
Abstract
Random parameter logit models address unobserved preference heterogeneity in discrete choice analysis. The latent class logit model assumes a discrete heterogeneity distribution, by combining a conditional logit model of economic choices with a multinomial logit (MNL) for stochastic assignment to classes. Whereas point estimation of latent class logit models is widely applied in practice, stochastic assignment of individuals to classes needs further analysis. In this paper we analyze the statistical behavior of six competing class assignment strategies, namely: maximum prior MNL probabilities, class drawn from prior MNL probabilities, maximum posterior assignment, drawn posterior assignment, conditional individual-specific estimates, and conditional individual estimates combined with the Krinsky–Robb method to account for uncertainty. Using both a Monte Carlo study and two empirical case studies, we show that assigning individuals to classes based on maximum MNL probabilities behaves better than randomly drawn classes in market share predictions. However, randomly drawn classes have higher accuracy in predicted class shares. Finally, class assignment based on individual-level conditional estimates that account for the sampling distribution of the assignment parameters shows superior behavior for a larger number of choice occasions per individual.
Keywords
Random parameter logit models are the main empirical strategy for addressing unobserved preference heterogeneity in discrete choice analysis ( 1 , 2 ). Heterogeneity (or mixing) distributions are usually taken from parametric families, either continuous or discrete. In the latent class conditional logit (LCL) model, preference parameters are assumed to have a heterogeneity distribution that is discrete ( 3 – 6 ). In fact, LCL choices are governed by a conditional logit model, whereas assignment to classes is determined by a multinomial logit (MNL) specification ( 2 ).
Mixed logit models with parametric and continuous heterogeneity distributions—such as normally distributed parameters—provide preference estimates that can be hard to interpret or have inference problems ( 7 – 11 ). However, the discrete nature of the estimates of latent class logit models makes inference easier in relation to both interpretability and derivation of welfare measures such as willingness-to-pay (WTP) metrics. As a result, use of LCL models has proven a popular choice in empirical work. After seminal work that spread the use of LCL models in choice modeling, recent examples include a vast variety of applications, from preference location by crime offenders to valuation of endangered marine species, and recreational demand in the Alps, just to give three examples of the range of problems for which latent class logit models have been applied beyond more traditional applications (such as travel mode choice, vehicle ownership, and residential choice) ( 5 , 6 , 12–21).
Despite the growing popularity of LCL models, there is a need for better understanding of statistical inference with the model. Whereas Romero-Espinosa et al. studied statistical and asymptotic behavior of interval estimates of conditional LCL preference parameters at the individual level, further analysis is needed to characterize the behavior of empirical strategies for assigning individuals to a specific class ( 22 ). The latent class assignment problems can relate to random draw sampling methods and Bayesian procedures of preference parameter estimation. Using different class assignment strategies may affect the accuracy of predicting latent class shares and chosen alternative shares. In addition to the popular class assignment method using prior probabilities and a maximum-value-draw strategy, there also exist other methods which need to be studied ( 23 – 25 ). In this paper we focus on these issues and analyze the statistical behavior of six competing class assignment strategies that are econometrically valid but have not been fully examined in the literature, namely: maximum prior MNL probabilities, class drawn from prior MNL probabilities, maximum posterior assignment, drawn posterior assignment, conditional individual-specific estimates, and conditional individual estimates combined with the Krinsky–Robb (KR) method ( 26 ). Our contribution lies in the methodical comparison of these class assignment strategies for latent class logit models.
This paper is organized as follows. The next section reviews the latent class logit model and describes the six empirical strategies for assignment to classes mentioned above. The section after that uses a Monte Carlo study to compare the empirical performance across all strategies in different regimes. Our comparison is then supplemented in the penultimate section with two case studies, one focused on response to automated electric vehicles and the other on consumer valuation of emission savings when purchasing a new vehicle. The final section concludes.
The Latent Class Logit Model
Following a general choice setting, we assume that consumer
On the one hand, conditional on class
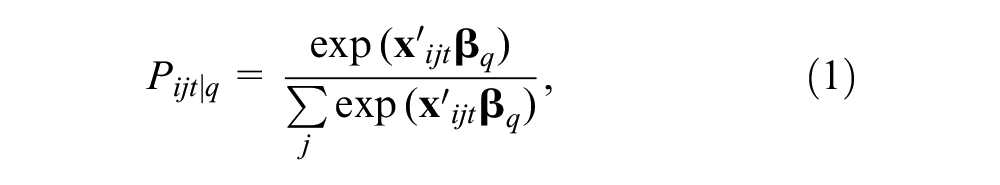
where
On the other hand, and since the underlying class of an individual is not observed, class assignment assumes the following MNL probabilities:
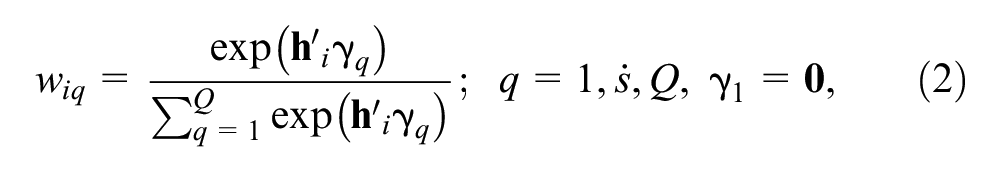
where
Empirical Strategies for Assignment to Classes
Using Bayes’ theorem, posterior MNL probability for assignment to classes can be derived as (see Train) ( 27 ):
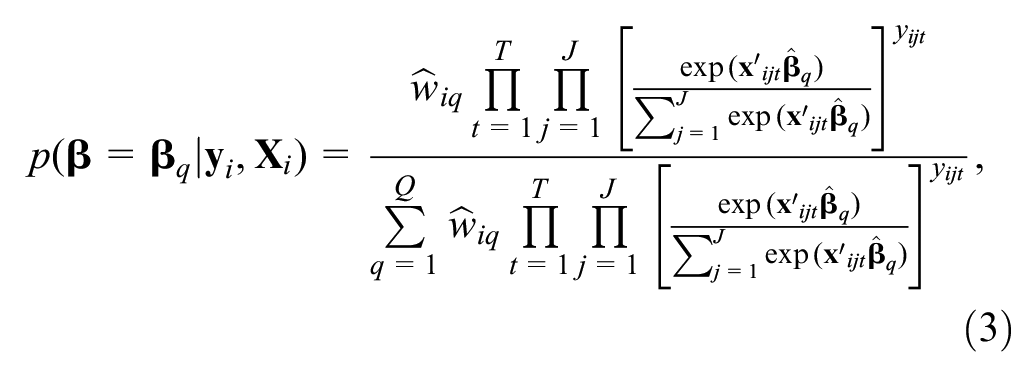
where
Note that
Given the prior and posterior MNL class assignment probabilities shown above, four strategies for class assignment can be derived. The first two strategies are based on prior class assignment probabilities alone, which only depend on consumer information. In contrast to prior strategies, posterior assignment strategies use the posterior MNL probabilities wherein consumers’ choices are embedded. For each of the two types of assignment probabilities, we introduce two strategies for individual-level latent class assignment: 1) assign a certain consumer a class according to maximum probability (as in Scarpa and Thiene) ( 23 ); and 2 ) randomly draw a class for a consumer from the estimated latent class probabilities.
