
Abstract
While considerable knowledge exists about blatant gender discrimination and violence targeting women, less is known about gender microaggressions. To understand gender microaggressions’ frequency, prevalence, and effects, researchers need robust quantitative measures. To advance gender microaggressions scholarship and support researchers’ efforts to identify high-quality measures, we conducted a psychometric scoping review. We identified 24 original, quantitative, multi-item measures designed to assess gender microaggressions or related constructs. Included measures needed at least one item assessing gender microaggressions and be used with adult women in the United States. Results indicated an increase in the number of measures including gender microaggressions’ items in recent years, with a major expansion in the number of named gender microaggressions’ measures. We found limited reporting of demographic information. Psychometric testing and characteristics varied across measures. While most (n = 20) reported internal consistency reliability, only two-thirds (n = 16) reported undergoing validity testing. When examining microaggressions named measures (n = 10), we found inconsistent adherence to microaggressions’ theoretical and conceptual foundations. Substantial work remains to develop a “gold standard” measure that does not conflate subtle and blatant acts, assesses the full thematic range of gender microaggressions, and is psychometrically valid across different social contexts and diverse groups of women.
Blatant forms of gender discrimination and violence, such as physical assault and verbal threats, have been linked to increased short- and long-term health and mental health challenges, as well as other negative outcomes (e.g., lower incomes) that disproportionately impact women (Campbell et al., 2003; National Academies of Sciences, Engineering, and Medicine, 2017). Although gender discrimination occurs through blatant forms of mistreatment, it also manifests through covert or subtle forms such as sexist jokes (Capodilupo et al., 2010; Gartner & Sterzing, 2016). Scholars have proposed that as overt prejudice has become less socially acceptable, gender microaggressions—subtle, often-unintentional indignities and insults (Sue, 2010)—have begun to take its place in reinforcing dominant social norms that marginalize women and maintain systems of oppression (Gartner, 2019; Sue, 2010; Wong et al., 2014).
Although theoretical and early empirical work suggest that the subtle and chronic nature of microaggressions can have a cumulative, deleterious effect on health outcomes (Nadal, 2010), research examining women’s experiences of gender microaggressions is less developed than research on blatant gender discrimination. In particular, the psychometric rigor of gender microaggressions’ measures has been called into question by some scholars (e.g., Fisher et al., 2019; Lilienfeld, 2017), with no systematic review of measures presently available. Given that reliable and valid instruments are necessary to understand the prevalence, frequency, and effects of gender microaggressions, this gap poses challenges for researchers and practitioners alike. To advance this nascent area of scholarship, we conducted a scoping review to identify quantitative measures assessing the frequency of gender microaggressions and to map their psychometric characteristics and the populations and contexts for which they were developed. Our results are intended to support researchers’ efforts to examine the frequency, prevalence, and consequences of gender microaggressions to advance knowledge and inform policy and practice.
Operationalizing Microaggressions
Microaggressions refer to “the everyday verbal, nonverbal, and environmental slights, snubs, or insults, whether intentional or unintentional, that communicate hostile, derogatory, or negative messages to target persons based solely upon their marginalized group membership” (Sue, 2010, p. 3). Originally coined by Pierce et al. (1977) to refer to derogatory representations of African Americans, Sue et al. (2007) expanded on the concept by proposing that racial microaggressions have a tripartite categorization involving microinsults (i.e., demeaning, rude, insensitive comments), microinvalidations (i.e., negating someone’s experiences and/or feelings), and microassaults (i.e., explicit discrimination, such as name-calling or refusing to work with someone because of their minority identity). Microaggressions, as a construct, have since expanded to encompass other marginalized groups, including women (Capodilupo et al., 2010; Nadal, 2010; Sue, 2010; Sue & Capodilupo, 2008).
Microaggressions may occur interpersonally, through comments and actions (Sue, 2010), and environmentally, through social norms, policies, and social media (Sue et al., 2007). They have a set of unique features, including their commonplace occurrence, subtle nature, ambiguous intent, and likelihood of being enacted by well-meaning people (Sue, 2010). Perpetrators of microaggressions typically use the ambiguous nature of microaggressions to their advantage in social encounters, by offering alternate explanations for their actions or excusing them away as minor and/or inconsequential. Microaggression recipients may second-guess their experiences, requiring additional cognitive processing, which can increase their stress load (Meyer, 2003) and, over time, may contribute to the onset of mental health problems such as depression, anxiety, trauma, and lower self-esteem (Nadal, 2010).
Although microaggressions are generally understood as subtle and unintentional, often perpetrated unconsciously, the inclusion of microassaults suggests they can also include blatant and purposeful acts, such as slurs, catcalling, or hate speech that aim to marginalize, control, and/or harm their targets. Sue (2010) posited that unlike microinsults and microinvalidations, microassaults are based on conscious biases toward the target group. For women, this can include blatant behaviors such as “unwanted sexual advances toward women, sexual harassment, and forced sexual intercourse” (Sue, 2010, p. 169). The microassault subcategory has been subject to some debate because labeling overt experiences, such as forced sexual intercourse, as microassaults not only increases conceptual ambiguity but may be invalidating of such potentially traumatic experiences. Gartner and Sterzing (2016) documented and problematized the conceptual congruity and divergence among the related constructs of gender microaggressions, sexual harassment, and sexual assault found in the microaggressions literature. They called for more precision in the operationalization of gender microaggressions, with microassaults more accurately subsumed under the related but distinct constructs of harassment and assault. We have adopted the same stance in our scoping review and thus distinguish between subtle experiences and those that may be overt and intentional, even if both are labeled as microaggressions in our included measures.
Extending Foundational Sexism Research
Gender microaggressions scholarship is built upon a strong theoretical and empirical foundation of scholarship focusing on sexism (Swim & Cohen, 1997), objectification of women (Fredrickson & Roberts, 1997; Fredrickson, Hendler et al., 2011), gender role stereotypes (Eagly & Karau, 2002; Koenig et al., 2011), and “chilly climates” (Hall & Sandler, 1984). As gender microaggressions have not been studied extensively, many scholars rely on these other literatures and racial microaggressions scholarship to support the contention that gender microaggressions exist and adversely affect women’s health and mental health (Capodilupo et al., 2010; Nadal, 2010; Nadal et al., 2013). Broadly, these other literatures have contributed to our understanding of the mechanisms, prevalence, and effects of various manifestations of subtle gender discrimination (Fredrickson & Roberts, 1997; Harvie et al., 1998; Sternglanz & Lyberger-Ficek, 1977; Swim & Cohen, 1997). Important parallels exist between sexism studies and microaggressions scholarship. For example, early workplace sexual harassment research found similar adverse outcomes to studies examining microaggressions among people of color (Sue et al., 2007, 2008) including higher levels of depression and anxiety and lower job satisfaction (Fitzgerald et al., 1994).
These types of parallel findings also exist for subtle sexism and other related constructs (e.g., everyday sexism and objectification theory), in part, because of their conceptual overlap with gender microaggressions (Nadal, Hamit et al., 2013). Swim and Cohen (1997) operationalized subtle sexism as a type of sexism that is hidden or unnoticed because it is embedded in cultural and societal norms. Nadal, Hamit et al. (2013) recommended extending this strong foundation of subtle sexism research to include a model of gender microaggressions by focusing on the areas in which microaggressions scholarship has distinguished itself from sexism literature: (a) the distinction between interpersonal and environmental microaggressions, where subtle sexism has focused predominantly on interpersonal manifestations; (b) the emergent and unique taxonomies for gender microaggressions (discussed below); (c) the classification of gender microaggressions into microinsults, microinvalidations, and microassaults; and (d) that gender microaggressions may be intentional or unintentional (Nadal, Hamit et al., 2013). We support these recommendations, but as noted, suggest that gender microaggressions research not include blatant, intentional acts of gender discrimination and violence (i.e., microassaults).
