
Abstract
This article presents a comparative study of adaptive filter–based power curve models to estimate wind turbine power output. In the real world, wind turbines are never subjected to ideal conditions; thus, adaptive filter–based power curves serve best when estimating the power in a time-varying environment. Adaptive filter–based power curve is implemented using various algorithms like least mean square, kernel least mean square, recursive least square, and kernel recursive least square algorithms. All models have been developed on National Renewable Energy Laboratory datasets. The performance of various models has been compared on the basis of parameters like mean absolute error, root mean square error, and R-squared score. In addition to this, the learning curves of each method have been obtained to show the performance variation over time.
Keywords
Introduction
To optimize the operational cost and improve the reliability of the wind energy power system, a reliable and accurate model for performance measurement of a wind turbine is required. In the wind energy industry, it is usually convenient to express the performance by power curve from which actual performance can be determined regardless of how the turbine is operated (Carrillo et al., 2013; Lydia et al., 2014). The power curve of the wind turbine establishes the relationship between wind speed and wind power. An ideal power curve is shown in the left panel of Figure 1. Ideal power curve gives a typical power extraction, but it cannot be valid for every model.
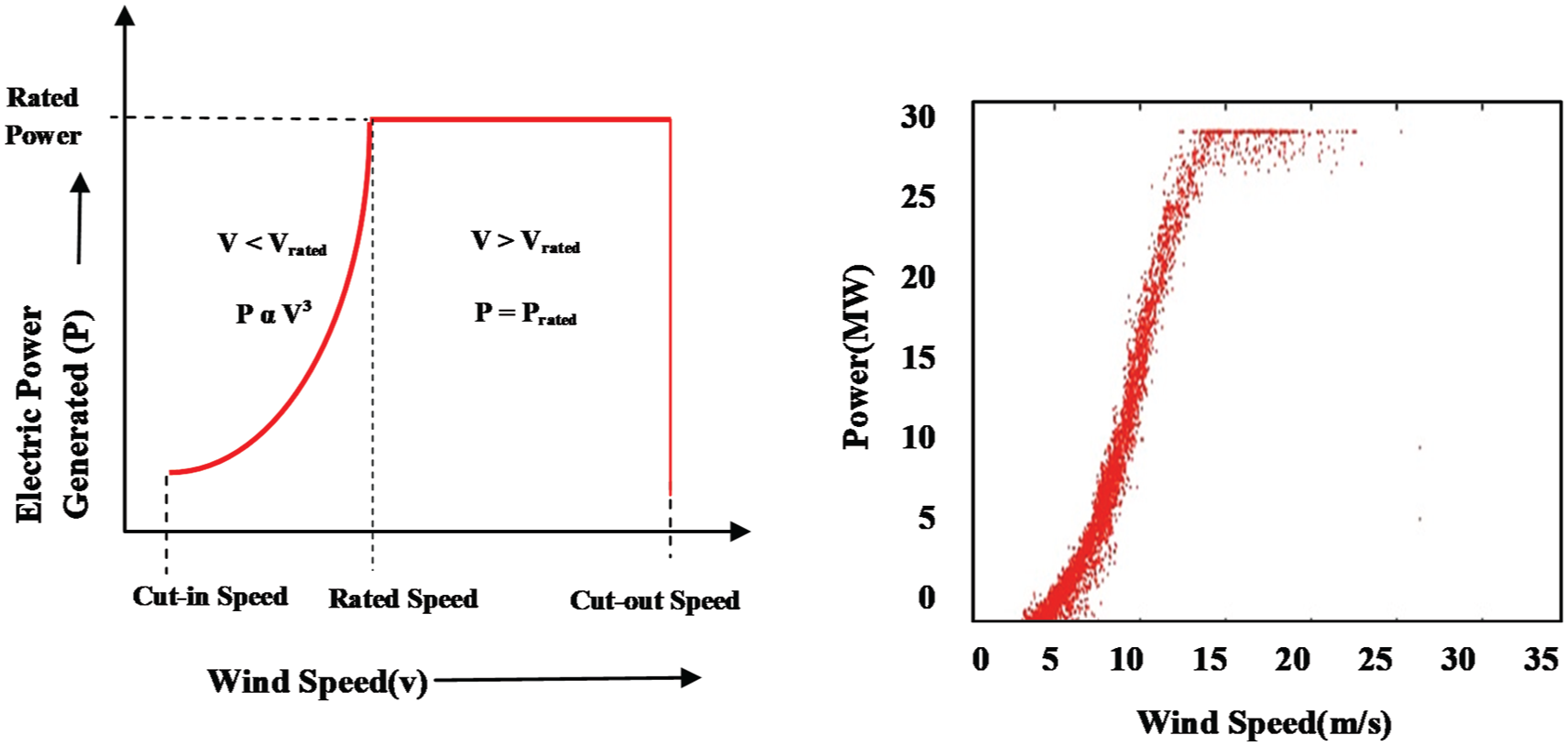
Left panel shows the ideal power curve and the right panel shows actual power production data plotted using NREL dataset.
Thapar et al. (2011) stated that commercially available wind turbines have their own design and rating that be a cause of the differences in the shape of their power curves. The actual power curve of the machine is supplied by the manufacturer, which characterizes the response of the machine, that is, the output that a wind turbine will produce at any given location, at particular wind speed. The actual power curve of the machine only considers the turbine design and rating; therefore, when installing at different customer sites, the actual power output of the turbine presents a more complicated picture. In the right panel of Figure 1, scatter plot has been used to show how much wind power is affected by wind speed. The data points provided in the resource file of National Renewable Energy Laboratory’s (NREL; 2012) HOMER software have been used for plotting. In this plotting, the hourly observations of the year 2012 are used. Previously, a number of studies were undertaken to develop the quality power curve to estimate the power production of wind turbine and some of them are reported in Kusiak et al. (2008), Li et al. (2001), Wadhvani et al. (2017), and Wan et al. (2014). Research started with various statistical models in which the power curve is obtained by using various parametric regression methods. Parametric regression method aims to estimate the