
Abstract
The purpose of this commentary is to focus on the clinical utility of the four- and five-factor structural models for the Wechsler Adult Intelligence Scale—Fourth Edition (WAIS-IV) and Wechsler Intelligence Scale for Children-Fourth Edition (WISC-IV). It provides a discussion of important considerations when evaluating the clinical utility of the four-factor and five-factor models of the WISC-IV and the WAIS-IV. Topics covered include psychometric issues, alignment with Cattell–Horn–Carroll (CHC) theory of cognitive abilities (CHC theory), the importance of conative factors, developmental considerations, effort, environmental factors, and variability between individuals. The discussion concludes with a specific review of the purposes of the current studies and the implications for clinical utility.
Sometimes psychometric strength does not mean clinical meaningfulness. In their works on Wechsler Intelligence Scale for Children—Fourth Edition (WISC-IV) and Wechsler Adult Intelligence Scale—Fourth Edition (WAIS-IV; Wechsler, 2003, 2008) validation of four-factor and five-factor interpretive approaches, Weiss and colleagues (Weiss, Keith, Zhu, & Chen, 2013) make the case for the clinical utility of both a four- and five-factor model for interpretation of the WISC-IV and the WAIS-IV. Although there are some psychometric issues that pertain to the results of the studies, the clinical meaningfulness of the approach is open for debate. The authors provide references for numerous independent studies that have supported four- and five-factor model approaches to the structure of the WISC-IV (Benson, Hulac, & Kranzler, 2010; Bodin, Pardini, Burns, & Stevens, 2009; Chen & Zhu, 2012; Keith, Fine, Taub, Reynolds, & Kranzler, 2006) and the WAIS-IV (Bensen, Hulac, & Kranzler, 2010; Ward, Bergman, & Herbert, 2011); however, there has been no comprehensive research support for the clinical validity of such approaches. Although Weiss and colleagues did a good job of demonstrating the psychometric strength of their argument, the clinical meaningfulness remains in doubt.