In addition to these four strategies based on actual class assignment probabilities, consumers can also be assigned to a class by consideration of their conditional point estimate
Conditional Estimates at the Individual Level
From the posterior MNL probabilities shown in the previous section, it is possible to derive conditional estimates of preference parameters at the individual level ( 26 , 27 ). Equation 4 for the conditional preferences is essentially an expected preference parameter vector over the posterior class assignment probabilities from Equation 3:
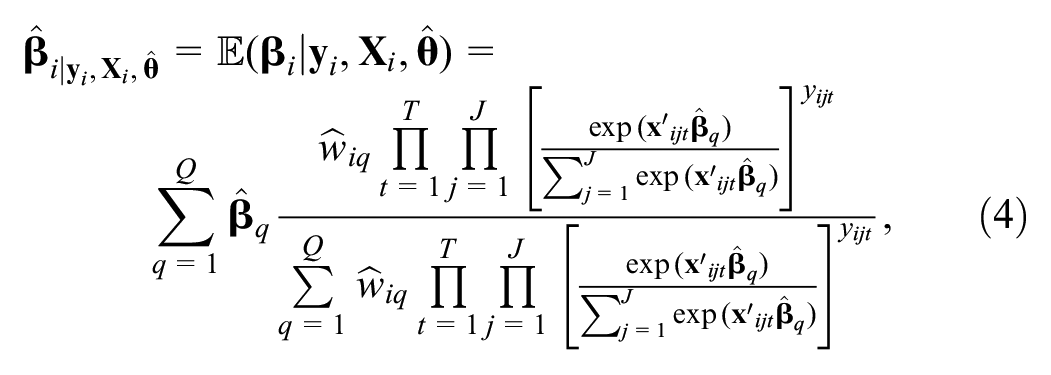
where
In addition to the point estimates introduced above, it is also worth noting that inference on the expected preference parameters can be taken into account in the uncertainty in the determination of
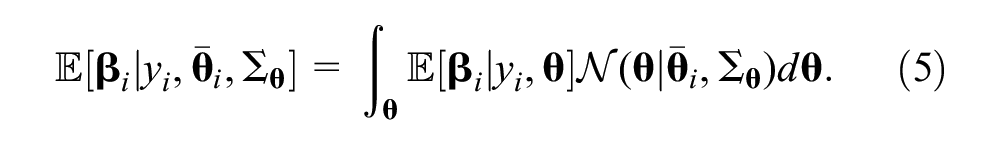
To circumvent the heavy computations associated with evaluation of the multi-dimensional integral, a sampling method can be set to calculate the conditional estimates that accounts for the sampling distribution of the meta-parameter
where
In sum, the possibility of working with conditional estimates at the individual level provides another empirical strategy of assignment to classes, where a given individual is assigned to the class with population point estimates that are closest to the conditional point estimates. Thus, it is possible to implement the following:
Monte Carlo Study
Simulation Plan
To compare the performance of the several competing latent class assignment strategies described in the previous section, we conducted a Monte Carlo study. Similar to the simulation done by Sarrias and Daziano, we also assumed multiple sets of scenarios with three alternatives
Formally, the true latent utility of alternative

where
For the preference parameters, we assumed the following discrete unobserved heterogeneity distributions


Simulated databases were constructed for a baseline size N = 1,000. For each individual, five scenarios with differing numbers of choice occasions were created, namely
Given this simulation plan, we were able to compare statistical results across different latent class assignment strategies mainly from the perspective of preference space estimates, assigned latent class shares, and predicted choice shares. Specifically, we focused on the following statistics:
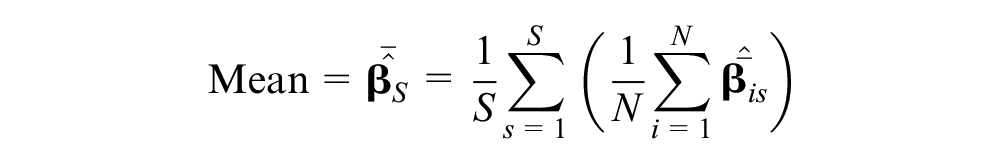
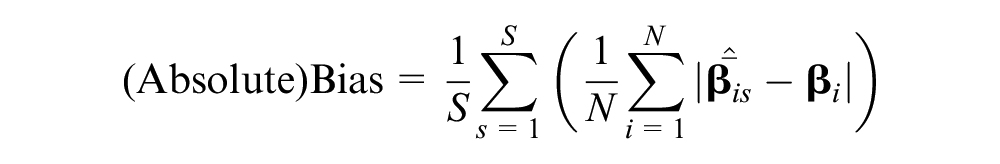
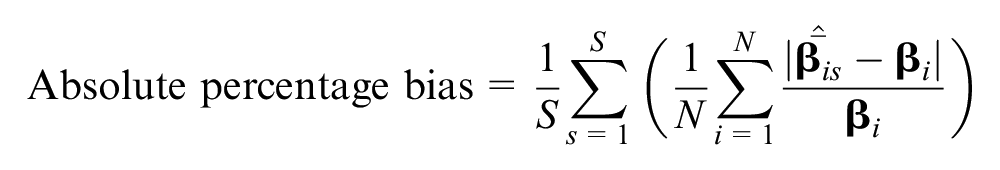
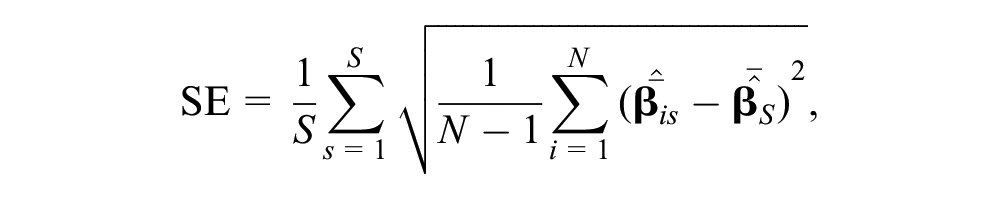
where
Besides this series of statistics, we also considered the empirical coverage probability (COV). COVs tell the proportion of simulated samples for which the estimated
On the other hand, to evaluate different strategies’ behavior on market shares and latent class shares, the following additional statistics were calculated:
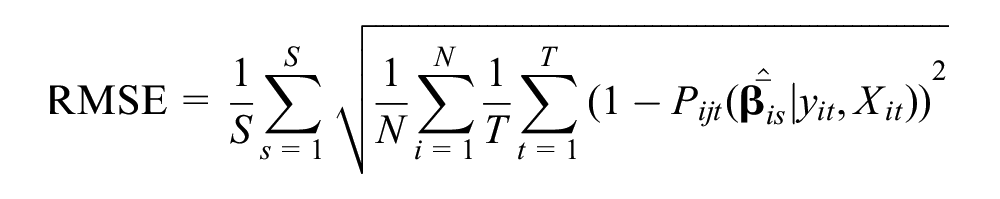
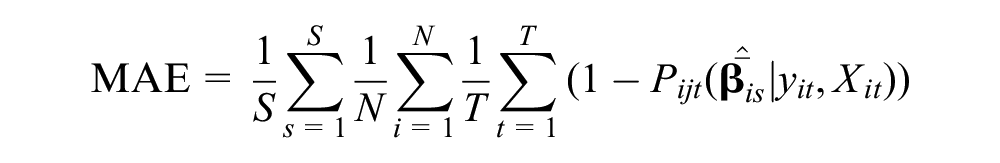
where
In addition, consideration is given to average percent correctly predicted (PCP). In fact, just as with assignment probabilities, we present PCP results obtained through two approaches, namely: (1) choosing an alternative with a maximum choice probability, and (2) randomly picking an alternative according to the estimated choice probabilities. In the tables, these two statistics are denoted by PCP(max) and PCP(drawn), respectively.