target function of independent variables called the “regression function” which helps to characterize the variations of the dependent variable. In this method, for a known functional relationship between the dependent and independent variables, the parameters of the function are estimated, which best fits the observational data. Lydia et al. (2013), Shokrzadeh et al. (2014), and Wadhvani and Shukla (2018) have introduced various parametric regression techniques for power curve modeling, such as linearized segmented regression, four-parameter and five-parameter logistic regression, polynomial regression, spline regression, natural cubic spline regression, and locally weighted spline regression. Anyone of these can be used for curve fitting depending on the pattern of the data available for prediction. However, these models were restricted by their nature and did not solve the problem of nonlinearity in the datasets. To overcome these limitations and to enhance the accuracy and quality of the power curve, other popular data-driven methods include support vector machines (Zhu et al., 2013), neural networks (Morshedizadeh et al., 2017b), and fuzzy logics (Üstüntaş and Şahin, 2008). In their research, Morshedizadeh et al. (2017a) have preferred the combination of fuzzy logic and neural networks to model the power curve as they are able to precisely model a wide range of possible shapes of curves. Although the reported approaches improved the quality of the power curve, one of the limitations with these models is that they do not consider the dynamic behavior of the power curve. In view of the above limitation, researchers have observed that the properties of the power curve (i.e. shape and curvature) vary over time. Even in the small time domain, any change in weather conditions is immediately reflected in the properties of the curve. Recently, Lee et al. (2015) and Long et al. (2015) have proposed power curve modeling approaches to monitor the wind power generation performance by analyzing the variations of wind power curves over the time. In their research, multivariate approaches have been used to monitor multiple parameters simultaneously.
After several studies, it has been observed that the wind turbine may produce a different amount of power even if the wind speed is the same. The reason for the nonlinear relationship between wind speed and output power is the highly volatile and uncertain nature of wind. At different points of time, in dissimilar climate conditions, the status of the variables under study (i.e. wind speed and wind power) may change. For any change, if across new observations, the variance of the error term is not constant, then heteroscedasticity arise in time series data. In prediction, this type of predicament where heteroscedasticity occurs in observational data makes prediction a difficult task. For all these reasons, in power curve modeling, time-domain analysis of observational data is required, which is able to predict the power with varying residual error. Use of adaptive filters in prediction can be a solution to the problem. Earlier applications of adaptive filters were limited to signal processing, channel equalization and identification, adaptive feedback cancelation, signal control, prediction, and so on. Prapulla et al. (2008) have proposed the least mean square (LMS) adaptation technique for equalization of
