
Abstract
This paper documents the construction of an updated and comprehensive bridge between Compustat and the Longitudinal Business Database (LBD) spanning 1976–2020. The Compustat–LBD linkage is one of the most requested resources in the U.S. Federal Statistical Research Data Centers, yet no publicly documented, comprehensive bridge has existed to date. We fill this gap with a multi-stage matching framework that combines EIN matching, refined fuzzy name and address algorithms, NAICS alignment, telephone records, and a novel ExecuComp–LEHD linkage. The resulting bridge matches roughly 85% of unique GVKEYs and 95% of economic activity, providing a valuable resource for longitudinal research on U.S. businesses, corporate governance, and executive compensation. By detailing all matching procedures we deliver a production-quality tool for integrating public-company financials to firm-level microdata.
Keywords
Introduction
The integration of comprehensive financial and business datasets is crucial for understanding corporate behavior and its broader economic implications. This paper presents a refined methodology for creating an updated bridge between Compustat data and the Longitudinal Business Database (LBD), covering the period from 1976 to 2020. By linking company identifiers from Compustat with firm identifiers in the LBD, this bridge facilitates enhanced analyses of public companies’ financial and operational dynamics over an extensive historical period.
Our approach incorporates a multifaceted data collection process, leveraging public and private sources to compile a rich dataset of public firms. The primary data source, Compustat Fundamentals, provides detailed financial and employment information, which is supplemented with historical company data from Compustat Historical Header Data, Center for Research in Security Prices (CRSP) and SEC filings. These combinations of datasets allow us to track companies consistently over time using unique identifiers such as GVKEY.
This paper makes a particularly important contribution to the federal statistical research environment. The Compustat–LBD linkage is one of the most requested and frequently cited crosswalks in the Federal Statistical Research Data Centers (RDCs), yet no publicly documented, comprehensive, or methodologically consistent bridge has existed to date. We address this gap by producing the most complete and transparent Compustat–LBD crosswalk to date, spanning 1976–2020 and constructed using a multi-stage matching framework that integrates EINs, probabilistic name and address matching, NAICS-based refinement, telephone records, and a novel ExecuComp–LEHD linkage. Our procedures yield a match rate of roughly 85% of GVKEYs and over 95% of total employment, revenue, and assets in Compustat. By documenting each step of the data construction, scoring, de-duplication, and validation process, we deliver a reproducible and scalable resource that directly responds to long-standing research demand and enhances the ability of scholars to connect financial market data with establishment-level economic microdata.
