
Abstract
The Cattell–Horn–Carroll (CHC) model is a comprehensive model of the major dimensions of individual differences that underlie performance on cognitive tests. Studies evaluating the generality of the CHC model across test batteries, age, gender, and culture were reviewed and found to be overwhelmingly supportive. However, less research is available to evaluate the CHC model for clinical assessment. The CHC model was shown to provide good to excellent fit in nine high-quality data sets involving popular neuropsychological tests, across a range of clinically relevant populations. Executive function tests were found to be well represented by the CHC constructs, and a discrete executive function factor was found not to be necessary. The CHC model could not be simplified without significant loss of fit. The CHC model was supported as a paradigm for cognitive assessment, across both healthy and clinical populations and across both nonclinical and neuropsychological tests. The results have important implications for theoretical modeling of cognitive abilities, providing further evidence for the value of the CHC model as a basis for a common taxonomy across test batteries and across areas of assessment.
Introduction
The construct validities of cognitive ability tests used for clinical diagnostic assessment, especially neuropsychological tests, do not appear to be well established. For example, Dodrill (1997, 1999) pointed out that commonly cited neuropsychological constructs (e.g., attention, learning, and motor abilities) are not clearly and consistently supported by empirical research. Other studies have identified uncertainty in the construct validities of various neuropsychological tests (e.g., Chaytor & Schmitter-Edgecombe, 2003; Dodrill, 1997, 1999; Gansler, Jerram, Vannorsdall, & Shretlen, 2011; Jurado & Rosselli, 2007; Salthouse, 2005; Salthouse, Atkinson, & Berish, 2003; Spooner & Pachana, 2006).
Sometimes, validity interpretations rely on clinical usage and established practice as much as on rigorous construct validity evaluations (Lezak, Howieson, & Loring, 2004; E. Strauss, Sherman, & Spreen, 2006). An example is the taxonomy of “neurocognitive domains” provided in Diagnostic and Statistical Manual of Mental Disorders (5th ed.; DSM-5; American Psychiatric Association [APA], 2013). The taxonomy apparently derives from informal clinical usage, without a clear empirical or theoretical justification, but is intended to provide a guide to diagnostic assessment practices and interpretation of individual patient mental status.
In contrast to less formal clinical taxonomies, the Cattell–Horn–Carroll (CHC) model is based on psychometric intelligence and cognitive ability research conducted over much of the last century (McGrew, 2005; Reynolds, Keith, Flanagan, & Alfonso, 2013). The CHC model is a factor analysis–based model, which describes the major (broad ability) and minor (narrow ability) sources or factors of individual differences captured by cognitive tests. The factor structure of cognitive tests provides a critical test of construct validity and also provides insight on the cognitive abilities, as represented by factors, that underlie cognitive test performance (M. E. Strauss & Smith, 2009; Widaman & Reise, 1997). For clinical assessment, the most relevant constructs in the CHC model include the broad constructs of visuospatial ability (Gv), working memory (Gsm), long-term memory encoding and retrieval (Glr), acquired knowledge or crystallized ability (Gc), processing speed (Gs), and fluid reasoning (Gf). However, there is also an additional level of more specific constructs known as narrow abilities, and there are other less well-understood broad constructs, such as auditory ability (Ga) and tactile ability (Gh; McGrew, 2009).
The CHC model is the result of the integration of John Carroll’s (1993) exploratory factor analytical review of over 460 data sets and the developing consensus in the intelligence literature around the work of Raymond Cattell, John Horn, and other scholars represented by modern Gf–Gc theory (McGrew, 2005). The CHC model is the most strongly supported, empirically derived taxonomy of cognitive abilities (Ackerman & Lohman, 2006; Kaufman, 2009; McGrew, 2005; Newton & McGrew, 2010) and has influenced the development of most contemporary intelligence tests (Bowden, 2013; Kaufman, 2009; Keith & Reynolds, 2010). For a description of CHC constructs, see McGrew (2009), Schneider and McGrew (2012), or the Supplemental Materials. For a history of the CHC model, see Schneider and Flanagan (2015), Schneider and McGrew (2012), and Ortiz (2015).
The present article is based on the premise that carefully conducted group studies, using well-researched psychometric methodology and guided by the high-quality cognitive ability research incorporated in the CHC model, can be used to address current questions in clinical construct validity. However, the CHC model is primarily supported by studies with nonclinical cognitive ability tests in community and educational samples (Carroll, 1993). In contrast, clinical assessment often involves clinical tests, or tests specifically developed for assessment of clinical cognitive symptoms, which have been less studied with respect to the CHC model. Furthermore, clinical assessment often involves special populations, such as individuals with disorders or particular brain injuries. Finally, some constructs that are commonly assessed in clinical assessment are not present in the CHC model, such as executive function.
Therefore, for the CHC model to have utility in clinical and neuropsychological assessment, the critical issues are (a) the generality of the CHC constructs across tests, (b) the generality of the CHC model across populations, and (c) the potential integration of neuropsychological constructs, most notably executive function, into the CHC model.
The Generality of the CHC Model Across Tests
One possible reservation regarding the CHC model is that constructs measured by one test battery may not be the same constructs measured by other test batteries (Horn, 1991; Reynolds et al., 2013; Tucker, 1958). However, the CHC model is consistent with all contemporary intelligence test batteries (see Table 1). Studies with multiple test batteries provide a stronger test of the hypothesis that the CHC constructs are shared across test batteries. In a landmark paper, Woodcock (1990) showed that a CHC precursor, modern Gf–Gc theory, and by extension the CHC model, was consistent with the factorial structure of data sets with Woodcock–Johnson–Revised in conjunction with the Kaufman Assessment Battery for Children, the Stanford–Binet IV, the Wechsler Intelligence Scale–III, or the Wechsler Adult Intelligence Scale–Revised (WAIS-R), respectively. Several additional cross-battery factor analyses have been conducted recently, and these also show that the CHC constructs are independent of the test used to measure the respective constructs (see Table 1).