Adaptive filter–based power curve modeling
An adaptive filter is a data-processing device that enables to find the time-varying input–output relationship in an iterative manner. As in Arora and Wadhvani (2017) and Clarkson (1993), an adaptive filter can be understood and defined via four basic features: the input signal to the filter, the filter structure, the structure parameters, and the adaptive algorithm. The filter structure of an adaptive filter defines the filter input–output relationship. Each adaptive filter consists of different sets of structure parameters which change themselves with every iteration in order to re-calibrate the filters’ input–output relationship. When a specific filtering structure is selected, the number and type of parameters associated with it can be modified as per requirement. Finally, the adaptive algorithm describes how the parameters will adjust or update themselves over time. The adaptive algorithm is also used as a form of an optimizer that minimizes the error for a particular dataset. Proper selection of structure parameters and adaptation algorithms is an utmost important task while implementing an adaptive filter. Typically, the parameters of the filter structure are updated through a process of sequential learning where data are available with time, usually one at a time. One of the problems with sequential learning is that it is more computationally intensive as it uses every training data for the adaption process. An alternative to this can be active learning, which uses a subset of informative training data for the adaption process. Consequently, active learning can significantly reduce the computational complexity with equivalent performance.
In order to capture the relationship between input and output variables, adaptive filters can be categorized into two ways: linear adaptive filters and nonlinear adaptive filters. Linear adaptive filter builds a linear relationship between input and output signal while the nonlinear adaptive filter builds the same relationship by projecting the input data to higher dimensional feature space and then estimating the filter parameters. The linear adaptive filter is shown in the left panel of Figure 2, where linear sequential learning updates the structure parameters in response to change in statistical variations in the filter structure in which the filter operates. The linear filter comprises a set of adjustable parameters denoted by
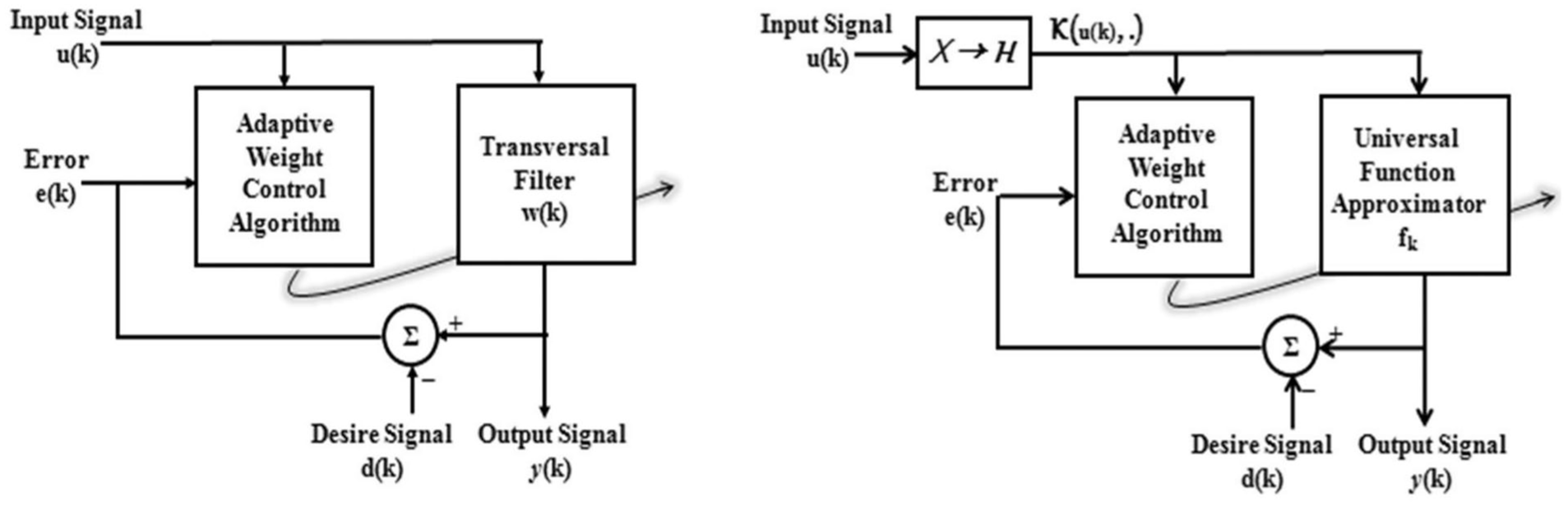
The left panel shows the linear adaptive filter and the right panel shows the nonlinear adaptive filter.
In the right panel of Figure 2, the elementary structure of the nonlinear adaptive filter is shown. Here, u(k) is input, d(k) is desired output, y(k) is actual output, and