Our ultimate goal is to link each GVKEY in Compustat to a firmid in the LBD for every year; however, we should note that this link is not always one-to-one. Even though they both identify companies, they serve different purposes based on their data focus. A GVKEY identifies a company (issue, currency, index) in the Capital IQ Compustat database, which focuses on financial data and security issuances. A firmid identifies an economic unit as defined by the US Census Bureau: a company is an economic unit comprising one or more establishments under common ownership or control. 1 The latter definition focuses on the operational structure of a business while the former focuses more on the financial aspect of the business.
The relationship between GVKEY and FIRMID can be complex. Although we tried to do one-to-one GVKEY–FIRMID matching, this is not always possible. First, we find that it is usually the case that a GVKEY corresponds to one or more FIRMIDS and not the other way around (one firmid to more than one GVKEY) as shown in Figure 1.
2
Second, our disambiguation process only allows a firmid to belong to one and only one GVKEY each year; this means the scenario with an “X” in Figure 1 isn’t possible. Relationship between GVKEYs and FIRMIDS.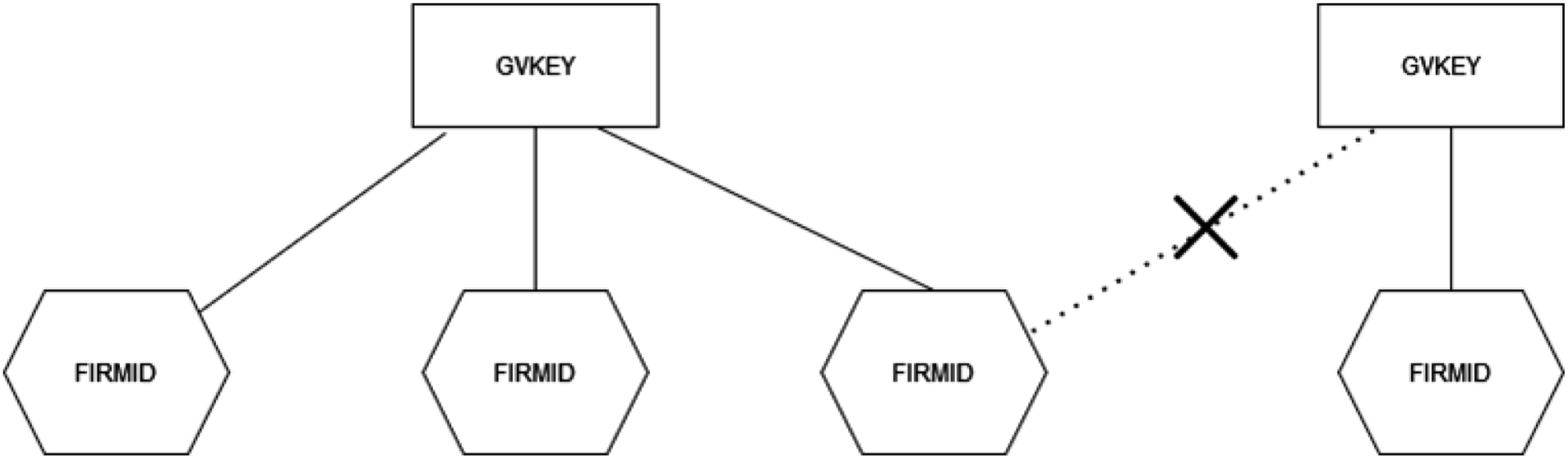
To achieve accurate matches between Compustat and LBD data, we employed a series of sophisticated fuzzy matching techniques. These techniques involved matching on variables like company name, address, Employer Identification Number (EIN), and industry codes, ensuring a high degree of accuracy in linking records across datasets. The resulting Compustat–LBD bridge, accessible within the Integrated Research Environment (IRE) data warehouse, represents a significant resource for researchers conducting longitudinal studies on U.S. businesses. 3
Our methodology also addresses critical challenges such as data standardization, de-duplication, and refinement of matching criteria. By systematically cleaning and organizing the data, we ensure the reliability of our matches, focusing on financially active companies within the United States. Furthermore, the integration of executive information data through probabilistic name-matching techniques enhances the scope and depth of our analysis, providing valuable insights into corporate governance and executive compensation. Matching process flowchart.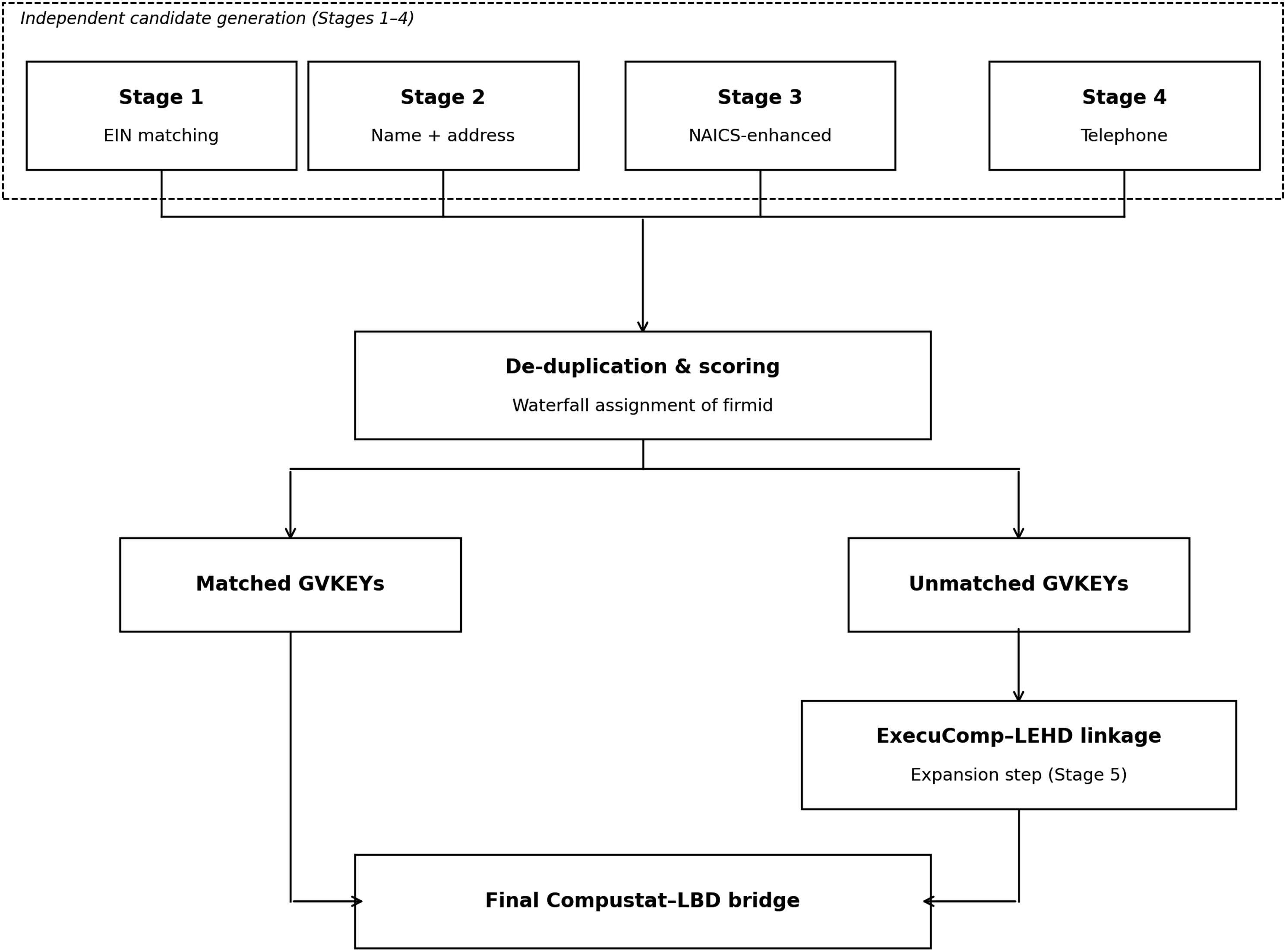
This paper details each stage of our matching process, from initial data preparation to the final de-duplication of matches (Figure 2). We present comprehensive statistics on matching success rates, illustrating the robustness of our approach. Ultimately, the Compustat–LBD bridge offers a powerful tool for economic researchers, enabling more precise and comprehensive analyses of corporate behavior over the past four decades. Qualified researchers with approved proposals can access the resulting Compustat–LBD bridge through the Federal Statistical Research Data Centers.
