
Abstract
Résumé
Ne rêvons-nous pas tous de pouvoir conclure que nos résultats sont « statistiquement significatifs », c’est-à-dire associés à une probabilité p inférieure à un seuil, généralement de 5% ? Dans cet article, nous montrons d’abord que p n’est pas ce qu’on croit, et qu’il conduit à une dichotomisation fallacieuse et à une sous-évaluation de l’incertitude de l’effet testé. Nous proposons ensuite une nouvelle mesure directe de la plausibilité de cet effet. A partir d’un exemple tiré d’un article, nous l’illustrons et la complétons de contextualisations concrètes reposant sur des contrastes graphiques entre intervalles crédibles. Finalement, nous soulignons que la démarche proposée contribue à réaliser à quel point l’interprétation de p, ou de toute autre probabilité, doit être prudente dès lors qu’il s’agit d’émettre une conclusion dans un environnement incertain à propos de l’existence ou non d’un effet.
« La connaissance progresse en intégrant en elle l’incertitude, non en l’exorcisant. »
Introduction
En marketing, spécifiquement dans le cadre d’une démarche hypothético-déductive, nous testons classiquement des hypothèses, relatives aux effets de facteurs que nous voulons mettre en évidence. A la recherche de résultats (différences ou associations) que nous espérons convaincants, nous nous référons, quasiment toujours, à la valeur p d’une probabilité que nous confrontons à un seuil, généralement de 5%. Si p est inférieure ou égale à ce seuil, d’aucuns sont tentés de qualifier, de façon mécanique, les résultats de significatifs. A l’inverse, lorsque p est supérieure à 5%, les mêmes peuvent être enclins à affirmer, tout aussi mécaniquement, qu’il n’y a pas de différence ou pas de relation, respectivement entre deux groupes ou deux variables, parce que l’estimation de cette différence, ou du degré d’association n’est, croient-ils, pas statistiquement significative.
Il arrive même que des chercheurs renoncent à communiquer leurs résultats craignant qu’ils n’intéressent pas éditeurs, évaluateurs et lecteurs de revues scientifiques parce que les valeurs p s’y rapportant sont supérieures à 5%. D’autres malheureusement ne présentent que les seuls résultats en-deçà de ce seuil, une dérive appelée best-of tactic (Laurent, 2013 : 323). Ce biais de sélection affecte les travaux de réplication pourtant indispensables au développement de connaissances robustes. D’autres enfin, avant même d’avoir terminé leur enquête ou expérimentation, veulent s’assurer que l’analyse de leurs données ne produise pas des résultats de tests transgressant la fatidique limite des 5%. En conséquence, ils décident de ne pas compléter leur échantillon appréhendant que l’ajout d’observations conduise à un test assorti d’une valeur p dépassant ce plafond (un des comportements non éthiques souligné par Levelt Committee et al., 2012).
Le présent article fait écho aux appels répétés des statisticiens mettant en garde contre l’assuétude à la confrontation de p à ce plafond aussi peu justifié qu’invariable (e.g. Amrhein et al., 2019a ; Wasserstein et Lazar, 2016 ; Wasserstein et al., 2019). Notre objectif est d’abord de relayer ces appels et de provoquer une réelle prise de conscience dans la communauté marketing et des sciences de gestion. Nous nous efforçons ensuite de présenter un indicateur plus approprié que p en ce qu’il permet de juger de la véracité de l’hypothèse soumise à l’épreuve des faits, habituellement désignée par
Dans la première partie, nous nous employons à sensibiliser aux erreurs d’interprétation de p et au caractère fallacieux de la dichotomisation entre résultats significatifs et non significatifs qui en découle.
Afin d’éviter ces erreurs, nous préconisons, dans une deuxième partie, une mesure directe de la plausibilité de l’effet testé, mesure optimiste de la probabilité de
(1) nous exposons leur raisonnement permettant de traduire p, en coefficient de réduction (ou augmentation) de l’incertitude quant à la réalité de l’effet
(2) nous montrons ensuite comment exploiter une borne supérieure de ce facteur
1
B(p) pour actualiser la probabilité a priori de l’effet :
Enfin, dans une troisième partie revisitant un exemple tiré d’un article publié (Herrmann, Derbaix et Kacha, 2018), nous montrons concrètement en quoi
Pratiques courantes d’inférence
Le but d’une démarche inférentielle est de déduire d’un échantillon de données – issues d’expérimentations, ou récoltées par voie d’observations ou d’enquêtes – des généralisations propres à cerner, le plus fidèlement possible, l’univers étudié (marché ou segment). Le plan d’échantillonnage se calque sur un modèle, le plus réaliste possible, de cet univers. Ce modèle prend la forme d’un jeu cohérent d’hypothèses, articulant les caractéristiques et variables pertinentes pour cerner le champ de recherche dans cet univers. L’analyse statistique des données rassemblées vise à quantifier, le plus précisément possible, les paramètres qui spécifient formellement les hypothèses à tester. Pour juger du réalisme de chacune de ces hypothèses, on estime la probabilité de rejeter à tort l’hypothèse nulle
Clarification
Soit un facteur dont l’incidence présumée est modélisée par une relation dont un paramètre
- égale ou inférieure à d, si on est persuadé que
- égale ou supérieure à d, si on croit
- aussi extrême (positivement ou négativement) que d, si on suppose
La formalisation mathématique de cette définition est explicitée dans le tableau de synthèse 5.
Dans les cas de tests unidirectionnels – si la distribution de l’estimateur est symétrique (ce qui est souvent le cas), et pour autant que d présente le signe attendu –, il convient de diviser par deux la valeur p fournie par les logiciels statistiques, ce qu’on oublie souvent. En revanche, si le signe de d est contraire, l’effet doit être considéré comme étant non établi. Ce point est particulièrement critique lorsque
Méprise originelle compréhensible
La définition de p n’est ni élémentaire, ni opérationnelle. Rien de surprenant à ce qu’elle soit perçue si ardue, qu’en pratique on veuille la simplifier au risque d’en perdre le sens et de lui accorder un crédit qu’elle ne mérite pas. Matthews (2019 : 205) et de nombreux autres (e.g. Goodman, 2008 ; Greenland et al., 2016) ont dressé une liste très complète des pratiques entachant l’interprétation de p. Ainsi, ils dénoncent que l’erreur la plus souvent commise consiste à confondre p avec la probabilité d’absence d’effet,
En fait, p n’est que la valeur prise par la probabilité d’obtenir des résultats supportant autant, voire davantage,
Un irrépressible besoin de seuils
La référence quasi-systématique à des seuils arbitraires pour étalonner p a entrainé une dichotomisation dogmatique opposant les résultats prétendus significatifs aux autres, considérés non significatifs 2 . Ces seuils sont arbitraires, car ils ont été prédéterminés indépendamment du contexte, sans tenir compte des conséquences (asymétriques) des faux négatifs et faux positifs 3 . En matière de pré-test d’innovations, par exemple, un faux positif entraîne un coût monétaire, alors que d’un faux négatif résulte une perte d’opportunité 4 . En ce qui concerne le label significatif décerné dès lors que p est inférieure à 5% (ou à 1%, . . .), il est peu informatif quant à la réalité de l’effet présumé. Mutatis mutandis, disqualifier une hypothèse parce que p excède 5% ne permet pas de conclure à l’absence d’effet 5 . Cette dichotomisation, et les labels trompeurs qui vont de pair, sont par conséquent à proscrire définitivement (Amrhein et al., 2019a ; Wasserstein et al., 2019).
Reflets d’une forme d’aversion au risque, les jugements, fondés uniquement sur p, hiérarchisés en degrés de signification rigides, risquent :
d’induire la diffusion de conclusions sans nuances, voire fausses ;
d’alimenter des polémiques en cas de non-réplication ;
de polluer des revues de littérature (méta-analytiques ou non) ;
et in fine de mettre en péril le processus de développement des connaissances scientifiques.
Le marketing n’échappe pas à cette tendance à s’affranchir de l’incertitude. Nous sommes nombreux à avoir osé tirer des conclusions que les seules valeurs p calculées ne suffisent pas à légitimer. Les deux exemples résumés dans le tableau 1 – extraits des travaux de deux des auteurs du présent article – sont assez représentatifs de ces pratiques toujours courantes.
Deux exemples de dérives « significatives ».


