
Abstract
In this study, 98 regression models were specified for easily estimating shortest distances based on great circle distances along the U.S. interstate highways nationwide and for each of the continental 48 states. This allows transportation professionals to quickly generate distance, or even distance matrix, without expending significant efforts on complicated shortest path calculations. For simple usage by all professionals, all models are present in the simple linear regression form. Only one explanatory variable, the great circle distance, is considered to calculate the route distance. For each geographic scope (i.e., the national or one of the states), two different models were considered, with and without the intercept. Based on the adjusted R-squared, it was observed that models without intercepts generally have better fitness. All these models generally have good fitness with the linear regression relationship between the great circle distance and route distance. At the state level, significant variations in the slope coefficients between the state-level models were also observed. Furthermore, a preliminary analysis of the effect of highway density on this variation was conducted.
Calculating route distances along transportation networks is a classical and well-established procedure in transportation fields. Route distances are usually estimated using classic shortest paths algorithms including, but not limited to, Dijkstra’s algorithm, the Bellman–Ford algorithm, the Floyd–Warshall algorithm, and so on. Open-source codes of these algorithms are publicly available, and they are also usually included in commercial software (e.g., ArcGIS pro). Accessing these tools is typically not an issue for well-trained transportation engineers who are experienced in network modeling and analysis. However, this still requires noticeable efforts. In addition to the ability to use the right tool or algorithm, transportation engineers are usually required to establish the transportation network represented either in graph or GIS shapefiles for different network scopes. Corrections and adjustments are also inevitable if high-quality transportation network data are not available. In addition, route distance calculation could cause computational challenges if both the network size and the number of origin–destination (O-D) pairs required for route distance calculations are large. These challenges create obstacles for many transportation projects, especially project teams that have limited access to or do not have sufficient training to use these tools and/or if calculating exact route distances is not the primary focus.
An alternative method is to use statistical regression models to estimate the route distance using the great circle distance between any two O-D pairs with their geographic coordinates. An example of a previous application is the usage of the simple linear regression model based on the intra-city New York City (NYC) data to evaluate the feasibility of battery electric vehicles in taxi fleets in the city of New York ( 1 , 2 ). The NYC model is shown in Equation 1 (distances are measured in miles), and its slope coefficient (also known as circuity) is 1.4413, close to the square root of 2, which reflects the taxicab geometry pattern of the roadway networks in NYC ( 1 , 3 ). With a sample of 51 Metropolitan Statistical Areas (MSAs), another study evaluated the historical trends in the changing slope coefficient with recent street network expansion ( 4 ). In addition to passenger vehicle route distance estimation, there is also a prior application for freight shipment, and a slope of 1.22 was suggested to estimate freight route distances using the great circle distances ( 5 ). All of these prior regression models are mode-, scope-, and geography specific, and therefore cannot be simply generalized to other scopes.

There is no database available in the literature for this type of regression model for estimation of the inter-city passenger vehicle trip distance. Therefore, in this study, the aim is to develop a database that contains regression models to estimate the route distance for passenger vehicles along U.S. interstate highways at both national and individual state geographic scopes. For simplicity, by using models for a general audience, similar to the model reported by Zhan et al., the reported regression models are in the form of simple linear regression models using only the great circle distance as the explanatory variable to estimate the route distance ( 1 ).
Data and Methods
To generate the empirical regression models to estimate the route distance at both U.S. national and state-level scopes, the U.S. mainland interstate highway network was used in the analysis, as shown in Figure 1. The interstate highway network was preprocessed into a network graph in our previously reported study ( 6 ). Along the graph, the interstate highway network is represented using the undirected graph G(N, A), in which N represents nodes and A represents undirected arcs symmetrically connecting these nodes. To represent the U.S. mainland interstate highway network, 4,300 nodes are present in the graph, connected with 10,666 undirected arcs. The median arc length is 10.23 mi and the maximum length is 29.6 mi.
