
Abstract
This study investigated whether emotional responses to a music genre could be predicted by stereotypes of the culture with which the music genre is associated. A two-part study was conducted. Participants listened to music samples from eight distinct genres: Fado, Koto, Heavy Metal, Hip Hop, Pop, Samba, Bolero, and Western Classical. They also described their spontaneous associations with the music and their spontaneous associations with the music’s related cultures: Portuguese, Japanese, Heavy Metal, Hip Hop, Pop, Brazilian, Cuban, and Western culture, respectively. Results indicated that a small number of specific emotions reported for a music genre were the same as stereotypical emotional associations of the corresponding culture. These include peace and calm for Koto music and Japanese culture, and anger and aggression for Heavy Metal music and culture. We explain these results through the stereotype theory of emotion in music (STEM), where an emotion filter is activated that simplifies the assessment process for a music genre that is not very familiar to the listener. Listeners familiar with a genre reported fewer stereotyped emotions than less familiar listeners. The study suggests that stereotyping competes with the psychoacoustic cues in the expression of emotion.
Stereotyping refers to an unrefined, socially-constructed association (see also Hilton & Von Hippel, 1996; Sherman, Stroessner, Conrey, & Azam, 2005), and is highly relevant to various aspects of music (Reeves, Gilbert, & Holman, 2015). In music psychology, studies investigating stereotyping have broadly focused on stereotypes concerning music fans and musical preference (for a review, see Greasley & Lamont, 2016). Fans of a particular genre (or style) of music can be so judged, such as Hip Hop followers being considered misogynistic. In fact, Rentfrow and Gosling (2007) reported consistent labels for fans of particular music genres, which include stereotyping related to personality, values, and alcohol and drug use, and these stereotypes were largely identified regardless of national boundaries (Rentfrow, McDonald, & Oldmeadow, 2009).
These relationships are explained by social identity and related theories (Smith, 2014; Tarrant & North, 2004; Tekman & Hortaçsu, 2002), which focus on the cognitive processing of an ‘in-group’ (e.g., White, middle-class Americans) in assessing the character of an ‘out-group’ (e.g., Black-Americans) and the music (e.g., Hip Hop) the out-group is believed to practice and prefer (see Reyna, Brandt, & Viki, 2009). Rodríguez-Bailón, Ruiz, and Moya (2009) examined Spanish people’s stereotypes towards Gypsy and North African people. Participants responded to a series of items and had to associate them with either a pleasant (peace) or unpleasant (vomit) word stimulus. In a later session, these words were replaced with Flamenco and Classical music as the pleasant stimuli and noise as the unpleasant. By comparing levels of prejudice between the word stimuli, Flamenco music, and Classical music responses, the researchers reported how perception of Gypsy people was more positive when associated with Flamenco music than when compared to Classical music. These results suggest that the implicit attitudes towards Flamenco music changed the perception of participants towards Gypsy people. However, neither Flamenco nor Classical music had any effect on the perception of North African people. The researchers concluded that the perception of a culture can be mediated by means of a music genre, rather than the intrinsic features of the music (e.g., timbre, tempo).
The extant research indicates that individuals can be stereotyped according to the music genre they listen to. Might it therefore be possible that the music genre itself comes to be associated with particular emotions as a result of socially-constructed association? The current research investigated this question.
Stereotypes can bias participants’ judgement of genre
Stereotyping may bias participants’ judgment of and evaluations about music genres. Neguţ and Sârbescu (2014) asked participants to rate lyrics belonging to Rock and Hip Hop genres using items measuring suggestibility and aggressive behavior. Beforehand, one group of participants was informed that the songs contained obscene or violent lyrics and the other group was not. Participants who were informed evaluated Rock and Hip Hop music to be more negative, consistent with Rock and Hip Hop stereotypes of anti-social behavior, substance abuse, and sexual misconduct. The study suggests that when participants are primed with a plausible generalization about a genre, it conditions their response to a particular music exemplar of that same genre. Stated differently, priming the listener about a music genre appears to contribute to how the music will be interpreted, and so could trigger stereotyping of other pieces of music of the same genre.
Emotion associations with music genres
Zentner, Grandjean, and Scherer (2008) investigated emotional responses to music amongst listeners with distinct music preferences. In one of four studies, participants responded to a survey in which they rated their music preference and familiarity for five genres chosen by the research team: Classical, Jazz, Pop/Rock, Latin American, and Techno. Based on these responses, the same participants were then divided in five groups (one for each genre), which consisted of listeners with high familiarity and high preference towards one of these five music genres. Participants were given a list of 146 ‘feeling’ labels and asked to rate, on a scale from 1 to 5, the frequency with which they felt and perceived that feeling with regard to the music. The researchers concluded that: Jazz and Classical music were associated with longing, amazement, spirituality, and peacefulness; Techno and Latin American with disinhibited, excited, active, agitated, energetic, and fiery; and Pop/Rock with aggressive, angry, enraged, irritated, and revolted. The consistency of emotion associations with genres raises the question of the potential role of stereotyping as a predictor of emotional responses to music genre. That is, might the emotion label for a genre have its bases in the stereotyped emotion of the culture with which the music is associated in addition to psychophysical aspects that typify the music of each genre?
