
Abstract
In a large-scale study conducted in 4- to 5-year-old French-speaking preschoolers (N = 12,162), early literacy skills were assessed with four short tasks designed to investigate three domains related to learning to read: letter knowledge, phonological skills, and vocabulary. This tool was developed in response to the lack of available literacy screening tools for this population. Item response theory (IRT) analyses were used to examine the discrimination and difficulty parameters of each item. Then, a structural model confirmed that all the scores contributed to a latent ability, namely, early literacy. Three variables, namely, sociodemographic zone, age, and gender, are related to performance on literacy skills. Finally, an IRT with these variables as covariates confirms that all of them explained the difference in the scores in each domain except for zone in the case of letter-name knowledge (without significant link). This initial tool for French-speaking preschoolers could be used to identify children with early difficulties and help promote early language interventions to combat subsequent difficulties in learning to read.
One of the challenges facing researchers in the field of developmental psychology research is to provide tools for the early identification of children who may have difficulties in learning to read. If we want to directly assess young children, what type of reading-related tasks could be proposed? Longitudinal studies have provided some answers to this question and different tools have already been administered, in particular in the case of English-speaking children (Hjetland et al 2019; Schatschneider et al., 2004; Shaywitz et al., 1992; Torgesen & Wagner, 2002). The aim of this study was to examine (a) the characteristics of a new tool for use with French-speaking children and (b) the links between scores and individual variables and the sociodemographic status of schools.
From Early Literacy to Success in Reading: What Are the Predictors?
Many studies have shown the importance of specific emergent literacy skills for later successful reading development (Catts et al., 2002, 2012; Lonigan et al., 2000; Snowling et al., 2000; Spira et al., 2005). Among these early literacy skills, three variables have been considered important in identifying children at risk of reading delay (Hatcher et al., 2004). The first is phonological awareness (Blachman, 1997; Wagner & Torgesen, 1987). Next, letter-name knowledge appears to be a strong predictor of early reading development (Foulin, 2005) and its role is independent of that played by phonological awareness (Muter et al., 1998). Finally, vocabulary is predictive of both reading and phonological awareness (Edwards et al., 2004; Lonigan et al., 2000; Munson et al., 2005). More precisely, some researchers (Elbro et al., 1998; Fowler, 1991) have suggested that the link between vocabulary and phonological skills arises because the increase in the size of the lexicon consolidates children’s phonological representations. In fact, children become more effective as they become more able to make generalizations about the phonological structure of language, and this suggests that vocabulary growth encourages the segmentation of phonological representations (Walley, 1993). Similarly, the National Early Literacy Panel (NELP) conducted a meta-analysis of about 300 studies involving data about the predictive relation between a skill measured during the preschool period and reading achievement in children learning to read in an alphabetic language (Lonigan et al., 2008). The results of this meta-analysis indicated that children’s abilities related to print knowledge (alphabet knowledge), phonological awareness, and oral language (vocabulary, word knowledge) are strong and independent predictors of their later reading outcomes.
Many studies have been conducted in English. However, alphabetic orthographies differ in the transparency of their letter-sound mappings. We considered languages to have a “deep orthography” when the grapheme–phoneme relationships are complex and inconsistent, whereas a “shallow orthography” contains consistent grapheme–phoneme correspondences. 1 The generalizability of findings based on English-language studies has been questioned. Thus, studies have investigated the role of phonological awareness, memory, vocabulary, rapid naming, and nonverbal intelligence in reading performance across five languages lying at differing positions along a transparency continuum (Finnish, Hungarian, Dutch, Portuguese, and French). The results have shown that the predictors of reading performance in alphabetic languages are relatively universal, although their precise weight varies systematically as a function of orthographic transparency (Ziegler et al., 2010). In the same way, Caravolas et al. (2013) conducted a cross-linguistic comparison of the patterns of growth during the early phases of reading development in consistent versus inconsistent orthographies. They followed three language groups (English, Czech, and Spanish) and assessed them six times between kindergarten and the end of second grade. Their results shown that although children may learn to read more quickly in more consistent orthographies, there may nevertheless be universal cognitive prerequisites for learning to read in all alphabetic orthographies. In French, very few studies have been conducted in children from before the beginning of formal reading instruction. As one exception, Piquard-Kipffer and Sprenger-Charolles (2013) performed a follow-up study of French-speaking children from the beginning of kindergarten to the end of second grade and showed that a high proportion of the variance in reading at Age 8 (52.8%) was predicted by the “classical” predictors of reading acquisition assessed at Age 5: pre-reading level, letter-name knowledge, phonemic segmentation and phonological short-term memory.
Although, for most children, early reading and writing skills develop during the preschool period (Lonigan et al., 2000; Whitehurst & Lonigan, 1998), many children reach the end of kindergarten without having acquired these skills. This then leads to considerable reading difficulties as of the first years of primary school. If assessed early, children at risk of reading disabilities can be identified as young as Age 3 or 4. The use of screening tools in the early preschool years could help identify children in need of monitoring, potential interventions, or remediation (Catts et al., 2015; Snowling, 2013; Spencer et al., 2013).
Very few screening tools are available for early literacy skills in French-speaking preschool children. The francophone literature refers to several batteries which assess various domains to examine the language disorders of young children. These tracking or screening tools take the form of tools restricted to the evaluation of oral language, such as, for example, ERTL4 for 4-year-old children and ERTL6 for 5- to 6-year-old children (Watier et al., 2006) and involving no specific targeting, parental questionnaires (Callu et al., 2003), or general batteries, for example, the BSEDS battery (Health Examination: School Developmental Assessment for Children aged 5 to 6 years; Zorman & Jacquier-Roux, 2001; 2011), which is a standardized screening instrument widely used with the French preschool population and which assesses children’s cognitive, motor, and social development. To our knowledge, targeted tracking tools intended to identify early difficulties in literacy skills are not used in France. Our aim is to present a new screening tool for 4- to 5-year-old French-speaking children.
How to Assess Early Literacy Skills?
Numerous screening tools for measuring emergent literacy skills in preschoolers have proved useful in identifying children’s global risk status. These are usually brief measures that provide insights into children’s current skills. These measures have been designed to be administered by individuals with little assessment experience. The results of screening assessments are often interpreted on the basis of one or more thresholds indicating the likelihood that a child will require additional assessment, follow-up, or instruction. A screening assessment could be used to identify children who might be in need of a diagnostic assessment. Once these at-risk children have been identified, a diagnostic assessment provides accurate information about their specific abilities in key areas of early literacy. Unlike screening assessments, diagnostic measures require specialized experience relating to the acquisition, scoring, and interpretation of the data.
There are currently several tools available for screening early literacy in English-speaking children. Although the following list is not exhaustive, we present some frequently used screening tools here (see Table 1 for a summary synthesis).
