
Abstract
Traffic sign recognition is a crucial method by which autonomous driving systems acquire road information, and is predominantly based on deep neural networks (DNNs). However, the recognition results of DNNs are not always trustworthy for traffic signs subject to abnormal disturbance. Recently, the phenomenon of adversarial examples successfully deceiving DNNs has garnered considerable attention. Because DNN-based computer vision techniques are becoming increasingly prevalent in traffic scenarios, the misclassification of attacked traffic signs by DNN classifiers poses serious safety hazards. Although numerous methods have been proposed for crafting physical adversarial examples that are robust in the real world, most existing defense approaches focus on digital attacks, which necessitate the adversary infiltrating the embedded system; thus, it becomes challenging to obtain results. A reliable approach for defending against physical adversarial traffic signs enables autonomous vehicles to achieve trusted perception of traffic signs. In this paper, we present a deep image prior-based pipeline to defend against robust adversarial traffic signs in the real world, an approach that circumvents the need for prior data sets during training. Our approach protects the safety of autonomous vehicles by performing image reconstruction of captured traffic sign images. The genuine traffic sign class can be inferred by leveraging the consistency of the victim classifier’s decision results for reconstructed images at different stages. Additionally, we evaluate the efficacy of our defense pipeline for detecting other potential types of physical adversarial traffic signs that may exist in the real world, thus demonstrating the generalizability of our approach.
Keywords
Traffic sign recognition is an important approach through which autonomous vehicles acquire road information. Vehicles need to recognize traffic signs correctly and follow their instructions. However, traffic signs subject to abnormal disturbance can easily fool deep neural network (DNN)-based identification techniques, and misclassification is the result. Recently, the existence of attacked adversarial traffic signs has cast doubt on the credibility of DNN-based traffic perception technology. The rapid development of deep learning technology has led to the widespread application of computer vision to various tasks such as image classification, image segmentation, and target detection ( 1 , 2 ). Advanced DNN-based computer vision techniques provide powerful perception tools for complex traffic scenarios ( 3 ) and provide critical technical support in the deployment of autonomous vehicles. However, although the latest results from DNNs have shown great power ( 4 , 5 ), they have also demonstrated that neural networks are susceptible to deception by intentionally crafted distorted natural images with tiny perturbations added, even though these perturbations are imperceptible to humans. Deng et al. ( 3 ) provide an in-depth analysis of several adversarial attacks and defense methods for driving models employed by self-driving cars, demonstrating that adversarial attacks pose a significant security threat to autonomous driving. Arnab et al. ( 6 ) present the first rigorous evaluation of modern semantic segmentation models designed to counter adversarial attacks, showing that model performance degrades significantly after an attack, posing a potential risk to autonomous vehicles.
Physical adversarial traffic signs are more common and practical in the real world. Depending on the mode of deployment, adversarial attacks can be categorized into digital attacks and physical attacks. Digital attacks refer to attacks on digital pixels after the camera image is taken, whereas physical attacks refer to attacks on physical objects before the camera image is taken. Many studies ( 7 – 10 ) have proposed different methods for generating digital adversarial examples (AEs), but the utility of these has not been proved fully because of the challenge of intervening in the embedded system to perturb the images captured by a camera. Lu et al. ( 11 ) indicated that certain AEs generated by minor perturbations to the image in carefully chosen directions are not sufficient to cause great concern. Robust physical AEs may be of more practical relevance.
There have been many studies devoted to generating physical adversarial traffic signs capable of deceiving CV systems ( 12 – 18 ); these traffic signs are misidentified by classifiers, for example, misidentifying “No passing” as a speed limit sign “60,” which severely threatens personal safety. However, effective defense methods against physical adversarial traffic signs still need to be proposed. Wei et al. ( 19 ) divided existing physical adversarial defense methods into preprocessing, in-processing and post-processing according to different stages, suggesting that existing physical adversarial defense methods are primarily for adversarial patches. However, in the real world, physical adversarial traffic signs are generated in a variety of ways. In addition to adversarial patches, robust adversarial traffic signs crafted by Duan et al. and Huang et al. ( 14 , 20 ), optical adversarial signs introduced in Sitawarin et al., Zhong et al., and Giulivi et al. ( 13 , 21 , 22 ), and adversarial scratches on traffic signs have been proved to work well in the real world, a factor that significantly challenges the reliability of autonomous vehicles. Therefore, it is crucial to propose a valid defense strategy for these traffic signs.
A reliable approach for defending against physical adversarial traffic signs enables autonomous vehicles to achieve trusted perception of traffic signs. In this paper, a classifier-oriented effective defense method against physical adversarial traffic signs is proposed, and the deep image prior (DIP) ( 23 ) algorithm is introduced to reconstruct traffic sign images. Because of the simplicity and robustness of the characteristics of traffic signs, we infer the true class of a traffic sign based on the decision-making result of the victim classifier during image reconstruction; the result can then be classified into the post-processing defense mechanism ( 19 ).
