
Abstract
The present study investigates whether obstruent voicing may or may not affect the imagery of different strengths of motor execution. In a modified version of the implicit association test, participants responded to discrimination tasks that include viewing static pictures of athletes in motion and hearing mono-syllabic linguistic sounds. The results suggest that voiced obstruents are compatible with the motion imagery that implies stronger motor executions, whereas voiceless obstruents are compatible with the imagery that implies weaker motor executions. These results provide experimental support for crossmodal associations between the auditory perception of linguistic sounds, namely, the voicing of obstruents, and the visually induced imagery of different levels of strength in motor actions.
Introduction
Crossmodal correspondence is a compatibility effect between attributes or dimensions of a stimulus in different sensory modalities. Most of the individuals share such effects, suggesting that crossmodal correspondence is the universal nature in human perception (Spence, 2011). The historical evidence for the existence of crossmodal correspondences has emerged from early studies of sound symbolism, which is defined as a crossmodal association between linguistic sounds and particular perceptual elements. The present study investigates a sound symbolic association between auditory perceptions of consonants and bodily motion imagery.
There are two major streams of research on sound symbolism concerning two visual dimensions of objects: size and shape. For size-related sound symbolism, previous research has demonstrated that smaller objects tend to be associated with front and high vowels such as [i], while larger objects tend to be associated with back and low vowels such as [a] or [o] (e.g., Shinohara & Kawahara, 2010; Thompson & Estes, 2011). For shape-related sound symbolism, many studies have attested to the associations between round shapes and sonorants, and between angular shapes and obstruents (e.g., Berlin, 2006; Nielsen & Rendall, 2013; Westbury, 2005).
There have been a number of proposals for the mechanisms to explain how certain phonemes come to be associated with particular perceptual features. Sidhu and Pexman (2017) suggest five possible mechanisms (see also, Spence, 2011 for crossmodal correspondences): (a) phoneme features statistically co-occurring with stimuli in the environment, (b) shared properties among phoneme features and stimuli, (c) overlapping neural processes, (d) associations developed through the evolutional process, and (e) language patterns. One or some of these mechanisms are suitable for accounting for sound symbolic associations with particular visual dimensions such as an object’s size and shape, but not for fully explaining those with other dimensions in vision, such as motion, or dimensions in other modalities.
Recent research has demonstrated that sound symbolism connects visually perceived kinematic properties of bodily motions with linguistic sounds (Imai, Kita, Nagumo, & Okada, 2008; Koppensteiner, Stephan, & Jäschke, 2016; Shinohara, Yamauchi, Kawahara, & Tanaka, 2016). This suggests that sound symbolism can go beyond the visual images of static sizes or shapes. However, the researchers have not yet answered how particular phonemes are associated not only with visually perceived dimensions of bodily motions but also with dimensions that we perceive through proprioception or kinesthesia during the execution of our own body movements. In the present study, we seek to propose a bodily-action basis account for sound symbolism. We believe the research focusing on motion-related sound symbolic phenomena will provide a new perspective for addressing the question regarding how proto-language evolved in ancestral hominids (Larsson, 2015).
Our current hypothesis originates from the idea that sound symbolic associations are caused by internally experienced sensorimotor mappings between the articulator and the body movements (Ramachandran & Hubbard, 2001; Vainio, Schulman, Tiippana, & Vainio, 2013). If this is the case, there should be an association between particular features of phonemes and sensorimotor representations (e.g., powerfulness, smoothness, sense of speed, etc.) resulting from executing body movements. For instance, Vainio et al. (2013) demonstrate that pronouncing the mono-syllable [mɑ] evokes quicker reactions for the power grip, such as grasping, while pronouncing the mono-syllable [pu] induces quicker reactions for the precision grip, such as pinching. Although the authors explain such associations based on the similarity of mouth-hand shaping (i.e., wide vs. narrow apertures), this result would also suggest that consonants—[m] and [p], in this case—might connect with stronger or weaker motor executions of the hand muscles in the performance of power or precision grips, respectively. Shinohara et al. (2016) address the effect of consonants more clearly, demonstrating that voiced obstruents, compared with voiceless ones, are more likely to be associated with a large amplitude of hand gestures than a small amplitude of hand gestures. Biomechanically, to perform the larger action in space requires larger muscular force compared with less muscular force required to perform the smaller action. Combining these previous insights on sound symbolism with biomechanical facts, we hypothesize that voiced or voiceless consonants can be associated with different strengths of bodily motor executions.
