
Abstract
We review different regression models related to water quality that incorporate spatial aspects in their model. Spatial aspects refer to the location of different sites and are usually characterized by the distance between different points and directions by which they are related to each other. We focus on spatial lag and error, spatial eigenvector-based, geographically weighted regression, and spatial-stream-network-based models. We evaluated different studies using these methods based on how they dealt with clustering (spatial autocorrelation) of response variables, incorporated those clustering in the error (residual spatial autocorrelation), used multi-scale processes, and improved the model performance. The water-quality-based regression modeling approaches are shifting from straight-line distance-based spatial relations to upstream–downstream relations. Calculation of spatial autocorrelation and residual spatial autocorrelation was dependent upon the type of spatial regression used. The weights matrix is used as available in the software and most of the studies did not attempt to modify it. Different scale processes like certain distance from rivers versus consideration of entire watersheds are dealt with separately in most of the studies. Generally, the capacity of the predictor variables to predict the response variable significantly improves when spatial regressions are used. We identify new research directions in terms of spatial considerations, weights matrix construction, inclusion of multi-scale processes, and identification of predictor variables in such models.
I Introduction
Water quality, defined as the physical, chemical, and biological characteristics of water, is directly associated with human and ecosystem health. Water quality itself is dependent on various factors, including land cover, land use, land management, atmospheric deposition, geology and soil type, climate, topography, and catchment hydrology (Lintern et al., 2018). Water-quality parameters vary across space and time as a consequence of variations in these different factors. For effective water-quality management, it is crucial to understand these factors and the pathways by which they affect water quality. Understanding the spatial patterns of water-quality parameters and factors affecting them, therefore, is crucial in pinpointing locations of interventions for improving water quality in surface water bodies.
The most common approach of water-quality research involves the statistical method, which typically process raw quantitative data using mathematical models, formula, and techniques to extract information and generate meaningful output (Nature Statistics, 2019). Regressions are the most common statistical methods to understanding the relationship between water quality and watershed characteristics (Chang, 2008; Shi et al., 2016; Zhou et al., 2012). Regression approaches may or may not include spatial aspects of water-quality parameters (Ullah et al., 2018). Spatial aspects refer to location and relative position to each other, usually analyzed using spatial statistical methods. A relatively new sets of spatial statistical approaches, which typically extend from linear regression analysis, attempt to incorporate spatial processes to identify environmental and spatial determinants of water quality in surface water (Blanchet et al., 2008; Legendre, 1993).
Many studies have examined spatial aspects of water quality (e.g. spatial autocorrelation and distribution of high and low values along a river network) using various modeling techniques to explore the effect of landscape-level variables in the water quality. These studies include several review papers that synthesized different aspects of water-quality research. Giri and Qiu (2016) reviewed the current understanding of the relationship between land use and water quality, while Ullah et al. (2018) examined different statistical approaches to modeling water quality using land-use types as predictor variables. Lintern et al. (2018) conducted a comprehensive review of key factors affecting the spatial patterns of water quality, while Guo et al. (2019) reviewed various factors affecting temporal patterns of water quality. Isaak et al. (2014) conducted a review of research on a group of spatial statistics, spatial-stream network (SSN)-based models. However, there is not any comprehensive review related to the spatial aspects of water-quality modeling that offers water-quality researchers a way to understand the basic concept of the spatial statistics and help them choose an appropriate modeling approach.
We carry out this review to compare different statistical models based on their effectiveness in addressing spatial aspects of water quality. We specifically examine spatial autocorrelation of the water-quality parameters, residual spatial autocorrelation (RSAC), use of weights matrix, and incorporation of directional spatial processes in the model. First, we discuss how these methodologies have evolved, and later we perform a systematic literature review to identify knowledge gaps related to spatial autocorrelation, the use of multi-scale processes, and directional spatial processes. We review papers related to spatial lag and error model, spatial eigenvector-based models, geographically weighted regression (GWR), and SSN-based models. We recognize that there are other spatial modeling approaches that are not covered in this review, including spatial kriging, P-splines, and several spatial autoregressive models (e.g. McLean et al., 2019).
II Spatial statistical approaches in water-quality studies
In watershed science, watershed, basin, or sub-basin are considered units of analysis. Extracting predictor variables that affect surface water quality mostly involves consideration of the entire watershed. Several ways exist to incorporate different scales in the water-quality modeling endeavor (Allan, 2004; Mainali and Chang, 2018). One of the most common involves creating a buffer of a specified distance from stream or lakes. Some studies also use a threshold distance upstream from the sampling point (e.g. Shi et al., 2017). Some new methods provide higher weight to the landscape factors close by the streams based on Euclidean (straight line) distance, flow distance, or flow accumulation (Grabowski et al., 2016; King et al., 2005; Peterson et al., 2011).
Spatial variations in the watershed properties draining into the river result in variable water quality across different parts of the river, which typically lead to a specific spatial pattern of water quality. As nearby places are more alike than distant spaces (Tobler, 1970), there might be a cluster of high or low values of water-quality parameters. This phenomenon, spatial autocorrelation, is a measure of whether a data value of one location is independent of the data values of other locations (Sokal and Oden, 1978). Spatial autocorrelation can be positive when similar data values are close to each other, or negative when dissimilar data values are neighbored (Legendre, 1993; Sokal and Oden, 1978). Spatial autocorrelation opens new avenues to statistically analyze seemingly obvious but ignored spatial patterns of water quality and their relations with the watershed attributes (Legendre, 1993).
A family of statistical tools is being used to analyze spatial autocorrelation among sampling stations. Moran’s I is the most commonly used measure to evaluate the pattern of the attributes as clustered, dispersed, or random in space. This is a global statistics, one that offers a single set of statistics for the entire set of data. Moran’s I has been used to analyze different water-quality attributes in order to identify whether the water-quality attributes show any global pattern of spatial dependence (Liu et al., 2016; Miralha and Kim, 2018; Pratt and Chang, 2012). As Moran’s I statistics only offer information about the level of spatial autocorrelation for an entire set of data, we cannot use it to identify any local clusters. There are a few statistical approaches developed to identify local clusters in spatial data and they are also being used to explore clusters of sites with degraded or not-degraded water quality. Getis–Ord’s Gi and local Moran’s I are commonly used in such local statistics (Anselin, 1995; Getis and Ord, 1992). These methods identify whether or not similar high or low values are clustered together locally and identify those clusters in geographical space. Many water-quality-analysis works have used these statistics to explore local relations in a sampling space (Brody et al., 2005; Mainali and Chang, 2018; Tu and Xia, 2008).
The spatial autocorrelation in any data is associated with spatial dependence among neighboring data points, resulting in a spatially biased trend and violating the assumption of independence of most standard parametric statistical procedures (Cliff and Ord, 1972; Legendre, 1993; Sokal and Oden, 1978). In regression analysis, biases due to such neighboring data points need to be accounted for, as they can produce autocorrelated residuals (differences between actual and predicted values) and ultimately inflate Type I error, leading to wrongfully rejecting the null hypothesis (Bini et al., 2009; Cliff and Ord, 1972; Miralha and Kim, 2018). It is not possible to account for such influence only using traditional simple linear regression approaches that assume that data points are randomly distributed in the sampling space, and that model residuals are not autocorrelated. Several spatial regression approaches that account for such spatial dependence are being used in water-quality modeling, including spatial lag model, spatial error model, GWR, spatial eigenvector mapping, and SSN-based models (Blanchet et al., 2008; Borcard and Legendre, 2002; Brunsdon et al., 1998; Getis and Griffith, 2002; Ver Hoef and Peterson, 2010; Ver Hoef et al., 2018).
III Spatial weights matrix and spatial regression models in water-quality studies
1 Spatial weights matrix
The spatial dependence between sampling points is formally expressed as a weights matrix and is a necessary element of spatial regression models (Anselin, 2001; Getis and Aldstadt, 2004). Each spatial weight refers to the relative influence of different spatial units under consideration to the candidate spatial unit. These weights matrices can be defined in several ways, according to spatial interactions among different factors under consideration, and the hypotheses of interest (Sokal and Oden, 1978). The most essential aspect of the weights matrix is defining a neighborhood set for each location. The neighborhood sets are specified for each location as the row and the neighbors as the columns in a matrix. Non-zero weight is assigned when observations are within a given number of nearest neighbors or a specified distance. In the spatial statistics literature, the weight can be specified based on Euclidean distance, economic distance, number of nearest neighbors, or empirical flow matrices (Anselin, 2001). The weights matrices use several approaches to incorporate the effect of adjacent observations. Sometimes, a certain number of nearest neighbors is used, while in other cases only observations within a certain distance are used, with the same weight to all the observations within that distance (Figure 1). Spatial regression models usually differ in terms of conceptualizing the spatial relationships, usually through the weights matrix. In this section, we discuss how these different spatial regression approaches are conceptualized and used in water-quality modeling endeavors (Figure 2).

