
Abstract
Introduction
Dans son livre consacré aux méthodes de la comparaison en sciences sociales, Charles Ragin propose une distinction fondamentale entre les approches « case-oriented comparative methods » et les approches « variable-oriented approach » (Ragin et Becker, 1992). S’il propose de synthétiser ces deux types d’approches par les méthodes de type QCA (Qualitative Comparative Methods), la distinction qu’il opère avant cette synthèse se révèle être d’un grand intérêt pour comprendre les différences principales entre les méthodes qualitatives et les méthodes quantitatives. Alors que les premières sont principalement « case-oriented », les secondes sont « variables-oriented » (Levi-Faur, 2015). Si les développements des méthodes qualitatives et quantitatives depuis les dernières décennies ont montré que cette frontière est relative et que l’on a tout intérêt à ne pas en faire une paroi étanche, il n’en reste pas moins que les deux univers visent fondamentalement deux logiques différentes : l’étude des cas ou l’analyse des variables.
Partant d’un point de vue quantitatif, nous souhaitions montrer que dans ce domaine les « cas » occupent une place plus importance que ce que ne laisse penser l’apparent détachement des modélisations statistiques vis-à-vis des « cas » individuels. C’est en particulier par l’analyse de ce que les modélisations n’expliquent pas, leurs « résidus », que nous souhaitons rappeler ici quelques nécessaires précautions méthodologiques dont tout modélisateur doit tenir compte. Les « résidus » constituent en fait une quantité à la fois essentielle et souvent passée sous silence des analyses statistiques, et en particulier des modélisations. Nous souhaitons ici présenter quelques éléments montrant en quoi l’analyse des résidus permet de mieux comprendre « ce que la modélisation fait » aux cas individuels et de quelle manière les cas individuels continuent, même modélisés dans des ensemble de variables dont on recherche les liens structurels, de « frapper à la porte » des analyses quantitatives.
Quelques rappels sur les modélisations des données d’enquêtes - Les résidus définissent le modèle
Alors que l’analyse des résidus occupe souvent une place marginale dans l’analyse et la publication des résultats de modélisations de données d’enquêtes (peu d’utilisateurs en science politique procèdent à de réelles analyses des résidus de leur modèles, et encore moins publient ou font partager au lecteur les conclusions de ces analyses), il convient de rappeler ici tout d’abord que ces sont en fait les hypothèses faites sur la distribution des résidus qui définissent un modèle statistique et sa forme fonctionnelle (que le modèle soit linéaire ou ne le soit pas).
Dans la mesure où le modèle de régression constitue la technique de modélisation la plus fréquemment utilisée par les spécialistes d’analyse des données en sciences sociales, il est tout d’abord important de rappeler en quoi les hypothèses faites sur la distribution et les propriétés des résidus la définissent.
Comme son nom ne l’indique pas toujours, la régression est une technique dont le but est d’ajuster un modèle théorique sur des observations. Le mot ajustement serait indiscutablement plus adapté que le mot de modélisation : ajustement linéaire pour la régression linéaire, « ajustement fonctionnel » pour la régression non linéaire (Cibois, 1999).
La modélisation des données, notamment d’enquêtes, procède par une analyse de régression linéaire dans la situation suivante : on cherche à expliquer, puis à prévoir, les valeurs d’une variable dépendante quantitative Y (ou même souvent ordinale comme une échelle de satisfaction ou d’accord sur une opinion, par exemple mesurée par une échelle de Likert à cinq points) à partir d’un certain nombre de variables quantitatives X1,…, XK en général mieux contrôlées ou dont les valeurs sont supposées connues avant celles de Y. Dans la terminologie usuelle : - Y est, selon le contexte, la variable à expliquer ou la variable endogène (pour les économistes), ou la variable dépendante (cette dénomination s’est imposée en sociologie ou en science politique, même si l’on peut émettre un doute sur la pertinence de cette mauvaise traduction de l’anglais), - X1,…, XK sont les variables explicatives, ou exogènes (économie), ou indépendantes (expression qui s’est aussi imposée alors qu’elle repose sur un quasi contresens, car ces variables dites indépendantes « n’expliqueront » Y que si elles lui sont assez fortement liées).