Dans un commentaire co-signé par 854 autres scientifiques
6
, publié dans Nature, Amrhein et al. (2019a) s’élèvent contre ce seuil quasi-immuable
Issue : la voie bayésienne
Un test d’hypothèse nous éclaire quant à la probabilité d’un résultat empirique
De p à
, en quête d’un indicateur de la plausibilité de
Après avoir rappelé que p n’est qu’une jauge de la cohérence des données avec l’hypothèse nulle, nous en justifions ici deux transformations, de portée pragmatique 9 :
- la première, appelée facteur bayésien maximum, noté
- la seconde transforme la première en une mesure optimiste de la probabilité a posteriori de
Sellke et al. (2001), qui les ont développées, ont qualifié de calibrations
10
de p, ces deux indicateurs de la contribution de p à la réduction (ou accroissement) de l’incertitude planant sur
Cheminement du raisonnement : définitions et notation.
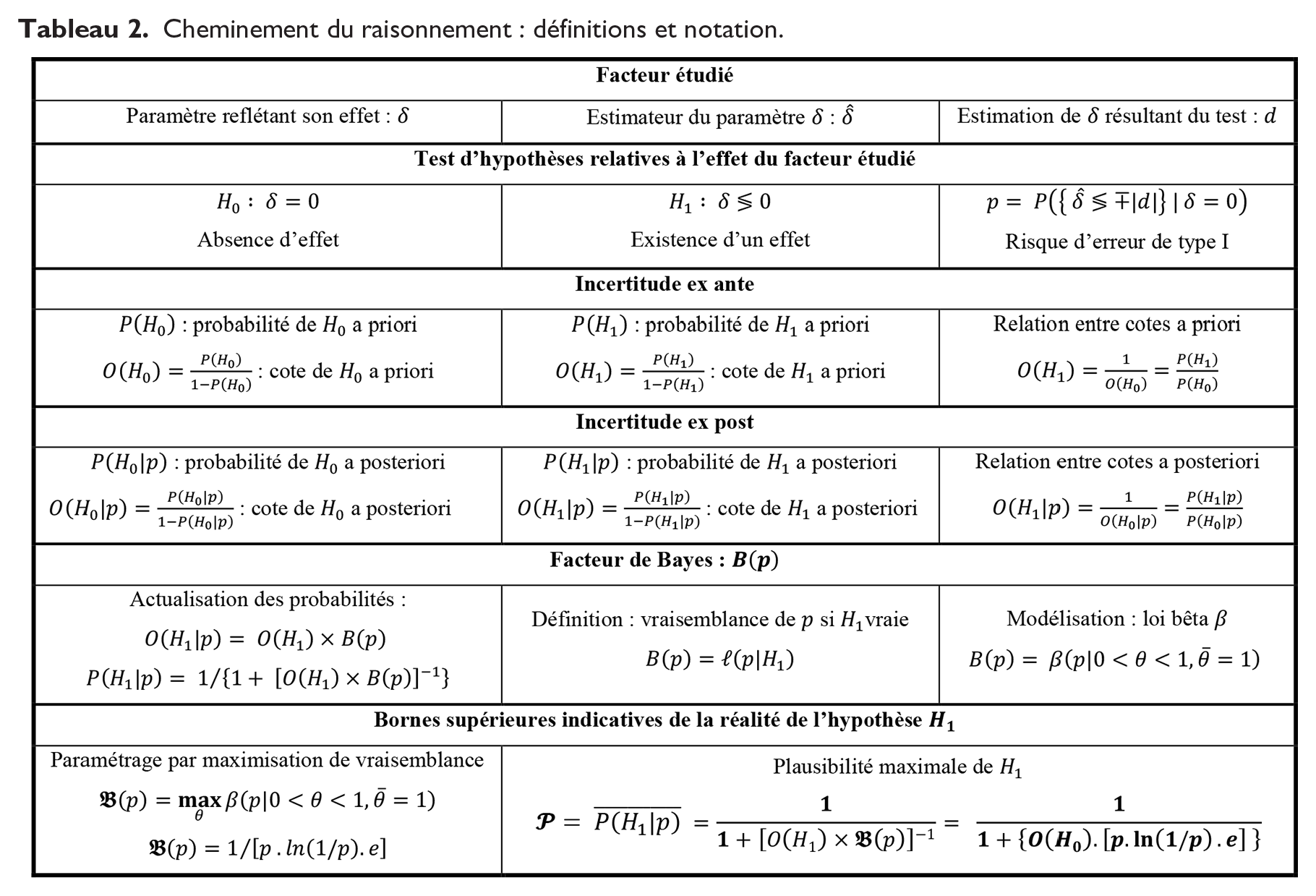

Facteur bayésien
La valeur p est instructive en ce qu’elle ramasse – on ne peut plus concisément – les résultats du test et nous pousse à revoir nos attentes quant à l’effet escompté : elle peut soit ébranler (p élevée), soit renforcer (p faible), nos (in)certitudes initiales (« prior beliefs »). Statistiquement, p doit inciter à corriger à la baisse ou à la hausse la cote a priori (« prior odds ») de
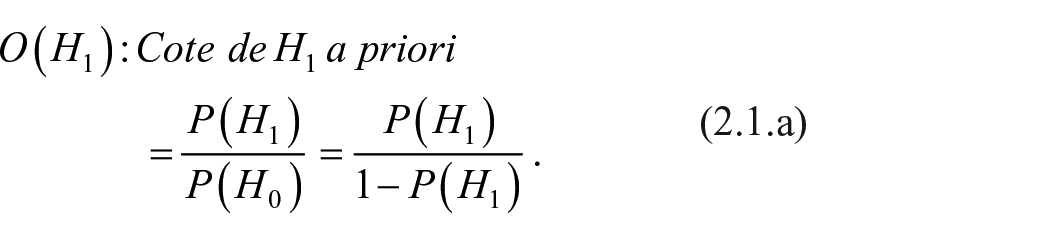
L’information tirée du test et synthétisée par p doit modifier les conjectures premières, qui se muent alors en cote a posteriori :
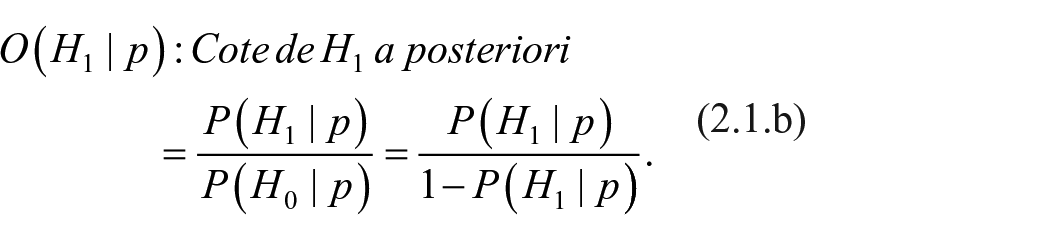
Cette mise à jour, ex post, de l’état d’incertitude, conditionnée par

