
Abstract
Résumé
Il n’existe pas à notre connaissance de méthode de régression linéaire garantissant systématiquement que le signe des coefficients concorde avec celui de la corrélation simple entre la variable à expliquer et chacun des régresseurs et dont la valeur ne se cale pas sur la contrainte qu’on pourrait leur imposer. Or ce double impératif – un coefficient positif et suffisamment différent de zéro pour chaque variable – est souvent requis par les praticiens travaillant, notamment, dans le domaine de la satisfaction où la colinéarité statistique est la norme. L’objectif de cet article est de leur fournir une méthode formelle qui réponde à cette attente et produise des résultats comparables à ceux de méthodes statistiquement fondées, au respect strict et systématique du signe près.
Introduction
Bien que les causes et les conséquences de la multicolinéarité dans le cadre du modèle de régression linéaire aient été étudiées extensivement depuis Farrar et Glauber (1967) et que l’on dispose désormais d’une panoplie importante d’outils de diagnostic et de procédures adaptés à ce problème récurrent, certains praticiens attendent toujours que leur soit proposée une méthode de régression signée, c’est-à-dire un dispositif qui associe à toutes les variables un coefficient de régression non nul et dont le signe soit identique à celui de leur corrélation simple avec la variable à expliquer. On pense notamment aux études de satisfaction impliquant un grand nombre d’items corrélés pour lesquelles, faisant fi du rasoir d’Ockham, un tel objectif est souvent requis.
Si plusieurs propositions l’atteignent ponctuellement comme, par exemple, les régressions contraintes de type Ridge (Hoerl et Kennard, 1970) ou Lasso et ses variantes (Tibshirani, 1996 ; Gaines et Zhou, 2016), les régressions sur composantes de type PCR (Jolliffe, 1982), PLS (Tenenhaus, 1998) ou CCR (Magidson, 2013), la régression en cascade (Bachelet, 1996), aucune hormis la dernière ne garantit le caractère non nul et positif des coefficients des régresseurs, car aucune n’a été conçue avec cet objectif en tête 1 .
Ces méthodes ont en effet le mérite (statistique) et l’inconvénient (managérial) de ne pas chercher à résoudre un problème d’optimisation mal posé, en l’occurrence un problème sans solution, sinon triviale. Or, vouloir absolument que tous les critères susceptibles d’expliquer un phénomène aient un coefficient non nul et doté du « bon » signe est une ambition qui présente tous les symptômes d’un problème mal posé, en particulier la redondance. Pour s’en persuader, il suffit de voir le sort réservé aux solutions brutales (recours aux expédients en substituant
Le but de cette note est de proposer au praticien une démarche sous-optimale, mais rigoureuse, pour atteindre au mieux cet objectif statistiquement déraisonnable. Nous commençons par préciser le contexte dans lequel cette démarche s’inscrit puis, dans la mesure où nous en aurons besoin pour la justifier et la tester, nous effectuons un bref rappel des outils de diagnostic de la multicolinéarité et de la façon dont trois des méthodes les plus utilisées – Ridge, PLS et CCR – tentent d’en atténuer les effets indésirables. Notre démarche est ensuite exposée, puis testée comparativement sur des données simulées et réelles. Nous concluons sur ses avantages et ses limites et proposons quelques pistes de recherche pour les lever.
Le contexte
Le contexte qui motive cette recherche est celui de la mesure de l’importance des critères de satisfaction à l’égard d’un produit, d’un service ou d’une expérience, telle qu’elle se pratique dans les entreprises (Ray et Sabadie, 2006 ; Windal et Desmet, 2000). Sans préjuger de la diversité des approches qu’on y trouve, l’une des figures souvent imposées, une fois la liste des critères établie, et à supposer qu’il s’agisse d’importance déduite plutôt que déclarée, consiste à calculer un poids strictement positif pour chacun de ces critères. Leur nombre est souvent élevé (10, 20, 30…) et ils sont en général corrélés les uns avec les autres, quoique sans excès. On ne se retrouve pas, en effet, dans les cas de figure de quasi-colinéarité qui caractérisent certains jeux d’essais (Tomassone et al, 1992) utilisés pour tester les modèles.
Le but visé – un poids strictement positif – est dans ce contexte une contrainte qu’il faut impérativement respecter. Ces poids font partie des processus que mettent en place certaines entreprises pour le suivi quantitatif et l’amélioration de leurs prestations. On cherche moins ici à identifier des « leviers », les quelques critères qui pèsent le plus sur la satisfaction globale, qu’à respecter un cahier des charges, quitte par la suite à utiliser ces poids dans une optique plus souple de hiérarchisation. Ce point est important, car il s’oppose au principe de parcimonie cher aux scientifiques. On ne prétend pas non plus que le recours au modèle linéaire, la non-prise en compte d’éventuels segments 2 ou l’insistance à obtenir un poids strictement positif soient les meilleures façons de traiter la mesure de l’importance des critères de satisfaction. On se contente de prendre acte d’une attente insatisfaite et, à tort ou à raison, de tenter d’y apporter une réponse.
Par ailleurs, en vertu même de la contrainte initiale, on ne se situe pas dans une optique de maximisation d’une fonction objective parce qu’elle conduirait inévitablement à une solution triviale, le prix à payer quand on force des critères dans une équation de régression où ils n’ont, statistiquement parlant, pas leur place. Libéré de cet impératif d’optimisation, on propose une heuristique qui produit des poids strictement positifs et « voisins » au sens de la corrélation d’une méthode retenue comme garde-fou. La consigne est alors respectée et la proximité des poids avec ceux issus de procédés statistiquement fondés sert de caution à notre démarche.
S’adressant avant tout à des praticiens, on cherche également à rendre plus intuitifs et visibles les effets néfastes de la colinéarité statistique sur chacune des variables. Montrer à quel « moment » un coefficient bascule dans le négatif ou pourquoi telle inflexion de ce coefficient est accidentelle plutôt que structurelle est, avec le respect du cahier des charges, un objectif prioritaire de cette recherche.
Outils de diagnostic de la colinéarité statistique
Le rappel de cette section s’appuie en particulier sur les travaux de Belsley et al (1980) et Foucart (1992 ; 2006). La colinéarité statistique entre les variables tend, pour les coefficients des variables les plus corrélées, à :
Augmenter leur taille.
Inverser leur signe.
Gonfler leur variance.
Les rendre instables d’un échantillon à l’autre.
Dans notre contexte managérial de colinéarité diffuse où tout est lié, mais sans excès, ce sont les conséquences n° 2 et 4 qui se manifestent le plus souvent et que l’on souhaite atténuer. Les cas d’extrême colinéarité sont rares (point n° 1) et le praticien peut s’accommoder d’une inflation modérée de la variance (point n° 3).
Le facteur d’inflation de la variance
Pour mesurer l’importance de cette colinéarité et identifier les variables qu’elle affecte le plus, on dispose, entre autres critères, du facteur d’inflation de la variance (FIV) – défini comme :
En pratique (Saporta, 1990), on estime à 3 le seuil au-dessus duquel le FIV commence à poser un problème d’estimation. L’intérêt de cette mesure simple à comprendre et facile à calculer –
L’indice de conditionnement de Belsley
Considérons maintenant les valeurs propres
Sur la base d’études de simulation, les auteurs constatent que des corrélations faibles entre les variables sont associées à des indices de l’ordre de 5 à 10 ; des corrélations fortes, à des indices de l’ordre de 30 ou plus. Entre 20 et 30, la situation de multicolinéarité est ambiguë, au-dessus de 100, pathologique.
