
Abstract
This meta-analysis determined game-based learning’s (GBL) overall effect on students’ computational thinking (CT) and tested for moderators, using 28 effect sizes from 24 studies of 2,134 participants. The random effects model results showed that GBL had a significant positive overall effect on students’ CT (g = 0.677, 95% confidence interval 0.532–0.821) with significant heterogeneity among effect sizes. Among game types, role-playing yielded the largest GBL effect size, followed by action, puzzles, and adventures. Moreover, the effect of GBL on CT was weaker among students in countries that were more individualistic than others. Lastly, interventions between four hours and one week showed the largest GBL effect size, followed by those over four weeks, up to four hours, and between one week and four weeks.
Introduction
Students’ game-based learning (GBL) is linked to their greater mathematics achievement (meta-analyses show effect sizes of 0.13 for Tokac et al., 2019 and 0.37 for Byun & Joung, 2018), and GBL’s close fit with computational thinking (CT) might yield an even larger effect. To explain why GBL might especially suit learning CT, we map GBL processes (complex story, rules, goals/subgoals, autonomy, feedback, tries, Burke, 2014) on to CT processes (complex simulation, problem solving, sequence/algorithm, conditional logic, loop, debug; Brennan & Resnick, 2012). As past studies of GBL and CT show mixed results (e.g., positive effect: Du, 2020; negative effect: Lee et al., 2014), we meta-analyze 28 effect sizes from 24 studies of 2,134 participants.
Theoretical Framework
After defining GBL and CT, we explicate how GBL maps on to CT, and discuss how various factors might affect GBL’s effects on CT. GBL is learning by playing a game within a complex story with rules. Students achieve an overall goals by attaining subgoals, using their autonomy to make decisions, receive feedback on the outcomes of their decisions, and making further tries if needed (Burke, 2014). For example, in a treasure hunt game, a student helps a turtle look for 2 treasure chests with three maps (1 real, 2 fake), starting at an origin. This complex story (treasure hunt) has rules (turtle turns and moves forward), an overall goal (get two treasures) and several sub-goals (determine real map, go to location, dig, get treasure). The student has autonomy to make decisions (use which map?), receives feedback (digging at this location uncovers no treasure chest), and can try again (use another map). Lastly, the results appear on a leaderboard, which provides a status award to high scorers (extrinsic/instrumental motivation, from Ryan & Deci’s self-determination theory in 2017).
Papert (1980) introduced and Wing (2006) defined it: “computational thinking involves solving problems, designing systems, and understanding human behavior, by drawing on the concepts fundamental to computer science.” Key CT concepts and skills include simulation, problem solving, sequences/algorithms, loops, conditional logic, and debugging (Brennan & Resnick, 2012).
GBL Processes Map on to CT Processes
Applying GBL to learning CT, a student writes a Logo computer program to ensure that the turtle finds the two treasure chests, developing CT knowledge and skills en route. To succeed within the complex treasure hunt story, a student’s Logo program simulates turtle decisions and actions, solving problems along the way (such as how to find the real map). As a student has autonomy to decide which map to use first, (s)he might start with the treasure chest location closest to the origin (of all three maps), and write the Logo program accordingly. To achieve subgoals, the computer program includes sequences/algorithms such as moving from the current location latitude to the treasure chest location latitude on the current map: (a). compute steps from current location latitude to treasure location latitude, (b). turn turtle in that direction, (c). move this number of steps (latitude motion). After the turtle digs at a location, the game gives feedback: (no) treasure chest here. Accounting for different possible feedback, a student uses if-then statements (conditional logic) to determine the next sequence of actions: if found treasure chest, go to next treasure chest location on map; else get another map. As some actions are repeated, a student can write loop statements: repeat algorithm until correct map is found. Typically, the first program fails. However, the game allows multiple tries, so the student can scrutinize the program instructions and consequent game actions, identify its flaw(s) and revise accordingly (debug). Although well-designed GBL for CT can yield many benefits, a good GBL design is non-trivial, so poorly designed GBLs can be too (a). difficult and frustrate students or (b). easy and bore students—both of which can demotivate students (Burke, 2014; Ryan & Deci, 2017).
As many GBL processes map on to CT processes, we propose two hypotheses. First, GBL is more effective than traditional instruction at helping students learn CT. H-1a. GBL outperforms traditional instruction at increasing students’ CT.
Second, the close mapping of GBL on to CT yields larger effect sizes than GBL on other subjects such as mathematics. H-1b. GBL’s effect size on CT is larger than its effect size on mathematics.
