
Abstract
Course reviews, which is designed as an interactive feedback channel in Massive Open Online Courses, has promoted the generation of large-scale text comments. These data, which contain not only learners' concerns, opinions and feelings toward courses, instructors, and platforms but also learners' interactions (e.g., post, reply), are generally subjective and extremely valuable for online instruction. The purpose of this study is to automatically reveal these potential information from 50 online courses by an improved unified topic model Behavior-Sentiment Topic Mixture, which is validated and effective for detecting frequent topics learners discuss most, topics-oriented sentimental tendency as well as how learners interact with these topics. The results show that learners focus more on the topics about course-related content with positive sentiment, as well as the topics about course logistics and video production with negative sentiment. Moreover, the distributions of behaviors associated with these topics have some differences.
Keywords
Introduction
Massive Open Online Courses (MOOCs) provides new sources of data and opportunities for large-scale experiments that can advance teaching and learning (Reich, 2015). As the advent of learning analytics and educational data mining (Siemens & Baker, 2012), most previous works were mainly conducted from structured data by the quantitative analysis in MOOCs (Halawa, Greene, & Mitchell, 2014; Kizilcec, Piech, & Schneider, 2013; Wen & Rosé, 2014), for example, the statistics of learners' clickstream activities and exam grades, for the purpose of discovering individual preferences, engagement patterns, and revealing the relationship between diverse interactive behaviors, and final performance in MOOCs (Guo, Kim, & Rubin, 2014; Taylor, Veeramachaneni, & O'Reilly, 2014). Nowadays, a large amount of unstructured textual data is produced by the application of interactive technologies in MOOCs, such as discussion forums, course reviews, or chat rooms. By means of these tools, learners are usually willing to express themselves when they engage in the process of learning activities. Therefore, the qualitative analysis of online textual conversations produced by learners can be adopted to obtain in-depth understanding of their implicit psychological features and subtle behaviors. Among various interactive tools in MOOCs, this study is particularly interested in course reviews, which is thought to be more appropriate for our study. Because unlike in forums where learners have more objective technical discussions related to the professional knowledge for specific courses (Brinton et al., 2014; Klisc, McGill, & Hobbs, 2017), course reviews contain more personal concerns and subjective opinions directly related to content of courses, style of instructors, construction of platform, and so forth.
Currently, owing to the ever-growing scale of learners and learners-generated reviews, it is quite time and labor consuming for both learners and instructors to manually read through all reviews for courses. Consequently, this has brought great challenges to observe and track the focused topics hidden in learners-generated reviews. In addition, sentimental detection for different topics is as important as what learners really care about. While learners are encouraged to rate a course after completion, these courses' marks are typically similar such that it is challenging to accurately identify and assess their emotional tendencies. Moreover, merely making an evaluation at the level of domains (e.g., courses and products) is apparently insufficient (El-Halees, 2011; Leong, Lee, & Mak, 2012; Wan, 2011). For example, when a learner hesitates to choose an appropriate course, he or she may want to know not only the topics that other learners frequently talk about (e.g., course content and video production) but also their attitudes toward these topics, such as discontent over the difficulty of course. In this case, it is imperative to discern the latent topics involved in learners-generated reviews and their associated sentiments toward various topics (Ramesh, Goldwasser, Huang, Daumé, & Getoor, 2014; Wen, Yang, & Rose, 2014; Xu, Zhang, & Wang, 2015).
Additionally, it is also critical to understand explicit behavioral tendencies of learners' interaction with the texts in social learning environments. Qiu, Zhu, and Jiang (2013) applied Latent Dirichlet Allocation (LDA) to a Twitter data set, but they found that the interest of topics of some users was hardly distinguished because of their almost identical topic distributions. When examining users' behavioral patterns, they found a significant difference. Furthermore, some of the users were more likely to publish original posts while others mostly tended to engage in interactions such as reply, retweet, and mention. More importantly, Zhao, Cheng, Hong, and Chi (2015) claimed that users typically presented different types of behaviors around different topics in social media. Moreover, by constructing learners' online social profiles characterized from their behavioral signals, more personalized topic recommendations could be accurately provided for different types of behaviors. In a sense, the behavior types (e.g., post a review or respond to a review) should be regarded as an important feature in connecting with learners' evaluated topics.
Therefore, in order to detect learners' focused topics, topics-oriented sentimental tendencies, as well as how learners interact with these topics, this study proposes a machine learning method called Behavior-Sentiment Topic Mixture (BSTM) to promote effective practices in social learning environments, which is an improved unified topic model. In BSTM, both sentiment and behavior features are taken into account on the exploitation of latent semantic topical space of textual reviews. As a result, for learners, they could quickly look at the detailed various aspects of course evaluation (El-Halees, 2011), thus making an optimal choice of which courses are more appropriate; for educators, they could identify learners' psychological problems and get prepared for timely intervention in the learning process (Leong et al., 2012); for administrators, they could refine the function and design of platform to improve learners' interactive experiences (Brinton et al., 2014).