Summary of Studies Showing CHC-Consistent Models for Popular Intelligence Batteries, Analyzed Alone or With Another Intelligence Battery.

Note. CHC = Cattell–Horn–Carroll.
One cross-battery study of particular value involved the Wechsler Intelligence Scale for Children–III, Wechsler Intelligence Scale for Children–IV, Kaufman Assessment Battery for Children–II, Woodcock–Johnson III, and Peabody Individual Achievement Test–Revised test batteries in a single analysis (Reynolds et al., 2013). All children in the sample were administered the Kaufman Assessment Battery for Children–II along with one or more of the other test batteries as part of the Kaufman Assessment Battery for Children–II test validation process (Kaufman & Kaufman, 2004). Reynolds and colleagues (2013) found that all but one of the 39 subtests loaded on the predicted CHC factor and that the CHC factors generalized across each battery. Woodcock–Johnson III Picture Recognition was found to load better on the long-term memory encoding and retrieval ability (Glr) factor than on the expected visuospatial ability (Gv) factor, but this is not incongruent with the CHC model and may instead suggest that Picture Recognition is primarily dependent on associative abilities rather than on visuospatial abilities. Evidence to date shows that, when conducted in a careful, confirmatory factor analysis framework, the evidence supports the hypothesis that CHC constructs transcend particular test batteries. This is an important observation because if the CHC model generalizes to other test batteries and populations, then the CHC model may provide a useful practical guide to test development and interpretation and, ultimately, a general model of diagnostic assessment.
The Generality of the CHC Model Across Populations
Another potential reservation is that constructs underlying test performance may depend on the population. This issue is analytically described by the mathematics of measurement invariance (Meredith, 1993; Widaman & Reise, 1997). Measurement invariance is observed when the conditional distribution of the observed variables given values of the latent variables is equal across populations. Establishing measurement invariance is necessary for assuring the generality of construct validity across populations, including unambiguous interpretation of convergent and discriminant validity and interpretation of group mean differences (Horn & McArdle, 1992; Meredith & Teresi, 2006; Widaman & Reise, 1997).
To date, a limited number of studies have examined whether factor models of intelligence or other cognitive ability tests show measurement invariance across putatively different community control and clinical populations. Published studies are summarized in Table 2. Some studies were explicitly based on the CHC model, whereas other studies were consistent with the CHC model. Not included in Table 2 are studies that have not clearly distinguished measurement and structural invariance and therefore reported ambiguous results (e.g., Dickinson, Goldberg, Gold, Elvevåg, & Weinberger, 2011; Dickinson, Ragland, Calkins, Gold, & Gur, 2006; Genderson et al., 2007; Leeson et al., 2009). Every study that has examined measurement invariance in the recommended sequence without conflating structural invariance (Widaman & Reise, 1997) has found evidence of measurement invariance of constructs across diverse populations reporting factor structures compatible with the CHC model.
Summary of Measurement Invariance Studies of CHC-Consistent Models of Cognitive Tests.
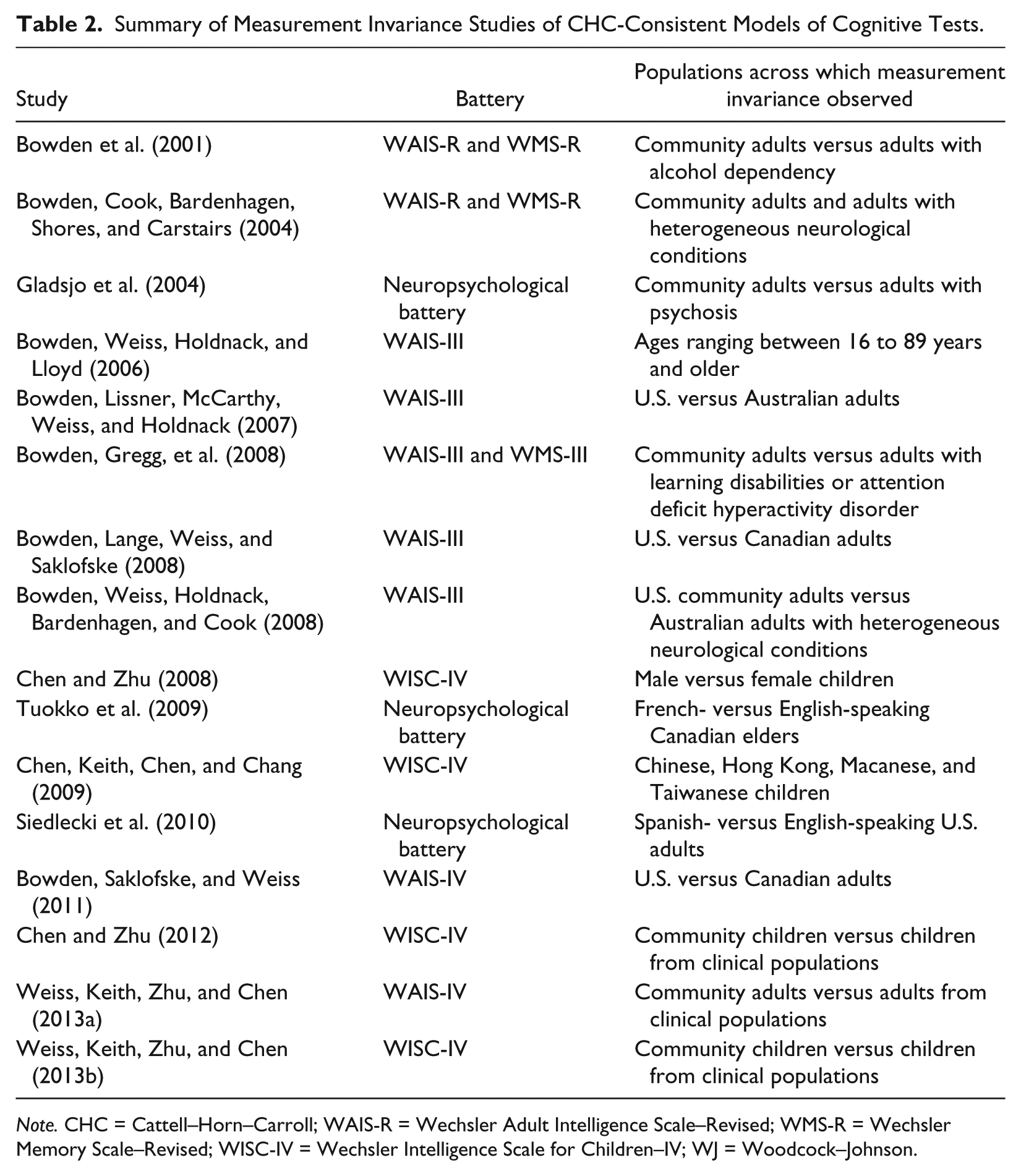
Note. CHC = Cattell–Horn–Carroll; WAIS-R = Wechsler Adult Intelligence Scale–Revised; WMS-R = Wechsler Memory Scale–Revised; WISC-IV = Wechsler Intelligence Scale for Children–IV; WJ = Woodcock–Johnson.
