
Abstract
Spatial contextual cueing refers to the facilitation of visual search when invariant spatial configurations of the target and distractors are learned. Using the instance theory of automatization and the reverse hierarchy theory of visual perceptual learning, this study explores the acquisition of spatial contextual cueing. The findings support the reverse hierarchy theory, which predicts that the acquisition of spatial contextual cueing progresses in an easy-to-difficult cascading manner. However, these findings are inconsistent with instance theory, which predicts that the acquisition of spatial contextual cueing in easy-half-repeated trials would keep pace with that in difficult-half-repeated trials. This study concludes that compared with instance theory, reverse hierarchy theory more plausibly explains the acquisition of spatial contextual cueing.
In our daily lives we constantly carry out visual search to locate task-relevant visual information while ignoring irrelevant visual information. Spatial contextual cueing refers to the facilitation of visual search when invariant spatial configurations of the target and distractors are learned (Chun & Jiang, 1998; for reviews, see Chun, 2000; Jiang & Sisk, 2020).
Instance Theory
As discussed in Chun and Jiang (1998) and Jiang and Song (2005) and as I have previously discussed (Lie, 2015), the instance theory of automatization (Logan, 1988, 1990) offers a plausible account for acquisition of spatial contextual cueing.
According to instance theory, in spatial contextual cueing, each task performance is mandatorily encoded and stored separately as a specific processing episode, and each processing episode undergoes mandatory retrieval when an identical or similar task is encountered. Retrieval of the processing episodes is, with practice, the foundation for improvement to performance. In particular, a race between the general algorithm for carrying out a particular task and the memory process that retrieves previous solutions for the task determines the performance of the task, with the memory process typically outpacing the algorithmic process. Yet, dissimilar to the algorithmic process, which is able to carry out the task without reliance on previous experience, to be effective the memory process requires enough previous experience with the task. Therefore, the algorithmic process dominates the initial performance of the task. As more task experience is gained, the memory process incrementally outpaces and outperforms the algorithmic process. By practicing, performance improvement occurs in the transition from the algorithmic process to the memory process.
Instance theory postulates that during encoding, only important task aspects are attended to and consequently encoded (Lassaline & Logan, 1993; Logan & Etherton, 1994), whereas during retrieval, only aspects of the past processing episodes relevant to the attended task aspects are retrieved (Boronat & Logan, 1997; Logan et al., 1996). In spatial contextual cueing the visual search task and the learning of spatial contexts are two separate processes (see Yang & Merrill, 2014). Detailed visual features of the distractors are likely to be attended to during the visual search task, especially when they are relevant for distinguishing between the target and the distractors. However, according to instance theory, this does not imply that they are necessarily encoded in conjunction with spatial contexts. Whether they are encoded in conjunction with spatial contexts depends not on whether they are relevant to the visual search task but on whether they are relevant to the learning of spatial contexts—whether attention to them helps distinguish between spatial contexts.
Reverse Hierarchy Theory
As I have previously discussed (Lie, 2015), the reverse hierarchy theory of visual perceptual learning (Ahissar & Hochstein, 2004; Ahissar et al., 2009) offers an alternative account for the acquisition of spatial contextual cueing (see also Goujon et al., 2015).
The rest of this part presents a review of reverse hierarchy theory together with an explanation of how it can account for the acquisition of spatial contextual cueing. Firstly, the visual processing hierarchy is described. Then, the respective roles of stimulus variability and task difficulty in visual perceptual learning are explained followed by a description of the easy-to-difficult cascade and the reverse hierarchy. Lastly, the reverse hierarchy theory's account of the acquisition of spatial contextual cueing is discussed.
