
Abstract
Humans have expertise with visual words and faces. One marker of this expertise is the inversion effect. This is attributed to experience with those objects being biased towards a canonical orientation, rather than some inherent property of object structure or perceptual anisotropy. To confirm the role of experience, we measured inversion effects in word matching for familiar and unfamiliar languages. Second, we examined whether there may be more demands on reading expertise with handwritten stimuli rather than computer font, given the greater variability and irregularities in the former, with the prediction of larger inversion effects for handwriting. We recruited two cohorts of subjects, one fluent in Farsi and the other in Punjabi, neither of whom were able to read the other's language. Subjects performed a match-to-sample task with words in either computer fonts or handwritings. Subjects were more accurate and faster with their familiar language, even when it was inverted. Inversion effects were present for the familiar but not the unfamiliar language. The inversion effect in accuracy for handwriting was larger than that for computer fonts in the familiar language. We conclude that the word inversion effect is generated solely by orientation-biased experience, and that demands on this expertise are greater with handwriting than computer font.
Introduction
Over 50 years ago (Yin, 1969) reported that “while all mono-oriented objects tend to be more difficult to remember when upside-down, faces are disproportionately affected ” (p. 141). This observation has led to the proposal that faces are processed in a specialized manner—for review, see (Farah et al., 1995; Rossion, 2009; Valentine, 1988). It has been combined with effects showing the influence of whole-face processing such as the part-whole effect (Tanaka & Simonyi, 2016) and the composite face effect (Murphy et al., 2017), and studies of the processing of features versus their configuration in the face (Barton et al., 2001; Leder & Bruce, 2000; Searcy & Bartlett, 1996), to infer that holistic effects are reduced in the perception of inverted faces. Thus, it is proposed that, since our perceptual experience with faces is overwhelmingly biased to the upright orientation, face recognition develops an orientation-dependent expert mechanism that is likely holistic in nature, and that the face inversion effect is one index of that expertise.
As stated in the original report (Yin, 1969), inversion effects are not unique to faces, but are also seen with other objects with a canonical orientation. One particular class of visual stimuli that has both a canonical orientation and a claim to expertise in a literate population is visual words. The earliest study of a word inversion effect showed that the mirror reflection of one letter is easily seen in upright words but poorly detected in inverted words (Parks, 1983). This was considered a parallel to the Thatcher illusion for faces, in which grotesque rotations of local features like the eyes and mouth are not perceived when the face is inverted (Thompson, 1980), an effect attributed to disrupted whole-object processing. Subsequent studies have replicated this Thatcher-like effect in inverted words but not in random letter arrays, that is non-words (Navon & Raveh, 2004; Wong et al., 2010). Effects of inversion on other measures of reading proficiency have followed. The word-length effect is the relation between reading time and the number of letters in a word, and this is minimal in upright words and prolonged in inverted words (Björnström et al., 2014; Koriat & Norman, 1985; Navon, 1978). Inversion increases contrast thresholds (Martelli et al., 2005) and reduces the perceptual efficiency (Albonico et al., 2018) for word recognition. When searching for a target word within an array of words, inversion increases the set-size effect, the extra time needed with each additional stimulus in that array (Hemström et al., 2019).
Thus, while the word inversion effect has not been studied as extensively as the face inversion effect, there is consistent evidence of its existence. As with faces, it seems likely that this develops through long experience with a stimulus class that is seen predominantly in a canonical orientation. If so, one possibility that may be better afforded by words than faces is the chance to test and confirm the role of experience in generating the inversion effect. For faces, the role of experience may be reflected in the fact that the face inversion effect is larger for faces belonging to the subjects’ own ethnic group (Hayward et al., 2013). However, all faces have a similar structure and a similar set of features, and substantial inversion effects are still seen for other-race faces, even if less than for own-race faces. Hence this can be regarded only as a partial test of the contribution of experience to the inversion effect. Words, on the other hand, are artificial stimuli, and while written languages with a common genealogy—for example, English and French—may share alphabets, morphemes, and words, those from very different cultures—for example, English and Mandarin—do not and are mutually unintelligible. Therefore, a comparison between familiar and unfamiliar languages with distinctly different scripts is a strong test of the hypothesis that visual experience generates the inversion effect, rather than the latter being some inherent property of the stimulus class.
