
Abstract
Based on the sharable content object concept of advanced distributed learning, an ontology-based intelligent content object (ICO) that can automatically reason and be reused is proposed. Then, by extending the advanced distributed learning or sharable content object reference model (SCORM) specification, an interoperable model for the ICO is developed; it involves (a) adding an ontological model of general domain knowledge for intelligent tutoring systems to the SCORM specification and encapsulating the design details of the heterogeneous knowledge ontologies, (b) adding a hierarchical data structure for the current ontology element to the communication data model in the run-time environment of the SCORM specification, (c) extending the application program interface in the run-time environment of the SCORM specification to enable the ICO to query various knowledge ontologies in a consistent way, and (d) adding an Ontology section to the content aggregation model in the SCORM specification to ensure that the same ICO can be associated with different knowledge ontologies. The proposed model extends the SCORM-based courseware model from a multimedia-based structured courseware to the intelligent courseware based on a knowledge ontology and can significantly improve the overall intelligence of the learning system along the lines of the specification, thereby providing a reference for the future development of the SCORM specification.
Keywords
Introduction
Due to the rapid development of computer technology and the Internet, educational technology is facing two major challenges. The first challenge is determining how to use multiple technologies from artificial intelligence, education, and cognitive psychology to simulate the individualize teaching of human teachers and conduct open teaching by means of human–computer interaction with targeted instruction, and ultimately, complete the computer’s gradual transition from assisting a teacher to replacing the teacher (Barr & Feigenbaum, 1981; Sokolnieki, 1991). Such intelligent tutoring systems (ITSs) have been a popular topic and challenge in educational technology since the 1970s, and many mature products have been developed, including ELM-ART (Brusilovsky, Schwarz, & Weber, 1996), E-TCL (El-Khouly, Far, & Koono, 2000), Protus 2.0 (Vesin, Ivanović, Klašnja-Milićevic, & ´Budimac, 2012), AG TUTOR (Mahmoud & El-Hamayed, 2016), and so on. Currently, scholars are working on further improvements of the intelligence of ITSs, and one of the important technologies under development is intelligent learning content with automatic reasoning and automatic generation using a domain ontology based on a semantic network or description logic (DL; Mahmoud & El-Hamayed, 2016; Stankov, Rosić, Žitko, & Grubišic, 2008; Žitko, Stankov, Rosić, & Grubišic, 2009). While web-oriented ITSs are becoming more used in educational community and proved to be increasingly effective, they are difficult and expensive to build (Žitko et al., 2009). The second challenge is adapting to today’s highly developed information age under the Internet, without repeating the development of teaching courseware to share various types of teaching resources while ensuring their interoperability across various heterogeneous learning systems has become a very urgent problem that must be solved (Rosi´c, Glavini´c, & Stankov, 2006). To this end, since 1997, many international organizations have been engaged in research on and the development of technical specifications for distance education; the best-known groups include the IEEE learning technology standards committee (IEEE/LTSC, 1997), the IMS global learning consortium (IMS, 1997), the JTC1/SC36 working group organized by the international organization for standardization (ISO, 1999), and the advanced distributed learning (ADL) initiative organized by the US Federal Government (ADL, 1999). With the full support of Macromedia as the world’s largest network multimedia software company for the sharable content object reference model (SCORM; ADL, 2000) and the specifications of the Aviation Industry Computer-Based Training Committee (AICC) for its Adobe software (Macromedia, 2002), the promotion and application of technical specifications for distance education developed rapidly.
Currently, the most typical technical specification for ITSs is the SCORM specification released by the ADL (2000) initiative of the US Federal Government. This specification has been incorporated into the ISO standard for learning technology systems and has been supported by many software platforms, including Adobe (Macromedia, 2002). The SCORM specification can break the design method of the traditional closed learning system and develop a content aggregation model (CAM; ADL, 2009a) based on sharable content objects (SCOs; ADL, 2009b) and a sequencing and navigation (ADL, 2009c) model based on production rules, which separate the contents and the pedagogical strategies from the run-time environment (RTE) and allow teachers to design them in accordance with the uniform standards. At the same time, the SCORM specifications set up a standardized RTE (ADL, 2009d) for learning systems; it enables heterogeneous learning systems to exchange and reuse various resources and thereby realizes an interoperable model of distributed online ITSs. However, the current domain knowledge model in the SCORM specification only adopts structure-oriented courseware for students; it does not introduce the subject expert model based on a domain ontology, whose target model is only to provide an adaptive learning system model to learners that offers personalized teaching based on structured static learning units (the learning content needs to be designed in advance) and production rules. The overall intelligence of the current SCORM is not high; therefore, it cannot support domain ontology-based intelligent dynamic learning units with self-generation and reasoning functions.
The concept of an ontology, which originated in philosophy, has been widely used in information science in recent years. In particular, the application of ontologies to the web has led to the emergence of the semantic web. An ontology is a unanimous agreement on shared concepts. Using knowledge sharing as its core concept, ontologies have been widely used in knowledge engineering from the beginning. The DL of ontologies is developed on the basis of semantic networks and frames. A DL is a decidable subset of first-order logic with good semantics, a powerful means of expressing knowledge, and deterministic reasoning (Baader, Calvanese, & McGuinness, 2003). Currently, the semantic web and ontologies have been widely used in ITSs, including for the semantic annotation and semantic retrieval of learning resources (Brut, Sedes, & Dumitrescu, 2011; Lama et al., 2012), the development and aggregation of intelligent learning content based on domain ontologies (Nešić, Gašević, Jazayeri, & Landoni, 2011; Marciniak, 2014), and ontology-based personalized learning (Mahmoud & El-Hamayed, 2016; Vesin et al., 2012), and natural language interfaces (Dzikovska, Steinhauser, Farrow, Moore, & Campbell, 2014; Zhu, Cao, & Su, 2011).
Based on the DL, the World Wide Web Consortium (W3C) has released the web ontology language (OWL; W3C, 2003), whose aim is to standardize the representation and storage of ontologies. The emergence of the OWL has played a certain role in promoting the development of domain ontologies, but the OWL ontology model has two drawbacks. First, its implementation is based on the self-describing extensible markup language (XML), which includes a great deal of redundant information in the markup elements used to store information; the associated files are too large and access to them is inefficient; therefore, it is only suitable for the development of small domain ontologies. Second, to ensure the clarity of the structure and the determinism of reasoning, the OWL requires each concept in the taxonomic ontology to have exactly one parent node; no multiple inheritance is allowed, which is not sufficient for the complex relationships between concepts in ITSs (Stankov et al., 2008). To improve the efficiency of access, the famous Protégé ontology editor (Noy & McGuinness, 2001) allow that its ontologies can be converted into a variety of formats, including OWL, resource description framework (RDFs), XML schemas, and databases, so an ontology authored by Protégé editor may have a variety of storage formats and access interfaces (Tang, 2013). Moreover, various types of large-scale ontology have adopted compact binary or unmarked plain text files, such as the private structured binary files with the unique access interface used in the large-scale general ontology WordNet (Fellbaum,1998) and the open-source plain text files used in large domain ontologies such as the Systematized Nomenclature of Medicine (SNOMED-CT) exemplified by the Unified Medical Language System of the National Library of Medicine, which both support multiple inheritance. In fact, many of the ontologies in ITSs are in non-OWL format (Kazi, Haddawy, & Suebnukarn, 2012; Stankov et al., 2008; Tang, 2013). Therefore, learning contents based on knowledge ontologies currently cannot be moved and reused across learning systems supporting different ontology interfaces, which has resulted in the repetitive development of many ontology-based intelligent learning contents. Moreover, various interfaces for accessing ontologies are currently under development for professional software developers; these are generally very complex and difficult for ordinary content developers (teachers) to master, which seriously restricts the application of ontology in the ITSs. Therefore, it has become an urgent problem to standardize the structure and access interfaces of the ontology in the ITSs.