Visual processing in the cortex is classically modelled as a hierarchy of increasingly sophisticated processes carried out by a hierarchy of visual cortical areas (Felleman & Essen, 1991; see Hegdé & Felleman, 2007, for a contemporary perspective). The higher the visual cortical area, the larger is the receptive fields of its neurons (Reid & Usrey, 2013). A neuron's receptive field in a visual cortical area refers to the visual field area that prompts a maximum response from the neuron. Neurons in lower visual cortical areas have smaller receptive fields that analyze visual features in finer detail, whilst neurons in higher visual cortical areas have larger receptive fields that analyze visual features in coarser detail. The size of the receptive field increases incrementally across visual cortical areas and the visual features they optimally react to also increase in generality and complexity (Reid & Usrey, 2013).
Reverse hierarchy theory operates on the assumption that the visual specificity of visual perceptual learning is reflective of the visual cortical area's response selectivity where learning occurs. Neurons at low levels of the visual system selectively respond to visual features at particular orientations and particularly to retinal positions; therefore, visual perceptual learning at low levels is assumed to be specific to these specific orientations and retinal positions. On the other hand, neurons at high levels generalize over orientation and location; thus, visual perceptual learning at high levels is assumed to generalize over orientation and location.
Visual specificity of visual perceptual learning is modulated by at least two factors: stimulus variability and task difficulty.
The more varying the stimuli during training, the less specific is the resulting visual perceptual learning (Ahissar & Hochstein, 2004). As mentioned above, neurons at low levels are specifically tuned. The greater the extent stimuli vary during training, the less likely particular populations at lower levels are stimulated in an overlapping way, and the less likely visual perceptual learning progresses to lower levels.
Aside from variability in the stimuli, task difficulty (in terms of task precision, i.e., the extent to which the target differ from the distractors, rather than task performance level, see Jeter et al., 2009) is also able to modulate the visual specificity of visual perceptual learning. The more difficult the task during training, the more specific is the resulting visual perceptual learning (Ahissar & Hochstein, 1997).
Visual perceptual learning progresses in a cascade, in that learning easy conditions precedes learning difficult conditions, both temporally and contingently. Learning difficult conditions requires at least one exposure to easy conditions. On presentation of only difficult trials, none or little learning was observed (Ahissar & Hochstein, 1997; see also Lawrence, 1952). When trials with varying difficulties were presented in an interleaved manner, the easier conditions were learned first, and any difficult condition learning occurred only after easy condition learning was substantially achieved (Ahissar & Hochstein, 1997).
To recap, generic visual perceptual learning occurs at high levels of the visual system, that specific visual perceptual learning occurs at lower levels, and that visual specificity of visual perceptual learning is hindered and promoted by stimulus variability and task difficulty, respectively. It follows from the visual perceptual learning easy-to-difficult cascade that visual perceptual learning starts at high levels of the visual system and then progresses to low levels when visual perceptual learning at high levels is substantially achieved and when greater visual specificity helps the task (top-down driven) or when the task environment shaped by stimulus variability and task difficulty favors a greater visual specificity (bottom-up driven). This hierarchy of visual perceptual learning is described as reverse because visual perceptual learning progresses counter-current to visual processing.
From the perspective of reverse hierarchy theory, spatial contextual cueing as a form of visual perceptual learning cascades from high to low levels of the visual system and the acquisition of spatial contextual cueing progresses in a cascading manner whereby learning easy conditions comes prior to learning difficult conditions. Reverse hierarchy theory predicts that in spatial contextual cueing, when trials with different degrees of difficulty are presented in an interleaved manner, easy conditions would be learned first.
The Present Experiment
The present experiment was designed to test two conditions under which instance theory and reverse hierarchy theory would make disparate predictions. Task difficulty was manipulated by shifting the similarity between the target and the distractors (Duncan & Humphreys, 1989). In both conditions, each spatial context was divided into halves: half of the distractors were dissimilar to the target (i.e., easy distractors), while the other half were similar to the target (i.e., difficult distractors). In the first condition (the easy-half-repeated condition, henceforth abbreviated as condition E), the spatial configuration of the easy distractors was constant, while the spatial configuration of the difficult distractors varied. In the second condition (the difficult-half-repeated condition, henceforth abbreviated as condition D), the spatial configuration of the difficult distractors was constant, while the easy distractors’ spatial configuration varied. The two conditions were presented in an interleaved manner throughout the experiment. In both conditions detailed visual features were irrelevant for distinguishing between spatial contexts.