Psychometric Issues
The current research studies clearly demonstrate the measurement invariance of the normative and clinical samples. They demonstrate that the WAIS-IV and WISC-IV measure the same constructs in both groups, respectively. This may be true generally speaking, but it may not hold true for the clinical groups individually. This is critical for establishing the clinical validity and meaningfulness of this fundamental assumption. There are specific reasons for this conclusion. First, the size of the clinical sample for the WISC-IV was 422 children with “various clinical diagnoses.” The size of the WAIS-IV clinical sample was 411 adults with “various clinical diagnoses.” Weiss and colleagues do specify the composition of the heterogeneous groups from the WISC-IV and the WAIS-IV. These numbers are listed below in Table 1 and Table 2 for the WISC-IV and WAIS-IV, respectively. The Tables compare the number of participants from each special group and their percentage of the whole sample and the number of participants from the standardization special group studies.
Comparison of WISC-IV Clinical Sample in the Present Study and WISC-IV Standardization Clinical Sample.
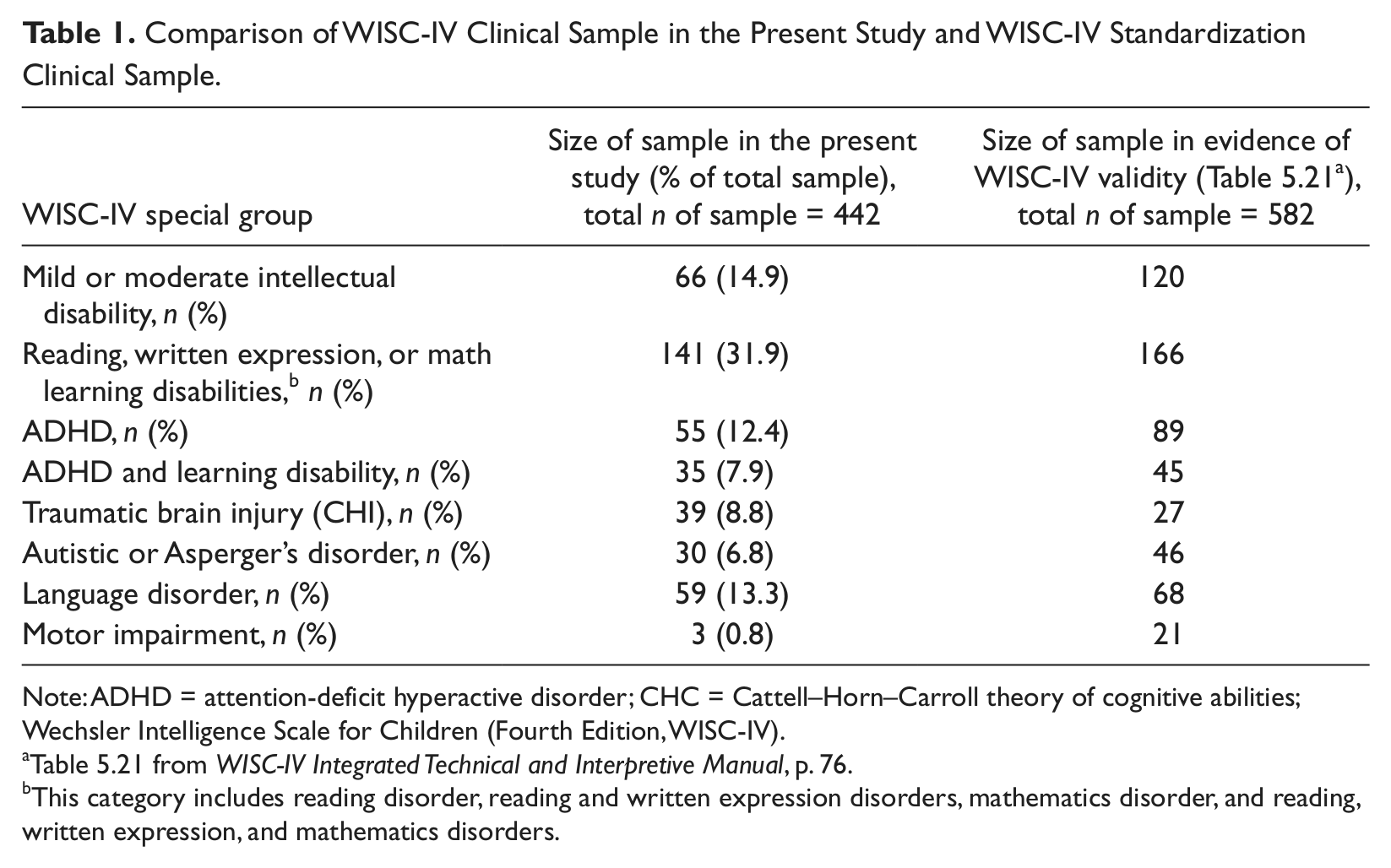
Note: ADHD = attention-deficit hyperactive disorder; CHC = Cattell–Horn–Carroll theory of cognitive abilities; Wechsler Intelligence Scale for Children (Fourth Edition, WISC-IV).
Table 5.21 from WISC-IV Integrated Technical and Interpretive Manual, p. 76.
This category includes reading disorder, reading and written expression disorders, mathematics disorder, and reading, written expression, and mathematics disorders.
Comparison of WAIS-IV Clinical Sample in Current Study and WAIS-IV Standardization Clinical Sample.