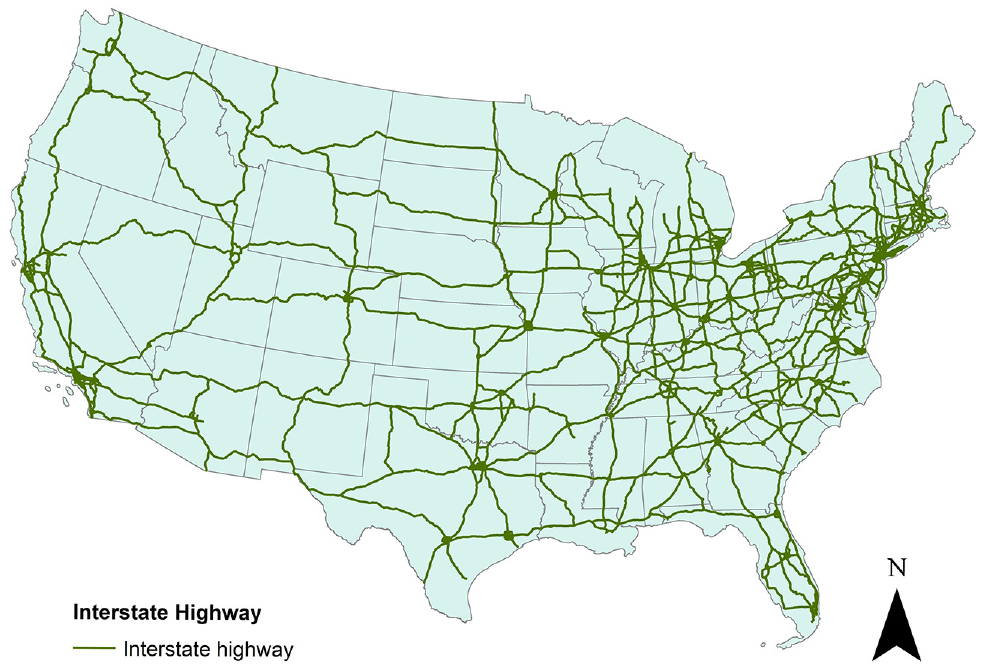
U.S. mainland interstate highway network.
The empirical statistical models on the route distance are fitted by random sampling of O-D pairs between 4,300 nodes. The great circle distance is estimated based on coordinates of both the origin and destination nodes for each O-D pair. The coordinates are determined based on this geographic location using the ArcGIS software. The route distance between each O-D pair is calculated using Dijkstra’s algorithm along the graph with the open-source C++ code ( 7 ). Simple linear regression is conducted to fit the regression models. The general formula I is shown in Equation 2. In Equation 2, a is the slope coefficient, and b (unit: miles) is the intercept. As an alternative to the general formula in 2, another regression model is also fitted without the intercept, as shown in Equation 3. All distances are measured in miles.


The models were developed for the national scale with 10,000 sampled O-D pairs, and models for all U.S. mainland states with a maximum 500 sampled O-D pairs for each state-level model. All regression analyses are conducted using R.
Results
With 10,000 sampled O-D pairs at the national scale, Equation 4 shows the fitted empirical model, the National Model I, to estimate the route distance along U.S. interstate highways at the U.S. national scope. The model has good fitness over the 10,000 sampled distance data and has an adjusted R-squared value of 0.983. It is noted that the slope coefficient is 1.227 lower than the value of 1.441 obtained for the NYC model ( 1 ). This is because interstate highways have a reduced taxicab geometry pattern compared to the NYC roadways and the actual route distance is closer to the great circle distance.
The National Model I in Equation 4 is limited as it can yield unexpected results, especially when the great circle distance is relatively small. For example, when the great circle distance is close to 0, the route distance should also be close to 0. However, with the intercept, the model yields a route distance of 20.611 mi. To overcome this issue, the regression model was also fitted without the intercept, and the new National Model II is shown in Equation 5. Compared to Equation 4, this new model has a slightly higher slope coefficient, and has a higher adjusted R-square of 0.995. The results indicate that a potential better fitness of the regression model is obtained without the intercept for estimating the route distance.