Related Work
In this section, abundant work related to our research is introduced from two following aspects, text mining in E-learning context and sentimental detection and behavioral analysis based on topic model.
Text Mining in E-Learning Context
In the field of E-learning, text mining is regarded as one of the core technologies promoting the application of learning analytics (Leong et al., 2012; Simsek, Shum, Liddo, Ferguson, & Sándor, 2014; Yu & Luna, 2013). Understanding textual contents generated from online learners can uncover their concerns, attitudes, and even behavior motivation. Rather than focusing on the learners' summative assessment in the online education community, the applications of text mining in E-learning are more emphasized to assess the learners' learning process. Such applications have covered a wide range of topics including mining of learners' opinions (El-Halees, 2011; Leong et al., 2012), assessment of learners' knowledge ability (Klein, Kyrilov, & Tokman, 2011), warning of learners' behavioral risks (Ehrenreich, Underwood, & Ackerman, 2014), visualization of learners' profiles (Simsek et al., 2014), and so forth. We note that among these topics, the mining of learners' opinion is more relevant to our study. For example, Yu and Luna (2013) employed the text mining techniques to detect and extract semantic knowledge from comments in an E-learning system. The result demonstrated that the key critical topics and praiseful topics from learners were identified.
Starting from 1994, many prior works have paid attention to the sentimental states of learners in the learning environments (Altrabsheh, Cocea, & Fallahkhair, 2015; O'regan, 2003; Sylwester, 1994). Compared with recognition of physiological features (Woolf et al., 2009), facial expressions (Grafsgaard, Wiggins, Boyer, Wiebe, & Lester, 2013), and speeches signals (Bahreini, Nadolski, & Westera, 2016), text-oriented sentimental analysis is the least invasive for online learners' interaction. Along this way, there are two main lines of researches in the field of sentiment analysis applied in E-learning settings. On the one hand, some studies first adopted opinions mining methods to discern learners' sentimental polarities derived from textual interactive activities toward courses, and then provided dynamic feedbacks for instructors to adjust their teaching methodologies and for learners to enhance their self-awareness (El-Halees, 2011; Kontogiannis, Valsamidis, Kazanidis, & Karakos, 2014; Leong et al., 2012; Rodriguez, Ortigosa & Carro, 2012; Yu & Luna, 2013). On the other hand, some studies tended to explore the relationship between the sentimental tendencies of learners and dropout rate (Adamopoulos, 2013; Ramesh, Goldwasser, Huang, Daumé, & Getoor, 2013, Ramesh et al., 2014; Wen et al., 2014). Interestingly, a novel view was indicated by Wen et al. (2014) that students with positive sentiment were not consistent with an enjoying course experiences, and students with negative sentiment were not consistent with a frustrating course experiences.
Given the current works on the exploration of learners' behavioral interaction and participation of text-based content in the online learning community (Anderson et al., 2012, 2014; Ehrenreich et al., 2014), most of them have simply utilized a series of statistical indicators, such as the number of posts, to discover learners' behavioral differences (Romero, López, Luna, & Ventura, 2013), thus revealing their behavioral regularities and even predicting their academic success (Tobarra, Robles-Gómez, Ros, Hernández, & Caminero, 2014). While these statistical indicators, to some extent, can be beneficial to explain learners' behavioral preferences and profiles, it is not sufficient to get a deeper understanding of behavioral analysis. This is because these behavioral indicators do not map any semantic information-hidden textual contents.
Sentimental Detection and Behavioral Analysis Based on Topic Model
Since the growing amounts of electronic archives or corpus has brought administrators huge burdens in categorizing and querying, it is almost impossible for them to accomplish this task just depending on human intervention. To tackle this problem, Blei, Ng, and Jordan (2003) proposed the LDA model for the first time, which was known as a popular unsupervised topic model that could automatically identify potential thematic meaning in large-scale textual sets. In subsequent years, extending on the basic LDA, many variants considering the dimension of time (Fu, Yang, Huang, & Cui, 2015), topical structure (Grimmer, 2010), and metadata information (Ramesh et al., 2014) had been applied in diverse fields. However, these researchers often offered an automatic process for detecting potential textual topics without considering the feature of sentiment, especially in the context of online education. In recent years, the studies on topic modeling are presented by combining topic and sentiment collectively in a document. From the view of unified model generated, it has shown to be superior to a single topical language model. For example, Mei, Ling, Wondra, Su, and Zhai (2007) first introduced a novel probabilistic model called Topic Sentiment Mixture (TSM), in which sentiment is considered as a topic independent language model and each word came from either certain topic or sentiment. Ramesh et al. (2013, 2014) proposed a probabilistic soft logic model, which embeds substantive linguistic features derived from seeded topic analysis, in order to extract topics and the corresponding polarities of sentiment of forum posts in MOOCs. These models do not establish a clear mapping relation between topics and sentiments and therefore cannot be explicitly used to separate topics and sentiments. Jo and Oh (2011) extended Sentence-LDA to Aspect and Sentiment Unification Model (ASUM), which could discover pairs of sentiments and topics. ASUM posited that each document was a mixture over positive and negative sentiments, and each sentiment drew the probabilistic distribution over the specific evaluative topics. By contrast, BSTM focuses on discerning a series of underlying topics in each review and these topics' corresponding sentimental polarities.