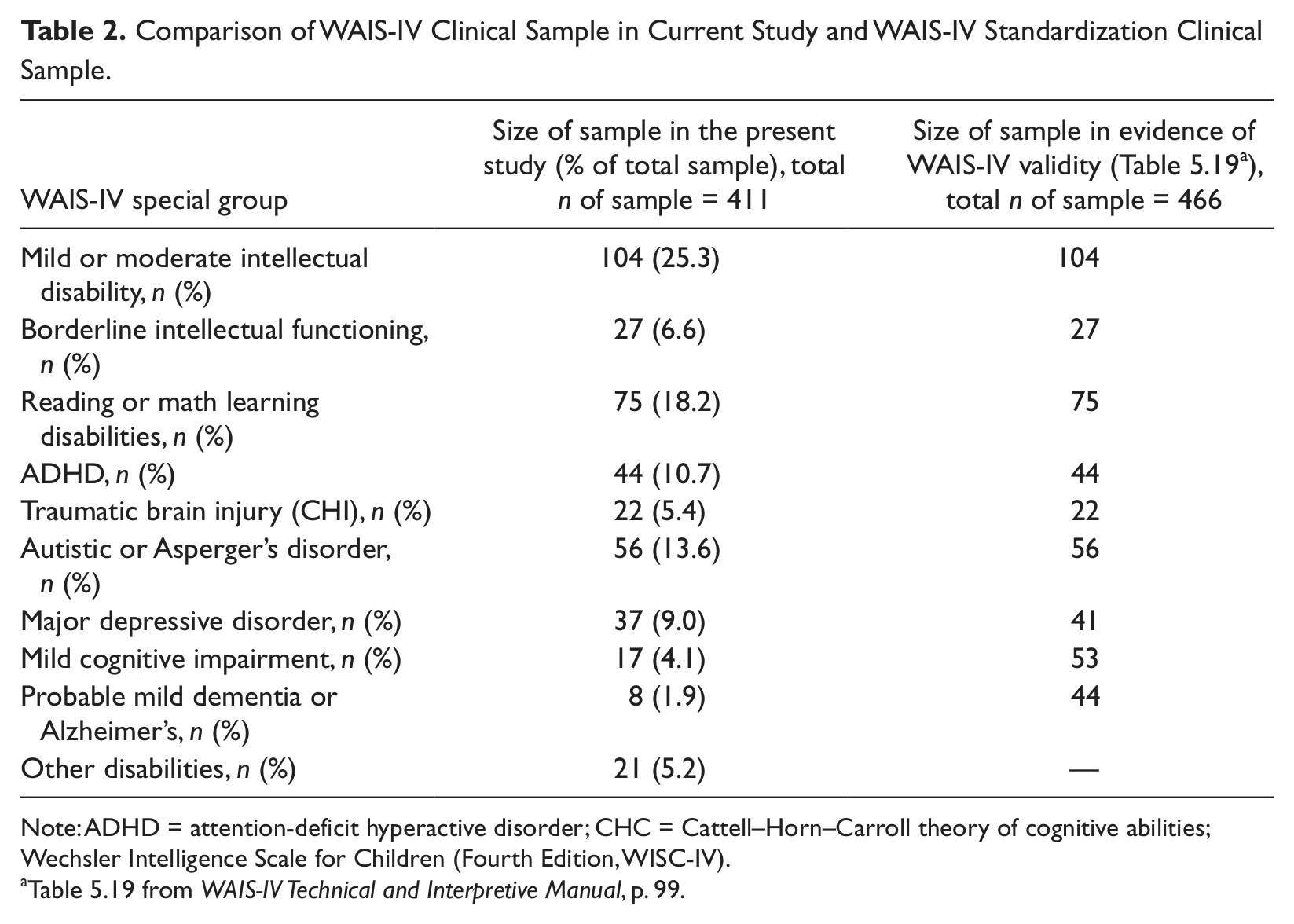
Note: ADHD = attention-deficit hyperactive disorder; CHC = Cattell–Horn–Carroll theory of cognitive abilities; Wechsler Intelligence Scale for Children (Fourth Edition, WISC-IV).
Table 5.19 from WAIS-IV Technical and Interpretive Manual, p. 99.
The sizes of the overall combined samples are appropriate for the analyses that were conducted. It is unclear how Weiss and colleagues were able to get 39 Traumatic Brain Injury subjects for the WISC-IV clinical group from the WISC-IV sample, since there were only 27 included in the special group study detailed in the WISC-IV Integrated Manual (Table 5.21, p. 76). The WAIS-IV sample is almost all inclusive of the special study groups with the exception of major depressive disorder, mild cognitive impairment, probable mild dementia or Alzheimer’s, and other disabilities. Specific reasons as to the exclusions from the first three groups and the composition of the other disabilities should be provided. These initial analyses were consistent with currently accepted statistical procedures for establishing measurement invariance. The authors made sure to demonstrate this conclusion through multiple statistical models, resulting in a conclusion that was supported empirically.
From a psychometric standpoint, one problem with the analyses is that the various clinical groups are combined into a single comparison group. For the clinician, the comparison group may have little clinical significance because it is not clear who is in the group and how it might apply to the specific individual that they are working with. For example, if the clinical sample was made up of individuals who had higher levels of intellectual and cognitive functioning within each special group, such as attention-deficit hyperactive disorder (ADHD), Asperger’s disorder, and motor impairment, it is highly likely that the conclusion of measurement invariance would be much easier to demonstrate. Again, however, the clinical utility of this conclusion is debatable.
