
Abstract
We argue that critical evaluation achieves the reflexivity needed to facilitate collaboration by proposing boundary-negotiating artefacts to configure a joint action domain. Those objects become mediators for innovation by triggering controversies, conceived preventatively via an organized extension of what Boltanski calls ‘truth tests’ to ‘reality tests’ so that they dynamize ongoing affairs. However, critical evaluation must also anticipate actors’ reappropriation of boundary-negotiating artefacts in the effort to protect their rights, stakes or room for manoeuvre. Three scenarios commonly arise: avoidance or utopian projecting, enactment of inverted reality tests, and disavowal through role exchange. The article develops these propositions through the reconstruction of a modified theory-based evaluation of a collaborative research programme. The programme set out to explore how evidence from health research could be used rapidly and effectively in the context of practical problems and organizational challenges, so an internal evaluation was set up to facilitate learning during the process. What ensued, however, was a loss of trust between partners, resolved only by repositioning the evaluation as a reflective academic study, reducing its reflexive capacity to intervene on the level of activity and organizational integration. We conclude that doing successful critical evaluation and, more generally, achieving political pertinence for social scientific discourses depends on creating the conditions in which actors are able to take the risks and share the costs associated with the enhanced level of reflexivity necessary to engage in collective action as well as knowledge production.
This article presents the history of a critical evaluation carried out by the first two authors in an effort to facilitate collaborative research, procedurally characterized in terms of truth and reality tests (Boltanski, 2009), and in terms of struggles around intermediary objects designed as an explicit evaluation support and further specified as boundary-negotiating artefacts (Lee, 2007). There are two reasons for our choice of subject and approach. A first, pragmatic, reason is the desire to engage reflexively with our own situationally dominated position as evaluators – researchers commissioned to critically evaluate implementation of another programme of research. Positioned as hired experts invested with the hope that, through critical questioning, we could improve the way collaboration functioned, we were faced with the uncomfortable experience of dealing with rather hostile reactions from some participants to the interpretations we placed on their activities, as well as with a sense that we had failed to facilitate any process of change or improvement.
On the other hand our situationally dominated position as evaluators, and the ambivalence of acting as both appraisers (‘taking measures’ in the sense of ranking, measuring or making judgements about others) and facilitators (‘taking measures’ in the sense of enacting a policy and thereby altering others’ practice, in this case by facilitating change and brokering compromises [Callon et al., 2001: 298–299]), made it more difficult to ignore dissent. It therefore became incumbent on us to pursue an ongoing reflexive sociological explanation (Latour, 2007: 141–142) in order to build and maintain the joint action domain with the participants. Writing now from a retrospective position, with the help of an external interpreter (the third author), who played the role of critical opponent and agent of continuous theoretical reflection, it is possible to further develop such a reflexive sociological explanation through a reconstruction of the history of the evaluation perceived from the position of evaluators – stakeholders whose decisions have a direct impact on the other participants in a joint action domain. This framing allows us to understand participants’ sense of unease about evaluators’ interpretations and propositions in terms of their own need to preserve room for manoeuvre.
Our second, more theoretical, motivation for writing this article is linked to the fact that the evaluated research programme was itself a process of organizing, or coping with the indefinite stream of happenings through the configuration of affairs (Kabele, 2010). There is a link between configuration and evaluation based on the principle that the agreement of orders of worth or value and the associated ranking of people and things is intrinsic to the configuration of a space of social action (Boltanski & Thévenot, 1991), just as ‘epistemic cultures’ emerge through the structuration of knowledge production and evaluation (Knorr Cetina, 1999). Informed by ethnomethodology, social constructivism and especially by a pragmatic sociological approach, this theoretical position directed our attention to the orders of worth used in maintaining organizational integration (Boltanski, 2009) and to the institutional logics emerging in the course of new collaborative practices (Friedland & Alford, 1991). Notwithstanding our failure to facilitate improvement, our experience may actually testify to successful coping with the indefinite stream of happenings if we interpret the shift in our remit – from formative problem solving to academic reflection – which is described below as a sign that reflexivity can have a confirmatory in addition to a critical function.
The perspective reported in this article remains that of the evaluators. Even if we now write from a meta-analytical position, we cannot, and would not wish to, disassociate ourselves from the strategic and reputational interests that pertain to our involvement in the collaborative research programme. An evaluators’ perspective supposes the compliance of the evaluated, and any attribution of non-compliance through voice, passive resistance or exit can naturally be read as an attempt to throw blame for failure of the collaboration onto them. Obviously, the validity of assignments of blame or liability for failure, in the absence of voices from the ‘other side’, is in principle untrustworthy. We therefore claim validity not for the assignments of blame that are unavoidably implicit in the account, but merely for our reconstruction of the evaluators’ practice, which we investigate by describing a series of episodes – interventions in the evaluated research programme – and (following the evaluators’ agenda) by pausing after each episode to focus on the types of tests that were proposed, resisted and enacted, and on the disputes that arose around boundary-negotiating artefacts.
First we briefly contextualize our case. Then we build a theoretical basis for studying critical evaluation, defining a number of key terms, which we borrow mainly from a pragmatic sociology, and explaining their importance for our case. In the following section we describe our methods and study design. We then reconstruct the course of the evaluation as a story unfolding in five episodes (summarized in row 3 of Appendix Table1). We conclude by demonstrating the relevance of our case to broader questions of the communicability, use-value and political pertinence of sociological knowledge.
Contextualization of the analysed case
The case reconstructed below is the critical evaluation of a collaborative research programme in the sphere of local health services (primary care) in the UK involving academic researchers, health service managers and an initially unspecified range of further actors who might be interested in a research-driven programme to promote better health behaviour among groups at risk from vascular disease. Some of the projects, for example, concerned the design, take-up and patient and professional experiences of NHS and local government programmes to establish a system of preventative health checks in primary care. 1 Given the widely publicized disconnect between academic research and practice in the health service (Cooksey, 2006), the collaborative research programme wanted to explore how evidence from health research could be used rapidly and effectively in the context of current practical problems and organizational challenges. The programme’s collaborative framing was constructed in response to a funding opportunity designed to stimulate novel and experimental ways of working between hitherto unfamiliar partners. It therefore illustrates an important trend, which has seen policymakers deploying funding opportunities and other organizational devices in an attempt to stimulate innovation, based on an assumption that it is encouraged by disciplinary and professional heterogeneity (Jouvenet, 2013).
A modified theory-based evaluation 2 (Connell et al., 1995; Pawson & Tilley, 1997) was commissioned as one of the key mechanisms for organizational learning, focusing not on individual projects but on organizational processes at the programme level. The aim was both to inform the ongoing development of the programme and to learn lessons for the design of similar initiatives in the future. The emphasis was meant to be on formative learning and facilitation more than on judgement, measurement or appraisal.
Initially the evaluation was assigned to one social scientist, who was a permanent member of staff in the same research unit as the principal investigator and the research team leading the collaborative programme. Later a second evaluator, also a social scientist, was appointed on a short-term contract. Core partners, who regularly attended steering group meetings, plus a few other individuals whom core partners identified as key actors, were the other participants who engaged directly with the evaluation and developed a relationship to the boundary-negotiating artefacts that supported it. The arenas for their collaborative interpretation were workshops and interviews where evaluators interacted with these partners. These dialogical situations crystallized controversies strong enough to engender a redistribution of competences (Akrich, 1993a) as some of the evaluated parties assumed meta-evaluative roles. The sociological interest of these performances also prompted the evaluators to assume a meta-analytical role, culminating in this article.
Theorizing critical evaluation and its application
Using relevant theoretical knowledge about joint action and its concerted organization, as well as about criticism, evaluation and collaboration, to reconstruct the case introduced above, we came to the central argument presented in this article, which is examined step by step in this section: critical evaluation achieves the reflexivity needed to facilitate collaborative research by proposing boundary-negotiating artefacts to configure a joint-action domain. Those objects can become mediators for innovation by triggering controversies, conceived preventatively via an organized extension of what Boltanski calls ‘truth tests’ to ‘reality tests’ so that they dynamize ongoing affairs. However, critical evaluation must also anticipate actors’ reappropriation of boundary-negotiating artefacts in the effort to protect their rights, stakes or room for manoeuvre. In the following subsections we structure our argument around Explanatory propositions regarding strategic choices for structuring joint-action domains, the role of critical evaluation and qualifying questioning, and the dilemma of how to extend simple truth tests to more critical types of enquiry.
‘[I]nterested in the procedures by which individuals and groups establish the reality of things’ and the ‘tangibility tests through which actors forge new understandings’ (Chateauraynaud, 2004), pragmatic sociology makes confirmatory justification, critique, controversies and the search for compromises, together with the collective organization of tests of the worth of things, central features both of its theory of joint action and, at another level of reflexivity, of the business of sociological investigation (Boltanski, 2009). This is based on the assumption that, in moments of dispute, actors will invoke tests in order to make sense of what is happening, enable decision-making and establish the relative worth of participants in the dispute. So studying how these tests are enacted is instructive if we are to understand how often-fragile social orders are maintained. Moreover, since the possibility of a lasting compromise is greater if it can be inscribed in material or symbolic intermediary objects as external reference points, disputes are marked by the creation of structuring artefacts that observers can regard as traces of emerging compromises, based on the success of their proposers in winning support for their objects as the ones which will structure the terms of collaboration and the configuration of the joint-action domain (Lee, 2007). Controversies have previously been studied as an alternance of tests in the search for a commonly acceptable and accessible form of test (Chateauraynaud, 2004; Latour, 2007), on the grounds that controversies are situations in which actors are compelled to invoke critical capacities and registers of justification (Boltanski, 1990; Thévenot, 2001) or to make visible the silent work of infrastructures (Star, 1999). We, on the other hand, approach disputes and criticism by reconstructing a process in which tests were commissioned (an evaluation) and then focusing on controversies which were either induced or, on the contrary, suppressed, in the course of testing, along with the intermediary objects used to facilitate and stabilize – or, alternatively, to circumvent and resist – the particular tests proposed. In other words, the situation was one in which the disputatious character of critical evaluation was intentionally mobilized to try to facilitate new understanding.
