
Abstract
Natural language processing (NLP) tools have been applied successfully in improving predictions in a wide range of research areas. However, what works in one area may not work in conflict research. This paper therefore seeks to offer an initial assessment of the most prominent NLP methods for conflict prediction tasks. It evaluates the performance of features extracted from a conflict dictionary, two sentiment dictionaries, a word-scaling approach, dynamic topic models and a transformer model on a classical conflict prediction task. The results highlight the importance of considering different NLP approaches, depending on the availability of text sources and other predictor variables.
Introduction
The promise that accurately predicting the next crisis or conflict holds has long motivated researchers. Particularly with recent advancements in computational power, more easily available data sources, and improved statistical modeling techniques, this area of conflict research has received increased attention from academics and policymakers alike. However, even though there have been significant improvements in recent years, models that reliably and accurately predict conflict onset, escalation, or severity still leave room for improvement.
One approach that has produced promising results is the inclusion of predictive features extracted from text data (Boussalis et al., 2022; Chadefaux, 2014; Mueller and Rauh, 2018, 2022). These efforts have mostly focused on using one natural language processing (NLP) approach, namely topic modeling (Blei et al., 2003; Blei and Lafferty, 2006). However, NLP encompasses a multitude of different approaches, many of which offer promising methods to extract information from texts, that could be used for conflict prediction (Maerz and Puschmann, 2020). 1 Furthermore, the findings from the 2022 conflict prediction competition hosted by the political Violence and Impacts Early-Warning System team have underlined the importance of using diverse sets of features and modeling techniques in improving forecasts (Vesco et al., 2022).
Hence, in this paper, I seek to contribute to these efforts by highlighting how different NLP methods can be used to extract features for conflict prediction and by providing a comprehensive assessment of how these features perform across different text corpora as well as feature combinations. I create features based on CrisisWatch reports and BBC Monitoring newspaper articles, using a conflict dictionary (Häffner et al., 2023), two sentiment dictionaries (Dunphy, 1974; Hutto and Gilbert, 2014), a word-scaling approach (Benoit and Laver, 2003), and a transformer model (Hu et al., 2022). These features are then used in a true out-of-sample prediction task where I seek to predict conflict severity—operationalized as the logarithm of fatalities—for a given country month, up to 6 months into the future, based on Uppsala Conflict Data Program Georeferenced Event Dataset (UCDP GED) data (Hegre et al., 2017). I also assess their predictive performance in comparison with other features commonly used for prediction tasks. These “traditional”—socio-economic, conflict history, political, and societal—features will serve as baseline models.
The rest of the article is structured as follows. First, I will give an overview of how conflict prediction has progressed over time and highlight the broad spectrum of approaches applied. Second, commonly used NLP techniques and how they could support prediction efforts are discussed. Next, I go into more technical details on how these NLP approaches can be used to extract relevant features from text data. I also outline the prediction task, outcome variable, and other variables used in the baseline models. This is followed by a discussion of the results and what one can learn from this comprehensive assessment of NLP methods for conflict prediction.
Literature
Predicting conflicts has long been a key area of interest for scholars of international relations, conflict researchers, and policy-makers. Given the important role that prediction could play in preventing conflicts and the high stakes associated with it, this longstanding interest is not surprising. However, for a long time, these efforts were limited in their scope through constraints in computational power as well as limited data availability. Hence, early efforts to forecast or predict conflict were mostly limited to strategic analyses of individual cases (see e.g. Azar et al., 1977; de Mesquita et al., 1985; Raphael, 1982) and employed, from a current viewpoint, rather simple modeling approaches (Choucri, 1974; Choucri and Robinson, 1978; Rummel, 1969).
With better availability of data on political violence (see e.g. Azar, 1980; Boschee et al., 2018; Hegre et al., 2019) as well as improvements in modeling techniques (see e.g. Schrodt, 1991), researchers started to undertake more systematic approaches to this problem. Early efforts in this regard sought to model country-level conflict risk on a global level using newly available data sources and contemporary statistical approaches. The promises these advances held spurred a proliferation of attempts to provide reliable crisis early warning tools and approaches; these included government-supported (see e.g. Goldstone et al., 2010) and independent academic efforts (Brandt et al., 2011; King and Zeng, 2001; Schneider et al., 2011; Weidmann and Ward, 2010).
A wide range of modeling approaches has been employed in this regard, using game theory (de Mesquita, 2010), agent-based modeling (Cederman, 2003; Lemos et al., 2013), and simulations (Brandt et al., 2014), as well as machine learning, ensemble modeling techniques, and deep learning methods (Brandt et al., 2022; Montgomery et al., 2012; Walterskirchen et al., 2024). The range of outcome variables to predict has been similarly large, with researchers trying to predict genocide and mass killings (Goldsmith et al., 2013; Koren, 2017; Mayersen, 2020; Scharpf et al., 2014), interstate disputes (Gleditsch and Ward, 2013), leadership changes (Beger et al., 2014; Ward and Beger, 2017), political instability (Bowlsby et al., 2019), protest (Pinckney and Daryakenari, 2022), armed conflict (Hegre et al., 2013; Tikuisis et al., 2013; Ward et al., 2013) or its duration (Pilster and Böhmelt, 2014).
A lot of effort has also focused on finding better variables (or features) to improve the prediction of conflict. Using theoretical-driven approaches to identify features of importance has been important in this regard. Hegre et al. (2016) investigate how different socio-economic pathways can affect conflict likelihood depending on development trajectories. Gohdes and Carey (2017), for example, investigate how the killing of journalists can serve as an indicator for future levels of repression in a country. The presence of militias has also been found to be an important feature in predicting strategic mass killings (Koren, 2017). In their article Blair et al. (2017) investigate how to use local-level survey data to improve predictions. Online material has also become an increasingly popular source to extract features for prediction tasks. Oswald and Ohrenhofer (2022) employ Wikipedia metadata to derive features for their forecasting model. Similarly, Timoneda and Wibbels (2022) use metadata extracted from Google Trends to predict protest dynamics. Zeitzoff (2011) investigates how social media can be probed to gain insights into micro-dynamics of conflict. Recently, including unstructured data, in the form of newspaper articles, has also been shown to be a viable avenue for extracting relevant features for crisis early warning. Chadefaux (2014) uses the frequency of conflict-related reporting and Mueller and Rauh (2018, 2022) apply topic modeling to newspaper articles to provide more reliable forecasts. Similarly, Boussalis et al. (2022) use topic models to analyze diplomatic correspondence to predict militarized interstate disputes. Moving away from topic models, Häffner et al. (2023) introduce an approach to create conflict dictionaries that can be applied to text corpora, which can be used for prediction tasks.
However, while there have been important advances in the accuracy and reliability at which conflicts can be predicted, given the high stakes involved, there is still room for improvement. This has also been underlined by the findings of the recent prediction competition hosted by the VIEWS team (Hegre et al., 2019, 2022; Vesco et al., 2022). They highlight the importance of using diverse modeling approaches, in terms of both the model architecture and features used.
Natural language processing and conflict prediction
Building on the promising developments in the area of text-as-data approaches, in this article, I seek to contribute to the growing literature on conflict prediction in two ways. First, I provide an overview and guidelines on how to generate features for prediction tasks from some of the most common and widely used NLP tools. Second, I provide a comparative assessment of the predictive power of these features.
As outlined above, the focus on NLP tools is motivated by previous research demonstrating the promise of incorporating information extracted from textual data in conflict prediction models. In line with them, I argue that reports and newspaper articles include relevant information about current and future dynamics of conflict in a country. Such reports are generally written by experts with pertinent background knowledge. Additionally, these experts often spend many years covering their areas and are able to gain deep insights over the span of their careers, giving them the ability to better contextualize developments and events. Nonetheless, accessing this information is not a trivial matter and there are many different approaches to doing so. Furthermore, given the ongoing discussions on what makes variables good predictive features 2 and the broad spectrum of available NLP approaches, it is not a priori clear what techniques lead to suitable features for conflict prediction.
