
Abstract
With the increase in the number of automated vehicles, roads will contain a mix of automated vehicles and human-driven vehicles. At present, rule-based driving strategy control of automated vehicles in mixed traffic flow makes it difficult to obtain optimal control. Therefore, this study proposes a learning-based driving strategy for connected and autonomous vehicles under mixed traffic flow. The proposed method differs from other driving strategies in two respects. First, both the lane-change and car-following policies are included, and the Deep Q-network algorithm is utilized to train the two policies in a mixed traffic-flow environment. Second, the proposed driving strategy considers both traffic efficiency and safety when designing the reward function. Through simulation experiments, the differences in traffic efficiency and safety of this method and the rule-based method were compared and analyzed under different traffic densities and penetration rates of connected and autonomous vehicles. Simulation results show that the driving strategy improves the average velocity (by 7.02 km/h) and traffic safety (especially in high-density traffic), compared with traditional rule-based driving strategy.
With the continuous advancements in single-vehicle intelligence technology and vehicle infrastructure integration technology, connected and autonomous vehicles (CAVs) have been developed. Vehicle-to-vehicle, vehicle-to-base, and base-to-base interactions are acquired using onboard and roadside devices. This enables CAVs to obtain increasingly accurate real-time traffic data, thereby reducing traffic accidents, congestion, and trip delays ( 1 , 2 ). However, the complete replacement of human-driven vehicles (HDVs) by CAVs has not been achieved. This will lead to a mixed traffic-flow (MTF) scenario consisting of both CAVs and HDVs for a long time in the future ( 3 ). Therefore, improving transportation efficiency while ensuring traffic safety is the next major task facing MTF.
At present, there is rich experience in both domestic and international research in relation to MTF. Researchers have proposed driving strategy methods using dynamical models ( 4 ), mathematical algorithms ( 5 ), and game theory ( 6 ). With the development of onboard sensors and network connectivity technology, CAVs collect data through onboard sensors as the input to strategy methods and subsequently analyze the data to obtain a CAV-appropriate driving strategy ( 7 ). Existing non-learning-based driving strategy methods can only be used in fixed situations. On the contrary, learning-based driving strategy methods are more common; they only have to adjust the state, action, and reward functions for different scenarios for training a driving strategy to fit the target scenario. The current research on rule-based driving strategies demonstrates that rule-based approaches guarantee driving. The introduction of machine learning approaches is expected to optimize efficiency indicators while ensuring safety, further expanding the driving strategies.
Therefore, based on the existing research, this study further expands the application of Deep Q-network (DQN) in the driving strategy initialization. A CAV driving strategy was divided into lane-change and car-following policies. Based on the Markov decision process (MDP), the corresponding state parameter, action parameter, and reward function were established, in which the reward function considered traffic efficiency and safety. Subsequently, a DQN algorithm was used to solve the MDP problem. A neural network was developed for the CAV driving strategy. Finally, a simulation platform was built using MATLAB, and the reward function of the platform was verified. Under identical conditions, the DQN- and rule-based driving strategies were tested. The traffic efficiency and safety indicators (CAVs as a proportion of total traffic flow) were analyzed under different densities and CAV penetration rates, thereby validating the proposed method. The contributions of this study are as follows:
(i) A DQN-based driving strategy method developed for CAVs is applied to MTF. This method is more versatile than non-learning-based driving strategies. This implies that most common scenarios can be learned using the proposed method.
(ii) Compared with the rule-based approach, this can increase the average vehicle velocity to 7.02 km/h under all density conditions and CAV penetration situations. Particularly, in the 0 to 41 vehicle/km range and CAV penetration range of 35 to 60%, the DQN-based driving strategy increases the average velocity of MTF by 23.13 km/h, compared with the rule-based driving strategy. The proposed driving strategy improves the safety of high-density traffic based on the traffic density indicator time to collision (TTC).
(iii) The experiments in this study demonstrated that if CAVs are selected for a learning-based driving strategy in the MTF, CAVs with high penetration rates make the formulation of the driving strategy difficult. This implies that vehicles in front and back of the same lane often choose the same driving strategy. This phenomenon occurs mainly at low to medium traffic densities; that is, the vehicle itself is in an efficient driving condition. However, conflicting driving strategies between vehicles affect optimal driving behavior, leading to less efficient driving in the overall traffic flow. Thus, with low to medium traffic density conditions, moderate penetration of CAVs is more suitable than higher penetration conditions.
Review on Driving Decision-Making
Compared with HDVs, CAVs have better controllability. They can direct the entire traffic flow and improve the road efficiency by adjusting the CAV drive. The driving process of the CAVs can be divided into three steps: environmental perception, driving strategy planning, and control execution. Among these, driving strategy is particularly important in the context of MTF, that is, a complex traffic scene. At present, rule-based and learning-based approaches are often used for the driving strategy ( 7 ).
