
Abstract
The principle of compositionality, an important postulation in language and cognition research, posits that the meaning of a complex expression is determined by the meaning of its constituting parts and the operation performed on those parts. Here, we provide strong evidence that this principle plays a significant role also in interpreting facial expressions. In three studies in which perceivers interpreted sequences of two emotional facial expression images, we show that the composite meaning of facial expressions results from the meaning of its constituting expressions and an algebraic operation performed on those expressions. Our study offers a systematic account as to how the meaning of facial expressions (single and sequences) are being formed and perceived. In a broader context, our results raise the possibility that the principle of compositionality may apply to human communication modalities beyond spoken language, whereby a minimal number of components are expanded to a much greater number of meanings.
An important presupposition in language and cognition research is the principle of semantic compositionality, commonly attributed to Frege (Janssen, 2001; Pelletier, 1994). This principle postulates that the meaning of a complex expression is determined by the meaning of its constituting parts and the operation performed on those parts (e.g., Dummett, 1981; Pelletier, 1994).
Various notions of “compositionality” have been suggested, highlighting different aspects of the principle. For example, the notion of systematicity, according to which the meanings of complex symbols are systematically determined by their composition (Hirst, 1992). Another notion is the algebraic relationship between the parts and the resulting meanings (Smith, 1987). Take the formation of the word compounds dog sledge and sledge dog (Hoeksema, 2000). The meaning of the compound dog sledge is determined by the meaning of its parts and the operation performed on them. It is different from the meaning of sledge dog, which results from a mirrored operation on the same components.
A broader account of compositionality refers to a combination of concepts. People construct many concepts for diverse categories, such as objects, actions, words, and mental states (Barsalou, 2017). They effortlessly combine these concepts to more complex concepts such as sentences and phrases. Such complex concepts usually vary considerably in meaning from the original concepts (Barsalou, 2017). For an example of variation from the original concept, an algebraic product of a vector representation of a two-word compound is closer to the vector representation of a related meaning than to the vectors of the constituting words (e.g., V"(“Yellow”) [algebraic operator] V"(“Press”) was closer to the words “Gossip” and “Celebrity” than to the words “Yellow” or “Press” Giesbrecht, 2009).
The principle of compositionality can be demonstrated for facial expressions when represented as combinations of facial Action Units (AUs) or perceived emotional expressions. Action units describe 28 visible facial movements, forming prototypical facial expressions (Ekman & Friesen, 1976). For example, based on this nomenclature, a happy expression is comprised of AUs 6, 12, and 25, while anger is comprised of AUs 4, 7, and 24. Recently, Du et al. (2014) found that the production of mixed expressions involved muscle movements of their superordinate expressions (e.g., muscle movements of happily surprised expression included the muscle movements of happy and surprised expressions). In compositionality terms, we would argue that the meaning of mixed expressions was determined by the operation of unification (U; AU must appear in either one or two of the constituting facial expressions) of their constituting facial expressions, defined by their AUs 1 . Another example is the dynamic evolvement of facial expressions. Jack et al. (2014) revealed a confusion between surprise versus fear expressions at the early stages of their formation, which share common AUs. As the expression evolves, an additional emerging AU 2 changes the perception from fear to surprise. In the terminology of the principle of compositionality, the meaning of surprise expression was determined by meaning unification (U) of AUs of fear with the additional AU.
Our study extends and generalizes these previous findings by offering a broader account of compositionality, referring to a combination of concepts. Importantly, our study goes beyond previous studies, employing the principle of compositionality to quantify the relationship among different perceived emotional expressions presented temporally. Furthermore, we offer a unifying mathematical framework and theory to quantify the relationship between temporally presented facial expressions.
Recent work suggests that the semantic meaning of emotional facial expressions is affected by the contextual relations between neighboring expressions (context effect; e.g., Russell, 1991; Thayer, 1980). Studies already revealed that a facial expression presented to participants affects their perception of subsequent expression (Reinl & Bartels, 2015; Russell, 1991; Russell & Fehr, 1987; Thayer, 1980). For example, Russell (1991) found that a contempt facial expression followed by a sad expression was interpreted as disgust.
However, when the contempt facial expression followed a disgust expression, it was perceived as sadness. Critically, these previous studies were constrained by focusing on the effect of specific facial expressions (e.g., contempt) on the interpretation of subsequent expressions (sadness and disgust). As such, they might have overlooked a general system of rules that governs the interpretation of a sequence of two facial expressions. We suggest that the compositionality principle may govern such interpretation.
Our study addresses the conceptualization that isolated expressions are rarely experienced in daily life, as human communication is based on deciphering streams of expressions during personal interactions. Hence, here we test how the principle of semantic compositionality accounts for the perception of sequences of facial expressions.
