
Abstract
The vast amount of data being generated in and about cities creates both an opportunity and a dilemma for urban policymakers and planners. This paper articulates the theoretical, practical, and pedagogical foundations for the fields of urban informatics and civic analytics and outlines the challenges to effectively applying big data and computational methods to urban management, policy, and planning. It describes the state of the field, defines the range of applications in the urban context, and presents key considerations in training scientists that both acknowledge and capitalize on shifting modes of learning, working, and decision making. Situated within the ethical and moral landscape of data analytics, it articulates the knowledge and skills needed by future urban science practitioners and concludes with a discussion of data-driven problem solving in the urban context.
Introduction
The convergence of two phenomena—the ability to collect, store, and process an expanding volume of data and the increasing level of global urbanization—has resulted in the opportunity and need to use large-scale data sets and analytics to address fundamental challenges of city operations, policy, and planning. However, this opportunity has been constrained by the lack of trained specialists that have both an ability to analyze massive data and an understanding of city functions within and across urban domains and systems. The question is how to effectively apply the tools of informatics in the urban context to improve decision-making processes, increase the efficiency and equity of operations and service delivery, and support evidence-based policy and planning.
Common issues facing city managers and planners can be addressed by parsing the detailed data that city agencies regularly collect (Barbosa et al. 2014). When combined with other, correlative data sources—pulled from social media feeds, transit cameras, and myriad sensors—the potential to understand and improve quality of life in cities increases. A major obstacle preventing city officials from unlocking these insights is the lack of personnel with specific training and deep expertise. Compounding this skills gap, individual agencies have been limited in their ability to conduct large-scale analytics by an incongruity between incentives for process innovation and existing legacy organizational and institutional structures. However, as local governments face tightening budgets and greater demands for city services, many cities, including New York, NY, Chicago, IL, Pittsburgh, PA, and South Bend, IN, have made new efforts to overcome these constraints by cultivating both internal and citizen-driven capacity for data investigation and discovery that can cross agency boundaries, with encouraging results.
While the marketing rhetoric around Smart Cities is replete with unfulfilled promises, and the persistent use (and misuse) of the term big data has generated confusion and distrust around potential applications, the reality remains that disruptive shifts in ubiquitous data collection (including mobile devices, GPS, social media, and synoptic video) and the ability to store, manage, and analyze massive data sets require that urban planners have new capabilities to respond to these innovations. In the emerging field of urban informatics, and its corollary civic analytics, core competencies cross traditional boundaries of computer and data science, urban planning and public policy, and operations research and management. This necessitates both technical and nontechnical (or noncomputing) skills as well as breadth and depth across informatics disciplines and domain applications. These skills include knowledge of programming (software tools such as Python, R, etc.), data mining and management (e.g., Hadoop/MapReduce), applied mathematics and statistics, machine learning, and visualization (e.g. Carto, D3), as well as urban systems science and the social, political, and economic realities facing both developed and developing cities.
Training urban scientists and data practitioners to extract usable insight from data extends far beyond just programming or “hacking” skills. They must be knowledgeable about a wide range of urban data—both structured and unstructured—and be aware of the biases inherent in its definition, collection, and analysis. They must be able to manage and integrate large, disparate data sets of varying types and use a range of analytical techniques to interpret and visualize outcomes in such a way that can be communicated effectively to nontechnical audiences. They must understand city governance, structure, and history sufficiently to identify and assess problems, collect and organize appropriate data, utilize suitable analytical approaches, and ultimately produce results that meet the needs of a diverse citizenry while recognizing the constraints faced by city agencies and policymakers. This is not an easy task and requires a nuanced understanding of urban social and political dynamics and a significant appreciation of data governance, privacy, and ethics.
This paper articulates the theoretical, practical, and pedagogical foundations for the fields of urban informatics and civic analytics and the challenges to effectively applying computational methods to urban management, policy, and planning. It describes the state of the field, defines the need for computational methods in city decision making, and presents the balances and tensions in training scientists that both acknowledge and capitalize on shifting modes of learning, working, and decision making. It articulates a core curriculum for urban data scientists and outlines the knowledge and skills needed by future urban practitioners. The paper concludes with recommendations for data-driven problem solving in the urban context and a discussion of the pitfalls of a singular reliance on quantitative methods for urban planning.
Background on the Field and State of Practice
State of the Field
Like many disciplines, the study of cities is being disrupted by the introduction of big data and data-driven approaches to discovery and knowledge formulation (Kitchin 2014a). Although there is a long history of the use and limits of empirical methods in planning theory and practice (Lee 1973), the field of urban informatics remains relatively nascent, much as during the emergence of neuroeconomics, computational biology, and genomics (Glimcher et al. 2013; Waterman 1995). As the field begins to mature, there is greater clarity in the focus and meaning of various terms that have evolved in recent years to describe this shifting landscape. To level and motivate this discussion, the following are proposed definitions for the common terminology encountered in the urban big data and smart cities discourse.
Urban science is the scientific study of cities through experimentation and interdisciplinary research. It can be defined by its objective to understand urban dynamics using observational or measured data and scientific methods from physical, natural, and social sciences. It is characterized by a discovery-driven and theoretically motivated approach to natural and social phenomenology in the built environment. This term is often used interchangeably with a science of cities, although the latter phrase has typically referred to more defined efforts to derive mathematical constructs of city form and function (Batty 2013; Bettencourt 2013; Bettencourt and West 2010).
Urban informatics is the study of urban phenomena through a data science framework of urban sensing, data mining and integration, modeling and analysis, and visualization to generate new insights that simultaneously advance methods in computational science and address domain-specific urban challenges. It is focused on urban computing and computer science techniques to explore, describe, predict, and to a lesser extent, explain urban phenomena with the intent of applying new knowledge that can be used by domain experts to solve problems.
And finally, civic analytics is the application of data science to enable data-driven and evidenced-based public sector decision making in city operations, policy, and planning. Civic analytics is driven by problem-oriented applications that generate new actionable insight from data. It is characterized by knowledge in both data science applications and domain-specific policy fields such that the civic data analyst is able to empirically explore a particular problem and generate viable alternatives for interventions to solve it.
The distinction between urban informatics and civic analytics rests on the emphasis of their respective goals. Where urban informatics focuses on advances in computing and data science tools and methods, the objective of civic analytics is to solve persistent urban challenges using machine learning and other computational methods as tools. A civic analyst must be able to understand the full suite of analytical approaches, recognize what methods are appropriate for what types of problems, translate and interpret analytical output to change organizational behavior and public management practices, and evaluate the effectiveness of interventions. This process necessitates close coordination between the analyst and policymakers throughout the project, where substantive engagement by domain experts allows for continuous refinement of project scope and goals, qualitative knowledge transfer, and empirical validation based on lessons learned.