Gender Microaggressions Research
The examination of gender microaggressions as a construct began a decade ago with Capodilupo et al.’s (2010) qualitative study aimed at developing a gender microaggressions taxonomy. Through focus groups with adult women, these researchers specified the following microaggression themes: (a) sexual objectification (e.g., being catcalled), (b) second-class citizenship (e.g., receiving differential salaries for the same work), (c) assumptions of inferiority (e.g., overlooking women for physical tasks), (d) assumptions of traditional gender norms (e.g., expecting women to cook and clean), (e) use of sexist language (e.g., calling sexually active women “sluts”), and (f) environmental invalidations (e.g., social norms that only boys play baseball). Additionally, they described two potential emergent themes: denial of the reality of sexism (e.g., a supervisor negating a complaint of sexism) and leaving gender at the door (e.g., having to act like a man to get ahead in the workplace). The first quantitative study of gender microaggressions was published that same year and addressed gender microaggressions in therapy (Owen et al., 2010). This study found that gender microaggressions were associated with a decrease in therapeutic alliance and positive therapeutic outcomes. Subsequent studies have found that gender microaggressions are associated with reactions of guilt and shame (Nadal, Hamit et al., 2013) as well as depressive symptoms, elevated stress, and post-traumatic stress (Gartner, 2019).
While empirical attention on gender microaggressions has grown, additional scholarship is needed if researchers are to more fully understand their frequency, prevalence, and consequences. Quantitative studies are particularly necessary, as their findings can play a critical role in policy development and inform practice concerning the relationship between microaggressions and gender-based health disparities (Lau & Williams, 2010).
Measurement of Microaggressions
Quantitative microaggressions research has expanded in many areas in recent years, including race (e.g., Nadal, 2011; Torres-Harding et al., 2012), sexual orientation (e.g., Fisher et al., 2019; Sterzing & Gartner, 2018; Woodford et al., 2015), ability status (e.g., Conover et al., 2017; Kattari, 2019), and intersectional measures (e.g., Lewis & Neville, 2015). Concurrent with these advances, concerns have been raised about the conceptual clarity and validity of empirical findings in microaggressions research. Notably, Lilienfeld (2017) questioned microaggressions’ conceptual clarity, raising concerns about the subjectivity of microaggressive experiences and ambiguity in intentionality. Related critiques have been made regarding the state of microaggressions measurement, calling for advances in the field to establish reliable and valid instruments (Fisher et al., 2019; Lau & Williams, 2010). As the conceptualization and measurement of microaggressions have been challenged, correlational and causal models reliant on these foundations have been criticized and even dismissed as conceptually and methodologically underdeveloped (Lilienfeld, 2017). Further, although there have been some developments, scholars have called for empirical examinations of microaggressions to employ an intersectional lens, capturing the multidimensional impact not assessed in single-identity measures (Nadal et al., 2015; Sterzing et al., 2017).
Measurement problems are pervasive and cause for debate even in well-established fields including psychology (e.g., Borsboom, 2006; Fried & Flake, 2018), education (e.g., Quellmalz et al., 2013; Sussman, 2016), and health (e.g., Cano & Hobart, 2011; Cano et al., 2019). Nevertheless, for researchers and practitioners to accurately understand gender microaggressions and their impact, valid and reliable quantitative measures must be available. To advance these efforts and guide researchers in finding the best gender microaggression measures for their projects, we conducted a psychometric scoping review of original quantitative measures assessing experiences of gender microaggressions. Given gender microaggressions’ roots in earlier studies of subtle sexism and related constructs, in our review, we included measures assessing encounters with subtle gender discrimination not specifically named as microaggressions. Although the original authors may not have used the term gender microaggressions when referring to their measures or items, the measures/items reflect experiences that are covert, potentially unintentional, and convey negative messages to their targets. For example, the Schedule of Sexist Events (SSE; Klonoff & Landrine, 1995) is not a named gender microaggressions measure but contains items that assess microaggressions (e.g., “failed to show you the respect you deserved”) and has been used as a “gold standard” measure to establish construct validity for numerous gender microaggressions measures (e.g., Derthick, 2015; Lewis & Neville, 2015; Miyake, 2018).
To address these gaps, our scoping review aimed to (a) identify original, multi-item measures and/or subscales assessing the experiential frequency of gender microaggressions, (b) synthesize the contexts and population demographics for which measures were designed and tested, (c) report the psychometric testing completed at the time of development, (d) examine microaggression-specific/named measures in terms of their consistency with microaggressions theory and frameworks, and (e) provide recommendations to strengthen future gender microaggressions scholarship.
Method
Positionality Statement
A scoping review was selected for its applicability to our research aims and its utility for examining research in emergent fields of study (Colquhoun et al., 2014). We designed and implemented the review with built-in checks and balances to foster rigor, along with consensus-building among us. We recognize the importance of positionality in research and the potential effects of our social identities and concomitant experiences on our project (Carr, 2000; Sikes, 2004; Wellington et al., 2005). Our team consists of students and junior and mid-career academics who engage in research addressing the inclusion of vulnerable populations, including women and lesbian, gay, bisexual, transgender, and queer (LGBTQ) populations. We represent various genders (one nonbinary individual [socialized as female], two cisgender women, and three cisgender men), all identify as LGBQ and are non-Hispanic White. A commitment to social justice and inclusion drives our research, including that on microaggressions. Our various identities and experiences reflect insider and outsider perspectives to the study of gender microaggressions, which can shape the research process (e.g., selection of particular variables to extract; Hammersley, 1993; Herod, 1999). Our collective engagement in the research process, including the use of consensus-based decision-making, helps to limit the impact of biases on study processes and outcomes. Additionally, with the exception of one team member, everyone has previously published on microaggressions.
Scoping Review
Scoping reviews are a form of knowledge synthesis that seek to map the key concepts underpinning a research area and can be used for a range of purposes (e.g., to examine the extent, range, and nature of activity; identify gaps in research; determine the value of undertaking a systematic review; Arksey & O’Malley, 2005; Colquhoun et al., 2014). Scoping reviews are a useful method for examining research in emergent fields of study (Colquhoun et al., 2014). Our review adhered to Arksey and O’Malley’s (2005) 5-stage methodology, which details a systematic process for searching the extant literature, extracting data, and synthesizing findings. The stages are (a) identifying the research questions; (b) identifying relevant documents; (c) selecting documents; (d) charting the data; and (e) collating, summarizing, and reporting the results.
Document Identification
Given our intent to identify and evaluate original measures assessing women’s experiences of gender microaggressions, we first devised a search strategy to locate relevant documents. The first author, in consultation with a social science librarian and the research team, identified the search terms and established the search specifications. As gender microaggressions conceptualization and measurement are nascent, search terms inclusive of a broader array of gender discrimination were used to enable us to identify relevant measures, including measures assessing microaggressions that are not named as microaggressions’ measures. The search had three categories of terms: (a) population (e.g., women, female, girls), (b) discrimination (e.g., sexism, harassment), and (c) subtle/covert (e.g., microaggression, everyday sexism, covert sexism). The list of terms and the search specification is presented in Appendix A. We selected databases based on a high likelihood of indexing social science and health-related journal articles, dissertations, and reports: MEDLINE, PsycINFO, Social Work Abstracts, ProQuest Dissertations. Databases were searched using two database aggregators: ProQuest and EbscoHost. Search fields were limited to the title, abstract, and subject terms of each document.
We exported search results from the database aggregators as generic text files containing the metadata for each identified document: title, abstract, journal, and year of publication. The BibWrangleR software package for R (Victor et al., 2015) was used to convert files into an analyzable data frame for subsequent review. Our initial search was conducted in June 2017 and updated in January 2019. A total of 1252 unique documents were identified across both searches. We also manually identified 15 additional documents that were listed in the reference section of relevant literature reviews or mentioned in the documents from our database searches (see Figure 1).
