
Abstract
Virtual reality (VR) has a high potential to facilitate education. However, the design of many VR learning applications was criticized for lacking the guidance of explicit and appropriate learning theories. To advance the use of VR in effective instruction, this study proposed a model that extended the cognitive-affective theory of learning with media (CATLM) into a VR learning context and evaluated this model using a structural equation modeling (SEM) approach. Undergraduate students (n = 77) learned about the solar system in a VR environment over three sessions. Overall, the results supported the core principles and assumptions of CATLM in a VR context (CATLM-VR). In addition, the CATLM-VR model illustrated how immersive VR may impact learning. Specifically, immersion had an overall positive impact on user experience and motivation. However, the impact of immersion on cognitive load was uncertain, and that uncertainty made the final learning outcomes less predictable. Enhancing students’ motivation and cognitive engagement may more directly increase learning achievement than increasing the level of immersion and may be more universally applicable in VR instruction.
Introduction
Virtual reality (VR) is a fully-immersive 3-D multimedia environment where individuals can interact with a computer generated world (Aukstakalnis & Blatner, 1992; Milgram & Kishino, 1994; Onyesolu & Eze, 2011; Oxford, 2019). VR offers powerful affordances related to 3-D immersion, spatial representations, and multi-sensory cues (Salzman et al., 1999; Shin, 2017), and these characteristics allow learners to experience real or imagined environments that might be otherwise inaccessible (Huang & Roscoe, 2021). Prior studies have demonstrated learning from VR when studying microscopic processes (e.g., chemical reactions; Bennie et al., 2019), large-scale processes (e.g., solar system events; Huang et al., 2021), dangerous processes (e.g., emergency in mines; Grabowski, 2019), or processes too difficult or expensive to explore in real life (e.g., construction; Angulo & Velasco, 2014). In addition, other research has found that VR can enhance spatial knowledge, intrinsic motivation, and transfer of new abilities to real-world situations (Huang, 2019; Ragan et al., 2015; Timcenko et al., 2017).
However, in a recent review of 59 publications (published between 2009 and 2018) on VR learning applications for higher education, Radianti et al. (2020) observed that about two-thirds of these articles did not incorporate an explicit learning theory. This issue is crucial because design and implementation of effective educational technology interventions is enhanced by grounding such work in testable theoretical models of learning (Granić & Marangunić, 2019; Valverde-Berrocoso et al., 2020). These models provide insight into fundamental learning processes and outcomes, which in turn inform decisions about technology features and pedagogy. Radianti et al. (2020) further argued that many extant learning theories do not include elements specifically related to learning with VR (e.g., immersion, presence, or embodiment). Thus, a substantive amount of work in the field of VR learning may be either unguided by a clear model of learning or may be using models that are incomplete. To advance the use of VR in effective instruction, it may be useful to extend and test learning theories for use in that context.
The cognitive-affective theory of learning with media (CATLM) is a popular model among VR learning researchers and developers, and represents a very plausible and straightforward candidate for elaboration based on VR learning principles (Mayer, 2020; Moreno & Mayer, 2007). In brief, CATLM is a theory for understanding learning with instructional materials beyond words and images (e.g., manipulatives). This theory articulates mechanisms for meaningful learning that may occur when learners directly interact with the instructional system (e.g., dialogue, control, and manipulation) in a multimodal learning experience (Moreno & Mayer, 2007). The advantages of including different types of sensory interactions (e.g., auditory, visual, and tactile) and different domains of human functioning (e.g., cognition, motivation, and emotion) make CATLM seem an ideal foundation for understanding the VR learning process. CATLM has been credited in the design of computer simulations, computer-based instruction, online learning, and serious games (e.g., Domagk et al., 2010; Krämer & Bente, 2010; Plass & Schwartz, 2014; Ritterfeld et al., 2009; Sosa et al., 2011). With regards to VR learning, CATLM has been used to define the parameters and evaluation of user experience and user-centered instructional design, such as visualizations (Birt et al., 2015), human-robot collaboration (Shu et al., 2019), teaching concepts, and procedures (Ta, 2018); and to inform pedagogy for increasing learning performance, such as knowledge construction (Spek et al., 2008), knowledge transfer (Petersen et al., 2020), and behavior involvement (Sajjadi et al., 2018).
Importantly, as a theory developed before the most recent boom of VR technologies, CATLM may not fully encompass VR learning for two reasons. First, CATLM assumes that motivation affects learning in an interactive multimodal environment (e.g., VR) (Leutner, 2014). However, CATLM does not include several essential constructs of VR environments (e.g., immersion, presence, and embodiment) that may have connections with motivation in VR learning (Johnson-Glenberg, 2018; Parong & Mayer, 2018). As a result, the model does not specifically articulate the claim that motivation would be important for VR learning. Second, in the field of VR, the model has been used to influence design principles but has not been fully validated (Makransky et al., 2019; Mayer, 2020). There is a lack of evidence assessing how and whether elements of VR design (e.g., level of immersion) and elements of CATLM (e.g., cognitive load) indeed interact to influence learning.
Current Study
The purposes of this study are to (a) extend CATLM for VR learning and (b) to evaluate the applicability and validity of the resulting model. Specifically, we briefly summarize CATLM principles and assumptions and then suggest extensions to this model based on VR learning environments. This review results in an updated theoretical model with multiple testable hypotheses. We then describe a study in which undergraduate participants learned with different VR formats over several sessions. Data were collected on participants’ learning performance along with their subjective experiences of presence, embodiment, motivation, and cognitive demands. Structural equation modeling (SEM) methods are then used to explore relations among variables and test whether these connections align with our extended model of CATLM for VR.