Urban informatics brings together aspects of computer science, physics, operations research, management science, decision sciences, and urban planning. As such, to date the subject has appeared in the literature within several disciplines, often with researchers using a new language (or a lexicon borrowed from computing) to describe traditional, quantitative social science methods or others using established computer science tools or physical models applied to urban data (Bettencourt 2014; Townsend 2013; Zheng et al. 2014).
An increasing chorus of researchers is demonstrating the uses of big data in the urban context (Kontokosta and Johnson 2017; Singleton, Spielman, and Folch 2018; Thakuriah, Tilahun, and Zellner 2015). The focus of these studies tends to be on using new sources of data and computing methods from the computer and physical sciences to improve operational decisions in city management (Batty 2012; Bettencourt and West 2010; Ferreira et al. 2015; Hong et al. 2018; Keller, Koonin, and Shipp 2012; Kitchin 2014b; Kontokosta et al. 2018). Others examine the influence of information and community technologies (ICT) and the Internet of things (IoT) on creating “Smart Cities” that track and automate many systems-level functions currently using manual or analog processes (Batty et al. 2012; Caragliu, Del Bo, and Nijkamp 2011; Zanella et al. 2014). While the analysis of data is a necessary extension of IoT-enabled technologies, there is often a disconnect between the adoption of urban technologies and the changes in city agency organizational behavior and decision making needed to leverage the information generated by these technologies (Carter and Bélanger 2005; Kontokosta 2016b).
Much of the literature, however, ignores or is unaware of the rich history of planning practice and theory that has struggled with how best to integrate new technologies and quantitative methods into decision processes (Batty 2014; Dalton 1986; Innes 1995; Krizek, Forysth, and Slotterback 2009). Increasing recognition of the need for new, integrated models that capture behavioral and biophysical relationships and processes represents a sharp departure from domain-specific models built on generalized assumptions and rules of thumb (Alberti and Waddell 2000; Wegener 1994). The limitations of models derived from sparse input data—such as those that rely solely on survey data—have constrained the practical usefulness of such approaches in the past and created a justified backlash in planning practice (Klosterman 1994). Similarly, the challenge of incorporating “evidence” or “fact” into planning decisions has long been debated, a response to the rational comprehensive model that emerged in the middle of the twentieth century and the conceptualization of the planner as apolitical technocrat (Davidoff 1965; Healey 1992). These themes have reemerged in current debates on the impact and influence of big data on the science and practice of planning (Batty 2013; Kitchin 2014a). However, three elements of the current data era are fundamentally different from historical empirical periods. First, new real-time, high-resolution data streams allow planners to move away from sample (n) and subsamples of the population (N), which, when taken to its limits, can eliminate significant uncertainty caused by sampling errors and bias (although these have been replaced by new challenges, described in the following). Second, the massive quantity of available observational and measured data means that models can be calibrated and parameterized without simplifying assumptions about behavior, ecological conditions, or other phenomena and validated to a degree previously not possible. Finally, the ubiquity of ICT and IoT technologies enables unprecedented levels of engagement and participation by citizens with their local government, a reality that can shift how knowledge is spread, value-driven priorities are incorporated into investment and evaluation criteria, and models are interpreted and tested.
While competing definitions exist for this emerging field, those offered here provide a starting point for the discussion of the skills needed by the next generation of city managers, planners, and policymakers. The core competencies are a direct function of the nature of problems facing today’s cities and the constraints that urban decision makers face in balancing competing needs, goals, and priorities. These issues are considered in the next section.
State of the Practice
City governments, for their part, are becoming increasingly data-driven in their management approach, buoyed by open data mandates and the realization that the process of measure-verify-act-evaluate can result in more efficient delivery of services and management of infrastructure (Batty 2013; Goldsmith and Crawford 2014). New government roles such as chief analytics officer, chief data officer, or chief innovation officer speak to the significance of data analytics and technology innovation to current and future city governance. A clear example is the creation of the Mayor’s Office of Data Analytics (MODA) in New York City. Launched in 2009, the office was designed to operate within City Hall to integrate and, ultimately, analyze data from more than forty city agencies, responding to requests from individual commissioners for deeper insight into their own agencies’ operations. Although numerous cities have followed suit, including the Office of New Urban Mechanics in Boston or the Office of Performance Management in New Orleans, the original mission of NYC’s MODA has shifted in recent years, reflecting a broader change in how city governments view data analytics within the organizational structure. Increasingly, city agencies are building internal data science capabilities and teams (see e.g., the launch of the NYC Planning Lab within the Department of City Planning or the Predictive Analytics Group within the Chicago Police Department), leaving city-wide or mayoral office data teams to focus on interagency data sharing, data standards, and data integration.
Perhaps further confounding the adaptive challenge presented by new data streams and technologies, the private sector has taken to the “smart cities” market aggressively after recognizing the massive investment opportunity—estimated at up to $3 trillion per year—represented by civic technology and urban IoT (Manyika et al. 2015). But there remain nontrivial constraints to the widespread adoption of data-driven practices and the utilization of data technologies in service of citizen needs and well-being. Described in the following are three infrastructural issues that many cities now face during this transition.
Computing infrastructure
Most cities lack the fundamental computing and database infrastructure to support big data analytics. Antiquated information technology systems designed for storage rather than integration and analysis constrain city agencies’ ability to access the rich data resources embedded in most cities’ day-to-day operations. Furthermore, data collection efforts—from parking tickets to land use characteristics—were historically designed with a single use case in mind. Parking tickets were recorded in a way sufficient to enable the collection of fines; land use characteristics were coded and stored to allow for annual property tax assessments. However, the real opportunity for cities is to integrate and analyze these data to (1) explore patterns and discover unexpected correlations between seemingly unrelated aspects of urban life, (2) ask and answer a much wider range of potentially relevant policy and planning questions, and (3) improve citizen engagement through information transparency and accessibility. As part of this infrastructural limitation, city database systems and access protocols severely impede the ability to ingest or share data in order to leverage the vast data repositories already in hand by multiple stakeholders, including universities, industry, and the general public. For instance, merging high-resolution building energy use data from private sector firms with public sector energy disclosure data could greatly enhance our knowledge of building energy efficiency and urban energy systems (Kontokosta 2013).