Balkwill and Thompson (1999) proposed a model of emotion perception in music in which emotion is mediated by either the psychophysical cues of the music (i.e., timbre, tempo), the culture-specific cues (i.e., additional expertise, such as expert cultural knowledge) or both. There is well-established documentation of how emotion is evoked or expressed by psychophysical cues (Gabrielsson & Lindström, 2010; Juslin, 2005; Juslin & Laukka, 2003) and culture-specific cues (Argstatter, 2016; Demorest, Morrison, Nguyen, & Bodnar, 2016; Fritz, Schmude, Jentschke, Friederici, & Koelsch, 2013). Because of the social construction of stereotyping, it fits within the umbrella of culture-specific cues. But to better understand where it fits, we turn to the BRECVEMA framework of emotion in music.
Juslin and Vastfjall (2008) explored the prevalence of underlying psychological mechanisms when music elicits an emotion in a listener. Nine mechanisms were gradually developed (Juslin, 2013; Juslin, Harmat, & Eerola, 2014; Juslin, Liljeström, Västfjäll, & Lars-Olov, 2010) as the BRECVEMA framework, specifically:
Brain stem reflex: An innate response to the psychophysical cues of the music, such as increasing loudness.
Rhythmic entertainment: An adjustment of an internal rhythm (e.g., heat rate) towards an external rhythm in the music, which in turn affects a listener’s emotion by means of proprioception (i.e., variation of muscle contraction).
Evaluative conditioning: A process of regular pairing of a piece of music and other positive or negative stimuli resulting in a conditioned emotion.
Contagion: An internal ‘imitation’ of the perceived emotion in the music.
Visual imagery: Mental images conjured by a listener while listening to the music resulting in an experienced emotion.
Episodic memory: A conscious memory recollection made by the listener triggered by the music.
Musical expectancy: An emotional response based on the satisfaction or disruption of gradual unfolding of the music’s syntactical structure.
Aesthetic judgement: A subjective evaluation of the music’s aesthetic value based on a personal set of criteria.
It is possible to explain emotional stereotyping of music genre through mechanism 3, evaluative conditioning. A stereotype may emerge through repeated pairings of a music genre and the culture from which it emanates. Stereotyping has mostly been examined in relation to negative associations and genres of problem music, including, Alternative Rock, Hard Rock, Heavy Metal, Hip Hop, Rap, Punk Rock, Trance, House, Electro, and Techno (Kennedy, 2010; North & Hargreaves, 2007). However, if formed through evaluative conditioning, the formation of emotion stereotypes might not be just negative.
The stereotype theory of emotion in music
In line with the evaluative conditioning mechanism, the stereotype theory of emotion in music – STEM (Susino & Schubert, 2017) proposes that listeners can perceive emotion in music based on stereotyped associations held by the listener about the encoding culture (i.e., the culture representative of a particular music genre, such as Portuguese culture encoded in Fado music). Consequently, some music genres may be spontaneously paired with a small set of emotions directly influenced by a previously held stereotype.
For example, Japanese culture expresses anger less frequently than North American cultures (Safdar et al., 2009), and so prototypical Japanese music (i.e., music identified as typically Japanese) may more likely be paired with emotions such as calm or peaceful rather than anger. If this kind of evaluative conditioning of music and emotion is plausible it may, under some circumstances, compete with emotions generated by the psychoacoustical cues of the music or autobiographical associations.
According to STEM, a listener who reports a stereotyped association with the encoding culture will filter out the otherwise “intended” emotion in the music and instead activate a stereotyped emotion (for more information, see Susino & Schubert, 2017). Since stereotyping occurs as a result of the perspective of the “other” (Sherman, Allen, & Sacchi, 2016), a limited familiarity with the culture or object being stereotyped (in this case the music), should produce a stronger stereotyping (unrefined, socially-constructed, categorical) response than an individual who is highly familiar with the object in question. Therefore, low familiarity genres would more likely produce stereotyped emotion responses, should emotion stereotyping be a driving force of our responses to less familiar music. For the purpose of this research, Table 1 offers working definitions of the key terms used in this article based on recent literature.
Working definitions of key terms used in this article.

Aim
This study aimed to establish whether different music genres yield spontaneous, stereotypical emotions and to compare results of the present study with those reported by Zentner and colleagues (2008). Two hypotheses were tested:
H1. Emotions used to describe a genre will overlap with the emotions used to describe the culture of that music.
H2. Participants with low familiarity with a music genre will associate stereotypical emotions more than participants with high familiarity.