Extending Cognitive-Affective Theory of Learning with Media for Virtual Reality Contexts
Overview
A total of nine variables and 20 hypothesized relationships are articulated within our extended model. Among these concepts, five are sourced directly from CATLM (i.e., prior knowledge, cognitive load, cognitive engagement, motivation, and learning achievement) and four are added from the literature on VR learning (i.e., VR format, embodiment, presence, and time). In this research model, three concepts (i.e., VR format, time, and prior knowledge) are defined as external variables. The remaining concepts are recognized as constructs. It is worth noting that cognitive load is operationalized here as a two-level construct with two subordinate constructs: extraneous cognitive processing and essential cognitive processing. Figure 1 visually summarizes the hypothesized research model. Subsequent sections provide more specific details and explanations of the model components. Hypothesized model.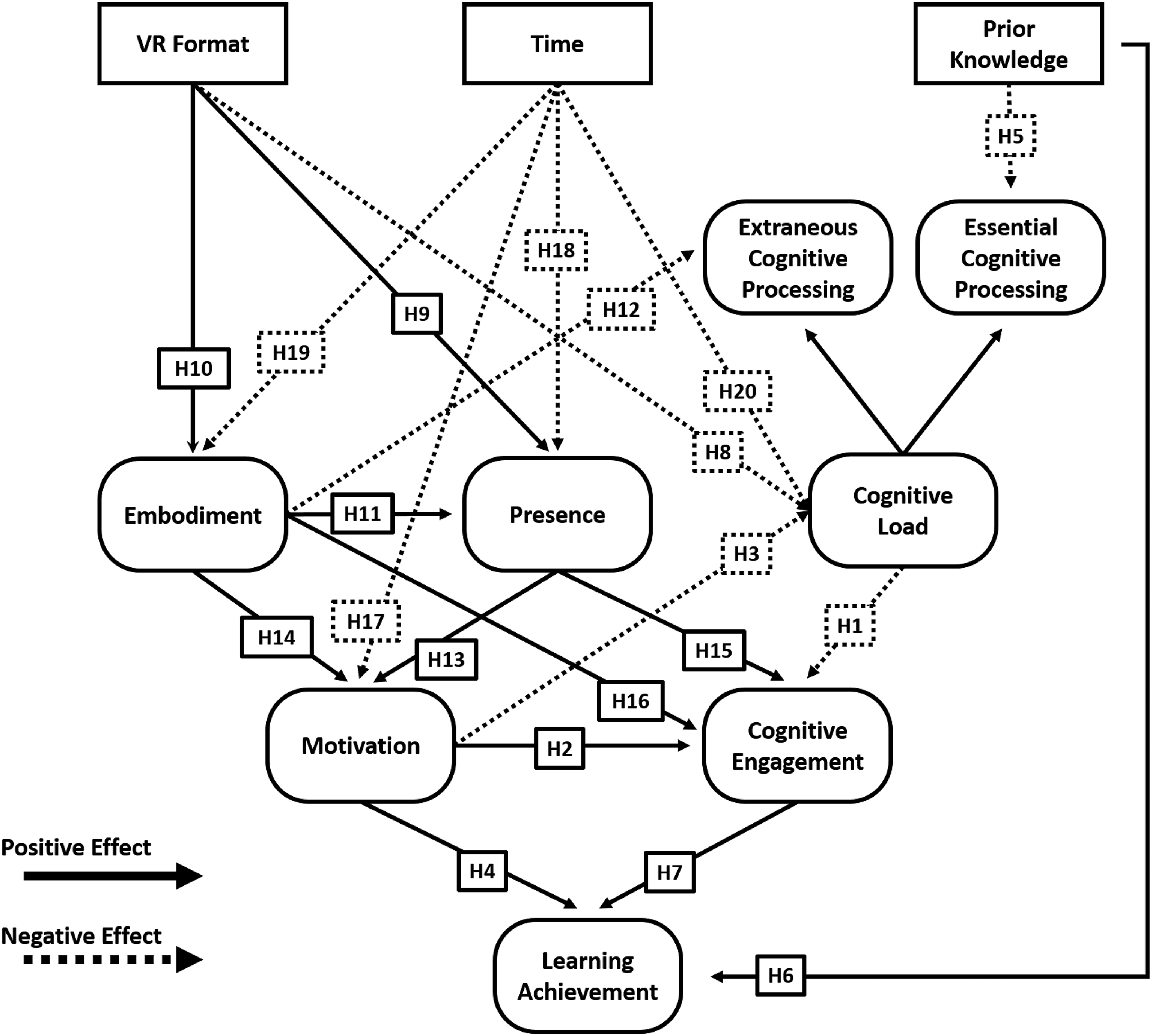
Foundations of Cognitive-Affective Theory of Learning with Media
CATLM (Moreno & Mayer, 2007) provides a coherent perspective for learning in interactive multimodal environments—learning environments that may combine text, narration, illustrations, music, and/or sound effects. Prior articulations of CATLM are based upon evidence-based observations of human cognition and affect, which give rise to several core constructs that directly or indirectly influence learning: cognitive load, cognitive engagement, motivation, and prior knowledge.
With regard to design, various formulations have described two or three aspects of cognitive processing that must be considered. Essential processing refers to processes inherent to the task and learning (e.g., noticing and selecting relevant information), and extraneous processing occurs when learners must contend with irrelevant information or distracting details that contribute minimally to the task (e.g., a confusing interface). Both essential and extraneous processing represent cognitive load due the design of the multimodal learning environment (Kalyuga, 2011). In contrast, generative processing entails cognitive engagement that extends beyond inherent requirements in order to facilitate recall and comprehension (e.g., self-explaining and self-questioning learning strategies) (Chi et al., 2018; Kalyuga, 2011; Mayer, 2020; Sweller, 2010). Deeper cognitive engagement may also include metacognitive processes for self-evaluation and regulation (Adadan, 2020; McGuinness, 1990; Moreno & Mayer, 2007). Such engagement represents learners’ in-the-moment learning experience (Boyle et al., 2012; Shernoff & Strati, 2011), sometimes characterized by higher intensity of arousal, attention, involvement, and persistence (Cordova & Lepper, 1996; Garris et al., 2002; Parker & Lepper, 1992).
According to CATLM, motivation positively influences learners’ cognitive engagement (i.e., generative processing) (Kuldas et al., 2014; Roets et al., 2008; Schnotz & Kürschner, 2007). In academic settings, motivation can be defined as a desire to learn or improve achievement (Mayer, 2020), and strongly motivated individuals are more likely to use strategies (e.g., Holmes, 2018; Schiefele, 1991) to reduce extraneous processing, manage essential processing, or foster generative processing (Mayer, 2020). Motivation can reduce the perceived effort (i.e., perceived cognitive load) associated with a learning task (Song et al., 2019), and a higher degree of cognitive engagement is sometimes associated with a flow state (Csikszentmihalyi, 1997; Whitton, 2011). Motivation also seems to maintain attention to the learning task and encourage persist when difficulties are encountered (Svinicki, 2004). There is an overall positive relationship between motivation and learning performance in classroom teaching (Keller, 2010; Lee et al., 2010; Lepper & Iyengar, 2005; Pintrich, 2003).
Within CATLM, prior knowledge has at least two effects on learning in an interactive multimodal environment. First, prior knowledge supports learners in identifying and selecting useful information (Mashfufah et al., 2019). Second, prior knowledge facilitates constructing new knowledge based on new information (Altas, 2015). Learners with more extensive domain knowledge and expertise can better pay attention to new relevant information and build upon their existing knowledge (Barab et al., 2007). In other words, their required essential cognitive processing is reduced. In addition, prior VR learning research shows that pre-training of background information can promote further knowledge gains (Petersen et al., 2020). Overall, instructional designers can implement a variety of methods to help learners activate and apply their prior knowledge and pursue more optimal cognitive and metacognitive strategies in interactive multimodal learning environments (McGuire, 2015; Moreno & Mayer, 2007) such as guided activities (e.g., Plass & Kaplan, 2016), problem solving (e.g., Hou & Li, 2014), self-explaining (e.g., Hsu et al., 2012), prompts for reflection (e.g., McConnel, 2018), explanatory feedback (e.g., Johnson et al., 2017), pace control (e.g., Biard et al., 2018), and pre-training (e.g., Petersen et al., 2020; Pineda, 2015).
