
Abstract
The two studies conducted by Weiss, Keith, Zhu, and Chen in 2013 on the Wechsler Adult Intelligence Scale (WAIS-IV) and the Wechsler Intelligence Scale for Children (WISC-IV), respectively, provide strong evidence for the validity of a four-factor solution corresponding to the current hierarchical model of both scales. These analyses support the calculation of the four index scores and the Full Scale IQ. In this article, we discuss some limits of these validation efforts: (a) the incomplete measurement of the construct, (b) the problem of correspondence between factors and broad abilities, (c) the gap between a structural model and a functional model of intelligence, and (d) the difficulty of combining the measurement of global intelligence and broad abilities. Finally, the option of a five-factor model underlying the index scores is analyzed and its potential for future Wechsler scales is discussed.
“Validity refers to the degree to which evidence and theory support the interpretations of test scores entailed by proposed uses of tests” (AERA, APA, & NCME, 1999, p. 9). From that viewpoint, the analyses reported in Weiss, Keith, Zhu, and Chen (2013a, 2013b) provide strong evidence supporting the calculation of the Full Scale IQ and the four Index scores in the Wechsler Intelligence Scale for Children (WISC-IV) and the Wechsler Adult Intelligence Scale (WAIS-IV). The correlations observed between the subtests are consistent with a hierarchical model of intelligence with g at the apex and four or five broad abilities, corresponding to Gc, Gf, Gv, Gsm, and Gs in the Cattell–Horn–Carroll (CHC) model, at the second level of the structure. However, Weiss et al. (2013a, 2003b) results also show that interpretations based on factor index scores is complex and that the relations between the factor index scores and the latent variables in the models are not straightforward. The Weiss et al. (2013a, 2003b) results are supportive of the calculation of the composite scores of the WISC-IV and WAIS-IV, but they are insufficient for a comprehensive interpretation of the index scores. In this article we discuss this issue starting from a historical review of the structure of the Wechsler scales, showing the improvement of the fit between the subtests intercorrelations and the underlying ability structure. Then, we discuss some limitations to the validity evidence presented by Weiss et al. (2013a, 2003b): (a) the incomplete measure of the construct, (b) the problem of correspondence between factors and broad abilities, (c) the gap between a structural model and a functional model of intelligence, and (d) the difficulty of combining the measurement of global intelligence and broad abilities. Finally, the five-factor model versus the four-factor model will be discussed. Is a five-factor model the future of the Wechsler scales?
Seventy Years of Improvement of the Structure of the Wechsler Scales
If we look back at the first edition of the Wechsler scales, the Wechsler–Bellevue Intelligence Scale published in 1939, the improvement of the factor structure across 60 years can be appraised. The first Wechsler scale was inspired by the Army α and Army β tests, used by Wechsler as a young psychologist in the U.S. army (Matarazzo, 1981). The Wechsler–Bellevue distinguished between Verbal tests and Performance tests, with many tests based on scales from the Army α and β tests. In the Verbal scale, four subtests came from the Army α test (information, comprehension, arithmetic, and similarities) and two subtests of the Performance scale came from the Army β test (digit symbol and picture completion).
Interestingly, in the Wechsler–Bellevue Intelligence Scale, vocabulary was classified as an alternate subtest. Wechsler (1944, p.99) justified this decision because “the number of words a man acquires must necessarily be influenced by his education and cultural opportunities.” Considered as potentially unfair, vocabulary was not included in the calculation of the Full Scales IQ. Later, Wechsler changed his opinion about this subtest following the observation that vocabulary had the highest correlation with the Full Scale IQ and was no more influenced by education than the other subtests of the Verbal scale. In the second edition of the test, the (WAIS; Wechsler, 1955), vocabulary was included as a regular subtest of the Verbal scale. Table 1 shows the subtests and the scales of the original version of the Wechsler–Bellevue Intelligence Scale. Nine of the 11 original subtests, often with modifications in content and direction, are still in the WAIS-IV and the WISC-IV, but are now assigned to different groupings.
Subtests and Scales of Wechsler–Bellevue Intelligence Scale.

Note: Wechsler, 1944.