When considering evaluation we draw on a dual – narrative–argumentative – theory of social construction (Kabele, 2005, 2010), according to which social actors construct reality in a deliberative fashion by counterposing ‘what is’ and ‘what should be’ versions of their world (Boltanski’s ‘lived’ and ‘instituted’ reality), including the ‘grammars of normality’ and ‘orders of worth’ they use to evaluate ongoing affairs (i.e. the repertoire of legitimate tests). Evaluation is one means of applying ideals and principles in order to relate ‘what is’ to ‘what should be’. We therefore assign it a critical function, in line with the argument of Messner et al. (2008), who nevertheless distinguish between critical practices that emerge routinely in organizational life and those that are formally institutionalized as meta-practice. Routinely emerging criticism flows from clashes of rationalities between organizational members or units and is therefore likely to be endemic in joint-action domains – indeed its imputed constructive effects are one of the factors underpinning the very rationale of collaborative research programmes. Where a critical function is formally assigned to an evaluator, the latter is ‘able to criticize with impunity because they occupy a unique structural position in relation to the organization’ (Messner et al., 2008: 73). As with all forms of delegation to expert authority, however, the allocation of trust is complex since an evaluator necessarily has to take up a position internal to the organizational domain (to gain credibility and access to participants), which makes her a new and potentially disruptive partner. She may be officially sanctioned to make ‘tangibility’ tests by applying a frame that differs from and potentially challenges those of organizational members, but the practical authorization to do so is less easily established because of the resistance of the evaluated.
The potential of critical evaluation to achieve the reflexivity needed to facilitate collaboration rests on its capacity to stage a series of willed contests or ‘preventative socio-technical controversies’ (Callon et al., 2001: 354) during which evaluators, armed with social scientific knowledge, might help form and stabilize a joint-action domain with evaluated parties. This depends on the organization of certain types of test and the introduction of certain types of artefact. However, the meaning ascribed to both tests and artefacts is collectively negotiated, and its details unpredictable. By reconstructing the succession of tests organized and the career of artefacts introduced during the evaluation, we show how the staging (or avoiding) of controversies contributed to the progressive installation of a distinct evaluation regime (in the informal sense of the term evaluation) as part of the configuration of the project’s joint-action domain. The coordination dimension of any domain is given by the interleaving of participants’ contributions to joint action through the creation of formal or informal empowerments with constraints derived from the justified and deliberate application of experience. Following a pragmatic approach, a joint-action domain is thus a personally and materially delimited sphere of activity in which actors ‘take hold’ of their environment (Thévenot, 2001) or institute its reality in order to mutually coordinate their room for manoeuvre in space and time, with greater or lesser degrees of reciprocity, in order to attribute entitlements and competency to act. Joint-action domains can be more or less stable, more or less permanent and more or less all-encompassing with regard to actors’ attachments and associations. In the broad sphere of science, they range in type from new epistemic communities (Knorr Cetina, 1999) to borderlands that enable exchange without sacrificing distinct disciplinary roots (Marcovich & Shinn, 2011). In the former case, boundaries are evidently crossed or pushed, and new boundaries demarcated; while in the latter, boundaries tend to be stable, becoming ‘a precondition and a resource for extra-community communication, interaction and exchange’ (Marcovich & Shinn, 2011: 589) but allowing collaborators to communicate effectively without crossing them.
Why proposing boundary-negotiating artefacts is an effective strategy for configuring a new joint-action domain
When collaboration occurs between organizations, the engagement of collective dispositions and devices, recursively formed through the above-mentioned tangibility tests, is particularly important (e.g. Gray, 2004). Coordination is then affected by controversies framed around partisan views of externalities, which these tests can help to bridge, but without guaranteeing a truly effective solution. Possible solutions are sometimes connected with boundary objects, which rely heavily on standardization and are more prevalent at the routine end of the spectrum of forms of coordinated work; and sometimes with boundary-negotiating artefacts, which are more relevant to non-routine coordinated work, ‘used to push boundaries rather than merely sailing across them’ (Lee, 2007: 307). They stimulate participants’ claim-making practices in order to provoke network adjustments or a redistribution of competences (Akrich, 1993a, 1993b). Essentially boundary objects act as what Latour calls intermediaries, while boundary-negotiating artefacts are mediators (Latour, 2007). Mediators intervene actively in disputes between partners and can facilitate (but also complicate) problem definition, discovery of new solutions and (if the dispute is resolved) relatively stable compromises and legitimate decisions. They are useful devices in critical evaluation since their novelty forces actors (if they are to use them at all, which is far from guaranteed) to work out how to use them (Latour, 2007: 115). Since the very process of appropriating a new artefact provokes cognitive-social reconfigurations (Akrich, 1993b), this affordance can be leveraged by critical evaluators, who can effectively seek to stimulate collaborators to collectively equip the objects with ‘user manuals’ (Labatut et al., 2012; Lee, 2007). Over time, the circulation of mediators no longer generates any new claims, as common interpretations are negotiated. Once they have been linked to an invisible infrastructure of standards, categories, classifications and conventions acceptable to more than one domain, they can then fulfil the role of intermediaries that permit communication between social worlds: they become ‘fully fledged’ boundary objects (Star & Griesemer, 1989). Critical evaluation also mobilizes this tendency, but its incidence can be a mark of collaborative failure as much as success. We can only determine which when we follow the career of intermediary objects from a dual perspective of action and attribution (Akrich, 1993b), tracing the usage patterns that develop towards them and the testing that goes on around them in the life of a project.
How critical evaluation can assist collaboration by raising the level of reflexivity in joint-action domains
Critical evaluation can increase the level of reflexivity and therefore facilitate a change from a practical to a metapragmatic register (Boltanski, 2009), the effect of which is to change the type of question that participants are inclined to ask (themselves) about their ongoing interaction, or the type of tangibility tests invoked: instead of asking strictly practical questions about how to accomplish the current task, they start to ask ‘qualifying’ questions about the meaning of what’s happening to them by indexing situated action to ‘what should be’ versions of their world derived from ideals and principles. There are two types of ‘qualifying’ questions that can be used for tests – confirmatory ones and critical ones, according to either adherence to or departure from accepted beliefs or standards and relevant facts of instituted reality. Confirmatory questioning serves to preserve the status quo expressed by instituted reality. On the contrary, critical questioning enacts inquests that are too coordination costly to perform in everyday situations, 3 putting in doubt that which it is normally more economical to take for granted, including the very repertoire of tests (e.g. legal norms and definitions) that are the authorized means of validating whether a given social or natural order ‘holds’ for pragmatic or ritualistic purposes (Boltanski, 2012: 30–41). Both confirmatory and critical questioning represent responses to the risky nature of organizational processes and problems through enacting tests of current organizational habits and established understandings. But only critical questioning can have a strong facilitative impact for organizational change and open future knowledge horizons by generating new understandings.
How ‘qualifying’ questioning can be made effective by mobilizing Boltanski’s tests
Confirmatory questioning is naturally associated with truth tests, and critical questioning with reality tests. 4 We can understand a truth test as one that operates within a single modality (either ‘ought to be’ or ‘be’), whereas a reality test opens and detects a distance between ‘ought to be’ and ‘be’ modes (Boltanski, 2009: 160) or between lived and instituted reality (Boltanski, 2012: 39). So a truth test does not problematize the relationship between words and worlds (symbolic forms and the state of things) but rather uses words to confirm – rationalize, legitimize or justify – both words and worlds. There is a significant difference between how truth tests operate in ‘ought to be’ and ‘be’ modes. The former can only operate in public, frontstage action; whereas the latter are often situated in private, backstage action (Goffman, 1956). Both absorb indefiniteness by seeking to confirm ostensive or practical scripts as part of the process of defining a situation, and serve as a means of allocating hope and trust while avoiding controversy. Such confirmation by no means always produces an ‘optimal’ solution (Rapoport & Chammah, 1965); but, in most everyday situations of ongoing affairs, truth tests provide a ‘good enough’ guide to joint action because of the relative stability and predictability of a social or natural order (including, for example, a routinized research environment such as a laboratory). A reality test, by contrast, deliberately heightens indefiniteness by calling into question the ‘reality of reality’ in the process of looking at ‘what is’ through the lens of what ‘ought to be’ (Boltanski, 2012), thereby stimulating controversy as the preferred decisional or existential mode, and implying the possibility or even necessity for change. The point of reference (the instituted) might be defined in terms of an aspirational model (an ideal or perfect world), a statistical mean (the ‘average person’) or an enforceable agreement that establishes standards it is necessary to ‘live up to’. In each case reality tests are generally associated with mediators (Latour, 2007), and some of the configurative work is delegated to boundary-negotiating artefacts (Lee, 2007), since what reality tests test is the resistance of something to its translation into something else: an activity is performed, the performance evaluated, and that evaluation is used to literally push a boundary by refashioning or updating an ideal or a ‘notion of good’, the latter being thereby instituted or realized as learning occurs (Thévenot, 2001). In order to organize reality tests as devices of critical evaluation, an evaluator therefore has to balance the dual roles of appraiser and facilitator because the controversies stirred by reality tests relate as much to collective action as to knowledge production and require political as well as scientific resolutions. 5
How the critical capacity of evaluation can be enacted either by metaphoric inverted truth tests or by the extension of simple truth tests to more complex reality tests
Some, more abstract, distanced or theoretical forms of evaluation mobilize what could be called metaphoric inverted truth tests, in which the critical effect comes from semantic innovation and from the emergent sense of ‘metaphoric torsion’ whose focal reference is a possible world constructed by written or spoken text (Black, 1962). Metaphors, therefore, are linguistic operators that are validated not on the basis of truth but on the basis of the probability or congruence of the world they propose (Ricoeur, 1972: 105); this lends them an implicit critical force with respect to instituted reality extending beyond the confirmatory questioning of Boltanski’s truth test. It has been argued that this mode of questioning is typical of knowledge conversions in modern Japanese organizations, whose planning ethos attempts to stimulate creativity by increasing uncertainty through a similar enlargement of a company’s imaginative repertoire (Nonaka & Takeuchi, 1995); but it is also, of course, characteristic of literature, especially poetry and, we would argue, of laboratory-based or otherwise ‘confined’ (social) scientific research.