Examples of Screening Tools for Assessing Early Literacy in English-Speaking Children Together With the Main Domains Investigated.

Note. PA = phonological awareness; PK = print knowledge; LK = letter knowledge.
present in the screening tool.
The Test of Preschool Early Literacy (TOPEL; Lonigan et al., 2007) measures print knowledge, definitional vocabulary and phonological awareness. The Get Ready to Read, Revised Screening Tool (GRTR-R; Lonigan & Wilson, 2008; Whitehurst & Lonigan, 2001) is a 25-item task that measures print knowledge, linguistic awareness and emergent writing. The calculation of the psychometric indices of the GRTR-R confirms its internal coherence as well as its concurrent (Molfese et al., 2004) and predictive validity (Phillips et al., 2009; Wilson & Lonigan, 2009). The Individual Growth and Development Indicators (IGDIs; McConnell, 2002) contains a number of tasks designed to measure an array of developmental domains from birth to 8 years of age. The tasks relevant to early literacy are alliteration and rhyming (measures of phonological awareness) and a picture-naming task (a measure of oral language). Studies on the psychometric indices of IGDIs tasks have shown their reliability, their concurrent validity, and their predictive validity (Wilson & Lonigan, 2009). The Pre-School Knowledge Screening Program for Phonological Awareness (PALS-PreK; Invernizzi et al., 2001) provides operational measures of two types of phonological awareness, letter knowledge, letter-sound knowledge, print awareness, nursery rhyme awareness, and name writing. PALS-PreK measures the most important precursors to successful literacy acquisition: alphabet knowledge, phonological awareness, and print concepts (Townsend & Konold, 2010). The Dynamic Indicators of Basic Early Literacy Skills (DIBELS; Good & Kaminski, 2002) include early literacy measures such as initial sound fluency, phoneme segmentation fluency, letter naming fluency, and nonsense word fluency. Numerous researchers have investigated its effectiveness, and the results support the validity of kindergarten DIBELS in predicting ever more complex reading skills (Al Otaiba et al., 2008; Burke et al., 2009; Ritchey, 2011). Finally, the Early Literacy Skills Assessment Tool (ELSAT; Iyer et al., 2018) is a brief screening tool for emergent literacy delays in 4-year-olds. Three main domains are assessed: knowledge and awareness of printed words, knowledge of letters, and phonological awareness. The authors validated also a very short version of ELSAT with only 10 items. However, their study has some limitations as the sample size was small and the correlations with each of three reference measures were between .41 and .62.
In summary, the short, accurate, and easy-to-use screening tools reported in the English literature constitute an excellent way for all educational practitioners to get a profile of children’s literacy skills. Finally, these tools are based on a few language areas which have a powerful ability to predict success in reading, mainly letter knowledge, print knowledge, phonological awareness, and vocabulary. In our study, we propose a short screening tool that will make it possible to identify delays in early literacy skills in French-speaking children. We think that a composite measure of vocabulary, letter knowledge, and phonological awareness could identify 4- to 5-year-old French-speaking children at risk of reading difficulties. Based on our experience in a large-scale study in which children were assessed twice in kindergarten (Ecalle et al., 2015), we were able to construct short, suitable tasks from our data collected at the beginning of Kindergarten.
The Effects of Individual and Sociodemographic Variables on Literacy Skills
Among various variables which have an effect on literacy skills in young children, we report here some studies which have examined the effects of gender, age, and the sociodemographic status of schools. The evidence regarding sociodemographic factors predicting literacy development has come from primarily American, English-speaking samples.
Numerous studies have documented gender differences in young children’s early reading skills. Girls have been shown to outperform and gain literacy skills at a faster rate than boys in the early school years (Below et al., 2010; Clark & Kragler, 2005; Deasley et al., 2018; Harper & Pelletier, 2008; Lee & Al Otaiba, 2015). More precisely, gender differences in vocabulary growth (Huttenlocher et al., 1991), phonological awareness (Lundberg et al., 2012), letter-sound knowledge (Sigmundsson et al., 2017, 2018), and letter-writing scores (Puranik et al., 2013) have been found among children in preschool and first grade. These gender differences occur very early. A study exploring them in emerging language skills (productive vocabulary, combining words) in 13,783 European children from 10 non-English language communities, including French, from Age 0.08 to 2.06 showed that girls are slightly ahead of boys and that this is also true of French children (Eriksson et al., 2012). The same gender differences have also been shown in the language skills of French-speaking children during the preschool period (Peyre et al., 2019) as well as in their reading skills (see the results of Progress in International Reading Literacy Study [PIRLS 2011] in Colmant, 2012).
Because the children in any given class have different dates of birth, classrooms will always have an oldest and youngest child. Children born in the fourth trimester (e.g., October, November, and December) are the youngest children in the class, whereas children born in the first trimester (January, February, and March) are the oldest. A meta-analysis (Stipek, 2002) of research investigating the relationship between age and different abilities (e.g., emergent literacy skills, grammar, numeracy skills, IQ tests) has shown that older children have an advantage compared with their younger counterparts. Thus, numerous birthday-effect studies have indicated that younger children are at a disadvantage compared with their older peers (Bedard & Dhuey, 2006; Crone & Whitehurst, 1999; Datar, 2006; Oshima & Domaleski, 2006; Stipek & Byler, 2001). In a recent study (Huang & Invernizzi, 2013), the emergent literacy skills of the oldest and youngest children were investigated using the fall PALS-K (Phonological Awareness Literacy Screening for Kindergarteners; Invernizzi et al., 2004) summed score as the outcome variable. The results showed that the youngest children had lower emergent literacy scores than their oldest peers.
In France, priority education networks, that is, networks for children with specific educational needs, have been created to try to cope with delays in reading acquisition related to children’s family contexts. These networks, the so-called REP (Réseau d’Education Prioritaire) include schools that are located in disadvantaged areas in terms of their social, economic, and cultural status. These zones were defined in France in 1981 and they have the same aims as Title 1 schools in United States, that is, to help underprivileged children and to bridge the gap between them and their peers in “normal” zones (without any specific difficulties). Actually, in the French educational system, schools are divided into three zones according to their socioeconomic status (SES; see Supplemental Appendix A) and their children’s learning difficulties. The principle is to allow teachers to share their educational resources. Ministerial directives emphasize the focus of priorities for school learning, and give priority to oral and written language. One of the objectives of our study is to compare the early literacy skills of preschool children in disadvantaged areas (and mainly with low social status) and children in regular classes (mainly from medium socioeconomic backgrounds).