Originally, the distinction between a Verbal scale and a mainly nonverbal Performance scale was justified by its clinical usefulness. Afterward, Wechsler found theoretical and empirical arguments in Alexander’s (1935) research supporting the Verbal and the Performance scales. Using the new factor analysis techniques developed by Thurstone, Alexander (1935) found evidence that the correlations among the Wechsler scales were consistent with a hierarchical model of intelligence. He observed that intellectual tasks are influenced by two factors, corresponding to verbal intelligence and practical intelligence. These factors are not independent, with a correlation of about .50. Alexander explained this correlation by a general factor underlying verbal and practical intelligence. The two factors found by Alexander were considered to be the basic functional unities of intelligence and were identified later in several other factor analyses. Vernon (1950) included these factors in his hierarchical model of human abilities. In Vernon’s model, the g factor is at the apex of the structure and two major group factors are at the second level. Vernon called them verbal–educational (v:ed) and practical (k:m). Recently, Vernon’s model has experienced something of a revival because of supporting evidence from Johnson and Bouchard (2005).
During the 1950s, two-factor analyses conducted by Cohen (1957, 1959) on the standardization samples of the WAIS and the WISC showed that the subtests of the Wechsler scales could be organized into a larger number of subscales. Based on his own factor analysis of the WISC-R, Kaufman (1975) suggested that this test could be organized into three meaningful subscales. Because they were so similar to Cohen’s factors, Kaufman used Cohen’s labels for the three factors: Verbal Comprehension (including information, similarities, vocabulary, and comprehension), Perceptual Organization (including picture completion, picture arrangement, block design, object assembly, and mazes) and Freedom from Distractibility (including arithmetic, digit span, and coding). Nevertheless, the original organization of the Wechsler scales into two subscales and a full scale survived until after David Wechsler’s death in 1981.
The first important modification of the test structure only happened with the publication of the third version of the WISC-III (Wechsler, 1991). Having in mind Kaufman’s suggestion of three subscales, the WISC-III developers tried to improve the measurement of the third factor introducing a new subtest called symbol search. However, factor analyses showed that, following the introduction of this new subtest, a fourth factor (called Processing Speed) emerged. Symbol search and coding had the highest loading on this factor. In contrast, arithmetic and digit span had the highest loading the third factor. Based on these factor analysis results, the WISC-III manual proposed to calculate four Index scores (Verbal Comprehension, Perceptual Organization, Freedom from Distractibility, and Processing Speed) as an alternative to the classical Verbal IQ and Performance IQ. This suggestion was not very successful and psychologists continued to prefer the traditional composite scores. Moreover, the four-factor structure was not found in several adaptations of the WISC-III (Georgas, Weiss, van de Vijver, & Saklofske, 2003). This unstable factor structure across languages and cultures was related to the factor loading of the arithmetic subtest. In some cultures, the verbal component of this subtest was more important than in other cultures, the consequence being a higher loading of arithmetic on the Verbal Comprehension factor.
In order to improve the measurement of the four factors, several modifications among the subtests were introduced in the third version of the WAIS-III (Wechsler, 1997). Table 2 shows the revised four-factor organization of the WAIS-III subtests. In this organization, picture arrangement, comprehension, and object assembly no longer contributed to the Index scores; however, the calculation of a Verbal IQ and a Performance IQ were still possible in the WAIS-III. The calculation of the Full Scale IQ was based on the subtests used for the Verbal IQ and the Performance IQ, that is, including comprehension, picture arrangement, and object assembly. Despite the strong factor structure underlying the four index model and because the calculation of the traditional Verbal and Performance IQs was still possible, the use of the Index scores was not widespread among psychologists.
Subtests Contributing to the Four Indexes of the WAIS-III.
