
Abstract
Two photos of an unfamiliar face are often perceived as belonging to different people—an error that disappears when a face is familiar. Face learning has been characterized as increased tolerance of within-person variability in appearance and is facilitated by exposure to such variability (e.g., differences in expression, lighting, and aesthetics). We hypothesized that increased tolerance of variability in appearance might lead to reduced discrimination and that misidentifications would be reduced if a face was learned in the context of a similar-looking identity. After validating our stimuli (Experiments 1a and 1b), we conducted three experiments investigating face learning. In two of these, participants learned three faces (Experiment 2: 15 images/identity and Experiment 3: 5 images/identity), two of which were similar. In a recognition task, misidentifications did not change as a function of similarity, although participants recognized more images of the target in Experiment 2 (i.e., after learning 15 images). In Experiment 4, participants learned one identity and the number of images studied varied across groups. Recognition of new images increased with the number of images studied, with no changes in false alarms; sensitivity (A′) marginally increased. The results suggest that recognition and discrimination reflect separable processes with minimal influence of between-person similarity on discrimination.
Modern society is heavily reliant on government-issued ID (e.g., passport, driver’s license), a practice driven by the misconception that we are experts at recognizing faces. Whereas we accurately recognize novel instances of familiar faces and discriminate them from similar-looking individuals, these tasks are much more difficult for unfamiliar faces. Two images of the same person can appear to belong to two different people, and images of two different people can appear to belong the same person.
Sorting tasks are especially sensitive to the challenge of recognizing that multiple images belong to the same person. Jenkins, White, Van Montfort, and Burton (2011) asked participants to sort a deck of 40 face photographs (showing natural variability in appearance), such that each pile contained only one identity. Unknown to the participants, the deck contained 20 images of each of two people. When sorting images of familiar faces, participants correctly made two piles. When sorting images of unfamiliar faces, participants created multiple piles (median = 7.5); they perceived multiple identities—a pattern of overdiscrimination. Jenkins et al. proposed that a hallmark of familiarity was the ability to recognize an identity despite variability in appearance. Past research had underestimated the challenge of recognizing unfamiliar faces by using highly controlled stimuli.
Although tolerating within-person variability in appearance is one hallmark of familiarity, so too is the ability to discriminate between identities. Misidentification errors (placing photos of two different people into the same pile) are rare in sorting tasks (see Jenkins et al., 2011)—even when faced with the challenge of sorting images of other-race faces (Zhou & Mondloch, 2016). Minimal misidentification errors suggest that discriminating between unfamiliar identities is relatively easy. However, misidentification errors are common in other tasks, including same/different tasks (Proietti, Laurence, Matthews, Zhou, & Mondloch, 2018), old/new recognition tasks (Bruce, 1982; Klatzky & Forrest, 1984), and lineup tasks (Megreya & Burton, 2006), especially on target-absent trials (Matthews & Mondloch, 2018a). Misidentification errors are also shown by trained professionals when matching individuals to face photographs (White, Kemp, Jenkins, Matheson, & Burton, 2014). Such findings suggest that the probability of failing to discriminate identities is very task-dependent. These errors are especially costly, as they can lead to false incarceration in the legal system. In fact, misidentifications played a role in the wrongful conviction of approximately 75% of individuals exonerated by “The Innocence Project” (2016). Thus, face learning must involve both increased tolerance to within-person variability in appearance and improved sensitivity to differences between identities such that new instances of a familiar identity are recognized while misidentifications remain, or become increasingly, rare. Here, we investigated what constrains misidentifications while tolerance to within-person variability increases.
Exposure to multiple images of a face facilitates tolerance to within-person variability in a variety of task conditions. Participants better recognize new images of an identity in an old/new recognition task after viewing multiple static images or a video of that person as compared with after viewing a single image (Baker, Laurence, & Mondloch, 2017; Murphy, Ipser, Gaigg, & Cook, 2015). Likewise, after learning the face-name pairs of several identities, participants are more accurate on match trials (when the presented name matches the face) after being exposed to high-variability images than after being exposed to low-variability images (Ritchie & Burton, 2017). Participants perform more accurately on match trials (when presented with two different images of an identity) when they are shown multiple images of the target identity than when shown a single image (White, Burton, Jenkins, & Kemp, 2014) and they are more accurate in locating a novel image of a target identity in a large array after having been exposed to multiple images (containing variability in appearance) of the target than after being exposed to a single image (Dowsett, Sandford, & Burton, 2016; Matthews & Mondloch, 2018a).
However, exposure to multiple images does not always improve discrimination. In the aforementioned studies, errors of discrimination (i.e., false alarms in old/new and lineup tasks; errors on mismatch trials on name-face matching tasks and same/different tasks) often remained unchanged (Murphy et al., 2015; Ritchie & Burton, 2017; White, Burton, et al., 2014); such errors occurred on approximately 15% to 20% of trials. False alarms necessarily decrease as accuracy increases when a target is present in a large array (Dowsett et al., 2016); however, false alarms increase on target-absent trials following exposure to multiple images of the target identity (Matthews & Mondloch, 2018a), suggesting that exposure to multiple images of an identity can increase misidentifications. The aim of this study was to examine what promotes improved discrimination in the context of face learning. To do so, we turned to one conceptualization of how we mentally represent faces: Valentine’s (1991) multidimensional face space (MDFS) model.
Valentine (1991) proposed that faces are represented in an MDFS, with each vector representing a dimension along which faces vary (e.g., distance between the eyes, nose length). The location of each identity is determined by its values on each dimension, with similar faces lying in close proximity to one another. Valentine’s model provides a powerful account for differential discrimination across face categories (e.g., typical vs. distinctive faces; own- vs. other-race faces). Tanaka and colleagues argued that each identity is not represented by a single point in face space, but by an attractor field—a region within MDFS that reflects the range of inputs that are perceived as belonging to a given identity (Tanaka, Giles, Kremen, & Simon, 1998; Tanaka & Corneille, 2007; see Lewis & Johnson, 1999, for a similar argument based on Voronoi regions). The size of an identity's attractor field is constrained by the density of nearby representations (i.e., by its location in MDFS); any overlap of attractor fields would lead to misidentification errors (Tanaka et al., 1998). Attractor fields provide one conceptualization of our ability to recognize facial identities despite changes in appearance (e.g., in expression, hairstyle, point of view or lighting). A related conceptualization has been proposed by Burton, Kramer, Ritchie, and Jenkins (2016) who argue that each face is represented in a person-specific coding space, the dimensions of which capture idiosyncratic within-person variability in appearance. This model is agnostic as to the role of a between-person face space but also requires that perceivers learn both the variability in appearance that does belong to that identity (for recognition) and variability that does not (for discrimination).
One conceptualization of face learning, then, is that exposure to multiple different images of a face increases the size of its attractor field, increasing tolerance to within-person variability in appearance. If the size of an attractor field is limited by near neighbors (NNs) in MDFS, then learning a new face in the context of an NN might reduce misidentification errors. We directly tested this prediction in three experiments.