For the present study, we used a modified version of the implicit association test (IAT; Greenwald, McGhee, & Schwartz, 1998) to test this hypothesis. The IAT has been previously applied to research on sound symbolism and crossmodal correspondence (e.g., Lacey, Martinez, McCormick, & Sathian, 2016; Parise & Spence, 2012). In such studies, the IAT has proven to be a useful tool for studying the implicit or explicit associations between different sensory modalities. The rationale behind the original version of the IAT is that participants’ performance improves in a sped-up discrimination task when the same response key is assigned to a set of associated stimuli (the compatible condition), while their performance would be poorer or would not improve when the same key is assigned to a set of unrelated stimuli (the incompatible condition).
To determine whether voiced or voiceless consonants may be associated with sensorimotor representations regarding the strength of motor execution, we performed the IAT experiment based on an implied motion paradigm. We presented participants with a random sequence of unimodal visual targets (i.e., static pictures of athletes in motion) and unimodal auditory targets (i.e., vocal sounds of mono-syllables). Because studies have shown that static images of an object in motion can evoke an image of its dynamic motion (i.e., the implied motion phenomenon; Freyd, 1983), we assume that static pictures of athletes in motion can evoke images of their bodily motion. Based on these assumptions, we expected faster reactions for compatible conditions—voiced obstruents /b, d, g, z/ with the images implying stronger motor executions, or voiceless obstruents /p, t, k, s/ with the images implying weaker motor executions—than for incompatible conditions. The places of articulation for these eight consonants were controlled across the voiced and voiceless obstruent groups.
Method
Preparation of Materials
Auditory stimuli
The auditory materials were mono-syllabic sounds in Japanese. A male native Japanese speaker read aloud eight mono-syllables—/ba, da, ga, za/ for the voiced obstruent group (hereafter +Voice) and /pa, ta, ka, sa/ for the voiceless obstruent group (hereafter –Voice)—into a microphone (ECM-PCV80U, SONY, Japan). These sounds were recorded on a computer at a sampling rate of 44.1 kHz with 16-bit resolution. They were edited into separate sound files with an utterance duration of approximately 350 ms. The intensity of all the syllables was modified to 75 db. The recordings and modifications of the sounds were made with Praat software Version 6 (http://www.praat.org, Netherlands).
Visual stimuli
First, 20 static photographs, each showing an athlete performing a typical action in a well-known sport, were collected from a website. The first author obtained a license to use these digital photographs (Getty Images, http://www.gettyimages.com). The 20 photographs were tested in a preliminary investigation where 62 participants (9 females and 53 males, mean age of 19.9 years) graded the athlete’s action in each photograph on a 5-point semantic differential scale ranging from 1 (very weak execution) to 5 (very strong execution). Their judgment was based on their intuition of the amount of strength the athlete seemed to be exerting in order to execute the sport’s action. Using the ratings, we selected 16 photographs as the sources for the target visual stimuli: Eight photographs that received relatively lower scores (mean = 2.5) were served for stimuli of the weaker motor execution category (hereafter referred to as Weak-Image) and eight photographs that received relatively higher scores (mean = 4.2) were served for those of the stronger motor execution category (hereafter referred to as Strong-Image). Irrelevant backgrounds surrounding the athletes in the photographs were partially cropped, and the image sizes were adjusted so that the athletes’ actions fit within a black frame of 640 × 640 pixels. To minimize the effect of color on the participants’ responses, all pictures were transformed into grayscale images (see Figure 1 for sample photographs).

