
Abstract
We assessed the simple view of reading as a framework for Grade 3 reading comprehension in two ways. We first confirmed that a structural equation model in which word recognition, listening comprehension, and reading comprehension were assessed by multiple measures to inform each latent construct provided an adequate fit to this model in Grade 3. We next examined how well prekindergarten (pre-K) oral language (vocabulary, grammar, discourse) and code-related (letter and print knowledge, phonological processing) skills predicted Grade 3 reading comprehension, through the two core components of the simple view: word recognition and listening comprehension. Strong relations were evident between pre-K skills and the complementary Grade 3 constructs of listening comprehension and word recognition. Notably, the pre-K latent constructs of oral language and code-related skills were strongly related to each other, with a much weaker (nonsignificant) relation between the complementary Grade 3 constructs of listening comprehension and word recognition.
Keywords
The Simple View of Reading (Gough & Tunmer, 1986) provides a powerful, yet straightforward, framework for the study of reading comprehension. There is significant support for the central tenet of this framework that reading comprehension is the product of word recognition and listening comprehension: When considered together, measures of these two broad skill sets explain sizable and significant variance in reading comprehension (Garcia & Cain, 2014) across a wide age range. Because of its validity, the simple view has had a substantial impact beyond academia, influencing educational policy and practice on the need to foster the skills that underpin word reading (Kendeou, Savage, & van den Broek, 2009) and also those that support comprehension (Snow, 2002). In this special issue celebrating the reach and impact of the simple view, we consider its explanatory power for reading development. We examine the relative influence of listening comprehension and word recognition on reading comprehension in beginner readers of English, and the relation between prekindergarten (pre-K) language skills and knowledge and Grade 3 listening comprehension, word recognition, and reading comprehension.
Our first aim was to examine the concurrent influence of word recognition and listening comprehension on reading comprehension in Grade 3. We use the term “word recognition” to refer to the application of knowledge of letter–sound relationships and letter patterns, as well word-specific orthographic knowledge, for regular and irregular word reading (Wang, Nickels, Nation, & Castles, 2013). We use “listening comprehension” to refer to understanding of text read aloud, which has also been referred to as linguistic comprehension (Gough & Tunmer, 1986) and language comprehension (Cragg & Nation, 2006). The simple view predicts diachronic change in their influence: As word recognition accuracy and fluency develop through formal literacy instruction, the strength of the prediction of reading comprehension from word recognition decreases and listening comprehension becomes the more substantial predictor. This basic pattern for English readers is confirmed by meta-analysis (Garcia & Cain, 2014) and empirical work (Language and Reading Research Consortium [LARRC], 2015b). Our focus in the current study is the concurrent prediction of reading comprehension in Grade 3. Whereas Garcia and Cain’s (2014) meta-analysis suggests a stronger influence of word recognition than listening comprehension for this age group, recent empirical work using the same measures as the current study found that in Grade 3 listening comprehension was the stronger predictor (LARRC, 2015b). That finding is in line with studies of readers of Finnish (Lepola, Lynch, Kiuru, Laakkonen, & Niemi, 2016; Torppa et al., 2016), a transparent orthography for which word reading fluency is achieved earlier than for more opaque orthographies such as English (Seymour, Aro, & Erskine, 2003). Given the influence of the simple view on the teaching of reading (e.g., Kirby & Savage, 2008), we sought to test the reproducibility of the LARRC (2015b) finding for Grade 3 English speakers, with the same measures, but a larger and different set of participants.
Our second and central aim was to examine the prediction of reading comprehension longitudinally, within the framework of the simple view. Neither word recognition nor listening comprehension is unidimensional; thus, it is important to sample the range of skills and knowledge that informs each construct. Longitudinal studies have included preschool measurement of a range of code-related precursors to word recognition, including letter and sound identification and phonological processing skills. When sampled comprehensively in this way, preschool skills are found to influence reading comprehension indirectly through later word recognition (Catts, Herrera, Nielsen, & Bridges, 2015; Kendeou, van den Broek, White, & Lynch, 2009; Storch & Whitehurst, 2002; Torppa et al., 2016). With regard to listening comprehension, recent tests of the simple view report that vocabulary and listening comprehension both load onto a single construct (Braze et al., 2016; Tunmer & Chapman, 2012). In line with this, longitudinal studies of reading comprehension development find that greater variance is explained by models that include both vocabulary and discourse-level measures of oral language (47%–88%; Catts, Herrera, Cocoran Nielsen, & Sittner Bridges, 2015; Kendeou, van den Broek, et al., 2009; Lepola et al., 2016) than by models that include only vocabulary (32%; Torppa et al., 2016). Vocabulary, grammar, and discourse-level comprehension all inform the construct of oral language in the early years (Foorman, Herrera, Petscher, Mitchell, & Truckenmiller, 2015; LARRC, 2015a), but research to date has not investigated how oral language predicts later reading comprehension via listening comprehension, that is, they have not directly addressed the longitudinal prediction of reading comprehension within the simple framework. We address that limitation in our article. Furthermore, in contrast to other studies, we included a range of oral language skills—vocabulary, grammar, and discourse-level—to provide a comprehension sampling of this construct.
Although code-related skills and oral language are related in the early years, their subsequent development is broadly independent (Kendeou, van den Broek, et al., 2009; Lepola et al., 2016; Storch & Whitehurst, 2002; Torppa et al., 2016) and the correlations between concurrent measures of word recognition and listening comprehension by Grades 2 to 4 are weak (Catts, Hogan, & Fey, 2003; Kendeou, Savage, et al., 2009). However, a recent study of 7-year-olds found that the best fitting model of the simple view included a pathway between concurrent word recognition and listening comprehension (Tunmer & Chapman, 2012). Vocabulary was included as an indicator of listening comprehension, which may have influenced model fit because of its relation to both word recognition and listening comprehension (LARRC, 2015b). In the current study, we conceptualized listening comprehension as understanding of passages spoken aloud (Hoover & Gough, 1990), and contrasted models in which word recognition and listening comprehension were independent or related.
Current Study
Our first aim was to confirm that the basic model of the simple view of reading provided a good estimation of reading comprehension in Grade 3 (LARRC, 2015b). To address this aim, we used structural equation modeling (SEM) to examine the relations between listening comprehension, word recognition, and reading comprehension in a large sample of Grade 3 children. Our second set of analyses focused on our central aim to determine if language skills and knowledge assessed before the start of formal literacy instruction predicted later reading comprehension, through listening comprehension and word recognition. These analyses examined continuity in the development of these components within the framework of the simple view. There are relations between code-related skills and oral language in preschool (Kendeou, van den Broek, et al., 2009) and between word recognition and listening comprehension in Grade 3 (Tunmer & Chapman, 2012). Thus, we also examined whether the two constructs in pre-K and Grade 3 were independent or related and also whether they were related across time with the addition of cross-lagged longitudinal relations. Previous studies have not found significant cross-lagged relations over 2 years (Kendeou, van den Broek, et al., 2009), but it is possible that such effects may be evident over a longer period of time. The unique contribution of our study is the examination of how well oral language and code-related skills assessed in prekindergarten predict reading comprehension 5 years later, through the two core components of the simple view: listening comprehension and word recognition, and the extent to which their influence is independent.
Method
Participants
The participants were part of a larger longitudinal study of reading and listening comprehension in preschool to third-grade children. The original sample was 420 children in prekindergarten in the initial year of the study and who progressed to Grade 3 five years later, which was a final sample of 305 children (77 children left the study before Year 5, and 38 progressed only to Grades 1 or 2). They were selected through preschool centers at four data collection sites (Arizona, Kansas, Nebraska, Ohio) via recruitment packs sent home to the children’s caregivers. Approximately the same number were recruited from each site, with key demographic characteristics (e.g., eligibility to receive free/reduced price lunch and membership in racial/ethnic categories) of the sample similar to the child population at that site. The final sample’s mean age in pre-K was 5 years 1 month. The majority (94.1%) was White/Caucasian with English as the home language (94.1% for each variable), with more boys than girls (56.1% vs. 43.9%), and 9.5% of the children received free/reduced lunch. Full details are reported in (LARRC, Farquharson, & Murphy, 2016).