The CHC Model and Executive Function
Executive function is an umbrella term for intentional, top-down cognitive processes including problem solving, reasoning, planning, regulation, and working memory that are believed to be necessary for independent, self-serving behavior (Diamond, 2013; Lezak et al., 2004). It is hypothesized that much neurological and psychiatric dysfunction can be described in terms of failure of executive function (e.g., Barch, 2005; Diamond, 2013; Penadés et al., 2007; Royall et al., 2002; Shallice, 1982). However, executive function is not well defined, and there is disagreement in the literature regarding the unity or diversity of executive function, the factor dimensionality of executive function, and equivalence of executive function with (pre)frontal cortex function (Alvarez & Emory, 2006; Jurado & Rosselli, 2007; Roca et al., 2010; Royall et al., 2002).
Although executive function is considered to have central importance in contemporary neuropsychological assessment (Lezak et al., 2004), executive function is not overtly described by the CHC model. Limited research has been conducted to investigate the distinctiveness of executive function in relation to traditional cognitive constructs such as those described by the CHC model. The available research is mixed and does not clearly support executive function as distinct constructs (Floyd, Bergeron, Hamilton, & Parra, 2010; Friedman et al., 2006; Jewsbury, Bowden, & Strauss, 2016; Salthouse, 2005; Salthouse et al., 2003).
The Present Study
The question of whether the CHC model is compatible with the factor structure of clinical and neuropsychological tests can be broken up into three specific, testable hypotheses. First, does the CHC model apply to diverse cognitive and neuropsychological tests? Second, does the CHC model apply to clinically relevant populations? Third, does the CHC model need to be expanded to account for the clinical construct of executive function?
Method
Data Analysis
Confirmatory factor analysis was conducted with Mplus Version 6.1 (Muthén & Muthén, 2010) with maximum likelihood estimation. Goodness of fit was evaluated on the basis of the maximum likelihood chi-square, as well as commonly reported fit indices including the root mean square error of approximation (RMSEA), the standardized root mean square residual (SRMR), the comparative fit index (CFI), and the nonnormed fit or Tucker–Lewis index (TLI). The fit indices were compared with the cutoff values suggested by Hu and Bentler (1999), namely, <.06 for the RMSEA, <.08 for the SRMR, and >.95 for the CFI and TLI as indicating good fit. However, the caveats voiced by Marsh, Hau, and Wen (2004) were considered, in particular the caveat that it is harder to satisfy Hu and Bentler’s cutoff rules for good model fit with a relatively large number of indicators (viz., more than two or three per factor).
For most data sets, only the correlation or covariance matrices were available. The raw, individual-level data set was only available for the data set from Duff, Schoenberg, Scott, and Adams (2005). The analysis for this data set was conducted with full information maximum likelihood estimation based on the raw scores. To account for skewness in the neuropsychological variables, nonnormality robust estimators were also used for the data from Duff and colleagues (specifically, MLR or robust maximum likelihood with chi-square asymptotically equivalent to the Yuan-Bentler T2* test statistic; MLM or maximum likelihood with Satorra-Bentler chi-square statistic; and MLMV or maximum likelihood with mean- and variance- adjusted chi-square statistic; note that other differences exist in the standard error estimation and missing data treatment; details in Muthén & Muthén, 2010, and the Supplemental Materials).
Sample of Studies Used for Confirmatory Factor Analysis
To locate studies, a search of Google Scholar and PsycINFO was conducted in June 2013 with combinations of the keywords factor analysis, neuropsychology, neuropsychological tests, neuropsychological population, neuropsychological sample, clinical sample, clinical population, mixed sample, mixed population, referral sample, referral population, executive function, Stanford Binet, Woodcock Johnson, WISC, and WAIS. To supplement the search, reviews of citations by, and citations of, key relevant articles were also examined. Although a large number of factor analyses were found, only nine data sets satisfied the selection criteria for reanalysis described below.
Confirmatory Study Selection Criteria
To ensure that high-quality data sets were included, the criteria for study selection were relatively strict as follows:
1. To allow for a confirmatory analysis to be conducted, at least the correlation matrix was available either in the article or from the authors.
2. For an adequate sample size, the sample size was at least 200.
3. To be relevant for the present topic, the data set had tests commonly used in neuropsychological assessment.
4. To allow identification of multiple CHC constructs, the data set had at least 15 different tests or subtests. This was chosen as an arbitrary but objective criterion to attempt to avoid factor solutions with sole indicators and to ensure that there would be adequate sampling of the CHC constructs, especially to model alongside a potential executive function factor where possible. Because most data sets of cognitive batteries were considered, a priori, likely to yield at least four CHC factors (typically Gv/Gf, Gc, Gsm, and Gs), a minimum of three indicators is desirable to identify a factor (Brown, 2006; Kline, 2011), and at least three additional indicators would be required to identify an executive factor; 15 indicators was considered a workable minimum number of indicators.