Samples of the visual target stimuli for the weaker motor execution category (left) and the stronger motor execution category (right).
Design of the IAT Tasks
The IAT consisted of five discrimination tasks that were performed in blocked design: one for visual, two for auditory, and two for visual-auditory mixed stimuli conditions. The three unimodal conditions were implemented as practice blocks for the two mixed stimuli conditions. In each task, the participants were asked to determine which of two predetermined categories a presented stimulus belonged to, and then to press one of two keys, which was assigned for each category. The predetermined categories were as follows.
In the visual condition block, the participants performed a discrimination between the two image categories: Strong-Image versus Weak-Image. The key assignments for the two image categories were identical throughout the IAT blocks for each participant.
In one block for the two auditory conditions, they performed a discrimination between the two sound categories: +Voice versus –Voice. The other auditory block was similar to this, but the response key assignments were reversed for the two sound categories (i.e., reversed auditory condition).
In one block for the mixed stimuli conditions, either the target sound or the target image was presented in each trial. Thus, the participants performed a discrimination between +Voice and –Voice or between Strong-Image and Weak-Image. For this task, the key assignments were compatible with our hypothesis (i.e., compatible condition). That is, one key was assigned for both +Voice and Strong-Image, while the other key was assigned for both –Voice and Weak-Image. In the other mixed stimuli block, the key assignments were incompatible with our hypothesis (i.e., incompatible condition): One key was assigned for both +Voice and Weak-Image, while the other key was assigned for both –Voice and Strong-Image.
In the two blocks for the mixed stimuli conditions, test trials were divided into two subblocks to avoid fatigue. Each subblock contained half of the 16 images from the visual condition block.
Apparatus
The presentation of the stimuli and the collection of responses were controlled by a personal computer running an IAT application program that was originally developed using commercial software (LabVIEW version 2015 for Windows, National Instruments, USA). The visual target stimuli were presented on a 21-in. LCD display with a resolution of 1920 × 1080 pixels and a refresh rate of 60 Hz. For the auditory target stimuli, a high-quality audio head-phone (MDP-XB500, SONY, Japan) was used.
Participants
Twenty native Japanese speakers (5 females and 15 males, 18–22 years old) participated in the experiment after providing written informed consent. All participants reported normal or corrected normal vision and audition. All of the participants were right handed according to the Edinburgh Handedness Inventory (Oldfield, 1971) and were naïve to the experiment. All procedures for this experiment were approved by the ethics review board of the first author’s institution (#27-04).
Procedure
The experiment was conducted in a quiet, dimly-lit room. The participants sat in front of the computer display. They were instructed to focus on the center of the display and were then asked to respond to each stimulus by pressing one of the two keys on a computer keyboard as rapidly and as accurately as possible. They were instructed to press the “z” key on the QWERTY keyboard using the left index finger and the “2” key of the numeric keypad using the right index finger. The two keys were on the same row of the keyboard. Their index fingers remained atop the two keys during the IAT task.
Figure 2 illustrates the sequence of the stimulus presentations. Each trial began with the presentation of a red fixation point at the center of the display for a randomized interval of 250 to 350 ms. After the removal of the fixation point, a random interstimulus interval of 250 to 350 ms followed. Next, a target stimulus was presented. An auditory stimulus (sound) was presented via the participant’s head-phone, and a visual stimulus (image) was presented at the center of the display. No image appeared at the each auditory stimulus lasted approximately 350 ms. Each visual target stimulus remained on the display for 350 ms before it was removed. When a participant gave an incorrect response, a red cross appeared on display and remained there for 500 ms. An intertrial interval of 1000 ms was given following the completion of each trial routine.