The rule-based approach combines dynamics models with experience and traffic characteristics to determine the driving strategy. Autonomous vehicles choose the appropriate driving strategy based on the scenario they are in, depending on which a multi-factor perceptional following model is proposed. This considers several factors such as vehicle synergistic optimization, velocity difference of multiple CAV vehicles, and spacing of multiple HDVs, through which the average velocity and traffic flow of the system can be effectively improved ( 4 ). Chen et al. extracted information from the strategy process of human drivers and developed a lane-changing algorithm for autonomous vehicles. It provided ideal velocity control actions and decisions in relation to whether to change lanes in real-world urban environments, while ensuring safety ( 5 ). Yu et al. proposed a lane-changing policy model suitable for autonomous vehicles in mixed environments based on the dynamic multiplayer game theory. They further proposed a hybrid splitting algorithm to obtain the Nash equilibrium solution in multiplayer games, thus obtaining the optimal strategy for autonomous vehicles’ lane-changing policy ( 6 ). Martin-Gasulla et al. investigated the phenomenon in which low penetration rates of CAVs decrease the overall vehicle throughput. They aimed to alleviate this phenomenon at urban intersections by classifying CAVs and preset green-time start-up and produced a calibrated micro simulation model using VISSIM, which can reflect this operational solution ( 8 ). Cao et al. set up a nonlinear dynamic time headway strategy for urban roads in a networked vehicle environment based on this new MTF flow. They analyzed the basic graphic model of MTF in cooperative adaptive cruise control (CACC) vehicles under different permeabilities, using CACC as a model of networked vehicles ( 9 ).
The learning-based approach involves learning from data through trial and error to obtain effective driving patterns for different road environments. Reinforcement learning is a machine learning tool that enables proxy vehicles to interact with their environment to gradually improve their driving behavior ( 10 ). You et al. modeled the interaction between autonomous vehicles and the environment as a random MDP. The driving strategies of experienced drivers were considered as the learning objectives. By designing the MDP’s reward function, the expected driving strategies of autonomous vehicles are obtained using reinforcement learning ( 11 ). However, this reinforcement learning mode can only be used in situations where the road environment is less complex, and the vehicle logic is relatively simple. Consequently, autonomous driving strategies are often combined with deep reinforcement learning to address these complex issues. As a classical deep reinforcement learning algorithm, the DQN algorithm is widely used to solve the problems associated with autonomous vehicles. Zhang et al. proposed an improved DQN lane-change policy model for autonomous vehicles. Using two neural networks with identical structure and different frequency of parameter updating to train simultaneously improved the success rate of the lane-change policy and convergence velocity of the network ( 12 ). Quek et al. used both the 2D environment built by DQN in Python and 3D environment built by Unity to control the vehicle and realized the ability of vehicle navigation and avoiding obstacles without prior information of the surrounding environment ( 13 ). Ko et al. proposed speed coordination and combined control for traffic congestion with waste of fuel consumption in bottleneck sections. They used DQN to train CAV driving behavior to alleviate traffic congestion in bottleneck sections ( 14 ).
Thus, current research on CAVs in MTF focuses on rule-based methods. Only a few studies have focused on learning-based methods. In addition, existing learning-based CAV driving strategy studies are incomplete. Only a few studies have addressed lane-changes, vehicle followings, and simultaneous impacts on traffic efficiency and safety.
Organization
This paper is organized as follows: the next section introduces the basic concept of reinforcement learning and constructs a DQN-based approach. Following this, a section establishes a simulation platform and calibrates reward function parameters, HDV driving strategy, and rule-based CAV driving strategy. There follows a section that compares and concludes a DQN-based driving strategy method with a rule-based driving strategy. The final section summarizes the study and provides its outlook.
DQN-Based Driving Strategy Methodology
The parameters for the theoretical method include input and output parameters of the CAV driving strategy, DQN algorithm, and neural network training parameters.
General Framework
The context of this research is urban expressway. CAV driving research can be approximately divided into three steps: (1) perception and data collection of the surroundings; (2) deciding whether to change lanes and plan lanes following the strategy; and (3) implementing driving behaviors.
In general, step (1) is to collect the peripheral data through onboard sensors and roadside devices.
To achieve this goal, we hypothesize that the target vehicle obtains information in relation to both the surrounding vehicles and vehicle itself in real time,
Step (2) comprises the main content of this research. In this paper, the two steps for CAVs in lane-change policy and CAV following policy are simplified. The lane-changing policy is first considered, followed by the car-following policy attributable to the difference of the former decision, resulting in different environment status data. However, the lane-change policy as the first step is used to predict the nature of the assumptions. It does not necessarily imply that the CAV will undergo lane changing. In the actual driving process, CAV lane-change behavior and following behavior are considered simultaneously.
In the initial phase, the CAV does not have any effective lane-change or car-following driving behavior. Rather, it has a driving behavior that benefits the most from trial and error under different environmental conditions. The lane-change and vehicle-following policies are based on the DQN algorithm. The entire algorithm is divided into two stages. The first stage is Q-learning training, in which the CAV selects reward functions from different actions in different environments, which are stored in tabular form. The second stage is neural network training. The corresponding neural network is learned and generated using the value function matrix of the action state obtained in the first stage.
In this study, the driving strategy in step (2) is implemented in a considerably short time. Thus, no specific research on step (3) was presented. Instead, the CAV is set to drive directly to the appropriate spot in the moments following lane-change or car-following policies. This ignores the details of vehicle movements between these two moments. The overall framework is shown in Figure 1.