Conceptualization of different weights matrices. 1) Spatial contiguity: a spatial weights matrix is created based on whether polygons share a common boundary or not (a binary decision with 0 or 1). For example, for P1, four polygons (i.e. P2, P3, P6, P8, and P9) are considered as neighbors based on Queen’s connectivity), or P6 will not be included if a zero-distance common boundary (i.e. point connectivity) does not count (Rook’s connectivity). A contiguity-based spatial weights matrix can be specified with either the length of a common boundary or the area of an adjacent polygon instead of 0–1 binary values. For example, for the length of a common boundary, P9 has the longest common boundary with P1 and, thus, will have the largest weight, while P8 shares the shortest common boundary with PI and has the smallest weight. For the area of an adjacent polygon, P3 is the largest adjacent polygon of P1 and will have the largest weight, while P2, which is the smallest adjacent polygon of P1, has the smallest weight. 2) Nearest neighbor: sometimes weight can also be provided based on the numbers of neighbors for each candidate polygon (k-nearest neighbor). If we only use one closest neighbor, polygons (first order) defined in the Queen’s case (P2, P3, P6, P8, and P9) are considered. If two nearest neighbors (second order) are considered, in addition to the polygons adjacent to P1, the polygons sharing a boundary with those (P2, P3, P6, P8, and P9) are also included during the weights matrix construction for the candidate polygon (P1), which results in the inclusion of P4, P7, and P10, but not P5. Nearest neighbors (which are often called k-nearest neighbors) are specified with a fixed number of neighbors. It is often adoptively utilized for a case in which observations are not (relatively) evenly distributed. For example, one remote point (it is often specified for points) may not have any neighbor, which is a problem in spatial analysis. To avoid this problem, k-nearest neighbors can be utilized. 3) Threshold distance: spatial neighbors can be specified based on a preset distance from the centroid of a polygon. Here, with a threshold distance d1, polygons inside the circle of radius d1 are considered as spatial neighbors for polygon P1. In this case, P1 has four neighbors: P2, P3, P8, and P9. If d2 is used for a threshold distance, all polygons but P4 and P5 are neighbors of P1 and have a non-zero weight.
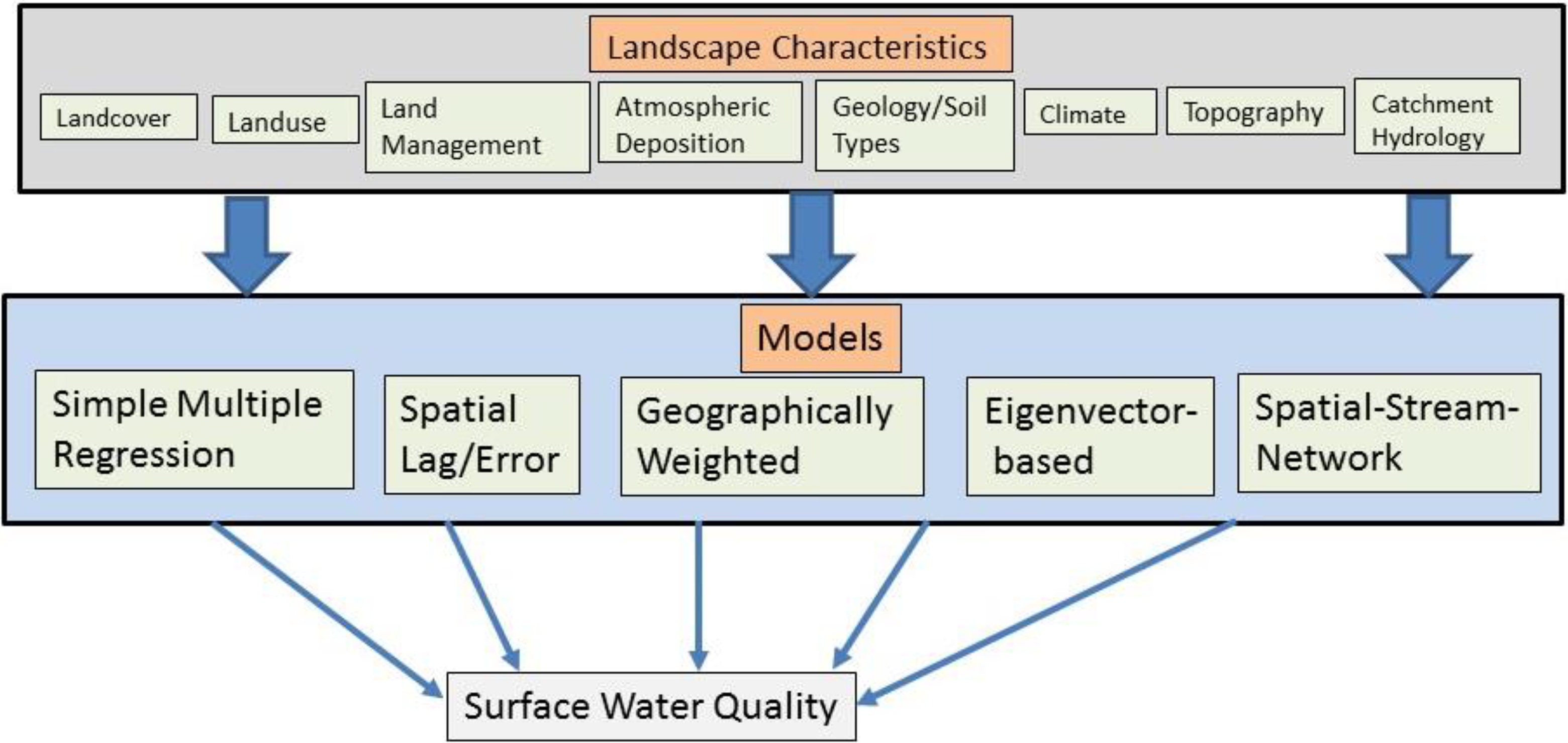
Use of different landscape characteristics (Lintern et al., 2018) in different spatial statistical modeling approaches considered in this review.
2 Spatial lag and error model
Spatial lag models and spatial error models are the most commonly used global regression models that account for spatial dependence among observations in a model specification. Global models refer to the regression models that produce a single set of model parameters for a set of data. A spatial lag model (Anselin, 1988, 2001) is applied when response variables suffer from significant spatial autocorrelation. A spatially lagged variable is created by averaging the values of the response variable at neighboring locations (Figure 3). The spatial lag model includes a spatially lagged dependent variable with a weights matrix to account for the spatial autocorrelation. Such a weights matrix is often constructed without consideration of a stream network, so it tends to have more neighboring sites than that of a stream network (Figure 3(a)). A spatial error model (Anselin, 2001) is used when model residuals suffer from significant spatial autocorrelation. This is similar to the spatial lag model except that it accounts for spatial autocorrelation in the error term.