Dans sa version linéaire, de loin la plus utilisée, ce modèle est :
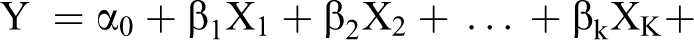
Ce modèle est assorti d’un ensemble d’hypothèses sur le comportement des résidus, dont la version la plus courante est : ε est aléatoire et de loi indépendante de X, ε est de moyenne nulle et d’écart type constant, les observations de ε sont indépendantes entre elles, ε obéit à une loi normale (ou n’en est pas « trop » loin !)
On symbolise souvent ces hypothèses ainsi : E(∊) = 0, en moyenne le modèle est bien spécifié E(∊2) = σ2, la variance de l ‘erreur est constante (homoscédasticité) E(∊i , ∊j) = 0, les erreurs sont non-corrélées Cov(∊,x) = 0, l’erreur est indépendante de la variable explicative ∊ ≡ Normale(0, σ2
∊)
La résolution du modèle consiste alors à estimer les coefficients β1, β2,…βk par la méthode des moindres carrés dit « ordinaires » (méthode OLS). Sous les hypothèses précédentes, la résolution du modèle conduit à des estimations sans biais, convergentes vers les « vraies valeurs » du modèle. Cette méthode consiste à minimiser la sommes des carrés des résidus, c’est-à-dire, des écarts entre les valeurs observées de Y et celles que produit le modèle.
L’estimation se conclut par un test de validité dont l’hypothèse nulle, H0, est la nullité des coefficients β1, β2,…βk, c’est à dire l’absence de relation entre les valeurs de Y et celles des variables explicatives X1,…, XK
Dans cette théorie, le caractère quantitatif des variables est essentiel : il faut que le calcul de l’expression α0 + β1X1 + β2X2 +…+ βkXK ait un sens et soit comparable aux valeurs de Y. C’est précisément sur ce point que cette approche connaît ses limites dans le cas où Y est qualitative, ce qui conduit au développement et à la définition d’autres modélisations connues sous le nom de régression logistique. Dans le cas d’une régression logistique, les résidus ont un rôle tout aussi important que pour une modélisation linéaire dans la définition du modèle. Nous ne prolongeons pas ici la présentation de cette forme de modélisation, mais elle soulève des problèmes tout à fait importants pour l’analyse des résidus étant donné qu’une modélisation logistique représente la réalisation empirique d’une modélisation sur une variable latente continue que l’on ne peut observer (si la valeur observée sur cette variable latente dépasse un seuil, la variable indicatrice observée prend la valeur 1 et sinon 0).
Résidus, cas individuels et variables
Quelle que soit la forme fonctionnelle que prend le modèle de régression, une donnée fondamentale des modélisations statistiques, qui les sépare nettement des analyses de cas ou des analyses qualitatives, est le postulat d’effets « moyens ». Prenons le cas d’une analyse de régression linéaire simple, à deux variables dont l’une est « dépendante » et l’autre « indépendante ». Dans ce cas, la résolution du modèle consiste à identifier les estimateurs des deux paramètres connus sous le nom de « constante » (α0) et « pente » de la régression (estimateur β, estimateur de B dans la population). La solution consiste à minimiser le carré des résidus, c’est-à-dire le carré des écarts entre les valeurs de Y observées et les valeurs de Y prédites (les fameux « Y » chapeau ou « Y hat »). L’estimateur de la pente de la régression donne la variation moyenne de Y estimé accompagnant la variation d’une unité de X, la variable explicative ou « indépendante ».
Ce que le modèle de régression linéaire (mais aussi le modèle de régression logistique) fait aux cas individuels est un aspect majeur de la modélisation : celle-ci propose de substituer aux valeurs individuelles de Y des valeurs moyennes. Autrement dit, alors que dans les données observées chaque cas varie de manière individuelle et représente une combinatoire unique de traits ou de caractéristiques individuels (les variables et leurs relations structurelles), l’analyse de régression propose que chaque cas, qui se caractérise par une même combinaison de variables, obtienne sur la variable dépendante la même valeur. C’est le paradigme des « effets moyens » du modèle de régression.