In the extension of truth tests to reality tests, which is more relevant to our case of critical evaluation in collaborative research, truth tests serve to align the perspectives and attributions through which actors configure or institute reality. As much as it sounds like a contradiction in terms, confirmatory questioning then becomes the basis for critical questioning insofar as the alignment it enables is a prerequisite for an organized confrontation between instituted and lived reality (i.e. for preventative controversies) that, as with metaphor, can create space for new understandings via a displacement of ideals. In this case, however, the mechanism is different: it consists in the modification of imputations by reattributing causes to new entities that do not correspond to indigenous categories. This manoeuvre can easily fail if the act of critical questioning diverges too far from the strict norms that render a speech act acceptable to the evaluated parties (Rennes & Susen, 2010: 160). It can also fail because it depends on the reactions of participants (in our case the evaluated parties), whom it subjects, directly or indirectly, to comparison through measurement, ranking or appraisal, and who, in order to defend their stakes, dignity or reputation, develop counter-strategies that range from engagement to disavowal. Hence it is far from a given that the innovative potential of critical questioning will actually be realized. If the job of evaluators is to apply tests through proposing boundary-negotiating artefacts, the other actors in collaborative research also bear their own responsibilities and reveal dispositions for certain types of test as basic instruments for constructing the social and making sense of events. They may therefore use those objects not to comply with the tests proposed by evaluators but to develop counter-strategies of engagement or disavowal, i.e. they resist them or propose alternative tests in order to protect their own rights or stakes.
In summary, we propose that critical evaluation in collaborative research situations derives its force from an extension of truth tests to reality tests, while it must also account for the counter-strategies of engagement or disavowal that the evaluator’s preventative controversies meet when they are put as proposals to evaluated parties. Hence the effects of critique depend both on the structural and procedural background of the critical act, i.e. the way criticism is organized, and on the unpredictable (but predictably variable) reactions of criticized parties and their positions (Messner et al., 2008: 75). Some of these ‘predictable variations’ are shown in Figure 1. The extension of tests is difficult to organize insofar as the intrusiveness of reality tests can easily lead to escape into utopian projecting that leaves participants inactive, or to an exchange of roles in which the latter evaluate the evaluator. A similarly effective counter-strategy is an inverted reality test if a subgroup of participants insists on proposing a new way of looking at ‘what ought to be’ through the lens of ‘what is’. In the case of collaborative research, inverted reality tests naturally converge to accusations of bias and one-sidedness. Just as Périlleux has argued that workers have recourse to two distinct strategies to ‘disavow’ performance evaluation (Périlleux, 2005), these strategies block the organization of reality tests in one of two ways: by making doubtful the input definition of the situation, i.e. through the multiplication of measures, in the case of inverted reality tests; or by providing a justification that the extension is superfluous, excessively costly or illegitimate, and thereby voiding or denying the consequentiality of the test, in the case of utopian projecting and role exchange. The role of artefacts is crucial here – they can either stabilize the tests associated with a given or proposed order of worth or they may become vehicles for circumventing the institutionalized or proposed tests (Guggenheim & Potthast, 2012). Hence the introduction of objects as devices for configuring particular types of test is a risky venture that is always prone to sabotage. In this perspective all reality tests at least latently compete with their inverse form, and actors retain the liberty not merely to contest the accuracy of the appraisal but to act as if the test has not taken place (Périlleux, 2005: 114-115). However, truth tests in ‘ought to be’ mode provide a frontstage preventative strategy against inverted reality tests, whereas truth tests in ‘be’ mode can be used either as a defence against inverted reality tests (if they deprive opponents of factual arguments) or as a platform for their launch (if they supply facts about power asymmetries that confirm accusations of bias). The most important point to note is that criticism is vulnerable to failure because it must be organized (i.e. certain tasks of coordination have to be successfully carried out), and yet it can never be fully institutionalized given that the role of institutions is to decree what holds as reality, while the role of criticism is to question aspects of how reality holds together (Rennes & Susen, 2010: 162). As will be seen, there can therefore be a discrepancy between an evaluator’s intention to organize a critical extension of truth tests to reality tests and their power to perform it.
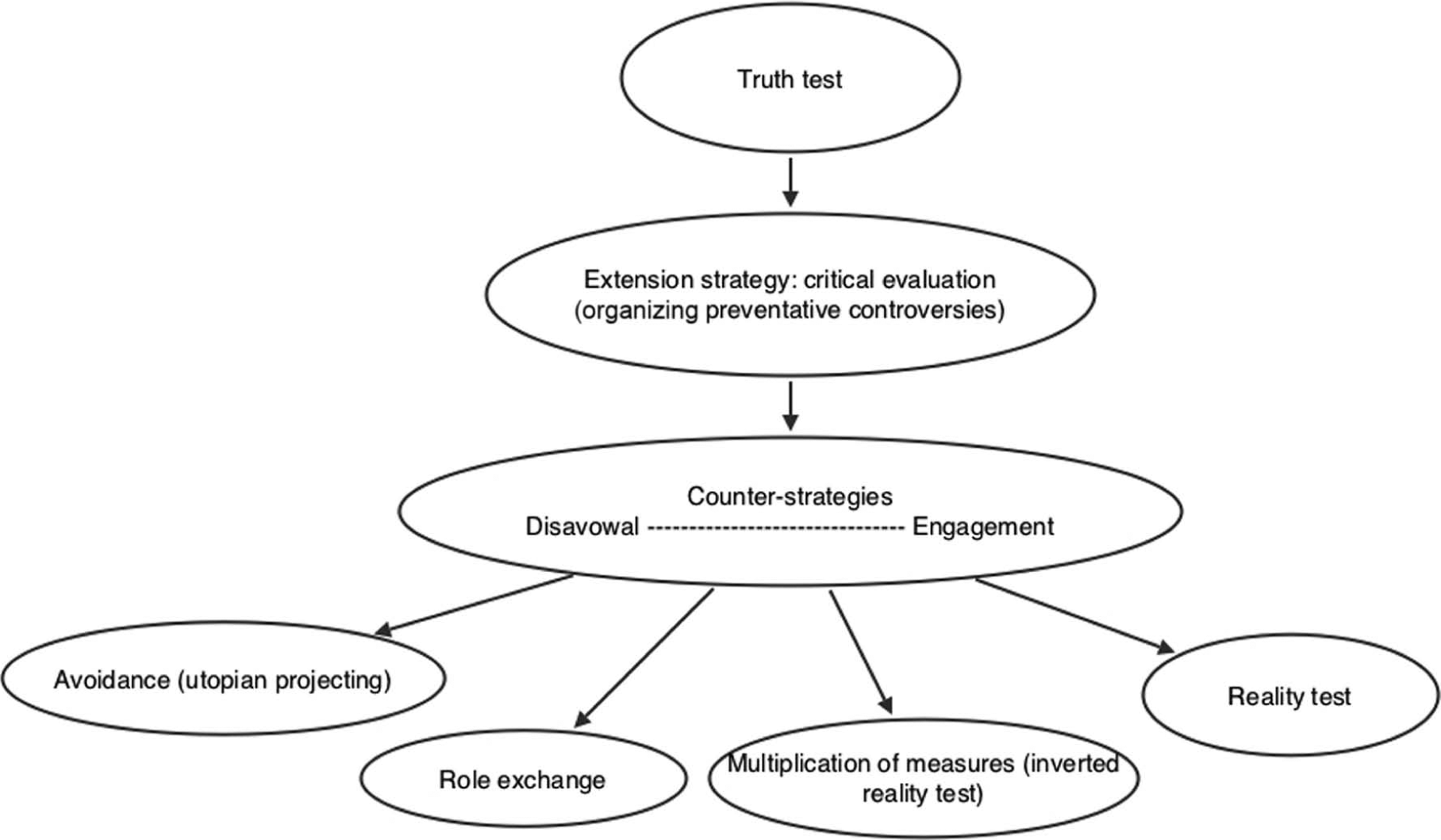
Critical questioning in collaborative research situations.
Methodological note
Our descriptive method in this paper obeys the ethnomethodological maxim to ‘follow the actors’ as they engage in critical practice, and since we model a joint-action domain as a sociotechnical network, we trace both the intersubjective and the interobjective associations made in its assembly, ‘document[ing] [the actors’] innovations … in order that they teach us what collective existence has become in their hands … and what stories are the best adapted to account for the new associations they are obliged to establish’ (Latour, 2007: 22). Following the evaluators’ agenda, we compare the tests they proposed with what actually happened as events unfolded within a process of organizing collaborative research. We do so by reconstructing a series of episodes (from the initial commission through two formative workshops and two rounds of interviews) that the evaluators attempted to coordinate, pausing to focus on disputes that arose around certain objects (e.g. the project protocol, an early feedback report, a proposed logic model, the first internal evaluation report and a draft academic paper; see Appendix Table 1). Those boundary-negotiating artefacts were mostly proposed by the evaluators as methodological devices for revealing traces of networks, social relations and social structures, and thereafter for integrating the emerging action domain. Each object has a career, which begins during a certain episode. Sometimes it is limited to that episode, whereas other objects reappear during later episodes, though not necessarily in the same guise. In keeping or at variance with evaluators’ intentions/predictions, they were subsequently used or rejected/disavowed by the other actors. Pursuing this line of inquiry allows us, now in the role of authors, to perceive how action was coordinated diachronically, via the choice/negotiation of strategies of engagement and/or disavowal, as well as how action was coordinated synchronically (at moments of dispute), via the interpenetration of different justification registers associated with relatively stable modes of existence (Boltanski, 2009; Dodier, 1993; Kabele, 2010). We reconstruct how each boundary-negotiating artefact was configured and what kind of tests it permitted actors to perform or circumvent as they accounted for ongoing social action, focusing all the time on the interaction of evaluators and evaluated. At the start of each episode, we review the key objects and the roles they played. We then identify the kinds of tests being organized or proposed within each episode and which objects were mobilized. Except where otherwise indicated, all quotations are taken from the evaluators’ research journal.