On examine ensuite le tableau de décomposition des variances. La variance de l’estimateur
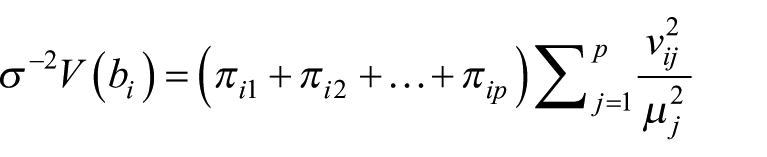
où
Supposons que p indices de conditionnement exactement soient « élevés » (de l’ordre de 30 ou plus). Alors :
– Les indices k ∈ {1, 2,…, K} tels que
– Dans le cas contraire, et plus cette somme est proche de 1, plus les coefficients
– Enfin, cette somme étant fixée, la précision des
L’indice de distorsion de Foucart
A ce stade du diagnostic, on aura isolé la plupart des paires de variables responsables de la colinéarité statistique, lesquelles coïncident en général avec les coefficients de corrélation les plus élevés. Foucart (1992), toutefois, s’appuyant sur les propriétés des matrices symétriques définies positives, démontre que des corrélations modérées peuvent également perturber l’estimation des coefficients de régression. Il existe en effet un intervalle de variation ]a, b[ tel que, quel que soit
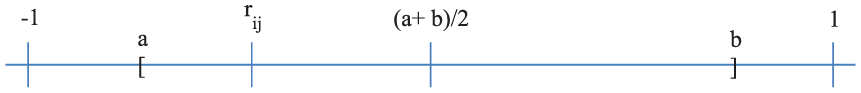
Il se trouve que lorsque
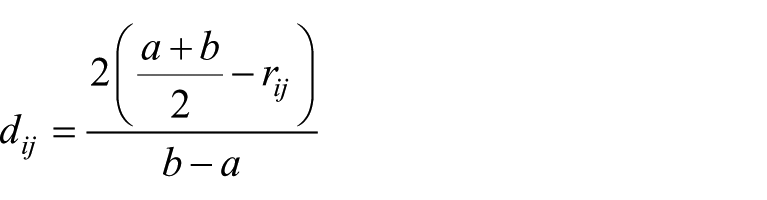
Une petite valeur de

où les
Les méthodes de régression de référence
Parmi toutes les familles de méthodes développées pour atténuer les effets de la colinéarité statistique sur les estimateurs linéaires (Birkes et Dodge, 2003), nous en retiendrons deux qui serviront de références à la méthode proposée dans cette note : la régression pénalisée et la régression sur composantes.
La régression pénalisée
L’objectif de la régression pénalisée est de faire en sorte que la « norme » des coefficients
Si ces méthodes réduisent efficacement la taille et l’instabilité des coefficients, le lasso tendra à produire des coefficients exactement égaux à 0 (« sparse recovery »). C’est une grande qualité dans certains contextes, en particulier celui de la sélection des variables, mais ce n’est pas l’objectif recherché ici.
Pour cette raison et parce qu’elle est très facile à mettre en œuvre, nous lui préférerons la régression ridge dont l’estimateur est donné par :
La régression sur composantes
La régression orthogonale (PCR) est intuitivement très attractive. En éliminant des composantes principales celles qui ne sont que faiblement liées au critère à expliquer ou instables, parce que dotées d’une valeur propre trop faible, on atténue fortement les effets de la colinéarité. La régression PLS (Partial Least Squares) initialement proposée par Wold (Tenenaus, 1998) et la régression CCR de Magidson (« Correlated Component Regression ») poursuivent cet objectif en y apportant une amélioration de taille : alors que les composantes principales ne font qu’extraire le maximum de variance des prédicteurs (X) sans tenir compte du critère à expliquer (y), les composantes PLS et CCR sont optimisées pour en être prédictives.
PLS : à chaque itération, on maximise le carré de la covariance entre y et
CCR : les composantes successives ne sont plus nécessairement orthogonales et la méthode est invariante d’échelle. Elle produira ainsi les mêmes résultats, que les données aient été standardisées ou non. Selon son auteur, la première composante mesure l’effet direct d’un régresseur sur la variable à expliquer ; les composantes suivantes servent à prendre en compte les effets de médiation (« suppressor variables »).
Seul caveat dans notre contexte : rien ne garantit la stricte positivité des coefficients de régression au-delà de la première composante dont on ne se satisfait pas. Il faut en général au moins deux composantes pour atteindre une qualité d’ajustement du même ordre que celle de méthodes concurrentes. En PLS, la première composante produira toujours des coefficients positifs, mais ces coefficients, proportionnels à la corrélation simple entre X et y, ne peuvent constituer une mesure du poids intrinsèque d’une variable.
Néanmoins, la robustesse de ces deux méthodes, nonobstant la présence occasionnelle de signes négatifs, justifie qu’on les retienne pour étalonner la nouvelle proposition. Nous avons choisi de l’adosser à PLS pour identifier l’un de ses éléments clés, le pas optimal. Dans notre contexte de satisfaction à colinéarité diffuse, CCR aurait suggéré le même pas 3 .
La régression signée
La régression signée (RS) consiste à rétrocéder aux variables dotées de coefficients négatifs par les moindres carrés ordinaires (MCO) une partie du poids capté par les autres variables. Pour y parvenir, on introduit la notion de « trajectoire optimale de corrélation partielle » entre chacun des régresseurs
Sans perte de généralité, dénotons par l’indice 1 la variable « pivot », celle dont on recherche la trajectoire. Soit E l’ensemble des N régresseurs : {1, 2, 3,…, N}. A l’étape k de la procédure, on se trouve face à trois sous-ensembles :
– L’item pivot : {1}
– L’ensemble « IN » des variables déjà entrées dans la régression : {2, 3,…, k}.
– L’ensemble « OUT » des variables qui ne sont pas encore entrées dans la régression : {k+1, k+2,…, N}.
Rappelons que l’on calculera successivement autant de trajectoires que de régresseurs. Parmi les
Soit j un élément de l’ensemble OUT et
On notera que ce principe est très différent de celui de la régression pas-à-pas qui consiste à choisir l’item j de {1, OUT} qui augmente le plus le
Au signe près, la corrélation partielle entre l’item pivot et y sachant Z (ici : IN et j) est égale à :
– à la corrélation simple entre y et 1 (l’item pivot) quand Z = ∅ (ensemble vide)
– à la corrélation partielle quand Z = E~1 (E hors item 1).
Ainsi, quel que soit l’ordre d’introduction des variables, on obtiendra toujours la même corrélation partielle entre y et l’item pivot en fin parcours (
Rappelons qu’au pas 0, la corrélation
L’idée de base de la régression signée est de ne pas aller jusqu’au terme de cette trajectoire, l’équivalent du coefficient de régression MCO, où se regroupent les variables les plus corrélées au pivot, mais de s’arrêter « avant » à un pas qu’il reste à déterminer, sachant que ce pas doit être identique pour toutes les variables pour n’en privilégier aucune. L’une des règles de fixation de ce pas est évidente : si
Calcul numérique des trajectoires
Il n’est pas nécessaire d’effectuer les
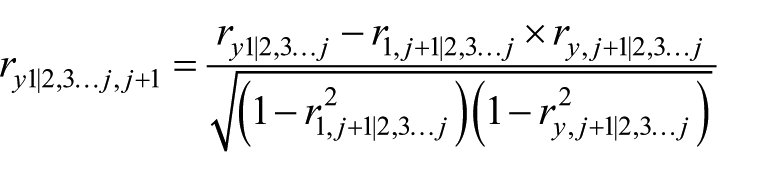
A l’étape
Ce calcul est très rapide, car il manipule uniquement les entrées de la matrice des corrélations et non les données elles-mêmes. Comme pour PLS, il n’y pas de matrice à diagonaliser ou inverser ni de valeurs manquantes à remplacer, puisque les corrélations sont calculées deux à deux ; comme pour CCR, la méthode est invariante d’échelle, puisque le calcul des poids ne fait intervenir que la matrice des corrélations. Ces trois propriétés, en particulier la seconde, font de RS un outil particulièrement adapté aux données incomplètes. Un pseudo-code assorti d’un exemple numérique est disponible en annexe.
Surapprentissage (overfitting)
Pour minimiser le risque de surapprentissage, PLS et CCR ont recours à la validation croisée pour déterminer le nombre optimal de composantes. L’échantillon initial est divisé en k sous-échantillons. Dans sa forme la plus simple (k=2), l’un sert à calibrer les paramètres, l’autre à les tester ; si k>2, les sous-échantillons servent tour à tour au calibrage et au test.