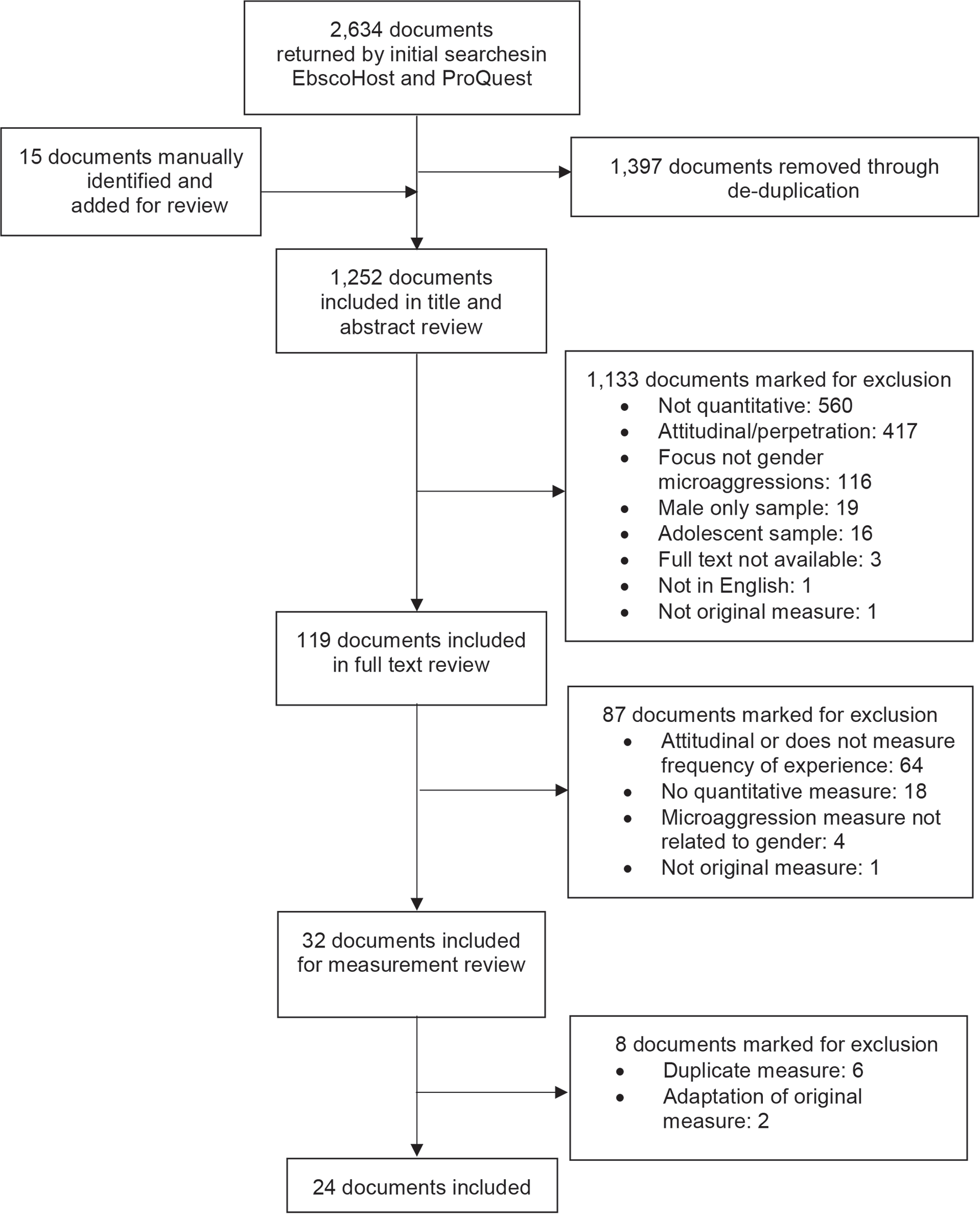
Diagram of included documents.
Selecting Documents for Inclusion
Next, we reviewed each document for inclusion in the study. Included documents were those that (a) reported on the use of an original, multi-item measure with (b) at least one item assessing the frequency of women’s experience(s) of gender microaggressions that was (c) utilized with a sample that included (at least in part) women over the age of 18 residing in the United States (U.S.). Measures were considered original if they were reported as newly generated instruments not substantially based on any previous measure. Given the previously discussed conceptual overlap between subtle sexism and gender microaggressions, measures were included if they contained at least one gender microaggression item to provide a holistic picture of the state of gender microaggressions measurement. Further, measures containing items addressing both subtle and blatant discrimination were included as they capture the range of experiences currently encompassed in Sue’s (2010) tripartite microaggressions categorization. To meet the criterion of frequency of experience, a measure had to assess encounters with behavioral manifestations of gender microaggressions; thus, attitudinal measures (e.g., Swim & Cohen, 1997) and those that only assessed the impact of or targetsf’ responses to microaggressions (e.g., Prather, 2015) were excluded. Measures designed for adult women in the U.S. were the focus because gender expectations may differ by age and culture (Garza & Feagin, 2019), though no original measures were excluded exclusively for non-U.S. origin. We did not exclude measures normed partially on men, transgender, or genderqueer populations because a measure could be designed to assess gender microaggressions broadly.
Based on these criteria, each document was assessed for inclusion via a 2-stage process: (a) title and abstract review and (b) full text review. Each document was assigned to two team members at both stages. If both reviewers were in agreement, the document was included or excluded accordingly; discordant appraisals were resolved by a third team member. Our screening resulted in 24 documents reporting on original measures to be included in the study.
Charting the Data
Once the final sample was determined, data from each document and the corresponding measure were extracted and then charted with a focus on measure characteristics, demographics of the sample with which each measure was tested/utilized, and reported psychometric testing and properties. Measure characteristics included (a) measure name (or construct assessed, if no name was assigned); (b) subscales and dimensions (subscales were defined as the sub-constructs within the larger scale; dimensions were defined as constructs measured for each subscale, such as temporal period); (c) number of items (measure total and per subscale/dimension); (d) whether subtle only (noted as “subtle” in results tables) or subtle and blatant forms of discrimination (noted as “mixed” in results tables) were assessed; and, (e) the intended context for which the measure was developed (e.g., workplace, school). As discussed, the microaggressions category of microassaults poses operationalization challenges, therefore only subtle behaviors (e.g., slights, invalidations) were considered “subtle.” If measures were judged to include items that captured subtle behaviors as well as overt and intentional behaviors such as name-calling and harassment, the measure was classified as “mixed.” Measures with ambiguous items that could be interpreted as subtle or blatant were also classified as mixed.
Given our interest in understanding the samples used to norm the identified measures, we also charted the demographic characteristics of the sample(s) reported in each manuscript. Our objectives were to (a) provide descriptive statistics for these samples and (b) evaluate the range of demographics that were assessed. We documented if age, race and ethnicity, sexual orientation, gender/sex, gender identity, socioeconomic status (SES), disability, religious affiliation, and citizenship status were reported for each sample, and charted the descriptive statistics when available. Because SES and religious affiliation tend to be operationalized in various ways, we documented whether these variables were reported but did not list the descriptive statistics.
Lastly, we charted the psychometric properties of each measure when explicitly documented by the study author(s). For reliability, we charted reported Cronbach’s alpha values for the overall measure and subscales. We also charted other forms of reliability (e.g., test-retest) when reported. We then documented whether the following forms of validity testing were conducted: (a) face validity, or whether the items comprising a measure make sense at face value; (b) content validity, or whether items represent all facets of the construct as assessed by experts; (c) construct validity, or whether the measure assesses what it is designed to measure (including discriminant, convergent, and known-group validity); (d) criterion-related validity, or whether the measure maps on to some set standard or criterion (including concurrent, predictive, and incremental validity); and (e) factor structure, or tests of measure dimensionality (including exploratory and confirmatory factor analysis; DeVellis, 2012; Singleton & Straits, 2017).
To avoid making false inferences, only procedures explicitly reported by the document’s author(s) as tests of validity were recorded. Compared to the other forms of validity, the assessment of face and content validity are more subjective in nature and may be less frequently reported by authors; yet, both of these forms are also testable (e.g., Hardesty & Bearden, 2004; Moores et al., 2012), and, in the case of face validity, can offer important information regarding respondents’ interpretations of and responses to scale items (DeVon et al., 2007). Further, face and content validity remain necessary prerequisites for establishing other statistically testable forms of validity (Nunnally, 1994). Importantly, assessment and reporting on each type of validity remains a best practice for researchers (Carretero-Dios & Pérez, 2007), consistent with internationally accepted standards for test construction (American Educational Research Association et al., 2014).
Results
The final sample of 24 measures is presented in Table 1 in order of publication year.
Gender Microaggression Measure Characteristics (by Publication Year).