Method
Design
The design of the present study is based on Zentner et al. (2008), with some modifications. Zentner and colleagues collected responses from listeners familiar with and fond of the music genres investigated. However, by limiting responses only to listeners with a preference towards a specific genre, emotion terms selected may skew towards positively-valenced emotions, in particular because positive attitude to music increases with familiarity (Kreutz, Ott, Teichmann, Osawa, & Vaitl, 2008; Pereira et al., 2011; Schellenberg, Peretz, & Vieillard, 2008; Schubert, Hargreaves, & North, 2014). Furthermore, Gowensmith and Bloom (1997) demonstrated how aversiveness (i.e., low preference) to a genre will induce specific negatively-valenced emotions. By analyzing responses to Heavy Metal music from familiar and less-familiar listeners, Gowensmith and Bloom (1997) concluded that listeners with low preference to this genre reported higher levels of anger than listeners with higher preference. This could explain why the participants recruited by Zentner and associates (2008) had a lower mean rating for terms related to anger, fear, and sadness, all negatively-valenced emotions (Unoka, Fogd, Füzy, & Csukly, 2011), than positively-valenced terms, such as joy or amazed.
Asking listeners to “imagine” listening to music, as was the case in Zentner et al. (2008), can also be problematic because the researcher cannot be sure what was imagined. One solution is to ask the listener to report the music they were thinking of. However, such a method might lead to discovery of examples that were not intended by the researcher. Playing a small number of related exemplars of an intended genre could address this issue because exemplars can evoke a general (“prototypical”) mental representation such as a music genre (Fei-Fei, Fergus, & Perona, 2007). This approach has been adopted by a number of researchers (Gjerdingen & Perrott, 2008; Nosofsky, Little, Donkin, & Fific, 2011; Storms, De Boeck, & Ruts, 2000).
A further point of concern is classifying music into genres, an issue well documented in the literature (Aucouturier & Pachet, 2003; Correa, Perez-Reche, & Costa, 2012; Panagakis, Benetos, & Kotropoulos, 2008). There is no universal consensus on membership with any particular genre of music (e.g., Eerola, 2011; Rentfrow & Gosling, 2003, 2006, 2007; Zentner et al., 2008), in part because of an in-group/out-group effect (Allport, 1954). This means that, for example, Brazilian listeners may rapidly distinguish the various subgenres of Samba music, yet may think all Hip Hop music sounds alike. But Hip-Hop fans, in contrast, may recognize the subtle differences between Hip Hop and Gangsta Rap, yet may think all Samba sounds the same (for a detailed explanation, see Gjerdingen & Perrott, 2008). That is, in-group membership through culture or fandom informs the detail of genre categorization. Thus, investigating such broad genre categories may represent different music to different people, making the possibility of identifying a small set of emotions for each genre problematic. Pop charts, for example, are saturated with many genres, including Electronic, Country, Rock, and Hip Hop (Huq, 2007), not to mention that there is also a cultural-dependent distinction within genre labels with different cultures representing the same genre label differently, such as American Hip Hop and British Hip Hop, and different ways of categorizing music are being used (e.g., by mood, by country). Nevertheless, while genre is a fluid way of categorizing music, genre labelling remains widely used in music research, music streaming services, and commercial charts. Interestingly, ordinary music listeners can accurately label a commercial genre in as short as 250 ms (Gjerdingen & Perrott, 2008). We adopted the genre label used on the official Billboard music charts for each music stimulus used in this study (http://www.billboard.com/charts) when possible. And for the music pieces which were not identifiable in any of these charts, we relied on the label recommendations of two expert musicians within their respective genre (see Table 2). Furthermore, we let the participants use their own interpretation as triggered by the musical exemplars provided, rather than dictating a highly specified way of understanding genre. Thus, limitations due to participant bias, imagining genre, and genre labelling are matters we attempted to mitigate in the design of the present study.
