
Abstract
Brazilian listeners (N = 303) were asked to identify emotions conveyed in 1-min instrumental excerpts from Wagner’s operas. Participants included musically untrained 7- to 10-year-olds and university students in music (musicians) or science (nonmusicians). After hearing each of eight different excerpts, listeners made a forced-choice judgment about which of eight emotions best matched the excerpt. The excerpts and emotions were chosen so that two were in each of four quadrants in two-dimensional space as defined by arousal and valence. Listeners of all ages performed at above-chance levels, which means that complex, unfamiliar musical materials from a different century and culture are nevertheless meaningful for young children. In fact, children performed similarly to adult nonmusicians. There was age-related improvement among children, however, and adult musicians performed best of all. As in previous research that used simpler musical excerpts, effects due to age and music training were due primarily to improvements in selecting the appropriate valence. That is, even 10-year-olds with no music training were as likely as adult musicians to match a high- or low-arousal excerpt with a high- or low-arousal emotion, respectively. Performance was independent of general cognitive ability as measured by academic achievement but correlated positively with basic pitch-perception skills.
Music can induce emotions and influence moods (Västfjäll, 2002). Accordingly, people listen to music to change how they feel (Shifriss, Bodner, & Palgi, 2015). Musical characteristics such as tempo, mode, consonance, pitch register, loudness, and complexity have systematic associations with specific emotions, some of which overlap with prosodic cues in speech (Juslin & Laukka, 2003). Associations between musical cues and emotions stem from both universal and culture-specific features, as evidenced by listeners’ ability to identify emotions expressed in music from a foreign culture, and by native listeners’ superiority at such identification (Balkwill & Thompson, 1999; Balkwill, Thompson, & Matsunaga, 2004; Fritz et al., 2009).
Two cues to emotion that have received considerable attention are tempo and mode (Hunter & Schellenberg, 2010). Changes in tempo are used cross-culturally to express different emotions in music, whereas changes in mode are used only in some cultures, including Western music. For Western adults, music in major mode with fast tempo is associated with happiness, whereas minor, slow music is associated with sadness. Sensitivity to the connotation of tempo cues is evident earlier in development than sensitivity to mode cues, such that young children make reliable happy/sad judgments based on tempo (Dalla Bella, Peretz, Rousseau, & Gosselin, 2001; Mote, 2011), but not on mode until 6 years of age (Dalla Bella et al., 2001; Giannantonio, Polonenko, Papsin, Paludetti, & Gordon, 2015; Gregory, Worrall, & Sarge, 1996; cf. Kastner & Crowder, 1990). Young children also prefer fast tempo music regardless of mode (Hunter, Schellenberg, & Stalinski, 2011). In a cross-cultural study, Pygmies from the Congo exhibited elevated levels of arousal in response to Western music with fast tempo, which suggests a universal link between tempo and arousal (Egermann, Fernando, Chuen, & McAdams, 2015). Temporal cues other than tempo, such as rhythmic regularity, undoubtedly played an additional role when members of the Mafa tribe from Cameroon identified emotions conveyed by Western music (Fritz et al., 2009).
The circumplex model (Posner, Russell, & Peterson, 2005) posits that emotions vary along two dimensions – arousal and valence. For Western adults, fast and slow tempi evoke high and low levels of arousal, respectively, whereas major and minor mode evoke positive and negative moods, respectively (Husain, Thompson, & Schellenberg, 2002). Vieillard et al. (2008) created a corpus of musical excerpts such that each was in one of four quadrants from the model: happy (high arousal, positive valence), sad (low/negative), scary (high/negative), and peaceful (low/positive). Adults’ arousal and valence ratings of the excerpts formed discrete clusters in two-dimensional space, in line with the model. Nevertheless, when other adults were asked to match the excerpts with the target emotions, performance was far from perfect (e.g., 67% correct for peaceful excerpts). Clearly, matching music with emotions poses some difficulty unless happiness and sadness are contrasted directly (Kratus, 1993; Terwogt & van Grinsven, 1991).