Instance theory predicts that detailed visual features, which are relevant for distinguishing between the target and the distractors but not between spatial contexts, would be attended to during the visual search task but would not be encoded in conjunctions with spatial contexts, and thus the acquisition of spatial contextual cueing in the easy-half-repeated condition would keep pace with that in the difficult-half-repeated condition. In contrast, reverse hierarchy theory predicts that learning the spatial configuration of the easy distractors would be easier than that of the difficult distractors (easier in terms of task precision rather than task performance level), thus the acquisition of spatial contextual cueing in the easy-half-repeated condition would precede that in the difficult-half-repeated condition when the two conditions are presented in an interleaved manner.
Method
Participants
Twenty undergraduate students (18–24 years old; 10 males and 10 females) volunteered for the experiment. All participants reported normal or corrected-to-normal vision.
Apparatus and Stimuli
The experiment was run on a computer with a 22-inch (55.9-cm) screen. The software presentation (version 23.0) from Neurobehavioral Systems (2022) was used to deliver stimuli and to record responses.
Each display contained 13 visual objects (one target, six easy distractors, and six difficult distractors) appearing in an invisible 8 × 6 grid that occupied the entire screen. The visual objects were slightly jittered to prevent collinearities in the display. The visual objects were made up of two perpendicular lines of equal length (1.13 cm) and thickness (0.28 cm). The target was a T-shape rotated 90° to the left or to the right. The distractors were L shapes oriented at 0°, 90°, 180°, or 270°. The offset at the junction of the L shapes was 0.14 cm in the easy distractors and 0.28 cm in the difficult distractors. The background was gray, and the visual objects were white.
Design
Each experiment session comprised eight blocks. There were two within-participant variables: condition (E, D, and R) and block. Each block consisted of 24 trials (eight for each condition).
In condition E, the spatial configurations of the easy distractors were constant and were predictive of the target locations, while the spatial configurations of the difficult distractors varied, and the visual identities of both the easy and the difficult distractors within their respective locations were randomly varied. In condition D, the spatial configurations of the difficult distractors were constant and were predictive of the target locations, while the easy distractors’ spatial configurations varied, and both the easy and the difficult distractors’ visual identities within their respective locations were randomly varied. In condition R, which served as a control baseline, the spatial configurations of the distractors varied randomly and were not predictive of the target locations. Figure 1 shows example search displays of conditions E and D schematically.