As a well-known social scientist Erving Goffman (1978) said, people created different images to other audiences in their everyday life and engaged in conversations with different topics. In other words, they usually interacted with different topics by using different types of behaviors. Zhao et al. (2015) employed a matrix factorization technique to build a topic recommender, for improving user's topical interest profiles according to their various behavioral signals. Their results showed that this technique was capable of providing more personalized topic-based content recommendations by separating a user' profiles into several behavioral profiles. Although this study does not adopt the method of topic modeling, it clearly indicates that user behavior types should be utilized as an important contextual feature. A similar work to our study, Qiu et al. (2013) introduced an LDA-based behavior-topic model combining user topic interests and behavioral patterns in online social network settings. Nevertheless, these studies usually ignore the distinct feature of sentiment derived from textual content which has not been well embedded in the existing topic models. By contrast, sentiment information on evaluating the detailed topics of reviews and behavior information on expressing these specific topics are all considered to guide the generative process of BSTM. Furthermore, because of the discrepancy of context, the existing models may not be applicable to the analysis of online learners' course reviews in MOOCs settings.
Research Questions
Many researchers have made great progress in discerning the collection of hidden topics and the corresponding sentiments toward these topics effectively in the field of business intelligence (Jo & Oh, 2011; Xu et al., 2015) and social network (Fu et al., 2015; Mei et al., 2007). Until now, only a few studies have incorporated behavior feature derived from their interactions with the textual contents into topic modeling in social medial platforms (Qiu et al., 2013; Zhao et al., 2015). However, to the best of our knowledge, there are no studies simultaneously incorporating sentiment and behavior features into topic modeling, in order to automatically discover sentimental and behavioral tendencies of learners' concerned topics in social learning setting. Therefore, this study puts emphasis on the automatic analysis of course reviews from the three dimensions including topic, sentiment, and behavior detection in a MOOC platform. Additionally, in view of the optimization of experimental results, the effectiveness of our proposed BSTM needs to be validated. More specifically, this study targets at four research questions described as follows:
Compared with the standard models, can BSTM achieve better performance? And how to determine the suitable number of topics to ensure the best performance of BSTM? What are the most concerned topics mined from course reviews among learners in a Chinese MOOC? What are the associated sentimental tendencies toward learners' concerned topics? How do learners interact with their concerned topics?
BSTM Analysis Model
To answer the above four questions, a unified topic model called BSTM model is proposed in this section, which will be utilized in exploiting implicit topics, emotion information, as well as explicit interactions inferred from online learners' course reviews in a MOOC.
Study Preparation
Seed words: Seed words are commonly consisted of basic features represented by coherent concepts that make up a topic and are closely related to courses. Some of them are selected from the course syllabus and collected from nonstandard Web words generated from learners, for example, “学神/super scholar” and “潜水/lurk.” Sentiment words: Sentiment words, which contain subjective emotions, are usually used to express individual opinions, attitudes, and views toward diverse aspects. In our study, a Chinese sentiment lexicon is set up, including 9,594 positive words and 12,884 negative words, that is, a total of 22,478 sentiment words. Behavioral categories: In the Chinese MOOC platform called Guokr Web, learners are able to post reviews, reply to reviews, like reviews, and even show their earned certificates. Note that showing earned certificate is a special behavior and is considered as an effective incentive to encourage learners to increase their learning participation. For learners, it may show a kind of self-affirmation. Review structure: A review consisted of several sentences, each of which is assumed to be a specified topic, a corresponding sentiment label, and a dominant behavior. Each sentence is composed of several words, and each one either belongs to topic-specific words or sentiment words.
Model Description
BSTM is an extension of Sentence-LDA (Jo & Oh, 2011) that imposes a constraint that all words in a single sentence are generated from one topic on a sentence level, instead of a document level for each word corresponding to one topic. It assumes that when generating one sentence of a review, we first choose a distribution of a mixture of several topics. Then, a topic is randomly sampled from the distribution and this topic follows a Bernoulli distribution of sentiment. Finally, each word of one sentence is randomly sampled from the chosen pair of topic-sentiment. Thus, more fine-grained topics with the distribution of sentiments and behaviors can be directly identified. In other words, our model is able to not only uncover what learners say but also present how they say as well. Figure 1 illustrates the graphical representations of BSTM.