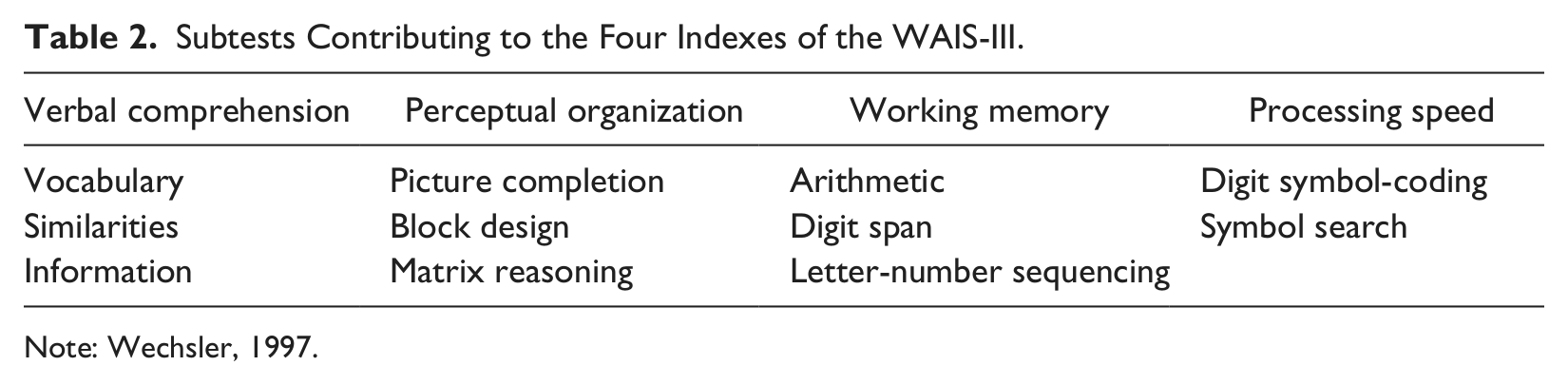
Note: Wechsler, 1997.
The revolution came with the fourth edition of the WISC-IV (Wechsler, 2003) for several reasons. First, the calculation of the Verbal and Performance IQs is no longer an option and is replaced by the calculation of the four Indexes. These Indexes are strengthened: (a) Comprehension replaced information in the Verbal Comprehension Index (VCI), (b) Picture Concepts replaced Picture Completion in the renamed Perceptual Reasoning Index, and (c) Arithmetic is no longer a core subtest of the Working Memory Index. As a consequence, the confirmatory factor analysis of the normative sample and of clinical samples (Weiss et al., 2013b) demonstrates a strong validity of the four-factor structure underlying the WISC-IV. The core subtests of the four Indexes are now used to calculate the Full Scale IQ. Moreover, the four Indexes correspond to several broad abilities of the CHC model of intelligence.
Some Limits to the Validity Evidence
Incomplete Measurement of the Construct
Table 3 shows that the fit between the theoretical model and the test is not perfect. Only five among the 10 broad abilities of the CHC model are measured in the WISC-IV and the WAIS-IV. In the first section, we explained that this selection of broad abilities was a consequence of the history of the Wechsler scales. The first subtests were selected primarily on the basis of Wechsler’s clinical experience. After Wechsler’s death, several subtests were added or withdrawn across the editions of the Wechsler scales. The main reason for making these modifications was to strengthen the factor structure of the test. The reference to a theoretical model was not the primary justification. Only recently, the CHC model was used to support the factor structure of the Wechsler scales. However, the selection of the broad abilities of the CHC model was mainly driven by the existing tasks included in the Wechsler scales. Fluid Reasoning was the only exception. The Wechsler–Bellevue Intelligence Scale did not include good measures of fluid intelligence, nor did the next versions of the Wechsler scales for adults and for children. During the development of the WISC-IV, the decision was made to improve the measurement of fluid intelligence, leading to the creation of the matrix reasoning and picture concepts subtests. In the WAIS-IV, another measure of Gf, figure weight, was also added. In contrast, there is no rationale to justify why there is no measure of auditory processing (Ga) or why there is a measure of short-term memory (Gsm), but not of long-term retrieval (Glr) in the WISC-IV and the WAIS-IV.
Relation Between CHC Broad Abilities and the WISC-IV Indexes.

Names and acronyms according to Cattell–Horn model. cOnly in the Cattell–Horn model.