La valeur prise par la variable dépendante Y estimée remplace dès lors la valeur de Y observée : chaque individu qui prend la même valeur qu’un autre sur la variable explicative ou les variables explicatives obtient la même valeur sur la variable Y estimée. En d’autres termes, la modèle de régression opère un passage des cas individuels vers les variables : la modélisation constitue une « variable-oriented approach » pour reprendre la terminologie de Charles Ragin. Le graphique de régression qui montre la droite de régression visualise parfaitement de passage des cas vers les variables. Une illustration frappante de cette logique peut être donnée ci-dessus. Il s’agit du graphique de régression d’une analyse de régression linéaire réalisée sur les données d’une vaste enquête américaine (n = 3.826) sur les entrants au collège universitaire, les « freshmen ». Il s’agit d’analyser le lien statistique entre un indicateur de tolérance vis-à-vis des minorités (variable dépendante) et le pourcentage de minorités ethniques vivant là où les « freshmen » ont grandi.
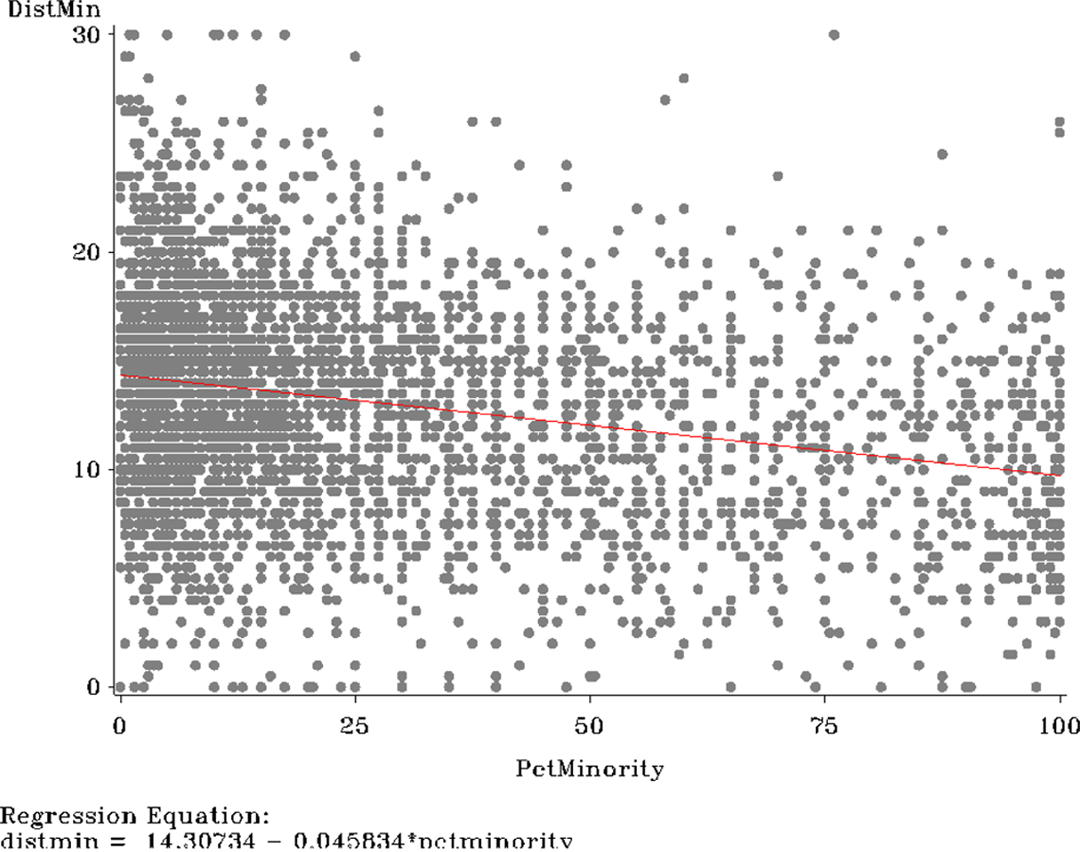
Graphique de régression d’une analyse de régression linéaire
On a représenté sur ce graphique la droite de régression (celle qui unit les valeurs prédites aux valeurs prises par les individus sur la variable explicative) simultanément aux points individuels. Ce graphique illustre de manière assez saisissante « ce que le modèle fait aux cas ». Sans entrer ici dans des développements plus longs, on voit qu’ici se rejoignent la plupart des préoccupations méthodologiques développées depuis plusieurs années à l’intersection des méthodes quantitatives et qualitatives : le questionnement sur les codages et les variables, sur les cas et les individus (groupés en variables), mais aussi les développements récents de l’analyse géométrique des données et la représentation graphique du nuage des individus.
