
Abstract
Everyday communication mostly occurs in the presence of various background noises and competing talkers. Studies have shown that musical training could have a positive effect on auditory processing, particularly in challenging listening situations. To our knowledge, no groups have specifically studied the advantage of musical training on perception of consonants in the presence of background noise. We hypothesized that musician advantage in speech in noise processing may also result in enhanced perception of speech units such as consonants in noise. Therefore, this study aimed to compare the recognition of stops and fricatives, which constitute the highest number of Persian consonants, in the presence of 12-talker babble noise between musicians and non-musicians. For this purpose, stops and fricatives presented in the consonant-vowel-consonant format and embedded in three signal-to-noise ratios of 0, −5, and −10 dB. The study was conducted on 40 young listeners (20 musicians and 20 non-musicians) with normal hearing. Our outcome indicated that musicians outperformed the non-musicians in recognition of stops and fricatives in all three signal-to-noise ratios. These findings provide important evidence about the impact of musical instruction on processing of consonants and highlight the role of musical training on perceptual abilities.
Keywords
Everyday communication often occurs in noisy environments where several speakers are talking simultaneously. For this reason, in some research studies, multitalker babble noise is used as a masker. The effect of babble noise depends on the number of talkers who speak concurrently, that is, the masking energy increases and speech intelligibility decreases with the number of competing talkers (Assmann & Summerfield, 2004; Simpson & Cooke, 2005). With this information, the human auditory system constantly challenges the selection of the target signal from other competitive inputs. Since speech perception in the presence of noise or competing talkers requires successful integration of cognitive, linguistic, and sensory processing, the ability of speech in noise (SIN) perception provides important information about auditory performance under difficult conditions and noisy environment (de Boer & Thornton, 2008; Kujala & Brattico, 2009). There is evidence that this ability can be improved by musical training (Strait & Kraus, 2011; Zendel & Alain, 2012).
Previous studies have shown that musical training during the first years of life plays an essential role in shaping the fundamental features of auditory system (Strait, Parbery-Clark, O’Connell, & Kraus, 2013), and long-term interactions with music could affect the auditory processing (Besson, Chobert, & Marie, 2011; Kraus & Chandrasekaran, 2010). Multiple components of auditory processing related to performance of SIN perception have been found to be enhanced in musicians, including processing of pitch (Bianchi et al., 2017; Bidelman, Gandour, & Krishnan, 2011), temporal cues (Bishop-Liebler, Welch, Huss, Thomson, & Goswami, 2014; Kuman, Rana, & Krishna, 2014), and syllable discrimination (Parbery-Clark, Tierney, Strait, & Kraus, 2012).
It has been proposed that there is a transfer of musical advantages from music to speech, possibly as a consequence of short and long-term plasticity inspired by corticofugal mechanisms. Indeed, musical training improves the top-down modulation from the cortex to the cochlea, such as increasing the signal-to-noise (SNR) ratio, excluding irrelevant information and increasing response efficiency (Anderson & Kraus, 2011; Besson et al., 2011; Luo, Wang, Kashani, & Yan, 2008; Perrot, Micheyl, Khalfa, & Collet, 1999). In addition, musical training may not only influence the activity of brain regions that are essential for both music and speech processing, such as the primary auditory cortex, superior temporal gyrus and auditory brainstem, but may also affect the activity of other brain structures that are more specifically involved in the processing of speech sounds, such as the superior temporal sulcus (Hickok, 2012; Hickok & Poeppel, 2007).
There is a growing body of evidence suggesting that the music advantage generalizes to other areas of the auditory system. For instance, musicians show improved performance on auditory-based cognitive tasks (Chan, Ho, & Cheung, 1998; Strait, Kraus, Parbery-Clark, & Ashley, 2010). Playing a musical instrument requires several perceptual and cognitive demands. Experienced musicians need to pay attention to fine musical sounds (notes) and be able to tune their instrument and analyze the sounds of other musicians’ instruments. These capabilities rely on the ability to separate and organize auditory units, and the term given to the processing of these actions is scene analysis, a skill that is essential for SIN perception (Bregman, 1993), and musicians’ long-term experience in auditory scene analysis (Carey et al., 2015; Strait & Kraus, 2014) could lead to better SIN processing. In addition, other improved cognitive abilities in musicians, such as working memory, short-term memory and auditory attention contribute to better SIN perception (Clayton et al., 2016), which aids in segregating the target auditory information from background sounds and as a result leads to better auditory scene analysis (Parbery-Clark, Skoe, Lam, & Kraus, 2009; Tervaniemi et al., 2009). Due to aforementioned explanations, one can argue that auditory processing differences between musicians and non-musicians can also result in better perception of the units of words and syllables such as consonants in background noises.