Therefore, it is important to assess not only how these different approaches fare in comparison with each other, but also in comparison with other variables, traditionally used in conflict prediction. While there are many NLP methods available, there are four groups of NLP techniques that are commonly used and have also been applied in conflict research: topic models, (sentiment) dictionaries, document scaling, and most recently bidirectional encoder representations from transformers (BERT) models. Topic models are an attempt to identify coherent themes across a large corpus of documents. They can be employed to identify central themes in a document or be used to model how topic compositions change over time. Applying them to newspaper articles or conflict reports can highlight how the focus of reporting changes and can serve as an indicator of underlying conflict risk. If reporting is increasingly covering conflict-related topics it could serve as a warning signal for future developments. 3 And indeed this has been shown to work by Mueller and Rauh (2018, 2022). They were able to show that including features extracted from newspaper articles through a dynamic latent Dirichlet allocation topic modeling (Blei et al., 2003; Blei and Lafferty, 2006) approach can significantly improve conflict prediction models. Similarly, Boussalis et al. (2022) show how extracting features from private information in the form of diplomatic cables can improve forecasts of militarized interstate disputes.
Sentiment dictionaries, lists of words with positive or negative connotations, have also been shown to be a useful approach in the study of conflict. These dictionaries aim to quantify the underlying tonality or polarity of a given document. With regard to conflict, one could expect that higher polarity and a more negative tone in reporting could highlight rising conflict tendencies. While sentiment dictionaries have not yet been used, to the best of my knowledge, as features in conflict prediction, they have been used to study armed groups in conflict settings. Greene and Lucas (2020) applied a standard sentiment dictionary in order to shed light on non-state armed group relationships. They were successful in identifying rivalries and alliances between Hezbollah and other non-state armed groups based on Hezbollah-produced and disseminated documents. Also focusing on non-state armed groups, Macnair and Frank (2018) analyzed the tonality of ISIS propaganda magazines to identify changes in rhetoric, also including the level of hostile language towards other non-state armed groups. Relatedly, Häffner et al. (2023) take the general idea of a sentiment dictionary but use deep neural networks trained on conflict reports and conflict event data to automatically create objective (model-driven) conflict dictionaries. They were able to show that such a dictionary is well suited to identifying documents that are associated with higher levels of conflict.
Document scaling techniques are also widely used NLP methods. They attempt to position documents relative to each other based on a given (supervised) or an undefined (unsupervised) dimension. Many of these techniques produce scores that can be understood as a measure of how similar documents are. Wordscores (Benoit and Laver, 2003) and Wordfish (Slapin and Proksch, 2008) are well-known examples in political science for the two different approaches (supervised and unsupervised). In conflict research, one could assume that conflict reports that are similar to each other also reflect similar conflict tendencies, particularly in supervised settings, where the scaling technique has been trained on conflict occurrence. There have also been attempts to leverage a hybrid approach to gain insights in the area of political science and conflict research. Watanabe (2020), for example, is able to classify newspaper articles for their polarity with regard to the state of the economy with a semi-supervised latent semantic scaling approach. Trubowitz and Watanabe (2021) employed a similar approach. The authors were able to automatically identify how adversarial or friendly the relationship between the US and other countries is by using New York Times news summaries.
Probably the most advanced NLP technique currently are transformer models. A particularly useful implementation of transformers is BERT models. These models are trained on millions of documents and are able to achieve a highly complex level of language representation and understanding. Furthermore, they are rather flexible and can be used for a variety of tasks. Their performance can be further improved when they are trained for specific domains. Hu et al. (2022) is such an example of a BERT model for the specific area of conflict research. However, given their complex and sophisticated architecture, they require vast amounts of computational power. This may explain why they currently have not been employed for the task of conflict prediction.
I create features generated by all these four approaches and evaluate their performance in a prediction task. The next section will outline how the prediction task is defined, describe the text feature extraction methods in more detail, and give an overview of the more structural features used as baselines to compare the text features with.
Research design
This section introduces the main datasets and features for the prediction models, the NLP approaches as well as the machine learning models used to generate the predictions. 4
Datasets
The prediction models contain variables from six different sources and include text data as well as variables capturing conflict dynamics and socio-economic and socio-political trends. I use two different text sources for the NLP methods: (1) newspaper articles from the BBC Monitoring (BBC) Dataset (from 2013 to 2020); and (2) expert-written CrisisWatch country reports (2003–2020) from the International Crisis Group. CrisisWatch reports are short, monthly descriptions of conflict-related trends for each country and are freely accessible online. 5 The BBC Data consist of all newspaper articles produced and collected by the BBC Monitoring team, which includes BBC articles but also translations of other international media reporting. It also includes expert reports and analyses, relatively similar to CrisisWatch (CW) reports. 6 As the time period for which I have text data available is different for CW and BBC, I build one dataset that contains features from CW including data from 2003 to 2020 and one dataset that contains features from BBC texts including data from 2013 to 2020. 7
In order to predict monthly (log) fatalities, I use the UCDP GED (Sundberg and Melander, 2013) 8 that contains “individual events of organized violence (phenomena of lethal violence occurring at a given time and place)” that are geo-coded as precisely as possible. In addition, I use the UCDP GED Dataset to extract actor-related features. For the UCDP GED and all following datasets, I extract variables from 2003 until 2020 and either aggregate or interpolate them to a country-month level. As many machine learning methods do not allow for missing observations and timesteps, instead of dropping these observations, I use the Multiple Imputation by Chained Equations approach with the lightgbm algorithm to impute the missing values. 9
Features related to civil society and political liberties are taken from the Varieties of Democracy Datset (Coppedge et al., 2023). 10 The public repository for the Rulers, Elections, and Irregular Governance dataset (Bell et al., 2021) 11 is utilized for election and leadership variables. Finally, I use the ethnic power relations (EPR) Power Access Data and Conflict Database 12 for power access and information on conflict history. The reader is referred to the Online Appendix for an overview of all variable names as well as which variable is used for which model.
Extracting text features
The two goals I pursue with this paper are on the one hand to test whether the inclusion of text features can boost predictive performance and on the other hand to identify which text feature extraction method outperforms the other. Therefore, I extract text features employing the following approaches: dictionary approaches (general-purpose as well as conflict-specific), topic models, BERT models, and word scaling techniques. I first build several benchmark models including a variety of structural and (socio-)political variables commonly used for modeling conflicts and in a second step add the textual features. As the text models have different underlying assumptions regarding the nature of texts, different preprocessing techniques are applied. The reader is referred to the Online Appendix for preprocessing steps regarding BERT models, topic models, and word scaling techniques. 13
Dictionary-based features
As mentioned above, I include two general-purpose sentiment dictionaries and two (for each document corpus separately) conflict-specific dictionaries based on an approach suggested by Häffner et al. (2023). Dictionary approaches usually rely on a set list of words and rules that are assigned positive or negative values to calculate a (sentiment) score per document. For Vader (Valence Aware Dictionary and Sentiment Reasoner) (Hutto and Gilbert, 2014) and the HGI4 (Harvard General Inquirer) (Dunphy, 1974) dictionary, these are words that generally tend to have positive or negative connotations and are manually collected and maintained. Following the approach proposed in Häffner et al. (2023) I create an Objective Conflict Dictionary from the CrisisWatch and BBC corpora by automatically extracting words that are associated with more or less conflict from a deep neural network trained on UCDP conflict events. The dictionaries contain words that are positively (and negatively) correlated with log fatalities as well as their relative feature importance score. Consequently, it is a context-specific dictionary that aims to measure overall conflict intensity but the words do not bear any inherent positive or negative meaning.
