
Abstract
In this research note it is shown that, by applying cointegration and causality techniques to U.S. state-level panel data, there is a negative long-run relationship between unionization and income inequality in the United States, and that causality is unidirectional from unionization to inequality.
During the past four decades, the United States, like many other nations, has experienced an increase in income inequality and a decline in union density. However, although a large body of research has examined the effects of unions on the U.S. wage distribution, only one study to date has explicitly examined the effects of unions on U.S. income distribution. Partridge, Rickman, and Levernier (1996) found, using data from 48 U.S. states for the period 1960 to 1990, that unionization has no statistically significant impact on income inequality.
Theoretically, unions can affect the distribution of income through several mechanisms, such as wage inequality, unemployment, and the wage share. As far as the mechanism of wage inequality is concerned, unions tend to reduce wage inequality within the union sector by pushing up the wages of low-skilled workers more than those of high-skilled workers, while they tend to increase wage inequality between unionized workers and nonunionized workers by raising the wages of their members relative to the wages of nonunionized workers (Checchi & García-Peñalosa, 2010).
As far as the effects of unions on employment are concerned, the traditional view is that an increase in union membership increases the bargaining power of unions, which enables unions to raise wages above the competitive market-clearing level. When unions fix wages at a level in excess of that at which all workers can be employed, some workers are unemployed. Higher unemployment, in turn, increases the proportion of people receiving unemployment benefits. Because income from unemployment benefits is typically less than income from work, an increase in unemployment increases the proportion of people with low incomes; this is generally associated with increased income inequality. The alternative view is that unions care about both wages and employment, and that in an imperfectly competitive labor market environment there is a scope for unions to increase wages at the expense of reductions in profits without adverse impacts on employment (Checchi & García-Peñalosa, 2010).
Although both wage inequality and unemployment increase income inequality, the effect of the wage share on income inequality is ambiguous. A higher wage share reduces the contribution of inequality of capital income to total income inequality but increases the contribution of wage inequality to total income inequality (Checchi & García-Peñalosa, 2010). Because the inequality of capital income is likely to exceed the inequality of wage income (Glyn, 2009), it is reasonable to assume that an increase in the labor share decreases income inequality.
As discussed in Bentolila and Saint-Paul (2003), unions can positively or negatively affect the labor share. If unions and firms bargain over both wages and employment, and workers are able to obtain a higher wage without suffering a decrease in employment, the labor share will increase. If unions and firms instead bargain only over wages, leaving firms free to determine employment unilaterally, higher union wages may combine with lower employment. In this case, an increase in union power can lead to a lower wage share.
Thus the net effect of unions on the distribution of income is theoretically unclear. However, it could also be that income inequality affects union density. Inequality-averse union members may perceive unions as unable to reduce wage inequality and to influence redistributive policy when inequality increases. If these individuals feel that their expectations regarding the efficacy of unions in reducing inequality have been disappointed, income inequality can lead to de-unionization (Checchi, Visser, & van de Werfhorst, 2010). Thus the direction of causality is also an open question, and this is one question the present study attempts to answer.
The objective of this research note is to examine the long-run relationship between unionization and income inequality in the United States using state-level panel data for the period 1964 to 2012. Specifically, the study makes the following contributions: First, I use panel cointegration methods to avoid spurious regressions in panel data. As discussed in more detail in the next section, panel cointegration estimators are robust under cointegration to a variety of estimation problems that often plague empirical work, including omitted variables and endogeneity (Coe, Helpman, & Hoffmaister, 2009). Moreover, panel cointegration methods can be implemented with shorter data spans than their time-series counterparts. Second, I use panel methods that explicitly account for potential cross-sectional dependence due to common shocks or spillovers among cross-sectional units at the same time. Failure to control for such unobserved common time-specific factors can lead to inconsistent estimates if these omitted factors are correlated with the explanatory variables and/or are nonstationary (Kapetanios, Pesaran, & Yamagata, 2011). And finally, I use a panel vector error correction model (VECM) to test the direction of causality.
The next section presents the basic empirical model, discusses some econometric issues, and lays out the empirical strategy. The third section presents the empirical results and the final section concludes with a summary of the main findings.
Model Specification and Empirical Strategy
Basic Model
The basic model takes the form