In two experiments, participants learned three new identities in the context of a sorting task adapted from the incidental learning paradigm used by Andrews, Jenkins, Cursiter, and Burton (2015). Two identities (NN) were similar in appearance and one identity was dissimilar to the other two (far neighbor [FN]). Participants sorted 45 images (15 per identity; Experiment 2) or 15 images (5 per identity; Experiment 3) into three piles based on identity. After the sorting task, participants completed a recognition task in which images of two learned identities (one NN and the FN) were intermixed with similar distractors. We predicted that learning an identity in the context of an NN would provide a more precise representation. Specifically, we hypothesized better sensitivity (higher A′) for the NN as compared with the FN, an effect that we predicted would be driven by a reduction in misidentifications (i.e., false alarms). In the final experiment (Experiment 4), each participant learned only one identity with the number of images studied varying across participants; we measured the influence of number of images on A′, hits, false alarms (FAs), and bias (B′′). Prior to conducting the main experiments (Experiments 2–4), we conducted two experiments (Experiment 1a and Experiment 1b) to validate the stimuli.
Experiment 1a
The aim of Experiment 1 was to validate our stimuli by confirming that we had two distinct sets of eight identities, such that the identities within Set A were more similar to each other (i.e., NNs in multidimensional space) than to all of the identities within Set B (i.e., FNs), and vice versa. In Experiment 1a, participants viewed pairs of images. Each pair comprised two images of the same identity, images of identities that belonged to the same set (Set A or Set B), or images of identities from different sets (i.e., an image of an identity from Set A and an image of an identity from Set B). After viewing each image pair, participants rated their similarity. We predicted that NN pairs (images from the same set) would be rated as more similar than FN pairs (images from different sets) but less similar than two images of the same person.
Methods
Participants
Twenty-two Caucasian Brock University students (all females; Mage = 19.68, SD = 1.84) participated in Experiment 1a. One additional participant was excluded from the final analyses, as they only completed a subset of the trials. Participants in this and all subsequent experiments were unfamiliar with the identities used (as confirmed by a familiarity questionnaire), gave informed consent prior to participation, were debriefed after task completion, and compensated for their time with $5 (Canadian) or psychology course participation credit.
Materials
Thirty images of eight European and Australian celebrities (Set A: Louise Thompson, Janina Uhse, Lucy Watson, and Erin Mcnaught; Set B: Hanna Verboom, Gigi Ravelli, Nora Amezeder, and Chantal Janzen) were gathered via a google search. All photographs were color images and had a roughly frontal view of the model’s face. Each image was edited in photoshop to be 50 mm by 70 mm in size (as in Jenkins et al., 2011). The images comprised naturalistic photographs taken on different days and different occasions; hairstyle, make-up, expressions, camera, and lighting all varied. The program was created using PsychoPy version 1.84.2 (Peirce, 2007) and was run on a Macintosh MacBook Pro; all images (4.5 × 5.5 cm) were presented on an LG monitor (21 × 12 in.), and participants were seated approximately 55 cm away from the monitor.
Procedure
As shown in Figure 1, participants performed a computerized rating task in which two images were simultaneously presented on the screen. Participants were asked to rate the level of similarity on a scale from 1 (not similar) to 7 (very similar). Similarity was defined to participants as they could potentially think of the two images as belonging to the same individual. The images and scale remained on screen until a response key was pressed. There were three trial types: same-identity trials (same-ID pairs), NN trials (NN pairs), and FN trials (FN pairs). Each participant completed 256 trials. The image pairs shown varied across participants and were randomly selected on each trial with the constraint that for any given participant there could be no more than 33 same-ID pairs overall, no fewer than 84 NN trials, and no fewer than 115 FN trials.
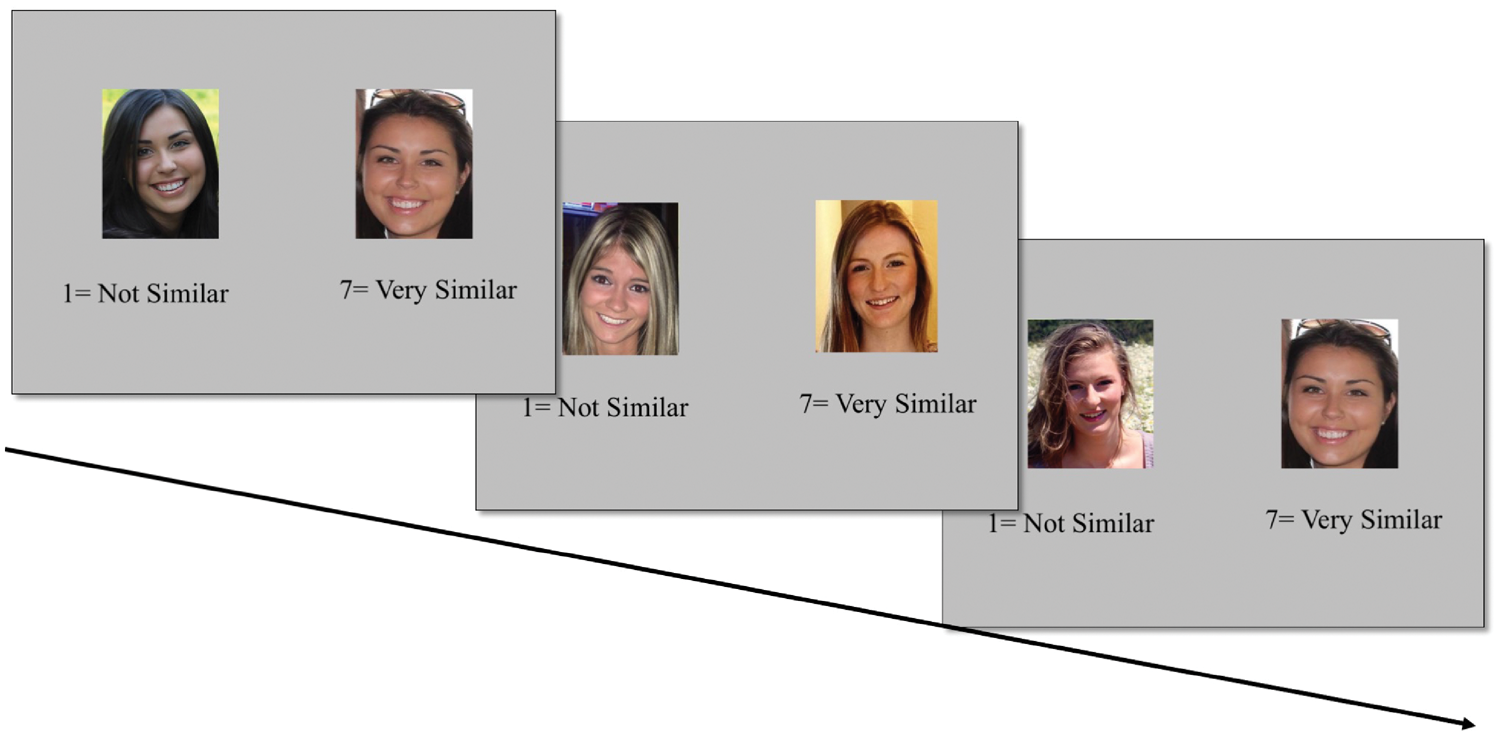
Depiction of three trials (from left to right: same-ID, NN, and FN) presented in the similarity rating task (Experiment 1a). Copyright restrictions prevent publication of the actual images used.