Ultimately all dictionaries are applied to the CrisisWatch and BBC texts and the resulting features are obtained by aggregating the positive and negative values. All positive and negative word scores of a document are summed up and the resulting sum is divided by document length. Note that this is not the only way to calculate document scores, but most scores account for document length. The Python library Loper and Bird (2002) and Pysentiment2 have been applied respectively to calculate the Vader and HGI4 sentiment scores.
Document scaling features
I also apply the popular Wordscores (Laver et al., 2003) text-scaling technique. Similar to dictionary approaches, text-scaling also relies on a bag-of-words representation of language. Documents that use similar language (measured as word frequencies) should also be closer in content. While there are different scaling methods, Wordscores belong to the supervised machine learning techniques and require reference texts as inputs. I apply Wordscores to both corpora of conflict reports. As with all text features, I train the Wordscores model on a separate subset of the respective documents (the training window) and in each corpus match it with the corresponding fatalities as reference scores. Those references are then used to predict the positions of the remaining texts. As before with the (sentiment) dictionary approach, I determine how closely those scores are aligned with fatalities and use them as features in the models to predict fatalities.
Topic model features
As Mueller and Rauh (2018) already demonstrated that the inclusion of features from topic models (TM) improves the predictive performance of models, I also include features from topic models in the prediction models. Topic models belong to the unsupervised machine learning methods and can be applied to reduce the high dimensionality of texts. I use relatively few topics (K = 5, 10, and 15 topics respectively) as I do not want to focus on single events and rather extract more general topics. Similar to Mueller and Rauh (2018), I include the share of each topic per country on a monthly level. However, I implement dynamic topic models (Blei and Lafferty, 2006) rather than standard topic models to account for changes in the distribution of topics over time as well as changes in their composition.
BERT-models features
Bidirectional encoder representations from transformers models are based on transformer models (Vaswani et al., 2017) and are considered the current state-of-the-art in NLP; they have produced impressive results in a variety of research areas. They often outperform traditional models as they are trained on massive corpora and leverage the attention algorithm that allows them to focus only on important parts of a sentence. These models can model language on a high level as they obtain positional information about a word as well as its relation to other words in a sentence.
There are different ways to include transformer models into prediction models. The most straightforward is to use an already pre-trained transformer model for sentiment classification and simply apply this model to the documents. The resulting sentiment scores can be included in the prediction model in the same way as the scores from the dictionary approaches. Another approach is to finetune a transformer model on the corpus (training dataset) by directly predicting log fatalities from raw texts. I rely on the newly released ConfliBERT on huggingface 14 and finetune it on log fatalities. As transformer models usually are designed to solve classification tasks, the final layer of the transformer model has to be transformed to solve a regression task. However, the final activation function cannot simply be linear as output values need to be strictly positive (fatalities usually are only positive numbers) and I adjust the activation function accordingly.
Model specifications
For each prediction task (t + 1, …, t + 6) I build an independent prediction model that directly predicts the logarithm of monthly fatalities (on a country level) for the next 1–6 months (direct multi-step forecasting). In order to model the time dependencies, I lag all input features. As I have different time periods available for each text source, I estimate all models for the CrisisWatch dataset and the BBC dataset separately and compare each to how they perform once different text features are added (Table 1).
Model specifications.
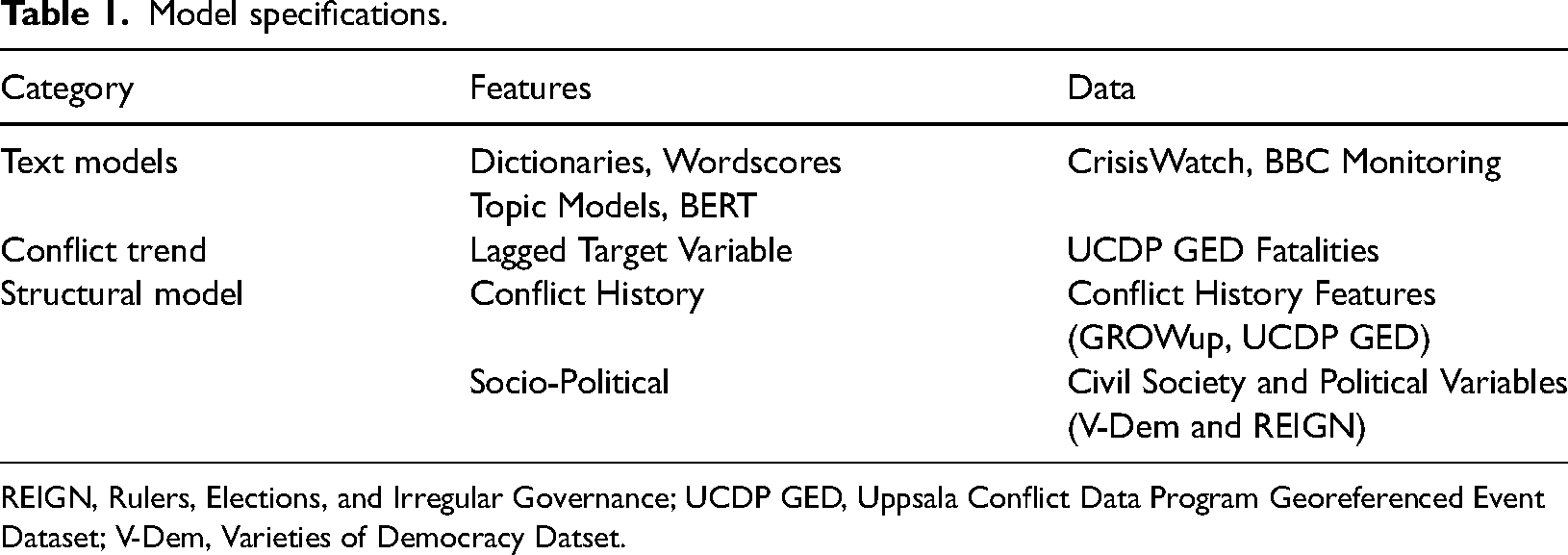
REIGN, Rulers, Elections, and Irregular Governance; UCDP GED, Uppsala Conflict Data Program Georeferenced Event Dataset; V-Dem, Varieties of Democracy Datset.
This results in a large number of models, since I explore how different text features are able to complement or supplement different categories of base features. In total, I trained 78 (39 BBC and 39 CW) models for the six prediction tasks. 15 For the BBC (CW) models, the time period from 2013 (2003) until 2019 is used to train the models while the year 2020 is the hold-out sample to test the prediction models. For all specifications, a Random Forest model is trained, by employing hyperparameter optimization and cross-validation, and the best-performing model is selected. 16 As a robustness check, I also estimate all models with gradient-boosted decision trees (XGBoost) to rule out that patterns are due to a certain modeling algorithm. In contrast to traditional cross-validation, I cannot randomly split the dataset into train and validation sets as when modeling time dependencies, future values might be used to predict past ones. Therefore, I employ a sliding window approach. For the hyperparameter optimization of the Random Forest model, I use the number of trees and the maximal depth as hyperparameters and employ Bayesian optimization with 30 trials to find the optimal parameter constellations. With regards to the maximal depth, I test configurations between 2 and 32. For the number of regression trees, I test constellations between 100 and 1000. As I train a model for each forecast horizon for all 140 models, I refrain from reporting all ideal hyperparameters for each model but rather report the general trends. For both the BBC and the CW corpus, the smallest depth, namely 2, was chosen in most cases as the ideal hyperparameter. The results for the number of trees vary more, but also, in this case, smaller trees are more frequently chosen. To avoid cross-contamination between the training and test sets I predict only the second half of 2020 as lagged input features are used in the models. Following the prediction task, I evaluate the performance of the models using mean squared error (MSE) and R2 values for each of the prediction steps. Thereby, I can evaluate which text features can add the most to the more traditional approaches to conflict prediction.