Behavior-sentiment topic mixture model (BSTM).
Descriptions of Notations of BSTM.
Here, BSTM model will be described in detail. First, we assume that a total number of L learners participate in interacting with course reviews. Each review is composed of several sentences and each sentence corresponds to only one topic. Let r be subreviews of m-th sentence, then each review can be denoted as The generative process for all learners' reviews in BSTM.
Parameter Estimation
In BSTM model, w is an observed known variable; Dirichlet prior parameters α, β, γ, and η are generally assigned based on our previous researches. The rest latent variables θ, ϕ, ψ, and π need to be estimated by the above known variables. The Gibbs Sample method proposed by Griffiths and coworkers (Steyvers & Griffiths, 2007) has shown to be effective to work out the appropriate parameter estimation problem. A joint conditional probability distribution incorporating behavior and sentiment information is given by

The approximate probability distribution of word w for topic k is

The approximate probability distribution of behavior b for topic k in sentence m is
The approximate probability distribution of sentiment j for topic k sentence m is

In this way, the variables learner-topic θ, topic-word ϕ, topic-behavior ψ, and topic-sentiment π are calculated, respectively, which enables us to observe the detailed evaluation information related to courses.
Method
This section describes the basic information of the subjects in this study, as well as the process of data collection and data analysis.
Participants
From January 2014 to June 2016, the dataset was retrieved from a MOOC platform, namely Guokr Web (mooc.guokr.com), which is one of the most popular MOOCs learning platforms in China. A total number of 6,556 unique learners enrolled in the top 50 rated courses (e.g., language, literature, finance, science, engineering, and management) in the platform. Their age is generally between 12 and 50, and most of them come from developed provinces or cities in China. In addition, the average number of participated courses for them is more than one. Besides, these learners posted at least one comment during or after the course. Note that this platform allows the users and organizations to analyze the online MOOC data just for the aim of research and management without learners' identification. In addition, our study does not use and reserve learners' personal information, such as names.
Data Collection
The Properties of the Data Sets.

The Coding Scheme of Learners' Interactive Behaviors.

Data Analysis
To detect sentimental and behavioral tendencies of learners' concerned topics that were hidden in the 12,524 course reviews, an improved unified topic model BSTM was developed and a two-stage content analysis was conducted. In the first phase, we used a quantitative analysis method to evaluate the effectiveness of the model for the first research question (see Research Questions section). In the second phase, the model generation technique was adopted to detect the potential topics learners were willing to evaluate in course reviews, topics-sentiments distributions, as well as topics-behaviors distributions for the second to fourth research questions (see Research Questions section). In addition, we also adopted descriptive statistics to compute the average probability of typical topics, between sentimental value of topics and behavioral probability correlation coefficient, and so on. The significant alpha was set to .05.
Results
This section presents not only the evaluation results for BSTM but also the results of the frequent topics learners discuss most, topics-oriented sentimental tendencies as well as how learners interact with these topics.
Evaluation Measures for BSTM
In this part, our proposed topic model BSTM is evaluated from two aspects. First, to validate the effectiveness of BSTM, a comparison with other two standard models (LDA and T-LDA) was made. Second, to ensure the best performance of BSTM, the number of topics was determined.
Comparison of model effectiveness
It is acknowledged that LDA is expected to obtain the distributions of topics over words which are easy to be distinguished from each other. In this case, BSTM aims to capture different topics, which are closely related to specific dominate behaviors and sentiments. To validate the effectiveness of BSTM integrating with the behavior and sentiment features, an empirical study on topical extraction is performed. The Kullback–Leibler (KL; Mei et al., 2007) divergence is generally used to calculate the similarity between two pairs of probability distributions. The smaller the KL score, the more distinct the different topics. In our study, we use it to measure the similarity of distributions of topics from T-LDA (Zhao et al., 2011), BSTM, and LDA over behaviors and sentiments. Here consider the computation of distribution of topic-behavior as an example. The equation of KL is as follows:

Since the KL divergence is asymmetrical, in this work, the average KL divergence is adjusted between them for a symmetric measurement by the following formula:
In BSTM, P k,b and Q k,b are equal to ϕ k,b . Note that T-LDA makes an assumption that each comment containing a series of words is only associated with one topic, and LDA constrains that each word within one review is assigned with one topic. In this case, the computation of co-occurrence of behaviors within one topic is different for T-LDA, BSTM, and LDA.
The purpose of this study focuses on the combination of behavior and sentiment features with topic analysis. Compared with T-LDA and LDA, BSTM obviously has a lower KL divergence score as presented in Figure 3(a) and 3(b), which indicates that the distributions of behaviors toward different topics are more effectively distinguishable and separable from each other, as in the case with the distributions of topics-sentiments. Thus, embedding behavior and sentiment features into topic modeling are verified for our experiments.