Finally, Brier scores were calculated to evaluate prediction performance ( 29 , 30 ):
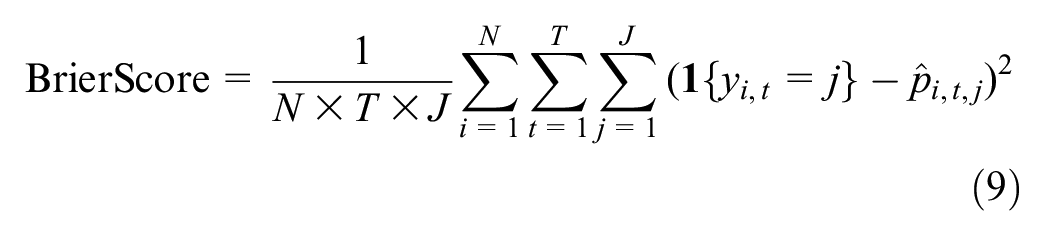
where
Lower Brier scores are an indication of better predictive accuracy.
Results
Tables 1 and 2 summarize parameter recovery results obtained through the six competing class assignment strategies. Table 1 displays aggregate Monte Carlo results for the estimation of the preference parameter
Latent Class Conditional Logit (LCL) Model—Three Classes: Aggregate Parameter Recovery (
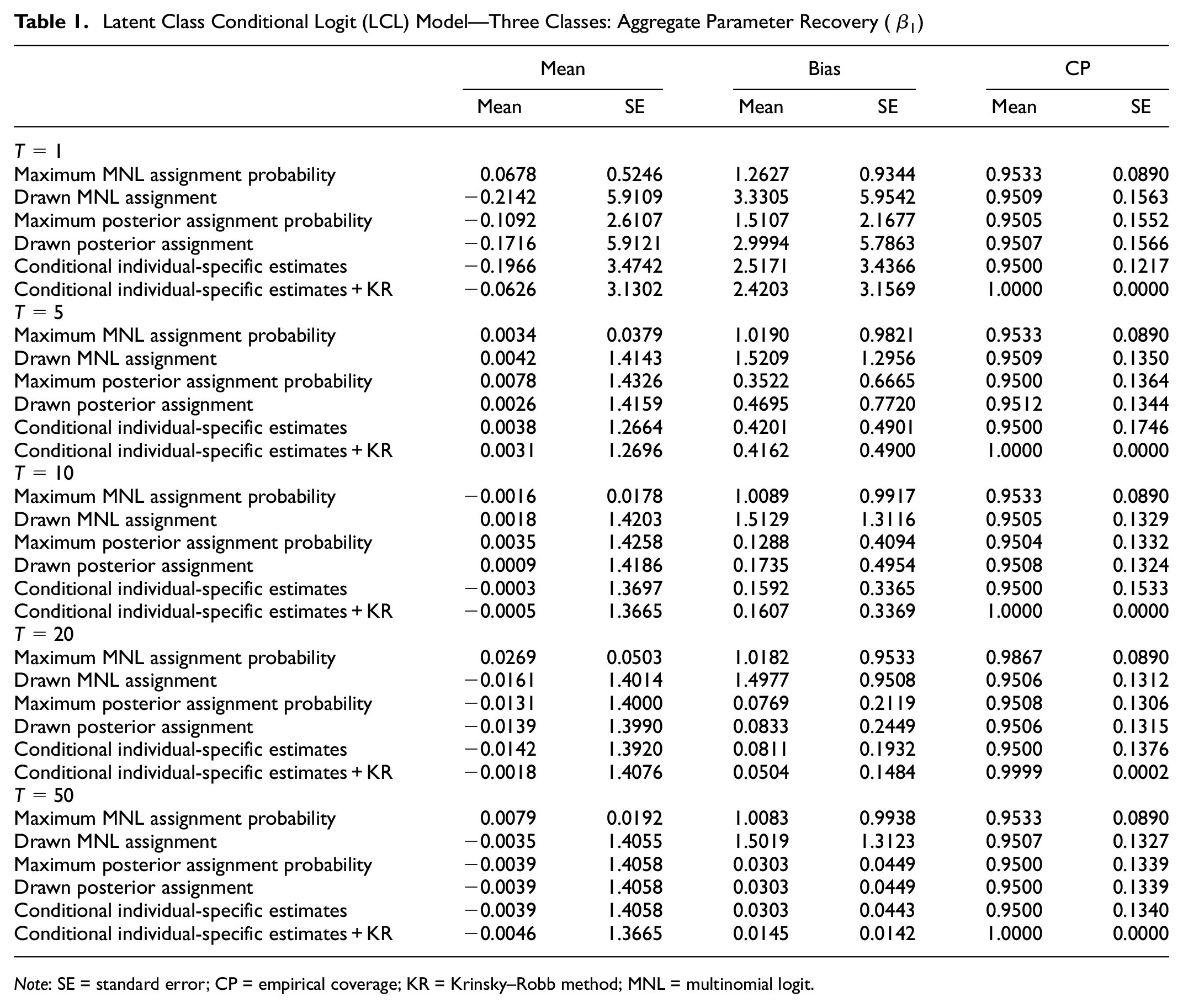
Note: SE = standard error; CP = empirical coverage; KR = Krinsky–Robb method; MNL = multinomial logit.
Latent Class Conditional Logit (LCL) Model—Three Classes: Detailed Parameter Recovery (T = 50, N = 1,000)
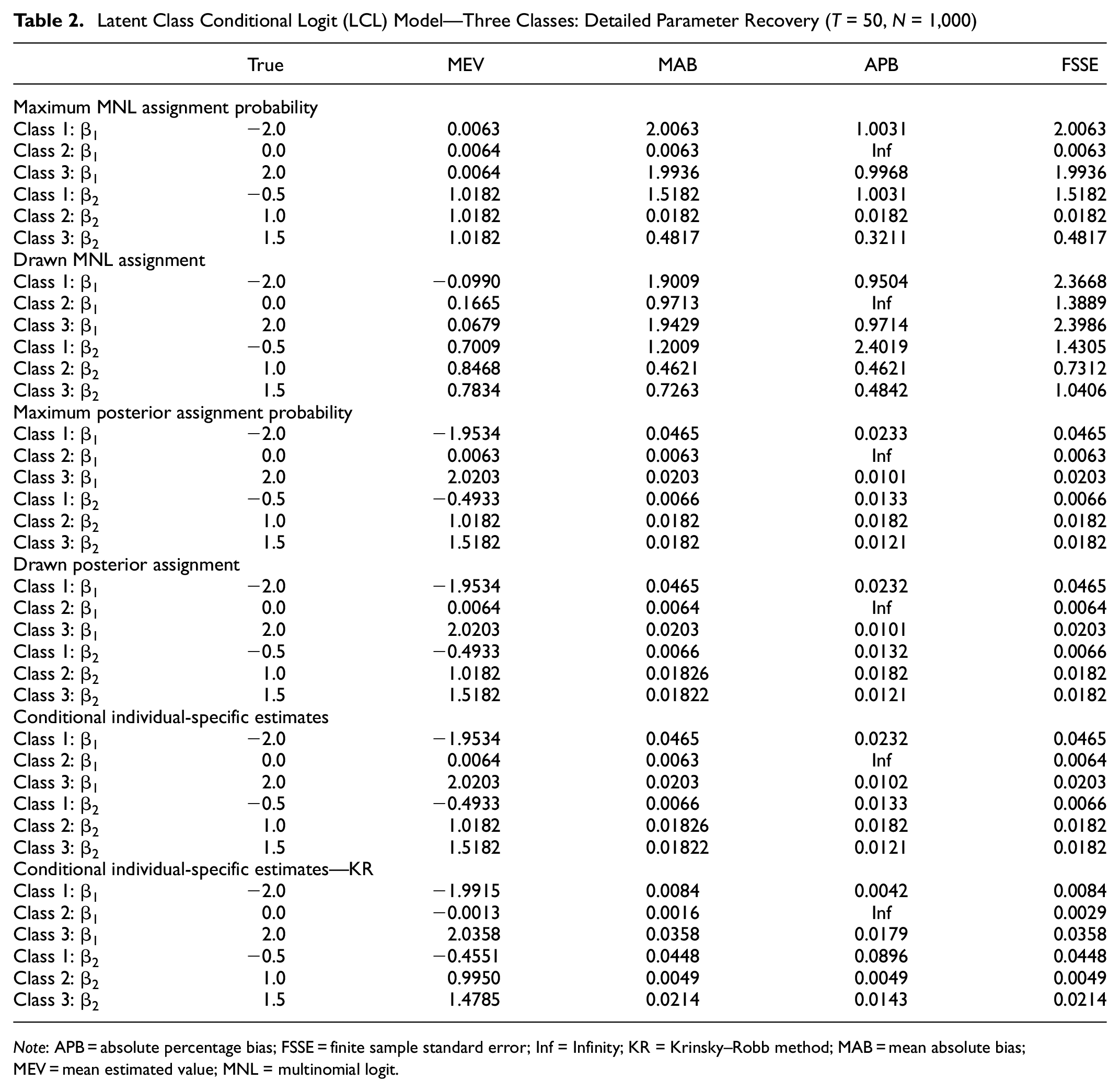
Note: APB = absolute percentage bias; FSSE = finite sample standard error; Inf = Infinity; KR = Krinsky–Robb method; MAB = mean absolute bias; MEV = mean estimated value; MNL = multinomial logit.