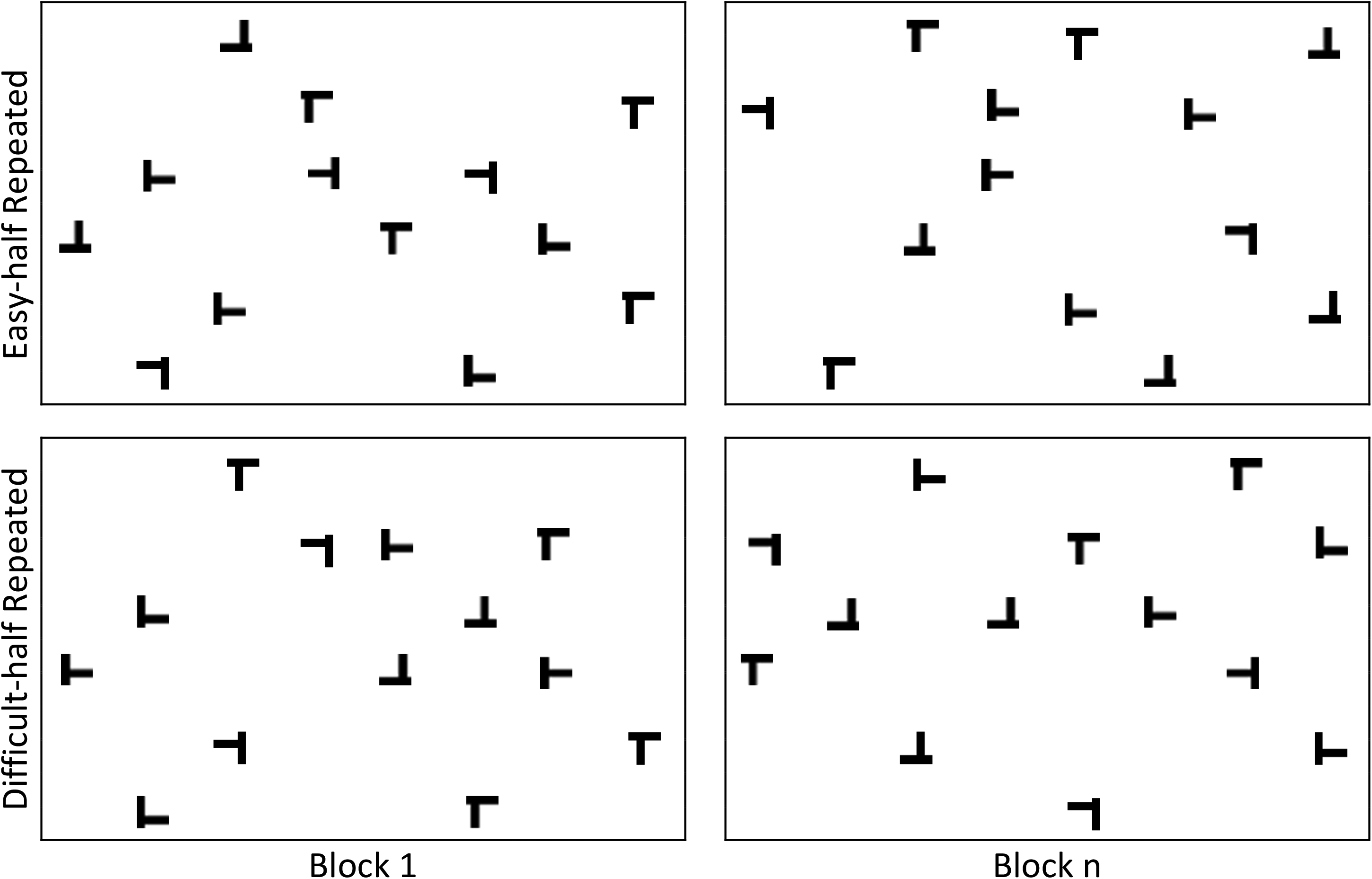
Example search displays with easy-half repeated and difficult-half repeated configurations (top and bottom panels, respectively).
The condition E set of stimuli consisted of eight randomly generated spatial configurations that were repeated across the blocks, once per block. Within each spatial configuration, the target appeared in the same location across the blocks, but for each block, the visual identity of the target was randomly chosen as either a left-pointing T shape or a right-pointing T shape such that the distractors’ spatial configuration, but not the target's visual identity and its corresponding motor response, was predictive of the target location. Within each spatial configuration for each block, the visual identity of each distractor was randomly chosen as the L-shape oriented at 0°, 90°, 180°, or 270°. The condition D set was generated in the same manner as the condition E set. The condition R set consisted of eight spatial configurations newly generated for each block. Within each spatial configuration, the target appeared in the same location across the blocks, while the spatial configuration of the distractors was randomly generated for each block. Within each spatial configuration, the visual identity of the target was randomly chosen as either a left-pointing T shape or a right-pointing T shape for each block, and the visual identity of each distractor was randomly chosen as the L shape oriented at 0°, 90°, 180°, or 270°.