Descriptive statistics
Before describing and comparing the model results, this section will provide more information on the text corpora as well as some descriptive statistics for the text features and the target variable. The two corpora are very different with regard to the following aspects. The CW corpus is considerably smaller. There is only one report for each country-month observation’ consequently, there are approximately 14,000 reports. The BBC corpus contains 1,365,150 newspaper reports; consequently, more computing power is needed to process the texts. However, after combining the two text corpora with the UCDP GED Dataset (Sundberg and Melander, 2013), the total number of observations is around twice as large for the CW data (with 23,773 observations) compared with the BBC data (13,284 observations). The relatively short time period that I can cover with the BBC data may pose a problem as conflicts are relatively rare and could potentially bias the results in favor of CrisisWatch reports. Another difference is the country coverage. Figure 1 and 2 show the coverage and the relative frequency of countries in the CW and the BBC corpus respectively. 17
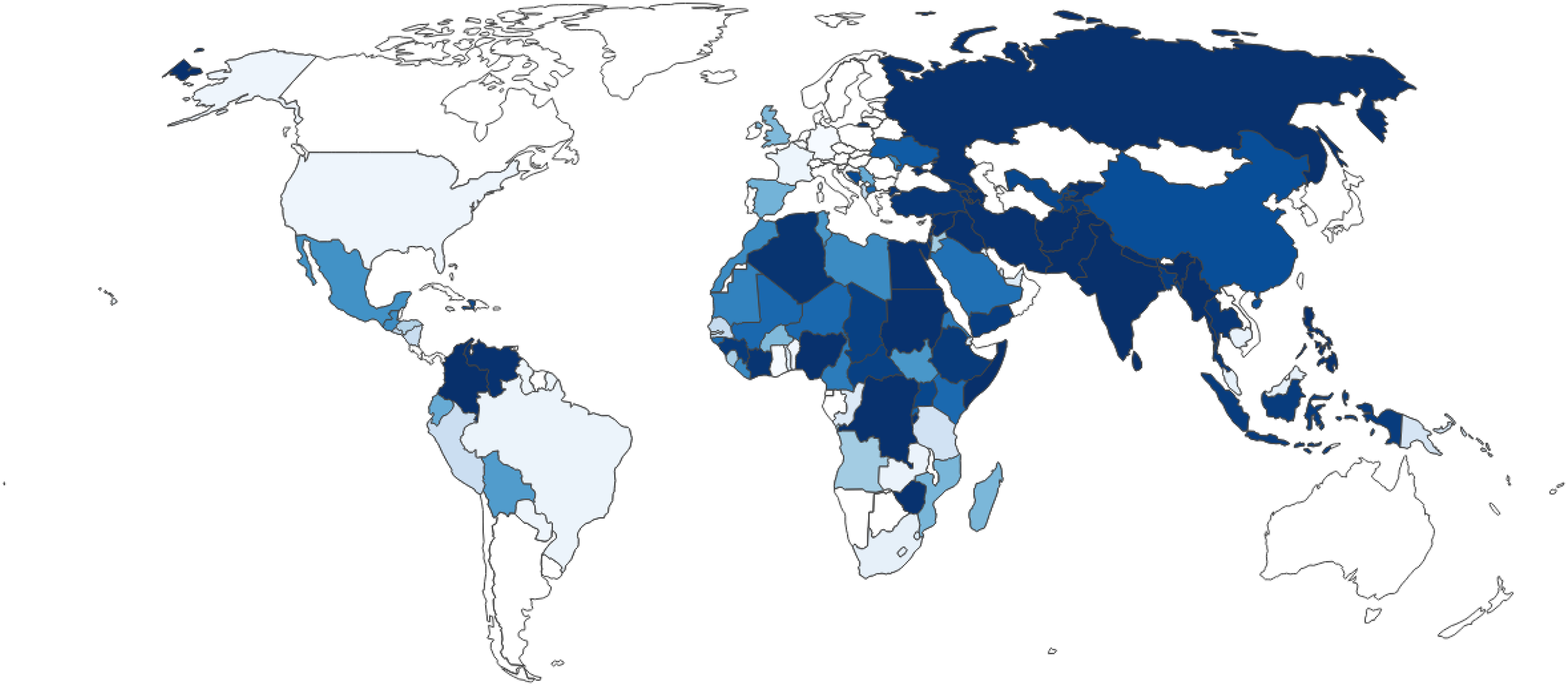
CrisisWatch country coverage.
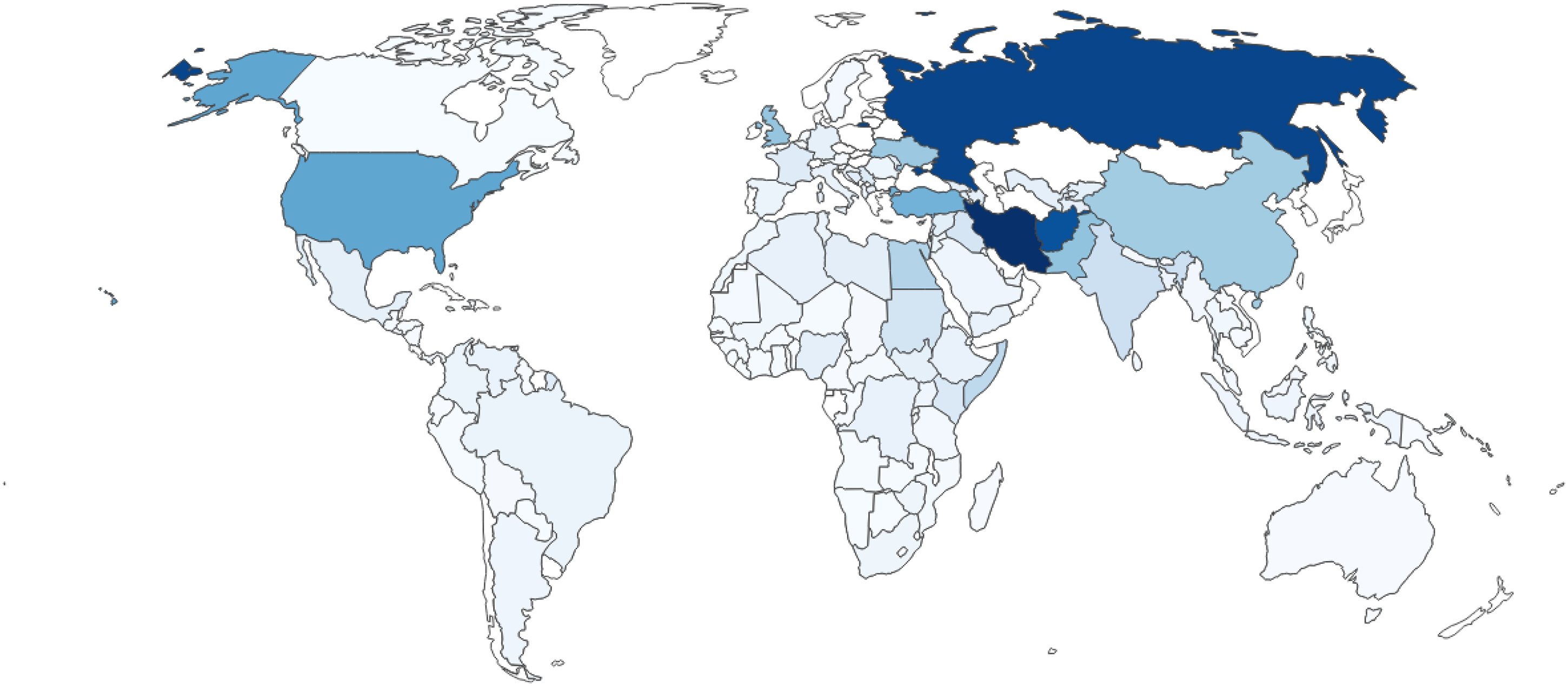
BBC monitoring country coverage.