Results and Discussion
As shown in Figure 2(a), similarity ratings validated our stimulus set. A repeated-measures analysis of variance (ANOVA) revealed a significant effect of trial type, F(2, 42) = 203.93, p < .001,

(a) Depiction of mean similarity rating (collapsed across identity) for each trial type. Error bars represent 95% confidence intervals and are corrected for within-subject error. (b) Similarity ratings for each identity separately such that each square depicts the average similarity rating for each pairing. Identities from Set A are labeled 1 to 4 and identities Set B are labeled 5 to 8. The upper diagonal shows ratings for same-ID pairings and the low-left square shows between-set pairings. As shown by the color bar, the strength of similarity rating is represented by each square’s color (higher similarity ratings are shown in warm colors and lower similarity ratings cool colors).
Having confirmed these sets, we conducted a second experiment (Experiment 1b) to examine the frequency of misidentification errors (i.e., mistaking one identity for being another) when the two identities were NNs versus FNs. We predicted that misidentifications would be more frequent for similar identities and less frequent for dissimilar identities.
Experiment 1b
Methods
Participants
Twenty-three Caucasian Brock University students participated in Experiment 1b (n = 1 male; Mage = 19.40, SDage = 1.64). An additional 10 participants were removed because they did not complete the questionnaire (n = 2), misidentified one of the three identities as someone they knew (n = 6), or were outliers (n = 2). 1
Procedure
The images from Experiment 1a were printed in color (50 mm by 70 mm in size) on white card stock. Participants were randomly assigned to sort images of three identities (two were NNs and one was an FN) from Experiment 1a. Identities were counterbalanced such that each identity was an NN and an FN an equal number of times. Participants were given a stack of 45 face photographs and were asked to sort the photographs based on identity. Although participants were informed that the stack of photos contained three identities, they were not informed that each identity was represented by 15 images. Participants were told that they could take as much or little time as needed to sort the photos. The researcher then took a picture of the final sorting product (via an Eos Rebel T3i Canon Digital SLR) to record participant performance.
Results and Discussion
Perfect accuracy would be reflected in 45 correct identifications, such that each of three piles contained 15 images of one identity. Images of an identity that were included within a pile primarily containing another identity were considered to be intrusion errors. On average, participants made 4.09 intrusion errors. As shown in Figure 3, the vast majority (91%) of intrusion errors involved NNs (M = 3.74, SD = 3.99) rather than FNs (M = 0.35, SD = 0.57). A paired-samples t test revealed that this difference was significant, t(22) = 4.06, p = .001, d = 0.85. 2

Depiction of the mean number of intrusion errors for each misidentification type (misidentifications between dissimilar identities versus misidentifications between similar identities) in the sorting task (Experiment 1b). Error bars represent 95% confidence intervals corrected for within subject error.
Collectively, the results from Experiments 1a and 1b validated our stimuli. The identities within each set (Set A: Louise Thompson, Janina Uhse, Lucy Watson, and Erin Mcnaught; Set B: Hanna Verboom, Gigi Ravelli, Nora Amezeder, and Chantal Janzen) are more similar to each other than to each of the identities from the other set.
Experiment 2
In Experiment 2, we examined whether learning an identity in the context of a similar looking identity promotes a more refined representation (i.e., accurate between-identity discrimination with increased tolerance to within-person variability in appearance). Participants learned three identities in an incidental learning task. Two identities were similar (i.e., NNs in MDFS) and one was dissimilar (an FN in MDFS). Images were presented sequentially, and participants were asked to indicate to which of the three identities each image belonged—a task that required attending to the similarities across images within each identity while discriminating between them. In the test phase, new images of the FN and one of the NNs were intermixed with images of other women; participants indicated whether each image belonged to the FN, the NN, or a different person. We predicted that learning a face in the context of a similar identity would constrain the amount of within-person variability tolerated, limiting misidentifications. Thus, we hypothesized that participants would show greater sensitivity (A′) for the NN compared with the FN, and that the difference in sensitivity would be driven primarily by a reduction in FAs.
Methods
Participants
Forty Caucasian Brock University students participated in Experiment 1 (n = 4 males; mage = 19.78, SDage = 2.96). An additional 11 participants were excluded from the analyses because they failed control trials (n = 4; see materials) or because of experimenter error (n = 7; i.e., program crash: n = 1, wrong identity presented as target: n = 6).
Stimuli
The stimuli from Experiments 1a and 1b were used in Experiment 2. This experiment was programmed using PsychoPy version 1.84.2 (Peirce, 2007) on a Macintosh MacBook Pro; all images (sorting and anchor images: 4 × 5 cm; test phase images: 5 × 6.5 cm) were presented on an LG monitor (21 × 12 in), and participants were seated approximately 55 cm away from the monitor.
Procedure
Sorting task
Participants were randomly assigned to learn three identities, two of which (NN target and NN nontarget) were from one set (e.g., Set A) and one of which (FN) was from the other set (e.g., Set B). Participants were familiarized with the identities in a computerized sorting task (adapted from Andrews et al., 2015) in which they sorted 45 images (15 per identity). These images were randomly selected from the initial set of 30 (per identity) for each participant.
Participants were informed that both their accuracy and response times (RT) would be recorded. As seen in Figure 4(a), the sorting task began with three Target Anchor images (one per identity) at the top of the screen. Each image was paired with a name and the corresponding response key (Jenna, “j”; Suzy, spacebar; and Fiona, “f”). This created three sections on the screen, such that each section was representative of one to-be-learned identity. On each trial, an image was presented in the bottom-center of the screen for 15 seconds. During this time, all previously presented images were visible. After 15 seconds, a cue (red frame) appeared around the image indicating that participants had 5 seconds to make their response. Our use of a computerized version of the sorting task allowed us to avoid any possible influence of confusion errors on participants’ representations of the identities. Independent of the participant’s response, each image was placed in the correct location on the computer screen (i.e., with other images of the same identity) and remained there throughout the sorting task.

A depiction of the sorting task (a) and recognition task (b). Copyright restrictions prevent publication of the actual images used.
Recognition task
Prior to beginning the recognition task, participants were allowed a brief study period (60 seconds) designed to increase the accuracy of the target identities’ representations. During this time, all images of the NN target and FN target were present, but NN nontarget images were removed. The images assigned to Jenna and Fiona always served as test stimuli, but which identities were assigned to those labels was randomized across participants.
Following the study period, participants’ recognition of the NN target and FN was tested in a three-alternative forced-choice task. Participants were asked to recognize novel images of these two target identities when intermixed with unlearned similar distractors; the similar distractors for each target identity comprised 15 images of an identity from the same set (excluding the NN nontarget). As shown in Figure 4b, on each trial, participants indicated if the image belonged to the NN target (i.e., Jenna, response = “j”), the FN target (i.e., Fiona, response = “f”), or neither (response = “space”). To verify that participants were attentive during the learning phase, we also presented 10 control stimuli comprising five learned images of each target identity. Participants were required to recognize four of these images per identity to be included in analyses; only four participants failed to do so. In short, 70 images were presented during the recognition task: 30 new images of the learned identities (15 per identity), 30 images of similar distractor identities (15 per identity), and 10 control stimuli. Participants were asked to perform the task as quickly and as accurately as possible.