The musician advantage on SIN processing is supported by behavioral and electrophysiological studies. Behavioral studies have assessed SIN perception using three of the most common behavioral tasks (Words-In-Noise, Quick-speech in noise and the Hearing-In-Noise Test). In this group of studies, participants had to detect target words or sentences coupled with informational or energetic maskers. Most of these studies have demonstrated that musicians have better performance on the clinical measures of SIN perception (Parbery-Clark et al., 2009; Ruggles, Freyman, & Oxenham, 2014; Zendel, Tremblay, Belleville, & Peretz, 2015). However, electrophysiological studies have suggested a neural basis for the musician advantage using tests such as speech Auditory Brainstem Response and the Frequency-Following Response. These studies mainly showed enhanced subcortical speech discrimination of musicians, and this advantage was correlated with their SIN performance (Coffey, Herholz, Chepesiuk, Baillet, & Zatorre, 2016; Parbery-Clark et al., 2012). However, to the best of our knowledge, there is still no study that specifically investigated the musician advantage on consonant recognition in noise. Correct perception of consonants is the basis of general speech intelligibility and provides essential acoustic information to understand the meaning of words, especially under challenging situations. Duration and Voice Onset Time (VOT) are known to be two important acoustic factors in consonant recognition (Baum & Blumstein, 1987; Lisker, 1957; Stevens, Blumstein, Glicksman, Burton, & Kurowski, 1992). Changes in the VOT allow the perception of a stop consonant as voiced (e.g., /b/) or voiceless (e.g., /p/) and is defined as the interval between the noise burst produced at consonant release and the onset of the waveform periodicity associated with vocal cord vibration (Lisker & Abramson, 1967). There is strong evidence that the long-lasting structural and functional changes caused by musical training across the auditory system not only lead to elaborated acoustic accuracy in response to musical components, such as duration, but also improve various aspects of speech processing, including VOT (Pantev, Roberts, Schulz, Engelien, & Ross, 2001; Parbery-Clark, Strait, Hittner, & Kraus, 2013; Schneider, Sluming, Roberts, Bleeck, & Rupp, 2005). Hence, it was hypothesized that musicians would exhibit better performance on consonant recognition in noise and that this benefit is mediated by their musical experience. This study aimed at comparing the performance of musicians and non-musicians on the recognition of Persian stops and fricatives, which constitute the majority of Persian consonants (16 consonants of 23 consonants), embedded in 12-talker babble noise (most common babble noise used in similar previous studies was four- or six-talker speech babble). Besides, by considering the constant presence of speech-shape noises in everyday communication environments, the importance of accurate consonant perception, and applying practical methods to enhance the consonant recognition in difficult listening conditions, conducting such a study seems to be substantial.
Materials and methods
Participants
In total, 40 right-handed native Persian-speaking adults, ranging in age from 20 to 30 years (mean age = 25.15, SD = 2.96, 19 males and 21 females) took part in the study. All participants had normal hearing (defined as < 25 dB HL pure-tone thresholds at octave frequencies from 250 to 8000 Hz), normal speech recognition thresholds (defined as <25 dB HL), and normal middle ear function (tympanometry = An type, middle ear pressure = +50 to −100 daPa) with the presence of ipsilateral and contralateral acoustic reflexes (in 500–3000 Hz freq) and no past or current neurological, audiological, or speech and linguistic disorders. All participants were recruited at the Faculty of Rehabilitation Sciences, Shahid Beheshti University of Medical Sciences (Tehran, Iran). To make sure that participants do not have age and sex differences, the two groups were matched in terms of age (musicians = 25.35 ± 3.23 years; non-musicians = 24.95 ± 2.74 years; U = 172.5, p, = .46) and sex χ(1) = 0.902, p = .342. Participants categorized as musicians (n = 20 [9 females and 11 males]) self-identified as having at least 10 years of formal musical training (mean years = 18.75, SD = 3.58), started playing an instrument before the age of 9 (mean age of commencement = 6.6 years, SD = 1.14 years), and had continued to practice consistently for at least three times a week within the 3 years before participation in the study. Also, the method of training varied across the musicians (e.g., group or private instruction, training on one or more instruments). Non-musicians (n = 20 [12 females and 8 males]) failed to meet these musicianship criteria and reported no formal musical training, and did not participate in any musical activity (other than informal listening) prior to the experiment. All participants provided with written informed consent for participation in the trial.