Problems of Correspondence Between Factors and Broad Abilities
The confirmatory factor analyses conducted by Weiss et al. (2013a, 2013b) provide evidence that the organization of the subtests into the four Indexes fit rather well a hierarchical model with four or five of the broad abilities of the CHC model (i.e., Gc, Gv/Gf, Gsm, and Gc); however, they do not provide strong evidence that WISC-IV and WAIS-IV Indexes are good measures of these broad abilities. There is not a one-to-one mapping between the Index scores and the corresponding latent variables of the CHC model.
According to the definition of Gc (Cattell, 1963; Horn, 1968) and the previous studies conducted on the tasks measuring this broad ability, the VCI can be considered as a reasonably good measure of Gc. However, the absence of relationship between VCI and the arithmetic subtest is surprising, because to answer the arithmetic items correctly, good verbal understanding of the questions is required, which is a subcomponent of Gc.
The Perceptual Reasoning Index should be considered a mixed measure of Gf and Gv. The Weiss et al. (2013a, 2013b) factor analyses of the WISC-IV and the WAIS-IV showed that the main difference between a four- and a five-factor solution is the splitting of the factor corresponding to the Perceptual Reasoning Index into a factor measuring Gv and another one measuring Gf. Block design, visual puzzle, and picture completion are typical tasks measuring Gv (Carroll, 1993) and are loading on the same factor. Matrix reasoning and figure weights are loading on another factor corresponding to Gf, but are also loading on the Gv factor. Picture concepts is the only subtest specifically measuring the Gf factor. These observations show the difficulty in measuring only Gf, because it is impossible to assess the reasoning without any content. When the content is spatial, it measures Gv in the same time as Gf.
The interpretation of the Working Memory Index seems more straightforward because the two core subtests (digit span and letter-number sequencing) have strong loadings on the short-term memory (Gsm) factor. However, we should bear in mind that the core subtests loading on the short-term memory factor represent only the common variance between these subtests. Based on the factor loadings we cannot infer that these subtests are comprehensive measures of Gsm. Digit span and letter-number sequencing provide only a measure of the nonsemantic auditory short-term memory requiring a verbal answer. Semantic short-term memory and visual short-term memory are not measured by the Working Memory Index. Similar limitations can be described for the Processing Speed Index. The two core subtests, coding and symbol search have high loadings on the processing speed factor, but they are only measures of the speed for processing simple visual stimuli requiring visuomotor answers. The speed for processing complex visual stimuli and auditory stimuli is not measured by the Processing Speed Index.
The case of the arithmetic subtest has to be discussed independently of the four Indexes. Arithmetic could be called a “swing subtest.” In the early versions of the Wechsler scales (from the Wechsler–Bellevue Intelligence Scale to the WISC-R), Arithmetic was considered as a good measure of the verbal–educational factor underlying the Verbal IQ (e.g., Vernon, 1950; Wallbrown, Blaha, & Wherry, 1974). In the WISC-III (1991), it was considered as a measure of freedom from distractibility. In the WAIS-III (1997), it became a measure of working memory. In the WISC-IV and the WAIS-IV (Weiss et al., 2013a, 2013b), it is now considered primarily as a measure of fluid reasoning and, secondarily, as a measure of short-term memory. These changes could be related to some modifications introduced in the subtest content, but it seems mainly determined by the other subtests included in the factor analysis. Arithmetic requires several abilities and knowledge (verbal comprehension, working memory, freedom from distractibility, numerical knowledge, procedural knowledge. . .). According to the subtests taken into account in the correlation matrix, the weight of each of these abilities and knowledge could change. The arithmetic subtest is a good illustration of the difficulty in creating tasks measuring one and only one ability. It is also a good example of the limits of factor analysis to provide validity evidence. Factor analysis cannot show more than the information included in the correlation matrix. According to the subtests included in the analysis, some components of the subtest variance will be revealed, while other components will stay in the shadow.