Comparison for T-LDA, BSTM and LDA, with levels of KL. (a) The dissimilarity of topics corresponding to behavior distribution and (b) The dissimilarity of topics corresponding to sentiment distribution.
Determining number of topics
To get a better model, we utilize a parameter turning way to repeatedly conduct tests. The Dirichlet prior parameters α, β, γ, and η are empirically assigned with 0.1, 0.01, 0.1, and 0.1, respectively. Besides, the number of topics is known as a critical factor. Our study bases on the computation of Perplexity, Similarity, Entropy (PSE) parameter, which is a comprehensive quantitative evaluation index including perplexity (Fu et al., 2015), similarity (Mei et al., 2007), and entropy (Qiu et al., 2013), to determine the suitable number of topics, thus effectively improving the performance of BSTM. The detailed formal description about the related parameters is presented as follows. PSE is a rational comprehensive assessing index, with a smaller value being preferred and is given by
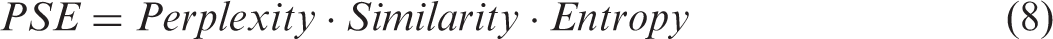
The experiment is performed gradually to determine the number of topics. First, for each test, the total number of iterations is set to 500 and the initial number of topics is set to 20. Then, 20 topics are added in each experiment until the value of PSE is smaller and more stable.
As shown in Figure 4, with the increase of numbers of iterations, the fitting rate of model becomes fast. All of the curves reach a steady state after 400 times sampling. It can also be clearly observed that when the number of topics is equal to 100, the values of PSE are no less than the curves with different topic numbers. This means that there is no slight decline when the number of topics is set to 80 and the performance of our model is difficult to be improved. Hence, 80 topics are chosen for further investigation in our study.
PSE values for varying number of topics (K).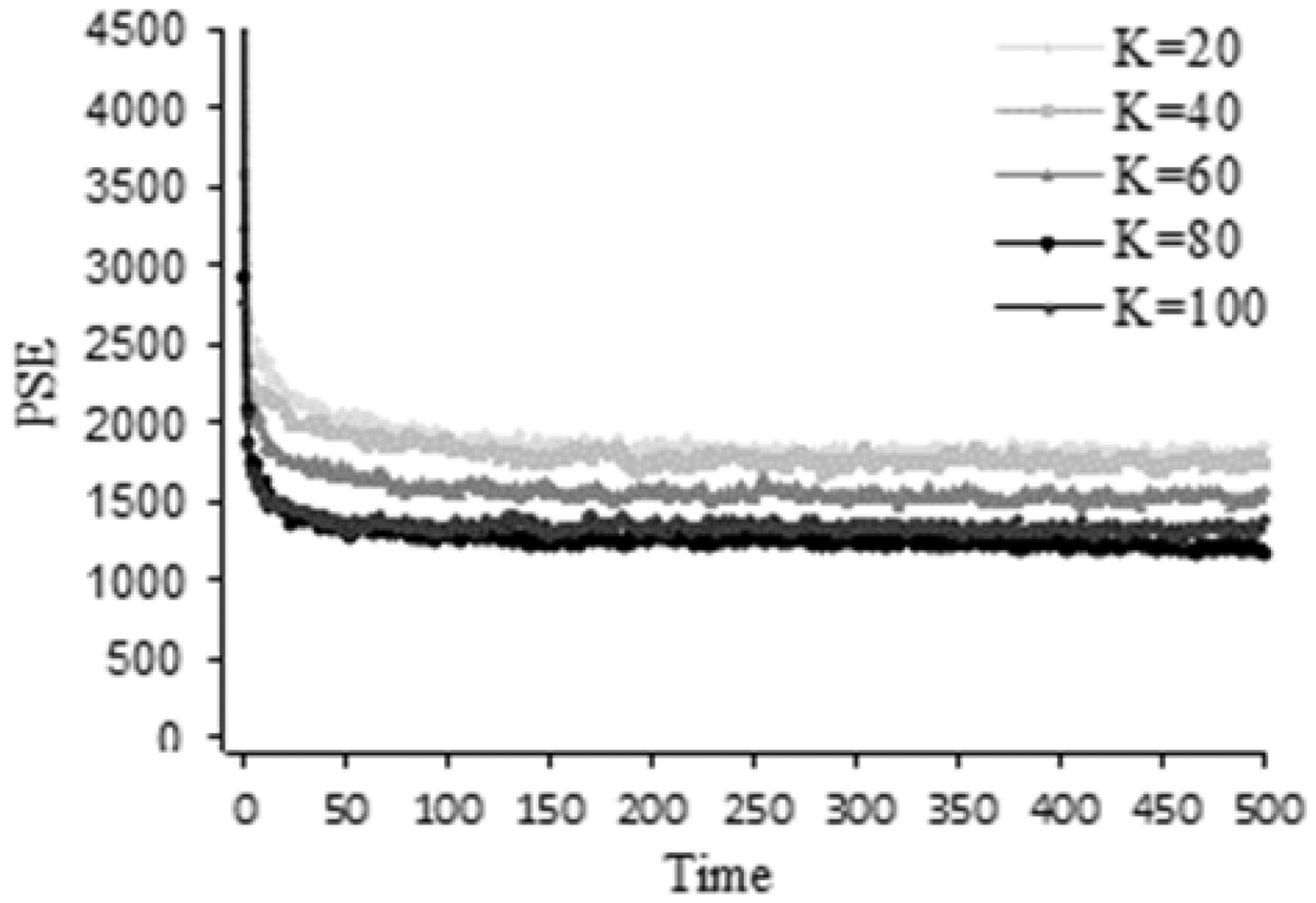
Discovery of Typical Topics From Online Learners' Course Reviews
Top Five Topics and Their Probability of Occurrence of Typical Words.