5. To provide confidence that the CHC constructs were correctly identified, the data set had tests with generally accepted and well-established construct validity (e.g., Wechsler Intelligence Scales for Adults or Children, Wechsler Memory Scales, Stanford–Binet Intelligence Scales, or Woodcock–Johnson Intelligence Scales) along with tests of more controversial construct validity (e.g., executive function tests).
The following two criteria were optional to obtain as wide a variety of data sets as possible, but for special relevance for the present topic, the following criteria were sought.
6. Ideally, the population was relevant to neuropsychological assessment (e.g., a clinical population).
7. Ideally, some tests are identified as executive function tests by the study authors.
Procedure
The models reported below were specified, a priori, to be consistent both with conceptual descriptions of CHC theory and previous research (Carroll, 1993; Flanagan, McGrew, & Ortiz, 2000; McGrew, 2009). When there were multiple indicators from the same test, the residuals were allowed to correlate to account for method variance (Kline, 2011; Larrabee, 2003). After the model was estimated, any nonsignificant factor loadings and residual correlations were removed from the model. The standardized residuals and modification indices were examined, but post hoc modifications were made with reluctance (MacCallum, Roznowski, & Necowitz, 1992). Modifications were only made when the associated modification index was significant and very large relative to other modification indices for the same model, and the modification was theoretically interpretable. The one post hoc modification, in one data set, that met this criterion is described in detail below.
The possible addition of an executive function construct to the respective CHC models, specified for each data set, was evaluated by adding an executive function factor to each model if the original authors hypothesized certain indicators to be executive function tests. Wherever executive function factors were specified in the present study, the tests selected as executive function indicators were exactly consistent with the original authors’ classification of executive function tests. This strategy required that the executive function indicators were double-loaded on the relevant CHC factor and the new executive function factor. Loading the executive function indicators on both the relevant CHC factor and the new executive function factor corresponds to the dominant conceptual view that executive function indicators are confounded with nonexecutive variance (known as the task impurity problem; Miyake, Friedman, Emerson, Witzki, Howerter, & Wager, 2000). However, this double-loaded model may be underidentifed. Therefore, as a second possible executive function model, the loadings of the executive function tests on CHC factors were removed, such that executive function tests were loaded only on the executive function actor.
Finally, the hypothesis that putative executive function tests might measure executive functions specific to each test was investigated. Reliable unique variance for each test was estimated with a method described in the Supplemental Materials. The hypothesis that putative executive function tests have greater unique variance than nonexecutive tests was examined with a t test.
Results
Nine data sets were selected for reanalysis. These data sets, along with the fit statistics of the associated CHC model, are shown in Table 3. Due to space limitations, only one reanalysis was described here in full detail as an example. The remaining reanalyses were described in full detail in the Supplemental Materials, and only the overall results were reported in the main body of the text.
Selected Studies and Fit Statistics for the CHC Model.
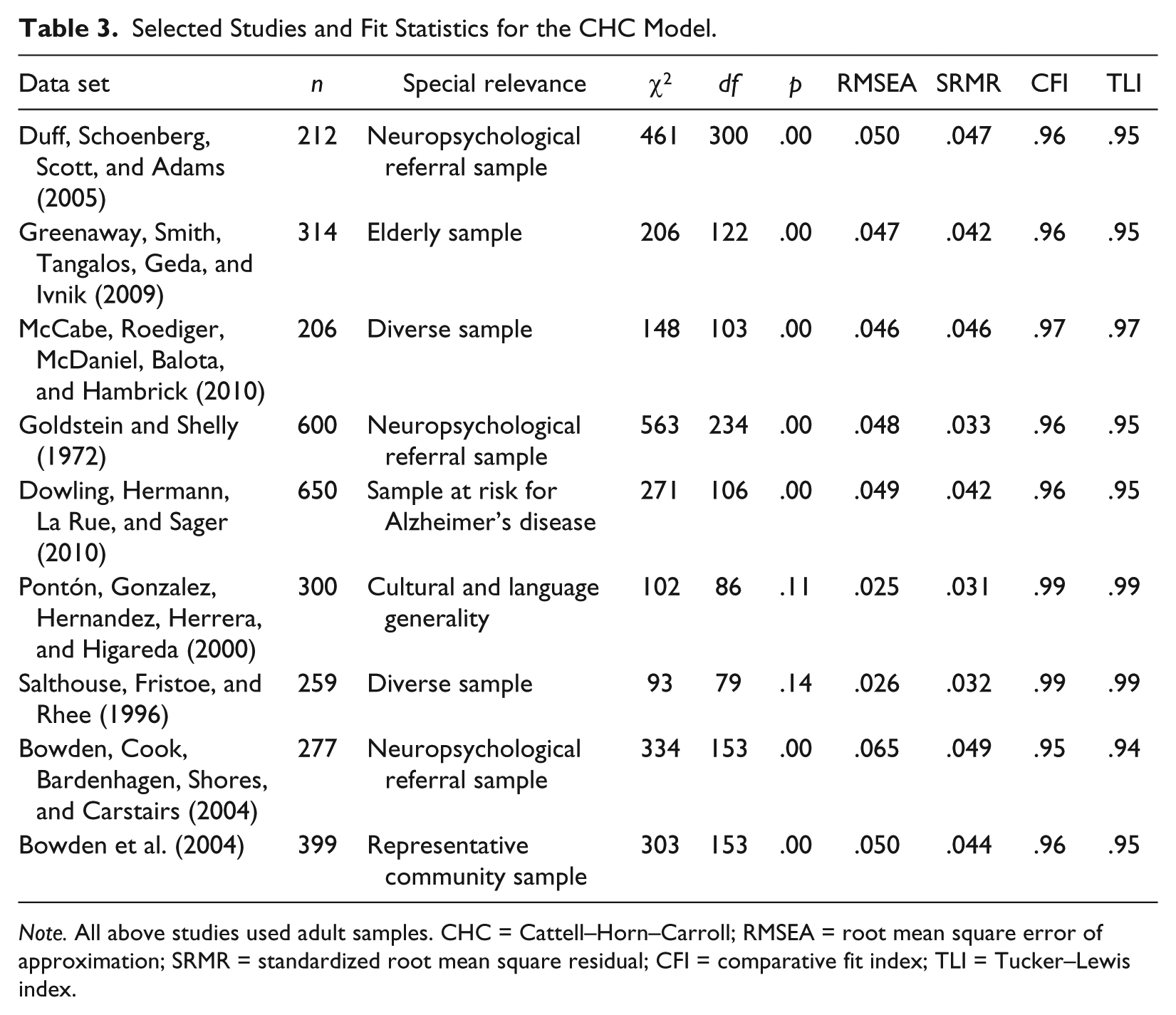
Note. All above studies used adult samples. CHC = Cattell–Horn–Carroll; RMSEA = root mean square error of approximation; SRMR = standardized root mean square residual; CFI = comparative fit index; TLI = Tucker–Lewis index.