Cette précaution est possible, mais ne nous semble pas indispensable en régression signée où, par construction, les variables les plus corrélées à chaque régresseur, donc celles qui pourraient poser un problème d’estimation, sont rejetées en fin de trajectoire. En fixant un pas inférieur au nombre de variables, on se prémunit en quelque sorte contre le surapprentissage : les variables sont toutes utilisées, mais pas tout le temps (pour toutes les variables), en particulier celles qui causent localement (pour une variable donnée) une inversion de signe.
Invariance d’échelle et constante
En RS, l’extraction des poids ne repose que sur la matrice des corrélations. La question de la constante, des valeurs manquantes
4
et de la standardisation des régresseurs ne se pose donc pas. Toutefois, si l’utilisateur souhaite utiliser cette méthode dans un cadre prédictif, il est indispensable, une fois les poids extraits de la matrice des corrélations, de remplacer ou d’éliminer les valeurs manquantes de
Test de significativité des poids
Les poids étant des corrélations partielles normées, tester un poids revient à tester une corrélation partielle. Si
Application de la régression signée à des données simulées
Trois situations de colinéarité statistique ont été simulées avec la fonction mvnorm du package MASS du logiciel R, selon la structure de la matrice des corrélations : diffuse, par blocs et Robinsonnienne
5
(tableaux 1 à 3). Les paramètres communs à chacun de ces trois cas sont le nombre d’unités statistiques (1000), le nombre de régresseurs
6
(25), leur poids (5 fois 0,06, 0,05, 0,04, 0,03, 0,02), leur moyenne (de 6 à 8), leur écart-type (1 pour tous) et le terme d’erreur (trois aléas : faible, moyen, fort) qui, ajouté à la somme des produits des poids par les régresseurs, engendre la variable à expliquer (
Données simulées à colinéarité diffuse.

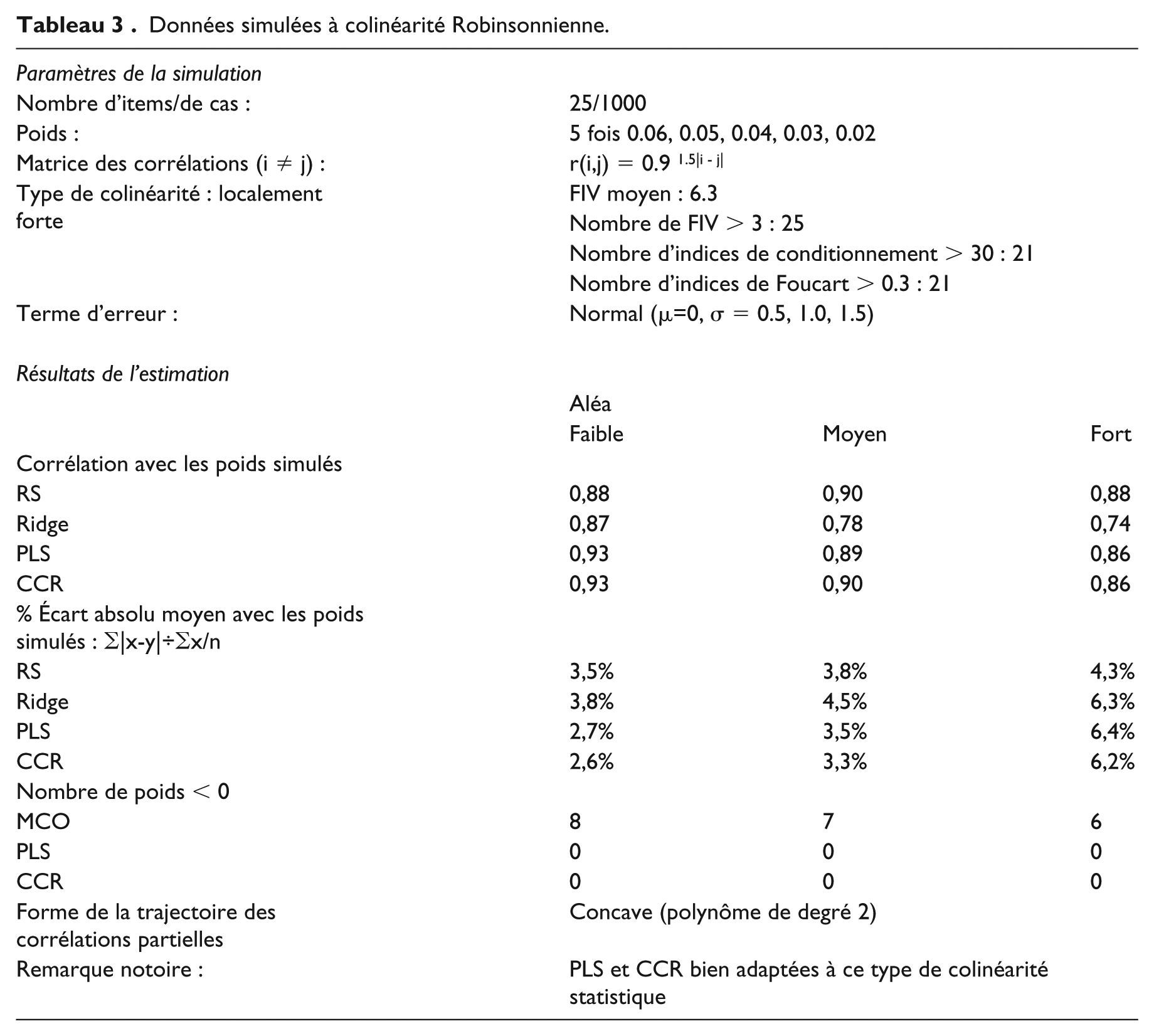
Données simulées à colinéarité par bloc.
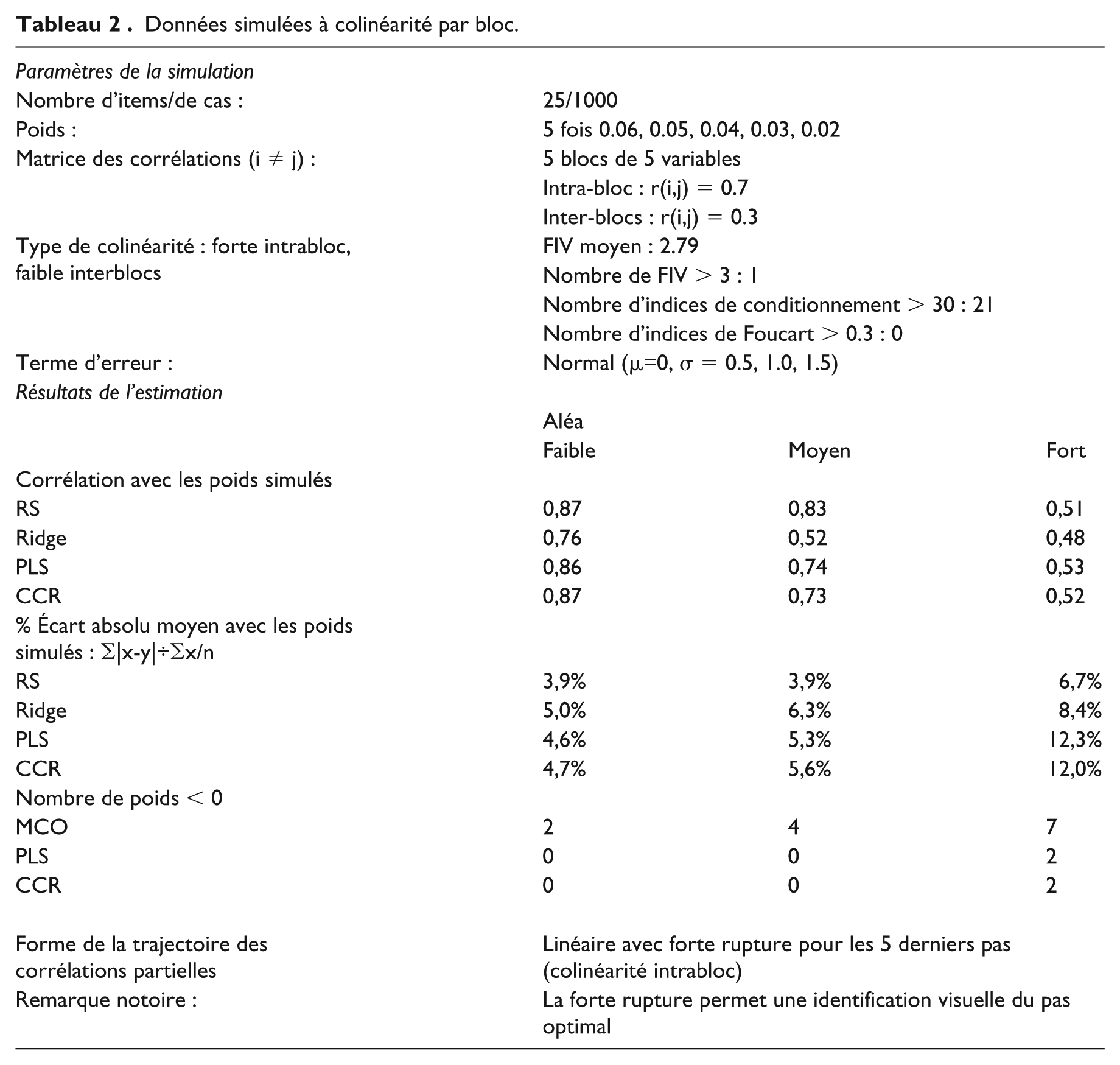
Données simulées à colinéarité Robinsonnienne.
