
Abstract
States, counties, and municipalities rely on pavement performance models to forecast future pavement conditions in their jurisdictions. Accurate prediction is essential for budget planning and the identification of candidates for rehabilitation. This study compares the performance of three different approaches to predict pavement conditions: (1) a sigmoidal or S-shaped curve; (2) a grey system model (GM); and (3) Gaussian process regression (GPR). All three models are trained on the same dataset for two types of pavements, asphalt with and without overlay and composite (i.e., asphalt over concrete), with each having two types of maintenance activities frequently performed by the South Carolina Department of Transportation. The trained models are then applied to separate test datasets. The prediction results indicate that GPR is the best model in three out of four cases using mean absolute error as the performance metric; the exception is the case involving the prediction of pavement serviceability index for asphalt pavement with mill-and-replace 1–2 in. + overlay 400 pounds per square yard rehabilitation treatment. When using mean absolute percentage error and root mean squared error as the performance metrics, the GPR model is the better model for predicting conditions of composite pavements, while the
Keywords
An integral element of a pavement preservation program for any state highway agency, county, or municipality is the ability to predict future conditions of pavements. Pavement performance models are developed for this purpose. In addition to being used to identify sections of roadways that need to be rehabilitated, they are also used to estimate and rationally allocate budget at the network level ( 1 ), evaluate the effectiveness of various rehabilitation treatments, and perform cost and benefit analyses ( 2 ). For these reasons, it is essential that pavement performance models yield accurate predictions of pavement conditions.
Most state agencies use some form of regression model, and some agencies use the S-shaped model, to predict pavement conditions because of their simplicity in model estimation and application ( 3 , 4 ). Both S-shaped models and multiple linear regression models are considered deterministic models. According to Montenegro ( 5 ), as a rule of thumb, a sample size of at least 10 times the number of parameters is needed when the ordinary least squares method is used to estimate the parameters. Thus, if a model has three parameters, the sample size should be at least 30. This sample size requirement is problematic for smaller agencies that do not have the resources to collect pavement condition data frequently. Additionally, there are situations in which the sample size may be limited, such as using project-level pavement condition data to determine the optimal maintenance plan to prolong the life of the pavement.
To overcome the problem of limited sample size, some researchers have explored the use of grey models (GMs) that are based on grey system theory. A GM is a system model based on an ordinary differential equation (ODE) in which some of the model parameters are unknown. GMs are often identified by two parameters,
There is a growing body of literature exploring machine-learning techniques for pavement performance prediction. Computational methods available in the machine-learning field include artificial neural networks, support vector machines, Gaussian process regression (GPR), and recurrent neural networks, among others. Among the machine-learning techniques, GPR has been shown to work well in applications that have small sample sizes ( 7 – 9 ); it is a non-parametric, Bayesian approach to regression. Another strength of GPR is that it does not over-fit the data. To date, no machine-learning methods have been applied to predict pavement conditions using a small sample size. This study seeks to address this gap in the literature. The research questions are: (1) can GPR be used to predict pavement conditions using a relatively small number of observations, and (2) how well does it compare with GMs and deterministic models, particularly an S-shaped model?
The objective of this paper is to assess the performance of GM and GPR models compared with the commonly used S-shaped models to predict pavement conditions using a relatively small sample size. The assessment is performed using South Carolina pavement functional and structural condition data. For the model training and testing, two types of pavements and two types of rehabilitation methods are chosen. The two pavement types are asphalt and composite (i.e., asphalt over concrete). These two pavement types make up the majority of pavements on interstates in South Carolina. The two rehabilitation methods are mill-and-replace 2–4 in. + OL 200 PSY (200 pounds per square yard overlay) and mill-and-replace 1–2 in. + OL 400 PSY. These two rehabilitation methods are the most frequently used treatments in the last 10 years in South Carolina by the number of projects and total lane miles. Once the models are trained, they are evaluated on a separate test dataset using the root mean square error (RMSE), mean absolute percentage error (MAPE), and mean absolute error (MAE) performance measures.
The remainder of this paper is organized as follows. The next section provides a review of relevant studies. The third section presents the methodology and data used in this study. The fourth section presents and discusses the results. Finally, the fifth section provides a summary of the study and concluding remarks.
Literature Review
Many studies have developed methods to predict pavement conditions accurately. The following review is limited to those that used deterministic, GM, and GPR models.
Deterministic Models
Shahin et al. (
10
) evaluated three mathematical curve-fitting techniques for modeling pavement condition index. The model they found to work best is a polynomial function where
State departments of transportation (DOTs) have sponsored several research projects to develop or improve on their existing pavement deterioration models. George et al. ( 15 ) developed an exponential regression model for the Mississippi DOT. Chan et al. ( 16 ) also found exponential regression to model pavement condition rating well for North Carolina DOT. With the goal of using the least number of independent variables, Gulen et al. ( 17 ) developed a regression model for Indiana DOT with age and annual average daily traffic (AADT) as independent variables. Similarly, Kim and Kim ( 18 ) evaluated the performance of three different regression models, with one to three independent variables, for the Georgia DOT. The model with three variables has service year, AADT, and interaction of service year and AADT as independent variables. For Kentucky DOT, Xu et al. ( 19 ) developed a regression model that yielded comparable performance to an artificial neural network. Their regression model has the cracking index, pavement age, average daily traffic, and International Roughness Index (IRI) as the independent variables. Tsai et al. ( 20 ) found the S-shaped or sigmoidal function to provide a good fit in a study sponsored by Georgia DOT.
Grey Model
Yu et al. ( 6 ) proposed a new Pavement Quality Index (PQI) model, which is a weighted function of four factors: 1) pavement condition index, 2) riding quality index, 3) rut depth, and 4) skid resistance index. Because of the need to determine the appropriate weights for these four factors, the authors proposed the use of GM. The authors reasoned that GM is suitable for situations where the collected pavement data may not correlate perfectly with actual conditions. The authors concluded that a GM(1,1) provided reasonable results for predicting the PQI of pavements that received micro-surfacing treatments. Tang and Xiao ( 21 ) also used a GM(1,1) to predict PQI. They found that applying monthly attenuations (defined as the difference in PQI between successive years) not only effectively lowered the condition number of the matrix but also ensured that the relative error was small. Zhang et al. ( 22 ) developed separate GM(1,1) models to estimate pavement smoothness, rut, and skid resistance. They assessed their models’ performance against field-measured data and found them to yield excellent accuracy based on the residuals and grey absolute correlation. Unlike previous studies, Du and Shen ( 23 ) derived a multivariate GM for which the function contains the previously measured rut depth and the number of loading cycles representing the traffic loading. Since there are two variables, their GM is a GM(1,2). Their analysis showed that 95 of the 96 rutting predictions were within the 2.5 mm tolerance level.
Gaussian Process Regression
The only study that has applied GPR to predict road surface conditions is the work of Heyns et al. ( 24 ). The authors proposed a speed calibration methodology, in which the underlying condition of the road is considered during the calibration phase. This approach makes it possible to obtain a dynamic calibration function that adjusts itself to the instantaneous nature of the road that the vehicle traverses. The dynamic calibration function was implemented by GPR. The results indicated that the proposed methodology may potentially be of use as a generic, simple, and cost-effective approach to perform real-time road condition monitoring.
Literature Review Summary
From the above review, it can be concluded that prior work using GM or GPR to predict pavement conditions is inconclusive in regard to their performance against commonly used deterministic methods for different pavement types and treatment types. To address this shortcoming, this study is the first to assess the performance of a GM and a GPR model to predict the condition of asphalt and asphalt over concrete pavements for mill-and-replace rehabilitation methods. The aim is to gain insight into whether a semi-parametric model (GM) and a non-parametric model (GPR) outperform the traditional parametric model (S-shaped).
Methods
Data Description
The primary interest of this study is to model pavement deterioration over time after receiving a rehabilitation treatment. The pavement serviceability index (PSI), a measure of pavement rideability, and pavement distress index (PDI), a measure of pavement distress, were selected to represent the pavement functional and structural conditions for which we want to estimate ( 4 ). PSI and PDI are two indices used by the South Carolina DOT (SCDOT) to quantify PQI. PQI is an overall rating index with a theoretical scale from 0 to 5, where 5 is considered a perfectly plane and distress-free pavement. PSI is related to the IRI as shown in the following equation.