with

with the constraint that

where
List of kernel functions applied in experiments.

In view of the fact that high-dimensional feature space is linear, KAFs can be thought of as a generalization of linear adaptive filters. Two popular algorithms, namely, LMS and RLS, have been used to update the structure coefficients of linear adaptive filters. The kernelized variants of LMS and RLS algorithms for weight updation of structure coefficients of nonlinear adaptive filters are KLMS and KRLS, respectively. They use kernel trick for mapping input data into a high-dimensional feature space, which is summarized in Liu et al. (2010).
LMS algorithm
The LMS algorithm is a class of linear adaptive algorithms.This algorithm updates the filter structure coefficients after evaluating the minimum mean square of the error signal. In general, the LMS algorithm performs two basic processes: the filtering process and the adaptive process. Role of the filtering process is to compute the output signal of the filter in accordance with input signals. Once the output signal is generated, it is then compared with the desired response to estimate net error. The aim is to automatically adjust the coefficients of the parameters in accordance with the estimated error. In all iterations of LMS algorithm, instantaneous value of squared estimation error, that is,
Calculates the output signal, that is,
Calculates the error signal,
Updates the filter coefficients by using the equation
where

where

Also, the trace of the correlation matrix can be taken as a good estimate of

The choice of µ is the deciding factor for calculating the convergence speed. When µ is small, then convergence takes slowly, whereas for a larger value of μ, fast convergence of the algorithm is seen. However, the LMS algorithm is easily affected whenever its inputs are calibrated. This causes difficulty in choosing appropriate learning rate µ.
KLMS algorithm
KLMS is nothing but the radial basis function with the different assignment of centers and different training procedure. Each input data point is taken into consideration to obtain the results. This leads to an increase in memory and computational requirements. In Liu et al. (2008), the author has explained learning of KLMS as the LMS performed on the example sequence at time instance k,

where e(k) represents the error which is the difference of actual value, d(k), and the predicted value,

When new training data come in with the input u(k) as the center and the difference between the predicted and the actual output as the coefficient

Kernel adaptive filtering algorithm has the limitation of the linearly growing structure with the input, which leads to an increase in memory and computational requirements. To deal with this problem, Vaerenbergh and Santamaria (2013) have applied different sparcification methods for taking only important input data as new centers. There are two versions of KLMS, namely, naïve online regularized risk minimization algorithm (NORMA) and quantized kernel least mean squares (QKLMS). NORMA is a KLMS algorithm with regularization that adds a penalty term to overcome the problem of over-fitting by reducing the importance given to noisy data. This algorithm uses a sliding-window dictionary mechanism in which it discards the oldest data points after certain iterations. In QKLMS algorithm, the dictionary is constructed by process of quantization to compress the feature space by reducing the number of centers in radial basis function, due to which network size and hardware complexity are reduced. In this method, redundant data are used to update the coefficient of the closest center. QKLMS does not include regularization since it has self-regularization property.
RLS algorithm
RLS is a class of adaptive filter which recursively updates the model coefficients relating to the input data point. The algorithm works best in time-varying or the non-stationary environment; however, it has higher computational complexity and low stability. The objective of the algorithm is the minimization of the sum of squared approximation errors up to the current time k. Along with this, a weighting factor is introduced in the cost function to ensure that less weight is assigned to earlier error samples so that statistical variations in the dataset can be identified more efficiently when the filter operates in the non-stationary conditions (Marshall et al., 1989). In all iterations of RLS algorithm, sum of squared estimation error, that is,