The Compustat–LBD bridge enables a range of empirical applications. Studies that have already leveraged this bridge or a predecessor include Giroud and Mueller, 1 who, using a predecessor bridge, show that firm leverage shapes establishment-level employment losses during the Great Recession, and Wallskog et al., 2 who leverage the bridge introduced in this paper to document the growth in within-firm pay inequality at public firms following a positive productivity shock. Davis et al. 3 similarly exploit a predecessor bridge to compare the growth rate volatility of privately held versus publicly traded firms across the business cycle. Beyond these examples, the bridge also stands to benefit research on corporate governance and firm behavior, such as studies examining board structure and audit quality, 4 where connecting firm-level financial data to establishment-level outcomes would open new empirical opportunities that neither Compustat nor the LBD can provide alone.
A large literature in economic measurement and administrative data construction informs this work. Foundational efforts in record linkage within the federal statistical system—including Jarmin and Miranda, 5 Chow et al., 6 and related work on record linkage best practices—document the evolution of the Business Register, the Longitudinal Business Database, and methods for creating longitudinal firm identifiers. Studies such as Handwerker and Mason 7 and Abowd et al. 8 highlight the conceptual and practical challenges of linking employers and establishments across financial, administrative, and survey data, often in the absence of unique identifiers. 4
Data
Public-firm data
Our primary source of public-firm information is Compustat Fundamentals, 5 which provides firm names, addresses, Employer Identification Numbers (EINs), financial metrics, and the unique firm identifier GVKEY for 1976–2020. Fundamentals serves three purposes in our construction. First, it provides the complete universe of GVKEY–year observations required for linkage. Second, it supplies the employment and financial variables used to identify active companies—those reporting positive employment, revenue, price, or assets in a given year. Third, the quantitative variables in Fundamentals (employment, revenue, assets, and market value) allow us to evaluate the share of economic activity successfully matched to the LBD.
To enrich historical coverage, we incorporate additional sources: 1. CRSP/Compustat Historical Header Data, which provides historical identifiers, locations, and naming conventions; 2. Compact Disclosure (1992–2006) and Edgar filings (2009–present), from which we extract supplemental historical names and addresses; and 3. CRSP Data, which contributes additional historical company names.
Drawing from these sources, we construct six core matching variables used later in the linkage process: (1) EIN, (2) company name, (3) street address, (4) city–state–ZIP, (5) telephone number, and (6) four-digit NAICS industry code. Together, these datasets provide a comprehensive and historically consistent view of public firms for linkage to the Business Register and the LBD.
Public-firm data cleaning and refinements
Before matching, we implement a set of cleaning and standardization procedures designed to preserve the full set of firms while improving identifier quality. We assign each observation to a specific year using the fiscal year when available (or data year otherwise). Company names, addresses, ZIP Codes, and EINs are standardized using text-substitution routines and SAS DQ Match (sensitivity 95), including removal of hyphens in EINs and refinement of ZIP code formats.
We then refine the Compustat universe to ensure consistency across sources and to focus on economically relevant public firms. Duplicate GVKEY–year observations are resolved by retaining non-financial service records when available. We also drop duplicate historical entries associated with mergers or acquisitions—identified using keywords such as merger or acquired by—when they replicate EIN–year combinations. Observations with CUSIPs indicating subsidiary status are removed under analogous duplicate conditions. Among remaining EIN–year duplicates, we retain the entry with the highest annual stock price.
To align with the scope of the Business Register and the LBD, we keep only firms located in the United States, exclude NAICS 525 financial entities, and restrict to firms with stko = 0 or 3, representing publicly traded companies on major exchanges or other trading platforms. Subsidiaries (stko = 1, 2) and leveraged-buyout entities (stko = 4) are excluded. Finally, we retain only active firms—those reporting positive employment, revenue, stock price, or total assets—ensuring the dataset reflects economically relevant public companies for the matching process.
ExecuComp
ExecuComp is an S&P dataset that provides annual information on top executives at publicly traded U.S. firms, including compensation, job titles, and personal identifiers. The data begin in the early 1990s and are linked to firms through the GVKEY identifier. We use ExecuComp to create a complementary bridge between GVKEYs and Census Bureau person records in the Longitudinal Employer–Household Dynamics (LEHD) infrastructure. Using probabilistic person identifiers (PIKs), we match executives to their employing establishments and infer LBD firmids. This provides additional GVKEY–firmid links for firms with incomplete EIN, name, or address information, and forms the last step of our matching algorithm. Additional information about the ExecuComp-LEHD is provided in the “Linking Executive Information Data” section below.