Results and Discussion
Sorting task performance
A repeated-measures one-way ANOVA was conducted to examine whether performance (i.e., number of images correctly identified) during the sorting task differed across identity types (NN target, NN nontarget, and FN). Mauchly’s test of sphericity was violated, p = .04. Therefore, Greenhouse–Geisser corrections are reported. The majority of images were sorted accurately (Mprop correct = 0.88, SD = 0.10). The number of correctly identified images differed as a function of similarity, F(1.73, 67.56) = 9.24, p = .001,
Recognition task performance
All participants recognized at least four of the five control images for each identity, with 30 of the participants performing without error. All subsequent analyses were based only on the 60 test stimuli. Consistent with Experiment 1b, very few misidentifications involved confusions between the two targets (3.82%) or misidentifying a distractor from one face set as belonging to the target from the other set (0.64%). These responses were excluded from all analyses.
A′ provides a measure of overall sensitivity, but hits (recognizing a new image of a target identity) and false alarms (misidentifying an image of a distractor as belonging to a target identity) provide unique information. A higher A′ score might reflect increased tolerance of within-person variability (i.e., hits) and/or a decrease in misidentifications (i.e., FAs). Because we hypothesized that learning a face in the context of an NN might constrain the amount of variability tolerated (i.e., reduce FAs), we analyzed these two components separately.
As shown in Figure 5 and in Supplemental Table (ST) 1, performance in the recognition task did not differ between the NNs and FNs. Preliminary inspection of the data revealed that participants made a large number of hits, but that FAs were rare. As such, we analyzed our data using A′ as a measure of sensitivity rather than d′ and with B′′ as a measure of bias rather than criterion. Perfect performance for a learned identity would be reflected in an A′ score of 1.00 and wholly unbiased performance would be reflected by a B′′ score of 0. Paired-samples t tests showed that sensitivity (A′) for NNs (M = 0.94, SD = 0.07) and FNs (M = 0.91, SD = 0.11) did not significantly differ, t(39) = 1.15, p = .26, d = 0.18. 3 Moreover, the proportion of hits (Mnear = 0.88, SD = 0.13; Mfar = 0.88, SD = 0.13), the proportion of FAs (Mnear = 0.10, SD = 0.13; Mfar = 0.15, SD = 0.24), and B′′ (Mnear = 0.03, SD = 0.65; Mfar= 0.10, SD = 0.63) all failed to differ between NN and FN (proportion of hits: p = .94, d = 0.01; proportion of FAs: p = .15, d = 0.23; B′′: p = .51, d = 0.10).
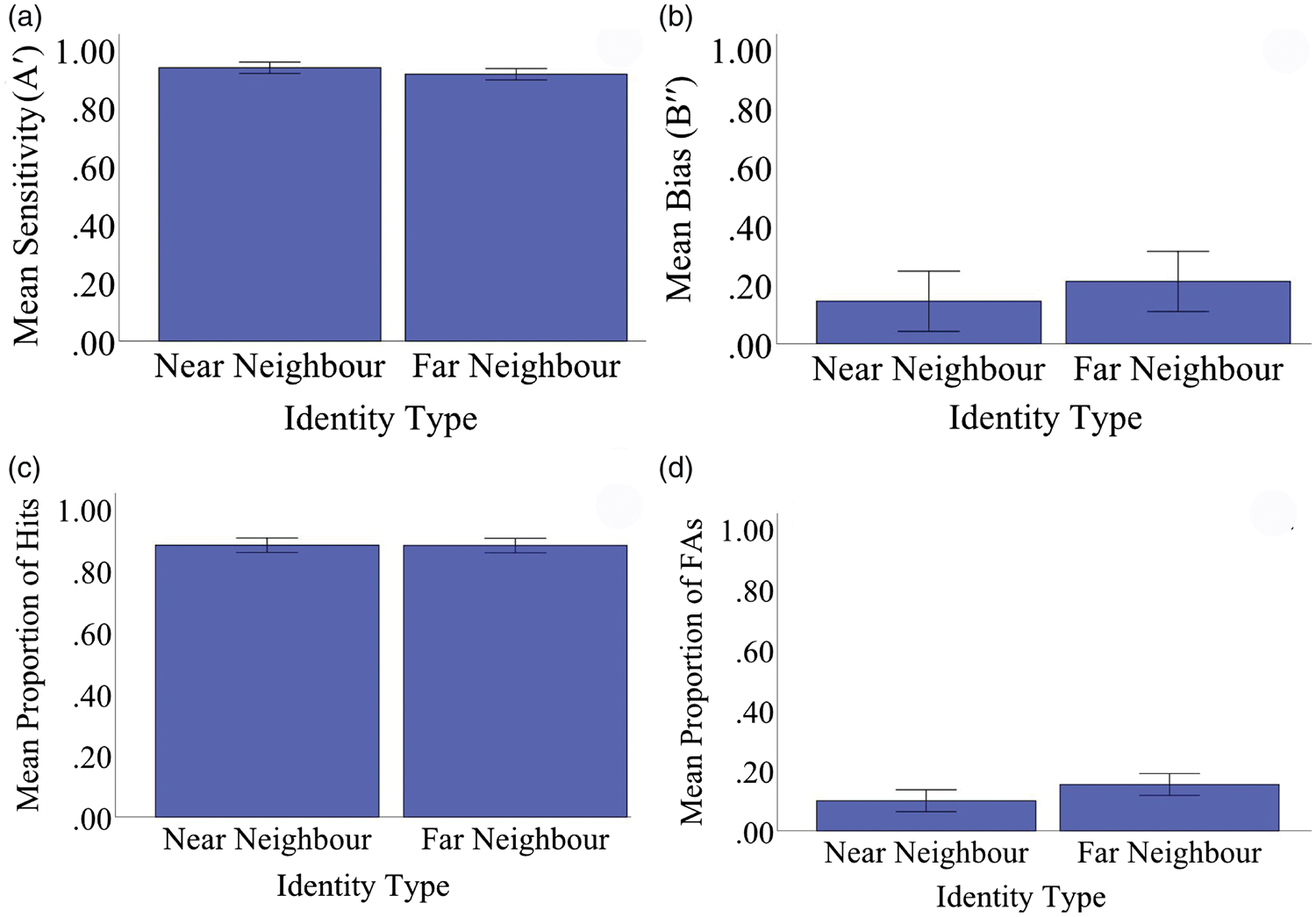
Performance in the recognition phase of Experiment 2. (a) Sensitivity (A′), (b) bias (B′′), (c) mean proportion of hits (correct identifications), and (d) mean proportion of FAs (misidentifications). Error bars represent 95% confidence intervals, corrected for within-subject error.
Recognition task RT
Paired samples t tests showed that RTs did not differ between NNs and FNs for either hits (Mnear = 1.62 seconds, SD = 0.67; Mfar = 1.70 seconds, SD = 0.83; p = .42, d = 0.13) or correct rejections (Mnear = 1.47 seconds, SD = 0.59; Mfar = 1.46 seconds, SD = 0.73; p = .88, d = 0.02), confirming the lack of speed/accuracy trade-off.
Relationships between learning and recognition
Pearson r correlations were performed to determine whether performance during the sorting task (number of images sorted correctly, z-scored) was related to each measure of performance during the recognition task, with separate analyses for NN versus FN. Performance in the sorting task was not significantly related to the proportion of hits (NN: r = .19, p = .25; FN: r = .05, p = .75) or B′′ (NN: r = .15, p = .35; FN: r = .19, p = .25) for either neighbor type but was negatively related to the proportion of FAs (NN: r = −.35, p = .03; FN: r = −.31, p = .05) and positively related to A′ (NN: r = .37, p = .02; FN: r = .34, p = .03).