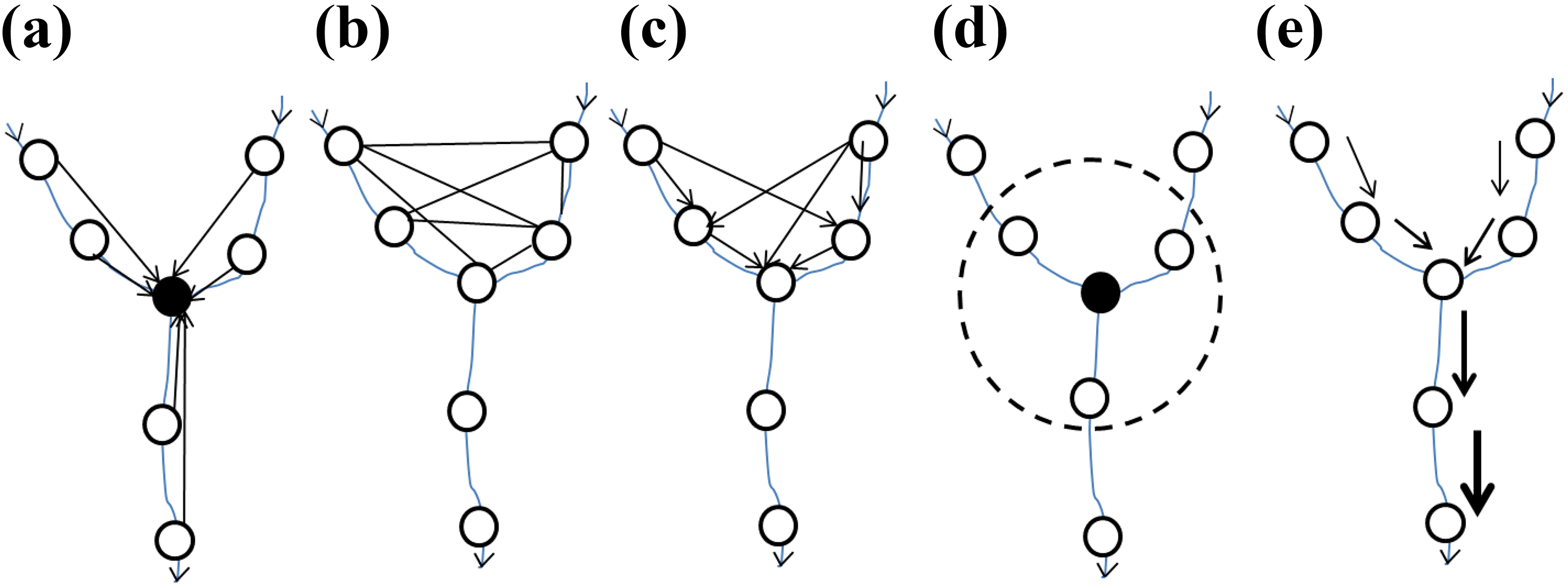
Spatial relations among sampling stations for a spatial weights matrix creation in different types of spatial modeling for surface water quality. The black arrows refer to directionality of the spatial relations and the dotted circle represents a certain bandwidth. (a) Both upstream and downstream stations affect a station of interest. (b) All surrounding stations are considered with no directionality between upstream and downstream stations (modified from Sharma et al., 2011). (c) Asymmetrical configuration: only upstream stations are considered, but stations in different tributaries could affect each other. (d) Only neighbors within a threshold distance are considered with no specific upstream and downstream relationships. (e) SSN model: arrows in SSN models refer to the direction of the relation and moving average function; the width of the arrow refers to the strength of the influence for each potential neighborhood location; spatial autocorrelation occurs when the moving average function overlaps (modified from Peterson and Hoef, 2010).
Several researchers have been using these methods to model water quality and reported a general improvement in model performance when such spatial models are used (Chang, 2008; Huang et al., 2016; Miralha and Kim, 2018). This improvement in the model performance typically relates to the degree of spatial autocorrelation and RSAC (Kim and Shin, 2016; Kim et al., 2016; Miralha and Kim, 2018).
3 GWR
Global spatial regression models, such as spatial lag models and spatial error models, are used to develop a spatially rectified global regression model by accounting for the spatial dependence of an entire dataset. They only produce a single set of statistics for the entire dataset under consideration. Therefore, they are a member of global spatial regression models. In reality, a relationship between predictors and a response variable can vary within a catchment, and the strength of those relations might also be different across regions. In order to address this issue, GWR can be used to allow model coefficients to vary for each observation and create a set of local models based on the location of sampling sites (Brunsdon et al., 1998). The observed data included in each local model are geographically weighted, depending on the proximity of the location, and are used to estimate local R 2 and coefficients for each sample observation. The number of samples included for each data point is defined using a bandwidth function (e.g. Figure 3(d)). Although a fixed-distance band can also be used, a flexible bandwidth that adapts to the spatial pattern of the data can be more effective, particularly when data are not evenly distributed over space (Fotheringham et al., 2002). During the modelling process, the nearby data points are weighted more heavily than those from more remote locations using a kernel function. GWR is increasingly used in water-quality modeling, not only to estimate the model parameters but also to explore the variabilities of those relationships in different watersheds (Chen et al., 2016; Chang and Psaris 2013; Pratt and Chang, 2012; Tu, 2011).
4 Moran’s eigenvector maps and spatial filtering
Eigenvector-based models are spatial models in which the vectors are derived using neighborhood criteria or distance with neighbors. In these models a matrix can be constructed based on the geographical distance between locations. This matrix is transformed into eigenvectors by eigenfunction decomposition (e.g. Figure 3(b)). This method was originally proposed by Borcard and Legendre (2002) as the principal component of neighborhood matrix, also called Moran’s eigenvector maps (MEMs). This method incorporates spatial autocorrelation in modeling ecological processes. Eigenvectors corresponding to positive eigenvalues are used as spatial descriptors in regression or canonical analysis (Borcard and Legendre, 2002). Vrebos et al. (2017) modeled the water quality of 75 stations in the Kleine Nete catchment in northern Belgium and reported that about 30% of variation was explained by catchment land cover while about 11% was explained by spatial eigenvectors created from Moran's Eigenvector Maps.
There are both distance-based eigenvector maps and spatial filtering based upon a geographic connectivity matrix (Borcard and Legendre, 2002; Getis and Griffith, 2002; Griffith, 2010; Griffith and Peres-Neto, 2006). Eigenvector-based spatial filtering is used to separate spatial effects in regression modeling from model residuals so that a standard regression model can be used without suffering from spatial autocorrelation (Getis and Griffith, 2002). Similar to the eigenvector mapping approach, it also uses “eigenfunctions of spatial configuration matrices to derive the spatial eigenvectors” (Griffith and Peres-Neto, 2006). This approach has been used to model soil attributes (Kim et al., 2016), plant diversity (Kim and Shin, 2016), crime patterns (Chun, 2014), and diseases (Jacob et al., 2008). Mainali and Chang (2018) used this approach to model the water-quality trends of the Han River Basin, South Korea, reporting that it significantly increased model performance and removed the RSAC.
5 Asymmetrical eigenvector maps (AEMs)
All of the spatial statistical approaches discussed in the previous section assume that the relations among sampling sites are multi-directional. The spatial associations of different points along the river are usually unidirectional as the water flows downstream (e.g. Figure 3(c)). Therefore, upstream water quality affects downstream water quality but not vice versa. Recently, new spatial statistical methods have been developed in order to account for such directionality in water-quality modeling. Blanchet et al. (2008) modified the MEM approach in order to incorporate the directional process of rivers and streams as AEMs. They propose that “gradients influencing spatial distribution can be studied via spatial variables (eigenfunctions) that represent directional spatial processes”. This is also a part of the eigenfunctions-based spatial filtering framework, with the added feature that it “constructs space in an asymmetric way” by only accounting for the sites connected through the water flow. The modeling involves defining a connection diagram based on the directional spatial process and creation of sites-by-edges matrix, which are transformed into spatial eigenvectors.
6 Spatial-stream network (SSN)
A river can be effectively represented as a dendritic network, and any scientific inquiries and management decisions related to river networks should acknowledge this (Peterson et al., 2013). Dendritic networks use points and lines in geographical space, and typically have a directional component (Peterson et al., 2013). The modification of the autocovariance model that incorporates the dendritic network structure of rivers is dubbed a SSN model (Ver Hoef et al., 2006, 2014). It uses a set of autoregressive functions to derive the predictor variables to be used in the regression modeling. The weight of those directional processes can be river distance, flow volume, or catchment size, or any relevant variables for the watershed of interest (e.g. Figure 3(e)). The SSN allows users to test spatial autocorrelation and develop models for various scenarios like flow-connected, flow-unconnected, and Euclidean distance (Isaak et al., 2017; Neill et al., 2018; Scown et al., 2017). It not only allows the development of models but also lets users explore the spatial properties of the data in relation to various in-stream processes (e.g. McGuire et al., 2014).