Learning with Virtual Reality
A number of VR developers and scholars have drawn upon principles relevant to CATLM to guide their work (e.g., Makransky & Lilleholt, 2018; Schrader & Bastiaens, 2012; Tcha-tokey et al., 2018), and VR learning appears to be within the scope of CATLM (see Moreno & Mayer, 2007). Nonetheless, unique aspects of VR inform several constructs that might be added to further tailor CATLM to the VR context. Specifically, the immersive nature of VR can contribute to learners’ sense of existing within the virtual environment (e.g., Shin, 2017; Shin et al., 2013; Tcha-tokey et al., 2018), and VR tools (e.g., motion tracking and headsets) can afford varying degrees of physical sensations, movements, gestures, and interaction with virtual objects (Johnson-Glenberg, 2018). Overall, considerations of VR learning suggest four elaborations of CATLM for VR: VR format, presence, embodiment, and time.
A Comparison of the Oculus Go and the Oculus Rift VR Systems.
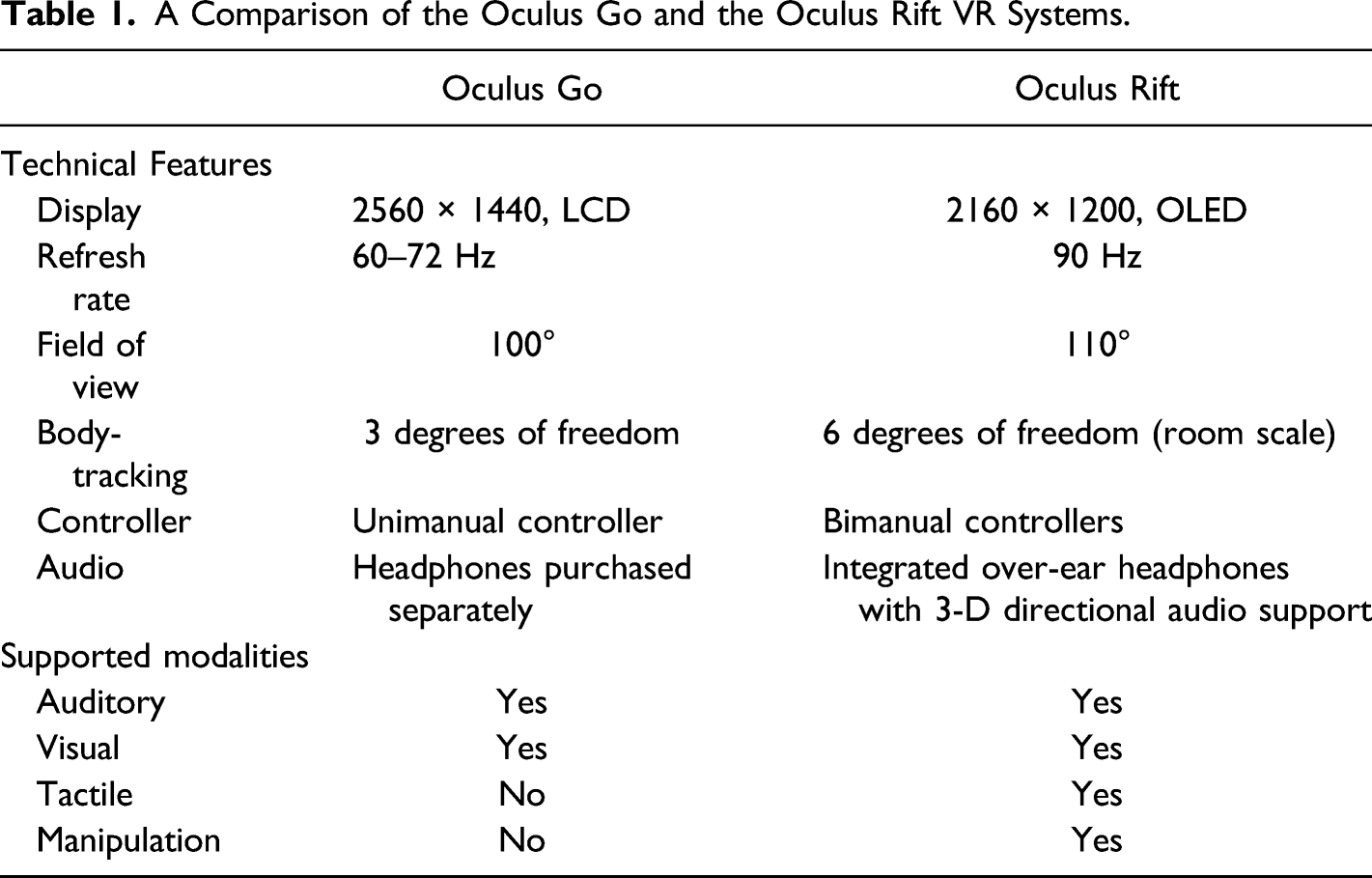
In addition, previous research showed that gestures and manipulation have the potential to help students learn new knowledge (Goldin-Meadow et al., 2001; Hu et al., 2015; Paas & Sweller, 2012). One explanation is that using two (or more) modalities to encode meaning magnifies the learner’s available cognitive capacity and reduces cognitive demand in a single processing channel (Goldin-Meadow, 2011). Due to more flexible interactions, high-end VR systems may offer an advantage for reducing cognitive load compared to mid-range VR systems.
Feelings of presence and embodiment are related to one another, as well as other subjective experiences of effort and motivation. Individuals who engage in more bodily movements with an identified virtual body report a higher degree of presence in a VR environment (Slater et al., 1995, 1998). Embodiment is related to the experience of autonomy and agency when controlling the virtual body (Johnson-Glenberg, 2018; Kilteni et al., 2012), and a high degree of embodiment potentially offers learners more choices for learning the subject matter. Due to this increased learning flexibility, learners’ perceived mental effort may be decreased. Finally, feelings of presence and embodiment in VR environments are novel for many learners. For example, learners can see the structure of the solar system and freely manipulate a planet in a VR environment, both of which are impossible in the real world. Due to curiosity, learners may be intrinsically motivated to learn (Malone & Lepper, 1987; Wade & Kidd, 2019).