To solve above problems, this study, for the first time, proposes a general ontology model that can be supported by most types of knowledge ontology and is suitable for intelligent teaching systems and further proposes an intelligent content object (ICO) based on the general ontology model and the SCO concept of ADL or SCORM specification. An ICO is a unique SCO that can communicate with a learning management system (LMS) at run-time and accesses the knowledge ontology in a consistent way, which enables it to be moved across heterogeneous LMSs supporting different ontology interfaces. Then, by extending the ADL or SCORM specification, an interoperable model for the ICO is developed. The proposed model can significantly improve the overall intelligence of the learning systems along the lines of the extended specification, and makes it possible, in these learning systems, to automatically generate sharable learning contents, automatically determine subjective questions, and automatically conduct Question-and-Answer (Q&A) sessions. Furthermore, the type of learning content in the SCROM specification is extended from single set of multimedia-based structured static courseware to multiset including ontology-based intelligent dynamic courseware that supports automatic generation and automatic reasoning.
Sharable ICO Based on a Knowledge Ontology
In the traditional learning system, the learning content or teaching courseware has a multilayer structure and it is divided into four levels: (a) the first level—a unit, (b) the second level—a lesson, (c) the third level—a topic, (d) the fourth level—an instructional item that is an undividable element of the subject matter. In e-learning, instructional items are usually designed as interoperable multimedia web pages. Therefore, in most of the currently available online learning systems, including the learning systems that follow the SCORM specification, the smallest unit of sharable learning content is usually a multimedia web page for students, which leads to many limitations. First, the multimedia material is not formalized knowledge for machines, and the machine cannot use it to perform automatic reasoning. Second, the professional knowledge of a concept, such as the concept’s definition, attribute, and characteristic must be provided by the teacher in materials that are related to the instructional item and cannot be directly referenced by other teachers in their courseware. Because teachers may not be the experts in their fields, the domain knowledge they provide is not necessarily professional and scientific, and different teachers may provide the same knowledge in different courseware, which leads to significant redundancy in knowledge. To overcome these shortcomings and improve the intelligence of the learning content, this study designed an interoperable intelligent learning content model based on the SCORM specification. This model liberates teachers from the arduous work of designing professional knowledge, and the knowledge in various fields is uniformly designed by subject experts in domain ontologies. The teachers directly refer to the subject knowledge through the domain ontology. In addition, using the model, teachers can directly use the formalized professional knowledge in the domain ontology to design intelligent learning content with reasoning functions; this ontology-based learning content is interoperable, which ensures that they can be moved, used, and reused across the heterogeneous learning systems that follow our model.
Referring to the SCO in the SCORM specification and to the concept of an open content object in the literature (Zhu, 2005, 2007), this study defines a shareable ICO as a learning object that can be tracked by the LMS in the form of web pages that obtains knowledge from an ontology. An ICO is a special type of the SCO described in the SCORM specification that can communicate with a LMS in the RTE. To enable an ICO to communicate with the knowledge ontology in a heterogeneous learning system, this study extends the ADL or SCORM-RTE (ADL, 2009d), including extending a secondary data structure of the current ontology element (COE) in its communication data model, while extending the communication methods of its application program interface (API) to enable it to set up and access the elements of the ontology in the COE. Using the extension of the ADL or SCORM specification in this study, the ICO proposed in this study can be created by embedding the communication API procedures to access the knowledge ontology into the web-learning resource using the hypertext transfer protocol. Similar to an SCO, at least an ICO object can locate the API adapter of LMS, initialize the API adapter by calling Initialize() to establish a dialogue with the LMS, and terminate the API adapter by calling Terminate() to end a dialogue with the LMS. The ICO should also include the API methods that access the knowledge ontology, the corresponding scripts to use the knowledge in a domain ontology for intelligent teaching, and related web-learning resources, as shown in Figure 1.
The framework for an ICO.
In the ICO shown in Figure 1, the content designer can obtain at least two types of knowledge from the ontology: The formalized domain knowledge that is based on semantic relations and can be reasoned, such as the following statement, which allows access to all the hypernyms of the current concept in the ontology: var subsumerSet=api.GetSet (“cmi.coe.concept.subsumerSet”).
The other knowledge is nonformalized domain knowledge based on data attributes of a concept, such as the following two statements, which access the text-based definition of the current concept: api.SetValue(“cmi.coe.concept.attribute,” “definition”) var definition = api.GetValue(“cmi.coe.concept.attribute.hasValue”).
Because an ICO use the standard communication interface to access the knowledge ontology in a LMS, it can be moved and reused across LMSs supporting different ontology interfaces and can communicate with various types of knowledge ontologies. For example, the same ICO can associate and communicate with the large-scale common knowledge ontology WordNet and with an OWL-based domain ontology, which shows that an ICO can perform the same intelligent teaching with different types of knowledge ontologies.
Interoperable Model of an ICO Based on the SCORM Specification
Nowadays the definition and application of the specifications in distance education are implemented through XML. The format definition of specification is described in a name space of XML schema. The XML has the inherent extensibility that is future-oriented compatibility (Walmsley, 2002). So, on the one hand, the specifications are allowed to refer to each other, for example, the IMS learning resource metadata information model (IMS, 2006) refers to the IEEE 1484.12.1-2002 standard for learning object metadata (IEEE/LTSC, 2002), and the ADL or SCORM specification refers to the IMS content packaging specification (IMS, 2007a) and AICC computer managed instruction data model; on the other hand, every specification can be extended by software development groups according to their demands (IEEE/LTSC, 2002; IMS, 2007a), for example, Chang, Hsu, Smith, and Wang (2004) propounded that enhancing SCORM metadata for assessment authoring in e-learning, and Zhu (2007) propounded that “Extending the SCORM Specification for references to the Open Content Object.”