General framework.
Reinforcement Learning
The basic framework for reinforcement learning is the MDP (
15
). The simplest MDP comprises four tuples: state S, action A, reward function R, and transition probability P. The MDP provides an agent with an arbitrary state
DQN-Based Lane-Change Policy Parameter
Here, the state parameters for the CAV lane-change policy include: the distance between the target vehicle and front of the current lane

Because this study deals with the dual carriageway of an urban expressway, the target vehicle only needs to consider whether it needs to change lanes.

To ensure that the CAV can change lanes under the premise of sufficient lane-change space, we consider the following two aspects before the lane-change behavior to account for the reward function of the lane-change policy.
Equation 3 considers whether there are other vehicles in an identical position on the adjacent carriageway of the current target vehicle. Suppose that there are two vehicles driving in parallel in the adjacent lanes, and a better driving space exists for one car in front of the other. According to driving habits, for driving safety reasons, the first car will not forcefully overtake to change lanes. Therefore, the reward function is set as follows: if there are no other vehicles, a reward

Equation 4 considers whether the lane change of the target vehicle is influenced by the distance to the future driving space ( 16 ). CAVs have more road traffic data than HDVs do. Thus, they can consider how fast a vehicle is moving in the front or adjacent lane of the current lane during the decision stage. They can judge whether to change lanes based on the velocity of the current and next lane and the longitudinal distance between the target vehicle and the vehicle in front of it. This implies that if the target vehicle chooses a lane that provides more driving space in the future, there is a larger incentive. This reward function is defined using the longitudinal distance between the vehicle in front of the selected lane and the target vehicle as well as the distance traveled by the vehicle in a future time step.

The reward function of the lane-change decision consists of two small reward functions.

DQN-Based Car-Following Policy Parameter
The CAV following policy presented here is formulated by the state parameters, including the target vehicle current velocity
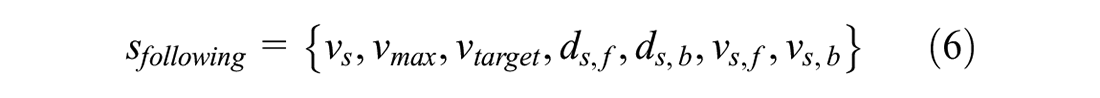
To optimize the calculation process, the original acceleration-oriented calculation was changed to a velocity-oriented calculation. It provides the CAV with six velocity options to increase its dynamic changes. Subsequently, the velocity interval ranged from the minimum to the maximum velocity. The minimum velocity is zero, and the maximum velocity is set according to road requirements.

To ensure that a CAV can maximize the driving efficiency under the premise of safety, the reward function of the car-following policy in this paper includes four aspects, including traffic safety of the CAV, driver’s comfort, driving distance and velocity limits.
Equation 8 considers the traffic safety of the CAV on the road, similar to the cellular automata model (
17
) presented by Taniguchi and Suzuki, which includes the TTC; a lower TTC value corresponds to a higher probability of danger. Therefore, the value must be inverted to ensure positive correlation with the reward function. To ensure the maximum security of the CAV, if the determined velocity of the CAV at the next moment is reduced, and the vehicle spacing in the front gives a reward


Equation 10 considers the impact of velocity changes on the driver’s comfort. The magnitude of the acceleration is closely related to the decision-making and control of autonomous vehicle systems. Jin et al. analyzed the interaction between passengers and autonomous vehicle systems (
18
). They proposed an acceleration control strategy for autonomous vehicles and divided the driving comfort into different acceleration intervals, stipulating that accelerations above 2 m/s
2
are significantly uncomfortable. If the acceleration of the target vehicle is in the comfort zone, a reward
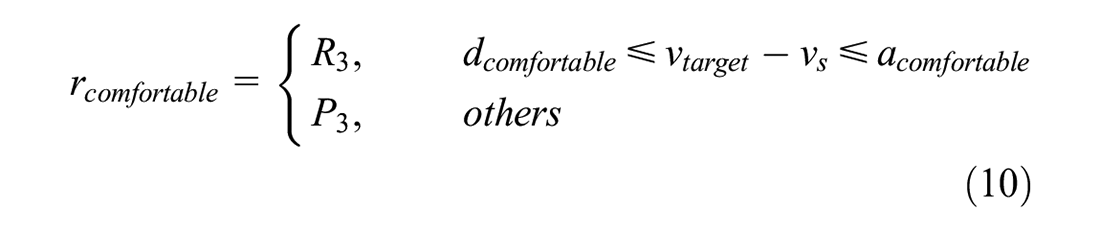
Equation 11 represents how the velocity and distance are used as a value function ( 19 ) when studying the car-following policy based on reinforcement learning to ensure that the CAV can travel at a certain velocity on the road. Therefore, the distance that the CAV can drive in the next time step is also a reward function for the following decisions in the text.