Materials and stimuli
Auditory evaluations were performed with a two-channel audiometer (ASTRA, GN OTO; Denmark) and an Interacoustic AT235 tympanometer. Phonetic and auditory discrimination tests were performed to ensure the health of speech production and normal auditory discrimination ability of participants. A total of 128 meaningful, monosyllabic Persian words in CVC formant (e.g., del [“heart,” in English], sar [“head”], miz [“chair”], sib [“apple”] etc.) were taken from the lists developed by Mosleh (2001). All of selected CVC consisted of stops (/b/, /p/, /t/, /d/, /g/, /k/, /q/, /ɂ/) and fricatives (/s/, /z/, /š/, /x/, /ž/, /v/, /f/, /h/) and were phonetically balanced. We attempted to select all CVCs composed of our 16 target consonants at initial and final positions, if they existed in the lists, combined with the 6 vowels (/i/, /â/, /e/, /u/, /o/, /a/). Some of the CVCs (26 of 128) considered for both initial and final positions and the rest of CVCs considered only for initial or final positions. These stimuli were recorded by a professional male speaker, who was familiar with phonetic science, in a professional recording studio. The interval between words was 4 s to provide the possibility of hand-writing responses and increasing the accuracy of the experiment. In this study, 12-talker babble noise, developed by Ahmadi et al. (2015), was used. Adobe Audition cs5.5 v4.0 software was used to construct the experiment and the stimuli were directly presented to the participants through a PC-based Astera audiometer.
Procedure
Participants completed all tasks in a single session. The laboratory visit lasted up to 1 hr, and all the tests were performed by the same audiologist. At the beginning of the appointment, participants answered questions covering risk factors for hearing health, neurological disorder, and use of potentially ototoxic medications, which could influence central auditory system, as well as smoking history. Otoscopy was done to ensure that the external ear was normal and there was no wax or debris in the ear canal. Tympanometry, as well as ipsilateral and contralateral acoustic reflexes, was measured in automatic mode. Pure tone and speech thresholds of all participants were tested individually in a quiet experimental room that met minimum ambient noise level. Prior to the main experiment, phonetic and auditory discrimination tests were performed. The right ear was assigned as the test ear, and both noise and CVCs were ipsilaterally presented to the right ear. Then the speech-in-noise test was explained to each subject; participants were asked to ignore the noise at each ratio and write each target word they identified from the background multitalker babble. The stimulus was presented at 30 dB above the speech recognition threshold (comfortable hearing level). First, participants listened to the monosyllabic words in silence and then coupled with the 12-talker babble noise in three SNR ratios (respectively, 0, −5, and −10 dB). Different CVC lists were randomly presented in each SNR to the right ear, and between each trial, break time was offered to relieve fatigue.
Consonant analysis
The written responses of the participants were preliminarily analyzed by an audiologist and a speech therapist. Although the subjects were told that all of the target items would consist of meaningful CVC syllables, there were deletions of either initial or final consonants, especially in the final position of CVCs. In addition, there were some consonant confusions due to misperception. For example, CVCs which contained unvoiced stops /p/, /t/, or /k/ were confused with each other, and in this case, participants wrote down even a new nonsense word (e.g., pam instead of kam). However, each consonant response was scored as correct if it matched the corresponding target stimulus consonant followed by the target vowel in initial or final position in original list. For instance, if initial consonant /s/ in sib was considered as target, it was scored as correct response in two conditions; if the participant transcribed the entire CVC correctly or merely initial CV of the word (e.g., sir instead of sib). Finally, the percentage of stops and fricatives which were correctly recognized calculated separately in each SNR.
Data analysis
All statistical analyses were conducted using SPSS (version 20). Two-way repeated-measures ANOVA was performed for all between- and within-group comparisons that included SNR (0, −5, −10) as within-subject factors and Group (musician vs. non-musician) as a between-subject factor. Post hoc Bonferroni analyses were used for multiple comparisons between SNRs.