Proposed cultural stereotype source, genres investigated, and music excerpts used for each genre.
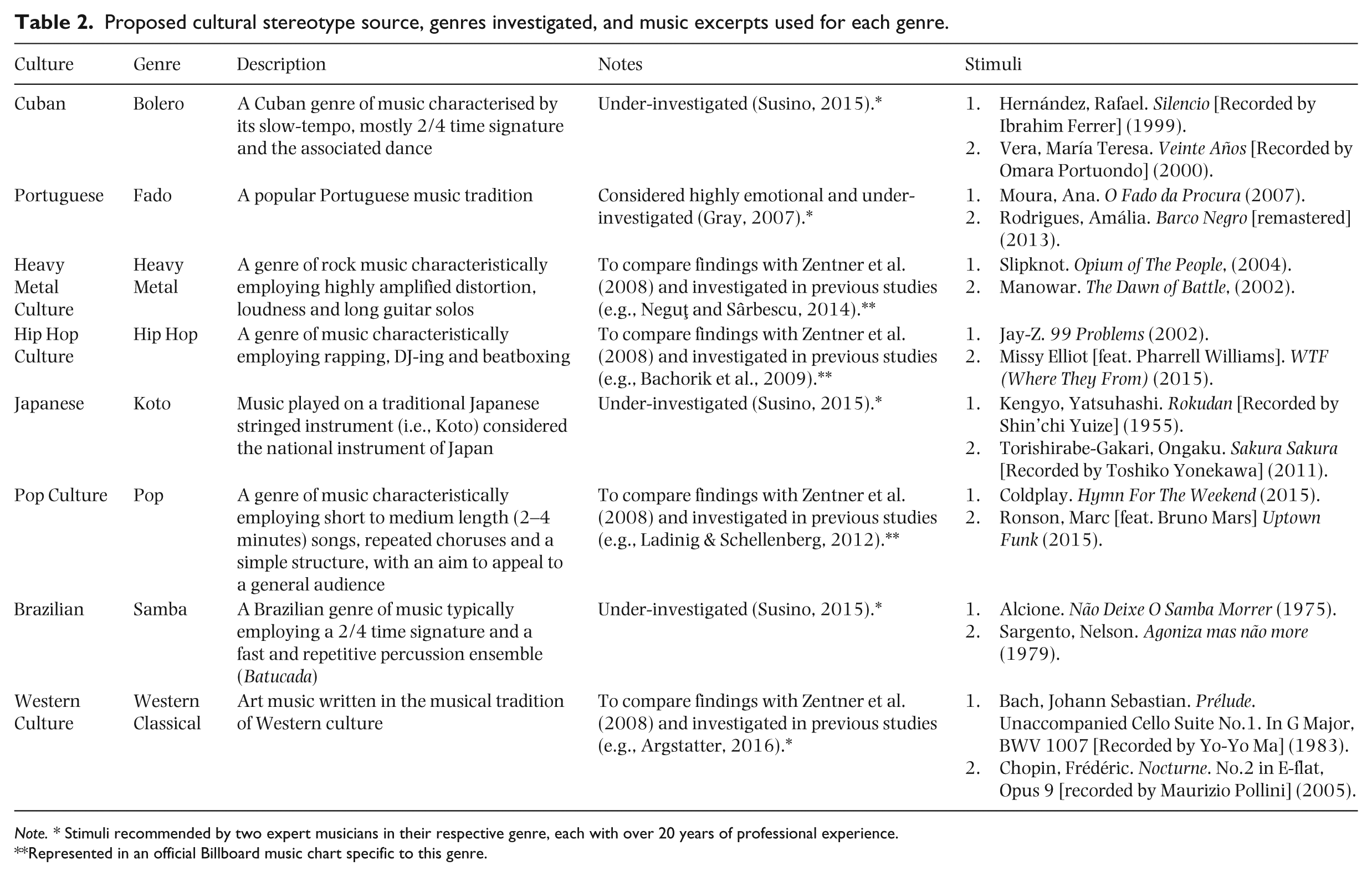
Note. * Stimuli recommended by two expert musicians in their respective genre, each with over 20 years of professional experience.
Represented in an official Billboard music chart specific to this genre.
Participants
Two hundred and twenty-two participants took part in the study. Their ages ranged from 18 to 42 years (M = 21.7, SD = 4.0); 79 participants were female and 143 were male. All participants were undergraduates at a multicultural university in Australia. Participants received course credit for participating in the study.
Materials
Responses were collected using the survey software Key Survey (http://www.keysurvey.com/). For the music genre phase, two short samples of music for each of eight music genres (i.e., 16 samples) were selected to evoke each of the eight distinct genres. For the culture phase, eight distinct cultures were presented to evoke associations corresponding with each of the eight music genres (see Table 2). In this phase, the target cultures were assumed to be the source associated with the music genre phases, such as Brazilian culture and Samba music. The justification of the genres selected for the current study is presented in Table 2.
Procedure
Ethics approval was obtained from the host university’s Ethics Advisory Committee. Participants were distributed at random into two groups. For group 1, a music genre phase was presented first, followed by a culture phase. The reverse was done for group 2, so that the culture phase was followed by the music phase. Participants completed the study online, in the participants’ own time.
Prior to commencing the music or culture phases, participants were asked to report their familiarity with each of the eight music genres using a five-point rating scale from 1 (Non-fan—Never listen to it) to 5 (Fan—Listen to it all the time). In the music genre phase, participants were asked: “Please listen to these two short music excerpts, typical of [target music genre]. What is the first thing that comes to your mind when you hear this music genre (not necessarily these two pieces)? Please provide just one or two words.” The eight genres in the music genre phase were presented in different random order for each participant.
For the culture phase, participants were asked to report their spontaneous associations to the target cultures: “In one or two words, what comes to mind when you think of [target culture]? You are welcome to guess.” The eight cultures in the culture phase were presented in different random order for each participant. Finally, participants reported demographic data, including their nationality and cultural background.
Results
Data pre-processing
The following data pre-processing steps were conducted for both the music genre phase and the culture phase open-ended responses based on Augustin, Wagemans, and Carbon (2012):
Correction of spelling errors.
Extraction of task-related parts from a sentence. For example: “I feel agitated when I hear this” was coded as “Agitated.” Or “makes me feel nostalgic and happy” was coded to one count of “Nostalgia” and one count of “Happy.”
Removal of function words (articles and pronouns).
Removal of qualifiers. For example, “generally relaxing” was coded as “Relaxing.”
Consolidating singulars and plurals of the same noun.
Consolidating nouns and corresponding verbs (for example, meditation and meditate).