As different vehicles have different driving functions, they require velocity limits. Equation 12 ensures that the target vehicle does not choose to move faster than its maximum velocity limit. Within this limit, a reward

The reward function for subsequent decisions consists of the four small reward functions.

DQN Algorithm
After setting up the three elements of the MDP, the function of the state action value is calculated using the Q-learning algorithm and stored in a Q-table. However, this method is feasible in environments with only few actions and states. Modeling CAV scenarios requires a relatively complex environment. Thus, the Q-table becomes significantly large. Additionally, it is inconvenient to call data if the values of the corresponding operations are stored in all different states in the Q-table. Therefore, we chose the neural network DQN algorithm based on the Q-learning algorithm. Based on the input stochastic state condition, the neural network is used to approach the state action value function and output the corresponding state action value under different actions. Finally, the CAV selects the action corresponding to the maximum value.

DQN Training
Here, machine learning and deep learning applications in MATLAB were utilized to train the DQN-based lane-change and car-following policies. There were five and seven inputs and two and six outputs for the two neural networks, respectively. The number of neurons in the hidden layer was set to ten based on the empirical formula for determining the number of neurons in the hidden layer. The number of nodes in the hidden, input, and output layers are represented by h, m, and n, respectively.

The complexity of subjects determines the number of hidden layers. The neural network was trained by setting different layers of hidden layers, comparing the training results and training time, and finally setting the hidden layers to two. Trainlm is the default algorithm in MATLAB, which has the fastest convergence speed among medium-sized neural networks. Other neural network parameters are the default parameters of the system as shown in Table 1.
Parameter Specification

Note: CAV = connected autonomous vehicle; DQN = deep Q-network.
Figure 2 shows how the loss function varies with the number of iterations during neural network training for both policies (set to 1,000). The loss function was no longer reduced (reaching the best value), and the training was completed. The average loss function of the training (blue line), validation (green line), and test (red line) sets were no longer reduced at the 1,000th lane-change policy iteration or approximately the 750th car-following policy iteration.

Number of training iterations: (a) Training iterations for lane change policy and (b) training iterations for car following policy.
Experimental Platform Construction and Other Vehicle Parameter Settings
Experimental Environment Setting
Considering the abundance of two-lane city roads and given that a two-lane city road can meet the minimum requirements for changing lanes and accompanying vehicles, this study considers a two-lane city expressway to be the research background.
In this study, a simulation platform to verify the validity of this method was established using the cellular automaton model ( 20 ). Because traffic participants are discrete in nature, using cellular automaton theory to simulate lane-change and car-following policies effectively avoids the approximation transition between discrete–continuous–discrete. The theory was proved to be feasible ( 21 ). To better simulate traffic flow on one-way two-lane city freeways, we referred to the simulation criteria of the cellular automaton model developed by Rickert et al. ( 22 ). Each cell was 7.5 m long and 3.5 m wide. Each road was circular and comprised 1,000 cells, with a total length of 7.5 km and simulation time of 1,000 s. To ensure the safety of vehicle and influence of its factors, the length and width of the CAV and HDV were set to 5 and 1.8 m, respectively. Assuming the vehicle was always at the center of the cell space, that is, the vehicle was 1.25 m from both the upper and lower edges of the cell space, there was a safe distance of 2.5 m between the vehicle and cell, which was maintained even if the vehicle was in two adjacent cells at the front and back. The cell space size as well as the vehicle length were maintained at such a size that the cell length was neither too short to accommodate a vehicle nor too long to cause the vehicle movement to change too fast, and the overall traffic flow change could be reflected roughly under that condition.
In the initial stage of the simulation, vehicles are generated at random locations in the cell space according to a certain CAV permeability and traffic density. Each vehicle was given an initial maximum velocity in the range of three to five cell length/s, that is, 81, 108, and 135 km/h, to ensure that the vehicles running on the simulated road meet the different maximum driving velocity of real vehicles resulting from their driver characteristics and vehicle characteristics. Each vehicle obtained its real-time velocity by multiplying its maximum velocity with a random value between 0 and 1 and rounding up.
Owing to the nature of the cellular automaton model, the vehicle directly performs the following lane-change behaviors to achieve cell-to-cell state transfer, that is, the vehicle does not stop in the middle of two longitudinal cells or between two transverse cells at the next moment. Instead, it directly reached the next cell, and only one vehicle could exist in each cell at a moment during the simulation. The velocity intervals of all types of vehicles were zero to five cell length/s, that is, 0, 27, 54, 81, 108, and 135 km/h. The road and vehicle settings are shown in Figure 3.