Reanalysis of dataset from Duff et al. (2005)
Duff and colleagues (2005) investigated the relationship between executive function tests and learning and memory tests. The participants were 212 patients referred for neuropsychological evaluation, with a variety of suspected neurological and psychiatric conditions (age M = 50 years, SD = 16.6; education M = 13.5 years, SD = 2.8).
Duff and colleagues’ (2005) individual-level data set was retrieved for this study. The present reanalysis was based on the individual-level data set with full information maximum likelihood estimation. The reanalysis involved all 15 indicators in the original study as well as the WAIS-R subtests, and Trail Making Test–Part A, which were not analyzed in the original study.
After specifying and examining the initial CHC model, the secondary loadings of Trail Making Test–Part B on Gsm (r = .10, SE = .10, p = .29) and WAIS-R Arithmetic on GvGf (r = −.04, SE = .11, p = .73) were removed because of nonsignificance, but all other a priori factor assignments were associated with significant loadings in the expected direction. On the basis of a relatively large modification index (36.61), residuals from WAIS-R Block Design and WAIS-R Object Assembly were allowed to correlate. Although this was not originally hypothesized, the size of the modification index suggests the correlation was not capturing sample-specific error and instead may represent the narrow ability visualization (Gv–Vz; McGrew, 2009). The final model is shown in Figure 1.
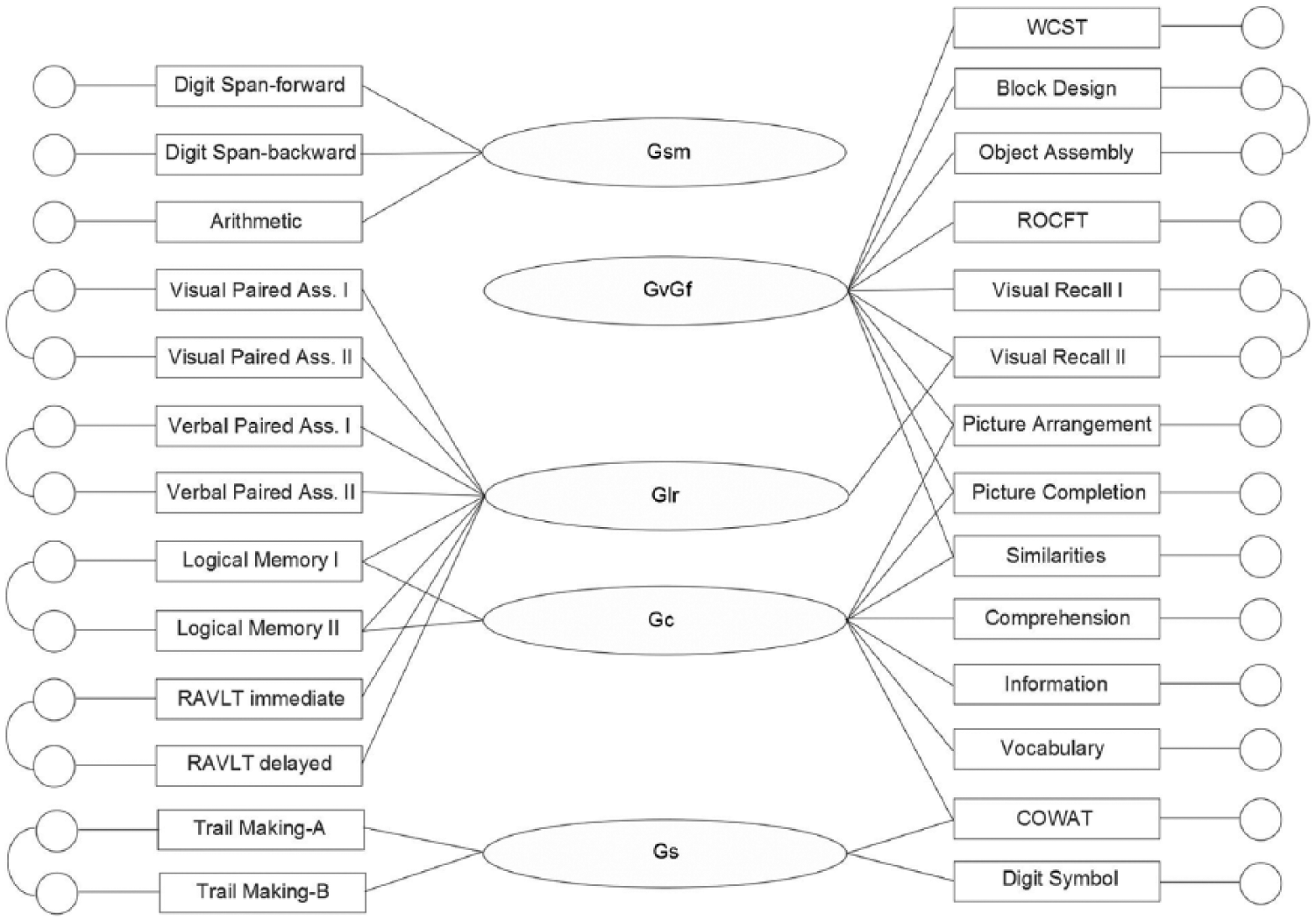
Final model for the Duff, Schoenberg, Scott, and Adams (2005) reanalysis.