Social background-related differences in reading achievement are well documented in the literature (Bowey, 1995; Duncan & Seymour, 2000; Lee & Al Otaiba, 2015). What is more, the achievement gap begins early (Arnold & Doctoroff, 2003; Chatterji, 2006). A large body of evidence from the national Early Childhood Longitudinal Study Kindergarten (ECLS-K) data suggests that socioeconomic background predicts entry-level literacy skills and early reading growth (McCoach et al., 2006). The low level of early literacy of children in disadvantaged areas, especially in terms of letter knowledge and vocabulary, could be related to the small number of books and limited shared reading activities usually observed in underprivileged families (Shahaeian et al., 2018; Stuart et al., 1998; Rowe & Goldin-Meadow, 2009). A recent study has shown that children from families with low SES have fewer experiences that promote the acquisition of basic reading skills, such as phonological awareness, vocabulary, and oral language (Buckingham et al., 2013). Children’s early reading skills are correlated with the home literacy environment, the number of books possessed, and parental distress (Bergen et al., 2016). In addition, poor households have less access to learning materials and experiences, including books, computers, and stimulating toys, to create an enabling environment for literacy (Bradley et al., 2001). To summarize, the scientific literature reports much research examining the expected effects of these three variables. In our study with French-speaking children, their effects on literacy scores will be examined.
Research Questions
Three domains, namely, letter-name knowledge, phonological skills, and receptive vocabulary, were assessed. The principal aim was to validate the instrument used in this study by examining the quality of the items and the ways in which some individual and contextual variables are related to early literacy outcomes. Four questions were therefore addressed: (a) What are the characteristics of the items (in terms of difficulty and discrimination levels) in each domain? (b) How are the three domains related to early literacy ability? (c) What relationship with literacy skills can be found for three variables, two of which are related to individuals (gender and age) and one to the sociodemographic environment of the schools? and (d) More specifically, how are the scores in each domain related to these three variables? We expected all three variables to have an effect on literacy skills: an effect of gender in favor of girls, an effect of age in favor of older children, and an effect of sociodemographic status of schools in favor of areas with no major social difficulties.
Method
Participants
In this research, we used data from a French cohort in which children are followed-up from birth to adulthood. During the second semester of preschool, the cohort children’s literacy skills were assessed in comparison with two or three other children chosen by their teachers from the same class and with dates of birth as close as possible to those of each corresponding cohort child. After obtaining consent from the parents, the teachers were able to conduct the assessment session, which they monitored in small groups during school hours. Children with severe intellectual or other disabilities were not included in our sample. Finally, the teachers entered the results they collected for each child in a document containing information about the children (age, gender) and their school status. However, no data about the status of the children’s parents were available. Indeed, in accordance with the Law “Information Technology and Civil Liberties” (n° 78–17 of January 6, 1978), the teachers were not permitted to collect data about the children’s racial and ethnic origins. However, a recent study (Grobon et al., 2019) indicates that in the cohort sample (N = 3,945), the parents’ educational level was subdivided as follows: below bachelor’s degree (16.7%), bachelor’s degree (17.3%), and at least some postgraduate education (66%). Literacy skill data were missing in more than 17% of the booklets, meaning that either the children did not complete the tasks or the teachers did not collect all the responses made by the children in their booklets. The children for whom literacy skills data were missing were excluded. Finally the analyses are based on 12,162 children (5,419 girls; 5,196 boys) aged from 52 to 63 months (mean age = 56.2 months; SD = 5.3 months) from 3,971 state schools that participated in the study. Some of the participants in this large sample (N = 794) were schooled in zones with specific educational needs, classified as REP.
Material and Procedure
This study was conducted with two important constraints. One was that a short screening tool was required for the researchers engaged in this long longitudinal study (see above), meaning that there were only a small number of items in only four tasks. The other was that some children had to be tested in groups in their classrooms.
Literacy and numeracy skills were assessed during two separate sessions of 25 to 30 min (here, we report only the data from the first session). The children responded to the items of four tasks presented in a booklet. Their teachers had a guide containing instructions for the administration of the tasks and another booklet in which they recorded each child’s answers. The four tasks investigated three domains: letter knowledge, phonological skills, and vocabulary. Given the limited time dedicated to the assessment of literacy skills, each task contained only a few items and each item was selected carefully based on our experience with older children in kindergarten (Ecalle et al., 2015). In this study (2015), we used a number of literacy tasks, in particular tasks relating to letter knowledge, phonological awareness, and vocabulary. For all the tasks in this study with younger children, we used the same tasks as in our kindergarten study. However, we first selected the items with the lowest scores obtained by the kindergarten children at the beginning of the school year to avoid a ceiling effect. A trial was administered at the beginning of each task.
Letter-name knowledge
The children had to circle the letter (among seven) named by the teacher. We selected 10 letters, five with high frequency (G, P, D, C, R, from 1.965 to 7.78) and five with low frequency (J, V, Q, T, B, from 0.254 to 1.77; see the frequency database Lexique in New & Pallier, 2001).
Phonological skills
A first oddity task was proposed. The teacher named three pictured words that contained either a common syllable (toupie-balai-bateau; spinning top-broom-boat; six items) or a common phoneme (ver-pipe-vase; worm-pipe-vase; three items). The children had to circle the picture name that did not share a common unit. In the second task, which was a syllable deletion task, the children had to retrieve a new pictured word after having deleted the first syllable of a first word. For example, the teacher named a first word (bijoux; jewels) and then named four test words (couronne-joue-genou-cœur; crown-cheek-knee-heart; here, the children had to circle joue [six items]).
Vocabulary
In a conventional receptive vocabulary task, the children were asked to circle the picture, out of four, that corresponded to the word named by the teacher (e.g., for the target word luge [toboggan], the other pictured words were fraise [strawberry], ski, cygne [swan]). A total of 10 words were presented, five with high frequency (tulipe tulip; chou cabbage; mouche fly; luge sledge; plonger diving) and five with low frequency (gland, acorn; livrer delivering; cintre hanger; chimpanzé chimpanzee; radeau raft) using U-G1 in the Manulex database (Lété et al., 2004).
Data Analysis
We start by presenting the descriptive data. We then perform an item response theory (IRT) analysis to examine the difficulty and discrimination of the items in each task. Next, we perform structural equation modeling (SEM) with literacy ability as a latent variable. We then perform a multivariate analysis of variance (MANOVA) to observe the effects of the three variables of gender, age, and sociodemographic zones of schools on the global literacy score. Finally, we simultaneously examine the characteristics of the items and their links to the three variables by creating an IRT-C model for each domain, with gender, age, and sociodemographic zone as covariates. All the analyses were run with Stata 14.
Results
Characteristics of Items in Each Task: Descriptive Data and IRT Analyses
First, we checked that the mean scores on the items were above chance level and found that this was the case for each item. In fact, in the forced-choice task with seven items, all the mean scores were greater than .14 (from .69 to .81). In the case of the three-item test, all the mean scores were greater than .33 (from .36 to .69), and in the case of the four-item test, the mean scores were greater than .25 (from .50 to .93; see Supplemental Appendix B). Descriptive data for the tasks are presented in Table 2 as a function of the frequency of the items.