In the case of analyzing choice predictions, each individual has been assigned to a class; the point estimates of the respective class can be used to evaluate the conditional logit choice probabilities of Equation 1 which can be then plugged into the expressions of root mean square error (RMSE) and maximum absolute error (MAE) as well as exploited for making an actual predicted alternative either using the maximum probability rule or the drawn alternative method. As shown in Table 1, and as expected, we can observe that assignment strategies related to posterior probabilities and conditional estimates generate lower bias when
Comparing bias values across class assignment strategies, strategy 3 displays the lowest bias when
Given a certain kind of latent class assignment probabilities, say, for example, prior probabilities, the maximum probability rule methods (strategies 1 and 3) bring lower bias values compared with those of the random draw method (strategies 2 and 4). This phenomenon can be explained through a linear programming problem in a
where
The feasible area of
In Table 2, we illustrate detailed parameter recovery based on the databases with
In Table 3, where we analyze correct disaggregate choice predictions by class assignment strategy, we observe that summary statistics including RMSE, MAE, and PCP do not become better when
Latent Class Conditional Logit (LCL) Model—Three Classes: Prediction Metrics
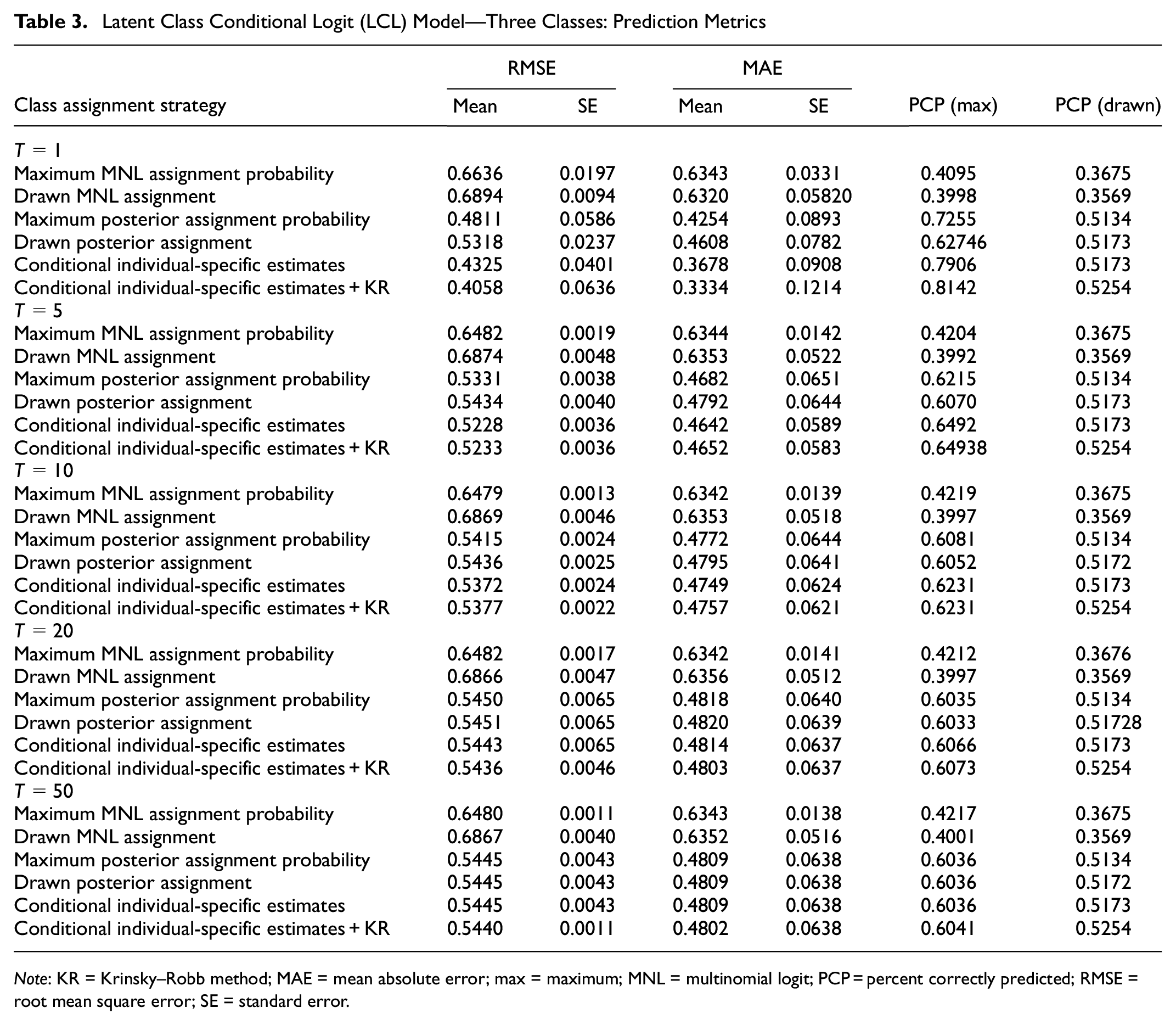
Note: KR = Krinsky–Robb method; MAE = mean absolute error; max = maximum; MNL = multinomial logit; PCP = percent correctly predicted; RMSE = root mean square error; SE = standard error.