The communication mechanism of an ICO with a LMS is evolved from the SCO of ADL or SCORM, so our interoperable model for the ICO can be implemented by extending the SCORM specification. The extensions to the SCORM specification mainly include the following four points:
To encapsulate the design details of various ontologies, an ontological model of general domain knowledge for ITSs is added to the SCORM specification; To standardize the communication data of ontology queries, a hierarchical data structure for the COE is added to the communication data model in the RTE of the SCORM specification according to the proposed general framework for knowledge ontologies; The API in the RTE of the SCORM specification is extended to enable an ICO to query the knowledge ontology in a consistent way; An Ontology section is added to the CAM in the SCORM specification to ensure that the same ICO can be associated with knowledge ontologies of different types.
This study constructs an intelligent content object interoperation model (ICOIM) with an ICO as its core and extends the courseware of the SCORM specification from multimedia-based structured courseware to ontology-based intelligent courseware, as shown in Figure 2.
From the structured courseware of SCORM toward the intelligent courseware of ICOIM.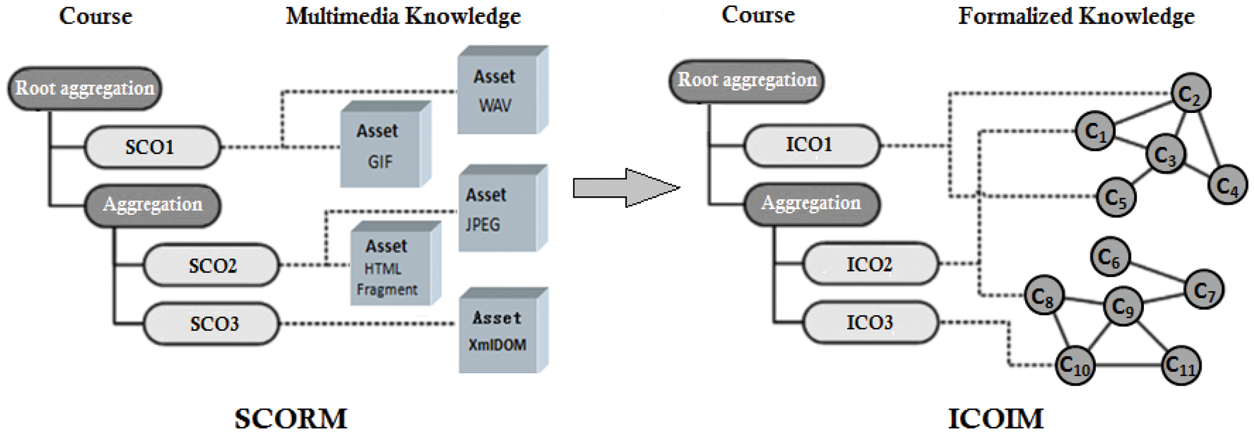
Knowledge Ontology Model for ITSs
The general framework of a knowledge ontology used in this study refers to the OWL ontology model proposed by the W3C, and the domain knowledge model of TEx-Sys (Stankov et al., 2008), which is based on the semantic networks with frames. In addition, we appropriately revise and constrain the OWL ontology model according to the knowledge demanded by intelligent teaching and the operability of querying the distributed knowledge ontology in the LMS. First, to provide the large number of conceptual features and domain relationships required by an ITS, the binary relations of Properties in the OWL ontology are extended to include conceptual attributes and conceptual relations. In our model, a conceptual attribute is a binary relationship between a concept and a data object (mainly containing values or characters), which is used to describe a characteristics of the concept. A conceptual relation specifically refers to a binary relationship between concepts, which is used to describe the association between concepts in a domain. At the same time, to facilitate distributed access to the ontology, the TBox in the OWL ontology is simplified, the construction of complex concepts based on the AND, OR, and NOT operators is eliminated, and only the restrictions asserted for attributes and relations based on atomic concepts are retained to formalize the theoretical knowledge in a