Domains Descriptive Data in the Three Domains (N = 12,162).

Note. α = Cronbach’s alpha; HF = high frequency; LF = low frequency; Tot = total; OdT = oddity task; SyDT = syllable deletion task.
Then we conducted an IRT analysis using a two-parameter logistic (2-PL) model. The item response function of the 2PL model takes the two parameters of difficulty and discrimination of items into account (Baker, 2001). To this end, we present two types of curves, namely, item characteristics curves (ICC) and item information functions (IIF), which provide specific and complementary characteristics for each item in each task. In the first graphs (IIC), high-discrimination items are represented by a steep slope, and items with a flat slope are poorly discriminated. The second graph (IIF) shows the information regarding latent ability revealed by an item. Instead of displaying all the characteristics for all items, we shall present these curves only for contrasted responses to items in each task (indeed, a graph containing all the items might not be easy to interpret; for the parameters for all the items, see Supplemental Appendix C). Consequently, the ICC graph shows the item difficulty index of the easiest and the hardest items (Figure 1). The IIF graph presents the level of information on latent ability provided by the two contrasted items: one with a large amount of information (with the steepest curve) and the other with little information (with the flattest curve).
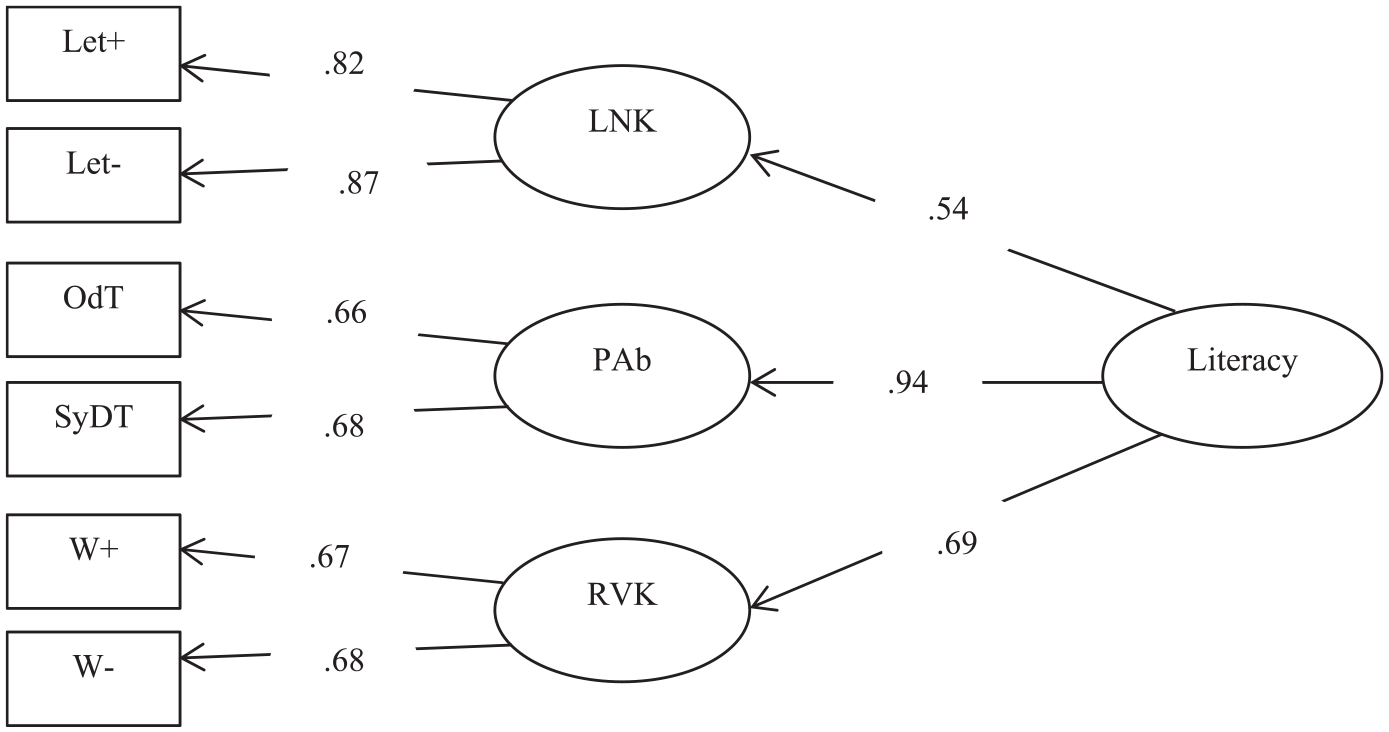
Structural model depicting Literacy and its links with letter-name knowledge (LNK), phonological ability (PAb) and receptive vocabulary knowledge (RVK).
In the letter-name task, we observed that the letter P was not only the item with the highest success rate but also that it provided the most information regarding latent ability, whereas the letter V was the most difficult and provided little information. For the oddity task, Item 2 with a common syllable was the easiest, and Item 2 with a common phoneme was the hardest. Similarly, the “syllabic” Item (three) provided the most information, and the “phonemic” item (two) provided little information about latent ability. In the syllable deletion task, the same two items appeared in the curves, with the first (two) being the easiest and providing the most information and the second (six) being the hardest (but differing by only a small amount from two) and providing less information. Finally, in the vocabulary task, the easiest item (luge; luge) was also the most informative, whereas the hardest item was seven (chimpanzé; chimpanzee) and the least informative was six (livrer; deliver).
Contribution of the Three Domains to Literacy
A higher order confirmatory factorial analysis (CFA) was conducted to examine the links between each component of literacy skills, that is, letter-name knowledge, phonological ability, and receptive vocabulary knowledge (RVK), with literacy considered as a second-order latent variable (Figure 2). In accordance with standard practice, the model fit was examined using multiple indices. The model is considered acceptable (Schreiber et al., 2006) when chi-square (χ2) is significant, the comparative fit index (CFI) > .95, the Tucker–Lewis index (TLI) > .95, the root mean square error of approximation (RMSEA) < .06, and the standardized root mean square residuals (SRMR) < .08. All the fit indexes in our model were as would be expected from SEM analyses: χ2(15) = 16,383.66, p < .0001; RMSEA = .01, CFI = .99; TLI = .99; SRMR = .005.