In addition, Table 4 reports that the aggregate class shares of all strategies closely approximate the true class shares even when
Latent Class Conditional Logit (LCL) Model—Three Classes: Class Shares
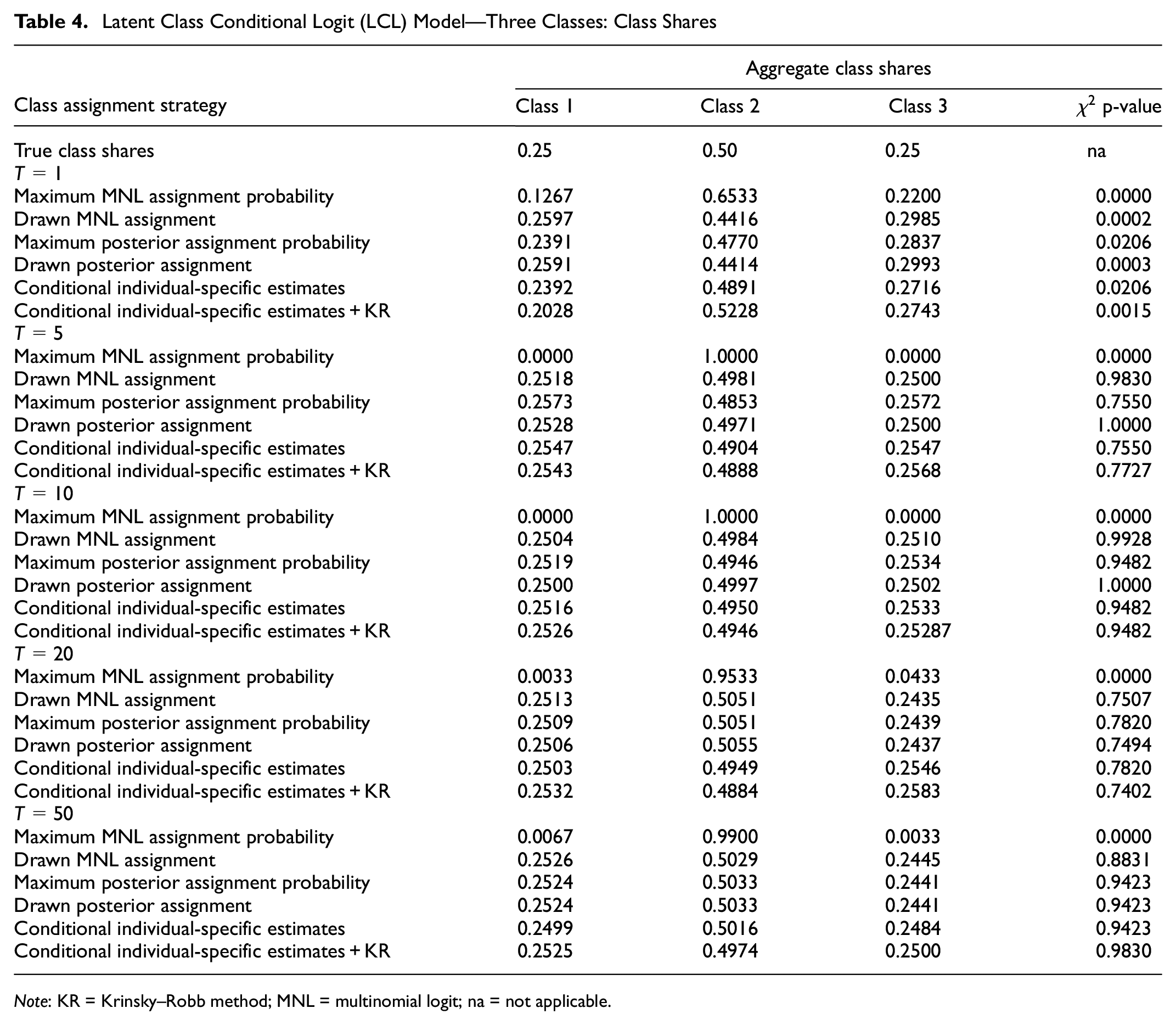
Note: KR = Krinsky–Robb method; MNL = multinomial logit; na = not applicable.
As a whole, we can see that, even though a larger
Looking at disaggregate correct class assignment, Table 5 reports the proportions of correct class assignments for all assignment strategies. Again, using prior probabilities (strategies 1 and 2) performs significantly worse than other strategies because of the lack of individual socio-demographic information in the Monte Carlo study setting. These observations match the analysis from Tables 1 and 2, as elaborated previously. For instance, while increasing
Latent Class Conditional Logit (LCL) Model—Three Classes: Individual-Level Class Assignments
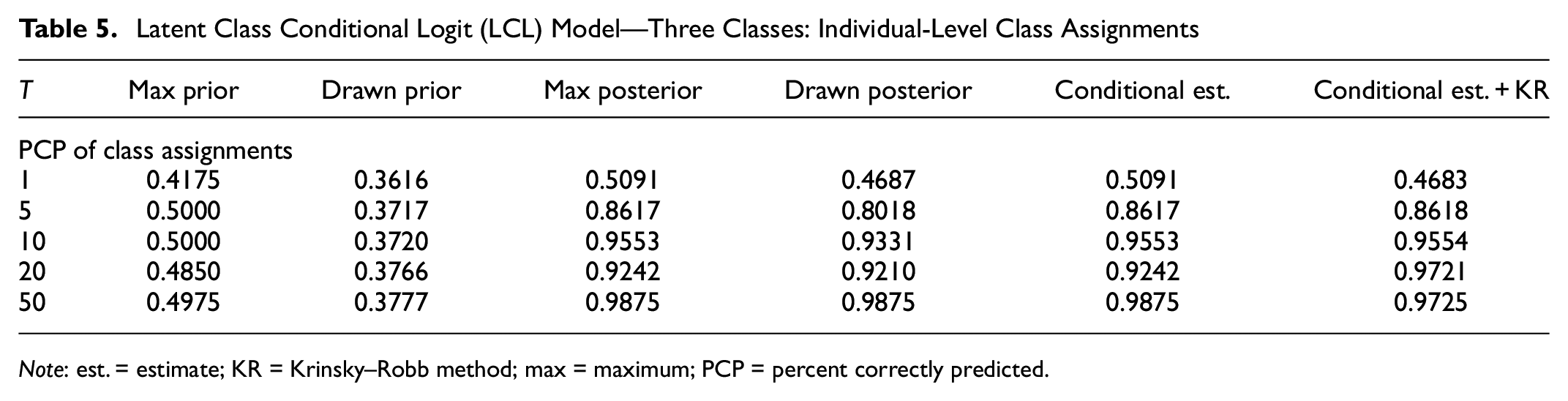
Note: est. = estimate; KR = Krinsky–Robb method; max = maximum; PCP = percent correctly predicted.
Finally, Table 6 reports Brier scores of individual-level choice predictions made by the different class assignment strategies. These score values reflect the accuracy of choice predictions, and a lower value implies more accurate predictions. These figures again confirm that strategies embedded with posterior probabilities have rather accurate choice predictions. However, the posterior probability strategies do not necessarily generate lower Brier scores when
Latent Class Conditional Logit Model (LCL)—Three Classes: Brier Scores
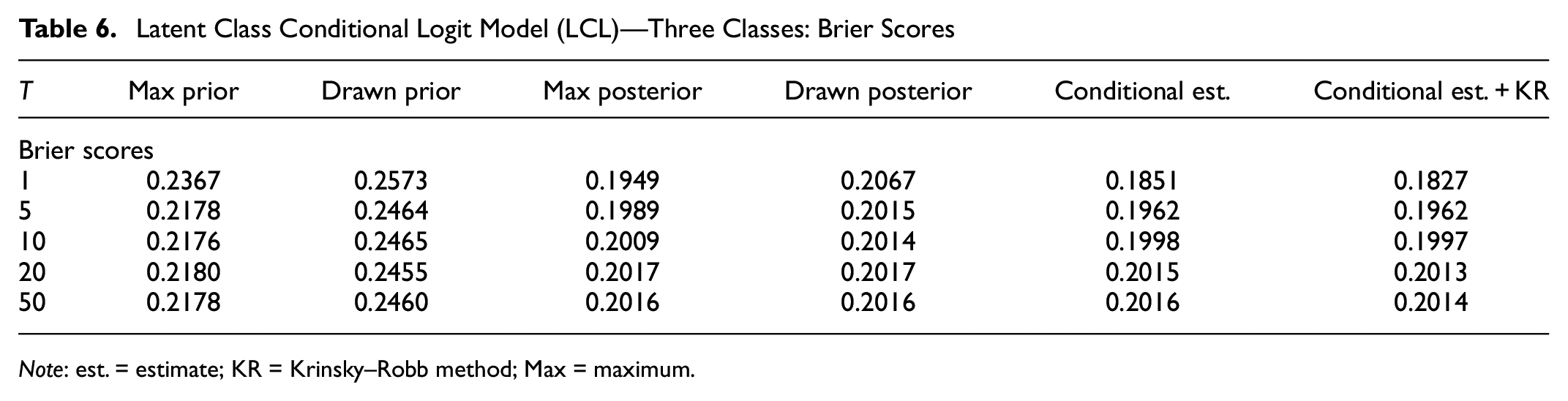
Note: est. = estimate; KR = Krinsky–Robb method; Max = maximum.