Business Register data preparation
This section describes the procedures used to prepare the Business Register (BR) for matching with Compustat. Earlier versions of the bridge relied on constructing a complete BR file for every year from 1976 to 2020—45 annual files, each containing all relevant BR variables. In contrast, the current approach builds a more efficient and modular structure consisting of six separate BR files, each centered on a single standardized matching variable essential to the Compustat linkage.
The six core BR files are: 1. 2. 3. 4. 5. 6.
One important point to highlight is that, when creating the standardized firm name, we observed that the source variables
Each file contains unique combinations of the relevant matching variable with the
Organizing the BR in this variable-specific manner, rather than maintaining 45 separate annual files, enables us to match Compustat variables (such as names, addresses, or EINs) to the BR across all years in a single join per matching variable. Appendix A provides additional detail on the construction of these six files.
This redesign offers substantial performance advantages. First, it reduces matching time by roughly three orders of magnitude. 9 Second, it reduces storage requirements by consolidating repeated BR information. 10
All BR files are constructed from CBPBR datasets (vintage v2020), with the exception of EIN-851—which is sourced from the BR “851” folders (1992–2001) and BR
Longitudinal Business Database preparation
While the Business Register (BR) files used firmids generated from CBPBR data, the final GVKEY–firmid bridge relies on firmids from the updated LBD (LBDREV).
11
Each BR record linked to a GVKEY–year Compustat observation contains an
LBD information plays two central roles in the construction of the bridge. First, we use employment and industry information to refine matching accuracy. To do this, we construct a dataset from LBDREV containing unique combinations of year, firmid, and 4-digit NAICS codes for 1976–2020, retaining only records where the establishment’s employment in a given industry accounts for at least 25% of its total employment and where payroll is positive. These industry measures support matching stages that incorporate 4-digit NAICS codes in combination with standardized name and address information. Second, LBD data are essential for the final de-duplication stage, where employment and industry consistency help identify the most plausible firmid when multiple candidates are linked to the same GVKEY–year.
Matching Business Register and Compustat
We match companies between the Compustat and Business Register (BR) databases using a multi-stage matching procedure in which stages operate independently. Each stage corresponds to a distinct set of identifying variables (e.g., EIN, name–address, NAICS-augmented name–address), and a given GVKEY–year observation may generate candidate matches in multiple stages. Matches produced at one stage are therefore not treated as final, nor are records removed from consideration in subsequent stages.
Within each stage, the matching is implemented through a sequence of steps, reflecting the fact that the underlying variables are stored in separate files within each database. For example, when matching on company name and address, we first match Compustat and BR records on company name. Conditional on these name matches, we then merge in address records, ensuring that the Compustat year aligns with the relevant BR name and address time window.
Because BR data on names, addresses, and geographic identifiers reside in independent files, stages that require overlapping information can reuse intermediate results from earlier stages (e.g., name–address matches) for computational efficiency. Importantly, this reuse does not restrict the set of candidates considered at later stages: all candidate GVKEY–firmid pairs generated across stages are retained, along with an indicator for the stage in which each candidate was identified.
The five matching stages are as follows: • Stage 1: Matching solely on the Employer Identification Number (EIN). • Stage 2: Matching on company name, street address, and different combinations of city, state, and ZIP code. • Stage 3: Matching on NAICS code in addition to company name, street address, and different combinations of city, state, and ZIP code, using lower similarity thresholds for the name or street address than in Stage 2. • Stage 4: Matching on telephone number in addition to company name and street address, using lower similarity thresholds for the name or street address than in Stage 2. • Stage 5: GVKEY–firmid pairs from the ExecuComp–LEHD bridge (see Section below).
After Stages 1–4 are completed, we attempt to assign an LBD firmid to each GVKEY–year observation through a waterfall-style de-duplication procedure, described in Section “Cleaning and De-duplicating Matches”. This procedure resolves cases in which a GVKEY is linked to multiple firmids by prioritizing matches based on stage, match quality, and consistency over time. Earlier, higher-confidence matches are retained, while lower-priority candidates are discarded. This separation between independent candidate generation and hierarchical resolution ensures transparency in match construction while preserving flexibility in the use of multiple matching criteria.
Stage 5 differs from Stages 1–4 in that it is used exclusively to expand the bridge rather than to generate competing candidates for de-duplication. GVKEY–firmid pairs identified through the ExecuComp–LEHD bridge are added only when a GVKEY was not previously matched in Stages 1–4. Because these links are based on high-confidence person-level identifiers—specifically, unique matches between executive names in ExecuComp and Protected Identification Keys (PIKs) in the LEHD—they are treated as definitive and do not enter the de-duplication procedure.
Linking executive information data
This section describes the construction of a bridge between the Compustat ExecuComp database and the Longitudinal Employer–Household Dynamics (LEHD) database. This linkage allows us to connect ExecuComp records to LBD firm identifiers without relying on company name or address information.
Compustat ExecuComp provides detailed name and demographic information for top executives at publicly traded firms, sourced from annual SEC filings (Form DEF 14A). Each executive is assigned a unique executive identifier (ExecID) and is linked to a firm’s unique Compustat identifier (GVKEY); the data include variables such as name, age, and salary. Using the Census Bureau’s Person Validation System (PVS) probabilistic name-matching algorithm, 12 we assign a protected identification key (PIK) to approximately 70% of executives listed in ExecuComp. Using these PIKs, we link ExecuComp executives to the LEHD database 13 and retrieve the corresponding EIN and firmid from LEHD employment records. This process establishes a direct connection between ExecuComp GVKEYs and LBD firmids based on person-level employment relationships.