Measures in Prekindergarten
The assessment battery described below includes multiple measures of three dimensions of oral language: vocabulary, grammar, and discourse-level, and multiple measures of code-related skills: letter name and sound knowledge, print knowledge, and phonological processing. We report the correlations between variables, the mean raw scores, and standard deviations for the sample included in our statistical analyses in Tables 1 to 3. We also report reliability (Cronbach’s alpha, unless otherwise stated) for our entire pre-K sample (N = 420). The measures were administered in the latter half of the school year. The administration and scoring protocols in the manual was followed for standardized measures, unless stated below.
Descriptive Statistics, Correlations, and Reliability for Pre-K Observed Variables for Latent Variable of Oral Language.
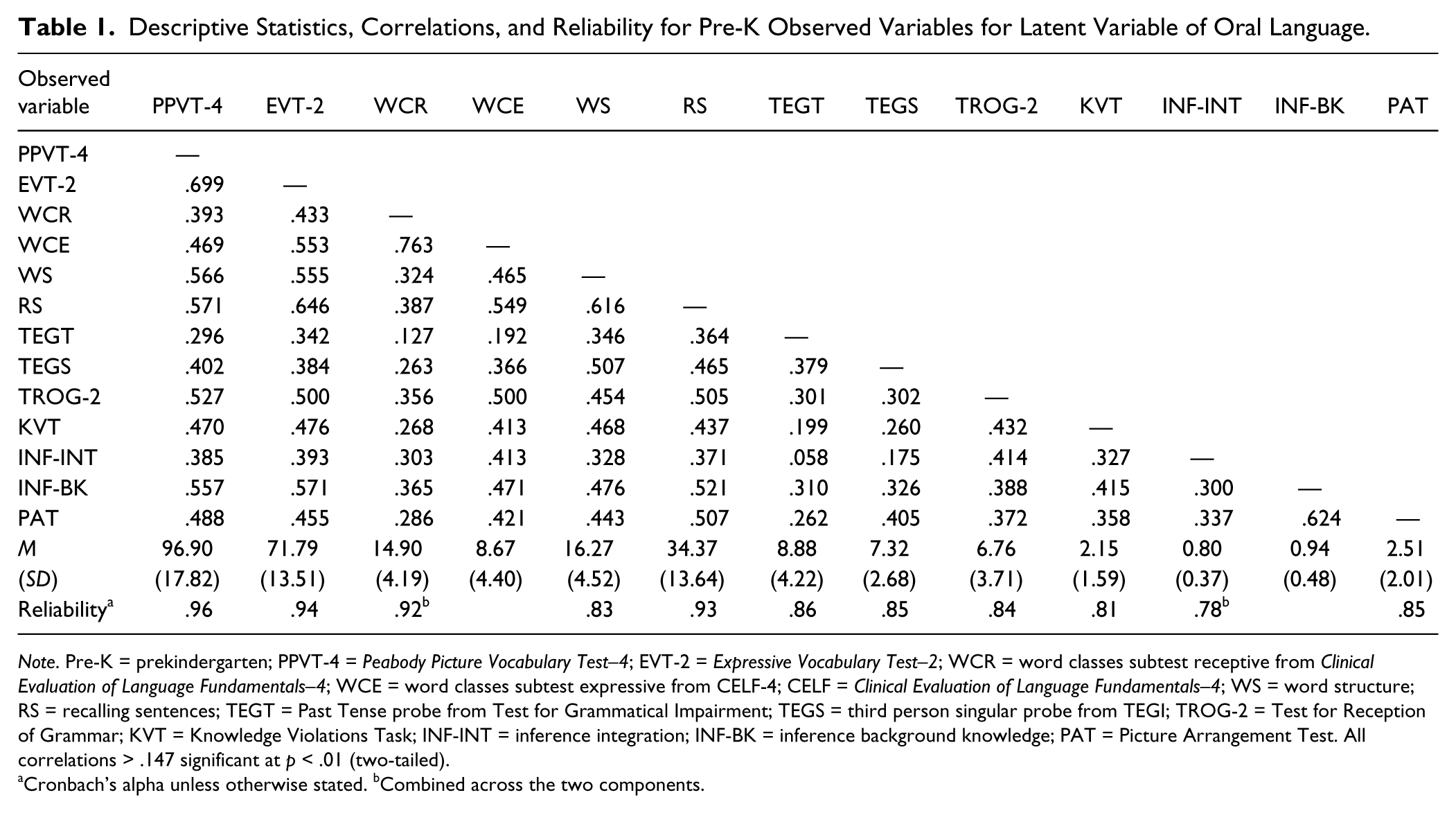
Note. Pre-K = prekindergarten; PPVT-4 = Peabody Picture Vocabulary Test–4; EVT-2 = Expressive Vocabulary Test–2; WCR = word classes subtest receptive from Clinical Evaluation of Language Fundamentals–4; WCE = word classes subtest expressive from CELF-4; CELF = Clinical Evaluation of Language Fundamentals–4; WS = word structure; RS = recalling sentences; TEGT = Past Tense probe from Test for Grammatical Impairment; TEGS = third person singular probe from TEGI; TROG-2 = Test for Reception of Grammar; KVT = Knowledge Violations Task; INF-INT = inference integration; INF-BK = inference background knowledge; PAT = Picture Arrangement Test. All correlations > .147 significant at p < .01 (two-tailed).
Cronbach’s alpha unless otherwise stated. bCombined across the two components.
Descriptive Statistics, Correlations, and Reliability for Pre-K Observed Variables for Latent Variable of Code-Related Skills.
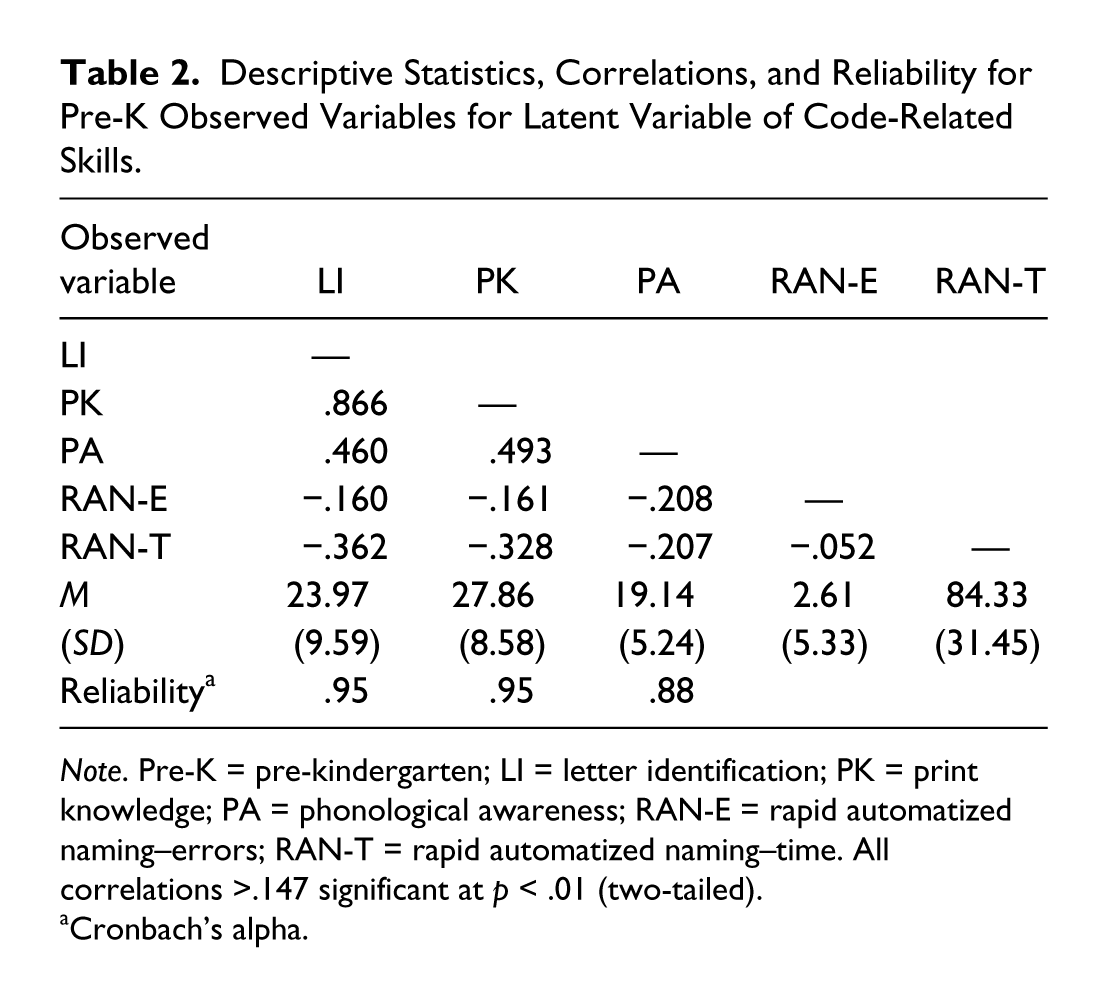
Note. Pre-K = pre-kindergarten; LI = letter identification; PK = print knowledge; PA = phonological awareness; RAN-E = rapid automatized naming–errors; RAN-T = rapid automatized naming–time. All correlations >.147 significant at p < .01 (two-tailed).