where
Defining the matrix

Finally,
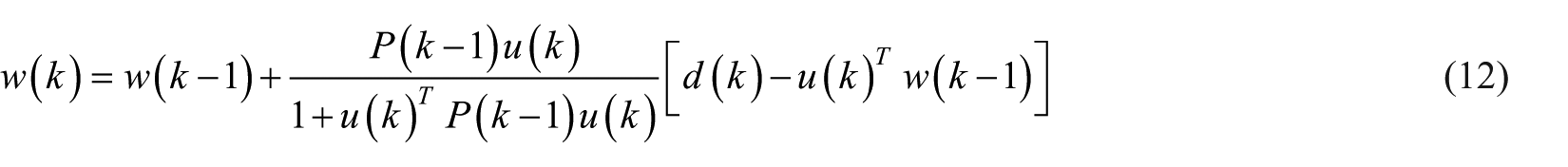
During its execution, this algorithm consumes previous samples of error signals, output signals, and filter weights, hence requiring higher memory configuration. Another prominent feature of the RLS algorithm is that, while realization, this algorithm uniformly distributes its computation load in each iteration. However, one of the limitations with the algorithm is that it is not suitable for online filtering due to time-consuming computations of inverse matrix least squares methods.
KRLS algorithm
KRLS algorithm applies kernel trick to transform the input data u(i) into the feature space Z as φ(u(i)). This can be simply denoted as φ(i). Here, feature space is a high-dimensional space; thus, regularization is required. As in Liu et al. (2010), the weighted cost function for KRLS can be defined as

The normal form for weights can be defined as
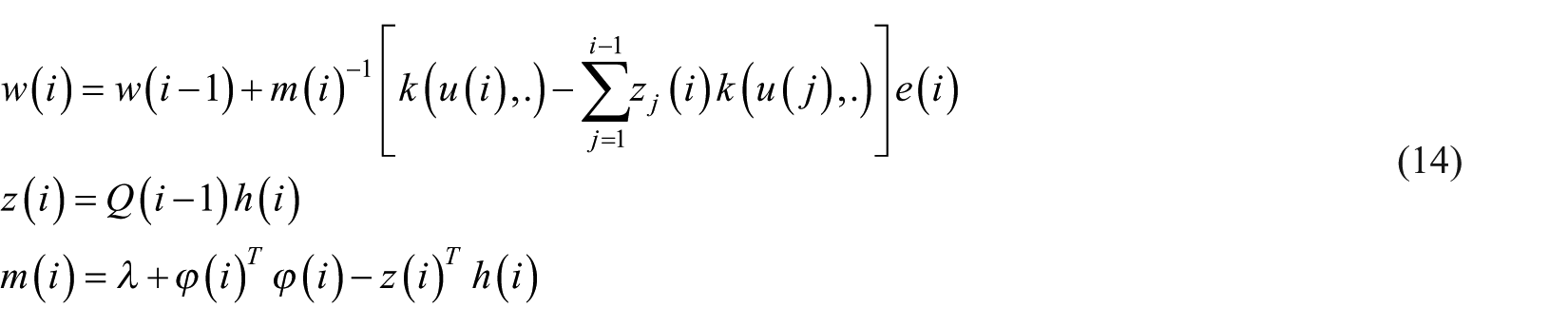
KRLS updates all the previous coefficients while KLMS never updates previous coefficients. The time and space complexity of KRLS is
Real data application
In order to evaluate the performance of all the algorithms discussed in “Adaptive filter–based power curve modeling” section, a case study that includes the real data of the wind farms in North America is presented. For experimental purpose, two datasets are taken from the resource file of NREL, which specializes in renewable energy efficiency, research, and development. Datasets A and B correspond to site-id A 124693 and site-id B126541 (NREL, 2012), respectively. The geographical location of the site-id A is longitude −120.005463 and latitude 46.901657 with an average wind speed of 6.744 m/s. Site-id B has longitude −123.375778 and latitude 48.64072 with an average wind speed of 5.296 m/s. NREL obtained all these observations from SCADA (supervisory control and data acquisition) system’s wind plant. There are more than 1 lakh data observations recorded from January 2012 to December 2012. Usually, data collection methods are loosely controlled, resulting in out of range values (e.g. data points with negative wind power values), inconsistent data combination (e.g. data points with high wind speed and low power values, data points with low wind speed and high power values), missing values, and so on. Empirical power curve fitting to the data that have not been carefully scrutinized for such problems can produce misleading results. Before any modeling is taken up, data should be pre-processed. In order to pre-process raw data, an outlier detection method similar to Warren et al. (2011) has been applied. Here, each input observation that assumed to come with known data distribution is fitted with an elliptic envelope, in which only those power values that stand at most three standard deviations away from the mean of the distribution are allowed. A Mahalanobis distance metric is the well-known formula for measuring such type of distances. Before applying the above strategy to pre-process the datasets, datasets are divided into subparts, as the data observations over the period of one complete year show the nonlinear wind–power relationship and do not follow a normal distribution. The subparts are assumed to be normally distributed, pre-processed one by one and, at last, merged together to form cleaned nonlinear dataset. Figure 3 shows the plot of the wind speed and the output power for dataset over a 1-month period in March 2012 with the fitted decision boundaries using Mahalanobis distance metric. Once both the datasets are cleaned, they can be used to assess the performance of an adaptive filter.