L’analyse des résidus - Comment se prémunir des « faux bons » résultats ?
Un exemple d’analyse des résidus d’une enquête
Si les distributions et les propriétés des résidus définissent en fait la forme fonctionnelle d’un modèle de régression, lorsque l’on applique un modèle particulier à des données observées, l’analyse des résidus va permettre de valider de manière plus stricte le modèle ou de l’invalider, s’il apparaît que les cas pour lesquels le modèle s’écarte le plus des données observées (résidus larges) sont les cas qui sont au cœur de l’analyse.
Résultats du modèle de régression estimée
Analyse de la variance

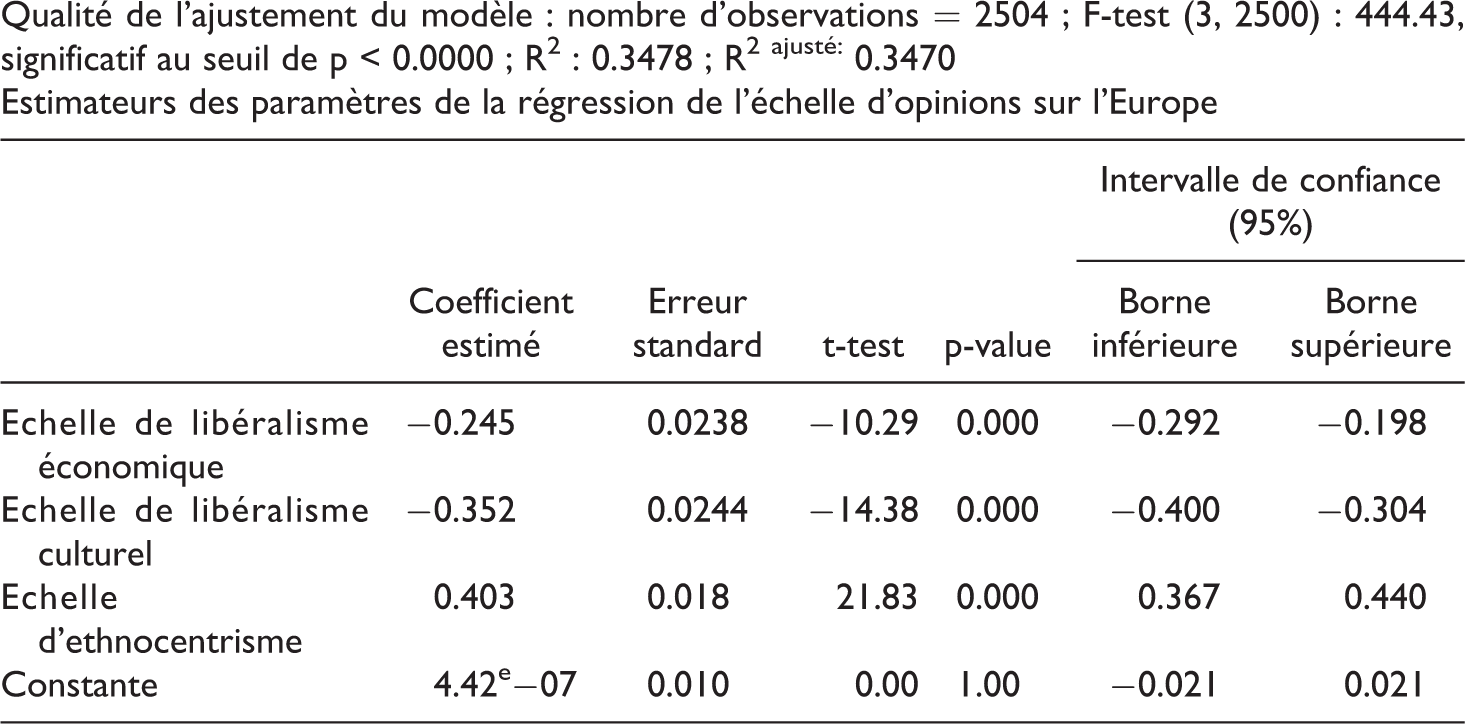
Qualité de l’ajustement du modèle : nombre d’observations = 2504 ; F-test (3, 2500) : 444.43, significatif au seuil de p < 0.0000 ; R2: 0.3478 ; R2 ajusté: 0.3470
Estimateurs des paramètres de la régression de l’échelle d’opinions sur l’Europe
Une seule observation sensiblement différente des autres peut faire une grande différence dans les résultats d’une analyse de régression. L’analyse statistique des résidus, qu’il s’agisse de cas traités séparément ou de groupes d’observations peut en effet changer considérablement le point de vue que l’on peut développer sur un modèle statistique, notamment sous deux aspects : la qualité de l’ajustement du modèle aux données observées (le « goodness