Le paragraphe suivant (Modélisation) détaille la manière dont la valeur de B(p) est déterminée. Le tableau 3 illustre numériquement les relations (2.1) et (2.2). Ainsi, par exemple, si
Mécanique de l’actualisation des cotes.
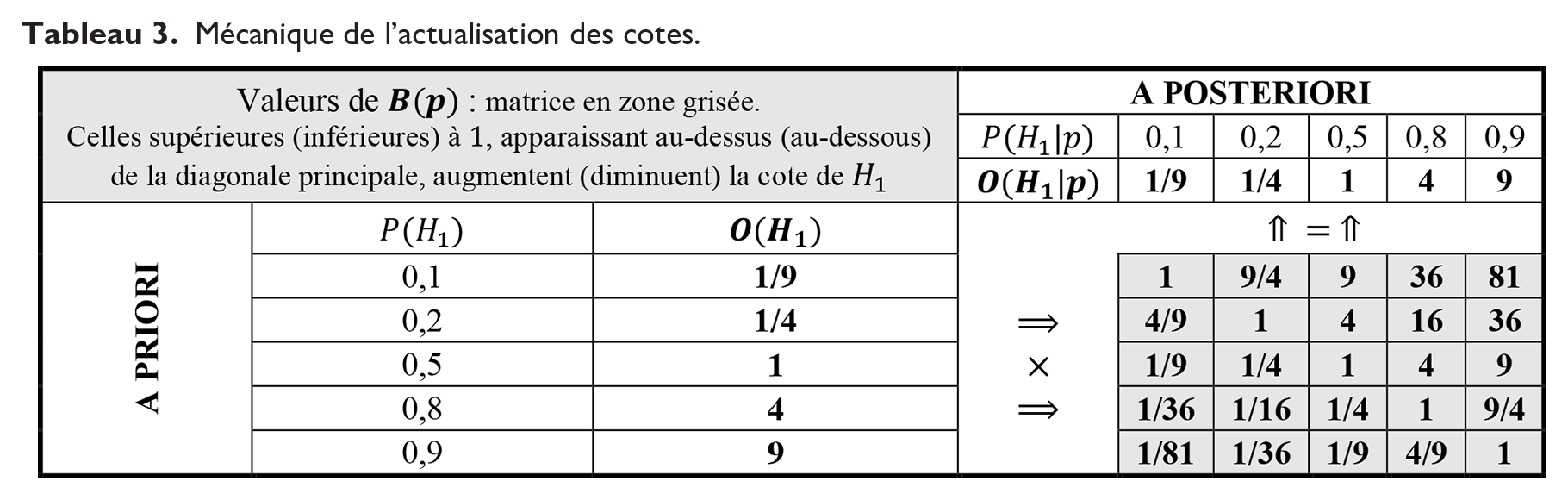
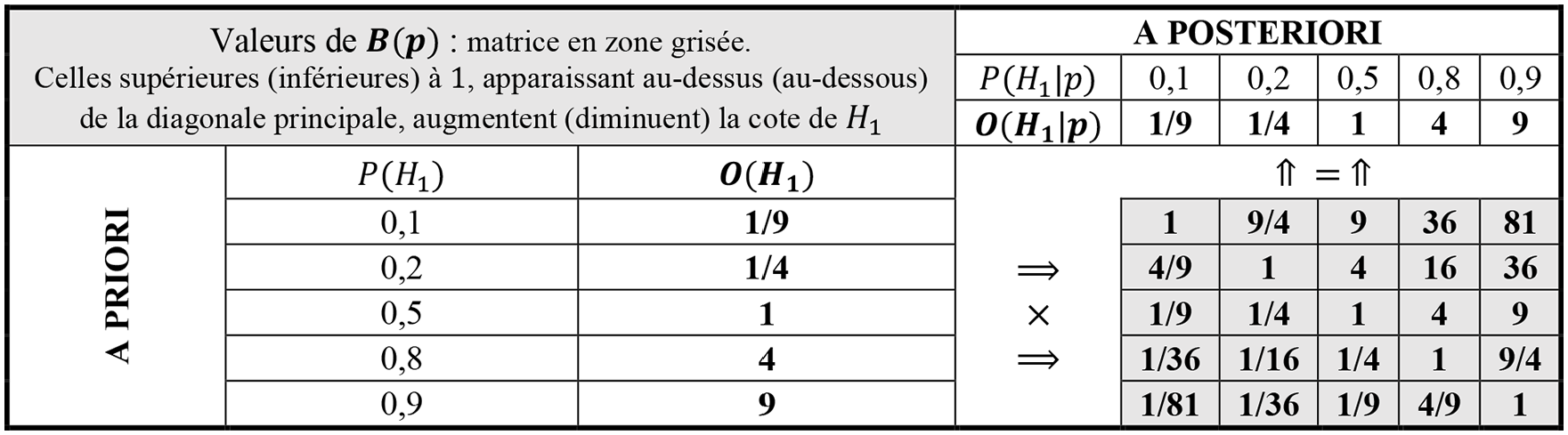
Concrétisant la valeur informative ajoutée par
Modélisation
Le facteur bayésien (2.2) est déterminé par le rapport indiquant la vraisemblance relative du résultat empirique au regard des deux hypothèses :

L’annexe I démontre qu’il est égal au rapport des vraisemblances conditionnelles de p. C’est-à-dire :

Son dénominateur est égal à l’unité, car si
L’allure que la fonction
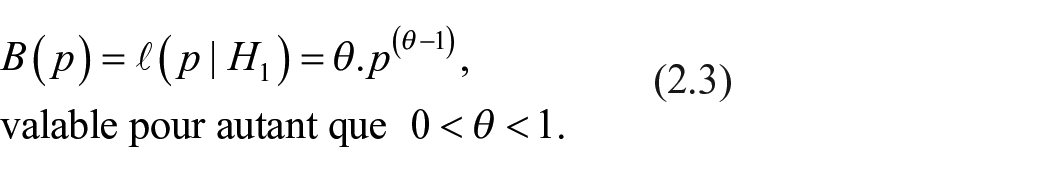
Elle est un cas particulier de la fonction bêta, dont l’annexe II prouve la pertinence. Son seul paramètre,
Distributions de probabilités adéquates pour
Paramétrage
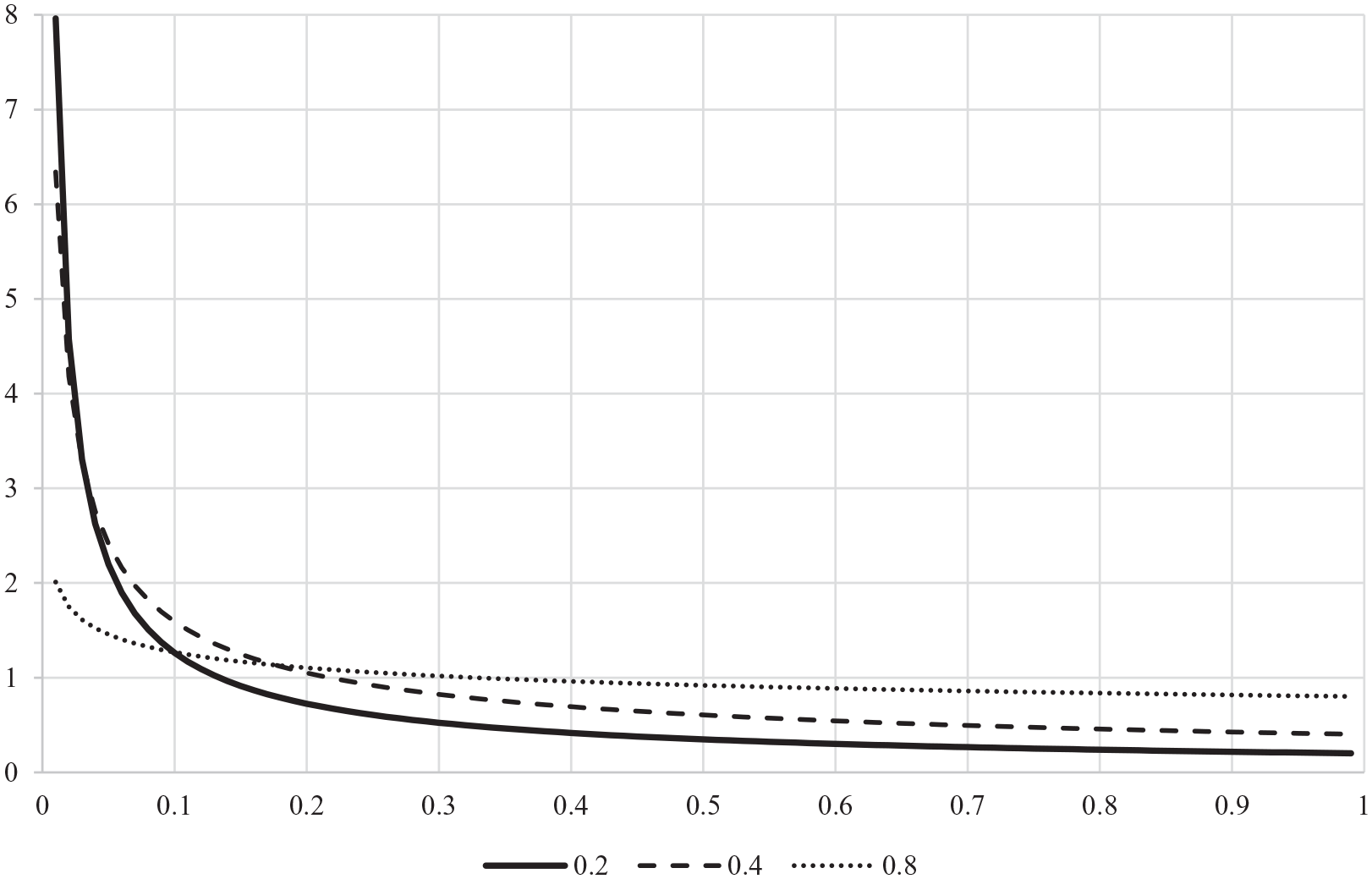
Reste à déterminer θ. La figure 2, duale 12 de la figure 1, y aide. Elle illustre l’incidence de ce paramètre, pour 7 valeurs de p précisées par la légende : de 1% (en trait continu) à 20% (en pointillés). Chacune de ces 7 courbes est strictement concave et présente un maximum global. Leurs maxima sont reliés par des segments fléchés, dont les pentes se réduisent à mesure que p augmente, jusqu’à tendre vers 0: asymptotiquement, les ordonnées des maxima tendent donc vers une limite inférieure, égale à 1, et leurs abscisses tendent elles aussi vers 1, point de convergence des courbes.
Sensibilité du facteur bayésien au paramètre.
Si tout