Simulation platform construction.
Reward Function Parameter Calibration
In the previous section, the settings of the reward function related to the DQN lane-change and car-following policies were developed. However, the reward and penalty values had to be further calibrated. In this study, we first assigned values to the reward and penalty using the enumeration method, that is,
In this study, the process was repeated 10,000 times to arrive at a matrix that links rewards and penalties to the overall average vehicle velocity, number of remaining vehicles, and acceleration variation.

After completing the data statistics, the three indicators were normalized. Consequently, the indicators were of the same order and easy to compare and analyze.

Finally, three metrics were summarized. The reward and penalty values corresponding to the maximum value were selected as the correction results of the reward function parameters.
Other Vehicle Parameters
In MTF, there are HDVs in addition to CAVs. Thus, it is necessary to set up lane-change and car-following models for HDVs. Simultaneously, to verify the validity of the DQN-based driving strategy, it must be compared with the traditional CAV lane-change and car-following policies.
In relation to the HDV lane-change decisions, the single-lane random cell automaton (STCA) traffic model proposed by Chowdhury et al. ( 23 ) was adopted in this study. The model stipulates that if the target vehicle
(i) does not have sufficient driving space in front of its current lane for it to continue at its current velocity at the next moment;
(ii) the adjacent lane has better driving space than that lane; and
(iii) there is no interference from other vehicles (as the change of vehicle state in the cellular automaton model is done instantaneously from the current moment to the next moment, the rule ensures that there is space to perform a lane change in the adjacent lane where the vehicle is located, which in turn ensures the safety of the vehicle),
then the target vehicle changes its lane, and the lane-change then updates the rules as per Equation 17.

For the HDV car-following policy, we chose the rule-based STCA proposed by Nagel and Schreckenberg (
20
). In this model, each cell can be either occupied by a car or be empty. Each car was assigned a velocity between 0 and
As a result of the constraints, the HDV is affected by the distance of the vehicle in front of it, thus always maintaining a safe distance greater than or equal to the length of one cell from the vehicle in front of it during driving. The vehicle update rules are as follows:

According to the manual vehicle driving test conducted by Sugiyama et al. (
24
), at the start of the race, manual vehicles are evenly distributed on the loop and travel at a uniform velocity. However, owing to uncertainties, some vehicles always slow down. This makes it impossible for the entire platoon to maintain uniform velocity. According to this characteristic, combined with the random deceleration rules in the STCA model, an artificially driven vehicle, whose velocity is not zero after implementing the lane-change and car-following policies, is decelerated with probability

Considering the CAV lane-change policy, the rule-based lane-changing model (
16
) proposed by Jin et al., which refers to the reward function of the lane-change policy based on DQN, was adopted here. Depending on the mode of lane-change, the size of the vehicle’s future driving space determines whether a lane-change is required at this moment. The vehicle will move to the lane that provides more space at the next moment when the target vehicle is in the current lane.



In relation to the CAV following decision, we adopted the intelligent driver model (IDM) proposed by Treiber et al. (
25
). The model consists of two parts: the acceleration trend in automatic state and the deceleration trend considering head-on collision.