Equation 1 yields a PSI value between 0 and 5, where 5 represents a perfectly smooth pavement surface. IRI is collected every one-tenth of a mile and is measured in inches per mile. For modeling purposes, an average PSI is used for the entire road section that was rehabilitated. Thus, each road section, regardless of its length, will have only one PSI value. For example, if a rehabilitation project involves a 1 mi long road section, then 10 IRI measurements are used to compute an average IRI per year, from which the average PSI is determined using Equation 1.
To calculate PDI, detailed distress data must be converted into a single scale index. For flexible (bituminous and composite) pavements, there are six recognized types of distresses: fatigue cracking, transverse cracking, longitudinal cracking, rut depth, patching, and raveling. For rigid (concrete) pavements, eight types of distresses are observed: surface deterioration, transverse cracking, longitudinal cracking, patching, punchouts, spalling, faulting, and pumping. The distress data are input as extent (percentage distressed area) and severity (low, moderate, high) for each observed distress location. The procedure SCDOT uses to calculate PDI is described in a report entitled South Carolina HPMA Index Models developed by Stantec ( 25 ). Similar to PSI, a PDI ranges from 0 to 5, where 5 represents a perfect (distress-free) pavement.
The PSI and PDI data used to train and test the performance of the models (S-shaped, GM, and GPR) in this study were provided by SCDOT. These data are shown in Tables 1 to 4. Each table contains data collected for a particular type of pavement that received a specific type of rehabilitation treatment. SCDOT has a different prediction model for each combination of pavement type and rehabilitation method. Each of the four datasets shown in Tables 1 to 4 is used to train and test the models (
4
). About 70% of the observations
Segments Containing PSI and PDI Data for Mill-and-Replace 2–4 in. + OL 200 PSY for Asphalt Pavement

Note: PSI = pavement serviceability index; PDI = pavement distress index; OL 200 PSY = 200 pounds per square yard overlay; N = north; W = west; S = south.
Segments Containing PSI and PDI Data for Mill-and-Replace 2–4 in. + OL 200 PSY for Asphalt over Concrete Pavement
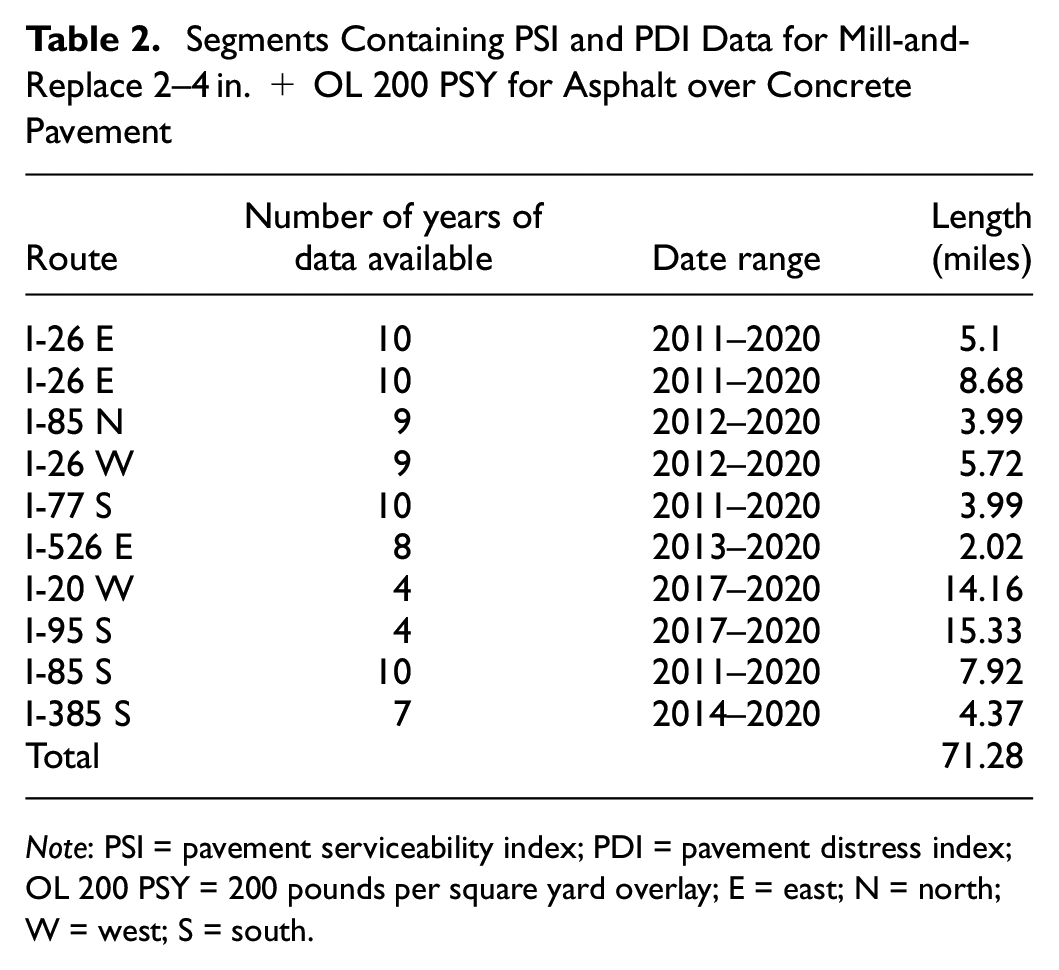
Note: PSI = pavement serviceability index; PDI = pavement distress index; OL 200 PSY = 200 pounds per square yard overlay; E = east; N = north; W = west; S = south.
Segments Containing PSI and PDI Data for Mill-and-Replace 1–2 in. + OL 400 PSY for Asphalt Pavement