Cette formule n’a de sens que si lorsque p est élevée,
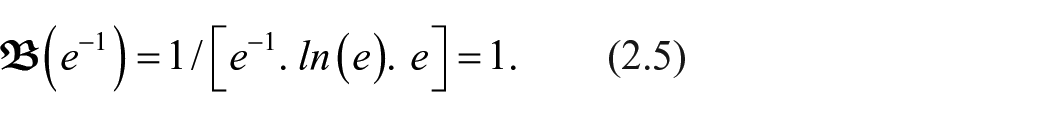
Donc, si
Autres possibilités de modélisation et paramétrage
D’autres lois statistiques que celle définie par
Probabilité a posteriori
En soi, B(p) suffit pour apprécier à quel point le test conforte – si B(p)>>1 – ou atténue nos préjugés favorables à
Tant Sellke et al. (2001 : 62–63), que Benjamin et Berger (2019 : 188), la calculent ; ces derniers – bien qu’ils promeuvent
Formule de calcul
Par inversion de la cote a posteriori
14
, donnée en
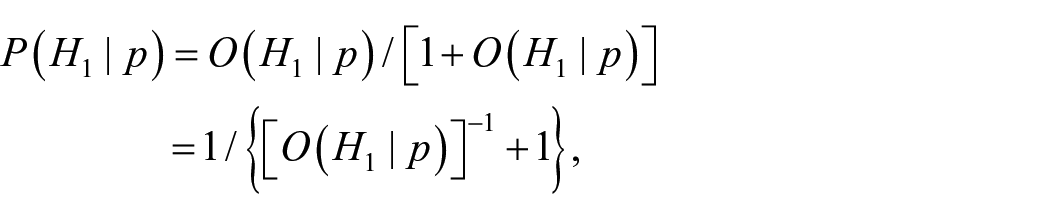
expression qui peut s’expliciter davantage en y substituant
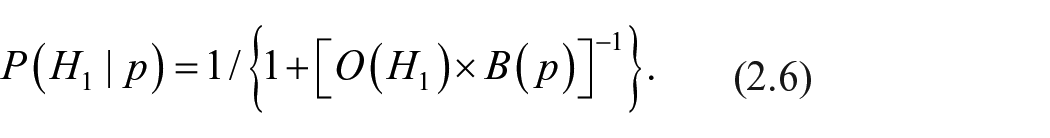
Si
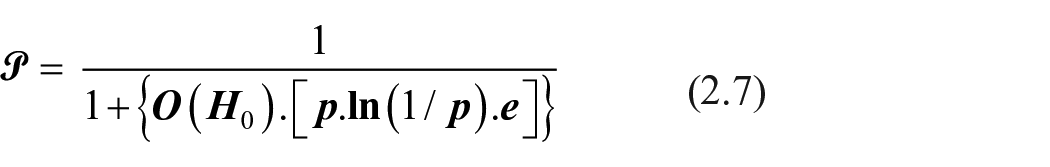
puisque
Présupposition essentielle
Appliquer
Ainsi,
Benjamin et Berger (2019 : 189) font remarquer que « s’il semble raisonnable d’assigner a priori (à
Concernant les expérimentations en psychologie, Benjamin et al. (2018 : 6) suggèrent une cote a priori de l’ordre de
Cohen (1994 : 1000), lui, fait sienne une remise en cause des méthodes de la psychologie « molle » (soft) dont les théories n’auraient a priori pas plus de
Adoptant une plus large perspective dans leurs conclusions, Benjamin et Berger (2019 : 189–190) opposent les domaines inexplorés (« ‘novel’ situations ») « dans lesquels les chances a priori d’une découverte n’excèdent pas la cote de 1 contre 1 », à d’autres scénarios – tels que les réplications ou études phasées 17 – pour lesquelles « les chances en faveur de l’hypothèse alternative peuvent être considérablement plus grandes ».
Mais quid des recherches appliquées qui n’ont pas la prétention de consolider empiriquement une percée théorique aux frontières de la connaissance, mais visent une plus grande efficience des processus organisationnels et l’optimisation des décisions prises
18
? Qui pourra convaincre des partenaires privés d’y participer (a fortiori, de les sponsoriser) si la probabilité a priori de succès du test est de moins de 50% ? Dans ces cas, analogues aux tests de médicaments, la prudence commande de considérer que
Mise en œuvre
La figure 3 visualise la relation entre
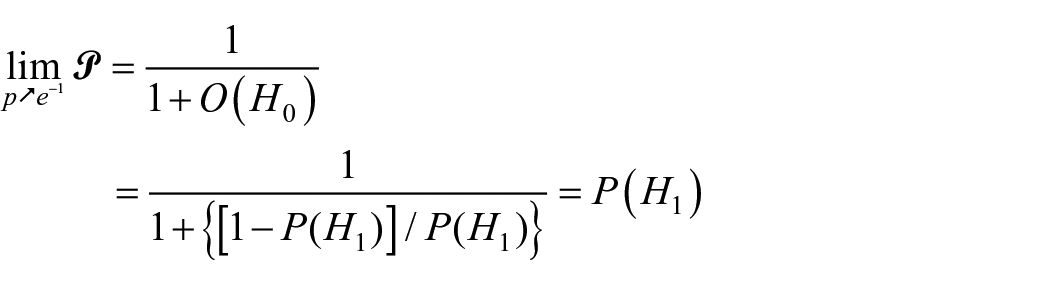
Au-delà de cette limite,
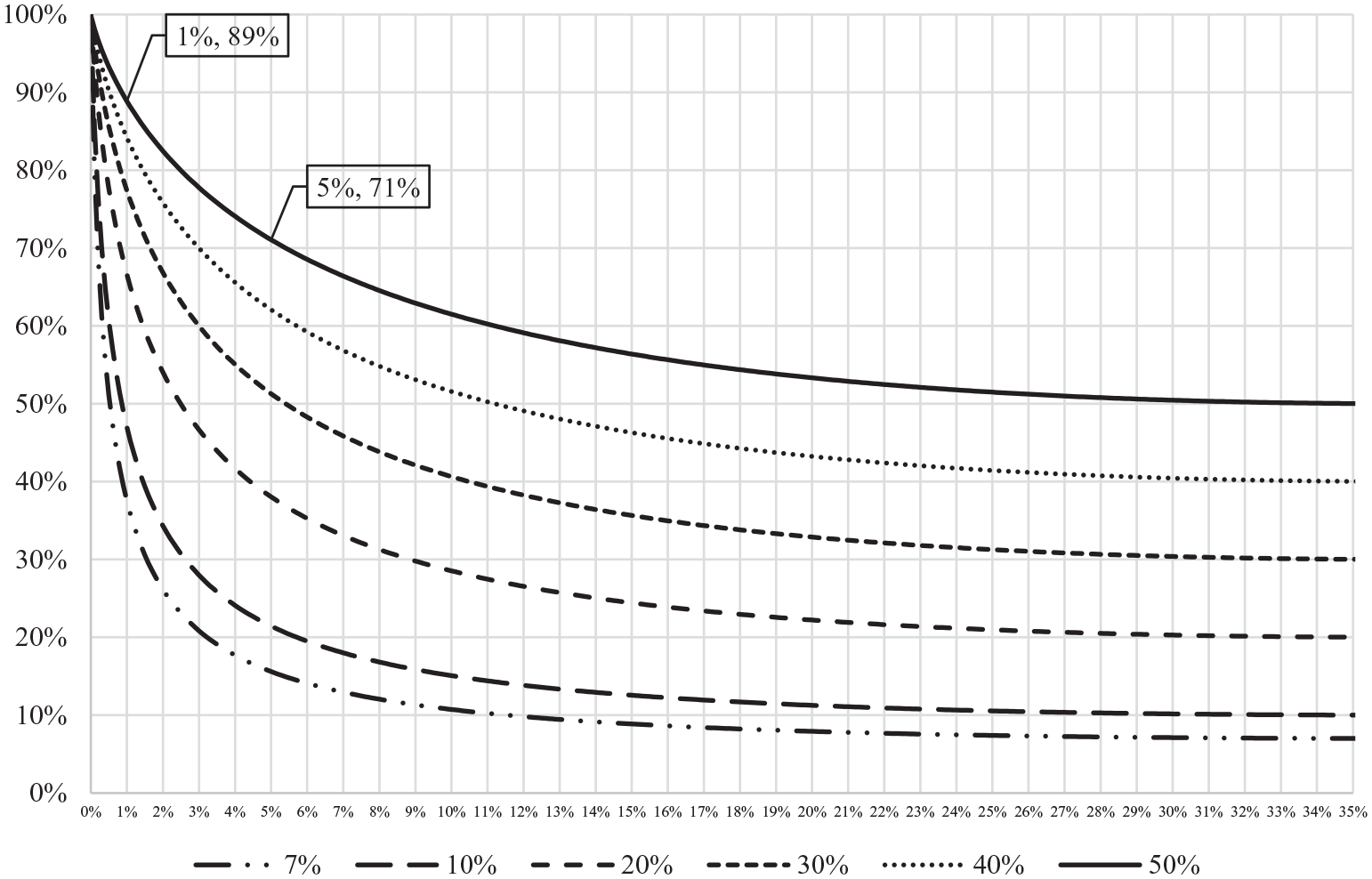
Probabilités a posteriori
Sur ce graphique, sont pointées – pour
Table de
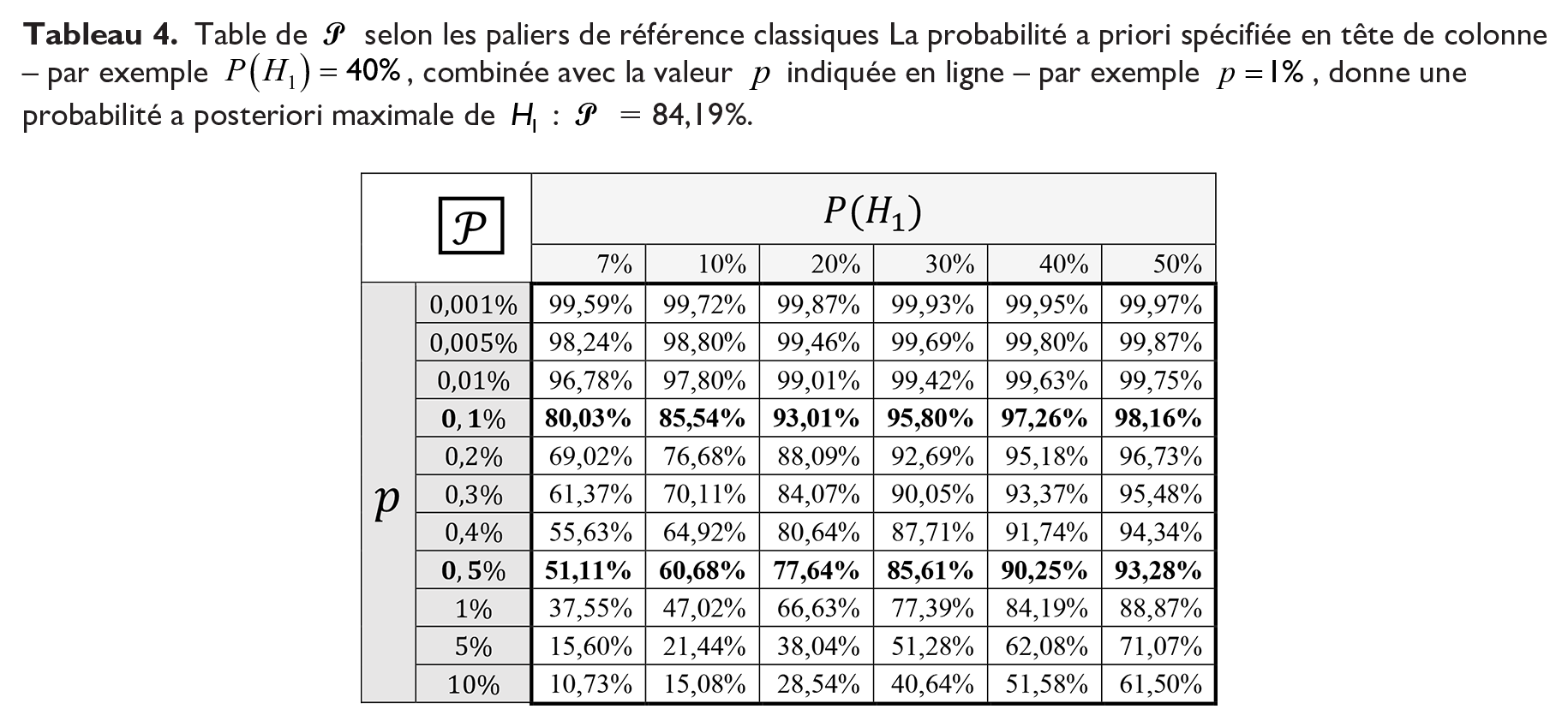