The Present Study
We study the principle of compositionality of facial expressions through the lens of language, namely as the perceiver verbally describes them. In the present case, the measurement units are not AUs comprising each emotion, but rather, the intact, full emotional expressions. This approach is consistent with the notion that concept compositionality combines individual concepts to construct more complex concepts (Barsalou, 2017; Hampton, 1997).
To enable a quantitative evaluation of this principle, we adopted the word embedding methodology, a standard methodology in natural language processing (NLP), allowing us to explore semantic relations between concepts conveyed by facial expressions. We conducted three studies and applied a data-driven analysis approach as detailed below. The goal of Study 1 was to prove that the vectors representing emotional words can represent emotional facial expressions (e.g., a happy facial expression can be represented by the vector representation of the word “happy”). The goal of Study 2 was to establish the principle of compositionality according to which the meaning of a complex expression is determined by the meaning of its constituting parts and the operation performed on those parts. Lastly, in Study 3, we analyzed how participants formed their perception of the sequences of expression given their constituents (e.g., what underlies the perception of the fear-contempt sequence as a sign of hesitation rather than fear or contempt). In these three studies, we found that the meaning of sequences of two emotional facial expressions is manifested by the weighted average (means of regression) of its discrete constituents.
Study 1
Method
Participants
Forty-seven participants 3 (19 female participants, aged 20–70) (M = 36.65) took part in an online study conducted from their homes at their own pace using Amazon's Mechanical-Turk platform. All participants had to reside in the United States and be fluent in English. To ensure that, prior to the study, participants were asked to declare that English was their native language and were asked not to participate if their English was not excellent. Furthermore, during the study, we provided participants a test to examine their English skills, requiring them to repeat in writing, using their own words, the instructions presented to them. The text served as an indication of their language fluency and comprehension of the task and was reviewed independently by two researchers.
Seven participants were excluded from the study because their language was not sufficiently fluent. To control for technical aspects of the stimulus display, participants were required to declare that they were participating in the experiment using a computer screen (not a mobile phone or a tablet) and were asked to provide the brand of their computer. In addition, for mobile users who continued the study after this request, access from mobile phones and tablets was automatically denied. The participants provided informed consent and received a payment of US$1 for their participation in the studies, which lasted 27 min on average. All methods were carried out per relevant guidelines and regulations, and informed consent was obtained from all participants. The ethics committee of the Psychology Department at the Ben-Gurion University of the Negev approved the studies, including all details.
Stimuli
Stimuli included eight facial expressions consisted of seven basic expressions (Ekman & Friesen, 1971), complemented by a neutral expression. Images were created by digitally averaging, using PsychoMorph 5 software (Tiddeman et al., 2001), the shape and reflectance of facial expressions portrayed by nine Caucasian female actors in the Radboud Faces Database (Langner et al., 2010). As detailed below, we used a data-driven approach, requiring the testing of all possible stimulus combinations. Therefore, to employ a reasonable number of tested sequences, we did the following: (1) We employed all eight basic expressions using faces of one gender only; (2) We chose to test female faces, in line with earlier work (DeBruine et al., 2007; Perrett et al., 1994; Sofer et al., 2015), which tested face averaging (typicality) effects; and (3) We used eight exemplars of emotional expression in line with previous studies that studied face attractiveness and typicality (DeBruine et al., 2007; Perrett et al., 1998; Rhodes et al., 2000) trustworthiness (Sofer et al., 2015, 2017), cultural effects (Rhodes et al., 2005; Sofer et al., 2017), perceptual adaptation (Rhodes et al., 2003), atypicality, and face recognition (Tanaka et al., 1998). These studies used exemplars created by averaging individual faces. Averaging nine different faces posing the same facial expression yielded a stimulus that represents the common facial features of a specific expression while reducing the effect of personal features posed by the actors (Figure 1).

Composite faces created by digitally averaging the shape and reflectance of facial expressions portrayed by nine Caucasian female actors in the Radboud Faces Database. Faces present seven basic emotional expressions and a neutral expression (from left to right): anger, contempt, disgust, fear, happiness, surprise, sadness, and neutral.
Design and Procedure
During the experiment, participants reviewed eight sets of single facial expressions (Figure 1) presented one at a time—(anger, happiness, contempt, disgust, fear, sadness, surprise, plus a neutral expression; Ekman, 2016; Ekman & Friesen, 1969; Keltner & Cordaro, 2017). Each set included a fixation image displayed for 2 s, followed by one of the facial expressions presented for 1 s, followed by a blank image (2 s; Figure 2). Sets were presented randomly. Previous studies comparing the effects of showing static versus dynamic facial expressions revealed only minimal differences, if any, between these two formats on the perception of short sequences of facial expressions (Dubé, 1997; Kamachi et al., 2013). Moreover, studies that compared the perception of dynamic sequences of facial expressions (i.e., animations) with a presentation of two static expressions from the series—the first and the last, did not reveal any perceptual differences (Ambadar et al., 2005). Hence, to simplify the experimental design, we opted to use only static facial expressions.