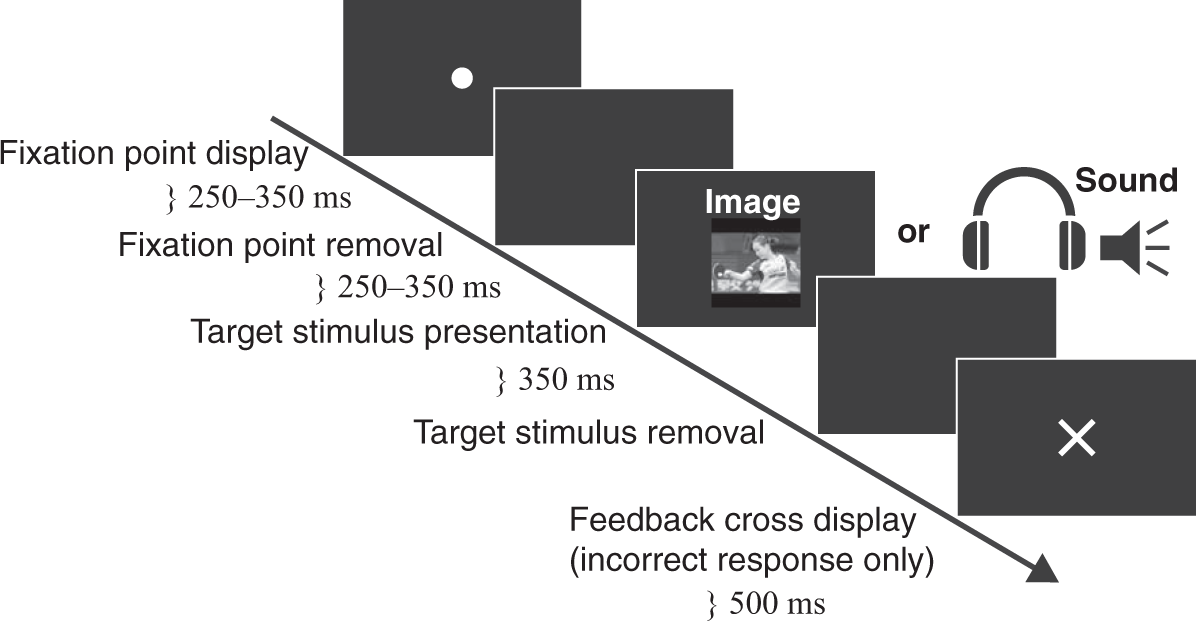
Schematic illustration of a sequence of the stimulus presentations for each trial. An auditory stimulus (sound) was given via a head-phone. A visual stimulus (image) was presented on a display. Either an image or a sound was given during one trial sequence. No image appeared on the display when the sound was given.
At the beginning of each task block, the participants were given instructions that included mappings between the target stimuli and the appropriate responses to be memorized (i.e., the predetermined stimulus categories and the keys assignments). In each task block, the target stimuli for one of the two categories were assigned to either the “z” key or the “2” key. The target stimuli for the other category were assigned to the other response key. These key assignments were shown to each participant on the display using figures that had (a) the mono-syllabic Japanese sounds represented by Katakana orthography (e.g., カ for /ka/ sound) and the keys to be pressed and (b) the visual images consisting of all visual target stimuli and the keys to be pressed.
Half of the participants performed the IAT tasks in the order of auditory, visual, compatible, reversed auditory, and incompatible conditions, while the other half performed those in the order of reversed auditory, visual, incompatible, auditory, and compatible conditions. The “z”- and “2”-key assignments for the stimulus-response mappings were counterbalanced between the participants.
At the beginning of each block and each subblock, the participants practiced task trials until they were certain of the target- response mapping. In the test trials, the target stimuli were presented in pseudo-random order and repeated three times within the task block. The total number of test trials were 24 (8 Sounds × 3 Trials) for the two auditory conditions, 48 (16 Images × 3 Trials) for the visual condition, and 96 ([8 Sounds + 8 Images] × 3 Trials × 2 Subblocks) for the mixed conditions. The participants rested between the task blocks. The reaction times (RTs) and the error rates (ERs) which were percentages of incorrect responses with respect to the total responses were collected automatically.