To ensure that this linkage contributes only high-confidence firm identifiers to the Compustat–LBD bridge, we impose a stringent quality restriction. Specifically, we retain only GVKEY–firmid links for which at least two distinct executive identifiers (ExecIDs) associated with the same GVKEY are mapped to employment records at the same firmid in the LEHD. This requirement substantially reduces the risk of spurious person-level matches and provides strong validation of the underlying firm linkage. While this criterion is conservative, we prioritize match quality over coverage in the current version of the bridge.
The resulting GVKEY–firmid links, constructed solely from ExecuComp and LEHD data, are used to expand the Compustat–LBD bridge by incorporating previously unidentified matches that were not captured in the EIN-, name-, address-, or NAICS-based matching stages.
Because ExecuComp coverage begins in the early 1990s and applies only to a subset of executives at publicly traded firms, this linkage does not operate over the full 1976–2020 period. Nevertheless, for the years and firms it covers, the ExecuComp–LEHD bridge meaningfully improves match completeness by supplying highly validated firmids that cannot be obtained through firm-level identifiers alone. 14
Matching rates
Compustat matching rate, 1976–2020.

Source: Compustat and Longitudinal Business Database. This table represents companies in Compustat (GVKEYs) that matched to LBD. Each GVKEY is counted once regardless of the number of years it appears. GVKEYs in Compustat are restricted to fiscal years 1976–2020, U.S. location (loc = USA), excluding NAICS 525, and traded on major exchanges (stko = 0 or stko = 3).
Annual Compustat–LBD match rates, 1976–2020.
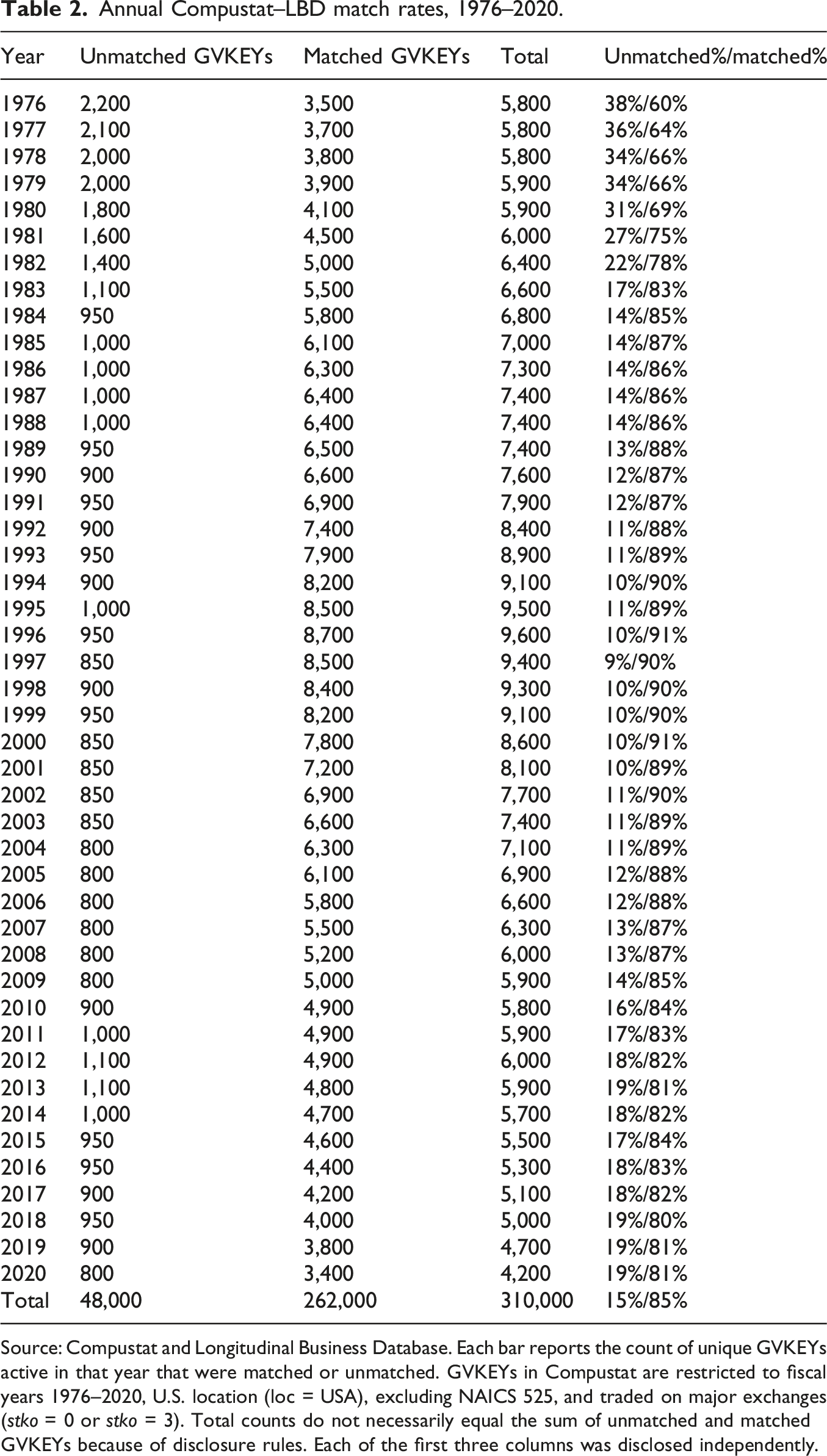
Source: Compustat and Longitudinal Business Database. Each bar reports the count of unique GVKEYs active in that year that were matched or unmatched. GVKEYs in Compustat are restricted to fiscal years 1976–2020, U.S. location (loc = USA), excluding NAICS 525, and traded on major exchanges (stko = 0 or stko = 3). Total counts do not necessarily equal the sum of unmatched and matched GVKEYs because of disclosure rules. Each of the first three columns was disclosed independently.