While perhaps not the primary function of government data systems, the ability to share data effectively across sectors and domains remains a critical gap in bringing data to bear on urban challenges. The private sector has attempted to fill this need, offering software-as-a-service (SaaS) models and attempting to convince city officials of the value of data “command centers” (Harrison et al. 2010). The reality has been that such off-the-shelf “solutions” fail to meet specific needs across a range of institutional requirements, are overly cumbersome and difficult to integrate with other software and platforms, and are based on proprietary technology that bind city agencies to a particular company despite the rapid obsolescence of these data technologies. By extension, an increasing concern given the ambiguous role of the private sector is this fine line between data acquired for surveillance and observational data collected to understand phenomenology. In some respects, the distinction can be drawn between data collected to track individuals and data used to recognize general patterns. The technologies used for both purposes are the same. For instance, WiFi probe request data from smart devices can be used to understand and model real-time population dynamics in and across a city, a potentially valuable resource for transportation planning, land use impact evaluation, and emergency response (Kontokosta and Johnson 2017; Traunmueller et al. 2018). These data are collected from the increasingly widespread deployments of municipal broadband networks, which, it is argued, create societal benefit through free WiFi access. However, the financial models to support these networks often involve public-private partnerships where the collected data are commoditized (and sold) for marketing, retail, or other monetary gain. How these data are collected, by whom, for what purpose, and other limitations on access and use remain undefined, in many cases, in the interactions between the public and private sectors, in part because of an incomplete technical understanding of these issues by public officials.
Human infrastructure
While city agencies no doubt attract very talented individuals, the skills needed by future generations of city managers and leaders have shifted dramatically. Functional capabilities in coding, data science, machine learning, database management, and so on could now be considered baseline requirements for city management. Moreover, city leaders need to couple these skills with the ability to understand analytical problem-solving methods, to communicate and interpret technical language, and to appreciate that most problems facing cities cannot be solved through data analysis alone. Several new degree programs have been created in recent years to address this gap. The emergence of programs at the intersection of data science and city planning speaks to both the growing demand for these skills by students and employers and the need to build a technically competent and socially aware cadre of experts.
Institutional infrastructure
The shift to a data-driven city governance model often requires city agencies and their leadership to overcome institutional capacity constraints and legacy bureaucracy. Most decision support systems and procedures were designed decades ago, and there is little incentive to innovate, perhaps understandably so, as city agencies are focused on delivering city services on a daily basis, leaving them little bandwidth for long-term planning and strategic investments. Data-driven approaches necessitate processes that combine analytical evidence with “ground-truth” experience and expertise. Merging the two is not as simple as it might sound: Shifting organizational behavior requires leaders that recognize the benefits of change and have the time, resources, and commitment to see it through. Additionally, city agencies often operate in siloes, thus rendering the type of collaboration necessary for urban informatics difficult to achieve. These boundaries then impact sharing of data and best practices and manifest themselves in such operational limitations as the absence of data standards, common data definitions, or universal identifiers to easily merge data collected from different sources and for different purposes.
Data-Driven Cities
A Typology of Problems and Applications
Urban informatics and civic analytics are driven by the nature of the problems to be solved (Figure 1). Each requires a different set of skills and knowledge but share common problem-solving approaches. In this respect, these challenges can be clustered into three groups: operational, policy, and planning.
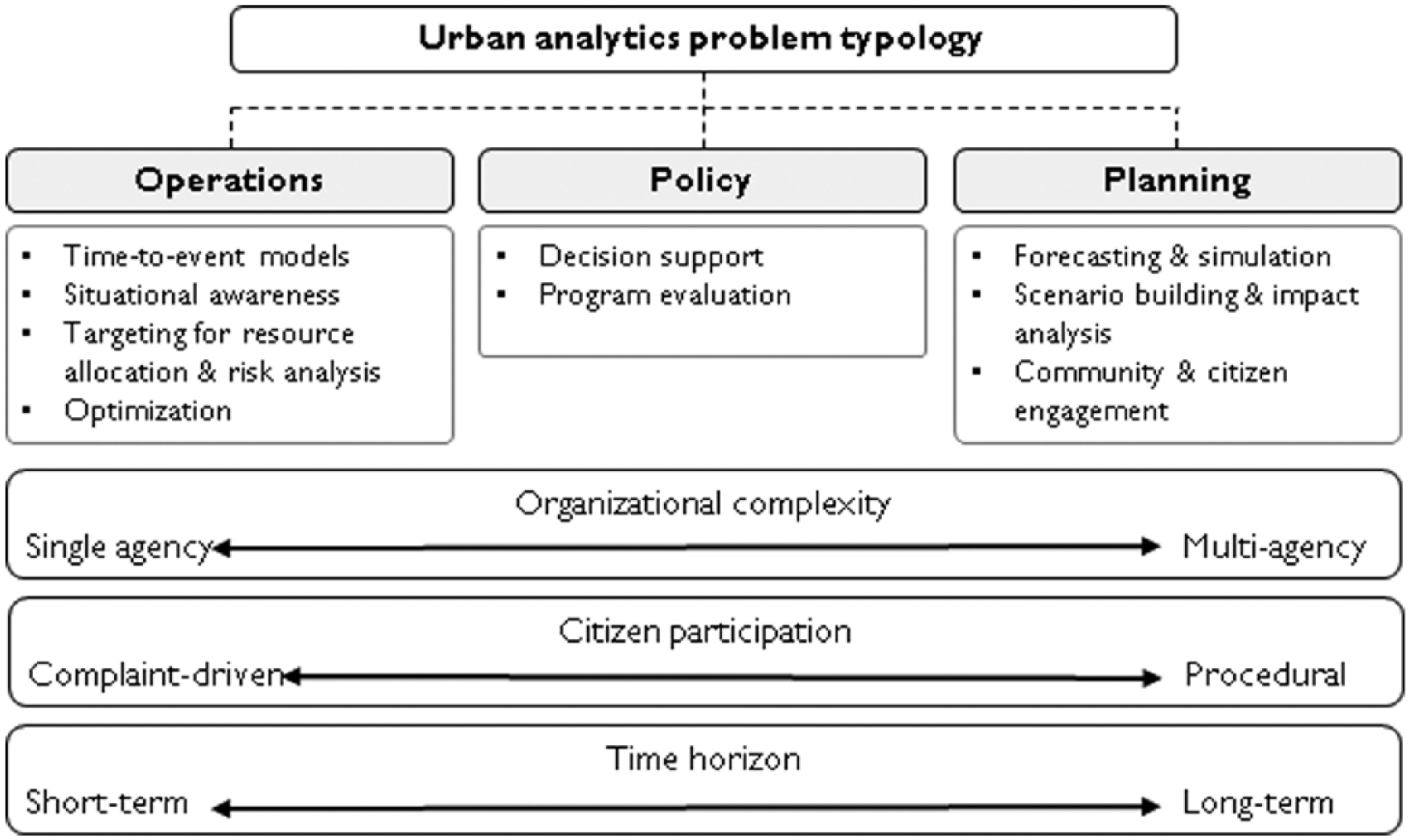
Urban informatics problem typology.