La seule différence entre les trois cas porte sur la matrice des corrélations
Colinéarité diffuse :
Colinéarité par bloc : la matrice des corrélations est constituée de 5 blocs contigus de 5 items avec une corrélation forte intrabloc (
Colinéarité Robinsonnienne :
Ces trois exemples illustrent le caractère polymorphe et insidieux de la colinéarité statistique. Le cas diagnostiqué comme le plus sévère (colinéarité Robinsonnienne) est celui qui produit les estimations les plus précises des poids simulés ; à l’inverse, le cas le plus favorable en apparence (colinéarité diffuse), s’avère être le plus difficile à traiter par toutes les méthodes. Nous recommandons d’ajouter la corrélation moyenne aux outils de diagnostic usuels de la colinéarité. Plus cette corrélation est élevée, moins les estimations seront fiables, indépendamment des problèmes spécifiques que peuvent poser des corrélations localement fortes. Pour dramatique que puisse être une quasi-colinéarité, elle s’élimine plus facilement qu’une colinéarité diffuse.
Les résultats de l’estimation
La qualité de la récupération des poids simulés est mesurée par deux indices, l’un de corrélation (entre poids simulés et estimés), l’autre de précision (écart absolu moyen entre poids simulés et estimés, exprimé en pourcentage de la moyenne des poids simulés). A cette aune, on tire les conclusions suivantes (Tableaux 1 à 3) :
Comme Ridge, RS satisfait l’objectif prioritaire de poids strictement positifs. Dans tous les cas de figure et d’aléa, MCO produit des coefficients de régression négatifs (de 2 à 8 selon les configurations). PLS s’accommode très bien de la colinéarité Robinsonnienne (aucun poids négatif) et, dans une moindre mesure, de la colinéarité par bloc (2 poids négatifs en cas d’aléa fort), mais ne fait pas mieux que MCO en cas de colinéarité diffuse (de 4 à 7 coefficients négatifs selon l’aléa).
Les estimations de Ridge sont moins précises que celles de RS et PLS en cas de colinéarité par bloc et Robinsonnienne, même en s’aidant de PLS pour choisir le ridge optimal
7
. La colinéarité diffuse lui est plus favorable, car c’est un cas de figure où le choix de
Les estimations de PLS et CCR sont très voisines, tant en qualité de récupération des poids qu’en occurrence de signes négatifs. La possibilité d’extraire des composantes corrélées ne règle donc pas le problème managérial et contre-intuitif d’inversion occasionnelle de signe.
En corrélation, PLS, CCR et RS se valent ; en précision, RS l’emporte. Parce qu’elle garantit des poids strictement positifs sans dégrader la précision des estimations, RS est une alternative viable à PLS et CCR lorsque la positivité des poids est requise.
La difficulté à recouvrer les poids simulés dépend moins de la force de l’aléa que de la structure des corrélations. Si un aléa fort nuit davantage à la précision des estimations qu’un aléa faible, la dégradation de cette précision est moins prononcée que celle observée entre une colinéarité Robinsonnienne et une colinéarité diffuse. L’examen des trajectoires des corrélations partielles contribuera à identifier à quel type de colinéarité l’on a affaire.
L’examen des trajectoires permettra parfois d’identifier le pas optimal. C’est le cas pour la colinéarité par bloc où la rupture est forte et intervient au même pas pour tous les items et aléas (Figure 1).
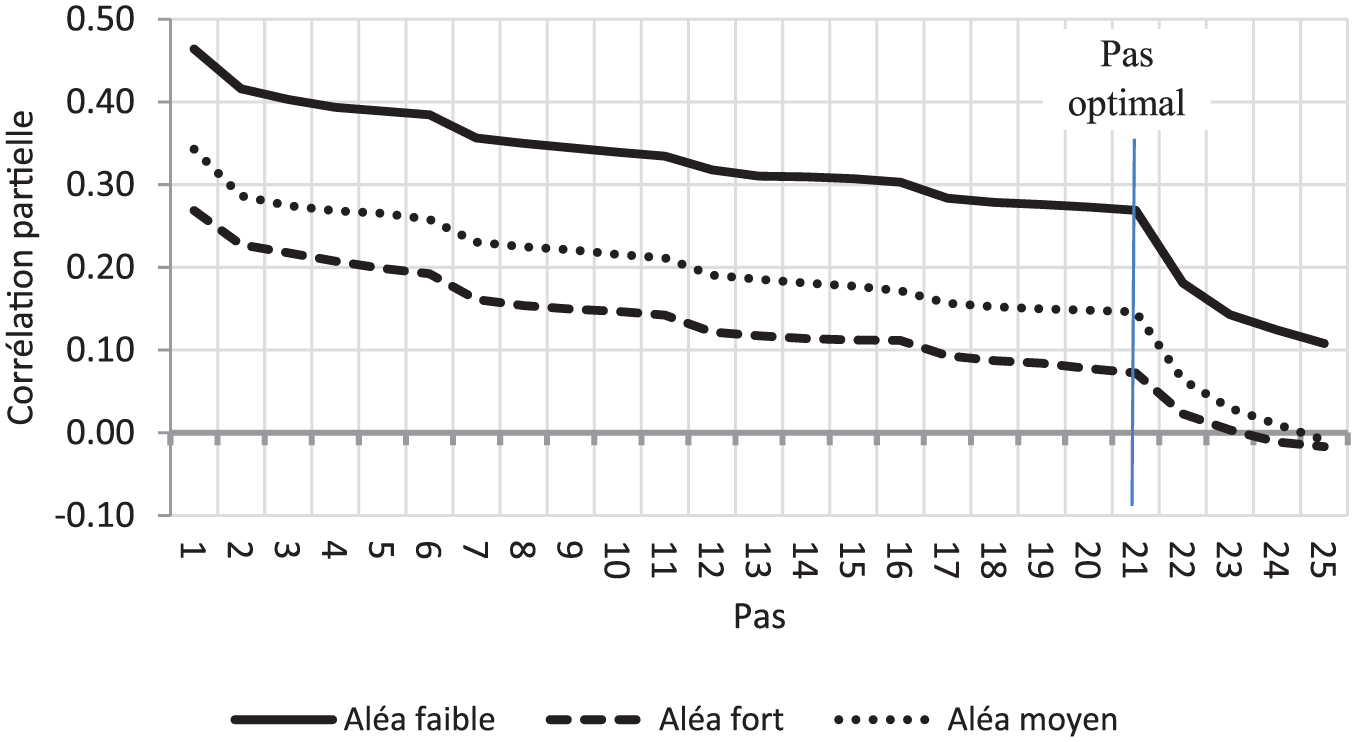
Trajectoire des corrélations partielles de l’item V1 (
Identification du pas optimal
La connaissance des poids simulés permet d’identifier le pas optimal ou pas qui maximise la corrélation entre les poids simulés et estimés. Comparer ce pas avec celui issu de la règle consistant à s’adosser à PLS ou celui que suggère une inspection visuelle des trajectoires fournit une mesure de la perte d’optimalité qu’induit ce nécessaire calage (Tableau 4). Cette comparaison est rassurante : pour tous types d’aléa et de colinéarité, la règle PLS identifie soit le pas optimal, soit un pas associé à une forte corrélation entre les poids estimés et simulés.