Critical evaluation as participative action research – case reconstruction
We can now tell the story of how the evaluation of a collaborative research programme, far from facilitating preventative controversies, itself became an object of controversy that was able to be resolved only by repositioning it as a reflective academic study, reducing its reflexive capacity to intervene on the level of activity and organizational integration. A confirmatory genre of inquiry had gained the upper hand over a critical one.
During the drama, the evaluators proposed a series of objects that could have facilitated – but ultimately failed to enable – a conversation between collaborating actors as to the value and meaning of their collective endeavour. The ensuing scenes saw negotiation and testing around or through these objects, characterized by a growing tension between the evaluators and many of the evaluated partners, which culminated in a crisis of mutual trust. The quasi-cathartic resolution restored trust by deflecting attention from problem-solving with respect to the collaborative research programme towards the representation of events in evaluation reports. In our adopted terminology, critical evaluation had proposed to facilitate innovation by organizing an extension of truth tests to reality tests, but in the end made do with a more conservative combination of truth tests and inverted truth tests after spurning several opportunities to pursue the evaluators’ proposed reality tests or to explore the inverted reality tests proposed in response by partners. Accordingly, the mediators introduced to facilitate the evaluation were not stabilized as newly instituted intermediaries but rather displaced by standardized intermediaries. Boundary-negotiating artefacts did not mature into boundary objects as a joint-action domain became normalized, but instead were supplanted by pre-defined boundary objects that allowed for a more distanced and formal mode of collaboration where boundaries would be respected rather than pushed. This still allowed for limited ‘cross-border’ communication, but not for boundary-crossing or boundary-shifting.
Episode 1. Initial commission
The story begins with the commissioning of an evaluation of a collaborative research programme between researchers from two universities and managers from a local health service organization. The terms for the evaluation were specified in the constitutive protocol for the collaborative research programme, drafted during the first year of the programme’s operation, which incorporated a section outlining the broad contours of an internal evaluation process to run concurrently with the programme’s remaining four years. The protocol defines the evaluator as ‘part of the team’ and the evaluation as ‘embedded research’, but does not define who or what is to be evaluated except, significantly, that it will concern the process of collaboration not the quality of research outputs. As we go on to characterize, there was always a discrepancy between the evaluators’ and the research team’s internalized understanding of the purpose of the evaluation, and the latter may well have seen it as a mechanism for measurement or appraisal of their work in spite of what was written in the protocol.
Initial commission.
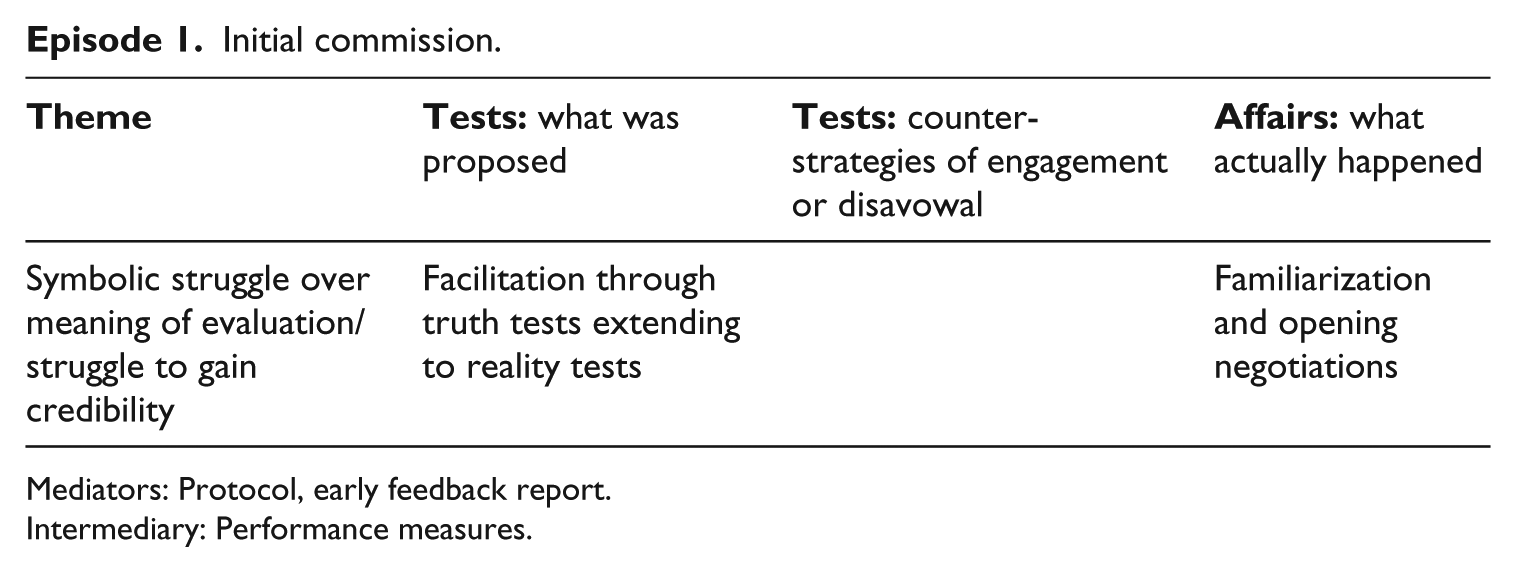
Mediators: Protocol, early feedback report.
Intermediary: Performance measures.
The protocol frames the evaluation at different levels of reflexivity: on the one hand, it is to be about ‘reconstructing the collaborative journey’ of academic researchers and health service managers, and fixing problems by ‘helping the team think about process and outcomes’. These could be called truth tests, but there is an invitation to extend them towards the critical register of reality tests when the protocol further specifies the research questions: ‘can it [health service–academic cooperation] be called a collaboration? What impact has it had on the local culture at the NHS/academic interface?’ The protocol frames reality tests as an extension of truth tests, and the evaluation as an extension of indigenous reflexivity, and it assumes that during these progressions evaluators will gain the authority and competence to help ‘fix problems’.
This way of formatting the tests that the evaluation should enact, however, put the latter at odds with the constitutional function of a classic research protocol – an intermediary to standardize understandings of aims and procedures, available to any member of a collective to confirm or denounce the correspondence between ongoing affairs and an ostensive script, i.e. to enact a truth test. Protocols that explicitly invite doubt that an enterprise is what it says it is – inviting a search for examples of events which do not correspond to instituted reality – are strange beasts. We suggest that this protocol was positioned more as a mediator – an object which invited change by calling forth controversies. In reality it had only an implicit presence in subsequent episodes. This was because the research team and the evaluators shared a tacit assumption that the protocol for a project construed in terms of ‘adaptive design’ should leave room for ongoing adjustment in the process of organizing. Just as the detective in a classic crime novel has to act beyond the strict limits of the legal order in order to uphold the moral order of the state (Boltanski, 2012: 110–112), the protocol was treated as a constitution to be honoured in the breach. Therefore, appealing to the protocol either to confirm or denounce practice would have missed the point and had little legitimatory value.
At the same time as the protocol was being drafted, the evaluator produced and circulated a report based on conversations with members of the collaborative team and on background reading about organizing collaborative research. It was designed to give ideas for activities that might be considered in order to improve the mechanisms of collaboration. It therefore put the evaluator in a facilitative position. The document was discussed at a project management meeting, but none of its proposals were followed up. It did not therefore qualify as an active object around which to organize the evaluation. Nevertheless, in relation to tests it helped set the level and criteria of criticism that the evaluator intended to engage.
Quite apart from this critical evaluation, the collaborative research programme was subject to formal performance measures determined by senior management and funders. These still had to be finalized when the evaluation began, and the evaluator had initially hoped to be able to use them to persuade the other partners that ‘soft’ collaborative outcomes should be considered. The indicators eventually adopted, however, did not refer to collaboration processes per se, and would not therefore legitimize such an argument. Instead they emphasized quantifiable measures of impact on the local healthcare economy and measures of scientific impact such as number of publications. The evaluator decided to detach the evaluation from these authoritative targets, which meant that it assumed a ‘self-authorizing’ character: the findings would carry weight only if those evaluated came to appreciate their intrinsic worth.
During the initial stage of the evaluation, three framing questions were dominant for the evaluator as she attempted to work out how to recognize and assess collaboration: What kind of research am I doing? How far can I challenge opinions and preferences? How do I position an internal, formative evaluation with respect to official and essentially summative performance measures? They reflected a symbolic struggle over the meaning of evaluation and a social struggle to gain credibility with partners. The provisional practical answers to these questions defined the stakes of the emerging joint-action domain.
Episode 2. First formative workshop
The evaluation began to assume a more solid form with the preparation of a ‘logic model’. The idea was grounded in the methodological traditions of realist and theory-based evaluation. Deciding which part of a large and complex programme to evaluate is a well-documented challenge as it is rarely possible to evaluate everything. One way of making this decision is to examine the logical chain of events that are assumed to take place in the programme, starting with the initial programme inputs and ending with the outcomes. This is known as a logic model (Owen, 2007). Beside their value as decisional tools, logic models can also help develop or uncover indigenous theories of change that ‘expand on results chains to articulate why the sequence of results is expected to occur’ (Treasury Board of Canada, 2012: 5). If this developmental process could be successfully coordinated, the evaluation would thereby facilitate programme design at the same time as furnishing a statement of values against which the evaluator could observe where and why the model either succeeded or broke down.