Differences in GBL’ s effects on CT
Game intervention design (game type, intervention duration), demographic factors (individualism, grade level/age) or measures (control group, CT assessment, instrumental validity) might account for differences in GBL effects on CT across studies.
Game Intervention
Game types might yield different GBL effects on CT. Specifically, simulations or role-playing GBL might outperform other types of GBL at improving student learning of CT or other subjects. As CT often involves simulations, simulation games include instant feedback, explicit encouragement for multiple tries, and supportive structures for sequences of steps (algorithms), which approximate and support CT more than other games (Liu, 2019). Meanwhile, when students role play, especially adult roles, they try to think and act like older people with superior knowledge and skills, which can yield higher performance than otherwise (Vygotsky, 2016). Such role play might improve students’ CT. Indeed, Yildiz et al. (2017) showed that algorithmic thinking was highest among students who played simulation games, followed by those who played role-playing games, adventure games, and action games.
Hence, we propose the following hypotheses. H-2a. Students in simulation GBL outperform all other students at CT. H-2b. Except for students in simulation GBL, students in role playing GBL outperform all other students at CT.
Neither the shortest nor the longest durations of game-based intervention typically yield the best results. Although longer interventions (e.g., days rather than minutes) can increase their cumulative intensity to yield larger results (Ross & Begeny, 2015), interventions across longer time periods (e.g., weeks) can be diluted by other events to yield weaker results (Nahmias et al., 2019). Together, these results suggest that an intermediate duration yields a peak effect (e.g., days; Racey et al., 2016). H-3. GBL interventions lasting days outperform those lasting minutes and those lasting weeks.
Demographics
Demographics (culture, grade/age) might also affect GBL effects on CT. Cultural values differ across countries and might moderate GBL’s motivation effects on CT. Unlike people in individualistic cultures (e.g., Canada, Germany), those in collectivist ones (e.g., China, Korea) value group goals more than individual goals (Hofstede, 2019), and rely more on nearby, extended family members (Shah, 2015). As such parents tell their children that their learning outcomes at school affect their family status and reputation (extrinsic motivation, Ryan & Deci, 2017), these children value extrinsic motivation more, compared to those in individualistic cultures (Ni et al., 2010). Hence, students with more extrinsic motivation have lower achievement in individualistic countries but not collectivist ones (Chiu & Chow, 2010; D’Ailly, 2003). As GBL uses both extrinsic motivation (leader board, immediate feedback; Burke, 2014) and intrinsic motivation (autonomy, sub-goals; Ryan & Deci, 2017), GBL might raise motivations and CT more for students in collectivist countries than in individualistic ones. H-4. GBL effects on CT are greater in countries that are collectivist.
Compared to younger students, older students have more knowledge and skills than younger students do (Daniel & Gagnon, 2011), so they might capitalize on them to adapt to GBL more quickly to learn more CT (Mao et al., 2022). Thus, we expect GBL to improve the CT of older students more than the CT of younger students. H-5. GBL effects on CT are greater for older students than for younger students.
Measures
Measures (control group condition, CT concepts vs. skills, instrument reliability) might also affect GBL effects on CT. Control groups in studies: (a). do not exist, (b). receive active instruction, (c). receive passive instruction, or (d). receive unreported instruction. As pre- and post-test studies without control groups ignore typical improvement over time via traditional instruction, they often overestimate treatment effects, compared to studies with both experimental and control groups (Lipsey & Wilson, 1993). For example, Lei et al.’s (2022) meta-analysis of GBL showed that studies with control groups showed smaller effects than other studies. H-6a. GBL effects on CT are smaller in studies with control groups.
While active instruction control groups (e.g., group discussion) might receive better instruction and outperform passive instruction control groups (e.g., watch educational videos, Sitzmann, 2011), GBL meta-analyses showed mixed results. For example, GBL effects against active control groups rather than passive control groups were weaker in Sitzmann (2011) but stronger in Wouters et al. (2013). Together, they suggest that the quality of instruction matters more than its passive or active nature (no hypothesis on active vs. passive instruction).