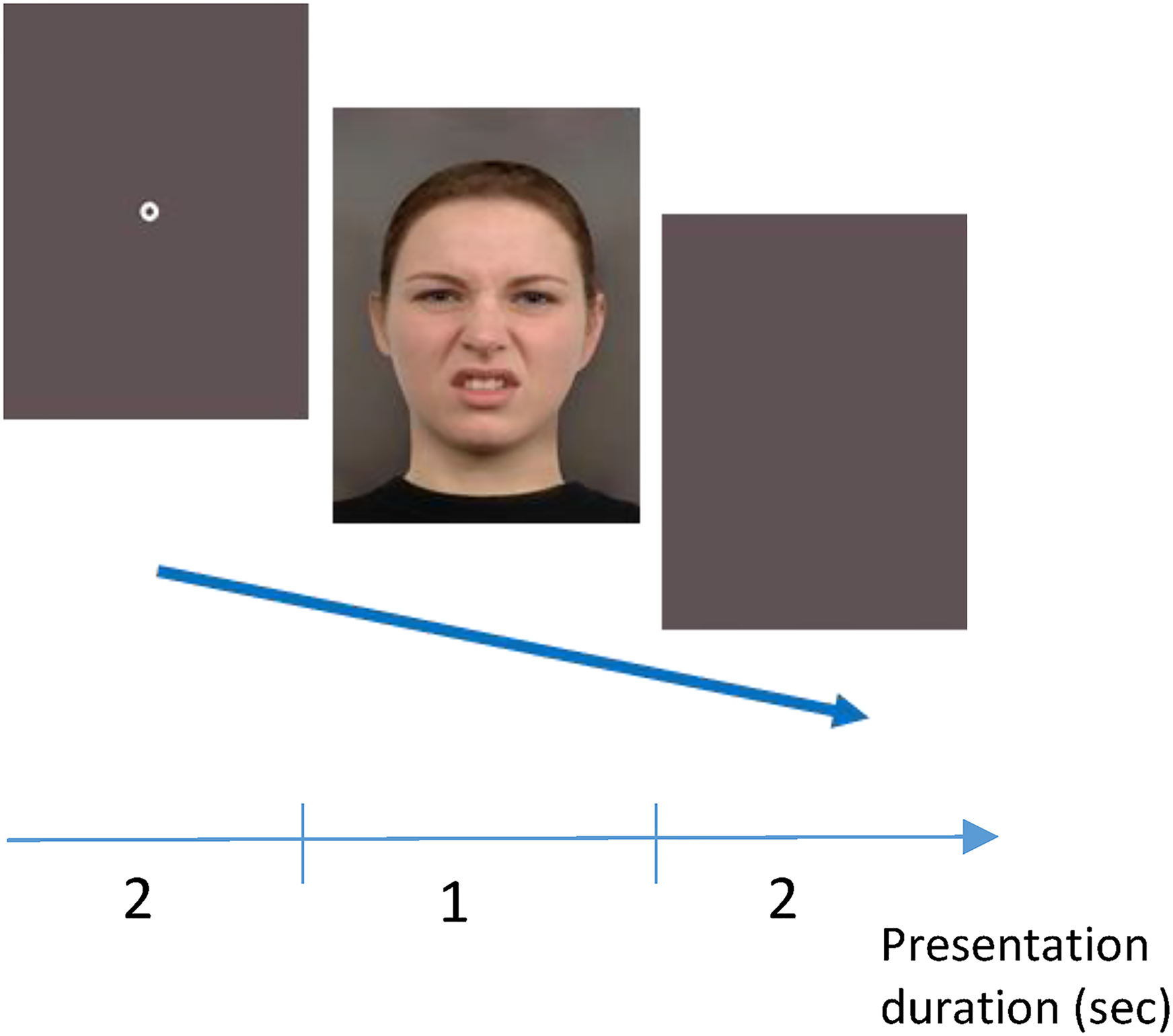
Illustration of experimental sets. Timeline of a single expression trial presented in Study 1.
After reviewing each set, participants were asked to report the woman's state of mind whose face was presented, using a single word that “freely comes to mind.” The free text allows the observer to have complete freedom in their interpretation of the sequence without being constrained by researchers’ a priori hypotheses.