Compared with existing physical adversarial defense methods, our method does not require a large-scale training set of physical AEs, nor does it need to train the network in advance but uses traffic signs in the process of image reconstruction based on DIP to deduce the true class. In addition, we find this method is also suitable for optical adversarial traffic signs and has a detection effect on adversarial signs in out-of-distribution attacks, indicating that our method has good generalization to various types of physical adversarial traffic signs. Our main contributions are as follows:
Based on the inherent priors of traffic signs, we propose an effective defense method for classifiers against physical adversarial traffic signs. This approach is easily deployable and serves to address the existing research gap in physical adversarial defense methods.
By leveraging the decision consistency of the classifier across different reconstruction stages, our method operates without the need for training data and advanced training.
We conduct extensive testing to assess the generalization capability of our method when handling various types of physical adversarial traffic signs present in real-world scenarios. The results demonstrate that our method exhibits a certain degree of defensive effectiveness against diverse types of physical adversarial traffic signs.
Related Works
AEs
In 2013, when studying the task of image classification, Szegedy et al. ( 4 ) found that adding tiny perturbations imperceptible to humans to the input image could cause serious incorrect classification by deep learning models, calling the disturbed image an adversarial example. The research on AEs is divided into two parts: attack; and defense. Attack refers to algorithms that generate AEs to disrupt the performance of deep learning models. Defense refers to algorithms that make deep learning models free from misrepresentation caused by AEs.
Depending on the mode of attack, AEs are categorized as digital adversarial examples and physical adversarial examples. Digital adversarial attacks ( 24 , 25 ) do not perturb the real-world target itself but, instead, add noise to the digital image after the photo image has been taken. Physical attack ( 26 – 28 ) interferes with the target, which has strong attack robustness in the real world, before the photo image is taken. A clean image is an image that has not been attacked in any way. With reference to the practice in Sitawarin et al. ( 13 ), to facilitate the image capture of traffic signs from various angles to verify that the resulting images successfully attack the classifier in all directions, we deploy traffic signs on walls outdoors in changing light conditions. An example of a physical adversarial traffic sign is shown in Figure 1.

Physical adversarial traffic sign in the real world.
Designing Robust Physical Adversarial Traffic Signs
The earliest attempts at physical AEs were carried out by Kurakin et al. ( 29 ), who printed out virtual AEs, photographed them, and passed them to a classifier. With some researchers questioning the effectiveness of such AEs in the real world, Athalye et al. ( 30 ) proposed the expectation over transformation method for generating physically robust AEs. Ivan et al. ( 31 ) drew on this approach to attack traffic sign recognition systems without considering the effects of different physical conditions. In the physical world, if an adversarial traffic sign easily loses its adversarial effect as a result of changes in brightness, viewing angle, and