As knowing a CT concept (e.g., define loops) is often easier (and a prerequisite) to applying its corresponding CT skills (e.g., correctly use loops in a program to achieve a subgoal), assessments of learning CT concepts rather than learning CT skills will often yield higher scores (Ma & Liu, 2019; Zhang & Nouri, 2019). Indeed, Wouters et al. (2013) found higher GBL effects on knowledge than on skills. H-6b. GBL effects on CT are larger in studies assessing CT concepts rather than CT skills
Reliability of CT assessment can also affect the GBL effect size on CT. Reliability is often lowest for researcher’s original, unvalidated instruments, higher for validated instruments, and highest for standardized tests (Tokac et al., 2019). Such instruments with more reliability often have less measurement error and hence are more likely to yield significant effect sizes (Cohen et al., 2003). H-6c. GBL effect on CT is most likely to be significant with standardized CT tests, less likely with validated CT tests, and least likely with other CT tests
Study Purpose
This study tests whether the strong mapping of GBL processes on CT processes yield positive GBL effects on CT (larger than GBL effects on mathematics). Furthermore, this meta-analysis tests whether GBL effects on CT differ across game intervention design (game type, intervention design), demographics (individualism, grade level/age), or measures (control group condition/instruction, CT concepts vs. skills, CT assessment validation).
Methods
Study Searching
In mid-March 2022, we searched the following electronic databases for relevant studies: EBSCO, Web of Science, ProQuest Dissertations and Theses Global, ScienceDirect, China National Knowledge Infrastructure, and WanFang DATA. We used this keyword search combination: (game-based learning, game, educational game, digital game, simulation game, role-playing game, serious game, computer game, or video game) AND (computational thinking, computational thinking skill, or computational thinking concept). Moreover, we reviewed the references of all reviews and included articles to find additional studies. The initial search yielded 2,305 articles (sources: 1,022 Web of science, 87 EBSCO, 35 ScienceDirect, 32 ProQuest Dissertations and Theses Global, 422 China National Knowledge Infrastructure, 685 WanFang DATA, and 22 from other sources). We removed 347 duplicate articles.
Study Selection and Coding
We included articles that fit all seven inclusion criteria: (a). used terms related to game-based learning in titles, keywords or abstracts; (b). used terms related to CT in any part, including the main texts; (c). were written in English or Chinese; (d). available in full-text, (e). empirically examine the effect of GBL on CT (excluding theoretical papers, reviews, and unrelated studies); (f). had an experimental or pre-post design (excluding surveys and qualitative studies); (g). reported sample sizes and at least one key measure (standard deviation, t, F or p values).
The first author and corresponding author independently evaluated and coded each study. Specifically, they applied these criteria with 95% agreement to remove 1,934 articles, and discussed disagreements to reach consensus. Hence, this meta-analysis included 24 studies from 2011–2022 (with 28 independent effect sizes, see Figure 1). PRISMA 2009 flow diagram.
Study Characteristics Included in Meta-Analysis.

Note. Control group (1 = No; 2 = Yes) with #C + #E indicate the numbers of participants in the control group and in the experimental group; Control condition (1 = None; 2 = Instruction not reported; 3 = Passive instruction; 4 = Active instruction); Game type (1 = Action, 2 = Role playing, 3 = Adventure, 4 = Simulation, 5 = Puzzle); Grade level (1= Kindergarten, 2 = Elementary school, 3 = Middle school, 4 = High school, 5 = College); Instrument reliability (1 = Other test, 2 = Validated test, 3 = Standardized test); Duration (1 = Up to 4 hours; 2 = Between 4 hours and 1 week; 3 = Within 1–4 weeks; 4 = Over 4 weeks; 5 = Not reported); Computational thinking construct (1 = Concept; 2 = Skill).
Demographics include grade level and individualism. The coders divided studies into 5 grade levels: kindergarten, elementary school, middle school, high school, and college. Based on the country, we retrieved its individualism cultural value from Hofstede (2019).
Measures include control group attributes, CT construct, and instrument reliability. The coders divided studies into four types of control conditions: none (e.g., Zhao & Shute, 2019), instruction not described (e.g., Chang, 2017), passive instruction (e.g., Hooshyar et al., 2021b), or active instruction (e.g., Rose et al., 2020). Also, they categorized CT outcomes as concepts or skills (Hooshyar et al., 2021a). Instrument reliability was coded as: standardized test, validated test, or other test (Tokac et al., 2019).
Inter-rater reliability was acceptable to high (Cohen’s kappa, Warrens, 2015): game type (0.824), intervention duration (0.825), individualism (1.000), grade level (1.000), control condition (0.873), CT construct (0.833) instrument reliability (0.833).
Next, we calculated the effect sizes for each independent sample within a study. If multiple independent samples of students participated in a game-based intervention study, we encoded them separately. If a study reported multiple components of CT within the same construct (concept or skill) or measured it multiple times after intervention within a sample, we used their mean and corresponding total effect size. We computed each study’s effect size, Hedges’s g (corrected Cohen’s d, Borenstein et al., 2005) via t, F, p values, or its sample sizes, means, and standard deviations in each group with Comprehensive Meta-Analysis 3.3.