Matched vs. unmatched Compustat firms (GVKEYs), 1976–2020.
Tabulation of stock ownership code match status in Compustat, 1976–2020.

Source: Compustat and Longitudinal Business Database. Note: stko = 0 in Compustat denotes publicly traded company, includes NYSE, ASE, NASDAQ, and Over-the-counter bulletin board. stko = 3 in Compustat denotes Company that is publicly traded but not on a major exchange, includes Other, Pink Sheet, other OTC, etc.
Characteristics of matched and unmatched GVKEYs in the Compustat–LBD bridge, 1976–2020.
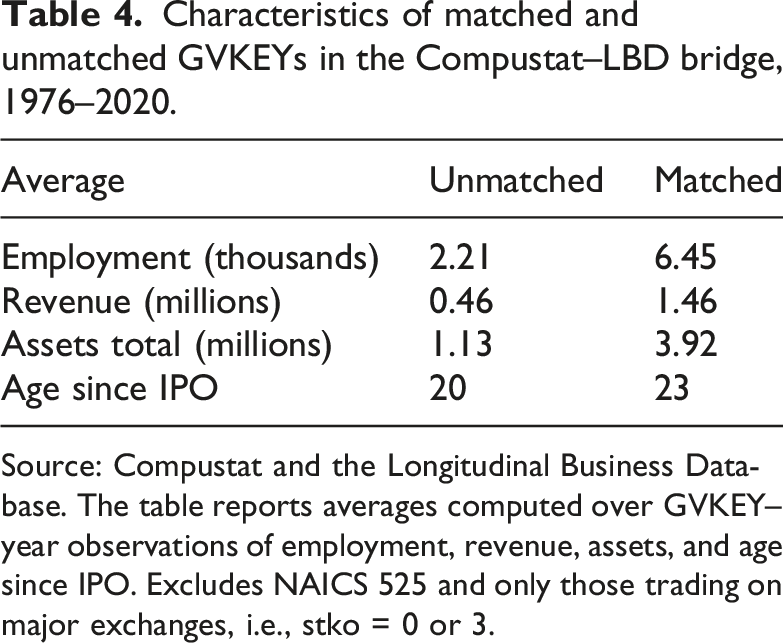
Source: Compustat and the Longitudinal Business Database. The table reports averages computed over GVKEY–year observations of employment, revenue, assets, and age since IPO. Excludes NAICS 525 and only those trading on major exchanges, i.e., stko = 0 or 3.
Percentage of total employment, revenue, and assets in Compustat matched to LBD, 1976–2020.
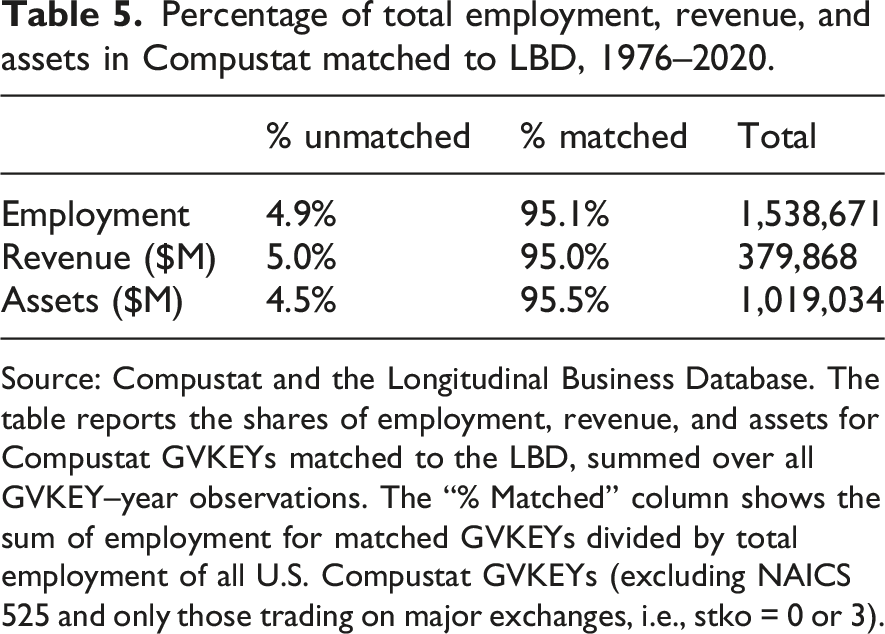
Source: Compustat and the Longitudinal Business Database. The table reports the shares of employment, revenue, and assets for Compustat GVKEYs matched to the LBD, summed over all GVKEY–year observations. The “% Matched” column shows the sum of employment for matched GVKEYs divided by total employment of all U.S. Compustat GVKEYs (excluding NAICS 525 and only those trading on major exchanges, i.e., stko = 0 or 3).