The scatter plot of the wind speed and the output power over a 1-month period in March 2012 with the fitted decision boundaries using Mahalanobis distance metric using dataset A.
The developed model characterizes the pattern of the actual data. To evaluate the ability of the model to generalize is important. Hence, parameters are required that evaluate the model on the basis of goodness of fit. The goodness of fit of the model can be decided by the loss function that judges the difference between estimated and true value. As in Kohavi (1995), mean square error (MSE), root mean square error (RMSE), and mean average error (MAE) have been applied as a loss function for measuring errors between desire output



where

here

The left panel, middle panel, and right panel show the MSE performance comparison of LMS and RLS algorithms, LMS and KLMS algorithms, and RLS and KLS algorithms, respectively, on the basis of their learning curves using dataset A.
While investigating the left panel of Figure 4, it can be observed that compared to LMS, RLS algorithm shows reasonably fast convergence and the error rate decreases along with iterations. The error rate for RLS is comparatively lower than LMS as the number of iteration proceeds. While comparing LMS and KLMS in the middle panel of Figure 4, initially, the LMS algorithm starts with low error rate compared to KLMS, but after some iterations, KLMS experiences a steep decline in error rate and outperforms in convergence criteria. However, KLMS is computationally intensive, as for each training observation, a new kernel element is allocated. Finally, comparing RLS and KRLS plot in the right panel of Figure 4, for initial iterations, KRLS proceeds with large errors while RLS proceeds with low error values. However, similar to the LMS and KLMS plots, there is a steep descent in the KRLS curve while RLS slowly converges to minimum error values. After some point, KRLS attains a constant curve close to 0. This shows the convergence rate of KRLS is much faster than RLS, but the computational complexity of KRLS is much higher than RLS as KRLS takes into account the previous weights and inputs which have been processed so far. However, the forgetting factor determines how much weight should be given to past values.