Cronbach’s alpha.
Grade 3 Descriptive Statistics, Correlations, and Reliability for Observed Variables.
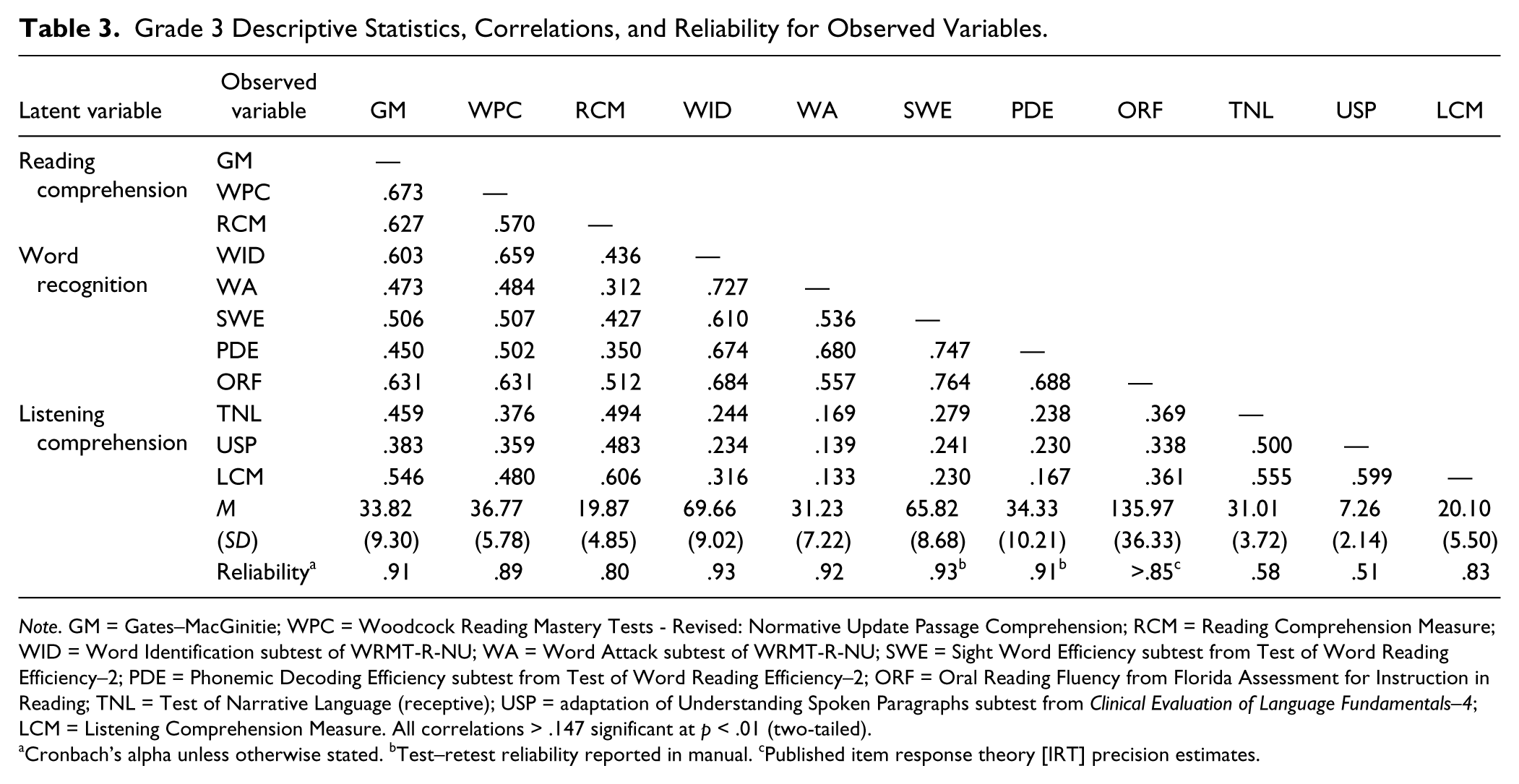
Note. GM = Gates–MacGinitie; WPC = Woodcock Reading Mastery Tests - Revised: Normative Update Passage Comprehension; RCM = Reading Comprehension Measure; WID = Word Identification subtest of WRMT-R-NU; WA = Word Attack subtest of WRMT-R-NU; SWE = Sight Word Efficiency subtest from Test of Word Reading Efficiency–2; PDE = Phonemic Decoding Efficiency subtest from Test of Word Reading Efficiency–2; ORF = Oral Reading Fluency from Florida Assessment for Instruction in Reading; TNL = Test of Narrative Language (receptive); USP = adaptation of Understanding Spoken Paragraphs subtest from Clinical Evaluation of Language Fundamentals–4; LCM = Listening Comprehension Measure. All correlations > .147 significant at p < .01 (two-tailed).
Cronbach’s alpha unless otherwise stated. bTest–retest reliability reported in manual. cPublished item response theory [IRT] precision estimates.
Oral language
Three measures of vocabulary were administered: The Peabody Picture Vocabulary Test–4 (PPVT-4; Dunn & Dunn, 2007) assessed receptive vocabulary, the Expressive Vocabulary Test–2 (EVT-2; Williams, 2007) assessed expressive vocabulary, and the Word Classes 1 subtest from the Clinical Evaluation of Language Fundamentals–4 (CELF-4; Semel & Wiig, 2006) assessed understanding of relationships between words and included both receptive and expressive components. Five measures of grammar were administered. The Word Structure (WS) subtest of the CELF-4 (Semel & Wiig, 2006) assessed understanding of morphology and pronouns. A stop rule of eight incorrect responses was utilized. The Recalling Sentences (RS) subtest of the CELF-4 assessed the ability to repeat back spoken sentences of increasing length and complexity. To better accommodate pre-K children, the first two items from the Recalling Sentences subtest of the CELF: Preschool, Second Edition (Semel & Wiig, 2006) were administered first, followed by the test items from the CELF-4 in the designated order. The Past Tense probe (TEGT) of the Rice/Wexler Test of Early Grammatical Impairment (TEGI; Rice & Wexler, 2001) assessed children’s production of regular and irregular past tense verbs. The Third Person Singular probe (TEGS) of the TEGI assessed children’s production of /-s/ or /-z/ in present tense verb forms with singular subjects. The Test for Reception of Grammar–Version 2 (TROG-2; Bishop, 2003) assessed comprehension of grammatical contrasts, with four items in each block to assess the same grammatical contrast. The total number of correct blocks was the score used.