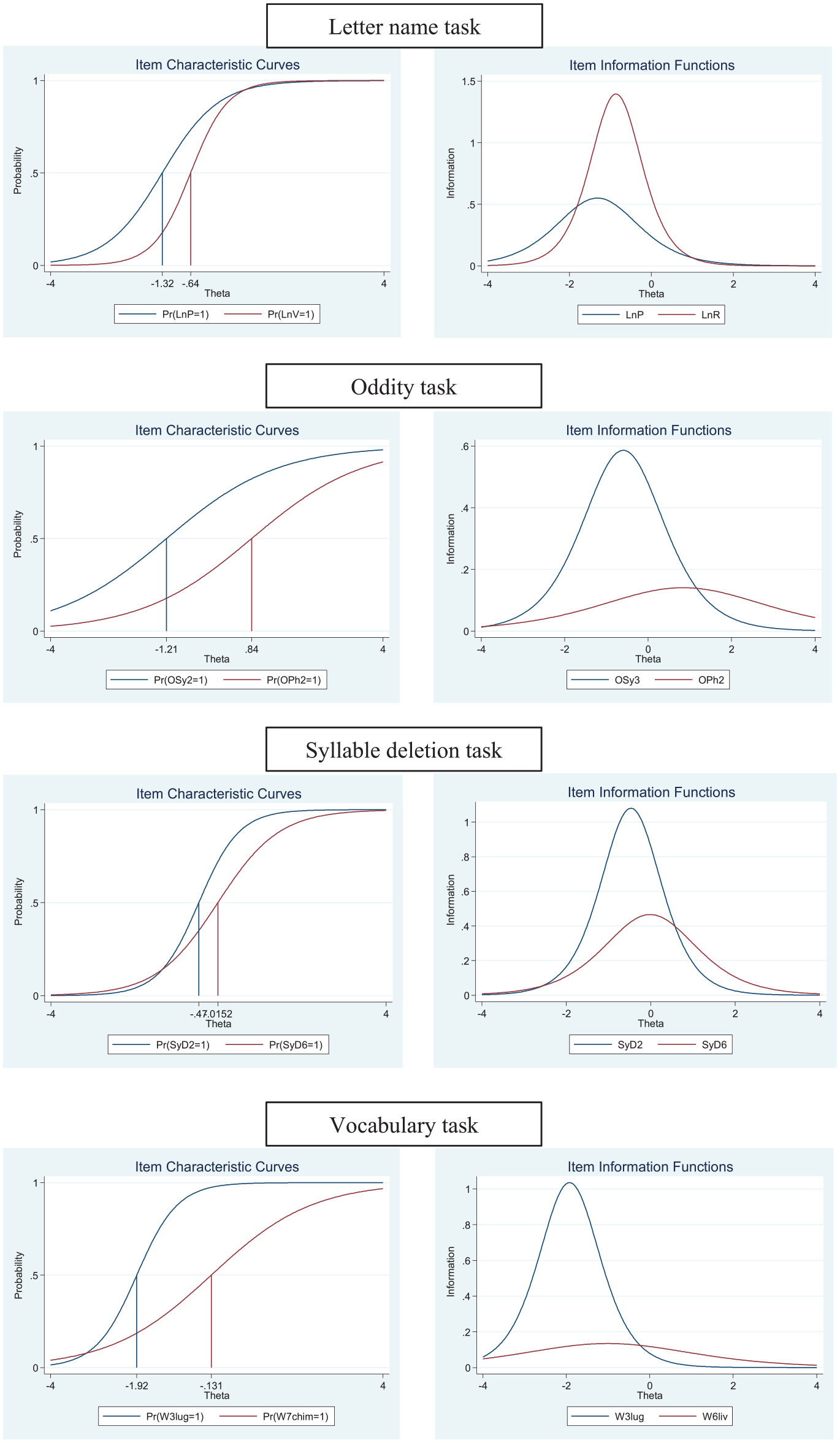
Characteristics for contrasted items in each task.
Effects of the Zone, Gender, and Age Variables on Global Literacy Scores
We conducted a MANOVA with the three between-factors Zone (REP vs. out of REP), Gender (boys vs. girls), and Age, according to the children’s dates of birth, which were divided into two groups: the older children being born in the first 6 months and the younger children being born in the last 6 months of the school year (Semester 1 vs. Semester 2). We observed (see Table 3) a significant main effect of Zone, F(1, 1067) = 25.37, p <.0001, with children out of REP obtaining higher scores, of Gender, F(1, 1067) = 5.31, p = .021, with girls outperforming boys, and of Age, F(1, 1067) = 29.05, p <.0001, with older children obtaining higher scores than younger ones. No significant interactions were found (Zone × Gender; Zone × Age; Gender × Age; Zone × Gender × Age).
Results of MANOVA in Function of Factors Zone, Gender, and Age.
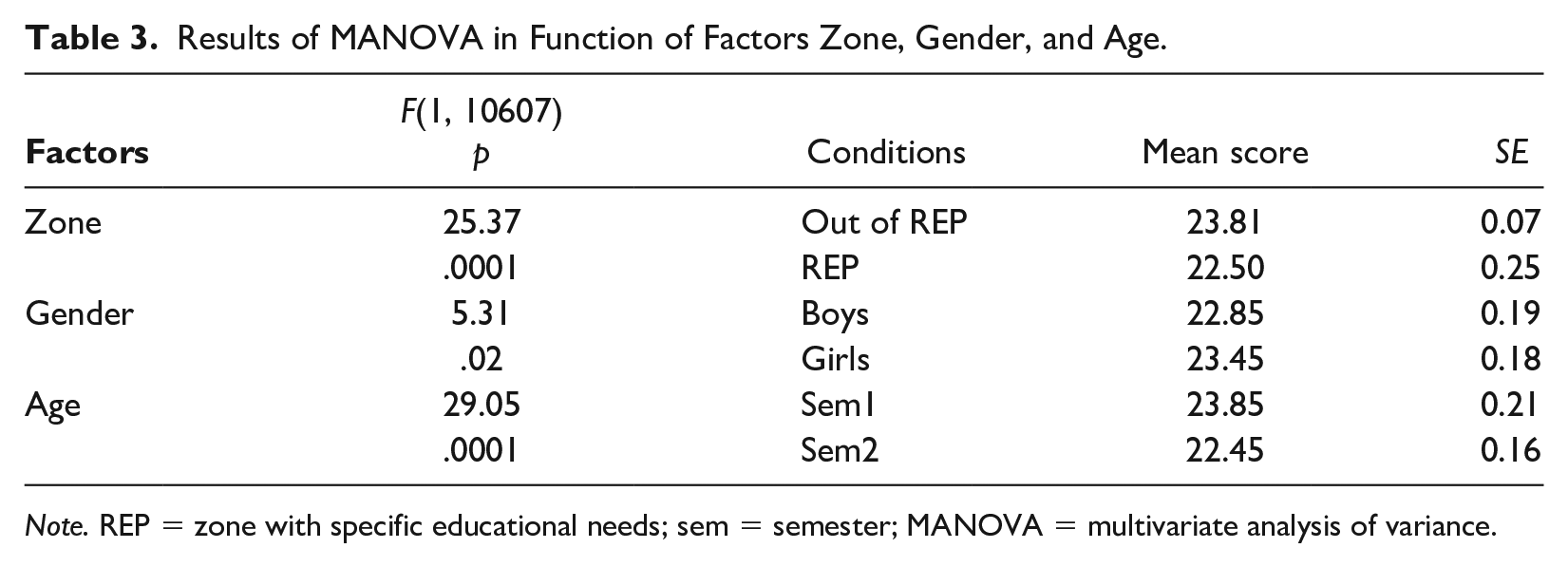
Note. REP = zone with specific educational needs; sem = semester; MANOVA = multivariate analysis of variance.