Table 3 shows that the CHC final model had a significant chi-square value, suggesting imperfect fit. However, the RMSEA, SRMR, and CFI values were better than their respective cutoff values, and the TLI value was on the cutoff value (Hu & Bentler, 1999). These conclusions did not change with the use of nonnormality robust methods (see Supplemental Materials).
In this data set, the original authors described five indicators as executive function tests. Adding an executive function factor modeled by Wisconsin Card Sort Test, Controlled Oral Word Association Test, Trail Making Test–Part B, WAIS-R Similarities, and WAIS-R Digit Span–backward to the CHC model, with each test also loaded onto the relevant CHC factor, produced a model with a nonpositive definite latent variable covariance matrix. This may be related to high estimated correlations between the executive function factor and Gsm and Gs (r = .91, SE = .32, and r = 1.05, SE = .14, respectively). The alternate model, where the indicators of the executive function factor were only loaded on the executive function factor, also resulted in a nonpositive definite latent variable covariance matrix, and similar high estimated correlations. As a consequence, both variants of the executive function model were not viable alternatives and the executive function factor was found to be statistically redundant.
Table 4 shows the estimates and standard errors for the unique variances for each indicator in the data set. On average, test indicators were made up of 54% (SD = 13) variance explained by the CHC constructs, 32% (SD = 10) unreliable variance, and 13% (SD = 15) reliable unique variance. The variance accounted for in the model by the correlated residuals is counted in the unique variance. The unique variance of the five executive function measures (M = 15%) was not significantly different from the unique variance observed for the 22 nonexecutive function measures (M = 13%; t = .21, df = 25, p = .84).
Unique Variance Estimates and Standard Errors for the Final CHC Model for the Duff, Schoenberg, Scott, and Adams (2005) Reanalysis.
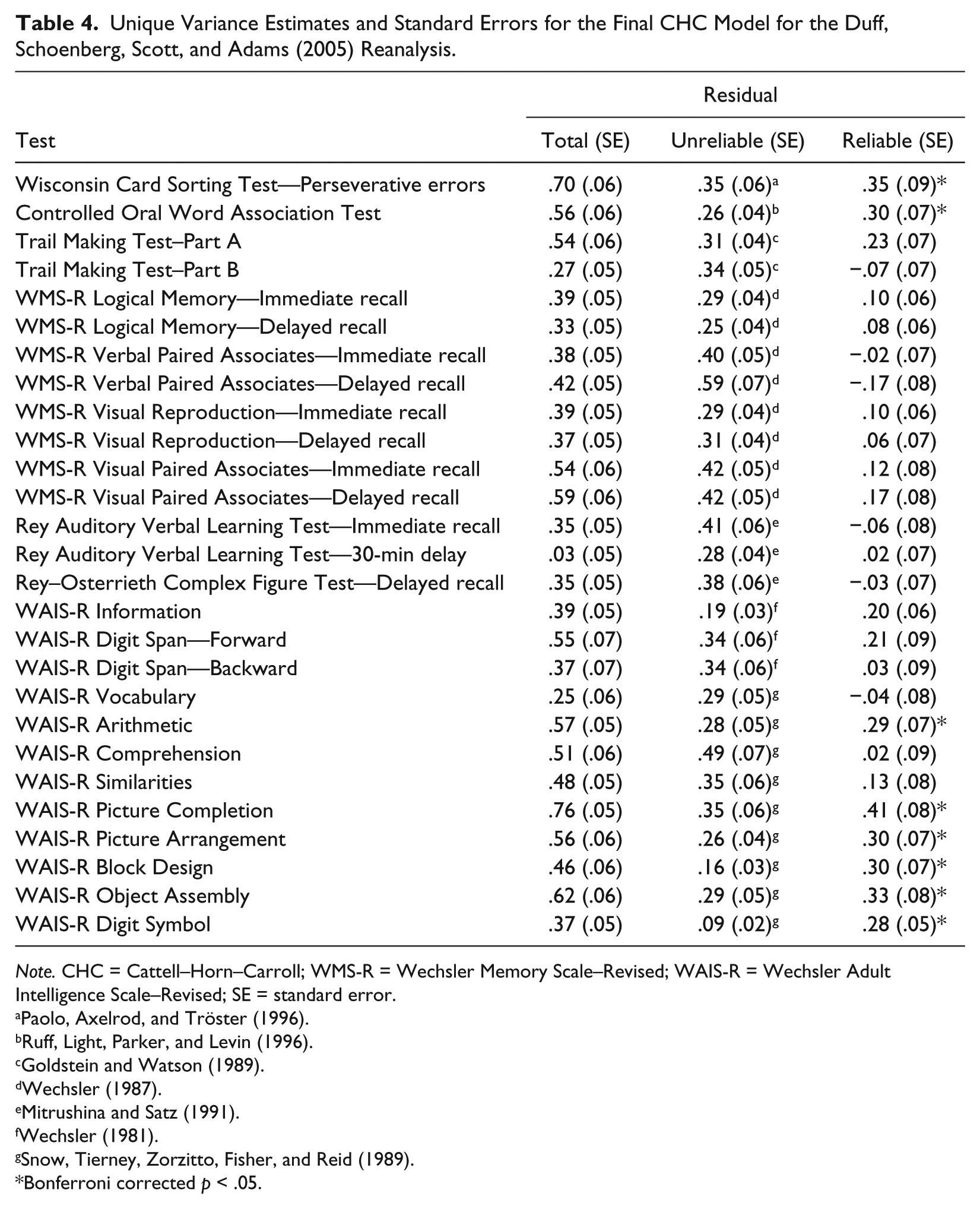
Note. CHC = Cattell–Horn–Carroll; WMS-R = Wechsler Memory Scale–Revised; WAIS-R = Wechsler Adult Intelligence Scale–Revised; SE = standard error.