Structural Model Versus Functional Model of Intelligence
Beyond the problem of selecting and measuring the broad abilities, the nature of these abilities has to be discussed. The root of the CHC model is the distinction made by Cattell (1941, 1963) between fluid intelligence (Gf) and crystallized intelligence (Gc). This model was later expanded by Horn (1968). In the 1990s, Carroll’s analyses (1993) of more than 460 data sets and his proposal of a Three-Stratum theory of cognitive abilities converged with the Cattell–Horn model, most of the broad abilities identified in both models being similar. Even though Gf and Gc are now included in a larger set of broad abilities in the CHC model, they still have a specific status. Based on the clinical observation of children showing depressed performances on the Working Memory (Gsm) and Processing Speed (Gs) Indexes in comparison to their performances on the Verbal Comprehension (Gc) and Perceptual Reasoning (Gv/Gf) Indexes, Saklofske, Profitera, Weiss, Rolfhus, and Zhu (2005) proposed to calculate a General Ability Index (GAI) in the WISC-IV. The GAI is based on the six core subtests of the Verbal Comprehension and Perceptual Reasoning Indexes. The GAI shows the importance attached to Gc and Gf measures in clinical settings.
In the Cattel–Horn’s model, Gc and Gf are the core of the broad abilities. The distinction between these two abilities is based on factorial, clinical, and developmental evidence. According to Cattell and Horn (1966), “fluid intelligence [represents] processes of reasoning in the immediate situation in tasks requiring abstracting, concept formation and attainment, and the perception of eduction of relations” (p. 255). “Crystalized ability is a consequence and function of fluid ability” (Cattell, 1963, p.16). During childhood, fluid ability supports the development of school and cultural abilities. Following a cumulative process, these abilities allow for the acquisition of new abilities, which are gradually integrated into a larger and more organized cluster. Through this process, crystallized intelligence becomes progressively more independent of fluid intelligence; however, Gf and Gc continue to be correlated, even in the adulthood (Horn & Cattell, 1966).
Because of the Gf and Gc status in the Cattell–Horn theory, it is difficult to consider these two abilities as having the same weight as the other broad abilities of the CHC model. In the WISC-IV and the WAIS-IV, Gf and Gc are measured by a larger number of subtests and therefore their weight in the Full Scale IQ is higher than the measures of Gsm and Gs. However, because of their transformation in composite scores, all having a mean of 100 and a standard deviation of 15, the four index scores are often interpreted as having the same weight in intellectual functioning. Such a misinterpretation is a confusion between structural and functional models of intelligence. Weiss et al. (2013a, 2013b) provide only evidence of the structural validity of the WISC-IV and the WAIS-IV, that is, validity of the organization of the subtests into hierarchical components (Indexes and IQ) in relation to the CHC model. Neither article provides validity evidence about the way the components are working together since the construct to which they are referring is basically a structural model of intelligence.
Measurement of IQ Versus Indexes
Global intelligence (IQ) and Indexes are measured in a different way. The technique to measure global intelligence was designed by Binet who developed the first test of intelligence at the beginning of the 20th century. According to Binet (1909), “an individual shows his/her value through his/her whole intelligence. [. . .]. We should succeed to appraise this totality” (p. 117). To reach this goal, Binet included in his test a wide range of intellectual tasks. He considered that “we can only identify the intellectual level of a child using a variety of tasks. Only the success to several tasks is significant” (Binet & Simon, 1908, p. 64). Wechsler’s conception of intelligence and its measurement was very close to Binet’s conception. Across his career, Wechsler (1975) was consistent on this issue: “What we measure with tests is not what tests measure— not information, not spatial perception, not reasoning ability. These are only means to an end. What intelligence tests measure, what we hope they measure, is something much more important: the capacity of an individual to understand the world about him and his resourcefulness to cope with its challenges” (p. 139). From this viewpoint, intelligence is an emerging quality, resulting from the quality of the underlying abilities, but also from their organization and coordination. An intelligent behavior can be compared to the execution of a symphony. The quality of this execution is related not only to the quality of each musician, but also to the way the orchestra is conducted. The symphony is not an individual property of each musician. It exists only because of the interaction between the musicians.