Operational challenges involve efficient systems operations and equitable delivery of city services. These are the focus of most applied data analytics research, primarily because they tend to involve problems with definable solutions, such as mapping disparities in 311 service complaints, and typically avoid the need for multiple stakeholders in decision making. These challenges lend themselves well to the application of data science methods, particularly machine learning, data exploration, and data visualization. Within the operational basket, three subgroups emerge. First, situation awareness problems are those that require a greater understanding of the location, use, or movement of a given asset or resource. For instance, the GPS mapping tool for the Department of Sanitation of the City of New York (DSNY) enables the agency to know where any vehicle in their fleet is at any given time. Second, the use of targeting to improve resource allocation is a common need among agencies. Given limited resources—whether it be police officers, building inspectors, or energy—cities must be able to deploy them in such a way that maximizes efficiency while minimizing cost. An example of this is work between New York City’s MODA and the Fire Department of New York (FDNY) to predict the locations of illegally converted buildings (Copeland 2015). Third, optimization problems seek to balance supply-demand at a given spatial and temporal resolution. These problems are more complex as they require data and domain knowledge of both the supply chain for a resource and the drivers of its consumption. Energy demand response and efficiency programs provide one useful example (Kontokosta 2016a), as does the problem of load balancing for bike sharing programs (Forma, Raviv, and Tzur 2015).
Policy challenges revolve around broader social, economic, and environmental goals and often require the ability to identify causal inference. An example is program evaluation, where the effects of a proposed or implemented policy are estimated. Here, it is necessary to design appropriate experiments (or quasi-experiments) to effectively understand counterfactual scenarios and identify suitable control and treatment groups to isolate the impact of the specific intervention (Card and Krueger 2000; Heckman 2001; Kontokosta 2012). Policy challenges require a different set of analytical tools than operational ones, including more extensive use of regression modeling and Bayesian inference, methods that can isolate statistical or probabilistic effects of individual variables. In addition, effectively addressing policy-related questions typically requires the collection of new data specifically needed for the question at hand. The availability of big data and the ability to process large-scale data sets represent a significant shift in public policy research (Foster et al. 2016). The capacity to evaluate policy decisions in near-real-time and simultaneously across multiple dimensions of impact creates new pressures on public decision-making processes built during a time when learning and evaluating interventions occurred, if at all, through survey data with low temporal frequency and spatial granularity. This increasing pace of data availability and feedback (depicted in Figure 2) also creates new models for policy design and testing, following a more entrepreneurial mindset of pilot deployments and “tinkering” as a viable path to policy implementation (Taylor Buck and While 2017).
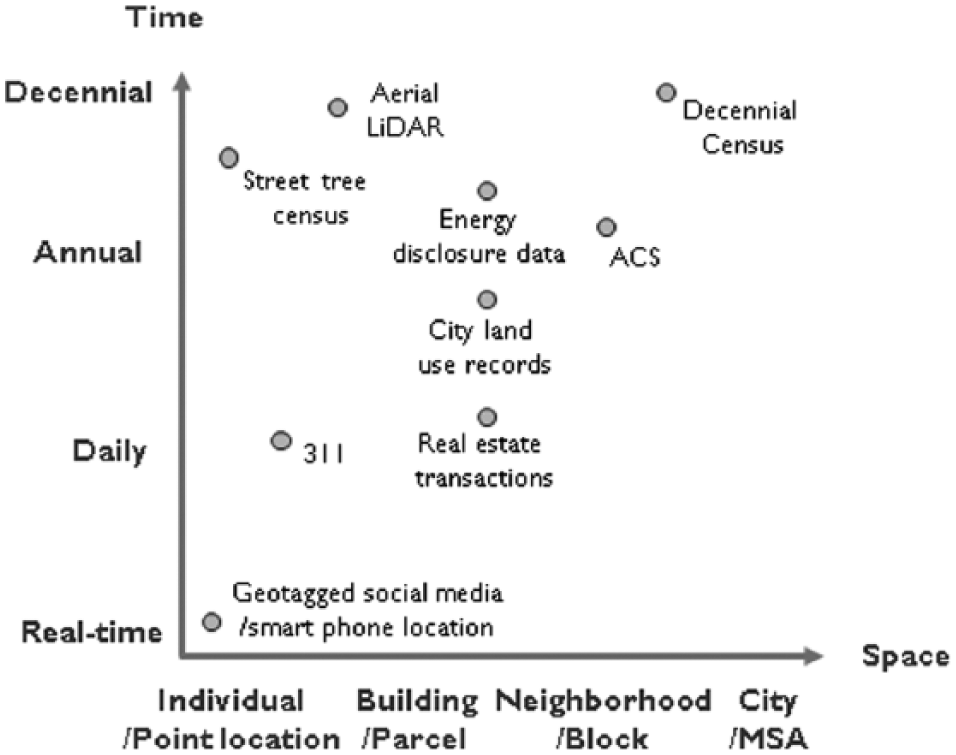
Spatial-temporal resolution of selected urban data.
Planning challenges comprise two distinct aspects of data analytics and technology adoption. First, analytical applications involve simulation, scenario modeling, and forecasting, which can be used to estimate the impact of various land use, transportation, and other infrastructure-related decisions. Planners can use urban informatics to more fully understand how urban space is being used and apply that knowledge to future expectations of demand or need. For example, geotagged social media data can be used to develop high-resolution population estimates and time-dependent mobility behaviors, knowledge that could inform transportation planning and service demand estimation, as well as impact evaluation of zoning and development proposals (Kontokosta 2016b; Wang et al. 2017). Long-term scenario modeling requires knowledge about how individual systems function, how these systems interact and create new dependencies and relationships, and how changes in systems behavior result in shifting outputs, often in complex, nonlinear ways. Urban modeling, reinforced by extensive domain knowledge, can be used to better inform planning decisions through more reliable estimates of future behaviors and outcomes (Waddell 2002). What is novel here is the availability of large-scale observational data to train and validate these models (Batty and Torrens 2005). Second, ICTs and the computing processes that enable their widespread use can be used to improve public engagement and citizen empowerment in decision-making processes. The emphasis is not on analytics to solve problems; rather, it is to enhance substantive participation by a wider range of stakeholders in typical deliberative planning processes of visioning, goal setting, and value definition (Arnstein 1969; Criado, Sandoval-Almazan, and Gil-Garcia 2013). In a similar vein, planners must recognize how technologies are shifting space utilization, social interactions, and the connection between virtual and physical experiences in cities (Brotchie et al. 2017; Calhoun 1998).