domain. In addition, to enhance the natural language processing ability of the ITSs, a synonymous set for a concept is added to the universal framework of the domain ontology that refers to WordNet to explain the different appellations of the same concept, attribute, or relation; this also makes up for the deficiency in the concept’s construction caused by omitting the AND, OR, and NOT operators. In addition, the general framework of the knowledge ontology in this model refers to the WordNet and the medical ontology SNOMED, and multiple inheritances are allowed in the taxonomy for concepts.
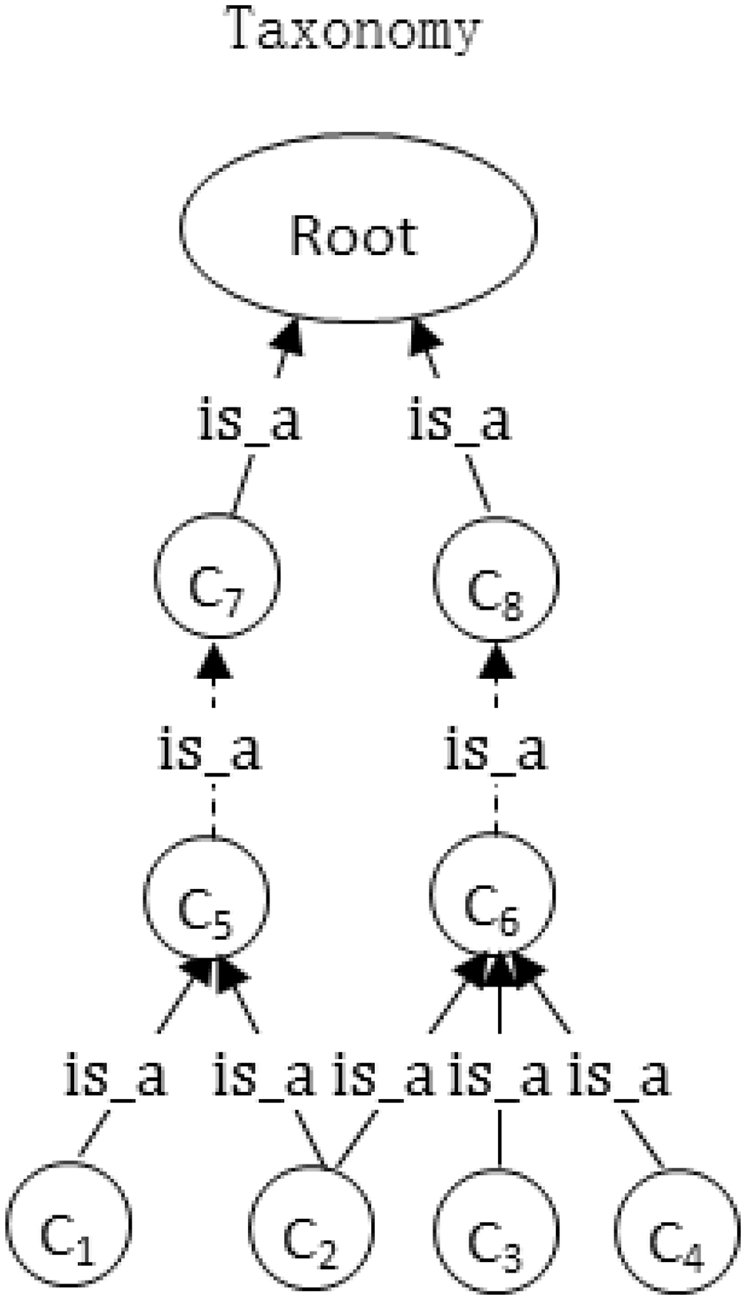
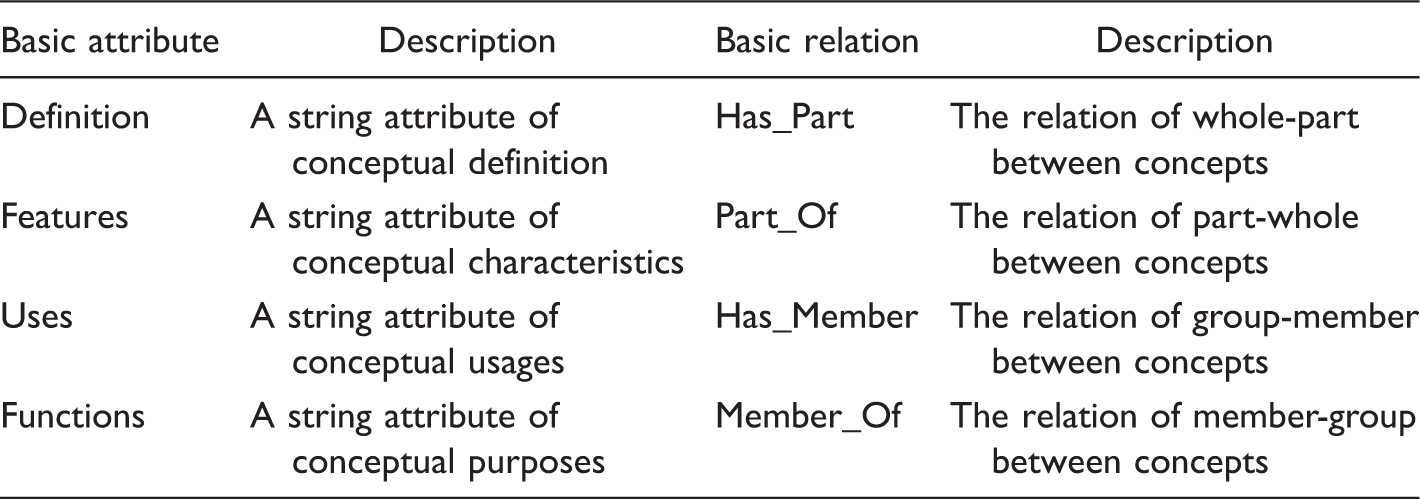
Finally, in the proposed general framework for the domain ontology of ITSs, the domain knowledge consists of six parts: concepts, a concept hierarchy (taxonomy), attributes, relationships, instances, and synonyms, as shown in Figure 3. Among these, the hierarchical structure of the concept taxonomy is the semantic network composed of is-a relationships with multiple inheritances, as shown in Figure 4. An attribute is a binary relationship between a concept and a data object that is mainly used to reflect a characteristic of the concept. In our knowledge model, attributes exist in concepts in the form of their restrictions and as values for the instances of concepts. An attribute restriction is an abstraction of the attribute’s value in all instances, that is, the attribute in all instances of a given concept has the same value and this value is extracted as a restriction for that attribute of the concept. A relation is a binary relationship between concepts. The relations in our model are divided into basic relations and domain relations. A basic relation is the most fundamental relationship between concepts shared by all domains, such as the inclusion, whole-part, and past-of relations. A domain relation is the specific relationship between the concepts of a domain, such as the relations of store and display in the computer domain. In our knowledge model, relations exist in the concepts in the form of relational restrictions, and relational values in the instances of concepts. In addition, there is an is-a relationship between an instance and a concept. Our proposed knowledge ontology model for ITSs can meet the demands of domain knowledge in most of the current ITSs (Brut et al., 2011; Dzikovska et al., 2014; Lama et al., 2012; Mahmoud & El-Hamayed, 2016; Marciniak, 2014; Nešić et al., 2011; Stankov et al., 2008; Vesin et al., 2012; Zhu et al., 2011; Žitko et al., 2009).
Knowledge ontology model for ITSs. Concept taxonomy with multiple inheritances.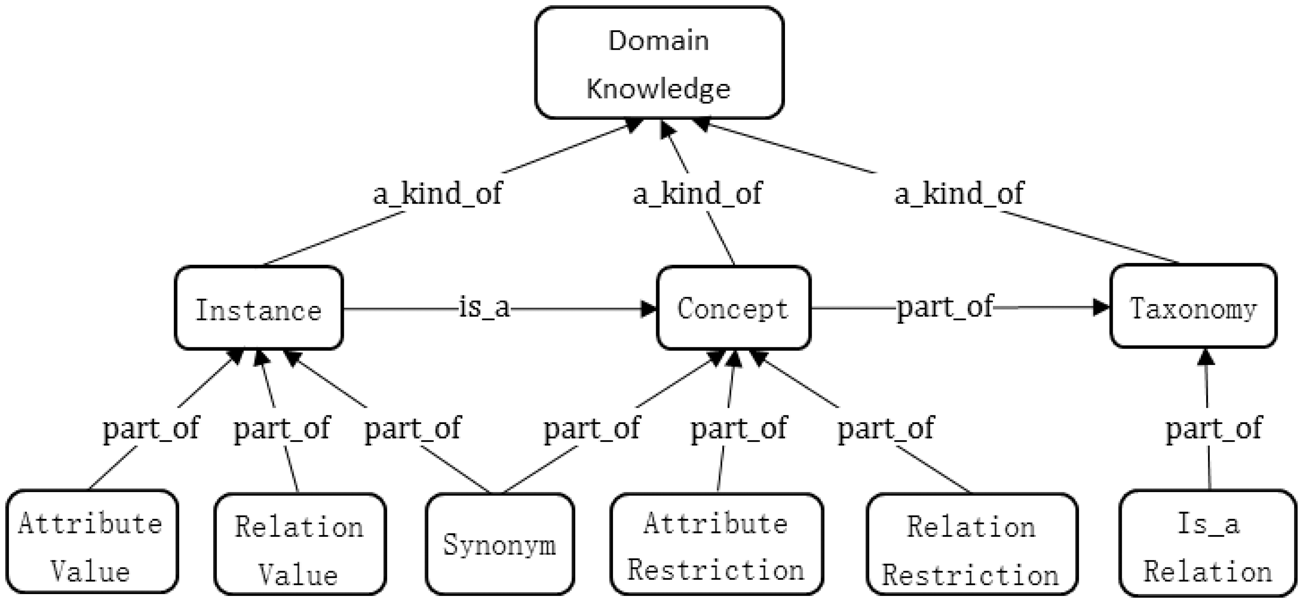
Standardized Naming for the Basic Attributes and Relationships of Concepts.