Results
There were significant main effects of SNR on recognition of stops, F(2, 37) = 264.6, p < .001, ES = 0.93, Power = 1, and fricatives, F(2, 37) = 274.9, p < .001, ES = 0.93, Power = 1. Scores of participants were significantly different in the three SNRs. Post hoc pairwise comparisons demonstrated significantly more significant consonant errors in the SNR = −10 condition compared with SNR = −5 condition, p < .001, and more errors in the SNR = −5 condition compared with SNR = 0 condition, p < .001. There was a significant main effect for “group” on recognition of stops, F(1, 38) = 34.1, p < .001, ES = 0.47, Power = 1, suggesting that musicians outperformed non-musicians on recognition of stops in the three SNRs. Furthermore, there was a significant main effect of Group on recognition of fricatives, F(1, 38) = 32.8, p < .001, ES = 0.45, Power = 1. Musicians had better performance on recognition of fricatives in three conditions of SNRs. There was no significant interaction between SNR and Group for stops, F(2, 37) = 2.95, p = .06, power = 0.54, or fricatives, F(2, 37) = 0.283, p = .75, power = 0.09; that is, an equal decrease in consonant recognition was found for both musicians and non-musicians across the levels of SNR (see Figure 1).
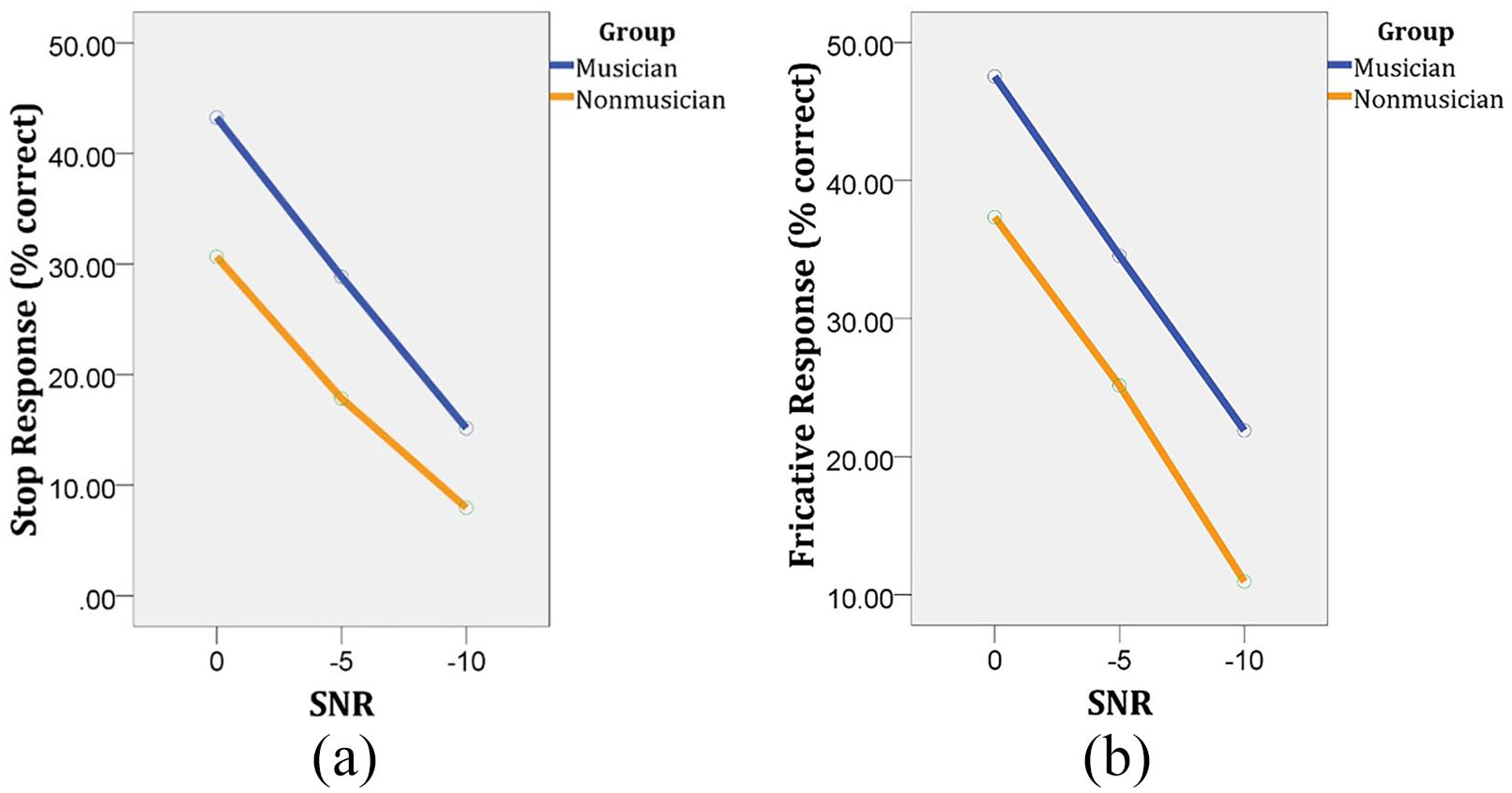
Interaction Effects Between SNR and Group on: (a) Stop Consonant and (b) Fricative Consonant Recognition. Consonant Recognition Scores Similarly Decreased Across the Levels of SNR for Both Groups (Non-Significant Interaction, p > .05).