Bonferroni corrected p < .05.
The reanalyses for the remaining eight data sets produced the same pattern of results to those observed for the reanalysis of the Duff et al. (2005) data. The full description of the confirmatory factor analyses for all nine data sets is provided in the Supplemental Materials. In every case, after the initial CHC model was specified, only one modification was made across any of the data sets, aside from dropping nonsignificant loadings that had negligible effects of the fit indices (see Supplemental Materials). As described above, residuals from WAIS-R Block Design and WAIS-R Object Assembly were allowed to correlate in the Duff et al. reanalysis. The correlation was replicated in the reanalyses of Goldstein and Shelly’s (1972); Salthouse, Fristoe, and Rhee’s (1996); and Bowden, Cook, Bardenhagen, Shores, and Carstairs’s (2004) data sets.
The only uncertainty in classifying the measures according to CHC theory was due to the tactile indicators in the Goldstein and Shelly (1972) data set. Little is known about the latent structure of tactile tests (Decker, 2010; Stankov, Seizova-Calić, & Roberts, 2001). The modeling of the tactile indicators was necessarily partly exploratory, where two alternate models were used to represent the tactile tests in the reanalysis of Goldstein and Shelly’s data set. While the results supported a left–right (or nondominant–dominant) dichotomy, further research is necessary to confirm and clarify whether this apparent dichotomy is replicable and goes beyond tactile tests such as applying to psychomotor tests.
As shown in Table 3, all CHC models fit excellently according to established cutoff criteria for approximate fit statistics (Hu & Bentler, 1999). A highly significant loss of fit was observed in all cases where the CHC model was simplified by merging the most highly correlated factors (see Supplemental Materials). In all studies where an executive function factor could be specified alongside the CHC models, the model was inadmissible. Even when the executive function factor was specified independently from the CHC factors, in all cases the resulting model had a nonpositive definite latent covariance matrix associated with the executive function factor. This suggests that the executive function factor was a linear function of the CHC factors and statistically redundant. Similarly, in these studies the putative executive function tests did not have significantly greater unique variance than nonexecutive function tests (see Supplemental Materials). Together, these results suggest that there is no distinct general executive function factor and that the putative executive function indicators do not individually measure specific executive functions separate from CHC constructs.
Discussion
In all reanalyses, the CHC model fit excellently and in line with the widely adopted, conservative fit guidelines described by Hu and Bentler (1999) and critiqued by Marsh et al. (2004). The finding that CHC model fit well across all data sets, considering that the data sets shared many tests in common that were modeled exactly the same for each data set, provides good evidence that the CHC model is an excellent fitting model that is replicable and consistent across diverse tests and populations. In particular, the data sets together provided replicated evidence for the CHC construct validity for many of the most popular neuropsychological tests and batteries (Rabin, Barr, & Burton, 2005). Furthermore, the CHC construct validity was supported across a range of clinically relevant populations, including patients referred for neuropsychological evaluation, community, elderly, and at-risk for Alzheimer’s disease populations (see Table 3). Finally, the CHC model was found to apply equally well to traditional instruments such as the WAIS and putative executive function measures that are commonly believed to measure constructs beyond the CHC constructs.
For every data set, the CHC model could not be reduced to fewer factors without significant loss of fit. This finding has several implications. First, cognitive ability could not be reduced to a single latent variable, thus showing the superiority of multiple-factor models of cognitive ability over a single-factor model of general intelligence (Schneider & Newman, 2015). Second, the results further support the CHC broad factors as distinct, well-supported constructs and the superiority of theory-based confirmatory factor analysis for the selection of the number of factors over exploratory methods (Keith, Caemmerer, & Reynolds, 2016). Finally, the results suggest that merging and collapsing across CHC broad factors to produce aggregated constructs such as executive function is not empirically supported (Jewsbury et al., 2016).
This article was based on the best quality data sets from the first author’s unpublished PhD dissertation that involved reanalysis of 31 published data sets (Jewsbury, unpublished). Based on the results of all 31 reanalyses, empirically verified CHC classification for the most popular clinical cognitive tests is given in Table 5.
Empirically Verified CHC Construct Validity of Popular Neuropsychological Tests.

Note. CHC = Cattell–Horn–Carroll; Gc = acquired knowledge or crystallized ability; Gs = processing speed; Glr = long-term memory encoding and retrieval; Gsm = working memory; Gv = visuospatial ability; Gf = fluid reasoning; FW = word fluency (see Jewsbury & Bowden, 2017); Gq = quantitative ability; Ga = auditory ability; X = empirically verified CHC classification; ? = a possible classification that has not been empirically verified or rejected.
Generality of the CHC Model
Several of the reanalyses involved conventional intelligence measures with well-replicated and uncontroversial construct validity (usually Wechsler scales) alongside clinical and neuropsychological measures. The finding that the clinical tests loaded on the same factors as the Wechsler and other intelligence tests provides good evidence that the constructs measured by clinical and intelligence tests are the same. This conclusion is made more relevant by the studies reviewed in the introduction that show that CHC-consistent models of the Wechsler scales show measurement invariance across age, language, gender, culture, and community versus clinical populations (see Table 2).
These results are consistent with previous research although the implications for theoretical convergence and conceptual clarification of cognitive assessment in clinical populations had received little attention to date. Larrabee (2000) reviewed the exploratory factor analyses in outpatient samples of Leonberger, Nicks, Larrabee, and Goldfader (1992) and Larrabee and Curtiss (1992, 1995) showing a common factor structure underlying WAIS-R, the Halstead–Reitan Neuropsychological Battery, and other diverse neuropsychological tests, and noted that the factor structure was consistent with Carroll’s (1993) taxonomy of cognitive abilities. Evidence to date suggests that the Wechsler Intelligence Scales may have similar criterion-related validity in samples of people with brain disease as has been found for other comprehensive neuropsychological batteries (e.g., Golden et al., 1981; Kane, Parsons, & Goldstein, 1985; Loring & Larrabee, 2006; Sherer, Scott, Parsons, & Adams, 1994).