To ease the readability of our proposed knowledge ontology model, we give a knowledge ontology instance fragment of computer domain composed of an is-a taxonomy with property relation restrictions, as shown in Figure 5. Where the axioms for concepts can be formed by relational restrictions, as shown in Figure 6. For example, the axiom An instance for the knowledge ontology model. Conceptual axioms based on relational restrictions.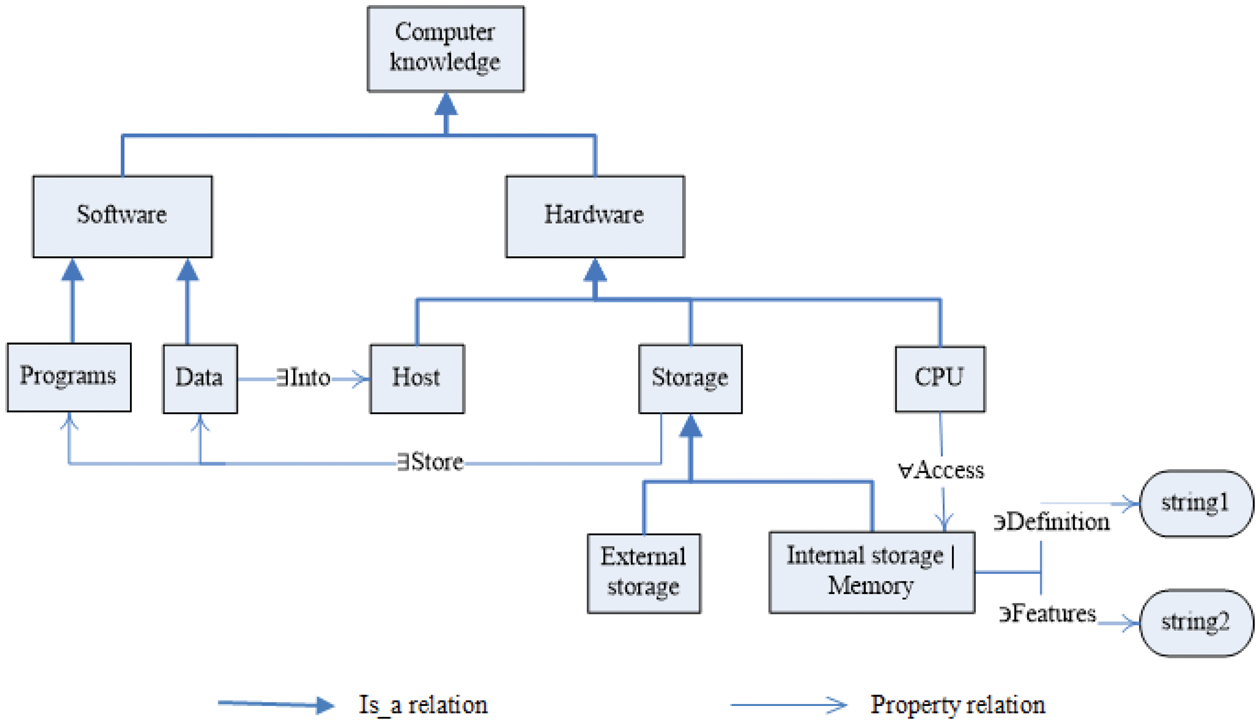

RTE for the ICO
To ensure the interoperability of an ontology-based distributed ICO across learning systems that support different ontology interfaces, this study designs a general RTE for ontology queries between an ICO and a LMS based on the ADL or SCORM-RTE (ADL, 2009d). First, to make the communication environment versatile, this study decomposes an ontology query into a query condition setting and a query result response, which is supported by the communication data structure of the COE, as shown in Figure 7. The query setting is used to transfer the known conditions of the query from the ICO to the LMS; the query result response is used to pass the results of the query to the ICO from the LMS. Consequently, the API and the communication data model of the SCORM or RTE are extended to enable the ICO to communicate with various types of knowledge ontology in a consistent approach. An ICO is a special SCO, whose initialization mechanism follows the ADL or SCORM specification for an SCO, that is, an ICO can only be initialized by a LMS.
Run-time environment for the ICO.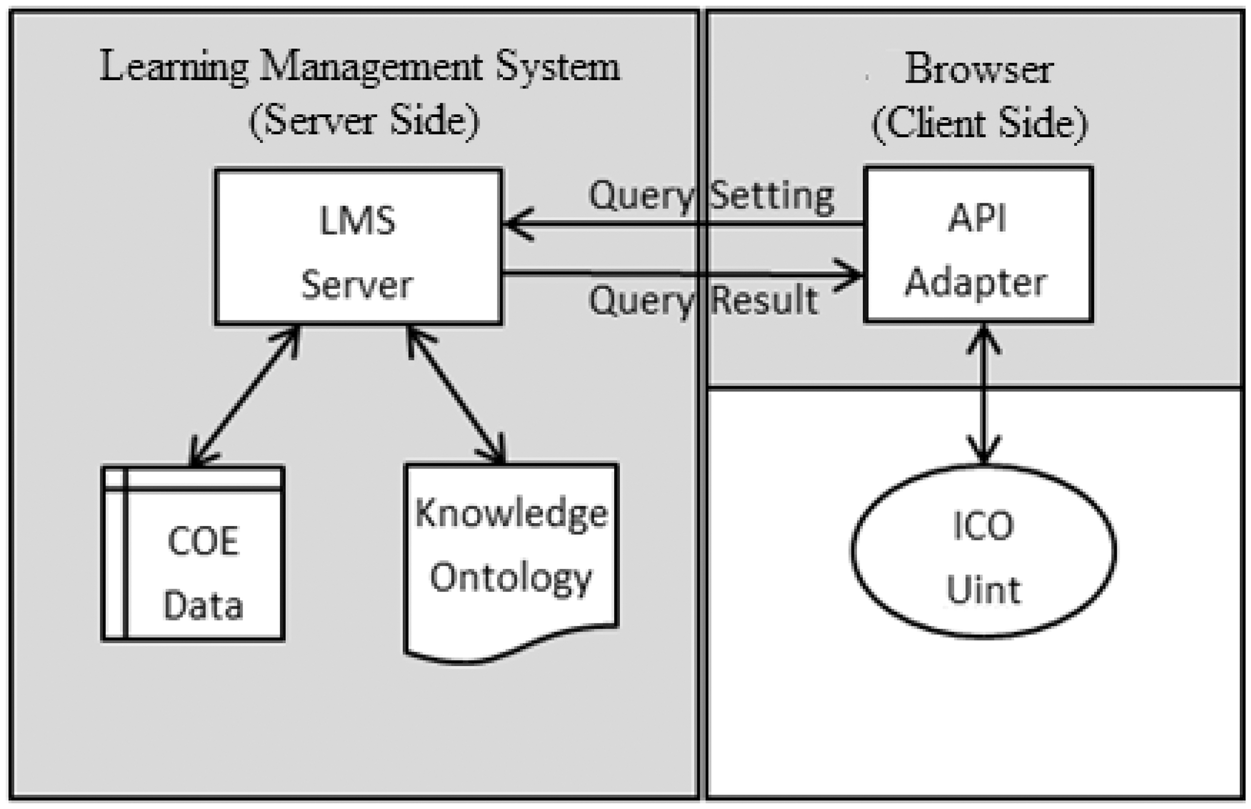
Universal Communication Interface for Distributed Ontology Queries
To implement the above communication mechanism, this study extends the following six API methods in the SCORM or RTE: Initialize(), Terminate(), SetValue(), GetValue(), GetLastError(), and GetErrorString()(ADL, 2009d). Among them, Initialize() is extended to enable it to activate the LMS to create an ontology query dialogue, which includes creating a data structure for the COE for the ICO to communicate with the server; Terminate() is extended to enable it to terminate an ontology query dialogue, which includes releasing the COE data structure constructed for the ontology query; SetValue() is extended to enable it to assign a value to a data element in the COE and thereby, set the condition of the ontology query; GetValue() is extended to enable it to return a single data element of the COE on the server side to the client and thereby return the result of the ontology query; GetLastError() and GetErrorString() are extended to enable them to return the error code of the last ontology query and the corresponding error message. To improve the efficiency of ontology query facilitate an ontology query, a large number of array (a collection of data) elements are set up in the COE, while the API method GetValue() in the SCORM or RTE can only return a single character. Below, we give the interface prototype of the most important API method SetValue():
SetValue() method
Method Syntax: return_value = SetValue(parameter_1, parameter_2) Description: The method is used to request the transfer to the LMS of the value of parameter_2 for the data element specified as parameter_1. Parameter: Parameter_1—The complete identification of a data model element to be set. Parameter_2—The value to which the contents of parameter_1 is to be set. The value of parameter_2 shall be a character string that shall be convertible to the data type defined for the data model element identified in parameter_1. Return value: The method can return one of two values. “true”—f the LMS accepts the content of parameter_2 to set the value of parameter_1. “false”—If the LMS encounters an error in setting the contents of parameter_1 with the value of parameter_2.
To access the array elements in the COE, the API for communication in the SCORM or RTE is extended, and a method, GetSet(), that returns an array of characters has been added.
GetValue() method