Pas PLS et corrélation avec les poids simulés en pourcentage de la corrélation du pas optimal.
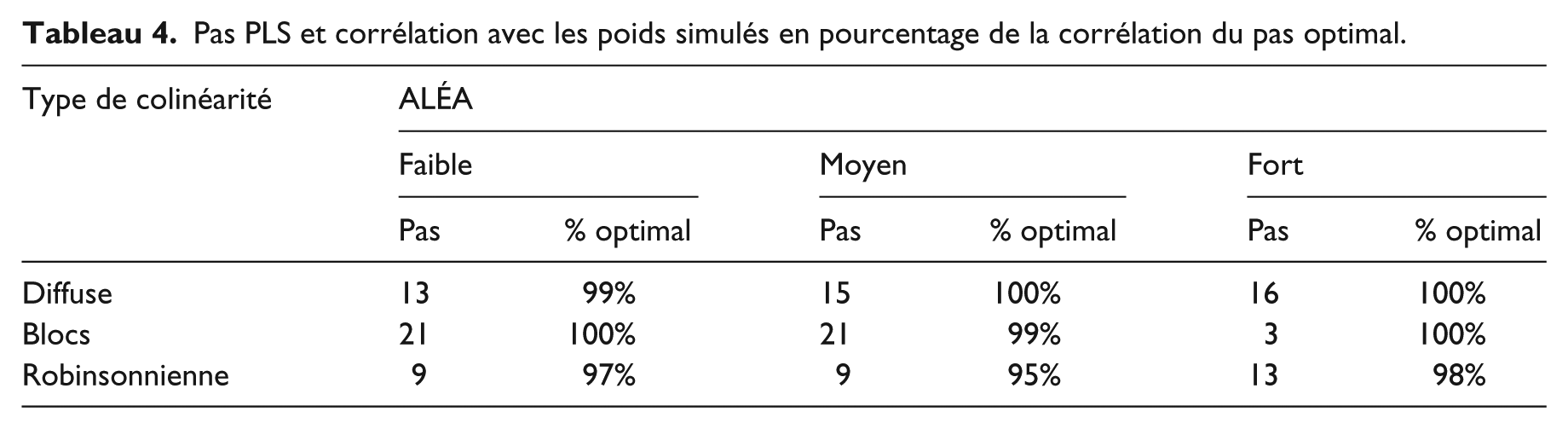
Sur la base de cette simulation, caler RS sur PLS s’avère efficace et permet de s’affranchir de la variabilité du pas optimal selon le type de colinéarité. Le pas optimal se situe en effet plutôt en début de trajectoire pour les formes concaves et plutôt en fin de trajectoire pour les formes convexes ou linéaires. Un examen visuel de chacune des trajectoires (ici : 25) peut conduire à modifier ce pas qui, rappelons-le, doit être le même pour tous les items, mais seule une règle simple (comme s’adosser à PLS) permet d’automatiser la démarche.
Fréquence des variables omises et structure des corrélations
Les variables de la trajectoire d’un régresseur se situant au-delà du pas optimal ne participent pas au calcul du poids de celui-ci. La fréquence des variables omises, tous régresseurs confondus, est liée à la structure de la matrice des corrélations. Pour la colinéarité par blocs, avec un pas de 21 (aléas faible et moyen), chacune des 25 variables est omise 4 fois, reflétant la forte corrélation intrablocs. Les 4 variables omises sont celles qui sont corrélées à hauteur de 0,70 avec le régresseur (V2 à V5 pour le régresseur V1, par exemple). Pour la colinéarité Robinsonnienne, les variables les plus corrélées aux autres sont celles qui se situent, par construction, au milieu de la matrice (V9 à V17). Elles sont donc omises plus souvent que les autres du calcul des poids. Pour la colinéarité diffuse, la fréquence des variables postérieures au pas optimal ne semble pas suivre de modèle précis bien que l’on s’attendît à ce qu’aucune ne soit omise plus qu’une autre (
Application de la régression signée à des données réelles
Les données réelles proviennent d’une enquête de satisfaction périodique portant sur respectivement 3319, 3483 et 3375 possesseurs de véhicules utilitaires achetés neufs en années T, T+1 et T+2. On dispose d’une batterie de 19 items regroupés en cinq grandes dimensions de satisfaction (Conduite, Confort, Qualité, Volume et Divers), mesurés par des notes de 1 à 10, ainsi que d’une note de satisfaction globale servant de variable à expliquer. Pour des raisons de confidentialité, ces items sont libellés de 1 à 19.
Ces données présentent tous les symptômes d’une colinéarité diffuse avec des statistiques pratiquement identiques pour les trois années :
Corrélation moyenne entre items de 0,43.
FIV moyen de 2,2.
Nombre d’items à FIV ⩾ 3 : 3
Nombre d’indices de conditionnement ⩾ 30 : 12
Nombre d’indices de distorsion ⩾ 0,3 en valeur absolue : 6.
Trajectoire des corrélations partielles : convexe.
Sur les 19 items, 11 sont impliqués dans des paires de corrélations à indice de distorsion excédant le seuil empirique acceptable, les mêmes d’une année à l’autre. Selon les méthodes, cette distorsion sera plus ou moins bien traitée.
Les résultats des régressions sont regroupés dans le tableau 5. On y trouve les poids par item et des mesures de la qualité et de la stabilité de l’ajustement entre périodes successives. Le fait qu’il s’agisse d’une étude périodique facilite le diagnostic des anomalies. On ne s’attend pas, en effet, à de fortes variations de poids d’une année à l’autre. Un exemple de trajectoires optimales et d’identification du pas est disponible en figure 3 pour l’année T+1.
Application de la régression signée à des données réelles – Poids des items et qualité de l’ajustement.