where TOPDECILEit is the income share of the top decile over time periods
The data on the top 10% income shares are drawn from the updated database of Frank (2009; available at http://www.shsu.edu/~eco_mwf/inequality.html), and the data on union density are from the Union Membership and Coverage Database constructed by Barry Hirsch and David Macpherson (available at http://www.unionstats.com/). Given that the longest period for which data on both variables are available for all 50 U.S. states and the District of Columbia is 1964 to 2012, the panel includes 2,499 observations on 51 cross-sectional units and 49 years.
I now discuss some econometric issues regarding the estimation of the long-run effect of unions on income inequality. These issues are grouped under four headings: (a) nonstationarity and cointegration, (b) omitted variables, (c) cross-sectional dependence, and (d) causality.
Nonstationarity and Cointegration
Whereas in all states there is a downward trend in union density since 1980 (or earlier), the income share data reveal a strong increase in inequality since the 1980s (or earlier) in all states, as shown in Figure 1. Such time series (that show no tendency to return to a constant mean) are said to be nonstationary.

TOPDECILEit (
Given that most economic time series are characterized by a stochastic rather than deterministic nonstationarity, it is reasonable to assume that the trends in TOPDECILEit and UNIONit are also stochastic through the presence of a unit root, rather than deterministic through the presence of polynomial time trends. In particular, it is likely that the two variables have one unit root, as is typical for most economic time series. Such time series are said to be integrated of order one or I(1); an I(1) variable must be differenced one time to make it stationary or I(0).
If TOPDECILEit and UNIONit are driven by separate I(1) trends, then any linear combination of these variables will also be I(1). In this case, there is no relationship between TOPDECILEit and UNIONit, implying that Equation 1 is a spurious regression. As shown by Entorf (1997) and Kao (1999), the tendency for spuriously indicating a relationship may even be stronger in panel data regressions than in pure time-series regressions. When variables are nonstationary, standard regression output must therefore be treated with extreme caution because results are potentially spurious.
If, in contrast, TOPDECILEit and UNIONit share a common stochastic trend (and no irrelevant nonstationary variables are included), then a linear combination of these variables will be I(0). In this case, TOPDECILEit and UNIONit are said to be cointegrated. Cointegration implies the existence of a long-run relationship between two or more integrated series. Cointegration of TOPDECILEit and UNIONit is thus the condition required for Regression 1 not to be spurious—a condition that must be tested.
Omitted Variables
A regression containing all the variables of a cointegrating relationship has a stationary error term, implying that no relevant integrated variables are omitted; any omitted nonstationary variable that is part of the cointegrating relationship would become part of the error term, thereby producing nonstationary residuals and thus leading to a failure to detect cointegration. If there is cointegration between a set of variables, then this stationary relationship also exists in extended variable space. In other words, the cointegration property is invariant to model extensions, which is in stark contrast to regression analysis where one new variable can alter the existing estimates dramatically (Juselius, 2006). Thus an important implication of finding cointegration is that no relevant nonstationary variables are omitted and that no additional variables are required to form a cointegrating relationship.
Of course, there are many factors that can affect income inequality and/or union density. Therefore, adding further nonstationary variables to the model may, on one hand, result in further cointegrating relationships (see, for instance, Brückner, Gerling, & Grüner, 2010). If, however, there is more than one cointegrating relationship, identifying restrictions are required to separate the cointegrating relationships. Otherwise, multicollinearity problems may arise. On the other hand, adding further nonstationary variables to the regression model may result in spurious associations. More specifically, if a nonstationary variable that is not cointegrated with the other variables is added to the cointegrating regression, the error term will no longer be stationary. As a result, the coefficient of the added variable will not converge to zero, as one would expect of an irrelevant variable in a standard regression.
Although these considerations justify a parsimonious model such as Equation 1 (if cointegrated), I nevertheless check the robustness of the results to the inclusion of additional variables, such as real state income per capita (INCOMEit), real state income per capita squared (INCOMESQit), and two measures of education: the proportion of the population with at least a high school degree (HIGHSCHOOLit) and the proportion with at least a college degree (COLLEGEit).
INCOMEit is intended to pick up the impact of the level of economic development on inequality. INCOMESQit is included to test whether there is an inverted-U relationship between income inequality and economic development, as proposed by Kuznets (1955), or whether the inequality-development relationship in the postwar United States is U-shaped, as found by Ram (1991) and Jacobsen and Giles (1998). As far as the education variables are concerned, several cross-national studies find a strong negative association between inequality and education, particularly secondary education (see, for instance, Nielsen, 1994; Nielsen & Alderson, 1995). The intuitive explanation, which is based on supply and demand for educated workers, is that increased availability of qualified personnel increases competition and produces a relative decline in the higher wages and salaries (Nielsen & Alderson, 1995). As a test of this explanation, I include HIGHSCHOOLit and COLLEGEit.
The income data are from the Regional Accounts Data of the Bureau of Economic Analysis (available at http://www.bea.gov/itable/iTable.cfm?ReqID=70&step=1#reqid=70&step=1&isuri=1) and are deflated using the consumer price index. The education data are from the updated database of Frank (2009). Because these data are available only up to 2010, I am forced to use the period 1964 to 2010 in the robustness checks.
Cross-Sectional Dependence
Another issue is the potential cross-sectional dependence of the data due to omitted common factors. Common factors may be a combination of “strong” factors representing national shocks, such as common business cycles, national financial crises, and macroeconomic policies at the federal level, and “weak” factors such as spatial spillovers between a limited number of states (Holly, Pesaran, & Yamagata, 2010). If both TOPDECILEit and UNIONit share common factors ft, such that
The standard approach to account for omitted common factors is to use demeaned data in place of the original data, which in pooled models is equivalent to the use of time dummies. The implicit assumption behind this approach is that the factor loadings of the common factors are homogeneous across the cross-sectional units,
An alternative approach is to use the common correlated effects (CCE) mean group estimator of Pesaran (2006). This estimator accounts for cross-sectional dependencies that potentially arise from multiple common factors and permits the individual responses to the common factors to differ across panel members. Another advantage is that the CCE estimator can be computed by ordinary least squares (OLS). The idea of the CCE estimator is to account for common factors by augmenting the estimating equation with cross-sectional averages of the dependent variable and the observed regressors as proxies for the unobserved factors. The cross-sectionally augmented regression of (1) for the ith cross-section is as follows:

where
The mean group procedure involves estimating separate regressions for each state and averaging the long-run coefficients. The mean group estimator and its standard error are calculated as follows:


While Pesaran (2006) proves the consistency of his estimator under the assumption that both the variables and the (unobservable) common factors are stationary, Kapetanios et al. (2011) show that the CCE estimator is consistent even when the data follow a unit root process, provided that the series involved are cointegrated.
Causality
It is well known that even the standard OLS fixed effects estimator is a consistent estimator of the cointegrating relationship and can therefore be used to estimate the cointegrating coefficients, even if the regressors in the cointegration relationship are endogenous. The problem is that in the presence of endogeneity (or reverse causality) the OLS t ratio is not asymptotically standard normal and thus useless for inference.
A related issue is that, although the existence of cointegration implies long-run Granger causality in at least one direction (Granger, 1988), cointegration does not indicate the direction of long-run causality. The standard approach to test for long-run causality (or weak exogeneity) in cointegrated panels is a two-step procedure (see, for instance, Canning & Pedroni, 2008; Eberhardt & Teal, 2013; Herzer, Strulik, & Vollmer, 2012).
In the first step, the previously estimated long-run relationship is used to construct the error correction term
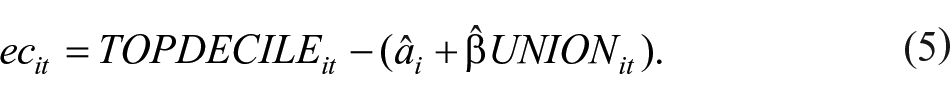
In the second step, the lagged error correction term is entered into a panel VECM, given here by
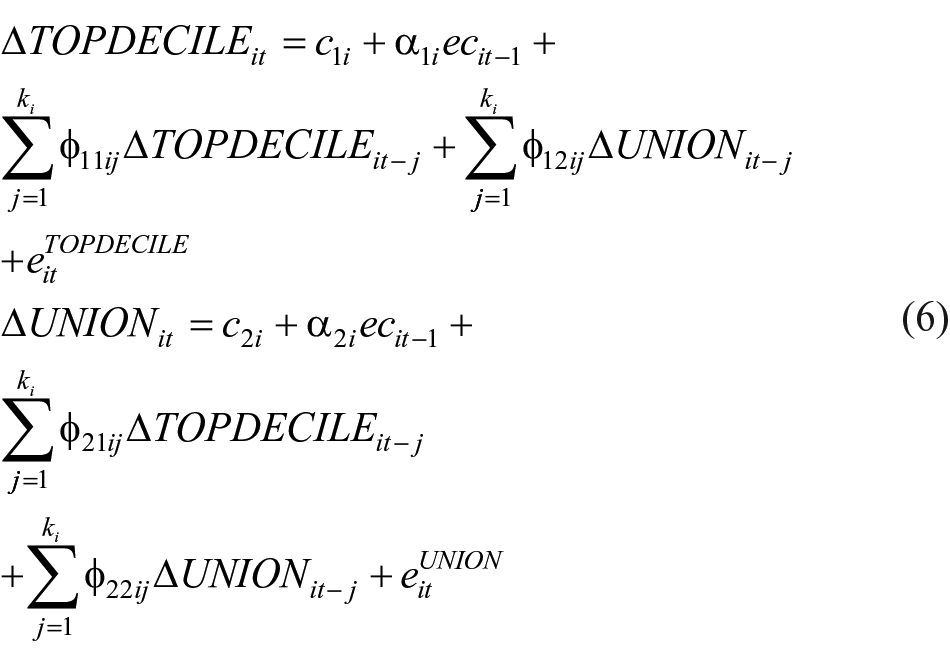
where k is the lag length (which is determined by the Schwarz criterion),
If the adjustment coefficient in the ΔTOPDECILEit equation is nonzero,
To account for cross-sectional dependence, I (again) compute the CCE mean group estimator. Accordingly, Equation 6 is augmented with cross-sectional averages of the dependent variables and the regressors, including
Thus the empirical strategy involves three steps. First, the relevant variables are pretested for unit roots and cointegration. In the second step, the long-run relationship is estimated and the robustness to the inclusion of additional variables is examined. Finally, the question of causality is investigated.
Empirical Analysis
Panel Unit Root and Cointegration Tests