For Wechsler, as for Binet, the only way to assess such a construct is to use a variety of tasks measuring a wide range of aptitudes and processes involved in intellectual activities. The mean of the performances to these tasks is the best indicator of global intelligence. The tasks are coming from a universe of tasks, that is, the set of all the possible intellectual tasks. They are a sample more or less representative of this universe. The selection of the tasks to include in an intelligence test is similar to an opinion poll based on a representative sample of the population of interest (Bartholomew, 2004). Based on the answers of this sample, the majority opinion of the whole population can be estimated with a relatively small error, depending of the size of the sample and the variability of the opinions in the population. Similarly, if the sampling of the tasks included in an intelligence test is correctly done, the mean performance of an individual on these tasks will be a good estimation of his/her global intelligence. However, the statistical rationale justifying Binet’s method of measuring global intelligence has some weaknesses. The analogy with an opinion poll is attractive, but there is an important difference between the procedures used by a pollster and a psychometrician. The first one refers to a precise definition of the population, from which he draws a random sample. The second one has, usually, only a vague definition of the universe of tasks, from which he draws some tasks. Therefore, when a psychometrician selects the tasks he wants to include in his/her intelligence test, he has no guarantee his/her selection is not biased and that the tasks are representative of the universe of intellectual tasks. From this viewpoint, the CHC model is an important improvement, providing a comprehensive description of the universe of intellectual tasks. If the psychometrician does a correct sampling of tasks based on the selection of the CHC model, he can expect a good estimation of global intelligence. Moreover, another sampling of tasks based on the same model should provide a similar estimation of global intelligence. From that viewpoint, the sampling of tasks included in the calculation of the Full Scale IQ in the WISC-IV and the WAIS-IV is a large selection among five broad components of the CHC model. Some components are not represented in this selection, mainly Ga and Glr. However, based on the current sampling of tasks, the mean of the 10 subtest scores can be considered as a rather good estimation of global intelligence.
The measurement of the broad abilities by the Index scores did not follow the same rationale. As explained in the previous sections, six of the current subtests of WISC-IV and seven of the current subtests of the WAIS-IV were originally selected in the Wechsler–Bellevue Intelligence Scale for their clinical utility and because they fitted a two-factor model. The other subtests (four in the WISC-IV and three in the WAIS-IV) were included later to support a four-factor structure. The selection of the broad abilities to be measured in the four-factor structure was mainly driven by the existing subtests. Because of the small number of subtests measuring each broad ability (three for Gc and Gf/Gv, and two for Gsm and Gs), each index score cannot be considered as a strong estimation of the corresponding broad ability. We have seen that the measurement of Gsm is biased in favor of the verbal short-term memory and Gs in favor of the visuomotor processing speed. To solve this problem, the number of tasks measuring each ability should be larger and the tasks should be more diversified. For example, Gsm is measured by only two tasks, which are redundant. A better measurement of Gsm would require a greater number of tasks and the tasks would need to be sufficiently diverse in terms of content and methods. However, improving the measurement of each broad ability in such a way that would lead to greatly increasing the number of subtests. The inclusion of a large number of new subtests in future Wechsler scales is not an option for practical reasons. Therefore, this way to improve the broad ability measures seems to be a dead end.
Is the Five-Factor Model the Future of the Wechsler Scales?
The first section of this article emphasized the importance of the validity evidences presented by Weiss et al. (2003a, 2003b) supporting the calculation of the four indexes. However, the results presented are more complex since, for the WAIS-IV and the WISC-IV, both the four-factor and the five-factor models are suitable. For the WAIS-IV, the five-factor model even provides a slightly better fit. From the practitioner viewpoint, the five-factor model seems to be an improvement in comparison with the four-factor model because it could provide more distinct measures of the intellectual components. We have seen that, in the four-factor model, the PRI is rather difficult to interpret since it is made of a mixed of Gf and Gv measures. A five-factor model could provide a better correspondence between the index scores and the broad abilities of the CHC model, disentangling Gf and Gv measures.