Darker blue indicates a higher share of reports concerning a country and lighter blue tones show a lower share. While the CW corpus shows a more equal distribution in the number of countries covered by reports, the BBC corpus shows a different picture: A large majority of reports concern Iran (9.6%), Russia (8.9%) and Afghanistan (8.3%). Although CrisisWatch also focuses more on countries with conflict-related events, the reporting is not dominated by a few countries. The last difference is the different styles and contents of the texts. While the CW reports are short, technical and rather “choppy” descriptions of conflict events, the BBC articles are newspaper articles and therefore less technical with more emphasis on readability and flow of language. Examples for a CW report can be found in the Supplementary Material; however, sharing BBC Monitoring newspaper articles is not possible for proprietary reasons. 18 I am interested in investigating which kind of text data can add more value to a prediction task and whether it is necessary to construct large resource-intense newspaper corpora for conflict prediction.
Tables 2 and 3 show the summary statistics for the textual features and the target variable, UCDP GED fatalities, for the BBC and the CW corpus respectively. The textual features from the dictionaries include negative and positive values while the BERT and Wordscores features are strictly positive as they were trained to mimic the characteristics of fatalities.
Descriptive statistics for CrisisWatch data.
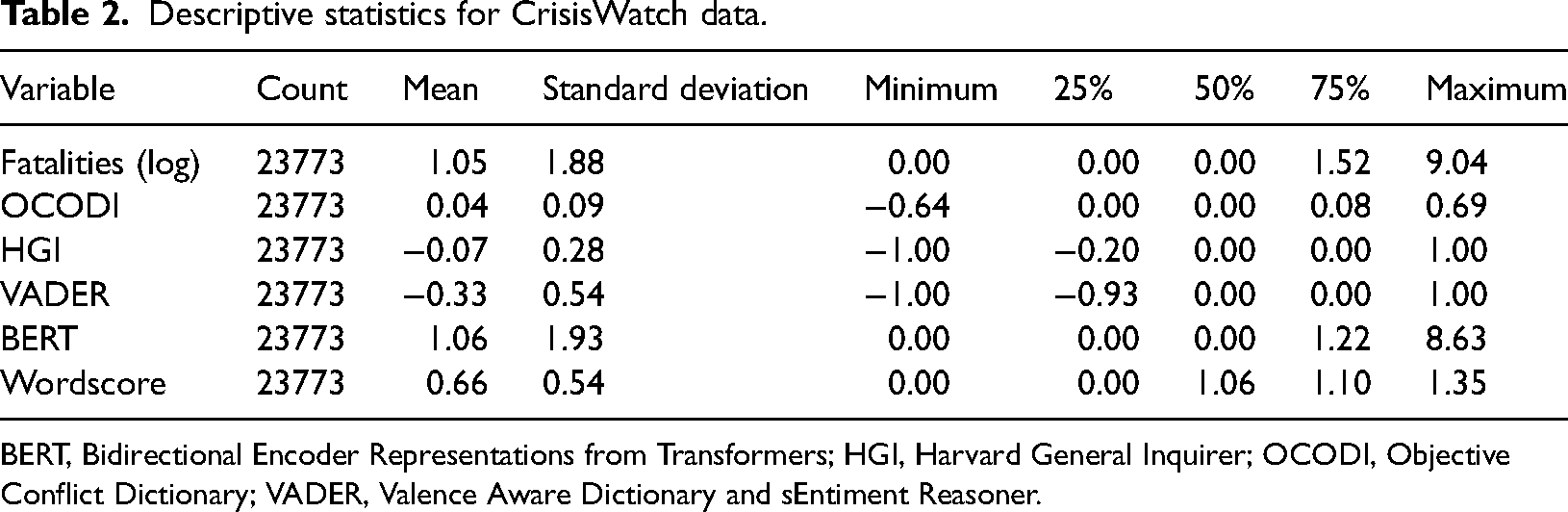
BERT, Bidirectional Encoder Representations from Transformers; HGI, Harvard General Inquirer; OCODI, Objective Conflict Dictionary; VADER, Valence Aware Dictionary and sEntiment Reasoner.
Descriptive statistics for BBC data.
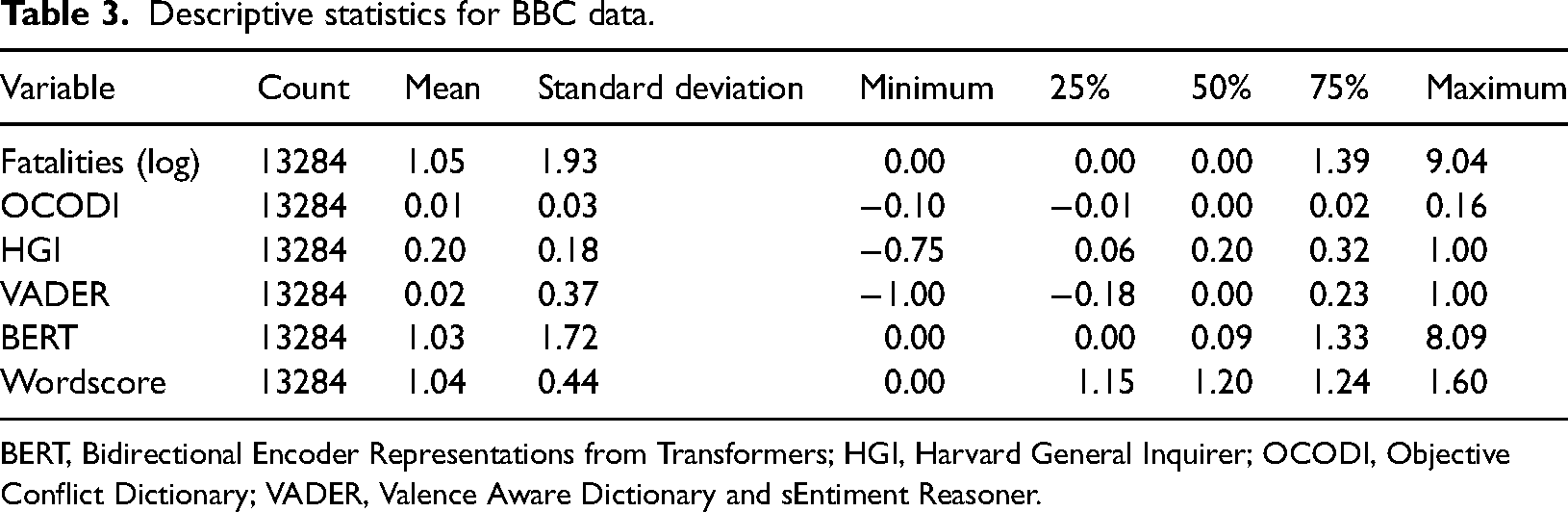
BERT, Bidirectional Encoder Representations from Transformers; HGI, Harvard General Inquirer; OCODI, Objective Conflict Dictionary; VADER, Valence Aware Dictionary and sEntiment Reasoner.