The stimuli were generated separately for each participant. The trials were intermixed within each block.
Procedure
Participants were individually tested in a quiet room. Each participant pressed the “Enter” key to begin the experiment session. Each trial began with a small (0.08 cm × 0.08 cm) white dot appearing in the middle of the screen for fixation. After a brief pause of 500 ms, the dot was replaced by an array of visual objects. The participant searched for the target and pressed a corresponding key as soon as she/he located the target. The participant pressed the “F” key if the target was pointing left and the “J” key if the target was pointing right. The response cleared the screen. After a brief pause of 1 s, the computer began the following trial. A mandatory break of 10 s was given at the end of every two blocks, after which the participant was allowed to proceed to the next block or to rest further if needed.
Each experiment session began with instructions followed by a practice block of 24 trials to familiarize participants with the task and procedure. The spatial configurations used in the practice block were generated separately from those used in the actual experiment blocks. The participants were instructed to perform the task as quickly and as accurately as possible.
Results
Overall error rates were low at 1.7%. The reaction times of all correct trials were subjected to a non-recursive outlier elimination procedure in which the criterion used to identify outliers (number of standard deviations from the cell mean) was dependent on the number of data points in the cell (Van Selst & Jolicoeur, 1994). This resulted in the exclusion of less than 2.3% of the data in the experiment. The mean reaction time was computed separately for each condition in each block (shown in Figure 2).
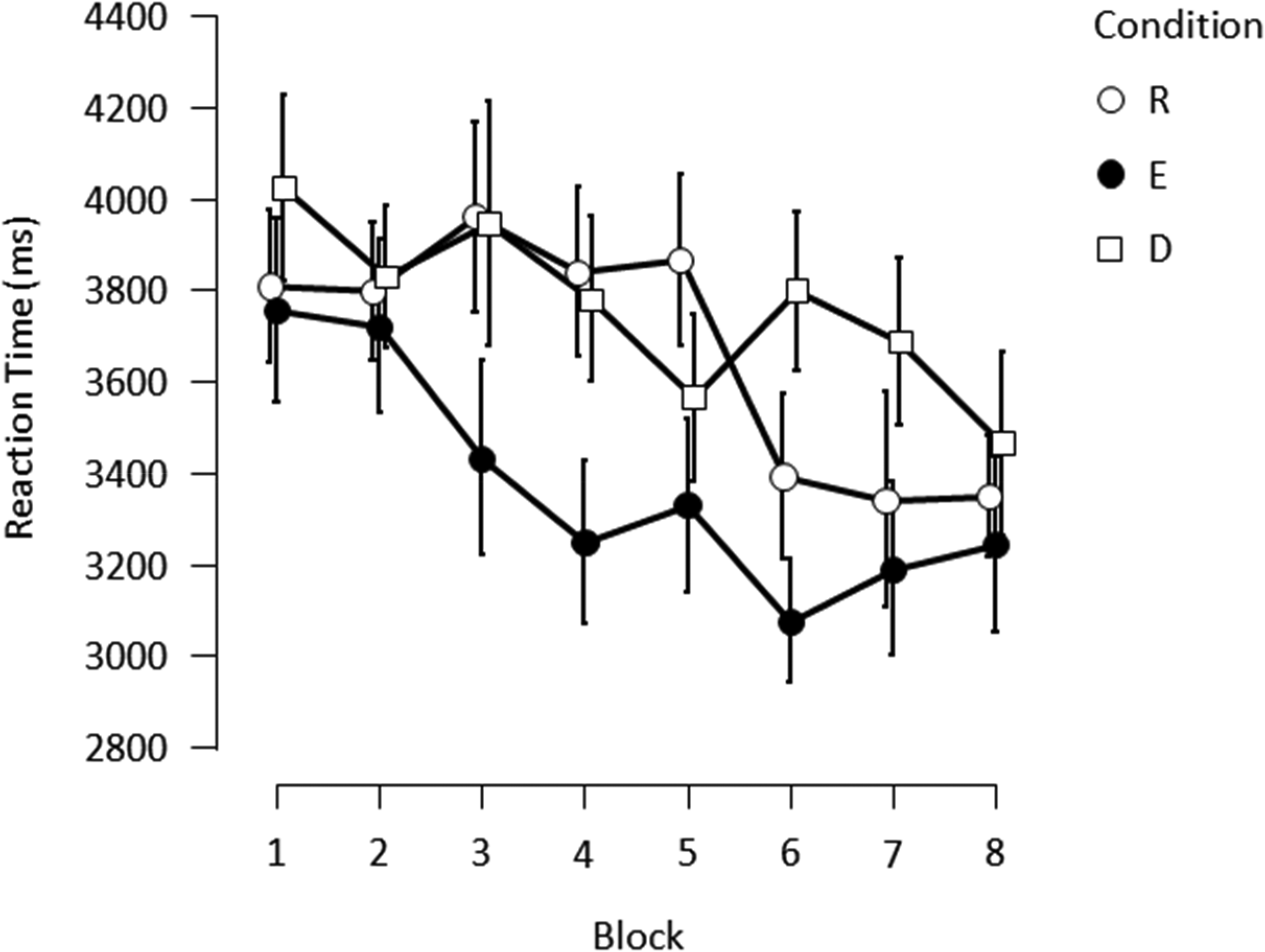
Mean correct reaction times as a function of block for each condition in the experiment. Error bars indicate standard errors.
There was a main effect of condition (F(2, 38) = 6.52, p = .004,
Discussion
Instance theory and reverse hierarchy theory offer distinct accounts for the acquisition of spatial contextual cueing. However, only the latter postulates that spatial contextual cueing is acquired in a cascading manner in the sense that learning of the spatial configurations of the easy distractors would precede that of the difficult distractors.