Consolidating words that have the same stem (i.e., part of a word) and synonyms using Synonym (http://synonym.com), and a synonym search based on the dataset of WordNet (https://wordnet.princeton.edu). For example, sad, sadness and saddened have the same stem, “sad.”
The term chosen to represent emotions with the same stem, such as “sad/sadness” was the one with the highest frequency.
Finally, responses were separated in two categories: emotions and non-emotion terms based on our working definition of emotion (see Table 1). In this paper we provide an analysis of the emotion terms only.
Emotions in response to the music
In line with previous studies (e.g., Augustin et al., 2012; Jacobsen, Buchta, Köhler, & Schröger, 2004; Zentner et al., 2008), each emotion word reported with a frequency of more than 5% of the total emotion words within its respective genre or culture was considered representative of its respective music genre or culture. As can be seen in Table 3, according to this criterion no emotion word is common to all eight music genres. A total of 20 emotions were reported across genres. “Dancing” was the most frequently reported emotion, appearing in Fado, Hip Hop, Pop, Samba and Bolero and with 85 counts reported for Brazilian Samba. It is worth noting that we treated the term “dancing” and “sex” as emotion words to be consistent with Zentner et al (2008) and other emotion word databases (Bradley & Lang, 1999; Mohammad & Turney, 2013). The second most frequently reported emotion associated with a genre was “Anger” (40 counts) for Heavy Metal music, followed by “Relaxing” (36 counts) for Western Classical music.
Emotions counts reported 5% and above of total emotion words per genre by familiarity rating level for the respective genre.
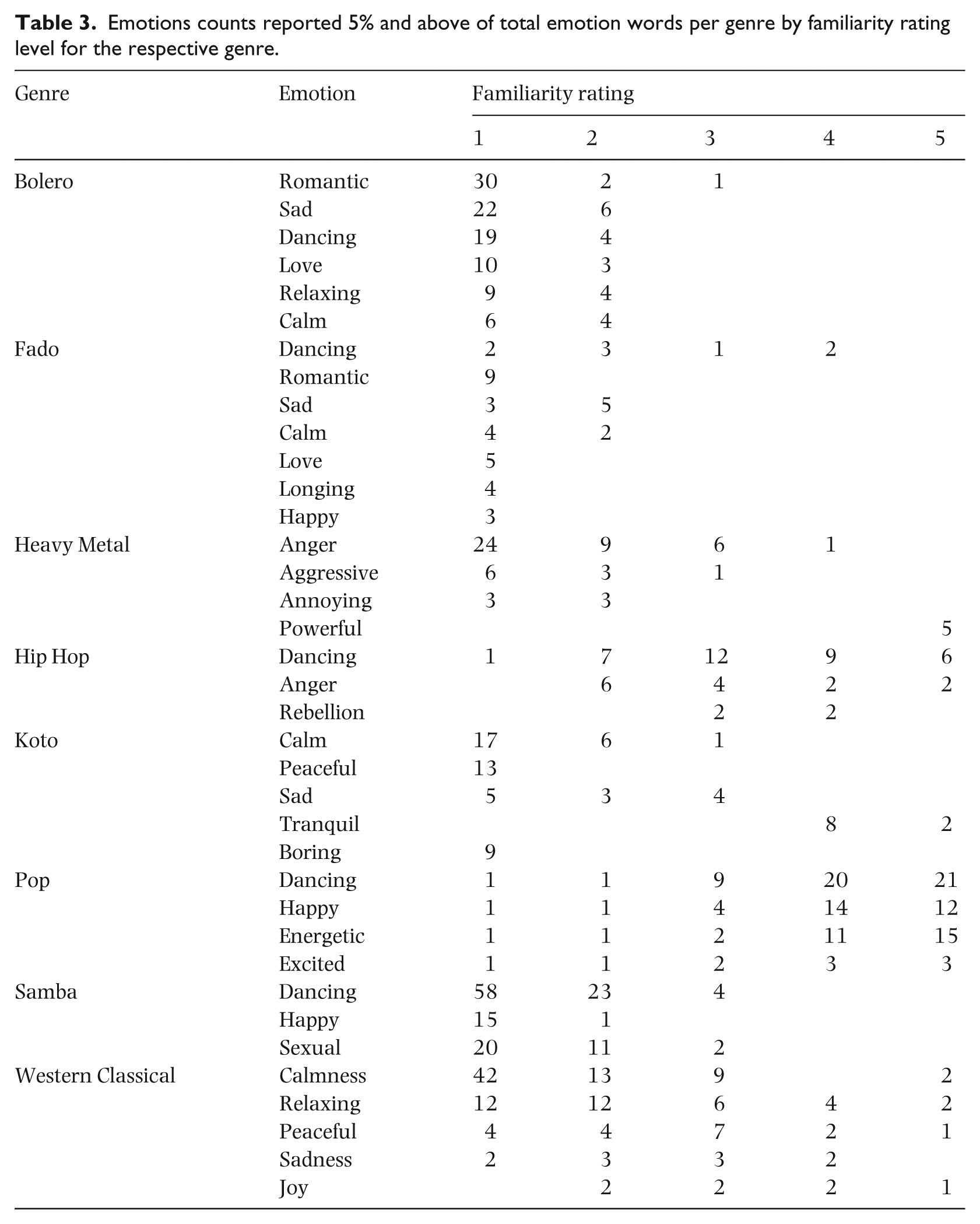
We compared the emotions reported in our study to those obtained by Zentner et al. (2008) for: (a) Western Classical music to Classical music; (b) Pop and Heavy Metal to Pop/Rock; and (c) Brazilian Samba and Cuban Son to Latin. Calm and relaxed were the most frequently reported emotions in both studies for the genres Western Classical music/Classical music. However, the emotions joy and sadness were only identified in our study. Anger and aggressive were the most frequently reported emotions in both studies for the genres Heavy Metal and Pop/Rock. Yet, no negatively-valenced emotions were identified in our investigation for the genre Pop. Lastly, Brazilian Samba and Cuban Bolero compared to the Latin genre generated mixed results. While in our study dancing was the most frequent “emotion” recalled for both Samba and Bolero, we did not find emotions related to the factor “Activation,” such as excited, active, and energetic, prominent responses in the Latin genre reported by Zentner and colleagues.