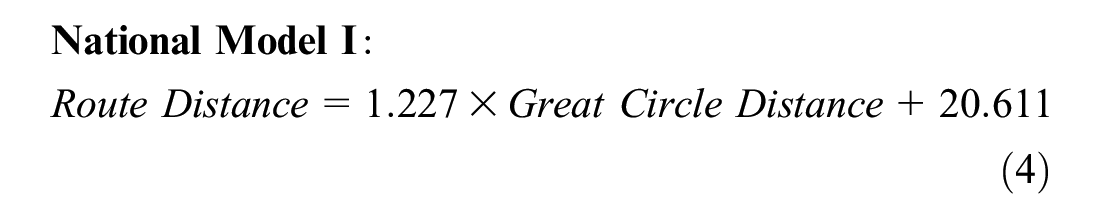
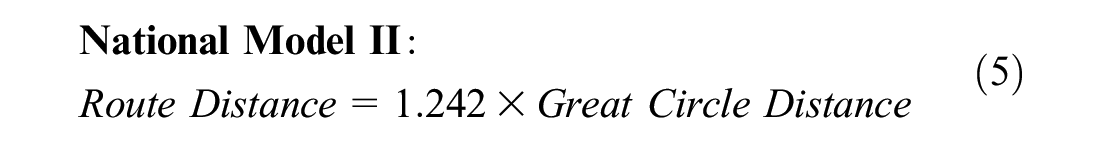
In addition to the national models in Equations 4 and 5 that could be used generally for any O-D pairs along the U.S. mainland interstate highways, we also fitted state-level empirical statistical models, namely State-Level Model I, to estimate O-D route distance within each state. Table 1 shows summaries of the linear regression models with intercepts for all 48 mainland states with key regression statistics of coefficients, t-values, p-values, and adjusted R-squares. All these models generally have good fitness with the linear regression relationship between the great circle distance and route distance, with the lowest R-square at 45.6%. All slope coefficients are significant, with p-values smaller than 0.001 for all states. The intercept coefficients are significant for some states (e.g., p-value: <0.001 for California [CA]), and are not significant for other states (e.g., p-value: 0.174 for Texas [TX]).
Statistics of State-Level Model I (with Intercepts)

Note: AL = Alabama; AZ = Arizona; AR = Arkansas; CA = California; CO = Colorado; CT = Connecticut; DE = Delaware; FL = Florida; GA = Georgia; ID = Idaho; IL = Illinois; IN = Indiana; IA = Iowa; KS = Kansas; KY = Kentucky; LA = Louisiana; ME = Maine; MD = Maryland; MA = Massachusetts; MI = Michigan; MN = Minnesota; MS = Mississippi; MO = Missouri; MT = Montana; NE = Nebraska; NV = Nevada; NH = New Hampshire; NJ = New Jersey; NM = New Mexico; NY = New York; NC = North Carolina; ND = North Dakota; OH = Ohio; OK = Oklahoma; OR = Oregon; PA = Pennsylvania; RI = Rhode Island; SC = South Carolina; SD = South Dakota; TN = Tennessee; TX = Texas; UT = Utah; VT = Vermont; VA = Virginia; WA = Washington; WV = West Virginia; WI = Wisconsin; WY = Wyoming.
Similar to the National Model II, we also fitted state-level models without intercepts, namely State-Level Model II, with key regression statistics as shown in Table 2. Compared to Tables 1, 2 does not contain any statistics of the intercept, which is excluded in the model. All slope coefficients have a significant fitness for all states with p-values < 0.001. For the state-level, Model II has higher adjusted R-squares compared to the Model I for all states. Combined with the national level results, it indicates that the presence of intercepts normally does not improve the fitness of the route distance regression models. However, there is no conclusion as to which model to choose, as the decision is highly dependent on additional considerations by different users.