As shown in Table 4, Topic 76 with the probability ratio of occurrence in all reviews maintains at 7.2%, far higher than the average rate 1.25%. Evidently, Topic 76 is one focused topic among online learners with the highest probability. The topic is mainly about course content. Through observing its detailed fine-grained semantic information, we find that most of learners in MOOCs are concerned about the quality and organization of course content. Topic 61 is likely related to a history course named “Records of the Grand Historian,” which is one of the China's famous ancient history. Topic 27 is mainly about the courses related to machine learning or mathematical statistics. It is notable that unlike the above topics, Topic 35 mainly refers to course logistics, including time of exam, accomplishment of exercises, and acquirement of certificates; Topic 78 mainly involves video production, including language of caption and link of download, and so forth.
Detection of Sentimental Tendencies Toward Learners' Concerned Topics
Top Five Topics and Their Corresponding Sentiment Words.
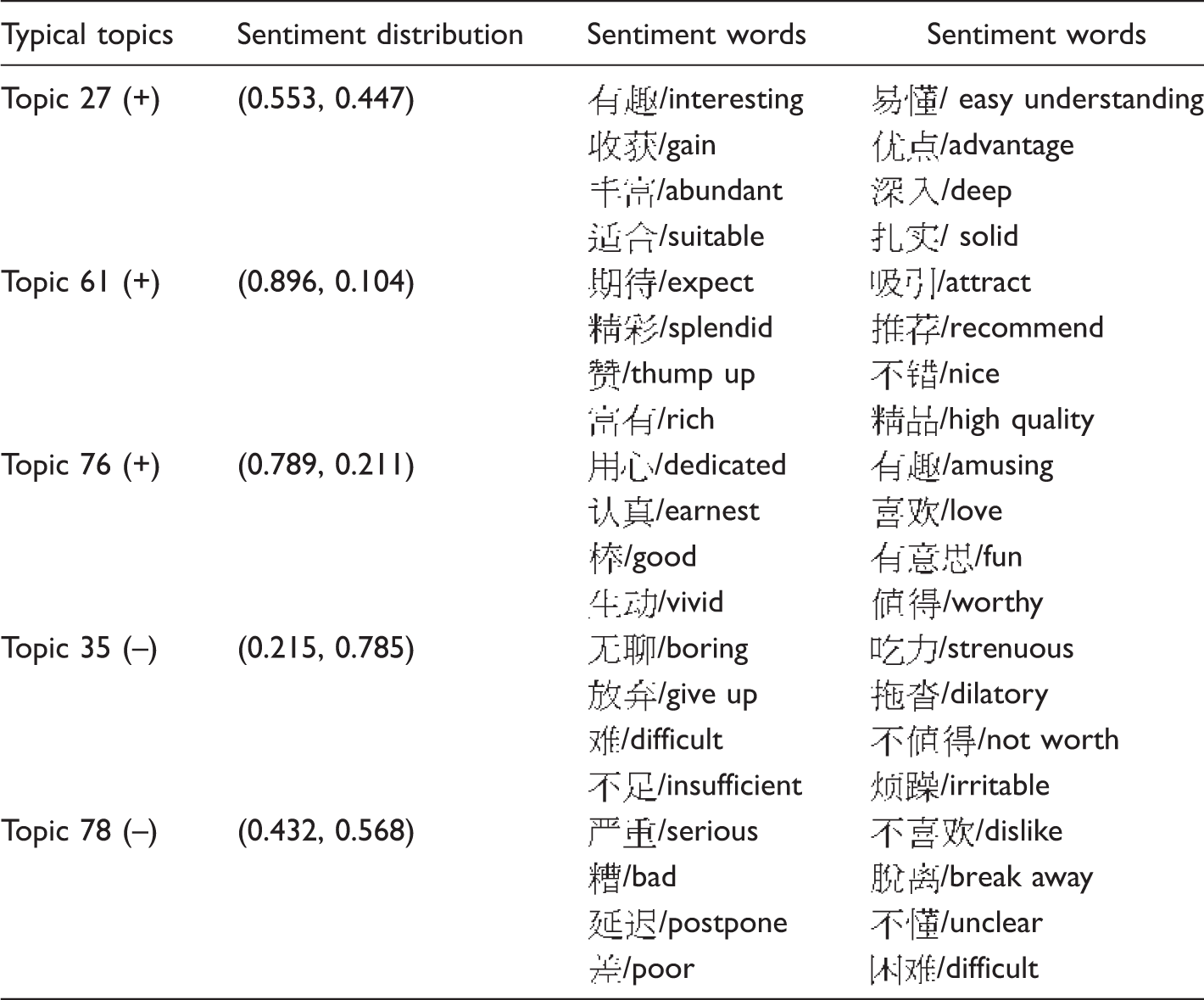
To detect the sentimental tendencies of learners' concerned topics, the experimental results involved in five prominent topics are presented in Table 5. We find that these most frequent topics discussed are assigned with either positive sentiment or negative sentiment, which to some extent could reflect learners' general sentimental states about them. Taking Topic 76 with highest probability as an example, we find that learners make a positive evaluation toward course content which is interesting, vivid, good, and worthy of learning. In particular, sentiment distribution for each topic is obviously different and needs to be further discussed.
The positive probability 0.789 of Topic 76 is much greater than its negative probability 0.211, which is different to the sentimental distribution of Topic 27. While Topic 27 is assigned to be positive as a whole, its positive sentiment probability 0.553 is slightly higher than its negative sentiment probability 0.447. This implies that learners hold a relatively neutral attitude toward Topic 27. In this case, a positive topic is more likely to be transformed to a negative one because of sentiment propagation (Zhao et al., 2014). Hence, instructors need to attach importance to this kind of “unsteady” topic. Absolutely, understanding the evaluation contents of negative topics is also essential (Mcgivern & Noret, 2011), which is beneficial for instructors to optimize design of course and improve learners' participation, especially when they encounter learning difficulties or other objective problems in accessing to learning resources. For example, the negative Topic 35 about course logistics is boring, difficult, and insufficient, with a higher negative sentiment probability 0.785; the negative Topic 78 about videos production is serious, postponed, and unclear, with a lower negative sentiment probability 0.568. Thus, we have reasons to believe that the existing problems within Topic 35 should be indeed given precedence.