Furthermore, both sense of presence and sense of embodiment have the potential to impact cognitive engagement and learning. The degree of cognitive engagement in a virtual environment is partially determined by the user’s evaluation of the balance between personal skills and any challenges encountered during the learning process (Takatalo, 2002). Thus, as a concept related to individuals’ perception of their relationship between self and the virtual world (Kilteni et al., 2012), presence can be recognized as a prerequisite for cognitive engagement. The possible effect of embodiment on cognitive engagement in a VR environment is attributed to the user interface. A more “natural” user interface (i.e., familiar behaviors with controls that align to everyday movements and interactions) enhances individuals’ sense of embodiment and facilitates behaving in a virtual environment similar to the real world (Bianchi-Berthouze, 2013; Brondi et al., 2015; Lindgren et al., 2016). When students learn in more-embodied settings, they report a higher degree of cognitive engagement than less-embodied settings (Lindgren et al., 2016).
Furthermore, motivation may influence learners’ behaviors by moderating attentional resources (Engelmann & Pessoa, 2007; Robinson et al., 2012; Wicken, 1992). Sufficient, involuntary focused attention is the pre-condition of generating spatial presence in a VR environment (Bystrom et al., 1999; Wirth et al., 2007; Witmer & Singer, 1998). Similarly, motivation positively impacts embodied senses in an environment with few distractions (Zestcott, 2017). Thus, learners’ sense of presence and embodiment may fluctuate as their motivation changes over time. Importantly, learners should also become more comfortable and adept at operating (and learning within) the VR system over time. Thus, the perceived difficulty or complexity of learning in a VR environment should decrease.
Evaluating the Extended Model
A strong theoretical model should be subject to testing and validation (Jaccard & Jacoby, 2010; Littlejohn et al., 2017). Theory testing assesses whether a theory aligns with reality—whether concepts and their relationships specified in the theory can be observed in practical instances (Hogan & Schmidt, 2002; Littlejohn et al., 2017). This assessment is a key step for establishing validity (Littlejohn et al., 2017), and such testing usually involves not only inspecting connections among a set of concepts but also delving into the underlying processes (Colquitt & Zapata-Phelan, 2007). Previous researchers have used a variety of methods to test and extend different theories, these methods including simple t-tests (e.g., Brancheau, 1989; March & Woodside, 2005), regression analyses (e.g., Brancheau, 1989; Ward et al., 2014), correlation analyses (e.g., Brown, 2004), SEM (e.g., Hogan & Schmidt, 2002; Straub et al., 1995; Viswesvaran & Ones, 1995), meta-analyses, and case studies (e.g., Chukwudi et al., 2020; Løkke & Sørensen, 2014).
SEM is a multivariate technique originating from factor analysis and path analysis (Wang & Wang, 2012) that enables researchers to assess the quality of measurement and examine the relationships among constructs at the same time. Distinct from other statistical methods (e.g., regression, ANOVA, and correlation analysis), SEM takes into account measurement errors in the observed variables involved in a model. Thus, the parameter estimates may be more accurate and less biased. SEM is most appropriate when the researcher has multiple constructs with several indicators and some of these constructs simultaneously act as independent variables in one relationship but dependent variables in other relationships (Hair et al., 2009). SEM procedures are guided more by theory than by empirical results, and are considered a confirmatory analysis useful for testing and potentially confirming theory (Hair et al., 2009). For these reasons, the current work has selected SEM methods to initially assess the proposed extended model of CATLM for VR.
The model evaluation work was embedded in a larger research project implemented at a large public university in the southwest of the United States. Data were collected by survey questionnaires and knowledge quizzes in a three-session VR learning study in the fall semester of 2019, and intervals between sessions spanned 4–7 days.
Participants
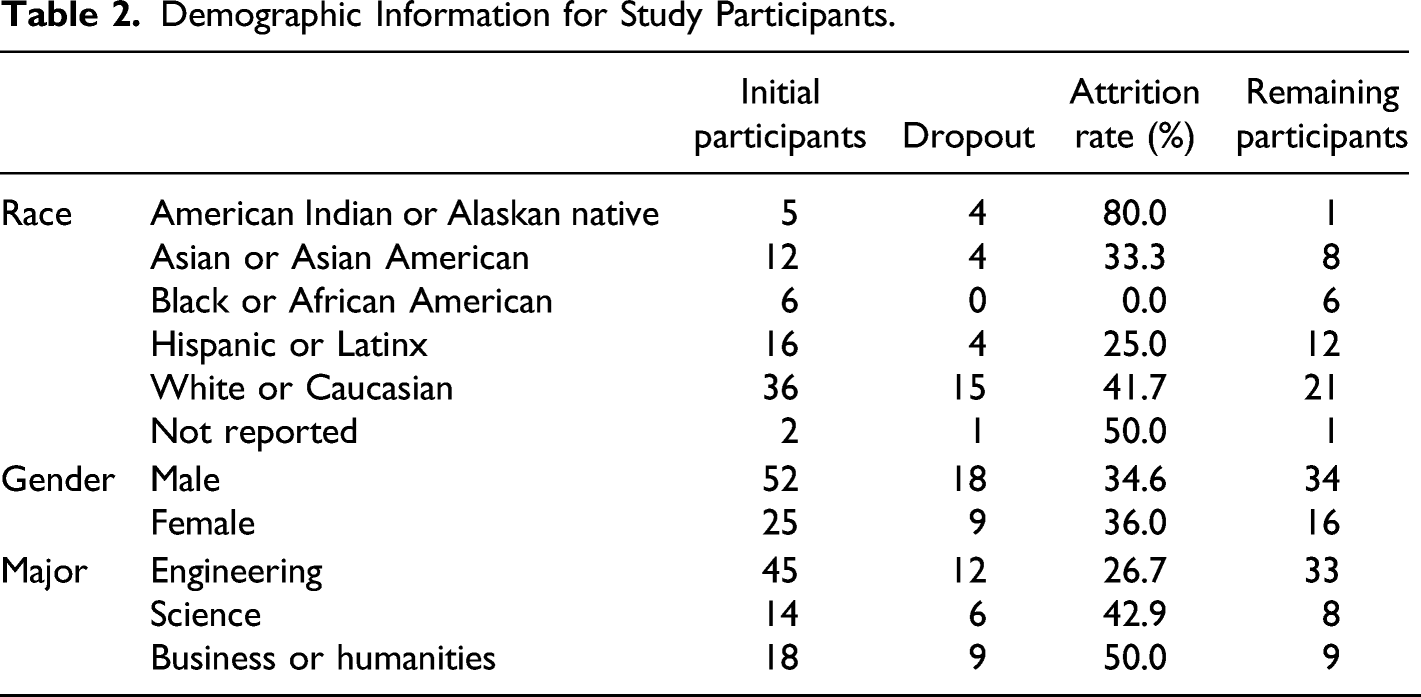
Demographic Information for Study Participants.