distance, it means that such an adversarial sign is not robust and is not enough to pose a threat to people. To create robust physical adversarial traffic signs, the dynamic arterial-responsive traffic system (DARTS) is proposed to introduce two methods as in Sitawarin et al. ( 13 ): out-of-distribution attacks; and in-distribution attacks. Out-of-distribution attacks enable the adversary to start from an arbitrary point in the image space to generate AEs, whereas in-distribution attacks carry out target attacks on traffic signs to generate physical adversarial traffic signs robust to changes in brightness, viewing angle, and distance. In our paper, generation of the robust adversarial traffic signs effective in the real world is based on DARTS.
To address the challenge of producing printable physical adversarial traffic signs in the real world, our pipeline consists of the following steps according to Sitawarin et al. ( 13 ):
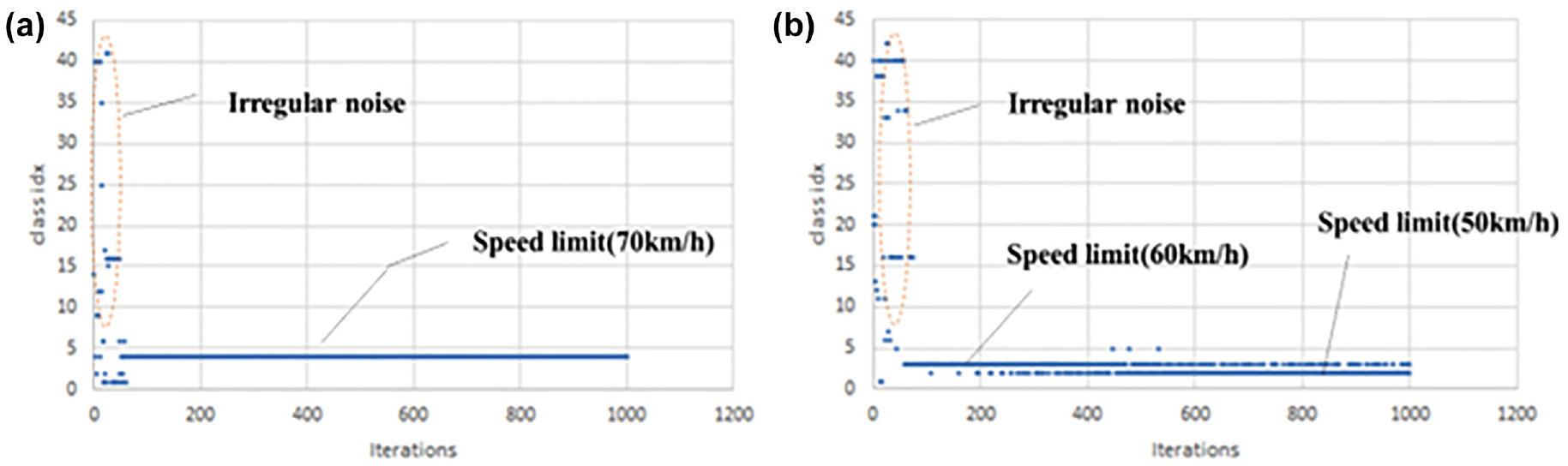
To generate robust adversarial traffic signs, let x be the input image and δ the adversarial perturbations. It is necessary to solve the following optimization problem:
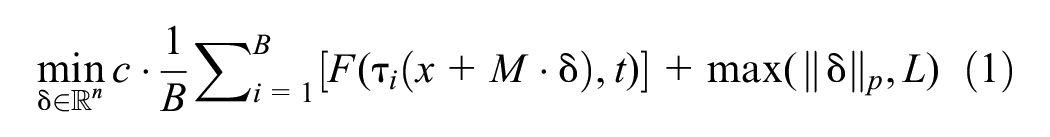
where M is the generated mask
Existing Defense Method against Physical AEs
Although many methods have been proposed to defend against digital AEs, physical AEs with strong noise are hard to defend against with such methods. Existing physical adversarial defense methods can be summarized as follows: preprocessing; in-processing; and post-processing according to different stages ( 19 ). Preprocessing methods include image completion ( 32 – 34 ) and image smoothing ( 35 , 36 ), which primarily defend against adversarial patches. In-processing methods are designed to improve the robustness of the DNN model itself, and these include adversarial training and structural modification, which require many prior physical AEs as the training set. The post-processing defense mechanism refers to human thinking patterns and the incentive model. After making preliminary predictions, more factors are combined to test the consistency of logic before obtaining the final classification results. This method tends to be more reliable, and our approach falls into this category.
Methodology
Motivation
Our defense pipeline is motivated by Dai et al. ( 37 ), and it studies image reconstruction from a robust/non-robust feature learning perspective. It suggests that the DIP reconstruction process undergoes two stages of feature learning. In the early stage it focuses on reconstructing the robust features in the image, but as the iterations increase it focuses on learning the non-robust features in the image, which is consistent with our findings in reconstructing physical adversarial traffic signs using DIP.
It is worth noting that for traffic signs, the recognition features are relatively simple and unique. During image reconstruction, the process of learning robust features or non-robust features presents phased characteristics, and is manifested by the preference of the classifier’s classification results for a certain class. We use the maximum frequency class to represent the main features learned by the generator at this stage.
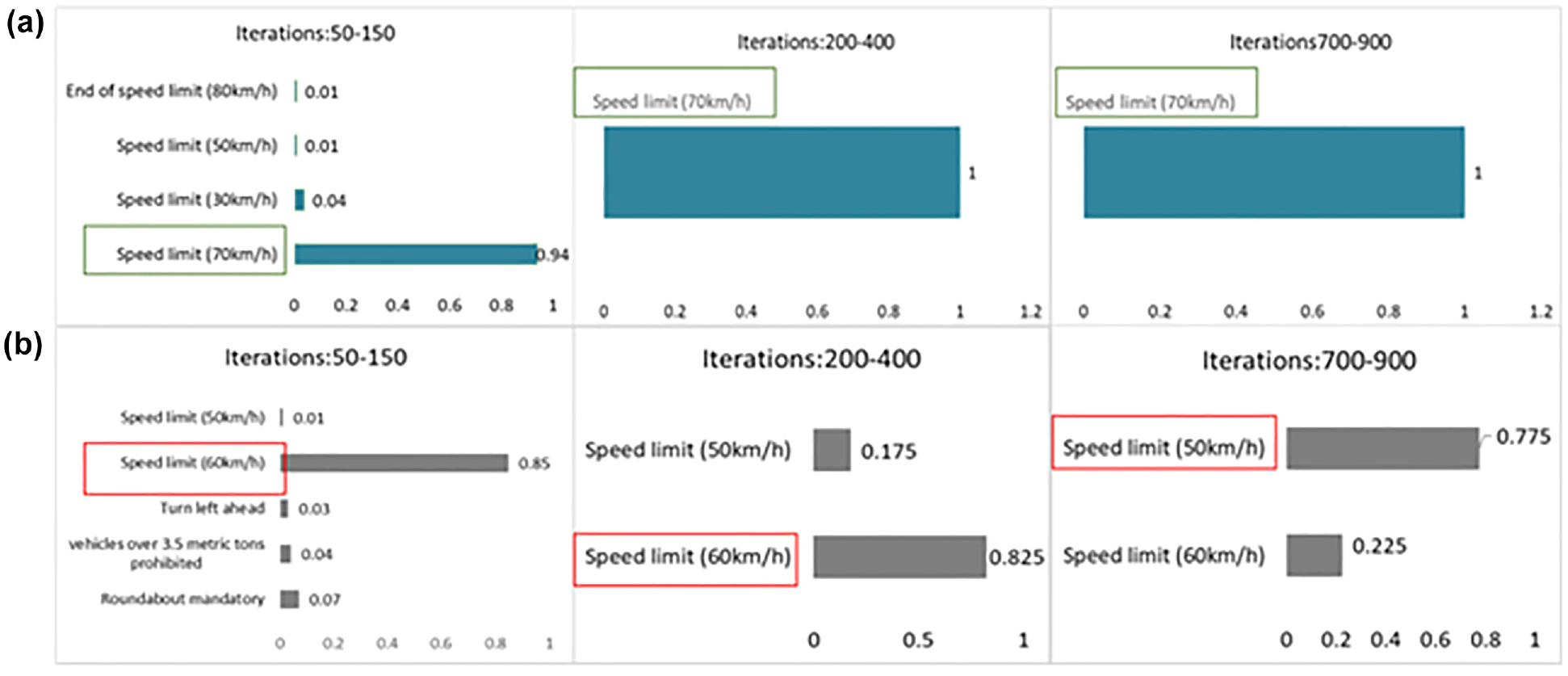