Discussion
We provided the first behavioral study on recognition of consonants in musicians. In line with our hypothesis, the recognition of fricatives and stops was better in musicians than in non-musicians in all three conditions tested. A possible explanation is that music training requires more accurate temporal processing than does ordinary speech, if small differences in timing are substantial for speech to distinguish VOT between consonants. As well, small differences in note timing are structurally important for music, but in speech, other acoustic features such as F0, vowel duration, and other factors play a role in discerning between words and syllables other than VOT. Furthermore, in communication environments, most words are expressed in syntactic and semantic contexts that help the distinctions between them. In contrast, it seems that music demands further of the auditory system and relies more on precise perception of timing (Mattys, White, & Melhorn, 2005; Patel, 2011). These findings suggest that music training could improve the distinction of speech units (i.e., consonants) by enhancing timing accuracy of auditory system.
Another notable point is the effect of musicianship on processing of acoustic parameters associated with consonant recognition. It seems that long-term musical experience enhances the sensitivity to acoustic features that are common to speech and music (e.g., duration) and provides musicians with more elaborated speech perception than non-musicians. This, in turn, may improve a stage of speech processing that is specific to the phonological parameter of speech and is not shared with music (e.g., VOT; Besson et al., 2011; Chobert, François, Velay, & Besson, 2014). It has been confirmed that musicians are more accurate in differentiating speech sounds with different VOTs (Kühnis, Elmer, Meyer, & Jäncke, 2013) and more sensitive to durational changes (Chobert et al., 2014). Therefore, it can be inferred that the positive effect of musical training on consonant perception is as a result of common processing between speech and music, as well as transfer effects from music to speech domain.
Music training may not only affect the consonant’s perception positively by improving acoustic processing, but may also influence this ability by enhancing cognitive abilities such as auditory working memory and auditory attention, which have been demonstrated to be important for speech perception in adverse listening circumstances (Besser, Koelewijn, Zekveld, Kramer, & Festen, 2013). The OPERA (Overlap, Precision, Emotion, Repetition, Attention) hypothesis suggests that cognitive processing mechanisms that are shared between music and speech domains might be improved by music training, since music places higher demands than speech on those processes (Patel, 2014). Then, enhanced cognitive abilities of musicians might also affect the processing of speech consonants.