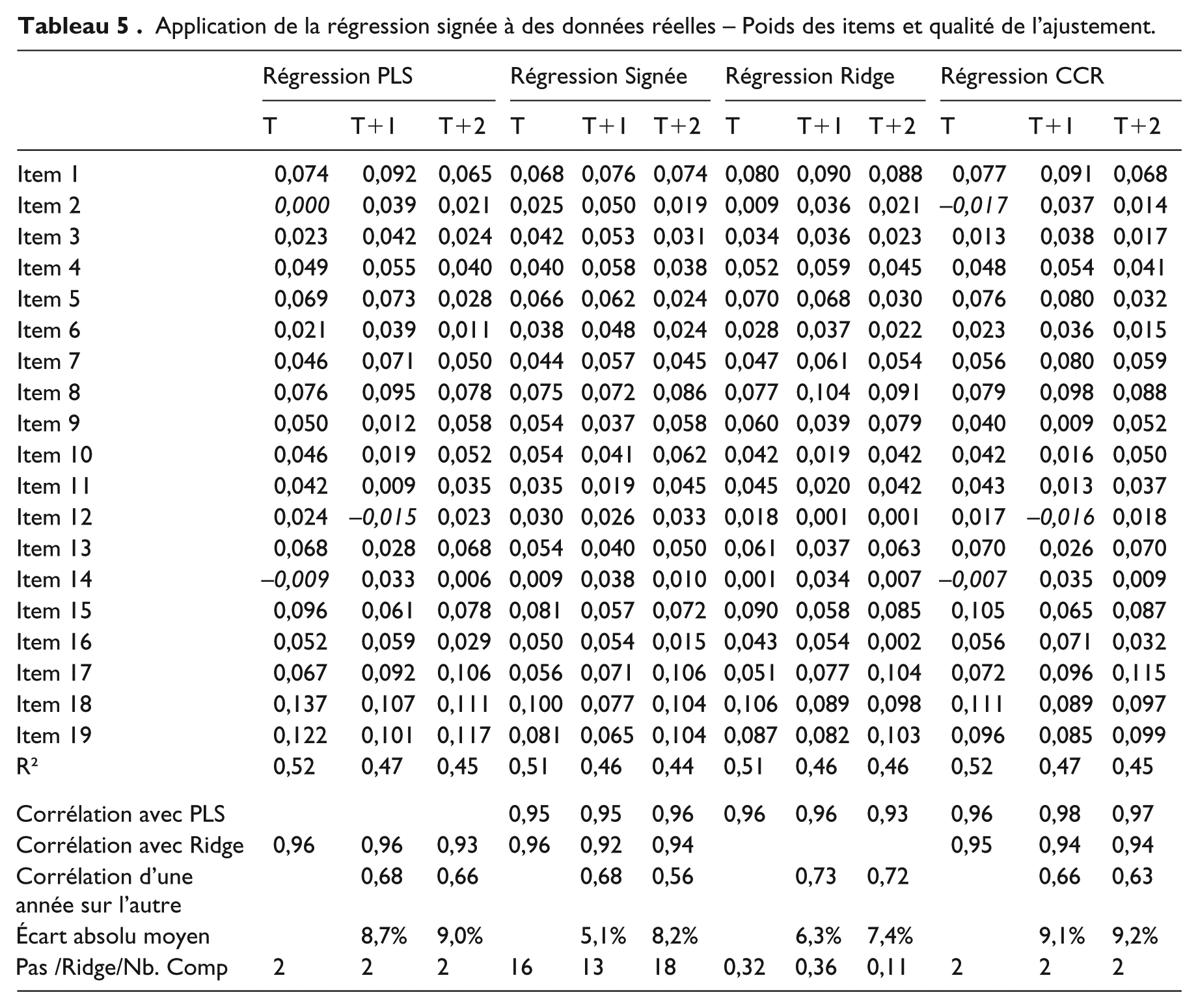
La qualité de l’ajustement, mesurée par le R², varie très peu entre méthodes. Par ailleurs, les quatre – PLS, CCR, RS et Ridge – produisent des poids très voisins, avec une corrélation entre méthodes excédant 0,95. Ce résultat corrobore ce que l’on a constaté avec les données simulées, en l’occurrence qu’aucune des quatre méthodes ne dominait les trois autres en présence de colinéarité diffuse.
Cette convergence globale des poids au sens de la corrélation ne signifie pas qu’il n’y ait pas de différences locales d’une méthode à l’autre, différences qu’il est instructif d’analyser avec les trajectoires des corrélations partielles.
Poids négatifs
En PLS et CCR, deux items en année T (Items 2 et 14) et un item en année T+1 (Item 12) sont dotés de poids négatifs. Pour ces trois items, Ridge respecte la contrainte de signe, mais à la marge : leur poids est pratiquement nul. L’examen de la trajectoire de l’item 12, par exemple (Figure 2), permet de comprendre pourquoi PLS et CCR lui octroient un poids négatif ou nul : la corrélation partielle devient négative au pas 16, après l’introduction de l’item 9 dans l’équation de régression en T+1. RS s’en accommode en fixant un pas antérieur à la rupture.
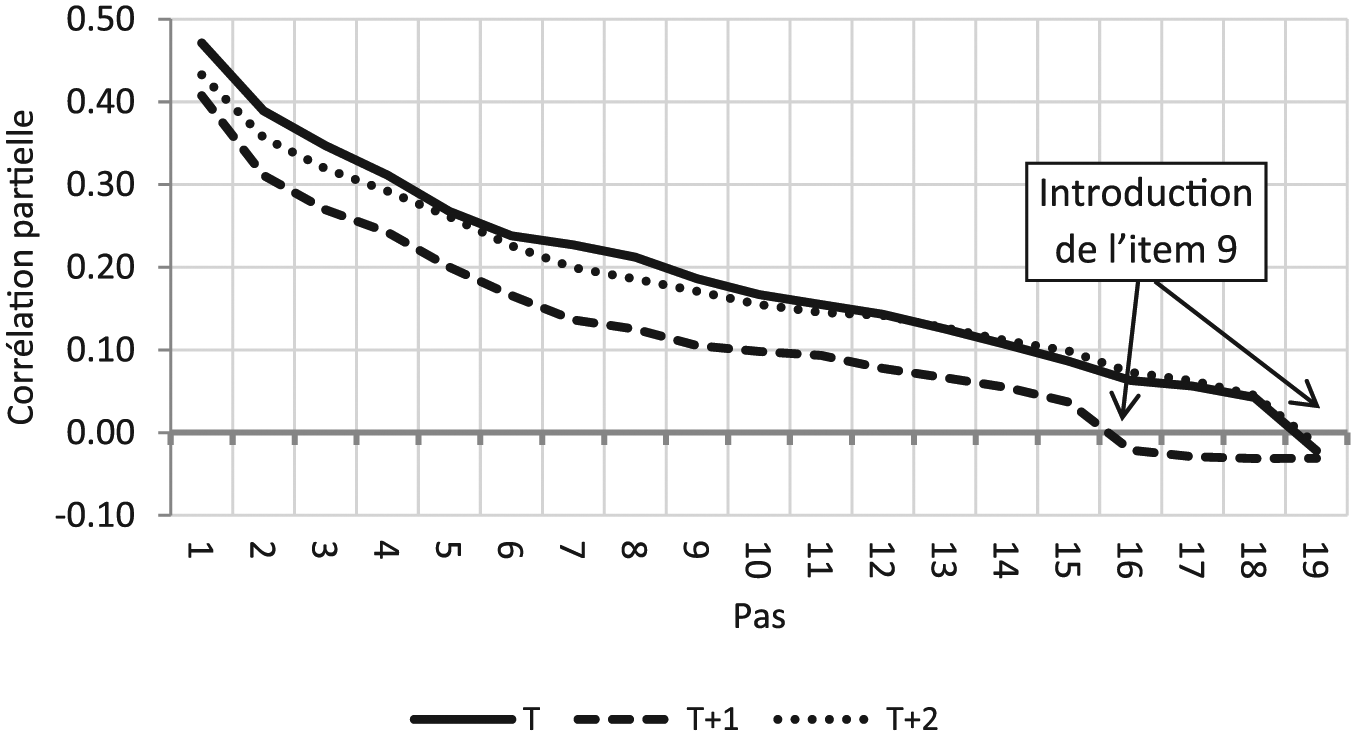
Trajectoire optimale de l’item 12.
Il fallait s’y attendre avec une corrélation entre ces deux items de 0,81 et un indice de distorsion de −0,67. On notera, toutefois, que les années T et T+2 connaissent exactement la même situation de colinéarité, telle que mesurée par ces deux quantités, à cette différence près que l’introduction de l’item 9 n’intervient pour ces deux années qu’au dernier pas. Sur la seule base de la corrélation et de l’indice de distorsion, rien ne permettait de prévoir que l’estimation de l’item 12 en T+1 en pâtirait plus qu’en T et T+2. Parce qu’elle s’inscrit dans une dynamique, la trajectoire des corrélations partielles est beaucoup plus riche d’enseignement qu’une simple mesure statique de la colinéarité.
Ici, par exemple, elle suggère que le poids de l’item 12 devrait être le même en T et T+2, à en juger par la proximité des deux courbes. C’est le cas pour PLS et RS, mais pas pour Ridge. On s’attend également à ce que le poids de cet item soit moins fort en T+1 en raison du décalage constant de la courbe vers le bas, tout en restant positif. C’est effectivement le cas pour RS, la seule méthode à traiter correctement la rupture, même si l’ajustement introduit par le choix du pas 13 (lequel prend en compte le contexte de colinéarité de tous les autres items) peut être jugé excessif.
Effet de bascule du poids d’un item vers un autre
Face à deux items fortement corrélés, MCO et Ridge, mais aussi, dans une moindre mesure, PLS tendent à privilégier l’un des deux items en lui octroyant plus de poids. Considérons les items 8 et 10 en T+1 (
Rétrocession du poids
Si l’on travaille en dimensions – regroupement d’items élémentaires – on constate que les quatre méthodes leur accordent pratiquement le même poids et que ce poids correspond à ce que l’on obtient par une régression multiple pas à pas. Cette dernière se contente d’exploiter 14 items sur 19 en ignorant un à deux items par dimension.