Empirical Case Studies
Data
To supplement the Monte Carlo study, the six class assignment strategies were applied to two empirical datasets using actual choice experiments. Both case studies relate to purchase preferences toward low-emission vehicles. Whereas the first case study, in addition to electrification, focuses on automated features, the second case study uses data that were collected to analyze economic valuation of carbon abatement. There are two main differences with the simulation setting. First, true parameters and true classes are, of course, unknown. Second, class assignment is informed by socio-demographic characteristics of the consumers.
Case Study 1: Automated Electric Vehicles
We first use microdata from a choice experiment that was designed to analyze early-market response to vehicle automation (
31
,
32
). The choice experiment was designed around three levels of automation of private light duty vehicles, namely: no automation, partial automation, and full automation. Automation was allowed for low-emission powertrains (hybrid electric, plug-in hybrid, and full battery electric). Details about both the design of the experiment and the data are provided by Daziano et al. (
31
). The conditional indirect utility for individual
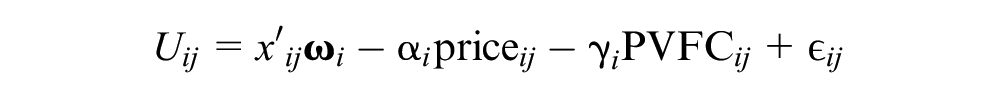
where
The parameters
In this dataset, there are 1,260 individuals (N = 1,260) that responded to a choice experiment with four alternatives, namely: a hybrid electric vehicle (HEV), a plug-in hybrid electric vehicle (PHEV), a battery electric vehicle (BEV), and a gasoline vehicle (GAS). In the statistical analysis, we assume three latent classes (
Case Study 2: Emission Valuation in Vehicle Purchases
The second choice experiment was designed to analyze the impact of environmental information framings on the maximum WTP for
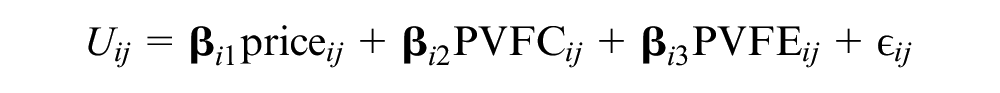
where
The parameter vector
In this dataset, there are 1,580 individuals with two alternative vehicles. We assume two latent classes according to the original probabilistic model selection study conducted in the paper by Daziano et al. ( 33 ).
Empirical Analysis
For both case studies, before applying each class assignment strategy, we trained a latent class logit model with a meta-parameter
Case Study 1: Prediction Metrics—Vehicle Automation Discrete Choice Experiment
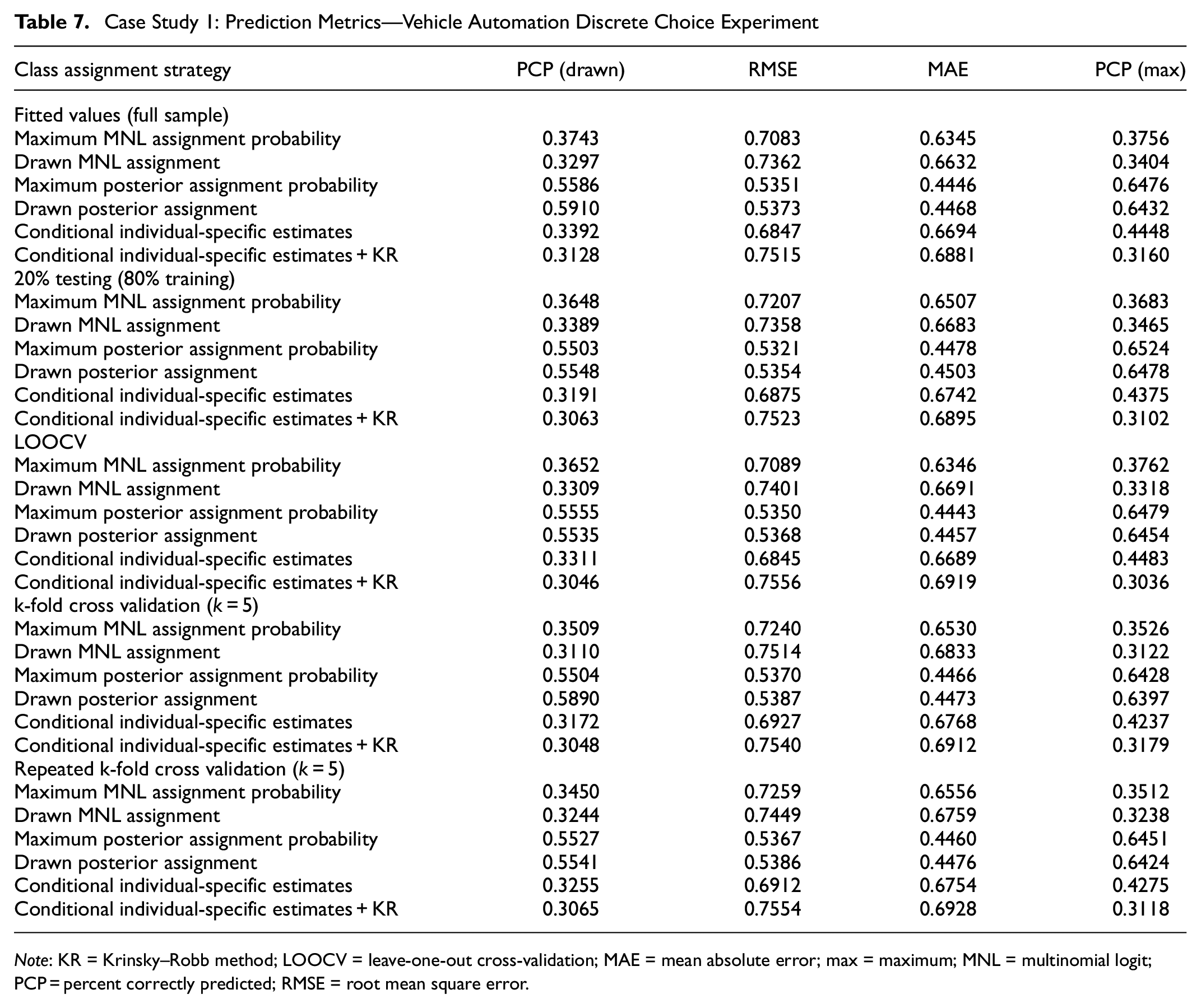
Note: KR = Krinsky–Robb method; LOOCV = leave-one-out cross-validation; MAE = mean absolute error; max = maximum; MNL = multinomial logit; PCP = percent correctly predicted; RMSE = root mean square error.