of fit » du modèle) et la pertinence sociologique du modèle. Il y a trois manières d’effectuer une analyse des résidus dont l’objectif est de détecter les cas individuels qui échappent de manière significative au champ d’application du modèle.
On peut tout d’abord procéder à l’analyse des valeurs aberrantes (outliers). En régression linéaire, une valeur aberrante est une observation caractérisée par une forte valeur. En d’autres termes, il s’agit d’une observation dont la valeur prise par la variable dépendante est inhabituellement forte compte tenu de ses valeurs sur les variables explicatives. Une valeur aberrante peut indiquer que le cas en question appartient à un sous-échantillon qu’il convient également d’analyser (elle peut également indiquer une erreur de saisie de données ou d’autres problèmes de collecte des données).
On peut ensuite effectuer une analyse des « leverage », ou « effets de levier ». Une observation avec une valeur extrême sur la variable prédictive est appelé un « point de levier élevé ». L’effet de levier est une mesure de la distance d’une observation à la moyenne des observations sur la variable dépendante. Ces cas particuliers peuvent avoir un effet sur l’estimation des coefficients de régression.
Les résidus les plus négatifs
hilo r gender

Enfin, on peut procéder à une analyse des observations « influentes ». Une observation est qualifiée « d’influente » si la suppression de cette observation modifie sensiblement l’estimation des coefficients. « L’influence » peut être considérée comme le produit de l’effet de levier et de l’effet d’un cas aberrant.
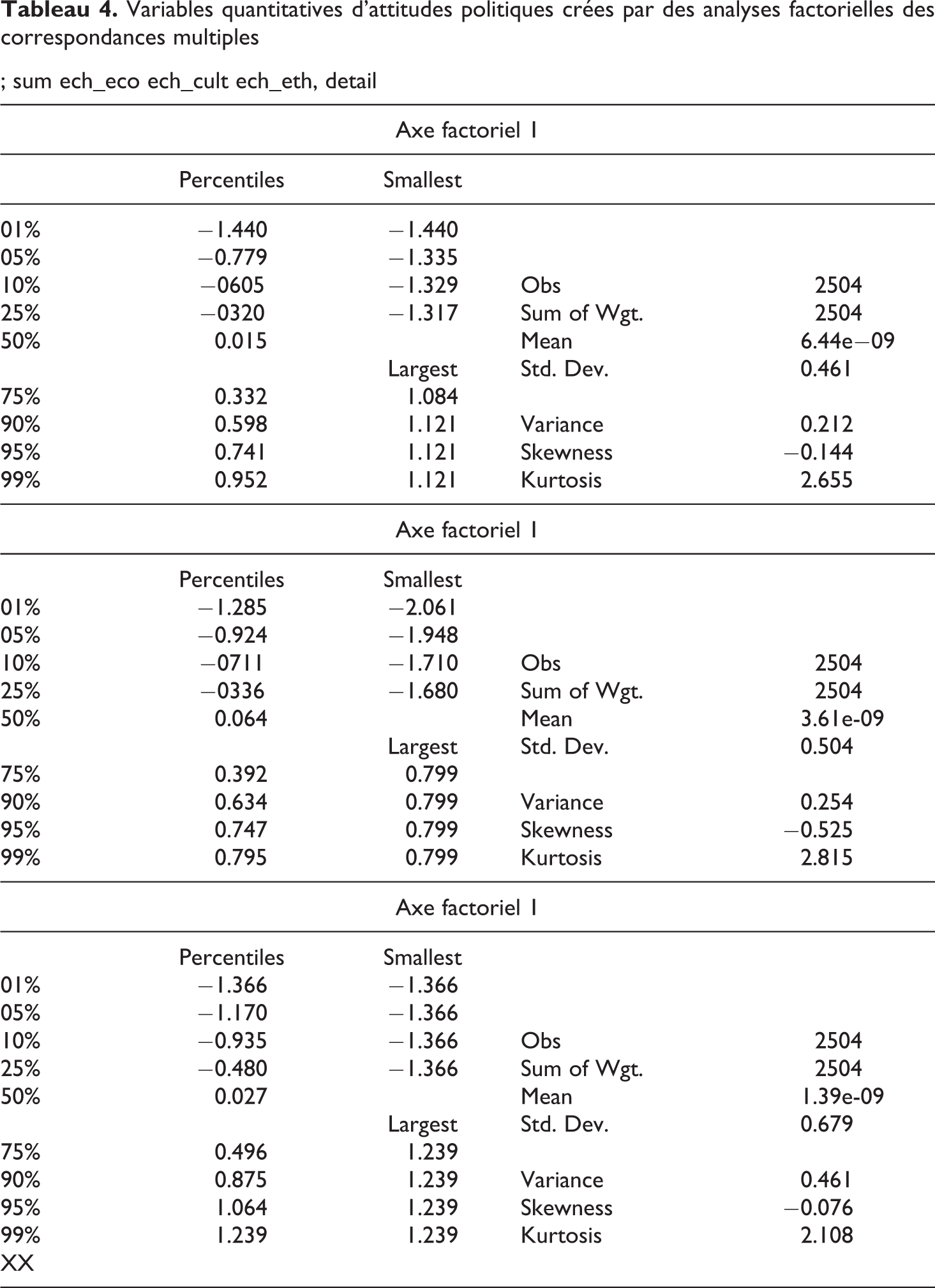
On peut illustrer l’intérêt d’une analyse des résidus à l’aide des données de l’enquête post-électorale du CEVIPOF de 2012 (CEVIPOF, 2012). On réalise ici une analyse de régression linéaire à partir de variables quantitatives d’attitudes politiques, crées par des analyses factorielles. Le modèle consiste ici à prédire les opinions sur l’Union européenne (échelle d’attitude créée à partir de plusieurs indicateurs et qui mesure l’attitude négative vis-à-vis de l’UE) par trois variables explicatives : une échelle d’attitudes vis-à-vis du libéralisme économique (ech_eco), vis-à-vis du libéralisme culturel (ech_cult) et une échelle d’attitudes ethnocentriques (ech_eth).
Le modèle explique assez bien la variation des attitudes vis-à-vis de l’UE (R2 = .347) et les tests statistiques sur les estimateurs montrent une significativité statistique très élevée. De nombreux utilisateurs des modèles de régression arrêtent ici leurs analyses et se réjouissent de la qualité du modèle et d’obtenir des tests statistiques « significatifs », ce qui semble valider la modèle.