Hunter et al. (2011) tested 5-, 8-, and 11-year-olds as well as adults with excerpts from Vieillard et al. (2008). Across age groups, genders, and emotions, identification exceeded chance levels, except for 5-year-old boys’ performance with sad and peaceful excerpts, which were often confused because they differed primarily in mode. Although happy and scary excerpts also differed in mode, additional cues allowed them to be distinguished (as in Fritz et al., 2009). For 5- and 8-year-olds more generally, girls outperformed boys, happiness and scariness were better recognized than sadness and peacefulness, and performance was poor compared to older children and adults. By 11 years of age, however, children were as accurate as adults regardless of gender.
The findings of Hunter et al. (2011) may not generalize to ecologically valid music because the stimulus excerpts were brief (12 s), performed on piano, and varied in tempo and mode but not in dynamics, texture, and so on. In related research that required children to match visual images (faces or line drawings) with excerpts from recordings, performance was poor and there was much disagreement even among adults (Heaton, Allen, Williams, Cummins, & Happé, 2008; Nawrot, 2003).
In the present investigation, we examined how musical expertise influences listeners’ ability to match emotions with 1-min excerpts of instrumental music taken from operas. Our sample included listeners of different ages (children and adults), and adult musicians and nonmusicians. Thus, musical expertise varied in: (1) informal exposure to music and basic cognitive development, and (2) formal training in music. We chose Richard Wagner’s music because when his operas were composed (mid-1800s, Romantic era), they were considered intensely emotional, and because Wagner wrote the libretto as well as the music (Randel, 1986). Thus, the libretto highlighted the different emotions Wagner presumably intended to convey with his music, and our task provided a measure of his “success.” Because music training is predictive of superior abilities at decoding musical emotions (Castro & Lima, 2014; Lima & Castro, 2011), the inclusion of adult musicians allowed us to estimate optimal performance, whereas the inclusion of musically untrained children allowed us to determine whether emotional meaning is conveyed to listeners with no formal exposure to music and much less listening experience.
We expected age- and training-related improvement in performance although successful differentiation of emotions based on valence was expected to show more marked improvement than differentiation based on arousal. We also examined whether performance was associated with basic music-perception skills or academic achievement.
Method
Participants
The listeners included 195 Brazilian children attending second to fifth grade at a private school, with no formal music training outside of school. There were 29 seven-year-olds (mean age 7.7, SD = 0.3, 8 girls), 57 eight-year-olds (M = 8.6, SD = 0.3, 30 girls), 54 nine-year-olds (M = 9.5, SD = 0.3, 31 girls), and 55 ten-year-olds (M = 10.5, SD = 0.3, 28 girls). Adults were Brazilian undergraduate and graduate students at public universities. (In Brazil, private schools rank higher than public schools, but public universities are superior to private universities.) The adults were divided approximately equally between music students (hereafter musicians; n = 57, 24 female; mean age 23.1, SD = 6.7) and science students (hereafter nonmusicians; n = 51, 41 female; mean age 27.6, SD = 7.3). Musicians and nonmusicians had an average of 9.7 (SD = 4.9) and 1.3 (SD = 2.4) years of music lessons, respectively. On average, musicians began their formal training at 11.5 years of age (SD = 4.9). Their main instrument was an orchestral string instrument for 14, guitar for 11, voice for 9, percussion for 7, piano for 6, and flute for 3. Other main instruments were played by 1 or 2 participants.
Stimuli
Stimuli were eight instrumental excerpts taken from recordings of Wagner’s operas (Abril Coleções, Ltda., Grandes Compositores, Wagner, PolyGram International Music, B. V., 1996). They were approximately 1 min but duration was determined so that each excerpt was coherent musically. The excerpts varied in terms of arousal and valence (see Table 1), such that two were in each of four quadrants: high arousal/positive valence, low/positive, high/negative, and low/negative. High-arousal excerpts were characterized by fast tempo, loud volume, and dense textures. Low-arousal excerpts had slow tempo, soft volume, and delicate textures. Positive-valence excerpts were predominantly in major mode with straightforward harmonies. Negative-valence excerpts were in minor mode with harmonies that contained more dissonances (e.g., diminished seventh chords, tones from outside the key). Although the excerpts were consistent with the narrative of the operas (e.g., sad sounding stimuli were excerpted from sad moments in the narrative), they also contained inconsistent musical cues (e.g., minor chords in a major-key excerpt).