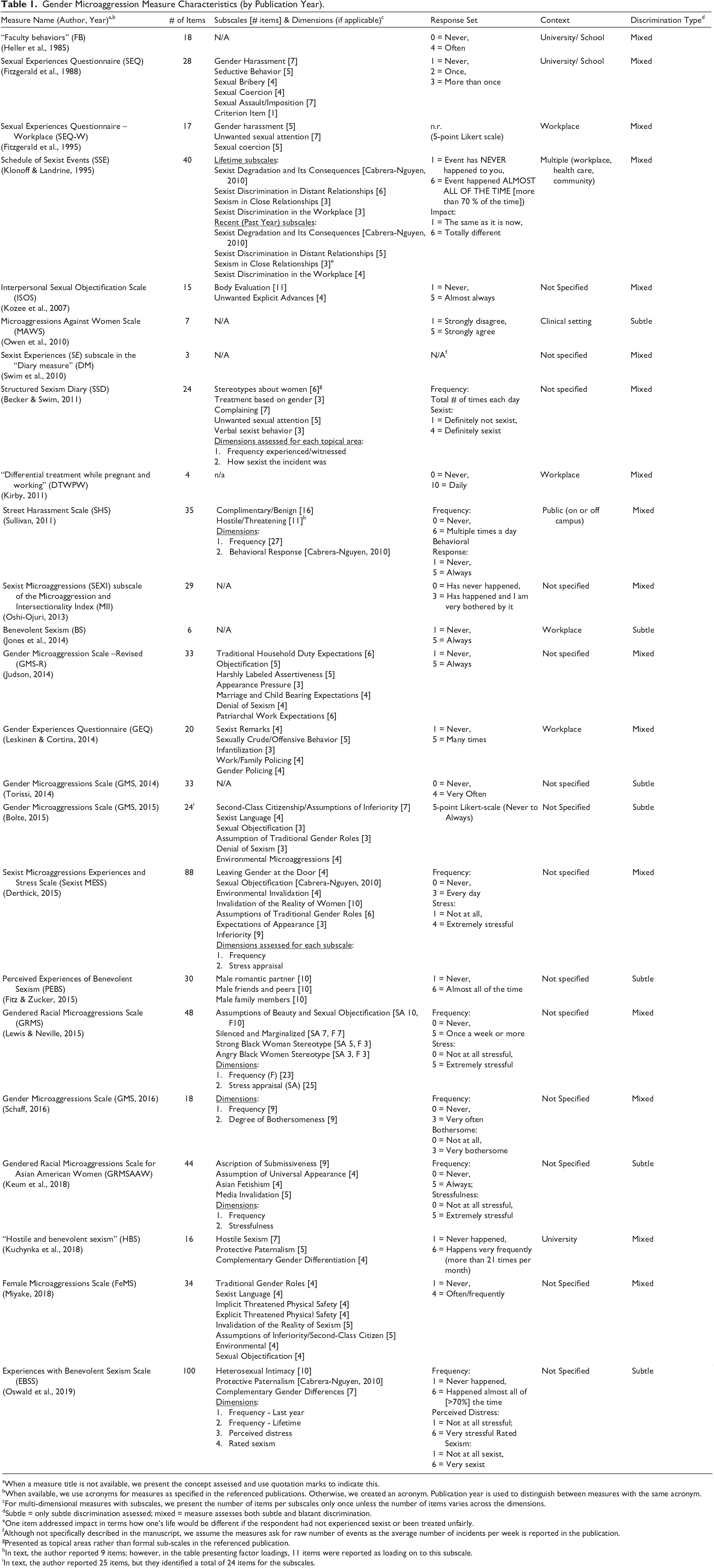
aWhen a measure title is not available, we present the concept assessed and use quotation marks to indicate this.
bWhen available, we use acronyms for measures as specified in the referenced publications. Otherwise, we created an acronym. Publication year is used to distinguish between measures with the same acronym.
cFor multi-dimensional measures with subscales, we present the number of items per subscales only once unless the number of items varies across the dimensions.
dSubtle = only subtle discrimination assessed; mixed = measure assesses both subtle and blatant discrimination.
eOne item addressed impact in terms how one’s life would be different if the respondent had not experienced sexist or been treated unfairly.
fAlthough not specifically described in the manuscript, we assume the measures ask for raw number of events as the average number of incidents per week is reported in the publication.
gPresented as topical areas rather than formal sub-scales in the referenced publication.
hIn text, the author reported 9 items; however, in the table presenting factor loadings, 11 items were reported as loading on to this subscale.
iIn text, the author reported 25 items, but they identified a total of 24 items for the subscales.
Measure Characteristics
Across the sample, the number of total items in each measure ranged from 4 to 100 (M = 29, SD = 23). Most measures (67%, n = 16) included subscales (ranging from 2 to 8 subscales; M = 6 items per subscale, SD = 4). Overall, the subscales evaluated a range of experiences from overt manifestations of gender discrimination, such as sexual harassment and assault (e.g., Sexual Experiences Questionnaire [SEQ]; Fitzgerald, Shullman et al., 1988) to more subtle manifestations, such as non-assaultive behaviors (e.g., Gender Experiences Questionnaire [GEQ]; Leskinen & Cortina, 2014) and environmental microaggressions (e.g., Sexist Microaggressions Experiences and Stress Scale [Sexist MESS]; Derthick, 2015). Based on an inductive analysis of subscale names, we identified the following common aspects of gender discrimination: (a) interpersonal discrimination, (b) environmental discrimination, (c) context of discrimination, and (d) perpetrator of discrimination.
Six measures (e.g., Gender Microaggressions Scale—Revised [GMS-R]; Judson, 2014) included subscales assessing different types of interpersonal gender microaggressions incidents such as traditional household duty expectations and denial of sexism in the GMS-R. Additionally, four measures included subscales that evaluated different subtypes of environmental microaggressions: (a) media incidents (e.g., “you have seen images of female bodies in the media that do not reflect your own body.” [Sexist MESS; Derthick, 2015]); (b) societal leadership incidents (e.g., “I observed that men hold more leadership positions in society than women.” [GMS2015; Bolte, 2015]); (c) workplace incidents (e.g., “I noticed there are few female role models in my chosen career.” [GMS2015; Bolte, 2015]); and (d) ambient discrimination (e.g., “You have overheard males being told to ‘not act like a girl’ or to ‘be a man.” [Sexist MESS; Derthick, 2015]). Two measures included subscales that examined gender discrimination by context, such as general social context and workplace (GMS-R; Judson, 2014; SSE; Klonoff & Landrine, 1995). Finally, the Perceived Experiences of benevolent sexism (PEBS; Fitz & Zucker, 2015) measure had subscales specific to perpetrator type (e.g., male romantic partners, male family members).
In terms of measure dimensions, four approaches were documented. Measures either assessed the (a) frequency of a set of incidents across different reference periods (e.g., the past year and lifetime; SSE; Klonoff & Landrine, 1995) 1 ; (b) frequency of a set of incidents and perceptions of how sexist each incident was (e.g., Structured Sexism Diary [SSD]; Becker & Swim, 2011); (c) frequency of incidents and perceptions of how stressful each incident was (e.g., Sexist MESS; Derthick, 2015); or (d) frequency of incidents and one’s behavioral responses to the incidents (e.g., Street Harassment Scale [SHS]; Sullivan, 2011). For example, in the SHS, after answering frequency questions, respondents were asked how often they respond to harassment in particular ways (e.g., “yelled back something”). Respondents were also invited to add additional responses or to provide comments. As reported in Table 1, multi-dimensional measures comprised two dimensions, with the exception of the Experiences with benevolent sexism Scale (EBSS; Oswald et al., 2019), which assessed four dimensions: past year frequency, lifetime frequency, perceived stress, and perceived degree of sexism.
In regard to measure response sets, the majority of measures (92%; n = 22) used an ordinal level response format across all subscales, including the multi-dimensional measures. Seventeen of the measures assessed frequency using categorical options such as “never,” “once,” and “more than once.” Four measures specified operational definitions in their response sets (e.g., “happens very frequently [more than 21 times per month]; Kuchynka et al., 2018). Using a Likert-type response set, the Microaggressions Against Women Scale (MASW; Owen et al., 2010) asked participants to report their level of agreement with statements reflecting experiencing microaggressions from one’s psychotherapist, such as “My therapist made stereotypical comments about women’s abilities, traits, or preferences,” with higher scores indicating greater perceived microaggressions. The Sexist Microaggressions (SEXI) subscale of the Microaggression and Intersectionality Index (MII; Oshi-Ojuri, 2013) utilized a response set integrating both frequency and appraisal of effect (e.g., “Has happened and I am very bothered by it”). Other Likert-type response sets were used to appraise how sexist or stressful an event was and respondents’ subsequent behavioral response. In contrast to the majority of measures, the Sexist Experiences (SE) subscale (Swim, Eyssell et al., 2010) and SSD (Becker & Swim, 2011) asked participants to report the total raw number of incidents experienced or observed.