Note: PSI = pavement serviceability index; PDI = pavement distress index; OL 400 PSY = 400 pounds per square yard overlay; E = east; W = west; S = south; N = north.
Segments Containing PSI and PDI Data for Mill-and-Replace 1–2 in. + OL 400 PSY for Asphalt over Concrete Pavement
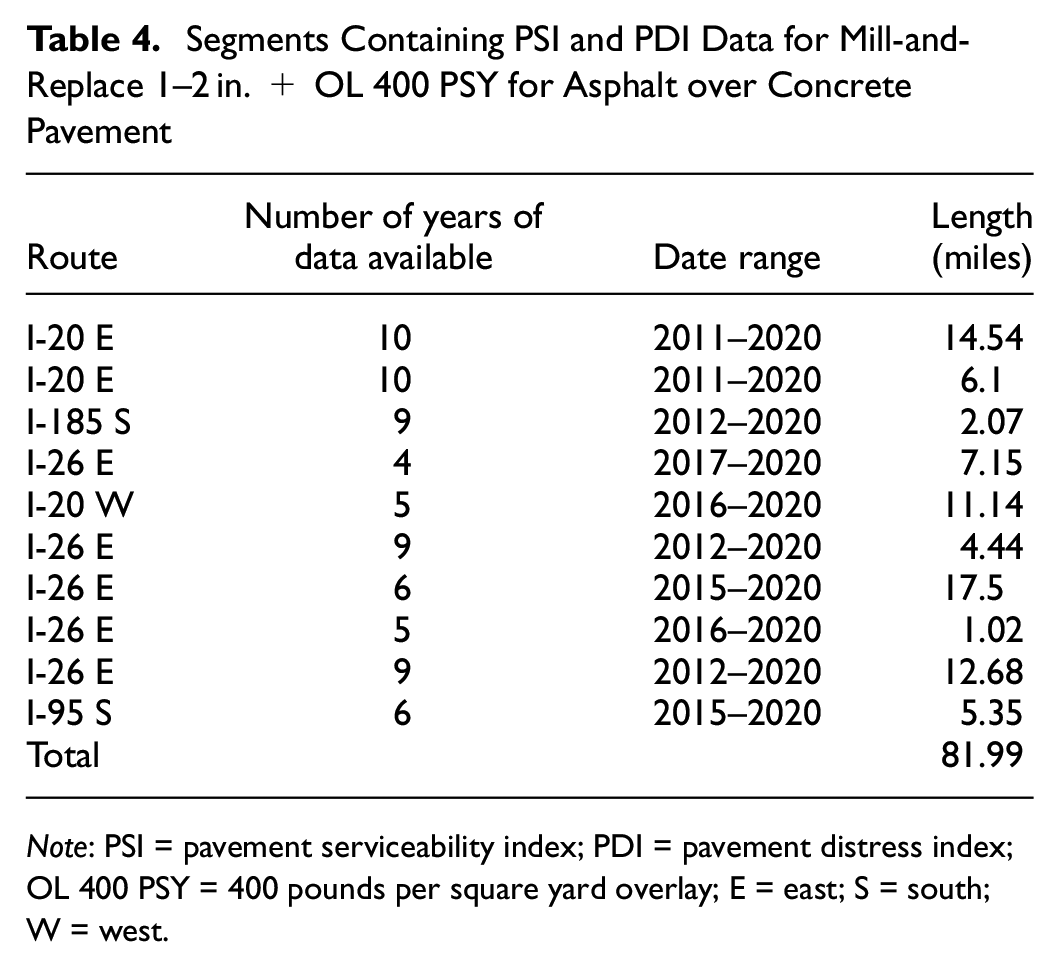
Note: PSI = pavement serviceability index; PDI = pavement distress index; OL 400 PSY = 400 pounds per square yard overlay; E = east; S = south; W = west.
Figures 1 and 2 show the average PSI and PDI of each segment over time for each treatment method and pavement type, respectively. Note that year 0 denotes the year the pavement segment was rehabilitated. It can be seen that the average PSI trends do not exhibit a monotonic decreasing trend. Taking Figure 2a (MR 2–4 in. + OL 200 PSY for asphalt pavement), for example, the PSI decreased slightly from year 7 to 8 and increased from year 8 to 9. Possible reasons include the use of different segments across the entire state and the use of different equipment and vendors to collect the IRI. Also, note that the PSI and PDI data exhibit serial correlation and are non-stationary.