IV A systematic review of current studies
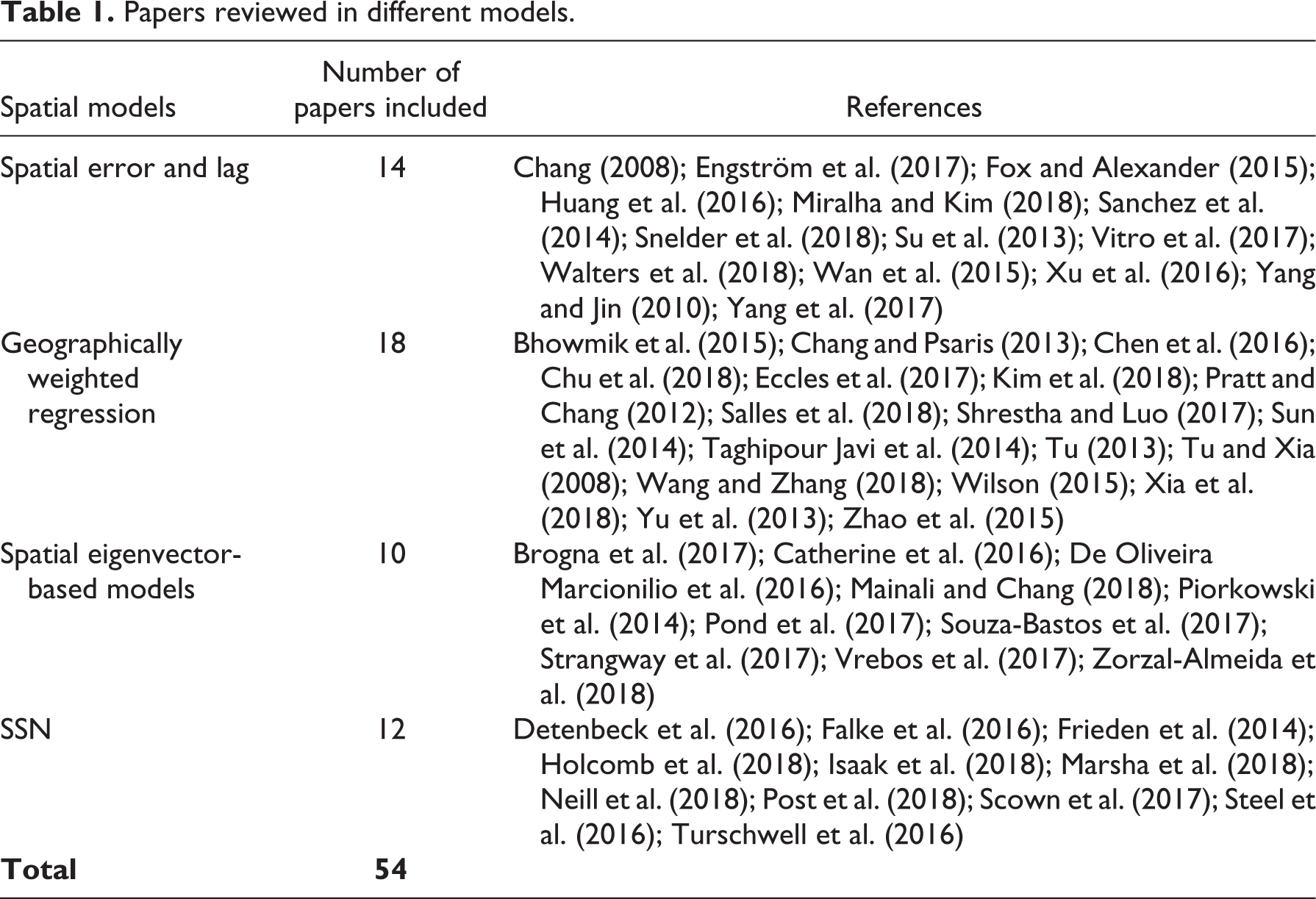
We carried out a systematic review of articles related to different types of spatial regression of water quality published from 2000 to 2018, using the Web of Science database on November 9, 2018 (Table 1). The search phrases we used included “water quality” and “spatial regression”, “water quality” and “eigenvector”, “water quality and “autocorrelation”, and “water quality” and “spatial-stream network”. We identified 54 articles with a water-quality focus that used at least one type of spatial regression (Table 1). Note that it may not be a comprehensive list, as we only searched for the term “water quality”. The water-quality information might well be published as water pollution, or in terms of individual parameter names such as temperature, pH, nitrogen, or phosphorus. These names were not included in our search terms. We also removed studies that did not have spatial regression approaches. Although we mostly focused on surface water, we also included a few groundwater-quality works in this review. We focused our review on the use of spatial statistical methods to account for spatial autocorrelation and RSAC, weights matrix construction, scale considerations, and improvements in model performance in different types of spatial statistical modeling. We also attempted to identify the spatial pattern of these studies to explore where such research efforts have been concentrated.
Papers reviewed in different models.
1 Geographic distribution of studies
The majority of study sites of research related to spatial statistical modeling of water quality are concentrated in the USA and China, with a few exceptions: Canada, Brazil, South Korea, Australia, and some countries in Europe (Figure 4). This is likely because of the fact that these countries have relatively dense networks of monitoring stations over a large area. Only 15 nations were represented from 54 studies. Although developing countries are most vulnerable to water-quality degradation (Schwarzenbach et al., 2010), very little research has been carried out there. This list may not be comprehensive, but we assume that this map represents the spatial pattern of current research related to spatial aspects of water quality.
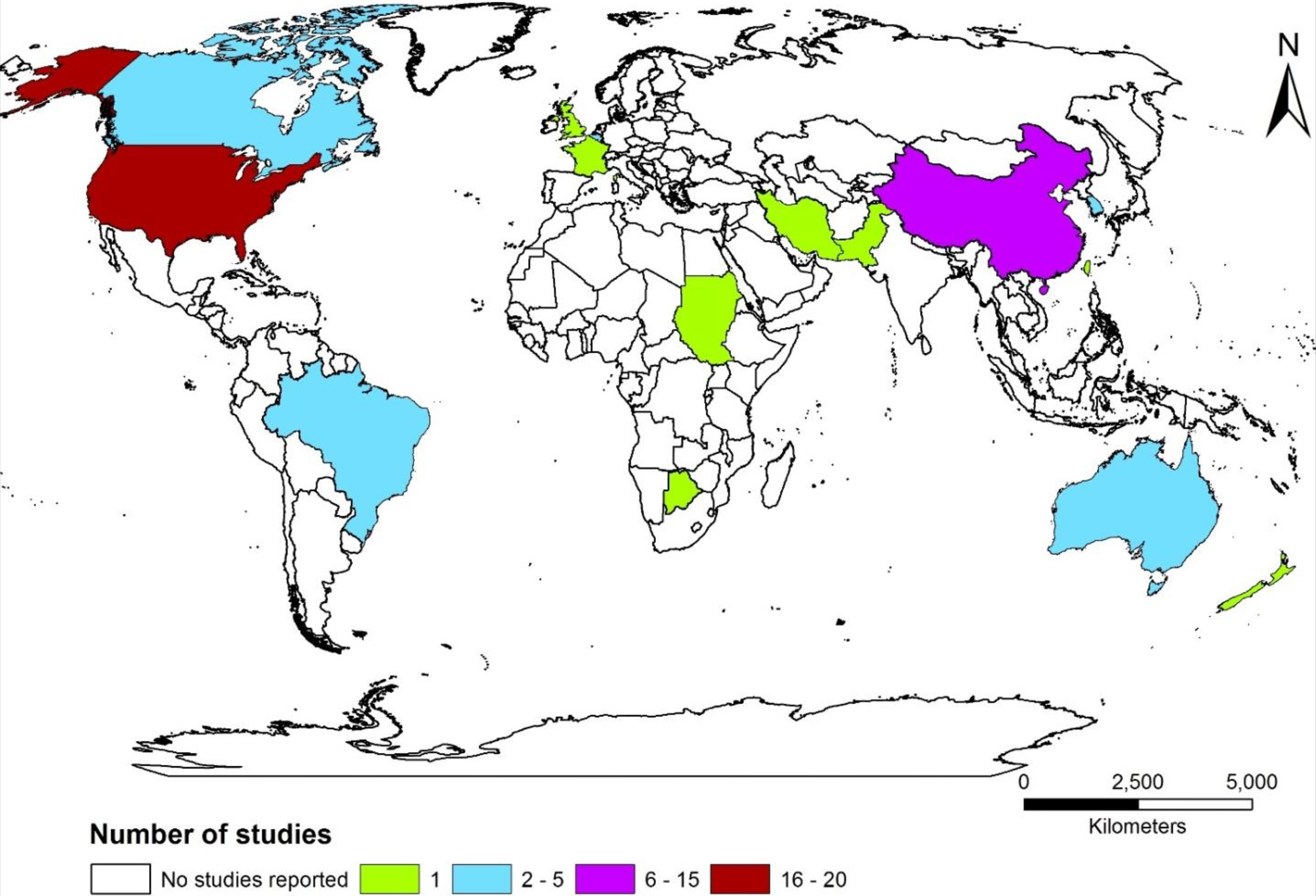
Country-wise distribution of the sites of the studies included in this review (n = 54).