The type of perceptual mechanism that is refined by experience and disabled by inversion has been much debated. The prevailing opinion is that expert face processing involves holistic processing, and that inversion impairs the use of this mechanism (Rossion, 2008). However, current views of reading propose that word processing involves a component-based hierarchy of stages in which line segments provide features for letter identification, which in turn generates word recognition (Rumelhart & McClelland, 1982). Despite this, there is also evidence for whole-object influences in word recognition (Feizabadi et al., 2021), perhaps through top-down lexical effects rather than as a primary processing mechanism. If inversion has a particularly strong effect on whole-object mechanisms, then reading conditions that place more demands on whole-word influences may generate stronger word-inversion effects.
One aspect of the visual text that may favour component-based processing is the high regularity of type or computer font. This contrast with the variability of faces, whose features and configurations differ from each other along a continuous spectrum and show dynamic changes and variable feature visibility due to their mobile three-dimensional structure. Under such circumstances, local component data may be less reliable, and integrating information from the whole object may support more accurate recognition. For written words, handwritten stimuli may provide a more similar processing challenge than computer font. The identification of letter components in handwriting is more difficult. Not only does the handwritten shape of the word or letter vary between different writers, but the same person never writes a word exactly the same way twice, the shape of a given letter in a word is partly determined by the context of neighbouring letters, and writing can change with mood, writing speed, and the medium or tools used, about which researchers working on automated handwriting identification are all too aware (Adak et al., 2019). Such variability may increase reliance on top-down whole-word or “lexical” effects for deciphering the handwritten text. Indeed, others have found that lexical effects such as word frequency, regularity, bidirectional consistency, and imageability are increased in handwritten compared to printed words (Barnhart & Goldinger, 2010; De Zuniga & Humphreys, 1991; Perea et al., 2016). While there have been no studies of inversion effects for handwritten words, one study found that a 90° clockwise rotation made reading more difficult than rotating 90° counterclockwise, and that this difference was larger for handwritten than computer fonts, which was attributed to the clockwise rotation being more dissimilar to the natural slant of most writing (Barnhart & Goldinger, 2013).
Our study had two goals. First, we investigated the relationship between experience-based expertise and the word inversion effect, by studying the reading by Farsi and Punjabi readers of their own and each other's written languages. These languages have little to no overlap in their script and would provide a strong test of the hypothesis that the inversion effect is driven by expertise gained through an orientation-dependent experience, rather than inherent properties of the visual stimuli. Second, we compared inversion effects in handwritten words and words in computer font. If whole-object aspects of visual processing are particularly vulnerable to inversion effects, then we predicted that word inversion effects would be greater for handwritten text, particularly for the familiar language.
Method
Subjects
Forty healthy subjects participated. One group of 20 was fluent in Farsi but not Punjabi (10 men, 10 women, age range 30–57, mean = 42.5 years, SD = 7.5 years) and the second group of 20 was fluent in Punjabi but not Farsi (8 men, 12 women, age range 18–67, mean = 29.1 years, SD = 12.5 years). Familiarity and fluency for each language were determined simply by the subjects’ self-appraisal. In the Farsi group, all subjects reported that Farsi was their first language and denied any experience with Punjabi. In the Punjabi group, 17 subjects reported that Punjabi was their first language, and three that it was their second language, and all denied any experience with Farsi. Due to COVID-19 restrictions, subjects were contacted by email and the test was administered online after they agreed to participate.
The protocol was reviewed and approved by the institutional review boards of the University of British Columbia, Vancouver Coastal Health, and Bethel University, and all subjects gave written informed consent in accordance with the principles of the Declaration of Helsinki.
Word Stimuli
For both Farsi and Punjabi, 18 words were selected. Words were either five, six, or seven letters long. For our three-alternative task, we assembled six sets of triplets, where the members of a triplet had the same length and the same first and last letter. In the absence of frequency databases specific to these cultures, words were selected so that the word frequency of their English translations was matched across the two languages and approximated within each triplet. The mean Kucera-Francis written word frequencies for Farsi was 37.9 and for Punjabi was 41.2 occurrences per million.