Materials
To facilitate the implementation of the study, the content of Titans of Space was evenly separated to four “units,” including Unit 1: Earth, Mercury, Venus, Mars and their moons; Unit2: Ceres, Jupiter and its moons; Unit 3: Saturn and its moons; and Unit 4: Chariklo, Uranus, Neptune, Pluto, and their moons. During the study, content in Unit 1 was used for training before the formal learning task in Session 1, Unit 2 was the learning task in Session 1, Unit 3 was the task in Session 2, and Unit 4 was the task in Session 3.
The recognition question required a participant to identify four celestial bodies they had learned in the unit using a drop-down menu of possible names. For scoring, one point was assigned per correct match. The recall questions asked the participants to describe “characteristics about the geology, climate, or orbit” about a given celestial body. For scoring, one point was assigned per correct fact. The stem of the understanding question was “What the life would be like on [a celestial body].” Responses were scored by assigning one point per valid argument. The argument had to be supported by factual details obtained in the VR materials, and there had to be a clear causal relationship between the claim and the fact(s). For example, “Enceladus would probably sustain life pretty well, with all the water one needs to live readily available, which could be converted to fuel machinery and breathe.” The evaluation question asked the participants to answer “which celestial body do you think has greater potential for humans to live on” on two given objects (e.g., Mars and Jupiter). Scoring assigned one point per reasonable comparison or contrast. For example, “Humans have greater potential to live on Mars because it obtains more sunlight than Jupiter.”
Two researchers independently scored participants’ responses. The Pearson correlation coefficient for inter-rater agreement reached 0.90, p < .001 after they had scored 50% items. One rater then completed the remaining scoring.
Procedure
At the beginning of the first session, participants provided informed consent all IRB protocols were followed. All participants were required to complete the pretest and then participate a short training (6–8 min) with content Unit 1. After completing the training, participants began the Unit 2 learning task. In the following two sessions, they studied Unit 3 and Unit 4, respectively. Each formal learning unit (i.e., Unit 2, Unit 3, and Unit 4) required approximately 15–20 min. After the VR learning task in each session, participants completed a questionnaire and a knowledge quiz.
Data Analytical Approach
The data analyzed via SEM included the set of 50 participants who completed the entire study (i.e., all measures and sessions). Importantly, all participants were assessed three times during the study, thus resulting in a total of 150 data points. This data set satisfied the requirement of minimum size for SEM, which is about 100–150 (Anderson & Gerbing, 1988; Ding et al., 1995; Tinsley & Tinsley, 1987).
Analyses were conducted using Mplus 7.4 software. The SEM approach included a two-step analysis (Anderson & Gerbing, 1988). The first step was an evaluation of the measurement model. The second step was an estimate of the structural model. Four common goodness-of-fit indices were used to assess how well the model represented the data for both the measurement model and the structural model: the relative χ2/df, root mean square error of approximation (RMSEA), Comparative Fit Index (CFI), Tucker-Lewis Index (TLI), and standardized root mean square residual (SRMR). The desired values were: χ2/df < 3 (Bagozzi & Yi, 1988), CFI and TLI >0.90 (Alwin & Hauser, 1975), and SRMR <0.08 (Hu & Bentler, 1999).
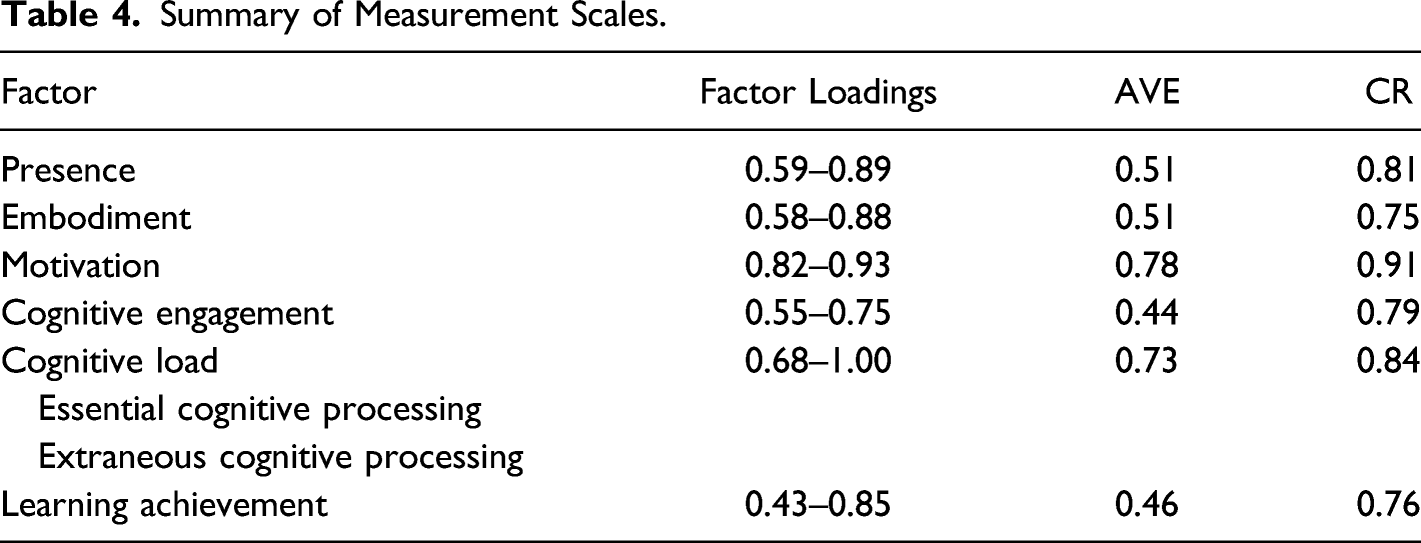
Additionally, the evaluation of the measurement model included establishing convergent validity and discriminant validity. Convergent validity requires that items belonging to the same factor converge or share a high proportion of variance in common (Hair et al., 2009). According to the recommendation of Hair and colleagues, convergent validity requires: (1) factor loadings ≥0.50, (2) average variance extracted (AVE) ≥ 0.50, and (3) composite reliability (CR) ≥ 0.70. Discriminant validity was established through a comparison between the AVE estimates for each factor and the squared inter-factor correlation associated with that factor.