Three measures of discourse skills were administered. Comprehension monitoring was assessed with a researcher-developed measure, the Knowledge Violations Task (KVT), based on previous research (Cain & Oakhill, 2006; Oakhill & Cain, 2012). The child heard short stories that were either entirely consistent or included inconsistent information. After each one, the child was asked whether the story made sense and, if not, what was wrong with it. One point was awarded when both components were correctly answered. Inference making was assessed with a researcher-developed measure based on previous research (Cain & Oakhill, 1999; Oakhill & Cain, 2012). One practice and two experimental stories were read aloud by the assessor. After each one, they asked four open-ended questions to assess the ability to generate inferences that require integration (INF-INT) of information in the text and four to assess the ability to generate inferences that require integration of textual information with background knowledge (INF-BK). These were scored 0 to 2 points, and the average score for each was calculated. Text structure knowledge was assessed with an adaptation of the Picture Arrangement Test (PAT) from the Wechsler Intelligence Scale for Children–Third Edition (WISC-III; Wechsler, 1992). There was one practice item and 12 test items. For each, children saw three to five picture cards in a fixed order and heard a sentence that described each. Their task was to arrange the pictures into the correct (temporal and causal) sequence. A ceiling rule of five incorrect items was applied.
Code-related skills
Four measures were administered: Letter knowledge was assessed using the Letter Identification (LI) subtest of the Woodcock Reading Mastery Tests–Revised: Normative Update (WRMT-R-NU; Woodcock, 1997) for which children named letters of the alphabet presented in isolation in a variety of fonts and styles. The Print Knowledge subtest of the Test of Preschool Early Literacy (TOPEL; Lonigan, Wagner, Torgesen, & Rashotte, 2007) assessed the ability to name and say the sounds of specific letters and to identify letters associated with specific sounds. Phonological awareness was assessed by the Phonological Awareness subtest of the TOPEL, which comprises auditory elision and blending tasks. Rapid automatized naming (RAN) was assessed with a modification of the RAN task in the CELF-4, which does not have a preschool version. Children were required to name arrays of colors, objects (familiar animals: cow, horse, pig), and colors and objects combined (red cow, blue horse, etc.). Both errors and time taken to name the array were recorded.
Measures in Grade 3
The assessment battery included multiple measures of reading comprehension, word recognition, and listening comprehension. We report the correlations between variables, mean raw scores, and standard deviations for the sample included in our statistical analyses (n = 305) in Table 2. We also report reliability (Cronbach’s alpha, unless otherwise stated) computed on a separate sample of children in Grade 3 (n = 120), where appropriate. The measures were administered in the latter half of the school year and the administration and scoring protocols in the manual was followed for standardized measures, unless stated below.
Reading comprehension
Three measures of reading comprehension were administered. The Gates–MacGinitie (MacGinitie, MacGinitie, Maria, & Dreyer, 2000) for Grade 3 is composed of a series of passages. Children answered questions (with multiple choice responses) after each one. The Passage Comprehension (WPC) subtest from the WRMT-R-NU (Woodcock, 1997) assessed reading comprehension with a cloze procedure. The Reading Comprehension Measure (RCM) was adapted from the Qualitative Reading Inventory (QRI-5; Leslie & Caldwell, 2011) and consisted of two narrative and two expository passages, which children read silently. They answered open-ended questions after each passage, tapping inferential and noninferential information. Five passages came from the QRI-5 and the remainder was created matched to these passages in terms of length and lexile. For each measure, the total number of items (questions) correct was used as the raw score.
Word recognition
We included measures of word and nonword reading accuracy and efficiency and passage reading fluency to provide a comprehensive sampling of the skills and knowledge that support word recognition. Accuracy was assessed by two subtests from the WRMT-R-NU. The Word Identification (WID) subtest measured the ability to accurately pronounce printed English words ranging from high to low frequency of occurrence. The Word Attack (WA) subtest assessed the ability to read pronounceable nonwords of increasing complexity. Two subtests of the Test of Word Reading Efficiency–Second Edition (TOWRE-2; Torgesen, Wagner & Rashotte, 2011) measured word reading efficiency by determining how many printed English words (Sight Word Efficiency [SWE] subtest) and pronounceable nonwords (Phonemic Decoding Efficiency [PDE] subtest) children could pronounce accurately in 45 s. Word reading fluency in context was assessed with an adaption of the Florida Assessment for Instruction in Reading: Oral Reading Fluency (ORF; State of Florida, 2009). Children read two passages aloud for up to 60 s. They were asked a comprehension question after each passage to encourage reading for meaning. Words read accurately per minute was calculated for each and a fluency score obtained from the lookup tables provided by the Florida Center for Reading Research (www.fcrr.org/lookup).
Listening comprehension
Three measures of listening comprehension were administered. In the Test of Narrative Language–Receptive (TNL; Gillam & Pearson, 2004), children listened to three passages and answered open-ended questions after each. The measure was administered according to test procedures with the exception that, prior to answering questions for the second passage, children retold the passage (used for other studies within the larger project). We administered a modified version of the Understanding Spoken Paragraphs subtest of the CELF-4 (Semel & Wiig, 2006), using only two test paragraphs instead of three for each grade. Reliability was low (.51). Exploratory factor analyses revealed a multifactor structure that could explain the low reliability. We also administered an experimental measure, the Listening Comprehension Measure (LCM), adapted in part from the QRI-5, and similar to the RCM in format. Interrater reliability (on 10% of the sample) was good (.96). For each measure, the total number of items (questions) correct was used as the raw score.
Procedures
All measures were administered by trained research staff in a quiet room in the child’s school, local university site, community center, or home. The full battery took 5 to 6 hr to complete, with measures administered in prescribed blocks each lasting 15 to 40 min. All measures were administered individually, with the exception of the Gates–MacGinitie, which was administered in small groups or individually, where necessary. Interrater reliability (intraclass correlation on 10% of the sample) was calculated for measures with open-ended questions (pre-K Inference, G3 modified Understanding Spoken Paragraphs, G3 listening and RCMs) and all were excellent (> .85; Cicchetti, 1984). Full detail on our training and assessment procedures can be found in LARRC et al. (2016).
Results
Descriptive Statistics
On inspection of skewness and kurtosis criteria, histograms, and boxplots of the data, the majority of variables showed adequate distribution with no severe departures from normality. No extreme outliers were identified within the data at either grade.
Structural Equation Models
For each research aim, we used SEM to assess the relations among variables in different theoretical models, using Version 0.5-23 of the R package lavaan (Rosseel, 2012). A Maximum Likelihood robust estimator (Finney & DiStefano, 2008) with Full Information Maximum Likelihood (FIML) method (Enders & Bandalos, 2001) was used to address missing data and mild violations of normality assumptions. We assumed that the data were Missing at Random (MAR), which is a requirement of the FIML. The two typical submodels in SEM were used: the measurement model and the structural model. The measurement model specifies the relationships between the observed (or measured) variables and their underlying unmeasured latent variable (as specified in Tables 1–4 and Figures 1 and 2). Measurement errors of observed variables were allowed to vary. The structural model specifies the hypothetical directed relations among the latent variables, as shown in Figures 1 to 3 and Figure A1 of the appendix, for each theoretical model. Note that measurement error is essentially regression residual uncorrelated with the corresponding latent variable, which cannot explain variance in the error. The use of multiple measures takes measurement error into account, thereby resulting in a better assessment of each latent variable. It consequently solidifies the entity of latent constructs before further testing the posited hypothesis about their directed relations. This feature is generally not available when only single measures are used and no measurement errors are considered.
Grade 3 Model Fit for Models Without (Independent) or With (Dependent) Pathway Between Word Recognition and Listening Comprehension.