Ten measures were created for specific contexts including university/school (n = 4), workplaces (n = 4), clinical settings (n = 1), and multiple settings (n = 1). The remaining 14 measures did not specify a context and thus were deemed general use measures. In the case of the SE subscale (Swim, Eyssell et al., 2010), the measure was categorized as general use because it was used with women attending university, but there was no indication that the measure was designed for or limited to the campus context.
Seven measures (29%) assessed only subtle (microinsults and microinvalidations) incidents of gender discrimination, while the remaining measures assessed a combination of subtle and blatant (microassaults, harassment, assaults) incidents; thus, they were labeled mixed. For example, one of the earliest published measures, Fitzgerald, Shullman et al. (1988) SEQ, was labeled mixed, with subtle items such as, “sexist remarks about career options” and blatant items such as “forceful attempts to touch or fondle.” Similarly, the recently published measure by Kuchynka et al. (2018) for assessing Hostile and benevolent sexism (HBS) was labeled mixed, with subtle items such as “accused of using your gender to your advantage” and blatant items such as “harassed or threatened.” Measures were also categorized as mixed because they contained ambiguous items that could conjure both subtle and blatant experiences. For example, Lewis and Neville (2015) GRMS contained the item “objectified me based on physical features.”
As indicated by their names, 10 measures (42%) were developed to specifically evaluate gender microaggressions. Six of these measures were categorized as mixed, including four measures that clearly contain items addressing blatant, microassault acts (e.g., naming calling, sexual assault). For example, the SEXI subscale includes “I’ve been judged, called names, or punished for participating in traditionally male role or behaviors” (Oshi-Ojuri, 2013). Additionally, the GMS-R includes “My body has been touched by men unknown to me in public places” (Judson, 2014).
Samples
As reported in Table 2, the measures were tested with a total of 37 samples. The majority of the 24 identified measures were used with just one sample (n = 17), while the other measures were used with two (n = 3) or three or more samples (n = 4). Sample sizes varied greatly, ranging from 20 to 1,394 participants (M = 362, SD = 325). Among the publications that reported mean age for their total samples, 2 measure respondents were, on average, 29 years (SD = 9), with the mean age ranging across studies from 18 to 55 years (50% of the samples had a mean age ≤27 years of age).
Sample Characteristics for Measures Ordered by Publication Year.
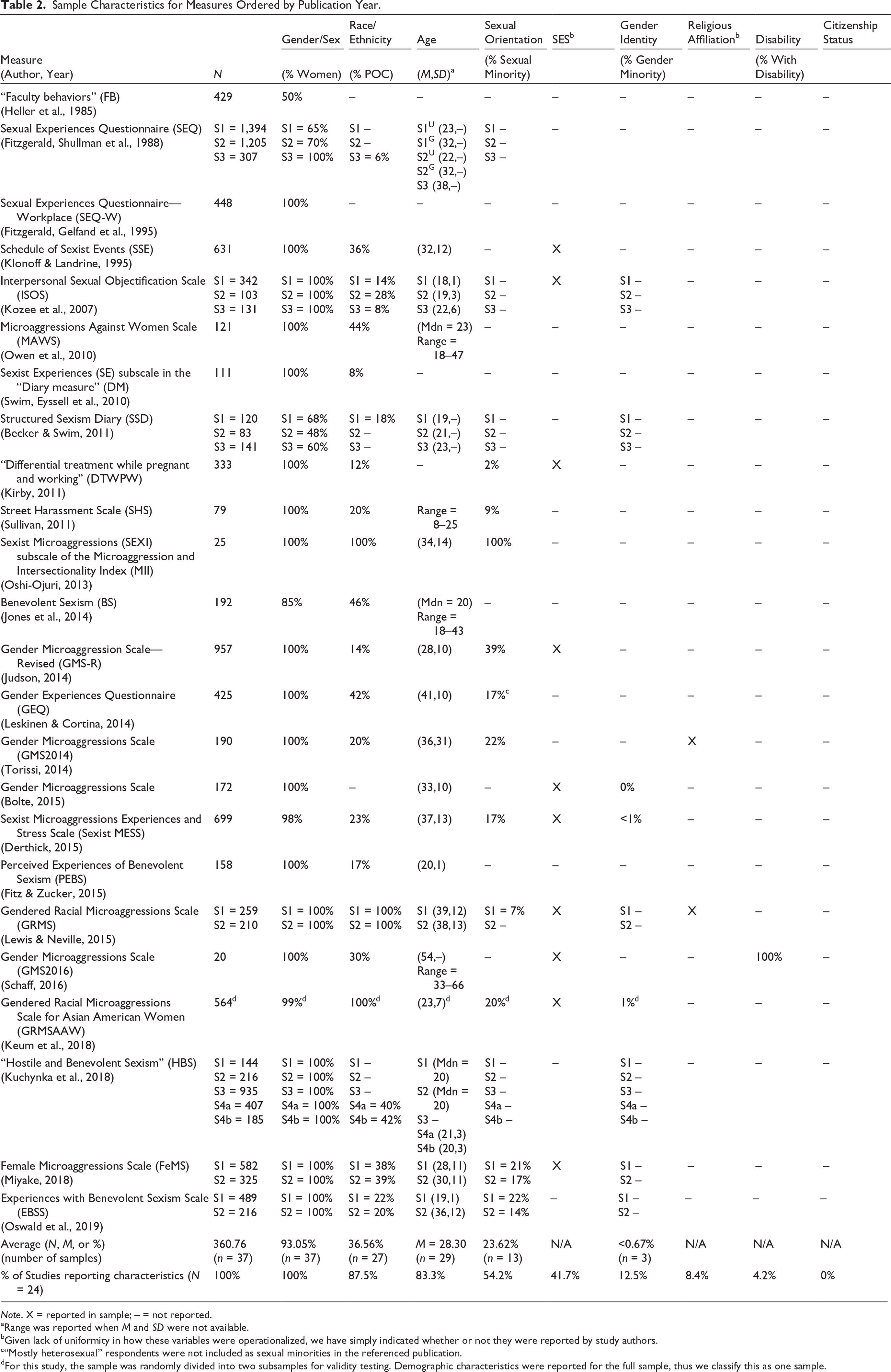
Note. X = reported in sample; – = not reported.
aRange was reported when M and SD were not available.
bGiven lack of uniformity in how these variables were operationalized, we have simply indicated whether or not they were reported by study authors.
c“Mostly heterosexual” respondents were not included as sexual minorities in the referenced publication.
dFor this study, the sample was randomly divided into two subsamples for validity testing. Demographic characteristics were reported for the full sample, thus we classify this as one sample.
Three measures were designed specifically for people of color: (a) SEXI (Oshi-Ojuri, 2013), (b) GRMS (Lewis & Neville, 2015), and (c) Gendered Racial Microaggressions Scale for Asian American Women (GRMSAAW; Keum et al., 2018); thus, the samples (n = 4) in those studies consisted of only people of color. Among the other measures for which respondent race and ethnicity was reported, the portion of racial/ethnic minorities ranged from 6% to 46% with just over half of these studies including 28% or fewer people of color. Information about participants’ race and ethnicity was not reported for 10 (27%) of the samples.
Concerning gender, 29 (78%) of the samples consisted of 100% female/women, while others ranged from 48% to 98% female/women. 3 Gender identity was reported for three (8%) samples. Transgender and non-binary participants were included in two (5%) of these samples at less than 1% of the overall sample (Sexist MESS; Derthick, 2015; GRMSAAW; Keum et al., 2018). Sexual orientation was reported for 13 of the samples, ranging from 2% to 100% sexual minority participants (54% of these samples consisted of ≤17% sexual minority participants). Oshi-Ojuri (2013) limited their survey to sexual minority women of color because they studied sexist, racist, and heterosexist discrimination, reflecting their interest in intersectionality.