We assessed study quality on the revised Jadad et al. (1996) Scale (0–5). Its criteria were as follows. Regarding double-blinding, a detailed description yielded two points, and its use without description yielded one point. Regarding random assignment of participants to conditions, a detailed description yielded two points, and its use without description yielded one point. Specified number of lost or withdrawn participants yielded one point. All 24 articles scored more than two points, indicating high-quality studies.
As these studies used different measures for different game interventions on different student populations, they were likely distinct and heterogeneous, so we used a random effect model, which likely better fit the sampling distribution, allowed effect sizes to vary, and allowed our conclusions to generalize more broadly (Borenstein et al., 2010). We also computed the Q statistic (Hedges, 1982) to determine the heterogeneity among effect sizes and the I 2 statistic (Higgins & Thompson, 2002) to determine the variance between studies (accounting for sampling error, Huedo-Medina et al., 2006).
We assessed publication bias with a funnel plot, fail-safe number, Egger’s regression, trim-and-fill, and single-study exclusions. A funnel plot with a severe asymmetric distribution of effect sizes suggests publication bias. When the minimum number of studies that render the computed effect size non-significant (fail-safe number, Nfs) falls below 5k+10 (k = number of studies), the danger of publication bias is substantial (Khoury et al., 2013). In Egger’s et al., (1997) regression, a significant intercept far from zero indicates risk of publication bias. We used trim-and-fill to calculate the number of missing studies and add their effects to yield an adjusted mean effect size (Duval & Tweedie, 2000). We also tested whether removing single studies with extreme effect sizes (outliers) substantially changed the overall effect size (Borenstein et al., 2009).
Results
Random-Effects Model of the Effect of GBL on CT.

Note. k = Number of effect sizes; CI = Confidence interval; LL = Lower limit; UL = Upper limit.
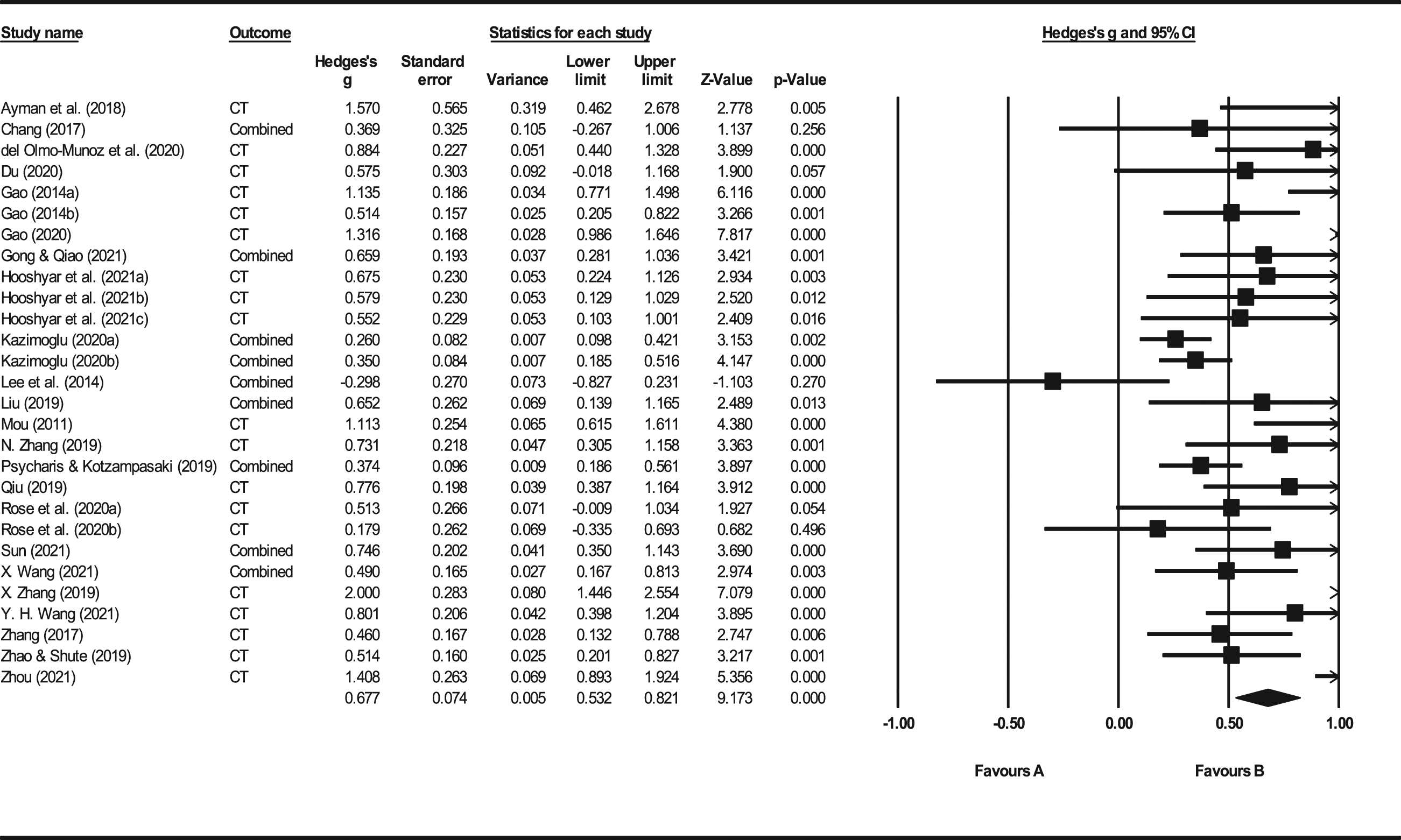
Forest plot for the random-effects model.