Tension and Balances
Developing a curriculum to train future urban data scientists needs to balance an exposure to data science and related technical skills with an understanding of urban management and planning. This tension is inherently reflected in the field itself, which has emerged with competing visions for how best to approach scientific discovery. On one hand are those that emphasize the applied science component of the field and focus on identifying problems first, and then collect the “right” data to address a defined question or hypothesis. On the other hand, a large segment of researchers views the new streams of data generated by, in, and about cities as a powerful tool for scientific discovery and advancing the fundamental science of complex systems dynamics. This group is driven by the exploration of data and any patterns or anomalies that may emerge. These competing approaches represent, in many respects, a false choice as advancements in basic science can be achieved through the process of problem solving, commonly referred to as Pasteur’s Quadrant (Stokes 2011). Described in the following section are several areas of tension that have emerged in the field.
State of the art versus state of the profession
One of the first tensions that emerges is around learning objectives: Should we train students to understand the state of the art or the state of the practice in which city agencies operate? There is a distinct difference that shifts the emphasis on which analytical tools are needed, what types of data to use, the nature of the problems addressed, and the measures of success. Defining curricular learning objectives in this regard will be an important consideration in how courses are allocated across topics and the level of depth attainable in different aspects of urban informatics. For instance, to train to the state of the art, one would want to provide students with an in-depth understanding of computer vision, natural language processing, or deep learning methods. The utilization of data extracted from video cameras for understanding city dynamics, as an example, provides a novel approach to common operational needs, such as pedestrian counts and flows, situation awareness and anomaly detection, and pedestrian behavior (Dollár et al. 2009). However, few agencies have the capacity to do such analysis. Those that do are severely constrained by privacy and other data ethics concerns, and most would have limited budget to hire someone specifically trained in such a specialized field. Moreover, given the risk tolerance of many organizations, integrating computer vision into operational practice may face institutional pressures over possible errors or uncertainties in the output. For example, technologies exist to utilize traffic cameras to detect illegally parked cars; despite the potential for cost savings and revenue enhancements, few law enforcement agencies have put such capabilities into practice (Buch, Velastin, and Orwell 2011).
On the other hand, many of the more routine operational challenges facing cities—particularly as they relate to service delivery—can be addressed with rather straightforward methods and tools from data science, including data mining, more efficient data management, and machine learning algorithms such as k-means clustering, logistic regression, and other predictive models. While these are not mundane topics, training to the state of practice puts the focus on how and when these tools should be applied and their limitations rather than their derivation or mathematical construct.
Correlation versus causation
The discussion of big data has often turned to the tension between correlation and causation (Anderson 2008). In many applications of big data analytics—search engine optimization and predicting online consumer behavior, for instance—causality is not needed to achieve an optimal outcome. Likewise, a theoretical framework is not necessary to recommend what book to buy based on previous purchasing habits—applying theories from psychology or behavioral science often do not improve the results beyond simple predictive analytics trained on historical consumer data. The case of cities is more nuanced and complex. Understanding the cause of a particular problem is vital to the effective design, evaluation, and implementation of a solution. In addition, the stakes are much higher as blind devotion to goodness-of-fit measures may cause the urban data scientist to miss a critical weakness of an analytical model or, as significantly, reinforce bias in outcomes based on the underlying data or model assumptions (Crawford and Schultz 2014).
Urban data versus urban problems
Another tension emerges from a debate on where the focus of urban informatics should rest. For some, particularly from the computer sciences, the emphasis naturally falls to the data. The problems, in this case, revolve around computing—new ways to visualize large data sets, algorithms to query data sets more efficiently, computational methods to reduce error caused by over-fitting, and so on. Success, then, is measured in these terms. On the other hand, many see the field, particularly those from social science and engineering backgrounds, as needing to focus on the problems defined by urban operational, infrastructural, or planning challenges, depending on their disciplinary lens.
As a result, there is an observable bimodal distribution of interest in those drawn to this emerging field, a division that impacts the types of problems and the nature of knowledge that receive the most attention. Some are interested in a deep exploration of the technical tools needed to manipulate urban big data, characterized by high resolution spatio-temporal datasets that require new computational methods and computing systems to process. Others are dedicated to solving persistent social problems that emerge from their domain knowledge, such as urban planners, who recognize the value of analytical and data-driven approaches to identifying viable alternatives. A rough distinction can be made, then, between those focused on urban data versus those focused on urban problems. This duality has implications for training both in terms of relevant skills and capabilities and measures of success.
Social sciences versus data sciences
There is also the question of which discipline to start from—should the field evolve as a computational social science or an applied data science? The distinction here reflects multiple aspects of urban science: to emphasize urban data and the challenges of extracting insight from data or to focus on an understanding of policy and the causes of urban problems using a data-driven approach to enhancing the efficacy of potential solutions. Both are promising areas of research, education, and practice.
Interpretability versus accuracy
Machine learning algorithms can be very effective in predicting events of interest to city managers and policymakers. Supervised and unsupervised learning methods, such as neural networks, Gaussian process regression, and ensemble classification, can be applied to a number of urban data problems; however, these methods typically come at the cost of being able to interpret, or unpack, the underlying process that produced the reported output (Ribeiro, Singh, and Guestrin 2016). These “black-box” models can provide greater predictive accuracy (Breiman 2001), but decision makers and the general public will not be able to inspect the assumptions and interactions used to derive the results. This is an important challenge for two reasons. First, to build trust in data-driven decision making, end-users will want (and should have the right) to understand how the output was produced—if not mathematically, at least conceptually. Foregoing this possibility may lead decision makers, rightly, to question the reliability of the models in practice. New York City’s proposed Local Law 49 of 2018, known as the “Open Algorithm Law,” presents an innovative policy approach to this issue.
Privacy versus resolution
With almost all big spatial-temporal data, there is a trade-off between protecting individual privacy and maximizing the resolution of input data, which can result in a more precise understanding of the phenomena being studied. This balance is a function of three parameters: (1) data access and security protocols in place, (2) perceived value to the individual providing data, and (3) level of trust between data provider and data user. Social media provides a clear example of this: Users voluntarily provide personally identifiable information (PII) because they derive some value from doing so (building social networks, etc.). There is also some implicit level of trust that the social media platform will not use their data inappropriately despite repeated examples to the contrary. However, this relationship exploits the significant information asymmetries between data providers (individuals) and those collecting and analyzing these data. Social media users tend to have little understanding of how their data are being stored and used and thus are not able to make a fully informed decision about how their data can be manipulated or shared. Privacy issues present both technical and socio-political challenges that have serious implications for data ethics and data governance. Ultimately, the disciplinary and curricular foundations for urban informatics rest on the resolution of the tensions described and the institutional context for this type of research within a particular academic environment. The choices are nontrivial as they will influence the nature and direction of the research and educational programs. For instance, establishing an urban informatics program in a civil engineering department will likely push the focus of the research to physical infrastructure and optimization problems using modeling tools from systems analysis. Situating this research and training in a planning department or school will lead to a greater emphasis on the problem context, building from domain expertise and knowledge of policy processes to develop data-driven recommendations to address them. In this case, however, the analytical tools may be more consistent with traditional econometric and spatial analyses found in quantitative social science research but with greater emphasis on extracting, integrating, and visualizing large-scale tabular data. As a result, many of the emerging urban informatics programs have been established either in independent disciplinary homes (e.g., New York University’s Center for Urban Science and Progress) or through a collaboration of policy schools and computer science departments (e.g., the University of Chicago’s program in Computational Analysis and Public Policy). Where degree programs have been established directly within schools of policy or planning (e.g., Northeastern University’s MS in Urban Informatics or University College London’s MSc in Smart Cities and Urban Analytics), they tend to draw heavily on computing and data science resources from other departments.
