations between the eyes and mouth indicating that most images in our database that had eyes also had a mouth or had none of them. In Experiment 2, we were able to examine the contribution of the eyes and the mouth separately and found that removing one of them significantly reduced faceness scores. These findings are consistent with the regression model that estimates the unique contribution of each of the features. These findings suggest that images with either mouth or eyes do not generate a strong percept of a face, but it is the presence of both of these features that is required to generate a face.

Stimuli used in the four versions of Experiment 2 in which a critical feature (a, Eyes; b, Mouth) or a non-critical feature (c, Ears; d, Teeth) were removed from the stimuli. Participants rated these images for faceness together with the stimuli that were presented in Experiment 1 so the same context is used for the ratings of the images with and without the feature.Note: Please refer to the online version of the article to view the figures in colour.
The importance of the eyes and the mouth for face detection in face-like inanimate stimuli was recently shown in a study with human and monkey participants that revealed increase in looking time to inanimate stimuli that are perceived as faces than non-face stimuli (Taubert et al., 2017). This study also reported increased fixations to the eyes and mouth regions of these stimuli, thus indicating the central role of these features in the percept of a face. In another study, the same stimuli were presented to monkeys with amygdala lesions (Taubert et al., 2018). Results showed no bias towards faces than non-face stimuli for both real and inanimate faces. Furthermore, eye movements were not directed to the eyes and mouth for both of the face stimuli. These findings suggest an important role of the amygdala in directing attention towards faces, which is generalized also to inanimate stimuli based on the same subset of critical features.
Previous developmental studies have indicated that newborns look longer at figures with top heavy configuration such as a T-shape than an inverted T-like images (Macchi, Turati, & Simion, 2004). Our findings that the critical features are eyes and mouth may correspond to this general T-shape pattern showing that the highest faceness scores were mostly correlated with the presence of the eyes and the mouth in the image. This study, however, primarily focused on the presence or absence of facial features. Face detection also depends on certain spatial relations among features (a.k.a. first-order configuration) (Maurer, Grand, & Mondloch, 2002) that was not manipulated in this study. The list of features did include proportion, symmetry and frame, but these features refer to second-order relations among features. The role of face-like second-order relations was examined recently by Vuong et al. (2017), who interestingly found enhanced matching performance for non-face stimuli that presented face-like spatial relations of features. Thus, future studies may modify the relative locations of the critical features that we revealed to examine its influence on faceness scores.
Previous studies employed other methods to determine which features are critical for face perception. For example, Schyns, Bonnar, and Gosselin (2002) developed the bubble technique to reveal what minimal information is needed to determine the gender, expression or identity of a face (Schyns et al., 2002). Mangini and Biederman (2004) added different levels of noise to face stimuli and measured the noise patterns under which participants can determine gender, expression or face identity (Mangini & Biederman, 2004). Sekuler, Gaspar, Gold, and Bennett (2004) also added noise to determine which minimal information is used to determine face identity for upright and inverted faces (Sekuler et al., 2004). Our study used a very different approach and rather than concealing different areas of the face, asked subject to evaluate the presence of its different features and examine their correlation with rating of the whole face. The disadvantage of our technique is that it requires pre-selection of features, whereas the above-mentioned methods can reveal any feature, including features that have no semantic meaning. However, our method allows us to go beyond local features and to examine the contribution of features such as proportion, symmetry or frame. Furthermore, it allows us to assess the contribution of each feature in the context of the entire face, rather than the role of local features in the absence of information from the rest of the face.
In a recent study, we discovered facial features that are critical for the identity of the face (Abudarham & Yovel, 2016). These features include the hair, eyebrow thickness, eye size, eye color and lip thickness. Similar to the method used in this study, Abudarham and Yovel (2016) showed that replacing these features with features from faces of different identities, changes the identity of a face, whereas changing other features such as mouth size or eye distance, did not change the identity of a face (see also, Abudarham, Shkiller, & Yovel, 2019; Abudarham & Yovel, 2018). Interestingly, the top features that mostly contributed to faceness scores were the eyes, mouth, hair and eyebrows (see Table 1). Whereas features like proportion and nose, that are not critical for face identification, also did not contribute to faceness scores. This correspondence is surprising given that face detection depends on features that are shared among all face stimuli, but not with non-face stimuli, whereas face identification depends on features that are different between different identities but shared within an identity. It is noteworthy that faceness scores were correlated with the presence of these features, whereas face identification depends on the specific characteristics of these features such as size, length or brightness. These findings suggest that a system that is tuned to the presence of these features as well as to detailed measurements of their shape or brightness can perform both detection and identification.
In summary, we revealed that face detection depends on a broadly tuned mechanism that classify an image as a face based on relatively minimal information that corresponds to the presence of the eyes and the mouth in the image. Such a template may generate false face percepts but assures that a real face will not be missed in the dynamic, cluttered and complex visual environment that we live in.
Supplemental Material
Supplemental material for What Is a Face? Critical Features for Face Detection
Supplemental Material for What Is a Face? Critical Features for Face Detection by Yael Omer, Roni Sapir, Yarin Hatuka and Galit Yovel in Perception
Footnotes
Acknowledgements
The authors would like to thank Naphtali Abudarham for his feedback on this manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplementary Material
Supplementary material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.