When comparing aggregate shares in Tables 8 and 10, there is no evident conclusion about which strategy has generally better market share predictions. Whereas predictions from Drawn MNL assignment have a higher p-value for a
Case Study 1: Market Shares—Vehicle Automation Discrete Choice Experiment. The Four Alternatives are: Hybrid Electric Vehicle (HEV), Plug-in Hybrid Electric Vehicle (PHEV), Battery Electric Vehicle (BEV), and Gasoline Vehicle (GAS)
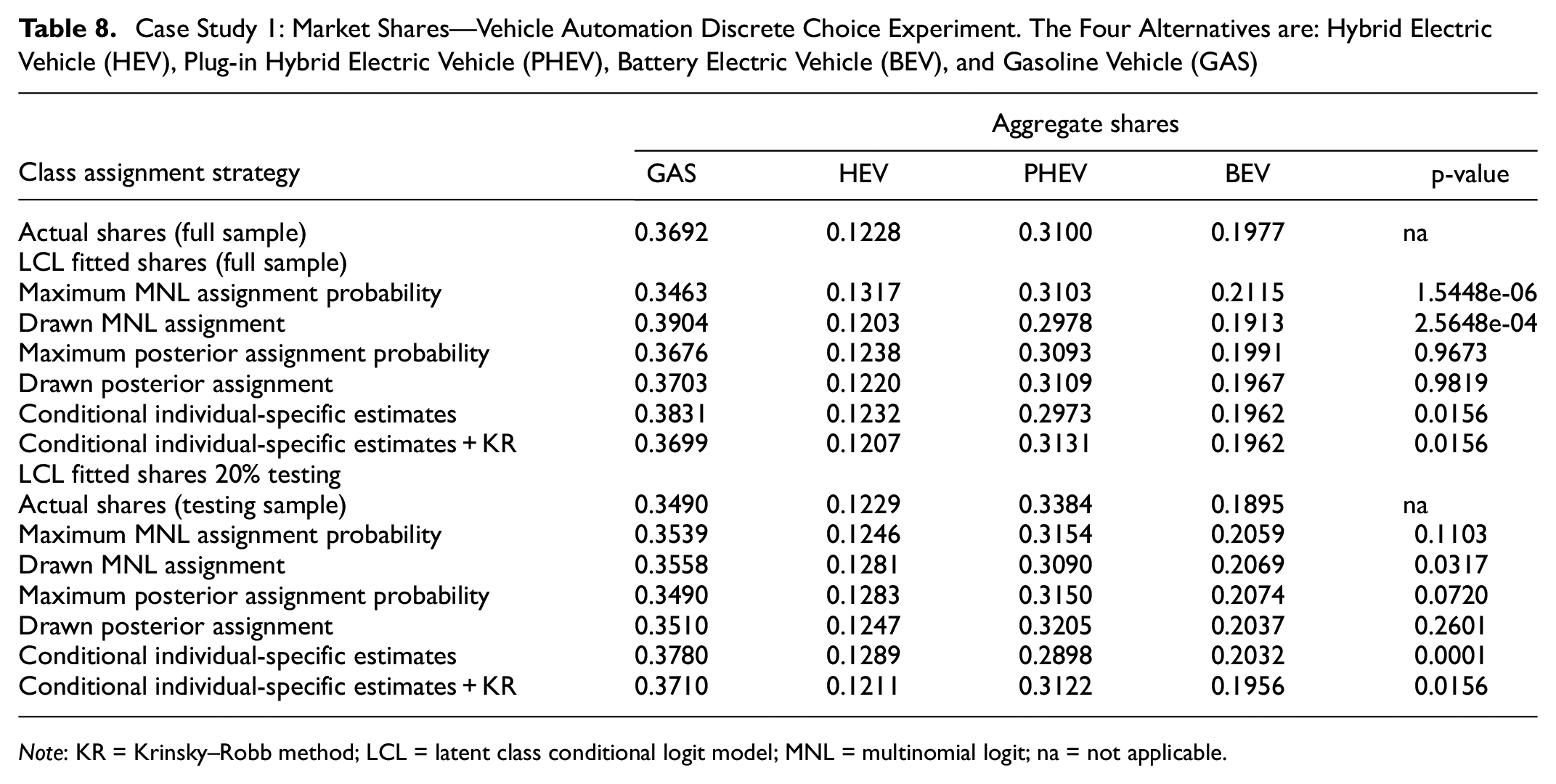
Note: KR = Krinsky–Robb method; LCL = latent class conditional logit model; MNL = multinomial logit; na = not applicable.
Case Study 2: Prediction Metrics—Emission Valuation Discrete Choice Experiment
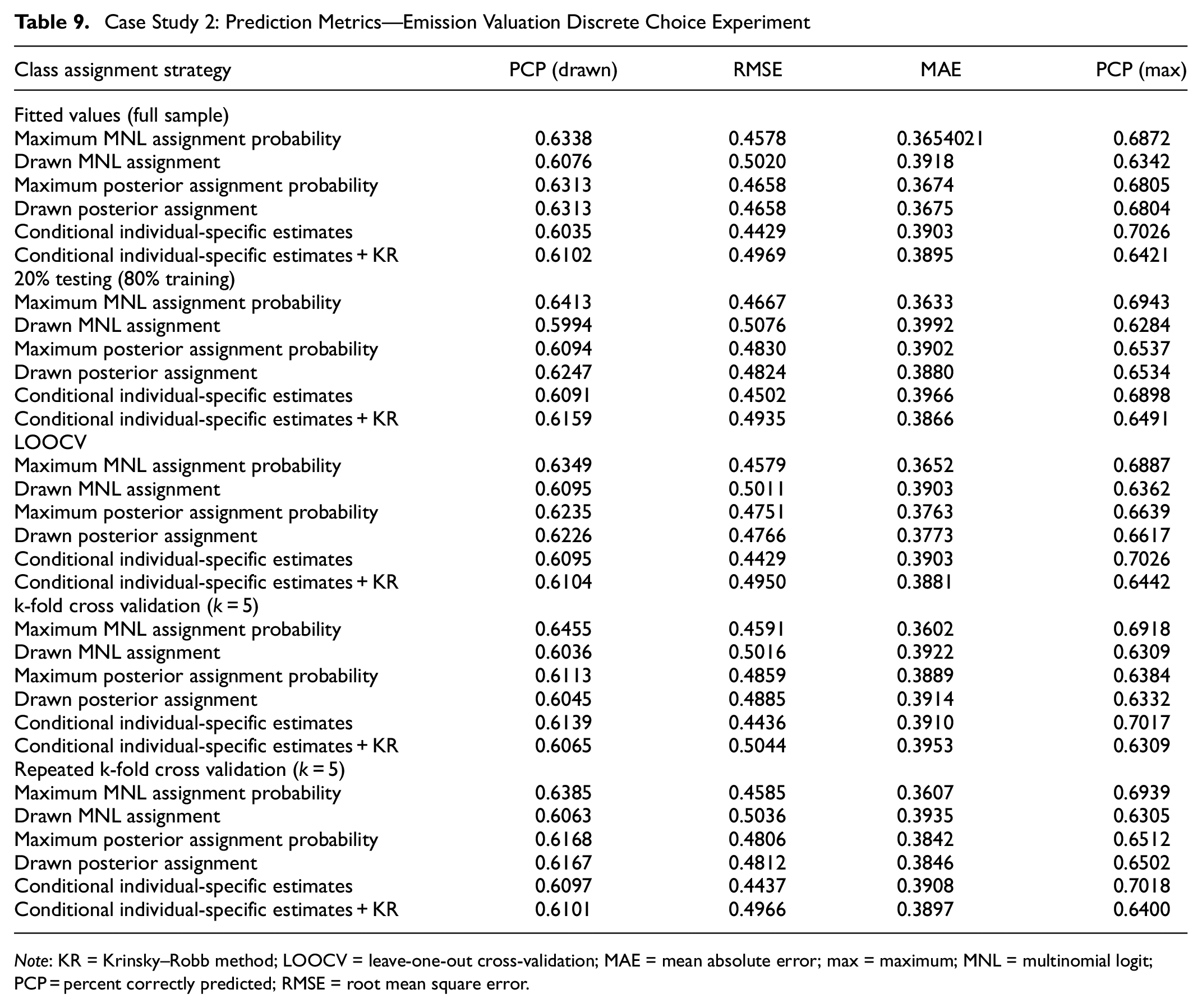
Note: KR = Krinsky–Robb method; LOOCV = leave-one-out cross-validation; MAE = mean absolute error; max = maximum; MNL = multinomial logit; PCP = percent correctly predicted; RMSE = root mean square error.