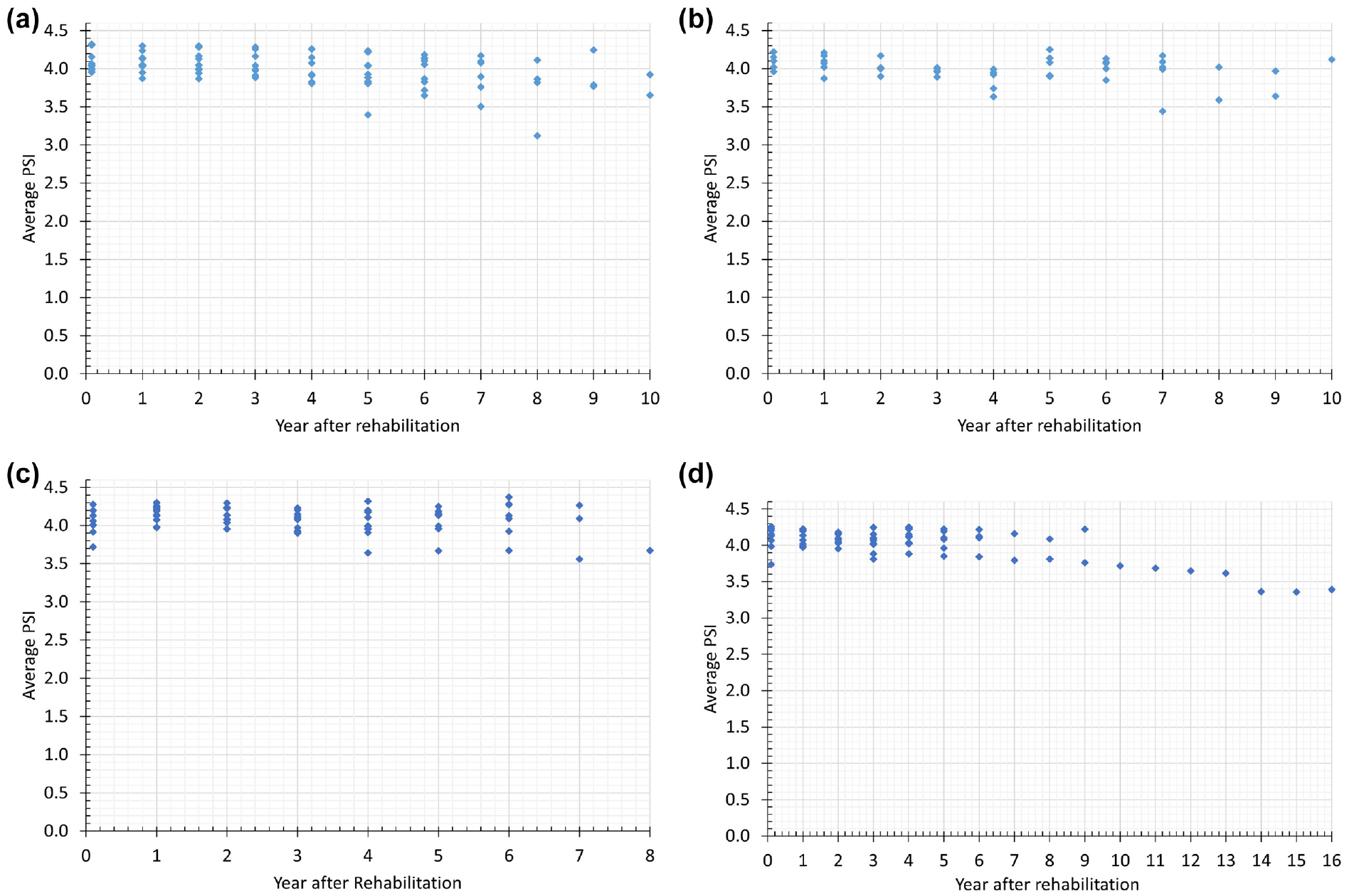
Average PSI of segments by treatment method and pavement type: (a) MR 2–4 in. + OL 200 PSY for asphalt pavement, (b) MR 2–4 in. + OL 200 PSY for asphalt over concrete pavement, (c) MR 1–2 in. + OL 400 PSY for asphalt pavement, and (d) MR 1–2 in. + OL 400 PSY for asphalt over concrete pavement.
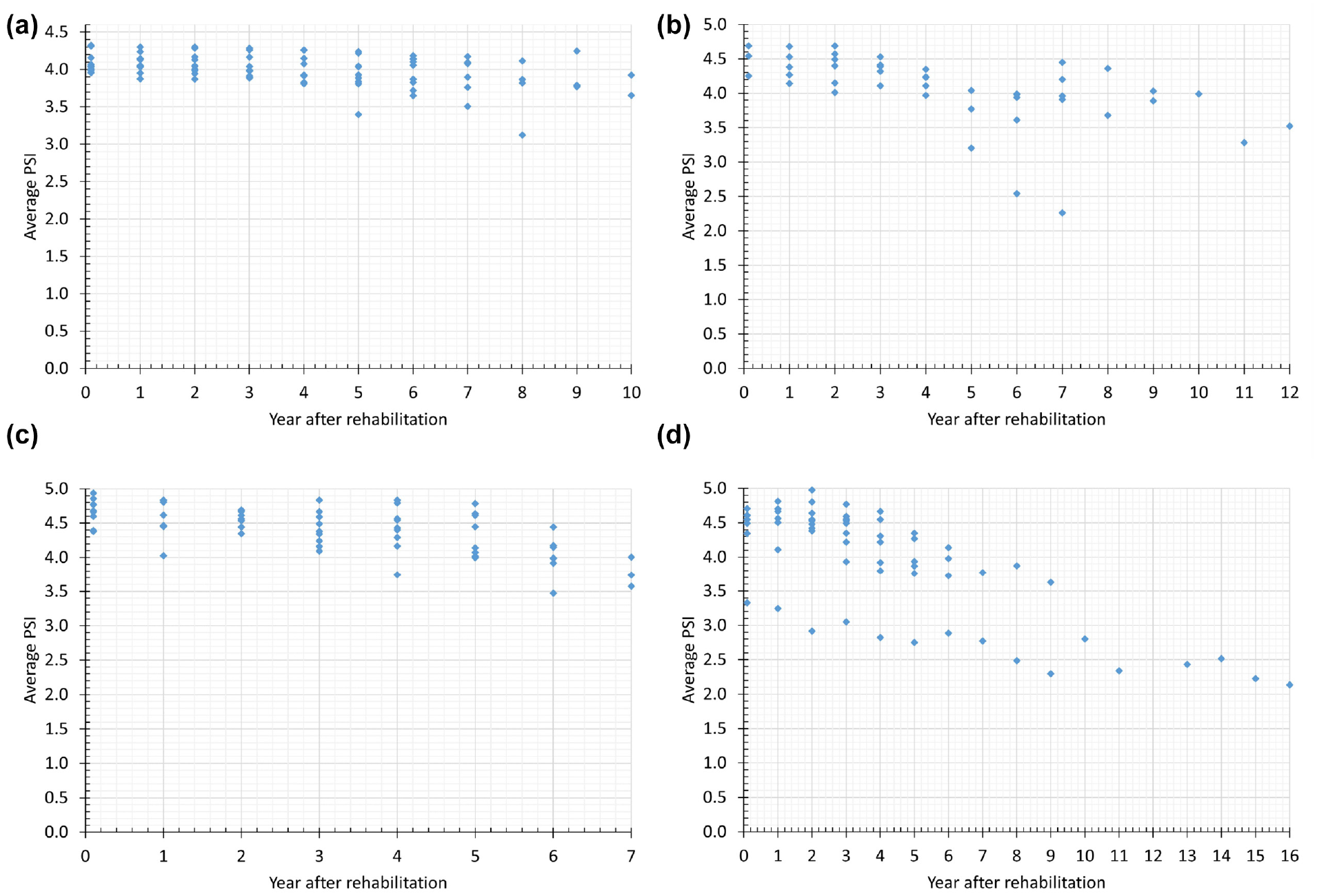
Average PDI of segments by treatment method and pavement type: (a) MR 2–4 in. + OL 200 PSY for asphalt pavement, (b) MR 2–4 in. + OL 200 PSY for asphalt over concrete pavement, (c) MR 1–2 in. + OL 400 PSY for asphalt pavement, and (d) MR 1–2 in. + OL 400 PSY for asphalt over concrete pavement.
Grey System Model—GM(1,1)
To model a time series, grey system theory (
26
) provides a family of GMs, where the most basic one is the first-order GM with one variable, often referred to as GM(1,1). The principles and estimation of GM(1,1) are briefly discussed here. Readers are referred to the work of Ju-Long (
25
) for additional information. Suppose that