For each language, we created two sets of stimuli: one set of handwritten words, and one set printed in computer fonts (Figure 1), each set containing all of the same 18 words. We note that, unlike most European languages, neither language has an upper and lower case.

Examples of the word stimuli used in the three-alternative match-to-sample task. The six handwritings and the six computer fonts are shown for both the Farsi (A) and the Punjabi (B) stimuli.
To create handwritten stimuli, each word was written by six different individuals for whom the script in question was their first language, using the same black pen, to give 108 stimuli for each language. Stimuli were checked subjectively by an experimenter for a reasonable degree of legibility. Each visual word stimulus was then digitized and adjusted in size using Adobe Photoshop CC 15, so that all visual words had a similar height of around 150 pixels. Background noise was removed too, and word stimuli were converted to grayscale and kept on a white background. Three of the handwritings were used for the possible sample stimuli, and three were reserved for the possible choice stimuli.
For computer font stimuli, we selected six computer fonts for each language. The fonts chosen for Farsi were B Tabassom, B Mahsa, Arabic Typesetting, B Mitra, B Morvarid, and B Davat, and the fonts chosen for Punjabi were AmrLipi, Adhiapak, Raaja, Karmic Sanj Book, AnmolKalmi, and Bulara. As for handwriting, three were used for the possible sample stimuli, and three reserved for the possible choice stimuli. Computer font stimuli were printed and digitalized following the same procedure for handwritten stimuli, giving 108 computerized stimuli for each language.
Procedure
The word test was created with Testable (https://www.testable.org). The tests consisted of four blocks, namely upright Farsi, inverted Farsi, upright Punjabi, and inverted Punjabi. Each of the word stimuli was seen once as a target word, for a total of 432 trials (108 trials per block). The order of the four blocks was counterbalanced within each of the two subject groups. Within each block, handwritten and computer font stimuli occurred in random order.
Each trial presented a three-alternative match-to-sample task (Figure 2). Subjects saw a target word for 1,250 ms, after which a white noise mask appeared for 150 ms, followed by the response screen, which displayed the three members of the appropriate triplet, one of which was the target word. The task was to indicate which of the three choices was the same as the target word. The response screen remained visible until they entered their response with a key press. On any given trial, the target word and the three choice words on the response screen were either all handwritten or all computer fonts. All three of the choice stimuli differed from