Analytical Approach
There is an agreement in the psychological literature about the meaning of basic facial expressions (anger, happiness, disgust, fear, sadness, surprise; Ekman, 2016; Ekman & Friesen, 1969; Keltner & Cordaro, 2017), at least within a culture (Jack et al., 2016). The meaning of contempt expression is consensual but to a lesser extent (Izard & Haynes, 1988; Matsumoto, 2005; Russell, 1991). Therefore, these consensual expressions can be employed to test our hypothesis that the semantic vectors of emotional words can represent emotional facial expressions (e.g., a sad facial expression can be represented by the vector representation of the word “sad”). Data supporting this hypothesis would indicate that vectors representing emotional words also represent the semantic meaning of the respective emotional facial expressions. We tested this prediction by applying word embedding—a concept used in language research—to facial expression research. Word embedding maps words to numerical vectors (Mikolov et al., 2013; Pennington et al., 2014), quantifying the similarity between vectors, using the cosine similarity. Cosine similarity is indicative of how likely it is for words A and B to appear close to each other in a similar context, such that words with similar meanings are located close to each other. For example, if
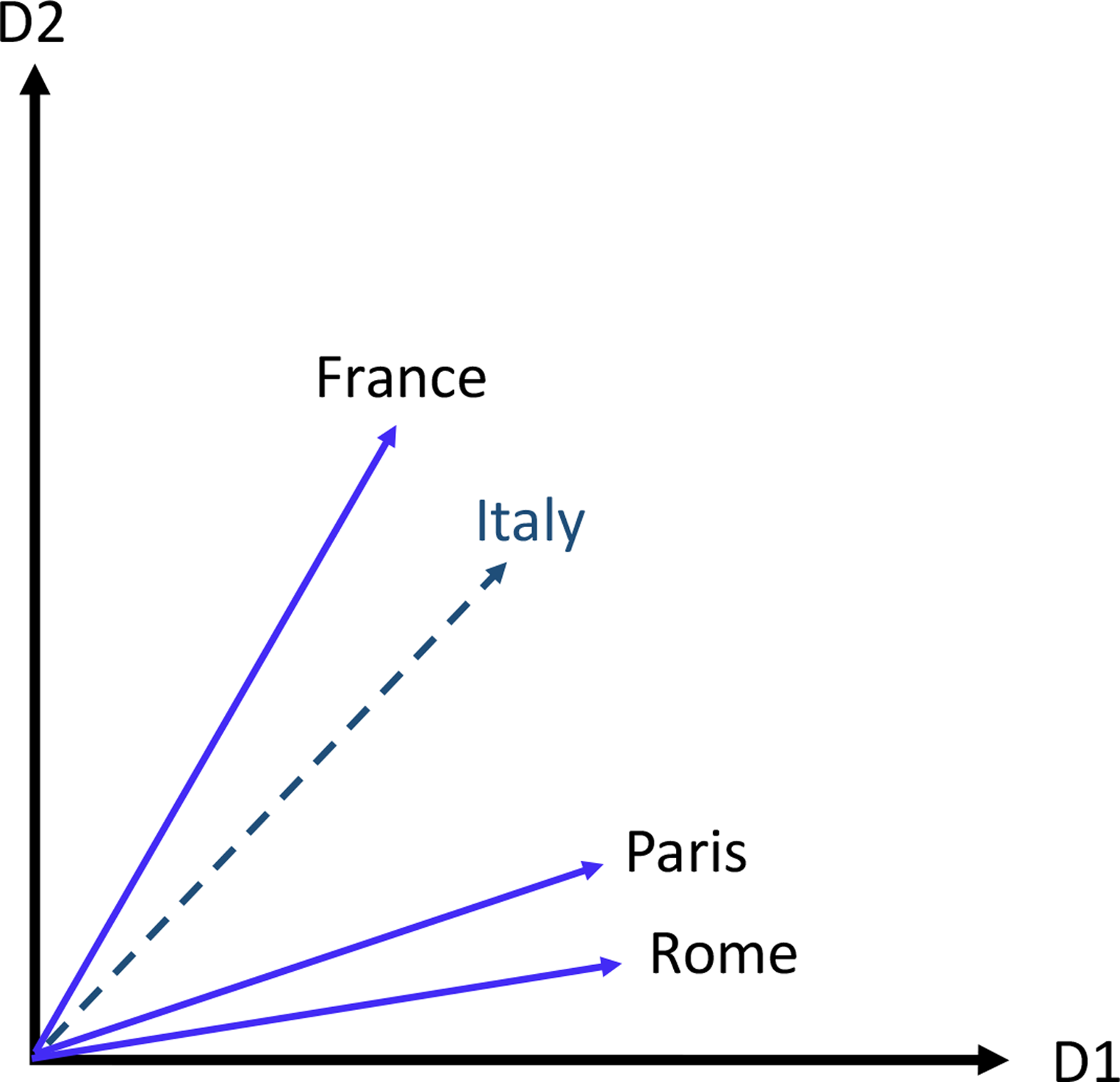
A 2D illustration of the application of vector arithmetics to analogies in the case of countries and their capital cities. In this example: vector V(“France”) – V(“Paris”) + V(“Rome”) = V(“Italy”).