Details about the music excerpts.

Procedure
We first established that the children knew eight different emotion words (in Portuguese), with two in each of four quadrants: happy and elated (high/positive), loving and peaceful (low/positive), angry and fearful (high/negative), and sad and distressed (low/negative). Excerpts were presented in a classroom (maximum 20 participants) over speakers. A different random order was used for each group of children. A response sheet containing eight emotion words and corresponding emoticons was distributed to each child. They were asked to select the emotion that best matched each excerpt.
To measure basic music-perception skills, children took the first four subtests (Scale, Contour, Interval, and Rhythm) from the Montreal Battery of Evaluation of Amusia (MBEA; Peretz, Champod, & Hyde, 2003), with subtests administered on separate days. Although the MBEA was designed to detect particularly poor musical abilities, it can also measure individual differences among typically developing individuals. Scores on the first three tests were averaged to form an aggregate pitch score. We also had access to spelling, arithmetic, reading, and aggregate scores from a standardized test of academic achievement that is used widely in Brazil (Stein, 1994).
The procedure was similar for adults except that the main experiment and MBEA were administered in a single session and we had no data measuring academic achievement. Adult musicians were also asked about their familiarity with Wagner’s music. Only two claimed to be very familiar; others had some or no familiarity. After the experiment, 11 musicians said they recognized one or more excerpt. When asked subsequently to name the operas, one musician could name two; four could name one.
Results
Overall performance was calculated as number of correct responses. Because both emotions from the appropriate quadrant were considered correct, chance performance was two correct out of eight (25%). We also calculated two additional scores that measured whether an excerpt was associated with the appropriate arousal level (high or low) or valence (positive or negative). Chance performance was four correct (50%). Descriptive statistics are provided in Table 2. For all three scores, performance exceeded chance levels for musicians, nonmusicians, and children, ps < .001. After Bonferroni correction, arousal and valence scores were correlated for children r = .245, p < .001, 1 but not for musicians or nonmusicians, ps > .1. Overall scores were associated positively with arousal and valence scores for all groups, rs > .4, ps < .001.
Mean percentage correct on the emotion-matching task.
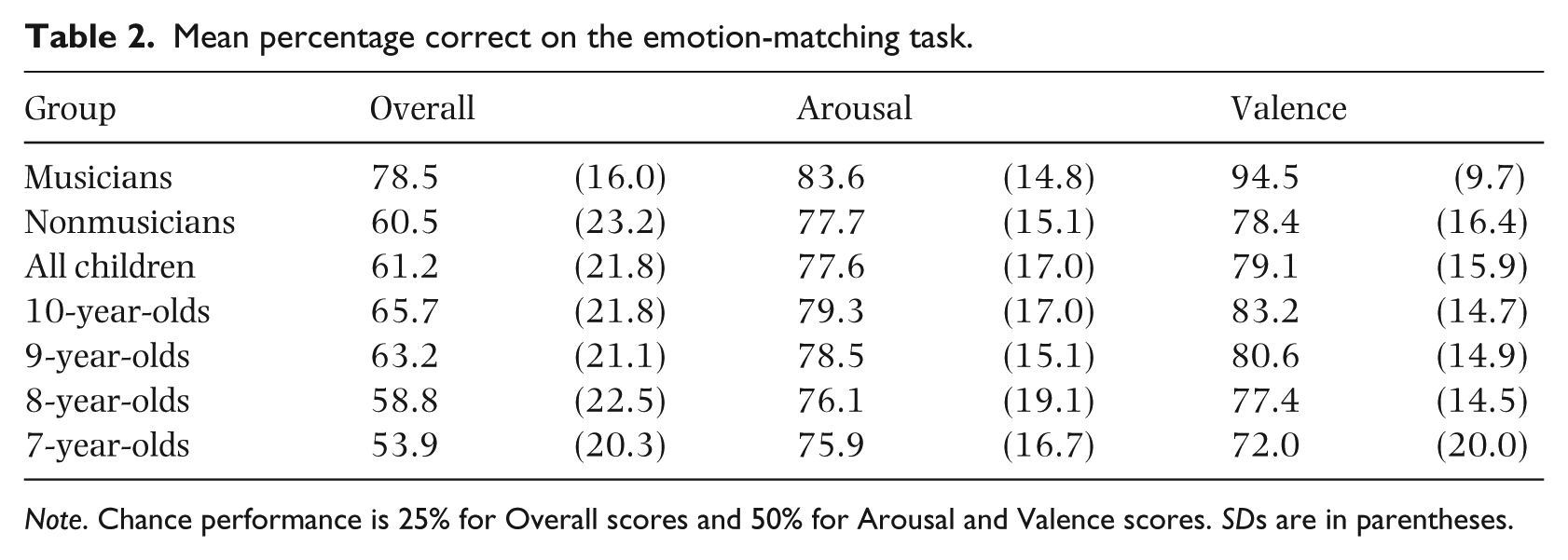
Note. Chance performance is 25% for Overall scores and 50% for Arousal and Valence scores. SDs are in parentheses.