Publication Bias and Sensitivity Analysis
We tested the likelihood of publication bias with a funnel plot, Nfs, Egger’s regression, trim-and-fill, and single-study exclusions. In the funnel plot, the 28 effect sizes were mostly symmetrically distributed across the axis (see Figure 3). Also, the Nfs of 2,273 far exceeded the threshold of 150 (z = 17.765, p < .001; 150 = 5 × 28 + 10; 5k + 10, Card, 2011). The intercept of Egg’s regression significantly exceeded zero (2.599, p = 0.003), indicating risk of publication bias. To address this possible publication bias, a random-effects trim-and-fill showed missing 4 studies on the right and raised the overall effect from 0.677 to 0.779. Also, removing possible single study outliers still yielded effect sizes within the 95% confidence interval (0.532–0.821; see Figure 4). Funnel plot of the effect sizes with 95% confidence interval. Forest Plot of Sensitivity Analysis for the one study removed.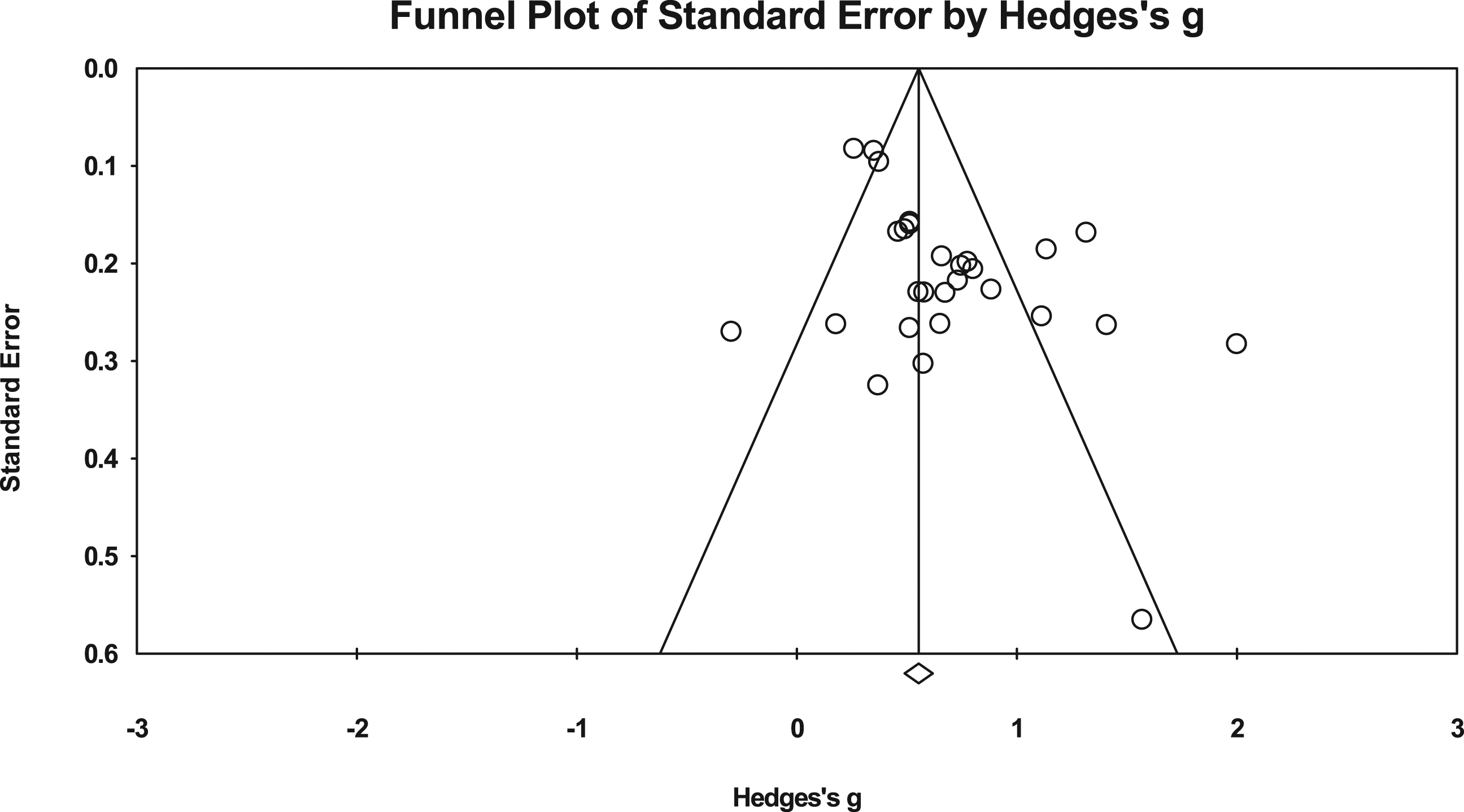

Moderator Analysis
The homogeneity test showed significant heterogeneity among effect sizes (Q = 117.264, p < .001, I 2 = 76.975, see Table 2 and forest plot in Figure 2). Hence, we tested for the following moderators: game intervention (game type, duration), demographics (individualism, grade/age), and measures (control group, CT assessment, instrument reliability).
Game Type and GBL Intervention Duration
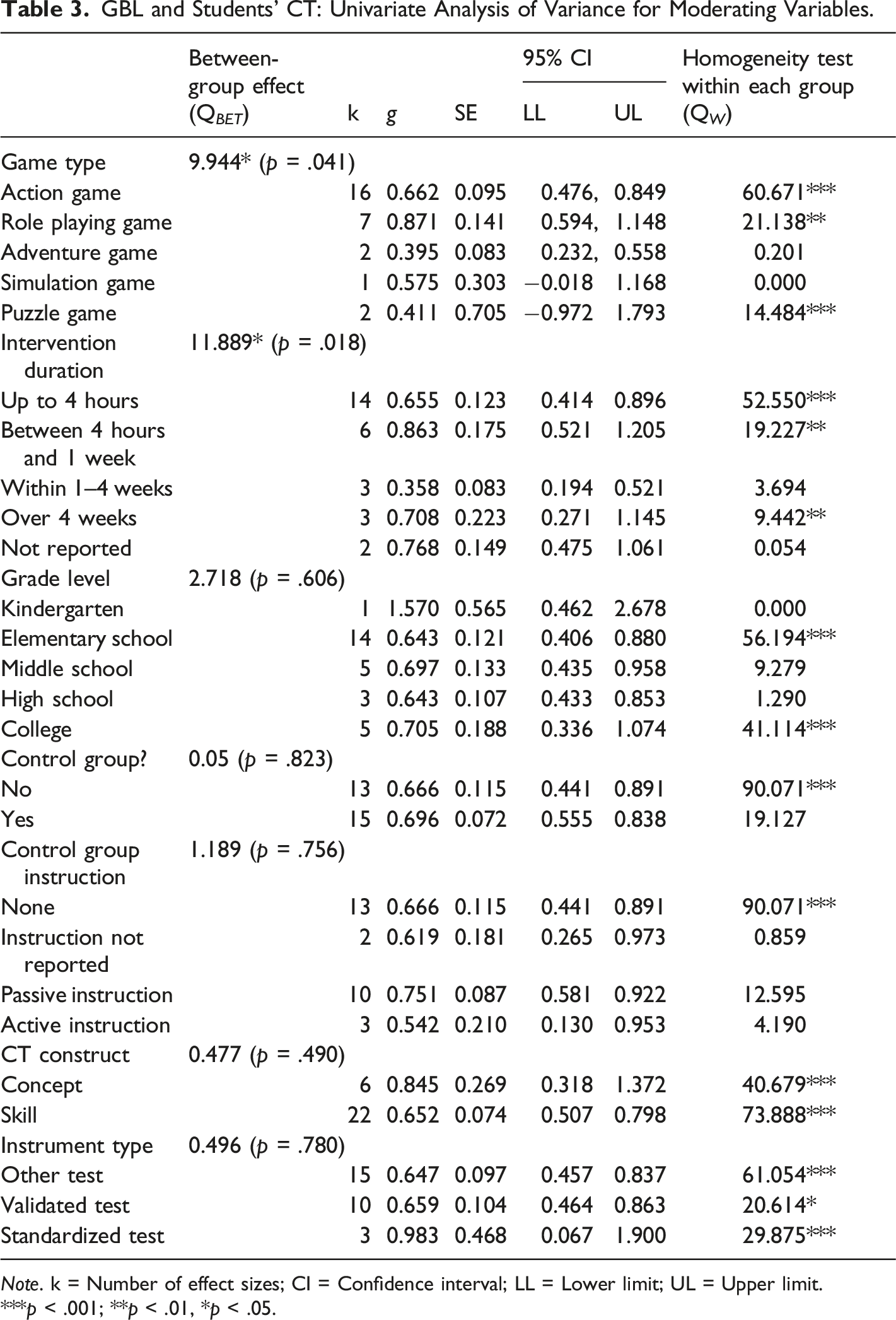
GBL and Students’ CT: Univariate Analysis of Variance for Moderating Variables.