Datasets A and B are also evaluated on the basis of MAE, RMSE, and R2 score, as shown in Tables 2 and 3, respectively. From Table 2 for dataset A, it clearly shows that KRLS shows the least values for RMSE with highest R2 score and have secured a position of 1 among all adaptive filters discussed above. The highest R2 score of KRLS indicates that KRLS algorithm was able to fit dataset as close as possible to observed values. KLMS acquired a second slot with second highest R2 score and with lowest MAE indicating a closer fit to the actual model. LMS and RLS perform nearly the same as their MAE, RMSE, and R2 scores are close enough, and both have secured a position of 4 and 3, respectively.
MAE, RMSE, and R2 score of various adaptive algorithms for dataset A.
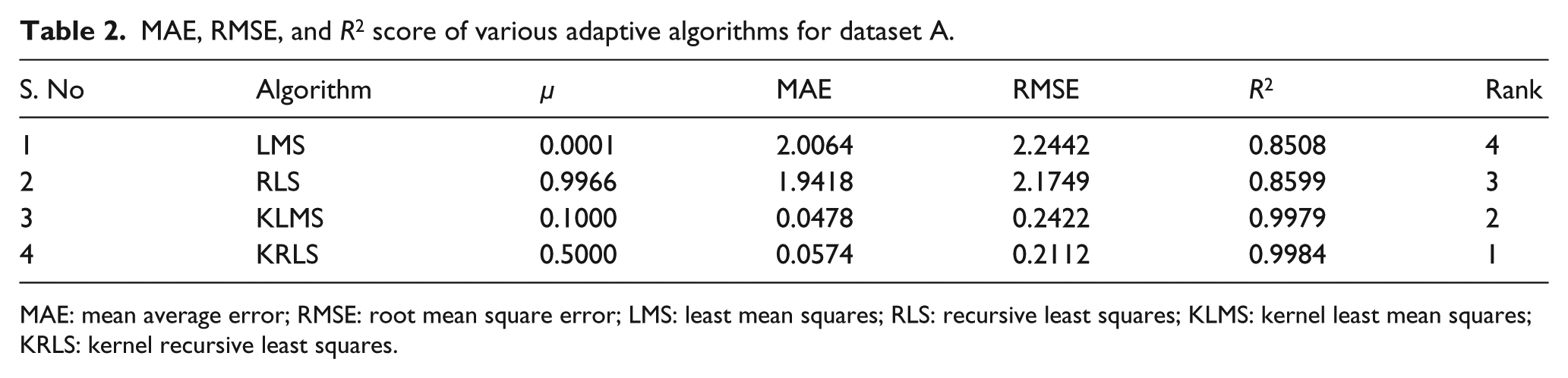
MAE: mean average error; RMSE: root mean square error; LMS: least mean squares; RLS: recursive least squares; KLMS: kernel least mean squares; KRLS: kernel recursive least squares.
From Table 3, it is clearly shown that KRLS shows the least values for MAE and RMSE with highest R2 score and have secured a position of 1 among all adaptive filters discussed above. However, the regularization parameter is further tuned to achieve better results. KLMS again secured a second slot with second highest R2 score. Good R2 score indicates a closer fit to the actual model, and hence, KRLS and KLMS produced excellent results. LMS and RLS again produced a poor fit on the dataset. MAE, RMSE, and R2 score for LMS and RLS were comparatively low with their kernel version, and both have again secured ranks 4 and 3, respectively.
MAE, RMSE, and R2 score of various adaptive algorithms for dataset B.
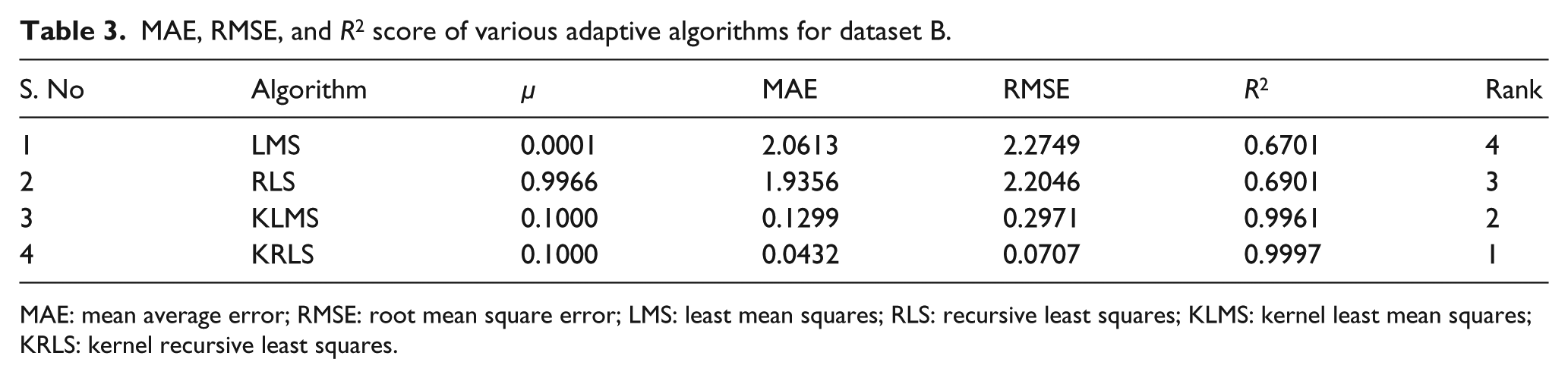
MAE: mean average error; RMSE: root mean square error; LMS: least mean squares; RLS: recursive least squares; KLMS: kernel least mean squares; KRLS: kernel recursive least squares.
Conclusion
Real wind power systems work under variable environmental conditions. To estimate the power production of such systems, this work presents a nonlinear model for power prediction. Two popular kernel-based adaptive learning approaches, that is, KLMS and KRLS, are applied to model the nonlinear power curve. The KLMS family is simple and computationally efficient. In contrast, KRLS family has the ability to adapt nonlinearity to a greater degree and thus provides a reasonably fast rate of convergence. Learning curves obtained for the different algorithms, that is, LMS, RLS, KLMS, and KRLS, have been analyzed on the basis of their MSE performance. Here, KRLS algorithm shows reasonable fast convergence on benchmark datasets. The performance achieved can be further improved by applying advanced sequential modeling approaches like recurrent neural network and their variants. These approaches have very low convergence rate for a specific dataset but perform optimally on the global scale.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.