2 Spatial autocorrelation in different spatial regressions
Theoretically, exploring the spatial autocorrelations of the dependent variables and residual autocorrelations, and examining the significance of spatial autocorrelations, are the first steps in incorporating spatial relations into the models. Although the relationship between RSAC and variation of the model (pseudo-) R 2 and coefficients is discussed in most of the studies, the relationship with the spatial autocorrelation of dependent variables is usually not taken into consideration. Many latest studies have reported that the spatial autocorrelation of dependent variables and RSAC are usually related; the choice of covariates also affects the significance of RSAC (Mainali and Chang, 2018; Miralha and Kim, 2018).
We find that the use of spatial autocorrelation statistics of the dependent variable is generally associated with the type of spatial regressions used. Approximately 43% of papers that used either a spatial lag model or a spatial error model calculated the spatial autocorrelation of the dependent variable, while only 30% of papers using an eigenvector-based model did so. Similarly, 43% of papers using GWR calculated the spatial autocorrelation of the dependent variable, while about 75% of Spatial Stream Network Model (SSNM) papers did so. Forty eight percent of spatial-error/lag papers, 70% of eigenvector-based papers, 61% of GWR papers, and 100% of SSN model papers tested for RSAC.
The analysis of spatial autocorrelation in water quality leads to a better understanding of the extent of spatial organization (clustered, dispersed, or random) of water-quality variables, and also helps explore the capacity of the independent variables to predict the water-quality pattern (e.g. Miralha and Kim, 2018). Accounting for spatial autocorrelation in regression can correct bias in parameter estimation and, hence, helps avoid an incorrect conclusion for potential factors. A higher percentage of RSAC testing in more recent studies stems from the fact that the independent variables might not explain all the spatial autocorrelation and results in RSAC – that is, it is the spatial autocorrelation in residuals that should be examined. A high level of spatial autocorrelation in the response variable may give a hint for spatial autocorrelation in residuals, but is not necessarily a reason to use spatial regression as long as there is no significant RSAC. A future research suggestion in this field would be checking for RSAC before using spatial regression models if the researchers are concerned that the regression model does not account for the spatial autocorrelation.
3 Spatial weights matrix
All spatial statistical modeling approaches are based on some form of spatial weights matrix. The most common type of weights matrix – distance matrix – is constructed using the distance among the sampling sites based on geographical coordinates; sites are weighted based on distance, number of neighbors, or other relevant attributes. The other attributes include Euclidean distance upstream, river distance upstream, catchment size, and river flow (Isaak et al., 2018). There are several standard distance matrices available for different types of spatial regression approaches. For example, spatial lag and spatial error methods use nearest-neighboring stations (Chang, 2008; Huang et al., 2014); the spatial filtering approach uses at least one neighbor; the geographically weighted approach mostly uses adaptive bandwidth to include the desired number of sites; and SSN uses river distance, flow volume, or upstream catchment area. However, spatial statisticians recommend modifying the weights matrix based on the hypothesis being tested, the scale of analysis, the spatial distribution of the sampling station, and spatial issues being addressed (Blanchet et al., 2008; Sokal and Oden, 1978).
Based on our review, we find that most of the papers use a “standard” weights matrix provided by the software on which the model is being implemented. Traditionally, spatial lag models use observations in all directions to create a spatial lag variable. Some studies attempted to modify the existing weights matrix to incorporate hydrologic connectivity. For example, Vitro et al. (2017) modified a spatial weights matrix to incorporate the effect of only upstream stations in a spatial lag model. They provided relative weights to upstream stations based on the proximity to the candidate station being considered. Engström et al. (2017) used two different weights matrices, one with all proximate stations and the other with proximate and upstream stations. Most other studies used only a set number of nearby stations to define weights. For example, Chang (2008) and Huang et al. (2014) used four closest stations, Su et al. (2013) used 10 such stations, and Yang and Jin (2010) used only adjacent stations. However, no study has tested how the study results might be sensitive to changes in weights matrices.
GWR uses an exponential (or Gaussian) distance decay function to create spatial weights among the sampling sites included within the specified distance defined by the bandwidth. A majority of the GWR papers use flexible (or adaptive) bandwidth to derive the spatial weights to be used in the regression models. An adaptive bandwidth allows the band (or buffer) around a sampling station to vary according to the number of nearby sampling stations. The bandwidth is small for clustered data and large for scattered data, based on the distance between sampling stations. Most of these papers use a software-defined standard bandwidth approach (mostly adaptive bandwidth) available in ArcGIS. We did not find any studies that use GWR by including the effect of only upstream stations. However, Tu (2013) used sampling stations only from mutually exclusive watersheds, thereby avoiding any complexity that would be caused by upstream stations in the model. While this approach avoids the issue of upstream influence on downstream water quality, the sample size will be lowered as many spatially dependent stations are discarded for analysis. Additionally, most studies did not address the potential issues of a small sample size when GWR models were used for water-quality studies. This can be a new research direction where researchers define the band only towards the upstream stations and weight those values to derive the local models, which, hypothetically, would better explain the local patterns. Our hypothesis is based on the general understanding of the river flow where most of the physical and chemical components flow downstream.
The research papers using MEM and AEM approaches also use a standard weights matrix based on the Borcard and Legendre (2002) method. As scale can be an issue in these kinds of weights matrices, some researchers construct eigenvectors at different scales. For instance, De Oliveira Marcionilio et al. (2016) calculated their weights matrix using eight different distance classes (50–450 m, with an interval of 50 m) to incorporate the effect of scale on their analysis. The SSN modeling approach was initially proposed to incorporate weights based on the stream distance, flow volume, or stream order. When flow volumes are not available, the catchment area is commonly used as a weight attribute (Ver Hoef and Peterson, 2010), but other attributes such as slope, Shreve’s stream order, and Euclidean distance among stations are also used depending upon the nature of the watershed and the availability of data.
We notice from this review that a spatial weights matrix typically does not gain enough attention, in spite of its being the backbone of spatial modeling. Most previous studies rely on a weights matrix readily available in the “standard” tools offered in software packages, rather than putting additional effort into generating a revised weights matrix that considers water flow along the hydrologic network. Therefore, researchers ought to be mindful of the spatial relations of water quality in the sampling space, and design the weights matrix to best capture such spatial relations. We also need to be aware of the spatial relations of water-quality sampling sites to source, mobilization process, delivery mechanism, and in-stream movement, and use appropriate weighting schemes to capture those processes.
4 Use of multi-scale processes
The predictor variables for regression analysis are generally derived using a watershed because all of the water flowing in the river comes from some part of the watershed, and watershed characteristics are reflected in river water quality (Allan, 2004). Researchers have worked to identify the scale at which water quality is best correlated with watershed characteristics (Figure 5). Although a majority of researchers used spatial lag/error, GWR, or MEM to extract predictor variables at different scales, they did not compare the effect of different scales in model prediction (Table 2). They rarely used different scaled data under the same regression model. The papers using SSN models, however, recognized the effects of variables at different scales and incorporated those in the models.