The original form of GM(1,1) is defined by the following equation ( 4 ).

Let
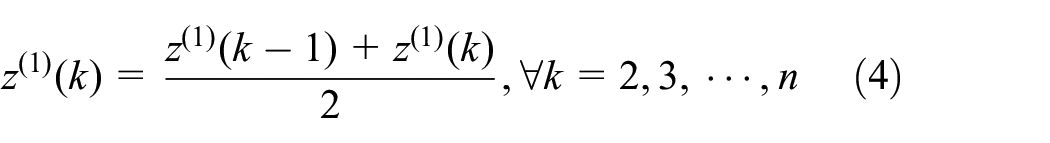
The basic form of GM(1,1) is given by the following equation.

If
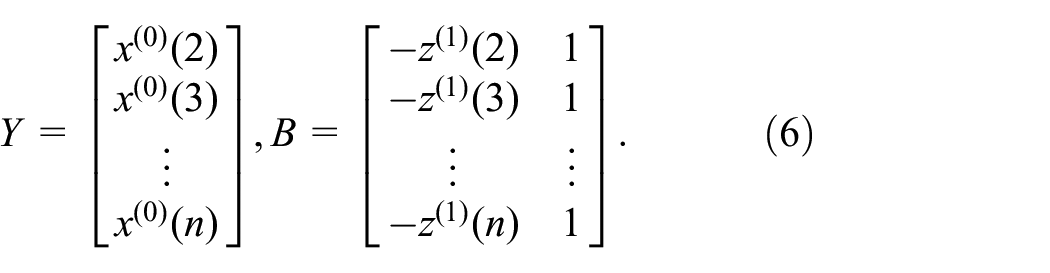
then, as in the work of Liu and Lin (
27
), the least squares estimate of the GM(1,1) model is

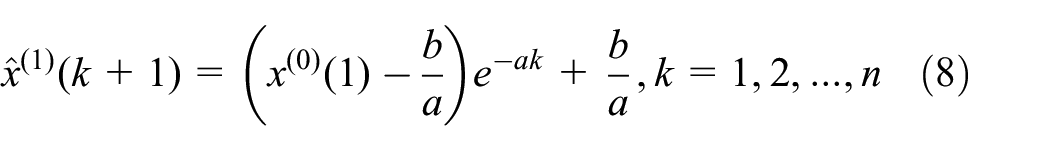
According to the definition in Equation 5, the restored values of
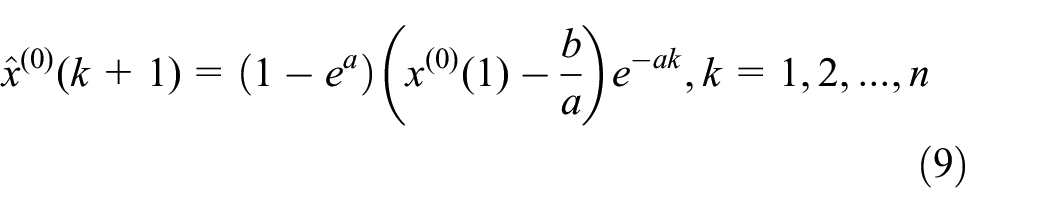
which can be used to produce forecasts for
In this study, Equation 9 is the main forecasting equation that generates values
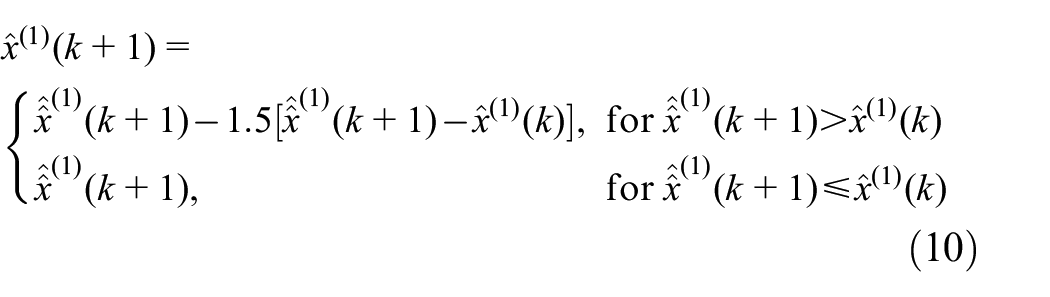
The number of conditions of the GM model matrix needs to be small to produce accurate estimates. A condition number for a matrix and related computational task measures how sensitive the answer is to perturbations in the input data and roundoff errors made during the solution process. The definition of the condition number depends on the choice of norm. When a matrix is said to be “ill-conditioned,” it refers to the sensitivity of its inverse, that is, of the condition number for inversion, and not of all the other condition numbers. If the condition number is not too much larger than one, the matrix is well-conditioned, which means that its inverse can be computed with good accuracy. If the condition number is very large, then the matrix is said to be ill-conditioned. Practically, such a matrix is almost singular, and the computation of its inverse, or solution of a linear system of equations, is prone to large numerical errors. If a matrix is not invertible, the condition number is taken to be infinity.
When applying the GMs to predict pavement condition using the South Carolina PSI and PDI data shown in Tables 1 to 4, its matrix was found to be ill-conditioned. This is because of having values that are similar or repeating in the input data. This general problem of the grey GM(1,1) model has been observed by Tang and Xiao (
21
). To overcome this issue, a Gaussian noise
GPR Models
Figure 3 shows the steps followed in this study to train and test the GPR model. Following the methodology presented in Zeng et al. ( 28 ), the prediction function of a linear regression model is:

where
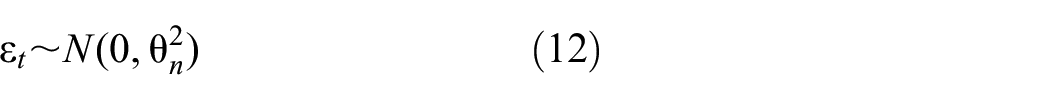

GPR model development and testing procedure.
The marginal likelihood of the sample data can be expressed as follows:

where
Given the observed outputs


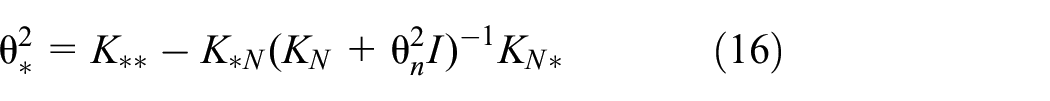
In the above equations,
The kernel, also known as the covariance function, plays a fundamental role in characterizing the covariance of the Gaussian process random variables. In conjunction with the mean function, the kernel serves as the defining component of a Gaussian process. An inherent problem with all kernels employed in GPR models (e.g., covLIN, covLINard, covMaterniso, covNoise, covPeriodic, covRQard, and covRQiso) is the adaptation to the trends observed in the training datasets, thereby producing predicted PSIs that could fluctuate from year to year, which would be incorrect. The pavement deterioration rate is expected to be monotonically decreasing. That is, the PSI of a pavement segment in a given year cannot be greater than the PSI from the previous year unless it was rehabilitated. To overcome the kerner’s inherent fluctuation characteristic, this study proposes to combine the following two kernels to yield the desired pavement deterioration behavior, thereby improving the model’s predictive power.
Radial-basis function (RBF) kernel:
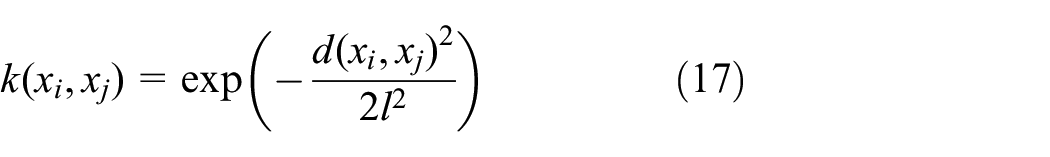
where
Matern kernel:
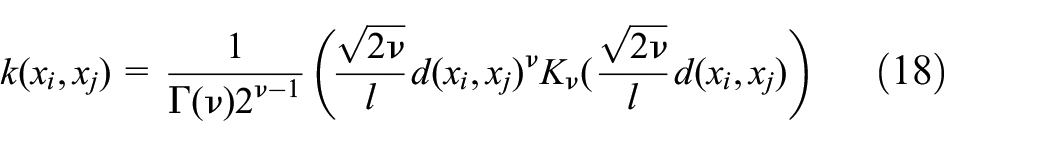
where
Results and Discussion
To evaluate the performance of the GM(1,1) model and the GPR model, their predicted PSI and PDI for the test datasets were compared against the predicted values of the following S-shaped model ( 29 ):

where
The metrics used to assess the performance of the models were: RMSE, MAE, and MAPE. According to Uwanuakwa et al. ( 30 ), evaluation of model performances should include RMSE and MAE at a minimum.
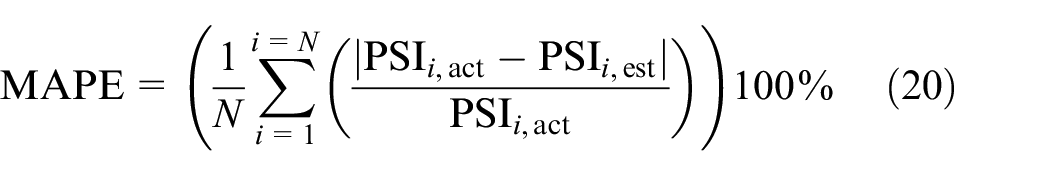
where


As mentioned in the “Methods” section, a contribution of this study is the use of a smoothing function (i.e., Equation 10) with the GM(1,1) model to avoid having a predicted PSI or PDI higher than the previous value. The effect of smoothing can be observed in Figure 4a. Another contribution is the use of two kernels (i.e., radial basis and Matern) instead of just one (radial basis) for the GPR model. The effect of using two versus one kernel for the GPR model can be observed in Figure 4b. In the following, all reported results for the GM(1,1) model include the use of the smoothing function and all reported results for the GPR model are with two kernels.
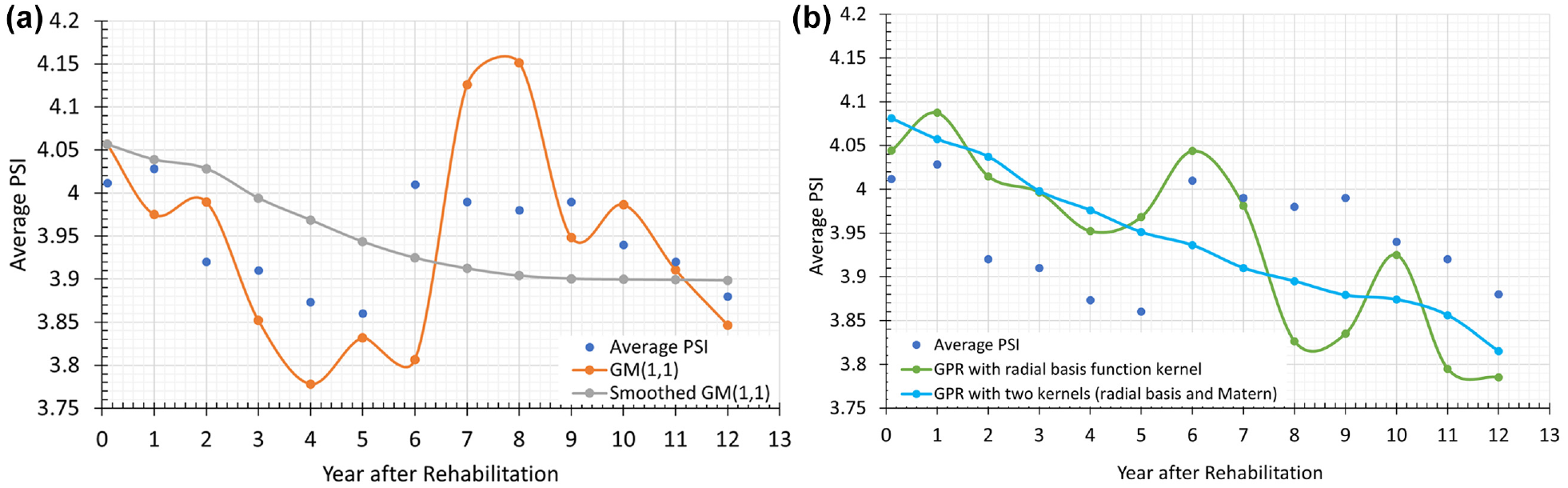
Comparison of GM(1,1) with and without smoothing and GPR with one and two kernels: (a) GM(1,1) model for MR 1–2 in. + OL 400 PSY for asphalt pavement and (b) GPR Model for MR 1–2 in. + OL 400 PSY for asphalt pavement.
The actual versus predicted PSIs and PDIs are shown in Figures 5 to 8. These plots allow for easier assessment and comparison of models’ performance. The predicted range is based on the number of years for which the data are available in the test datasets. The results of GM(1,1) are based on an interval size,