Ten (27%) of the samples included one or more indicators or correlates of SES: income (n = 7), class (e.g., working class; n = 4), employment status (n = 4), occupation (n = 4), partner/spouse’s occupation (n = 1), education level (n = 10), and partner/spouse’s highest level of education (n = 1). Religious affiliation was assessed in only two samples (5%) and assessment varied across studies (i.e., Christian or non-Christian; GRMS; Lewis & Neville, 2015; agnostic, atheist, Protestant, and Roman Catholic; GSM; Torissi, 2014). Disability status was only reported for one sample, specifically one used to test the GMS2016 (Schaff, 2016). This scale was explicitly designed to measure gender microaggressions among women with apparent disabilities, and therefore, the sample consisted entirely of women with a reported disability. Citizenship status was not reported for any of the samples.
Psychometric Properties
The reported psychometric properties of each measure are presented in Table 3. In terms of reliability, Cronbach’s alphas were reported for the majority of measures (79%, n = 19) and ranged from .42 to .97. Omega-H was reported for one measure (GRMSAAW; Keum et al., 2018), which is a test of internal consistency based on hierarchical structure (see Dunn et al., 2014). Two of the studies that reported Cronbach’s alphas engaged in other reliability testing: split half (Sexist MESS; Derthick, 2015; SEQ; Fitzgerald, Shullman et al., 1988) and test-retest (SEQ; Fitzgerald, Shullman et al., 1988). Among the measures without subscales, reported Cronbach’s alphas ranged from .75 to .96. For those with subscales, we found considerable variation in what aspects of each measure underwent reliability testing. Full-measure-only internal consistency was reported for the SEQ (Fitzgerald, Shullman et al., 1988), PEBS (Fitz & Zucker, 2015), and GMS2015 (Bolte, 2015), although they each were conceptualized to comprise multiple subscales (or levels, as Fitzgerald, Shullman et al. (1988) refer to them). Not all subscales were empirically derived, with question subsets for the measures by Fitzgerald, Shullman et al. (1988); SEQ) and Fitz and Zucker (2015); PEBS) developed without any formal method for determining underlying latent constructs (e.g., exploratory or confirmatory factor analysis). For four measures (Sexual Experiences Questionnaire—Workplace [SEQ-W]; Fitzgerald, Gelfand et al., 1995; HBS; Kuchynka et al., 2018; Female Microaggressions Scale [FeMS]; Miyake, 2018; EBSS; Oswald et al., 2019), Cronbach’s alphas were reported for subscales (range .42–.89), but not for overall measures. Cronbach’s alpha was reported for full measures (range .86–.97) and subscales (range .61–.96) for eight measures with subscales, including scales with multiple dimensions. Among the seven measures with multiple dimensions, reliability indicators were reported for subscales and full measures across both dimensions in three cases (SSE; Klonoff & Landrine, 1995; GRMS; Lewis & Neville, 2015; GRMSAAW; Keum et al., 2018) and only one dimension for the full measures and subscale in two cases (SHS; Sullivan, 2011; Sexist MESS; Derthick, 2015). The SSD (Becker & Swim, 2011) was the only two dimension scale with no reported reliability testing.
Summary of Psychometric Properties for Gender Microaggression Measures (by Publication Year).

Note. FACE = face validity, CONT = content validity, CONS = construct validity (includes discriminant, convergent, known-group), CRIT = criterion-related validity (includes concurrent, predictive, incremental), FACT = factor structure (includes Exploratory Factor Analysis, Confirmatory Factor Analysis, and Latent Class factor analysis); n.r. = not reported.
aWhen a measure title is not available, we present the concept assessed and use quotation marks to indicate this.
bWhen available, we use acronyms for measures as specified in the referenced publications. Otherwise, we created an acronym. Publication year is used to distinguish between measures with the same acronym.
cAll alphas reported are internal consistency reliability and represent total scale scores unless otherwise indicated.
dAlphas reported for Lifetime and Recent reference periods, respectively.
eGuttman split-half reliability.
Concerning validity, authors did not explicitly report any form of validity testing for eight (33%) measures, including the four measures with no reliability testing reported. Of the 16 measures with validity testing reported, factor structure testing was most commonly used (16 measures), followed by construct (n = 12), criterion (n = 5), content (n = 4), and face validity (n = 3). The GRMSAAW (Keum et al., 2018) was the most rigorously tested measure, with each type of validity testing, including face and content validity determined through expert review, and both exploratory and confirmatory factor analyses. Other examples of relatively extensive validity testing were Lewis and Neville (2015) GRMS, for which all forms of validity testing were reported except criterion validity, and the Interpersonal Sexual Objectification Scale (ISOS) developed by Kozee et al. (2007), which reported all forms of validity testing except face validity.
Three types of validity testing were reported for four of the identified measures, including the SEQ (Fitzgerald, Shullman et al., 1988) and SSE (Klonoff & Landrine, 1995). For the SEQ, content validity was not actually tested but was fostered by creating items informed by previously empirically developed categories of sexual harassment (Till, 1980). These researchers tested criterion validity by examining the correlation between the SEQ scores and the criterion item, “I have been sexually harassed.” Klonoff and Landrine (1995) tested factor validity of both SSE-lifetime and SSE-recent dimensions through exploratory factor analysis, and then examined construct validity by exploring the relationship between SSE scores (full and subscales across two dimensions) and stress indicators. Moreover, though they did not explicitly state that they were exploring known-group differences (a validity test), group differences were examined for both the SEQ and the SSE.
More minimal validity testing was reported for nine (38%) measures with the depth of testing ranging widely across measures. For example, Jones et al. (2014) carried out relatively extensive testing to examine the construct validity of the Benevolent Sexism (BS) measure. Construct validity was demonstrated with evidence of convergent and discriminant validity through the examination of significant correlations with incivility, job performance, and self-efficacy (non-significant relationships were found with education and job tenure). Construct validity was established by simultaneously factor analyzing the BS and incivility items, with two separate factors emerging that aligned with each construct. Although not explicitly conducted to show incremental validity of the BS measure, they also found that BS was negatively associated with job performance beyond incivility. By contrast, Oshi-Ojuri (2013) examined the factor structure of the SEXI subscale by subjecting it to factor analysis, resulting in nine factors; however, their sample consisted of only 25 people.
Gender Microaggression Measures and Microaggression Theory and Frameworks
A shared conceptualization of microaggressions informed by the work of Pierce et al. (1977), Sue (2010), and Nadal (2010) was consistently employed in the studies from which the 10 named microaggressions measures were drawn. These studies all described microaggressions as slights or indignities that were verbal, behavioral, or environmental in nature. Moreover, microaggressions were described as daily, common, or ubiquitous, with perpetrators often not conscious of the negative or derogatory nature of their communications or behaviors. Concerning Sue’s (2010) tripartite microaggression categorization of microassaults, microinsults, and microinvalidations, seven of the 10 named microaggressions measure studies described and defined this tripartite categorization; however, the naming of their scale factors or dimensions did not map onto the tripartite categorization. The other three studies—Microaggressions Against Women Scale (MAWS; Owen et al., 2010); GRMS (Lewis & Neville, 2015); GRMSAAW (Keum et al., 2018)—did not refer to Sue’s (2010) tripartite categorization. All of the measures addressed interpersonal microaggression experiences, and four measures included subscales specifically assessing environmental microaggressions (GMS 2015; Bolte, 2015; Derthick, 2015; GRMSAAW; Miyake, 2018; Keum et al., 2018).