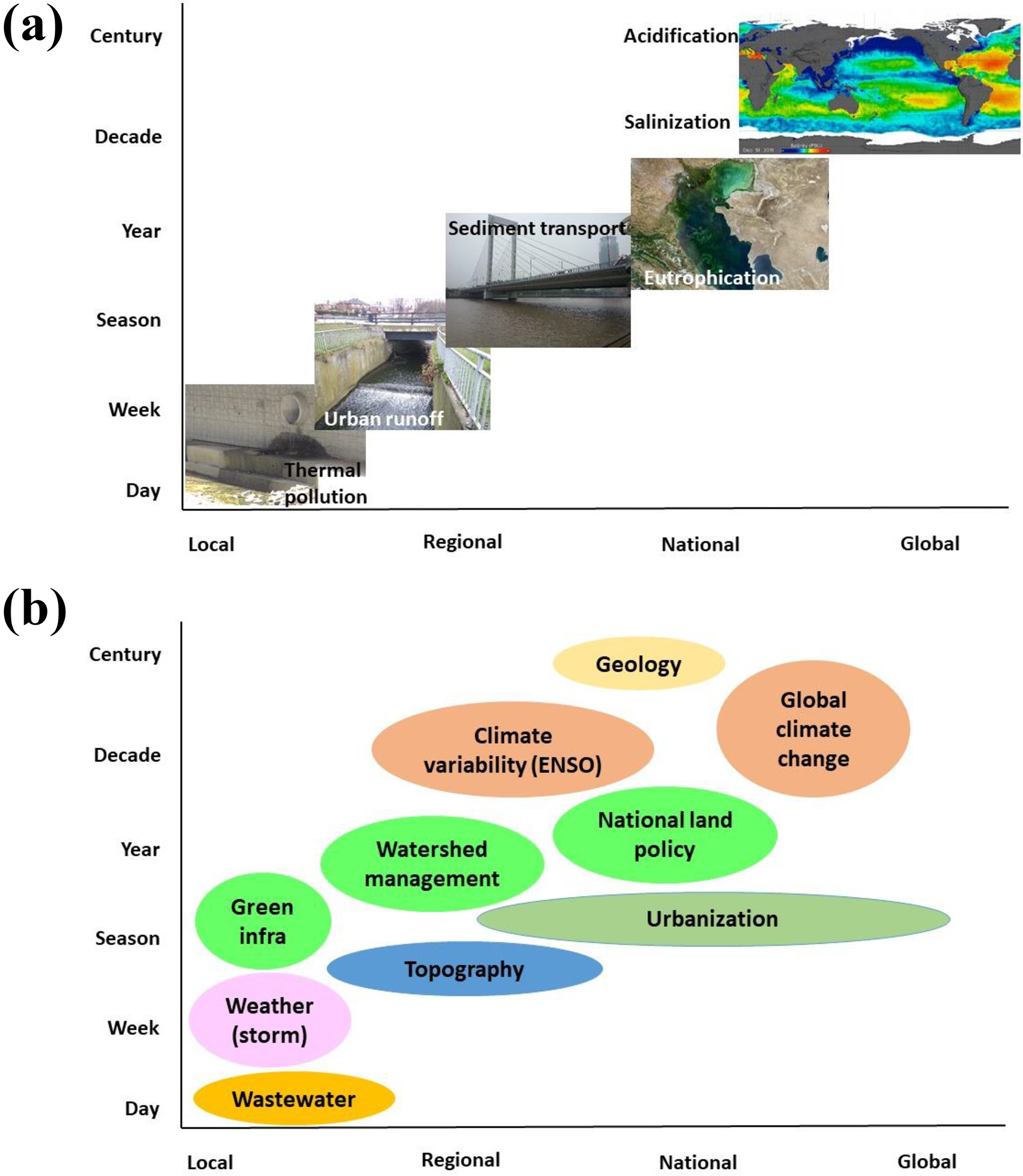
(a) Scale-dependent water-quality processes; (b) factors affecting water quality at different space and time scales.
Consideration of weights matrix, spatial autocorrelation, and residual spatial autocorrelation.
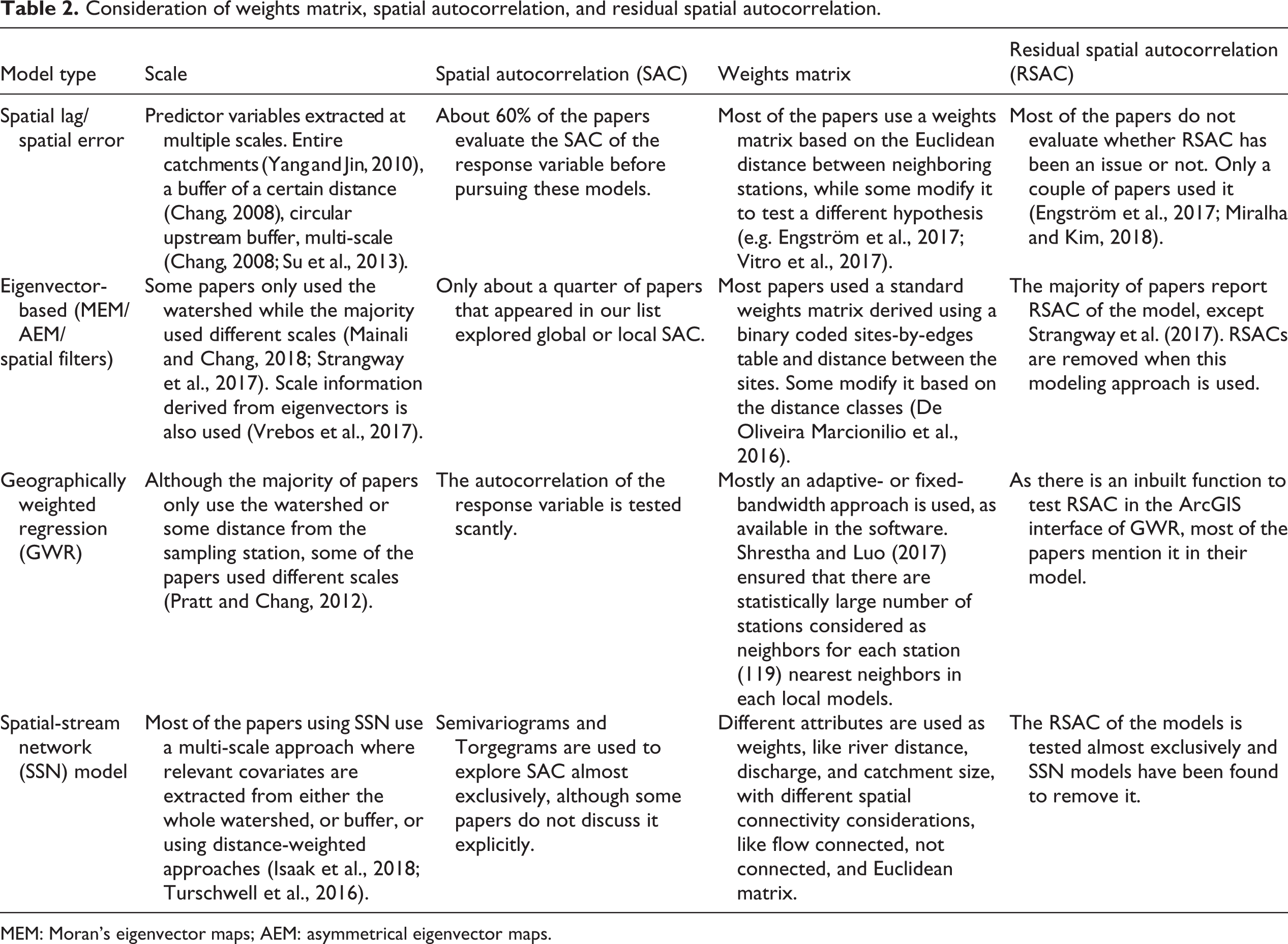
MEM: Moran’s eigenvector maps; AEM: asymmetrical eigenvector maps.
Some researchers have used different buffer distances from the river and/or sampling station. For example, vegetation cover within a 10 m buffer is used for temperature modeling by Isaak et al. (2018), while other variables were used at the watershed scale. Turschwell et al. (2016) used a 10 m buffer for riparian vegetation and additionally used inverse-distance-weighted effects of grazing land cover, while other variables were used as the lump attributes at the watershed scale, and reported significantly higher R 2 values when SSN models were used.