In this study, the acceleration for each step length is calculated using the IDM. As the IDM was originally used for continuous traffic flow, and the platform simulated in this study was discrete, the simulation time was divided into several small time steps. The acceleration of the vehicle under each small step is calculated using the IDM, such that the sum of the velocity and acceleration of the vehicle cannot exceed the maximum acceleration. The final acceleration is the max integer upward to fit the measurement of the cellular automata model.
Results and Discussion
To verify the effectiveness of the DQN-based driving strategy, the aforementioned rule-based lane-change model and IDM car-following model was combined to obtain the rule-based driving strategy. Both strategies were tested on a simulation platform with different initial traffic densities (two-lane urban expressway conditions at 0–226 vehicles/km) and CAV penetration rates (0%–100% CAV penetration rate). Each experiment was repeated 100 times. Each simulation time was set to 1,000 s under different initial conditions. At each time step, based on different driving strategies, traffic data were used to perform the corresponding driving behavior. The velocity and calculated TTC value were recorded the next moment after the execution.
Traffic Efficiency
The average velocities of the CAVs, HDVs, and other vehicles were chosen as the performance indicators for traffic efficiency. As shown in Figure 4, the horizontal and vertical coordinates on each small graph indicate the two-lane traffic density and CAV penetration rate, respectively. The average velocity of the corresponding vehicle was calculated for each traffic density and CAV penetration and visualized using different colors. The blue and red lines indicate faster and lower average velocities, respectively. The graph directly reflects the change in the running state of the entire traffic flow.
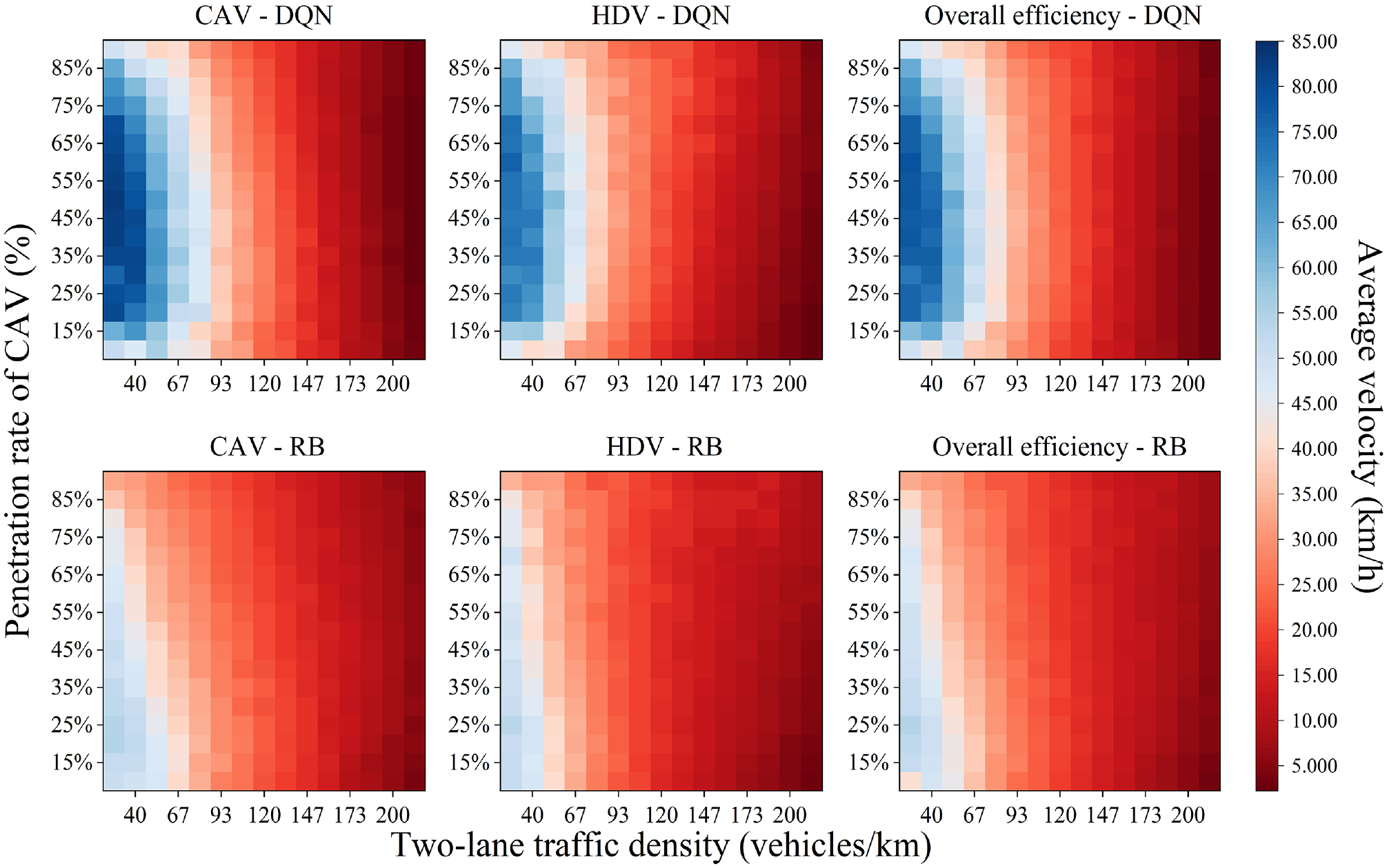
Travel efficiency analysis.
Horizontal coordinate analysis demonstrated that when the traffic density was between 0 and 82 vehicles/km, the DQN-based CAV driving strategy had significant advantages over the rule-based driving strategy in all three indices. This is because the DQN-based driving strategy completed all of its driving actions during the training phase of a potential driving environment to achieve the optimal driving behavior in that environment. An approach was designed to optimize the outcomes of different driving behaviors. The rule-based driving strategy had only one driving behavior in the form of a calculation of the acquired data in the actual driving situation. The method was oriented only to the optimal solution of the calculation formula. DQN-based CAVs can better adapt to the traffic-flow environment under medium and low traffic densities by increasing their own velocity to increase the overall average velocity. This ultimately improves the overall average velocity of all vehicles. Simultaneously, changes in the velocity of CAVs affect the overall traffic flow, changing the velocity available for HDVs.
Considering the vertical coordinate change analysis under the CAV driving strategy proposed here, a larger CAV penetration rate is not preferable. However, a rate within the interval of approximately 35 to 60% is advantageous. The explanation for this is that a DQN-based CAV will choose the best driving behavior in a situation where the traffic density is low, that is, the vehicle has the opportunity to choose its velocity. If there is a CAV in front of the vehicle, the two will often make identical driving decisions in the environment they are in. If the maximum speed of the front CAV is lower than that of the rear CAV, the velocity of the rear CAV is prevented from increasing, causing a chain reaction that reduces the average velocity across the road.