Furthermore, assuming that the heterogeneous clinical samples were pulled from the databases that were developed for the WISC-IV and WAIS-IV special group studies, not all individuals were included. The authors do explain that some individuals in the clinical group were excluded because Arithmetic was not administered. However, examining the tables from the WISC-IV and WAIS-IV special group studies (Table 5.21 and Table 5.19, respectively) one can easily see that the sizes of many of the individual clinical samples were very small. This may be the reason for collapsing several of the special groups to make a comparison group that had a large enough sample size to allow an adequate analysis. Are individuals who have reading disorders, reading and written expression disorders, mathematics disorders, and reading, written expression, and mathematics disorders similar enough to each other that collapsing them into one group sample makes scientific “sense?”
Further complicating the analyses is the composition of the special groups. In the WISC-IV Integrated Technical Manual (p. 75), the following caveat was provided:
The samples were not randomly selected but were selected based on availability. Therefore, these studies may not be representative of the diagnostic category as a whole. Because data in each special group sample were collected in a variety of clinical settings, the diagnoses of children within the same special group might have been made on the basis of different criteria and procedures. In addition, the sample sizes for some of the studies are small and cover only a portion of the WISC-IV age range. Finally, only group performance is reported. For these reasons, the data from these samples are presented as examples and are not intended to be fully representative of these diagnostic groups. The purpose of the studies is to provide evidence that the WISC-IV can provide valid estimates of intellectual ability for children in these special groups. Scores on the WISC-IV should never be used as the sole criteria for diagnostic or classification purposes. (p. 75)
A similar caveat is provided in the WAIS-IV Technical and Interpretation Manual (p. 98), indicating the need to exercise significant caution when drawing conclusions based on the special group studies.
Therefore, it is critically important to know the makeup of the clinical groups utilized in the sample. Arguably, this is the most important limitation to the clinical utility of the findings of the current research. The problem lies in the variability of the individuals given a specific diagnosis. In other words, one would have to assume that individuals who are accurately diagnosed with a reading disorder, for example, are similar with regard to their cognitive and intellectual strengths and weaknesses. Similarly, individuals accurately diagnosed with ADHD would be a homogeneous group. We know these assumptions to be unsupported in the research literature. There is a sizeable body of empirically based research that supports the heterogeneity of these and other diagnoses (Bruining et al., 2010; Faraone, 2000; Steinhausen, 2009).
Furthermore, attempts have been made to demonstrate the efficacy of aptitude by treatment interactions. This has not been supported empirically, and as a result, even though two individuals may carry the same diagnosis, the treatment interventions that would be implemented are different with different goals and different outcomes. The ability to apply these findings reliably and validly depend on the similarity of the samples to the specific individuals that the group data will be applied to. There is a clear need to understand that, if the clinical samples “were not randomly selected but were based on availability,” is there any empirical support for their use as a part of the comparison groups for the WISC-IV and WAIS-IV studies in the first place? In other words, is it psychometrically sound to make comparisons between a special group and the specific individual with that diagnosis?
Alignment With CHC Theory
The authors attempt to align the factorial structures of the WISC-IV and WAIS-IV respectively, to the CHC theory (Carroll, 1993, 2005). The CHC model is psychometrically sound, empirically driven, and research supported as a theory. However, there are some limitations of the theory that are currently being addressed. The model is a forced-factor model that, on the surface, suggests that the factors are discreet abilities based on their individual and specific factor loadings. The narrow-ability level of the model is empirically supported and made up of approximately 70 narrow abilities. Experts in CHC theory have looked at the narrow abilities and adjusted their placement on the basis of expert opinion. This reflects the need to blend the psychometric information with clinical knowledge in order to produce a more robust theory. CHC represents a profoundly positive step in this direction. However, experts in CHC theory would be among the first to say that although the factors load in certain places, they are not discreet entities. Many of the factors have cross-loadings. This is why there is a specific need to look more closely at the shared variances that contribute to the cross-factor loadings and their implications for interpretation.