Learners' Concerned Topics Separated by Dominant Behavioral Tendencies
Like topic-sentiment distribution, behavior is also thought of as a special property within topics in our proposed model. The close examination should be conducted to investigate how learners interact with topics while the focused topics discussed most among learners and their associated sentimental tendencies toward these topics have been identified.
Statistics About Dominant Behaviors Among All Learners.

Different Behavioral Tendencies for Typical Topics.

As shown in Table 7, there exists a certain difference in the four behavioral distributions associated with different topics. Topic 76 is mainly dominated by three behaviors of PO, LI, and SC; Topic 61 and Topic 35 is mainly dominated by PO and SC behaviors; Topic 27 is mainly dominated by PO and LI. This suggests that learners tend to post or like reviews to express their personal opinions and attitudes toward most focused topics, whereas they rarely choose to reply to others' original posts. Note that different from other typical topics, Topic 78 about video production is mainly dominated by just one behavior RE, which indicates that this topic attracts more learners to reply to others' reviews. Moreover, for each typical topic, most of learners are willing to show earned course certificates when they post reviews. For them, this behavior may be regarded as same as getting the badges of honor which brings incentives for their engagement (Anderson et al., 2014). Specifically, an interesting phenomenon is that Topic 61 and Topic 35 almost share the same distribution of behavior but are related to the different topics and different sentiment polarities. In addition, we performed a correlation analysis between 4 dominant behaviors and all 80 sentiment topics (56 positive topics and 24 negative topics). As a result, only RE presents a significant negative correlation to topics with a higher positive probability (r = −0.269, p < .05). That is, learners tend to express more negative topics when replying to others' posts. Intuitively, LI should be related to the topics with a higher positive probability, yet it seems that there does not exist any correlations between them. This indicates that learners may give others' reviews a thumbs up about both positive contents and negative contents in an irregular way.