Emotions induced by music genre compared to emotions induced by culture
To test H1, that emotions used to describe a stereotyped genre will considerably overlap with the emotions used to describe the source culture of the music, we compared the emotions recalled by music genre with the emotions recalled by the culture the music was thought to emanate from, for example, Cuban Bolero compared to Cuban Culture. Figure 1 illustrates how the responses were categorized for one music-genre — culture pair (Fado—Portugese) using a Venn Diagram and the results for all eight pairs are shown in Table 4.
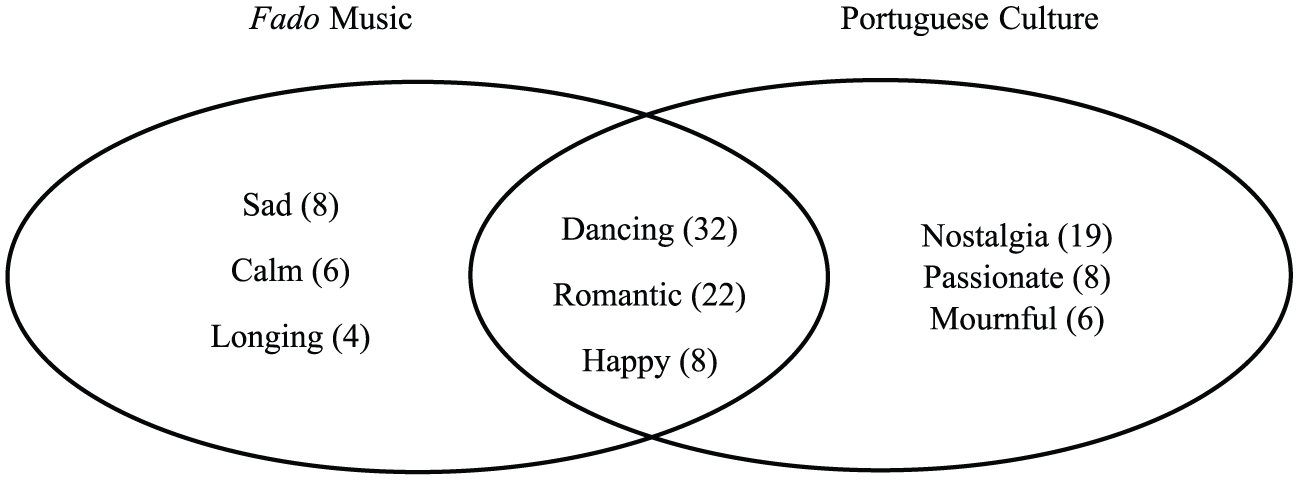
Venn diagram exemplifying Fado and Portuguese Genre/Culture pairing in Table 4, showing most frequently reported spontaneous emotions with their respective counts in parentheses recalled for Music Genre only (Music Genre Exclusive region), for Culture only (Culture Exclusive region), and for both Music Genre and Culture inclusive (overlapping Music Genre and Culture Inclusive region).
Spontaneous emotions and counts reported for music genres and respective culture.