First formative workshop.
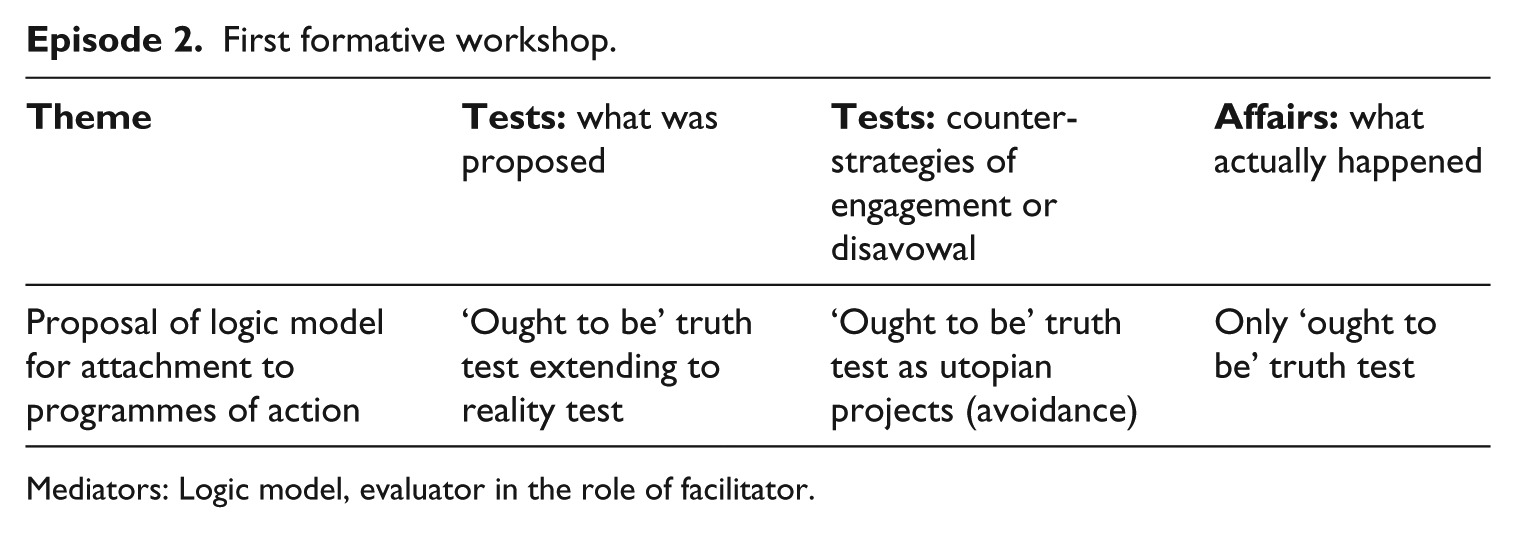
Mediators: Logic model, evaluator in the role of facilitator.
Our logic model (whose final form is shown in Appendix Figure 2) was developed interactively in three stages: interviews with individual partners to generate ideas and explicate assumptions; an online poll to narrow down priority areas and key principles; and a workshop, attached to a project management meeting, at which participants were asked to link problems, solutions and activities into logical chains, working together in subgroups and recording ideas by writing them on cards. This workshop exercise was designed to take participants through a progression from a truth test to a reality test in order to give innovative force to critical questioning: ‘[the] meeting will focus on getting a strong sense of what ought to happen before working out whether it has happened’ and thus define ‘a logical chain of events … [by focusing discussion] on whether we really think that the activities listed will lead to intermediate outputs, and eventual outcomes or impacts.’
In practice, however, only the first stage happened: the workshop discussion enacted truth tests confirming the logical consistency of the model itself but failed to make any strong associations with the day-to-day reality of the collaborative research programme. Participants’ imagination moved them away from the context of their own collaborative activities towards the design of a hypothetical new project, engaging them in truth tests of an ‘ought to be’ mode: ‘groups were thinking in a more abstract way – how to ensure that these goals could be met in future projects’. These ‘escape from reality tests’ – avoidance through utopian projecting – left the evaluator to try to deduce retrospectively a theory of change that participants had not succeeded in articulating, and hope that they would re-attach it to their programmes of action. This carried the risk of imposing the evaluator’s own preoccupations and assumptions on the figuration of the model. One entry in the research journal shows how this danger was perceived at the time: ‘There is a question about where to draw the line when it comes to goal clarification – I can’t keep going until the answer is the one I want!’ Yet trying not to impose one’s own ideas led the evaluator to compose a model that, in her view, consisted of ‘idealized ideas which still need[ed] operationalizing in the context of [the project]’ and which she feared would diverge considerably from ‘what is happening on the ground’.
In certain respects (e.g. the precocity of dialogue and the stress on open communication), the model seems radically utopian, but in others it appears conventional. In particular, it conforms to a linear view of knowledge production and translation (note the predominance of upward-pointing arrows) involving separate and discrete organizational actors, rather than evoking circularity and emerging structures. It also attempts to reconcile ‘the research goals with the collaborative goals’ – a concession to the research team’s unease about focusing the evaluation exclusively on process aspects. The logic model afforded them some protection by allowing for the possibility that final outcomes could (for the purposes of the evaluation) see ends justifying means (cf. Boltanski, 2009: 225). In both these regards, the evaluator had attempted to remain faithful to an implicit theory of change inferred from the workshop outputs and her other discussions with participants. Nevertheless, the evaluator anticipated that its use as an explanatory tool would eventually see it superseded and ‘allow a stronger logical framework for this type of collaboration [to be defined]’. For this to happen, the logic model would have had to become – at the very least – a familiar object in the joint-action domain. Yet although the evaluator(s) repeatedly tried to make the logic model present when interacting with partners (as shown by its reappearance in successive episode summary tables), it never gained the status of an object that other partners would refer to spontaneously in project management or in action planning. Its effect was limited to that of a methodological guide helping the evaluator to plan data collection and interview design, decide who and what to include in the evaluation, or think through how to pursue the investigation of particular relationships between mechanisms and outcomes.
The key framing questions that the logic model introduced were: What’s your theory of change? And an insistent request for justification, which could be characterized as the provocative question: So you call that a collaboration!? (cf. Boltanski, 2009).
Episode 3. Participative action research – interviews
The evaluator now entered the field as a participative action researcher, assuming she had negotiated the authorization, and acquired the competence, to pursue the evaluation on the basis of a reflexive and facilitative remit focusing on the mechanisms of collaboration. The evaluation journal records how the research was now framed: ‘Specific activities will be recorded as they are uncovered during data collection. As such, the evaluation won’t provide a blueprint for how to do a collaborative project, but will give a good idea of what needs to be achieved in order to reach a collaborative goal, and where the stumbling blocks lie.’
Participative action research – interviews.
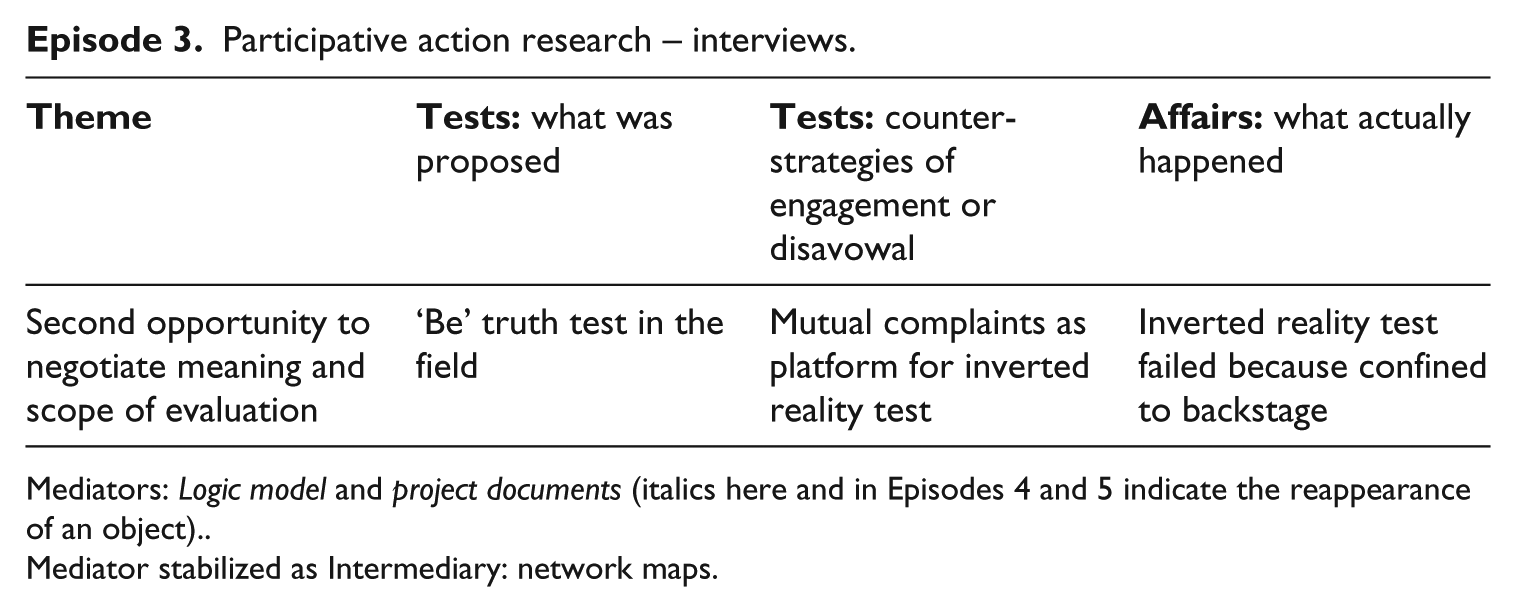
Mediators: Logic model and project documents (italics here and in Episodes 4 and 5 indicate the reappearance of an object).