Figure 2 shows the distribution of classification results for traffic sign reconstruction images as given by the classifier at different stages. Figure 3 shows the alteration of classification results as iterations increase. Irregular noise originates from the early stage of image reconstruction, for which the generator has not yet learned the features for the classifier to classify correctly. These two figures indicate that for clean and physical adversarial traffic signs, the classifier’s decision-making process is significantly different during the process of image reconstruction. We exploit class distribution to examine the decision-making process of classifiers at multiple stages of image reconstruction, summarizing this decision-making process as the decision result of each stage by the maximum frequency class and maximum frequency; we then infer the true class of traffic signs by testing the consistency of the decision results at multiple stages. Our defense pipeline is shown in Figure 4.
(a) Class distribution of the clean traffic sign “Speed limit (70 km/h)” at different stages during reconstruction, (b) class distribution of adversarial traffic sign “Speed limit (60 km/h)” misclassified as “Speed limit (50 km/h)” during reconstruction.
Two plots showing the class fluctuation with iterations for reconstructed images of clean traffic signs (a) “Speed limit (70 km/h)” and physical adversarial traffic signs, (b) “Speed limit (60 km/h)” misclassified as “Speed limit (50 km/h).”

Our defense pipeline based on the deep image prior method.
DIP
DIP ( 23 ) is an iterative generation model for image reconstruction that has no prior training data except for the input image itself. The performance of DNNs is usually attributed to the ability to learn the real image prior from many images, but the excellent results produced by DIP show the generator network is structured enough to capture large amounts of low-level image statistics before any learning. DIP employs a randomly initialized convolutional neural network to capture the features of the input image. In this method, the model does not need to be trained on a large-scale data set; instead, it uses an untrained deep learning model to model natural images. DIP performs image reconstruction through a generator network. First, the input noise is generated randomly, with the generator network randomly initialized. Then, the distance between the reconstructed image and the input image generated by each iteration is used as the optimized objective function to perform back propagation. The reconstructed image is generated after the network parameters are updated. The structure of DIP is shown in Figure 5.

Process of reconstructing a physical adversarial traffic sign with deep image prior.
Some recent studies ( 37 , 38 ) have proposed a method for defending digital AEs based on deep image prior using a denoising generator for DIP to fit the adversarial input. Ding et al. ( 38 ) map the reconstructed images during optimization to classifier decision space so that the boundary image can be located. This is then perturbed in the opposite direction along the boundary image to remove the adversarial noise. However, the true label is unknown as a result of the highly nonlinear properties of the decision boundary, and not only is the localization of boundary images difficult, the subsequent perturbations are hard to control. DIP driven defense against AEs (DIPDefend) analyzes the reconstruction process from a feature learning perspective and infers the appropriate number of stop iterations based on the peak signal-to-noise ratio (PSNR) curve of reconstructed images ( 37 ). The authors hypothesize that the “turning point” can be positioned by the PSNR curve, which unfortunately does not protect the victim classifier when AEs approach the decision boundary.