Preliminary analyses revealed no main effects of gender and no interactions, ps > .1. Gender was not considered further. A between-subjects analysis of variance (ANOVA) confirmed that overall scores varied as a function of group (children, musicians, nonmusicians), F(2, 300) = 15.79, p < .001, η2 = .095. Musicians performed better than children and nonmusicians, ps < .001, who did not differ, p > .9 (Tukey). A mixed-design ANOVA treated arousal and valence scores as a repeated measure, and group as a between-subjects variable. There was an interaction between scores and group, F(2, 300) = 5.50, p = .005, partial η2 = .035. For arousal scores, there was a small difference between groups, F(2, 300) = 3.04, p = .050, η2 = .020. Nonmusicians performed similarly to children, p > .9, and musicians, p > .1, but there was a small difference between children and musicians, p = .043. For valence scores, the difference among groups was more substantial, as predicted, F(2, 300) = 24.85, p < .001, η2 = .141, with musicians outperforming children and nonmusicians, ps < .001, who did not differ, p > .9. Alternative analyses revealed that valence scores were higher than arousal scores for musicians, t(56) = 4.38, p < .001, but similar for children and nonmusicians, ps > .3.
Examination of individual excerpts revealed that the largest difference between groups was for excerpt 3. Its slow tempo ensured that high-arousal emotions were picked rarely by any group (< 5%). Although the tonic – a major harmony – dominated the excerpt (for 40 of 64 s), minor harmonies were present in the middle, accompanied by an increase in loudness. For musicians, 81% chose peace or love (considered correct), but a substantial minority (16%) chose sad or distressed. For nonmusicians, the split was even (peace/love: 51%, sad/distressed: 49%). For children, a majority selected sad/distressed (52%; peace/love: 43%).
Age-related change among the children was examined with trend analysis. For overall scores, a significant linear trend reflected a monotonic increase in performance as a function of age, t(191) = 2.58, p = .011. There was no quadratic or cubic trend, ps > .7. For valence scores, the pattern was identical, with a significant linear trend, t(191) = 3.31, p = .001, but no quadratic or cubic trend, ps > .5. For arousal scores, not even the linear trend was significant, ps > .2. Additional pairwise comparisons revealed that there were no differences between nonmusicians and children at any age level, ps > .1. By contrast, musicians performed better than children of all ages on the overall scores and the valence scores, ps ⩽ .001. On the arousal scores, 7- and 8-year-olds performed worse than musicians, ps < .05, 9-year-olds were marginally worse, p = .076, and by 10 years of age, children performed equivalently to musicians, p > .1.