Results
Collecting and Preprocessing Participants’ Judgments
We first collected 141 words that described the “woman's state of mind” as perceived and described by participants from the seven expression images plus the neural expression. Words were collected and preprocessed, eliminating word duplications, fixing spelling mistakes, and transferring all verb-based impressions to a noun form.
The analysis yielded 73 unique word descriptors, which represented each of the 141 original words. Lastly, we replaced every word from the original list (of 141) with its unique word descriptor from the list of 73 words.
Transforming Participants’ Responses to Vectors
Following this preprocessing stage, we assigned vector representation to each of the 73 words, using the Twitter word corpus, relying on a commonly used embedding approach (Global Vectors for Word Representation [GloVe]; Pennington et al., 2014). GloVe also provided a set of word embedding, trained on Twitter's word corpus, including two billion tweets, over 250,000 words. Fifty dimensions represented each word. The Twitter word corpus was chosen for the present study because its writing style is nonedited real-life, short, concise, and emotional, presumably similar to participants’ free text words. We further performed dimensionality reduction using PCA, which was computed on the covariance matrix of the 372 emotion words. This step stems from the fact that our word embedding was trained using the entire English vocabulary, while we were interested in only the 372 emotion words, including 73 unique words in Study 1 and 299 unique words in Study 2 (see later).
We computed a 50 × 50 covariance matrix, using all 372 emotion words. Using and applying the Guttman-Kaizer criterion (Yeomans & Golder, 1982), we found that our data was projected on the top seven PCs. Next, we averaged participants’ judgment vectors (across each of the elements) for each of the seven facial expressions. Because participants’ age varied over a relatively wide range (20–70 years), we tested whether age could be a source of variance in our analysis. We calculated the age median (34) and split the data into two groups: a ≤ 34, N = 25; a > 34. N = 22. For each group, we averaged participants’ judgment vectors for each of the seven facial expressions and then compared the results of the two groups. All emotion vector pairs (e.g., V[anger,≤ 34], V[anger, > 34]) pointed at the same semantic expressions (i.e., anger), indicating that the two groups can be pooled together.
We computed the cosine similarity (cos α) between the semantic emotion vector, selected from the GloVe embedding, and the average vector of participants’ interpretations of that facial expression (see Figure 4 for an illustration of one emotion state). We discovered that participants’ average judgment vectors of five facial expressions—Anger, Disgust, Happiness, Sadness, and Surprise, were the closest to the vector representations of the respective semantic expressions, cos αs > 0.976. A binomial test indicated that the observed proportion of five correct vector representations out of seven (5/7) was significantly different from the expected proportion of 0.000972, p < .005.
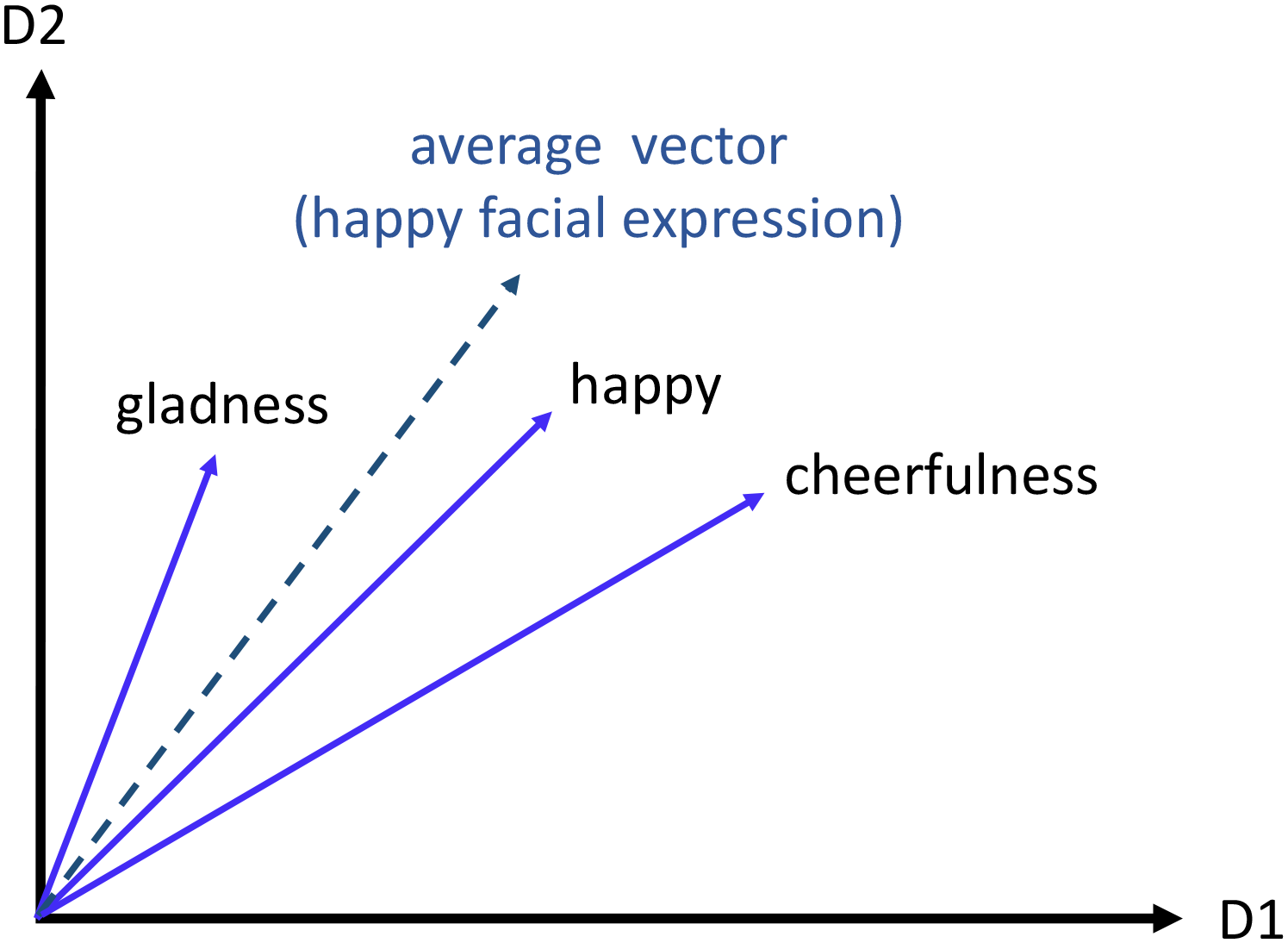