For each adversarial input, DIP provides a unique defender for a variety of attack modes. Specifically, given an adversarial example
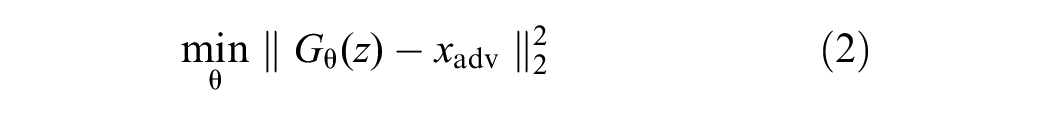
A DIP-Based Defense Pipeline for Physical Adversarial Traffic Signs
Our approach is similar to that of Ding et al. ( 38 ) in which the true class of traffic signs is inferred using the decision-making process of the victim classifier during image reconstruction. However, we do not waste time on finding transition images, because for robust adversarial traffic signs in the physical world, the decision-making process of the victim classifier has frequent class changes at a low number of iterations and the subsequent perturbations are difficult to control. It is worth noting that even with high-performance classifiers, the classification results are somewhat accidental; therefore, images that cross boundaries are not necessarily near the true decision boundary.
For most physical adversarial traffic signs, at an appropriate learning rate, DIP can learn adversarial noise after only a few iterations as a result of the simple features of traffic signs. Clean traffic signs often produce consistent results at different stages of decision-making and exhibit high-frequency characteristics. Physical adversarial traffic signs always go through the process of learning only robust features that can be correctly classified. As a result, decision-making outcomes at different stages often show inconsistencies, which can be used as a basis for the detection of physical adversarial traffic signs.
For the reconstruction of traffic sign images, we consider the decision-making process of the victim classifier in the first 1,000 iterations, selecting three reconstruction stages from this process: ideal robust; transition; non-robust. The selection of several iterations set at different stages is described in the Discussion section.
Ideal Robust Stage
When the number of iterations is small, the classifier’s decision-making process is stable for the first time at this stage albeit with occasional mutations. The reconstructed image already has the characteristics required for the classifier to classify correctly. The decision results at this stage often correspond to the true class of clean or physical adversarial traffic signs.
Non-Robust Stage
This phase corresponds to many iterations, and the classifier’s decision-making process again remains stable. For physical adversarial traffic signs, the reconstructed image has learned the non-robust characteristics of adversarial noise, and the decision results for the classifier at this stage point to adversarial target class.
Transition Stage
The noise intensity of different physical adversarial traffic signs is different. The transition stage is set to balance the selection of parameters for the number of iterations of different adversarial signs in the ideal robust stage and the non-robust stage. In the transition stage, the decision result of the classifier uncertainly points to the real class or the adversarial class.
Our defense consists of two steps: consistency detection; and decision-making. Detection is inferred by the consistency of the decision results for the victim classifier in three stages. If the decision-making results of three stages are consistent at a high frequency, the traffic sign is considered clean and trusted. Here, we add a threshold to the maximum class frequency of the non-robust stage to ensure the reconstructed images have behaved in a stable fashion as adversarial signs. If the decision results are inconsistent, then the traffic signs to be tested are suspicious and the autonomous vehicle could be alerted or a passenger could be requested to intervene. Later in the Discussion section, we also validated the effectiveness of this detection method for other types of physical adversarial traffic signs. In the decision-making phase, according to the preferences of DIP image reconstruction ( 37 ), the generator network learns clean robust features before learning adversarial noise. It is assumed that the process of learning clean robust features has been included in the first two stages. The projection onto the decision-making results in three stages as follows. First, when the decision results of the ideal robust stage and transition stage do not agree, but the decision results of the transition stage and non-robust stage do agree, it is inferred that the true class of the traffic sign is the decision result of the ideal robust stage. Second, when the ideal robust stage agrees with the decision result of the transition stage and disagrees with the decision result of the non-robust stage, it is inferred that the true class of the traffic sign is the result decision made in the ideal robust stage. Third, when the decision results of the three stages are different, this indicates that the generator network has learned adversarial noise in the transition stage and the real class of the traffic sign is the decision result of the ideal robust stage.
For the rest of the cases, we use the decision result in the transition stage as the true class. The basis of decision-making is shown in Figure 6.