Method syntax: return_value = GetSet(parameter) Parameter: The parameter represents the complete identification of a COE data element. Return value: The method can return a character string array containing the set associated with the parameter.
Communication Data Model for Ontology Queries
Our model records the known conditions and query results of the ICO’s ontology query using a hierarchical data structure in the COE. The data in the COE originate from both the client-side ICO and the server-side ontology and are updated by the LMS. In addition, the details of the designs of various types of knowledge ontology are encapsulated in the COE’s hierarchical data structure; therefore, the content developers (usually teachers) can simply use the common API methods SetValue(), GetValue(), and GetSet() to operate directly on the COE and access a variety of heterogeneous ontologies, which enhances the versatility and interoperability of the ontology-based intelligent learning content, as shown in Figure 7. The LMS creates and maintains a COE data structure for each distributed content object with which it communicates. The COE is created by the LMS on the server side at the beginning of the dialogue with an ICO, updated in real time during the dialogue, and released at the end of the dialogue.
Details of the Hierarchical Data Structure of the COE
The Hierarchical Data Structure of the COE.
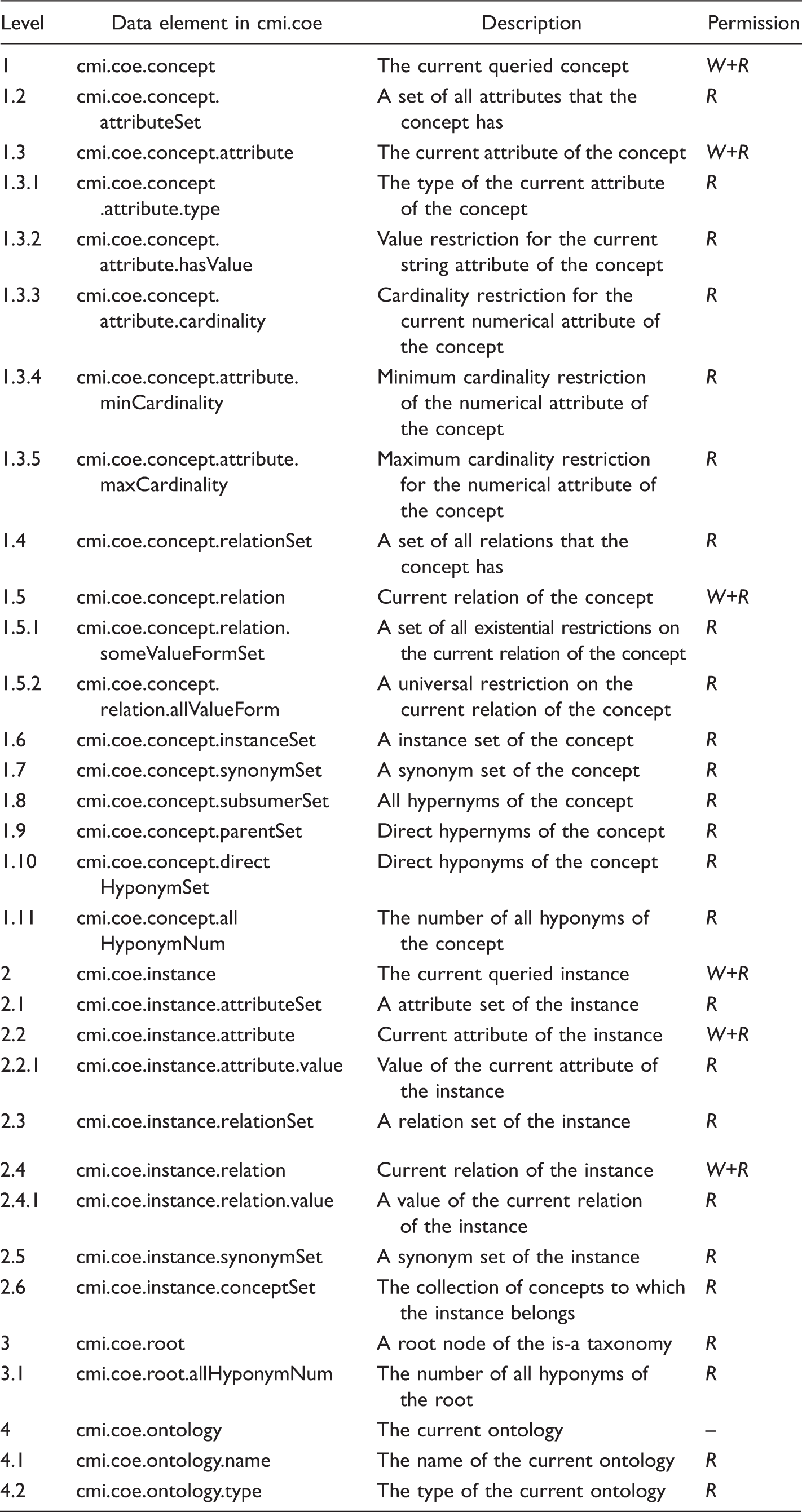
Note. W refers to permission to write by the common API method SetValue(), and R refers to permission to read by the common API method GetValue() or GetSet()
Approaches to Using COE Data
As mentioned earlier, accessing to the knowledge in an ontology through COE, first the query condition is set, and then query results can be obtained through COE. Moreover, the query conditions usually need to be set in several steps. To facilitate the setting of query conditions, our model sets a lot of data to provide clues for further inquiries in the COE structure, such as that the COE data cmi.coe.concept.attributeSet can return all available attributes that the current concept has, which can provide query clues for further querying the attributes of the current concept. Therefore, there are two ways to set the query conditions. The first approach is that the user already knows all the query conditions and directly gives them in COE, such as the following JavaScript statements to obtain the universal restriction of the Access relationship of CPU in Figure 5: api.SetValue(“cmi.coe.concept,” “CPU”); api.SetValue(“cmi.coe.concept.relation,” “Access”); var storage = api.GetValue(“cmi.coe.concept.relation.allValueForm”);
The other approach is that the user only knows the initial condition, and further conditions need to be obtained in the COE structure through step-by-step query, such as the following JavaScript statements to show the value restrictions of all the string attribute of the concept Memory in Figure 5: api.SetValue(“cmi.coe.concept,” “Memory”); var attributeSet = api.GetSet(“cmi.coe.concept.attributeSet”); for (i=0;i< attributeSet.length;i++){ api.SetValue(“cmi.coe.concept.attribute,” attributeSet[i]); var type= api.GetValue(“cmi.coe.concept.attribute.type”); if (type == “string”){ var string= api.GetValue(“cmi.coe.concept.attribute.hasValue”); alert(attributeSet[i]+ “:”+string); }
Extending the SCORM CAM for the ICO
The purpose of the content package in a specification is to provide a standardized way to exchange learning content between different systems or tools. The content package also provides a place for describing the structure (or organization) and the intended behavior of a collection of learning content (ADL, 2009a; IMS, 2007a). SCORM CAM is a set of specific use examples, or application profiles, of the IMS content packaging specification (ADL, 2009a).