Note. k = Number of effect sizes; CI = Confidence interval; LL = Lower limit; UL = Upper limit.
***p < .001; **p < .01, *p < .05.
GBL intervention duration significantly moderated GBL’s effect on CT (Q BET = 11.889, df = 4, p < .05). Interventions between four hours and one week showed the largest effect size (g = 0.863, k = 6, 95% confidence interval 0.521–1.205), followed by over those four weeks (g = 0.708, k = 3, 95% confidence interval 0.271–1.145), those up to four hours (g = 0.655, k = 14, 95% confidence interval 0.414–0.896), and those within one to four weeks (g = 0.358, k = 3, 95% confidence interval 0.194–0.521). Hence, these results support H-3 (days of GBL).
Individualism and Grade Level/Age
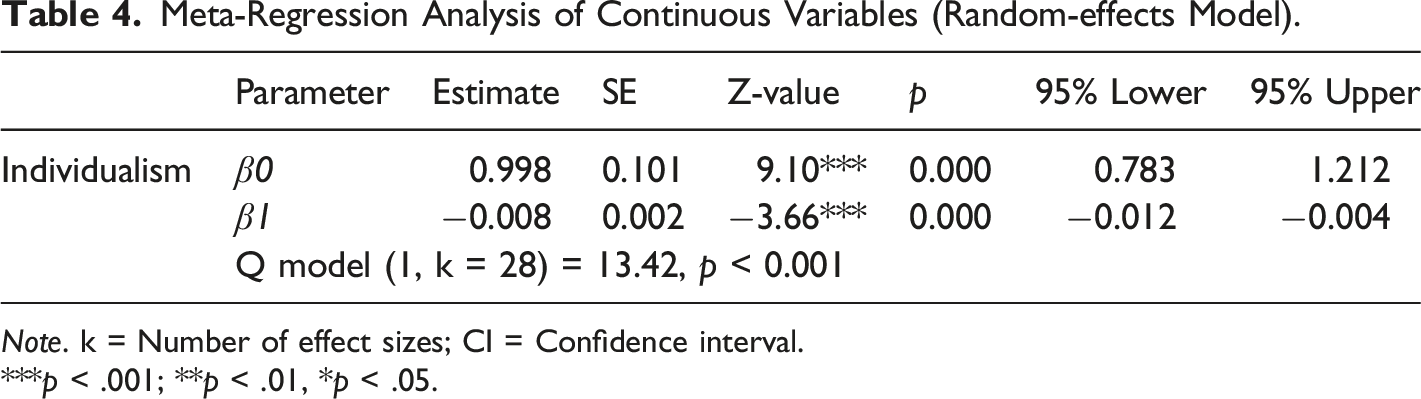
Meta-Regression Analysis of Continuous Variables (Random-effects Model).
Note. k = Number of effect sizes; CI = Confidence interval.
***p < .001; **p < .01, *p < .05.
Measures
Measures did not moderate GBL effects on CT. Control condition did not significantly moderate the GBL effect on CT, regardless of whether testing its presence (Q BET = 0.05, df = 1, p > .05) or its type of instruction (Q BET = 1.189, df = 3, p > .05; see Table 3). Also, CT construct did not significantly moderate the GBL effect on CT (Q BET = 0.477, df = 1, p > .05). Lastly, instrument reliability did not moderate the GBL effect on CT (Q BET = 0.496, df = 2, p > .05). Hence, these results show no support for H-6a, H-6b, or H-6c.