A la vue des valeurs
Avant eux, Johnson et al. (2017 : 9) – se référant au cas de probabilités a priori faibles :
La formule (2.7) montre que poser
Le tableau 5 schématise la façon de procéder pour mener à bien le test d’hypothèse.
Marche à suivre.
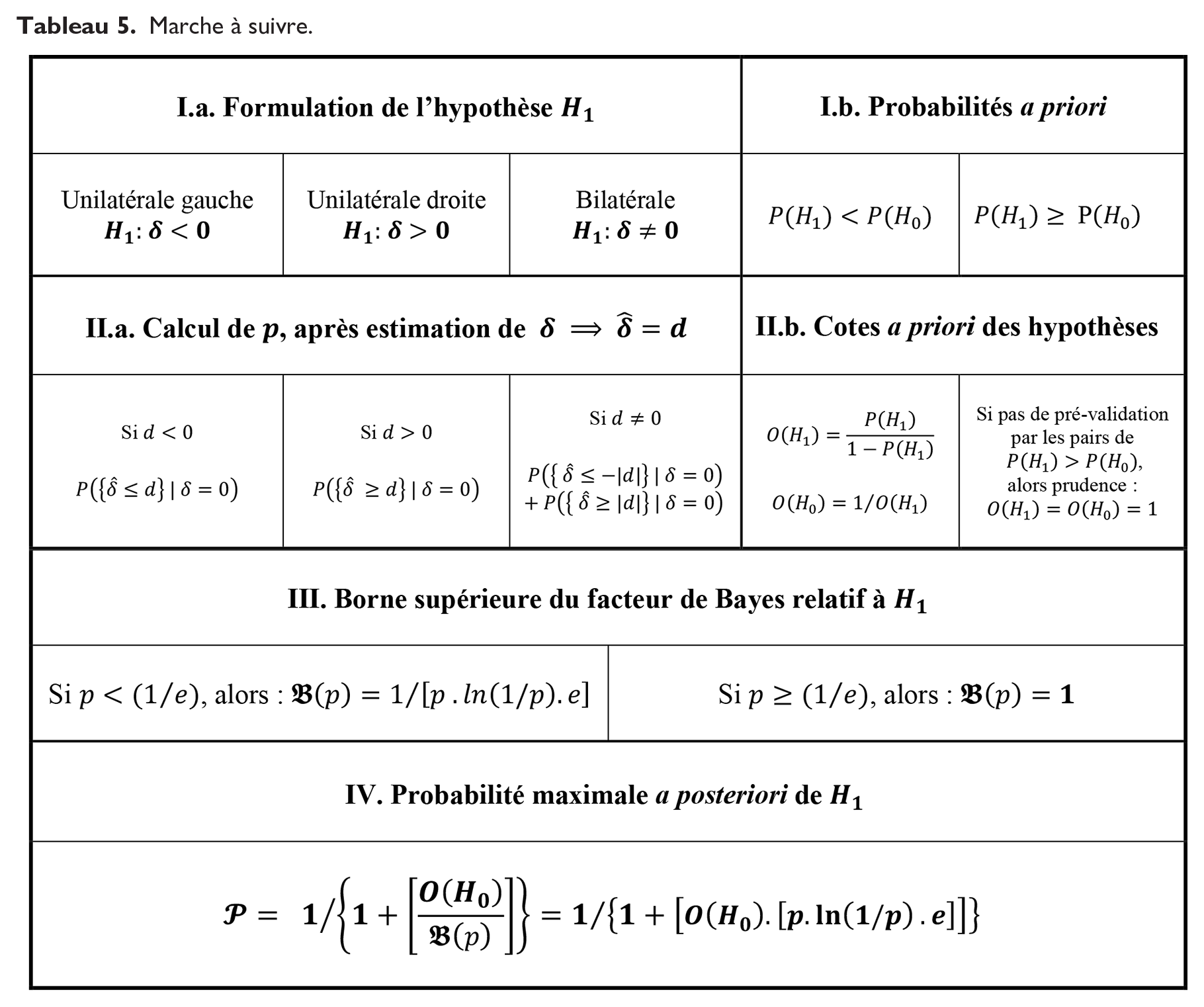