It is clear that the authors have attempted to account for the concern of cross-loadings in their analyses of the data. Both models demonstrate best fit when cross-loadings are included in the analyses. There is no empirical support for a unitary construct or ability that contributes to the successful performance of a given subtest on either the WAIS-IV or the WISC-IV. Inevitably, this fact is what limits the clinical utility of the four- or five-factor model that the authors present. In other words, each and every subtest on the WISC-IV and WAIS-IV requires multiple or “shared” abilities to successfully carry out the requirements of the task. Some of these are represented by mediating and modulating abilities, such as executive functions. Some are represented by specific intellectual abilities. All represent some degree of contribution from both of these sets of abilities and more. It may be appropriate to ask, “Can we deconstruct the tasks in such a way as to reliably and validly separate the contributions of any of the specific contributing abilities effectively?” For example, if an individual is unable to define a word on the Vocabulary subtest, is this evidence of a lack of knowledge (Gc), or can it possibly be reflective of another type of problem? Suppose the individual uses the word correctly in a sentence, indicating knowledge of the word’s meaning through correct contextual usage. The individual would receive the same “0” score for not knowing the word as they would for knowing the word but not being able to articulate their knowledge in words. The former reflects a lack of knowledge, whereas the latter may reflect an expressive language problem. The “0” scores would add up the exact same way quantitatively but would not mean the same thing qualitatively. In fact, this would clearly illustrate the multifactorial nature and clinical richness of the Wechsler instruments. Thus, there is a need to do an effective error analysis to clarify what intellectual or cognitive abilities were actually being reflected by a given subtest score.
One solution that has been demonstrated to be helpful in addressing the multifactorial nature of intellectual and cognitive abilities has been included in the Differential Ability Scale—II (DAS-II) Introductory and Technical Handbook (Elliott, 2007). The DAS-II Introductory and Technical Handbook includes tables of Shared Underlying Processes for Each Early Years and Each School Age subtest (Table 5.2 and Table 5.3, respectively). In addition to those tables, the DAS-II Introductory and Technical Handbook includes interpretive guidelines and considerations for each of the subtests. These include what abilities contribute to the successful performance of each subtest, as well as other possible explanations for low scores. Although it may be argued that the information provided is not exhaustive, it does address the multifactorial nature of each of the subtests. Furthermore, by analyzing the differences in scores on those subtests that share underlying processes, the clinician is better able to isolate the strengths and weaknesses of the individual. Consider the following example. A teacher indicates that a student has difficulty developing possible solutions to science problems. The DAS-II is administered and the individual has lower scores on the Verbal Similarities subtest when compared to the Sequential and Quantitative Reasoning, Pattern Construction, and Matrices subtests. These subtests share underlying processes in formulation and testing of hypotheses. The student presented with difficulty developing solutions to science problems but does show better skills in Nonverbal Reasoning and Spatial Ability compared to Verbal Ability. Therefore, it might be more beneficial to teach the student strategies for development and testing of possible solutions utilizing a nonverbal and/or spatial approaches, instead of a more verbally mediated model of problem solving. The clinician could also evaluate the different input and output requirements of the task to determine what skills or abilities are contributing to the individual’s difficulties.
The approach demonstrated in the DAS-II could be extended to the WISC-IV and the WAIS-IV. There is general acceptance that working memory, for example, is not isolated to the subtests that comprise the Working Memory Index. Working memory is required for the successful completion of all of the subtests on the WISC-IV and WAIS-IV to varying degrees. Therefore, although there is clear factorial support for a separate Working Memory Index, it is unlikely that conclusions related to working memory would be limited to performances on the subtests that contribute to the Working Memory Index. A matrix of shared underlying processes could be developed for the WISC-IV and WAIS-IV, guided by the cross-loadings that were demonstrated in these studies, as well as expert opinion, clinical experience, and qualitative data. In fact, one of the essential purposes of the WISC-IV Integrated Manual is to be able to “parse out” those abilities that are contributing to the successful and unsuccessful approaches to specific subtests.