An ICO is a special SCO that can be assembled in an XML content manifest. To achieve the reusability and interoperability of ICO, our model requires that an ICO does not specify the operated ontology during its design phase and must postpone the association of the ICO with the ontology it operates in the content packing manifest. To fulfill this specific requirement of ICO design, our ICOIM expands the structure of the SCORM content package’s manifest from a three-tier structure to a four-tier structure by adding an Ontologies section, as shown in Figure 8.
Expanding the structure of the SCORM content package’s manifest. A content packaging manifest to associate the Q&A content object with two different ontologies.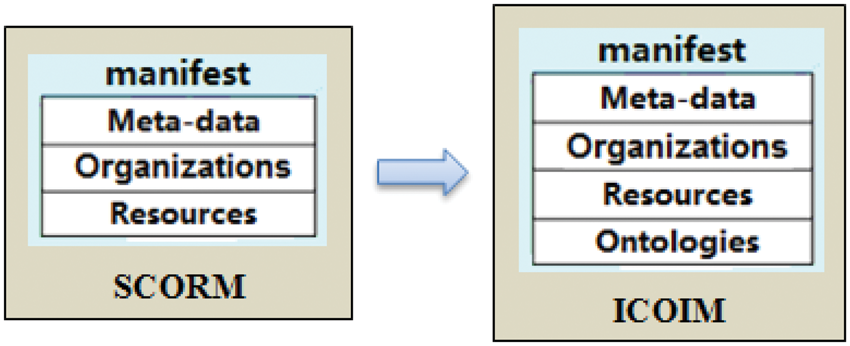

In our ICOIM content packaging model presented earlier, the extended <Ontologies> is used to describe the ontology used in the content package, which consists of one or more <Ontology> elements. Its XML format is as follows:
Description: This element describes all the ontologies used in the content package. Multiplicity: This element may occur 0 or 1 time in a <manifest> element. Sub-element: < ontology >.
Description: This element describes an ontology used in the content package. Multiplicity: This element may occur 1 or more times in a < ontologies > element. Attributes: ○ Identifier (required). An identifier, provided by the author or authoring tool, that is unique within the manifest. ○ Type (required). A string that identifies the type of ontology. Our interoperable model defines two types of “OWL” and “other.” ○ href (required). A reference to the entry point of this ontology. Elements:
<metadata>: The metadata describing the ontology.
<file>: A listing of files that this ontology is dependent on. This element is repeated as necessary for each file for a given ontology. The <file> element represents files that are local to the content package by a href attribute.
In our proposed ICOIM content packaging model, the association between the ICO object and the ontology to which the ICO object refers is done in the subelement <item> of the hierarchical organization in a content manifest. To achieve this association, we add an optional attribute: ontologyref for the <item> element in SCORM or CAM. The function and format of this attribute are described as follows:
In addition, in order to identify our proposed ICO content object in the Resource section of the content manifest, we extend an attribute icoimType and the corresponding attribute value “ICO” for the <resource> element.
All the extended elements of SCORM content packaging specification are defined in an XML schema file icocp.xsd (ADL, 2009a; Martin et al., 2000; Walmsley, 2002; W3C, 2001), which contains a hypothetical schema name space: “http://www.icoim.org/xsd/icocp_v1p0.”
Results
Goals and Methods of the Experiment
Our interoperability model is developed to enable the development of ICO content objects that are reusable and interoperable across multiple LMSs. For this to be possible, based on the SCORM specification, we design a common mechanism (API) for ICO content objects to communicate with an LMS, a predefined vocabulary (COE) forming the basis of the communication and a standardized way to exchange ICO learning content between different systems or tools. However, our proposed model is only a common agreement for the developers of LMSs and learning contents and does not require the use of a unified development tool or programming language to implement specific learning systems and learning objects.
In this section, how our proposed model results in the ICO’s interoperability is demonstrated through a specific example based on the SCORM specification and the JavaScript that follows the ECMAScript standard. First, a content object for is-a automatic Q&A was designed based on the knowledge ontology using our extended API. Then, our proposed ICO-based content packaging model was applied to make the content object associated with an OWL domain ontology and the WordNet common sense ontology, respectively. Finally, the 2004 edition of the SCORM specification’s RTE provided by ADL was extended, which was used to execute the Q&A content object.