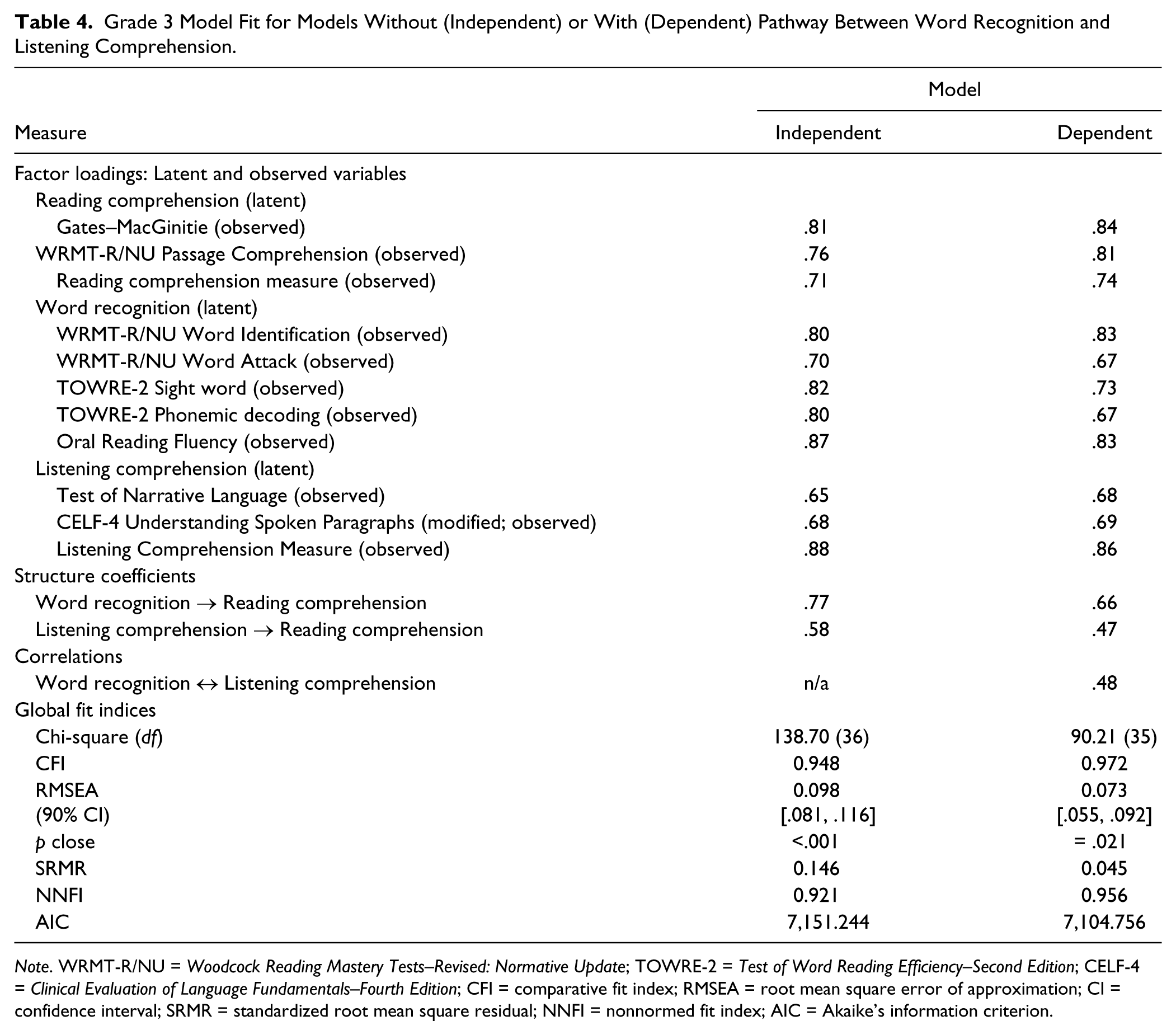
Note. WRMT-R/NU = Woodcock Reading Mastery Tests–Revised: Normative Update; TOWRE-2 = Test of Word Reading Efficiency–Second Edition; CELF-4 = Clinical Evaluation of Language Fundamentals–Fourth Edition; CFI = comparative fit index; RMSEA = root mean square error of approximation; CI = confidence interval; SRMR = standardized root mean square residual; NNFI = nonnormed fit index; AIC = Akaike’s information criterion.

Grade 3: Best fitting model with pathway between word recognition and listening.
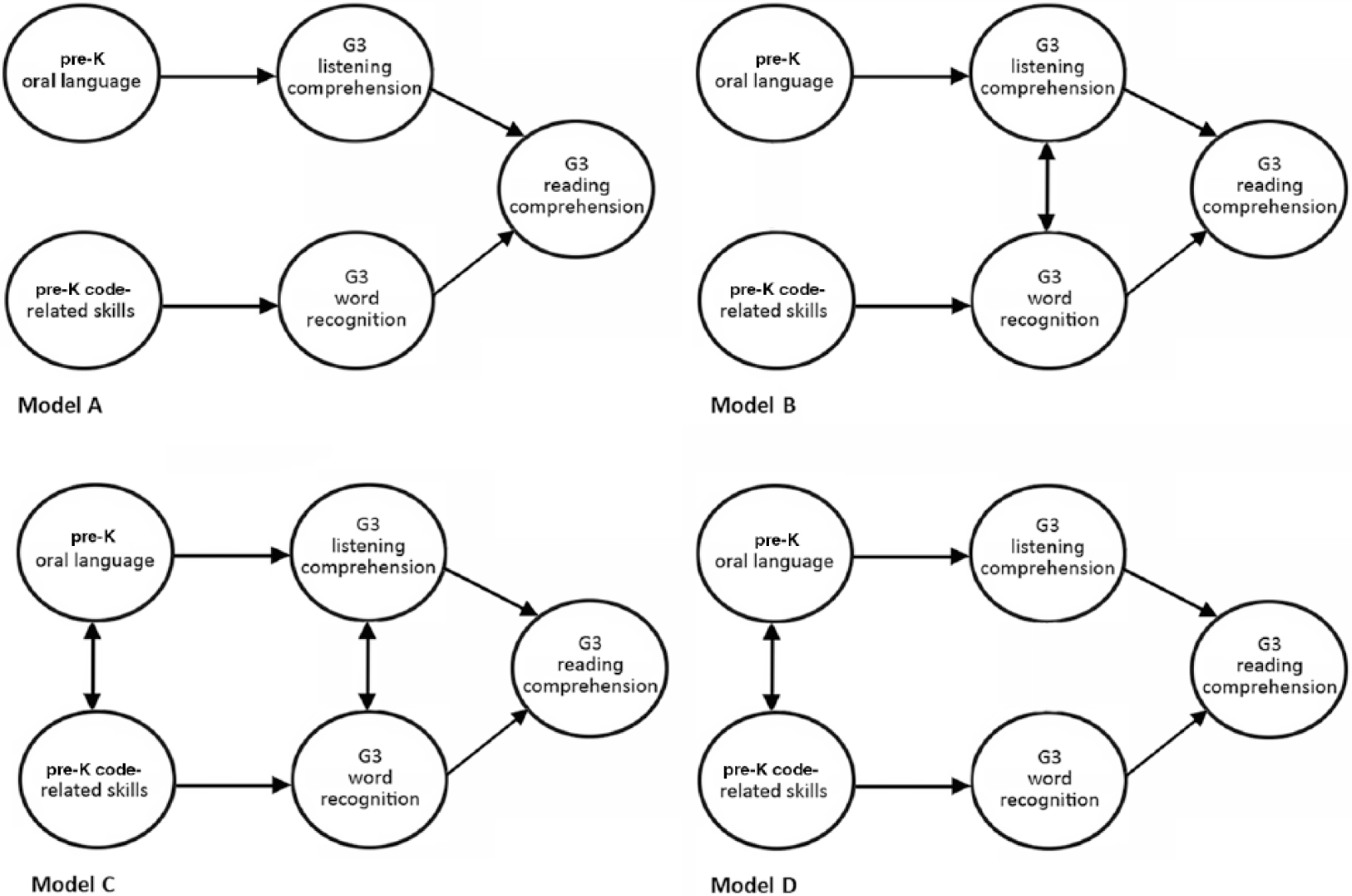
Longitudinal prediction from pre-K to Grade 3: Models.