Model results
Figure 3 gives a general overview of the performance of all 468 models separated by which text corpus is being used. As can be seen in the figure, the performance of models varies vastly. However, two general trends can be identified: first, despite the shorter training window, owing to the limited availability of articles, BBC models tend to perform slightly better. BBC models achieve the highest overall R2 for each timestep; however, some of the BBC models are also among the worst models. Second, predicting further into the future is more difficult than predicting the next month. The better performance of models for t + 6 is not a general trend but a result of t + 4 and t + 5 being more violent months and hence more difficult to predict. 19
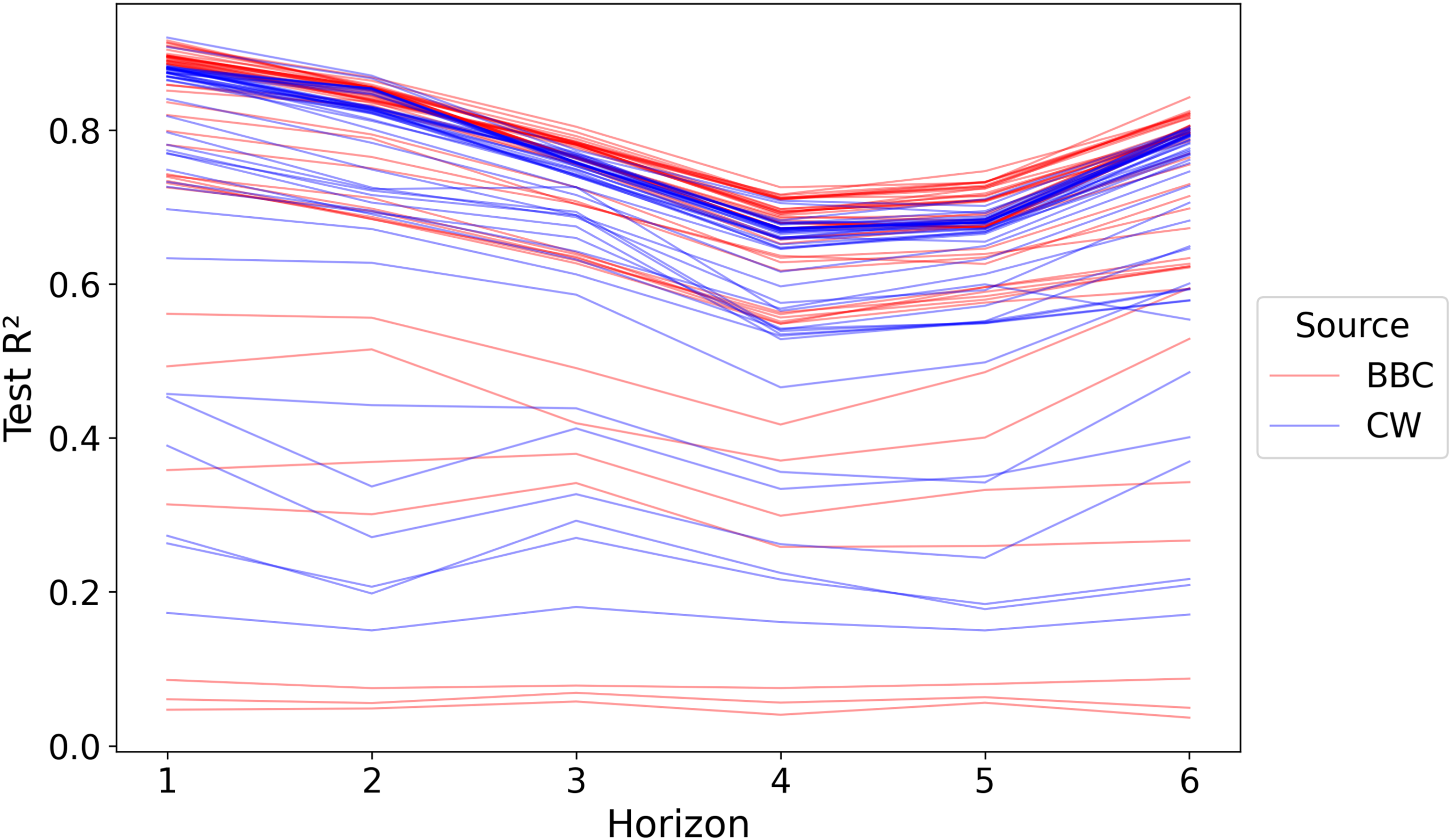
Overview and comparison of model performance for BBC and CrisisWatch data. Note: Each line shows the performance (R2) of one of the Random Forest prediction models for each of the six timesteps.
However, which groups of models tend to perform better and which text features add the most are more important questions. To answer them, I first have to establish the baselines with which the text features can be compared. Figure 4 (left) shows the performance of the two baseline model categories, Conflict Trend and the Structural model, in addition to all text features for both text corpora. As both baseline models include the lagged target variable, I expect them to achieve good performance metrics. Indeed, it can be seen that the two baseline models outperform all of the text features with R2 ' between 0.8 and 0.9. Although both models achieve very similar performance metrics, the Structural model outperforms the Conflict Trend model over all time steps in the BBC data. Interestingly, for the CW data, Conflict Trends only outperforms the Structural model in t + 2.
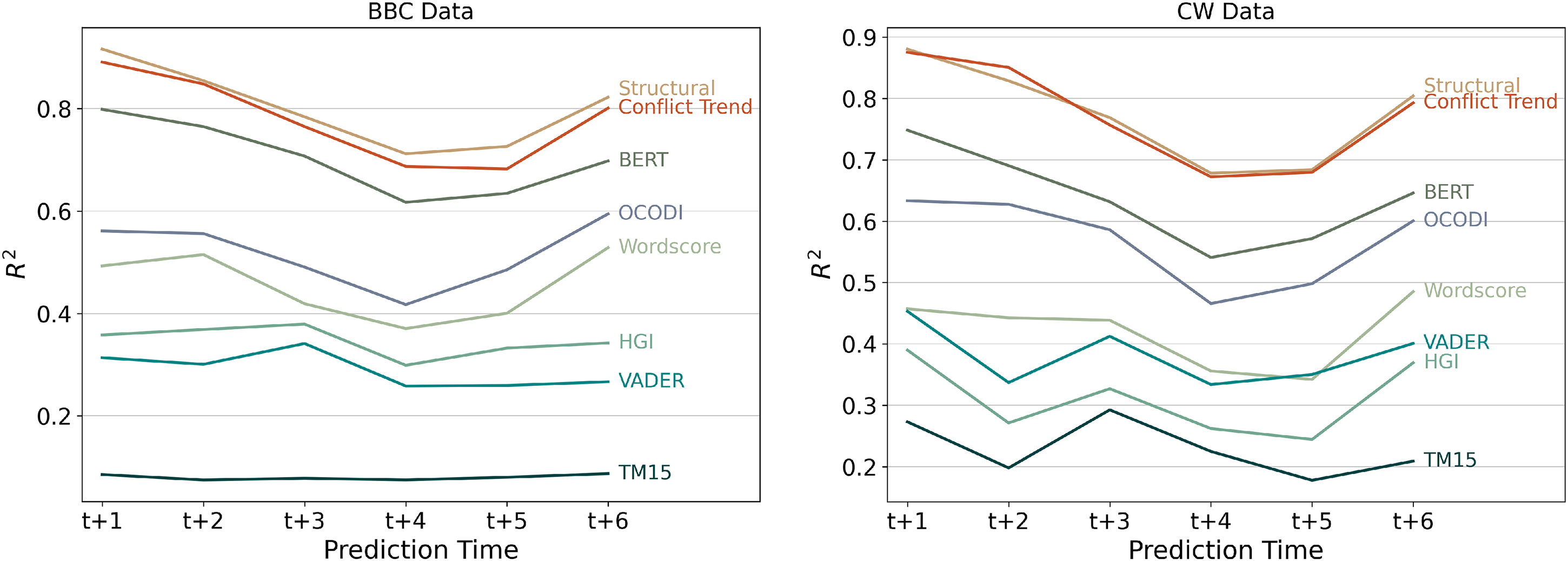
Text features and baseline models (BBC data, left; CrisisWatch data, right).