Discussion
The results of our study find that several prominent topics which are frequently discussed among learners have been labeled with different sentimental polarities (either positive or negative), and these topics have different sentimental distributions. A particular case is that one topic is assigned to the positive sentiment probability and negative sentiment probability with similar values. For example, the sentiment distribution of Topic 27 about machine learning is denoted as (0.554, 0.445). Although it is labeled as a positive topic, this topic is prone to be a negative one owing to the characteristics of sentiment propagation (Zhao et al., 2014). In addition, it is imperative for instructors to focus on negative topics like 35 about course logistics with higher negative sentiment probability preferentially. These negative topics spread fast (Mcgivern & Noret, 2011) and considerably go against the development of a harmonious and steady online learning community. And they may be responsible for online learners' low participation rate as described by Wen et al. (2014). Thus, in this case, to avoid the negative effects of topics on learners, instructors should take mediate measures in time to regulate and guide the interactive process of discourse context. As Shattuck and Anderson (2013) suggested, lack of clear and practical guidelines may lead to learners' fear and resistance.
A correlation analysis was conducted between 4 dominant behaviors (PO, LI, RE, SC) and all 80 topics with different sentimental polarities. The result shows that there is only one behavior RE closely related to the sentiment probability regarding topics and the RE behavior has a significant negative relevance with the positive sentiment probability. This implies that learners are more inclined to express negative sentiment toward concerned topics by replying to others' review. This case is very interesting and may be related to some specific topics. In addition, there is no direct correlation between the LI behavior and the positive sentiment probability toward topics. That is, learners tend to give others' reviews a thumbs up about both positive and negative aspects. One of the reasons may be that the LI behavior is easily followed among learners and is exclusively concerned with the text contents of the reviews (Sherman, Payton, Hernandez, Greenfield, & Dapretto, 2016).
Although the topic about course content discussed among learners has a higher probability, which are mainly dominated by the PO and LI behavior, only a small proportion of learners tend to reply to others' reviews about this topic. Unlike this topic, while the topic about video production discussed among learners has a lower probability, it actually attracts more learners to take part in responding with a higher behavior probability. With respect to the above two types of topics, the latter type can be thought to be a more enriched interactivity than the former one. Kiemer, Groschner, Pehmer, and Seidel (2015) remarked that courses with more interactive dialogues could significantly improve learners' internal motivation and behavioral participation. Therefore, it is necessary for instructors to pay more attention to this type of topic with more interactive discussions. Moreover, according to the results of learners' focused topics with diverse behavioral patterns, instructors are able to provide more adaptive and accurate recommendations for different learners, such as peers' reviews.
Previous studies have pointed out that reading through and searching for reviews was extremely time consuming (Jo & Oh, 2011; Wang, 2011; Xu et al., 2015) and thus difficult to operate repeatedly. Hence, compared with the traditional method of postcourse interviews and questionnaires, the method of unsupervised topic modeling BSTM may be a useful and practical alternative for course evaluation, and still needs to be further investigated.
Conclusion, Limitation, and Future Work
This study proposes a unified topic model BSTM by embedding the behavior and sentiment features into the computational analysis of large amounts of learners-generated course reviews in a MOOC. Compared with the benchmark model, BSTM has shown to be dominant. Furthermore, it can be generalizable to other types of learning contexts and can also be utilized in many potential applications such as opinion tracking, course-oriented review summarization, and behavior-driven personalized recommendation. Empirical experiments on real MOOC reviews data show that this approach is effective for automatically exploring the learners' concerned topics, topics-oriented sentimental tendencies, as well as how learners interact with these topics.
Thus, understanding the hidden feedbacks from course reviews can help instructors and administrators conduct timely teaching intervention when learners encounter dissatisfactions (e.g., lecture is boring, homework is difficult) and improve platform construction.
There are, however, still some limitations, which may lead to many directions for future work. First, the specific conditions in a Chinese MOOC by using BSTM may limit the ability to explain the findings of experimental analysis. To further generalize this model in other study contexts, a set of specific rules of phrase segmentation and sentence-oriented sentiment annotation depending on the context should be reconstructed. Second, since our model belongs to an unsupervised method in the field of natural language processing, the computational results should still be examined through logical reasoning, which may cause slight deviations on the obtained results. In such case, human efforts may be required to label textual contents afterwards. Third, because the number of learners' concerned topics is relatively large, it is, to some extent, difficult to elaborate all topics in conjunction with some detailed information like these topics' sentimental and behavioral tendencies. Therefore, how to exhibit these hidden valuable information in a visualized way, in which ought to be in accordance with learners' cognitive preferences (Jyothi, McAvinia, & Keating, 2012; Simsek et al., 2014), is worthy of more attentions. Finally, there seem to be some correlations among topics within the courses. Thus, it is necessary to determine these special relationships and group them for better understanding the potential semantic structure space of course content.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Research funds from the China Mobile Research Foundation of the Ministry of Education (Grand No. MCM20160401) the Research Funds from National Natural Science Foundation of China (Grant No. 61702207, L1724007).