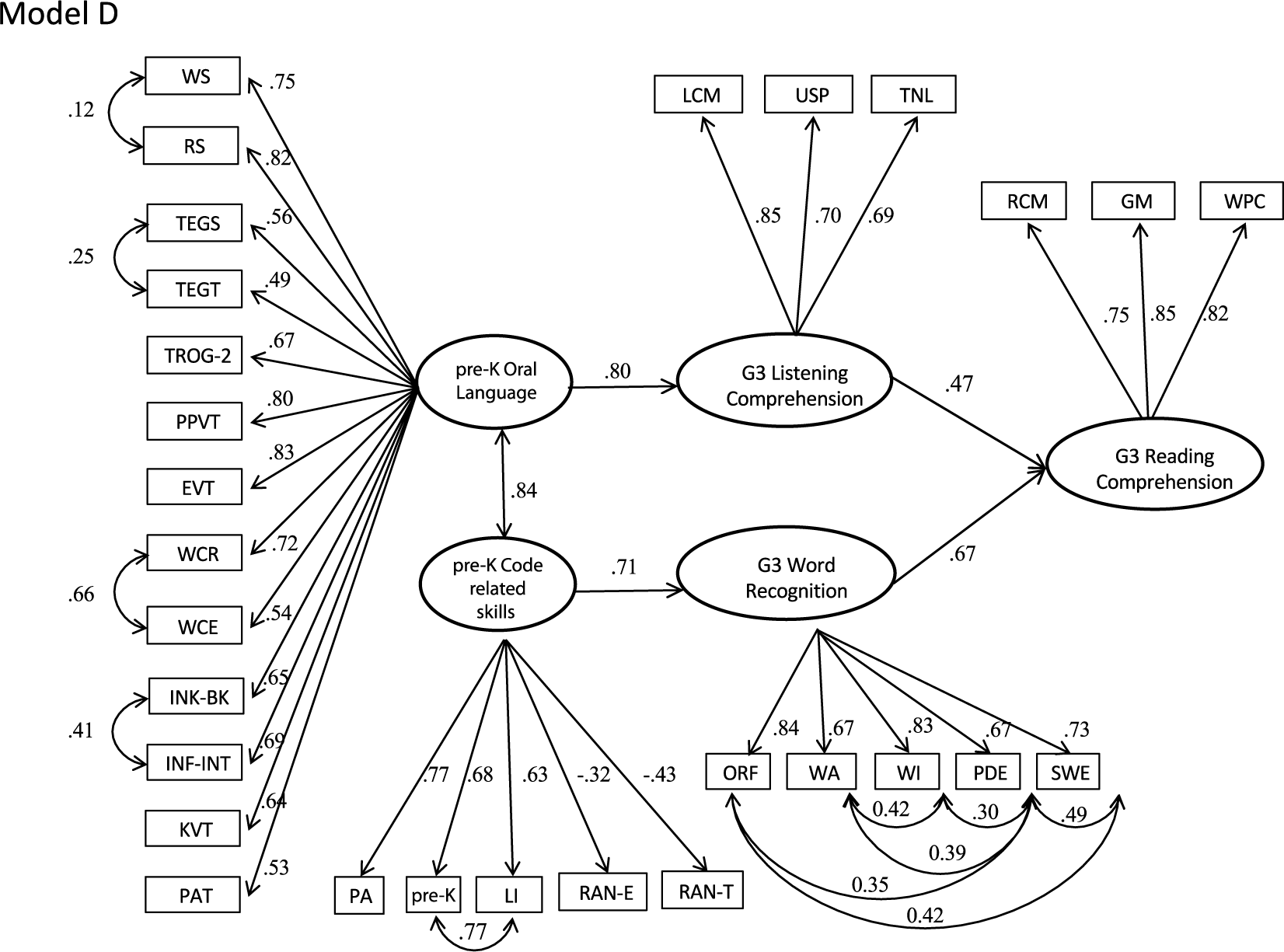
Longitudinal prediction from pre-K to Grade 3: Best fitting model.
To evaluate model fit, we examined a range of fit indices (Lomax, 2013; McCoach, Black, & O’Connell, 2007). The chi-square goodness-of-fit test is sensitive to sample size, so we expected this to be significant for all models and report it for completeness. We evaluated fit on the basis of the following indices: the root mean square error of approximation (RMSEA) for which values of less than .08 indicate acceptable fit (Browne & Cudeck, 1993; MacCallum & Austin, 2000), the standardized root mean square residual (SRMR) for which values of less than .05 indicate good fit (Byrne, 2012), and the comparative fit index (CFI) and the nonnormed fit index (NNFI) for which values greater than .90 indicate good fit (Lomax, 2013). We report 90% confidence intervals for the RMSEA and results of the closeness of fit test (Browne & Cudeck, 1993), which tests the null hypothesis that RMSEA is less than or equal to .05 (this test should be ns). Akaike’s information criterion (AIC) was used to compare competing models: smaller AICs indicate better fit (Kline, 2013) and the chi-square difference test was also used to compare fit of nested models. For each theoretical model, we present estimates from the standardized solution. The fit indices are reported in Tables 4 through 6 and the estimated parameters (including factor loadings, structure coefficients, and correlations) in the tables and Figures 1 and 2.
Longitudinal Models: Standardized Solution.
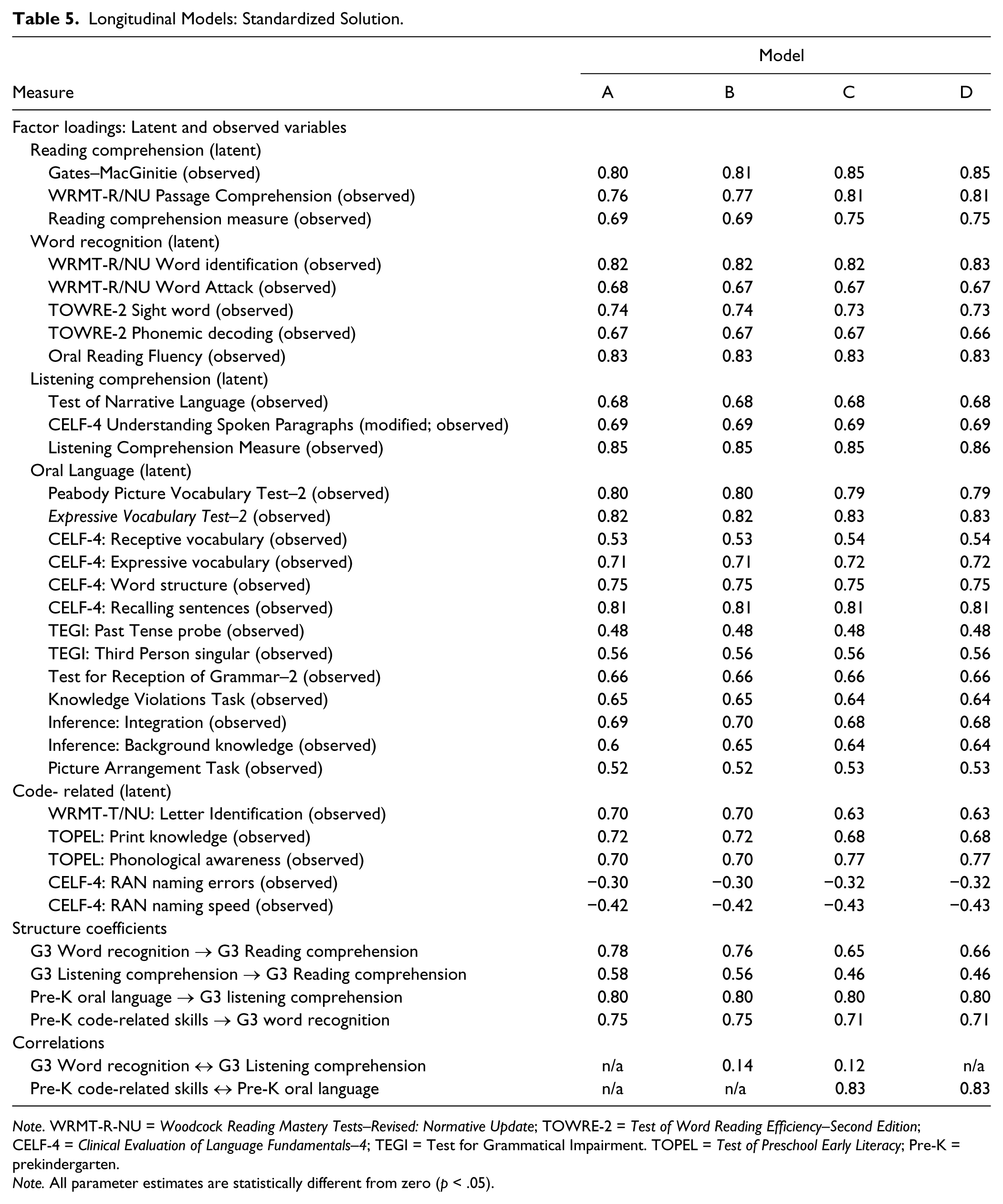
Note. WRMT-R-NU = Woodcock Reading Mastery Tests–Revised: Normative Update; TOWRE-2 = Test of Word Reading Efficiency–Second Edition; CELF-4 = Clinical Evaluation of Language Fundamentals–4; TEGI = Test for Grammatical Impairment. TOPEL = Test of Preschool Early Literacy; Pre-K = prekindergarten.