In short, we found no evidence that learning a face in the context of an NN refined the representation of the newly learned identity; neither A′ nor FAs differed. However, recognition performance was at or near ceiling. Mean number of hits for both the NN and FN were high (≥13 of 15) and FAs were low (≤3 of 15), suggesting that participants built a robust representation for both identities during training. Previous studies have shown that exposure to as few as six images of a face increases tolerance to within-person variability (Andrews et al., 2015; Dowsett et al., 2016; Matthews & Mondloch, 2018a, 2018b; Ritchie & Burton, 2017). Participants in this study viewed 15 images, which might have masked any effect of an NN early in the learning process. Thus, in Experiment 3, we administered the same tasks, but participants viewed only five images of each identity during the learning phase. We hypothesized that reducing the number of images to which participants are exposed would result in a less refined representation, decreasing A′ relative to Experiment 2 and enhancing the NN effect.
Experiment 3
Methods
Participants
Forty-four Caucasian Brock University students participated in Experiment 3 (n = 6 males; mage = 19.43, SDage = 1.87). An additional seven participants were excluded from the analyses because of failing criteria (n = 6; see “Materials” section in Experiment 1) or researcher error (n = 1).
Materials and procedure
Participants were tested using the same stimuli and procedure as Experiment 2 with one exception: Participants were exposed to five images per identity. These images were randomly selected from the initial set of 30 for each participant.
Results and Discussion
Preliminary analyses
To confirm that presenting only five images of each identity in the sorting task reduced learning, we collapsed across the NN and FN to create an overall mean value for A′, hits, FAs, and B′′ during the recognition task for participants in Experiment 2 versus Experiment 3. An independent samples t test revealed that participants showed greater sensitivity (A′) in Experiment 2 (after learning 15 images; M = 0.93, SD = 0.07) than in Experiment 3 (after learning 5 images; M = 0.86, SD = 0.12), t (67.16) 4 = 3.15, p = .002, d = 0.71. 5 This difference in sensitivity was driven by a reduction in hits in Experiment 3, t (73.95) = 3.88, p < .001, d = 0.82 and not a difference in FAs, t(82) = 1.11, p = .27, d = 0.28. However, there was a marginal difference in bias scores, such that participants were more neutral in Experiment 2 (M = 0.07, SD = 0.55) than in Experiment 3 (M = 0.28, SD = 0.48), t(82) = 1.86, p = .07, d = 0.39. Collectively, these results confirm that reducing the number of images sorted resulted in participants being at an earlier stage of learning.
Sorting task performance
The majority of images were sorted accurately (Mprop correct = 0.85, SD = 0.12). A repeated-measures one-way ANOVA revealed that the number of correctly identified images differed as a function of similarity, F(2, 86) = 7.04, p = .001,
Recognition task performance
All participants recognized at least four of the five control images for each identity; 32 participants performed without error.
As in Experiment 2, distractors were rarely identified as the opposing target (1.32%) and misidentifications between the two targets rarely happened (0.88%); these errors were excluded from the final analyses. As shown in Figure 6, after learning five images of three identities, A′ for NNs (M = 0.88, SD = 0.14) and FNs (M = 0.84, SD = 0.16) did not differ, t(43) = 1.33, p = .19, d = 0.02. Moreover, hits (Mnear = 0.78, SD = 0.19; Mfar = 0.76, SD = 0.19), FAs (Mnear = 0.14, SD = 0.20; Mfar = 0.20, SD = 0.25), and B′′ (Mnear = 0.31, SD = 0.59; Mfar = 0.24, SD = 0.58) all failed to differ for NNs versus FNs (proportion of hits: p = .47, d = 0.11; proportion of FAs: p = .11, d = 0.25; B′′: p = .49, d = 0.10). 6
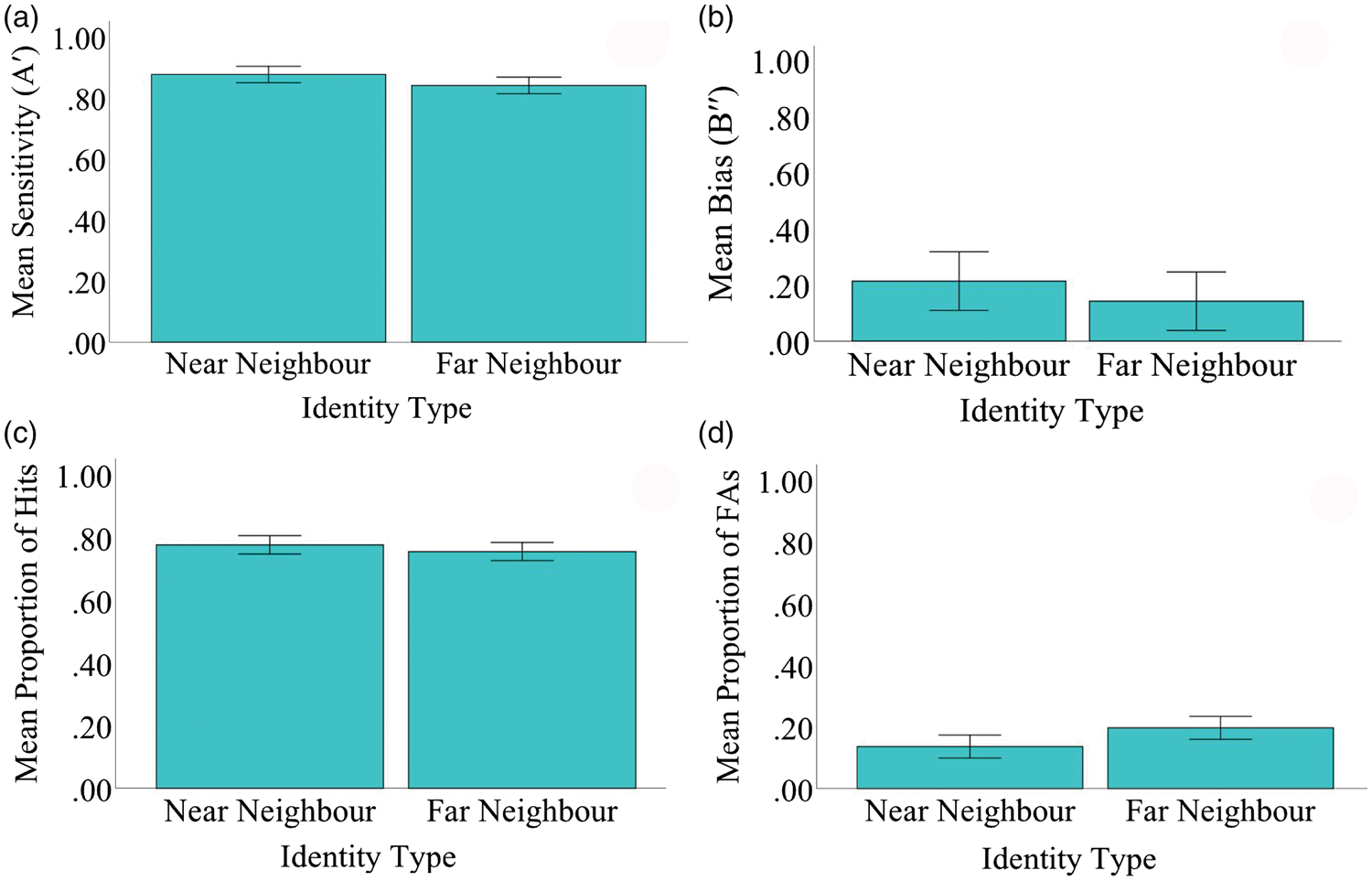
Performance in the recognition phase of Experiment 3. (a) Sensitivity (A′), (b) bias (B′′), (c) mean proportion of hits (correct identifications), and (d) mean proportion of FAs (misidentifications). Error bars represent 95% confidence intervals, corrected for within-subject error.