The Urban Informatics Curriculum
The urban informatics curriculum must reflect the needs and tensions of the field. How a particular program is situated will be a function of its institutional and intellectual home, the expertise of the faculty, and the extent of the relationship between the particular university and the city or municipality in which it is located. From a pedagogical standpoint, the curriculum described here moves away from training to the well-known “T”-shaped skillset (Brown and Wyatt 2010) to a “π”-shaped representation that links substantive disciplinary and domain skills (the two legs) with analytical reasoning and problem-solving capabilities (the horizontal bar), as shown in Figure 3. Disciplines are core informatics technologies targeted at building applied sciences skills that support data-driven research in the respective domains. Conceptually, these include data acquisition, integration, analysis, and visualization. The domains are the fields of expertise directly relevant to urban planning (e.g., sustainability, housing, transportation, public health, etc.). Ultimately, successful students need to have depth in an informatics discipline (e.g., machine learning or data visualization) and an urban domain and possess the ability to bridge these with proficiency in fundamental analytical reasoning and communication skills that can connect technical concepts to practice.
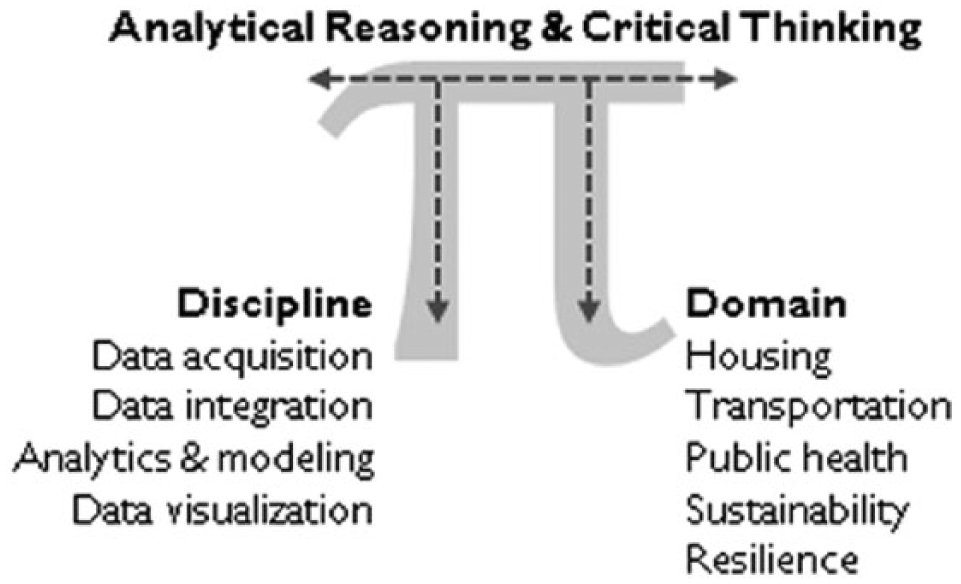
The π-shaped pedagogical structure for urban data scientists.
Core Competencies and Skills
Students should have a breadth of computing skills that expand the traditional data science toolkit and be able to apply them responsibly to problems with significant social, economic, and environmental implications. They need to understand data collection methods and sensing technologies and be able to manipulate, integrate, and analyze large, disparate data sets of varied sources and types. The nature of the data (large-scale, diverse, often unstructured) and the analytical approaches (nonlinear, graph and network representations, decision trees, etc.) require skills that depart from functional capabilities of traditional statistical packages and quantitative approaches commonly found in planning curricula (Edwards and Bates 2011; Friedman 1996; Kaufman and Simons 1995). Specifically, the urban data scientist skillset needs to include a substantive foundation in programming, linear algebra, and statistics and be able to execute and interpret a range of machine learning models. Additional training in simulation techniques, such as agent-based modeling, and network analysis are beneficial and gaining broader application in the transportation planning domain, for instance. Beyond traditional data science and econometric techniques, urban informatics requires an understanding of the technical parameters of various sensor modalities (remote, in situ, mobile), field deployment of sensors in urban environments, and management and analysis of sensor-derived data. Since decision making is core to the field, urban data scientists must be able to interpret, visualize, and incorporate analytics into existing processes or shape and implement new data-driven approaches that leverage these methods. Therefore, what specific skills are appropriate and relevant will depend on the institutional home for the program and how that program chooses to resolve the tensions described previously.
In addition to computing, students should understand how cities operate across various urban domains in the context of operational, policy, and planning decisions and processes. They need to recognize and account for the constraints embedded in complex urban systems, including subsystem interactions and economic, political, and social context. Urban informatics students should obtain the following capabilities:
Theoretical foundations: an understanding of urban theory from the social sciences and emerging applications drawn from the natural and physical sciences;
Urbanism: the ability to define and understand urban challenges in the sphere of operations, policy, and planning, particularly related to sustainability and social equity, coupled with an appreciation of the social, economic, and political constraints that influence urban decision making;
Critical reasoning: the ability to utilize their informatics/data science toolkit to define and address specific challenges, derive actionable insight from data, and interpret and communicate findings to support implementation;
Research and experimental design: an understanding of research methods designed to derive causal relationships and support policy and program evaluation;
Urban science: the ability to utilize novel approaches in an interdisciplinary and experimental environment to model city activity, resource flows, and land use processes to yield a deeper understanding of city form and function.
As important, and potentially more so, is the horizontal connector in the π ideograph: the capacity for problem solving and analytical reasoning (Provost and Fawcett 2013). Students and practitioners need to understand how to identify, define, and evaluate problems while assessing the appropriateness and feasibility of a data-driven approach to address them. Once identified and scoped, the urban data scientist should consider the range of analytical tools to draw from and decide which methodology is most applicable given the nature of the data, the nature of the problem, and desired output. Implicit in this deliberation is the significance of interpretability of the model and results: In some cases, a trade-off between model accuracy or goodness of fit may be made to ensure that the model can be unpacked and understood by both the user of the tool and the stakeholders that will be affected by its results.