Statistical Analysis
A one-way repeated measures analysis of variance (ANOVA) with the five condition task blocks as the within-participants factor was conducted for the ERs and the mean RTs that had been calculated for each participant. For RTs, when a significant main effect of the task factor was found, two-way repeated measures ANOVAs were performed with two factors: compatibility (compatible vs. incompatible conditions) and modality, whose factor consisted of the visual target trial subset and the auditory target trial subset in these two task blocks. For all repeated measures ANOVAs, a Greenhouse–Geisser correction was applied when the assumption of sphericity was violated.
Results
The individual means of RTs for one participant were larger than three standard deviations from the group means. Thus, all data obtained from this participant were excluded from the analysis. Incorrect responses and outliers, that is, the RTs that fell three standard deviations above or below the individual means or were smaller than 400 ms, were also excluded from the RT analysis. In the current experiment, 6.6% and 1.0% of all the trials were removed as errors and outliers, respectively.
Table 1 shows group means and standard deviations of RTs and ERs for each task block. One-way repeated measures ANOVAs revealed that the task block factor had no significant effect on the ERs, F(2.82, 50.67) = 1.30, p = .26,
Means and Standard Deviations of RTs and ERs for Each Task Block.
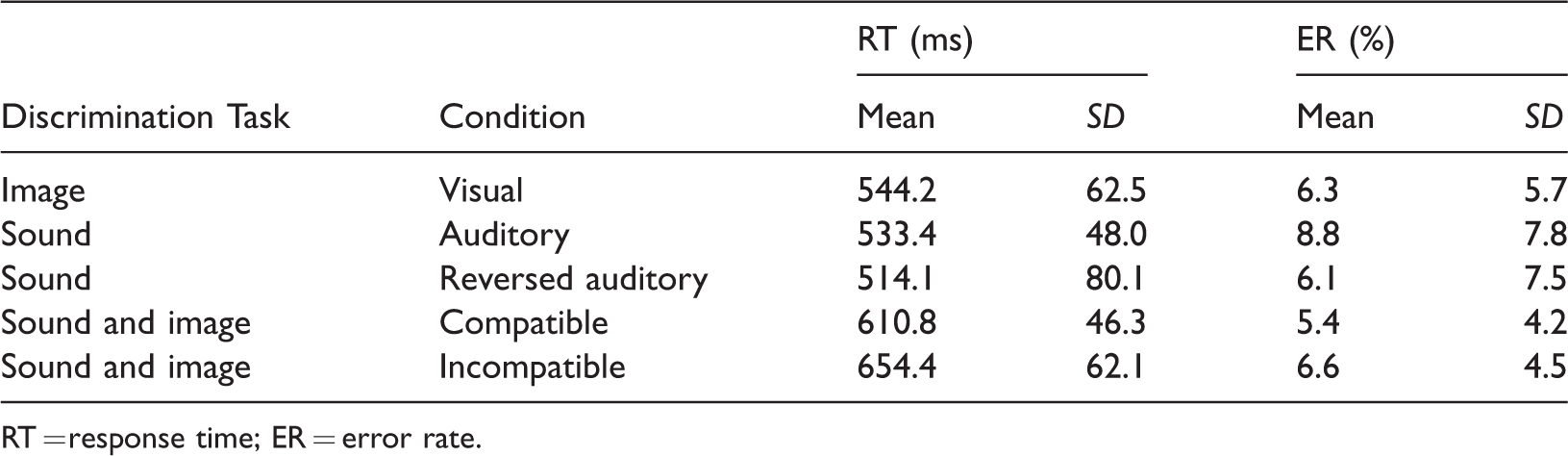
RT = response time; ER = error rate.