Given that so-called first-generation panel unit root tests, which assume cross-sectional independence can exhibit severe size distortions in the presence of cross-sectional dependence, I employ a second-generation panel unit root test to account for potential cross-sectional dependence. More specifically, I use the cross-sectionally augmented Dickey–Fuller test (ADF) panel unit root test proposed by Pesaran (2007). This test, which is based on an average of the individual (state specific) ADF t statistics, is designed to filter out the cross-sectional dependence by augmenting the individual ADF regressions with the cross-sectional averages of lagged levels and first differences of the individual series (as proxies for the unobserved common factors).
Table 1 reports the results of the test for the variables in levels and in first differences. The test statistics do not reject the null hypothesis that TOPDECILEit and UNIONit have a unit root in levels, whereas the unit root hypothesis is rejected for the first differences. Thus, it can be concluded that both TOPDECILEit and UNIONit are integrated of order one, I(1).
Panel Unit Root Tests.

Note. c (t) indicates that I allow for different intercepts (and time trends) for each state. Four lags were used to adjust for autocorrelation. The relevant 5% (1%) critical value is −2.58 (−2.68), with an intercept and a linear trend, and −2.10 (−2.20) with an intercept.
Indicate rejection of the null hypothesis of a unit root at the 1% level.
To ensure that the relationship between TOPDECILEit and UNIONit is not spurious, I use the panel cointegration tests of Westerlund (2007). The Westerlund tests are conditional error correction model based tests that evaluate the significance of the lagged dependent variable (TOPDECILEit-1) in the conditional error correction model, which in our case is given by

The group-mean statistics denoted Gτ and Gα (using the nomenclature in Westerlund, 2007) test the null of no cointegration against the alternative that there is cointegration for at least one cross-sectional unit, and the panel statistics Pτ and Pα test the null of no cointegration against the simultaneous alternative that the panel is cointegrated. To account for cross-sectional dependence, I use the bootstrap approach of Westerlund (2007).
As can be seen from Table 2, all test statistics reject the null hypothesis of no cointegration at the 1% significance level, indicating that there is a long-run relationship between union density and income inequality.
Panel Cointegration Tests.