An important factor that possibly influenced present result is the characteristic of our background noise. When babble noise consists of one or two talkers, listeners with normal hearing can utilize the gaps in the masking noise to identify the target speaker. As the number of competing talkers increases, such as our 12-talker babble noise, masking also increases and the gaps in temporal envelope decrease; however, in this situation listeners may still be able to use time-varying cues of multitalker babble and the target talkers (Buus, 1985; Carhart, Tillman, & Greetis, 1969). As it was mentioned earlier, evidence suggests that persistent musical practice is associated with better spectral and temporal perception ability of the acoustic stimulus (Abrams et al., 2011; Meha-Bettison, Sharma, Ibrahim, & Mandikal Vasuki, 2018; Zuk et al., 2013). Thus, enhanced consonant perception in musicians possibly arises from the improvement of detection of temporal cues in the left-auditory hemisphere (Elmer, Hänggi, Meyer, & Jäncke, 2013; Meyer et al., 2005). Another important consideration is that when target speech and background noise are separated spatially, individuals use spatial cues to detect speech targets. Conversely, if target speech and noise are reached from the same location to the ear, spatial cues no longer aid the stream segregation; in this case, frequency discrimination is an important predictor of SIN performance, and it is confirmed that musicians are better at detecting frequency differences (Rammsayer & Altenmüller, 2006; Tervaniemi, Just, Koelsch, Widmann, & Schröger, 2005; Zendel & Alain, 2009). With regard to ipsilateral presentation of target signal and multitalker babble in our study, better performance of musicians on the consonant perception is probably related to this improved skill. Our result is in line with studies that showed presenting the target and the noise from the same source resulted in better SIN performance in musicians (Parbery-Clark et al., 2009; Swaminathan et al., 2015).
Our study reveals that with SNR decreasing, both groups similarly recognized fewer consonants. It is worth noting that the non-significant results for interactions are likely to be the reflection of small sample sizes (Power < 0.8) in our study and significant differences may emerge with larger samples. However, musicians still showed a much higher absolute score at each SNR. These outcomes suggest that in most challenging listening situations, musicians are less affected in perceiving of target speech than non-musicians. Although several studies have supported better performance of musicians on SIN tasks (Başkent & Gaudrain, 2016; Slater et al., 2015; Soncini & Costa, 2006), the outcome of Boebinger et al. (2015) study on SIN perception conflicted with the result of this study. The study demonstrated no significant difference between musicians and non-musicians on SIN measurements. One probable reason for this inconsistency is the difference in material applied in the two studies. Boebinger et al. (2015) used simple sentences instead of words as target stimuli, which could provide a good deal of semantic and syntactic information and increase the predictability of the trial for both groups. Another possible explanation is that in Boebinger et al. (2015) study, some members of non-musician group received a limited amount of music instruction, which may have affected the results of the study. While in this study, none of the non-musicians received musical training.
Clinical implications and future directions
Studies have shown that some populations, such as older adults (Liberman & Shankweiler, 1985) and children (Bogliotti, Serniclaes, Messaoud-Galusi, & Sprenger-Charolles, 2008) with developmental dyslexia have difficulty in perceiving consonants. They confuse the identity of a range of fricatives in syllables and are impaired in processing of VOT, which allows perceiving stops as voiced (e.g., /b/) or voiceless (e.g., /p/; Cornelissen, Hansen, Bradley, & Stein, 1996; Masterson, Hazan, & Wijayatilake, 1995). These populations also experience more difficulty in the SIN perception, which could be related to their phonological impairment (Dole, Hoen, & Meunier, 2012). Besides, it has been indicated that musical training improves the processing of both duration and VOT variations (Chobert, Marie, François, Schön, & Besson, 2011). Thus, long-term musical training with an early start may improve the perception of consonants and prevent abnormal linguistic growth such as learning disabilities in individuals with dyslexia disorders.
Since clinical cognitive evaluation was not performed in this study, it is not possible to precisely discuss the relationship between consonant recognition and cognitive function. It is recommended that this research be performed along with cognitive function tests. In this study, the musicians played a variety of classical and Persian instruments, and the effect of playing each of these instruments on the recognition of consonants was not investigated. It is suggested that similar study be performed on individuals with experience of playing similar instruments. As well, further research is needed to determine which aspects of music education (rhythm, melody, musical playing style) have the most impact on improvement of consonant recognition ability.
Conclusion
In summary, this study showed that musicians achieved better recognition scores of stops and fricatives coupled with different vowels at three SNR ratios. In fact, it can be inferred that musical training enhances the recognition of consonants in challenging listening conditions. Also, recognition score of stops and fricatives decreased at a similar rate in both groups as a function of SNR. Based on these results, musical instruction is recommended in rehabilitative programs for certain populations such as adults and children with learning disabilities, so as to improve recognition and perception of the consonants with higher precision.
Footnotes
Acknowledgements
The authors would like to thank all participants for their contributions to this work. They thank Amir Ahmadi for providing the masking material.
Author’s note
The current study was part of MSc thesis by Ebtesam Sajjadi (Register No: 941519001) at Shahid Beheshti University of Medical Sciences.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.