Wechsler’s Legacy Includes the Importance of Conative Factors
Early on in David Wechsler’s clinical career, Wechsler demonstrated his appreciation for the importance of the conative factors that affect performance as well as the cognitive factors that affect performance (Wechsler, 1950). Conative factors are the aspect of mental processes or behaviors directed toward action or change and include impulse, drive, desire, volition, and effort. In 1950, Wechsler published a paper in which he discussed the importance of factor-analytic studies, and the limitations of those approaches. He spoke of the importance of basic validity and factor analysis. Wechsler stated, “Now, it is a remarkable finding that when matrices of intelligence tests are factored, the amount of variance accounted for is seldom more than 60 per cent of the total, and, what is perhaps of equal significance, the greater the number of different tests included, the smaller, generally, the total per cent of variance accounted for; and this is seemingly independent of the number of factors extracted” (p. 655).
Wechsler realized that approximately 40% of the variance was unaccounted for. By utilizing the works of Spearman, Thorndike, Thurstone, and Alexander, just to name a few, he arrived at the conclusion that personality factors, conative factors, and emotional factors influence performance on measures of intellectual abilities. In fact, he stated, “The point here is not that personality traits can be discovered in psychometric performance, or, what needs no special argument, that personality and abnormal conditions influence intelligence test findings, but that personality traits enter into the effectiveness of intelligent behavior, and, hence, into any global concept of intelligence itself” (p. 658).
Some 60 years later, in the Preface to WAIS-IV Clinical Use and Interpretation: Scientist-Practitioner Perspectives, Alan S. Kaufman reiterated the fact that at the time of Wechsler’s death in 1981, and immediately prior to the publication of the WAIS-R, factor-analytic studies could still only account for 60% of the variance (Kaufman, 2010; see also Weiss, Saklofske, Schwartz, Prifitera, & Courville, 2006). Wechsler was convinced that the remaining 40% was attributable to the conative variables (now defined as noncognitive variables that affect test performance, such as motivation and perseverance). Few individuals know that when David Wechsler died, he was more focused on these conative factors than the cognitive factors that helped develop his extraordinary reputation as a clinician.
Attempts have been made to address the clinical applicability of the WISC-IV and WAIS-IV to specific clinical populations (Cullum & Larrabee, 2010; Goldstein & Saklofske, 2010). Nonetheless, a problem that must be addressed is the ability to preserve the individual’s cognitive and conative characteristics when that individual’s scores are compared to group data. For example, the WISC-IV and the WAIS-IV are administered individually. The individual’s results are compared with a representative normative sample. Depending on the composition and heterogeneity of the normative sample, intraindividual variability may be minimized when compared to the group. In other words, the individual fails to reflect the “threshold” differences for the scores to be considered significantly different from the normative group, let alone clinically meaningful. Intraindividual differences can be “washed out” when compared against a group metric. Yet the individual still manifests deficits when trying to function effectively in their environment. In this situation, the individual might “fall through the cracks” and not receive necessary interventions.
Another example of a confounding variable is that there are certain “guidelines” that are put in place for comparisons that are not based on statistically sound principles but are required for documentation or eligibility purposes. For example, some school districts and disability determination procedures require the use of the Full Scale IQ (FSIQ) score in determining eligibility for services, regardless of the threat to validity caused by significant index score or subtest score variability. Therefore, determination of eligibility for services may be based on an incorrect application of a statistical procedure. In fact, the issue of score validity is also true at the index level, and arguably, the subtest level. The greater the “scatter” of scores that contribute to an index or subtest score hierarchically, the greater the threat to validity. Two individuals with the exact same FSIQ score or index score can present with extremely different abilities, strengths, and weaknesses. With appropriate error analyses, it is possible for the clinician to appreciate the contributions that item-level performances contribute to subtest-level scores, which in turn contribute to the index-level scores, which influence the overall ability level defined as g. This could improve the diagnostic utility of the psychometric approaches described in the present research. At this time, this approach would be aspirational because there are conflicting positions on the research support for profile analysis (Gottfredson & Saklofske, 2009).