The finding that intelligence and clinical tests measure the same constructs has important implications for test selection in clinical practice. Assuming similar nomothetic span (Whitely, 1983), tests for a given construct should be chosen on the basis of how reliable they are so as to maximize diagnostic precision (Chapman & Chapman, 1983). Putative executive function measures that have limited reliability (Denckla, 1994; Rabbitt, 1997) should not be used over more reliable tests that measure the same constructs.
Validity of Executive Function
The results of the reanalyses found that the executive function factor was redundant when the CHC constructs were modeled, in each of the data sets examined. Indeed, the finding that the CHC model fit well in each data set provides evidence that there are no additional constructs measured by commonly used clinical tests examined in the present study, over and above the CHC broad factors. The examination of unique variance provided a direct test of the hypothesis that the unexplained variance is greater for executive as opposed to nonexecutive tests. The results failed to support the hypothesis that there is more unique variance in putative executive tests. Furthermore, the size of the estimated unique variances suggests that there is limited capacity for putative executive function tests to have additional predictive and diagnostic utility above what is attributable to the common factors in the CHC model.
The putative executive function tests were distributed across the CHC constructs such as Gs, Gsm, Gv, and Gf. In other words, tests commonly grouped under the executive function rubric do not load on the same construct. This finding of heterogeneous construct loadings has two important implications. First, the results suggest that there is no unitary executive function construct underlying all executive function tests, consistent with arguments by Parkin (1998) based on neuropsychological evidence. Executive function should not be referred to as a separate domain of cognition on the same level as broad CHC constructs such as processing speed (Gs) and visuospatial abilities (Gv). Averaging or combining various executive function test scores potentially leads to results that confound cognitive constructs. Therefore, systematic reviews and meta-analyses should not group tests under the executive function rubric. Rather the CHC taxonomy may be more useful for systematic reviews and meta-analyses (Loughman, Bowden, & D’Souza, 2014). Second, the results suggest that equating executive function with Gf, as has been advocated (e.g., Blair, 2006; Decker, Hill, & Dean, 2007), may be misleading, as not all executive function tests are Gf tests.
Current Status of the CHC Model
The CHC model is incomplete and evolving (McGrew, 2009). Some aspects of the factor structure of cognitive ability tests remain uncertain. For example, the classification of tactile and kinesthetic abilities as broad constructs and their associated narrow structure is unclear (Decker, 2010; Stankov et al., 2001). Another example is the classificaiton of memory abilities, where recent evidence suggests encoding and retrieval are better considered distinct abilities as opposed to combining encoding and retrieval as Glr (Jewsbury & Bowden, 2017). It is expected that as more comprehensive and detailed analyses are conducted, the CHC model will develop into an even more robust and comprehensive description of the structure of diagnostic cognitive tests. Nevertheless, even in its current incomplete state, the CHC model has broad utility and is strongly empirically supported. Much theoretical refinement of cognitive assessment may be facilitated if the CHC model were to be adopted as the default model in any new investigation of individual differences in cognition. Such a strategy would improve consistency of methods in the field of clinical diagnostic assessment and facilitate establishment of a general theoretical paradigm of individual differences.
The introduction of a table of “neurocognitive domains” to the DSM-5 illustrates the need for a generally accepted and empirically supported taxonomy of cognitive abilities. Presently, most authoritative texts have their own idiosyncratic cognitive taxonomy that appear to have been derived from clinical consensus and perhaps only loosely from comprehensive empirical studies (e.g., APA, 2013; Lezak et al., 2004; E. Strauss et al., 2006). Clearly, a unified, empirical taxonomy is preferred for consistent, evidence-based assessment. Neurocognitive “domains” such as language, memory, and attention can sometimes be interpreted as compatible with the CHC model due to semantic overlap of these domains with the CHC constructs. However, model derivation should be based on rigorous, consistent criteria, including confirmatory factor analysis (M. E. Strauss & Smith, 2009).
Adoption of the CHC model as the basic taxonomy of cognitive abilities in both clinical and nonclinical populations would allow for more contentious issues to be properly evaluated. A common view is that studies of nonclinical or mixed clinical populations may obscure cognitive differences specific to a certain clinical condition or set of conditions (e.g., Delis, Jacobson, Bondi, Hamilton, & Salmon, 2003). However, an empirically based and well-supported factor model does not deny the possibility of condition-specific dimensions of cognition but instead would allow the issues to be evaluated directly with the methods of measurement invariance (Meredith, 1993).
Conclusion
Analysis of a representative sample of the best available relevant data sets revealed that the same cognitive constructs that are reflected in test scores in community and educational samples appear to underlie individual differences captured by neuropsychological tests, including in various clinically relevant populations. The present results suggest that the CHC model of cognitive abilities is an empirically grounded taxonomy for the evaluation of construct validity of diagnostic cognitive tests and provides a basic theoretical paradigm for clinical cognitive assessment. Finally, to paraphrase an anonymous reviewer, the results provide evidence for a common taxonomy of cognitive abilities that enables greater consistency in the meaning and interpretation of test results across test batteries and practitioners alike.
Supplemental Material
Supplemental_ – Supplemental material for The Cattell–Horn–Carroll Model of Cognition for Clinical Assessment
Supplemental material, Supplemental_ for The Cattell–Horn–Carroll Model of Cognition for Clinical Assessment by Paul A. Jewsbury, Stephen C. Bowden and Kevin Duff in Journal of Psychoeducational Assessment
Footnotes
Acknowledgements
The authors thank the two anonymous reviewers for their constructive criticism and suggestions.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplementary material is available for this article online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.