Cleaning and de-duplicating matches
The goal of the de-duplication step is to assign the most appropriate LBD firmid to each GVKEY–year observation when multiple candidate matches are generated across matching stages. De-duplication is the only step in which hierarchy is imposed: all candidate GVKEY–firmid pairs identified in Stages 1–4 are retained up to this point and are evaluated jointly.
To compare competing candidates, we summarize match characteristics using a set of standardized scores, constructed so that higher values indicate stronger agreement, all else equal. We group these measures into two categories: match quality and match quantity.
Match quality scores capture the strength of agreement across identifying variables. These include string similarity measures (GEDN or Jaro–Winkler) for firm name and street address, 15 an indicator for 3-digit ZIP code agreement, and binary flags for agreement on Employer Identification Number (EIN) and telephone number within a given match pass. We also incorporate indicators for NAICS code agreement, separately defined at the 4-digit, 2-digit, and 1-digit levels. In addition, we consider agreement between Compustat and LBD employment measures for a given candidate firmid.
Match quantity scores capture the persistence of a candidate match over time and are defined as the number of years in which a given GVKEY–firmid pair appears in the candidate set.
Using these measures, we apply a waterfall-style de-duplication procedure. For each GVKEY–year, we sequentially apply increasingly restrictive selection criteria, prioritizing first the match stage and then match quality and match quantity. Higher-confidence candidates—such as those identified in earlier matching stages or exhibiting stronger and more consistent agreement across variables and over time—are prioritized, while lower-ranked candidates are discarded. In cases where multiple candidates remain observationally equivalent after all criteria are applied, we retain all such matches and flag them for user discretion.
This procedure ensures that the final Compustat–LBD bridge reflects the richest available information from the matching stages while producing a transparent and interpretable assignment of firm identifiers.
Despite this de-duplication procedure, some GVKEY–year observations may remain linked to multiple qualifying firmids. This occurs when no single candidate strictly dominates others along the match-stage indicators, match quality scores, and match quantity measures. In such cases, we preserve all observationally equivalent GVKEY–firmid pairs and explicitly flag these records as ambiguous. Retaining these candidates ensures transparency in the linkage process and allows users to apply project-specific judgment or additional information in downstream analysis.
To facilitate replication and independent validation, the full set of programs used to construct the bridge will be made available to qualified researchers through the Federal Statistical Research Data Centers alongside the crosswalk file itself.
Validation of match quality
High match rates alone do not guarantee that the resulting GVKEY–firmid links are correct. To assess the accuracy of the bridge, we implement three complementary validation procedures.
As a first check, we visually inspected approximately 2000 randomly selected name and address matches produced by the fuzzy matching procedure. For each sampled pair, we examined whether the Compustat firm name and address corresponded plausibly to the matched Business Register record. This exercise was instrumental in selecting the sensitivity threshold for SAS DQ Match. We tested sensitivity levels of 85, 90, and 95—the latter being the highest precision setting available—and found that lower thresholds generated a substantial number of false positives upon visual review. A particularly common error at lower thresholds was the matching of similar but entirely different names or locations, such as linking “123 South Main Street” to “123 North Main Street,” which share high character-level similarity but refer to entirely different physical locations. Sensitivity 95 consistently avoided these errors while maintaining strong match coverage, and we therefore adopt it as our standard throughout the bridge construction.
As a second check, we exploit the fact that our matching framework includes two independent routes to the same GVKEY–firmid link: direct EIN matching (Stage 1) and fuzzy name and address matching (Stages 2–3). For firms that were successfully matched via EIN, we verify whether the name and address matching procedure independently recovers the same firmid. Agreement between these two matching routes provides strong evidence that the underlying link is correct, since EIN matching and name–address matching rely on entirely different identifying information. We find a high rate of concordance between the two approaches, confirming that the fuzzy matching procedure is not generating spurious links that contradict the more reliable EIN-based matches.
As a third check, we compare employment reported in Compustat with employment observed in the LBD for matched GVKEY–firmid pairs. For GVKEYs matched to a single firmid, we use LBD firm-level employment directly; for GVKEYs matched to multiple firmids—reflecting cases where a single public company operates under more than one Census firm identifier—we sum employment across all linked firmids before computing the comparison. The resulting correlation between Compustat and LBD employment is 0.92, indicating a strong and systematic relationship between the two measures and providing confidence that the bridge captures the correct economic entities.
Taken together, these three validation procedures provide complementary evidence that the Compustat–LBD bridge produces high-quality matches.
Limitations and guidance for users
While the matching procedures described above substantially improve the linkage between Compustat and the LBD, several limitations remain. These limitations arise from both the underlying structure of the administrative and financial data and the constraints of record-linkage methodologies. This section provides guidance to help researchers interpret the linked data and apply it appropriately in empirical work.