each other in the style of handwriting or computer font, and in turn differed from the sample stimulus. Hence, word identification had to generalize across irrelevant stylistic variations, for both handwritten and computer font trials. Subjects were given a rest break between each block. At the beginning of the experiment, subjects had sixteen practice trials, half Farsi and half Punjabi, half upright and half inverted, half handwriting and half computer font, with feedback to familiarize them with the task.
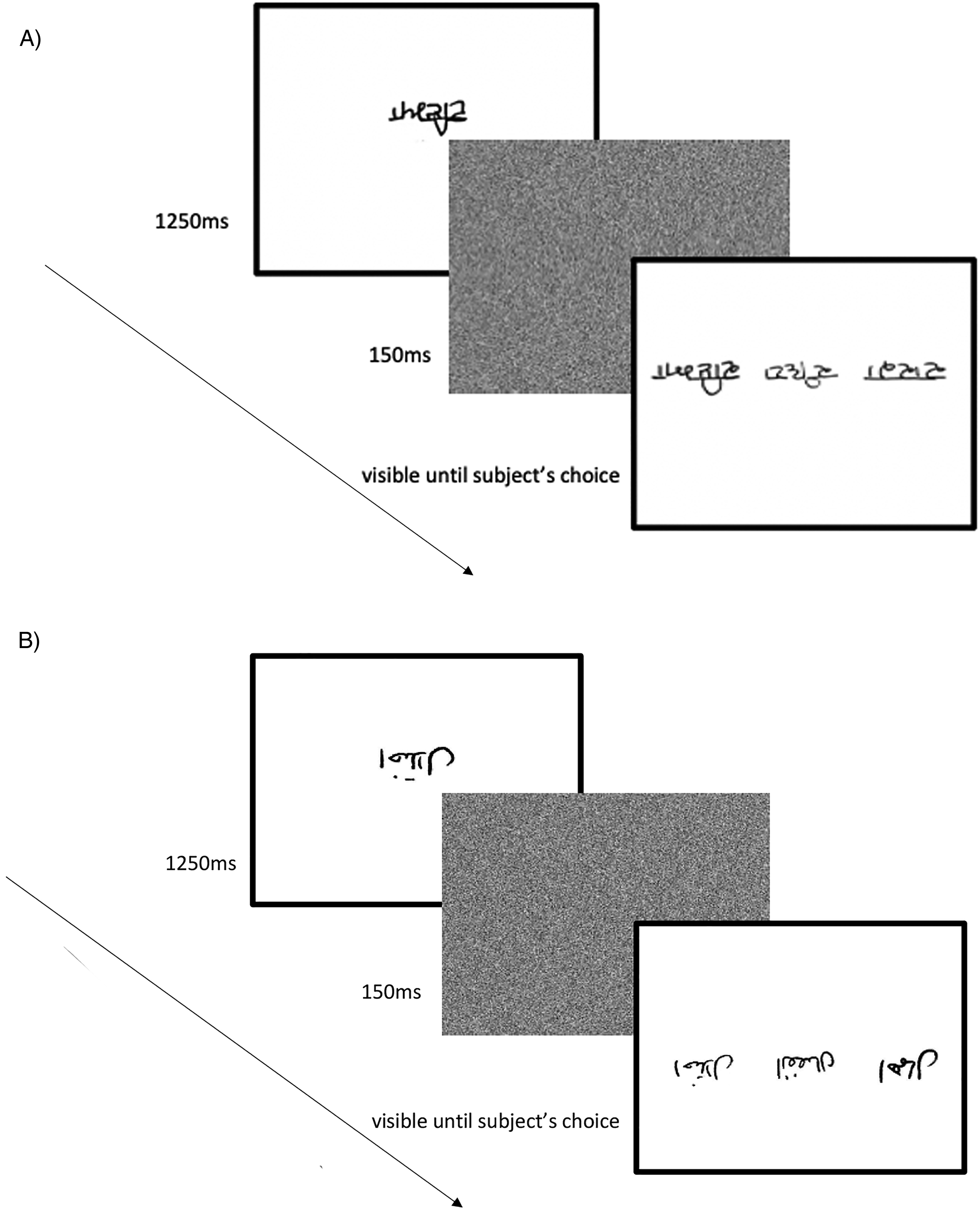
Illustrations of a typical trial in the three-alternative match-to-sample task for both the inverted Farsi (A) and upright Punjabi (B) conditions with handwritten stimuli. Each target word was shown for 1,250 ms, followed by a mask screen for 150 ms, which was followed by the response screen, displayed until the subject made a response indicating which of the three response options matched the target word. Note that the sizes of the stimuli in the figure do not reflect the actual sizes used.
Subjects were also required to complete the online version of the Cambridge Face Memory Test (Duchaine & Nakayama, 2006), in both its upright and inverted versions. The CFMT was included to investigate the possible presence of similarities between the effect of inversion on faces and visual words. For both the Farsi and Punjabi subjects, the order of the tests was counterbalanced, and since subjects performed the three experiments in one day, they were advised to take a 20–60-minute rest break in between the two word tests and the Cambridge Face Memory Test tests.
Data Analysis
Accuracy and response times of correct trials only were analysed with repeated-measures ANOVA, with orientation (upright, inverted), style (computer font, handwriting), and language familiarity (familiar, unfamiliar) as within-subject factors. Trials with response times that were 3 SDs above or below the mean for each subject were omitted from the response time analysis. Significant differences were explored by Bonferroni post hoc multiple comparisons (corrected p-values are reported). The effect sizes in the ANOVAs were also measured by computing the Partial Eta Squared (ηp2).
For both accuracy and response time, we calculated four inversion effects for each subject, one for each of the four possible combinations of style and familiarity. The inversion effect was simply the subtraction between upright and inverted performance, signed so that a positive value indicated superior upright performance. We performed one-sample t-tests to determine whether the inversion effects were different than 0 (indicating no difference in performance between the upright and inverted orientations). We then performed dependent-sample t-tests to compare the size of the inversion effect for font and handwriting.