Note. All parameter estimates are statistically different from zero (p < .05).
Longitudinal Models: Global Fit Indices.
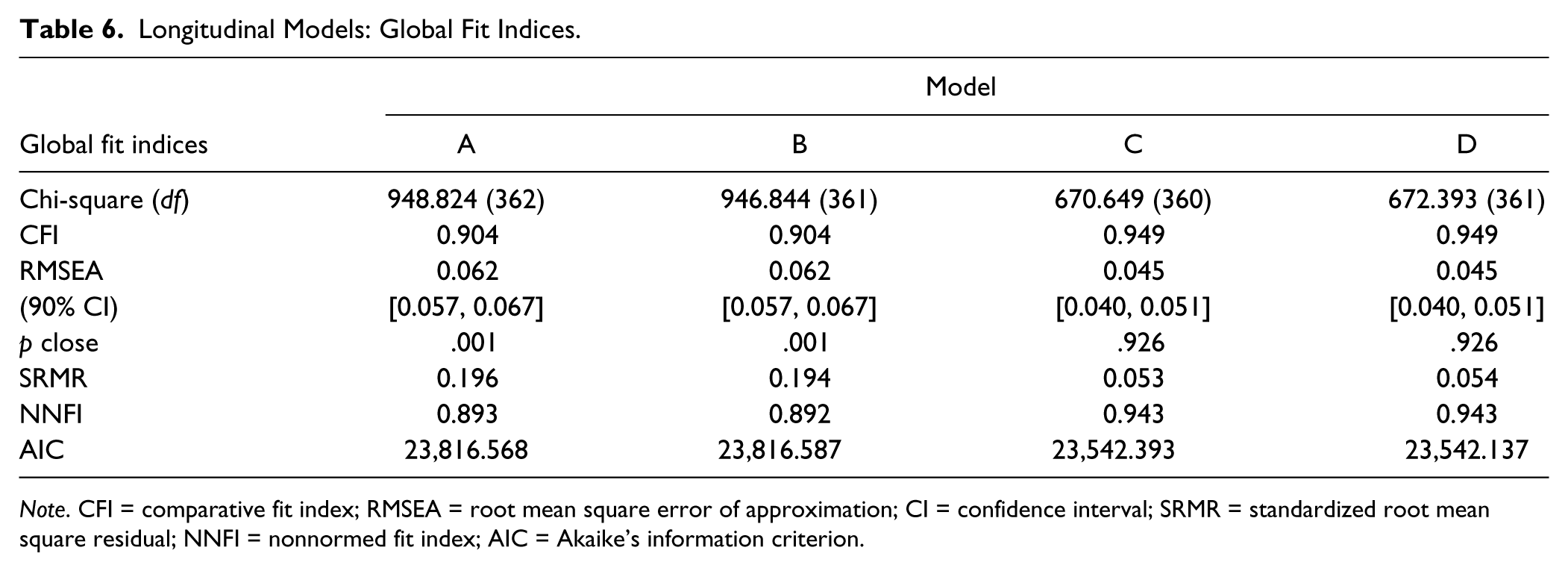
Note. CFI = comparative fit index; RMSEA = root mean square error of approximation; CI = confidence interval; SRMR = standardized root mean square residual; NNFI = nonnormed fit index; AIC = Akaike’s information criterion.
Prediction of Grade 3 reading comprehension by concurrent measures of listening comprehension and word recognition
In this first pair of analyses, we sought to confirm that the basic model of the simple view of reading reported in LARRC (2015b) was retained in a new sample of participants. We tested the fit of two models to determine whether listening comprehension and word recognition were independently related to reading comprehension (independent model), or whether the best fitting model included a pathway between the two (dependent model).
The basic theoretical model hypothesized that listening comprehension and word recognition independently influence reading comprehension. This provided a good estimation of Grade 3 reading comprehension explaining around 94% of the variance. All of the factor loadings and structure coefficients were significantly different from zero (p < .05) and in the expected direction (i.e., positive). Model fit was only moderate. The second model that included an additional hypothesized relation between word recognition and listening comprehension (see Figure 1) produced a better fit to the data, although we note that the closeness of fit test for RMSEA remained significant. The adjusted Satorra-Bentler (S-B) Δχ2 difference test confirmed that the dependent model was the superior fitting model: Δχ2 = 40.44, p < .001. In contrast to LARRC (2015b), there was a stronger relation between word recognition and reading comprehension (.66) than between listening comprehension and reading comprehension (.47; coefficients reported in LARRC, 2015b, were .48 and .60, respectively). We consider reasons for this difference in the “Discussion” section.
Longitudinal prediction of Grade 3 reading comprehension by prekindergarten oral language and code-related skills
Our second, central, research question examined the prediction of Grade 3 reading comprehension by pre-K oral language (vocabulary, grammar, discourse) and code-related skills (letter and print knowledge, phonological awareness, and RAN). All models hypothesized that pre-K oral language and code-related skills predicted Grade 3 reading comprehension through their influence on listening comprehension and word recognition, respectively. We first compared the fit of four different models to examine whether oral language and decoding skills develop along independent pathways or whether there was interdependence between the constructs within time (see Figure 2). In the first model, the pathways from the pre-K code-related and listening comprehension are independent; the second model allows for covariance between the pre-K constructs (Lepola et al., 2016; Storch & Whitehurst, 2002); the third model additionally allows for covariance between the G3 constructs (Kendeou, van den Broek, et al., 2009); and the fourth model excluded the relationship between the Grade 3 constructs, found to be nonsignificant by Kendeou, van den Broek, et al. (2009). The standardized solution for each model is reported in Table 5 and the global fit indices in Table 6.
All models explained sizable variance in Grade 3 reading comprehension (all R2 > .94). In addition, we found longitudinal continuity between the pre-K constructs of oral language and code-related skills and their complementary constructs in Grade 3. The two models that allowed for concurrent covariance either between the two pre-K constructs of decoding and listening comprehension (Model C) or additionally between the G3 constructs of word recognition and listening comprehension (Model D) had the best fits. In the more complex model, the additional relation between Grade 3 listening comprehension and word recognition was not significant (p > .10). This model was not a significantly better fit than the model without this relation (Model C): Δχ2 = 1.92, df = 2, p > .10. Thus, the more parsimonious model, without the relation between Grade 3 listening comprehension and word recognition is preferred.
We tested four variants of these models that included cross-lagged longitudinal relations across years. These are shown in the appendix. The best fitting models were those that also included within time relations between pre-K code-related skills and oral language and G3 word recognition and decoding (C–CL and D–CL, respectively). Neither models provided a better fit to the data than the models without longitudinal relations, S-B Δχ2 difference test: Δχ2 < 4.0, p > .10 for both. Thus, the more parsimonious models without the cross-lagged longitudinal relations are preferred.