Prendre en compte la colinéarité aboutit donc, dans un contexte de colinéarité diffuse, à rétrocéder du poids aux items les plus vulnérables, ceux dont la faible corrélation avec la variable à expliquer, relativement à celle des autres items, ne parvient pas à compenser leur forte intercorrélation. Dans cet exercice, comme l’illustrent les exemples ci-dessus, c’est RS qui répond le mieux à cet objectif.
Conclusion et voies de recherche
Cet article comble un manque, celui d’une méthode de régression dont l’objectif prioritaire est de produire systématiquement pour toutes les variables des coefficients dont le signe concorde avec celui de la corrélation simple entre la variable à expliquer et chacun des régresseurs et dont la valeur ne se cale pas sur la contrainte. Nous l’avons appelée RS : « Régression Signée ». L’idée de base est qu’il existe entre la corrélation simple et la corrélation partielle une étape intermédiaire qui permet d’atteindre cet objectif.
On introduit à cet effet la notion de trajectoire optimale de corrélation partielle qui retrace le chemin parcouru par chaque régresseur entre le moment où il est seul dans l’équation de régression (corrélation simple) et celui où il est rejoint par l’ensemble des régresseurs (corrélation partielle). Chaque régresseur est doté de sa propre trajectoire, établie indépendamment de celles des autres régresseurs.
Cette trajectoire est définie de manière à préserver au mieux la corrélation partielle du régresseur dont on recherche la trajectoire au fur et à mesure de l’introduction des autres régresseurs dans la fonction de régression. Si l’ordre d’introduction des variables varie d’un régresseur à l’autre, tous sont, à chaque pas, en quelque sorte, logés à la même enseigne au sens où le choix de la variable à introduire dans l’équation de leur trajectoire se fait au mieux de leur intérêt.
La forme de ces trajectoires, convexe, concave ou linéaire, identique pour tous au bruit et aux ruptures spécifiques près, varie selon la structure de la matrice des corrélations entre régresseurs. Ces ruptures peuvent être systématiques (cf la simulation par blocs) ou occasionnelles, c’est-à-dire propres à une paire de régresseurs. Les trajectoires constituent par ailleurs un outil diagnostic visuel très puissant.
L’étape finale du processus consiste à fixer le curseur entre la corrélation simple (premier pas) et la corrélation partielle (dernier pas)
8
. La condition nécessaire est que ce pas, le même pour tous les régresseurs, doit être tel qu’il garantisse le caractère strictement positif des corrélations partielles (pas nécessaire :
A ce stade de notre recherche, nous avons opté de fixer ce pas en calant les coefficients RS sur ceux de la régression PLS, une méthode simple, robuste et efficace. Les coefficients RS correspondent donc au pas qui satisfait la contrainte de signe et maximise la corrélation avec leurs homologues PLS.
Les simulations réalisées suggèrent que RS est une bonne alternative à PLS ou CCR lorsque la contrainte du respect du signe de la corrélation simple est imposée. En situation de données réelles, les trajectoires, outre de rendre visuel l’impact insidieux de la colinéarité, permettent parfois de déterminer le pas optimal. Le calcul des trajectoires est rapide, grâce au recours à la récursivité, et il tolère les valeurs manquantes. Avec la régression signée, le praticien dispose enfin d’une méthode lui garantissant des poids strictement positifs et statistiquement fondés.
Limites et voies de recherche
Deux limites de cette nouvelle approche méritent d’être soulignées, l’une d’ordre méthodologique, l’autre, plus fondamentale, d’ordre théorique.
Limite méthodologique
Adosser RS à PLS ou CCR pour le choix du pas optimal est efficace, mais contestable. Si rien n’empêche l’utilisateur de leur substituer un autre référent, l’idéal serait de s’en passer.
Choisir systématiquement
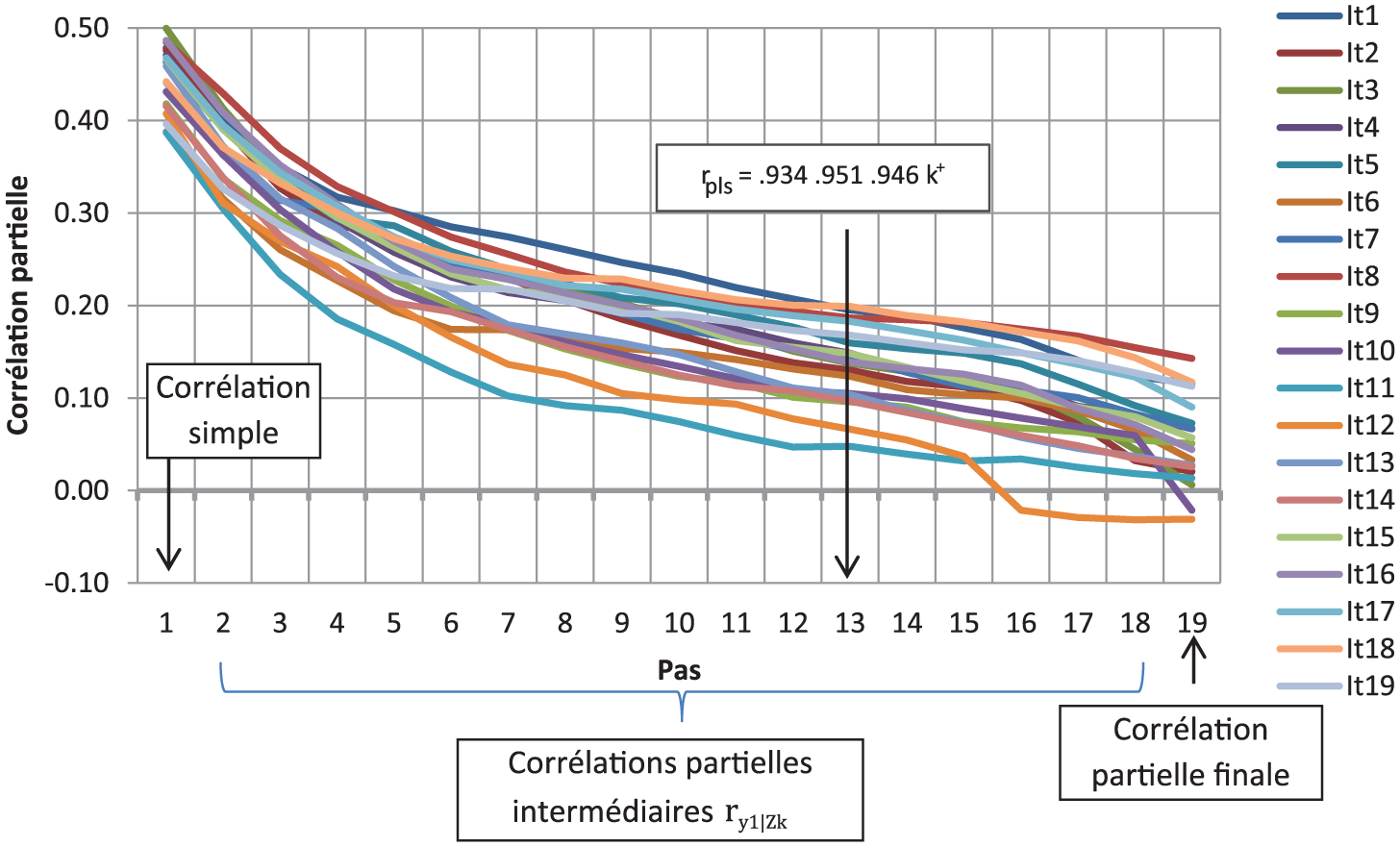
Trajectoires optimales et identification du pas – Enquête VU – Année T+1.