After establishing the baselines, I can now turn to the performance of the text features. In Figure 4, in addition to the two baselines, I see the performance of models using only the different text features. As standalone features, no text feature can beat the baseline models; however, this was expected. Among all text features, it is not surprising that a transformer-based model achieves the best performance with an R2 close to 0.8. It is impressive to achieve such a performance only on information contained in texts. Nonetheless, all features from NLP methods that are directly linked to the target variable (BERT, OCODI, Wordscores) reach acceptable levels of R2. Features that are not directly linked to the target, general-purpose dictionaries, and topic models (TM15), 20 achieve a considerably lower performance. For the Vader and HGI dictionaries, this comes as less of a surprise but given the good performance of topic models shown by Mueller and Rauh (2022), these results are unexpected.
Next, I compare how these models perform across the distribution of fatalities. Figure 5 shows the model performance for each of these models across different bins of the outcome variable.
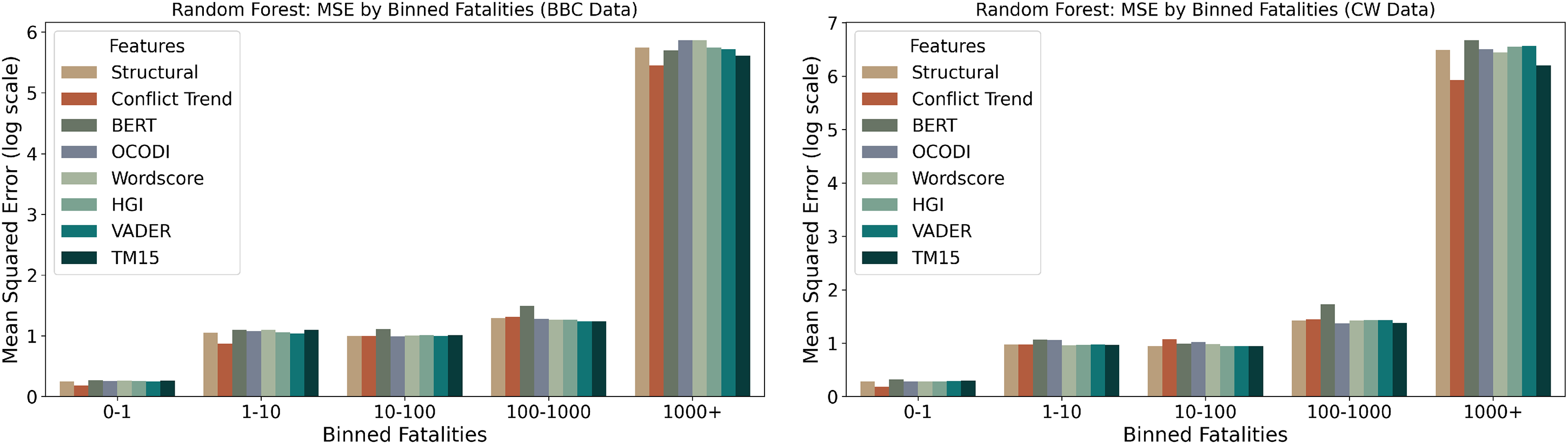
Model performance by binned fatalities (BBC, left; CrisisWatch, right). Note: As the models are predicting the log of fatalities, the mean squared error (y-axis) is shown on the log scale for easier visualization. The bins, however, were back-transformed to unlogged fatalities to be more interpretable.
Across both datasets, a clear trend emerges of the MSE increasing substantially with higher fatality bins, reflecting the greater difficulty of accurately predicting large-scale events. For both datasets, models based on structural features and conflict trends are often exhibiting the lowest MSE across most bins, particularly in the lower and intermediate fatality ranges. Somewhat surprisingly, models relying on textual features do not display markedly higher errors, with maybe the exception of BERT, which has slightly higher errors in the middle three bins. This holds true across datasets and even in the highest fatality bin (1000+). 21 Notably, the relative performance of models remains stable between the two datasets, although overall MSE values are somewhat higher in the BBC data. These results suggest that there is not a huge difference between models, even for rare, high-severity events.
Since the goal of this paper is to improve our understanding of how text features can complement traditional conflict prediction models, next I investigate which NLP approach adds the most to the baseline models. In Figure 6 we can see the results when combining each of the text features with the conflict trends variables. As a reference, the figures also include the results for the conflict trends and the structural models. For both datasets, the results are very similar and it becomes apparent that text features are no silver bullet. The differences in performance are marginal. Simply adding text features to prediction models does not significantly improve their predictive performance. Although most text features increase the performance in comparison with the Conflict Trend baseline model, the Structural model outperforms all models on the BBC data and is only slightly beaten by the TM15 model in the CW data. However, again, the differences in performance are marginal. Interestingly, the text features that did not perform well as standalone features (Topic models, general-purpose dictionaries, and Wordscore), better complement the baseline models. It comes as a surprise that BERT is the only text feature that does not seem to complement existing approaches well. Although BERT is the best (standalone) text feature, it does not improve the baseline models. This may be because BERT can capture conflict trends reasonably well only from texts, but cannot help explain additional variability beyond that. Unsupervised or general-purpose approaches seem to capture latent information that is not directly correlated with conflict trends but can add to conflict history.
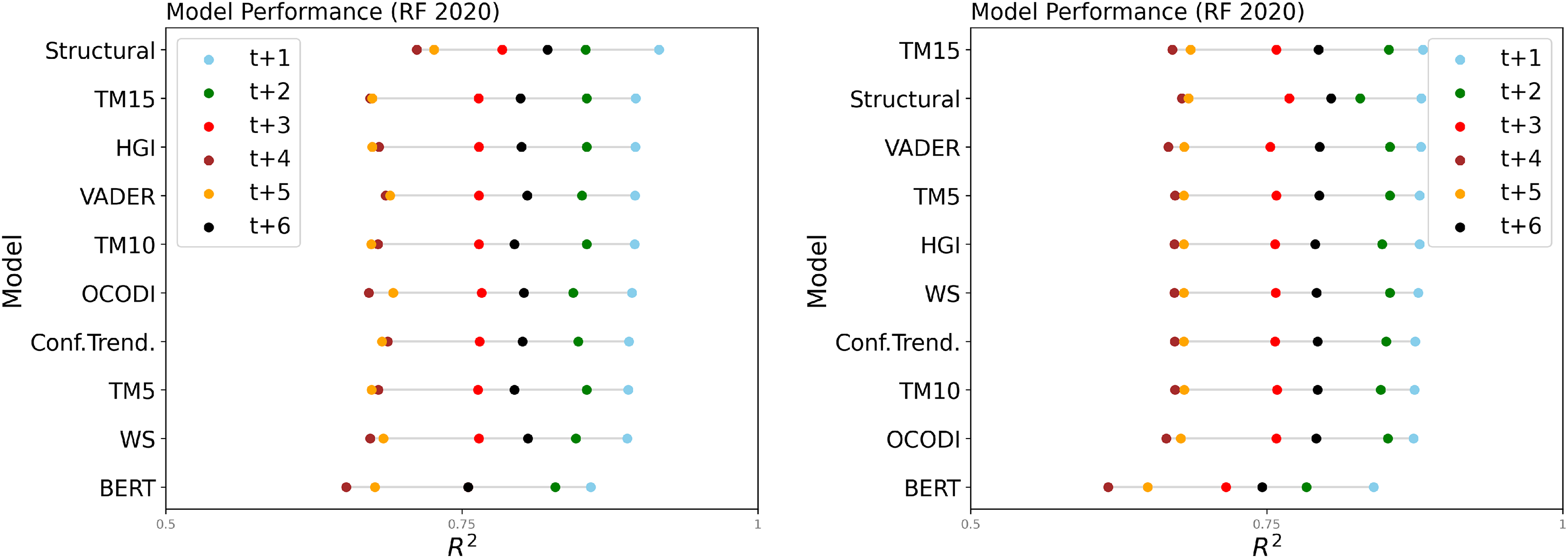
Improving upon the baseline models (BBC, left; CrisisWatch, right). Note: All Random Forest models include the lagged target (t − 1 to t − 6) variable as features. Hence, e.g. BERT includes the BERT features and the Conflict Trends features, as I wish to investigate how much the individual text features can add.