Comparison of estimated PSI/PDI for asphalt pavement and MR 1–2 in. + OL 400 PSY rehabilitation treatment: (a) comparison of estimated PSI for asphalt pavement and MR 1–2 inches + OL 400 PSY rehabilitation treatment and (b) comparison of estimated PDI for asphalt pavement and MR 1–2 inches + OL 400 PSY rehabilitation treatment.
Comparison of estimated PSI/PDI for asphalt over concrete pavement and MR 1–2 in. + OL 400 PSY rehabilitation treatment: (a) comparison of estimated PSI for asphalt over concrete pavement and MR 1–2 in. + OL 400 PSY rehabilitation treatment and (b) comparison of estimated PDI for asphalt over concrete pavement and MR 1–2 inches + OL 400 PSY rehabilitation treatment.

Comparison of estimated PSI/PDI for asphalt pavement and MR 2–4 in. + OL 200 PSY rehabilitation treatment: (a) Comparison of estimated PSI for asphalt pavement and MR 2–4 in. + OL 200 PSY rehabilitation treatment and (b) comparison of estimated PDI for asphalt pavement and MR 2–4 in. + OL 200 PSY rehabilitation treatment.
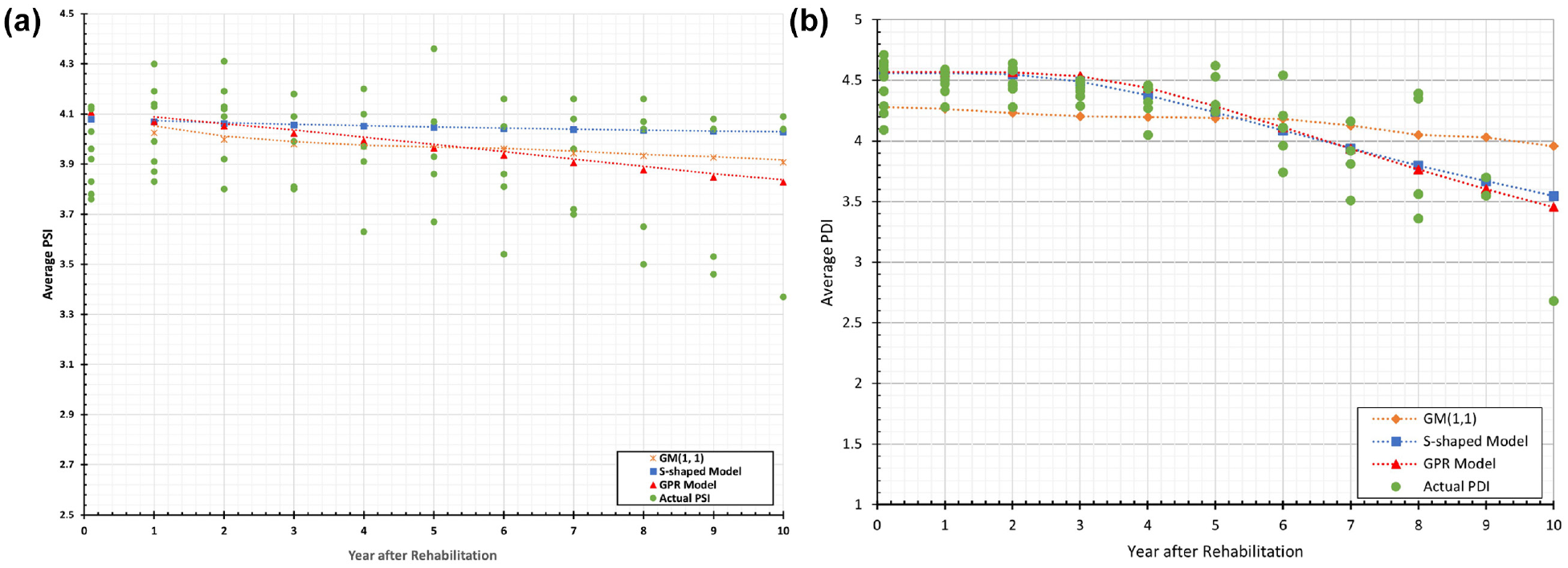
Comparison of estimated PSI/PDI for asphalt over concrete pavement and MR 2–4 in. + OL 200 PSY rehabilitation treatment: (a) Comparison of estimated PSI for asphalt over concrete pavement and MR 2–4 in. + OL 200 PSY rehabilitation treatment and (b) comparison of estimated PDI for asphalt over concrete pavement and MR 2–4 in. + OL 200 PSY rehabilitation treatment.
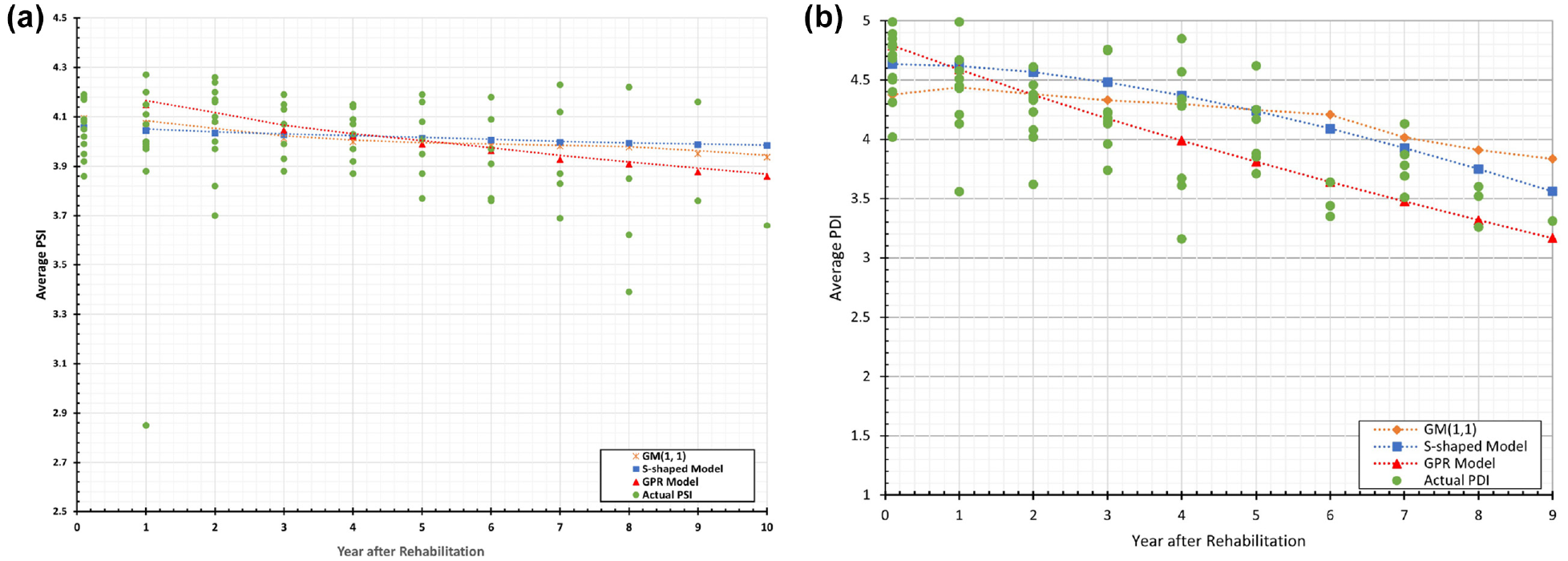
MR 1–2 in. + OL 400 PSY for Asphalt Pavement
It can be seen in Figure 5 that there is a significant variation in the average PSI and PDI between route segments. For example, two years after an asphalt pavement received the MR 1–2 in. + OL 400 PSY rehabilitation treatment, one segment has an average PSI as low as 3.0 while another segment has an average PSI as high as approximately 4.28. It can be seen visually that the GPR and
Actual versus Predicted PSIs/PDIs for Different Pavement Types and Rehabilitation Methods