Discussion
Reading for understanding is the ultimate aim of reading. Our data show that we can describe reading comprehension in young readers adequately from the two core components of the simple view of reading: Significant variance in Grade 3 reading comprehension was explained by the ability to read words and comprehend oral language. Our study has extended our understanding of reading development, demonstrating that we can predict the simple view in Grade 3 from oral language and print knowledge assessed in preschool before the start of formal literacy instruction. This extends previous research by including a more comprehensive range of oral language measures to predict reading comprehension across a longer period of development and confirms the relatively independent development of the two core components of the simple view. We relate our findings to the extant literature and discuss their practical implications.
In line with previous research, we explained sizable (>90%) variance in Grade 3 reading comprehension by latent constructs of concurrent listening comprehension and word recognition (LARRC, 2015b). Thus, our data confirm the utility of the simple view for describing reading ability in young readers. Typically, greater variance is explained when using latent variables compared with single observed variables in multiple regression because of the reduction in measurement error; for example, prediction of reading comprehension for this age group from the components of the simple view using multiple regression is typically between 50% and 70% of variance (Cutting & Scarborough, 2006; Spear-Swerling, 2004). In addition, we believe that the substantial variance explained in our study is, in part, due to our use of multiple measures to comprehensively assess each construct, including nonword and real word reading accuracy and fluency to indicate word recognition and assessments of both narrative and expository text comprehension, which tapped inferential and literal comprehension, to indicate listening and reading comprehension. Of note, studies that include a greater range of word reading and comprehension measures predict up to 80% even with multiple regression (Nation & Snowling, 2004; Tunmer & Chapman, 2012). Our best fitting model allowed relations between word recognition and listening comprehension, which is in keeping with Tunmer and Chapman (2012). We discuss the implications of this finding when we consider the longitudinal analyses, below.
Word recognition had a slightly stronger relationship with reading comprehension than did listening comprehension. This is in line with other studies of this age group (see Garcia & Cain, 2014, for a summary) but in contrast to a related study that administered the same measures with the same procedures to a different sample (LARRC, 2015b). The children in both studies were sampled from the same school districts, ruling out differences in measures or educational practice as a source of these discrepant findings. However, a lower proportion of the current sample were from high-income families: just under 40% reported annual family income >US$80k, compared with nearly 50% in LARRC (2015b), and a greater proportion of the current sample had an Individualized Education Program: 12.2% versus 7%. Future research should examine how these and other background factors influence the contribution of listening comprehension and word recognition to reading comprehension.
Turning to the longitudinal analyses, we found that oral language and code-related skills in prekindergarten predicted reading comprehension 5 years later. Of note was the very strong relationship between preschool measures of oral language (vocabulary, grammar, and discourse) and Grade 3 listening comprehension, demonstrating significant continuity over a 5-year period (see also Lepola et al., 2016). The relationship between print knowledge, phonological awareness, and later word recognition skills is well established (Catts, Fey, Zhang, & Tomblin, 1999; Storch & Whitehurst, 2002). Previous research has not included such comprehensive assessment of oral language (vocabulary, grammar, and discourse-level skills) in preschool to predict reading comprehension via listening comprehension. In this regard, our study is unique and speaks to the importance of oral language skills developed before the start of formal reading instruction.
In line with previous research (Kendeou, van den Broek, et al., 2009), our best fitting longitudinal model showed that listening comprehension and word recognition in Grade 3 were broadly independent, whereas the latent variables representing these constructs in pre-K were strongly related. Our findings extend this work in two critical ways: first, the prediction across 5 years of development compared with the 2-year period studied by Kendeou and colleagues; second, the prediction of reading comprehension through the two components of the simple view: word recognition and listening comprehension. One reason for the strong relationship in pre-K is that both are informed by a common variable, for example, there are strong links between the development of vocabulary and phoneme awareness in preschool (Metsala & Walley, 1998). A body of work demonstrates that different aspects of the home literacy environment support the longitudinal prediction of oral language skills and word reading (Sénéchal, LeFevre, Thomas, & Daley, 1998), which may explain the separate developmental trajectories reported here.
Several implications for assessment, intervention, and curriculum design stem from our findings. Previous work confirms the predictions of the simple view that reading comprehension difficulties can arise because of weaknesses in word reading, listening comprehension, or both (Cain & Oakhill, 2006; Catts, Adlof, & Weismer, 2006; Torppa et al., 2007). Our longitudinal findings show that preschool oral language is strongly predictive of later reading comprehension via listening comprehension and confirm that the developmental pathways of listening comprehension and word reading are largely independent. These findings indicate that preschool assessment may usefully identify children at risk of later reading comprehension difficulties and raises the possibility of early targeted intervention to mitigate such risk. In addition, the strong influence of a range of oral language skills from pre-K through Grade 3 supports the call for these to be included in the early years curriculum (Dickinson, Golinkoff, & Hirsh-Pasek, 2010).
We note several limitations. First, our research design included a very comprehensive assessment of oral language skills in preschool, but it would not be practical to include multiple measures of vocabulary, grammar, and discourse when screening children to identify those at risk of later reading comprehension difficulties. Although oral language skills in the early years form a single latent construct (LARRC, 2015a), it would be useful to identify a cluster of key predictors that can be used by professionals in early years’ settings. Second, although we included multiple measures of reading comprehension, listening comprehension, word recognition in Grade 3, and oral language and code-related skills in pre-K, we did not include other variables such as motivation and executive function/working memory, which are important both for concurrent reading comprehension (Guthrie, Wigfield, Metsala, & Cox, 1999; Sesma, Mahone, Levine, Eason, & Cutting, 2009) and its longitudinal prediction (Lepola et al., 2016; Pike, Swank, Taylor, Landry, & Barnes, 2013). Given the interrelations between these variables and language development, future work should focus on disentangling their interrelations across development. Third, our study was not designed to speak to reading development in children learning to read in an additional language or those at risk of reading or language impairment through familial factors; there may be different developmental relations for those populations.
Three decades on, the simple view of reading remains a useful framework for describing the complex phenomenon of reading comprehension as the product of word reading and listening comprehension. We have shown that preschool indicators of these two components predict reading comprehension 5 years later, demonstrating the importance of early language skills for reading comprehension. We recommend that educators exploit this continuity in the development of language comprehension to develop effective curricula and assessment tools.
Footnotes
Appendix
Author Note
This paper was prepared by a Task Force of the Language and Reading Research Consortium (LARRC) consisting of Kate Cain (Convener) and Yi-Da Chiu. LARRC project sites and investigators are as follows:
Jill Pentimonti is now at American Institutes for Research (AIR). Stephen A. Petrill was a LARRC co-investigator from 2010-2013. Hugh Catts is now at Florida State University. J. Ron Nelson was a LARRC co-investigator from 2010-2012.
We are deeply grateful to the numerous staff, research associates, school administrators, teachers, children, and families who participated. Key personnel at study sites include: Crystle Alonzo, Lisa Baldwin-Skinner, Lauren Barnes, Garey Berry, Beau Bevens, Jennifer Bostic, Shara Brinkley, Janet Capps, Tracy Centanni, Beth Chandler, Lori Chleborad, Emmanuel Cortez, Willa Cree, Dawn Davis, Kelsey Dickerhoof, Jaclyn Dynia, Michel Eltschinger, Kelly Farquharson, Tamarine Foreman, Yvonne Fraser, Abraham Aldaco Gastelum, Rashaun Geter, Sara Gilliam, Alexandria Hamilton, Cindy Honnens, Miki Herman, Hui Jiang, Elaine Joy, Jaime Kubik, Trudy Kuo, Gustavo Lujan, Chi Luu, Junko Maekawa, Carol Mesa, Denise Meyer, Maria Moratto, Kimberly Murphy, Marcie Mutters, Amy Pratt, Trevor Rey, Lizeth Sanchez-Verduzco, Amber Sherman, Shannon Tierney, Stephanie Williams, and Gloria Yeomans-Maldonado.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by grant # R305F100002 of the Institute of Education Sciences’ Reading for Understanding Initiative.