In the Online Appendix, I provide tables that display the R2 (and MSE) for all models over the whole forecast horizon for both the Random Forest as well as the XGBoost models. These results warrant a discussion of the tradeoff between performance gains and computational costs. Some text processing techniques are more computationally expensive than others. In particular, transformer models require sophisticated IT infrastructure, while applying off-the-shelf dictionaries is comparatively inexpensive. While the high computational cost for transformer models seems worth the gains in performance when there are no other features available, the performance drop-off when using them to complement other features suggests focusing on computationally cheap methods, like sentiment dictionaries or Wordscores, when computational power is limited. Topic models, on the other hand, while also computationally expensive, particularly when implementing dynamic topic models as I do here, can complement the baseline models well and the increased computational cost seems to be warranted. While these considerations should not be the only factors guiding the choice of NLP approach, it is important to keep in mind that increased complexity and computational cost of a model does not necessarily translate to increased performance in all settings.
Overall, text features seem to capture ongoing conflict dynamics and appear to have the potential to complement traditional input features for prediction models. However, on a global level with conflict history available, I have shown that few features can supplement conflict trends as predictors. The results and the findings by Mueller and Rauh (2022) point in the direction that text features could add more to predictions of conflict onset in cases where there is no conflict history (the so-called hard case problem) instead of global-level conflict intensity. Although further research is needed to systematically identify the conditions and cases in which text features can improve existing conflict prediction models, this paper is a first attempt to provide an overview of the potential benefits of using text features for crisis early warning models. Other interesting areas of further research might be to extend this evaluation to a more granular level, meaning to move beyond the country-month level. In general, it is advisable to use a high-quality newspaper corpus. The challenges associated with constructing such a newspaper corpus, however, are plenty, especially concerning country coverage and the challenge of constructing a diverse corpus consisting not only of articles from one international newspaper agency.
Conclusion
Conflict prediction continues to be a challenging task. However, the potential benefits of anticipating the next conflict or crisis continue to motivate researchers to improve upon existing approaches. In particular, the multifaceted and dynamic nature of conflicts, coupled with challenges related to data, human behavior, and the importance of contextual factors, contributes to the ongoing difficulty in accurately predicting when and how conflicts will arise.
However, with recent advancements in computational performance and wider and easier access to new data sources through the internet, researchers have been able to improve the predictive performance of models. Applying natural language processing methods to large corpora of text documents stands out as one promising direction to improve upon these efforts even more. In particular, conflict reports and newspaper articles could be helpful in this regard, as they include relevant information about current and future dynamics of conflict in a country.
Therefore, in this article, I examined strategies to extract features from text data for out-of-sample conflict prediction using different NLP techniques, providing an overview of the most popular NLP approaches and presenting a comparative assessment of their benefits for crisis-early-warning models. I do so by applying topic models, dictionary approaches, a document scaling method, and transformer models to two text corpora (CrisisWatch reports and BBC Monitoring news articles) and investigate how well these features can help predict conflict intensity. While text features alone cannot reach the same predictive performance as using conflict trends or other structural data, some of them, particularly transformer models, reach acceptable levels of performance, considering that these predictions are based on text data alone. I find that the integration of NLP methods for conflict prediction underscores the potential of leveraging textual data to enhance the accuracy and depth of forecasting models. Although NLP is not a silver bullet, the findings reveal that incorporating NLP tools can offer valuable insights and can complement and, depending on the context, even supplement alternative approaches. This is underlined by the results, showing that including text features in the prediction models improves their performance, even if only marginally. Building on this, training NLP models, specifically models that can be fine-tuned on conflict data (e.g. BERT or OCODI), on the residuals of structural models may be a natural next step, as this could enable each approach to capture unique information and further enhance the predictive power of traditional models. 22 I sought to identify the most effective NLP approach based on the nature of text sources and the availability of other structural variables. The assessment of various NLP methods on distinct corpora, encompassing general newspaper articles and expert-authored CrisisWatch reports, emphasizes the need for a tailored approach that aligns with the specific characteristics of the data at hand. Furthermore, increased model complexity and computational cost does not always translate into better performance and, depending on the context, applying a simpler NLP approach may save computing time at no expense of performance. With no single NLP approach outperforming the others, these results underline the importance of continuously investigating new approaches and their applicability to conflict prediction.
Crucially, this research sheds light on the complementarity of NLP features with traditional structural variables like socio-economic indicators, conflict history, and political indicators. The synergy between these approaches reinforces the idea that a holistic understanding of conflict prediction requires the integration of a diverse set of data sources and modeling approaches. Given the importance of improving conflict prediction models, I hope that this study can serve as an initial step toward assessing the efficacy of different NLP methods. While I evaluated how well models fare at predicting conflict intensity, future research looking at how different text features could help predict outbreaks or escalations of violence, in line with findings by Mueller and Rauh (2022), could prove beneficial.
Finally, natural language processing, and machine learning more generally, are fast-developing research areas that have seen an immense boost in popularity in recent years. Particularly the new Generative Pre-trained Transformer model family is evolving rapidly, with impressive results in many different areas. However, currently, there is no straightforward or intuitive way to apply these generative models for prediction tasks on tabular data. While they may be helpful in prediction adjacent tasks, their usefulness for generating features for conflict prediction is limited for now. Moving forward, continued assessment in different contexts will be essential to evaluate future approaches and improve the accuracy of conflict prediction.
Supplemental Material
sj-pdf-1-cmp-10.1177_07388942261422045 - Supplemental material for Text as data for crisis-early warning: A comparative assessment of NLP methods for conflict prediction
Supplemental material, sj-pdf-1-cmp-10.1177_07388942261422045 for Text as data for crisis-early warning: A comparative assessment of NLP methods for conflict prediction by Julian Walterskirchen in Conflict Management and Peace Science
Supplemental Material
sj-txt-2-cmp-10.1177_07388942261422045 - Supplemental material for Text as data for crisis-early warning: A comparative assessment of NLP methods for conflict prediction
Supplemental material, sj-txt-2-cmp-10.1177_07388942261422045 for Text as data for crisis-early warning: A comparative assessment of NLP methods for conflict prediction by Julian Walterskirchen in Conflict Management and Peace Science
Footnotes
Acknowledgments
The Center for Crisis Early Warning (Kompetenzzentrum Krisenfruherkennung) is funded by the German Federal Ministry of Defense and the German Federal Foreign Office. The views and opinions expressed in this article are those of the authors and do not necessarily reflect the official policy or position of any agency of the German government. I gratefully acknowledge the computing time granted by the Institute for Distributed Intelligent Systems and provided on the GPU cluster Monacum One at the Bundeswehr University Munich to fine-tune the BERT models. The empirical analysis for the revised manuscript was enabled by resources provided by the National Academic Infrastructure for Supercomputing in Sweden, partially funded by the Swedish Research Council through grant agreement no. 2022-06725. I want to especially thank Sonja Häffner for her substantial contribution to the initial draft of this paper. All remaining errors are my own. I would also like to thank Christoph Dworschak, Christian Oswald, and the participants of the CCEW Symposium 2023 for their comments and helpful feedback.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Data availability statement
Replication code and data for this article are available via Harvard Dataverse at https://doi.org/10.7910/DVN/MNT4UQ. However, the BBC Monitoring news articles are proprietary and cannot be shared.
Supplemental material
Supplemental material for this article is available online.