A 2D (D1, D2) illustration of vector representation of participants’ judgments, judging a happy facial expression, computed as the average of the words “gladness,” “happiness,” and “cheerfulness” (dashed blue line). The vector of the word “happiness” was the closest to the average vector of participants’ judgments of the happy facial expression.
Among all 372 expression vectors, the vector representing the word “sadness” was the closest to participants’ average judgment vector of the sad facial expression, cos αsad = .999. Cosine similarity for other four facial expressions were Cosαhappiness = .999, Cosαanger = .989, Cosαdisgust = .980, Cosαsurprise = .976. Interestingly, the participants’ judgment vector of the fear facial expression was the closest to the vector representation of the word Scare, Cosαscare = .939 rather than Fear, Cosαfear = .925. The testing of the raw data confirmed this vector computation. Out of 40 participants, 18 judged this facial expression as a sign of scare, while only 11 judged it as a sign of fear. The rest of the interpretations (e.g., shock, terror, surprise) did not affect the valence of the average judgment.
Also, participants’ average judgment vector of the “contempt” facial expression reflected the known weaker consensus about this particular expression (e.g., Matsumoto, 2005; Russell, 1991). The average vector was the closest to “hesitation,” cos α hesitation = .99.
Overall, these results supported our prediction that semantic emotion vectors derived from a word corpus embedding represent participants’ interpretation of facial expressions. These findings lay the foundations for testing our assertion that, indeed, the principle of semantic compositionality is applicable for understanding the meaning of a sequence of facial expressions.
Study 2
In Study 2, we examine our prediction implicating that the meaning of sequences of two emotional facial expressions (two-sequence) is manifested by the weighted average of their discrete constituents as predicted by the compositionality principle (e.g., Dummett, 1981; Pelletier, 1994). This assertion is based on previous studies that examined the evaluation of affective video clips (e.g., Fredrickson & Kahneman, 1993; Haberman et al., 2009; Varey & Kahneman, 1992) and found that participants judgment of the affect, conveyed by the clips, was based on the weighted average of their judgments of “snapshots” of each scene in the clips, regardless of their respective duration. In terms of the compositionality principle, the resulted impression of the affective experience was determined by the meaning of its constituting parts (snapshots) and the operation performed (weighted average) on those parts. Here we test how the compositionally principle applies to sequences of facial expressions.
Method
To test our prediction, we conducted regression analysis. A significant regression of participants’ judgment by the two vectors representing the expressions would support our prediction. However, a nonsignificant regression or a significant interaction between the two expressions would not conform with the principle, according to which the meaning of a complex phrase is composed of the meaning of its constituents and the rules for their combination but nothing else.
More formally, let

Participants
Same as in Study 1.
Stimuli
Similar to Study 1.