Mediator stabilized as Intermediary: network maps.
What remained unclear was the scope of the evaluation, or who and what to include. Immediately after the workshop, the evaluator met separately with a member of the research team and two representatives of the health service organization, and asked each of them to draw a map of the network of actors involved in the collaborative research programme. The aim of the exercise was a ‘be’ mode truth test – to check participants’ definitions of who belongs to the collaboration, thus confirming qualifications rather than investigating the nature of these qualifications. The network maps aided the evaluator in the selection of interviewees, and the research team subsequently made use of one of the network maps to remind themselves who they needed to talk to. In other words, it began life as a mediator but quickly became stabilized as an intermediary, which is signalled by the fact that it was not updated or modified.
Next the evaluator conducted interviews with seven members of the collaborative programme: the principal investigator, two members of the research team from one of the universities, two representatives of the health service organization and two representatives of the local authority who had been identified as significant new partners through the network mapping exercise. The interview schedule matched the enumeration of mechanisms and outcomes as incorporated into the logic model and mobilized several textual objects in order to provoke discussion, such as project planning documents. The aim was to generate insights that could be quickly fed back to partners with the aim of improving communicative aspects of organization.
The main framing questions at this phase of the evaluation were exploratory: Who is and ought to be involved in the collaborative research programme? Who is doing what with whom? The aim was to map these activities onto the template provided by the logic model. Some of the interviewees took advantage of this second opportunity to influence the meaning and scope of the evaluation by expressing complaints about the relationships between partners, possibly seeking to delegate a certain power to the evaluation to act as a mediator. In principle, here was an opportunity to explore an alternative reality test – in this case a measure of the correspondence between actors’ capacities and their position in the emerging domain. However, the partnership lacked a forum where mutual complaints could safely be aired in public, meaning that most of the complaints were issued ‘off the record’ and could not be fed back either to the management group or individual project teams. This appears to confirm Périlleux’s claim that the efficacy of reality tests depends on the openness of public arenas ‘where people can really put their capacities to the test’ (Périlleux, 2005: 129).
Before any further feedback was provided to partners after the interviews had been completed, the evaluator approached the principal investigator to request assistance with the increasing workload of the evaluation process, gaining agreement to appoint a part-time research fellow (the first author) for a year. While increasing the capacity of the evaluation team, the short period of the appointment reinforced the imperative to focus the evaluation on gaining insights that would be valid and applicable in the short term, midway through Year 4 of the programme’s five-year term, i.e. before the research programme would have realized its own outcomes. This was in keeping with the characterization of the evaluation in the protocol, but it may have reawakened unease within the research team about the general purpose of the evaluation and the legitimacy of short-term appraisals of academic research.
Episode 4. Second formative workshop
Based on a thematic analysis of the interview data, their observation notes from project management meetings and the project documents provided to them by the research team, the evaluators produced a report that was circulated to partners as material for discussion at a second workshop, again attached to a project management meeting. The report consisted of two objects: a text, which described and interpreted three themes that the evaluators had identified as significant aspects of organizing collaboration; and a pair of process flowcharts, which mapped the project history and related these events to the theories of change depicted by the logic model as well as to a typology modelling the material and symbolic infrastructure of the collaboration. The report therefore mobilized confirmatory ‘ought to be’ truth tests (by referring back to the logic model) but sought to extend these to reality tests by acting as a problem-formulating and theory-revealing tool – a mediator that could facilitate change or improvement in organizational aspects of the process of collaboration.
Second formative workshop.
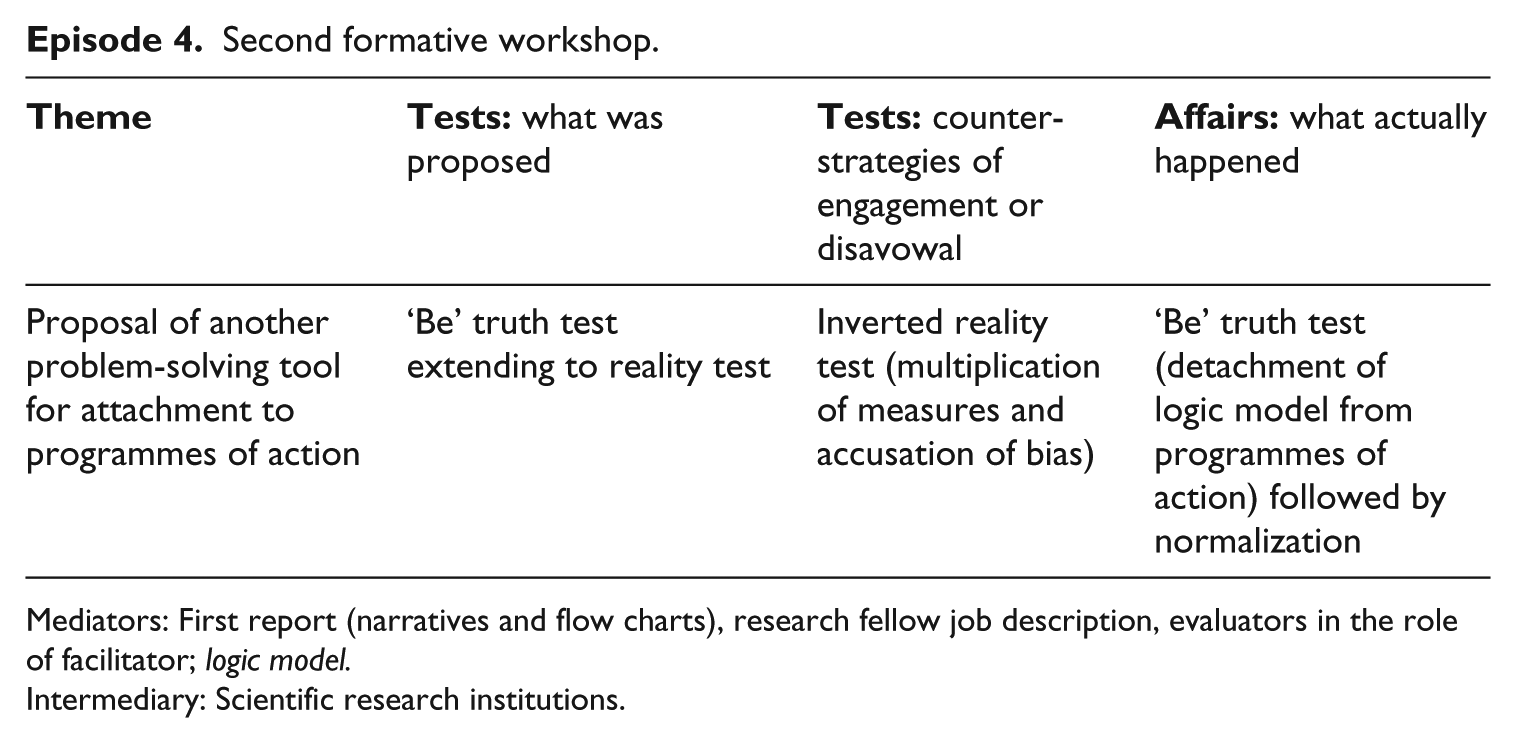
Mediators: First report (narratives and flow charts), research fellow job description, evaluators in the role of facilitator; logic model.
Intermediary: Scientific research institutions.
What happened was a near replay of events at the first formative workshop, but this time with ‘fatal’ consequences. Partners subjected the materials presented to them to a truth test, but of a different kind from what the evaluators were proposing. Their truth test operated in ‘be’ mode, focusing on the recognizability of the account of reality – the perceived accuracy with which the text, in particular, represented their experiences. The research team, for example, accused the account of bias and one-sidedness: they felt that the tone of the report was overly critical of them and conversely too lenient on the health service organization, which they blamed for some of the difficulties that the collaboration process had encountered. The objects proved unable to facilitate a discussion about change and improvement because they failed a truth test that was a necessary preliminary to participants being able to ‘play the game’ of the proposed reality test. 6 Instead the discussion revealed a gap between preferred comparative frameworks: whereas the evaluation report referred to processual dimensions of organizing collaboration derived either from generic theoretical models or from the logic model, the research team indexed their explanations of the difficulties of collaboration to wider contextual factors such as the organizational instability of the local healthcare landscape and the management structure of the wider programme the research formed a part of. They normalized the emerging account of reality by recontextualizing it. To the evaluators’ framing questions (Is this what you look like? What would you have done differently? What should change going forward?), they responded with alternative framing questions of their own (Are we exceptional? What were the effects of contextual factors and initial conditions?), questions which proposed an inverted reality test based on a reframing of the likely or possible barriers to collaboration. Their practical effect was to detach discussion at the workshop from the objects provided by the evaluators and reattach it to objects that were not present, and could not easily be made present at that moment in time, such as the institutions that shape academic research and government policy initiatives (contextual factors that had not formed part of the evaluators’ prior analysis). With this ‘multiplication of measures’ (Périlleux, 2005), neither the planned nor the alternative reality tests were put into practice.
The textual sections of the report were actually used to try to stabilize a representation of events, that is, to negotiate an account that all parties could recognize in two senses: that it reflected their experience (that they could recognize themselves in it), and that it looked more like a standard research output – the type of account that they owed to several external audiences (they could recognize its value in pragmatic terms). The tacit agreement that emerged from the second workshop was that similar narratives could be presented as outputs of the evaluation that might be of interest to senior programme management as well as to an academic audience, without any onus on partners to attach them to their own programmes of action or use them as mechanisms of domain configuration. Rather than being agents of innovation, evaluation outputs instead became subject to a process of normalization with reference to the conventions of academic writing and the choice of journal, theoretical approach and epistemological genre. In this sense they were read not as a mediator for change but as a standardized intermediary, although in a grammatical sense they accomplished a mediation by facilitating a compromise to reposition the evaluation from problem-solving to external accounting, or to reduce the level of reflexivity (and the height of the stakes) involved in the evaluation.