Taking the average overall vehicle velocity in the interval of 0 to 82 vehicles/km and a CAV penetration rate between 35% and 60%, the average overall vehicle velocity of the DQN-based driving strategy reaches 60.81 km/h. In contrast, that of the rule-based driving strategy only reaches 37.68 km/h, that is, a difference of 23.13 km/h. Therefore, the DQN-based driving strategy is more traffic-efficient compared with the rule-based driving strategy.
Presently, CAVs are being developed to bring a more efficient way of travel. However, current CAVs rely only on the information obtained by their sensor equipment to make driving strategies conducive to driving. They do not have a system–body unified scheduling for all CAVs. In this context, the above experimental results are not significantly advantageous for developing single-vehicle intelligence in the mainstream direction promoted today. As CAVs account for an increasing share of road traffic, CAVs will likely adopt conservative measures to drive at low velocities on roads with high CAV penetration. Therefore, a single-vehicle intelligence approach, similar to the one in this study, does not apply to high penetration. Future research on CAV technology should not be limited to single-vehicle intelligence. Rather, it should be directed toward multi-vehicle collaboration to avoid conservative driving behavior ( 26 ). CAV manufacturers can start from the cooperative driving of two vehicles and expand to multiple vehicles. This method can finally expand to the entire road or even the entire road network of all CAV cooperative driving to make the whole area of travel efficient.
To ensure the reliability of the above experimental results, we used the VISSIM microscopic simulation platform for secondary development to evaluate the simulation results of DQN-based driving decisions in the cellular automaton model. Combined with the experimental design of the cellular automata model and considering the limitations of the VISSIM simulation platform itself, the following adjustments were required:
Owing to the limitations of the VISSIM simulation platform, the vehicle input changed from two-lane traffic density to two-lane traffic flow.
To accommodate the different maximum driving velocities of vehicles assumed in the cellular automata model, the expected velocities of the initial input vehicles were distributed equally according to the classification of 60, 70, 80, 90, and 100 km/h.
With the exception of vehicles based on the DQN driving strategy, all vehicles complied with the VISSIM driving rules.
The final simulation results of the VISSIM platform are similar to those of the cellular automata model platform. The average velocities of vehicles with a medium CAV penetration rate were optimal under low- and medium-flow conditions, as shown in Figure 5.
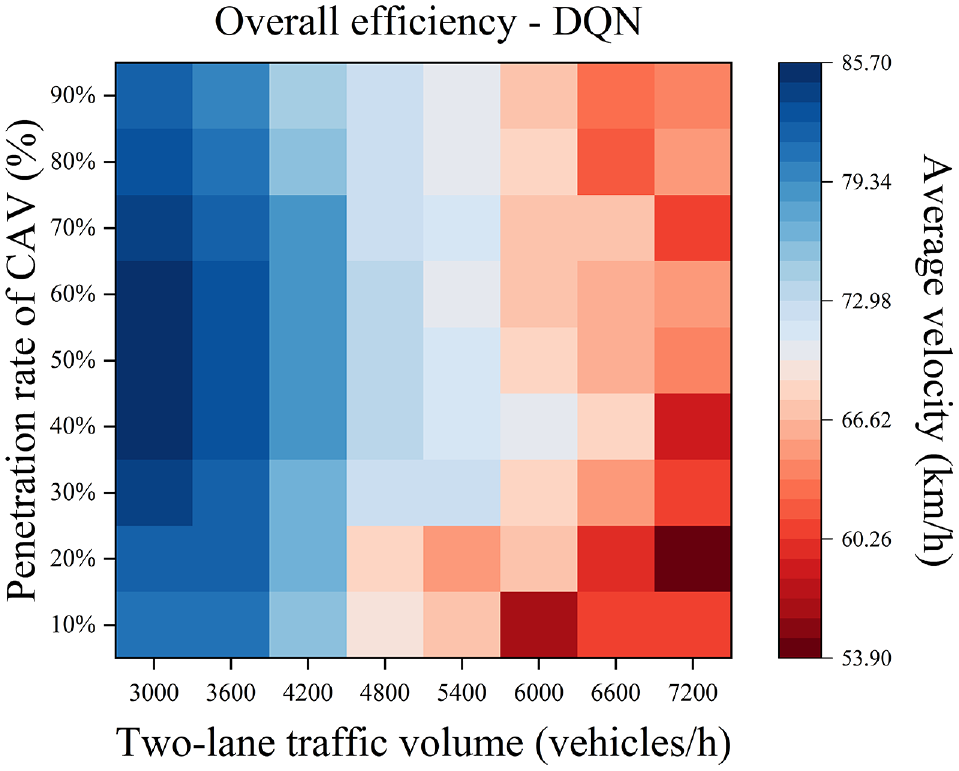
VISSIM simulation platform evaluation experimental results.
Traffic Safety
Assessment of vehicle traffic safety includes the presence of single-behavior threat metrics, optimization methods, formal methods, probabilistic frameworks, and data-driven approaches, such as machine learning ( 27 ). Considering the application scenario of this paper, the TTC index is chosen as the traffic safety assessment criterion ( 28 ). When considering traffic safety, vehicles with a TTC index of less than 1.5 s are identified as having a higher rear-end collision risk factor. Furthermore, the ratio of the number of vehicles to the total number of vehicles is an assessment.