Performance in the recognition phase of Experiment 4. (a) Sensitivity (A′), (b) bias (B′′), (c) mean proportion of hits (correct identifications), and (d) mean proportion of FAs (misidentifications). Error bars represent 95% confidence intervals.
Recognition task RT
Paired samples t tests revealed that RTs did not significantly differ between NNs and FNs for hits (Mnear = 1.95 seconds, SD = 1.26; Mfar = 1.82 seconds, SD = 1.03; p = .44, d = 0.12) or correct rejections (Mnear = 1.95 seconds, SD = 1.47; Mfar = 1.99 seconds, SD = 1.11; p = .86, d = 0.03). Thus, as in Experiment 3, there was no speed/accuracy trade-off.
Relationships for performance during learning and recognition
Sorting performance for the NNs was not significantly related to any outcome measures (hits: r = .18, p = .25; FAs: r = −.20, p = .19; A′: r = .22, p = .14; B′′: r = .025, p = .87). Sorting performance for the FN was marginally related to the proportion of hits made for the FN (r = .29, p = .055) and significantly related to B′′ (r = −.21, p = .04) but was not related to any other outcome measure (FAs: r = .11, p = .50; A′: r = .003, p = .99).
A direct comparison to Experiment 2 confirmed that exposure to multiple images of a face improves sensitivity to identity; participants in Experiment 3, who sorted 5 images per identity, had lower sensitivity scores and made fewer hits than participants in Experiment 2, who sorted 15 images per identity. The difference in sensitivity and hits is consistent with previous reports that exposure to within-person variability improves subsequent recognition of the learned identity (e.g., Baker et al., 2017; Dowsett et al., 2016; Matthews & Mondloch, 2018a; Ritchie & Burton, 2017; Zhou, Matthews, Baker, & Mondloch, 2018) and confirms that the sorting task functions as a training protocol when the number of identities participants perceive within the set of photos is constrained by the experimenter (Andrews, Burton, Schweinberger, & Wiese, 2017; Andrews et al., 2015).
Contrary to our main hypothesis, the FA rate was not reduced by learning an NN face during the study phase. Furthermore, the FA rate did not differ across experiments (i.e., as a function of the number of images seen during the study phase). The FA rate remained at about 15% to 20%, comparable to that observed in previous face learning studies (Murphy et al., 2015; Ritchie & Burton, 2017; White, Kemp, et al., 2014).
Although not significant, the false alarm rates in Experiments 2 and 3 were numerically smaller in the NN than the FN condition, providing a hint that learning a face in the context of a similar identity might promote learning. To determine whether the effect is robust when power is increased, we analyzed Experiments 2 and 3 together. As shown in ST 2, in a 2 (Experiment: 2 vs. 3) × 2 (Neighbor Type: NN vs. FN) mixed ANOVA, the effect of neighbor type on A′ approached significance, but the effect size was small, F(1, 82) = 2.96, p = .09,
There are two potential explanations for our failure to find an NN effect on FA rates. One possibility is that presenting similar-looking identities during learning does constrain the range of variability tolerated, but that our use of eight attractive female identities (all of whom were reasonably similar to one another) masked that effect. Our selection of identities was aimed at encouraging participants to attend equally to all images during the sorting task; had we included one very unattractive identity, for example, participants might have responded categorically to those images rather than building a robust representation of a particular face. Experiments 1a and 1b did confirm that the identities within each face set were more similar to one another than to faces in the other set—a finding that was confirmed in both the sorting and recognition tasks in Experiments 2 and 3. However, our decision to present each participant with three attractive female identities, all of which are more similar to each other than to most other (i.e., older, male, unattractive) faces in the population, might have resulted in the NNs constraining the size of the FN’s attractor field, masking any effect of one neighbor being nearer (more similar) than the other.
A second possibility is that the amount of excess variability (i.e., images of other faces that are perceived as belonging to a target identity) in appearance tolerated for any newly learned face does not increase during the learning process (i.e., does not exceed the amount of excess variability tolerated for wholly unfamiliar faces)—except in special cases such as target-absent trials in a lineup task (Matthews & Mondloch, 2018a). This possibility suggests that learning only involves improved recognition of new instances with no increase in misidentifications and allows no role for NNs—at least in adults with a well-populated face space.
We teased these possibilities apart in Experiment 4 by using a between-subjects design in which participants performed a face recognition task after viewing images of only one identity. Participants rated the likeness of 3, 6, or 10 images to each other and to a single anchor image prior to completing an old/new recognition task. Participants in the control condition (no-training [NT]) simply studied the anchor image. Based on Experiments 2 and 3, we hypothesized that A′ and hits would increase as a function of the number images seen during the study phase. If the failure to find an NN effect in Experiments 2 and 3 is attributable to the similarity of images in our two face sets (i.e., to the NNs constraining FAs both for each other and the FN), then FAs should increase as a function of the number of images studied, showing either a linear or quadratic trend. However, if learning a new face only involves improved sensitivity to identity with no increase in misidentifications, then FAs should not vary across groups. Experiment 4 also allowed us to verify that learning had occurred in Experiment 3 (i.e., when participants sorted only five images per identity). To verify that learning had occurred in Experiment 3, we contrasted A′, proportion hits, and proportion false alarms in Experiment 3 to those in the NT condition of Experiment 4. Because the task was very brief and required a very large sample size, we tested MTurk workers.
Experiment 4
Methods
Participants
One hundred and sixty Caucasian MTurk workers from the United States were tested and included in the final analyses for Experiment 4 (97 males; Mage = 37.18, SD = 11.04); 40 participants completed each condition and were paid US$2. An additional 38 participants were excluded from the final analyses for failing to pass attention check trials (N = 16; see procedure), computer glitches (N = 14), and for recognizing (N = 1) or misidentifying the learned identity (N = 7).
Materials
Experiment 4 used the same stimuli as in the previous experiments and was programmed on Qualtrics. Four of the eight identities (two per each set) were randomly selected to be learned, and the remaining identities were used as similar and dissimilar distractors for each learned identity.
Procedure
Participants were randomly assigned to one of the four conditions (NT, 3 images, 6 images, or 10 images) and to one of the four learned identities. First, participants were introduced to the target identity; the introduction consisted of an image of the target identity (i.e., the Target Anchor image from Experiments 2 and 3) that was displayed on screen above a few brief statements. (Above is an image of a woman named Fiona. Fiona recently started working as a nurse at a local hospital. During her spare time, Fiona likes to go for walks, read mystery novels and watch cooking shows.) The statements were designed to facilitate the formation of an identity in the absence of having to tell people apart.