Developmental Considerations
Weiss and colleagues discuss the implications of the research studies, which suggest that there is statistical support for breaking the Perceptual Reasoning Index into two separate factors, a Perceptual Organization Index and a Fluid Reasoning Index. They explain the difficulty in identifying quantitative marker variables in the WISC-IV like they were able to do with the WAIS-IV. In fact, they state, “It is presently unclear if this finding is due to the additional quantitative marker subtest (Figure Weights) present in WAIS-IV but not WISC-IV, or a cognitive developmental trend specific to adults.” The cognitive developmental trend is more likely to be present in children than in adults, unless the authors are speaking of cognitive decline with aging (Salthouse, 1996, 2011; Salthouse & Ferrer-Caja, 2003; Soubelet & Salthouse, 2011; Tucker-Drob, 2011). This finding presents another threat to the clinical utility of the conclusions of the present research studies. It is possible to argue that there are other explanations accounting for the difficulty in identifying quantitative marker variables on the WISC-IV. The WISC-IV age range is 6 to16 years. During this time, a child is developing arithmetic/quantitative knowledge from the basic concept of numbers and value to higher-level conceptual applications such as algebra, geometry, trigonometry, and beyond. Theoretically, as the child ages, they develop higher levels of reasoning and problem solving, moving from the concrete to the abstract. The degree of variability during this developmental process would make identifying a consistent marker variable quite difficult. In addition to the variability just discussed, there is significant variability in the scope and sequence of the curricula that these skills are based upon. The increased variability in both of these processes adds to the problem of developing a marker that would consistently mean the same thing from individual to individual when applied in a clinical situation.
The main point of the paragraph above was to bring attention to a significant set of problems when considering the clinical utility of primarily psychometric approaches to understand the performance of an individual on a given set of measures. How do we maintain the “individual” when compared to a group metric? There is so much variability in a normalized sample that the individual must be “really discrepant” before the significant difference can be demonstrated. This presents a dilemma for identification of the individual who, despite their average scores, are having difficulty functioning effectively.
Furthermore, an individual can demonstrate the basic or core skills/abilities necessary to complete a task but be unable to complete the task. Often, the “whole is greater than the sum of the parts.” In other words, we may be able to demonstrate that an individual has the basic or core skills/abilities, but they “break down” when those abilities have to be integrated or work together to perform a higher-level task. Unfortunately, there are very few, if any, instruments that assess the process of integrating skills and abilities.
Four-Factor or Five-Factor Models
The authors suggest that “for individuals with consistent subtest scores,” the current four-factor model is appropriate. “For individuals with discrepant subtest scores” the five-factor structure may be more appropriate. What constitutes consistent subtest scores and what constitutes discrepant subtest scores? The current research did not provide guidance to assist the clinician in determining the thresholds that would direct the clinician to either the four-factor or the five-factor model. There are practical implications for this guidance. The five-factor model is based on the 15 subtests of the WISC-IV and WAIS-IV, whereas the four-factor model is based on only 10 subtests. At what point would the clinician know that all 15 subtests would be necessary in order to use the five-factor model? They would actually have to complete all 15 subtests before they would be able to reliably and validly decide which model is most appropriate for that individual. Is it likely, given time and reimbursement limitations, that a clinician would do the 15 subtests on the WISC-IV or WAIS-IV? Is the benefit of the five-factor model worth the extra time?
In fact, the authors comment on the controversial nature of the “choice of four- or five- factor models” relative to the Wechsler measures. The discussion includes the need to consider the contribution of additional variables before drawing clinically meaningful conclusions. In addition to the conative measures mentioned above, other variables often mentioned are culture, age, and subtest combination.
Importance of Effort
Wechsler stated that effort is important in the process of valid assessments of abilities. Others have echoed the importance of effort testing in assessment (Harrison, Green, & Flaro, 2012). The authors of this study did not include any indication that measures of effort were utilized during the data collection phase and standardization of the WISC-IV and WAIS-IV. It is probable that some individuals persevered when faced with difficulty during the standardization process, whereas others gave up when faced with difficulty. These individual differences in approach add to the threats to the validity of the norms, and thus, the conclusions of clinical utility of the two models. It would follow that there would be implications for clinical interpretation based on whether good effort was demonstrated or not. Is it reasonable to assume that all or most individuals gave good effort during the standardization phases of the WISC-IV and WAIS-IV? How do we know? Of course, this is true of most of the assessment instruments that have been developed and not limited to the WISC-IV and WAIS-IV. Testing for effort, motivation, and engagement would likely increase the cost of development of an instrument, and therefore, increase the cost to purchase the instrument. However, since the authors are presenting a theoretical argument on the basis of a psychometric approach, theoretical threats to validity and clinical meaningfulness of their results must also be discussed.