Results
Descriptive Statistical Analysis
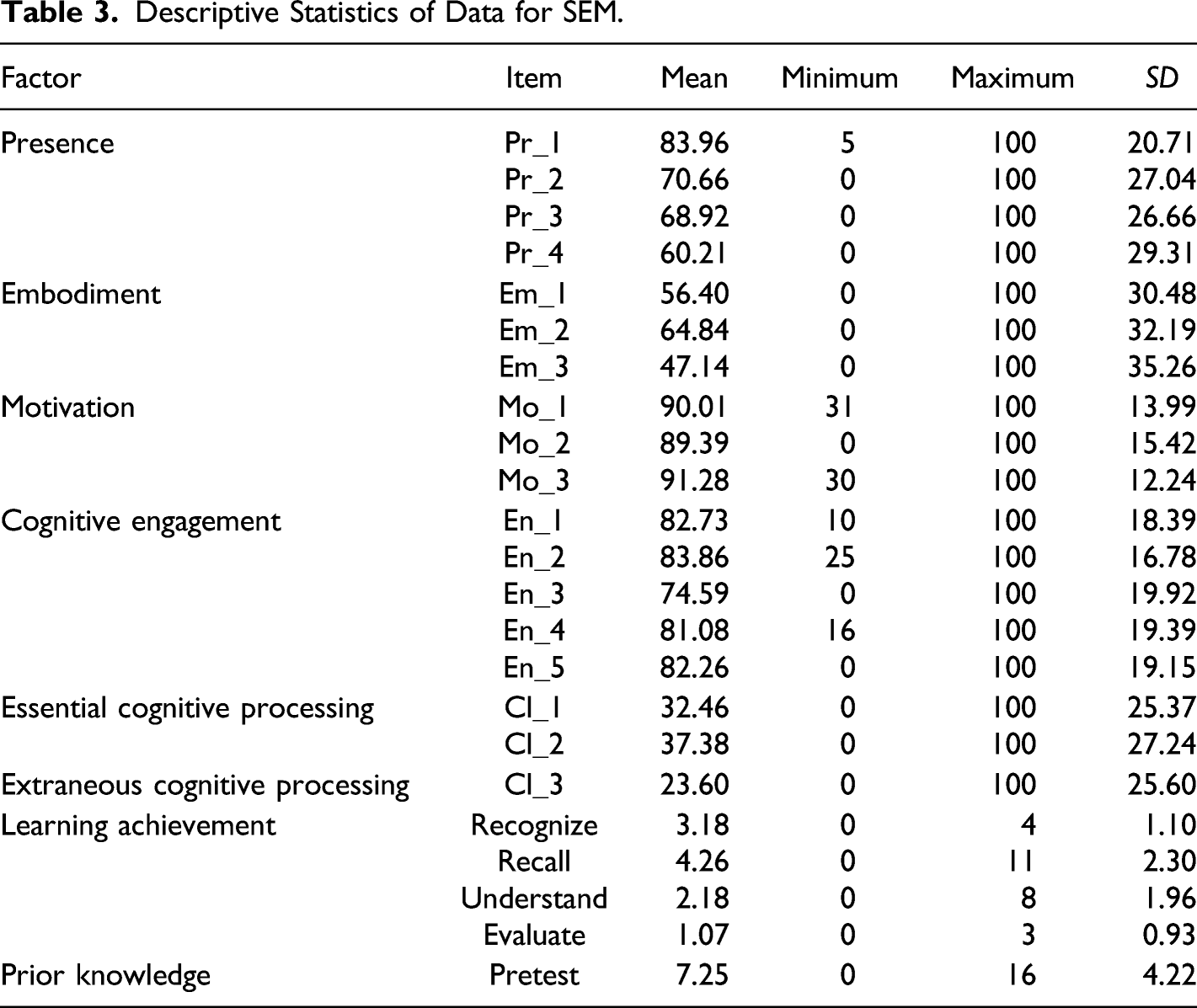
Descriptive Statistics of Data for SEM.
Measurement Model Evaluation
A confirmatory factor analysis (CFA) was conducted to assess the quality of the measurement model for the remaining 147 data points. The assessment results of the measurement model fitness were as follows: χ2/df = 1.357, RMSEA = 0.049, CFI = 0.932, TLI = 0.918, SRMR = 0.069. All the values of these indices were in good model fit. Therefore, the goodness-of-fit statistics supported the measurement model.
Summary of Measurement Scales.
Standardized Factor Correlation Matrix.

Note. *** p < .001; ** p < .01; * p < .05; 1 = Presence; 2 = Embodiment; 3 = Motivation; 4 = Cognitive engagement; 5 = Extraneous cognitive processing; 6 = Essential cognitive processing; 7 = Cognitive load; 8 = Learning achievement; 9 = VR condition; 10 = Time; 11 = Prior knowledge.
Structural Model Evaluation
Parameter Estimates for the Hypothesized Structural Model.

Note. *** p < .001; ** p < .01; * p < .05

Simplified structural model.
In addition to the ten significant direct paths shown in Figure 2, VR format had a significant indirect effect on presence through embodiment (β = 0.28, p < 0.001). The test also provided the R2 to indicate the amount of variance in the dependent factors that could be explained by other factors and external variables. Overall, the model explained 19.6% of the variance in presence, 39.2% in embodiment, 23.9% in motivation, 57.8% in cognitive engagement, 46.3% in essential processing, 100.0% in extraneous processing, 10.5% in cognitive load, and 22.6% in learning achievement. All of these values satisfied the cut-off value of R2 (R2 ≥ 10.0%) in SEM (Falk & Miller, 1992).
Model Modification
To further explore the simplified structural model, correlations between factors were examined based on the data in Table 5. Specifically, there were 11 statistically significant correlations that were not included in the initially hypothesized model. Thus, 11 potential new relations representing these correlations were added to the simplified structural model by steps. However, no significant relationships were observed after these elements were added to the model. Furthermore, we also explored the possible interaction between VR format and time. Results showed that this interaction had no significant effect on embodiment, presence, or cognitive load. Thus, the simplified structural model shown in Figure 2 was the final model in this study.
Discussion
Researchers have criticized that many VR learning studies have not been sufficiently guided by explicit learning theories, and there are few learning theories that incorporate distinctive elements associated with VR environments (Radianti et al., 2020). To advance the use of VR in effective instruction, this study proposed a model that extended CATLM into a VR learning context and evaluated this model using an SEM approach. Overall, the final SEM model (i.e., CATLM for Virtual Reality, or CATLM-VR) supported the core propositions of CATLM. This support demonstrated that the original CATLM was a relevant initial framework for VR studies and practice. In addition, the new model also illustrated how VR format impacts VR experiences and learning. This illustration addressed key gaps by incorporating specific VR factors in CATLM. To the best of our knowledge, this is the first study to theoretically extend CATLM with supporting empirical data. Using SEM, testing provided parameter estimates for all identified relationships among factors simultaneously with a consideration of measurement errors. Thus, the result appears reliable. Furthermore, the established model describes what future modules should consider including to become effective VR learning experiences, and thus has the potential to direct educators in the design VR learning applications and activities.
Are the principles of Cognitive-Affective Theory of Learning with Media applicable to Virtual Reality learning?