Rating task
Participants in the 3-, 6-, and 10-image conditions were shown each image individually and asked to rate the image based on each image’s likeness to the anchor image and all previously presented images on a 7-point Likert-type scale (1 = extremely bad; 7 = extremely good). Each image remained on screen until participants indicated their response. After completion of the rating task, a display that contained all of the images that the participants had just rated and the instructions Please keep these images in mind when performing the next task remained on screen until they indicated that they were ready to proceed via a key press. Participants in the NT condition viewed the anchor image until they indicated that they were ready to proceed via a key press.
Recognition task
Participants’ recognition of the target identity was tested in a dichotomous forced-choice task. Participants viewed novel images of the learned identity intermixed with unlearned similar and dissimilar looking distractors and were asked to indicate whether each image belonged to the target identity. Sixty-five images were presented during the recognition task: 15 new images of the target identity, 20 images of similar distractors (10 per each of two identities from the same set), and 20 images of dissimilar distractors (10 per each of two identities from the other set). The remaining images (N = 10) were control stimuli and comprised images that had been presented in the rating task, with control images repeated as dictated by the number of previously seen images available. The control images for the NT condition consisted of the anchor image. Images were presented sequentially and remained on screen until participants indicated whether the image belonged to the target identity.
Results and Discussion
Rating task performance
Images were rated as being a good likeness (M = 5.22, SD = 1.02), a pattern that was consistent across conditions (M3 im = 5.47, SD3 im = 0.99; M6 im = 5.33, SD6 im = 0.91; M10 im = 4.87, SD10 im = 1.09).
Recognition task performance
All participants included in the analysis recognized at least seven of the control images, with 124 performing without error.
As in Experiments 2 and 3, dissimilar distractors were rarely identified as the target (1.55%). Such errors were excluded from the final analyses so that A′ and FAs were based on similar distractors (NNs).
To determine whether sensitivity to identity varied as a function of the number of images learned, we conducted an independent-samples one-way ANOVA. As shown in Figure 7(a) and in ST 3, there was a marginal effect of learning condition on sensitivity (A′), F(3, 156) = 2.34, p = .08, η2 = 0.04. Tukey’s honest significant difference post hoc analyses revealed that although participants in the NT condition (MA′ = 0.79, SD = 0.14) were marginally less sensitive than those in the 10-image (MA′= 0.86, SD = 0.11) condition (p = .08), participants in the NT condition were not less sensitive than those in the 3-image (p = .22) or the 6-image (p = .17) conditions. Participants in the 3-image were not less sensitive than those in the 6-image (p = .99) or 10-image (p = .96) conditions, and participants in the 6-image condition were not less sensitive than those in the 10-image condition (p = .98). These marginal differences in sensitivity were driven by an increase in hits, F(3, 156) = 11.46, p < .001, η2 = 0.18. Participants in the NT (M = 0.34, SD = 0.24) condition made significantly fewer hits than those in the 3-image (M = 0.51 , SD = 0.21), p < 0.001; 6-image (M = 0.55, SD = 0.17; p < 0.001) and 10-image (M = 0.56, SD = 0.15), p < 0.001; conditions. Participants in the 3-image condition did not make fewer hits than those in the the 6- (p = 0.95) and 10-image conditions (p = 0.99), and participants in the 6-image condition did not make fewer hits than those in the 10-image condition (p = 0.90). As in Experiments 2 and 3, the proportion of FAs was low overall (M = 0.15, SD = 0.19) and did not vary across conditions, F(3, 156) = 1.91, p = .13, η2 = 0.03. B′′ differed significantly across conditions, F(3, 156) = 2.84, p = .04, η2 = 0.05; participants in the NT condition (M = 0.55, SD = 0.60) were more conservative than those in the 6-image condition (M = 0.18, SD = 0.64), p = .04; however, participants in the NT condition were no more conservative than those in the 3-image (p = .13) or 10-image (p = .19) conditions. Participants in the 3-image condition were not more conservative than those in the 6-image (p = .95) or 10-image (p = .99) conditions, and participants in the 6-image condition did not differ from those in the 10-image condition (p = .90). Collectively, these findings suggest that face learning does not include a stage at which images of another person are more likely to be perceived as belonging to the target identity than they were when the face was wholly unfamiliar, even when a single face is being learned in isolation. Rather, under our task conditions, learning is characterized as an increased ability to recognize valid instances of the learned identity.
As shown in ST 4, we also compared the proportion of FAs made by participants in the NT condition of Experiment 4 with the proportion of FAs made by participants in Experiments 2 and 3. If learning a face in the context of other identities in Experiments 2 and 3 constrained the amount of variability tolerated but did so equally for the NN and FN target, then the FA rate should be lower in Experiments 2 and 3 than in Experiment 4. If learning a face in the context of other identities provided no benefit, then the FA rate should be comparable across experiments. Independent-samples t tests (two-tailed) revealed no difference between the proportion of FAs in the NT condition of Experiment 4 (M = 0.09, SD = 0.18) and the proportion of FAs for the NN in Experiments 2 and 3 (Experiment 2: MNN = 0.10, SDNN = 0.13, p = .90, d = 0.06; Experiment 3: MNN = 0.14, SDNN = 0.20, p = .29, d = 0.26), or the FN in Experiment 2 (M = 0.15, SD = 0.24, p = .23, d = 0.28). The proportion of FAs was lower in the NT condition of Experiment 4 than for the FN in Experiment 3 (MFN = 0.20, SD = 0.25), p = .03, d = 0.50, a pattern opposite to that expected had similarity between NN and FN played a role in our failure to find an NN effect in Experiments 2 and 3.
Finally, we conducted independent-samples t tests comparing A′ and the proportion of hits made in the NN and FN conditions of Experiment 3 to the NT condition of Experiment 4. The proportion of hits was significantly higher in both the NN (M = 0.78, SD = 0.19) and the FN (M = 0.76, SD = 0.19) conditions than in the NT condition (M = 0.45, SD = 0.3), ps < .001, d = 1.24 and 1.20 respectively. A′ was significantly higher in the NN condition (M = 0.88, SD = 0.14) than in the NT condition (M = 0.79, SD = 0.14), p = .01, d = 0.64, with no difference for the FN condition (M = 0.84, SD = 0.11), p = .18, d = 0.33. Collectively, these findings provide evidence that sorting five images of three identities did lead to face learning.
The results of Experiment 4 replicate previous reports that exposure to within-person variability improves subsequent recognition of a newly learned identity (e.g., Baker et al., 2017; Dowsett et al., 2016; Ritchie & Burton, 2017; Zhou et al., 2018); hits significantly increased and sensitivity marginally increased when participants viewed multiple images as compared with a single image. Experiment 4 provides no evidence that exposure to variability in the appearance of a newly learned identity increases misidentifications. Relative to the NT condition, FAs did not increase in any condition, despite the inclusion of multiple images of two similar distractors during the test phase. Furthermore, the FA rate was not higher in Experiment 4 than in Experiments 2 and 3, providing no evidence that the presence of similar distractors constrained misidentifications in the first two experiments. Rather, across experiments and conditions, the FA rate hovered around 15%, comparable to that observed in previous studies (e.g., Murphy et al., 2015; Ritchie & Burton, 2017; White, Kemp, et al., 2014). We discuss implications for face learning in the General Discussion.