Like any other natural processes, the factors affecting water quality operate at different scales. These factors have to be identified based on the understanding of the scale related to the source, mobilization, delivery, and instream processes related to these parameters (Lintern et al., 2018). This also depends on the scale at which disturbances drive water quality (Pond et al. 2017). If an “upland disturbance” is a driving factor of deteriorating water quality, using data derived only at the riparian buffer scale does not work (Pond et al., 2017). Our review also shows that the scale effects in water-quality modeling using landscape characteristics are not universal, as they vary by parameters studied, location, seasons, and covariates used (Liu et al., 2017; Mainali and Chang, 2018).
Isaak et al. (2018) argue that the covariates used in modeling approaches should come from a review of the literature and an understanding of a plausible mechanism that could cause a variation in a particular water-quality parameter. If the scale is not clear for the parameter, it is always safe to start with the watershed scale and incorporate other scales (e.g. Mainali and Chang, 2018). In large-scale analysis, the availability of particular datasets also determines the scale at which covariates are extracted. Our review shows that the researchers should be able to provide explanations for the reasons behind choosing a particular covariate, its scale, and the need for any weights treatment in the spatial statistical modeling of water quality.
Water flowing from various parts of a watershed drains into surface water bodies via multiple pathways. Water quality along the stream network, therefore, depends on the sources of the parameter, their delivery, and instream processes occurring in the vicinity of an area where water flows (Lintern et al., 2018). To best capture such spatial variations, researchers need to collect data or install the monitoring network carefully. The spatial and temporal scale of data collection and monitoring should be informed by the available geographical information of the watershed related to land use, human impact, geology, and hydrological characteristics of the stream. While increasing the spatial and temporal scale of analyses could help improve our understanding of the relationship between water quality and landscape variables, such effort requires time and resources (both human and computation resources). To make optimum use of time and resources, a selection of the data collection sites and appropriate scale should incorporate all the relevant characteristics of the range of watershed conditions (Jackson et al., 2015).
While it is beyond the scope of this paper to list all of the different scales at which predictor variables are extracted, here we list different statistical methods to effectively include different scale processes in water-quality modeling identified in the papers we reviewed. Multi-scale datasets can be treated with principal component analysis to reduce the dimension of the data and include the variability of different scale processes (Miralha and Kim, 2018). Redundancy analysis can identify which variables at what scale can explain variation in water quality, and use them as a predictor in the spatial regression (Strangway et al., 2017). To avoid overfitting the data that identify the best subset of the covariates, a “Best Subset Regression” can be used (Scown et al., 2017). The Best Subset Regression uses Akaike information criteria (AIC) variation to identify a maximum number of covariates set by the analyst. A review of the potential factors affecting water quality is of the utmost importance before undertaking any water-quality modeling efforts. From our review, we notice that there might be dozens of such candidate covariates. An appropriate variable reduction or selection method should be used in order to include a manageable number of water-quality parameters representing different scales.
5 Comparison of model performance
As expected, the spatial regression models typically explain the variation of the dependent variable better than their aspatial counterparts (Table 3). Studies using spatial lag and error models generally reported improved model performances from an aspatial linear regression model. An increase in R 2 and a decrease in AIC indicate the improved model performance of these models over an aspatial one (Chang, 2008; Engström et al., 2017; Huang et al., 2014; Yang and Jin, 2010). While using an eigenvector-based spatial filtering approach, Mainali and Chang (2018) reported that the model strengths (R 2) significantly increase when an aspatial model suffered from RSAC. However, most of the eigenvector-based spatial statistical models we reviewed did not make an explicit comparison between aspatial and spatial models, as they used landscape characteristics and eigenvectors in the same model and used redundancy analysis to parse out the effect of “environmental” and “spatial” predictors (Souza-Bastos et al., 2017; Vrebos et al., 2017). GWR-based models consistently showed higher model strengths than linear regression. Chu et al. (2018) reported that GWR performed better than linear regression, which was superseded by geographically and temporally weighted regression. Similarly, Tu (2013) reported that the model performance increased by up to 10-fold when GWR was used against linear regression models. Tu and Xia (2008) also found some “dramatic” increases in R 2 when GWR models were used. Most other papers using GWR for water-quality modeling also reported a significant increase in model performance (Kim et al., 2018; Pratt and Chang, 2012; Shrestha and Luo, 2017; Sun et al., 2014; Yu et al., 2013). The SSN-based models have shown to produce high R 2 values in modeling water-quality parameters. An R 2 value of higher than 0.9 was reported for modeling summer temperature using SSN (Isaak et al., 2018). Turschwell et al. (2016) found SSN performing strongest among different models used. However, in some cases, SSN-based models did not significantly improve model performance (e.g. Frieden et al., 2014). These varying results appear to be associated with the choice of water-quality parameters, landscape variables, the scale of analysis, sample size, and watershed conditions.
Improvement of model performance using spatial statistical models.
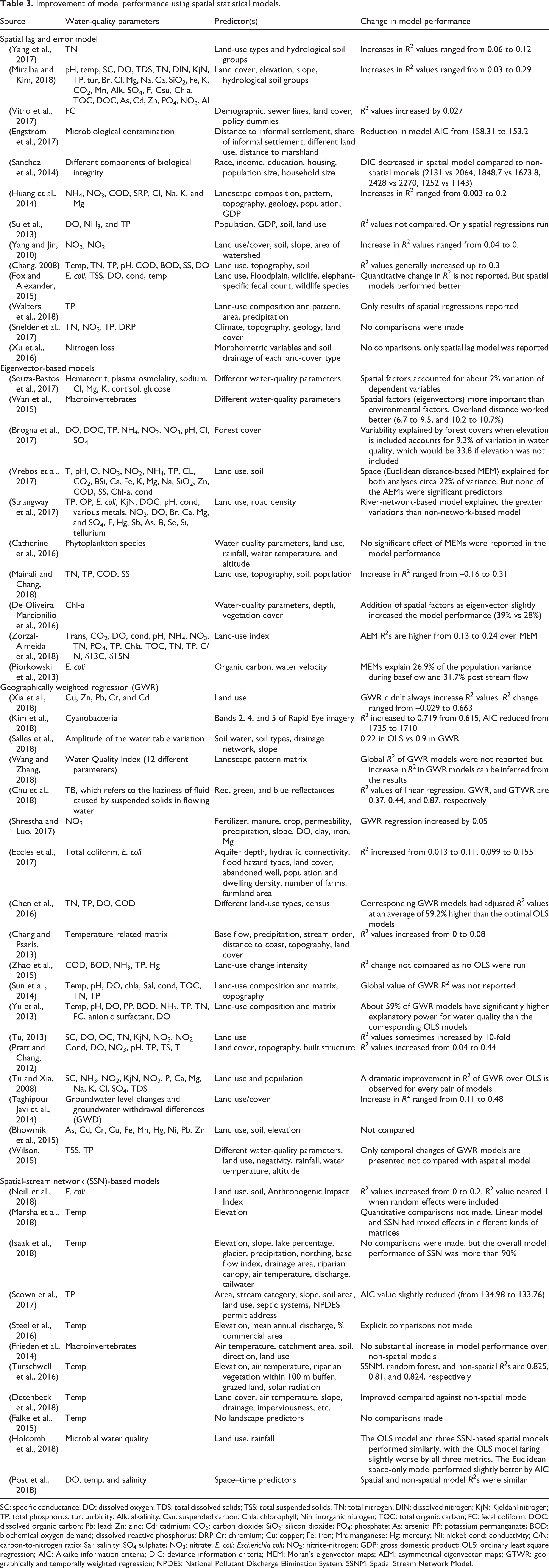
SC: specific conductance; DO: dissolved oxygen; TDS: total dissolved solids; TSS: total suspended solids; TN: total nitrogen; DIN: dissolved nitrogen; KjN: Kjeldahl nitrogen; TP: total phosphorus; tur: turbidity; Alk: alkalinity; Csu: suspended carbon; Chla: chlorophyll; Nin: inorganic nitrogen; TOC: total organic carbon; FC: fecal coliform; DOC: dissolved organic carbon; Pb: lead; Zn: zinc; Cd: cadmium; CO2: carbon dioxide; SiO2: silicon dioxide; PO4: phosphate; As: arsenic; PP: potassium permanganate; BOD: biochemical oxygen demand; dissolved reactive phosphorus; DRP Cr: chromium; Cu: copper; Fe: iron; Mn: manganese; Hg: mercury; Ni: nickel; cond: conductivity; C/N: carbon-to-nitrogen ratio; Sal: salinity; SO4 sulphate; NO3: nitrate; E. coli: Escherichia coli; NO2: nitrite-nitrogen; GDP: gross domestic product; OLS: ordinary least square regression; AIC: Akaike information criteria; DIC: deviance information criteria; MEM: Moran’s eigenvector maps; AEM: asymmetrical eigenvector maps; GTWR: geographically and temporally weighted regression; NPDES: National Pollutant Discharge Elimination System; SSNM: Spatial Stream Network Model.