La partie
Complémentairement, emprunter la voie bayésienne, amorcée en
En
En
Pour concrétiser la démarche décrite, nous avons, au tableau 6, revisité des résultats rapportés tout récemment par Song et al. (2021 : 175–176). Ils sont extraits de leur remarquable article portant sur l’effet modérateur de la tendance à s’attendre à, et accepter, les inégalités (power distance belief, dénoté PDB) sur les préférences des consommateurs pour des produits conçus par des utilisateurs versus ceux conçus par des concepteurs professionnels.
Exercice pédagogique.
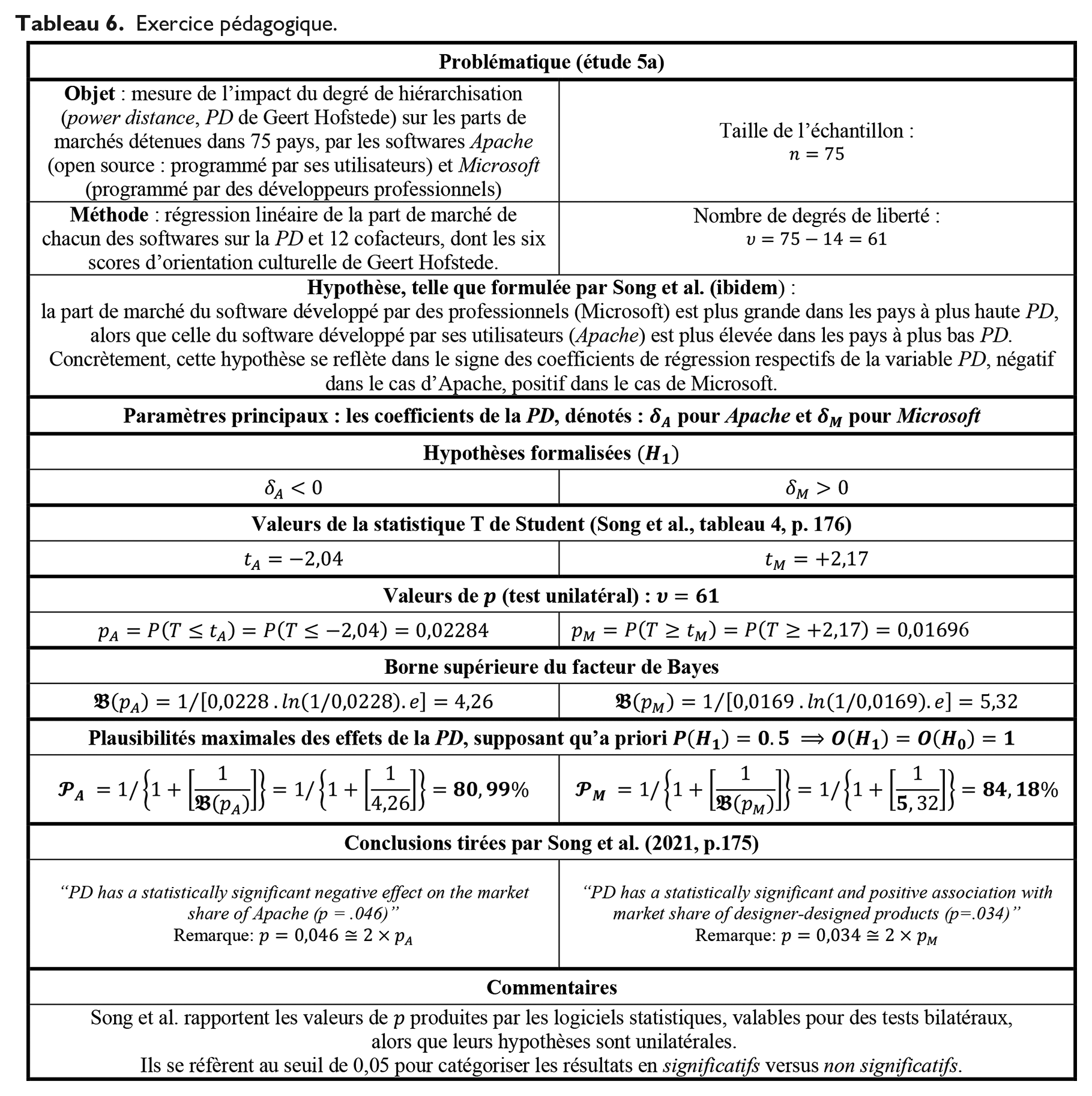

Epilogue provisoire
Figure 3 et tableau 4 nous apprennent que
Néanmoins
par évaluation des enjeux socio-économiques spécifiques des décisions prises sur base de
par référence aux normes, à établir par les experts du domaine concerné, comme la gradation du type de celle présentée au tableau 7, transposition d’une catégorisation des valeurs du facteur de Bayes, proposée par Held and Ott (2018 : 4, tableau 2).
Qualification de la crédibilité de l’hypothèse.


Dans tous les cas, la valeur de
Pertinence managériale
Herrmann et al. (2018) rapportent une expérimentation montrant l’effet du parrainage sportif sur les comportements des consommateurs-supporters en réponse à un publipostage promotionnel pour une chaîne de 28 points de vente. En l’absence de publication scientifique sur cet effet de levier, les auteurs s’appuient sur les attentes optimistes du parrain qui espère un effet positif.
Premier diagnostic
Le tableau 8 résume les résultats de leur expérimentation (Herrmann et al., 2018 : 85–86). S’y trouvent présentées les fréquences relatives :
des comportements favorables spécifiés par l’indice (f) : visite de magasin (f = v) ou achat en magasin (f = a) à l’enseigne du parrain ;
de deux groupes (G) :
- le groupe exposé, identifié par : XX, ayant reçu le publipostage dans lequel la chaîne est mentionnée comme sponsor du club de football parrainé,
- et le groupe de contrôle, non-exposé, identifié par :
Les probabilités de comportements favorables des groupes sont notées :

Elles sont estimées par les proportions correspondantes
Comportements des supporters.


Sur base de ces données, Herrmann et al. (2018) testent :
pour les deux types de comportement favorable :
De ces pourcentages, ils concluent que : « les supporters de l’équipe parrainée ont plus souvent tendance à adopter des comportements favorables (visites en magasin et achats) à l’enseigne du parrain en réponse au publipostage qui met en avant son activité de parrainage, qu’en réponse au publipostage qui ne le mentionne pas. » Ils ajoutent à propos des visites que la « différence est significative avec un risque d’erreur de première espèce de moins de 1% ( pour les visites : et pour les achats :
Ce type d’interprétation – monnaie courante, dont le marketing ne détient pas le monopole – porte involontairement à croire que :
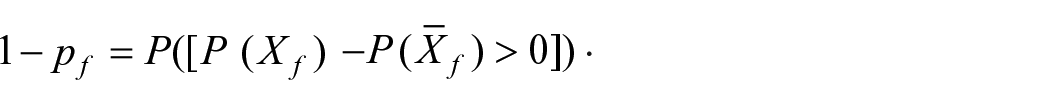
Cela est pourtant faux comme le montre l’application de la démarche préconisée au tableau 5, dont les résultats sont présentés étape par étape dans le tableau 9.
Calcul de la plausibilité des effets.

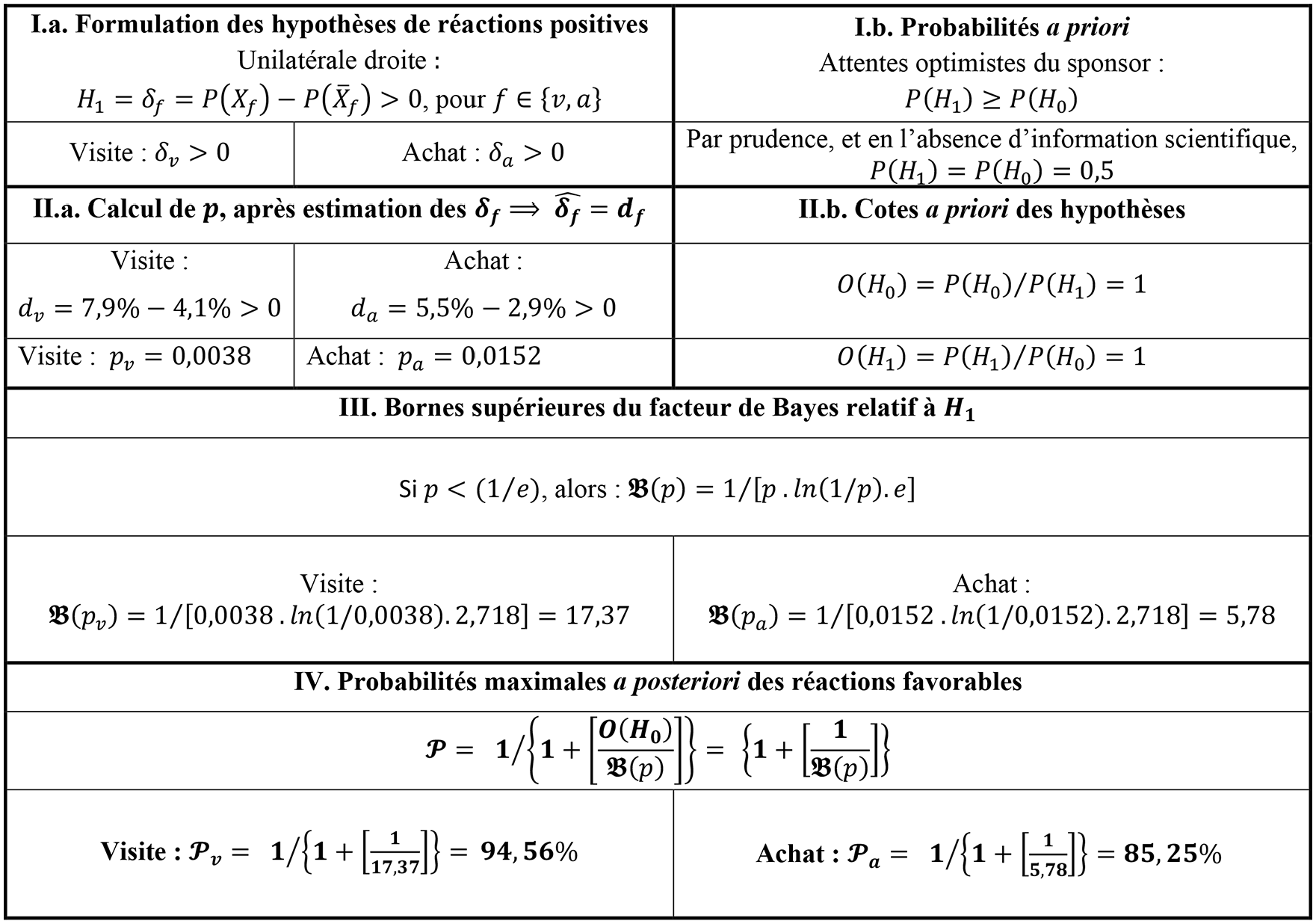
En conclusion, si on suppose a priori que
94,56% de chances que le fait de mentionner le parrain sur le publipostage entraîne une augmentation des comportements de visite en magasins au sein de la population des supporters ;
85,25% de chances que le fait de mentionner le parrain sur le publipostage entraîne une augmentation des comportements d’achat au sein de la population des supporters.
L’effet de levier du parrainage apparaît donc moins établi qu’au regard de
Analyse de sensibilité aux a priori
Vu le caractère exploratoire de l’étude ici revisitée, nous avons supposé