Les résidus les plus fortement positifs
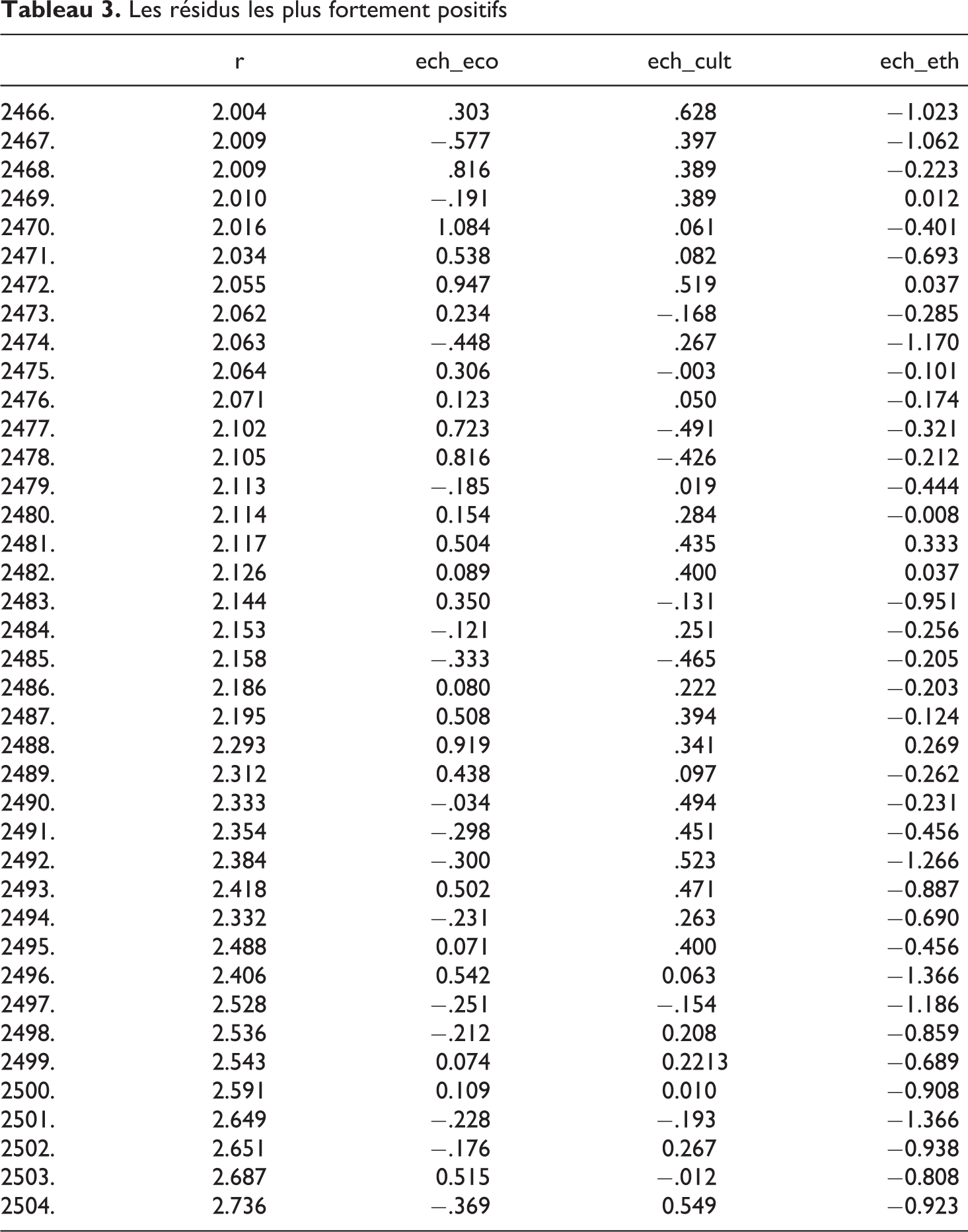
Mais si on prend le temps d’analyser les résidus du modèle, on s’aperçoit dès la première analyse et par une simple méthode graphique, que certains cas individuels prédits présentent des écarts aux données observées importants (résidus standardisés supérieurs à + ou – 2). Pour s’en rendre compte, on peut réaliser un graphique de type « stem and leaf » sur les valeurs standardisées des résidus. Mais le nombre élevé d’observations (n=2.504) rend cette tâche peu pratique. On peut en revanche, isoler les résidus les plus élevés et les caractériser, par exemple en termes de genre : les cas qui s’ajustent le moins bien aux données observées, sont-ils plus fréquemment observés lorsqu’il s’agit d’hommes ou alors de femmes ? Il est tout à fait intéressant de constater que les résidus les plus négatifs sont en général des hommes et les résidus les plus positifs des femmes.