With respect to addressing gender microaggressions themes (Capodilupo et al., 2010), among the 10 named gender microaggressions measures, only the GMS2015 (Bolte, 2015) consisted of subscales that completely adhered to Capodilupo and colleagues’ (2010) gender microaggressions taxonomy. Four measures had partial adherence, meaning that they included at least one theme from the taxonomy, and the authors added different subscales (GMS-R; Judson, 2014; SexistMESS; Derthick, 2015; GRMS; Lewis & Neville, 2015; FeMS; Miyake, 2018). For example, the SexistMESS (Derthick, 2015) was comprised of subscales consistent with the gender microaggressions taxonomy (e.g., “Assumptions of Traditional Gender Roles” and “Sexual Objectification”), as well as subscales not included in the taxonomy (e.g., “Expectations of Appearance”). While some partial adherence measures had slight variation from the gender microaggressions taxonomy, others only included one or two of the original themes (e.g., GRMS; Lewis & Neville, 2015; FeMS; Miyake, 2018). Finally, the GRMSAAW (Keum et al., 2018) did not include any themes from the gender microaggressions taxonomy, and four other named microaggressions measures did not have any subscales (MAWS; Owen et al., 2010; MII; Oshi-Ojuri, 2013; GMS; Torissi, 2014; GMS2016; Schaff, 2016).
Discussion
This scoping review identified an accelerated pace at which researchers are working to assess the frequency of gender microaggressions and other forms of subtle sexism, with nearly 80% (n = 19) of the reviewed measures created within the last 10 years. Seven of the measures assessed only subtle gender discrimination and 17 of them inquired about a mix of subtle and blatant discrimination. Overall, these mixed measures capture a spectrum of gendered experiences, and, as a result, are improvements over blatant-only measures; however, subtle-only measures, particularly those grounded in the gender microaggressions literature (e.g., GMS2015; Bolte, 2015), are needed to better understand gender microaggressions as a construct. Measures, such as SSD (Becker & Swim, 2011) and FeMS (Miyake, 2018), which have blatant- and subtle-specific subscales are useful in understanding the differential impacts of these types of discrimination. Given the various types of gender microaggressions that women experience, measures like the GMS2015 (Bolte, 2015), which assesses a range of subtle discriminatory experiences (e.g., being treated as second-class citizens, assumption of traditional gender roles, denial of sexism, and environmental microaggressions), are particularly important contributions to the field.
Context and Measure Development
Most measures identified in this scoping review (58%; n = 14) were intended to assess the frequency of microaggressions that take place in any environment (i.e., general use measures) across the participants’ life. Conversely, 10 measures were created for specific contexts, such as university/school, workplaces, and multiple settings. While general use measures have advantages with regard to widespread application across settings, context-specific measures (e.g., for educational environments) have notable potential to improve the development of primary prevention strategies, including efforts to change organizational culture and climate (Gartner, 2019). Kuchynka et al. (2018), for example, examined sexism as experienced by women majoring in a science, technology, engineering, and mathematics (STEM) field. This context-specific measure allowed the researchers to more directly evaluate the impact of sexism on intentions to major in a STEM field and STEM GPA, while also providing practical implications for designing interventions tailored to STEM classrooms and other university-specific systems (e.g., avoiding paternalistic messaging targeting women and providing support for any struggling students). Moreover, Sterzing et al. (2017) described the need for more context-specific measures of microaggressions, including ones that look at spaces beyond the workplace, clinical, and educational settings. For instance, our review did not identify any measures designed to assess the frequency of gender microaggressions within the family context, where women may experience gender microaggressions from immediate and extended family.
Populations and Measure Norming
Our findings identified a need for improved practices in capturing key demographics. When validating an instrument, demographics (e.g., race, gender identity, sexual orientation) play a crucial role for researchers and practitioners interested in the applicability of a tool for different populations. Based on the information reported in the included studies, we found that many measures were validated with predominantly homogenous samples. We identified the following factors contributing to this lack of diversity reported in samples: (a) a true lack of diversity in the sample, (b) the absence of questions to assess (and thus ability to report) the actual diversity of their sample, and (c) insufficient conceptualization of demographic constructs (and thus lack of consistency in assessment and reporting).
First, some of the study samples lacked diversity, especially in terms of race, and reported on this aspect of their sample. For example, Swim, Eyssell et al. (2010) assessed and reported on race, but only 8% of their sample identified as people of color. Of course, select measures were created for use with women of color; therefore, our study also documented samples with 100% women of color. A second challenge was that the majority of studies did not evaluate a range of diverse identities among their samples; for instance, they did not have questions to capture ability status and gender identity. This issue also applied to race, with 10 of the 37 samples not evaluating participant race. A third issue was the lack of accurate and consistent conceptualization and language necessary for the meaningful collection of demographic information about constructs such as SES and religion. Due to inconsistent conceptualization, we were unable to readily examine trends in the diversity of samples that reported on these indicators. Inconsistency was also noted with sex and gender categories, which were conflated in two studies included in this review. While not unique to gender microaggressions research (Westbrook & Saperstein, 2015; Woodford et al., 2019), the problematic conflation of sex and gender have been critiqued as grounded in cisnormativity (Bauer et al., 2009). Future gender microaggression research should be anchored in established best practices for assessing assigned sex at birth, gender identity, and sexual orientation in every study (Badgett, 2009; The GeniUSS Group, 2014).
Advancing the scientific rigor of research through establishing a gold standard of demographic measures to be included across studies would provide consistent critical information for researchers interested in using or adapting scales. While researchers may express instrument length and participant burden concerns when adding demographic items not directly related to their research questions, the potential to elevate measurement science arguably outweighs the increased effort (Sifers et al., 2002).
Reliability
It is recommended that the reliability of a measure be established through internal consistency (i.e., homogeneity of items for the latent construct) and test-retest reliability (i.e., consistency over time; DeVellis, 2012). Most researchers performed and reported on tests of internal consistency for their measures (83%; n = 20; types: Cronbach’s alpha; McDonald’s Omega-H). Despite accepted best practices (DeVellis, 2012), four measures did not report any indicators of internal consistency, and thus, failed to provide readers with the required information to evaluate each measure’s potential utility as a tool to assess this latent construct.
Our findings highlight important discrepancies in how researchers chose to report coefficients of internal consistency for scales with multiple subscales. For example, three measures (SEQ, GMS2016, and PEBS) provided reliability coefficients for the total scale but not their individual subscales, while four provided reliability coefficients for the subscales but not the total measure. This can cause significant confusion for readers when articles lack clear instruction on when the total score or individual subscales can and cannot be used as determined by its psychometric properties. Importantly, the SEQ (Fitzgerald, Shullman et al., 1988) was the only measure to provide indicators of test-retest reliability to assess response consistency over time (DeVellis, 2012). Test-retest is challenging to assess generally (e.g., due to potential for recall bias; Coughlin, 1990), but may also be less conceptually appropriate for gender microaggressions, which are generally ephemeral, context-specific, and dependent on the number of daily interpersonal interactions (Sue, 2010). In other words, indicators of poor test-retest may actually be a sign of changes in the frequency of microaggressions across the testing periods. From our review, it is evident that more transparency in reporting is needed, whereby authors present the range of reliability tests considered in the design and execution of the new instrument, what tests were included in the final analysis, and a detailed rationale for these determinations.
Validity
This psychometric review identified only one measure—GRMSAAW (Keum et al., 2018)—for which each major type of validity (face, content, criterion-related, construct, and factor structure) was assessed and explicitly reported. Sixteen (67%) articles included in our review reported their measures were factor analyzed (types: exploratory factor analysis, confirmatory factor analysis, latent class analysis). Factor analytic techniques are an essential step to ensuring the scale items map onto the underlying latent construct and/or subconstructs (Comrey, 1988). Of note, SEQ (Fitzgerald, Shullman et al., 1988) and PEBS (Fitz & Zucker, 2015) did not utilize a formal statistical method to assess the factor structure of their subscales, which were entirely conceptually derived. Additionally, 21% (n = 5) of measures underwent criterion-related validity testing (types: predictive, concurrent, incremental) to determine the predictive ability of the new measure compared to an existing measure (Carmines & Zeller, 1979). This low rate of criterion-related testing, particularly incremental validity, is consistent with Lilienfeld (2017) critique of microaggressions research. Specifically, incremental validity provides an estimate of the meaningful contribution made by a new measure above and beyond extant measures of the same or similar construct (Lilienfeld, 2017, p. 157, citing Meehl, 1959; Sechrest, 1963). Incremental validity testing is vital to supporting the theoretical claim that microaggressions exert a unique impact on health and other outcomes beyond more blatant forms of gender discrimination and violence. Without robust, psychometrically validated instruments, this area of scholarship will remain open to criticism, and, more importantly, we are delaying progress in finding effective solutions to prevent and treat gender discrimination, violence, and health-related disparities.