Design and Procedure
The design and procedure of Study 2 were similar to Study 1 with the following exceptions: (1) Each participant reviewed 28 sequences, randomly selected from the total of 56 combinations of sequences of two images (two-sequences) consisting of the eight facial expressions of Study 1. The number of sequences per participant was limited to 28 to avoid exhausting the participants. (2) Each trial (Figure 5) included a fixation image presented for 2 s, followed by two pictures of facial expressions. Each face image was displayed for 1 s and portrayed one of eight facial expressions (including a neutral expression) followed by a blank image (2 s). (3) Vector representation was based on both Twitter and Wikipedia word corpora. As in Study 1, participants were asked to describe their impressions about the “woman's state of mind” using single words. Encouraging participants to expand their vocabulary, they were asked to use other words than those used in Study 1.

Illustration of the timeline of two expressions trial presented in Study 2.
Results
Collecting and Preprocessing Participants’ Judgment
Preprocessing was similar to Study 1. We collected 1920 words that described the “woman's state of mind” as perceived from the 56 stimuli of two expressions. The analysis yielded 372 unique word descriptors (including the 73 words found in Study 1), assigned by respective vector representations. Following this preprocessing stage, we replaced every word from the original list (of 1920) with its unique word descriptor from the list of 372 words, after which we assigned vectors to each of the 372 words. Next, we performed a dimensionality reduction process using PCA as in Study 1, yielding seven PCs.
To pin down how the compositionality principle manifests for sequences of two emotional facial expressions (two-sequence), one could solve the constrained multiple regression problem of Eq. (1) and examine whether a statistically significant result is obtained. However, solving constrained multiresponse multivariate regression is not a simple task. Instead, we relaxed the constraint that the coefficients a,

For
In case that all
The scenario where all coefficients
We used the Holm–Bonferroni method (Holm, 1979) to control for family-wise errors stemming from the fact that we have seven hypotheses rather than one. All seven regressions were found to be significant, F(3, 60) = 12 ± 5, ps < .001,
To measure the robustness of our results, we repeated the same computations, using the Wikipedia text corpus (rather than Twitter's), relying on GloVe (Pennington et al., 2014). This time the Guttman-Kaizer criterion suggested projecting the 50 dimensions on the top 10 PCs. Similar averages were obtained with Wikipedia's word embedding compared with Twitter's, suggesting that our results are robust and text-independent. All
Study 3
The findings of Study 2 indicate that the meaning of a sequence of facial expressions is the composition of its discrete constituents and that the effect of the second expression was more substantial than the effect of the first one. However, it is still unclear which operation was performed on these constituents. In cognitive terms, the question is how participants formed their perception of the two-expression sequence. It is possible that they evaluated the sequence as a weighted average composition of the two constituting expressions. Another alternative is that the findings could result from a mere recency effect on the judgments of the expressions. Breaking down the results of Study 2, we conducted Study 3 to test whether recency would indeed affect participants’ judgments.
Method
For each of the 56 two-expressions sequences, we computed the cosine similarity (cos α) between the average vector of participants’ interpretations of that facial expression and the closest expression word (vector). If the recency effect would be dominant, then the meaning of the second expression could override the meaning of the first one.
Participants
Same participants as in Study 2.
Stimuli
Similar to Study 2.
Design and Procedure
Similar to Study 2.
Results
We found three groups that differ in the effect of the facial expressions on sequence's perception: (1) In this group, which included the majority (81%) of the two-sequence expressions, the overall meaning of the sequence was the weighted average of its discrete constituents. For each of the two-expression sequences, the overall meaning of a sequence was different from the meaning of its discrete constituents. For example, the fear-contempt sequence was perceived as a sign of hesitation, cos α = .984; the happy-disgust sequence was perceived as a sign of annoyance, cos α = .970; and the surprise-disgust sequence was perceived as a pity, cos α = .940 (See Table 3 of Supplementary appendix). (2) In this group (3%), the meaning of the first expression overrides the meaning of the following expression. For example, angry-surprised sequence was perceived as anger, cos α = .970, while fearful-surprised sequence was perceived as fear, cos α = .979. (3) In this group (15%), the meaning of the second expression overrides the meaning of the first one. Interestingly, such results were obtained only when either fear or happy expressions were part of the sequence. For example, contempt-happy sequence was perceived as a sign of happiness, cos α = .985, disgust-fear as well as sad-fear sequences were interpreted as a sign of fear, cos α = .949 and cos α = .977, respectively. More interesting is the combination of happy and fearful expressions. When the happy expression was the second, participants perceived the sequence as a sign of happiness, cos α = .961, but when the fear expression was second, the sequence was interpreted as a sign of fear, cos α = .987. All in all, these findings support the view that the meaning of a sequence of facial expressions is the weighted average of its discrete constituents and not a result of recency effect.