En dépit d’un a priori extrêmement pessimiste, la contribution informative de l’expérimentation n’est toutefois pas négligeable puisque 20 :
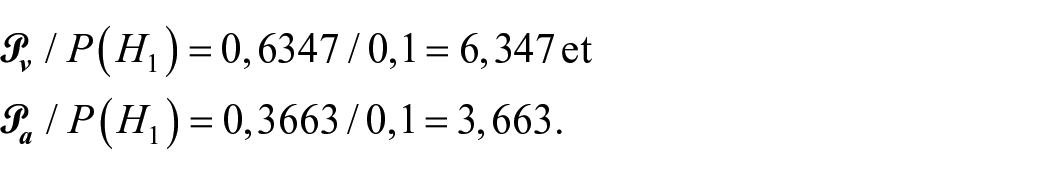
Mode d’étalonnage robuste
Sans aucun doute
Par conséquent, il faut d’abord pouvoir comparer statistiquement des effets les uns aux autres. Ici, l’analyse porte sur une réponse qualitative (nominale, binaire : comportement favorable, ou pas) à un stimulus (exposition, ou non) qui est, lui aussi, de même nature. En pareil cas, le ratio de cotes (« odds ratios ») de réaction positive, du groupe traité par rapport au groupe de contrôle, est recommandé. Agresti (2007 : 28–34) plaide en faveur de ratios de cotes en argumentant :
d’abord, qu’une même différence entre deux proportions est plus importante quand les deux proportions sont proches de 0, ce qui est le cas pour Herrmann et al. (tableau 7). Ainsi, des augmentations de 2 à 4%, comme de 50 à 52% sont bien toutes deux égales à 2 points, mais la première est bien plus conséquente (×2) que la seconde (×1,04) ;
ensuite, qu’un ratio de cotes est une mesure d’association synthétisant, de manière très parlante, un tableau de contingence deux par deux.
Conformément à