Lastly, despite best psychometric and dissemination practices, 33% (n = 8) of measures had no reported validity testing. In some of these studies, articles included details of what may have been forms of validity testing, but because these procedures (e.g., correlations) were not depicted as validity testing, they were not included in our review. Thus, consistent with the critique by Lilienfeld (2017), our findings suggest few gender microaggression measures are currently available that (a) report robust psychometric validation and (b) assess only the subtle aspects of gender discrimination. This creates substantial obstacles to understanding the frequency, prevalence, and impact of gender microaggressions in comparison to more blatant acts of discrimination and violence. On a positive note, GRMS (Lewis & Neville, 2015) and GRMSAAW (Keum et al., 2018), which are both intersectional measures, were two of the strongest microaggression measures identified in this review based on their completeness of psychometric testing and reporting.
Gender Microaggression Named Measures
Ten measures were named as gender microaggressions measures. Of these, four measures—MASW (Owen et al., 2010); GMS (Torissi, 2014); GMS2015 (Bolte, 2015); GRMSAAW (Keum et al., 2018)—focused exclusively on subtle forms of gender discrimination. The other six named microaggression measures either explicitly assessed both subtle and blatant forms of gender discrimination and violence, or, because of ambiguous wording, included items that could apply to both subtle and blatant discrimination. It is important that researchers clearly differentiate gender microaggressions from more overt discrimination and violence that would be better described and studied as aspects of overt discrimination and/or sexual assault (Gartner & Sterzing, 2016). The removal of microassaults or direct, conscious acts of sexual harassment and violence is an important step in addressing the conceptual ambiguity that currently exists between gender microaggressions and these other related gender-based constructs. Moreover, with respect to ambiguously worded items, though vagueness can be beneficial in capturing a range of experiences, clarity is essential to respondents accurately understanding and precisely answering questions.
Results were mixed with respect to how well named microaggressions measures reflected the distinct nature of microaggressions as outlined in the literature (e.g., Nadal, Hamit et al., 2013). We found that all manuscripts using named microaggressions measures employed current definitions of microaggressions as subtle, often-unintentional acts of discrimination. But, as noted, four gender microaggressions named measures also included blatant acts, and only four specifically addressed environmental microaggressions through subscales. Though some of the authors referenced Sue’s (2010) tripartite categorization in their studies, none of the measures contained subscales or dimensions specifically aligned with this framework. If researchers and practitioners are to understand the unique impacts of various types of microaggressions (e.g., environmental), specific measures and/or subscales are needed. Most importantly, considering growing contemporary regressive social norms and discourses toward women (e.g., changes to Title IX, threats to abortion access), developing environmental microaggressions measures is critical to researchers and practitioners in their efforts to understand the consequences of these microaggressions on women’s wellbeing.
Only five of the named microaggressions measures employed themes from Capodilupo and colleagues’ (2010) gender microaggressions taxonomy. The GMS2015 (Bolte, 2015) reflected all themes, while others used selected themes and additional subscales. Adding other thematic categories may reflect the changing nature of gender microaggressions, and excluding categories may help to ensure a measure is appropriate for the intended population and/or context. However, when doing so, researchers should provide a rationale for their decisions, which would be important to other researchers considering using these measures, especially in terms of content validity. Given the absence of a gold standard gender microaggressions measure, it is imperative that researchers designing measures consider the conceptual foundations established in the field and are transparent in their decision-making processes. Engaging in a participatory process with members of the intended research population and experts will help to facilitate relevant, comprehensive, and culturally appropriate measures.
Limitations
Our review has several limitations. First, the language used to describe gender microaggressions and gender discrimination has changed over time and continues to evolve; as such, our search terms may not have captured every article in this area. Second, psychometric reviews are largely dependent on the quality of reporting in each article. We identified, for example, studies that utilized their new measure to examine health-related outcomes, which could be seen as evidence of construct validity but may not have been labeled as such in the manuscript. By recording only explicitly reported reliability and validity tests, we aimed to avoid making false inferences from the authors’ work and to encourage clearer reporting of psychometrics in the microaggressions literature. Nevertheless, our restrictive approach may result in an underreporting of the extent to which these measures have been psychometrically tested. As such, readers are encouraged to review the original published article before making a final selection on what measure of gender microaggressions to use. Finally, the literature search was current as of January 2019; thus, as with all systematic reviews, our review is not inclusive of measures published after our cut-off date.
Practice Implications
The development of a gold standard measure of gender microaggressions, including population- (e.g., refugee women) and context-specific (e.g., family setting) adaptations, has important implications for practice settings. Presently, no scientific consensus has emerged regarding the prevalence and incidence of gender microaggressions to provide definitive guidance to policy makers on how best to address this social problem. This stands in contrast to the more psychometrically advanced areas of sexual harassment and assault (Gartner & Sterzing, 2016). Contingent on practice setting and population, we recommend that practitioners rely on the three measures that were the most psychometrically validated. First, for assessing subtle experiences with Asian American women, the GRMSAAW (Keum et al., 2018). Second, for assessing subtle and blatant experiences with Black women, the GRMS (Lewis & Neville, 2015). Finally, for a general use measure for both subtle and blatant items, the ISOS (Kozee et al., 2007). However, practitioners must review each measure in detail (e.g., psychometrics, thematic coverage) before making their final determination to ensure the best fit for their context and population.
Conclusion
In this psychometric scoping review, we synthesized the currently available measures of gender microaggressions. Moreover, we provided a summary of each measure’s context and reported psychometric properties to assist researchers in selecting the best available tool for their research question and study population. We also examined the consistency between named gender microaggression measures and conceptualizations of microaggressions found in the literature. We identified several research gaps, including the lack of explicit reporting of reliability and validity testing conducted, measures tested with samples that were homogenous or for which diversity characteristics were unknown, and lack of context-specific measures. These issues raise concerns about the quality and utility of available gender microaggression measures. We hope researchers will address these issues in their future investigations of gender microaggressions. All scientific forms of dissemination need to be held to the highest standards; this is most certainly true of studies implementing novel measures or explicitly aiming to design and test a measure. These are often the only means that academic and non-academic (e.g., clinicians, diversity consultants) audiences have to discern the quality and applicability of these tools. We recommend researchers precisely follow the best practices in scale design and reporting of psychometrics (Cabrera-Nguyen, 2010). Moreover, detailed empirical or conceptual rationales are needed for the performance and/or exclusion of psychometric assessments.
The construct of gender microaggressions rests on a strong body of theoretical and empirical literature, emerging from interdisciplinary academic inquiry in such fields as social psychology, women and gender studies, and social work. As highlighted by this review, a considerable body of recent work has emerged to operationalize gender microaggressions, with 19 out of the 24 measures reviewed published during the last decade alone. Yet, substantial work remains to be done to advance quantitative gender microaggressions research through identification of gold standard measures that do not conflate subtle and blatant acts of gender discrimination, employ core tenants of gender microaggressions conceptualization, are psychometrically valid across a range of different social contexts (e.g., education, employment, family), and appropriate for diverse groups of women.
Footnotes
Appendix A
Search Specifications.

| Category | Terms |
|---|---|
| Population | “wom?n*” OR “gender” OR “sex” OR “girl*” OR “female*” |
| AND | |
| Discrimination | “sexism*” OR “sexual harassment” OR “misogyn*” OR “gender insult*” OR “gender victimization” OR “gender bullying” OR “objectification” OR “gender harassment” OR “sexist hostilit*” OR “interpersonal objectification” OR “sexual objectification*” OR “sexist” OR “overt sexism” OR “sex* discrim*” OR “gender* discrim*” |
| AND | |
| Subtle/covert | “subtle sexism*” OR “everyday sexism*” OR “covert sexism*” OR “modern sexism*” OR “modern-day sexism*” OR “modern day sexism*” OR “gender slight*” OR “subtle sexual harassment” OR “microaggression*” OR “benevolent sexism*” OR “micro aggression*” OR “micro-aggression*” |
Note: “*” is used as a wildcard during searching that returns terms with the same stems. Example: “misogyn*” will return “misogyny”, “misogynistic”, etc. “?” is used as wildcard for a single letter in the middle of a word. Example: “wom?n” will return “woman”, “womyn, “women”, etc.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.