Episode 5. Deliberation over the paper – feedback interviews
The outcome of the second workshop had shifted the evaluators’ remit: from formative problem-solving to drafting an academic paper that could be ‘signed off’ as an acceptable representation of a difficult experience of organizing collaborative research, and which would point to lessons that could be learned for programmes of this type. The framing question became: ‘What should be done in situations like this?’ They thus abstracted from the immediate context, absolved partners of the need to act on the evaluation’s findings and set up a truth test, which was still hypothetically extendable into a reality test, but only if the other partners chose to act based on the information they received from the evaluators. The two elements – truth tests and reality tests – were clearly demarcated and disconnected so that the second became optional. The key truth test (the verisimilitude of the representation of events) was itself negotiated in a second round of feedback interviews, which took place after a draft academic paper had been circulated by the evaluators explicitly inviting comment from partners.
Deliberation over the paper – feedback interviews.
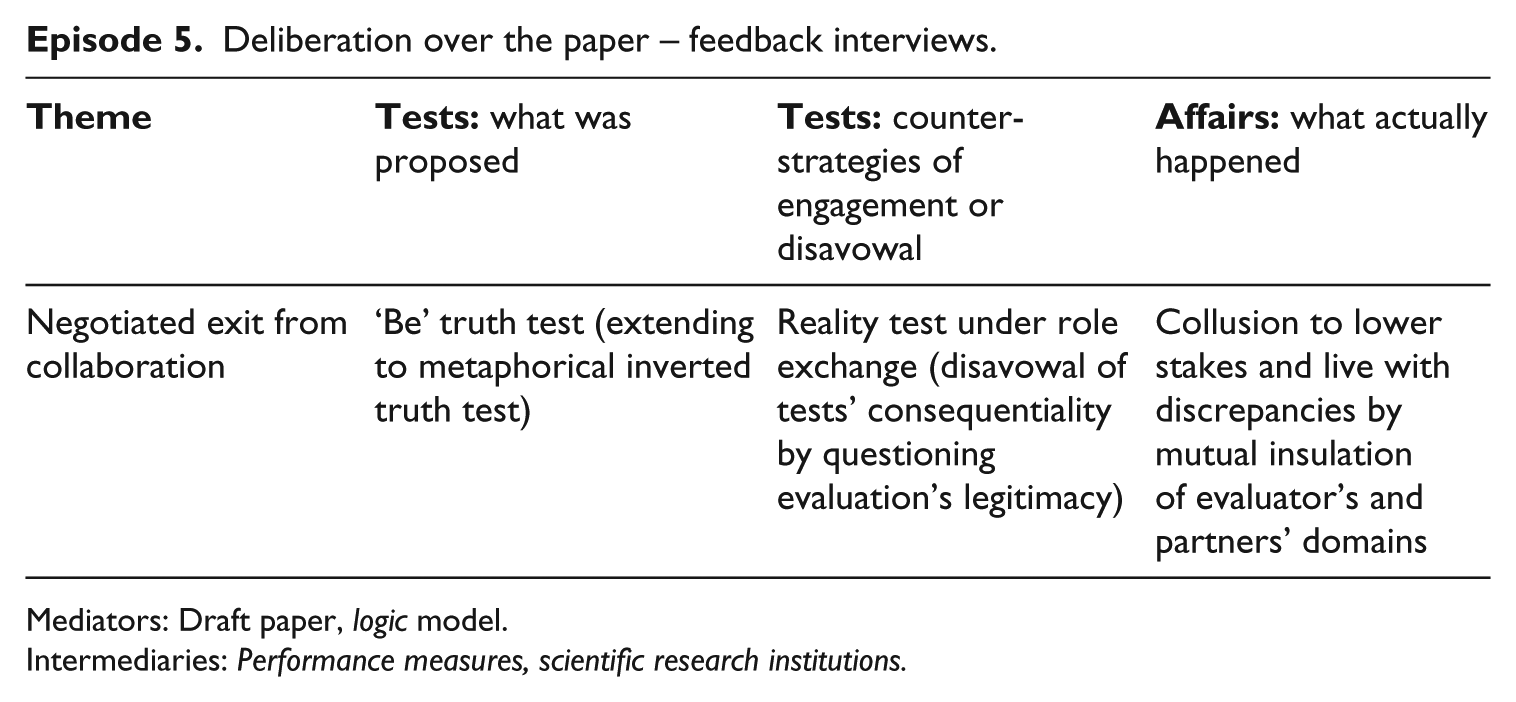
Mediators: Draft paper, logic model.
Intermediaries: Performance measures, scientific research institutions.
The draft paper adopted a polyvocal style in an effort to capture the different perspectives of partners on the evolution of the collaboration. In order to avoid repeated accusations of bias, it was also reframed as ‘just’ an academic sociological study, downplaying the consequentiality of the account. Hand in hand with this went a reaffirmation of the evaluators’ responsibility for the authorship of reports, obliging them to invoke a justification register based on criteria of scientific quality (a truth test) rather than one based on usability to partners (a reality test). Critical extension relied on the power of metaphor rather than on an organized staging of preventative controversies. One consequence, for example, was that, whereas the protocol had reserved the evaluators’ right to pass judgements about individuals – ‘the focus of the research is on making the findings useful to the [name of] project which may mean that the actions of individuals and/or organizations will be identified’ – the consensus that emerged after the second interviews was for much stronger anonymization. This actually allowed the evaluators to switch into a more comfortable genre of inquiry accompanied by a more familiar ‘grammar of normality’ and repertoire of tangibility tests (characterized mainly by truth tests in ‘be’ mode), and absolved the evaluated of the need to work out a new, localized ‘genre’ of knowledge use (Cook & Brown, 1999).
There was a final twist to the tale, however, since partners interviewed started to ‘investigate’ the quality of the evaluation, turning the tables by applying a reality test to the latter. Mirroring the evaluator’s initial provocative question of: ‘So you call that a collaboration!?’, the dominant framing question at this stage became: ‘So you call that an evaluation!?’ This new reality test – placing the formerly evaluated partners in the position of evaluators of the evaluation – referred to a different type of ‘instituted reality’ from the original one. Instead of testing lived experience against yardsticks derived from a model of an ideal or perfect world, it invoked the performance measures on which the programme was obliged to routinely report to senior management. There was an irony to this in that what enabled the evaluation to pass the inverted reality test was that it could indeed be re-attached to the programme’s (initially rejected) performance measures and incorporated into progress reports insofar as it represented a measurable, reportable output that could help meet a target for numbers of scientific publications.
Discussion
The underlying narrative thread is a gradual assertion of confirmatory at the expense of critical questioning following on from the imposition of two engagement/disavowal strategies, which we have called utopian projecting and inverted reality tests. Essentially what we witnessed, most visibly at both formative workshops, was a failure of truth tests to extend towards reality tests. Partners only played half the ‘game’ that we as evaluators proposed to them, subverting the key reality tests by focusing on the preliminary truth tests, first in ‘ought to be’ and then in ‘be’ mode. The assertion of a confirmatory genre of questioning saw the clear demarcation of the action domains of evaluators and evaluated, and the separation of truth tests from reality tests, evaluation as appraisal from evaluation as facilitation, as well as sociological from indigenous reflexivity.
The situations in which we are willing to put to the test the ‘reality of reality’ are surprisingly limited. To do so is costly (since even simple truths can no longer be taken for granted) and risky (because official representations of reality are liable to be undermined). Authors of detective stories and spy thrillers are able to take their readers on such a journey thanks to the plausibility that their descriptions of enigmas and plots obtained in the context of ‘inquietude’ as to the modern state’s claim to guarantee the stability of ‘instituted reality’ (Boltanski, 2012). Evaluation needs to achieve a comparable plausibility in order to persuade the evaluated to participate in reality tests. Especially in a formative evaluation, this plausibility must ultimately be self-authorizing, stemming from a shared conviction that the (self-)knowledge that it is possible to obtain is likely to be worth the additional costs and risks associated with its production. If this evaluation failed to achieve a sufficient level of plausibility, the question is: In what sense was the balance of costs and risks unfavourable?
For partners, withholding authorization to extend truth tests to reality tests was an effective and accessible defence against the risk of losing face or room for manoeuvre if the task of domain configuration was delegated to, or shared with, evaluators. For us as evaluators, indexing the evaluation to an academic register of worth was, among other things, a way of defusing the potential for dispute with one or more partners. For both sides, the prize to be gained by undergoing all the costs and risks of a reality test was perceived as rather meagre, since we shared a scepticism about the capacity of any intervention to make the ‘lived reality’ of this collaborative experiment come to resemble the ‘instituted reality’ proclaimed by the wider research programme or by our own protocol. Our modification of theory-based evaluation for the purposes of critical evaluation probably added to this scepticism, as it underestimated the consequences of the positional changes for both evaluators and evaluated in the passage from evaluation as appraisal to evaluation as facilitation, which meant that evaluators lacked access to a convincing complementary theory of change. This theory shortage made it problematic to assume that the logic model would be authorized to act as a mediator or boundary-negotiating artefact. In the resulting collusion, neither our proposed extension of truth tests to reality tests nor the spontaneous alternative reality tests counter-proposed by partners were taken up as occasions for constructively exploring controversies. As evaluators, we were probably caught off-guard by these counter-proposals and were unable to channel ‘routinely emerging criticism’ into the collective learning process that formative evaluation was supposed to facilitate. An alternative interpretation is that we simply misread the type of tests required: in a time-limited programme that most participants evidently did not wish to extend, the type of artefact needed to coordinate joint action might be just a crude written device or a normalized convention that can ‘reduce the cost of maintaining a tolerable degree of order’ (Schmidt & Wagner, 2005: 401). In such a situation, the ‘good enough’ character of truth tests is likely to be preferred to the more demanding commitments of reality tests.