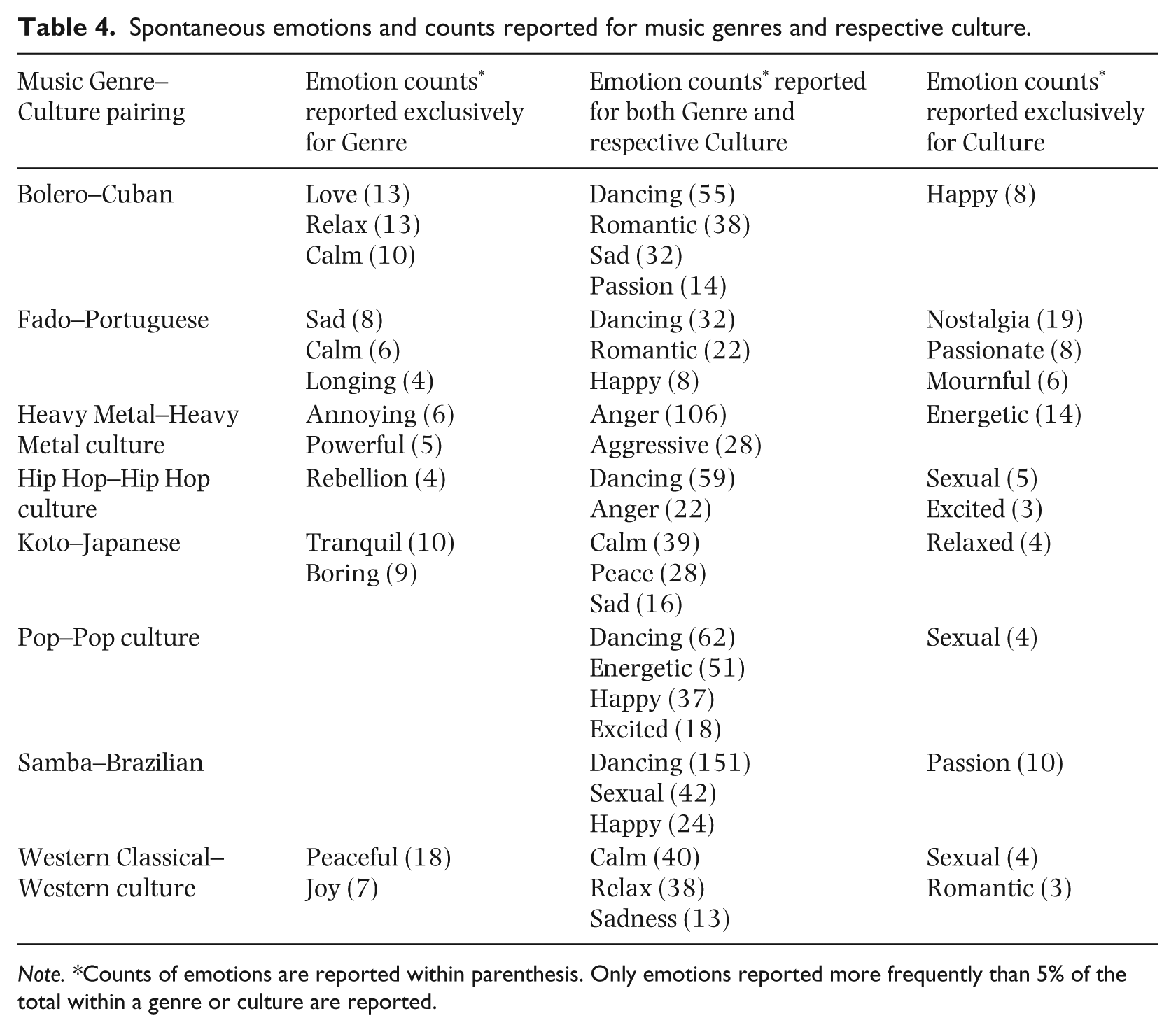
Note. *Counts of emotions are reported within parenthesis. Only emotions reported more frequently than 5% of the total within a genre or culture are reported.
Using a two-tailed Fisher’s exact test we examined the proportion of overlapping emotion terms for each music-genre—culture pair. The expected distribution of emotions representing each regions o the Venn diagram was set to be 25:50:25 (with 25% of the count expected for the Music Genre Exclusive region, 50% for the Music and Culture Inclusive region and 25% for the Culture Exclusive region). As shown in Table 5 results indicated a significant deviation from the expected distribution (p = 0.05), except for Fado music and Portuguese Culture: χ2(1, N = 113) = 5.05, p = .08. Spontaneous emotions evoked by music and culture were not equally distributed. Of the 1,177 emotion counts reported with a frequency of more than five percent across all three regions, 907(77%) were reported in the Music and Culture Inclusive region, 176(15%) in the Music exclusive region and 94(8%) in the Culture exclusive region (p < .0001, two-tailed). Therefore, emotions associated with a culture could be used to predict emotions associated with music from the same culture, supporting H1.
Fisher’s exact test statistics.

Note. +25:50:25 is the proportion used for expected counts, where 50% is the intersecting region and the remaining two 25% are the exclusive music genre or exclusive culture regions respectively.
**p < .0001, two-tailed.
Genre by familiarity
Using the raw familiarity ratings, Pop music was overall the most familiar genre (M = 4.14, SD = .94), while Fado was the least familiar (M = 1.41, SD = .63). To test H2, we examined if participants who reported the same emotions in both phases (Music and Culture) rated the music as less familiar than participants who reported different emotions exclusively for each phase. A Kruskal-Wallis test compared the median differences for familiarity ratings of participants between the three regions: Music Genre Exclusive, Culture Exclusive and Music Genre and Culture Inclusive. There was a statistical significant difference between the three regions, (Χ2 (2, N = 1232) = 9.712, P = .008. Median familiarity ranks were lower in the Music and Culture Inclusive region compared to the Music Genre Exclusive and Culture Exclusive regions. The highest-ranking familiarity score was 670.14 for the Culture Exclusive region. The second highest median familiarity score was 669.05 for the Music Genre Exclusive region. The lowest median familiarity score of 600.27 was observed for the Music Genre and Culture Inclusive regions. These results support H2, that participants with low familiarity with a music genre stereotype more than participants with high familiarity and that the sources of the stereotype is that of the culture associated with the music genre.