Note. Bootstrap p values in parentheses. To avoid overparametrization and the resulting loss of power, only one lag was included in the tests.
(**) Indicate rejection of the null hypothesis of no cointegration at the 1% (5%) level.
Long-Run Relationship
As discussed above, I use the CCE mean group estimator of Pesaran (2006) to estimate the long-run relationship between the top decile income share and union density. Column 1 of Table 3 presents the results. The estimated coefficient on union density is negative and statistically significant at the 1% level. Given that the CCE estimator is intended for the case in which the regressors are exogenous, the reported significance levels should be treated with caution, however. Nevertheless, given that the variables are cointegrated, it can be safely concluded from the results in Table 3 that there is a negative long-run relationship between income inequality and union density.
CCE Estimates.

Note: The dependent variable is TOPDECILEit. t Statistics in parenthesis.
(**) Indicate significance at the 1% (5%) level.
More specifically, the estimate in Column 1 implies, if viewed causally, that, in the long run, a one-percentage-point increase in union density reduces, on average, the top 10% income share by 0.000514 percentage points. To evaluate the magnitude of this effect, consider the average annual change in union density,
As discussed in the previous section, the finding of cointegration between the top decile income share and union density implies that there are no omitted variables. Nevertheless, I check the robustness of the results to the inclusion of income per capita, income per capita squared, the proportion of the population with at least a high school degree, and the proportion of the population with at least a college degree.
As can be seen from Table 3, although the estimated coefficient of INCOMESQit is not significant, the coefficient on INCOMEit is positive and statistically significant in all specifications. This suggests that, for the period 1964 to 2012, there is an approximately linear positive relationship between income inequality and economic development. A possible reason for this finding is that the coefficient of the income variables captures, in part, the effect of skill-biased technological change on income inequality. Accordingly, skill-biased technical change as a source of economic growth induces an increase in the relative productivity of skilled labor that raises its relative demand and, ceteris paribus, the skill premium and thus wage inequality (see, for instance, Aghion, Caroli, & Garcia-Peñalosa, 1999; Autor, Katz, & Kearney, 2008; Mollick, 2012).
The proportion of the population with at least a high school degree has an insignificant relationship with the top decile income share (see columns 4 and 5), while COLLEGEit is significantly negatively associated with TOPDECILEit (see column 5). Most important, the effect of union density remains negative and significant even after controlling for INCOMEit, INCOMESQit, HIGHSCHOOLit, and COLLEGEit.
Causality
To test the direction of long-run causality, I use the residuals from the long-run relationship,
Tests for Long-Run Causality.

Note. The reported values are the t values on the error-correction terms.
Indicate rejection of the null hypothesis of weak exogeneity at the 1% level.
In the second row of Table 4, I test the robustness of this result by using a trivariate VECM with INCOMEit as an additional variable in the error correction term (which is given by
Conclusion
This study has found that in the United States there is a negative long-run relationship between income inequality and union density and that long-run causality is unidirectional from unionization to inequality. The principal quantitative result of this study is that de-unionization explains about 5% of the increase in income inequality in the United States.
It should be noted, however, that the present analysis does not account for possible structural breaks. The justification for this is that the CCE estimator used in this study has, to date, not been extended to allow for structural breaks in the observed series. Moreover, the results of Stock and Watson (2008) suggest that possible structural breaks in the means of the unobserved common factors will not affect the consistency of the CCE estimator. If there are structural breaks in the observed series, then this could change the results, at least quantitatively, but it is unlikely that the conclusions would change qualitatively.
It should also be explicitly noted that the CCE estimator is robust to various forms of cross-sectional dependencies, irrespective of whether these are because of spatial spillovers and/or unobserved common factors (Pesaran & Tosetti, 2011). Nevertheless, it would be interesting to extend this study to include a spatially lagged dependent to test the sensitivity of the results to an alternative model specification.
Another interesting extension would be to use the CCE approach to analyze the effects of unionization on income inequality for a large sample of countries. And finally, it would be interesting to know whether the effect of unionization on inequality depends on factors such as bargaining coverage, the generosity of unemployment benefits, and minimum wage laws. I leave these issues for future research.
Footnotes
Acknowledgements
I thank three anonymous referees for their helpful comments and suggestions.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.