What is the Weight of the Variables in Each Latent Ability Involved in Each Domain?
To address this issue, we successively fitted the 2-PL model with the latent variables letter-name knowledge, phonological ability, and RVK. Moreover, because three variables, that is, Zone, Gender, and Age are related to the outcomes, we added them in each model simultaneously to examine their links with the latent variable (IRT-C model with covariates). At the technical level, we used logit as the link between each item and the latent variable, and the variables were introduced as covariates in the structural model (for Zone, children in REP were rated 1, those out of REP 0; for Gender, boys: 0, girls: 1; for Age, older: 1, younger: 2). In the 2-PL model, it was necessary to restrict the variance of the latent variable to 1. Below, we therefore present each model with the coefficients between items and the latent variable to obtain a correspondence with the discrimination coefficients. 2 Only significant coefficients (p < .05) between covariates and the latent variable are presented.
With regard to letter-name knowledge (Figure 3), all the items were well discriminated. Moreover, Gender and Age, but not Zone, made a significant contribution to the latent variable. Indeed, Gender (r = .13, z = 5.70, p < .0001) and Age (r = −.27, z = 11.62, p < .0001) were significantly related to the latent ability (LNK) in favor of the girls, who outperformed the boys, with the older children also outperforming their younger counterparts.
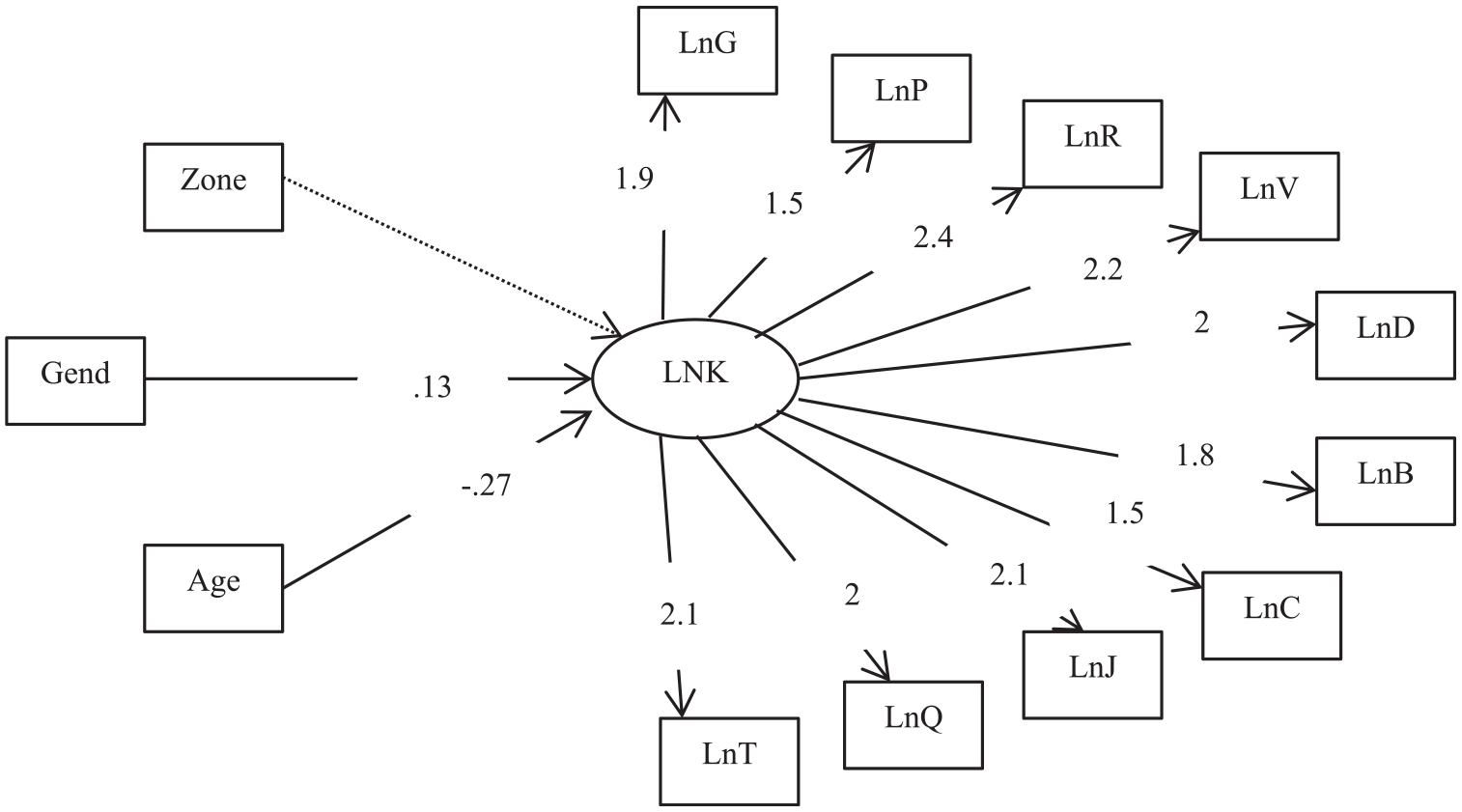
The 2-PL IRT-C model with letter-name knowledge (LNK) as latent variable and zone, gender and age as covariates.
In the case of the phonological tasks, we assume that a common latent trait, referred to as phonological ability, contributes to success. We, therefore, introduced all the items from the oddity task and syllable deletion task (Figure 4). We found that the discrimination coefficients for items with a common phoneme were low in the oddity task. The three covariates are significantly related to the latent variable, phonological ability: for Zone (r = −.15, z = −3.33, p <.001) with children schooled out of REP outperforming the others, for Age (r = −.25, z = 10.88, p <.0001) with the older children outperforming the others, and for Gender (r = .08, z = 3.58, p <.0001) with girls outperforming boys.