General Discussion
Jenkins et al. (2011) argued that the marker of familiarity with an identity is the ability to recognize it despite variability in appearance; whereas participants sort different images of the same identity into multiple piles when tested with unfamiliar faces, they make no such errors when sorting images of familiar faces. Exposure to variability in appearance facilitates accurate recognition of novel instances of a newly learned identity (e.g., Andrews et al., 2015; Baker et al., 2017; Dowsett et al., 2016; Murphy et al., 2015; Ritchie & Burton, 2017)—a finding replicated in the current experiments. Accuracy was higher after sorting 15 (Experiment 2) versus 5 images (Experiment 3) of an identity and marginally higher after rating the likeness of multiple images versus viewing a single image (Experiment 4). This increased accuracy was driven by an increase in the proportion of hits (see Menon, White, & Kemp, 2015a; Murphy et al., 2015; Ritchie & Burton, 2017; White, Burton, et al., 2014; Zhou et al., 2018 for a similar pattern).
The primary aim of the current studies was to investigate the mechanism underlying improved between-identity discrimination. Whereas exposure to within-person variability in appearance improves recognition, misidentification rates often remain at nearly 15% to 20% of mismatch trials (e.g., Murphy et al., 2015; Ritchie & Burton, 2017; White, Burton, et al., 2014). The process of learning a new face can be conceptualized as an attractor field growing, increasingly encompassing the way in which that face varies in appearance (Laurence, Zhou, & Mondloch, 2016). Based on evidence that the size of an attractor field is constrained by nearest neighbors (Tanaka et al., 1998), we hypothesized that learning a new face in the context of a similar identity would build a more precise representation, such that novel instances of the newly learned identity would be included in the learner’s representation, but instances of a similar looking identity would not. Although inspired by Tanaka’s attractor field model, our hypothesis was also based on the logic that sorting images of three people, two of whom were previously judged to be highly similar in appearance, would enhance attention to differences between faces rather than just the similarity between different images of the same person.
Our findings do not provide any strong evidence that learning a face in the context of a similar identity benefits learning by reducing false alarms. Indeed, false alarms were low overall and in Experiment 4, when participants learned only a single identity, we found no evidence that the process of learning included a stage in which increased tolerance of variability led to increased false alarms. The low false alarm rates we report are consistent with other studies that failed to find an increase in false alarms as a face becomes familiar (e.g., Baker et al., 2017; Ritchie & Burton, 2017; White, Burton, et al., 2014). In contrast, when participants are asked to detect a face embedded in a 30-image lineup (Matthews & Mondloch, 2018a) or to indicate if a novel image is of the same identity as two simultaneously presented images (Menon et al., 2015a—Experiment 3) FAs increase with learning, perhaps because under these task conditions participants adopt a more liberal criterion (Menon et al., 2015a; Menon, White, & Kemp, 2015b; Zhou et al., 2018).
Although there was no effect of neighbor type in either experiment on its own, we found some evidence of an NN effect by combining Experiments 2 and 3 (i.e., by increasing our power). Although only a small-to-medium effect was detected despite a doubling of our sample size, this pattern provides some support for our hypothesis. The hint of an NN effect begs the question of which learning (e.g., sorting, studying individual faces, making same/different judgments) and test (e.g., matching, old/new recognition, lineup) conditions are most sensitive to the ability to recognize an identity despite variability in a face’s appearance and which are most sensitive to the ability to tell highly similar faces apart. Under conditions in which face discrimination is especially challenging (e.g., in a 30-person lineup task), NNs might play a bigger role. Future studies might integrate our sorting task into a lineup testing protocol to test this possibility.
The fact that different learning and testing paradigms vary in their sensitivity to hits versus false alarms is reminiscent of evidence that the mirror effect, which is ubiquitous for many stimulus categories, is absent for face recognition. The mirror effect refers to the finding that stimuli that are most easily recognized after being studied in a learning phase are also most easily categorized as new (i.e., as not previously seen; see Glanzer, Adams, Iverson, & Kim, 1993 for a review). Such an effect appears to be absent for faces in both old/new tasks (e.g., Hancock, Burton, & Bruce, 1996) and matching tasks, at least when faces are unfamiliar (e.g., Kokje, Bindemann, & Megreya, 2018; Megreya & Burton, 2007). Faces that are easily recognized, perhaps because they are distinct, are not necessarily easily discriminated, providing more evidence of the dissociability of hits versus false alarms in face recognition.
Potential Mechanisms
The impact of exposure to within-person variability in appearance on face learning might be accounted for by the predictive coding model, according to which expectations about visual information are compared with perception at each level of processing in the brain (Summerfield & Egner, 2009; Trapp, Schweinberger, Hayward, & Kovács, 2018). Violated expectations (i.e., when expectations and perceptions do not match) result in an increase in neural activity, which has been related to learning (Apps & Tsakiris, 2013; Havron, de Carvalho, Fiévet, & Christophe, 2019; Ylinen, Bosseler, Junttila, & Huotilainen, 2017). Exposure to variability in appearance might promote face learning via violated expectations with regard to the ways in which a particular individual can look, a possibility that we are currently investigating.
Future Directions
As noted earlier, studies investigating face learning consistently show improved recognition of a learned identity with no parallel decrease in misidentifications. Future research should examine whether a similar pattern is observed for other facial judgments. For example, likeness ratings of individual photographs increase with familiarity (Ritchie, Kramer, & Burton, 2018), suggesting that we perceive two images of the same person as more similar when that face is familiar. It remains unknown if similarity ratings of images of different people decrease with familiarity, a finding that would suggest that learning increases distinctiveness.
The accuracy with which faces are recognized and discriminated varies across tasks, with FA rates being especially high on target-absent trials in lineup tasks (Matthews & Mondloch, 2018a). Future studies should examine whether an NN effect emerges under these task conditions.
Finally, the lack of NN effect might be attributable to our participants having a well-populated face space; the hundreds of faces already represented in face space might have masked any benefit of adding a single highly similar neighbor while learning a new identity. Future studies could examine whether misidentifications increase during the learning process in the context of a more sparsely populated face space. Children are less accurate than adults when sorting unfamiliar faces (Laurence & Mondloch, 2016) and learn new faces less efficiently (Baker et al., 2017); likewise, adults are less accurate when sorting unfamiliar other-race faces than unfamiliar own-race faces (Laurence et al., 2016) and learn other-race faces less efficiently (Zhou et al., 2018). These findings have been attributed to differential experience and might indicate conditions that are more sensitive to the impact of learning multiple identities simultaneously (i.e., to an NN effect).
In conclusion, more research is needed to examine the process by which a precise and robust representation of facial identity emerges, such that all images of an identity are recognized while images of very similar looking identities are not. Although both recognition and discrimination contribute to overall accuracy/sensitivity to identity, they reflect separable processes that may be impacted by different learning mechanisms. Given that errors in either judgment have very different practical implications (i.e., denying a citizen entry at the border versus allowing an imposter in), it is important to understand how to reduce both error types.
Supplemental Material
Supplemental material for Two Sides of Face Learning: Improving Between-Identity Discrimination While Tolerating More Within-Person Variability in Appearance
Supplemental Material for Two Sides of Face Learning: Improving Between-Identity Discrimination While Tolerating More Within-Person Variability in Appearance by K. A. Baker and C. J. Mondloch: on behalf of the IMSVISUAL consortium in Perception
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Natural Sciences and Engineering Research Council of Canada.
Supplemental material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.