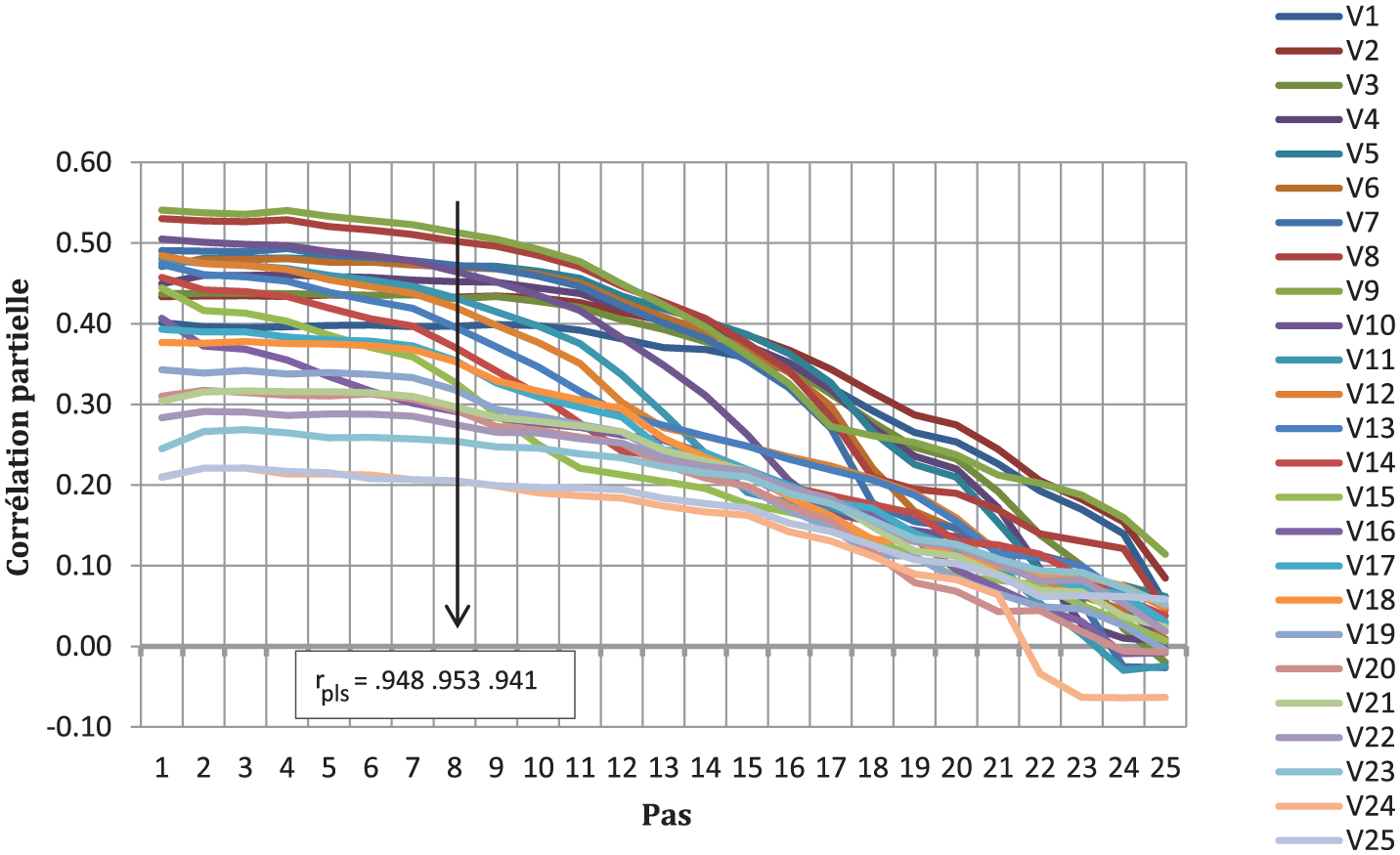
Trajectoires optimales et identification du pas – Colinéarité Robinsonnienne – Aléa faible.
Choisir le pas
En revanche, la progression du
Hormis le calage sur PLS ou CCR, l’examen de la forme des trajectoires optimales et la présence de ruptures systématiques (communes à plusieurs items) restent le moyen le plus fiable d’identification du pas optimal. La règle serait alors la suivante :
– Si la trajectoire est linéaire ou convexe, le pas optimal est égal à
– Si la trajectoire est concave, un polynôme de degré 2 en est une bonne approximation (a+bx+cx2). La simulation montre que le pas optimal correspond approximativement à l’entier le plus proche de
– En cas de rupture forte et systématique (Figure 1), le pas optimal correspond au pas précédant cette rupture.
Appliquée aux données simulées, cette règle fournit une bonne approximation du pas optimal 9 .
Limite théorique
On pourrait arguer que le rôle d’un scientifique n’est pas de résoudre les problèmes mal posés, mais de les poser correctement. Dans le contexte de cet article, cela conduirait à tenter de convaincre les managers à « vivre » avec des facteurs de satisfaction à importance nulle ou négative, laquelle importance correspondrait aux « vrais » résultats, multicolinéarité comprise. L’objectif poursuivi dans cet article nuirait alors à la validité des résultats et ne serait qu’un artifice de communication visant à rassurer certains managers et les conforter dans leur utilisation dévoyée des études de satisfaction.
Cet argument n’est pas sans fondement. Si une inversion de signe peut révéler un processus de médiation ou de modération (Chumpitaz et Vanhamme, 2003), il n’est pas impossible, « en théorie », qu’un facteur présupposé de satisfaction ne pèse pas sur la satisfaction globale. Et la différence pratique entre un facteur nul et un facteur de très faible importance n’est pas immédiate. Encore faut-il que le modèle soit bien spécifié : ni RS, ni PLS, ni CCR ne sont adaptées à une structure des données intrinsèquement hiérarchique, sauf à ne travailler qu’avec les items du niveau le plus bas. Une surabondance d’items, source de poids nuls ou négatifs, est souvent le signe d’une structure hiérarchique non prise en compte. La présence de segments de clientèle aux attentes divergentes peut également conduire à des coefficients nuls. Il faut alors conduire l’analyse sur ces segments ou recourir à un modèle spécialisé (classes latentes).
La colinéarité statistique peut être limitée, mais rarement éliminée 10 . Dans le domaine automobile, par exemple, les notes de satisfaction des items « esthétique de l’intérieur » et « qualité de finition de l’intérieur » sont très corrélées, l’esthétique en quelque sorte, déteignant sur la qualité. Ces deux notions, liées dans la tête du client, le sont beaucoup moins dans celle du constructeur qui ne souhaite pas faire l’économie de l’une d’entre elles pour cause de colinéarité. C’est à ce type de dépendance inévitable que la méthode s’adresse en priorité.
L’ambition de cet article n’est pas de tester une hypothèse ni de résoudre la sempiternelle question de l’importance des critères de satisfaction – chacun sait que le modèle compensatoire sous-jacent à la régression linéaire est une pauvre approximation des phénomènes asymétriques et non linéaires potentiellement à l’œuvre dans le processus de satisfaction et de la théorie prévalente (confirmation des attentes) – mais de répondre à un souhait de managers qui, par métier, arbitrant des compromis, prenant des décisions et cherchant à donner du sens à leur action, attendent des solutions plutôt qu’une liste de problèmes. On ne peut pas motiver les ingénieurs responsables de la conception d’un sous-ensemble en affirmant qu’il ne pèse rien dans la satisfaction du produit dans lequel il s’insère. Les managers sont ainsi faits qu’ils peuvent s’accommoder d’un poids de 0,001, mais pas d’un poids de 0,000 et encore moins d’un poids de −0,001. Laisser aux seules données le soin de déterminer le signe d’une relation est hasardeux, car un signe contraire aux attentes signale presque toujours un problème de théorie, de données, de spécification ou d’estimation (Kennedy, 2003).
La régression signée ne court pas après une chimère (la « vraie » importance d’un facteur de satisfaction) ; elle constitue une réponse approximative et rigoureuse à la démarche consistant à profiter de la « voix du client » (une étude de satisfaction) pour fonder une action qui, sinon, ne s’appuierait que sur l’expertise et les convictions personnelles des concepteurs, et de le faire d’une manière qui en facilite l’appropriation.
Footnotes
Annexe : Pseudo-code et exemple chiffré de calcul des trajectoires optimales
Le cœur de la régression signée repose sur le calcul de la trajectoire optimale des corrélations partielles de chaque régresseur. Le pseudo-code ci-dessous indique comment mettre à profit la formule récursive de la section intitulée « Calcul numérique des trajectoires » pour les obtenir.