The first seven hypotheses included in the research model were directly derived from CATLM hypotheses. Among these seven hypotheses, following six were supported by the final SEM model: H1: Cognitive load has a direct and negative effect on cognitive engagement. H2: Motivation has a direct and positive effect on cognitive engagement. H3: Motivation has a direct and negative effect on cognitive load. H5: Prior knowledge has a direct and negative effect on essential cognitive processing. H6: Prior knowledge has a direct and positive effect on learning achievement. H7: Cognitive engagement has a direct and positive effect on learning achievement.
These six validated relationships encompass fundamental cognitive processes described in CATLM. First, the two-factor structure of cognitive load and the negative effect of cognitive load on cognitive engagement match the claim in CATLM that there are three types of cognitive processing, and cognitive processing is restricted by the learner’s cognitive capacity. Second, the direct effect of prior knowledge on essential cognitive processing is aligned with the claim that prior knowledge can help the learner select meaningful new information in working memory. Third, the direct effects of motivation on cognitive load and cognitive engagement are consistent with the statement that motivation affects cognitive processing in learning. Fourth, the direct effect of cognitive load on cognitive engagement, and the direct effects of cognitive engagement and prior knowledge on learning achievement, support the described process that new information is selected, organized, and then integrated into new knowledge with existing knowledge.
Only H4 (“Motivation has a direct and positive effect on learning achievement”) was not supported in the final model and therefore removed. This removal might be explainable with respect to the distracting effects of hedonic motivation during knowledge construction (Makransky et al., 2019)—if learners focus too much on enjoyment or “fun,” they invest less effort in learning tasks. Therefore, there is not a straightforwardly positive effect of motivation on learning achievement. This removal is also aligned with the assumption in CATLM that cognitive engagement mediates the effect of motivation on learning achievement (i.e., learning is the result of cognitive processing of the information rather than merely desire to learn). Thus, it is rational to conclude that principles of CATLM are still applicable to VR learning based on the results of the first seven hypotheses.
How Does the Virtual Reality Format Impact Learning?
In contrast to initial expectations, VR format only showed a significant direct effect on embodiment, but not on presence or cognitive load. The weak relationship between VR format and cognitive load might be attributed to the relative ease of understanding the learning content in the VR application. Table 3 indicates that all items measuring perceived cognitive processing had a mean of less than 40 on the 0–100 scale. Thus, participants did not seem to perceive the learning process as highly demanding. This explanation is aligned with the claim that modality effects on learning are less applicable in low cognitively demanding conditions (Moreno, 2006; Sweller et al., 1998; Tindall-ford et al., 1997). Another possible explanation is that there was a mismatch between the advantage of gestures in learning and the questions in the knowledge quizzes. According to the cube of educational embodiment in VR (Johnson-Glenberg, 2018), manipulation helps individuals learn the content congruent with their gestures because of reduced cognitive demands. Particularly, in Johnson-Glenberg et al. (2021) recent path analysis on low and high embodied groups in either VR or on a desktop, the high embodied groups (with more congruent manipulation) always learned more content. In this study, grabbing and rotating virtual planets might help these participants remember the location of a site on a planet (e.g., a large canyon is on the north of a high mountain on Mars). However, the knowledge quizzes did not explicitly include questions that needed participants to indicate the position of a site. Thus, participants might not pay enough attention to this type of information in their VR learning experience, and the impact of VR format on cognitive load was small. The finding that VR format had a significant direct effect on embodiment, and a significant indirect effect on presence through embodiment, may be explainable if sense of presence is determined by visual display and interaction, simultaneously (Makransky & Petersen, 2021). The higher-immersion VR format did not possess a much more advanced visual display compared to the moderate immersion VR format, but did include substantive interaction affordances (e.g., bimanual control and body tracking). Thus, VR format had a significant effect on embodiment, and the effect of VR format on presence was mediated by embodiment in this model.
Furthermore, both presence and embodiment had a significant effect on motivation but not on cognitive engagement. These findings may be explained in terms of deeper perception of the surrounding environment and virtual body as antecedents—but not requirements—of cognitive engagement in multimodal learning (Hoffman & Nadelson, 2010; Hoffman & Novak, 2009). Prior studies that found the influence of presence and embodiment on cognitive engagement did not necessarily involve a consideration of motivation as the mediator (e.g., Animesh et al., 2011; Nijs et al., 2012; Zaman et al., 2010).
It is surprising that no significant relationship was found between embodiment and extraneous cognitive processing. This result may be explained from embodiment itself. A high level of embodiment implies a more flexible control of the virtual body and thus, more autonomy in a VR environment (Kilteni et al., 2012). Although cognitive processing can benefit from the ability of flexible controlling the virtual body, autonomy may lead to more unnecessary actions/exploration. These unnecessary actions can cause additional extraneous cognitive processing. Thus, the relationship between embodiment and extraneous cognitive processing is uncertain. This finding and explanation are aligned with Makransky et al. (2020) study in which students in the VR group performed not better than the video group until an optimal learning strategy was introduced in the VR group.
Finally, the factor of time (i.e., the number of sessions that a participant experienced in the VR environment) was not retained in the final model. Neither time nor its interaction with VR format exhibited any significant effect on other factors (i.e., motivation, embodiment, presence, and cognitive load). However, previous findings that students’ motivation, and learning decreased over time in digital learning environments (Li & Ma, 2010; Tsay & Kofinas, 2018). This difference may be explained by the duration of the assessed learning activities. Both Li and Ma (2010) and Tsay and Kofinas’ (2018) studies took one semester as the unit to measure students’ changes. Our study only included three sessions and lasted approximately half a month for each participant. In other words, longer duration may be an important factor when we assess the impact of time (i.e., novelty) on motivation and learning.
In conclusion, evaluations of the extended model indicated that the impact of VR format on learning derived primarily from its influence on learners’ motivation in this study. Due to the relatively large difference in behavior control affordances, the direct effect of VR format on learners’ senses stemmed more from sense of embodiment than presence. Nevertheless, both embodiment and presence increased learners’ motivation. A high level of motivation fostered cognitive engagement while a high level of cognitive engagement seemed to support more effective learning in VR.
Limitations
It is worth mentioning that there are potential limitations to this study. Data used for the model evaluation were collected from participants three times. A correlation likely exists between data points from the same participant in different sessions. Thus, we conducted exploratory factor analyses for data in each session. Overall, the factor structure in our SEM was stable in each session (see Supplemental Material). In other words, the possible bias caused by the repeated measure is small.