Results
Accuracy
There were significant main effects of familiarity (F(1,39) = 4.34, p < .001;

Accuracy (A) and response times (B) results for the two familiarity conditions in both the upright and inverted orientations. Error bars indicate 1 SE. Significance is indicated by * for p < .05, ** for p < .01, and *** for p < .001.
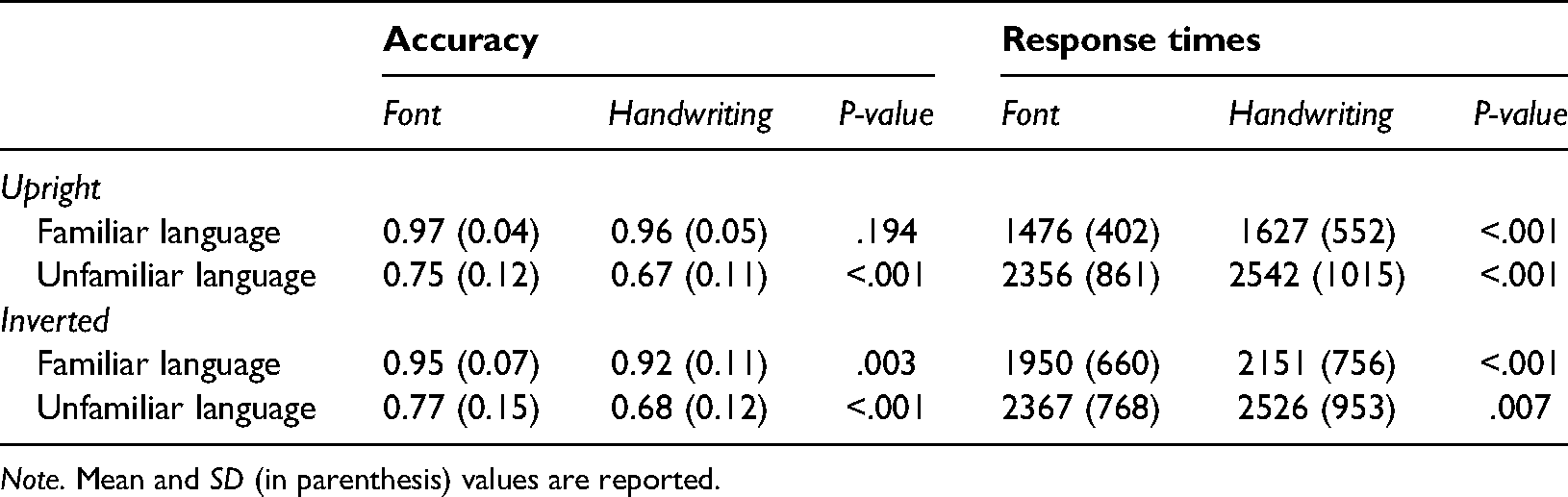
Font versus handwriting comparison in the two orientation conditions for both languages.
Note. Mean and SD (in parenthesis) values are reported.
Did the results differ between our Farsi and Punjabi subjects? We repeated the ANOVA with language group as a factor, to determine if there were any significant interactions (Figure 4A). On the accuracy data, there was an interaction between language group and familiarity (F(1,38) = 5.49, p = .024). Bonferroni-corrected post hoc contrasts showed that accuracy for the familiar language was greater for Punjabi than Farsi subjects (M = 0.987, SD = 0.04, vs. M = 0.917, SD = 0.04; p < .001), while the two groups did not differ in the unfamiliar condition (i.e., Punjabi M = 0.713, SD = 0.11, Farsi M = 0.724, SD = 0.11, p = .750). However, both groups were more accurate for the familiar than for the unfamiliar language (p < .001 for both). No other interactions with language group were significant.

Accuracy (A) and response times (B) results for the two familiarity conditions are shown separately for language group. Error bars indicate 1 SE. Significance is indicated by *for p < .05, ** for p < .01, and *** for p < .001.
Response Times
All main effects of familiarity (F(1,39) = 15.78, p < .001;
We again examined whether the results differed between Farsi and Punjabi subjects, by repeating the ANOVA with language group as a factor (Figure 4B). There was a similar interaction between language group and familiarity (F(1,38) = 65.18, p < .001). While both groups were faster with familiar words, Punjabi subjects were slower than Farsi subjects for the familiar words (Punjabi M = 2154, SD = 406; Farsi M = 1447, SD = 407; p < .001) but faster for unfamiliar words (Punjabi M = 1993, SD = 726; Farsi M = 2902, SD = 720; p < .001). The contrast between familiar and unfamiliar languages was significant for Farsi subjects (p < .001) but not for Punjabi subjects (p = .262). No other interactions with language group were significant.