First, one-to-many GVKEY–firmid relationships are an inherent feature of the corporate and establishment structures captured in Compustat and the LBD, rather than an artifact of the matching procedure. A single GVKEY may legitimately correspond to multiple firmids in a given year, reflecting the complexity of real-world business structures where a single public company—representing a unique issue-currency-index in Compustat—may operate under more than one Census firm identifier. About 25% of all GVKEY–year observations in Compustat from 1976 to 2020 are matched to more than one firmid in a given year. We therefore retain all plausible GVKEY–firmid links rather than imposing an arbitrary selection rule, and flag these cases for user discretion. Researchers who require a unique firm identifier for their application may apply project-specific filtering rules; for example, some prior work has selected the firmid with the highest LBD employment as a pragmatic approximation of the dominant economic entity associated with a given GVKEY.
Second, in a small subset of cases, multiple firmid candidates arise not from genuine corporate complexity but from the limitations of the matching procedure itself. Ambiguity of this kind tends to occur when historical data are incomplete or inconsistent—for instance, when EIN records are missing, address information is outdated, or a firm has a common name or operates across multiple locations—making it difficult to confidently distinguish among competing candidates on the basis of match quality scores alone. Unlike the one-to-many relationships described above, these cases reflect uncertainty in the linkage rather than a true underlying correspondence between a single GVKEY and multiple Census firms. When several firmids receive similar match-quality scores and no dominant candidate can be identified, the bridge retains all qualifying firmids and explicitly flags these records as ambiguous, preserving transparency and allowing users to apply project-specific judgment.
Finally, data quality and availability vary across years and sources. From the Compustat side, EIN information is less complete in earlier decades, address records are occasionally missing or outdated, and ExecuComp person identifiers are not available for the pre-1990s period. These factors imply that match certainty improves over time, and users conducting long-run analyses should account for variation in match quality across years.
Overall, the bridge provides a high-quality, transparent, and scalable linkage, but not a perfectly deterministic one. Awareness of the limitations described above will help researchers apply the data appropriately and draw valid conclusions from the resulting linkage.
Conclusion
This paper details the creation of an updated bridge between Compustat and the Longitudinal Business Database (LBD) spanning 1976–2020. This comprehensive linkage facilitates enhanced analysis of firm behavior and performance by integrating detailed financial data across multiple decades. Our rigorous matching process, leveraging fuzzy name and address matching along with EIN, telephone number, and industry code, has resulted in a high match rate, ensuring the robustness and reliability of the dataset.
The incorporation of historical data from diverse sources, including CRSP, SEC filings, and ExecuComp, further enriches the dataset, providing a thorough representation of public companies over time. The creation of six distinct Business Register files focusing on specific matching variables significantly optimized the matching process, reducing both time and storage requirements. Additionally, the longitudinal aspect of the LBD data, with its detailed employment and NAICS codes, was instrumental in refining the matching and de-duplication stages.
Importantly, this bridge addresses one of the most frequently requested data linkages in the Federal Statistical Research Data Center system. By providing a publicly documented Compustat–LBD crosswalk, we fill a long-standing gap faced by researchers seeking to combine public-company financials with firm and establishment-level economic microdata. The resulting resource can substantially broaden the scope of empirical work on corporate governance, executive compensation, business dynamics, and the evolution of U.S. firms.
Footnotes
Acknowledgements
We are grateful to Cheryl Grim and Richard Beem of the U.S. Census Bureau for their valuable guidance and thoughtful feedback on this paper. The Compustat–LBD crosswalk is available to qualified researchers through the U.S. Federal Statistical Research Data Centers (FSRDC), subject to project approval and Census Bureau confidentiality requirements. Any opinions and conclusions expressed herein are those of the authors and do not represent the views of the U.S. Census Bureau. The Census Bureau has ensured appropriate access and use of confidential data and has reviewed these results for disclosure avoidance protection (Project 7514232: CBDRB-FY24-CES022-003).
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Notes
Appendix
To construct each of the six independent BR files, we performed the following steps: • Create annual files from CBPBR, BR, or SSL files containing the match variable(s) and cleaned firmid and estabid (including both active and inactive firms). • Combine all annual files by successively merging on the combination of the match variable (e.g., name or address), firmid and estabid, and then updating the set of BR annual flag variables indicating presence (active or inactive) or absence of each variable combination for that BR year. • Standardize the match variable(s) (only for firm name, street address, city, and telephone number). • Collapse on the standardized match variable, firmid, and estabid. (Some records with different non-standardized values have identical standardized values, and these need to be combined, with the annual flags updated to reflect all contributing data.) • Create DQ Match codes using sensitivity 95 and appropriate data-type specification, for standardized firm name, street address, city. We tested alternative sensitivity levels of 90 and 85 and found that lower thresholds produced false positive matches that are incorrect upon visual inspection. Sensitivity 95, the highest precision setting available in SAS DQ Match, consistently avoided these spurious matches while maintaining strong coverage across firm name, street address, and city. We therefore adopt sensitivity 95 as our standard throughout the bridge construction. • Determine first and last BR years present and first and last years active for each record.