In the present experiment, spatial contextual cueing was indeed found to be acquired in an easy-to-difficult cascading manner—the acquisition occurred in the easy-half-repeated condition but not yet in the difficult-half-repeated condition, and more importantly, the task performance in the easy-half-repeated condition was found to be quicker than that in the difficult-half-repeated condition.
The theory that spatial contextual cueing as a form of visual perceptual learning is acquired in an easy-to-difficult cascading manner is corroborated not only by the behavioral evidence discussed above and behavioral evidence obtained from related visual perceptual learning experiments with humans (Ahissar & Hochstein, 1997, Figure 1), but also by behavioral evidence obtained from related auditory perceptual learning experiments with gerbils (Caras & Sanes, 2017, Figure S4). All these findings convergently support reverse hierarchy theory and are inconsistent with instance theory. Combined with the findings of Lie (2015), the present experiment suggests that, compared with instance theory, reverse hierarchy theory more plausibly explains the acquisition of visual specificity in spatial contextual cueing in particular and the acquisition of spatial contextual cueing in general.
In addition to providing support to the reverse hierarchy theory's account of the acquisition of spatial contextual cueing, the present experiment also extends previous findings on different temporal dynamics of learning of target and distractors locations in spatial contextual cueing. Using a hybrid paradigm of a visual search task and a probe dot detection task, Ogawa et al. (2007) found that, in spatial contextual cueing, learning of target locations developed rapidly within the first few repetitions of the spatial contexts, whereas learning of distractors locations gradually progressed across the experimental sessions. The present experiment further suggests that, in spatial contextual cueing, there are different temporal dynamics of learning of easy distractors locations and difficult distractors locations—the former preceding the latter. Further studies using the hybrid paradigm are needed to clarify the relative temporal dynamics of learning of target, easy distractors, and difficult distractors locations in spatial contextual cueing.
Footnotes
Author Contribution
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.