Inversion Effects
For accuracy (Figure 5A), inversion effects for the familiar language were significantly different than zero (font: 0.027, t(39) = 2.63, p = .012; handwriting: 0.051, t(39) = 3.33, p = .002), while the ones for the unfamiliar language were not (font: −0.014, t(39) = −0.66, p = .510; handwriting: −0.012, t(39) = −0.70, p = .488). The inversion effect for the familiar language was almost twice as large for handwriting than computer font (t(39) = 2.70, p = .010), while this comparison was not significant for the unfamiliar language (t(39) = 0.15, p = .880).

Accuracy (A) and response times (B) inversion effects for the familiar and unfamiliar languages, in both the computer font and handwriting conditions. Error bars indicate 1 SE. Significance is indicated by * for p < .05, ** for p < .01, and *** for p < .001.
For response time (Figure 5B), again, inversion effects for the familiar language were significantly different than zero (font: 475 ms, t(39) = 5.97, p < .001; handwriting: 524 ms, t(39) = 5.85, p < .001), while the ones for the unfamiliar language were not (font: 11 ms, t(39) = 0.13, p = .898; handwriting: −16 ms, t(39) = −0.19, p = .853). The inversion effects for font and handwriting did not differ between each other in either the familiar or the unfamiliar language (both p’s > .05).
Discussion
As predicted, our results show a strong effect of familiarity on written word processing. Both upright and inverted words were recognized more accurately and faster for the familiar language. Confirming the prediction of the expertise hypothesis, there was a word inversion effect in accuracy and reaction time for the familiar language, but none for the unfamiliar language. Inversion effects for the familiar language were found for both computer fonts and handwritten stimuli, but the inversion effect on accuracy were almost twice as large for handwritten stimuli than for computer font.
The superior performance for the inverted familiar language over the upright or inverted unfamiliar language indicates that experienced reading mechanisms are still accessible by inverted words. This is against a strong view of the inversion effect, that only upright stimuli access expertise, while inverted stimuli are processed by generic object recognition processes. Rather, the results suggest there is persistent but less efficient use of those experienced mechanisms by inverted stimuli, similar to the conclusions of some other studies for face inversion effects (Pichler et al., 2012; Richler et al., 2011; Sekuler et al., 2004).
The fact that there is no word inversion effect for the unfamiliar language is strong evidence that this effect is the product of orientation-biased experience. While it might seem self-evident that an orientation effect should not occur for stimuli that one has not seen before, this is not necessarily a given. The structures of objects in our world are largely determined by gravity, and perceptual systems that evolved to function in such a world may have inherent anisotropies and biases, for example, the higher spatial resolution of attention in the lower than the upper visual field (Intriligator & Cavanagh, 2001), and the various directional anisotropies in orientation (Maloney & Clifford, 2015) and motion processing (Pilz & Papadaki, 2019). Writing systems may have developed to exploit innate perceptual preferences, so that there may be a “right-side up” even for unfamiliar written languages. Our results show that, even if that were the case, this does not generate a significant inversion effect in the perception of unfamiliar languages. Therefore, the word inversion effect can be wholly attributed to perceptual experience. The importance of experience is also supported by findings that the Chinese word inversion effect in non-native speakers is correlated with the degree of their fluency with Chinese (Wong et al., 2019).