V Conclusions
Spatial modeling of water quality is gaining increased attention, and researchers have been using novel and creative ways to incorporate spatial aspects into surface-water-quality modeling. Our review identifies a few aspects of these methods of modeling that stood out: Research in this field is dominated by resource-rich countries like the US and China. This may be associated with the availability of data over a large geographical area. There is still insufficient emphasis on spatial autocorrelation and RSAC, which deserve more attention as these techniques can help understand unidirectional, multidirectional, and river-network-based spatial attributes of the dependent variable and overall models of surface water quality. A suggestion based on this review would be to check for RSAC before performing spatial regression models if the researchers are concerned with the regression model not being able to account for the spatial autocorrelation. Weights matrices have great potential in informing spatial autocorrelation of dependent variables at different scales, and in helping test several hypotheses of spatial eco-socio-hydrological processes in relation to surface water. Thus, testing the model’s sensitivity to different weights matrices needs further investigation. However, no study considered in our review has tested the sensitivity of a model against the changes in weight metrics. Our reviews show that the modification of a weights matrix should be informed by spatial organization of water-quality data points, understanding of the source, mobilization, and delivery of a particular water-quality parameter, the hypothesis being tested, and the scale of analysis. In most regression models except SSNs, predictor variables extracted from different scales are used differently to compare the model strength. A fusion of predictor variables extracted from different scales, such as in a multi-scale model, might be better suited to predict water quality, as different processes occur at several different scales simultaneously. A thorough review of source, mobilization, delivery, and instream flow mechanism of the water-quality parameters under consideration might be necessary in order to include suitable predictor variables, multi-scale processes, and identify appropriate weights matrix in the model. This should be accompanied by proper variable reduction statistics, like brute-force reduction, in order to include manageable and meaningful predictors. Although most of the spatial models recognize and incorporate the directional aspects of water flow, we did not find any papers using GWR. Researchers can attempt to modify GWR to incorporate directional process and river-network structures. Researchers should also explore different spatial representations of the landscape matrix (e.g. composition, patterns, distance weighting, and hydrological weighting) in order to identify an appropriate approach to using them in the spatial modeling of water quality.
See Appendix 1 for a list of the software available for implementing the spatial statistical approaches reviewed in this paper.
Footnotes
Acknowledgements
We appreciate Dr. Anna Linton, who provided constructive comments on an earlier version of the manuscript. Barbara Brower and Alexander Ross at Portland State University helped improve the language of the manuscript. Views expressed are our own and do not necessarily reflect those of the sponsoring agency.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This material is based upon work supported by the US National Science Foundation NSF-GSS Grant #1560907.
Appendix 1
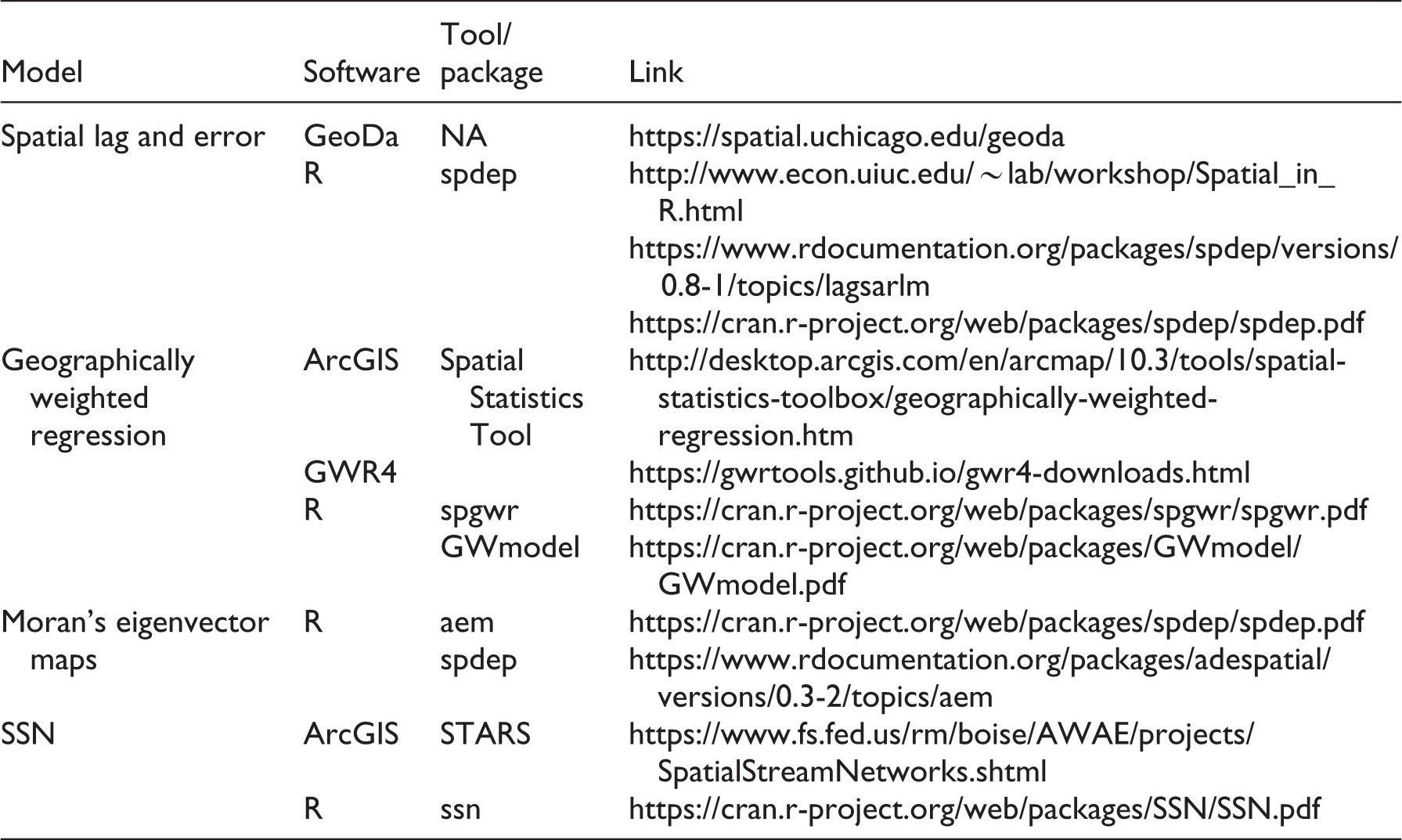
| Model | Software | Tool/package | Link |
|---|---|---|---|
| Spatial lag and error | GeoDa | NA | https://spatial.uchicago.edu/geoda |
| R | spdep |
http://www.econ.uiuc.edu/∼lab/workshop/Spatial_in_R.html
https://www.rdocumentation.org/packages/spdep/versions/0.8-1/topics/lagsarlm https://cran.r-project.org/web/packages/spdep/spdep.pdf |
|
| Geographically weighted regression | ArcGIS | Spatial Statistics Tool | http://desktop.arcgis.com/en/arcmap/10.3/tools/spatial-statistics-toolbox/geographically-weighted-regression.htm |
| GWR4 | https://gwrtools.github.io/gwr4-downloads.html | ||
| R | spgwr | https://cran.r-project.org/web/packages/spgwr/spgwr.pdf | |
| GWmodel | https://cran.r-project.org/web/packages/GWmodel/GWmodel.pdf | ||
| Moran’s eigenvector maps | R | aem | https://cran.r-project.org/web/packages/spdep/spdep.pdf |
| spdep |
https://www.rdocumentation.org/packages/adespatial/versions/0.3-2/topics/aem | ||
| SSN | ArcGIS | STARS | https://www.fs.fed.us/rm/boise/AWAE/projects/SpatialStreamNetworks.shtml |
| R | ssn | https://cran.r-project.org/web/packages/SSN/SSN.pdf |