To do this effectively, students should know how to work in interdisciplinary teams under time/budget pressure and communicate and interpret complex technical language for a variety of stakeholders. This capacity for “data storytelling” is a critical component of extracting insight from data, one that is undervalued in traditional data science programs (Kosara and Mackinlay 2013). The urban data scientist must also be able to work directly with the management team responsible for implementing possible solutions by incorporating feedback, understanding evolving constraints, and accounting for evidence from past practices and failed interventions. What are often called “soft skills” within science and engineering disciplines are central to the urban planning field and become vital competencies for the urban data scientist (Heckman and Kautz 2012; Kumar and Hsiao 2007).
Ethics and Algorithms
A final element in the foundational knowledge base involves data governance, data ethics, and privacy issues (Lane et al. 2014). Understanding the proper use of data—particularly big data—and the limits of what can and should be done are both morally and technically challenging dilemmas. For researchers and practitioners, responsible handling of data, including PII and data that can become so after merging with other data sets, is paramount to the application of analytics in the public realm.
Students and practitioners in the field must also be cognizant of inherent biases in data-driven operational and policy decision making. Biases can and often do exist in the data themselves, primarily through sampling or selection, that can result from systematic differences across a city’s socio-spatial landscape. With social media data, for instance, users of a particular app are typically not representative of the city as a whole (Li, Goodchild, and Xu 2013). City administrative records, especially those derived through self-reporting mechanisms such as 311 complaints, can also be biased based on where services are delivered (thus affecting data coverage) or because of behavioral concerns such as the propensity to report a complaint or interact with government (Kontokosta Hong, and Korsberg 2017). These biases are particularly pronounced by race and income, with poor, minority residents and other underrepresented groups most often vulnerable to further prejudice or discrimination resulting from incomplete data or algorithms (perhaps, more accurately, the programmers creating the algorithms) that do not account for structural, legal, or political inequities (Caliskan, Bryson, and Narayanan 2017; Chouldechova 2017). Finally, access to technology and connectivity can limit some residents—particularly those in underserved or economically distressed communities—from communicating with city government, thus creating data gaps or a data poverty among certain demographics (Van Dijk and Hacker 2003). This is often referred to as the digital divide (Graham 2002; Norris 2001).
Other equity concerns emerge from the models, their output, and their use. Many in city government or the general public are not familiar with the models that urban data scientists can bring to bear (O’Neil 2016). This lack of understanding limits interpretability and transparency of the results, which can lead to a lack of trust in the outputs or missed opportunities to receive stakeholder feedback on the assumptions and inputs used to generate the results. These concerns become even more acute when certain types of machine learning algorithms are used since these types of learning techniques can be difficult to explain in practice. This “black box” problem is magnified as deep learning and artificial intelligence gain widespread use (Zeng, Ustun, and Rudin 2017) and create even greater challenges in meaningfully engaging traditional underrepresented and underserved communities.
Real-World Problem Solving and Experiential Learning
Ultimately, urban data scientists cannot solve problems in a traditional lab environment. To effectively understand the problems facing a city agency, the urban data scientist needs to understand how a particular agency works, how it makes decisions, what constraints it faces, and how it measures (and incentivizes) success. For instance, a new sanitation truck routing algorithm might improve collection efficiency but could be infeasible in practice because of union labor rules governing sanitation workers and drivers. Integrating data-derived insight with ground-truth knowledge is the linchpin of usable output, one that can only be taught through hands-on projects using real data and direct engagement with subject matter experts. To this end, experiential learning is an important component of the urban informatics curriculum, much as it is in planning. This element of the program should follow five principles:
Quantitative and scientific: Projects should utilize data science methodologies (data mining, analysis, database management, visualization, and/or web integration) to ingest, analyze, and develop insight from multiple data sources. Outputs and results should be tested for robustness and validated.
Impact-driven: A central goal of an applied project is to make an impact on a critical urban issue. This requires being results-focused and forward-looking to drive change. Projects should promote new approaches or new applications of techniques in addressing the urban challenge and innovative ways for implementing and evaluating recommendations.
Stakeholder focused: While projects may be sponsored by a range of public or nonprofit entities, the project should directly address an aspect of public service delivery or quality of life for city dwellers and incorporate community engagement and citizen participation.
Directly engaged with practitioners: Regular access to subject matter experts and the project sponsor and fostering an ongoing dialogue on the data and problem are critical components of a successful project. Substantive partnerships with city agencies facilitate this type of interaction and help increase the likelihood of project outputs being adopted and implemented.
Multidisciplinary: Teams should represent a diversity of backgrounds. Ideally, depending on the problem, the team composition should account for all phases of the project lifecycle, with skills in data mining, analysis and visualization, planning expertise, and as appropriate, public policy, management, and social-behavioral sciences, among many others.
Too often, when first given a new data set and a problem, the data scientist’s initial tendency is to start exploring data. Often this involves some data cleaning steps, followed by feature selection (a process in machine learning to discover significant variables based on modeled interactions), and last, model development and performance testing. This inevitably leads to “chasing R2” or “p-hacking” (Head et al. 2015), where the data scientist becomes narrowly focused on model performance and goodness of fit and ignores the rationale, viability, and relevance of their choice of model inputs; the interpretation of results; and their applicability to the initial problem. While “data wrangling” is a necessary component of the analytics process, in the applied urban informatics context, one must shift the sequence. Problem definition and understanding the problem context are critical to developing usable solutions. This upfront work enables the urban data scientist to assess the problem and determine an appropriate analytical approach to solving it. An implementable solution requires balancing computational complexity with interpretability, accessibility, and usability. We can define the workflow of an urban informatics project as indicated in Figure 4.