As others have noted (Hayward et al., 2013), an inversion effect does not prove that whole-object processing is involved with upright stimuli, and hence one cannot claim that our results imply holistic processing for familiar languages but not unfamiliar ones. Other methods that show interference or facilitation from whole-object processing speak more specifically to that issue, but there are few studies contrasting the effects between familiar and unfamiliar languages. Grossi et al. (2009) examined the word-superiority effect for Italian and English, an effect that shows better recognition of letters when they are embedded in words than when these letters are seen in isolation or in random letter strings. Native Italian speakers who learned English as adults showed superiority effects for both languages, whereas native English speakers who did not know Italian showed superiority effects just for English. The composite word effect is the illusion that a word-half in two stimuli differs when it is actually the same, if they are aligned with other halves that do differ, and is attributed to interference from whole-object processing (Murphy et al., 2017; Young et al., 1987). The few studies on the influence of language familiarity on the composite word effect have produced mixed results, with some finding composite word effects for accuracy in Chinese or English in native readers but not novice readers (Wong et al., 2011; Wong et al., 2012), while others found the opposite for Chinese (Chung et al., 2018; Hsiao & Cottrell, 2009). These few studies indicate that it is not clear whether the benefits of familiarity with a written language are attributable to enhanced whole-word processing, and, indirectly, whether the latter may contribute to the emergence of a word inversion effect.
We found larger inversion effects for handwriting than for computer font with the familiar language. Because of its variability and irregularities, handwritten text is generally considered more difficult to read. Some studies found poorer performance when handwritten and typed text was mixed in lists, from which they concluded that the two may involve different recognition mechanisms (Corcoran & Rouse, 1970). A tachistoscopic study found a reduced right hemifield advantage for handwriting compared to font, and suggested that there was a greater contribution from the right hemisphere when reading handwritten text (Hellige & Adamson, 2007), as subsequently found in a functional imaging study (Qiao et al., 2010). Given the right-hemisphere dominance for face processing, one might thus ask whether the reading of handwritten words recruits similar mechanisms to those used for faces and which are responsible for larger experience-based inversion effects, thereby explaining a greater inversion effect for handwriting than font. Also, the evidence that handwritten text shows larger modulation by top-down lexical information (Barnhart & Goldinger, 2010; De Zuniga & Humphreys, 1991; Perea et al., 2016) raises the possibility of enhanced whole-word processing for handwriting, which might contribute to larger inversion effects, in an analogy with the hypothesized link between holistic face processing and the face inversion effect (Rossion, 2008).
Another factor that is relevant for comparisons between handwritten and computer font stimuli is a prototype effect, which has been reported in face recognition (Cabeza et al., 1999; Rakover, 2013). The prototype is a “central value” of series of related stimuli, essentially a representation of the mean physical properties of that series. The similarity of a stimulus to its prototype influences categorization and recognition (Rosch & Mervis, 1975), and indeed typical faces (i.e., those similar to an “average” face) are categorized as faces faster than unusual faces (Valentine, 1991). High regular computer fonts are likely more similar to word prototypes than handwritten ones, given all the irregularities of the latter, and this may account for the main effects of slower and less accurate word recognition with handwriting. Whether a prototype effect can also explain the greater inversion effect for handwriting than computer font for the familiar language is not clear. If so, the implication would be that prototype effects are magnified by inversion, as suggested by the greater difference between handwriting and computer font for inverted compared to upright stimuli in the familiar language (Table 1).
One possible limitation is the fact that the difference in orientation effects on accuracy between font and handwriting for the familiar language was evident with the calculated inversion effects as the dependent variable, but not as a triple interaction in the ANOVA of accuracy. This may reflect the fact that orientation effects on raw accuracy are modest compared to the fivefold greater effects of familiarity. Furthermore, between-subject differences in language fluency in these immigrant communities may have generated variability in accuracy. In contrast to raw accuracy, a dependent variable that focuses on the relative differences in performance between two conditions, such as the inversion effect, minimizes the effects of fluency, familiarity, or other factors that impact raw accuracy scores. Hence, the inversion effect likely had greater power to detect the handwriting/font difference in our sample.
In conclusion, we found inversion effects only for familiar languages. Such a result is consistent with the view that inversion effects arise from a perceptual expertise gained through experience with objects having a canonical orientation, rather than reflecting inherent biases in perception or writing structure. When written words were made more variable and difficult using handwritten stimuli, the inversion effect for accuracy increased for the familiar language. This is consistent with predictions based on greater recruitment of top-down whole-word influences by handwritten stimuli, and a greater vulnerability of whole-object processing to inversion, based on an analogy with current concepts of face processing. However, further work is needed to prove that this is the explanation of our findings, and to clarify whether such word processing effects are correlated with or dissociated from those for face recognition.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.