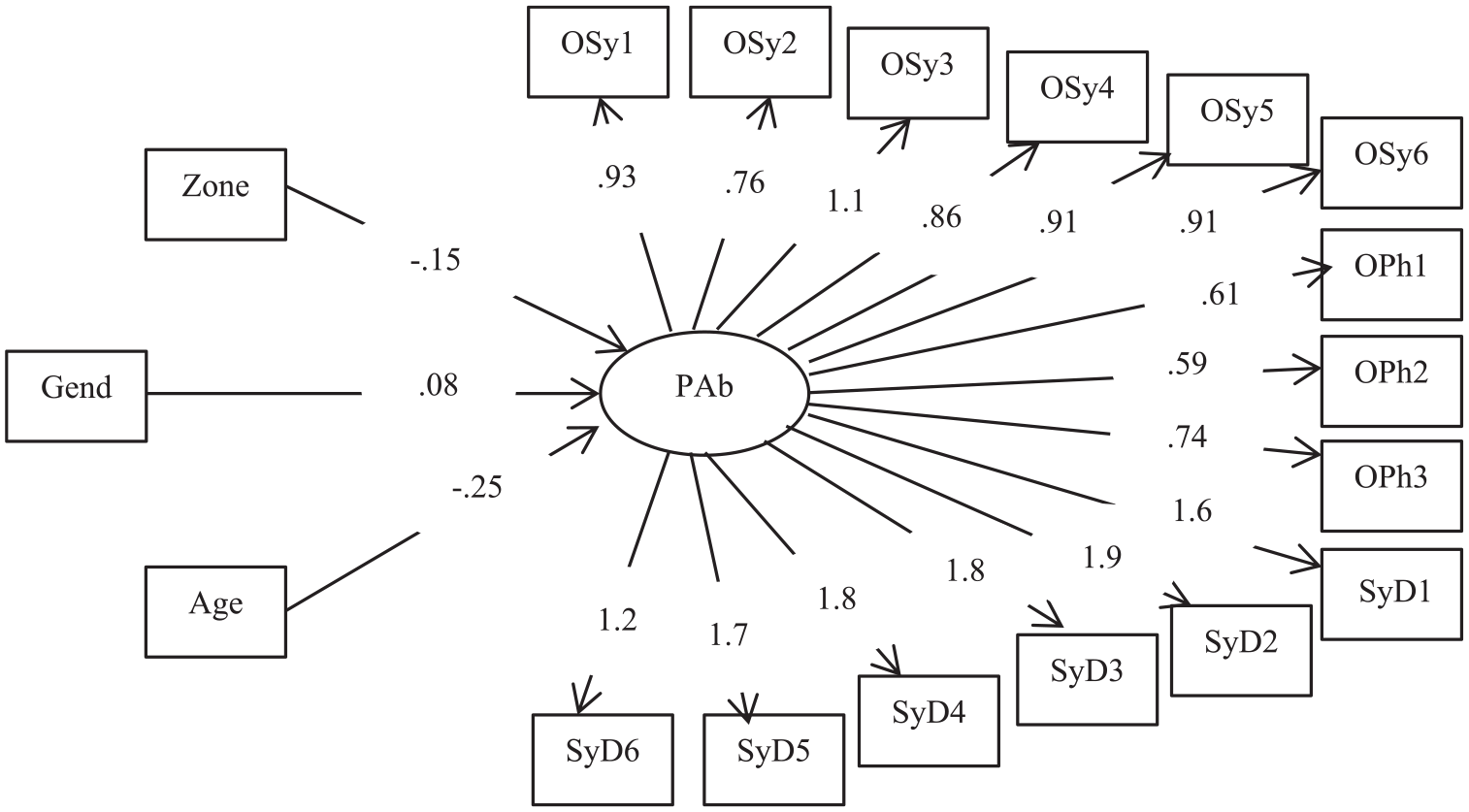
The 2-PL IRT-C model with phonological ability (PAb) as latent variable and zone, gender and age as covariates.
A latent ability referred to as RVK is involved in the vocabulary task. The three variables are significantly associated with this latent ability (Figure 5), Zone (r = −.49, z = −9.78, p <.0001) with children out of REP performing better than those in REP, Gender (r = .07, z = 2.76, p = .006) with girls outperforming boys, and for Age (r = −.25, z = 9.20, p <.0001) with older performing better than younger children.
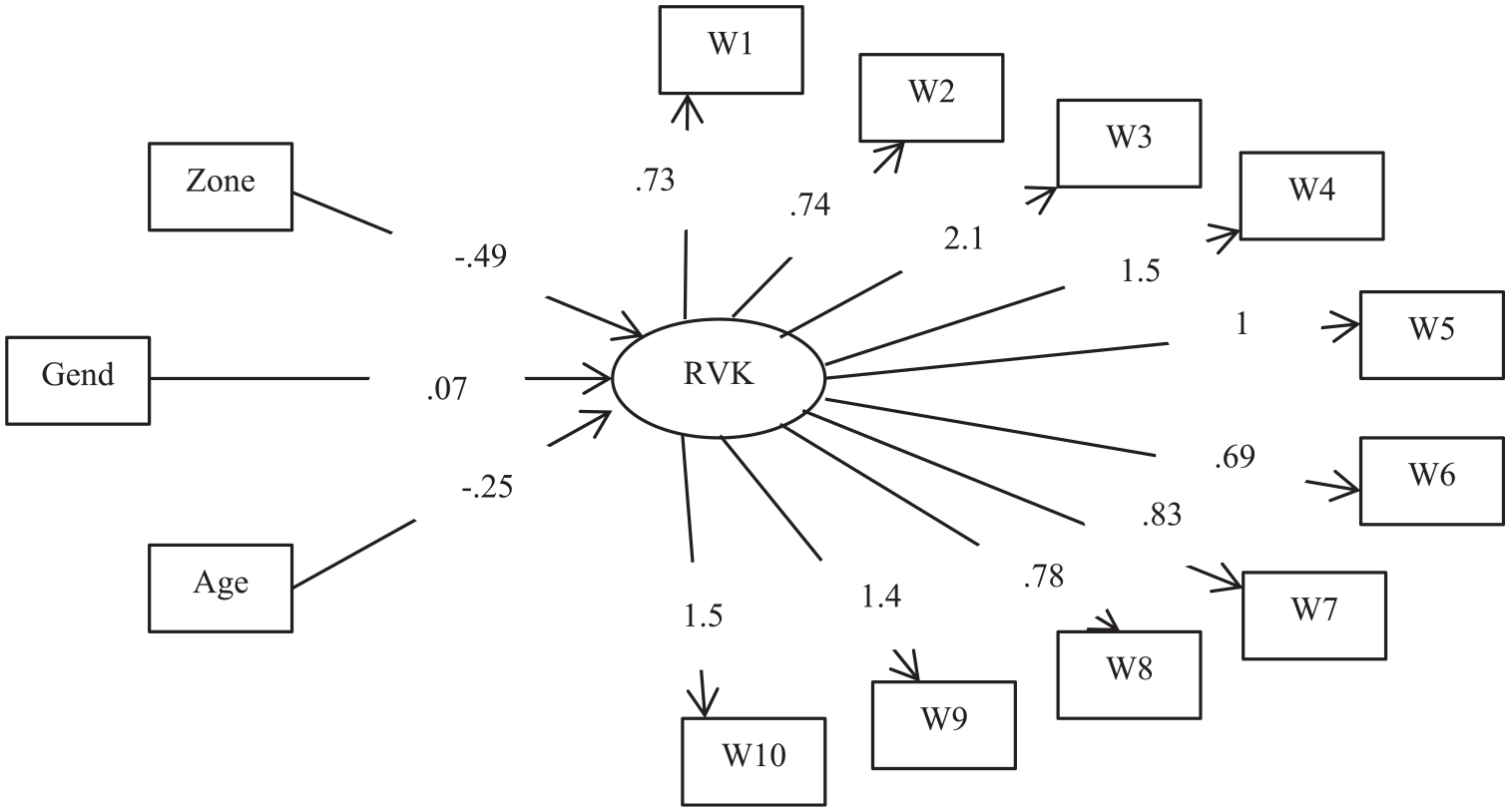
The 2-PL IRT-C model with receptive vocabulary knowledge (RVK) as latent variable and zone, gender and age as covariates.