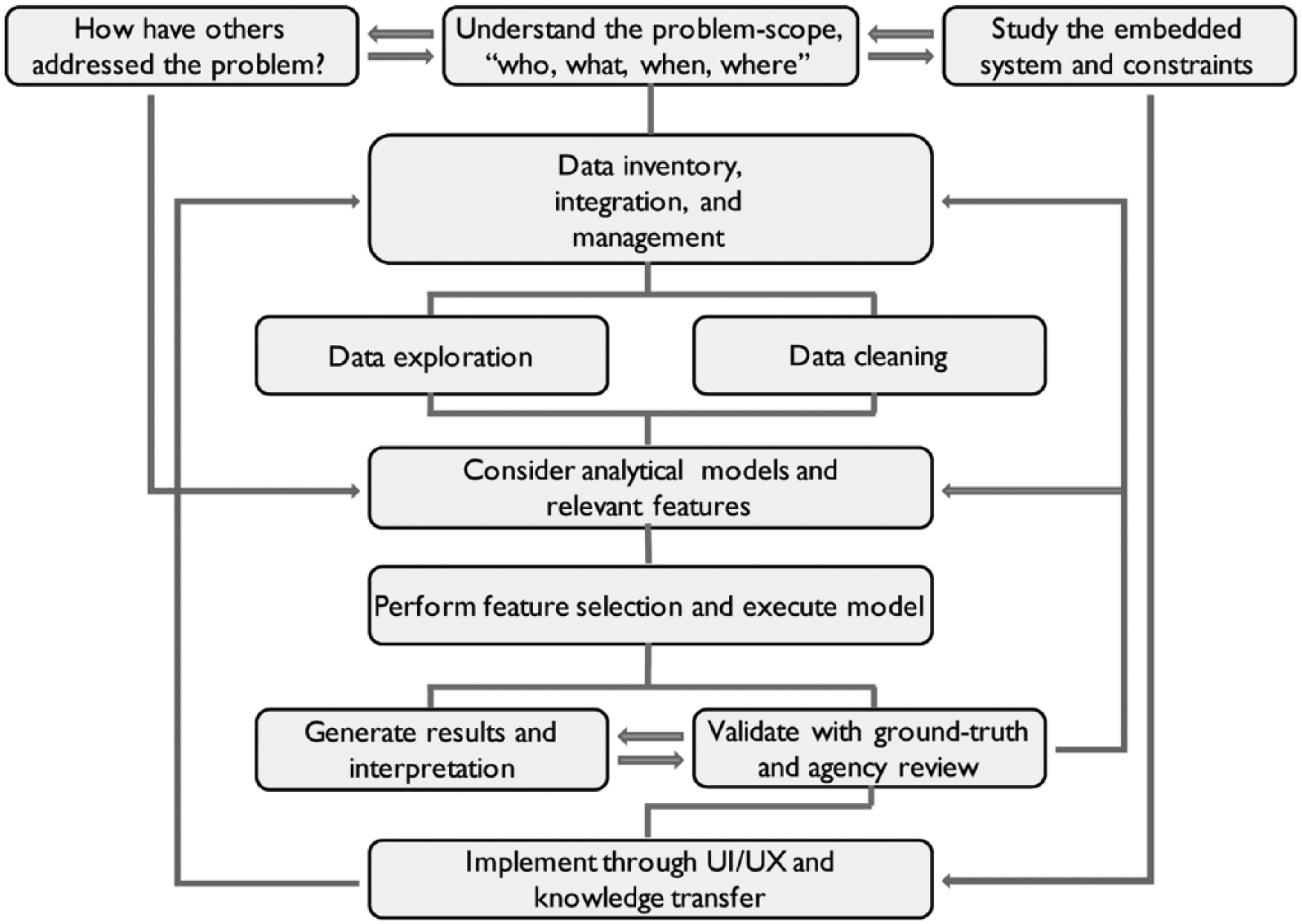
The urban analytics project workflow to achieve actionable insight from data.
The first step is to understand the system in which the problem originates. As Meadows (2002) points out, one must be willing to “dance” with the system, watch how it behaves, understand its rhythm, and assess where weaknesses and opportunities emerge. For example, in working with the NYC Department of Sanitation on routing optimization, one needs to understand how and why routes exist as they currently do: Why were decisions made to do it this way? What constraints and incentives influenced the decisions? How are resources allocated, and what can be accomplished within the current method? How much room is there to introduce a new operational process? These types of questions are a necessary element of due diligence to understand the scope of the problem, the rationale for the current way of doing things, and what solutions could reasonably be implemented. While this suggests an incremental approach to problem solving, not unlike how Lindblom (1959) viewed organizational change, for the practitioner, this represents a path to actionable insight. A perhaps counterintuitive extension of this process requires that the urban data scientist know when analytical approaches are not suitable for a particular problem and when other qualitative methods may produce greater insights. Of course, researchers in the field are free to embrace scientific discovery unencumbered by these constraints, which returns us to previously discussed debates around the state of the art versus the state of the profession. Both a “blue sky” research program and an applied, impact-driven agenda are needed to advance and further define the field.
Conclusion and Future Directions
The interest in data-driven city governance and the growth of urban-focused data science and analytics programs will continue. The need for such skills in city government and in private and nonprofit organizations that work with cities is accelerating as new performance management and data-driven service delivery approaches are replacing legacy processes and outmoded information technology infrastructure. The increasing complexity of urban life also requires that planners bring to bear new data and new computational methods to understand the dynamics of urbanism, forecast and predict future needs, and comprehensively evaluate policy alternatives. The rapid proliferation of urban sensors and IoT devices will further reinforce the need for technology- and analytics-focused city leaders.
There are, of course, limits to the application of urban informatics to city operations and planning. Availability of the “right” data for a given problem will continue to be a challenge as city agencies remain siloed with respect to data sharing and operations. In addition, novel sensing technologies and the adoption of more traditional modalities have yet to scale, and therefore the application of such derived data remains largely exploratory. Similarly, the widespread interest in the use of social media to understand urban function has revealed promising insights, but representativeness and other biases embedded in these data must be more fully considered before they can be used for real-world decision making. The computing challenges are solvable; the real uncertainty lies with how to integrate data-driven processes into public sector management and, more significantly, urban decision-making processes.
As stresses on urban infrastructure build and demand for social and operational services increase, cities need to find ways to more efficiently and effectively extract value from existing investments while developing new innovations to meet the changing and diverse needs of citizens. Data-driven approaches, including the application of sensing and communication technologies, have shown promise in improving decision making and positively impacting quality of life. This paper identified three primary infrastructural constraints to the widespread adoption of data-driven decision-making processes in cities and outlined the tensions in training future urban data scientists and city leaders. This framework provides the basis for the continued evolution and definition of the urban informatics field. As concerns about data bias, algorithmic ethics, and equity in data-driven decision making become more pronounced, the urban data scientist must be able to navigate complex technical, social, and political dilemmas. Establishing the core competencies and skills needed to extract actionable insight from data is the starting point for more significant shifts in urban governance and the application of computational methods to address persistent operational, policy, and planning challenges.
Footnotes
Acknowledgements
This work represents lessons learned as the inaugural Deputy Director of the NYU Center for Urban Science and Progress (CUSP), during which time I led the design, implementation, and oversight of one of the first graduate programs in Urban Informatics. I would like to thank the faculty and staff that helped launch and manage the graduate programs at CUSP, particularly the insight and expertise of Steven Koonin, Michael Holland, Claudio Silva, Ingrid Gould Ellen, Kaan Ozbay, Gregory Dobler, Michael Flowers, Geoffrey West, Michael Batty, Luis Bettencourt, Logan Werschky, and Neil Klieman, among many others. I would also like to thank all of the CUSP Master of Science in Applied Urban Science and Informatics graduates, who are now using the skills described here to help makes cities better places to live. A preliminary version of this paper was presented at the SCOPE 2017 International Workshop.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work has been funded, in part, by a grant by the MacArthur Foundation. This material is based on work supported, in part, by the National Science Foundation under Grant No. 1653772.