We next examined whether sensitivity to emotional cues in Wagner’s music was related to music-perception abilities or academic achievement. Descriptive statistics for the MBEA are provided in Table 3. For musicians, ceiling effects precluded further consideration of their scores. Bonferroni-corrected correlations calculated separately for nonmusicians and children revealed that pitch perception was associated positively with overall scores (nonmusicians: r = .428, p < .01; children: r = .244, p < .01), and valence scores (nonmusicians: r = .464, p < .005; children: r = .199, p < .05), but rhythm perception had no associations with emotion matching. Finally, although there was linear age-related improvement in children’s academic abilities for the aggregate score and for each subtest, ps < .001, there were no associations between academic achievement and emotion-matching abilities, ps > .1.
Mean percentage correct on the MBEA.
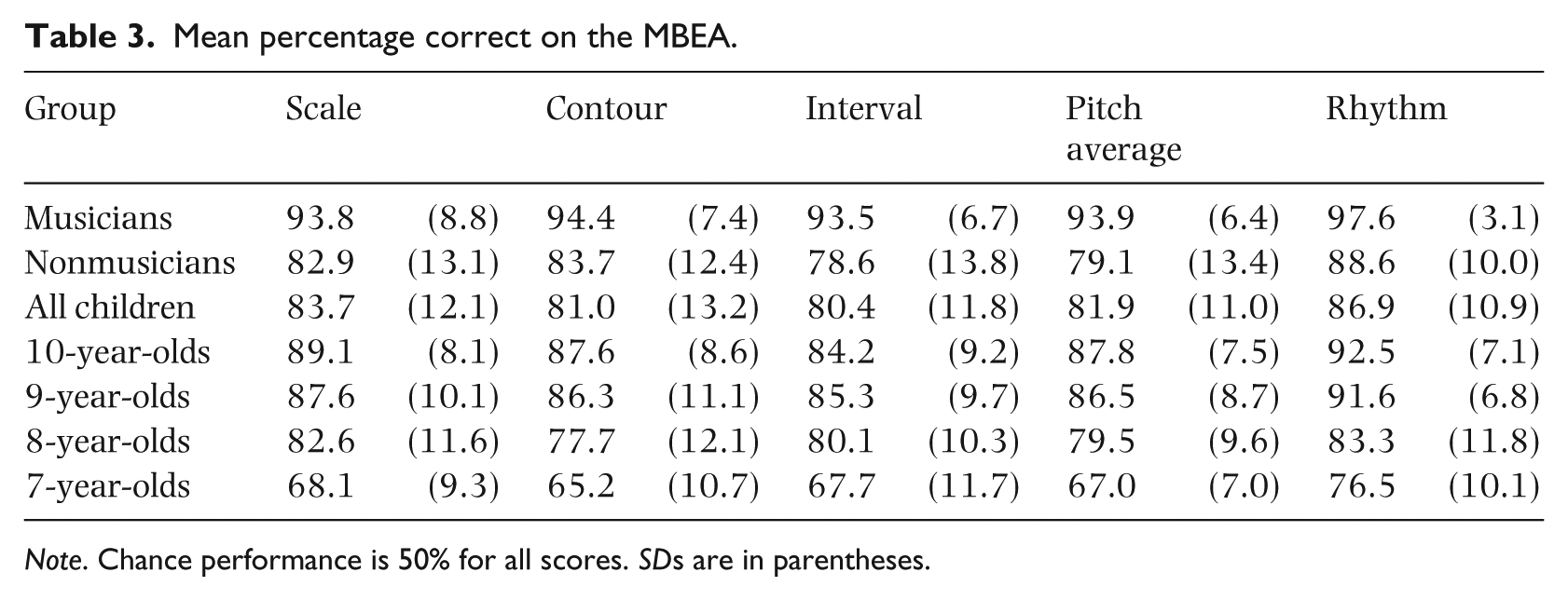
Note. Chance performance is 50% for all scores. SDs are in parentheses.