Discussion
We now have some of the information we need to answer the four questions addressed in this research. The IRT analysis allows us to answer the first question by examining the characteristics of each item in each task. More importantly, by simultaneously using the two parameters, difficulty and discrimination, and the “item information function” graph, we are now able to select the best items which, if necessary, will allow us to condense this screening tool to a minimum (see Iyer et al., 2018). The second question refers to the links between the three domains, which are well known as predictors of reading skills, and an early literacy ability. These domains, which we investigated in four tasks, are closely related to a latent variable, “early literacy ability.” Indeed, the CFA showed that this latent variable is closely linked to letter knowledge, vocabulary knowledge, and, primarily, to phonological awareness, with the coefficient in this latter case being high. To answer the third question, we observed significant effects of the three variables Zone, Age, and Gender on the global scores. The children in sociodemographic zones with a high percentage of low SES (REP; zone with specific educational needs) achieved lower scores than their peers out of REP. The older children (those born in the first semester) outperformed the younger ones and the girls performed better than the boys. And finally, for the fourth question, we examined our data in each domain using an IRT-C model, that is, with the three variables as covariates. This allowed us to determine how these variables are related to each domain individually. Gender and Age were associated at a significant level with letter knowledge, phonological awareness, and vocabulary knowledge. However, Zone was linked significantly only to phonological awareness and vocabulary knowledge. This could mean that the link of sociodemographic status (determined via the Zone variable) is more important with language skills (vocabulary and phonological skills) than for a skill which depends more on conventional knowledge, here the names of the letters, which are acquired more often at school (and more rarely in the family). In summary, our results concerning all these expected links are consistent with the numerous reports in the literature (see the part of the “Introduction” section on this point).
Some limitations can be pointed out. A One concerns the lack of information about the parents’ SES (it should be remembered that the teachers were not allowed to indicate SES in this survey). Another relates to the impossibility of scheduling a listening comprehension task due to the lack of assessment time. We also did not include a task relating to print concepts which could also be used in an early literacy screening tool (see, for example, GRTR-R (Lonigan & Wilson, 2008) and PALS-PreK (Invernizzi et al., 2001). And using our screening tool, we were unable to evaluate two psychometric qualities, test–retest reliability and external validity, without using another short tool assessing certain language and/or cognitive skills among the same children. Finally, the two constraints (a short test with few items; administered in small groups) which, initially, were considered a serious limitation to assessing literacy skills may, ultimately, prove advantageous in terms of producing a screening tool with ecological validity for school-based applications. A last remark referred to our sample which was “limited” after a number of children were excluded because their booklets were not complete. However, the analyses were conducted with more than 12,000 young children, a very large sample.
Therefore, our study makes an important contribution to the assessment of early literacy skills. In fact, to our knowledge, it is the first study developed for and administered to a very large sample of French-speaking children. It could, therefore, be a valuable screening tool for educational practitioners (teachers, speech therapists, pediatricians, etc.), enabling them to identify young children in difficulty. For example, we can consider as a criterion the threshold of one standard deviation below the average for each area. It can be assumed that low scores in two or in all three areas simultaneously are an indicator of subsequent difficulties in learning to read.
Conclusion
Children’s reading success in elementary school can be predicted from their emergent literacy skills. In this study, a short screening tool including just a few items and based on only three domains which are known to be strong predictors of reading was administered to a very large sample of 4- to 5-year-old children. In cases where this tool reveals (very) poor performance, it could help identify which children could benefit from early interventions at school and/or from speech therapists. Another solution when poor performance is observed by educational practitioners would be to guide parents in entering into more language interactions with their children (e.g., in the form of shared book reading, shared writing activities, and sharing nursery rhymes, songs, poetry, etc.). Finally, in an ongoing longitudinal study, our data collected with 4- to 5-year-old children will be analyzed and linked with reading outcomes recently obtained in Grade 1 and this should establish the power of this initial screening tool for French-speaking children.
Supplemental Material
Supplementary_material – Supplemental material for A Brief Screening Tool for Literacy Skills in Preschool Children: An Item Response Theory Analysis
Supplemental material, Supplementary_material for A Brief Screening Tool for Literacy Skills in Preschool Children: An Item Response Theory Analysis by Jean Ecalle, Xavier Thierry and Annie Magnan in Journal of Psychoeducational Assessment
Footnotes
Acknowledgements
We thank Laure Gravier (Ined) for creating the task administration workbooks, and Marie-Aline Charles and Bertrand Geay, Director and Deputy Director of the Elfe Unit, respectively.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Elfe (French Longitudinal Study of Children ![]() ) is managed by the French National Institute for Demographic Studies (INED) and the National Institute for Health and Medical Research (INSERM), in partnership with the French National Blood Service (EFS); the Elfe study has also the backing of a consortium of ministries and public institutions. Elfe receives assistance within the RECONAI platform in the form of a grant from Agence nationale de la recherche (ANR-11-EQPX-0038).
) is managed by the French National Institute for Demographic Studies (INED) and the National Institute for Health and Medical Research (INSERM), in partnership with the French National Blood Service (EFS); the Elfe study has also the backing of a consortium of ministries and public institutions. Elfe receives assistance within the RECONAI platform in the form of a grant from Agence nationale de la recherche (ANR-11-EQPX-0038).
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.