Variables quantitatives d’attitudes politiques crées par des analyses factorielles des correspondances multiples
; sum ech_eco ech_cult ech_eth, detail
Autrement dit le modèle s’ajuste moins bien aux cas féminins que masculins, une indication qu’il faut sans doute contrôler les effets de genre. On voit sur cet exemple simple que le modélisateur qui passerait outre l’analyse des résidus, se contentant de se satisfaire de la qualité de l’ajustement aux données observées du modèle, passerait en fait à côté d’un élément d’interprétation fondamental.
On peut compléter cette analyse, dont le but est de détecter soit les « cas aberrants », soit les « points de levier » ou les « cas influents », en listant par ordre d’importance les résidus dont la valeur absolue est supérieure à 2 et en donnant pour chacun les valeurs prises par les cas en question sur les variables explicatives. Pour des raisons de commodité de présentation, on donne ci-dessus les cas pour lesquels les résidus standardisés sont de valeur supérieur à +2, car nous ne voulons qu’illustrer à nouveau la puissance de l’analyse des résidus. Pour rendre l’analyse compréhensible on donne également ci-dessus les statistiques descriptives de base des variables explicatives (pour les trois variables explicatives, ces statistiques explicatives sont données dans l’ordre suivant : l’échelle de libéralisme économique, de libéralisme culturel et d’ethnocentrisme, bien que la sortie logiciel indique à chaque fois « Axe factoriel l »). En comparant les tableaux 3 et 4 on peut ainsi comprendre ce qui caractérise, sur les variables explicatives, les cas marqués par les valeurs positives des résidus standardisés les plus fortes.
L’analyse des résidus les plus fortement positifs (au nombre de 39) nous permet ainsi d’identifier le profil des cas observés lorsque les valeurs des résidus standardisés sont significatifs et les plus élevés en valeurs.
On s’aperçoit dès lors que les résidus les plus fortement positifs sont très fréquemment observés lorsque l’échelle d’ethnocentrisme obtient des valeurs négatives et l’échelle de libéralisme culturelle des valeurs positives. Ce type d’analyse, très simples à réaliser alors même que l’analyse des résidus peut être très sophistiquée, guide le modélisateur vers des analyses plus complexes comme pourrait l’être la prise en compte d’effets d’interaction ou la prise en compte d’autres facteurs explicatifs.
Conclusion
Nous avons souhaité présenter ici quelques rappels et quelques outils très simples à mettre en œuvre pour analyser les « résidus » issus des modélisations statistiques, notamment du modèle de régression linéaire. Ce type d’analyses peut bien entendu procéder à des mesures (notamment en termes de distance entre valeurs observées et valeurs prédites de la variable dépendante, par exemple la distance de Cook) nettement plus sophistiquées. Mais nous souhaitions surtout montrer en quoi les méthodes quantitatives de type « variable-oriented » peuvent avec grand profit ne pas oublier que l’origine des données collectées et analysées est de nature individuelle. Le paradigme des « effets moyens » sur les variables au sein duquel le modèle de régression opère est un paradigme puissant ; mais bien souvent ses utilisateurs négligent les contrôles pourtant simples à mettre en œuvre de leurs « résidus » : trop occupés à analyser les relations structurelles entre les variables, ils oublient que les « individus » n’ont pas disparu des données analysées. L’analyse des « résidus » procède en ce sens à un très sain et utile rappel : si la perspective fondamentale des analyses modélisatrices est la mise à jour de relations structurelles entre variables, leur base empirique est constituée des données individuelles. En ce sens, l’analyse des résidus des modélisations statistiques n’est pas sans rappeler les développements récents de l’analyse géométrique des données qui proposent d’analyser simultanément dans les plans factoriels les modalités des variables et les points-individus (Perrineau et al., 2000).