Ratings and spontaneously evoked emotions for participants with low genre familiarity
Table 3 shows the respondents’ familiarity ratings and the emotions they spontaneously associated with each music genre. Non-familiar listeners most frequently reported “calm” for both Western Classical and Koto music, while “romantic” was the most associated emotion with Bolero and Fado by non-familiar listeners. “Anger” and “aggressive” were the most frequently reported emotions for Heavy Metal by non-familiar participants, while both “dancing” and “happy” were the most reported emotions by familiar listeners for Hip Hop, and the highest reported for Samba by non-familiar listeners.
Discussion and conclusion
The aim of this research was to establish if cultural stereotyping affects emotional responses to music. Specifically, we investigated whether emotions reported for a music genre could be explained by emotions associated with non-musical, but related cultural stereotypes. Eight music genres and their assumed encoding culture pairs were investigated. Seven encoding cultures meaningfully predicted the emotions evoked in corresponding music genres. These include anger and aggression for Heavy Metal music, common stereotypes associated with Heavy Metal culture (Arnett, 1991) and romantic reported for Bolero music, a common stereotype paired with Cuban culture (Simoni, 2013). Emotions associated with Samba music were also common stereotypes reported for Brazilian culture, such as sexual (Ford, Vieira, & Villela, 2003) and happy (Rezende, 2008). The STEM (Susino & Schubert, 2017) proposes that the assessment of emotion in music can be influenced by a filter which activates a simple (emotional) representation through stereotyping. Cultural stereotypes may trigger automatic emotional associations with the music associated with a particular culture, and these may compete with the emotions generated by psychoacoustic features or autobiographical associations.
We further hypothesized that low familiarity with a music genre will lead to more stereotyping than high familiarity, mediating the proportion of emotions overlapping in both the music genre and encoding culture conditions. The hypothesis was supported, with less-familiar listeners reporting a disproportionately larger number of like emotions for both music genre and culture conditions, as opposed to highly familiar participants. These results, therefore, support the idea that a listener with low familiarity with a music genre processes emotion through a stereotype filter that allows assessment of the music to be made without requiring high cognitive load (Sherman et al., 2016). In the STEM, ease of processing is represented by a filter which can be bypassed if the listener has sufficient expertise (or familiarity) for the music genre in question. The bypassing is possible because the knowledge the listener has acquired about the music genre means that the simplifying, automated stereotyped cues need not be activated for the purpose of making such assessments.
However, one of the music genre–culture pairs, Fado–Portugese, did not produce hypothesized results. One reason could be that familiarity with Fado was so low in the sample that a stereotyping filter was not activated because of absence of any notable mental representation of the associated culture, rather than insufficiently refined knowledge. Some exposure or familiarity would be required of the individual with the music and the stereotype to be able to form some implicit, evaluative conditioned response.
Our results are in line with the cue-redundancy model (Balkwill & Thompson, 1999), which suggests emotion perception in music is informed by psychophysical and culture-specific cues. However, whilst the cue-redundancy model offers a valuable distinction between these cues, it does not explain the nature of these differences. STEM further develops the cue-redundancy model because in addition to arguing for two broad sources of emotion, part of the cultural source can now be specifically explained partly in terms of stereotyping. That is, STEM develops the model by allowing more focussed predictions, and the present study supports those more specific predictions, namely that emotion in music is dependent to some extent on the cultural stereotyping of the music genre being perceived. Indeed this article presents the first direct empircal test of STEM, and while supporting the theory, also recommends a modification with regard to individuals who have very low familiarity with a culture and/or genre, and therefore lack the capacity to make an emotional intepretation of a genre based on a stereotype because of the absense of a mental representation of such a stereotype. The finding also suggests a more nuanced interpretation of Juslin’s Evaluative Conditioning mechanism of emotion in music (Juslin, 2013), by proposing that subconsious, automatic learning of cultural stereotypes may also contribute to how one develops emotional responses to music. The study has limitations. Future work should consider in more detail whether different music genres drawn from the same culture may also influence results, such as Taiko Drumming or Gagaku for Japanese culture in contrast to Koto used in our study. Our intention was to choose ‘typical’ genres of the culture in question, but, as this example shows, this is not always a straight forward process.
This is to our knowledge the first study to measure the spontaneous emotions reported in response to specific music genres and their associated culture. Our results supported the novel theoretical position that emotion pairings in music by relatively less familiar listeners can be explained by activation of a stereotype filter. It therefore has implications particularly useful for cross-cultural studies in music and the study of emotion, and studies of dis/liking genre, but also in the fields of music therapy, music education, social work, and cultural studies.
Footnotes
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research reported in the article was support by the Australian Government Research Training Program Scholarship (RTP2016LO1602) and the Australian Research Council (DP160101470 and FT120100053).