Conclusion
By reconstructing how the use (and non-use) of evaluators’ boundary-negotiating artefacts affected the types of test an evaluation was able to organize, we have shown how evaluators and evaluated eventually reached for pre-formatted objects that naturalized their relationship based on a conventional division of roles and an easily valorizable end-product. In place of mediators that could – following the negotiation of preventative controversies – institute a novel regime of justification or mode of existence, the joint-action domain was configured with recourse to intermediaries familiar to each of the relatively stable social worlds thereby interlinked. Mediators could have marked the advent of new collaborative arrangements and materialized radical organizational innovations (Shinn, 2005) through the ‘creative destruction’ of old practice (Schumpeter, 1942), whereas intermediaries, by avoiding the dangers in intergroup conflict of ‘destruction without attribute’, enabled actors to continue to inhabit separate organizational realities while loosely coordinating their action based on a collusion that maximized each partner’s room for manoeuvre. Things were returned to an order that allowed conventional utilizations and a functional instrumentalization of reality (Thévenot, 2001). Such a collusion, which involved repositioning the evaluation in order to secure the cultural resources necessary to perform scientifically legitimate truth tests while abandoning the quest for the institutional position and reputational power necessary to organize socially legitimate reality tests, was in one sense perfectly rational, particularly when we take into account the perspective of the evaluated (Périlleux, 2005) and the general preference of collaborators from different domains to seek mechanisms for interaction that avoid the need to cross or push boundaries (Marcovich & Shinn, 2011).
The experience has wider relevance to the communicability, use-value and political pertinence of social scientific discourses. First, there is a constant danger in social sciences of imposing researchers’ views and visions over those of actors, forcing actors to look for safeguards against the ‘prophetic tendency’ of social sciences (Latour, 2007: 277). Any sociological enterprise that extends from the production to the use of knowledge carries twin aims, one scientific – to explain the social; the other political – to compose the collective. In our model of critical evaluation, fulfilling the latter aim involves complementing explanation with a theory of change that can actually be realized. Since any researcher can be tempted to over-determine their theories of change with reference to a preceding explanatory framework, there is a risk of prematurely ‘composing the collective’ if researchers impose their own definition of the collective over that of actors themselves (Latour, 2007: 233–234). Our construction of the logic model is an illustration of this risk: in the absence of a clearly articulated theory of change, the evaluator drew on well-known procedural models for collaborative research that resulted in a model acceptable to but not usable by the actors – or, to be more precise, usable in the context of a truth test but not a reality test because it was too distant from their lived reality and its potential to change. This remoteness is illustrated by the very fact that we can reproduce the logic model in Appendix Figure 2 without the need to alter the wording to protect anyone’s identity, as if the logic model were ready-made for (academic) ‘sociological’ purposes in its scrupulous avoidance of passing judgement on individual actors (Boltanski, 2012: 359). Pre-emptive facilitation therefore hindered the extension of truth tests into reality tests.
Second, we conclude that critical evaluation failed because the conditions were not created whereby actors could take the risks and share the costs associated with the enhanced level of reflexivity necessary to engage in both collective action and knowledge production. Boundary-negotiating artefacts configure ‘risky’ practices that go beyond the standardized modalities of collaboration which typical boundary objects rely on (Star & Griesemer, 1989) – for example, compilation artefacts are associated with discussion, structuring artefacts with negotiation, inclusion artefacts with mobilization (Lee, 2007). Given our collective failure to equip the boundary-negotiating artefacts proposed with instructions for use during the difficult-to-control dynamics of workshops, discussion and deliberation, the pragmatic solution was to fall back on pre-formatted objects with more conventional utilizations obeying normalized standards, together with tests that emphasized functionalities and qualifications over transformative possibilities and prospects. Our case thus has a clear lesson for critical evaluation that aims to facilitate organizational change or learning: the transformative power of social scientific knowledge will be reduced if inadequate care is given to the construction of a ‘good’ arena and associated ‘public regime’ of justification with clear rules of agenda-setting and definitions of qualified persons, to assist the organization of reality tests through the support of critical questioning (Périlleux, 2005; Thévenot, 2001).
Footnotes
Appendices
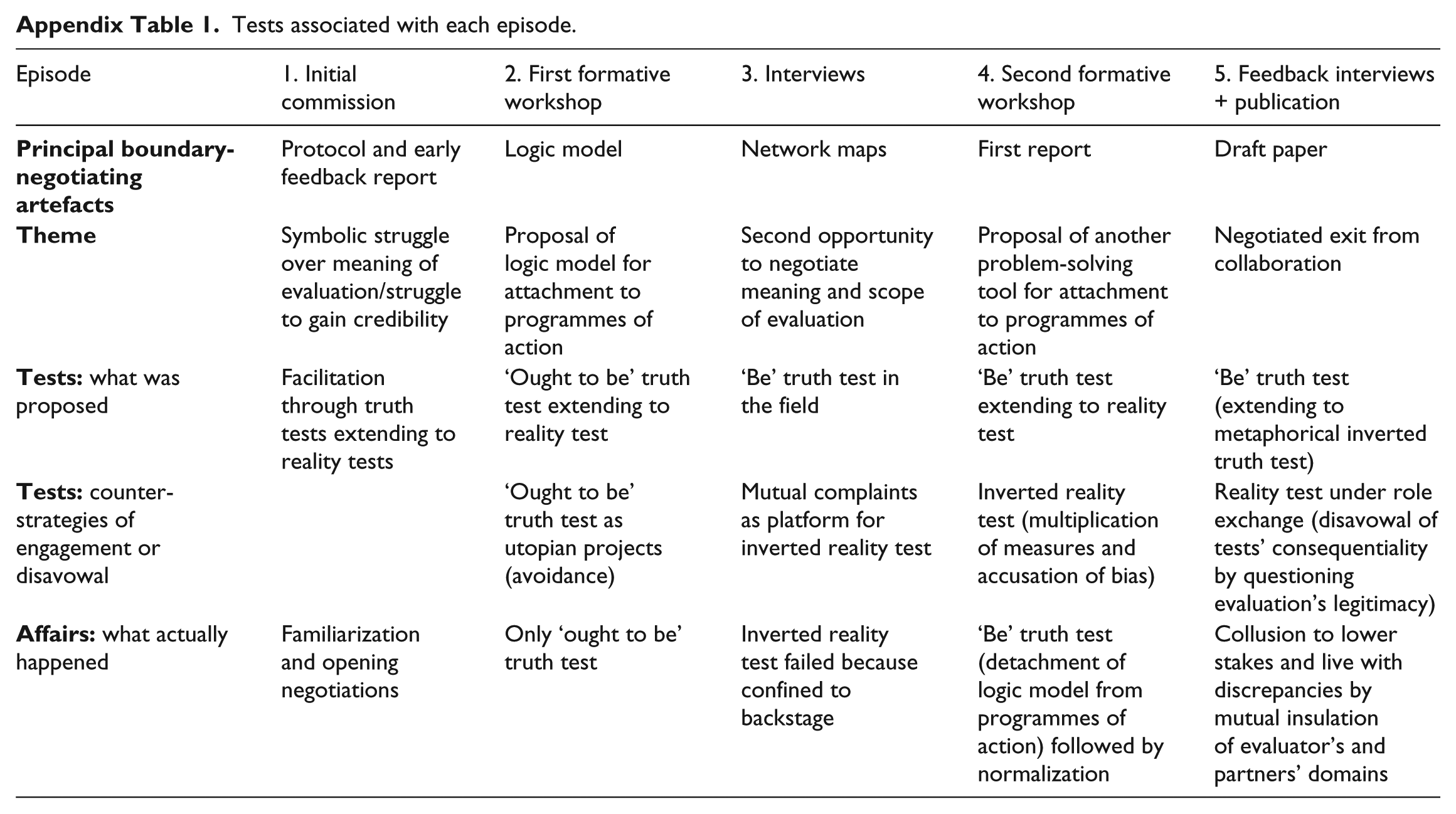
Tests associated with each episode.
| Episode | 1. Initial commission | 2. First formative workshop | 3. Interviews | 4. Second formative workshop | 5. Feedback interviews + publication |
|---|---|---|---|---|---|
|
|
Protocol and early feedback report | Logic model | Network maps | First report | Draft paper |
|
|
Symbolic struggle over meaning of evaluation/struggle to gain credibility | Proposal of logic model for attachment to programmes of action | Second opportunity to negotiate meaning and scope of evaluation | Proposal of another problem-solving tool for attachment to programmes of action | Negotiated exit from collaboration |
| Facilitation through truth tests extending to reality tests | ‘Ought to be’ truth test extending to reality test | ‘Be’ truth test in the field | ‘Be’ truth test extending to reality test | ‘Be’ truth test (extending to metaphorical inverted truth test) | |
| ‘Ought to be’ truth test as utopian projects (avoidance) | Mutual complaints as platform for inverted reality test | Inverted reality test (multiplication of measures and accusation of bias) | Reality test under role exchange (disavowal of tests’ consequentiality by questioning evaluation’s legitimacy) | ||
| Familiarization and opening negotiations | Only ‘ought to be’ truth test | Inverted reality test failed because confined to backstage | ‘Be’ truth test (detachment of logic model from programmes of action) followed by normalization | Collusion to lower stakes and live with discrepancies by mutual insulation of evaluator’s and partners’ domains |
Disclaimer
Although this work was funded under the National Institute for Health Research Collaborations for Leadership in Applied Health Research and Care (NIHR CLAHRC) for LYB (Leeds, York and Bradford) – a collaboration between two universities, the NHS, and Social Services, the views and opinions expressed in this paper are those of the authors and not necessarily those of the NHS, the NIHR, or the Department of Health.
Funding
This work was supported by the National Institute of Health Research (KRD/012/001/006) and by the Czech Science Foundation GA ČR (P404/11/2098).