Discussion
This meta-analysis of 28 effect sizes from 24 studies showed a medium positive GBL effect on students’ CT, moderated by game type, intervention duration, and individualism.
GBL Effect on CT
GBL had a positive overall effect on students’ CT (g = 0.677), much larger than GBL effects on mathematics (0.13 for Tokac et al., 2019 and 0.37 for Byun & Joung, 2018). This result supports our claim that the close mapping of GBL processes (complex story, rules, goals/subgoals, autonomy, feedback, tries, Burke, 2014) on to CT processes (complex simulation, sequence/algorithm, problem solving, conditional logic, loop, debug; Brennan & Resnick, 2012) helps students learn CT.
This result suggests both theoretical and practical implications. Regarding theory, scholars can create theoretical models of mappings of GBL processes on to cognitive processes in other academic subjects (English, history, science, etc.). Then, they can test whether mappings with greater correspondences between GBL processes and cognitive processes in a subject domain yield greater GBL effects on student learning in that subject. Practically, the positive GBL effect on students’ CT suggests that educators consider how to help teachers incorporate GBL into their lessons to help their students learn more CT.
Moderators
The present study found that game type, intervention duration, and individualism moderated the GBL effect on CT. By contrast, grade level/age, control group condition, CT assessment, and instrument reliability did not moderate this effect.
Game Type
Game type moderated the effect of GBL on CT. GBL with role-playing games yielded a larger effect on CT than GBL with action games, simulation games, puzzle games or adventure games. This result aligns with the claim that students’ role playing (especially adult roles) encourages them to think and act like older people with superior knowledge and skills (Vygotsky, 2016). This result also partially coheres with Yildiz et al.’s (2017) result showing that algorithmic thinking was highest among students who played simulation games, then by those who played role-playing games, compared to other games. As our meta-analysis included few studies of simulations, puzzles or adventure games, more future studies can include these games to help future meta-analyses determine whether GBL with role playing rather than these game types help students learn more CT.
Practically, the many GBL studies with action games or role-playing games in this meta-analysis enable confidence in the greater effectiveness of role-playing GBL over action game GBL for learning CT. Hence, when role-playing GBL and action game GBL are both viable for learning specific CT concepts or skills, these results suggest that educators use role-playing GBL rather than action game GBL in the absence of other compelling reasons.
Intervention Duration
GBL interventions between four hours and one week showed the strongest GBL effect on CT, aligning with our proposal that the peak effect occurs for GBL interventions lasting days rather much shorter GBL interventions (minutes) or much longer GBL interventions (weeks). This intermediate peak result is also consistent with other intervention duration results showing that extremely short interventions (e.g., minutes) can lack sufficient cumulative intensity and effectiveness (Ross & Begeny, 2015), while other events can dilute the impacts of longer interventions (e.g., weeks, Nahmias et al., 2019). Practically, these results suggest that educators design GBL learning with intermediate durations (four hours to one week) to maximize students’ CT learning. Future studies with different GBL intervention durations can further narrow the window of the optimal GBL intervention duration for GBL of CT.
Individualism
The effect size of GBL on CT was smaller among students in individualistic countries. This result aligns with the view that compared to students in individualistic cultures, those in collectivist cultures value group interests (Hofstede, 2019) and extrinsic motivation more (Ni et al., 2010; e.g., from their family, Shah, 2015), so extrinsic motivation aspects of GBL, such as leadership boards (Burke, 2014), benefit these students more. Future fine-grained studies can test the validity of this hypothesized mechanism; if supported, this mechanism suggests the greater use of leadership boards and other extrinsic motivation aspects of GBL in collectivist cultures but less use of them in individualistic cultures.
Limitations and Future Research
This meta-analysis has three major limitations: number of primary studies, inadequate information about moderators, and limited languages of published studies. First, this literature search only yielded 24 relevant studies of GBL effects on CT. As this small number of studies has low statistical power for study-level variables (e.g., moderators such as simulation game type), their results might not be generalizable. Specifically, we must cautiously interpret non-significant results at the study-level (possible false negatives), though we retain confidence in our significant results (Cohen et al., 2003). After researchers conduct more primary studies of GBL and CT, future meta-analyses can include such studies for more statistical power.
Second, many primary studies lacked information regarding key moderator variables, such as student gender and game difficulty (Wang et al., 2010). As a result, our meta-analysis could not test whether they moderate GBL effects on CT. Future studies can include such information to enable testing of their moderation effects in future meta-analyses.
Lastly, the authors only read Chinese and English, so this meta-analysis only included studies published in Chinese or English. Future teams of researchers with literacy in more languages can include more studies in their meta-analyses.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.