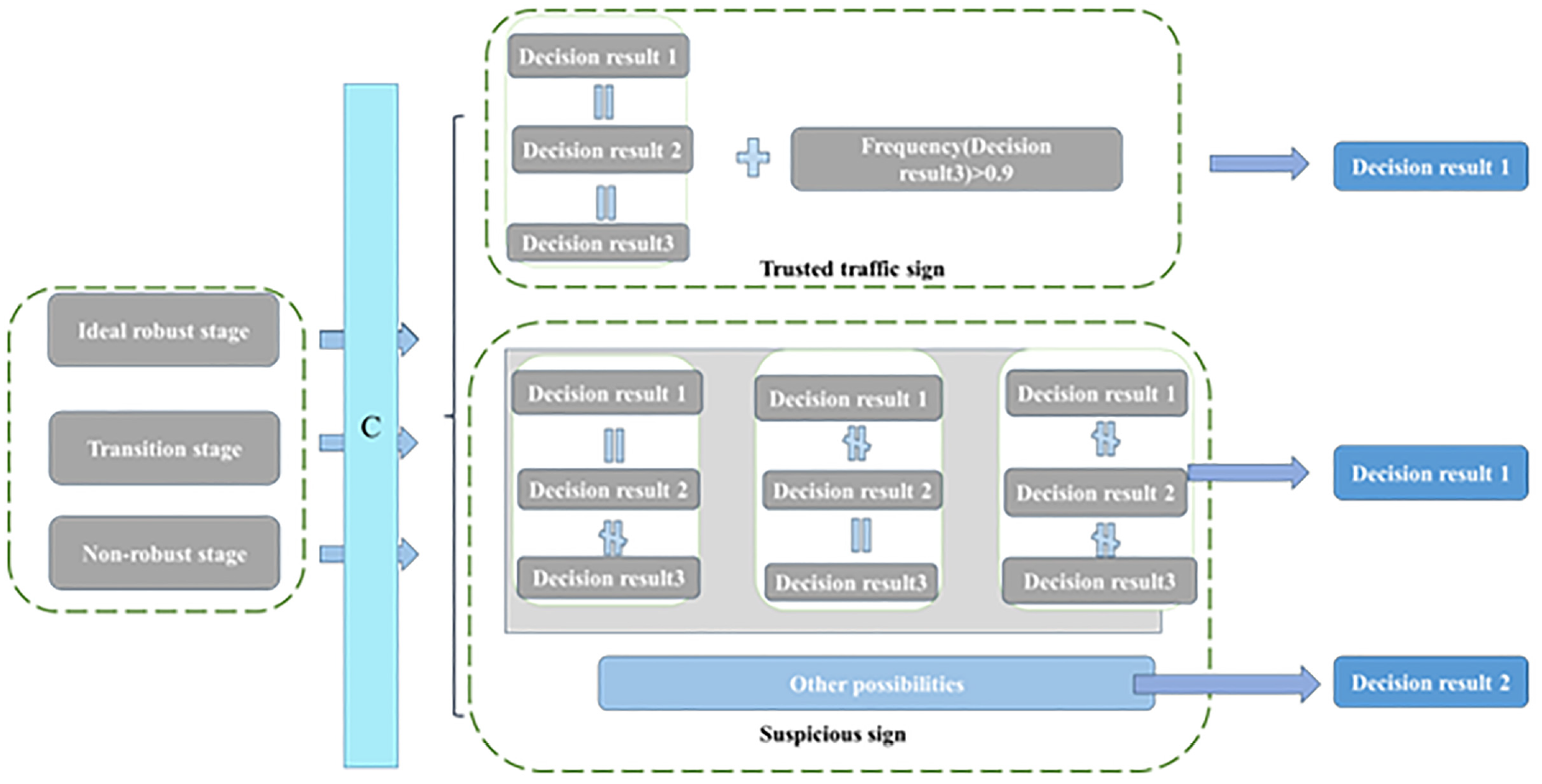
Method for inferring the true category of traffic signs based on the consistency of decision-making in three stages.
Experiments
Experiment Setup
Data Preparation
We trained a multiscale convolutional neural network on the German Traffic Sign Recognition Benchmark (GTSRB) as the victim classifier and as in Sitawarin et al. ( 13 ) exploited high-resolution traffic sign images to generate physical adversarial traffic signs. Next, we printed out the generated AEs and took photos outdoors at distances of 1.5 m, 3 m, and 6.5 m. Three angles were randomly selected from between 30° and 150°. For each physical adversarial example, we used an Honor 90 Pro smartphone camera to take nine images from different distances and angles, cropping out the traffic signs from the images and then passing them to the classifier to verify whether they were deceptive. We retained 11 adversarial traffic signs with deceptive effects at all 9 locations and considered them as robust physical adversarial traffic signs, obtaining 99 pictures in total for physical adversarial traffic signs. Simultaneously, for comparison, we printed out seven clean traffic signs the classifier was able to classify correctly. A total of 54 images were taken under the same settings, at which point the classifier was still able to classify all of them correctly.
Attack Model and Data Set
We trained a multiscale convolutional neural network on the GTSRB data set, which contains 43 classes of red, green, blue (RGB) traffic sign images with different resolutions, and achieved the best accuracy of 98.70% on the test set. Because our defense approach is generally based on image reconstruction having no relation to the internal structure of the classifier, we only discuss white box attack in this paper.
Parameters and Metric
For the proposed DIP defense method, we use the DIP denoising model officially published in Ulyanov et al. ( 23 ) for image reconstruction. Because of the particularity of traffic signs, it is good enough to set the number of iterations to 1,000 in our experiment. In our defense pipeline, we need to determine the number of iterations corresponding to different stages in advance, excluding the influence of random noise at the beginning of iterations. For this, we set the number of iterations in the ideal robust stage to 50–200, the transition stage to 200–400, and the non-robust stage to 400–800. We use the classification accuracy of traffic signs as a measure of defense effectiveness.