Statistics of State-Level Model II (without Intercepts)
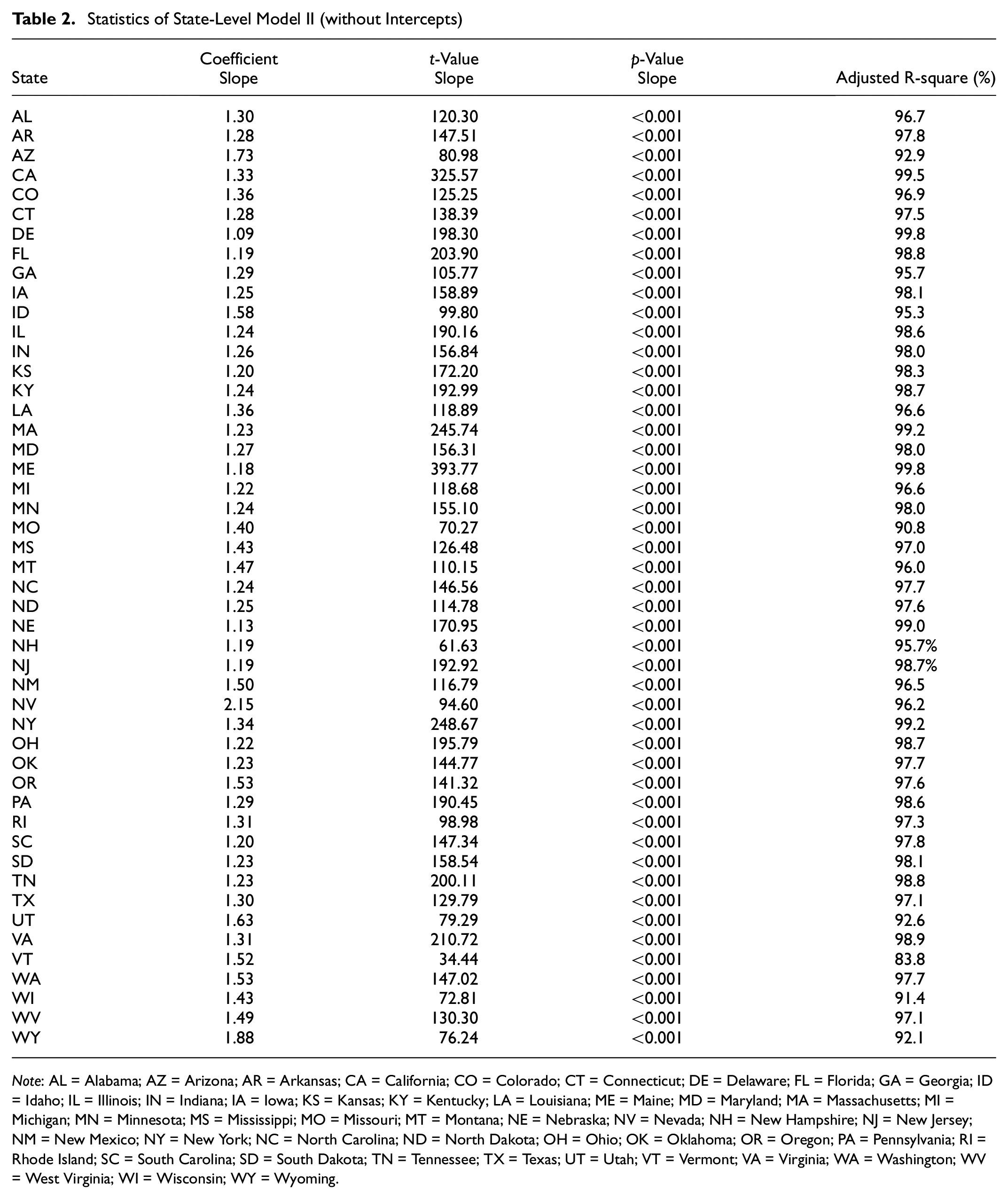
Note: AL = Alabama; AZ = Arizona; AR = Arkansas; CA = California; CO = Colorado; CT = Connecticut; DE = Delaware; FL = Florida; GA = Georgia; ID = Idaho; IL = Illinois; IN = Indiana; IA = Iowa; KS = Kansas; KY = Kentucky; LA = Louisiana; ME = Maine; MD = Maryland; MA = Massachusetts; MI = Michigan; MN = Minnesota; MS = Mississippi; MO = Missouri; MT = Montana; NE = Nebraska; NV = Nevada; NH = New Hampshire; NJ = New Jersey; NM = New Mexico; NY = New York; NC = North Carolina; ND = North Dakota; OH = Ohio; OK = Oklahoma; OR = Oregon; PA = Pennsylvania; RI = Rhode Island; SC = South Carolina; SD = South Dakota; TN = Tennessee; TX = Texas; UT = Utah; VT = Vermont; VA = Virginia; WA = Washington; WV = West Virginia; WI = Wisconsin; WY = Wyoming.
With all slope coefficients being significant, huge variations are observed between states and slopes for both Model I and Model II. For example, for Model I, it could range between 1.08 and 2.49. Figure 2 shows the geographic variations on the slope coefficient with the intercept. It is shown that the slope coefficients are generally higher in the west region of the U.S. compared to the other parts of the country. This indicates the same great circle distance measured between any O-D pair could result in much longer route distance in this region.