However, after a closer look at the Gf and Gv measures in the five-factor model, the situation is not so clear and the interpretation of the index scores corresponding to Gf and Gv is less easy than expected. Let’s start with the five-factor structure of the WAIS-IV. Five subtests are measuring the factor corresponding to Gv (block design, matrix reasoning, visual puzzles, figure weights, and picture completion) and three subtests are measuring the factor corresponding to Gf (matrix reasoning, figure weights, and arithmetic). The measure of Gv is clearly stronger, since it can be estimated through three specific subtests, that is, having high and unique loading on the Gv factor. On the other hand, the Gf measure is weaker since the three subtests show cross loadings. Matrix reasoning and figure weights have cross loadings on the Gv and Gf factors, and arithmetic has cross loadings on the Gf and Gsm factors. Therefore, the interpretation of an index score based on these three subtests would not be easier than the interpretation of the current PRI. In a five-factor model, only the interpretation of an index score based on block design, visual puzzles, and picture completion would be easier, the correspondence with Gv being straightforward.
In the WISC-IV, the interpretation of the index scores based the five-factor structure is even more complex. Four subtests are measuring the factor corresponding to Gv (block design, picture concepts, matrix reasoning, and symbol search) and three subtests are measuring the factor corresponding to Gf (matrix reasoning, figure weights, and arithmetic). Only block design provides a strong and specific measure of Gv. Picture concepts shows cross loadings on Gc and Gv, matrix reasoning shows cross loadings on Gv and Gf, and symbol search shows cross loadings on Gf and Gs. The interpretation of an index score based on these four subtests would be rather complex. A similar judgment can be made about an index score based on the three subtests having their highest loading on the Gf factor. Only arithmetic provides a strong and specific measure of Gf. This last observation is very surprising because this subtest has never been identified as a Gf measure in the previous versions of the Wechsler scales (see above the history of arithmetic in the Wechsler scales).
Even if, at first glance, the organization of the WAIS-IV and WISC-IV subtests according to a five-factor model seems attractive, it does not lead to an easier interpretation of the index scores. The only improvement is observed in the WAIS-IV, where the interpretation of a measure of Gv based on block design, visual puzzles, and picture completion would be straightforward. Both in the WAIS-IV and the WISC-IV, the measurement of Gf would continue to be a problem. Measuring only fluid reasoning is perhaps mission impossible, because the material on which fluid reasoning is working has always an impact on the factor structure. For future Wechsler scales, the goal should be to disentangle Gv and Gf measures, leading to a five index scores organization. The development of an index score measuring specifically Gv is now possible, as we can see with the WAIS-IV. The next challenge will be the development of an index score measuring more specifically Gf.
Conclusion
The two studies conducted by Weiss et al. (2013a, 2013b), respectively, on the WAIS-IV and the WISC-IV, provide strong validity evidence of a four-factor solution corresponding to the current hierarchical model of both scales. Their evidence supports the calculation of the four index scores and the Full Scale IQ; however, four- and five-factor models were suitable. The close data fit of the two models is a consequence of the complexity of several subtests included in the WAIS-IV and the WISC-IV. Therefore, despite validity evidence of the factor structure of both scales, the index scores interpretation is not straightforward. There is no one-to-one correspondence between the factors and the broad abilities of the construct, that is, the CHC model. On the one hand, some broad abilities of the model are not measured by the current indexes. On the other hand, the Perceptual Reasoning Index is measuring more than one broad ability, and the Working Memory and the Processing Speed Indexes do not provide a comprehensive measure of the corresponding broad abilities.
The complexity of the current indexes is partly the consequence of the historical development of the Wechsler scales. They were not developed from a theoretical model of intelligence, but from Wechsler’s experience. The tasks were selected for their clinical usefulness. A large number of these original tasks are still used in the latest versions of the Wechsler scales. However, the new tasks selected to measure a specific construct (e.g., matrix and figure weights selected to measure Gf) are also complex and their interpretation is not straightforward. Does it mean it is impossible to create tasks measuring one and only one broad ability? One century ago, Binet observed the difficulty in assessing complex intellectual abilities, as global intelligence. He considered that the only way to measure this last construct was to use a large number of intellectual tasks, the central tendency of the scores to these tasks being the best estimation of global intelligence. A similar procedure should be used to measure broad abilities. However, the number of tasks included in an intelligence test is limited for practical reasons. It is difficult to use more than two or three tasks to measure each broad ability. Therefore, the estimation of a broad ability can be biased because of the impact of a specific ability measured by a subtest. The only solution to this problem comes from the test user who should know the components of each subtest and be able use this knowledge to interpret the index scores.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.