Generating Physical Adversarial Traffic Signs
As a result of the relatively low resolution of the GTSRB test images, we used high-resolution traffic signs provided in Sitawarin et al. ( 13 ) for attacking, and printed them out for real-world experiments (Figure 7). We selected 11 adversarial traffic signs that successfully attacked the classifier at all 9 positions; the average confidence of the classifier to misidentify traffic signs is 0.91. We then took photos of the traffic signs and cropped them out for subsequent defense.

Physical adversarial traffic signs robust to different distances and angles in the real world, taken from nine locations at different distances and angles.
Reconstruction of Traffic Signs Based on DIP
We adopted U-Net architecture as the generator network, using the DIP algorithm to reconstruct the cropped images of clean traffic signs and physical adversarial traffic signs (Figure 8). If the number of iterations is set at 1,000, the reconstructed images of adversarial traffic signs all learn the adversarial noise at a later stage, in which the classification result of the classifier behaves steadily as a misclassification.

(a) Reconstruction process of clean traffic signs, and (b) reconstruction process of physical adversarial traffic signs.
The reconstructed image starts with irregular random noise. With fewer iterations, the reconstructed images initially have identification features, such as the rough outline of the speed limit sign and the red circle box. As the iterations increase, the existence of adversarial noise can be found in reconstructed images.
Physical Adversarial Traffic Sign Defense Based on DIP
We identify each image generated during the reconstruction process using a classifier to obtain a decision process that varies with the number of iterations. Classifications for the ideal robust stage, transition stage, and non-robust stage are counted, with maximum frequency category and corresponding frequency as the decision-making result for each stage (Figure 9).

Distribution of the decision results for each stage.
Consistency Detection
Trusted traffic signs have decision results that are consistent at a high frequency across the three stages, whereas adversarial traffic signs produce different decision results at different stages. It is worth noting that in our experiments we find traffic signs with no perturbation are judged as suspicious signs in a few cases (e.g., shadow covering, scratch interference), even though they are not AEs. However, this does not affect the correct classification obtained through the decision-making step. For unknown traffic signs, our defense pipeline is highly sensitive to traffic signs subject to abnormal interference.
Decision-Making
Inferring the true class of traffic signs based on the decision-making process in Figure 8, our defense pipeline results in “No vehicles,”“No vehicles,”“Speed limit 60 km/h,” and “Speed limit 100 km/h” for the traffic signs in Figure 9, which is factually correct.
Discussion
Results for Physical Adversarial Attack
Because of the relatively large difference in the distribution of our generated physical adversarial signs and clean traffic signs, we try to use a style migration algorithm for defense that treats apparent adversarial noise as a style, as in Zhu et al. ( 39 ). In He and Singhal ( 40 ), the authors attempt to use CycleGAN to defend against digital AEs.
To verify the superior performance of our method for physical adversarial traffic signs, we try to preprocess traffic signs using the JPEG ( 41 ), filter transform ( 42 ), and CycleGAN methods for defending digital AEs and compare these with our method. The defense effect is shown in Table 1.
Success Rate for Correctly Classifying Traffic Signs Using Different Defense Methods

The results show that the JPEG method is unable to defend against physical adversarial traffic signs. CycleGAN is less effective, and the bilateral filter method performs better in filter transform. In contrast, our defense approach has better defense performance against physical adversarial traffic signs.
Attempts at Other Types of Physical Adversarial Traffic Signs
Adversarial Signs Based on Out-of-Distribution Attacks
Sitawarin et al. ( 13 ) proposed a method for generating adversarial traffic signs from out-of-distribution attacks in which the adversary makes the classifier misclassify by logo attacks and custom sign attacks on non-traffic sign targets (Figure 10). For such attacks, it is more important to be able to detect the anomaly of the signs before classification instead of classifying. We try to utilize the defense pipeline in this paper to experiment on 10 such signs, of which 6 are considered suspicious according to the results. In the real world, this can be used to alert people before the classifier gives a result for signs, rather than blindly using the classifier to identify all the signs directly.

Defense against adversarial signs generated according to out-of-distribution attacks.
Optical Adversarial Attack Based on Shadow Projection
Zhong et al. ( 21 ) describe some very common optically adversarial traffic sign images in which shadow casting makes the classifier misidentify traffic signs. We conducted experiments using the defense pipeline in this paper to defend such signs, finding that our defense against such physical adversarial traffic signs is also effective. Figure 11 shows a correct decision result of “Speed limit 30.”

Maximum frequency class distribution at three reconstruction stages of the traffic sign misclassified as “Speed Limit 50” with high confidence.