Note: PSI = pavement serviceability index; PDI = pavement distress index; MAPE = mean absolute percentage error; RMSE = root mean square error; MAE = mean absolute error; MR = rehabilitation method; OL 200/400 PSY = 200/400 pounds per square yard overlay; GM = grey system model; GPR = Gaussian process regression.
MR 1–2 in. + OL 400 PSY for Asphalt over Concrete Pavement
Similar to the results shown in Figure 5, there is a significant variation in the average PSI and PDI between route segments for asphalt over concrete pavements that received MR 1–2 in. + OL 400 PSY rehabilitation treatment as shown in Figure 6. By inspection, it can be seen that the GPR model predicted the fastest deterioration rate, followed by
MR 2–4 in. + OL 200 PSY for Asphalt Pavement
The actual and predicted PSIs and PDI for asphalt pavements after receiving the MR 2–4 in. + OL 200 PSY rehabilitation treatment is shown in Figure 7. Similar to the trends shown in Figure 6, it can be seen that the GPR model predicted faster pavement deterioration compared with
MR 2–4 in. + OL 200 PSY for Asphalt over Concrete Pavement
The actual and predicted PSIs and PDI for asphalt over concrete pavements after receiving the MR 2–4 in. + OL 200 PSY rehabilitation treatment are shown in Figure 8. For this combination of pavement type and rehabilitation method, all three models produced estimates that are close to one another. A close inspection shows that the
Discussion
The model validation results indicate that both the
Aside from their methodological differences, there are two main practical differences between the S-shaped, GM(1,1), and GPR models. The first is that the GPR and GM(1,1) models do not necessarily predict a higher rate of deterioration as the pavement gets older as is the case with S-shaped model. The second practical difference is that the GM(1,1) model runs in a rolling horizon manner, and thus, it makes use of the latest available data. As such, it is better at capturing potential abrupt changes in pavement conditions. From an implementation perspective, the S-shaped model is the easiest to implement; it can be set up and run on a spreadsheet. On the other hand, a GPR or GM(1,1) model will require the use of a programming and numeric computing platform such as MATLAB or Python.
Summary and Conclusions
This study evaluated the performance of three different approaches to predict pavement functional conditions (PSI) and pavement structural conditions (PDI) from South Carolina. The aim was to determine whether a semi-parametric model (GM) and a non-parametric model (GPR) outperform the traditional parametric model (S-shaped). After training the models on the training datasets, they were then tested on separate test datasets. The prediction results for both PSI and PDI indicated that the
The study demonstrated the applicability and effectiveness of using
Footnotes
Authors Contribution
The authors confirm contribution to the paper as follows: study conception and design: J. Wang, G. Comert, N. Begashaw, N. Huynh, A. Kouyate, R. Mullen, S. Gassman, and C. Pierce; data collection: A. Kouyate; analysis and interpretation of results: J. Wang, G. Comert, N. Huynh, and A. Kouyate; draft manuscript preparation: J. Wang, G. Comert, N. Begashaw, N. Huynh, A. Kouyate, R. Mullen, S. Gassman, and C. Pierce. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The study was supported by the South Carolina Department of Transportation (SCDOT) [grant number: SPR No. 743].
Any opinions, findings, conclusions, or recommendations expressed in this paper are those of the authors and do not necessarily reflect the views of the SCDOT.