The task block factor had a significant effect on the RTs, F(2.54, 45.86) = 35.86, p < .001,
Figure 3 shows the differences between compatible and incompatible conditions more clearly. A two-way repeated measures ANOVA revealed that compatibility had a significant effect on the RTs, F(1, 18) = 23.89, p < .001,

Mean RTs for the modality subsets in the compatible (Comp) and incompatible (Incomp) condition blocks. Error bars represent the standard errors of the mean across participants. *p < .005.
Discussion
As predicted, voicing in obstruents significantly affected the discrimination process of the relative strength of the motor executions. Specifically, the RTs for the combination of voiced obstruents and stronger motor executions or the combination of voiceless obstruents and weaker ones were shorter than those for the reversed combinations. Because the IAT compatibility effect indicates associations between the crossmodal target categories (Parise & Spence, 2012), this result provides new behavioral evidence to support the existence of motion-sound symbolic associations between voicing in obstruents and the imagery of the relative strength of physical motion.
Previous studies have demonstrated that dynamic properties of auditory stimuli such as continuous changes in pitch and speaking rates tend to be associated with motion imageries (Maeda, Kanai, & Shimojo, 2004; Shintel & Nusbaum, 2007). In the present study, the pitch and speaking rates were controlled between the sound stimuli. Thus, the crossmodal effect found between motion and sound may be attributable to two salient differences between the voiced and voiceless obstruents. Acoustically, voiced obstruents, as compared with voiceless ones, have a lower first formant frequency (F1) and a lower fundamental frequency (F0) at the edges of flanking vowels (Kingston & Diehl, 1995). In articulation, voiced obstruents require the vibration of the vocal folds with a closure period, while voiceless obstruents are not accompanied by this type of vibration of the vocal folds. Voiced obstruents also have larger tensile stresses of vocal folds with vibrations.
At least two different mechanisms may be responsible for establishing the motion-sound symbolic associations: (a) natural statistics including simple co-occurrence of action events and (b) correspondence in the magnitude of brain activity. Hitting larger objects produces bass sounds, which are likely to have lower frequencies. Larger objects afford stronger motor executions of actions so that we expect large objects to be heavier than small objects (Buckingham & Goodale, 2010). Such statistical co-occurrences of action events might induce a linkage between the voiced or voiceless obstruents (i.e., lower or higher frequencies of F0 and F1 of flanking vowels) and stronger or weaker motor executions, respectively.
Another possibility is that both stronger motor executions and larger tensile stresses of vocal folds with vibrations might induce more brain activity. When an individual listens to verbal stimuli, there may be an activation of the speech-related motor center (Fadiga, Craighero, Buccino, & Rizzolatti, 2002). Observing motor actions may activate the motor circuits that are involved in producing such movements (Rizzolatti, Fadiga, Gallese, & Fogassi, 1996). When inputs to these two systems are compatible, neural processing might be facilitated, resulting in a shorter RT. Viewing images of stronger motor executions may also activate the observer’s motor centers in a way that may be compatible with hearing voiced obstruents.
The limitation of the present study is that we confined the sample to Japanese-native speakers. The Japanese mimetics system exhibits systematic correspondences between voiced or voiceless consonants and the image of heaviness or lightness, respectively. Perceptual dimensions of heaviness or lightness originate from the magnitude of muscular force when it is acting on an object or the body. Thus, the relationship between the stronger or weaker executions of actions and voicing in obstruents might depend on the Japanese mimetics system. Cross-linguistic studies are necessary to address this issue.
Footnotes
Acknowledgement
The authors really appreciate the constructive comments made by the anonymous reviewers of the first version of our manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
Acknowledgements
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by a Grant-in-Aid for Challenging Exploratory Research from Japan Society for The Promotion of Science (Grant No. 15k12653) to N. Y. and (Grant No. 16K12990) to H. T.