Second, the factors in CATLM-VR are still limited. Beyond the constructs that our study included, the original CATLM also mentions other factors such as metacognitive skills, emotion, and feedback. Additionally, VR learning may be affected by some factors not included in both CATLM and CATLM-VR, such as learners’ previous VR experience, interest, and the congruence of gestures to the learning content. A future consideration is how to best integrate these factors and develop a more comprehensive model that enriches our understanding. Third, this study only used one VR application (with two versions) to collect data from adult undergraduate students at one university in the United States. Participants felt that the learning content in this VR application was easily understood, but manipulation was not quite useful because they could get most of the knowledge from the textual reading. However, learners who have less prior knowledge (e.g., middle school students) may not feel the VR learning content is simple and easily understood. Manipulation may be more effective to help these novices than adult undergraduates (Kalyuga, 2007). In this situation, VR format may have a significant effect on cognitive load. Thus, a more generalized model is advocated to be built in the future based on more factors, different types of VR applications, and a broader population.
Implications
This study has theoretical and practical implications for VR learning in motivational and cognitive aspects, respectively. VR can afford learners a sense of embodiment and presence that contribute to higher motivation. The motivational path, which proceeds from VR format to motivation, confirms the value of using multi-processing channels on enhancing learners’ user experience in a VR environment (Anazco, 2020; Birt et al., 2015; Deng, 2017; Fernandes et al., 2016; Shu et al., 2019; Ta, 2018). Some researchers claimed that users’ increased motivation in a new media environment was due to the novelty and this increasing was unsustainable (Clark, 1983; Koch et al., 2018). CATLM-VR reveals that the impact of time (i.e., novelty) on user experience, motivation, and cognitive load were small and ignorable in this study. In other words, the benefits of high immersion on user experience and motivation are inherent. Increasing the level of immersion is an effective method to provide better user experience to learners and enhance their motivation in VR instruction.
Although a higher level of immersion can enhance motivation, the effect of immersion—or more broadly, multimodal interaction—on learning is uncertain. High immersion has the potential to facilitate learning (Makransky & Petersen, 2021). However, CATLM-VR reveals that VR format did not have a significant effect on cognitive load for the learning content was simple in our study. This finding can explain why additional multi-sensory stimuli in a VR environment can neither decrease cognitive load nor benefit learning achievement in some situations (i.e., Anazco, 2020; Deng, 2017). Therefore, if the learning content is easily understood, educators may not need to select higher-immersion (and more expensive) formats for their VR instruction. In addition, motivation and cognitive engagement play mediation roles in a VR learning process. Enhancing students’ motivation and cognitive engagement may more directly increase learning achievement than increasing the level of immersion and may be more universally applicable in VR instruction. The specific methods can be encouragement, positive feedback (Deci & Ryan, 2010), and designing activities that help students construct and elevate knowledge by themselves (e.g., reflection, self-explain, and debate) (Chi & Wylie, 2014).
Conclusion
This study proposed a model to extend CATLM into VR learning contexts, which was evaluated via SEM methods. The final, simplified CATLM-VR model supported the core principles and assumptions of CATLM in a VR context and addressed key gaps by incorporating specific VR-related factors in CATLM. To the best of our knowledge, this is the first study to theoretically extend CATLM based on supporting empirical data. Findings in this study have the potential to guide the design of VR learning applications and VR learning activities.
Supplemental Material
sj-pdf-1-jec-10.1177_07356331211053630 – Supplemental Material for Extending the Cognitive-Affective Theory of Learning with Media in Virtual Reality Learning: A Structural Equation Modeling Approach
Supplemental Material, sj-pdf-1-jec-10.1177_07356331211053630 for Extending the Cognitive-Affective Theory of Learning with Media in Virtual Reality Learning: A Structural Equation Modeling Approach by Wen Huang, Rod D. Roscoe, Scotty D. Craig and Mina C. Johnson-Glenberg in Journal of Educational Computing Research
Footnotes
Acknowledgments
The authors would like to thank Dr Robert Gray, Zhen Zhao, Elena Kalina, Vanessa Ly, Ricardo Nieland Zavela, Samuel Arnold, and Chelsea Johnson for their assistance.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was partially funded by the Graduate Research Support Program (GRSP) at Arizona State University.
Supplemental Material
Supplemental material for this article is available online.
Author Biography
![]() She has a varied background as a screenwriter, experimental psychologist, and game designer. Her lab has been at the forefront of creating “embodied” and kinesthetically-active games using sensors and motion capture technologies for over a decade and a half. Dr. Johnson-Glenberg presents nationally and internationally. Some recent publications include design guidelines for learning VR at Frontiers in Robotics and AI and, a rubric that teachers can use to score the quality of a VR lesson.
She has a varied background as a screenwriter, experimental psychologist, and game designer. Her lab has been at the forefront of creating “embodied” and kinesthetically-active games using sensors and motion capture technologies for over a decade and a half. Dr. Johnson-Glenberg presents nationally and internationally. Some recent publications include design guidelines for learning VR at Frontiers in Robotics and AI and, a rubric that teachers can use to score the quality of a VR lesson.
Appendix A
Subjective Experiences Questionnaire Items.
Factor
Item Text
Source
Presence
Please rate your sense of being in the universe. I had a sense of being in the universe… [0 = “at no time” to 100 = “almost all the time”]
Slater et al. (1994, 1995)
To what extent were there times during the experience when the universe was the “reality” for you? There were times during the experience when the universe was the reality for me… [0 = “at no time” to 100 = “almost all the time”]
Do you think of the universe more as images that you saw, or more as somewhere that you visited? The universe seemed to be more like… [0 = “images that I saw” to 100 = “somewhere I visited”]
During the experience, did you often think to yourself that you were just in a room, or did the universe overwhelm you? During the experience I was thinking that I was really in the room… [0 = “most of the time” to 100 = “rarely”]
Embodiment
[Items were rated on a scale of 0 = “strongly disagree” to 100 = “strongly agree”]
Gonzalez-Franco and Peck (2018)
It felt as if the virtual body or body part I saw was someone else’s. (R)
It felt like I could control the virtual body or body part as if it was my own
I felt as if the movements of the virtual body were influencing my own movements
Motivation
[Items were rated on a scale of 0 = “not true at all” to 100 = “very true”]
Deci and Ryan (1994)
I enjoyed doing this activity very much
This activity is fun to do
I would describe this activity as very interesting
Engagement
[Items were rated on a scale of 0 = “never” to 100 = “always”]
Jackson and Eklund. (2004)
I felt that I was competent enough to meet the demands of the learning task
I had a strong sense of what I wanted to do
I had a good idea about how well I was doing while I was involved in the activity
I was completely focused on the learning task at hand
I had a feeling of total control over what I was doing
Essential cognitive processing
[Items were rated on a scale of 0 = “not at all the case” to 100 = “completely the case”]
Ayres (2006) and Leppink et al. (2013)
The learning content was difficult
The learning content was complex
Extraneous cognitive processing
[Items were rated on a scale of 0 = “not at all the case” to 100 = “completely the case”]
It was difficult to learn in this VR environment
Cierniak et al. (2009)
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.