Discussion
The principle of semantic compositionality is an important presupposition in the field of language research. In the present study, we tested the hypothesis that this principle also applies to facial expressions. We showed that the meaning of a sequence of two facial expressions is determined by the meaning of its constituting parts and an operation performed on those parts. First, we demonstrated the applicability of the principle through the lens of “algebraic compositionality.” We showed that the meaning of mixed expressions, operationalized by their AUs, was determined by the unification (U) of their constituting facial expressions. Second, we used a broader account of the compositionality of concepts to test our prediction. We showed that compositionality governs a systematic rule across two-sequence emotional expressions.
To test our hypotheses, we developed a computational framework utilizing language modeling and feature learning methods used in language research. Using vector representation of emotion states and performing algebraic vector operations, we found that the principle of semantic compositionality also applies to sequences of facial expressions, consistently with our prediction. Participants’ interpretation of the sequences of two facial expressions, represented by their respective vectors, was expressed as a weighted average of the single constituting expressions comprising them. The present study demonstrated that people use basic facial expressions to create a much larger emotional state vocabulary.
These findings offer a systematic complimentary account of how the variety of more subtle emotional states, such as hesitation (a fearful expression followed by contempt) or bitterness (a happy expression followed by sad), is being produced and perceived. The results go beyond existing studies which investigated various aspects associated with emotional states such as (i) the number of basic facial expressions (Ekman, 2016; Ekman & Friesen, 1969; Keltner & Cordaro, 2017), (ii) the combined muscle movements of two expressions within a third expression, (e.g., a sadly fearful expression combined muscle movements of sad and fear expressions; Du et al., 2014), and (iii) studies which focused on the temporal evolvement within single facial expressions (e.g., Jack et al., 2014).
However, an important question is how the concept of compositionality fits established ideas and phenomena within the field of cognition. Psychological research has shown that past experiences shape current perception in several ways such as priming (Labroo et al., 2008), aftereffect (Webster & MacLin, 1999), and positive serial dependence (Fischer & Whitney, 2014; Liberman et al., 2014). It is possible that some or all these mechanisms contribute to our findings to some extent. Another theory that is related to the perception of a sequence of facial expressions, is the “componential theory” (Scherer, 1984; Scherer & Ellgring, 2007). The theory proposes that a facial expression is created and perceived through a sequential process, wherein new expression components are added to the former, matching the eliciting emotional event with a stored schema. The process ends, when no new information is fed, yielding a final perception (e.g., face-to-face interaction ceased). We suggest that the principle of semantic compositionality alludes to the final stage described by the componential theory; the last step is represented by the algebraic operation computed on the constituent components. A postulation of this sort may offer a bridge between psychological theories and new theories from the field of NLP. Initial support for this proposal is gleaned from studies showing that participants could assign weights to discrete events (“snapshots”), averaging facial expressions based on their location in the sequence, independently of set size or time of exposure (e.g., Fredrickson & Kahneman, 1993; Haberman et al., 2009; Varey & Kahneman, 1992).
It is still an open question whether the compositionality principle holds for sequences of more than two facial expressions and how. Although all various notions of the compositionality principle do not limit its applicability to a certain number of constituting parts, the examples used by researchers mainly refer to two parts (e.g., Hoeksema, 2000; Medin & Shoben, 1988; Pelletier, 1994). Furthermore, the stimuli used in the study were exemplars of the seven emotional expressions, neglecting expression variation that could support generalization. A future study can include more samples of each expression. It can also expand our understanding of the compositionality principle's applicability for sequences of more than two facial expressions. One possibility is that participants’ interpretation of a sequence of several facial expressions stems from a weighted averaging of the all-single expressions comprising the sequence. Another alternative assumes a more complex algebraic operation on the constituting parts; the meaning of a sequence of facial expressions is determined by only two expressions: the most significant (intense) expression and the last one(s). All other expressions of the sequence are zero weighted. Such postulation is in line with the Peak/End average rule (Fredrickson, 1991, 2000; Kahneman, et al. 2000), according to which people's perceptions of past emotional events are affected by their experience in just two instances: the climax and the ending.
In a broader context, the present study raises the possibility that the theoretical framework of the principle of semantic compositionality can be applied to other human communication modalities, such as music; a minimal number of basic notes are expanded to endless musical compositions.
Supplemental Material
sj-docx-1-pec-10.1177_03010066221077573 - Supplemental material for The Compositionality of Facial Expressions
Supplemental material, sj-docx-1-pec-10.1177_03010066221077573 for The Compositionality of Facial Expressions by Carmel Sofer, Galia Avidan, Dan Vilenchik and Ron Dotsch in Perception
Footnotes
Acknowledgments
The authors thank the ABC robotics initiative at Ben Gurion University of the Negev and The Israeli Ministry of Defense for financial support. The funders had no role in study design, data collection, analysis, decision to publish, or manuscript preparation. The authors thank Dr. Gideon Rosenthal and Prof. Yair Neuman for fruitful discussions and comments. The authors also thank Tal Weisman for data collection.
Authors’ Note
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.