Concrètement, pour la visite en magasin, ce rapport s’estime par :
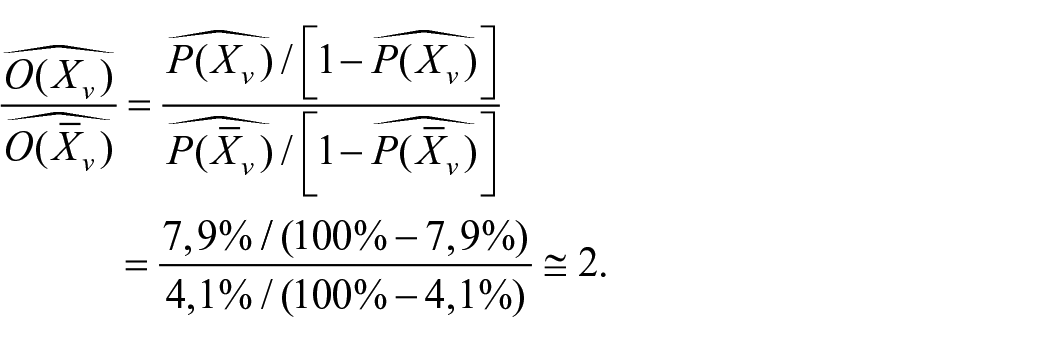
Les six exemples d’analyse de la crédibilité d’effets présentés par Matthews (2019 : 204–205) sont, tous, exclusivement basés sur l’examen des intervalles de confiance (IC) de ratios de cotes. Leur représentation graphique, par des segments parallèles, permet de mieux relativiser la taille des effets. Ce n’est donc pas un hasard si un tel schéma a été utilisé dans Nature, par Amrhein et al. (2019a : 306), pour contraster deux estimations ponctuelles identiques 22 , dont l’une pourtant ne permet pas de rejeter l’hypothèse nulle pour cause d’imprécision.
Dans leur éditorial, tirant les leçons des quelque 400 pages du numéro spécial exceptionnel de The American Statistician, Wasserstein et al. (2019: 14), recommandent de « faire plein usage, tout à la fois, de l’estimation ponctuelle, ainsi que de l’amplitude et de la localisation de l’IC par rapport à la ligne marquant l’absence d’effet ». A leur suite, retenons que :
qu’elle soit statistiquement convaincante ou pas, l’estimation ponctuelle s’interprète comme la valeur de l’effet la plus compatible avec les données, telles qu’elles ont été analysées ;
la preuve empirique de la réalité de l’effet s’avère d’autant plus convaincante que l’IC est étroit et éloigné de la valeur-repère d’absence d’effet.
Application
Ne disposant ni de valeurs de référence suffisantes quant aux effets de levier du parrainage sportif (Herrmann et ses collègues (2018: 18) parlent d’ailleurs d’« une première contribution sur cette question importante de l’effet de levier du parrainage »), ni de données relatives à la rentabilité des promotions de la chaîne de magasins, nous nous sommes contentés de vérifier si les effets de la mention du sponsor sur les supporters, sont bien supérieurs aux effets de cette même mention sur les non-supporters. Pour ce faire, nous avons calculé les
La figure 4 synthétise les
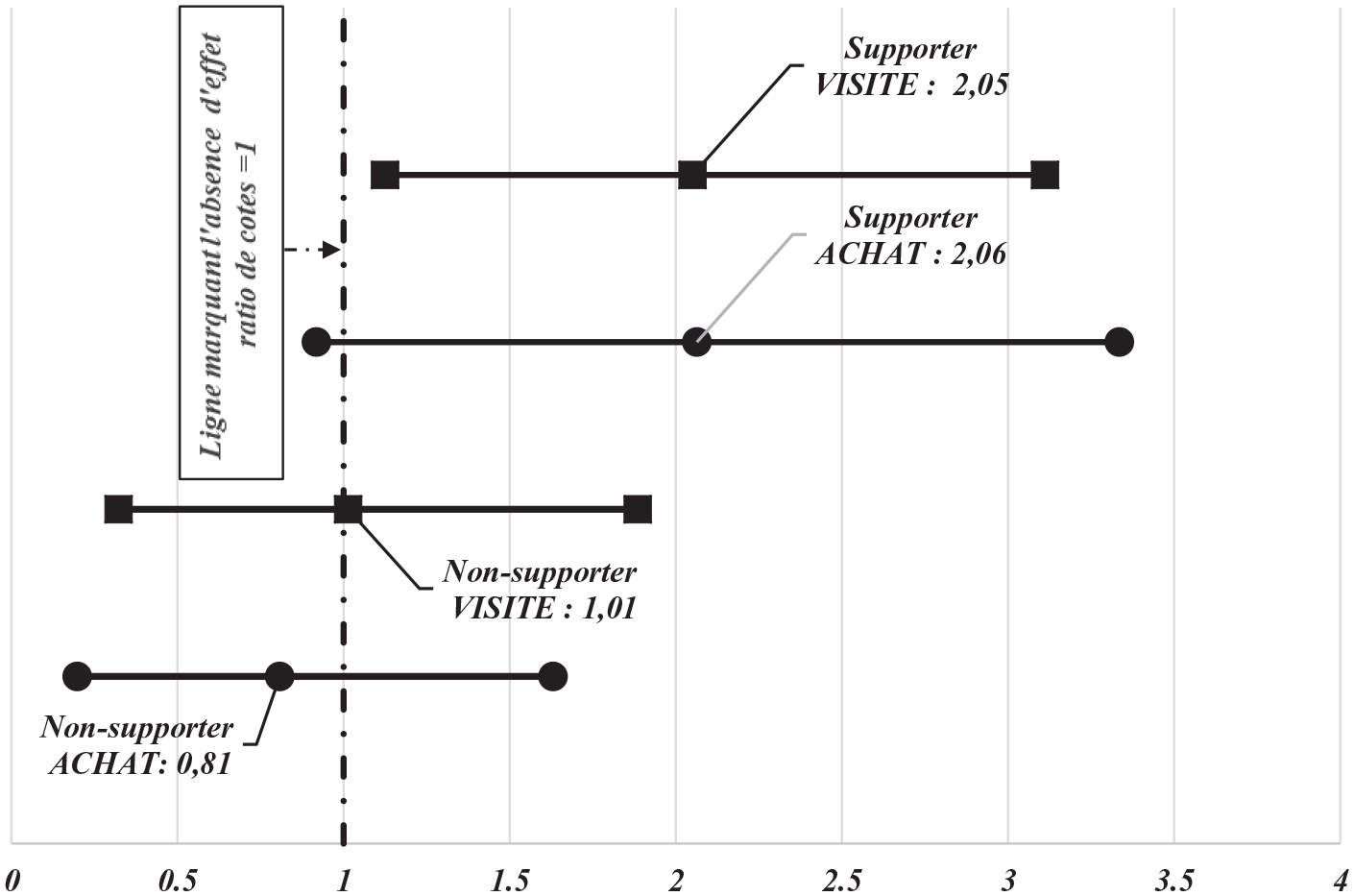
Intervalles crédibles à 95% des ratios de cotes 23 .
Le modèle spécifié traite visite en magasin et achat, tour à tour, comme variables dépendantes, et la mention du sponsor, ou non, comme facteur explicatif.
Les
Ce calibrage graphique révèle que :
Côté supporters
l’
alors que la borne inférieure de l’
les estimations ponctuelles des ratios de cotes de leur réaction favorable se montent à plus du double de celles des non-supporters, tant pour les visites en magasin que pour les achats.
Côté non-supporters
les deux estimations ponctuelles des ratios de cotes sont assez proches de 1 : concernant les visites, elle lui est même très légèrement supérieure, tandis que pour les achats, elle lui est un peu inférieure ; ainsi, le risque d’un effet négatif n’est pas à écarter, particulièrement sur leur achats ;
les parties droites des intervalles crédibles de leurs réactions recouvrent assez notablement, les portions gauches de ceux relatifs à celle des supporters ; il ne serait donc pas impossible d’observer chez les non-supporters des effets aussi positifs que ceux produits sur les supporters.
Ces différents constats complètent l’interprétation des résultats livrée par Herrmann et ses co-auteurs (2018). Ainsi, s’ils avaient bien souligné des effets positifs sur les supporters, leur analyse ne leur avait pas permis de soupçonner que :
chez les supporters, l’effet de levier pourrait être relativement plus conséquent sur leurs achats que sur leurs visites en magasins ;
si des effets positifs de la même ampleur ne sont pas totalement à exclure chez les non-supporters, a contrario, le risque d’un effet négatif sur ceux-ci n’est pas négligeable.
Il convient donc de s’interroger sur les raisons d’éventuels effets négatifs sur le segment a priori indifférent de ceux qui ne supportent pas le club sponsorisé (mais qui pourraient compter dans leurs rangs de fervents partisans d’autres associations sportives, voire rivales).
Conclusion et recommandations
Après avoir rappelé que p n’était qu’un indice de la compatibilité des données avec l’hypothèse
prendre mieux conscience à quel point leurs inférences peuvent être hasardeuses,
en connaissance de cause, nuancer modestement leurs commentaires,
en conséquence, assumer pleinement l’incertitude qui affecte leurs conclusions, en se gardant de recourir à des catégorisations rigides et simplistes qui masquent cette incertitude,
sans crainte rapporter des résultats parfois étiquetés comme « peu probants », issus de données fiables et valides, d’autant plus instructifs qu’ils sont éventuellement à contrecourant.
Mais qu’on ne se méprenne pas,
accepter un risque d’erreur, de première espèce de 5% revient à considérer comme supportée une hypothèse
un test conduisant à une valeur
De façon plus générale, la démarche proposée nous incite à la vigilance : dès lors qu’il s’agit d’inférer l’existence (ou non) d’un effet dans une population à partir d’un échantillon, on ne peut se fier à des règles automatiques gommant l’incertitude.
Toutefois, on ne peut se focaliser sur un indicateur statistique synthétique, tel que
Green (2021 : 3), dans sa toute récente critique des théories avancées par les psychologues, qu’il juge trop « vagues », préconise le « développement de théories suffisamment détaillées et rigoureuses pour produire des prévisions des tailles exactes des effets attendus » de sorte que l’analyse statistique puisse vérifier que « les effets observés approximent ces prévisions et pas simplement s’ils s’avèrent non nuls ». Ainsi, concernant les expérimentations visant à tester une nouvelle forme d’action promotionnelle, il convient de s’assurer que sa mise en œuvre soit profitable. Il s’agit donc de prévoir le seuil de rentabilité que l’effet (ici de levier) devra dépasser, disons :
En dehors des cas impliquant une incidence financière, la définition d’un niveau – plancher ou plafond –, autrement dit la formulation d’hypothèses non pas sur l’existence ou non d’un effet mais spécifiant l’ampleur (minimale ou maximale) de l’effet escompté, doit s’appuyer soit sur des considérations théoriques pertinentes et précises, soit sur des résultats empiriques antérieurs se rapportant à une problématique identique ou similaire (Witte et Zenker, 2017).
Contextualiser la probabilité estimée, par l’examen des estimations – respectivement ponctuelle et par intervalle crédible – de l’ampleur de l’effet supposé est donc recommandé. Cette relativisation conduit à proscrire des expressions très couramment rencontrées telles que « statistiquement significatif », « statistiquement non significatif » ou encore « marginalement (borderline) significatif », de même que certains verbes comme « prouve » ou « démontre ». Il convient également de rapporter les valeurs p sous forme de valeurs continues et d’égalités, et non d’inégalités comme trop souvent actuellement (e.g.
D’autres manières rigoureuses de traiter le concept de signification statistique et les problèmes associés – comme par exemple la problématique de la réplication – ont été proposées dans la littérature. Plus sophistiquées, elles dépassent le cadre de cet article. Nous renvoyons dès lors aux articles qui en traitent : Amrhein et al.(2019b) ; Billheimer (2019) ; Blume et al. (2019) ; Colquhoun (2019) ; Gannon et al. (2019) ; Goodman et al. (2019) ; Manski (2019) et Manski et Tetenov (2019) ou encore Matthews (2019). Le lecteur intéressé pourra les trouver dans le numéro spécial de The American Statistician (2019, 73(1)), dont la lecture a motivé la rédaction du présent article. Une autre calibration de p a également été retenue par ses éditeurs (Wasserstein et al., 2019 : 4). Celle-ci, proposée par Greenland (2019 : 107, 109) :
Enfin et pour rappel, la valeur d’une recherche et ses chances d’être publiée ne doivent évidemment pas être d’abord fonction des résultats et des valeurs de probabilités (quelles qu’elles soient) issus des tests statistiques effectués. Les points fondamentaux à considérer prioritairement sont la précision des concepts mobilisés, la qualité de l’argumentation théorique, la pertinence des questions de recherche et l’adéquation de la méthodologie adoptée (design de l’étude, validité et fiabilité des outils de mesure, représentativité de l’échantillon). Au-delà, et à l’instar de ce que recommandent désormais de nombreux auteurs en psychologie ou en marketing (voir par exemple Witte et Zenker, 2017 ou Babin et al., 2021), il importe d’inscrire davantage les recherches menées dans un processus de développement cumulatif de connaissances scientifiques robustes.
Footnotes
Annexe I. Révision objective des croyances
Remerciements
Les auteurs remercient le Rédacteur-en-Chef, le Rédacteur-en-Chef Associé et les trois évaluateurs anonymes pour la pertinence de leurs critiques et suggestions ; celles-ci ont significativement contribué à l’amélioration de cet article.