Design of an Is-a Automatic Q&A Content Object
The method for designing an ontology-based is-a automatic Q&A content object is as follows: A Q&A content object accepts only questions in the form of “Is concept1 a type of concept2?” and automatically parse concept1 and concept2 in JavaScript. Then, the method in the extended API and the extended communication data model are used to query the knowledge ontology in the LMS and obtain all the hypernyms of concept1. Finally, whether concept2 is in the hypernym set of concept1 is determined, and the answer is provided. The Q&A content object is designed and implemented using the API wrapper provided in the sample run-time environment (SRTE), version 1.1.1, of SCORM 2004 fourth Edition (ADL, 2009e). Details of the design are shown in Appendix A. The getAPIHandle() method in the API wrapper is used to obtain the API adapter object provided by the LMS on the client side, and the method initAPI() in the API wrapper is used to initialize the API adapter object.
Design of the Content Package for the Q&A Content Object
In an ICO’s content package, all the elements that are used, respectively, adhere to two different name spaces (IMS, 2007a, 2007b; Walmsley, 2002; W3C, 2001):
The name space of IMS content packaging specification, which is also followed by SCORM specification. The name space of the elements extended by our ICO content packaging model to the IMS content packaging specification.
In an ICO’s content package, only the name space of IMS content packaging specification is defined as the default name space. Therefore, when the elements extended by our model are used, a prefix “icocp” representing the name space of our ICO content packaging model must be appended.
According to the above method of applying our ICO content packaging model, a content packaging manifest to associate the Q&A content object with two different ontologies is designed as Figure 9.
Implementation of the RTE for the Q&A Content Object
The client-side Java program in the SRTE, version 1.1.1, of SCORM 2004 fourth Edition was revised to extend its API. The Java program that relates to the SRTE’s data model was revised to add support for the communication data model of the COE in the proposed model. The SRTE’s Java program for parsing the DOM was revised to add support for the content packaging model of the proposed model. Finally, the designed Q&A content object was implemented and executed in the extended SRTE environment, as shown in Figure 10.
The extended SRTE environment for the ICO.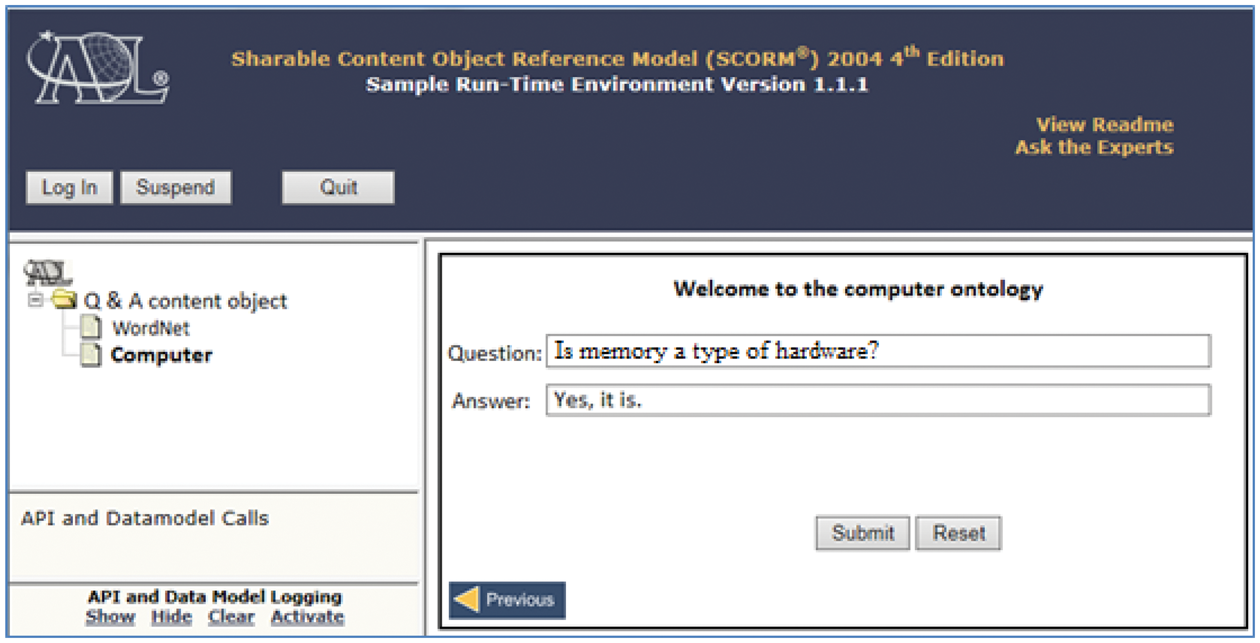
Conclusions
Based on the SCO content object of ADL, this article proposes a shared ICO, and on the basis of the SCORM specification, forms an ICOIM that extends the SCORM’s multimedia-based structured courseware model into an intelligent courseware model based on knowledge ontology, which can be used for the automatic generation of shared learning contents, the automatic judgment of subjective questions, and automatic question-answering, and can significantly improve the overall intelligence of the learning system in line with the specification. From the experimental results and the examples in each section, we can draw several conclusions for our model as follows:
(1) Figures 3 to 6 show the knowledge ontology framework in our mode can provide at least two types of knowledge: The formalized domain knowledge that is based on semantic relations and can form the concept axiom shown in Figure 6. This kind of knowledge can be used for reasoning and is the core material for designing intelligent learning objects such as the Q&A content object in Appendix A. Another kind of knowledge is the nonformalized domain knowledge based on the data attributes of concepts, which is centrally managed in a domain ontology, thus separating the domain knowledge from the content design and making the domain knowledge in the courseware more scientific and low redundant, such as the conceptual learning content object in Appendix B.
(2) Appendixes A and B show that the content designers (usually teachers) can use the common API communication methods and COE ontology communication data structure provided by our model to design various intelligent learning objects based on the knowledge ontology. More importantly, under our model support, the designer can get rid of the details of the structures and interfaces of various heterogeneous ontologies and focus on learning strategies and content integration. And the designed ICO can be moved and reused in different LMSs.
(3) The experimental results show that our proposed interoperability model for ICOs can be implemented by extending the SRTE, version 1.1.1, of SCORM 2004 fourth edition (ADL, 2009e), which means that our model can be integrated into the future version of the SCORM specification and may provide a reference for the future development of the SCORM specification.
In the future, we will refine the proposed model, including further refining the ITSs’ general knowledge ontology model to support the logical expression expressions, the standardized naming of the basic attributes and relationships for concepts and refining the communication data model for ontology queries, and enhancing the functionality of the API method of ontology queries. Ultimately, a more comprehensive and practical interoperability model is formed and distributed for interested organizations to share.
Footnotes
Appendix A
Appendix B
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work has been supported by the National Natural Science Foundation of China under the contract numbers 61363036 and 61462010.