Environmental Factors
Environmental factors and variations in individual abilities over the course of the day should also be considered (Pike, Iervolino, Eley, Price, & Plomin, 2006). Currently, there are no generally accepted and consensually validated guidelines for considering individual factors in a reliable and valid qualitative manner. For example, the individual tested after a meal may be affected by parasympathetic activity involved with digesting food and the impact that this process has on alertness and arousal. Someone who is well rested may have fewer confounding variables to consider when interpreting their results compared to someone who is very tired. Someone who is well nourished may have fewer confounding variables to consider than individuals who are malnourished or hungry. Again, although these factors are taught in graduate programs, there is little if any systematic strategy for integration of these findings into the individual performances on the abilities measures. In general, these get subsumed under error variance for the group data but not systematically evaluated on the individual level. As a result, there are these additional threats to the clinical meaningfulness of scores.
Variation From Individual to Individual
Finally, it is necessary to consider an individual’s approach to task completion on the WISC-IV and WAIS-IV. The skills that are being deployed to complete a task will vary from individual to individual. For example, there are different relative contributions of underlying cognitive and intellectual processes to solving the items on the Arithmetic subtest in an individual who does the math in their head compared to the individual who uses their finger to figure the problem out on the table. The same is true of the individual who performs Digit Span Backward by visualizing the reversed order of the number sequence and the individual who performs the task by repeating the sequence forward silently, verbalizing only the last number, going forward again and verbalizing the next to last number, and so on. Finally, there is a difference in abilities that are utilized when an individual uses a trial-and-error approach to a task versus a strategic, careful, and organized approach to the same task. Although it is appropriate to speak generally of the factors that are being reflected by the four- and five-factor models, there is a clear limitation on the clinical utility of one versus the other on an individual clinical level.
It could be argued that the opinions presented in this commentary are suggesting that unless we have “pure” ability factors or subtests, what we are attempting to measure clinically will always be complex, and therefore, the clinician and not the assessment measure is necessary to make clinical decisions. There are several responses to this argument. First, any instrument is only as good as the training and knowledgebase of the individual using it. Second, this is not an either/or situation. Good clinicians use their data to test hypotheses and arrive at data-supported conclusions. Finally, it is the clinician, not the test, who provides context to the results of a test (Weiss, Chen, Harris, Holdnack, & Saklofske, 2010, in Weiss, Saklofske, Coalson, & Raiford, 2010). For example, administering Digit Span or Similarities to an individual who is hearing-impaired may result in a poor performance. Is it because of the hearing difficulty or is it because the individual lacks content knowledge or both? Wechsler emphasized the context in which scores were achieved as an important component to their meaningful interpretation. The clinician has their tools just as the carpenter, mechanic, and electrician have theirs. The tools by themselves are not sufficient. As Edith Kaplan would say, “You can buy the best carpentry tools that money can buy, but that will not make you a carpenter.”
Conclusion
Weiss and colleagues set three primary purposes of the present research studies. They were to explore the constructs underlying the four- and five-factor structural models for the WISC-IV and WAIS-IV; the abilities measured by the subtests and cross-loadings were tested and verified, and further, whether there was sufficient measurement invariance to support the hypothesis that the 15 subtests on the WISC-IV and the WAIS-IV effectively measure latent abilities similarly in the normative sample and the clinical sample. The authors were able to demonstrate measurement invariance effectively with psychometric approaches designed for that purpose. However, some questions remain due to failure to specifically describe the composition of the clinical sample. Although the data do support the conclusion that the 15 subtests on WISC-IV and WAIS-IV effectively measure latent abilities similarly in both samples, the utility of this finding at the individual clinical level may not be adequately demonstrated. Failure to consider the multifactorial basis of the tasks and the individual differences in approaches to the tasks cast doubt on the conclusions that a primary and secondary interpretive model for WISC-IV and WAIS-IV is adequate at the individual clinical level. Finally, the four-factor and five-factor structural models are psychometrically supported, but the overall clinical utility is questionable. Sometimes psychometric strength does not effectively result in clinical utility. This is one of those times.
Footnotes
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.