Geographic variations of the slope coefficient in the state-level empirical statistical models of route distance estimation.
Many potential factors could contribute to this variation in the slope coefficients at different states, including, but not limited to, highway distribution patterns, highway density, highway curvatures, and so forth. Many of these factors are difficult to measure and aggregate at state levels. An extensive evaluation of these factors’ effects is beyond the scope of this study and will be considered in future work. This paper only evaluates the effect of one factor, the highway density, on the actual slope coefficients. Compared to other factors, the highway density (unit: miles/100-square miles) is relatively easy to measure, and in this study, can be estimated using Equation 6.
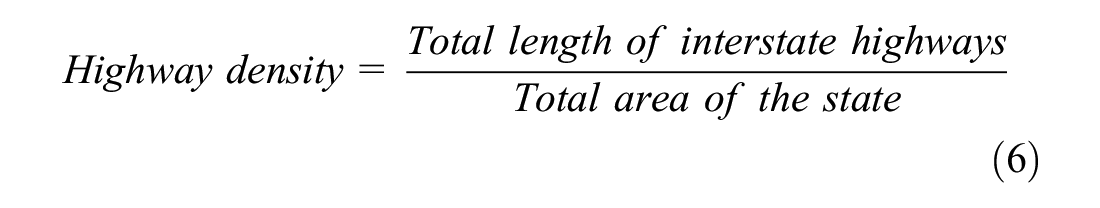
Figure 3 shows scatterplots of the slope coefficients for State-Level Model I (with intercept) and interstate highway densities for all mainland states. It is shown that when the highway density is relatively higher (e.g., >4 mi/100-square miles), the variation of slope coefficients is relatively smaller, and the actual slope remains consistently low at the 1.1–1.4 level. The reason is that higher density results in better highway coverage and the route between most O-D pairs tends to take straight lines. On the other hand, if the highway density is relatively low, significant variation is observed in the slope coefficients between states. In this case, the actual O-D route distance heavily depends on other factors, such as the actual distribution patterns of the interstate highway systems as well as their connectivity. An investigation of the effects of other factors will be considered in future work.

Scatterplots of slope coefficients (with intercept) and interstate highway densities for 48 mainland states.
Conclusion
In this study, a set of empirical regression models was developed to estimate route distances between O-D pairs along interstate highways. Both national-level and state-level models were developed. These models provide an easy-to-use database that allows transportation professionals to quickly estimate route distances for different transportation projects. These models were developed using the simple linear regression model, and only consider one explanatory variable, the great circle distance which is easier to determine based on the coordinates of any origin and destination. For each geographic scope (i.e., national or one of the states), two different models were considered, with and without the intercept. Based on the adjusted R-squared value, it was observed that models without intercepts generally have a better fitness. We also provided preliminary evaluations of the variations in regression coefficients between different state-level models. We found that the highway density is a key factor that contributes to this variation.
For simplicity, this study only considers the interstate highway network, and the empirical statistical models could only estimate route distances along the interstate highways. In reality, other roadway systems (i.e., state, county, and city highways) should also be considered to fully evaluate the route distance between any O-D pair in the U.S. However, this will require additional network preparation in the graph form and larger network systems could result in additional computational efforts. Extending the current scope to all highway systems will be considered in future work.
Footnotes
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: Z. Lin, F. Xie; data collection: N. Liu, F. Xie; analysis and interpretation of results: N. Liu, F. Xie, Z., Lin, M. Jin; draft manuscript preparation: N. Liu, F. Xie, Z., Lin. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the DOE Office of Energy Efficiency and Renewable Energy, Vehicle Technologies Office (Analysis Program). This manuscript has been authored by UT-Battelle, LLC under Contract No. DE-AC05-00OR22725 with the U.S. Department of Energy. The United States Government retains and the publisher, by accepting the article for publication, acknowledges that the United States Government retains a non-exclusive, paid-up, irrevocable, world-wide license to publish or reproduce the published form of this manuscript, or allow others to do so, for United States Government purposes. The Department of Energy will provide public access to these results of federally sponsored research in accordance with the DOE Public Access Plan (![]() ).
).
Data Accessibility Statements
All data generated during this study are included in this published article. All input data analyzed during the current study are available from the corresponding author on reasonable request or from TEEM.ornl.gov.