Case Study 2: Market Shares—Emission Valuation Discrete Choice Experiment
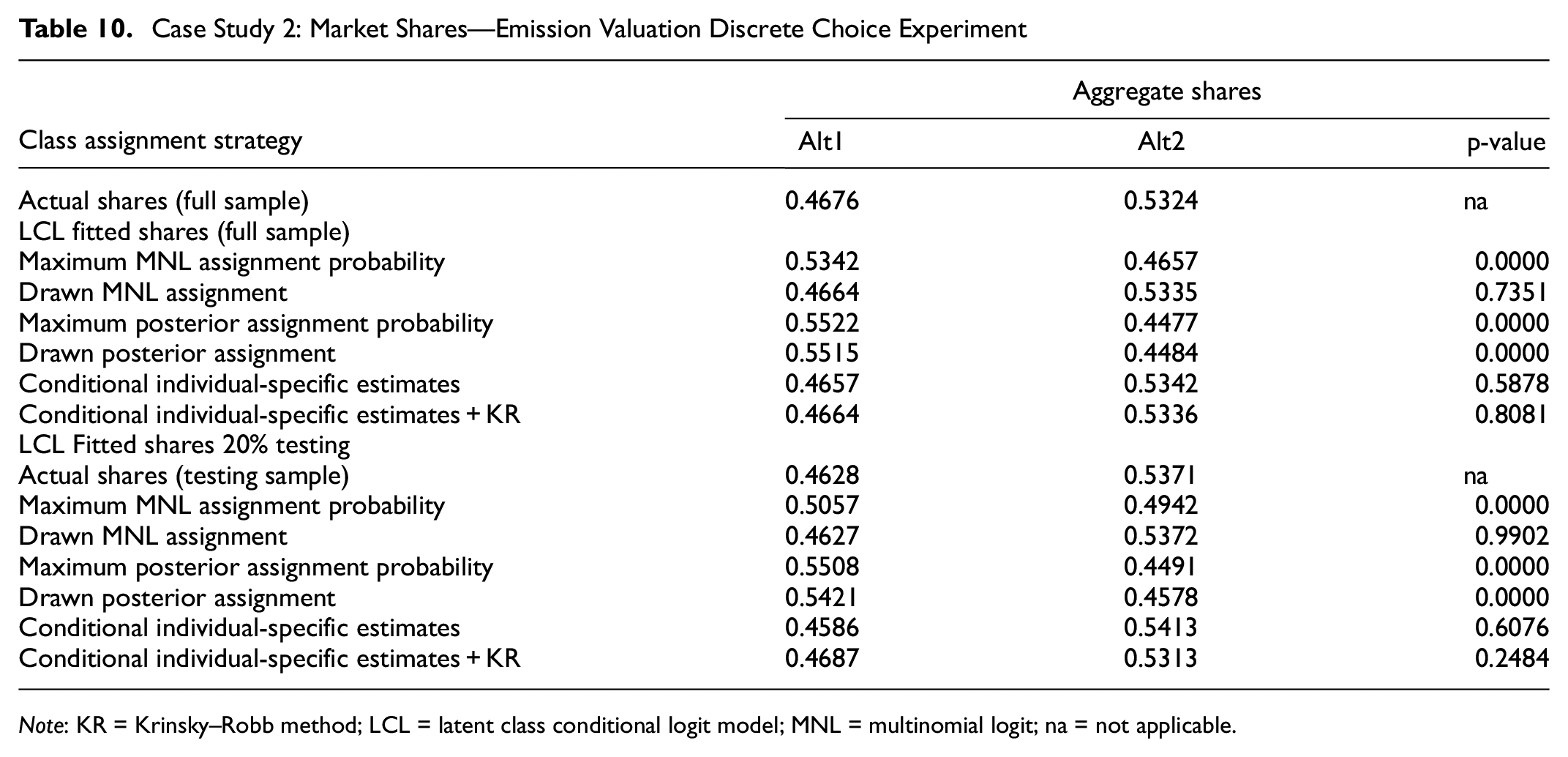
Note: KR = Krinsky–Robb method; LCL = latent class conditional logit model; MNL = multinomial logit; na = not applicable.
Conclusions
In this paper, we have discussed and applied six different class assignment strategies for latent class logit models. Whereas maximum prior and posterior class assignment have been applied in some previous studies, we argue that individuals can also be assigned to a class by randomly drawing a class from a multinomial distribution with probabilities given by MNL probabilities, either prior or posterior. We have also argued and implemented class assignment exploiting individual-level parameter estimates that come from the expected posterior means that are conditional to the sequence of choices made by the individual. Appendix A presents pseudocode of the implementation of the six class assignment strategies under study. By conducting a Monte Carlo study, we have analyzed the behavior of the identified class assignment strategies focusing on preference parameter recovery, choice predictions, and class share inference. In addition, we used two empirical case studies to supplement the results of the simulation study.
The results of the Monte Carlo study have the following implications. Given a moderate number of choice occasions by a consumer (i.e.,
The results of the two empirical case studies, when actual classes are not known, suggest that drawn posterior assignment (strategy 4) performs best from the perspective of aggregate shares. However, maximum probability assignment performs better at predicting individual choices.
In sum, just plugging in point estimates in the MNL probabilities of class assignment—which is equivalent to prior class assignment and is commonly used in practice—should be avoided. For analyzing expected class shares, individual-level conditional estimates implemented with the KR method should be preferred, although posterior assignment performs almost as well.
Finally, as future avenue of research we would like to explore how the different class assignment strategies behave in the context of the novel latent class logit specification with consumer-surplus feedback from the class-specific conditional logit models to the class assignment MNL model ( 34 – 36 ).
Supplemental Material
sj-docx-1-trr-10.1177_03611981221121266 – Supplemental material for On Assignment to Classes in Latent Class Logit Models
Supplemental material, sj-docx-1-trr-10.1177_03611981221121266 for On Assignment to Classes in Latent Class Logit Models by Wangwei Wu and Ricardo A. Daziano in Transportation Research Record
Footnotes
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: W. Wu, R. Daziano; data collection: W. Wu, R. Daziano; analysis and interpretation of results: W. Wu, R. Daziano; draft manuscript preparation: W. Wu, R. Daziano. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Technical developments were supported by the National Science Foundation Grant SES-2031841.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.