Effect of Number of Iterations Parameters
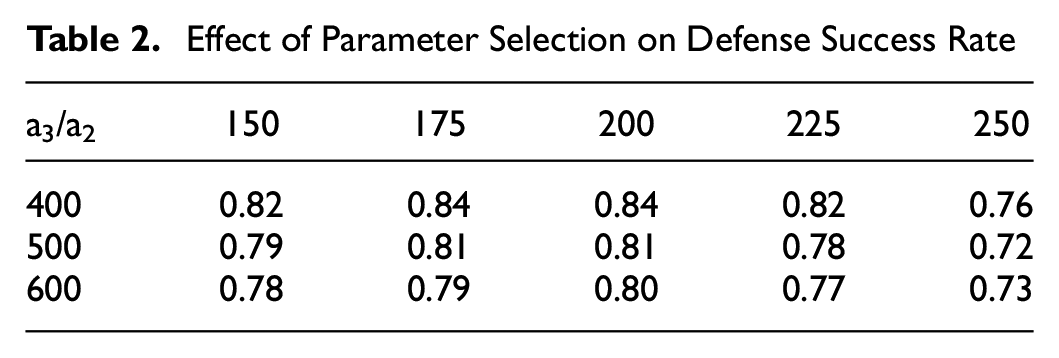
The division into three decision stages relies on the selection of the number of iterations, which also affects the subsequent decision results of the classifier, so we consider the influence of the varying number of iterations on the effectiveness of our defense. Because the key is to find a phase in the early stages of the reconstruction process in which only robust features are learned without noise resistance, we consider only the parameters for the number of iterations in the ideal robust stage from a1 to a2, and the transition stage from a2 to a3. The final number of iterations for the non-robust stage needs to be large enough. Based on the results from the experiment, we choose 800 to be sufficient. According to the process of reconstructing traffic signs, at the very beginning, most of the reconstructed images are irregular noise. Depending on the image characteristics of traffic signs, a1 is fixed at 50. The influence of changes in the number of iterations on the defense effect is shown in Table 2. The selection of a2 is the most critical, and this relates to the ability to embody the class of robust features.
Effect of Parameter Selection on Defense Success Rate
Features of Our Approach
For the defense of physical AEs, research has proposed many methods for adversarial patches, but physical adversarial traffic signs generated using patches are only one real-world scenario. Robust physical adversarial traffic signs generated using existing research are common threats to autonomous vehicles, but research on defense against such adversarial signs is relatively deficient. Instead of a preprocessing-based defense approach that passes potentially clean signs to the classifier for identification after finding the right number of stopping iterations or alterations of reconstructed images, we validate the effectiveness of the DIP-based method for defending against such physical adversarial traffic signs by inferring the correct class through the consistency of decision results at different stages during the image reconstruction process. Samangouei et al. ( 43 ) proposed Defense-GAN for defending digital AEs by reconstructing images, but this method, which is also based on preprocessing, is currently mostly used for small data sets such as the Modified National Institute of Standards and Technology database and the CelebFaces Attributes data set.
We make full use of the decision information of the victim classifier in the reconstruction process to infer the correct class based on the maximum frequency class distribution of the whole process, which greatly improves the reliability of our method. However, the defense pipeline in this paper is proposed for traffic signs with simple features; our approach may not be applicable to other targets with more complex image features. Nevertheless, for autonomous vehicles, misrecognition of traffic signs is the main threat, and our study was conducted to address this from the point of view of real-life applications.
It goes without saying that autonomous driving systems need to be deployed with efficient defense methods, and there is also room for optimization in our approach, for example, using more advanced image reconstruction methods ( 44 , 45 ) or using prior knowledge to optimize randomly initialized generator network parameters to perform defense with fewer iterations.
Conclusions
In this paper, we propose an effective image reconstruction-based defense pipeline against robust physical adversarial traffic signs, leveraging the capability of DIP to learn the inherent priors of images. Our approach obviates the need for a resource-intensive prior physical adversarial data set to collect numerous robust physical adversarial signs in real-world scenarios. Additionally, we conducted experiments with other types of physical adversarial traffic signs, achieving favorable outcomes that emphasize the robust generalization ability of our defense pipeline. Most of the recent research on physical adversarial defense methods has focused predominantly on patch-based approaches, and there has been a dearth of investigation into physical adversarial traffic signs prevalent in real-world settings. As part of our future work, we will continue to explore novel methods for defending against AEs that compromise the safety of autonomous vehicles.
Footnotes
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: S. Huang, Q. Tan; data collection: Q. Fan, Y. Zhang; analysis and interpretation of results: Q. Tan, Z. Zhang; draft manuscript preparation: S. Huang, Q. Tan, X. Li. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is supported by the Chongqing Natural Science Foundation of China (CSTB2022NSCQ-MSX1454), the Shanghai Artificial Intelligence Innovation Development Special Support Program (2020-RGZN-02041), and the Sichuan Province Science and Technology Program (2019YFG0040).