Under different traffic density conditions and CAV penetration rates, DQN-based driving strategy and rule-based driving strategy methods were adopted, respectively. No collisions occurred during the experiment. The experimental results show that the ratio of rule-based driving strategy to high-risk vehicles was approximately zero under low traffic density conditions. That of the DQN-based driving strategy method can be maintained at low values. Under moderate traffic density conditions, the proportion of high-risk vehicles increases with an increase in penetration rates in both vehicles. The performance of the DQN-based driving strategy method was more stable at high densities, with the CAVs remaining at low operational levels. The proportion of high-risk vehicles was within a reasonable range for CAV penetration. Contrastingly, the performance of the rule-based driving strategy was less stable, especially with high CAV penetration, where the proportion of high-risk vehicles approached approximately 30%. The performance details are shown in Figure 6.

Driving safety analysis.
General Analysis
The mean velocities for the CAVs, HDVs, and other vehicles for all densities and CAV penetration rates, and the averages of each distribution proportion of TTC were calculated. The absolute differences between the values obtained using the two strategies were determined. In relation to traffic efficiency metrics, the DQN-based driving strategy was better than the rule-based driving strategy at 7.46, 6.5, and 7.02. In relation to traffic safety, the differences between the two strategies were reduced. The TTC indicator for the DQN-based driving strategy exhibited a more uniform distribution; that is, it fluctuated negligibly under all circumstances. The rule-based driving strategy was more severely polarized when the driving environment was more ideal, whereby the TTC indicators were maintained in an ideal state. Once the driving environment becomes complex, the original driving rules that operate in the driving environment may fail. Therefore, a DQN-based driving strategy is more adaptable to different driving environments than a rule-based driving strategy. When considered together, the DQN-based driving strategy increases the overall vehicle efficiency by 7.02 km/h compared with that of the rule-based driving strategy. In contrast, the rule-based driving strategy resulted in only a 3.77% improvement in the CAV high-risk vehicle ratio. The detailed analysis is presented in Table 2.
Total index analysis

Note: CAV = connected autonomous vehicle; DQN = deep Q-network; HDV = human-driven vehicle; TTC = time to collision.
Conclusions
In this paper, we proposed a driving strategy method based on the DQN algorithm for CAVs in MTF and conducted experiments on the rule-based driving strategy method in a built simulation platform. The details are as follows:
The CAV driving process was divided into four steps. Steps 2 and 3 are vehicle lane-change and car-following policies, respectively. Both steps are MDPs. Subsequently, the state, action, and reward functions were established for both processes.
The DQN algorithm was used to train these two strategy methods. The neural network enables CAVs to select the most effective traffic behavior in an MTF environment.
To verify the validity of this strategy, a simulation platform was established using MATLAB. The proposed strategy was compared with the rule-based CAV driving strategy method. The experimental results were verified using the VISSIM simulation platform. Experimental results show that under low and medium traffic density conditions, this strategy achieved significantly better traffic efficiency than that of the rule-based CAV driving strategy. By contrast, the proportion of high-risk vehicles increased slightly. The CAV penetration rate with the maximum benefit was within the range of 35 to 60%.
The research presented here is limited to the theoretical and simulation stages. The driving strategy method based on the DQN is a discrete model. It reflects the change in traffic flow but not the specific movement of vehicles. In the future, we plan to establish a driving strategy model suitable for a continuous traffic-flow environment and use a simulation model to conduct experiments. An open-source trajectory dataset or actual dataset will be used to validate the proposed strategy method ( 29 , 30 ). With permissible conditions, we will ultimately experiment with real CAVs on road.
Footnotes
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: J. Wang, J. Zhao; data collection: J. Wang, C. Hu; analysis and interpretation of results: J. Wang, C. Hu, J. Zhao; draft manuscript preparation: J. Wang, C. Hu, J. Zhao, S. Zhang, Y. Han. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was financially supported by the National Natural Science Foundation of China under Grant Nos. 52102398 and 52122215 and Science & Technology Commission of Shanghai Municipality under Grant Nos. 23692107600, 22692194300 and 20ZR1439300.
Data Accessibility Statement
The data used to support the findings of the case study are included in the paper.