Discussion
We examined children’s and adult musicians’ and nonmusicians’ ability to match emotions with excerpts from recordings of Wagner’s operas. Children performed surprisingly well (61.25% correct on average, chance = 25%) even though the excerpts sounded nothing like the artificial, emotionally obvious stimuli used in previous research (Dalla Bella et al., 2001; Giannantonio et al, 2015; Gregory et al., 1996; Hunter et al., 2011; Vieillard et al., 2008). In fact, children’s performance was equivalent to adult nonmusicians. Nevertheless, effects due to aging and music training were also evident, such that (1) emotion matching improved systematically among the children as a function of age, and (2) adult musicians outperformed nonmusicians and children. In line with predictions, sensitivity to cues associated with valence varied more substantially as a function of musical expertise than sensitivity to cues associated with arousal. For the children, sensitivity to valence cues improved with increases in age, but sensitivity to arousal cues did not. In fact, nonmusicians and 10-year-olds were as likely as musicians to match a high- or low-arousal excerpt with a high- or low-arousal emotion, respectively.
Gender had no effect on response patterns. In previous developmental research on emotion and music, gender was associated with response patterns in some instances (Allgood & Heaton, 2015; Giomo, 1993; Hunter et al., 2011) but not in others (Dalla Bella et al., 2001; Dolgin & Adelson, 1990; Kratus, 1993). Gender was not a variable of particular interest, however, and conflicting findings could stem from different stimuli, procedural differences, a sample from a different culture, or an unreliable effect. A novel and more important finding was that despite improvements in performance from age 7 to 10, even the youngest children were as accurate as adult nonmusicians in judging the emotions conveyed by our stimulus excerpts. In other words, even 7-year-olds decoded the emotions conveyed in orchestral music written by a composer who lived in a foreign culture in a different century. This finding raises the possibility that children’s capacities – in Brazil and elsewhere – are systematically underestimated, and that the kinds of musical materials that are age-appropriate in educational contexts may be broader than previously thought. As Vygotsky (1978) noted, tasks and stimuli that are slightly beyond a student’s understanding are ideal for learning.
Why do the abilities of young children with no music training seem precocious? The presumed natural link between tempo and arousal is implicated, but emotion matching based on valence cues was equally good, such that informal exposure to music undoubtedly played an important role. Although the Romantic era had declined by the end of the nineteenth century, Romantic-sounding music remains common in contemporary film and television soundtracks. For example, virtually all of the scores composed by John Williams (e.g., Harry Potter, Jaws, Jurassic Park, Raiders of the Lost Ark, Schindler’s List, Star Wars, Superman) were written in a quasi-Romantic style, and many children have seen (and heard) these movies many times. Familiarity with Wagner’s operas was much less likely to be a factor, however, because even musicians did not know them well.
Despite the observed improvements with age and formal training in music, adult musicians did not perform at ceiling levels. For example, 41% chose “angry” or “fearful” for an excerpt taken from the Funeral March in Siegfried. One might consider this to reflect a failure on Wagner’s part. Alternatively, it could represent the composer’s attempt to make a scene ambiguous emotionally, even though the dramatic context is clearly sad. In general, Wagner’s compositional style avoided emotional stereotypy, and our results point to multiple emotional interpretations of his music that are likely to vary within and across listeners and listening contexts, as well as musical structures and libretti. Such variation helps to explain why listeners often continue to enjoy recordings after hearing them multiple times.
A major limitation of the present study was the small set of stimulus excerpts. Nevertheless, our study is the first to ask whether basic music-perception abilities predict the ability to decode emotions from Romantic-era music that is harmonically, melodically, and texturally rich. The lack of an association between general ability (i.e., academic achievement) and emotion recognition is consistent with the proposed distinction between cognitive abilities and emotional intelligence (Mayer, Salovey, & Caruso, 2004). By contrast, the association between pitch perception and emotion decoding is inconsistent with proposals that music-perception abilities are independent of the ability to decode emotions from music (Gosselin, Paquette, & Peretz, 2015). Future research could attempt to clarify these issues, and to explore whether the present findings generalize to a larger set of musical materials from other cultures and historical periods.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The contribution of EGS was funded by the Natural Sciences and Engineering Research Council of Canada.